diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..6e8b41a4f34ed0ce238ebe06fab50f1f9dd2e6f3 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+STPoseNet/tmpni7swzfb filter=lfs diff=lfs merge=lfs -text
diff --git a/STPoseNet/.github/ISSUE_TEMPLATE/bug-report.yml b/STPoseNet/.github/ISSUE_TEMPLATE/bug-report.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d611ca787611de7e52d30c32094dec37025b46cd
--- /dev/null
+++ b/STPoseNet/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -0,0 +1,85 @@
+name: 🐛 Bug Report
+# title: " "
+description: Problems with YOLOv8
+labels: [bug, triage]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting a YOLOv8 🐛 Bug Report!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/ultralytics/issues) to see if a similar bug report already exists.
+ options:
+ - label: >
+ I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
+ required: true
+
+ - type: dropdown
+ attributes:
+ label: YOLOv8 Component
+ description: |
+ Please select the part of YOLOv8 where you found the bug.
+ multiple: true
+ options:
+ - "Training"
+ - "Validation"
+ - "Detection"
+ - "Export"
+ - "PyTorch Hub"
+ - "Multi-GPU"
+ - "Evolution"
+ - "Integrations"
+ - "Other"
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Bug
+ description: Provide console output with error messages and/or screenshots of the bug.
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Environment
+ description: Please specify the software and hardware you used to produce the bug.
+ placeholder: |
+ - YOLO: Ultralytics YOLOv8.0.21 🚀 Python-3.8.10 torch-1.13.1+cu117 CUDA:0 (A100-SXM-80GB, 81251MiB)
+ - OS: Ubuntu 20.04
+ - Python: 3.8.10
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Minimal Reproducible Example
+ description: >
+ When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to **reproduce** the problem.
+ This is referred to by community members as creating a [minimal reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/).
+ placeholder: |
+ ```
+ # Code to reproduce your issue here
+ ```
+ validations:
+ required: false
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve YOLOv8 for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the YOLOv8 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/STPoseNet/.github/ISSUE_TEMPLATE/config.yml b/STPoseNet/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9018a6213fc1572409baa15bd107a2e8ebc378b8
--- /dev/null
+++ b/STPoseNet/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,11 @@
+blank_issues_enabled: true
+contact_links:
+ - name: 📄 Docs
+ url: https://docs.ultralytics.com/
+ about: Full Ultralytics YOLOv8 Documentation
+ - name: 💬 Forum
+ url: https://community.ultralytics.com/
+ about: Ask on Ultralytics Community Forum
+ - name: 🎧 Discord
+ url: https://ultralytics.com/discord
+ about: Ask on Ultralytics Discord
diff --git a/STPoseNet/.github/ISSUE_TEMPLATE/feature-request.yml b/STPoseNet/.github/ISSUE_TEMPLATE/feature-request.yml
new file mode 100644
index 0000000000000000000000000000000000000000..39158a0cff8586a57d2fde3d4390e511fd314129
--- /dev/null
+++ b/STPoseNet/.github/ISSUE_TEMPLATE/feature-request.yml
@@ -0,0 +1,50 @@
+name: 🚀 Feature Request
+description: Suggest a YOLOv8 idea
+# title: " "
+labels: [enhancement]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for submitting a YOLOv8 🚀 Feature Request!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/ultralytics/issues) to see if a similar feature request already exists.
+ options:
+ - label: >
+ I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Description
+ description: A short description of your feature.
+ placeholder: |
+ What new feature would you like to see in YOLOv8?
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Use case
+ description: |
+ Describe the use case of your feature request. It will help us understand and prioritize the feature request.
+ placeholder: |
+ How would this feature be used, and who would use it?
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
+
+ - type: checkboxes
+ attributes:
+ label: Are you willing to submit a PR?
+ description: >
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve YOLOv8 for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the YOLOv8 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ options:
+ - label: Yes I'd like to help by submitting a PR!
diff --git a/STPoseNet/.github/ISSUE_TEMPLATE/question.yml b/STPoseNet/.github/ISSUE_TEMPLATE/question.yml
new file mode 100644
index 0000000000000000000000000000000000000000..258e26baaaea111cbf37efaf27cd6cf5cbf15831
--- /dev/null
+++ b/STPoseNet/.github/ISSUE_TEMPLATE/question.yml
@@ -0,0 +1,33 @@
+name: ❓ Question
+description: Ask a YOLOv8 question
+# title: " "
+labels: [question]
+body:
+ - type: markdown
+ attributes:
+ value: |
+ Thank you for asking a YOLOv8 ❓ Question!
+
+ - type: checkboxes
+ attributes:
+ label: Search before asking
+ description: >
+ Please search the [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) to see if a similar question already exists.
+ options:
+ - label: >
+ I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Question
+ description: What is your question?
+ placeholder: |
+ 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ validations:
+ required: true
+
+ - type: textarea
+ attributes:
+ label: Additional
+ description: Anything else you would like to share?
diff --git a/STPoseNet/.github/dependabot.yml b/STPoseNet/.github/dependabot.yml
new file mode 100644
index 0000000000000000000000000000000000000000..ab54fc791b69ea16c4d5244c3a524c9c76ad8b79
--- /dev/null
+++ b/STPoseNet/.github/dependabot.yml
@@ -0,0 +1,28 @@
+# To get started with Dependabot version updates, you'll need to specify which
+# package ecosystems to update and where the package manifests are located.
+# Please see the documentation for all configuration options:
+# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
+
+version: 2
+updates:
+ - package-ecosystem: pip
+ directory: "/"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 10
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
+
+ - package-ecosystem: github-actions
+ directory: "/"
+ schedule:
+ interval: weekly
+ time: "04:00"
+ open-pull-requests-limit: 5
+ reviewers:
+ - glenn-jocher
+ labels:
+ - dependencies
diff --git a/STPoseNet/.github/translate-readme.yml b/STPoseNet/.github/translate-readme.yml
new file mode 100644
index 0000000000000000000000000000000000000000..102bba604414a56748034fdc0451547182796f73
--- /dev/null
+++ b/STPoseNet/.github/translate-readme.yml
@@ -0,0 +1,26 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# README translation action to translate README.md to Chinese as README.zh-CN.md on any change to README.md
+
+name: Translate README
+
+on:
+ push:
+ branches:
+ - translate_readme # replace with 'main' to enable action
+ paths:
+ - README.md
+
+jobs:
+ Translate:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: Setup Node.js
+ uses: actions/setup-node@v3
+ with:
+ node-version: 16
+ # ISO Language Codes: https://cloud.google.com/translate/docs/languages
+ - name: Adding README - Chinese Simplified
+ uses: dephraiim/translate-readme@main
+ with:
+ LANG: zh-CN
diff --git a/STPoseNet/.github/workflows/ci.yaml b/STPoseNet/.github/workflows/ci.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2b3e62f9ea3dbcbed795c39739c791816c5a0c8a
--- /dev/null
+++ b/STPoseNet/.github/workflows/ci.yaml
@@ -0,0 +1,247 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLO Continuous Integration (CI) GitHub Actions tests
+
+name: Ultralytics CI
+
+on:
+ push:
+ branches: [main]
+ pull_request:
+ branches: [main]
+ schedule:
+ - cron: '0 0 * * *' # runs at 00:00 UTC every day
+ workflow_dispatch:
+ inputs:
+ hub:
+ description: 'Run HUB'
+ default: false
+ type: boolean
+ tests:
+ description: 'Run Tests'
+ default: false
+ type: boolean
+ benchmarks:
+ description: 'Run Benchmarks'
+ default: false
+ type: boolean
+ gpu:
+ description: 'Run GPU'
+ default: false
+ type: boolean
+
+jobs:
+ HUB:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event_name == 'push' || (github.event_name == 'workflow_dispatch' && github.event.inputs.hub == 'true'))
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ['3.11']
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: 'pip' # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -e . --extra-index-url https://download.pytorch.org/whl/cpu
+ - name: Check environment
+ run: |
+ yolo checks
+ echo "RUNNER_OS is ${{ runner.os }}"
+ echo "GITHUB_EVENT_NAME is ${{ github.event_name }}"
+ echo "GITHUB_WORKFLOW is ${{ github.workflow }}"
+ echo "GITHUB_ACTOR is ${{ github.actor }}"
+ echo "GITHUB_REPOSITORY is ${{ github.repository }}"
+ echo "GITHUB_REPOSITORY_OWNER is ${{ github.repository_owner }}"
+ python --version
+ pip --version
+ pip list
+ - name: Test HUB training
+ shell: python
+ env:
+ API_KEY: ${{ secrets.ULTRALYTICS_HUB_API_KEY }}
+ MODEL_ID: ${{ secrets.ULTRALYTICS_HUB_MODEL_ID }}
+ run: |
+ import os
+ from ultralytics import YOLO, hub
+ api_key, model_id = os.environ['API_KEY'], os.environ['MODEL_ID']
+ hub.login(api_key)
+ hub.reset_model(model_id)
+ model = YOLO('https://hub.ultralytics.com/models/' + model_id)
+ model.train()
+ - name: Test HUB inference API
+ shell: python
+ env:
+ API_KEY: ${{ secrets.ULTRALYTICS_HUB_API_KEY }}
+ MODEL_ID: ${{ secrets.ULTRALYTICS_HUB_MODEL_ID }}
+ run: |
+ import os
+ import requests
+ import json
+ api_key, model_id = os.environ['API_KEY'], os.environ['MODEL_ID']
+ url = f"https://api.ultralytics.com/v1/predict/{model_id}"
+ headers = {"x-api-key": api_key}
+ data = {"size": 320, "confidence": 0.25, "iou": 0.45}
+ with open("ultralytics/assets/zidane.jpg", "rb") as f:
+ response = requests.post(url, headers=headers, data=data, files={"image": f})
+ assert response.status_code == 200, f'Status code {response.status_code}, Reason {response.reason}'
+ print(json.dumps(response.json(), indent=2))
+
+ Benchmarks:
+ if: github.event_name != 'workflow_dispatch' || github.event.inputs.benchmarks == 'true'
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ['3.10']
+ model: [yolov8n]
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: 'pip' # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: |
+ python -m pip install --upgrade pip wheel
+ pip install -e ".[export]" coverage --extra-index-url https://download.pytorch.org/whl/cpu
+ yolo export format=tflite imgsz=32 || true
+ - name: Check environment
+ run: |
+ yolo checks
+ echo "RUNNER_OS is ${{ runner.os }}"
+ echo "GITHUB_EVENT_NAME is ${{ github.event_name }}"
+ echo "GITHUB_WORKFLOW is ${{ github.workflow }}"
+ echo "GITHUB_ACTOR is ${{ github.actor }}"
+ echo "GITHUB_REPOSITORY is ${{ github.repository }}"
+ echo "GITHUB_REPOSITORY_OWNER is ${{ github.repository_owner }}"
+ python --version
+ pip --version
+ pip list
+ - name: Benchmark DetectionModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}.pt' imgsz=160 verbose=0.26
+ - name: Benchmark SegmentationModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-seg.pt' imgsz=160 verbose=0.30
+ - name: Benchmark ClassificationModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-cls.pt' imgsz=160 verbose=0.36
+ - name: Benchmark PoseModel
+ shell: bash
+ run: coverage run -a --source=ultralytics -m ultralytics.cfg.__init__ benchmark model='path with spaces/${{ matrix.model }}-pose.pt' imgsz=160 verbose=0.17
+ - name: Merge Coverage Reports
+ run: |
+ coverage xml -o coverage-benchmarks.xml
+ - name: Upload Coverage Reports to CodeCov
+ uses: codecov/codecov-action@v3
+ with:
+ flags: Benchmarks
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+ - name: Benchmark Summary
+ run: |
+ cat benchmarks.log
+ echo "$(cat benchmarks.log)" >> $GITHUB_STEP_SUMMARY
+
+ Tests:
+ if: github.event_name != 'workflow_dispatch' || github.event.inputs.tests == 'true'
+ timeout-minutes: 60
+ runs-on: ${{ matrix.os }}
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest]
+ python-version: ['3.11']
+ torch: [latest]
+ include:
+ - os: ubuntu-latest
+ python-version: '3.8' # torch 1.8.0 requires python >=3.6, <=3.8
+ torch: '1.8.0' # min torch version CI https://pypi.org/project/torchvision/
+ steps:
+ - uses: actions/checkout@v3
+ - uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: 'pip' # caching pip dependencies
+ - name: Install requirements
+ shell: bash # for Windows compatibility
+ run: | # CoreML must be installed before export due to protobuf error from AutoInstall
+ python -m pip install --upgrade pip wheel
+ if [ "${{ matrix.torch }}" == "1.8.0" ]; then
+ pip install -e . torch==1.8.0 torchvision==0.9.0 pytest-cov "coremltools>=7.0.b1" --extra-index-url https://download.pytorch.org/whl/cpu
+ else
+ pip install -e . pytest-cov "coremltools>=7.0.b1" --extra-index-url https://download.pytorch.org/whl/cpu
+ fi
+ - name: Check environment
+ run: |
+ yolo checks
+ echo "RUNNER_OS is ${{ runner.os }}"
+ echo "GITHUB_EVENT_NAME is ${{ github.event_name }}"
+ echo "GITHUB_WORKFLOW is ${{ github.workflow }}"
+ echo "GITHUB_ACTOR is ${{ github.actor }}"
+ echo "GITHUB_REPOSITORY is ${{ github.repository }}"
+ echo "GITHUB_REPOSITORY_OWNER is ${{ github.repository_owner }}"
+ python --version
+ pip --version
+ pip list
+ - name: Pytest tests
+ shell: bash # for Windows compatibility
+ run: pytest --cov=ultralytics/ --cov-report xml tests/
+ - name: Upload Coverage Reports to CodeCov
+ if: github.repository == 'ultralytics/ultralytics' # && matrix.os == 'ubuntu-latest' && matrix.python-version == '3.11'
+ uses: codecov/codecov-action@v3
+ with:
+ flags: Tests
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+
+ GPU:
+ if: github.repository == 'ultralytics/ultralytics' && (github.event_name != 'workflow_dispatch' || github.event.inputs.gpu == 'true')
+ timeout-minutes: 60
+ runs-on: gpu-latest
+ steps:
+ - uses: actions/checkout@v3
+ - name: Install requirements
+ run: pip install -e .
+ - name: Check environment
+ run: |
+ yolo checks
+ echo "RUNNER_OS is ${{ runner.os }}"
+ echo "GITHUB_EVENT_NAME is ${{ github.event_name }}"
+ echo "GITHUB_WORKFLOW is ${{ github.workflow }}"
+ echo "GITHUB_ACTOR is ${{ github.actor }}"
+ echo "GITHUB_REPOSITORY is ${{ github.repository }}"
+ echo "GITHUB_REPOSITORY_OWNER is ${{ github.repository_owner }}"
+ python --version
+ pip --version
+ pip list
+ - name: Pytest tests
+ run: pytest --cov=ultralytics/ --cov-report xml tests/test_cuda.py
+ - name: Upload Coverage Reports to CodeCov
+ uses: codecov/codecov-action@v3
+ with:
+ flags: GPU
+ env:
+ CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
+
+ Summary:
+ runs-on: ubuntu-latest
+ needs: [HUB, Benchmarks, Tests, GPU] # Add job names that you want to check for failure
+ if: always() # This ensures the job runs even if previous jobs fail
+ steps:
+ - name: Check for failure and notify
+ if: (needs.HUB.result == 'failure' || needs.Benchmarks.result == 'failure' || needs.Tests.result == 'failure' || needs.GPU.result == 'failure') && github.repository == 'ultralytics/ultralytics' && (github.event_name == 'schedule' || github.event_name == 'push')
+ uses: slackapi/slack-github-action@v1.24.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/STPoseNet/.github/workflows/cla.yml b/STPoseNet/.github/workflows/cla.yml
new file mode 100644
index 0000000000000000000000000000000000000000..bb9c26a1ac0d0c9cad9bb3a803f57d3e73c8fa96
--- /dev/null
+++ b/STPoseNet/.github/workflows/cla.yml
@@ -0,0 +1,37 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: CLA Assistant
+on:
+ issue_comment:
+ types:
+ - created
+ pull_request_target:
+ types:
+ - reopened
+ - opened
+ - synchronize
+
+jobs:
+ CLA:
+ if: github.repository == 'ultralytics/ultralytics'
+ runs-on: ubuntu-latest
+ steps:
+ - name: CLA Assistant
+ if: (github.event.comment.body == 'recheck' || github.event.comment.body == 'I have read the CLA Document and I sign the CLA') || github.event_name == 'pull_request_target'
+ uses: contributor-assistant/github-action@v2.3.0
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
+ # must be repository secret token
+ PERSONAL_ACCESS_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
+ with:
+ path-to-signatures: 'signatures/version1/cla.json'
+ path-to-document: 'https://docs.ultralytics.com/help/CLA' # CLA document
+ # branch should not be protected
+ branch: 'main'
+ allowlist: dependabot[bot],github-actions,[pre-commit*,pre-commit*,bot*
+
+ remote-organization-name: ultralytics
+ remote-repository-name: cla
+ custom-pr-sign-comment: 'I have read the CLA Document and I sign the CLA'
+ custom-allsigned-prcomment: All Contributors have signed the CLA. ✅
+ #custom-notsigned-prcomment: 'pull request comment with Introductory message to ask new contributors to sign'
diff --git a/STPoseNet/.github/workflows/codeql.yaml b/STPoseNet/.github/workflows/codeql.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..526f5e4880345d15ab25cfb25ea4e2e94973b6ca
--- /dev/null
+++ b/STPoseNet/.github/workflows/codeql.yaml
@@ -0,0 +1,41 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: "CodeQL"
+
+on:
+ schedule:
+ - cron: '0 0 1 * *'
+
+jobs:
+ analyze:
+ name: Analyze
+ runs-on: ${{ 'ubuntu-latest' }}
+ permissions:
+ actions: read
+ contents: read
+ security-events: write
+
+ strategy:
+ fail-fast: false
+ matrix:
+ language: [ 'python' ]
+ # CodeQL supports [ 'cpp', 'csharp', 'go', 'java', 'javascript', 'python', 'ruby' ]
+
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v3
+
+ # Initializes the CodeQL tools for scanning.
+ - name: Initialize CodeQL
+ uses: github/codeql-action/init@v2
+ with:
+ languages: ${{ matrix.language }}
+ # If you wish to specify custom queries, you can do so here or in a config file.
+ # By default, queries listed here will override any specified in a config file.
+ # Prefix the list here with "+" to use these queries and those in the config file.
+ # queries: security-extended,security-and-quality
+
+ - name: Perform CodeQL Analysis
+ uses: github/codeql-action/analyze@v2
+ with:
+ category: "/language:${{matrix.language}}"
diff --git a/STPoseNet/.github/workflows/docker.yaml b/STPoseNet/.github/workflows/docker.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..faf0bcc9753e7514b2114b66abc1269edd40fa05
--- /dev/null
+++ b/STPoseNet/.github/workflows/docker.yaml
@@ -0,0 +1,133 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest images on DockerHub https://hub.docker.com/r/ultralytics
+
+name: Publish Docker Images
+
+on:
+ push:
+ branches: [main]
+ workflow_dispatch:
+ inputs:
+ dockerfile:
+ type: choice
+ description: Select Dockerfile
+ options:
+ - Dockerfile-arm64
+ - Dockerfile-jetson
+ - Dockerfile-python
+ - Dockerfile-cpu
+ - Dockerfile
+ push:
+ type: boolean
+ description: Push image to Docker Hub
+ default: true
+
+jobs:
+ docker:
+ if: github.repository == 'ultralytics/ultralytics'
+ name: Push
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ max-parallel: 5
+ matrix:
+ include:
+ - dockerfile: "Dockerfile-arm64"
+ tags: "latest-arm64"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-jetson"
+ tags: "latest-jetson"
+ platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-python"
+ tags: "latest-python"
+ platforms: "linux/amd64"
+ - dockerfile: "Dockerfile-cpu"
+ tags: "latest-cpu"
+ platforms: "linux/amd64"
+ - dockerfile: "Dockerfile"
+ tags: "latest"
+ platforms: "linux/amd64"
+ steps:
+ - name: Checkout repo
+ uses: actions/checkout@v3
+
+ - name: Set up QEMU
+ uses: docker/setup-qemu-action@v2
+
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v2
+
+ - name: Login to Docker Hub
+ uses: docker/login-action@v2
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_TOKEN }}
+
+ - name: Retrieve Ultralytics version
+ id: get_version
+ run: |
+ VERSION=$(grep "^__version__ =" ultralytics/__init__.py | awk -F"'" '{print $2}')
+ echo "Retrieved Ultralytics version: $VERSION"
+ echo "version=$VERSION" >> $GITHUB_OUTPUT
+
+ VERSION_TAG=$(echo "${{ matrix.tags }}" | sed "s/latest/${VERSION}/")
+ echo "Intended version tag: $VERSION_TAG"
+ echo "version_tag=$VERSION_TAG" >> $GITHUB_OUTPUT
+
+ - name: Check if version tag exists on DockerHub
+ id: check_tag
+ run: |
+ RESPONSE=$(curl -s https://hub.docker.com/v2/repositories/ultralytics/ultralytics/tags/$VERSION_TAG)
+ MESSAGE=$(echo $RESPONSE | jq -r '.message')
+ if [[ "$MESSAGE" == "null" ]]; then
+ echo "Tag $VERSION_TAG already exists on DockerHub."
+ echo "exists=true" >> $GITHUB_OUTPUT
+ elif [[ "$MESSAGE" == *"404"* ]]; then
+ echo "Tag $VERSION_TAG does not exist on DockerHub."
+ echo "exists=false" >> $GITHUB_OUTPUT
+ else
+ echo "Unexpected response from DockerHub. Please check manually."
+ echo "exists=false" >> $GITHUB_OUTPUT
+ fi
+ env:
+ VERSION_TAG: ${{ steps.get_version.outputs.version_tag }}
+
+ - name: Build Image
+ if: github.event_name == 'push' || github.event.inputs.dockerfile == matrix.dockerfile
+ run: |
+ docker build --platform ${{ matrix.platforms }} -f docker/${{ matrix.dockerfile }} \
+ -t ultralytics/ultralytics:${{ matrix.tags }} \
+ -t ultralytics/ultralytics:${{ steps.get_version.outputs.version_tag }} .
+
+ - name: Run Tests
+ if: (github.event_name == 'push' || github.event.inputs.dockerfile == matrix.dockerfile) && matrix.platforms == 'linux/amd64' # arm64 images not supported on GitHub CI runners
+ run: docker run ultralytics/ultralytics:${{ matrix.tags }} /bin/bash -c "pip install pytest && pytest tests"
+
+ - name: Run Benchmarks
+ # WARNING: Dockerfile (GPU) error on TF.js export 'module 'numpy' has no attribute 'object'.
+ if: (github.event_name == 'push' || github.event.inputs.dockerfile == matrix.dockerfile) && matrix.platforms == 'linux/amd64' && matrix.dockerfile != 'Dockerfile' # arm64 images not supported on GitHub CI runners
+ run: docker run ultralytics/ultralytics:${{ matrix.tags }} yolo benchmark model=yolov8n.pt imgsz=160 verbose=0.26
+
+ - name: Push Docker Image with Ultralytics version tag
+ if: (github.event_name == 'push' || (github.event.inputs.dockerfile == matrix.dockerfile && github.event.inputs.push == 'true')) && steps.check_tag.outputs.exists == 'false'
+ run: |
+ docker push ultralytics/ultralytics:${{ steps.get_version.outputs.version_tag }}
+
+ - name: Push Docker Image with latest tag
+ if: github.event_name == 'push' || (github.event.inputs.dockerfile == matrix.dockerfile && github.event.inputs.push == 'true')
+ run: |
+ docker push ultralytics/ultralytics:${{ matrix.tags }}
+ if [[ "${{ matrix.tags }}" == "latest" ]]; then
+ t=ultralytics/ultralytics:latest-runner
+ docker build -f docker/Dockerfile-runner -t $t .
+ docker push $t
+ fi
+
+ - name: Notify on failure
+ if: github.event_name == 'push' && failure() # do not notify on cancelled() as cancelling is performed by hand
+ uses: slackapi/slack-github-action@v1.24.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/STPoseNet/.github/workflows/greetings.yml b/STPoseNet/.github/workflows/greetings.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5f0289a5f957dc4a229cf5a21c6ab29fa0a6366a
--- /dev/null
+++ b/STPoseNet/.github/workflows/greetings.yml
@@ -0,0 +1,58 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: Greetings
+
+on:
+ pull_request_target:
+ types: [opened]
+ issues:
+ types: [opened]
+
+jobs:
+ greeting:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/first-interaction@v1
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+ pr-message: |
+ 👋 Hello @${{ github.actor }}, thank you for submitting a YOLOv8 🚀 PR! To allow your work to be integrated as seamlessly as possible, we advise you to:
+
+ - ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
+ - ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
+ - ✅ Update YOLOv8 [Docs](https://docs.ultralytics.com) for any new or updated features.
+ - ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
+
+ See our [Contributing Guide](https://docs.ultralytics.com/help/contributing) for details and let us know if you have any questions!
+
+ issue-message: |
+ 👋 Hello @${{ github.actor }}, thank you for your interest in YOLOv8 🚀! We recommend a visit to the [YOLOv8 Docs](https://docs.ultralytics.com) for new users where you can find many [Python](https://docs.ultralytics.com/usage/python/) and [CLI](https://docs.ultralytics.com/usage/cli/) usage examples and where many of the most common questions may already be answered.
+
+ If this is a 🐛 Bug Report, please provide a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us debug it.
+
+ If this is a custom training ❓ Question, please provide as much information as possible, including dataset image examples and training logs, and verify you are following our [Tips for Best Training Results](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results/).
+
+ Join the vibrant [Ultralytics Discord](https://ultralytics.com/discord) 🎧 community for real-time conversations and collaborations. This platform offers a perfect space to inquire, showcase your work, and connect with fellow Ultralytics users.
+
+ ## Install
+
+ Pip install the `ultralytics` package including all [requirements](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) in a [**Python>=3.8**](https://www.python.org/) environment with [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/).
+
+ ```bash
+ pip install ultralytics
+ ```
+
+ ## Environments
+
+ YOLOv8 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+ - **Notebooks** with free GPU: ${{ env.PR_TITLE }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
+ - name: Notify on Slack (Failure)
+ if: failure()
+ uses: slackapi/slack-github-action@v1.24.0
+ with:
+ payload: |
+ {"text": " GitHub Actions error for ${{ github.workflow }} ❌\n\n\n*Repository:* https://github.com/${{ github.repository }}\n*Action:* https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}\n*Author:* ${{ github.actor }}\n*Event:* ${{ github.event_name }}\n*Job Status:* ${{ job.status }}\n*Pull Request:* ${{ env.PR_TITLE }}\n"}
+ env:
+ SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_YOLO }}
diff --git a/STPoseNet/.github/workflows/stale.yml b/STPoseNet/.github/workflows/stale.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a3d623dbad14106aff59327527377b52cb5e626b
--- /dev/null
+++ b/STPoseNet/.github/workflows/stale.yml
@@ -0,0 +1,47 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+name: Close stale issues
+on:
+ schedule:
+ - cron: '0 0 * * *' # Runs at 00:00 UTC every day
+
+jobs:
+ stale:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/stale@v8
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+
+ stale-issue-message: |
+ 👋 Hello there! We wanted to give you a friendly reminder that this issue has not had any recent activity and may be closed soon, but don't worry - you can always reopen it if needed. If you still have any questions or concerns, please feel free to let us know how we can help.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Feel free to inform us of any other **issues** you discover or **feature requests** that come to mind in the future. Pull Requests (PRs) are also always welcomed!
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ stale-pr-message: |
+ 👋 Hello there! We wanted to let you know that we've decided to close this pull request due to inactivity. We appreciate the effort you put into contributing to our project, but unfortunately, not all contributions are suitable or aligned with our product roadmap.
+
+ We hope you understand our decision, and please don't let it discourage you from contributing to open source projects in the future. We value all of our community members and their contributions, and we encourage you to keep exploring new projects and ways to get involved.
+
+ For additional resources and information, please see the links below:
+
+ - **Docs**: https://docs.ultralytics.com
+ - **HUB**: https://hub.ultralytics.com
+ - **Community**: https://community.ultralytics.com
+
+ Thank you for your contributions to YOLO 🚀 and Vision AI ⭐
+
+ days-before-issue-stale: 30
+ days-before-issue-close: 10
+ days-before-pr-stale: 90
+ days-before-pr-close: 30
+ exempt-issue-labels: 'documentation,tutorial,TODO'
+ operations-per-run: 300 # The maximum number of operations per run, used to control rate limiting.
diff --git a/STPoseNet/.gitignore b/STPoseNet/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..c8987d84a7f1cd74618a8c1a01c9d7c819f40bfe
--- /dev/null
+++ b/STPoseNet/.gitignore
@@ -0,0 +1,165 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# Profiling
+*.pclprof
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+.idea
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# VSCode project settings
+.vscode/
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+mkdocs_github_authors.yaml
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+
+# datasets and projects
+datasets/
+runs/
+wandb/
+tests/
+.DS_Store
+
+# Neural Network weights -----------------------------------------------------------------------------------------------
+weights/
+*.weights
+*.pt
+*.pb
+*.onnx
+*.engine
+*.mlmodel
+*.mlpackage
+*.torchscript
+*.tflite
+*.h5
+*_saved_model/
+*_web_model/
+*_openvino_model/
+*_paddle_model/
+pnnx*
+
+# Autogenerated files for tests
+/ultralytics/assets/
diff --git a/STPoseNet/.idea/.gitignore b/STPoseNet/.idea/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..26d33521af10bcc7fd8cea344038eaaeb78d0ef5
--- /dev/null
+++ b/STPoseNet/.idea/.gitignore
@@ -0,0 +1,3 @@
+# Default ignored files
+/shelf/
+/workspace.xml
diff --git a/STPoseNet/.idea/inspectionProfiles/Project_Default.xml b/STPoseNet/.idea/inspectionProfiles/Project_Default.xml
new file mode 100644
index 0000000000000000000000000000000000000000..02c85104b22b59a770afdb4c7f24dbfa7833197c
--- /dev/null
+++ b/STPoseNet/.idea/inspectionProfiles/Project_Default.xml
@@ -0,0 +1,24 @@
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.idea/inspectionProfiles/profiles_settings.xml b/STPoseNet/.idea/inspectionProfiles/profiles_settings.xml
new file mode 100644
index 0000000000000000000000000000000000000000..105ce2da2d6447d11dfe32bfb846c3d5b199fc99
--- /dev/null
+++ b/STPoseNet/.idea/inspectionProfiles/profiles_settings.xml
@@ -0,0 +1,6 @@
+
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.idea/misc.xml b/STPoseNet/.idea/misc.xml
new file mode 100644
index 0000000000000000000000000000000000000000..5412abcc1a35a12e9136781e563364a9f2d78eeb
--- /dev/null
+++ b/STPoseNet/.idea/misc.xml
@@ -0,0 +1,4 @@
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.idea/modules.xml b/STPoseNet/.idea/modules.xml
new file mode 100644
index 0000000000000000000000000000000000000000..ce68848455afea2f111f989f2c4f48d9ed246e6d
--- /dev/null
+++ b/STPoseNet/.idea/modules.xml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.idea/ultralytics-main.iml b/STPoseNet/.idea/ultralytics-main.iml
new file mode 100644
index 0000000000000000000000000000000000000000..ad4c83af4f280ab0196f0e4202dcaa647e8d3348
--- /dev/null
+++ b/STPoseNet/.idea/ultralytics-main.iml
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.idea/workspace.xml b/STPoseNet/.idea/workspace.xml
new file mode 100644
index 0000000000000000000000000000000000000000..bf6b0bae9e025a1656f6b682cc50778a7ceeaf84
--- /dev/null
+++ b/STPoseNet/.idea/workspace.xml
@@ -0,0 +1,198 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 1693292470208
+ 1693292470208
+
+
+
+
+
+
+ file://$PROJECT_DIR$/ultralytics/engine/trainer.py
+ 261
+
+
+ file://$PROJECT_DIR$/ultralytics/models/yolo/detect/predict.py
+ 38
+
+
+ file://$PROJECT_DIR$/ultralytics/engine/predictor.py
+ 458
+
+
+ file://$PROJECT_DIR$/ultralytics/engine/predictor.py
+ 560
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/STPoseNet/.pre-commit-config.yaml b/STPoseNet/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..efbdd7c65437a4b600f01b9d1154a260f1522b4b
--- /dev/null
+++ b/STPoseNet/.pre-commit-config.yaml
@@ -0,0 +1,73 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Pre-commit hooks. For more information see https://github.com/pre-commit/pre-commit-hooks/blob/main/README.md
+
+exclude: 'docs/'
+# Define bot property if installed via https://github.com/marketplace/pre-commit-ci
+ci:
+ autofix_prs: true
+ autoupdate_commit_msg: '[pre-commit.ci] pre-commit suggestions'
+ autoupdate_schedule: monthly
+ # submodules: true
+
+repos:
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.4.0
+ hooks:
+ - id: end-of-file-fixer
+ - id: trailing-whitespace
+ - id: check-case-conflict
+ # - id: check-yaml
+ - id: check-docstring-first
+ - id: double-quote-string-fixer
+ - id: detect-private-key
+
+ - repo: https://github.com/asottile/pyupgrade
+ rev: v3.10.1
+ hooks:
+ - id: pyupgrade
+ name: Upgrade code
+
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.12.0
+ hooks:
+ - id: isort
+ name: Sort imports
+
+ - repo: https://github.com/google/yapf
+ rev: v0.40.0
+ hooks:
+ - id: yapf
+ name: YAPF formatting
+
+ - repo: https://github.com/executablebooks/mdformat
+ rev: 0.7.16
+ hooks:
+ - id: mdformat
+ name: MD formatting
+ additional_dependencies:
+ - mdformat-gfm
+ - mdformat-black
+ # exclude: "README.md|README.zh-CN.md|CONTRIBUTING.md"
+
+ - repo: https://github.com/PyCQA/flake8
+ rev: 6.1.0
+ hooks:
+ - id: flake8
+ name: PEP8
+
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.2.5
+ hooks:
+ - id: codespell
+ args:
+ - --ignore-words-list=crate,nd,strack,dota,ane,segway,fo
+
+# - repo: https://github.com/asottile/yesqa
+# rev: v1.4.0
+# hooks:
+# - id: yesqa
+
+# - repo: https://github.com/asottile/dead
+# rev: v1.5.0
+# hooks:
+# - id: dead
diff --git a/STPoseNet/CITATION.cff b/STPoseNet/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..8e85b7a7519db1054fe4d73805cea5d4ec5a2c3b
--- /dev/null
+++ b/STPoseNet/CITATION.cff
@@ -0,0 +1,20 @@
+cff-version: 1.2.0
+preferred-citation:
+ type: software
+ message: If you use this software, please cite it as below.
+ authors:
+ - family-names: Jocher
+ given-names: Glenn
+ orcid: "https://orcid.org/0000-0001-5950-6979"
+ - family-names: Chaurasia
+ given-names: Ayush
+ orcid: "https://orcid.org/0000-0002-7603-6750"
+ - family-names: Qiu
+ given-names: Jing
+ orcid: "https://orcid.org/0000-0003-3783-7069"
+ title: "YOLO by Ultralytics"
+ version: 8.0.0
+ # doi: 10.5281/zenodo.3908559 # TODO
+ date-released: 2023-1-10
+ license: AGPL-3.0
+ url: "https://github.com/ultralytics/ultralytics"
diff --git a/STPoseNet/CONTRIBUTING.md b/STPoseNet/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4f12c6a42c343f28f2997dfcf72c63cd7b99e40
--- /dev/null
+++ b/STPoseNet/CONTRIBUTING.md
@@ -0,0 +1,115 @@
+## Contributing to YOLOv8 🚀
+
+We love your input! We want to make contributing to YOLOv8 as easy and transparent as possible, whether it's:
+
+- Reporting a bug
+- Discussing the current state of the code
+- Submitting a fix
+- Proposing a new feature
+- Becoming a maintainer
+
+YOLOv8 works so well due to our combined community effort, and for every small improvement you contribute you will be
+helping push the frontiers of what's possible in AI 😃!
+
+## Submitting a Pull Request (PR) 🛠️
+
+Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
+
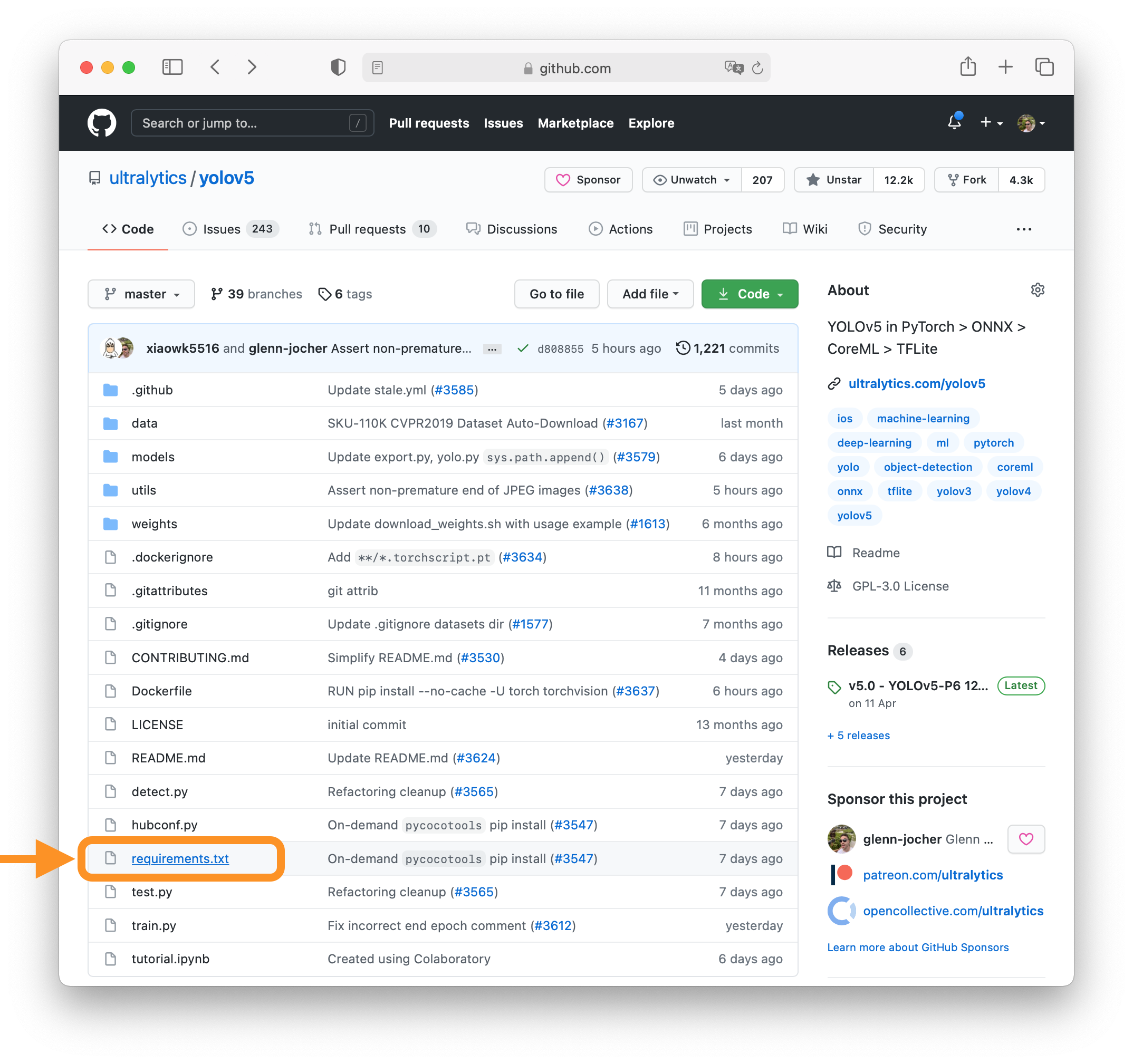
+### 1. Select File to Update
+
+Select `requirements.txt` to update by clicking on it in GitHub.
+
+
+
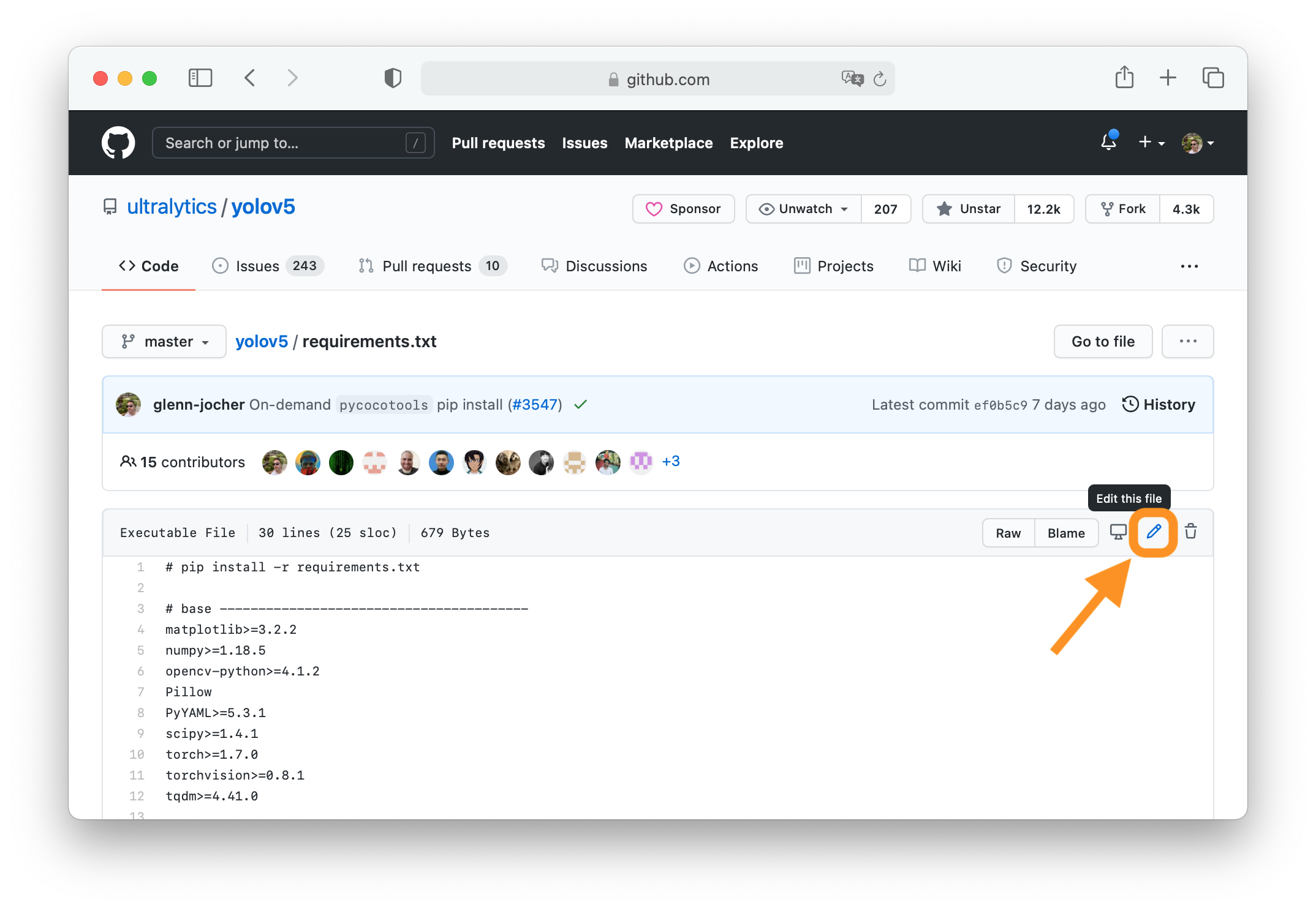
+### 2. Click 'Edit this file'
+
+Button is in top-right corner.
+
+
+
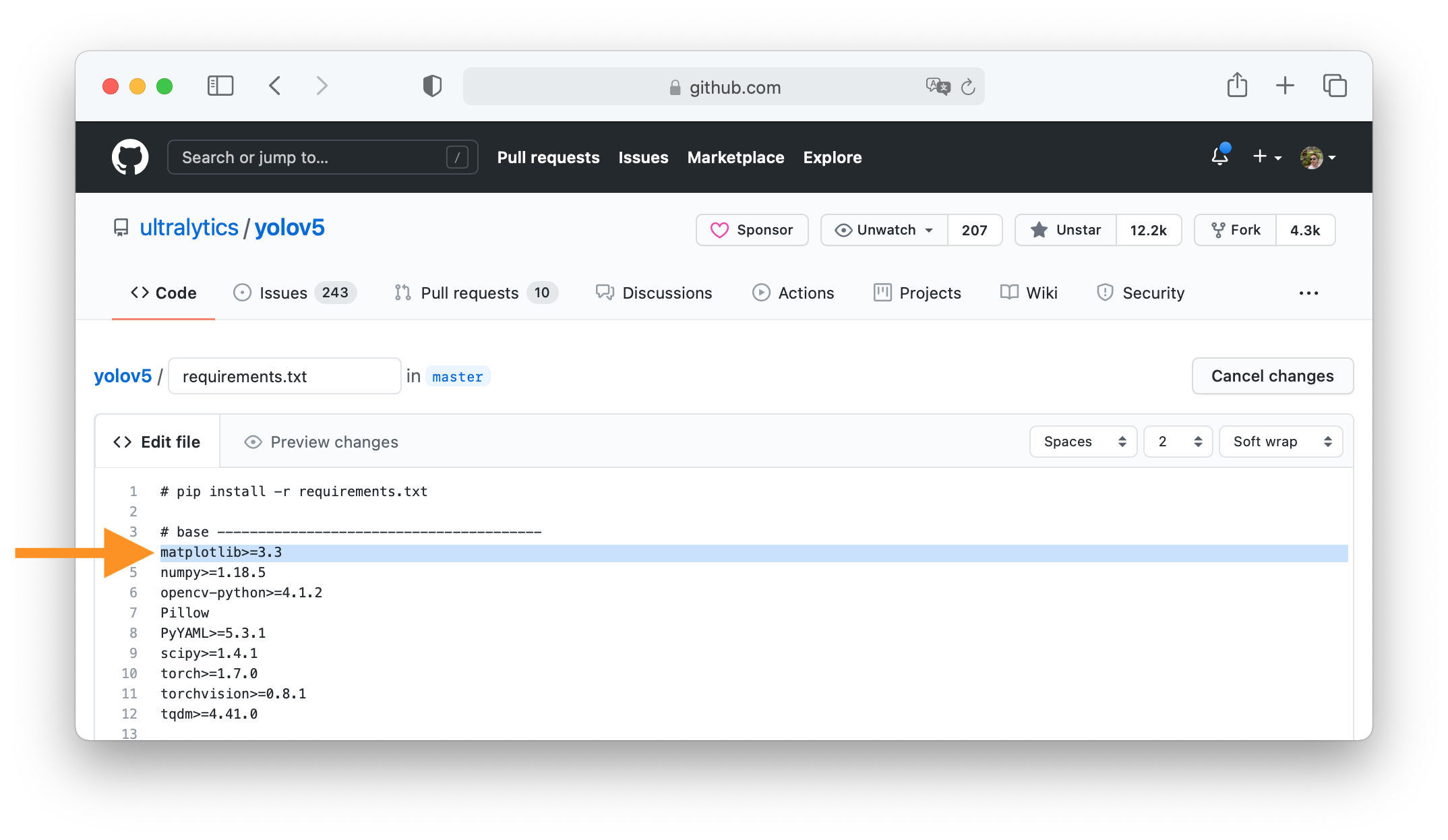
+### 3. Make Changes
+
+Change `matplotlib` version from `3.2.2` to `3.3`.
+
+
+
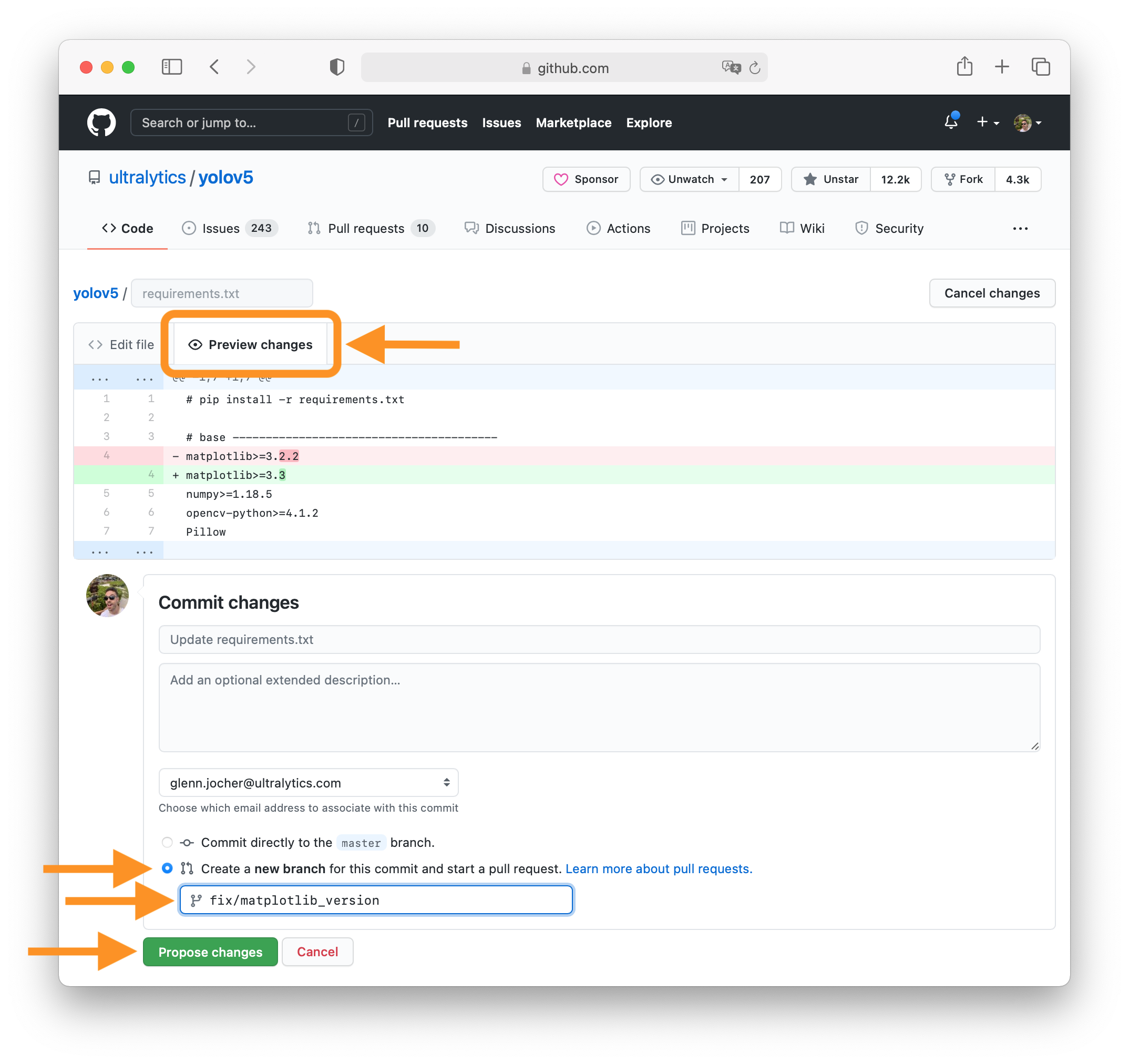
+### 4. Preview Changes and Submit PR
+
+Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
+for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
+changes** button. All done, your PR is now submitted to YOLOv8 for review and approval 😃!
+
+
+
+### PR recommendations
+
+To allow your work to be integrated as seamlessly as possible, we advise you to:
+
+- ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update
+ your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
+
+
+
+- ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
+
+
+
+- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
+ but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
+
+### Docstrings
+
+Not all functions or classes require docstrings but when they do, we
+follow [google-style docstrings format](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings).
+Here is an example:
+
+```python
+"""
+ What the function does. Performs NMS on given detection predictions.
+
+ Args:
+ arg1: The description of the 1st argument
+ arg2: The description of the 2nd argument
+
+ Returns:
+ What the function returns. Empty if nothing is returned.
+
+ Raises:
+ Exception Class: When and why this exception can be raised by the function.
+"""
+```
+
+## Submitting a Bug Report 🐛
+
+If you spot a problem with YOLOv8 please submit a Bug Report!
+
+For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
+short guidelines below to help users provide what we need in order to get started.
+
+When asking a question, people will be better able to provide help if you provide **code** that they can easily
+understand and use to **reproduce** the problem. This is referred to by community members as creating
+a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces
+the problem should be:
+
+- ✅ **Minimal** – Use as little code as possible that still produces the same problem
+- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
+- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
+
+In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
+should be:
+
+- ✅ **Current** – Verify that your code is up-to-date with current
+ GitHub [main](https://github.com/ultralytics/ultralytics/tree/main) branch, and if necessary `git pull` or `git clone`
+ a new copy to ensure your problem has not already been resolved by previous commits.
+- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
+ repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
+
+If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
+**Bug Report** [template](https://github.com/ultralytics/ultralytics/issues/new/choose) and providing
+a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better
+understand and diagnose your problem.
+
+## License
+
+By contributing, you agree that your contributions will be licensed under
+the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
diff --git a/STPoseNet/MANIFEST.in b/STPoseNet/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..def1ad3c3a3950d81bf8e7aeb83d37953c1ed74f
--- /dev/null
+++ b/STPoseNet/MANIFEST.in
@@ -0,0 +1,8 @@
+include *.md
+include requirements.txt
+include LICENSE
+include setup.py
+include ultralytics/assets/bus.jpg
+include ultralytics/assets/zidane.jpg
+recursive-include ultralytics *.yaml
+recursive-exclude __pycache__ *
diff --git a/STPoseNet/README.md b/STPoseNet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..26c4980bb4820d31e720a89d12281b2f2fa42966
--- /dev/null
+++ b/STPoseNet/README.md
@@ -0,0 +1,55 @@
+# STPoseNet
+This is a pose recognition model for laboratory mice based on yolov8.
+
+## The repository includes:
+
+Source code of STposeNet built on YOLO v8
+Training code for STposeNet
+Data enhancement code for STposeNet
+Keypoints identification program for STposeNet
+
+## Using STPoseNet
+
+### **Create a new environment**
+
+[requirements.txt](https://github.com/lvrgb777/STPoseNet/blob/master/STPoseNet/requirements.txt) supports the normal running of STPoseNet. Before using STPoseNet, ensure that the environment is configured according to this file.
+```
+-conda create -n STPoseNet python=3.8
+-pip install -r requirements.txt
+```
+### **Dataset preparation**
+
+In this folder [Neurofinder](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/Neurofinder), We provide two images for testing.
+* In this folder, [leftImg8bit](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/Neurofinder/test/leftImg8bit) stores the two-photon calcium imaging and [gtFine](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/Neurofinder/test/gtFine) stores the corresponding GT.
+* [generate_dataset.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/Neurofinder/generate_dataset.py) is used to generate [image list](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/Neurofinder/imglists). After adding new images, run this code to generate the list for training and test code can read new images.
+
+### **Model preparation**
+
+This folder [models](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/models) is used to store the pretrained model and the test model. The test model can be downloaded from our [huggingface](https://huggingface.co/XZH-James/NeuroSeg2/tree/main).
+
+### **training or testing**
+
+After abtaining the dataset and model, running [test.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/test.py) to test the image.
+Running [train.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/train.py) to train the new dataset.
+
+### **The result**
+
+[logs/evalution](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/logs/evalution/Neurofinder) contains the results of the neurons segmentation of NeuroSeg-II.
+* [plt/difference](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/logs/evalution/Neurofinder/plt/difference) stores the segmented image by NeuroSeg-II.
+* [evaluation_log.csv](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/logs/evalution/Neurofinder/evaluation_log.csv) is the score for this test.
+
+## Other matters
+
+### **Core code**
+In [neuroseg2](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2) are the core code of NeuroSeg-II.
+* [model.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2/model.py) and [utils.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2/utils.py) are the code of overall structure.
+* [Down.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2/Down.py) is the code of FPN+.
+* [attention.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2/attention.py) is the code of attention mechanism.
+* [visualize.py](https://github.com/XZH-James/NeuroSeg2/blob/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/neuroseg2/visualize.py) is the code for visual segmentation result.
+
+### **Code of preprocessing**
+In [utilities](https://github.com/XZH-James/NeuroSeg2/tree/main/NeuroSeg%E2%85%A1-main/NeuroSeg%E2%85%A1-main/utilities) are the code for preprocessing.
+
+## Contact information
+
+If you have any questions about this project, please feel free to contact us. Email address: zhehao_xu@qq.com
diff --git a/STPoseNet/docker/Dockerfile b/STPoseNet/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..d7ed382acb05e6e233e8a7a8874a4b0bef77f5ec
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile
@@ -0,0 +1,83 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference
+
+# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch or nvcr.io/nvidia/pytorch:23.03-py3
+FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime
+RUN pip install --no-cache nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+# RUN alias python=python3
+
+# Security updates
+# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
+RUN apt upgrade --no-install-recommends -y openssl tar
+
+# Create working directory
+WORKDIR /usr/src/ultralytics
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -e ".[export]" thop albumentations comet pycocotools pytest-cov
+
+# Run exports to AutoInstall packages
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires <= Python 3.10, bug with paddlepaddle==2.5.0
+RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
+# Fix error: `np.bool` was a deprecated alias for the builtin `bool`
+RUN pip install --no-cache numpy==1.23.5
+# Remove exported models
+RUN rm -rf tmp
+
+# Set environment variables
+ENV OMP_NUM_THREADS=1
+# Avoid DDP error "MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library" https://github.com/pytorch/pytorch/issues/37377
+ENV MKL_THREADING_LAYER=GNU
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest && sudo docker build -f docker/Dockerfile -t $t . && sudo docker push $t
+
+# Pull and Run with access to all GPUs
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
+
+# Pull and Run with access to GPUs 2 and 3 (inside container CUDA devices will appear as 0 and 1)
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
+
+# Pull and Run with local directory access
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
+
+# Kill all
+# sudo docker kill $(sudo docker ps -q)
+
+# Kill all image-based
+# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/ultralytics:latest)
+
+# DockerHub tag update
+# t=ultralytics/ultralytics:latest tnew=ultralytics/ultralytics:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew
+
+# Clean up
+# sudo docker system prune -a --volumes
+
+# Update Ubuntu drivers
+# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
+
+# DDP test
+# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
+
+# GCP VM from Image
+# docker.io/ultralytics/ultralytics:latest
diff --git a/STPoseNet/docker/Dockerfile-arm64 b/STPoseNet/docker/Dockerfile-arm64
new file mode 100644
index 0000000000000000000000000000000000000000..e4c7be4a85ca258fc08bb9bcadd7c2c40a5634b1
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile-arm64
@@ -0,0 +1,39 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM arm64v8/ubuntu:22.10
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+# RUN alias python=python3
+
+# Create working directory
+WORKDIR /usr/src/ultralytics
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -e . thop
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/STPoseNet/docker/Dockerfile-cpu b/STPoseNet/docker/Dockerfile-cpu
new file mode 100644
index 0000000000000000000000000000000000000000..3e635963b77a3918ecc6cbe2d2e157bed12670c3
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile-cpu
@@ -0,0 +1,49 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM ubuntu:lunar-20230615
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+# RUN alias python=python3
+
+# Create working directory
+WORKDIR /usr/src/ultralytics
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
+
+# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
+RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -e ".[export]" thop --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Run exports to AutoInstall packages
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires <= Python 3.10, bug with paddlepaddle==2.5.0
+# RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
+# Remove exported models
+RUN rm -rf tmp
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-cpu && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-cpu && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/STPoseNet/docker/Dockerfile-jetson b/STPoseNet/docker/Dockerfile-jetson
new file mode 100644
index 0000000000000000000000000000000000000000..11f92f2ec440a8b08d901d63ae7460febfa7a27d
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile-jetson
@@ -0,0 +1,46 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:jetson image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Supports JetPack for YOLOv8 on Jetson Nano, TX1/TX2, Xavier NX, AGX Xavier, AGX Orin, and Orin NX
+
+# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch
+FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+# RUN alias python=python3
+
+# Create working directory
+WORKDIR /usr/src/ultralytics
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
+
+# Remove opencv-python from requirements.txt as it conflicts with opencv-python installed in base image
+RUN grep -v '^opencv-python' requirements.txt > tmp.txt && mv tmp.txt requirements.txt
+
+# Install pip packages manually for TensorRT compatibility https://github.com/NVIDIA/TensorRT/issues/2567
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache tqdm matplotlib pyyaml psutil pandas onnx thop "numpy==1.23"
+RUN pip install --no-cache -e .
+
+# Set environment variables
+ENV OMP_NUM_THREADS=1
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-jetson && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-jetson && sudo docker run -it --ipc=host $t
+
+# Pull and Run with NVIDIA runtime
+# t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
diff --git a/STPoseNet/docker/Dockerfile-python b/STPoseNet/docker/Dockerfile-python
new file mode 100644
index 0000000000000000000000000000000000000000..ecb2f651b88e1d70c70a1ae131648df0057ec802
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile-python
@@ -0,0 +1,49 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments
+
+# Use the official Python 3.10 slim-bookworm as base image
+FROM python:3.10-slim-bookworm
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+# g++ required to build 'tflite_support' and 'lap' packages, libusb-1.0-0 required for 'tflite_support' package
+RUN apt update \
+ && apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
+# RUN alias python=python3
+
+# Create working directory
+WORKDIR /usr/src/ultralytics
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/
+
+# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
+# RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
+
+# Install pip packages
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -e ".[export]" thop --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Run exports to AutoInstall packages
+RUN yolo export model=tmp/yolov8n.pt format=edgetpu imgsz=32
+RUN yolo export model=tmp/yolov8n.pt format=ncnn imgsz=32
+# Requires <= Python 3.10, bug with paddlepaddle==2.5.0
+RUN pip install --no-cache paddlepaddle==2.4.2 x2paddle
+# Remove exported models
+RUN rm -rf tmp
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-python && sudo docker build -f docker/Dockerfile-python -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-python && sudo docker run -it --ipc=host $t
+
+# Pull and Run with local volume mounted
+# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/STPoseNet/docker/Dockerfile-runner b/STPoseNet/docker/Dockerfile-runner
new file mode 100644
index 0000000000000000000000000000000000000000..35f871307177732662f7d1f62163441d6d4b87d4
--- /dev/null
+++ b/STPoseNet/docker/Dockerfile-runner
@@ -0,0 +1,37 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds GitHub actions CI runner image for deployment to DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference tests
+
+# Start FROM Ultralytics GPU image
+FROM ultralytics/ultralytics:latest
+
+# Set the working directory
+WORKDIR /actions-runner
+
+# Download and unpack the latest runner
+RUN curl -o actions-runner-linux-x64-2.308.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.308.0/actions-runner-linux-x64-2.308.0.tar.gz && \
+ tar xzf actions-runner-linux-x64-2.308.0.tar.gz && \
+ rm actions-runner-linux-x64-2.308.0.tar.gz
+
+# Install runner dependencies
+ENV RUNNER_ALLOW_RUNASROOT=1
+ENV DEBIAN_FRONTEND=noninteractive
+RUN ./bin/installdependencies.sh && \
+ apt-get -y install libicu-dev
+
+# Inline ENTRYPOINT command to configure and start runner with default TOKEN and NAME
+ENTRYPOINT sh -c './config.sh --url https://github.com/ultralytics/ultralytics \
+ --token ${GITHUB_RUNNER_TOKEN:-TOKEN} \
+ --name ${GITHUB_RUNNER_NAME:-NAME} \
+ --labels gpu-latest \
+ --replace && \
+ ./run.sh'
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-runner && sudo docker build -f docker/Dockerfile-runner -t $t . && sudo docker push $t
+
+# Pull and Run in detached mode with access to GPUs 0 and 1
+# t=ultralytics/ultralytics:latest-runner && sudo docker run -d -e GITHUB_RUNNER_TOKEN=TOKEN -e GITHUB_RUNNER_NAME=NAME --ipc=host --gpus '"device=0,1"' $t
diff --git a/STPoseNet/min_data_enhance.py b/STPoseNet/min_data_enhance.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d763d8713a78d0b2001ae939a31ae4a3889663a
--- /dev/null
+++ b/STPoseNet/min_data_enhance.py
@@ -0,0 +1,3 @@
+from tool.min_img_label import min_img
+
+min_img(r'F:\mouse_re\paper-data\dataset\comprrehensive_ea_fe_wm\comprehensive-min')
diff --git a/STPoseNet/mkdocs.yml b/STPoseNet/mkdocs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..dcc316f07604bf169b6cc8f7cf4b5d84e70b6139
--- /dev/null
+++ b/STPoseNet/mkdocs.yml
@@ -0,0 +1,507 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+site_name: Ultralytics YOLOv8 Docs
+site_url: https://docs.ultralytics.com
+site_description: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
+site_author: Ultralytics
+repo_url: https://github.com/ultralytics/ultralytics
+edit_uri: https://github.com/ultralytics/ultralytics/tree/main/docs
+repo_name: ultralytics/ultralytics
+remote_name: https://github.com/ultralytics/docs
+
+theme:
+ name: material
+ custom_dir: docs/overrides
+ logo: https://github.com/ultralytics/assets/raw/main/logo/Ultralytics_Logotype_Reverse.svg
+ favicon: assets/favicon.ico
+ icon:
+ repo: fontawesome/brands/github
+ font:
+ text: Helvetica
+ code: Roboto Mono
+
+ palette:
+ # Palette toggle for light mode
+ - scheme: default
+ # primary: grey
+ toggle:
+ icon: material/brightness-7
+ name: Switch to dark mode
+
+ # Palette toggle for dark mode
+ - scheme: slate
+ # primary: black
+ toggle:
+ icon: material/brightness-4
+ name: Switch to light mode
+ features:
+ - announce.dismiss
+ - content.action.edit
+ - content.code.annotate
+ - content.code.copy
+ - content.tooltips
+ - search.highlight
+ - search.share
+ - search.suggest
+ - toc.follow
+ - toc.integrate
+ - navigation.top
+ - navigation.tabs
+ - navigation.tabs.sticky
+ - navigation.expand
+ - navigation.footer
+ - navigation.tracking
+ - navigation.instant
+ - navigation.indexes
+ - content.tabs.link # all code tabs change simultaneously
+
+# Customization
+copyright: © 2023 Ultralytics Inc. All rights reserved.
+extra:
+ # version:
+ # provider: mike # version drop-down menu
+ robots: robots.txt
+ analytics:
+ provider: google
+ property: G-2M5EHKC0BH
+ # feedback:
+ # title: Was this page helpful?
+ # ratings:
+ # - icon: material/heart
+ # name: This page was helpful
+ # data: 1
+ # note: Thanks for your feedback!
+ # - icon: material/heart-broken
+ # name: This page could be improved
+ # data: 0
+ # note: >-
+ # Thanks for your feedback!Tell us what we can improve.
+
+ social:
+ - icon: fontawesome/brands/github
+ link: https://github.com/ultralytics
+ - icon: fontawesome/brands/linkedin
+ link: https://www.linkedin.com/company/ultralytics/
+ - icon: fontawesome/brands/twitter
+ link: https://twitter.com/ultralytics
+ - icon: fontawesome/brands/youtube
+ link: https://www.youtube.com/ultralytics
+ - icon: fontawesome/brands/docker
+ link: https://hub.docker.com/r/ultralytics/ultralytics/
+ - icon: fontawesome/brands/python
+ link: https://pypi.org/project/ultralytics/
+ - icon: fontawesome/brands/discord
+ link: https://ultralytics.com/discord
+
+extra_css:
+ - stylesheets/style.css
+ - https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css
+
+markdown_extensions:
+ # Div text decorators
+ - admonition
+ - md_in_html
+ - pymdownx.details
+ - pymdownx.superfences
+ - tables
+ - attr_list
+ - def_list
+ # Syntax highlight
+ - pymdownx.highlight:
+ anchor_linenums: true
+ - pymdownx.inlinehilite
+ - pymdownx.snippets:
+ base_path: ./
+ - pymdownx.emoji:
+ emoji_index: !!python/name:materialx.emoji.twemoji # noqa
+ emoji_generator: !!python/name:materialx.emoji.to_svg
+ - pymdownx.tabbed:
+ alternate_style: true
+
+ # Highlight
+ - pymdownx.critic
+ - pymdownx.caret
+ - pymdownx.keys
+ - pymdownx.mark
+ - pymdownx.tilde
+
+# Primary navigation ---------------------------------------------------------------------------------------------------
+nav:
+ - Home:
+ - Home: index.md
+ - Quickstart: quickstart.md
+ - Modes:
+ - modes/index.md
+ - Train: modes/train.md
+ - Val: modes/val.md
+ - Predict: modes/predict.md
+ - Export: modes/export.md
+ - Track: modes/track.md
+ - Benchmark: modes/benchmark.md
+ - Tasks:
+ - tasks/index.md
+ - Detect: tasks/detect.md
+ - Segment: tasks/segment.md
+ - Classify: tasks/classify.md
+ - Pose: tasks/pose.md
+ - Quickstart: quickstart.md
+ - Modes:
+ - modes/index.md
+ - Train: modes/train.md
+ - Val: modes/val.md
+ - Predict: modes/predict.md
+ - Export: modes/export.md
+ - Track: modes/track.md
+ - Benchmark: modes/benchmark.md
+ - Tasks:
+ - tasks/index.md
+ - Detect: tasks/detect.md
+ - Segment: tasks/segment.md
+ - Classify: tasks/classify.md
+ - Pose: tasks/pose.md
+ - Models:
+ - models/index.md
+ - YOLOv3: models/yolov3.md
+ - YOLOv4: models/yolov4.md
+ - YOLOv5: models/yolov5.md
+ - YOLOv6: models/yolov6.md
+ - YOLOv7: models/yolov7.md
+ - YOLOv8: models/yolov8.md
+ - SAM (Segment Anything Model): models/sam.md
+ - MobileSAM (Mobile Segment Anything Model): models/mobile-sam.md
+ - FastSAM (Fast Segment Anything Model): models/fast-sam.md
+ - YOLO-NAS (Neural Architecture Search): models/yolo-nas.md
+ - RT-DETR (Realtime Detection Transformer): models/rtdetr.md
+ - Datasets:
+ - datasets/index.md
+ - Detection:
+ - datasets/detect/index.md
+ - Argoverse: datasets/detect/argoverse.md
+ - COCO: datasets/detect/coco.md
+ - COCO8: datasets/detect/coco8.md
+ - GlobalWheat2020: datasets/detect/globalwheat2020.md
+ - Objects365: datasets/detect/objects365.md
+ - OpenImagesV7: datasets/detect/open-images-v7.md
+ - SKU-110K: datasets/detect/sku-110k.md
+ - VisDrone: datasets/detect/visdrone.md
+ - VOC: datasets/detect/voc.md
+ - xView: datasets/detect/xview.md
+ - Segmentation:
+ - datasets/segment/index.md
+ - COCO: datasets/segment/coco.md
+ - COCO8-seg: datasets/segment/coco8-seg.md
+ - Pose:
+ - datasets/pose/index.md
+ - COCO: datasets/pose/coco.md
+ - COCO8-pose: datasets/pose/coco8-pose.md
+ - Classification:
+ - datasets/classify/index.md
+ - Caltech 101: datasets/classify/caltech101.md
+ - Caltech 256: datasets/classify/caltech256.md
+ - CIFAR-10: datasets/classify/cifar10.md
+ - CIFAR-100: datasets/classify/cifar100.md
+ - Fashion-MNIST: datasets/classify/fashion-mnist.md
+ - ImageNet: datasets/classify/imagenet.md
+ - ImageNet-10: datasets/classify/imagenet10.md
+ - Imagenette: datasets/classify/imagenette.md
+ - Imagewoof: datasets/classify/imagewoof.md
+ - MNIST: datasets/classify/mnist.md
+ - Oriented Bounding Boxes (OBB):
+ - datasets/obb/index.md
+ - DOTAv2: datasets/obb/dota-v2.md
+ - Multi-Object Tracking:
+ - datasets/track/index.md
+ - Guides:
+ - guides/index.md
+ - K-Fold Cross Validation: guides/kfold-cross-validation.md
+ - Hyperparameter Tuning: guides/hyperparameter-tuning.md
+ - Integrations:
+ - integrations/index.md
+ - OpenVINO: integrations/openvino.md
+ - Ray Tune: integrations/ray-tune.md
+ - Usage:
+ - CLI: usage/cli.md
+ - Python: usage/python.md
+ - Callbacks: usage/callbacks.md
+ - Configuration: usage/cfg.md
+ - Advanced Customization: usage/engine.md
+ - YOLOv5:
+ - yolov5/index.md
+ - Quickstart: yolov5/quickstart_tutorial.md
+ - Environments:
+ - Amazon Web Services (AWS): yolov5/environments/aws_quickstart_tutorial.md
+ - Google Cloud (GCP): yolov5/environments/google_cloud_quickstart_tutorial.md
+ - Docker Image: yolov5/environments/docker_image_quickstart_tutorial.md
+ - Tutorials:
+ - Train Custom Data: yolov5/tutorials/train_custom_data.md
+ - Tips for Best Training Results: yolov5/tutorials/tips_for_best_training_results.md
+ - Multi-GPU Training: yolov5/tutorials/multi_gpu_training.md
+ - PyTorch Hub: yolov5/tutorials/pytorch_hub_model_loading.md
+ - TFLite, ONNX, CoreML, TensorRT Export: yolov5/tutorials/model_export.md
+ - NVIDIA Jetson Nano Deployment: yolov5/tutorials/running_on_jetson_nano.md
+ - Test-Time Augmentation (TTA): yolov5/tutorials/test_time_augmentation.md
+ - Model Ensembling: yolov5/tutorials/model_ensembling.md
+ - Pruning/Sparsity Tutorial: yolov5/tutorials/model_pruning_and_sparsity.md
+ - Hyperparameter evolution: yolov5/tutorials/hyperparameter_evolution.md
+ - Transfer learning with frozen layers: yolov5/tutorials/transfer_learning_with_frozen_layers.md
+ - Architecture Summary: yolov5/tutorials/architecture_description.md
+ - Roboflow Datasets: yolov5/tutorials/roboflow_datasets_integration.md
+ - Neural Magic's DeepSparse: yolov5/tutorials/neural_magic_pruning_quantization.md
+ - Comet Logging: yolov5/tutorials/comet_logging_integration.md
+ - Clearml Logging: yolov5/tutorials/clearml_logging_integration.md
+ - Ultralytics HUB:
+ - hub/index.md
+ - Quickstart: hub/quickstart.md
+ - Datasets: hub/datasets.md
+ - Projects: hub/projects.md
+ - Models: hub/models.md
+ - Integrations: hub/integrations.md
+ - Ultralytics HUB App:
+ - hub/app/index.md
+ - 'iOS': hub/app/ios.md
+ - 'Android': hub/app/android.md
+ - Inference API: hub/inference_api.md
+ - Reference:
+ - cfg:
+ - __init__: reference/cfg/__init__.md
+ - data:
+ - annotator: reference/data/annotator.md
+ - augment: reference/data/augment.md
+ - base: reference/data/base.md
+ - build: reference/data/build.md
+ - converter: reference/data/converter.md
+ - dataset: reference/data/dataset.md
+ - loaders: reference/data/loaders.md
+ - utils: reference/data/utils.md
+ - engine:
+ - exporter: reference/engine/exporter.md
+ - model: reference/engine/model.md
+ - predictor: reference/engine/predictor.md
+ - results: reference/engine/results.md
+ - trainer: reference/engine/trainer.md
+ - tuner: reference/engine/tuner.md
+ - validator: reference/engine/validator.md
+ - hub:
+ - __init__: reference/hub/__init__.md
+ - auth: reference/hub/auth.md
+ - session: reference/hub/session.md
+ - utils: reference/hub/utils.md
+ - models:
+ - fastsam:
+ - model: reference/models/fastsam/model.md
+ - predict: reference/models/fastsam/predict.md
+ - prompt: reference/models/fastsam/prompt.md
+ - utils: reference/models/fastsam/utils.md
+ - val: reference/models/fastsam/val.md
+ - nas:
+ - model: reference/models/nas/model.md
+ - predict: reference/models/nas/predict.md
+ - val: reference/models/nas/val.md
+ - rtdetr:
+ - model: reference/models/rtdetr/model.md
+ - predict: reference/models/rtdetr/predict.md
+ - train: reference/models/rtdetr/train.md
+ - val: reference/models/rtdetr/val.md
+ - sam:
+ - amg: reference/models/sam/amg.md
+ - build: reference/models/sam/build.md
+ - model: reference/models/sam/model.md
+ - modules:
+ - decoders: reference/models/sam/modules/decoders.md
+ - encoders: reference/models/sam/modules/encoders.md
+ - sam: reference/models/sam/modules/sam.md
+ - tiny_encoder: reference/models/sam/modules/tiny_encoder.md
+ - transformer: reference/models/sam/modules/transformer.md
+ - predict: reference/models/sam/predict.md
+ - utils:
+ - loss: reference/models/utils/loss.md
+ - ops: reference/models/utils/ops.md
+ - yolo:
+ - classify:
+ - predict: reference/models/yolo/classify/predict.md
+ - train: reference/models/yolo/classify/train.md
+ - val: reference/models/yolo/classify/val.md
+ - detect:
+ - predict: reference/models/yolo/detect/predict.md
+ - train: reference/models/yolo/detect/train.md
+ - val: reference/models/yolo/detect/val.md
+ - model: reference/models/yolo/model.md
+ - pose:
+ - predict: reference/models/yolo/pose/predict.md
+ - train: reference/models/yolo/pose/train.md
+ - val: reference/models/yolo/pose/val.md
+ - segment:
+ - predict: reference/models/yolo/segment/predict.md
+ - train: reference/models/yolo/segment/train.md
+ - val: reference/models/yolo/segment/val.md
+ - nn:
+ - autobackend: reference/nn/autobackend.md
+ - modules:
+ - block: reference/nn/modules/block.md
+ - conv: reference/nn/modules/conv.md
+ - head: reference/nn/modules/head.md
+ - transformer: reference/nn/modules/transformer.md
+ - utils: reference/nn/modules/utils.md
+ - tasks: reference/nn/tasks.md
+ - trackers:
+ - basetrack: reference/trackers/basetrack.md
+ - bot_sort: reference/trackers/bot_sort.md
+ - byte_tracker: reference/trackers/byte_tracker.md
+ - track: reference/trackers/track.md
+ - utils:
+ - gmc: reference/trackers/utils/gmc.md
+ - kalman_filter: reference/trackers/utils/kalman_filter.md
+ - matching: reference/trackers/utils/matching.md
+ - utils:
+ - __init__: reference/utils/__init__.md
+ - autobatch: reference/utils/autobatch.md
+ - benchmarks: reference/utils/benchmarks.md
+ - callbacks:
+ - base: reference/utils/callbacks/base.md
+ - clearml: reference/utils/callbacks/clearml.md
+ - comet: reference/utils/callbacks/comet.md
+ - dvc: reference/utils/callbacks/dvc.md
+ - hub: reference/utils/callbacks/hub.md
+ - mlflow: reference/utils/callbacks/mlflow.md
+ - neptune: reference/utils/callbacks/neptune.md
+ - raytune: reference/utils/callbacks/raytune.md
+ - tensorboard: reference/utils/callbacks/tensorboard.md
+ - wb: reference/utils/callbacks/wb.md
+ - checks: reference/utils/checks.md
+ - dist: reference/utils/dist.md
+ - downloads: reference/utils/downloads.md
+ - errors: reference/utils/errors.md
+ - files: reference/utils/files.md
+ - instance: reference/utils/instance.md
+ - loss: reference/utils/loss.md
+ - metrics: reference/utils/metrics.md
+ - ops: reference/utils/ops.md
+ - patches: reference/utils/patches.md
+ - plotting: reference/utils/plotting.md
+ - tal: reference/utils/tal.md
+ - torch_utils: reference/utils/torch_utils.md
+ - tuner: reference/utils/tuner.md
+
+ - Help:
+ - Help: help/index.md
+ - Frequently Asked Questions (FAQ): help/FAQ.md
+ - Contributing Guide: help/contributing.md
+ - Continuous Integration (CI) Guide: help/CI.md
+ - Contributor License Agreement (CLA): help/CLA.md
+ - Minimum Reproducible Example (MRE) Guide: help/minimum_reproducible_example.md
+ - Code of Conduct: help/code_of_conduct.md
+ - Environmental, Health and Safety (EHS) Policy: help/environmental-health-safety.md
+ - Security Policy: SECURITY.md
+
+# Plugins including 301 redirects navigation ---------------------------------------------------------------------------
+plugins:
+ - search
+ - mkdocstrings:
+ enabled: true
+ default_handler: python
+ handlers:
+ python:
+ options:
+ docstring_style: google
+ show_root_heading: true
+ show_source: true
+ - ultralytics:
+ add_desc: False
+ add_image: True
+ add_share_buttons: True
+ default_image: https://github.com/ultralytics/ultralytics/assets/26833433/6d09221c-c52a-4234-9a5d-b862e93c6529
+ - redirects:
+ redirect_maps:
+ callbacks.md: usage/callbacks.md
+ cfg.md: usage/cfg.md
+ cli.md: usage/cli.md
+ config.md: usage/cfg.md
+ engine.md: usage/engine.md
+ environments/AWS-Quickstart.md: yolov5/environments/aws_quickstart_tutorial.md
+ environments/Docker-Quickstart.md: yolov5/environments/docker_image_quickstart_tutorial.md
+ environments/GCP-Quickstart.md: yolov5/environments/google_cloud_quickstart_tutorial.md
+ FAQ/augmentation.md: yolov5/tutorials/tips_for_best_training_results.md
+ package-framework.md: index.md
+ package-framework/mock_detector.md: index.md
+ predict.md: modes/predict.md
+ python.md: usage/python.md
+ quick-start.md: quickstart.md
+ app.md: hub/app/index.md
+ sdk.md: index.md
+ usage/hyperparameter_tuning.md: integrations/ray-tune.md
+ reference/base_pred.md: reference/engine/predictor.md
+ reference/base_trainer.md: reference/engine/trainer.md
+ reference/exporter.md: reference/engine/exporter.md
+ reference/model.md: reference/engine/model.md
+ reference/nn.md: reference/nn/modules/head.md
+ reference/ops.md: reference/utils/ops.md
+ reference/results.md: reference/engine/results.md
+ reference/base_val.md: index.md
+ tasks/classification.md: tasks/classify.md
+ tasks/detection.md: tasks/detect.md
+ tasks/segmentation.md: tasks/segment.md
+ tasks/keypoints.md: tasks/pose.md
+ tasks/tracking.md: modes/track.md
+ tutorials/architecture-summary.md: yolov5/tutorials/architecture_description.md
+ tutorials/clearml-logging.md: yolov5/tutorials/clearml_logging_integration.md
+ tutorials/comet-logging.md: yolov5/tutorials/comet_logging_integration.md
+ tutorials/hyperparameter-evolution.md: yolov5/tutorials/hyperparameter_evolution.md
+ tutorials/model-ensembling.md: yolov5/tutorials/model_ensembling.md
+ tutorials/multi-gpu-training.md: yolov5/tutorials/multi_gpu_training.md
+ tutorials/nvidia-jetson.md: yolov5/tutorials/running_on_jetson_nano.md
+ tutorials/pruning-sparsity.md: yolov5/tutorials/model_pruning_and_sparsity.md
+ tutorials/pytorch-hub.md: yolov5/tutorials/pytorch_hub_model_loading.md
+ tutorials/roboflow.md: yolov5/tutorials/roboflow_datasets_integration.md
+ tutorials/test-time-augmentation.md: yolov5/tutorials/test_time_augmentation.md
+ tutorials/torchscript-onnx-coreml-export.md: yolov5/tutorials/model_export.md
+ tutorials/train-custom-datasets.md: yolov5/tutorials/train_custom_data.md
+ tutorials/training-tips-best-results.md: yolov5/tutorials/tips_for_best_training_results.md
+ tutorials/transfer-learning-froze-layers.md: yolov5/tutorials/transfer_learning_with_frozen_layers.md
+ tutorials/weights-and-biasis-logging.md: yolov5/tutorials/comet_logging_integration.md
+ yolov5/pytorch_hub.md: yolov5/tutorials/pytorch_hub_model_loading.md
+ yolov5/hyp_evolution.md: yolov5/tutorials/hyperparameter_evolution.md
+ yolov5/pruning_sparsity.md: yolov5/tutorials/model_pruning_and_sparsity.md
+ yolov5/roboflow.md: yolov5/tutorials/roboflow_datasets_integration.md
+ yolov5/comet.md: yolov5/tutorials/comet_logging_integration.md
+ yolov5/clearml.md: yolov5/tutorials/clearml_logging_integration.md
+ yolov5/tta.md: yolov5/tutorials/test_time_augmentation.md
+ yolov5/multi_gpu_training.md: yolov5/tutorials/multi_gpu_training.md
+ yolov5/ensemble.md: yolov5/tutorials/model_ensembling.md
+ yolov5/jetson_nano.md: yolov5/tutorials/running_on_jetson_nano.md
+ yolov5/transfer_learn_frozen.md: yolov5/tutorials/transfer_learning_with_frozen_layers.md
+ yolov5/neural_magic.md: yolov5/tutorials/neural_magic_pruning_quantization.md
+ yolov5/train_custom_data.md: yolov5/tutorials/train_custom_data.md
+ yolov5/architecture.md: yolov5/tutorials/architecture_description.md
+ yolov5/export.md: yolov5/tutorials/model_export.md
+ yolov5/yolov5_quickstart_tutorial.md: yolov5/quickstart_tutorial.md
+ yolov5/tips_for_best_training_results.md: yolov5/tutorials/tips_for_best_training_results.md
+ yolov5/tutorials/yolov5_neural_magic_tutorial.md: yolov5/tutorials/neural_magic_pruning_quantization.md
+ yolov5/tutorials/model_ensembling_tutorial.md: yolov5/tutorials/model_ensembling.md
+ yolov5/tutorials/pytorch_hub_tutorial.md: yolov5/tutorials/pytorch_hub_model_loading.md
+ yolov5/tutorials/yolov5_architecture_tutorial.md: yolov5/tutorials/architecture_description.md
+ yolov5/tutorials/multi_gpu_training_tutorial.md: yolov5/tutorials/multi_gpu_training.md
+ yolov5/tutorials/yolov5_pytorch_hub_tutorial.md: yolov5/tutorials/pytorch_hub_model_loading.md
+ yolov5/tutorials/model_export_tutorial.md: yolov5/tutorials/model_export.md
+ yolov5/tutorials/jetson_nano_tutorial.md: yolov5/tutorials/running_on_jetson_nano.md
+ yolov5/tutorials/yolov5_model_ensembling_tutorial.md: yolov5/tutorials/model_ensembling.md
+ yolov5/tutorials/roboflow_integration.md: yolov5/tutorials/roboflow_datasets_integration.md
+ yolov5/tutorials/pruning_and_sparsity_tutorial.md: yolov5/tutorials/model_pruning_and_sparsity.md
+ yolov5/tutorials/yolov5_transfer_learning_with_frozen_layers_tutorial.md: yolov5/tutorials/transfer_learning_with_frozen_layers.md
+ yolov5/tutorials/transfer_learning_with_frozen_layers_tutorial.md: yolov5/tutorials/transfer_learning_with_frozen_layers.md
+ yolov5/tutorials/yolov5_model_export_tutorial.md: yolov5/tutorials/model_export.md
+ yolov5/tutorials/neural_magic_tutorial.md: yolov5/tutorials/neural_magic_pruning_quantization.md
+ yolov5/tutorials/yolov5_clearml_integration_tutorial.md: yolov5/tutorials/clearml_logging_integration.md
+ yolov5/tutorials/yolov5_train_custom_data.md: yolov5/tutorials/train_custom_data.md
+ yolov5/tutorials/comet_integration_tutorial.md: yolov5/tutorials/comet_logging_integration.md
+ yolov5/tutorials/yolov5_pruning_and_sparsity_tutorial.md: yolov5/tutorials/model_pruning_and_sparsity.md
+ yolov5/tutorials/yolov5_jetson_nano_tutorial.md: yolov5/tutorials/running_on_jetson_nano.md
+ yolov5/tutorials/yolov5_roboflow_integration.md: yolov5/tutorials/roboflow_datasets_integration.md
+ yolov5/tutorials/hyperparameter_evolution_tutorial.md: yolov5/tutorials/hyperparameter_evolution.md
+ yolov5/tutorials/yolov5_hyperparameter_evolution_tutorial.md: yolov5/tutorials/hyperparameter_evolution.md
+ yolov5/tutorials/clearml_integration_tutorial.md: yolov5/tutorials/clearml_logging_integration.md
+ yolov5/tutorials/test_time_augmentation_tutorial.md: yolov5/tutorials/test_time_augmentation.md
+ yolov5/tutorials/yolov5_test_time_augmentation_tutorial.md: yolov5/tutorials/test_time_augmentation.md
+ yolov5/environments/yolov5_amazon_web_services_quickstart_tutorial.md: yolov5/environments/aws_quickstart_tutorial.md
+ yolov5/environments/yolov5_google_cloud_platform_quickstart_tutorial.md: yolov5/environments/google_cloud_quickstart_tutorial.md
+ yolov5/environments/yolov5_docker_image_quickstart_tutorial.md: yolov5/environments/docker_image_quickstart_tutorial.md
diff --git a/STPoseNet/mouse-pre.py b/STPoseNet/mouse-pre.py
new file mode 100644
index 0000000000000000000000000000000000000000..61472baa138b23a9c2cf908c58c90dfab88d5a34
--- /dev/null
+++ b/STPoseNet/mouse-pre.py
@@ -0,0 +1,15 @@
+from ultralytics import YOLO
+import os
+
+
+if __name__=='__main__':
+ os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
+
+ model = YOLO(model="The weight file trained in the second step (.\runs\pose\train\train\xxx.pt)")
+ results = model(r"Video files that need to be identified")
+
+ # # Call camera recognition
+ # model = YOLO(model="trained_weight\\chase_min_l.pt")
+ # results = model(0)
+
+
diff --git a/STPoseNet/mouse-train.py b/STPoseNet/mouse-train.py
new file mode 100644
index 0000000000000000000000000000000000000000..708fa8efbdf4238ec5189b27c5b002930654861a
--- /dev/null
+++ b/STPoseNet/mouse-train.py
@@ -0,0 +1,19 @@
+from ultralytics import YOLO
+import os
+from tool.min_img_label import min_img
+
+
+if __name__=='__main__':
+ os.environ["WANDB_MODE"] = "offline"
+ os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
+
+ # first train use it to enhance data
+ # min_img(r'F:\mouse_re\dataset\comprehensive-min')
+
+ # Load a model
+ model = YOLO('yolov8l-pose.yaml') # build a new model from YAML
+ model = YOLO('yolov8l-pose.pt') # load a pretrained model (recommended for training)
+ model = YOLO('yolov8l-pose.yaml').load('pretrain_weight.pt') # build from YAML and transfer weights
+
+ # Train the model
+ model.train(data='mouse-pose.yaml', epochs=400, imgsz=640)
diff --git a/STPoseNet/requirements.txt b/STPoseNet/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e38616df49b27640c4e5a64843def2f4d4f7d9af
--- /dev/null
+++ b/STPoseNet/requirements.txt
@@ -0,0 +1,45 @@
+# Ultralytics requirements
+# Example: pip install -r requirements.txt
+
+# Base ----------------------------------------
+matplotlib>=3.2.2
+numpy>=1.22.2 # pinned by Snyk to avoid a vulnerability
+opencv-python>=4.6.0
+pillow>=7.1.2
+pyyaml>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+torch>=1.8.0
+torchvision>=0.9.0
+tqdm>=4.64.0
+
+# Logging -------------------------------------
+# tensorboard>=2.13.0
+# dvclive>=2.12.0
+# clearml
+# comet
+
+# Plotting ------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export --------------------------------------
+# coremltools>=7.0.b1 # CoreML export
+# onnx>=1.12.0 # ONNX export
+# onnxsim>=0.4.1 # ONNX simplifier
+# nvidia-pyindex # TensorRT export
+# nvidia-tensorrt # TensorRT export
+# scikit-learn==0.19.2 # CoreML quantization
+# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
+# tflite-support
+# tensorflowjs>=3.9.0 # TF.js export
+# openvino-dev>=2023.0 # OpenVINO export
+
+# Extras --------------------------------------
+psutil # system utilization
+py-cpuinfo # display CPU info
+# thop>=0.1.1 # FLOPs computation
+# ipython # interactive notebook
+# albumentations>=1.0.3 # training augmentations
+# pycocotools>=2.0.6 # COCO mAP
+# roboflow
diff --git a/STPoseNet/tmpni7swzfb b/STPoseNet/tmpni7swzfb
new file mode 100644
index 0000000000000000000000000000000000000000..3086aea15d603caccea5ccafe8ca81958190ea12
--- /dev/null
+++ b/STPoseNet/tmpni7swzfb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:edcbd828f21e00f5836e2911b5de8979895f5cb8059800fb1d9a652c4e24be27
+size 5251072
diff --git a/STPoseNet/tool/__pycache__/min_img_label.cpython-38.pyc b/STPoseNet/tool/__pycache__/min_img_label.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..06798cd110442f88de86f47748381589d07527c3
Binary files /dev/null and b/STPoseNet/tool/__pycache__/min_img_label.cpython-38.pyc differ
diff --git a/STPoseNet/tool/min_img_label.py b/STPoseNet/tool/min_img_label.py
new file mode 100644
index 0000000000000000000000000000000000000000..784f5a1e4bb9442c665cbd3583a622b23aacc7f4
--- /dev/null
+++ b/STPoseNet/tool/min_img_label.py
@@ -0,0 +1,99 @@
+import copy
+import os
+import numpy as np
+import cv2 as cv
+import random
+
+
+def ObtainRandom(n):
+ list_info = [] # 定义一个空列表(用于接收产生的随机数)
+ list_ = int(n/10)
+ while list_ != 0:
+ info = random.randint(1, n) # 每次循环获取一次随机数
+ if info not in list_info: # 判断随机数是否在列表中
+ list_info.append(info) # 不在列表中 进行添加
+ list_ = list_-1
+ return list_info
+
+def min_img(path):
+ labels_path = path + '\\labels\\'
+ imgs_path = path + '\\images\\'
+ items = ('train', 'val')
+
+ total_num = len(os.listdir(imgs_path + 'train')) + len(os.listdir(imgs_path + 'val'))
+ val_list = ObtainRandom(total_num)
+
+ for k, item in enumerate(items):
+ if item == 'train':
+ m = total_num - len(val_list)
+ if item == 'val':
+ m = len(val_list)
+ list_txt = os.listdir(labels_path + item + '\\')
+ for j, file in enumerate(list_txt):
+ if j < m:
+ file_name = file.split('.')
+ if file_name[0] not in items:
+ img_path = imgs_path + item + '\\' + file_name[0] + '.jpg'
+ img = cv.imread(img_path)
+ # print(img_path)
+ img_size = img.shape
+ file_path = os.path.join(labels_path + item + '\\', file)
+ with open(file_path, "r") as labels:
+ label = labels.readlines()
+ label = label[0].split(" ")[1:-1]
+ for i in range(8):
+ label.remove('')
+ for i in range(3):
+ label.remove('2.000000')
+ label = list(map(float, label))
+
+ label_ = np.zeros(10)
+ for i in range(10):
+ if i % 2 == 0:
+ label_[i] = label[i] * img_size[1]
+ if i % 2 == 1:
+ label_[i] = label[i] * img_size[0]
+ label_int = label_.astype(int)
+
+ min_box = [[label_int[0]-label_int[2], label_int[1]-label_int[3]], [label_int[0]+label_int[2], label_int[1]+label_int[3]]]
+ for i in range(2):
+ if min_box[i][0] > img_size[1]:
+ min_box[i][0] = img_size[1]
+ if min_box[i][0] < 0:
+ min_box[i][0] = 0
+ for i in range(2):
+ if min_box[i][1] > img_size[0]:
+ min_box[i][1] = img_size[0]
+ if min_box[i][1] < 0:
+ min_box[i][1] = 0
+ min_img = img[min_box[0][1]:min_box[1][1], min_box[0][0]:min_box[1][0], :]
+
+ # print(j)
+ # print(label_int[0:4])
+ # print(min_box)
+ # cv.imshow('img', min_img)
+ # cv.waitKey()
+
+ min_img_size = min_img.shape
+ tf_set = min_box[0]
+ img_kps = copy.deepcopy(label_[4:])
+ min_kps = np.zeros(6)
+ for i in range(3):
+ min_kps[i * 2] = img_kps[i * 2] - tf_set[0]
+ min_kps[i * 2 + 1] = img_kps[i * 2 + 1] - tf_set[1]
+
+ i = len(list_txt) + total_num
+ min_name = 'min_' + file_name[0]
+
+ min_img_path = imgs_path + item + '\\' + min_name + '.jpg'
+ min_label_path = labels_path + item + '\\'
+ cv.imwrite(min_img_path, min_img)
+
+ f_txt = open(os.path.join(min_label_path + min_name + '.txt'), 'w')
+ f_txt.write("%s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s %s" %
+ (0, 0.5, 0.5, 0.5, 0.5,
+ min_kps[0] / min_img_size[1], '', min_kps[1] / min_img_size[0], '', str(2.000000), '',
+ min_kps[2] / min_img_size[1], '', min_kps[3] / min_img_size[0], '', str(2.000000), '',
+ min_kps[4] / min_img_size[1], '', min_kps[5] / min_img_size[0], '', str(2.000000)
+ ))
+ f_txt.close()
diff --git a/STPoseNet/trained_weight/weight_download.txt b/STPoseNet/trained_weight/weight_download.txt
new file mode 100644
index 0000000000000000000000000000000000000000..55379e0e40a70bfc44c6a02d32d21799b762ad0c
--- /dev/null
+++ b/STPoseNet/trained_weight/weight_download.txt
@@ -0,0 +1,2 @@
+链接:https://pan.baidu.com/s/10OoRX9jBjGijsdY_AXpWJA?pwd=mu9i
+提取码:mu9i
\ No newline at end of file
diff --git a/STPoseNet/ultralytics/__init__.py b/STPoseNet/ultralytics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8a41c7dd992083d0c2977e3e010d385d43b85d6
--- /dev/null
+++ b/STPoseNet/ultralytics/__init__.py
@@ -0,0 +1,12 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+__version__ = '8.0.165'
+
+from ultralytics.models import RTDETR, SAM, YOLO
+from ultralytics.models.fastsam import FastSAM
+from ultralytics.models.nas import NAS
+from ultralytics.utils import SETTINGS as settings
+from ultralytics.utils.checks import check_yolo as checks
+from ultralytics.utils.downloads import download
+
+__all__ = '__version__', 'YOLO', 'NAS', 'SAM', 'FastSAM', 'RTDETR', 'checks', 'download', 'settings' # allow simpler import
diff --git a/STPoseNet/ultralytics/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..24526109432f468f79ea888b340a7d22f2a41ea9
Binary files /dev/null and b/STPoseNet/ultralytics/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/assets/bus.jpg b/STPoseNet/ultralytics/assets/bus.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..40eaaf5c330d0c498fbe1dcacf9bb8bf566797fe
Binary files /dev/null and b/STPoseNet/ultralytics/assets/bus.jpg differ
diff --git a/STPoseNet/ultralytics/assets/zidane.jpg b/STPoseNet/ultralytics/assets/zidane.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..eeab1cdcb282b0e026a57c5bf85df36024b4e1f6
Binary files /dev/null and b/STPoseNet/ultralytics/assets/zidane.jpg differ
diff --git a/STPoseNet/ultralytics/cfg/__init__.py b/STPoseNet/ultralytics/cfg/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb938f3272d95e87832bfe7d8f626abdf5411a4d
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/__init__.py
@@ -0,0 +1,460 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+import re
+import shutil
+import sys
+from pathlib import Path
+from types import SimpleNamespace
+from typing import Dict, List, Union
+
+from ultralytics.utils import (ASSETS, DEFAULT_CFG, DEFAULT_CFG_DICT, DEFAULT_CFG_PATH, LOGGER, RANK, SETTINGS,
+ SETTINGS_YAML, IterableSimpleNamespace, __version__, checks, colorstr, deprecation_warn,
+ yaml_load, yaml_print)
+
+# Define valid tasks and modes
+MODES = 'train', 'val', 'predict', 'export', 'track', 'benchmark'
+TASKS = 'detect', 'segment', 'classify', 'pose'
+TASK2DATA = {'detect': 'coco8.yaml', 'segment': 'coco8-seg.yaml', 'classify': 'imagenet100', 'pose': 'coco8-pose.yaml'}
+TASK2MODEL = {
+ 'detect': 'yolov8n.pt',
+ 'segment': 'yolov8n-seg.pt',
+ 'classify': 'yolov8n-cls.pt',
+ 'pose': 'yolov8n-pose.pt'}
+TASK2METRIC = {
+ 'detect': 'metrics/mAP50-95(B)',
+ 'segment': 'metrics/mAP50-95(M)',
+ 'classify': 'metrics/accuracy_top1',
+ 'pose': 'metrics/mAP50-95(P)'}
+
+CLI_HELP_MSG = \
+ f"""
+ Arguments received: {str(['yolo'] + sys.argv[1:])}. Ultralytics 'yolo' commands use the following syntax:
+
+ yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of {TASKS}
+ MODE (required) is one of {MODES}
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ See all ARGS at https://docs.ultralytics.com/usage/cfg or with 'yolo cfg'
+
+ 1. Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
+
+ 2. Predict a YouTube video using a pretrained segmentation model at image size 320:
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
+
+ 3. Val a pretrained detection model at batch-size 1 and image size 640:
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
+
+ 4. Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+
+ 5. Run special commands:
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
+
+ Docs: https://docs.ultralytics.com
+ Community: https://community.ultralytics.com
+ GitHub: https://github.com/ultralytics/ultralytics
+ """
+
+# Define keys for arg type checks
+CFG_FLOAT_KEYS = 'warmup_epochs', 'box', 'cls', 'dfl', 'degrees', 'shear'
+CFG_FRACTION_KEYS = ('dropout', 'iou', 'lr0', 'lrf', 'momentum', 'weight_decay', 'warmup_momentum', 'warmup_bias_lr',
+ 'label_smoothing', 'hsv_h', 'hsv_s', 'hsv_v', 'translate', 'scale', 'perspective', 'flipud',
+ 'fliplr', 'mosaic', 'mixup', 'copy_paste', 'conf', 'iou', 'fraction') # fraction floats 0.0 - 1.0
+CFG_INT_KEYS = ('epochs', 'patience', 'batch', 'workers', 'seed', 'close_mosaic', 'mask_ratio', 'max_det', 'vid_stride',
+ 'line_width', 'workspace', 'nbs', 'save_period')
+CFG_BOOL_KEYS = ('save', 'exist_ok', 'verbose', 'deterministic', 'single_cls', 'rect', 'cos_lr', 'overlap_mask', 'val',
+ 'save_json', 'save_hybrid', 'half', 'dnn', 'plots', 'show', 'save_txt', 'save_conf', 'save_crop',
+ 'show_labels', 'show_conf', 'visualize', 'augment', 'agnostic_nms', 'retina_masks', 'boxes', 'keras',
+ 'optimize', 'int8', 'dynamic', 'simplify', 'nms', 'profile')
+
+
+def cfg2dict(cfg):
+ """
+ Convert a configuration object to a dictionary, whether it is a file path, a string, or a SimpleNamespace object.
+
+ Args:
+ cfg (str | Path | dict | SimpleNamespace): Configuration object to be converted to a dictionary.
+
+ Returns:
+ cfg (dict): Configuration object in dictionary format.
+ """
+ if isinstance(cfg, (str, Path)):
+ cfg = yaml_load(cfg) # load dict
+ elif isinstance(cfg, SimpleNamespace):
+ cfg = vars(cfg) # convert to dict
+ return cfg
+
+
+def get_cfg(cfg: Union[str, Path, Dict, SimpleNamespace] = DEFAULT_CFG_DICT, overrides: Dict = None):
+ """
+ Load and merge configuration data from a file or dictionary.
+
+ Args:
+ cfg (str | Path | Dict | SimpleNamespace): Configuration data.
+ overrides (str | Dict | optional): Overrides in the form of a file name or a dictionary. Default is None.
+
+ Returns:
+ (SimpleNamespace): Training arguments namespace.
+ """
+ cfg = cfg2dict(cfg)
+
+ # Merge overrides
+ if overrides:
+ overrides = cfg2dict(overrides)
+ if 'save_dir' not in cfg:
+ overrides.pop('save_dir', None) # special override keys to ignore
+ check_dict_alignment(cfg, overrides)
+ cfg = {**cfg, **overrides} # merge cfg and overrides dicts (prefer overrides)
+
+ # Special handling for numeric project/name
+ for k in 'project', 'name':
+ if k in cfg and isinstance(cfg[k], (int, float)):
+ cfg[k] = str(cfg[k])
+ if cfg.get('name') == 'model': # assign model to 'name' arg
+ cfg['name'] = cfg.get('model', '').split('.')[0]
+ LOGGER.warning(f"WARNING ⚠️ 'name=model' automatically updated to 'name={cfg['name']}'.")
+
+ # Type and Value checks
+ for k, v in cfg.items():
+ if v is not None: # None values may be from optional args
+ if k in CFG_FLOAT_KEYS and not isinstance(v, (int, float)):
+ raise TypeError(f"'{k}={v}' is of invalid type {type(v).__name__}. "
+ f"Valid '{k}' types are int (i.e. '{k}=0') or float (i.e. '{k}=0.5')")
+ elif k in CFG_FRACTION_KEYS:
+ if not isinstance(v, (int, float)):
+ raise TypeError(f"'{k}={v}' is of invalid type {type(v).__name__}. "
+ f"Valid '{k}' types are int (i.e. '{k}=0') or float (i.e. '{k}=0.5')")
+ if not (0.0 <= v <= 1.0):
+ raise ValueError(f"'{k}={v}' is an invalid value. "
+ f"Valid '{k}' values are between 0.0 and 1.0.")
+ elif k in CFG_INT_KEYS and not isinstance(v, int):
+ raise TypeError(f"'{k}={v}' is of invalid type {type(v).__name__}. "
+ f"'{k}' must be an int (i.e. '{k}=8')")
+ elif k in CFG_BOOL_KEYS and not isinstance(v, bool):
+ raise TypeError(f"'{k}={v}' is of invalid type {type(v).__name__}. "
+ f"'{k}' must be a bool (i.e. '{k}=True' or '{k}=False')")
+
+ # Return instance
+ return IterableSimpleNamespace(**cfg)
+
+
+def get_save_dir(args, name=None):
+ """Return save_dir as created from train/val/predict arguments."""
+
+ if getattr(args, 'save_dir', None):
+ save_dir = args.save_dir
+ else:
+ from ultralytics.utils.files import increment_path
+
+ project = args.project or Path(SETTINGS['runs_dir']) / args.task
+ name = name or args.name or f'{args.mode}'
+ save_dir = increment_path(Path(project) / name, exist_ok=args.exist_ok if RANK in (-1, 0) else True)
+
+ return Path(save_dir)
+
+
+def _handle_deprecation(custom):
+ """Hardcoded function to handle deprecated config keys."""
+
+ for key in custom.copy().keys():
+ if key == 'hide_labels':
+ deprecation_warn(key, 'show_labels')
+ custom['show_labels'] = custom.pop('hide_labels') == 'False'
+ if key == 'hide_conf':
+ deprecation_warn(key, 'show_conf')
+ custom['show_conf'] = custom.pop('hide_conf') == 'False'
+ if key == 'line_thickness':
+ deprecation_warn(key, 'line_width')
+ custom['line_width'] = custom.pop('line_thickness')
+
+ return custom
+
+
+def check_dict_alignment(base: Dict, custom: Dict, e=None):
+ """
+ This function checks for any mismatched keys between a custom configuration list and a base configuration list.
+ If any mismatched keys are found, the function prints out similar keys from the base list and exits the program.
+
+ Args:
+ custom (dict): a dictionary of custom configuration options
+ base (dict): a dictionary of base configuration options
+ e (Error, optional): An optional error that is passed by the calling function.
+ """
+ custom = _handle_deprecation(custom)
+ base_keys, custom_keys = (set(x.keys()) for x in (base, custom))
+ mismatched = [k for k in custom_keys if k not in base_keys]
+ if mismatched:
+ from difflib import get_close_matches
+
+ string = ''
+ for x in mismatched:
+ matches = get_close_matches(x, base_keys) # key list
+ matches = [f'{k}={base[k]}' if base.get(k) is not None else k for k in matches]
+ match_str = f'Similar arguments are i.e. {matches}.' if matches else ''
+ string += f"'{colorstr('red', 'bold', x)}' is not a valid YOLO argument. {match_str}\n"
+ raise SyntaxError(string + CLI_HELP_MSG) from e
+
+
+def merge_equals_args(args: List[str]) -> List[str]:
+ """
+ Merges arguments around isolated '=' args in a list of strings.
+ The function considers cases where the first argument ends with '=' or the second starts with '=',
+ as well as when the middle one is an equals sign.
+
+ Args:
+ args (List[str]): A list of strings where each element is an argument.
+
+ Returns:
+ List[str]: A list of strings where the arguments around isolated '=' are merged.
+ """
+ new_args = []
+ for i, arg in enumerate(args):
+ if arg == '=' and 0 < i < len(args) - 1: # merge ['arg', '=', 'val']
+ new_args[-1] += f'={args[i + 1]}'
+ del args[i + 1]
+ elif arg.endswith('=') and i < len(args) - 1 and '=' not in args[i + 1]: # merge ['arg=', 'val']
+ new_args.append(f'{arg}{args[i + 1]}')
+ del args[i + 1]
+ elif arg.startswith('=') and i > 0: # merge ['arg', '=val']
+ new_args[-1] += arg
+ else:
+ new_args.append(arg)
+ return new_args
+
+
+def handle_yolo_hub(args: List[str]) -> None:
+ """
+ Handle Ultralytics HUB command-line interface (CLI) commands.
+
+ This function processes Ultralytics HUB CLI commands such as login and logout.
+ It should be called when executing a script with arguments related to HUB authentication.
+
+ Args:
+ args (List[str]): A list of command line arguments
+
+ Example:
+ ```bash
+ python my_script.py hub login your_api_key
+ ```
+ """
+ from ultralytics import hub
+
+ if args[0] == 'login':
+ key = args[1] if len(args) > 1 else ''
+ # Log in to Ultralytics HUB using the provided API key
+ hub.login(key)
+ elif args[0] == 'logout':
+ # Log out from Ultralytics HUB
+ hub.logout()
+
+
+def handle_yolo_settings(args: List[str]) -> None:
+ """
+ Handle YOLO settings command-line interface (CLI) commands.
+
+ This function processes YOLO settings CLI commands such as reset.
+ It should be called when executing a script with arguments related to YOLO settings management.
+
+ Args:
+ args (List[str]): A list of command line arguments for YOLO settings management.
+
+ Example:
+ ```bash
+ python my_script.py yolo settings reset
+ ```
+ """
+ url = 'https://docs.ultralytics.com/quickstart/#ultralytics-settings' # help URL
+ try:
+ if any(args):
+ if args[0] == 'reset':
+ SETTINGS_YAML.unlink() # delete the settings file
+ SETTINGS.reset() # create new settings
+ LOGGER.info('Settings reset successfully') # inform the user that settings have been reset
+ else: # save a new setting
+ new = dict(parse_key_value_pair(a) for a in args)
+ check_dict_alignment(SETTINGS, new)
+ SETTINGS.update(new)
+
+ LOGGER.info(f'💡 Learn about settings at {url}')
+ yaml_print(SETTINGS_YAML) # print the current settings
+ except Exception as e:
+ LOGGER.warning(f"WARNING ⚠️ settings error: '{e}'. Please see {url} for help.")
+
+
+def parse_key_value_pair(pair):
+ """Parse one 'key=value' pair and return key and value."""
+ re.sub(r' *= *', '=', pair) # remove spaces around equals sign
+ k, v = pair.split('=', 1) # split on first '=' sign
+ assert v, f"missing '{k}' value"
+ return k, smart_value(v)
+
+
+def smart_value(v):
+ """Convert a string to an underlying type such as int, float, bool, etc."""
+ if v.lower() == 'none':
+ return None
+ elif v.lower() == 'true':
+ return True
+ elif v.lower() == 'false':
+ return False
+ else:
+ with contextlib.suppress(Exception):
+ return eval(v)
+ return v
+
+
+def entrypoint(debug=''):
+ """
+ This function is the ultralytics package entrypoint, it's responsible for parsing the command line arguments passed
+ to the package.
+
+ This function allows for:
+ - passing mandatory YOLO args as a list of strings
+ - specifying the task to be performed, either 'detect', 'segment' or 'classify'
+ - specifying the mode, either 'train', 'val', 'test', or 'predict'
+ - running special modes like 'checks'
+ - passing overrides to the package's configuration
+
+ It uses the package's default cfg and initializes it using the passed overrides.
+ Then it calls the CLI function with the composed cfg
+ """
+ args = (debug.split(' ') if debug else sys.argv)[1:]
+ if not args: # no arguments passed
+ LOGGER.info(CLI_HELP_MSG)
+ return
+
+ special = {
+ 'help': lambda: LOGGER.info(CLI_HELP_MSG),
+ 'checks': checks.check_yolo,
+ 'version': lambda: LOGGER.info(__version__),
+ 'settings': lambda: handle_yolo_settings(args[1:]),
+ 'cfg': lambda: yaml_print(DEFAULT_CFG_PATH),
+ 'hub': lambda: handle_yolo_hub(args[1:]),
+ 'login': lambda: handle_yolo_hub(args),
+ 'copy-cfg': copy_default_cfg}
+ full_args_dict = {**DEFAULT_CFG_DICT, **{k: None for k in TASKS}, **{k: None for k in MODES}, **special}
+
+ # Define common mis-uses of special commands, i.e. -h, -help, --help
+ special.update({k[0]: v for k, v in special.items()}) # singular
+ special.update({k[:-1]: v for k, v in special.items() if len(k) > 1 and k.endswith('s')}) # singular
+ special = {**special, **{f'-{k}': v for k, v in special.items()}, **{f'--{k}': v for k, v in special.items()}}
+
+ overrides = {} # basic overrides, i.e. imgsz=320
+ for a in merge_equals_args(args): # merge spaces around '=' sign
+ if a.startswith('--'):
+ LOGGER.warning(f"WARNING ⚠️ '{a}' does not require leading dashes '--', updating to '{a[2:]}'.")
+ a = a[2:]
+ if a.endswith(','):
+ LOGGER.warning(f"WARNING ⚠️ '{a}' does not require trailing comma ',', updating to '{a[:-1]}'.")
+ a = a[:-1]
+ if '=' in a:
+ try:
+ k, v = parse_key_value_pair(a)
+ if k == 'cfg': # custom.yaml passed
+ LOGGER.info(f'Overriding {DEFAULT_CFG_PATH} with {v}')
+ overrides = {k: val for k, val in yaml_load(checks.check_yaml(v)).items() if k != 'cfg'}
+ else:
+ overrides[k] = v
+ except (NameError, SyntaxError, ValueError, AssertionError) as e:
+ check_dict_alignment(full_args_dict, {a: ''}, e)
+
+ elif a in TASKS:
+ overrides['task'] = a
+ elif a in MODES:
+ overrides['mode'] = a
+ elif a.lower() in special:
+ special[a.lower()]()
+ return
+ elif a in DEFAULT_CFG_DICT and isinstance(DEFAULT_CFG_DICT[a], bool):
+ overrides[a] = True # auto-True for default bool args, i.e. 'yolo show' sets show=True
+ elif a in DEFAULT_CFG_DICT:
+ raise SyntaxError(f"'{colorstr('red', 'bold', a)}' is a valid YOLO argument but is missing an '=' sign "
+ f"to set its value, i.e. try '{a}={DEFAULT_CFG_DICT[a]}'\n{CLI_HELP_MSG}")
+ else:
+ check_dict_alignment(full_args_dict, {a: ''})
+
+ # Check keys
+ check_dict_alignment(full_args_dict, overrides)
+
+ # Mode
+ mode = overrides.get('mode')
+ if mode is None:
+ mode = DEFAULT_CFG.mode or 'predict'
+ LOGGER.warning(f"WARNING ⚠️ 'mode' is missing. Valid modes are {MODES}. Using default 'mode={mode}'.")
+ elif mode not in MODES:
+ raise ValueError(f"Invalid 'mode={mode}'. Valid modes are {MODES}.\n{CLI_HELP_MSG}")
+
+ # Task
+ task = overrides.pop('task', None)
+ if task:
+ if task not in TASKS:
+ raise ValueError(f"Invalid 'task={task}'. Valid tasks are {TASKS}.\n{CLI_HELP_MSG}")
+ if 'model' not in overrides:
+ overrides['model'] = TASK2MODEL[task]
+
+ # Model
+ model = overrides.pop('model', DEFAULT_CFG.model)
+ if model is None:
+ model = 'yolov8n.pt'
+ LOGGER.warning(f"WARNING ⚠️ 'model' is missing. Using default 'model={model}'.")
+ overrides['model'] = model
+ if 'rtdetr' in model.lower(): # guess architecture
+ from ultralytics import RTDETR
+ model = RTDETR(model) # no task argument
+ elif 'fastsam' in model.lower():
+ from ultralytics import FastSAM
+ model = FastSAM(model)
+ elif 'sam' in model.lower():
+ from ultralytics import SAM
+ model = SAM(model)
+ else:
+ from ultralytics import YOLO
+ model = YOLO(model, task=task)
+ if isinstance(overrides.get('pretrained'), str):
+ model.load(overrides['pretrained'])
+
+ # Task Update
+ if task != model.task:
+ if task:
+ LOGGER.warning(f"WARNING ⚠️ conflicting 'task={task}' passed with 'task={model.task}' model. "
+ f"Ignoring 'task={task}' and updating to 'task={model.task}' to match model.")
+ task = model.task
+
+ # Mode
+ if mode in ('predict', 'track') and 'source' not in overrides:
+ overrides['source'] = DEFAULT_CFG.source or ASSETS
+ LOGGER.warning(f"WARNING ⚠️ 'source' is missing. Using default 'source={overrides['source']}'.")
+ elif mode in ('train', 'val'):
+ if 'data' not in overrides and 'resume' not in overrides:
+ overrides['data'] = TASK2DATA.get(task or DEFAULT_CFG.task, DEFAULT_CFG.data)
+ LOGGER.warning(f"WARNING ⚠️ 'data' is missing. Using default 'data={overrides['data']}'.")
+ elif mode == 'export':
+ if 'format' not in overrides:
+ overrides['format'] = DEFAULT_CFG.format or 'torchscript'
+ LOGGER.warning(f"WARNING ⚠️ 'format' is missing. Using default 'format={overrides['format']}'.")
+
+ # Run command in python
+ # getattr(model, mode)(**vars(get_cfg(overrides=overrides))) # default args using default.yaml
+ getattr(model, mode)(**overrides) # default args from model
+
+
+# Special modes --------------------------------------------------------------------------------------------------------
+def copy_default_cfg():
+ """Copy and create a new default configuration file with '_copy' appended to its name."""
+ new_file = Path.cwd() / DEFAULT_CFG_PATH.name.replace('.yaml', '_copy.yaml')
+ shutil.copy2(DEFAULT_CFG_PATH, new_file)
+ LOGGER.info(f'{DEFAULT_CFG_PATH} copied to {new_file}\n'
+ f"Example YOLO command with this new custom cfg:\n yolo cfg='{new_file}' imgsz=320 batch=8")
+
+
+if __name__ == '__main__':
+ # Example: entrypoint(debug='yolo predict model=yolov8n.pt')
+ entrypoint(debug='')
diff --git a/STPoseNet/ultralytics/cfg/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/cfg/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c79e97c5f803f3b744d7f3dae831e4b9e695a173
Binary files /dev/null and b/STPoseNet/ultralytics/cfg/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/cfg/datasets/Argoverse.yaml b/STPoseNet/ultralytics/cfg/datasets/Argoverse.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..76255e4b276f96d0ce9579fc57349b85723917d2
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/Argoverse.yaml
@@ -0,0 +1,73 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: yolo train data=Argoverse.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── Argoverse ← downloads here (31.5 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: bus
+ 5: truck
+ 6: traffic_light
+ 7: stop_sign
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+ from tqdm import tqdm
+ from ultralytics.utils.downloads import download
+ from pathlib import Path
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download 'https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip' (deprecated S3 link)
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link']
+ download(urls, dir=dir)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert Argoverse annotations to YOLO labels
diff --git a/STPoseNet/ultralytics/cfg/datasets/DOTAv2.yaml b/STPoseNet/ultralytics/cfg/datasets/DOTAv2.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c663bdd5c449b87501246f35c9d73c159e447681
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/DOTAv2.yaml
@@ -0,0 +1,37 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# DOTA 2.0 dataset https://captain-whu.github.io/DOTA/index.html for object detection in aerial images by Wuhan University
+# Example usage: yolo train model=yolov8n-obb.pt data=DOTAv2.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── dota2 ← downloads here (2GB)
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/DOTAv2 # dataset root dir
+train: images/train # train images (relative to 'path') 1411 images
+val: images/val # val images (relative to 'path') 458 images
+test: images/test # test images (optional) 937 images
+
+# Classes for DOTA 2.0
+names:
+ 0: plane
+ 1: ship
+ 2: storage tank
+ 3: baseball diamond
+ 4: tennis court
+ 5: basketball court
+ 6: ground track field
+ 7: harbor
+ 8: bridge
+ 9: large vehicle
+ 10: small vehicle
+ 11: helicopter
+ 12: roundabout
+ 13: soccer ball field
+ 14: swimming pool
+ 15: container crane
+ 16: airport
+ 17: helipad
+
+# Download script/URL (optional)
+download: https://github.com/ultralytics/yolov5/releases/download/v1.0/DOTAv2.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/GlobalWheat2020.yaml b/STPoseNet/ultralytics/cfg/datasets/GlobalWheat2020.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..165004f6df6a14aae222063982ecf67cee543272
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: yolo train data=GlobalWheat2020.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+names:
+ 0: wheat_head
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from ultralytics.utils.downloads import download
+ from pathlib import Path
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / 'global-wheat-codalab-official' / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / 'global-wheat-codalab-official' / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/STPoseNet/ultralytics/cfg/datasets/ImageNet.yaml b/STPoseNet/ultralytics/cfg/datasets/ImageNet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c1aa155f8a814b880e4c534217f7d676bbf2e9f8
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/ImageNet.yaml
@@ -0,0 +1,2025 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
+# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
+# Example usage: yolo train task=classify data=imagenet
+# parent
+# ├── ultralytics
+# └── datasets
+# └── imagenet ← downloads here (144 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/imagenet # dataset root dir
+train: train # train images (relative to 'path') 1281167 images
+val: val # val images (relative to 'path') 50000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: tench
+ 1: goldfish
+ 2: great white shark
+ 3: tiger shark
+ 4: hammerhead shark
+ 5: electric ray
+ 6: stingray
+ 7: cock
+ 8: hen
+ 9: ostrich
+ 10: brambling
+ 11: goldfinch
+ 12: house finch
+ 13: junco
+ 14: indigo bunting
+ 15: American robin
+ 16: bulbul
+ 17: jay
+ 18: magpie
+ 19: chickadee
+ 20: American dipper
+ 21: kite
+ 22: bald eagle
+ 23: vulture
+ 24: great grey owl
+ 25: fire salamander
+ 26: smooth newt
+ 27: newt
+ 28: spotted salamander
+ 29: axolotl
+ 30: American bullfrog
+ 31: tree frog
+ 32: tailed frog
+ 33: loggerhead sea turtle
+ 34: leatherback sea turtle
+ 35: mud turtle
+ 36: terrapin
+ 37: box turtle
+ 38: banded gecko
+ 39: green iguana
+ 40: Carolina anole
+ 41: desert grassland whiptail lizard
+ 42: agama
+ 43: frilled-necked lizard
+ 44: alligator lizard
+ 45: Gila monster
+ 46: European green lizard
+ 47: chameleon
+ 48: Komodo dragon
+ 49: Nile crocodile
+ 50: American alligator
+ 51: triceratops
+ 52: worm snake
+ 53: ring-necked snake
+ 54: eastern hog-nosed snake
+ 55: smooth green snake
+ 56: kingsnake
+ 57: garter snake
+ 58: water snake
+ 59: vine snake
+ 60: night snake
+ 61: boa constrictor
+ 62: African rock python
+ 63: Indian cobra
+ 64: green mamba
+ 65: sea snake
+ 66: Saharan horned viper
+ 67: eastern diamondback rattlesnake
+ 68: sidewinder
+ 69: trilobite
+ 70: harvestman
+ 71: scorpion
+ 72: yellow garden spider
+ 73: barn spider
+ 74: European garden spider
+ 75: southern black widow
+ 76: tarantula
+ 77: wolf spider
+ 78: tick
+ 79: centipede
+ 80: black grouse
+ 81: ptarmigan
+ 82: ruffed grouse
+ 83: prairie grouse
+ 84: peacock
+ 85: quail
+ 86: partridge
+ 87: grey parrot
+ 88: macaw
+ 89: sulphur-crested cockatoo
+ 90: lorikeet
+ 91: coucal
+ 92: bee eater
+ 93: hornbill
+ 94: hummingbird
+ 95: jacamar
+ 96: toucan
+ 97: duck
+ 98: red-breasted merganser
+ 99: goose
+ 100: black swan
+ 101: tusker
+ 102: echidna
+ 103: platypus
+ 104: wallaby
+ 105: koala
+ 106: wombat
+ 107: jellyfish
+ 108: sea anemone
+ 109: brain coral
+ 110: flatworm
+ 111: nematode
+ 112: conch
+ 113: snail
+ 114: slug
+ 115: sea slug
+ 116: chiton
+ 117: chambered nautilus
+ 118: Dungeness crab
+ 119: rock crab
+ 120: fiddler crab
+ 121: red king crab
+ 122: American lobster
+ 123: spiny lobster
+ 124: crayfish
+ 125: hermit crab
+ 126: isopod
+ 127: white stork
+ 128: black stork
+ 129: spoonbill
+ 130: flamingo
+ 131: little blue heron
+ 132: great egret
+ 133: bittern
+ 134: crane (bird)
+ 135: limpkin
+ 136: common gallinule
+ 137: American coot
+ 138: bustard
+ 139: ruddy turnstone
+ 140: dunlin
+ 141: common redshank
+ 142: dowitcher
+ 143: oystercatcher
+ 144: pelican
+ 145: king penguin
+ 146: albatross
+ 147: grey whale
+ 148: killer whale
+ 149: dugong
+ 150: sea lion
+ 151: Chihuahua
+ 152: Japanese Chin
+ 153: Maltese
+ 154: Pekingese
+ 155: Shih Tzu
+ 156: King Charles Spaniel
+ 157: Papillon
+ 158: toy terrier
+ 159: Rhodesian Ridgeback
+ 160: Afghan Hound
+ 161: Basset Hound
+ 162: Beagle
+ 163: Bloodhound
+ 164: Bluetick Coonhound
+ 165: Black and Tan Coonhound
+ 166: Treeing Walker Coonhound
+ 167: English foxhound
+ 168: Redbone Coonhound
+ 169: borzoi
+ 170: Irish Wolfhound
+ 171: Italian Greyhound
+ 172: Whippet
+ 173: Ibizan Hound
+ 174: Norwegian Elkhound
+ 175: Otterhound
+ 176: Saluki
+ 177: Scottish Deerhound
+ 178: Weimaraner
+ 179: Staffordshire Bull Terrier
+ 180: American Staffordshire Terrier
+ 181: Bedlington Terrier
+ 182: Border Terrier
+ 183: Kerry Blue Terrier
+ 184: Irish Terrier
+ 185: Norfolk Terrier
+ 186: Norwich Terrier
+ 187: Yorkshire Terrier
+ 188: Wire Fox Terrier
+ 189: Lakeland Terrier
+ 190: Sealyham Terrier
+ 191: Airedale Terrier
+ 192: Cairn Terrier
+ 193: Australian Terrier
+ 194: Dandie Dinmont Terrier
+ 195: Boston Terrier
+ 196: Miniature Schnauzer
+ 197: Giant Schnauzer
+ 198: Standard Schnauzer
+ 199: Scottish Terrier
+ 200: Tibetan Terrier
+ 201: Australian Silky Terrier
+ 202: Soft-coated Wheaten Terrier
+ 203: West Highland White Terrier
+ 204: Lhasa Apso
+ 205: Flat-Coated Retriever
+ 206: Curly-coated Retriever
+ 207: Golden Retriever
+ 208: Labrador Retriever
+ 209: Chesapeake Bay Retriever
+ 210: German Shorthaired Pointer
+ 211: Vizsla
+ 212: English Setter
+ 213: Irish Setter
+ 214: Gordon Setter
+ 215: Brittany
+ 216: Clumber Spaniel
+ 217: English Springer Spaniel
+ 218: Welsh Springer Spaniel
+ 219: Cocker Spaniels
+ 220: Sussex Spaniel
+ 221: Irish Water Spaniel
+ 222: Kuvasz
+ 223: Schipperke
+ 224: Groenendael
+ 225: Malinois
+ 226: Briard
+ 227: Australian Kelpie
+ 228: Komondor
+ 229: Old English Sheepdog
+ 230: Shetland Sheepdog
+ 231: collie
+ 232: Border Collie
+ 233: Bouvier des Flandres
+ 234: Rottweiler
+ 235: German Shepherd Dog
+ 236: Dobermann
+ 237: Miniature Pinscher
+ 238: Greater Swiss Mountain Dog
+ 239: Bernese Mountain Dog
+ 240: Appenzeller Sennenhund
+ 241: Entlebucher Sennenhund
+ 242: Boxer
+ 243: Bullmastiff
+ 244: Tibetan Mastiff
+ 245: French Bulldog
+ 246: Great Dane
+ 247: St. Bernard
+ 248: husky
+ 249: Alaskan Malamute
+ 250: Siberian Husky
+ 251: Dalmatian
+ 252: Affenpinscher
+ 253: Basenji
+ 254: pug
+ 255: Leonberger
+ 256: Newfoundland
+ 257: Pyrenean Mountain Dog
+ 258: Samoyed
+ 259: Pomeranian
+ 260: Chow Chow
+ 261: Keeshond
+ 262: Griffon Bruxellois
+ 263: Pembroke Welsh Corgi
+ 264: Cardigan Welsh Corgi
+ 265: Toy Poodle
+ 266: Miniature Poodle
+ 267: Standard Poodle
+ 268: Mexican hairless dog
+ 269: grey wolf
+ 270: Alaskan tundra wolf
+ 271: red wolf
+ 272: coyote
+ 273: dingo
+ 274: dhole
+ 275: African wild dog
+ 276: hyena
+ 277: red fox
+ 278: kit fox
+ 279: Arctic fox
+ 280: grey fox
+ 281: tabby cat
+ 282: tiger cat
+ 283: Persian cat
+ 284: Siamese cat
+ 285: Egyptian Mau
+ 286: cougar
+ 287: lynx
+ 288: leopard
+ 289: snow leopard
+ 290: jaguar
+ 291: lion
+ 292: tiger
+ 293: cheetah
+ 294: brown bear
+ 295: American black bear
+ 296: polar bear
+ 297: sloth bear
+ 298: mongoose
+ 299: meerkat
+ 300: tiger beetle
+ 301: ladybug
+ 302: ground beetle
+ 303: longhorn beetle
+ 304: leaf beetle
+ 305: dung beetle
+ 306: rhinoceros beetle
+ 307: weevil
+ 308: fly
+ 309: bee
+ 310: ant
+ 311: grasshopper
+ 312: cricket
+ 313: stick insect
+ 314: cockroach
+ 315: mantis
+ 316: cicada
+ 317: leafhopper
+ 318: lacewing
+ 319: dragonfly
+ 320: damselfly
+ 321: red admiral
+ 322: ringlet
+ 323: monarch butterfly
+ 324: small white
+ 325: sulphur butterfly
+ 326: gossamer-winged butterfly
+ 327: starfish
+ 328: sea urchin
+ 329: sea cucumber
+ 330: cottontail rabbit
+ 331: hare
+ 332: Angora rabbit
+ 333: hamster
+ 334: porcupine
+ 335: fox squirrel
+ 336: marmot
+ 337: beaver
+ 338: guinea pig
+ 339: common sorrel
+ 340: zebra
+ 341: pig
+ 342: wild boar
+ 343: warthog
+ 344: hippopotamus
+ 345: ox
+ 346: water buffalo
+ 347: bison
+ 348: ram
+ 349: bighorn sheep
+ 350: Alpine ibex
+ 351: hartebeest
+ 352: impala
+ 353: gazelle
+ 354: dromedary
+ 355: llama
+ 356: weasel
+ 357: mink
+ 358: European polecat
+ 359: black-footed ferret
+ 360: otter
+ 361: skunk
+ 362: badger
+ 363: armadillo
+ 364: three-toed sloth
+ 365: orangutan
+ 366: gorilla
+ 367: chimpanzee
+ 368: gibbon
+ 369: siamang
+ 370: guenon
+ 371: patas monkey
+ 372: baboon
+ 373: macaque
+ 374: langur
+ 375: black-and-white colobus
+ 376: proboscis monkey
+ 377: marmoset
+ 378: white-headed capuchin
+ 379: howler monkey
+ 380: titi
+ 381: Geoffroy's spider monkey
+ 382: common squirrel monkey
+ 383: ring-tailed lemur
+ 384: indri
+ 385: Asian elephant
+ 386: African bush elephant
+ 387: red panda
+ 388: giant panda
+ 389: snoek
+ 390: eel
+ 391: coho salmon
+ 392: rock beauty
+ 393: clownfish
+ 394: sturgeon
+ 395: garfish
+ 396: lionfish
+ 397: pufferfish
+ 398: abacus
+ 399: abaya
+ 400: academic gown
+ 401: accordion
+ 402: acoustic guitar
+ 403: aircraft carrier
+ 404: airliner
+ 405: airship
+ 406: altar
+ 407: ambulance
+ 408: amphibious vehicle
+ 409: analog clock
+ 410: apiary
+ 411: apron
+ 412: waste container
+ 413: assault rifle
+ 414: backpack
+ 415: bakery
+ 416: balance beam
+ 417: balloon
+ 418: ballpoint pen
+ 419: Band-Aid
+ 420: banjo
+ 421: baluster
+ 422: barbell
+ 423: barber chair
+ 424: barbershop
+ 425: barn
+ 426: barometer
+ 427: barrel
+ 428: wheelbarrow
+ 429: baseball
+ 430: basketball
+ 431: bassinet
+ 432: bassoon
+ 433: swimming cap
+ 434: bath towel
+ 435: bathtub
+ 436: station wagon
+ 437: lighthouse
+ 438: beaker
+ 439: military cap
+ 440: beer bottle
+ 441: beer glass
+ 442: bell-cot
+ 443: bib
+ 444: tandem bicycle
+ 445: bikini
+ 446: ring binder
+ 447: binoculars
+ 448: birdhouse
+ 449: boathouse
+ 450: bobsleigh
+ 451: bolo tie
+ 452: poke bonnet
+ 453: bookcase
+ 454: bookstore
+ 455: bottle cap
+ 456: bow
+ 457: bow tie
+ 458: brass
+ 459: bra
+ 460: breakwater
+ 461: breastplate
+ 462: broom
+ 463: bucket
+ 464: buckle
+ 465: bulletproof vest
+ 466: high-speed train
+ 467: butcher shop
+ 468: taxicab
+ 469: cauldron
+ 470: candle
+ 471: cannon
+ 472: canoe
+ 473: can opener
+ 474: cardigan
+ 475: car mirror
+ 476: carousel
+ 477: tool kit
+ 478: carton
+ 479: car wheel
+ 480: automated teller machine
+ 481: cassette
+ 482: cassette player
+ 483: castle
+ 484: catamaran
+ 485: CD player
+ 486: cello
+ 487: mobile phone
+ 488: chain
+ 489: chain-link fence
+ 490: chain mail
+ 491: chainsaw
+ 492: chest
+ 493: chiffonier
+ 494: chime
+ 495: china cabinet
+ 496: Christmas stocking
+ 497: church
+ 498: movie theater
+ 499: cleaver
+ 500: cliff dwelling
+ 501: cloak
+ 502: clogs
+ 503: cocktail shaker
+ 504: coffee mug
+ 505: coffeemaker
+ 506: coil
+ 507: combination lock
+ 508: computer keyboard
+ 509: confectionery store
+ 510: container ship
+ 511: convertible
+ 512: corkscrew
+ 513: cornet
+ 514: cowboy boot
+ 515: cowboy hat
+ 516: cradle
+ 517: crane (machine)
+ 518: crash helmet
+ 519: crate
+ 520: infant bed
+ 521: Crock Pot
+ 522: croquet ball
+ 523: crutch
+ 524: cuirass
+ 525: dam
+ 526: desk
+ 527: desktop computer
+ 528: rotary dial telephone
+ 529: diaper
+ 530: digital clock
+ 531: digital watch
+ 532: dining table
+ 533: dishcloth
+ 534: dishwasher
+ 535: disc brake
+ 536: dock
+ 537: dog sled
+ 538: dome
+ 539: doormat
+ 540: drilling rig
+ 541: drum
+ 542: drumstick
+ 543: dumbbell
+ 544: Dutch oven
+ 545: electric fan
+ 546: electric guitar
+ 547: electric locomotive
+ 548: entertainment center
+ 549: envelope
+ 550: espresso machine
+ 551: face powder
+ 552: feather boa
+ 553: filing cabinet
+ 554: fireboat
+ 555: fire engine
+ 556: fire screen sheet
+ 557: flagpole
+ 558: flute
+ 559: folding chair
+ 560: football helmet
+ 561: forklift
+ 562: fountain
+ 563: fountain pen
+ 564: four-poster bed
+ 565: freight car
+ 566: French horn
+ 567: frying pan
+ 568: fur coat
+ 569: garbage truck
+ 570: gas mask
+ 571: gas pump
+ 572: goblet
+ 573: go-kart
+ 574: golf ball
+ 575: golf cart
+ 576: gondola
+ 577: gong
+ 578: gown
+ 579: grand piano
+ 580: greenhouse
+ 581: grille
+ 582: grocery store
+ 583: guillotine
+ 584: barrette
+ 585: hair spray
+ 586: half-track
+ 587: hammer
+ 588: hamper
+ 589: hair dryer
+ 590: hand-held computer
+ 591: handkerchief
+ 592: hard disk drive
+ 593: harmonica
+ 594: harp
+ 595: harvester
+ 596: hatchet
+ 597: holster
+ 598: home theater
+ 599: honeycomb
+ 600: hook
+ 601: hoop skirt
+ 602: horizontal bar
+ 603: horse-drawn vehicle
+ 604: hourglass
+ 605: iPod
+ 606: clothes iron
+ 607: jack-o'-lantern
+ 608: jeans
+ 609: jeep
+ 610: T-shirt
+ 611: jigsaw puzzle
+ 612: pulled rickshaw
+ 613: joystick
+ 614: kimono
+ 615: knee pad
+ 616: knot
+ 617: lab coat
+ 618: ladle
+ 619: lampshade
+ 620: laptop computer
+ 621: lawn mower
+ 622: lens cap
+ 623: paper knife
+ 624: library
+ 625: lifeboat
+ 626: lighter
+ 627: limousine
+ 628: ocean liner
+ 629: lipstick
+ 630: slip-on shoe
+ 631: lotion
+ 632: speaker
+ 633: loupe
+ 634: sawmill
+ 635: magnetic compass
+ 636: mail bag
+ 637: mailbox
+ 638: tights
+ 639: tank suit
+ 640: manhole cover
+ 641: maraca
+ 642: marimba
+ 643: mask
+ 644: match
+ 645: maypole
+ 646: maze
+ 647: measuring cup
+ 648: medicine chest
+ 649: megalith
+ 650: microphone
+ 651: microwave oven
+ 652: military uniform
+ 653: milk can
+ 654: minibus
+ 655: miniskirt
+ 656: minivan
+ 657: missile
+ 658: mitten
+ 659: mixing bowl
+ 660: mobile home
+ 661: Model T
+ 662: modem
+ 663: monastery
+ 664: monitor
+ 665: moped
+ 666: mortar
+ 667: square academic cap
+ 668: mosque
+ 669: mosquito net
+ 670: scooter
+ 671: mountain bike
+ 672: tent
+ 673: computer mouse
+ 674: mousetrap
+ 675: moving van
+ 676: muzzle
+ 677: nail
+ 678: neck brace
+ 679: necklace
+ 680: nipple
+ 681: notebook computer
+ 682: obelisk
+ 683: oboe
+ 684: ocarina
+ 685: odometer
+ 686: oil filter
+ 687: organ
+ 688: oscilloscope
+ 689: overskirt
+ 690: bullock cart
+ 691: oxygen mask
+ 692: packet
+ 693: paddle
+ 694: paddle wheel
+ 695: padlock
+ 696: paintbrush
+ 697: pajamas
+ 698: palace
+ 699: pan flute
+ 700: paper towel
+ 701: parachute
+ 702: parallel bars
+ 703: park bench
+ 704: parking meter
+ 705: passenger car
+ 706: patio
+ 707: payphone
+ 708: pedestal
+ 709: pencil case
+ 710: pencil sharpener
+ 711: perfume
+ 712: Petri dish
+ 713: photocopier
+ 714: plectrum
+ 715: Pickelhaube
+ 716: picket fence
+ 717: pickup truck
+ 718: pier
+ 719: piggy bank
+ 720: pill bottle
+ 721: pillow
+ 722: ping-pong ball
+ 723: pinwheel
+ 724: pirate ship
+ 725: pitcher
+ 726: hand plane
+ 727: planetarium
+ 728: plastic bag
+ 729: plate rack
+ 730: plow
+ 731: plunger
+ 732: Polaroid camera
+ 733: pole
+ 734: police van
+ 735: poncho
+ 736: billiard table
+ 737: soda bottle
+ 738: pot
+ 739: potter's wheel
+ 740: power drill
+ 741: prayer rug
+ 742: printer
+ 743: prison
+ 744: projectile
+ 745: projector
+ 746: hockey puck
+ 747: punching bag
+ 748: purse
+ 749: quill
+ 750: quilt
+ 751: race car
+ 752: racket
+ 753: radiator
+ 754: radio
+ 755: radio telescope
+ 756: rain barrel
+ 757: recreational vehicle
+ 758: reel
+ 759: reflex camera
+ 760: refrigerator
+ 761: remote control
+ 762: restaurant
+ 763: revolver
+ 764: rifle
+ 765: rocking chair
+ 766: rotisserie
+ 767: eraser
+ 768: rugby ball
+ 769: ruler
+ 770: running shoe
+ 771: safe
+ 772: safety pin
+ 773: salt shaker
+ 774: sandal
+ 775: sarong
+ 776: saxophone
+ 777: scabbard
+ 778: weighing scale
+ 779: school bus
+ 780: schooner
+ 781: scoreboard
+ 782: CRT screen
+ 783: screw
+ 784: screwdriver
+ 785: seat belt
+ 786: sewing machine
+ 787: shield
+ 788: shoe store
+ 789: shoji
+ 790: shopping basket
+ 791: shopping cart
+ 792: shovel
+ 793: shower cap
+ 794: shower curtain
+ 795: ski
+ 796: ski mask
+ 797: sleeping bag
+ 798: slide rule
+ 799: sliding door
+ 800: slot machine
+ 801: snorkel
+ 802: snowmobile
+ 803: snowplow
+ 804: soap dispenser
+ 805: soccer ball
+ 806: sock
+ 807: solar thermal collector
+ 808: sombrero
+ 809: soup bowl
+ 810: space bar
+ 811: space heater
+ 812: space shuttle
+ 813: spatula
+ 814: motorboat
+ 815: spider web
+ 816: spindle
+ 817: sports car
+ 818: spotlight
+ 819: stage
+ 820: steam locomotive
+ 821: through arch bridge
+ 822: steel drum
+ 823: stethoscope
+ 824: scarf
+ 825: stone wall
+ 826: stopwatch
+ 827: stove
+ 828: strainer
+ 829: tram
+ 830: stretcher
+ 831: couch
+ 832: stupa
+ 833: submarine
+ 834: suit
+ 835: sundial
+ 836: sunglass
+ 837: sunglasses
+ 838: sunscreen
+ 839: suspension bridge
+ 840: mop
+ 841: sweatshirt
+ 842: swimsuit
+ 843: swing
+ 844: switch
+ 845: syringe
+ 846: table lamp
+ 847: tank
+ 848: tape player
+ 849: teapot
+ 850: teddy bear
+ 851: television
+ 852: tennis ball
+ 853: thatched roof
+ 854: front curtain
+ 855: thimble
+ 856: threshing machine
+ 857: throne
+ 858: tile roof
+ 859: toaster
+ 860: tobacco shop
+ 861: toilet seat
+ 862: torch
+ 863: totem pole
+ 864: tow truck
+ 865: toy store
+ 866: tractor
+ 867: semi-trailer truck
+ 868: tray
+ 869: trench coat
+ 870: tricycle
+ 871: trimaran
+ 872: tripod
+ 873: triumphal arch
+ 874: trolleybus
+ 875: trombone
+ 876: tub
+ 877: turnstile
+ 878: typewriter keyboard
+ 879: umbrella
+ 880: unicycle
+ 881: upright piano
+ 882: vacuum cleaner
+ 883: vase
+ 884: vault
+ 885: velvet
+ 886: vending machine
+ 887: vestment
+ 888: viaduct
+ 889: violin
+ 890: volleyball
+ 891: waffle iron
+ 892: wall clock
+ 893: wallet
+ 894: wardrobe
+ 895: military aircraft
+ 896: sink
+ 897: washing machine
+ 898: water bottle
+ 899: water jug
+ 900: water tower
+ 901: whiskey jug
+ 902: whistle
+ 903: wig
+ 904: window screen
+ 905: window shade
+ 906: Windsor tie
+ 907: wine bottle
+ 908: wing
+ 909: wok
+ 910: wooden spoon
+ 911: wool
+ 912: split-rail fence
+ 913: shipwreck
+ 914: yawl
+ 915: yurt
+ 916: website
+ 917: comic book
+ 918: crossword
+ 919: traffic sign
+ 920: traffic light
+ 921: dust jacket
+ 922: menu
+ 923: plate
+ 924: guacamole
+ 925: consomme
+ 926: hot pot
+ 927: trifle
+ 928: ice cream
+ 929: ice pop
+ 930: baguette
+ 931: bagel
+ 932: pretzel
+ 933: cheeseburger
+ 934: hot dog
+ 935: mashed potato
+ 936: cabbage
+ 937: broccoli
+ 938: cauliflower
+ 939: zucchini
+ 940: spaghetti squash
+ 941: acorn squash
+ 942: butternut squash
+ 943: cucumber
+ 944: artichoke
+ 945: bell pepper
+ 946: cardoon
+ 947: mushroom
+ 948: Granny Smith
+ 949: strawberry
+ 950: orange
+ 951: lemon
+ 952: fig
+ 953: pineapple
+ 954: banana
+ 955: jackfruit
+ 956: custard apple
+ 957: pomegranate
+ 958: hay
+ 959: carbonara
+ 960: chocolate syrup
+ 961: dough
+ 962: meatloaf
+ 963: pizza
+ 964: pot pie
+ 965: burrito
+ 966: red wine
+ 967: espresso
+ 968: cup
+ 969: eggnog
+ 970: alp
+ 971: bubble
+ 972: cliff
+ 973: coral reef
+ 974: geyser
+ 975: lakeshore
+ 976: promontory
+ 977: shoal
+ 978: seashore
+ 979: valley
+ 980: volcano
+ 981: baseball player
+ 982: bridegroom
+ 983: scuba diver
+ 984: rapeseed
+ 985: daisy
+ 986: yellow lady's slipper
+ 987: corn
+ 988: acorn
+ 989: rose hip
+ 990: horse chestnut seed
+ 991: coral fungus
+ 992: agaric
+ 993: gyromitra
+ 994: stinkhorn mushroom
+ 995: earth star
+ 996: hen-of-the-woods
+ 997: bolete
+ 998: ear
+ 999: toilet paper
+
+# Imagenet class codes to human-readable names
+map:
+ n01440764: tench
+ n01443537: goldfish
+ n01484850: great_white_shark
+ n01491361: tiger_shark
+ n01494475: hammerhead
+ n01496331: electric_ray
+ n01498041: stingray
+ n01514668: cock
+ n01514859: hen
+ n01518878: ostrich
+ n01530575: brambling
+ n01531178: goldfinch
+ n01532829: house_finch
+ n01534433: junco
+ n01537544: indigo_bunting
+ n01558993: robin
+ n01560419: bulbul
+ n01580077: jay
+ n01582220: magpie
+ n01592084: chickadee
+ n01601694: water_ouzel
+ n01608432: kite
+ n01614925: bald_eagle
+ n01616318: vulture
+ n01622779: great_grey_owl
+ n01629819: European_fire_salamander
+ n01630670: common_newt
+ n01631663: eft
+ n01632458: spotted_salamander
+ n01632777: axolotl
+ n01641577: bullfrog
+ n01644373: tree_frog
+ n01644900: tailed_frog
+ n01664065: loggerhead
+ n01665541: leatherback_turtle
+ n01667114: mud_turtle
+ n01667778: terrapin
+ n01669191: box_turtle
+ n01675722: banded_gecko
+ n01677366: common_iguana
+ n01682714: American_chameleon
+ n01685808: whiptail
+ n01687978: agama
+ n01688243: frilled_lizard
+ n01689811: alligator_lizard
+ n01692333: Gila_monster
+ n01693334: green_lizard
+ n01694178: African_chameleon
+ n01695060: Komodo_dragon
+ n01697457: African_crocodile
+ n01698640: American_alligator
+ n01704323: triceratops
+ n01728572: thunder_snake
+ n01728920: ringneck_snake
+ n01729322: hognose_snake
+ n01729977: green_snake
+ n01734418: king_snake
+ n01735189: garter_snake
+ n01737021: water_snake
+ n01739381: vine_snake
+ n01740131: night_snake
+ n01742172: boa_constrictor
+ n01744401: rock_python
+ n01748264: Indian_cobra
+ n01749939: green_mamba
+ n01751748: sea_snake
+ n01753488: horned_viper
+ n01755581: diamondback
+ n01756291: sidewinder
+ n01768244: trilobite
+ n01770081: harvestman
+ n01770393: scorpion
+ n01773157: black_and_gold_garden_spider
+ n01773549: barn_spider
+ n01773797: garden_spider
+ n01774384: black_widow
+ n01774750: tarantula
+ n01775062: wolf_spider
+ n01776313: tick
+ n01784675: centipede
+ n01795545: black_grouse
+ n01796340: ptarmigan
+ n01797886: ruffed_grouse
+ n01798484: prairie_chicken
+ n01806143: peacock
+ n01806567: quail
+ n01807496: partridge
+ n01817953: African_grey
+ n01818515: macaw
+ n01819313: sulphur-crested_cockatoo
+ n01820546: lorikeet
+ n01824575: coucal
+ n01828970: bee_eater
+ n01829413: hornbill
+ n01833805: hummingbird
+ n01843065: jacamar
+ n01843383: toucan
+ n01847000: drake
+ n01855032: red-breasted_merganser
+ n01855672: goose
+ n01860187: black_swan
+ n01871265: tusker
+ n01872401: echidna
+ n01873310: platypus
+ n01877812: wallaby
+ n01882714: koala
+ n01883070: wombat
+ n01910747: jellyfish
+ n01914609: sea_anemone
+ n01917289: brain_coral
+ n01924916: flatworm
+ n01930112: nematode
+ n01943899: conch
+ n01944390: snail
+ n01945685: slug
+ n01950731: sea_slug
+ n01955084: chiton
+ n01968897: chambered_nautilus
+ n01978287: Dungeness_crab
+ n01978455: rock_crab
+ n01980166: fiddler_crab
+ n01981276: king_crab
+ n01983481: American_lobster
+ n01984695: spiny_lobster
+ n01985128: crayfish
+ n01986214: hermit_crab
+ n01990800: isopod
+ n02002556: white_stork
+ n02002724: black_stork
+ n02006656: spoonbill
+ n02007558: flamingo
+ n02009229: little_blue_heron
+ n02009912: American_egret
+ n02011460: bittern
+ n02012849: crane_(bird)
+ n02013706: limpkin
+ n02017213: European_gallinule
+ n02018207: American_coot
+ n02018795: bustard
+ n02025239: ruddy_turnstone
+ n02027492: red-backed_sandpiper
+ n02028035: redshank
+ n02033041: dowitcher
+ n02037110: oystercatcher
+ n02051845: pelican
+ n02056570: king_penguin
+ n02058221: albatross
+ n02066245: grey_whale
+ n02071294: killer_whale
+ n02074367: dugong
+ n02077923: sea_lion
+ n02085620: Chihuahua
+ n02085782: Japanese_spaniel
+ n02085936: Maltese_dog
+ n02086079: Pekinese
+ n02086240: Shih-Tzu
+ n02086646: Blenheim_spaniel
+ n02086910: papillon
+ n02087046: toy_terrier
+ n02087394: Rhodesian_ridgeback
+ n02088094: Afghan_hound
+ n02088238: basset
+ n02088364: beagle
+ n02088466: bloodhound
+ n02088632: bluetick
+ n02089078: black-and-tan_coonhound
+ n02089867: Walker_hound
+ n02089973: English_foxhound
+ n02090379: redbone
+ n02090622: borzoi
+ n02090721: Irish_wolfhound
+ n02091032: Italian_greyhound
+ n02091134: whippet
+ n02091244: Ibizan_hound
+ n02091467: Norwegian_elkhound
+ n02091635: otterhound
+ n02091831: Saluki
+ n02092002: Scottish_deerhound
+ n02092339: Weimaraner
+ n02093256: Staffordshire_bullterrier
+ n02093428: American_Staffordshire_terrier
+ n02093647: Bedlington_terrier
+ n02093754: Border_terrier
+ n02093859: Kerry_blue_terrier
+ n02093991: Irish_terrier
+ n02094114: Norfolk_terrier
+ n02094258: Norwich_terrier
+ n02094433: Yorkshire_terrier
+ n02095314: wire-haired_fox_terrier
+ n02095570: Lakeland_terrier
+ n02095889: Sealyham_terrier
+ n02096051: Airedale
+ n02096177: cairn
+ n02096294: Australian_terrier
+ n02096437: Dandie_Dinmont
+ n02096585: Boston_bull
+ n02097047: miniature_schnauzer
+ n02097130: giant_schnauzer
+ n02097209: standard_schnauzer
+ n02097298: Scotch_terrier
+ n02097474: Tibetan_terrier
+ n02097658: silky_terrier
+ n02098105: soft-coated_wheaten_terrier
+ n02098286: West_Highland_white_terrier
+ n02098413: Lhasa
+ n02099267: flat-coated_retriever
+ n02099429: curly-coated_retriever
+ n02099601: golden_retriever
+ n02099712: Labrador_retriever
+ n02099849: Chesapeake_Bay_retriever
+ n02100236: German_short-haired_pointer
+ n02100583: vizsla
+ n02100735: English_setter
+ n02100877: Irish_setter
+ n02101006: Gordon_setter
+ n02101388: Brittany_spaniel
+ n02101556: clumber
+ n02102040: English_springer
+ n02102177: Welsh_springer_spaniel
+ n02102318: cocker_spaniel
+ n02102480: Sussex_spaniel
+ n02102973: Irish_water_spaniel
+ n02104029: kuvasz
+ n02104365: schipperke
+ n02105056: groenendael
+ n02105162: malinois
+ n02105251: briard
+ n02105412: kelpie
+ n02105505: komondor
+ n02105641: Old_English_sheepdog
+ n02105855: Shetland_sheepdog
+ n02106030: collie
+ n02106166: Border_collie
+ n02106382: Bouvier_des_Flandres
+ n02106550: Rottweiler
+ n02106662: German_shepherd
+ n02107142: Doberman
+ n02107312: miniature_pinscher
+ n02107574: Greater_Swiss_Mountain_dog
+ n02107683: Bernese_mountain_dog
+ n02107908: Appenzeller
+ n02108000: EntleBucher
+ n02108089: boxer
+ n02108422: bull_mastiff
+ n02108551: Tibetan_mastiff
+ n02108915: French_bulldog
+ n02109047: Great_Dane
+ n02109525: Saint_Bernard
+ n02109961: Eskimo_dog
+ n02110063: malamute
+ n02110185: Siberian_husky
+ n02110341: dalmatian
+ n02110627: affenpinscher
+ n02110806: basenji
+ n02110958: pug
+ n02111129: Leonberg
+ n02111277: Newfoundland
+ n02111500: Great_Pyrenees
+ n02111889: Samoyed
+ n02112018: Pomeranian
+ n02112137: chow
+ n02112350: keeshond
+ n02112706: Brabancon_griffon
+ n02113023: Pembroke
+ n02113186: Cardigan
+ n02113624: toy_poodle
+ n02113712: miniature_poodle
+ n02113799: standard_poodle
+ n02113978: Mexican_hairless
+ n02114367: timber_wolf
+ n02114548: white_wolf
+ n02114712: red_wolf
+ n02114855: coyote
+ n02115641: dingo
+ n02115913: dhole
+ n02116738: African_hunting_dog
+ n02117135: hyena
+ n02119022: red_fox
+ n02119789: kit_fox
+ n02120079: Arctic_fox
+ n02120505: grey_fox
+ n02123045: tabby
+ n02123159: tiger_cat
+ n02123394: Persian_cat
+ n02123597: Siamese_cat
+ n02124075: Egyptian_cat
+ n02125311: cougar
+ n02127052: lynx
+ n02128385: leopard
+ n02128757: snow_leopard
+ n02128925: jaguar
+ n02129165: lion
+ n02129604: tiger
+ n02130308: cheetah
+ n02132136: brown_bear
+ n02133161: American_black_bear
+ n02134084: ice_bear
+ n02134418: sloth_bear
+ n02137549: mongoose
+ n02138441: meerkat
+ n02165105: tiger_beetle
+ n02165456: ladybug
+ n02167151: ground_beetle
+ n02168699: long-horned_beetle
+ n02169497: leaf_beetle
+ n02172182: dung_beetle
+ n02174001: rhinoceros_beetle
+ n02177972: weevil
+ n02190166: fly
+ n02206856: bee
+ n02219486: ant
+ n02226429: grasshopper
+ n02229544: cricket
+ n02231487: walking_stick
+ n02233338: cockroach
+ n02236044: mantis
+ n02256656: cicada
+ n02259212: leafhopper
+ n02264363: lacewing
+ n02268443: dragonfly
+ n02268853: damselfly
+ n02276258: admiral
+ n02277742: ringlet
+ n02279972: monarch
+ n02280649: cabbage_butterfly
+ n02281406: sulphur_butterfly
+ n02281787: lycaenid
+ n02317335: starfish
+ n02319095: sea_urchin
+ n02321529: sea_cucumber
+ n02325366: wood_rabbit
+ n02326432: hare
+ n02328150: Angora
+ n02342885: hamster
+ n02346627: porcupine
+ n02356798: fox_squirrel
+ n02361337: marmot
+ n02363005: beaver
+ n02364673: guinea_pig
+ n02389026: sorrel
+ n02391049: zebra
+ n02395406: hog
+ n02396427: wild_boar
+ n02397096: warthog
+ n02398521: hippopotamus
+ n02403003: ox
+ n02408429: water_buffalo
+ n02410509: bison
+ n02412080: ram
+ n02415577: bighorn
+ n02417914: ibex
+ n02422106: hartebeest
+ n02422699: impala
+ n02423022: gazelle
+ n02437312: Arabian_camel
+ n02437616: llama
+ n02441942: weasel
+ n02442845: mink
+ n02443114: polecat
+ n02443484: black-footed_ferret
+ n02444819: otter
+ n02445715: skunk
+ n02447366: badger
+ n02454379: armadillo
+ n02457408: three-toed_sloth
+ n02480495: orangutan
+ n02480855: gorilla
+ n02481823: chimpanzee
+ n02483362: gibbon
+ n02483708: siamang
+ n02484975: guenon
+ n02486261: patas
+ n02486410: baboon
+ n02487347: macaque
+ n02488291: langur
+ n02488702: colobus
+ n02489166: proboscis_monkey
+ n02490219: marmoset
+ n02492035: capuchin
+ n02492660: howler_monkey
+ n02493509: titi
+ n02493793: spider_monkey
+ n02494079: squirrel_monkey
+ n02497673: Madagascar_cat
+ n02500267: indri
+ n02504013: Indian_elephant
+ n02504458: African_elephant
+ n02509815: lesser_panda
+ n02510455: giant_panda
+ n02514041: barracouta
+ n02526121: eel
+ n02536864: coho
+ n02606052: rock_beauty
+ n02607072: anemone_fish
+ n02640242: sturgeon
+ n02641379: gar
+ n02643566: lionfish
+ n02655020: puffer
+ n02666196: abacus
+ n02667093: abaya
+ n02669723: academic_gown
+ n02672831: accordion
+ n02676566: acoustic_guitar
+ n02687172: aircraft_carrier
+ n02690373: airliner
+ n02692877: airship
+ n02699494: altar
+ n02701002: ambulance
+ n02704792: amphibian
+ n02708093: analog_clock
+ n02727426: apiary
+ n02730930: apron
+ n02747177: ashcan
+ n02749479: assault_rifle
+ n02769748: backpack
+ n02776631: bakery
+ n02777292: balance_beam
+ n02782093: balloon
+ n02783161: ballpoint
+ n02786058: Band_Aid
+ n02787622: banjo
+ n02788148: bannister
+ n02790996: barbell
+ n02791124: barber_chair
+ n02791270: barbershop
+ n02793495: barn
+ n02794156: barometer
+ n02795169: barrel
+ n02797295: barrow
+ n02799071: baseball
+ n02802426: basketball
+ n02804414: bassinet
+ n02804610: bassoon
+ n02807133: bathing_cap
+ n02808304: bath_towel
+ n02808440: bathtub
+ n02814533: beach_wagon
+ n02814860: beacon
+ n02815834: beaker
+ n02817516: bearskin
+ n02823428: beer_bottle
+ n02823750: beer_glass
+ n02825657: bell_cote
+ n02834397: bib
+ n02835271: bicycle-built-for-two
+ n02837789: bikini
+ n02840245: binder
+ n02841315: binoculars
+ n02843684: birdhouse
+ n02859443: boathouse
+ n02860847: bobsled
+ n02865351: bolo_tie
+ n02869837: bonnet
+ n02870880: bookcase
+ n02871525: bookshop
+ n02877765: bottlecap
+ n02879718: bow
+ n02883205: bow_tie
+ n02892201: brass
+ n02892767: brassiere
+ n02894605: breakwater
+ n02895154: breastplate
+ n02906734: broom
+ n02909870: bucket
+ n02910353: buckle
+ n02916936: bulletproof_vest
+ n02917067: bullet_train
+ n02927161: butcher_shop
+ n02930766: cab
+ n02939185: caldron
+ n02948072: candle
+ n02950826: cannon
+ n02951358: canoe
+ n02951585: can_opener
+ n02963159: cardigan
+ n02965783: car_mirror
+ n02966193: carousel
+ n02966687: carpenter's_kit
+ n02971356: carton
+ n02974003: car_wheel
+ n02977058: cash_machine
+ n02978881: cassette
+ n02979186: cassette_player
+ n02980441: castle
+ n02981792: catamaran
+ n02988304: CD_player
+ n02992211: cello
+ n02992529: cellular_telephone
+ n02999410: chain
+ n03000134: chainlink_fence
+ n03000247: chain_mail
+ n03000684: chain_saw
+ n03014705: chest
+ n03016953: chiffonier
+ n03017168: chime
+ n03018349: china_cabinet
+ n03026506: Christmas_stocking
+ n03028079: church
+ n03032252: cinema
+ n03041632: cleaver
+ n03042490: cliff_dwelling
+ n03045698: cloak
+ n03047690: clog
+ n03062245: cocktail_shaker
+ n03063599: coffee_mug
+ n03063689: coffeepot
+ n03065424: coil
+ n03075370: combination_lock
+ n03085013: computer_keyboard
+ n03089624: confectionery
+ n03095699: container_ship
+ n03100240: convertible
+ n03109150: corkscrew
+ n03110669: cornet
+ n03124043: cowboy_boot
+ n03124170: cowboy_hat
+ n03125729: cradle
+ n03126707: crane_(machine)
+ n03127747: crash_helmet
+ n03127925: crate
+ n03131574: crib
+ n03133878: Crock_Pot
+ n03134739: croquet_ball
+ n03141823: crutch
+ n03146219: cuirass
+ n03160309: dam
+ n03179701: desk
+ n03180011: desktop_computer
+ n03187595: dial_telephone
+ n03188531: diaper
+ n03196217: digital_clock
+ n03197337: digital_watch
+ n03201208: dining_table
+ n03207743: dishrag
+ n03207941: dishwasher
+ n03208938: disk_brake
+ n03216828: dock
+ n03218198: dogsled
+ n03220513: dome
+ n03223299: doormat
+ n03240683: drilling_platform
+ n03249569: drum
+ n03250847: drumstick
+ n03255030: dumbbell
+ n03259280: Dutch_oven
+ n03271574: electric_fan
+ n03272010: electric_guitar
+ n03272562: electric_locomotive
+ n03290653: entertainment_center
+ n03291819: envelope
+ n03297495: espresso_maker
+ n03314780: face_powder
+ n03325584: feather_boa
+ n03337140: file
+ n03344393: fireboat
+ n03345487: fire_engine
+ n03347037: fire_screen
+ n03355925: flagpole
+ n03372029: flute
+ n03376595: folding_chair
+ n03379051: football_helmet
+ n03384352: forklift
+ n03388043: fountain
+ n03388183: fountain_pen
+ n03388549: four-poster
+ n03393912: freight_car
+ n03394916: French_horn
+ n03400231: frying_pan
+ n03404251: fur_coat
+ n03417042: garbage_truck
+ n03424325: gasmask
+ n03425413: gas_pump
+ n03443371: goblet
+ n03444034: go-kart
+ n03445777: golf_ball
+ n03445924: golfcart
+ n03447447: gondola
+ n03447721: gong
+ n03450230: gown
+ n03452741: grand_piano
+ n03457902: greenhouse
+ n03459775: grille
+ n03461385: grocery_store
+ n03467068: guillotine
+ n03476684: hair_slide
+ n03476991: hair_spray
+ n03478589: half_track
+ n03481172: hammer
+ n03482405: hamper
+ n03483316: hand_blower
+ n03485407: hand-held_computer
+ n03485794: handkerchief
+ n03492542: hard_disc
+ n03494278: harmonica
+ n03495258: harp
+ n03496892: harvester
+ n03498962: hatchet
+ n03527444: holster
+ n03529860: home_theater
+ n03530642: honeycomb
+ n03532672: hook
+ n03534580: hoopskirt
+ n03535780: horizontal_bar
+ n03538406: horse_cart
+ n03544143: hourglass
+ n03584254: iPod
+ n03584829: iron
+ n03590841: jack-o'-lantern
+ n03594734: jean
+ n03594945: jeep
+ n03595614: jersey
+ n03598930: jigsaw_puzzle
+ n03599486: jinrikisha
+ n03602883: joystick
+ n03617480: kimono
+ n03623198: knee_pad
+ n03627232: knot
+ n03630383: lab_coat
+ n03633091: ladle
+ n03637318: lampshade
+ n03642806: laptop
+ n03649909: lawn_mower
+ n03657121: lens_cap
+ n03658185: letter_opener
+ n03661043: library
+ n03662601: lifeboat
+ n03666591: lighter
+ n03670208: limousine
+ n03673027: liner
+ n03676483: lipstick
+ n03680355: Loafer
+ n03690938: lotion
+ n03691459: loudspeaker
+ n03692522: loupe
+ n03697007: lumbermill
+ n03706229: magnetic_compass
+ n03709823: mailbag
+ n03710193: mailbox
+ n03710637: maillot_(tights)
+ n03710721: maillot_(tank_suit)
+ n03717622: manhole_cover
+ n03720891: maraca
+ n03721384: marimba
+ n03724870: mask
+ n03729826: matchstick
+ n03733131: maypole
+ n03733281: maze
+ n03733805: measuring_cup
+ n03742115: medicine_chest
+ n03743016: megalith
+ n03759954: microphone
+ n03761084: microwave
+ n03763968: military_uniform
+ n03764736: milk_can
+ n03769881: minibus
+ n03770439: miniskirt
+ n03770679: minivan
+ n03773504: missile
+ n03775071: mitten
+ n03775546: mixing_bowl
+ n03776460: mobile_home
+ n03777568: Model_T
+ n03777754: modem
+ n03781244: monastery
+ n03782006: monitor
+ n03785016: moped
+ n03786901: mortar
+ n03787032: mortarboard
+ n03788195: mosque
+ n03788365: mosquito_net
+ n03791053: motor_scooter
+ n03792782: mountain_bike
+ n03792972: mountain_tent
+ n03793489: mouse
+ n03794056: mousetrap
+ n03796401: moving_van
+ n03803284: muzzle
+ n03804744: nail
+ n03814639: neck_brace
+ n03814906: necklace
+ n03825788: nipple
+ n03832673: notebook
+ n03837869: obelisk
+ n03838899: oboe
+ n03840681: ocarina
+ n03841143: odometer
+ n03843555: oil_filter
+ n03854065: organ
+ n03857828: oscilloscope
+ n03866082: overskirt
+ n03868242: oxcart
+ n03868863: oxygen_mask
+ n03871628: packet
+ n03873416: paddle
+ n03874293: paddlewheel
+ n03874599: padlock
+ n03876231: paintbrush
+ n03877472: pajama
+ n03877845: palace
+ n03884397: panpipe
+ n03887697: paper_towel
+ n03888257: parachute
+ n03888605: parallel_bars
+ n03891251: park_bench
+ n03891332: parking_meter
+ n03895866: passenger_car
+ n03899768: patio
+ n03902125: pay-phone
+ n03903868: pedestal
+ n03908618: pencil_box
+ n03908714: pencil_sharpener
+ n03916031: perfume
+ n03920288: Petri_dish
+ n03924679: photocopier
+ n03929660: pick
+ n03929855: pickelhaube
+ n03930313: picket_fence
+ n03930630: pickup
+ n03933933: pier
+ n03935335: piggy_bank
+ n03937543: pill_bottle
+ n03938244: pillow
+ n03942813: ping-pong_ball
+ n03944341: pinwheel
+ n03947888: pirate
+ n03950228: pitcher
+ n03954731: plane
+ n03956157: planetarium
+ n03958227: plastic_bag
+ n03961711: plate_rack
+ n03967562: plow
+ n03970156: plunger
+ n03976467: Polaroid_camera
+ n03976657: pole
+ n03977966: police_van
+ n03980874: poncho
+ n03982430: pool_table
+ n03983396: pop_bottle
+ n03991062: pot
+ n03992509: potter's_wheel
+ n03995372: power_drill
+ n03998194: prayer_rug
+ n04004767: printer
+ n04005630: prison
+ n04008634: projectile
+ n04009552: projector
+ n04019541: puck
+ n04023962: punching_bag
+ n04026417: purse
+ n04033901: quill
+ n04033995: quilt
+ n04037443: racer
+ n04039381: racket
+ n04040759: radiator
+ n04041544: radio
+ n04044716: radio_telescope
+ n04049303: rain_barrel
+ n04065272: recreational_vehicle
+ n04067472: reel
+ n04069434: reflex_camera
+ n04070727: refrigerator
+ n04074963: remote_control
+ n04081281: restaurant
+ n04086273: revolver
+ n04090263: rifle
+ n04099969: rocking_chair
+ n04111531: rotisserie
+ n04116512: rubber_eraser
+ n04118538: rugby_ball
+ n04118776: rule
+ n04120489: running_shoe
+ n04125021: safe
+ n04127249: safety_pin
+ n04131690: saltshaker
+ n04133789: sandal
+ n04136333: sarong
+ n04141076: sax
+ n04141327: scabbard
+ n04141975: scale
+ n04146614: school_bus
+ n04147183: schooner
+ n04149813: scoreboard
+ n04152593: screen
+ n04153751: screw
+ n04154565: screwdriver
+ n04162706: seat_belt
+ n04179913: sewing_machine
+ n04192698: shield
+ n04200800: shoe_shop
+ n04201297: shoji
+ n04204238: shopping_basket
+ n04204347: shopping_cart
+ n04208210: shovel
+ n04209133: shower_cap
+ n04209239: shower_curtain
+ n04228054: ski
+ n04229816: ski_mask
+ n04235860: sleeping_bag
+ n04238763: slide_rule
+ n04239074: sliding_door
+ n04243546: slot
+ n04251144: snorkel
+ n04252077: snowmobile
+ n04252225: snowplow
+ n04254120: soap_dispenser
+ n04254680: soccer_ball
+ n04254777: sock
+ n04258138: solar_dish
+ n04259630: sombrero
+ n04263257: soup_bowl
+ n04264628: space_bar
+ n04265275: space_heater
+ n04266014: space_shuttle
+ n04270147: spatula
+ n04273569: speedboat
+ n04275548: spider_web
+ n04277352: spindle
+ n04285008: sports_car
+ n04286575: spotlight
+ n04296562: stage
+ n04310018: steam_locomotive
+ n04311004: steel_arch_bridge
+ n04311174: steel_drum
+ n04317175: stethoscope
+ n04325704: stole
+ n04326547: stone_wall
+ n04328186: stopwatch
+ n04330267: stove
+ n04332243: strainer
+ n04335435: streetcar
+ n04336792: stretcher
+ n04344873: studio_couch
+ n04346328: stupa
+ n04347754: submarine
+ n04350905: suit
+ n04355338: sundial
+ n04355933: sunglass
+ n04356056: sunglasses
+ n04357314: sunscreen
+ n04366367: suspension_bridge
+ n04367480: swab
+ n04370456: sweatshirt
+ n04371430: swimming_trunks
+ n04371774: swing
+ n04372370: switch
+ n04376876: syringe
+ n04380533: table_lamp
+ n04389033: tank
+ n04392985: tape_player
+ n04398044: teapot
+ n04399382: teddy
+ n04404412: television
+ n04409515: tennis_ball
+ n04417672: thatch
+ n04418357: theater_curtain
+ n04423845: thimble
+ n04428191: thresher
+ n04429376: throne
+ n04435653: tile_roof
+ n04442312: toaster
+ n04443257: tobacco_shop
+ n04447861: toilet_seat
+ n04456115: torch
+ n04458633: totem_pole
+ n04461696: tow_truck
+ n04462240: toyshop
+ n04465501: tractor
+ n04467665: trailer_truck
+ n04476259: tray
+ n04479046: trench_coat
+ n04482393: tricycle
+ n04483307: trimaran
+ n04485082: tripod
+ n04486054: triumphal_arch
+ n04487081: trolleybus
+ n04487394: trombone
+ n04493381: tub
+ n04501370: turnstile
+ n04505470: typewriter_keyboard
+ n04507155: umbrella
+ n04509417: unicycle
+ n04515003: upright
+ n04517823: vacuum
+ n04522168: vase
+ n04523525: vault
+ n04525038: velvet
+ n04525305: vending_machine
+ n04532106: vestment
+ n04532670: viaduct
+ n04536866: violin
+ n04540053: volleyball
+ n04542943: waffle_iron
+ n04548280: wall_clock
+ n04548362: wallet
+ n04550184: wardrobe
+ n04552348: warplane
+ n04553703: washbasin
+ n04554684: washer
+ n04557648: water_bottle
+ n04560804: water_jug
+ n04562935: water_tower
+ n04579145: whiskey_jug
+ n04579432: whistle
+ n04584207: wig
+ n04589890: window_screen
+ n04590129: window_shade
+ n04591157: Windsor_tie
+ n04591713: wine_bottle
+ n04592741: wing
+ n04596742: wok
+ n04597913: wooden_spoon
+ n04599235: wool
+ n04604644: worm_fence
+ n04606251: wreck
+ n04612504: yawl
+ n04613696: yurt
+ n06359193: web_site
+ n06596364: comic_book
+ n06785654: crossword_puzzle
+ n06794110: street_sign
+ n06874185: traffic_light
+ n07248320: book_jacket
+ n07565083: menu
+ n07579787: plate
+ n07583066: guacamole
+ n07584110: consomme
+ n07590611: hot_pot
+ n07613480: trifle
+ n07614500: ice_cream
+ n07615774: ice_lolly
+ n07684084: French_loaf
+ n07693725: bagel
+ n07695742: pretzel
+ n07697313: cheeseburger
+ n07697537: hotdog
+ n07711569: mashed_potato
+ n07714571: head_cabbage
+ n07714990: broccoli
+ n07715103: cauliflower
+ n07716358: zucchini
+ n07716906: spaghetti_squash
+ n07717410: acorn_squash
+ n07717556: butternut_squash
+ n07718472: cucumber
+ n07718747: artichoke
+ n07720875: bell_pepper
+ n07730033: cardoon
+ n07734744: mushroom
+ n07742313: Granny_Smith
+ n07745940: strawberry
+ n07747607: orange
+ n07749582: lemon
+ n07753113: fig
+ n07753275: pineapple
+ n07753592: banana
+ n07754684: jackfruit
+ n07760859: custard_apple
+ n07768694: pomegranate
+ n07802026: hay
+ n07831146: carbonara
+ n07836838: chocolate_sauce
+ n07860988: dough
+ n07871810: meat_loaf
+ n07873807: pizza
+ n07875152: potpie
+ n07880968: burrito
+ n07892512: red_wine
+ n07920052: espresso
+ n07930864: cup
+ n07932039: eggnog
+ n09193705: alp
+ n09229709: bubble
+ n09246464: cliff
+ n09256479: coral_reef
+ n09288635: geyser
+ n09332890: lakeside
+ n09399592: promontory
+ n09421951: sandbar
+ n09428293: seashore
+ n09468604: valley
+ n09472597: volcano
+ n09835506: ballplayer
+ n10148035: groom
+ n10565667: scuba_diver
+ n11879895: rapeseed
+ n11939491: daisy
+ n12057211: yellow_lady's_slipper
+ n12144580: corn
+ n12267677: acorn
+ n12620546: hip
+ n12768682: buckeye
+ n12985857: coral_fungus
+ n12998815: agaric
+ n13037406: gyromitra
+ n13040303: stinkhorn
+ n13044778: earthstar
+ n13052670: hen-of-the-woods
+ n13054560: bolete
+ n13133613: ear
+ n15075141: toilet_tissue
+
+
+# Download script/URL (optional)
+download: yolo/data/scripts/get_imagenet.sh
diff --git a/STPoseNet/ultralytics/cfg/datasets/Objects365.yaml b/STPoseNet/ultralytics/cfg/datasets/Objects365.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..415eff98352da330291de496d77d1e6280c01c48
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/Objects365.yaml
@@ -0,0 +1,443 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: yolo train data=Objects365.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Person
+ 1: Sneakers
+ 2: Chair
+ 3: Other Shoes
+ 4: Hat
+ 5: Car
+ 6: Lamp
+ 7: Glasses
+ 8: Bottle
+ 9: Desk
+ 10: Cup
+ 11: Street Lights
+ 12: Cabinet/shelf
+ 13: Handbag/Satchel
+ 14: Bracelet
+ 15: Plate
+ 16: Picture/Frame
+ 17: Helmet
+ 18: Book
+ 19: Gloves
+ 20: Storage box
+ 21: Boat
+ 22: Leather Shoes
+ 23: Flower
+ 24: Bench
+ 25: Potted Plant
+ 26: Bowl/Basin
+ 27: Flag
+ 28: Pillow
+ 29: Boots
+ 30: Vase
+ 31: Microphone
+ 32: Necklace
+ 33: Ring
+ 34: SUV
+ 35: Wine Glass
+ 36: Belt
+ 37: Monitor/TV
+ 38: Backpack
+ 39: Umbrella
+ 40: Traffic Light
+ 41: Speaker
+ 42: Watch
+ 43: Tie
+ 44: Trash bin Can
+ 45: Slippers
+ 46: Bicycle
+ 47: Stool
+ 48: Barrel/bucket
+ 49: Van
+ 50: Couch
+ 51: Sandals
+ 52: Basket
+ 53: Drum
+ 54: Pen/Pencil
+ 55: Bus
+ 56: Wild Bird
+ 57: High Heels
+ 58: Motorcycle
+ 59: Guitar
+ 60: Carpet
+ 61: Cell Phone
+ 62: Bread
+ 63: Camera
+ 64: Canned
+ 65: Truck
+ 66: Traffic cone
+ 67: Cymbal
+ 68: Lifesaver
+ 69: Towel
+ 70: Stuffed Toy
+ 71: Candle
+ 72: Sailboat
+ 73: Laptop
+ 74: Awning
+ 75: Bed
+ 76: Faucet
+ 77: Tent
+ 78: Horse
+ 79: Mirror
+ 80: Power outlet
+ 81: Sink
+ 82: Apple
+ 83: Air Conditioner
+ 84: Knife
+ 85: Hockey Stick
+ 86: Paddle
+ 87: Pickup Truck
+ 88: Fork
+ 89: Traffic Sign
+ 90: Balloon
+ 91: Tripod
+ 92: Dog
+ 93: Spoon
+ 94: Clock
+ 95: Pot
+ 96: Cow
+ 97: Cake
+ 98: Dinning Table
+ 99: Sheep
+ 100: Hanger
+ 101: Blackboard/Whiteboard
+ 102: Napkin
+ 103: Other Fish
+ 104: Orange/Tangerine
+ 105: Toiletry
+ 106: Keyboard
+ 107: Tomato
+ 108: Lantern
+ 109: Machinery Vehicle
+ 110: Fan
+ 111: Green Vegetables
+ 112: Banana
+ 113: Baseball Glove
+ 114: Airplane
+ 115: Mouse
+ 116: Train
+ 117: Pumpkin
+ 118: Soccer
+ 119: Skiboard
+ 120: Luggage
+ 121: Nightstand
+ 122: Tea pot
+ 123: Telephone
+ 124: Trolley
+ 125: Head Phone
+ 126: Sports Car
+ 127: Stop Sign
+ 128: Dessert
+ 129: Scooter
+ 130: Stroller
+ 131: Crane
+ 132: Remote
+ 133: Refrigerator
+ 134: Oven
+ 135: Lemon
+ 136: Duck
+ 137: Baseball Bat
+ 138: Surveillance Camera
+ 139: Cat
+ 140: Jug
+ 141: Broccoli
+ 142: Piano
+ 143: Pizza
+ 144: Elephant
+ 145: Skateboard
+ 146: Surfboard
+ 147: Gun
+ 148: Skating and Skiing shoes
+ 149: Gas stove
+ 150: Donut
+ 151: Bow Tie
+ 152: Carrot
+ 153: Toilet
+ 154: Kite
+ 155: Strawberry
+ 156: Other Balls
+ 157: Shovel
+ 158: Pepper
+ 159: Computer Box
+ 160: Toilet Paper
+ 161: Cleaning Products
+ 162: Chopsticks
+ 163: Microwave
+ 164: Pigeon
+ 165: Baseball
+ 166: Cutting/chopping Board
+ 167: Coffee Table
+ 168: Side Table
+ 169: Scissors
+ 170: Marker
+ 171: Pie
+ 172: Ladder
+ 173: Snowboard
+ 174: Cookies
+ 175: Radiator
+ 176: Fire Hydrant
+ 177: Basketball
+ 178: Zebra
+ 179: Grape
+ 180: Giraffe
+ 181: Potato
+ 182: Sausage
+ 183: Tricycle
+ 184: Violin
+ 185: Egg
+ 186: Fire Extinguisher
+ 187: Candy
+ 188: Fire Truck
+ 189: Billiards
+ 190: Converter
+ 191: Bathtub
+ 192: Wheelchair
+ 193: Golf Club
+ 194: Briefcase
+ 195: Cucumber
+ 196: Cigar/Cigarette
+ 197: Paint Brush
+ 198: Pear
+ 199: Heavy Truck
+ 200: Hamburger
+ 201: Extractor
+ 202: Extension Cord
+ 203: Tong
+ 204: Tennis Racket
+ 205: Folder
+ 206: American Football
+ 207: earphone
+ 208: Mask
+ 209: Kettle
+ 210: Tennis
+ 211: Ship
+ 212: Swing
+ 213: Coffee Machine
+ 214: Slide
+ 215: Carriage
+ 216: Onion
+ 217: Green beans
+ 218: Projector
+ 219: Frisbee
+ 220: Washing Machine/Drying Machine
+ 221: Chicken
+ 222: Printer
+ 223: Watermelon
+ 224: Saxophone
+ 225: Tissue
+ 226: Toothbrush
+ 227: Ice cream
+ 228: Hot-air balloon
+ 229: Cello
+ 230: French Fries
+ 231: Scale
+ 232: Trophy
+ 233: Cabbage
+ 234: Hot dog
+ 235: Blender
+ 236: Peach
+ 237: Rice
+ 238: Wallet/Purse
+ 239: Volleyball
+ 240: Deer
+ 241: Goose
+ 242: Tape
+ 243: Tablet
+ 244: Cosmetics
+ 245: Trumpet
+ 246: Pineapple
+ 247: Golf Ball
+ 248: Ambulance
+ 249: Parking meter
+ 250: Mango
+ 251: Key
+ 252: Hurdle
+ 253: Fishing Rod
+ 254: Medal
+ 255: Flute
+ 256: Brush
+ 257: Penguin
+ 258: Megaphone
+ 259: Corn
+ 260: Lettuce
+ 261: Garlic
+ 262: Swan
+ 263: Helicopter
+ 264: Green Onion
+ 265: Sandwich
+ 266: Nuts
+ 267: Speed Limit Sign
+ 268: Induction Cooker
+ 269: Broom
+ 270: Trombone
+ 271: Plum
+ 272: Rickshaw
+ 273: Goldfish
+ 274: Kiwi fruit
+ 275: Router/modem
+ 276: Poker Card
+ 277: Toaster
+ 278: Shrimp
+ 279: Sushi
+ 280: Cheese
+ 281: Notepaper
+ 282: Cherry
+ 283: Pliers
+ 284: CD
+ 285: Pasta
+ 286: Hammer
+ 287: Cue
+ 288: Avocado
+ 289: Hamimelon
+ 290: Flask
+ 291: Mushroom
+ 292: Screwdriver
+ 293: Soap
+ 294: Recorder
+ 295: Bear
+ 296: Eggplant
+ 297: Board Eraser
+ 298: Coconut
+ 299: Tape Measure/Ruler
+ 300: Pig
+ 301: Showerhead
+ 302: Globe
+ 303: Chips
+ 304: Steak
+ 305: Crosswalk Sign
+ 306: Stapler
+ 307: Camel
+ 308: Formula 1
+ 309: Pomegranate
+ 310: Dishwasher
+ 311: Crab
+ 312: Hoverboard
+ 313: Meat ball
+ 314: Rice Cooker
+ 315: Tuba
+ 316: Calculator
+ 317: Papaya
+ 318: Antelope
+ 319: Parrot
+ 320: Seal
+ 321: Butterfly
+ 322: Dumbbell
+ 323: Donkey
+ 324: Lion
+ 325: Urinal
+ 326: Dolphin
+ 327: Electric Drill
+ 328: Hair Dryer
+ 329: Egg tart
+ 330: Jellyfish
+ 331: Treadmill
+ 332: Lighter
+ 333: Grapefruit
+ 334: Game board
+ 335: Mop
+ 336: Radish
+ 337: Baozi
+ 338: Target
+ 339: French
+ 340: Spring Rolls
+ 341: Monkey
+ 342: Rabbit
+ 343: Pencil Case
+ 344: Yak
+ 345: Red Cabbage
+ 346: Binoculars
+ 347: Asparagus
+ 348: Barbell
+ 349: Scallop
+ 350: Noddles
+ 351: Comb
+ 352: Dumpling
+ 353: Oyster
+ 354: Table Tennis paddle
+ 355: Cosmetics Brush/Eyeliner Pencil
+ 356: Chainsaw
+ 357: Eraser
+ 358: Lobster
+ 359: Durian
+ 360: Okra
+ 361: Lipstick
+ 362: Cosmetics Mirror
+ 363: Curling
+ 364: Table Tennis
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from ultralytics.utils.checks import check_requirements
+ from ultralytics.utils.downloads import download
+ from ultralytics.utils.ops import xyxy2xywhn
+
+ import numpy as np
+ from pathlib import Path
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/STPoseNet/ultralytics/cfg/datasets/SKU-110K.yaml b/STPoseNet/ultralytics/cfg/datasets/SKU-110K.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e6deac21ef34c019070a27a55aad786b60901653
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/SKU-110K.yaml
@@ -0,0 +1,58 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: yolo train data=SKU-110K.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+names:
+ 0: object
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from pathlib import Path
+
+ import numpy as np
+ import pandas as pd
+ from tqdm import tqdm
+
+ from ultralytics.utils.downloads import download
+ from ultralytics.utils.ops import xyxy2xywh
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/STPoseNet/ultralytics/cfg/datasets/VOC.yaml b/STPoseNet/ultralytics/cfg/datasets/VOC.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..6bdcc4f13938c9185d31e34fc60aa0c57ec58978
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/VOC.yaml
@@ -0,0 +1,100 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: yolo train data=VOC.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+names:
+ 0: aeroplane
+ 1: bicycle
+ 2: bird
+ 3: boat
+ 4: bottle
+ 5: bus
+ 6: car
+ 7: cat
+ 8: chair
+ 9: cow
+ 10: diningtable
+ 11: dog
+ 12: horse
+ 13: motorbike
+ 14: person
+ 15: pottedplant
+ 16: sheep
+ 17: sofa
+ 18: train
+ 19: tvmonitor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from ultralytics.utils.downloads import download
+ from pathlib import Path
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ names = list(yaml['names'].values()) # names list
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in names and int(obj.find('difficult').text) != 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = names.index(cls) # class id
+ out_file.write(" ".join(str(a) for a in (cls_id, *bb)) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/STPoseNet/ultralytics/cfg/datasets/VisDrone.yaml b/STPoseNet/ultralytics/cfg/datasets/VisDrone.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a1a4a466ceaf1f2883c3abce6cba7045b96ce432
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/VisDrone.yaml
@@ -0,0 +1,73 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: yolo train data=VisDrone.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+names:
+ 0: pedestrian
+ 1: people
+ 2: bicycle
+ 3: car
+ 4: van
+ 5: truck
+ 6: tricycle
+ 7: awning-tricycle
+ 8: bus
+ 9: motor
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import os
+ from pathlib import Path
+
+ from ultralytics.utils.downloads import download
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(f'{os.sep}annotations{os.sep}', f'{os.sep}labels{os.sep}'), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco-pose.yaml b/STPoseNet/ultralytics/cfg/datasets/coco-pose.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..670d55bf691e558c048926b7e5951d6300eddd04
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco-pose.yaml
@@ -0,0 +1,38 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: yolo train data=coco-pose.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco-pose ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco-pose # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Keypoints
+kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
+
+# Classes
+names:
+ 0: person
+
+# Download script/URL (optional)
+download: |
+ from ultralytics.utils.downloads import download
+ from pathlib import Path
+
+ # Download labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + 'coco2017labels-pose.zip'] # labels
+ download(urls, dir=dir.parent)
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco.yaml b/STPoseNet/ultralytics/cfg/datasets/coco.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8a70a5b34bf2a4de112f7ed2c88c402d08203bbf
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco.yaml
@@ -0,0 +1,115 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: yolo train data=coco.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: |
+ from ultralytics.utils.downloads import download
+ from pathlib import Path
+
+ # Download labels
+ segments = True # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco128-seg.yaml b/STPoseNet/ultralytics/cfg/datasets/coco128-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8c2e3da33176757a977178d83318055e9ea89bb2
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco128-seg.yaml
@@ -0,0 +1,101 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: yolo train data=coco128.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco128-seg ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128-seg # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128-seg.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco128.yaml b/STPoseNet/ultralytics/cfg/datasets/coco128.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9749ab6c617701dd1e2dfe0682024014bfa225d2
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco128.yaml
@@ -0,0 +1,101 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: yolo train data=coco128.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco8-pose.yaml b/STPoseNet/ultralytics/cfg/datasets/coco8-pose.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e6fab8b59801488c0da236d4b048b5e19d131ccd
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco8-pose.yaml
@@ -0,0 +1,25 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO8-pose dataset (first 8 images from COCO train2017) by Ultralytics
+# Example usage: yolo train data=coco8-pose.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco8-pose ← downloads here (1 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8-pose # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Keypoints
+kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
+
+# Classes
+names:
+ 0: person
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco8-pose.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco8-seg.yaml b/STPoseNet/ultralytics/cfg/datasets/coco8-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e6faca1c32c29912427853071e2d7cc9632993ca
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco8-seg.yaml
@@ -0,0 +1,101 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO8-seg dataset (first 8 images from COCO train2017) by Ultralytics
+# Example usage: yolo train data=coco8-seg.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco8-seg ← downloads here (1 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8-seg # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco8-seg.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/coco8.yaml b/STPoseNet/ultralytics/cfg/datasets/coco8.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..eeb5d9dc78284bba1df8625361711b14c5a9eec3
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/coco8.yaml
@@ -0,0 +1,101 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
+# Example usage: yolo train data=coco8.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── coco8 ← downloads here (1 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco8 # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: person
+ 1: bicycle
+ 2: car
+ 3: motorcycle
+ 4: airplane
+ 5: bus
+ 6: train
+ 7: truck
+ 8: boat
+ 9: traffic light
+ 10: fire hydrant
+ 11: stop sign
+ 12: parking meter
+ 13: bench
+ 14: bird
+ 15: cat
+ 16: dog
+ 17: horse
+ 18: sheep
+ 19: cow
+ 20: elephant
+ 21: bear
+ 22: zebra
+ 23: giraffe
+ 24: backpack
+ 25: umbrella
+ 26: handbag
+ 27: tie
+ 28: suitcase
+ 29: frisbee
+ 30: skis
+ 31: snowboard
+ 32: sports ball
+ 33: kite
+ 34: baseball bat
+ 35: baseball glove
+ 36: skateboard
+ 37: surfboard
+ 38: tennis racket
+ 39: bottle
+ 40: wine glass
+ 41: cup
+ 42: fork
+ 43: knife
+ 44: spoon
+ 45: bowl
+ 46: banana
+ 47: apple
+ 48: sandwich
+ 49: orange
+ 50: broccoli
+ 51: carrot
+ 52: hot dog
+ 53: pizza
+ 54: donut
+ 55: cake
+ 56: chair
+ 57: couch
+ 58: potted plant
+ 59: bed
+ 60: dining table
+ 61: toilet
+ 62: tv
+ 63: laptop
+ 64: mouse
+ 65: remote
+ 66: keyboard
+ 67: cell phone
+ 68: microwave
+ 69: oven
+ 70: toaster
+ 71: sink
+ 72: refrigerator
+ 73: book
+ 74: clock
+ 75: vase
+ 76: scissors
+ 77: teddy bear
+ 78: hair drier
+ 79: toothbrush
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco8.zip
diff --git a/STPoseNet/ultralytics/cfg/datasets/mouse-pose.yaml b/STPoseNet/ultralytics/cfg/datasets/mouse-pose.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..276eee9539581b400b31dc5d2d46bbe13ca6ff69
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/mouse-pose.yaml
@@ -0,0 +1,13 @@
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: F:\mouse_re\paper-data\dataset\comprrehensive_ea_ch_wm\chase_50\train # dataset root dir
+train: images/train # train images (relative to 'path') 4 images
+val: images/val # val images (relative to 'path') 4 images
+test: # test images (optional)
+
+# Keypoints
+kpt_shape: [3, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+flip_idx: [0, 1, 2]
+
+# Classes
+names:
+ 0: mouse
diff --git a/STPoseNet/ultralytics/cfg/datasets/open-images-v7.yaml b/STPoseNet/ultralytics/cfg/datasets/open-images-v7.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bb1e3ff8158bb71bb1dafa96220d3e3b591d0f2c
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/open-images-v7.yaml
@@ -0,0 +1,661 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Open Images v7 dataset https://storage.googleapis.com/openimages/web/index.html by Google
+# Example usage: yolo train data=open-images-v7.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── open-images-v7 ← downloads here (561 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/open-images-v7 # dataset root dir
+train: images/train # train images (relative to 'path') 1743042 images
+val: images/val # val images (relative to 'path') 41620 images
+test: # test images (optional)
+
+# Classes
+names:
+ 0: Accordion
+ 1: Adhesive tape
+ 2: Aircraft
+ 3: Airplane
+ 4: Alarm clock
+ 5: Alpaca
+ 6: Ambulance
+ 7: Animal
+ 8: Ant
+ 9: Antelope
+ 10: Apple
+ 11: Armadillo
+ 12: Artichoke
+ 13: Auto part
+ 14: Axe
+ 15: Backpack
+ 16: Bagel
+ 17: Baked goods
+ 18: Balance beam
+ 19: Ball
+ 20: Balloon
+ 21: Banana
+ 22: Band-aid
+ 23: Banjo
+ 24: Barge
+ 25: Barrel
+ 26: Baseball bat
+ 27: Baseball glove
+ 28: Bat (Animal)
+ 29: Bathroom accessory
+ 30: Bathroom cabinet
+ 31: Bathtub
+ 32: Beaker
+ 33: Bear
+ 34: Bed
+ 35: Bee
+ 36: Beehive
+ 37: Beer
+ 38: Beetle
+ 39: Bell pepper
+ 40: Belt
+ 41: Bench
+ 42: Bicycle
+ 43: Bicycle helmet
+ 44: Bicycle wheel
+ 45: Bidet
+ 46: Billboard
+ 47: Billiard table
+ 48: Binoculars
+ 49: Bird
+ 50: Blender
+ 51: Blue jay
+ 52: Boat
+ 53: Bomb
+ 54: Book
+ 55: Bookcase
+ 56: Boot
+ 57: Bottle
+ 58: Bottle opener
+ 59: Bow and arrow
+ 60: Bowl
+ 61: Bowling equipment
+ 62: Box
+ 63: Boy
+ 64: Brassiere
+ 65: Bread
+ 66: Briefcase
+ 67: Broccoli
+ 68: Bronze sculpture
+ 69: Brown bear
+ 70: Building
+ 71: Bull
+ 72: Burrito
+ 73: Bus
+ 74: Bust
+ 75: Butterfly
+ 76: Cabbage
+ 77: Cabinetry
+ 78: Cake
+ 79: Cake stand
+ 80: Calculator
+ 81: Camel
+ 82: Camera
+ 83: Can opener
+ 84: Canary
+ 85: Candle
+ 86: Candy
+ 87: Cannon
+ 88: Canoe
+ 89: Cantaloupe
+ 90: Car
+ 91: Carnivore
+ 92: Carrot
+ 93: Cart
+ 94: Cassette deck
+ 95: Castle
+ 96: Cat
+ 97: Cat furniture
+ 98: Caterpillar
+ 99: Cattle
+ 100: Ceiling fan
+ 101: Cello
+ 102: Centipede
+ 103: Chainsaw
+ 104: Chair
+ 105: Cheese
+ 106: Cheetah
+ 107: Chest of drawers
+ 108: Chicken
+ 109: Chime
+ 110: Chisel
+ 111: Chopsticks
+ 112: Christmas tree
+ 113: Clock
+ 114: Closet
+ 115: Clothing
+ 116: Coat
+ 117: Cocktail
+ 118: Cocktail shaker
+ 119: Coconut
+ 120: Coffee
+ 121: Coffee cup
+ 122: Coffee table
+ 123: Coffeemaker
+ 124: Coin
+ 125: Common fig
+ 126: Common sunflower
+ 127: Computer keyboard
+ 128: Computer monitor
+ 129: Computer mouse
+ 130: Container
+ 131: Convenience store
+ 132: Cookie
+ 133: Cooking spray
+ 134: Corded phone
+ 135: Cosmetics
+ 136: Couch
+ 137: Countertop
+ 138: Cowboy hat
+ 139: Crab
+ 140: Cream
+ 141: Cricket ball
+ 142: Crocodile
+ 143: Croissant
+ 144: Crown
+ 145: Crutch
+ 146: Cucumber
+ 147: Cupboard
+ 148: Curtain
+ 149: Cutting board
+ 150: Dagger
+ 151: Dairy Product
+ 152: Deer
+ 153: Desk
+ 154: Dessert
+ 155: Diaper
+ 156: Dice
+ 157: Digital clock
+ 158: Dinosaur
+ 159: Dishwasher
+ 160: Dog
+ 161: Dog bed
+ 162: Doll
+ 163: Dolphin
+ 164: Door
+ 165: Door handle
+ 166: Doughnut
+ 167: Dragonfly
+ 168: Drawer
+ 169: Dress
+ 170: Drill (Tool)
+ 171: Drink
+ 172: Drinking straw
+ 173: Drum
+ 174: Duck
+ 175: Dumbbell
+ 176: Eagle
+ 177: Earrings
+ 178: Egg (Food)
+ 179: Elephant
+ 180: Envelope
+ 181: Eraser
+ 182: Face powder
+ 183: Facial tissue holder
+ 184: Falcon
+ 185: Fashion accessory
+ 186: Fast food
+ 187: Fax
+ 188: Fedora
+ 189: Filing cabinet
+ 190: Fire hydrant
+ 191: Fireplace
+ 192: Fish
+ 193: Flag
+ 194: Flashlight
+ 195: Flower
+ 196: Flowerpot
+ 197: Flute
+ 198: Flying disc
+ 199: Food
+ 200: Food processor
+ 201: Football
+ 202: Football helmet
+ 203: Footwear
+ 204: Fork
+ 205: Fountain
+ 206: Fox
+ 207: French fries
+ 208: French horn
+ 209: Frog
+ 210: Fruit
+ 211: Frying pan
+ 212: Furniture
+ 213: Garden Asparagus
+ 214: Gas stove
+ 215: Giraffe
+ 216: Girl
+ 217: Glasses
+ 218: Glove
+ 219: Goat
+ 220: Goggles
+ 221: Goldfish
+ 222: Golf ball
+ 223: Golf cart
+ 224: Gondola
+ 225: Goose
+ 226: Grape
+ 227: Grapefruit
+ 228: Grinder
+ 229: Guacamole
+ 230: Guitar
+ 231: Hair dryer
+ 232: Hair spray
+ 233: Hamburger
+ 234: Hammer
+ 235: Hamster
+ 236: Hand dryer
+ 237: Handbag
+ 238: Handgun
+ 239: Harbor seal
+ 240: Harmonica
+ 241: Harp
+ 242: Harpsichord
+ 243: Hat
+ 244: Headphones
+ 245: Heater
+ 246: Hedgehog
+ 247: Helicopter
+ 248: Helmet
+ 249: High heels
+ 250: Hiking equipment
+ 251: Hippopotamus
+ 252: Home appliance
+ 253: Honeycomb
+ 254: Horizontal bar
+ 255: Horse
+ 256: Hot dog
+ 257: House
+ 258: Houseplant
+ 259: Human arm
+ 260: Human beard
+ 261: Human body
+ 262: Human ear
+ 263: Human eye
+ 264: Human face
+ 265: Human foot
+ 266: Human hair
+ 267: Human hand
+ 268: Human head
+ 269: Human leg
+ 270: Human mouth
+ 271: Human nose
+ 272: Humidifier
+ 273: Ice cream
+ 274: Indoor rower
+ 275: Infant bed
+ 276: Insect
+ 277: Invertebrate
+ 278: Ipod
+ 279: Isopod
+ 280: Jacket
+ 281: Jacuzzi
+ 282: Jaguar (Animal)
+ 283: Jeans
+ 284: Jellyfish
+ 285: Jet ski
+ 286: Jug
+ 287: Juice
+ 288: Kangaroo
+ 289: Kettle
+ 290: Kitchen & dining room table
+ 291: Kitchen appliance
+ 292: Kitchen knife
+ 293: Kitchen utensil
+ 294: Kitchenware
+ 295: Kite
+ 296: Knife
+ 297: Koala
+ 298: Ladder
+ 299: Ladle
+ 300: Ladybug
+ 301: Lamp
+ 302: Land vehicle
+ 303: Lantern
+ 304: Laptop
+ 305: Lavender (Plant)
+ 306: Lemon
+ 307: Leopard
+ 308: Light bulb
+ 309: Light switch
+ 310: Lighthouse
+ 311: Lily
+ 312: Limousine
+ 313: Lion
+ 314: Lipstick
+ 315: Lizard
+ 316: Lobster
+ 317: Loveseat
+ 318: Luggage and bags
+ 319: Lynx
+ 320: Magpie
+ 321: Mammal
+ 322: Man
+ 323: Mango
+ 324: Maple
+ 325: Maracas
+ 326: Marine invertebrates
+ 327: Marine mammal
+ 328: Measuring cup
+ 329: Mechanical fan
+ 330: Medical equipment
+ 331: Microphone
+ 332: Microwave oven
+ 333: Milk
+ 334: Miniskirt
+ 335: Mirror
+ 336: Missile
+ 337: Mixer
+ 338: Mixing bowl
+ 339: Mobile phone
+ 340: Monkey
+ 341: Moths and butterflies
+ 342: Motorcycle
+ 343: Mouse
+ 344: Muffin
+ 345: Mug
+ 346: Mule
+ 347: Mushroom
+ 348: Musical instrument
+ 349: Musical keyboard
+ 350: Nail (Construction)
+ 351: Necklace
+ 352: Nightstand
+ 353: Oboe
+ 354: Office building
+ 355: Office supplies
+ 356: Orange
+ 357: Organ (Musical Instrument)
+ 358: Ostrich
+ 359: Otter
+ 360: Oven
+ 361: Owl
+ 362: Oyster
+ 363: Paddle
+ 364: Palm tree
+ 365: Pancake
+ 366: Panda
+ 367: Paper cutter
+ 368: Paper towel
+ 369: Parachute
+ 370: Parking meter
+ 371: Parrot
+ 372: Pasta
+ 373: Pastry
+ 374: Peach
+ 375: Pear
+ 376: Pen
+ 377: Pencil case
+ 378: Pencil sharpener
+ 379: Penguin
+ 380: Perfume
+ 381: Person
+ 382: Personal care
+ 383: Personal flotation device
+ 384: Piano
+ 385: Picnic basket
+ 386: Picture frame
+ 387: Pig
+ 388: Pillow
+ 389: Pineapple
+ 390: Pitcher (Container)
+ 391: Pizza
+ 392: Pizza cutter
+ 393: Plant
+ 394: Plastic bag
+ 395: Plate
+ 396: Platter
+ 397: Plumbing fixture
+ 398: Polar bear
+ 399: Pomegranate
+ 400: Popcorn
+ 401: Porch
+ 402: Porcupine
+ 403: Poster
+ 404: Potato
+ 405: Power plugs and sockets
+ 406: Pressure cooker
+ 407: Pretzel
+ 408: Printer
+ 409: Pumpkin
+ 410: Punching bag
+ 411: Rabbit
+ 412: Raccoon
+ 413: Racket
+ 414: Radish
+ 415: Ratchet (Device)
+ 416: Raven
+ 417: Rays and skates
+ 418: Red panda
+ 419: Refrigerator
+ 420: Remote control
+ 421: Reptile
+ 422: Rhinoceros
+ 423: Rifle
+ 424: Ring binder
+ 425: Rocket
+ 426: Roller skates
+ 427: Rose
+ 428: Rugby ball
+ 429: Ruler
+ 430: Salad
+ 431: Salt and pepper shakers
+ 432: Sandal
+ 433: Sandwich
+ 434: Saucer
+ 435: Saxophone
+ 436: Scale
+ 437: Scarf
+ 438: Scissors
+ 439: Scoreboard
+ 440: Scorpion
+ 441: Screwdriver
+ 442: Sculpture
+ 443: Sea lion
+ 444: Sea turtle
+ 445: Seafood
+ 446: Seahorse
+ 447: Seat belt
+ 448: Segway
+ 449: Serving tray
+ 450: Sewing machine
+ 451: Shark
+ 452: Sheep
+ 453: Shelf
+ 454: Shellfish
+ 455: Shirt
+ 456: Shorts
+ 457: Shotgun
+ 458: Shower
+ 459: Shrimp
+ 460: Sink
+ 461: Skateboard
+ 462: Ski
+ 463: Skirt
+ 464: Skull
+ 465: Skunk
+ 466: Skyscraper
+ 467: Slow cooker
+ 468: Snack
+ 469: Snail
+ 470: Snake
+ 471: Snowboard
+ 472: Snowman
+ 473: Snowmobile
+ 474: Snowplow
+ 475: Soap dispenser
+ 476: Sock
+ 477: Sofa bed
+ 478: Sombrero
+ 479: Sparrow
+ 480: Spatula
+ 481: Spice rack
+ 482: Spider
+ 483: Spoon
+ 484: Sports equipment
+ 485: Sports uniform
+ 486: Squash (Plant)
+ 487: Squid
+ 488: Squirrel
+ 489: Stairs
+ 490: Stapler
+ 491: Starfish
+ 492: Stationary bicycle
+ 493: Stethoscope
+ 494: Stool
+ 495: Stop sign
+ 496: Strawberry
+ 497: Street light
+ 498: Stretcher
+ 499: Studio couch
+ 500: Submarine
+ 501: Submarine sandwich
+ 502: Suit
+ 503: Suitcase
+ 504: Sun hat
+ 505: Sunglasses
+ 506: Surfboard
+ 507: Sushi
+ 508: Swan
+ 509: Swim cap
+ 510: Swimming pool
+ 511: Swimwear
+ 512: Sword
+ 513: Syringe
+ 514: Table
+ 515: Table tennis racket
+ 516: Tablet computer
+ 517: Tableware
+ 518: Taco
+ 519: Tank
+ 520: Tap
+ 521: Tart
+ 522: Taxi
+ 523: Tea
+ 524: Teapot
+ 525: Teddy bear
+ 526: Telephone
+ 527: Television
+ 528: Tennis ball
+ 529: Tennis racket
+ 530: Tent
+ 531: Tiara
+ 532: Tick
+ 533: Tie
+ 534: Tiger
+ 535: Tin can
+ 536: Tire
+ 537: Toaster
+ 538: Toilet
+ 539: Toilet paper
+ 540: Tomato
+ 541: Tool
+ 542: Toothbrush
+ 543: Torch
+ 544: Tortoise
+ 545: Towel
+ 546: Tower
+ 547: Toy
+ 548: Traffic light
+ 549: Traffic sign
+ 550: Train
+ 551: Training bench
+ 552: Treadmill
+ 553: Tree
+ 554: Tree house
+ 555: Tripod
+ 556: Trombone
+ 557: Trousers
+ 558: Truck
+ 559: Trumpet
+ 560: Turkey
+ 561: Turtle
+ 562: Umbrella
+ 563: Unicycle
+ 564: Van
+ 565: Vase
+ 566: Vegetable
+ 567: Vehicle
+ 568: Vehicle registration plate
+ 569: Violin
+ 570: Volleyball (Ball)
+ 571: Waffle
+ 572: Waffle iron
+ 573: Wall clock
+ 574: Wardrobe
+ 575: Washing machine
+ 576: Waste container
+ 577: Watch
+ 578: Watercraft
+ 579: Watermelon
+ 580: Weapon
+ 581: Whale
+ 582: Wheel
+ 583: Wheelchair
+ 584: Whisk
+ 585: Whiteboard
+ 586: Willow
+ 587: Window
+ 588: Window blind
+ 589: Wine
+ 590: Wine glass
+ 591: Wine rack
+ 592: Winter melon
+ 593: Wok
+ 594: Woman
+ 595: Wood-burning stove
+ 596: Woodpecker
+ 597: Worm
+ 598: Wrench
+ 599: Zebra
+ 600: Zucchini
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from ultralytics.utils import LOGGER, SETTINGS, Path, is_ubuntu, get_ubuntu_version
+ from ultralytics.utils.checks import check_requirements, check_version
+
+ check_requirements('fiftyone')
+ if is_ubuntu() and check_version(get_ubuntu_version(), '>=22.04'):
+ # Ubuntu>=22.04 patch https://github.com/voxel51/fiftyone/issues/2961#issuecomment-1666519347
+ check_requirements('fiftyone-db-ubuntu2204')
+
+ import fiftyone as fo
+ import fiftyone.zoo as foz
+ import warnings
+
+ name = 'open-images-v7'
+ fraction = 1.0 # fraction of full dataset to use
+ LOGGER.warning('WARNING ⚠️ Open Images V7 dataset requires at least **561 GB of free space. Starting download...')
+ for split in 'train', 'validation': # 1743042 train, 41620 val images
+ train = split == 'train'
+
+ # Load Open Images dataset
+ dataset = foz.load_zoo_dataset(name,
+ split=split,
+ label_types=['detections'],
+ dataset_dir=Path(SETTINGS['datasets_dir']) / 'fiftyone' / name,
+ max_samples=round((1743042 if train else 41620) * fraction))
+
+ # Define classes
+ if train:
+ classes = dataset.default_classes # all classes
+ # classes = dataset.distinct('ground_truth.detections.label') # only observed classes
+
+ # Export to YOLO format
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=UserWarning, module="fiftyone.utils.yolo")
+ dataset.export(export_dir=str(Path(SETTINGS['datasets_dir']) / name),
+ dataset_type=fo.types.YOLOv5Dataset,
+ label_field='ground_truth',
+ split='val' if split == 'validation' else split,
+ classes=classes,
+ overwrite=train)
diff --git a/STPoseNet/ultralytics/cfg/datasets/xView.yaml b/STPoseNet/ultralytics/cfg/datasets/xView.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bdc2d9175723235e80e20283fe23aa5177b9ba37
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/datasets/xView.yaml
@@ -0,0 +1,153 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# DIUx xView 2018 Challenge https://challenge.xviewdataset.org by U.S. National Geospatial-Intelligence Agency (NGA)
+# -------- DOWNLOAD DATA MANUALLY and jar xf val_images.zip to 'datasets/xView' before running train command! --------
+# Example usage: yolo train data=xView.yaml
+# parent
+# ├── ultralytics
+# └── datasets
+# └── xView ← downloads here (20.7 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/xView # dataset root dir
+train: images/autosplit_train.txt # train images (relative to 'path') 90% of 847 train images
+val: images/autosplit_val.txt # train images (relative to 'path') 10% of 847 train images
+
+# Classes
+names:
+ 0: Fixed-wing Aircraft
+ 1: Small Aircraft
+ 2: Cargo Plane
+ 3: Helicopter
+ 4: Passenger Vehicle
+ 5: Small Car
+ 6: Bus
+ 7: Pickup Truck
+ 8: Utility Truck
+ 9: Truck
+ 10: Cargo Truck
+ 11: Truck w/Box
+ 12: Truck Tractor
+ 13: Trailer
+ 14: Truck w/Flatbed
+ 15: Truck w/Liquid
+ 16: Crane Truck
+ 17: Railway Vehicle
+ 18: Passenger Car
+ 19: Cargo Car
+ 20: Flat Car
+ 21: Tank car
+ 22: Locomotive
+ 23: Maritime Vessel
+ 24: Motorboat
+ 25: Sailboat
+ 26: Tugboat
+ 27: Barge
+ 28: Fishing Vessel
+ 29: Ferry
+ 30: Yacht
+ 31: Container Ship
+ 32: Oil Tanker
+ 33: Engineering Vehicle
+ 34: Tower crane
+ 35: Container Crane
+ 36: Reach Stacker
+ 37: Straddle Carrier
+ 38: Mobile Crane
+ 39: Dump Truck
+ 40: Haul Truck
+ 41: Scraper/Tractor
+ 42: Front loader/Bulldozer
+ 43: Excavator
+ 44: Cement Mixer
+ 45: Ground Grader
+ 46: Hut/Tent
+ 47: Shed
+ 48: Building
+ 49: Aircraft Hangar
+ 50: Damaged Building
+ 51: Facility
+ 52: Construction Site
+ 53: Vehicle Lot
+ 54: Helipad
+ 55: Storage Tank
+ 56: Shipping container lot
+ 57: Shipping Container
+ 58: Pylon
+ 59: Tower
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+ import os
+ from pathlib import Path
+
+ import numpy as np
+ from PIL import Image
+ from tqdm import tqdm
+
+ from ultralytics.data.utils import autosplit
+ from ultralytics.utils.ops import xyxy2xywhn
+
+
+ def convert_labels(fname=Path('xView/xView_train.geojson')):
+ # Convert xView geoJSON labels to YOLO format
+ path = fname.parent
+ with open(fname) as f:
+ print(f'Loading {fname}...')
+ data = json.load(f)
+
+ # Make dirs
+ labels = Path(path / 'labels' / 'train')
+ os.system(f'rm -rf {labels}')
+ labels.mkdir(parents=True, exist_ok=True)
+
+ # xView classes 11-94 to 0-59
+ xview_class2index = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, -1, 3, -1, 4, 5, 6, 7, 8, -1, 9, 10, 11,
+ 12, 13, 14, 15, -1, -1, 16, 17, 18, 19, 20, 21, 22, -1, 23, 24, 25, -1, 26, 27, -1, 28, -1,
+ 29, 30, 31, 32, 33, 34, 35, 36, 37, -1, 38, 39, 40, 41, 42, 43, 44, 45, -1, -1, -1, -1, 46,
+ 47, 48, 49, -1, 50, 51, -1, 52, -1, -1, -1, 53, 54, -1, 55, -1, -1, 56, -1, 57, -1, 58, 59]
+
+ shapes = {}
+ for feature in tqdm(data['features'], desc=f'Converting {fname}'):
+ p = feature['properties']
+ if p['bounds_imcoords']:
+ id = p['image_id']
+ file = path / 'train_images' / id
+ if file.exists(): # 1395.tif missing
+ try:
+ box = np.array([int(num) for num in p['bounds_imcoords'].split(",")])
+ assert box.shape[0] == 4, f'incorrect box shape {box.shape[0]}'
+ cls = p['type_id']
+ cls = xview_class2index[int(cls)] # xView class to 0-60
+ assert 59 >= cls >= 0, f'incorrect class index {cls}'
+
+ # Write YOLO label
+ if id not in shapes:
+ shapes[id] = Image.open(file).size
+ box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
+ with open((labels / id).with_suffix('.txt'), 'a') as f:
+ f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
+ except Exception as e:
+ print(f'WARNING: skipping one label for {file}: {e}')
+
+
+ # Download manually from https://challenge.xviewdataset.org
+ dir = Path(yaml['path']) # dataset root dir
+ # urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
+ # 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
+ # 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
+ # download(urls, dir=dir)
+
+ # Convert labels
+ convert_labels(dir / 'xView_train.geojson')
+
+ # Move images
+ images = Path(dir / 'images')
+ images.mkdir(parents=True, exist_ok=True)
+ Path(dir / 'train_images').rename(dir / 'images' / 'train')
+ Path(dir / 'val_images').rename(dir / 'images' / 'val')
+
+ # Split
+ autosplit(dir / 'images' / 'train')
diff --git a/STPoseNet/ultralytics/cfg/default.yaml b/STPoseNet/ultralytics/cfg/default.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..9bc1219185fda7704bfc521fc3fcf6135f65303f
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/default.yaml
@@ -0,0 +1,116 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Default training settings and hyperparameters for medium-augmentation COCO training
+
+task: detect # (str) YOLO task, i.e. detect, segment, classify, pose
+mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
+
+# Train settings -------------------------------------------------------------------------------------------------------
+model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
+data: # (str, optional) path to data file, i.e. coco128.yaml
+epochs: 100 # (int) number of epochs to train for
+patience: 50 # (int) epochs to wait for no observable improvement for early stopping of training
+batch: 8 # (int) number of images per batch (-1 for AutoBatch)
+imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes
+save: True # (bool) save train checkpoints and predict results
+save_period: -1 # (int) Save checkpoint every x epochs (disabled if < 1)
+cache: False # (bool) True/ram, disk or False. Use cache for data loading
+device: # (int | str | list, optional) device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
+workers: 2 # (int) number of worker threads for data loading (per RANK if DDP)
+project: # (str, optional) project name
+name: # (str, optional) experiment name, results saved to 'project/name' directory
+exist_ok: False # (bool) whether to overwrite existing experiment
+pretrained: True # (bool | str) whether to use a pretrained model (bool) or a model to load weights from (str)
+optimizer: auto # (str) optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
+verbose: True # (bool) whether to print verbose output
+seed: 0 # (int) random seed for reproducibility
+deterministic: True # (bool) whether to enable deterministic mode
+single_cls: False # (bool) train multi-class data as single-class
+rect: False # (bool) rectangular training if mode='train' or rectangular validation if mode='val'
+cos_lr: False # (bool) use cosine learning rate scheduler
+close_mosaic: 10 # (int) disable mosaic augmentation for final epochs (0 to disable)
+resume: False # (bool) resume training from last checkpoint
+amp: True # (bool) Automatic Mixed Precision (AMP) training, choices=[True, False], True runs AMP check
+fraction: 1.0 # (float) dataset fraction to train on (default is 1.0, all images in train set)
+profile: False # (bool) profile ONNX and TensorRT speeds during training for loggers
+freeze: None # (int | list, optional) freeze first n layers, or freeze list of layer indices during training
+# Segmentation
+overlap_mask: True # (bool) masks should overlap during training (segment train only)
+mask_ratio: 4 # (int) mask downsample ratio (segment train only)
+# Classification
+dropout: 0.0 # (float) use dropout regularization (classify train only)
+
+# Val/Test settings ----------------------------------------------------------------------------------------------------
+val: True # (bool) validate/test during training
+split: val # (str) dataset split to use for validation, i.e. 'val', 'test' or 'train'
+save_json: False # (bool) save results to JSON file
+save_hybrid: False # (bool) save hybrid version of labels (labels + additional predictions)
+conf: # (float, optional) object confidence threshold for detection (default 0.25 predict, 0.001 val)
+iou: 0.7 # (float) intersection over union (IoU) threshold for NMS
+max_det: 300 # (int) maximum number of detections per image
+half: False # (bool) use half precision (FP16)
+dnn: False # (bool) use OpenCV DNN for ONNX inference
+plots: True # (bool) save plots during train/val
+
+# Prediction settings --------------------------------------------------------------------------------------------------
+source: # (str, optional) source directory for images or videos
+show: True # (bool) show results if possible
+save_txt: True # (bool) save results as .txt file
+save_conf: False # (bool) save results with confidence scores
+save_crop: True # (bool) save cropped images with results
+show_labels: True # (bool) show object labels in plots
+show_conf: True # (bool) show object confidence scores in plots
+vid_stride: 1 # (int) video frame-rate stride
+stream_buffer: False # (bool) buffer all streaming frames (True) or return the most recent frame (False)
+line_width: # (int, optional) line width of the bounding boxes, auto if missing
+visualize: False # (bool) visualize model features
+augment: False # (bool) apply image augmentation to prediction sources
+agnostic_nms: False # (bool) class-agnostic NMS
+classes: # (int | list[int], optional) filter results by class, i.e. classes=0, or classes=[0,2,3]
+retina_masks: False # (bool) use high-resolution segmentation masks
+boxes: True # (bool) Show boxes in segmentation predictions
+
+# Export settings ------------------------------------------------------------------------------------------------------
+format: torchscript # (str) format to export to, choices at https://docs.ultralytics.com/modes/export/#export-formats
+keras: False # (bool) use Kera=s
+optimize: False # (bool) TorchScript: optimize for mobile
+int8: False # (bool) CoreML/TF INT8 quantization
+dynamic: False # (bool) ONNX/TF/TensorRT: dynamic axes
+simplify: False # (bool) ONNX: simplify model
+opset: # (int, optional) ONNX: opset version
+workspace: 4 # (int) TensorRT: workspace size (GB)
+nms: False # (bool) CoreML: add NMS
+
+# Hyperparameters ------------------------------------------------------------------------------------------------------
+lr0: 0.01 # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # (float) final learning rate (lr0 * lrf)
+momentum: 0.937 # (float) SGD momentum/Adam beta1
+weight_decay: 0.0005 # (float) optimizer weight decay 5e-4
+warmup_epochs: 3.0 # (float) warmup epochs (fractions ok)
+warmup_momentum: 0.8 # (float) warmup initial momentum
+warmup_bias_lr: 0.1 # (float) warmup initial bias lr
+box: 7.5 # (float) box loss gain
+cls: 0.5 # (float) cls loss gain (scale with pixels)
+dfl: 1.5 # (float) dfl loss gain
+pose: 12.0 # (float) pose loss gain
+kobj: 1.0 # (float) keypoint obj loss gain
+label_smoothing: 0.0 # (float) label smoothing (fraction)
+nbs: 64 # (int) nominal batch size
+hsv_h: 0.015 # (float) image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # (float) image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # (float) image HSV-Value augmentation (fraction)
+degrees: 0.0 # (float) image rotation (+/- deg)
+translate: 0.1 # (float) image translation (+/- fraction)
+scale: 0.5 # (float) image scale (+/- gain)
+shear: 0.0 # (float) image shear (+/- deg)
+perspective: 0.0 # (float) image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # (float) image flip up-down (probability)
+fliplr: 0.5 # (float) image flip left-right (probability)
+mosaic: 1.0 # (float) image mosaic (probability)
+mixup: 0.0 # (float) image mixup (probability)
+copy_paste: 0.0 # (float) segment copy-paste (probability)
+
+# Custom config.yaml ---------------------------------------------------------------------------------------------------
+cfg: # (str, optional) for overriding defaults.yaml
+
+# Tracker settings ------------------------------------------------------------------------------------------------------
+tracker: botsort.yaml # (str) tracker type, choices=[botsort.yaml, bytetrack.yaml]
diff --git a/STPoseNet/ultralytics/cfg/models/README.md b/STPoseNet/ultralytics/cfg/models/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0edc4b06aa06c454bdd6d97087df6970e689871
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/README.md
@@ -0,0 +1,45 @@
+## Models
+
+Welcome to the Ultralytics Models directory! Here you will find a wide variety of pre-configured model configuration
+files (`*.yaml`s) that can be used to create custom YOLO models. The models in this directory have been expertly crafted
+and fine-tuned by the Ultralytics team to provide the best performance for a wide range of object detection and image
+segmentation tasks.
+
+These model configurations cover a wide range of scenarios, from simple object detection to more complex tasks like
+instance segmentation and object tracking. They are also designed to run efficiently on a variety of hardware platforms,
+from CPUs to GPUs. Whether you are a seasoned machine learning practitioner or just getting started with YOLO, this
+directory provides a great starting point for your custom model development needs.
+
+To get started, simply browse through the models in this directory and find one that best suits your needs. Once you've
+selected a model, you can use the provided `*.yaml` file to train and deploy your custom YOLO model with ease. See full
+details at the Ultralytics [Docs](https://docs.ultralytics.com/models), and if you need help or have any questions, feel free
+to reach out to the Ultralytics team for support. So, don't wait, start creating your custom YOLO model now!
+
+### Usage
+
+Model `*.yaml` files may be used directly in the Command Line Interface (CLI) with a `yolo` command:
+
+```bash
+yolo task=detect mode=train model=yolov8n.yaml data=coco128.yaml epochs=100
+```
+
+They may also be used directly in a Python environment, and accepts the same
+[arguments](https://docs.ultralytics.com/usage/cfg/) as in the CLI example above:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("model.yaml") # build a YOLOv8n model from scratch
+# YOLO("model.pt") use pre-trained model if available
+model.info() # display model information
+model.train(data="coco128.yaml", epochs=100) # train the model
+```
+
+## Pre-trained Model Architectures
+
+Ultralytics supports many model architectures. Visit https://docs.ultralytics.com/models to view detailed information
+and usage. Any of these models can be used by loading their configs or pretrained checkpoints if available.
+
+## Contributing New Models
+
+If you've developed a new model architecture or have improvements for existing models that you'd like to contribute to the Ultralytics community, please submit your contribution in a new Pull Request. For more details, visit our [Contributing Guide](https://docs.ultralytics.com/help/contributing).
diff --git a/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-l.yaml b/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-l.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bd20da16f0828a375f1f469c1e698d6351e67aa8
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-l.yaml
@@ -0,0 +1,50 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
+ # [depth, width, max_channels]
+ l: [1.00, 1.00, 1024]
+
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, HGStem, [32, 48]] # 0-P2/4
+ - [-1, 6, HGBlock, [48, 128, 3]] # stage 1
+
+ - [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
+ - [-1, 6, HGBlock, [96, 512, 3]] # stage 2
+
+ - [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
+ - [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
+ - [-1, 6, HGBlock, [192, 1024, 5, True, True]]
+ - [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
+
+ - [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
+ - [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
+
+head:
+ - [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
+ - [-1, 1, AIFI, [1024, 8]]
+ - [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
+ - [[-2, -1], 1, Concat, [1]]
+ - [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
+ - [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
+ - [[-2, -1], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
+
+ - [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
+ - [[-1, 17], 1, Concat, [1]] # cat Y4
+ - [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
+
+ - [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
+ - [[-1, 12], 1, Concat, [1]] # cat Y5
+ - [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
+
+ - [[21, 24, 27], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-x.yaml b/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-x.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..848cb52b1f7430331ec625f56e496feb31f3f8eb
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/rt-detr/rtdetr-x.yaml
@@ -0,0 +1,54 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# RT-DETR-x object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
+ # [depth, width, max_channels]
+ x: [1.00, 1.00, 2048]
+
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, HGStem, [32, 64]] # 0-P2/4
+ - [-1, 6, HGBlock, [64, 128, 3]] # stage 1
+
+ - [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
+ - [-1, 6, HGBlock, [128, 512, 3]]
+ - [-1, 6, HGBlock, [128, 512, 3, False, True]] # 4-stage 2
+
+ - [-1, 1, DWConv, [512, 3, 2, 1, False]] # 5-P3/16
+ - [-1, 6, HGBlock, [256, 1024, 5, True, False]] # cm, c2, k, light, shortcut
+ - [-1, 6, HGBlock, [256, 1024, 5, True, True]]
+ - [-1, 6, HGBlock, [256, 1024, 5, True, True]]
+ - [-1, 6, HGBlock, [256, 1024, 5, True, True]]
+ - [-1, 6, HGBlock, [256, 1024, 5, True, True]] # 10-stage 3
+
+ - [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 11-P4/32
+ - [-1, 6, HGBlock, [512, 2048, 5, True, False]]
+ - [-1, 6, HGBlock, [512, 2048, 5, True, True]] # 13-stage 4
+
+head:
+ - [-1, 1, Conv, [384, 1, 1, None, 1, 1, False]] # 14 input_proj.2
+ - [-1, 1, AIFI, [2048, 8]]
+ - [-1, 1, Conv, [384, 1, 1]] # 16, Y5, lateral_convs.0
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [10, 1, Conv, [384, 1, 1, None, 1, 1, False]] # 18 input_proj.1
+ - [[-2, -1], 1, Concat, [1]]
+ - [-1, 3, RepC3, [384]] # 20, fpn_blocks.0
+ - [-1, 1, Conv, [384, 1, 1]] # 21, Y4, lateral_convs.1
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [4, 1, Conv, [384, 1, 1, None, 1, 1, False]] # 23 input_proj.0
+ - [[-2, -1], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, RepC3, [384]] # X3 (25), fpn_blocks.1
+
+ - [-1, 1, Conv, [384, 3, 2]] # 26, downsample_convs.0
+ - [[-1, 21], 1, Concat, [1]] # cat Y4
+ - [-1, 3, RepC3, [384]] # F4 (28), pan_blocks.0
+
+ - [-1, 1, Conv, [384, 3, 2]] # 29, downsample_convs.1
+ - [[-1, 16], 1, Concat, [1]] # cat Y5
+ - [-1, 3, RepC3, [384]] # F5 (31), pan_blocks.1
+
+ - [[25, 28, 31], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v3/yolov3-spp.yaml b/STPoseNet/ultralytics/cfg/models/v3/yolov3-spp.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..406e019b4c84d9b8de5cfc7e9f9d9d49c5eead76
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v3/yolov3-spp.yaml
@@ -0,0 +1,48 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv3-SPP object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov3
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc]], # Detect(P3, P4, P5)
+ ]
diff --git a/STPoseNet/ultralytics/cfg/models/v3/yolov3-tiny.yaml b/STPoseNet/ultralytics/cfg/models/v3/yolov3-tiny.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..69d8e42ce68daee04bd777f22ebf8f4c6d60de9a
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v3/yolov3-tiny.yaml
@@ -0,0 +1,39 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv3-tiny object detection model with P4-P5 outputs. For details see https://docs.ultralytics.com/models/yolov3
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc]], # Detect(P4, P5)
+ ]
diff --git a/STPoseNet/ultralytics/cfg/models/v3/yolov3.yaml b/STPoseNet/ultralytics/cfg/models/v3/yolov3.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7cc0afa173e09af9f09f752b45ad8bd113db612f
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v3/yolov3.yaml
@@ -0,0 +1,48 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv3 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov3
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc]], # Detect(P3, P4, P5)
+ ]
diff --git a/STPoseNet/ultralytics/cfg/models/v5/yolov5-p6.yaml b/STPoseNet/ultralytics/cfg/models/v5/yolov5-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d4683771b50057b216aa48c5d8e5722a671d077c
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v5/yolov5-p6.yaml
@@ -0,0 +1,61 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv5 object detection model with P3-P6 outputs. For details see https://docs.ultralytics.com/models/yolov5
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov5n-p6.yaml' will call yolov5-p6.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 1024]
+ l: [1.00, 1.00, 1024]
+ x: [1.33, 1.25, 1024]
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/STPoseNet/ultralytics/cfg/models/v5/yolov5.yaml b/STPoseNet/ultralytics/cfg/models/v5/yolov5.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4a3fcedf7c8d8e935c637fe80f52f94310841f45
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v5/yolov5.yaml
@@ -0,0 +1,50 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 1024]
+ l: [1.00, 1.00, 1024]
+ x: [1.33, 1.25, 1024]
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
+ ]
diff --git a/STPoseNet/ultralytics/cfg/models/v6/yolov6.yaml b/STPoseNet/ultralytics/cfg/models/v6/yolov6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..cb5e32ac3a75d49ddbda9e4cecdc1265ed209401
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v6/yolov6.yaml
@@ -0,0 +1,53 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv6 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/models/yolov6
+
+# Parameters
+nc: 80 # number of classes
+activation: nn.ReLU() # (optional) model default activation function
+scales: # model compound scaling constants, i.e. 'model=yolov6n.yaml' will call yolov8.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv6-3.0s backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 6, Conv, [128, 3, 1]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 12, Conv, [256, 3, 1]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 18, Conv, [512, 3, 1]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 6, Conv, [1024, 3, 1]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv6-3.0s head
+head:
+ - [-1, 1, Conv, [256, 1, 1]]
+ - [-1, 1, nn.ConvTranspose2d, [256, 2, 2, 0]]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 1, Conv, [256, 3, 1]]
+ - [-1, 9, Conv, [256, 3, 1]] # 14
+
+ - [-1, 1, Conv, [128, 1, 1]]
+ - [-1, 1, nn.ConvTranspose2d, [128, 2, 2, 0]]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 1, Conv, [128, 3, 1]]
+ - [-1, 9, Conv, [128, 3, 1]] # 19
+
+ - [-1, 1, Conv, [128, 3, 2]]
+ - [[-1, 15], 1, Concat, [1]] # cat head P4
+ - [-1, 1, Conv, [256, 3, 1]]
+ - [-1, 9, Conv, [256, 3, 1]] # 23
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 10], 1, Concat, [1]] # cat head P5
+ - [-1, 1, Conv, [512, 3, 1]]
+ - [-1, 9, Conv, [512, 3, 1]] # 27
+
+ - [[19, 23, 27], 1, Detect, [nc]] # Detect(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-cls.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-cls.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5332f1d64ee32bdf8d5cb995e5ef3a3f6f970413
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-cls.yaml
@@ -0,0 +1,29 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8-cls image classification model. For Usage examples see https://docs.ultralytics.com/tasks/classify
+
+# Parameters
+nc: 1000 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 1024]
+ l: [1.00, 1.00, 1024]
+ x: [1.00, 1.25, 1024]
+
+# YOLOv8.0n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+
+# YOLOv8.0n head
+head:
+ - [-1, 1, Classify, [nc]] # Classify
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-p2.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-p2.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3e286aa96f6f9ba79970c8fead0e83782f70bfca
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-p2.yaml
@@ -0,0 +1,54 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8 object detection model with P2-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0 backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv8.0-p2 head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2f, [512]] # 12
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2f, [256]] # 15 (P3/8-small)
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 2], 1, Concat, [1]] # cat backbone P2
+ - [-1, 3, C2f, [128]] # 18 (P2/4-xsmall)
+
+ - [-1, 1, Conv, [128, 3, 2]]
+ - [[-1, 15], 1, Concat, [1]] # cat head P3
+ - [-1, 3, C2f, [256]] # 21 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 12], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2f, [512]] # 24 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 9], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2f, [1024]] # 27 (P5/32-large)
+
+ - [[18, 21, 24, 27], 1, Detect, [nc]] # Detect(P2, P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-p6.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3635ed97ebc4219188f174be99fa301daeaf49b8
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-p6.yaml
@@ -0,0 +1,56 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8 object detection model with P3-P6 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-p6.yaml' will call yolov8-p6.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0x6 backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [768, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 9-P6/64
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 11
+
+# YOLOv8.0x6 head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 8], 1, Concat, [1]] # cat backbone P5
+ - [-1, 3, C2, [768, False]] # 14
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2, [512, False]] # 17
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2, [256, False]] # 20 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 17], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 14], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2, [768, False]] # 26 (P5/32-large)
+
+ - [-1, 1, Conv, [768, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P6
+ - [-1, 3, C2, [1024, False]] # 29 (P6/64-xlarge)
+
+ - [[20, 23, 26, 29], 1, Detect, [nc]] # Detect(P3, P4, P5, P6)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose-p6.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..abf0cfcf96e70a810185c6c546f10905d734675e
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose-p6.yaml
@@ -0,0 +1,57 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8-pose-p6 keypoints/pose estimation model. For Usage examples see https://docs.ultralytics.com/tasks/pose
+
+# Parameters
+nc: 1 # number of classes
+kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+scales: # model compound scaling constants, i.e. 'model=yolov8n-p6.yaml' will call yolov8-p6.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0x6 backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [768, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 9-P6/64
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 11
+
+# YOLOv8.0x6 head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 8], 1, Concat, [1]] # cat backbone P5
+ - [-1, 3, C2, [768, False]] # 14
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2, [512, False]] # 17
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2, [256, False]] # 20 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 17], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 14], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2, [768, False]] # 26 (P5/32-large)
+
+ - [-1, 1, Conv, [768, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P6
+ - [-1, 3, C2, [1024, False]] # 29 (P6/64-xlarge)
+
+ - [[20, 23, 26, 29], 1, Pose, [nc, kpt_shape]] # Pose(P3, P4, P5, P6)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..725a5a0d0372e21d6e9333eb19cd9931cb2d9c5c
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-pose.yaml
@@ -0,0 +1,47 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8-pose keypoints/pose estimation model. For Usage examples see https://docs.ultralytics.com/tasks/pose
+
+# Parameters
+nc: 1 # number of classes
+kpt_shape: [3, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+scales: # model compound scaling constants, i.e. 'model=yolov8n-pose.yaml' will call yolov8-pose.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv8.0n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2f, [512]] # 12
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2f, [256]] # 15 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 12], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 9], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
+
+ - [[15, 18, 21], 1, Pose, [nc, kpt_shape]] # Pose(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-rtdetr.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-rtdetr.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a0581068f441617d3d215fb4c380f374e4da94d0
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-rtdetr.yaml
@@ -0,0 +1,46 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
+ s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
+ m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
+ l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
+ x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
+
+# YOLOv8.0n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv8.0n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2f, [512]] # 12
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2f, [256]] # 15 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 12], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 9], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
+
+ - [[15, 18, 21], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg-p6.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg-p6.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5ac093620f1f0bf9facdd8e6e34bc59e495f8bbc
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg-p6.yaml
@@ -0,0 +1,56 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8-seg-p6 instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-seg-p6.yaml' will call yolov8-seg-p6.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0x6 backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [768, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [768, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 9-P6/64
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 11
+
+# YOLOv8.0x6 head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 8], 1, Concat, [1]] # cat backbone P5
+ - [-1, 3, C2, [768, False]] # 14
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2, [512, False]] # 17
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2, [256, False]] # 20 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 17], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2, [512, False]] # 23 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 14], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2, [768, False]] # 26 (P5/32-large)
+
+ - [-1, 1, Conv, [768, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P6
+ - [-1, 3, C2, [1024, False]] # 29 (P6/64-xlarge)
+
+ - [[20, 23, 26, 29], 1, Segment, [nc, 32, 256]] # Pose(P3, P4, P5, P6)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..fbb08fc451307ea99dc7fe99f6edfe2eb40c4daf
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8-seg.yaml
@@ -0,0 +1,46 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024]
+ s: [0.33, 0.50, 1024]
+ m: [0.67, 0.75, 768]
+ l: [1.00, 1.00, 512]
+ x: [1.00, 1.25, 512]
+
+# YOLOv8.0n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv8.0n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2f, [512]] # 12
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2f, [256]] # 15 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 12], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 9], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
+
+ - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/models/v8/yolov8.yaml b/STPoseNet/ultralytics/cfg/models/v8/yolov8.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2255450f1715a3c244aed909a350f76f38c04170
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/models/v8/yolov8.yaml
@@ -0,0 +1,46 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
+ s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
+ m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
+ l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
+ x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
+
+# YOLOv8.0n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 3, C2f, [128, True]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 6, C2f, [256, True]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 6, C2f, [512, True]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 3, C2f, [1024, True]]
+ - [-1, 1, SPPF, [1024, 5]] # 9
+
+# YOLOv8.0n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 3, C2f, [512]] # 12
+
+ - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 3, C2f, [256]] # 15 (P3/8-small)
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 12], 1, Concat, [1]] # cat head P4
+ - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 9], 1, Concat, [1]] # cat head P5
+ - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
+
+ - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
diff --git a/STPoseNet/ultralytics/cfg/trackers/botsort.yaml b/STPoseNet/ultralytics/cfg/trackers/botsort.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..cbbf348c25237c3a1fe044f369e7819c87f0dcc6
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/trackers/botsort.yaml
@@ -0,0 +1,18 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Default YOLO tracker settings for BoT-SORT tracker https://github.com/NirAharon/BoT-SORT
+
+tracker_type: botsort # tracker type, ['botsort', 'bytetrack']
+track_high_thresh: 0.5 # threshold for the first association
+track_low_thresh: 0.1 # threshold for the second association
+new_track_thresh: 0.6 # threshold for init new track if the detection does not match any tracks
+track_buffer: 30 # buffer to calculate the time when to remove tracks
+match_thresh: 0.8 # threshold for matching tracks
+# min_box_area: 10 # threshold for min box areas(for tracker evaluation, not used for now)
+# mot20: False # for tracker evaluation(not used for now)
+
+# BoT-SORT settings
+gmc_method: sparseOptFlow # method of global motion compensation
+# ReID model related thresh (not supported yet)
+proximity_thresh: 0.5
+appearance_thresh: 0.25
+with_reid: False
diff --git a/STPoseNet/ultralytics/cfg/trackers/bytetrack.yaml b/STPoseNet/ultralytics/cfg/trackers/bytetrack.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5060f92622a9873dbdd0596e29172277c1cdbb99
--- /dev/null
+++ b/STPoseNet/ultralytics/cfg/trackers/bytetrack.yaml
@@ -0,0 +1,11 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Default YOLO tracker settings for ByteTrack tracker https://github.com/ifzhang/ByteTrack
+
+tracker_type: bytetrack # tracker type, ['botsort', 'bytetrack']
+track_high_thresh: 0.5 # threshold for the first association
+track_low_thresh: 0.1 # threshold for the second association
+new_track_thresh: 0.6 # threshold for init new track if the detection does not match any tracks
+track_buffer: 30 # buffer to calculate the time when to remove tracks
+match_thresh: 0.8 # threshold for matching tracks
+# min_box_area: 10 # threshold for min box areas(for tracker evaluation, not used for now)
+# mot20: False # for tracker evaluation(not used for now)
diff --git a/STPoseNet/ultralytics/data/__init__.py b/STPoseNet/ultralytics/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fa7e8458d432b8942b428c0d8598455d6904edc
--- /dev/null
+++ b/STPoseNet/ultralytics/data/__init__.py
@@ -0,0 +1,8 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .base import BaseDataset
+from .build import build_dataloader, build_yolo_dataset, load_inference_source
+from .dataset import ClassificationDataset, SemanticDataset, YOLODataset
+
+__all__ = ('BaseDataset', 'ClassificationDataset', 'SemanticDataset', 'YOLODataset', 'build_yolo_dataset',
+ 'build_dataloader', 'load_inference_source')
diff --git a/STPoseNet/ultralytics/data/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4902747808c84641cf958089578406f12c277855
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/augment.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/augment.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..65f935c4279d6985405eaec77a6b547261f38d39
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/augment.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/base.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4c1cedf47d42f99836335efbb8c8ccd37abe3b87
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/base.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/build.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/build.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fbe36efbd2daf0dc2d7e0fb093fd36c17d4fbdaa
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/build.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/converter.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/converter.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fd07efadfd7465cfd0b7a333cd2877a24a4cb868
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/converter.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/dataset.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/dataset.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..97ca3dfdad6949af8849c8d8ee0c55c00b1df8f4
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/dataset.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/loaders.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/loaders.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b470c9211a2d34b8536b45823b5985ff6d1127d3
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/loaders.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/__pycache__/utils.cpython-38.pyc b/STPoseNet/ultralytics/data/__pycache__/utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..53813dc8e8f4d6469915eeec5cbd9fc28db6a5b2
Binary files /dev/null and b/STPoseNet/ultralytics/data/__pycache__/utils.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/data/annotator.py b/STPoseNet/ultralytics/data/annotator.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4e08c768ff0cc47b9290c4b4d64576dc2bed562
--- /dev/null
+++ b/STPoseNet/ultralytics/data/annotator.py
@@ -0,0 +1,50 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from pathlib import Path
+
+from ultralytics import SAM, YOLO
+
+
+def auto_annotate(data, det_model='yolov8x.pt', sam_model='sam_b.pt', device='', output_dir=None):
+ """
+ Automatically annotates images using a YOLO object detection model and a SAM segmentation model.
+
+ Args:
+ data (str): Path to a folder containing images to be annotated.
+ det_model (str, optional): Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'.
+ sam_model (str, optional): Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'.
+ device (str, optional): Device to run the models on. Defaults to an empty string (CPU or GPU, if available).
+ output_dir (str | None | optional): Directory to save the annotated results.
+ Defaults to a 'labels' folder in the same directory as 'data'.
+
+ Example:
+ ```python
+ from ultralytics.data.annotator import auto_annotate
+
+ auto_annotate(data='ultralytics/assets', det_model='yolov8n.pt', sam_model='mobile_sam.pt')
+ ```
+ """
+ det_model = YOLO(det_model)
+ sam_model = SAM(sam_model)
+
+ data = Path(data)
+ if not output_dir:
+ output_dir = data.parent / f'{data.stem}_auto_annotate_labels'
+ Path(output_dir).mkdir(exist_ok=True, parents=True)
+
+ det_results = det_model(data, stream=True, device=device)
+
+ for result in det_results:
+ class_ids = result.boxes.cls.int().tolist() # noqa
+ if len(class_ids):
+ boxes = result.boxes.xyxy # Boxes object for bbox outputs
+ sam_results = sam_model(result.orig_img, bboxes=boxes, verbose=False, save=False, device=device)
+ segments = sam_results[0].masks.xyn # noqa
+
+ with open(f'{str(Path(output_dir) / Path(result.path).stem)}.txt', 'w') as f:
+ for i in range(len(segments)):
+ s = segments[i]
+ if len(s) == 0:
+ continue
+ segment = map(str, segments[i].reshape(-1).tolist())
+ f.write(f'{class_ids[i]} ' + ' '.join(segment) + '\n')
diff --git a/STPoseNet/ultralytics/data/augment.py b/STPoseNet/ultralytics/data/augment.py
new file mode 100644
index 0000000000000000000000000000000000000000..d24f798269438c1e2753c616234cecec920e6d47
--- /dev/null
+++ b/STPoseNet/ultralytics/data/augment.py
@@ -0,0 +1,907 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import math
+import random
+from copy import deepcopy
+
+import cv2
+import numpy as np
+import torch
+import torchvision.transforms as T
+
+from ultralytics.utils import LOGGER, colorstr
+from ultralytics.utils.checks import check_version
+from ultralytics.utils.instance import Instances
+from ultralytics.utils.metrics import bbox_ioa
+from ultralytics.utils.ops import segment2box
+
+from .utils import polygons2masks, polygons2masks_overlap
+
+
+# TODO: we might need a BaseTransform to make all these augments be compatible with both classification and semantic
+class BaseTransform:
+
+ def __init__(self) -> None:
+ pass
+
+ def apply_image(self, labels):
+ """Applies image transformation to labels."""
+ pass
+
+ def apply_instances(self, labels):
+ """Applies transformations to input 'labels' and returns object instances."""
+ pass
+
+ def apply_semantic(self, labels):
+ """Applies semantic segmentation to an image."""
+ pass
+
+ def __call__(self, labels):
+ """Applies label transformations to an image, instances and semantic masks."""
+ self.apply_image(labels)
+ self.apply_instances(labels)
+ self.apply_semantic(labels)
+
+
+class Compose:
+
+ def __init__(self, transforms):
+ """Initializes the Compose object with a list of transforms."""
+ self.transforms = transforms
+
+ def __call__(self, data):
+ """Applies a series of transformations to input data."""
+ for t in self.transforms:
+ data = t(data)
+ return data
+
+ def append(self, transform):
+ """Appends a new transform to the existing list of transforms."""
+ self.transforms.append(transform)
+
+ def tolist(self):
+ """Converts list of transforms to a standard Python list."""
+ return self.transforms
+
+ def __repr__(self):
+ """Return string representation of object."""
+ format_string = f'{self.__class__.__name__}('
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += f' {t}'
+ format_string += '\n)'
+ return format_string
+
+
+class BaseMixTransform:
+ """This implementation is from mmyolo."""
+
+ def __init__(self, dataset, pre_transform=None, p=0.0) -> None:
+ self.dataset = dataset
+ self.pre_transform = pre_transform
+ self.p = p
+
+ def __call__(self, labels):
+ """Applies pre-processing transforms and mixup/mosaic transforms to labels data."""
+ if random.uniform(0, 1) > self.p:
+ return labels
+
+ # Get index of one or three other images
+ indexes = self.get_indexes()
+ if isinstance(indexes, int):
+ indexes = [indexes]
+
+ # Get images information will be used for Mosaic or MixUp
+ mix_labels = [self.dataset.get_image_and_label(i) for i in indexes]
+
+ if self.pre_transform is not None:
+ for i, data in enumerate(mix_labels):
+ mix_labels[i] = self.pre_transform(data)
+ labels['mix_labels'] = mix_labels
+
+ # Mosaic or MixUp
+ labels = self._mix_transform(labels)
+ labels.pop('mix_labels', None)
+ return labels
+
+ def _mix_transform(self, labels):
+ """Applies MixUp or Mosaic augmentation to the label dictionary."""
+ raise NotImplementedError
+
+ def get_indexes(self):
+ """Gets a list of shuffled indexes for mosaic augmentation."""
+ raise NotImplementedError
+
+
+class Mosaic(BaseMixTransform):
+ """
+ Mosaic augmentation.
+
+ This class performs mosaic augmentation by combining multiple (4 or 9) images into a single mosaic image.
+ The augmentation is applied to a dataset with a given probability.
+
+ Attributes:
+ dataset: The dataset on which the mosaic augmentation is applied.
+ imgsz (int, optional): Image size (height and width) after mosaic pipeline of a single image. Default to 640.
+ p (float, optional): Probability of applying the mosaic augmentation. Must be in the range 0-1. Default to 1.0.
+ n (int, optional): The grid size, either 4 (for 2x2) or 9 (for 3x3).
+ """
+
+ def __init__(self, dataset, imgsz=640, p=1.0, n=4):
+ """Initializes the object with a dataset, image size, probability, and border."""
+ assert 0 <= p <= 1.0, f'The probability should be in range [0, 1], but got {p}.'
+ assert n in (4, 9), 'grid must be equal to 4 or 9.'
+ super().__init__(dataset=dataset, p=p)
+ self.dataset = dataset
+ self.imgsz = imgsz
+ self.border = (-imgsz // 2, -imgsz // 2) # width, height
+ self.n = n
+
+ def get_indexes(self, buffer=True):
+ """Return a list of random indexes from the dataset."""
+ if buffer: # select images from buffer
+ return random.choices(list(self.dataset.buffer), k=self.n - 1)
+ else: # select any images
+ return [random.randint(0, len(self.dataset) - 1) for _ in range(self.n - 1)]
+
+ def _mix_transform(self, labels):
+ """Apply mixup transformation to the input image and labels."""
+ assert labels.get('rect_shape', None) is None, 'rect and mosaic are mutually exclusive.'
+ assert len(labels.get('mix_labels', [])), 'There are no other images for mosaic augment.'
+ return self._mosaic4(labels) if self.n == 4 else self._mosaic9(labels)
+
+ def _mosaic4(self, labels):
+ """Create a 2x2 image mosaic."""
+ mosaic_labels = []
+ s = self.imgsz
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.border) # mosaic center x, y
+ for i in range(4):
+ labels_patch = labels if i == 0 else labels['mix_labels'][i - 1]
+ # Load image
+ img = labels_patch['img']
+ h, w = labels_patch.pop('resized_shape')
+
+ # Place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels_patch = self._update_labels(labels_patch, padw, padh)
+ mosaic_labels.append(labels_patch)
+ final_labels = self._cat_labels(mosaic_labels)
+ final_labels['img'] = img4
+ return final_labels
+
+ def _mosaic9(self, labels):
+ """Create a 3x3 image mosaic."""
+ mosaic_labels = []
+ s = self.imgsz
+ hp, wp = -1, -1 # height, width previous
+ for i in range(9):
+ labels_patch = labels if i == 0 else labels['mix_labels'][i - 1]
+ # Load image
+ img = labels_patch['img']
+ h, w = labels_patch.pop('resized_shape')
+
+ # Place img in img9
+ if i == 0: # center
+ img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ h0, w0 = h, w
+ c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
+ elif i == 1: # top
+ c = s, s - h, s + w, s
+ elif i == 2: # top right
+ c = s + wp, s - h, s + wp + w, s
+ elif i == 3: # right
+ c = s + w0, s, s + w0 + w, s + h
+ elif i == 4: # bottom right
+ c = s + w0, s + hp, s + w0 + w, s + hp + h
+ elif i == 5: # bottom
+ c = s + w0 - w, s + h0, s + w0, s + h0 + h
+ elif i == 6: # bottom left
+ c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
+ elif i == 7: # left
+ c = s - w, s + h0 - h, s, s + h0
+ elif i == 8: # top left
+ c = s - w, s + h0 - hp - h, s, s + h0 - hp
+
+ padw, padh = c[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
+
+ # Image
+ img9[y1:y2, x1:x2] = img[y1 - padh:, x1 - padw:] # img9[ymin:ymax, xmin:xmax]
+ hp, wp = h, w # height, width previous for next iteration
+
+ # Labels assuming imgsz*2 mosaic size
+ labels_patch = self._update_labels(labels_patch, padw + self.border[0], padh + self.border[1])
+ mosaic_labels.append(labels_patch)
+ final_labels = self._cat_labels(mosaic_labels)
+
+ final_labels['img'] = img9[-self.border[0]:self.border[0], -self.border[1]:self.border[1]]
+ return final_labels
+
+ @staticmethod
+ def _update_labels(labels, padw, padh):
+ """Update labels."""
+ nh, nw = labels['img'].shape[:2]
+ labels['instances'].convert_bbox(format='xyxy')
+ labels['instances'].denormalize(nw, nh)
+ labels['instances'].add_padding(padw, padh)
+ return labels
+
+ def _cat_labels(self, mosaic_labels):
+ """Return labels with mosaic border instances clipped."""
+ if len(mosaic_labels) == 0:
+ return {}
+ cls = []
+ instances = []
+ imgsz = self.imgsz * 2 # mosaic imgsz
+ for labels in mosaic_labels:
+ cls.append(labels['cls'])
+ instances.append(labels['instances'])
+ final_labels = {
+ 'im_file': mosaic_labels[0]['im_file'],
+ 'ori_shape': mosaic_labels[0]['ori_shape'],
+ 'resized_shape': (imgsz, imgsz),
+ 'cls': np.concatenate(cls, 0),
+ 'instances': Instances.concatenate(instances, axis=0),
+ 'mosaic_border': self.border} # final_labels
+ final_labels['instances'].clip(imgsz, imgsz)
+ good = final_labels['instances'].remove_zero_area_boxes()
+ final_labels['cls'] = final_labels['cls'][good]
+ return final_labels
+
+
+class MixUp(BaseMixTransform):
+
+ def __init__(self, dataset, pre_transform=None, p=0.0) -> None:
+ super().__init__(dataset=dataset, pre_transform=pre_transform, p=p)
+
+ def get_indexes(self):
+ """Get a random index from the dataset."""
+ return random.randint(0, len(self.dataset) - 1)
+
+ def _mix_transform(self, labels):
+ """Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf."""
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ labels2 = labels['mix_labels'][0]
+ labels['img'] = (labels['img'] * r + labels2['img'] * (1 - r)).astype(np.uint8)
+ labels['instances'] = Instances.concatenate([labels['instances'], labels2['instances']], axis=0)
+ labels['cls'] = np.concatenate([labels['cls'], labels2['cls']], 0)
+ return labels
+
+
+class RandomPerspective:
+
+ def __init__(self,
+ degrees=0.0,
+ translate=0.1,
+ scale=0.5,
+ shear=0.0,
+ perspective=0.0,
+ border=(0, 0),
+ pre_transform=None):
+ self.degrees = degrees
+ self.translate = translate
+ self.scale = scale
+ self.shear = shear
+ self.perspective = perspective
+ # Mosaic border
+ self.border = border
+ self.pre_transform = pre_transform
+
+ def affine_transform(self, img, border):
+ """Center."""
+ C = np.eye(3, dtype=np.float32)
+
+ C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3, dtype=np.float32)
+ P[2, 0] = random.uniform(-self.perspective, self.perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-self.perspective, self.perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3, dtype=np.float32)
+ a = random.uniform(-self.degrees, self.degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - self.scale, 1 + self.scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3, dtype=np.float32)
+ S[0, 1] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-self.shear, self.shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3, dtype=np.float32)
+ T[0, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[0] # x translation (pixels)
+ T[1, 2] = random.uniform(0.5 - self.translate, 0.5 + self.translate) * self.size[1] # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ # Affine image
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if self.perspective:
+ img = cv2.warpPerspective(img, M, dsize=self.size, borderValue=(114, 114, 114))
+ else: # affine
+ img = cv2.warpAffine(img, M[:2], dsize=self.size, borderValue=(114, 114, 114))
+ return img, M, s
+
+ def apply_bboxes(self, bboxes, M):
+ """
+ Apply affine to bboxes only.
+
+ Args:
+ bboxes (ndarray): list of bboxes, xyxy format, with shape (num_bboxes, 4).
+ M (ndarray): affine matrix.
+
+ Returns:
+ new_bboxes (ndarray): bboxes after affine, [num_bboxes, 4].
+ """
+ n = len(bboxes)
+ if n == 0:
+ return bboxes
+
+ xy = np.ones((n * 4, 3), dtype=bboxes.dtype)
+ xy[:, :2] = bboxes[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if self.perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
+
+ # Create new boxes
+ x = xy[:, [0, 2, 4, 6]]
+ y = xy[:, [1, 3, 5, 7]]
+ return np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1)), dtype=bboxes.dtype).reshape(4, n).T
+
+ def apply_segments(self, segments, M):
+ """
+ Apply affine to segments and generate new bboxes from segments.
+
+ Args:
+ segments (ndarray): list of segments, [num_samples, 500, 2].
+ M (ndarray): affine matrix.
+
+ Returns:
+ new_segments (ndarray): list of segments after affine, [num_samples, 500, 2].
+ new_bboxes (ndarray): bboxes after affine, [N, 4].
+ """
+ n, num = segments.shape[:2]
+ if n == 0:
+ return [], segments
+
+ xy = np.ones((n * num, 3), dtype=segments.dtype)
+ segments = segments.reshape(-1, 2)
+ xy[:, :2] = segments
+ xy = xy @ M.T # transform
+ xy = xy[:, :2] / xy[:, 2:3]
+ segments = xy.reshape(n, -1, 2)
+ bboxes = np.stack([segment2box(xy, self.size[0], self.size[1]) for xy in segments], 0)
+ return bboxes, segments
+
+ def apply_keypoints(self, keypoints, M):
+ """
+ Apply affine to keypoints.
+
+ Args:
+ keypoints (ndarray): keypoints, [N, 17, 3].
+ M (ndarray): affine matrix.
+
+ Returns:
+ new_keypoints (ndarray): keypoints after affine, [N, 17, 3].
+ """
+ n, nkpt = keypoints.shape[:2]
+ if n == 0:
+ return keypoints
+ xy = np.ones((n * nkpt, 3), dtype=keypoints.dtype)
+ visible = keypoints[..., 2].reshape(n * nkpt, 1)
+ xy[:, :2] = keypoints[..., :2].reshape(n * nkpt, 2)
+ xy = xy @ M.T # transform
+ xy = xy[:, :2] / xy[:, 2:3] # perspective rescale or affine
+ out_mask = (xy[:, 0] < 0) | (xy[:, 1] < 0) | (xy[:, 0] > self.size[0]) | (xy[:, 1] > self.size[1])
+ visible[out_mask] = 0
+ return np.concatenate([xy, visible], axis=-1).reshape(n, nkpt, 3)
+
+ def __call__(self, labels):
+ """
+ Affine images and targets.
+
+ Args:
+ labels (dict): a dict of `bboxes`, `segments`, `keypoints`.
+ """
+ if self.pre_transform and 'mosaic_border' not in labels:
+ labels = self.pre_transform(labels)
+ labels.pop('ratio_pad', None) # do not need ratio pad
+
+ img = labels['img']
+ cls = labels['cls']
+ instances = labels.pop('instances')
+ # Make sure the coord formats are right
+ instances.convert_bbox(format='xyxy')
+ instances.denormalize(*img.shape[:2][::-1])
+
+ border = labels.pop('mosaic_border', self.border)
+ self.size = img.shape[1] + border[1] * 2, img.shape[0] + border[0] * 2 # w, h
+ # M is affine matrix
+ # scale for func:`box_candidates`
+ img, M, scale = self.affine_transform(img, border)
+
+ bboxes = self.apply_bboxes(instances.bboxes, M)
+
+ segments = instances.segments
+ keypoints = instances.keypoints
+ # Update bboxes if there are segments.
+ if len(segments):
+ bboxes, segments = self.apply_segments(segments, M)
+
+ if keypoints is not None:
+ keypoints = self.apply_keypoints(keypoints, M)
+ new_instances = Instances(bboxes, segments, keypoints, bbox_format='xyxy', normalized=False)
+ # Clip
+ new_instances.clip(*self.size)
+
+ # Filter instances
+ instances.scale(scale_w=scale, scale_h=scale, bbox_only=True)
+ # Make the bboxes have the same scale with new_bboxes
+ i = self.box_candidates(box1=instances.bboxes.T,
+ box2=new_instances.bboxes.T,
+ area_thr=0.01 if len(segments) else 0.10)
+ labels['instances'] = new_instances[i]
+ labels['cls'] = cls[i]
+ labels['img'] = img
+ labels['resized_shape'] = img.shape[:2]
+ return labels
+
+ def box_candidates(self, box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
+ # Compute box candidates: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
+ w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
+ w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
+ ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
+ return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
+
+
+class RandomHSV:
+
+ def __init__(self, hgain=0.5, sgain=0.5, vgain=0.5) -> None:
+ self.hgain = hgain
+ self.sgain = sgain
+ self.vgain = vgain
+
+ def __call__(self, labels):
+ """Applies image HSV augmentation"""
+ img = labels['img']
+ if self.hgain or self.sgain or self.vgain:
+ r = np.random.uniform(-1, 1, 3) * [self.hgain, self.sgain, self.vgain] + 1 # random gains
+ hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
+ dtype = img.dtype # uint8
+
+ x = np.arange(0, 256, dtype=r.dtype)
+ lut_hue = ((x * r[0]) % 180).astype(dtype)
+ lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
+ lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
+
+ im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
+ cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed
+ return labels
+
+
+class RandomFlip:
+ """Applies random horizontal or vertical flip to an image with a given probability."""
+
+ def __init__(self, p=0.5, direction='horizontal', flip_idx=None) -> None:
+ assert direction in ['horizontal', 'vertical'], f'Support direction `horizontal` or `vertical`, got {direction}'
+ assert 0 <= p <= 1.0
+
+ self.p = p
+ self.direction = direction
+ self.flip_idx = flip_idx
+
+ def __call__(self, labels):
+ """Resize image and padding for detection, instance segmentation, pose."""
+ img = labels['img']
+ instances = labels.pop('instances')
+ instances.convert_bbox(format='xywh')
+ h, w = img.shape[:2]
+ h = 1 if instances.normalized else h
+ w = 1 if instances.normalized else w
+
+ # Flip up-down
+ if self.direction == 'vertical' and random.random() < self.p:
+ img = np.flipud(img)
+ instances.flipud(h)
+ if self.direction == 'horizontal' and random.random() < self.p:
+ img = np.fliplr(img)
+ instances.fliplr(w)
+ # For keypoints
+ if self.flip_idx is not None and instances.keypoints is not None:
+ instances.keypoints = np.ascontiguousarray(instances.keypoints[:, self.flip_idx, :])
+ labels['img'] = np.ascontiguousarray(img)
+ labels['instances'] = instances
+ return labels
+
+
+class LetterBox:
+ """Resize image and padding for detection, instance segmentation, pose."""
+
+ def __init__(self, new_shape=(640, 640), auto=False, scaleFill=False, scaleup=True, center=True, stride=32):
+ """Initialize LetterBox object with specific parameters."""
+ self.new_shape = new_shape
+ self.auto = auto
+ self.scaleFill = scaleFill
+ self.scaleup = scaleup
+ self.stride = stride
+ self.center = center # Put the image in the middle or top-left
+
+ def __call__(self, labels=None, image=None):
+ """Return updated labels and image with added border."""
+ if labels is None:
+ labels = {}
+ img = labels.get('img') if image is None else image
+ shape = img.shape[:2] # current shape [height, width]
+ new_shape = labels.pop('rect_shape', self.new_shape)
+ if isinstance(new_shape, int):
+ new_shape = (new_shape, new_shape)
+
+ # Scale ratio (new / old)
+ r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
+ if not self.scaleup: # only scale down, do not scale up (for better val mAP)
+ r = min(r, 1.0)
+
+ # Compute padding
+ ratio = r, r # width, height ratios
+ new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
+ dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
+ if self.auto: # minimum rectangle
+ dw, dh = np.mod(dw, self.stride), np.mod(dh, self.stride) # wh padding
+ elif self.scaleFill: # stretch
+ dw, dh = 0.0, 0.0
+ new_unpad = (new_shape[1], new_shape[0])
+ ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
+
+ if self.center:
+ dw /= 2 # divide padding into 2 sides
+ dh /= 2
+ if labels.get('ratio_pad'):
+ labels['ratio_pad'] = (labels['ratio_pad'], (dw, dh)) # for evaluation
+
+ if shape[::-1] != new_unpad: # resize
+ img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
+ top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
+ left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
+ img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT,
+ value=(114, 114, 114)) # add border
+
+ if len(labels):
+ labels = self._update_labels(labels, ratio, dw, dh)
+ labels['img'] = img
+ labels['resized_shape'] = new_shape
+ return labels
+ else:
+ return img
+
+ def _update_labels(self, labels, ratio, padw, padh):
+ """Update labels."""
+ labels['instances'].convert_bbox(format='xyxy')
+ labels['instances'].denormalize(*labels['img'].shape[:2][::-1])
+ labels['instances'].scale(*ratio)
+ labels['instances'].add_padding(padw, padh)
+ return labels
+
+
+class CopyPaste:
+
+ def __init__(self, p=0.5) -> None:
+ self.p = p
+
+ def __call__(self, labels):
+ """Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)."""
+ im = labels['img']
+ cls = labels['cls']
+ h, w = im.shape[:2]
+ instances = labels.pop('instances')
+ instances.convert_bbox(format='xyxy')
+ instances.denormalize(w, h)
+ if self.p and len(instances.segments):
+ n = len(instances)
+ _, w, _ = im.shape # height, width, channels
+ im_new = np.zeros(im.shape, np.uint8)
+
+ # Calculate ioa first then select indexes randomly
+ ins_flip = deepcopy(instances)
+ ins_flip.fliplr(w)
+
+ ioa = bbox_ioa(ins_flip.bboxes, instances.bboxes) # intersection over area, (N, M)
+ indexes = np.nonzero((ioa < 0.30).all(1))[0] # (N, )
+ n = len(indexes)
+ for j in random.sample(list(indexes), k=round(self.p * n)):
+ cls = np.concatenate((cls, cls[[j]]), axis=0)
+ instances = Instances.concatenate((instances, ins_flip[[j]]), axis=0)
+ cv2.drawContours(im_new, instances.segments[[j]].astype(np.int32), -1, (1, 1, 1), cv2.FILLED)
+
+ result = cv2.flip(im, 1) # augment segments (flip left-right)
+ i = cv2.flip(im_new, 1).astype(bool)
+ im[i] = result[i]
+
+ labels['img'] = im
+ labels['cls'] = cls
+ labels['instances'] = instances
+ return labels
+
+
+class Albumentations:
+ """Albumentations transformations. Optional, uninstall package to disable.
+ Applies Blur, Median Blur, convert to grayscale, Contrast Limited Adaptive Histogram Equalization,
+ random change of brightness and contrast, RandomGamma and lowering of image quality by compression."""
+
+ def __init__(self, p=1.0):
+ """Initialize the transform object for YOLO bbox formatted params."""
+ self.p = p
+ self.transform = None
+ prefix = colorstr('albumentations: ')
+ try:
+ import albumentations as A
+
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+
+ T = [
+ A.Blur(p=0.01),
+ A.MedianBlur(p=0.01),
+ A.ToGray(p=0.01),
+ A.CLAHE(p=0.01),
+ A.RandomBrightnessContrast(p=0.0),
+ A.RandomGamma(p=0.0),
+ A.ImageCompression(quality_lower=75, p=0.0)] # transforms
+ self.transform = A.Compose(T, bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
+
+ LOGGER.info(prefix + ', '.join(f'{x}'.replace('always_apply=False, ', '') for x in T if x.p))
+ except ImportError: # package not installed, skip
+ pass
+ except Exception as e:
+ LOGGER.info(f'{prefix}{e}')
+
+ def __call__(self, labels):
+ """Generates object detections and returns a dictionary with detection results."""
+ im = labels['img']
+ cls = labels['cls']
+ if len(cls):
+ labels['instances'].convert_bbox('xywh')
+ labels['instances'].normalize(*im.shape[:2][::-1])
+ bboxes = labels['instances'].bboxes
+ # TODO: add supports of segments and keypoints
+ if self.transform and random.random() < self.p:
+ new = self.transform(image=im, bboxes=bboxes, class_labels=cls) # transformed
+ if len(new['class_labels']) > 0: # skip update if no bbox in new im
+ labels['img'] = new['image']
+ labels['cls'] = np.array(new['class_labels'])
+ bboxes = np.array(new['bboxes'], dtype=np.float32)
+ labels['instances'].update(bboxes=bboxes)
+ return labels
+
+
+# TODO: technically this is not an augmentation, maybe we should put this to another files
+class Format:
+
+ def __init__(self,
+ bbox_format='xywh',
+ normalize=True,
+ return_mask=False,
+ return_keypoint=False,
+ mask_ratio=4,
+ mask_overlap=True,
+ batch_idx=True):
+ self.bbox_format = bbox_format
+ self.normalize = normalize
+ self.return_mask = return_mask # set False when training detection only
+ self.return_keypoint = return_keypoint
+ self.mask_ratio = mask_ratio
+ self.mask_overlap = mask_overlap
+ self.batch_idx = batch_idx # keep the batch indexes
+
+ def __call__(self, labels):
+ """Return formatted image, classes, bounding boxes & keypoints to be used by 'collate_fn'."""
+ img = labels.pop('img')
+ h, w = img.shape[:2]
+ cls = labels.pop('cls')
+ instances = labels.pop('instances')
+ instances.convert_bbox(format=self.bbox_format)
+ instances.denormalize(w, h)
+ nl = len(instances)
+
+ if self.return_mask:
+ if nl:
+ masks, instances, cls = self._format_segments(instances, cls, w, h)
+ masks = torch.from_numpy(masks)
+ else:
+ masks = torch.zeros(1 if self.mask_overlap else nl, img.shape[0] // self.mask_ratio,
+ img.shape[1] // self.mask_ratio)
+ labels['masks'] = masks
+ if self.normalize:
+ instances.normalize(w, h)
+ labels['img'] = self._format_img(img)
+ labels['cls'] = torch.from_numpy(cls) if nl else torch.zeros(nl)
+ labels['bboxes'] = torch.from_numpy(instances.bboxes) if nl else torch.zeros((nl, 4))
+ if self.return_keypoint:
+ labels['keypoints'] = torch.from_numpy(instances.keypoints)
+ # Then we can use collate_fn
+ if self.batch_idx:
+ labels['batch_idx'] = torch.zeros(nl)
+ return labels
+
+ def _format_img(self, img):
+ """Format the image for YOLOv5 from Numpy array to PyTorch tensor."""
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ img = np.ascontiguousarray(img.transpose(2, 0, 1)[::-1])
+ img = torch.from_numpy(img)
+ return img
+
+ def _format_segments(self, instances, cls, w, h):
+ """convert polygon points to bitmap."""
+ segments = instances.segments
+ if self.mask_overlap:
+ masks, sorted_idx = polygons2masks_overlap((h, w), segments, downsample_ratio=self.mask_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ instances = instances[sorted_idx]
+ cls = cls[sorted_idx]
+ else:
+ masks = polygons2masks((h, w), segments, color=1, downsample_ratio=self.mask_ratio)
+
+ return masks, instances, cls
+
+
+def v8_transforms(dataset, imgsz, hyp, stretch=False):
+ """Convert images to a size suitable for YOLOv8 training."""
+ pre_transform = Compose([
+ Mosaic(dataset, imgsz=imgsz, p=hyp.mosaic),
+ CopyPaste(p=hyp.copy_paste),
+ RandomPerspective(
+ degrees=hyp.degrees,
+ translate=hyp.translate,
+ scale=hyp.scale,
+ shear=hyp.shear,
+ perspective=hyp.perspective,
+ pre_transform=None if stretch else LetterBox(new_shape=(imgsz, imgsz)),
+ )])
+ flip_idx = dataset.data.get('flip_idx', []) # for keypoints augmentation
+ if dataset.use_keypoints:
+ kpt_shape = dataset.data.get('kpt_shape', None)
+ if len(flip_idx) == 0 and hyp.fliplr > 0.0:
+ hyp.fliplr = 0.0
+ LOGGER.warning("WARNING ⚠️ No 'flip_idx' array defined in data.yaml, setting augmentation 'fliplr=0.0'")
+ elif flip_idx and (len(flip_idx) != kpt_shape[0]):
+ raise ValueError(f'data.yaml flip_idx={flip_idx} length must be equal to kpt_shape[0]={kpt_shape[0]}')
+
+ return Compose([
+ pre_transform,
+ MixUp(dataset, pre_transform=pre_transform, p=hyp.mixup),
+ Albumentations(p=1.0),
+ RandomHSV(hgain=hyp.hsv_h, sgain=hyp.hsv_s, vgain=hyp.hsv_v),
+ RandomFlip(direction='vertical', p=hyp.flipud),
+ RandomFlip(direction='horizontal', p=hyp.fliplr, flip_idx=flip_idx)]) # transforms
+
+
+# Classification augmentations -----------------------------------------------------------------------------------------
+def classify_transforms(size=224, mean=(0.0, 0.0, 0.0), std=(1.0, 1.0, 1.0)): # IMAGENET_MEAN, IMAGENET_STD
+ # Transforms to apply if albumentations not installed
+ if not isinstance(size, int):
+ raise TypeError(f'classify_transforms() size {size} must be integer, not (list, tuple)')
+ if any(mean) or any(std):
+ return T.Compose([CenterCrop(size), ToTensor(), T.Normalize(mean, std, inplace=True)])
+ else:
+ return T.Compose([CenterCrop(size), ToTensor()])
+
+
+def hsv2colorjitter(h, s, v):
+ """Map HSV (hue, saturation, value) jitter into ColorJitter values (brightness, contrast, saturation, hue)"""
+ return v, v, s, h
+
+
+def classify_albumentations(
+ augment=True,
+ size=224,
+ scale=(0.08, 1.0),
+ hflip=0.5,
+ vflip=0.0,
+ hsv_h=0.015, # image HSV-Hue augmentation (fraction)
+ hsv_s=0.7, # image HSV-Saturation augmentation (fraction)
+ hsv_v=0.4, # image HSV-Value augmentation (fraction)
+ mean=(0.0, 0.0, 0.0), # IMAGENET_MEAN
+ std=(1.0, 1.0, 1.0), # IMAGENET_STD
+ auto_aug=False,
+):
+ """YOLOv8 classification Albumentations (optional, only used if package is installed)."""
+ prefix = colorstr('albumentations: ')
+ try:
+ import albumentations as A
+ from albumentations.pytorch import ToTensorV2
+
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+ if augment: # Resize and crop
+ T = [A.RandomResizedCrop(height=size, width=size, scale=scale)]
+ if auto_aug:
+ # TODO: implement AugMix, AutoAug & RandAug in albumentations
+ LOGGER.info(f'{prefix}auto augmentations are currently not supported')
+ else:
+ if hflip > 0:
+ T += [A.HorizontalFlip(p=hflip)]
+ if vflip > 0:
+ T += [A.VerticalFlip(p=vflip)]
+ if any((hsv_h, hsv_s, hsv_v)):
+ T += [A.ColorJitter(*hsv2colorjitter(hsv_h, hsv_s, hsv_v))] # brightness, contrast, saturation, hue
+ else: # Use fixed crop for eval set (reproducibility)
+ T = [A.SmallestMaxSize(max_size=size), A.CenterCrop(height=size, width=size)]
+ T += [A.Normalize(mean=mean, std=std), ToTensorV2()] # Normalize and convert to Tensor
+ LOGGER.info(prefix + ', '.join(f'{x}'.replace('always_apply=False, ', '') for x in T if x.p))
+ return A.Compose(T)
+
+ except ImportError: # package not installed, skip
+ pass
+ except Exception as e:
+ LOGGER.info(f'{prefix}{e}')
+
+
+class ClassifyLetterBox:
+ """YOLOv8 LetterBox class for image preprocessing, i.e. T.Compose([LetterBox(size), ToTensor()])"""
+
+ def __init__(self, size=(640, 640), auto=False, stride=32):
+ """Resizes image and crops it to center with max dimensions 'h' and 'w'."""
+ super().__init__()
+ self.h, self.w = (size, size) if isinstance(size, int) else size
+ self.auto = auto # pass max size integer, automatically solve for short side using stride
+ self.stride = stride # used with auto
+
+ def __call__(self, im): # im = np.array HWC
+ imh, imw = im.shape[:2]
+ r = min(self.h / imh, self.w / imw) # ratio of new/old
+ h, w = round(imh * r), round(imw * r) # resized image
+ hs, ws = (math.ceil(x / self.stride) * self.stride for x in (h, w)) if self.auto else self.h, self.w
+ top, left = round((hs - h) / 2 - 0.1), round((ws - w) / 2 - 0.1)
+ im_out = np.full((self.h, self.w, 3), 114, dtype=im.dtype)
+ im_out[top:top + h, left:left + w] = cv2.resize(im, (w, h), interpolation=cv2.INTER_LINEAR)
+ return im_out
+
+
+class CenterCrop:
+ """YOLOv8 CenterCrop class for image preprocessing, i.e. T.Compose([CenterCrop(size), ToTensor()])"""
+
+ def __init__(self, size=640):
+ """Converts an image from numpy array to PyTorch tensor."""
+ super().__init__()
+ self.h, self.w = (size, size) if isinstance(size, int) else size
+
+ def __call__(self, im): # im = np.array HWC
+ imh, imw = im.shape[:2]
+ m = min(imh, imw) # min dimension
+ top, left = (imh - m) // 2, (imw - m) // 2
+ return cv2.resize(im[top:top + m, left:left + m], (self.w, self.h), interpolation=cv2.INTER_LINEAR)
+
+
+class ToTensor:
+ """YOLOv8 ToTensor class for image preprocessing, i.e. T.Compose([LetterBox(size), ToTensor()])."""
+
+ def __init__(self, half=False):
+ """Initialize YOLOv8 ToTensor object with optional half-precision support."""
+ super().__init__()
+ self.half = half
+
+ def __call__(self, im): # im = np.array HWC in BGR order
+ im = np.ascontiguousarray(im.transpose((2, 0, 1))[::-1]) # HWC to CHW -> BGR to RGB -> contiguous
+ im = torch.from_numpy(im) # to torch
+ im = im.half() if self.half else im.float() # uint8 to fp16/32
+ im /= 255.0 # 0-255 to 0.0-1.0
+ return im
diff --git a/STPoseNet/ultralytics/data/base.py b/STPoseNet/ultralytics/data/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fbb82bf5ff13a44bcb12510b50f2bb20f47b0cf
--- /dev/null
+++ b/STPoseNet/ultralytics/data/base.py
@@ -0,0 +1,287 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import glob
+import math
+import os
+import random
+from copy import deepcopy
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from typing import Optional
+
+import cv2
+import numpy as np
+import psutil
+from torch.utils.data import Dataset
+from tqdm import tqdm
+
+from ultralytics.utils import DEFAULT_CFG, LOCAL_RANK, LOGGER, NUM_THREADS, TQDM_BAR_FORMAT
+
+from .utils import HELP_URL, IMG_FORMATS
+
+
+class BaseDataset(Dataset):
+ """
+ Base dataset class for loading and processing image data.
+
+ Args:
+ img_path (str): Path to the folder containing images.
+ imgsz (int, optional): Image size. Defaults to 640.
+ cache (bool, optional): Cache images to RAM or disk during training. Defaults to False.
+ augment (bool, optional): If True, data augmentation is applied. Defaults to True.
+ hyp (dict, optional): Hyperparameters to apply data augmentation. Defaults to None.
+ prefix (str, optional): Prefix to print in log messages. Defaults to ''.
+ rect (bool, optional): If True, rectangular training is used. Defaults to False.
+ batch_size (int, optional): Size of batches. Defaults to None.
+ stride (int, optional): Stride. Defaults to 32.
+ pad (float, optional): Padding. Defaults to 0.0.
+ single_cls (bool, optional): If True, single class training is used. Defaults to False.
+ classes (list): List of included classes. Default is None.
+ fraction (float): Fraction of dataset to utilize. Default is 1.0 (use all data).
+
+ Attributes:
+ im_files (list): List of image file paths.
+ labels (list): List of label data dictionaries.
+ ni (int): Number of images in the dataset.
+ ims (list): List of loaded images.
+ npy_files (list): List of numpy file paths.
+ transforms (callable): Image transformation function.
+ """
+
+ def __init__(self,
+ img_path,
+ imgsz=640,
+ cache=False,
+ augment=True,
+ hyp=DEFAULT_CFG,
+ prefix='',
+ rect=False,
+ batch_size=16,
+ stride=32,
+ pad=0.5,
+ single_cls=False,
+ classes=None,
+ fraction=1.0):
+ super().__init__()
+ self.img_path = img_path
+ self.imgsz = imgsz
+ self.augment = augment
+ self.single_cls = single_cls
+ self.prefix = prefix
+ self.fraction = fraction
+ self.im_files = self.get_img_files(self.img_path)
+ self.labels = self.get_labels()
+ self.update_labels(include_class=classes) # single_cls and include_class
+ self.ni = len(self.labels) # number of images
+ self.rect = rect
+ self.batch_size = batch_size
+ self.stride = stride
+ self.pad = pad
+ if self.rect:
+ assert self.batch_size is not None
+ self.set_rectangle()
+
+ # Buffer thread for mosaic images
+ self.buffer = [] # buffer size = batch size
+ self.max_buffer_length = min((self.ni, self.batch_size * 8, 1000)) if self.augment else 0
+
+ # Cache stuff
+ if cache == 'ram' and not self.check_cache_ram():
+ cache = False
+ self.ims, self.im_hw0, self.im_hw = [None] * self.ni, [None] * self.ni, [None] * self.ni
+ self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
+ if cache:
+ self.cache_images(cache)
+
+ # Transforms
+ self.transforms = self.build_transforms(hyp=hyp)
+
+ def get_img_files(self, img_path):
+ """Read image files."""
+ try:
+ f = [] # image files
+ for p in img_path if isinstance(img_path, list) else [img_path]:
+ p = Path(p) # os-agnostic
+ if p.is_dir(): # dir
+ f += glob.glob(str(p / '**' / '*.*'), recursive=True)
+ # F = list(p.rglob('*.*')) # pathlib
+ elif p.is_file(): # file
+ with open(p) as t:
+ t = t.read().strip().splitlines()
+ parent = str(p.parent) + os.sep
+ f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
+ # F += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
+ else:
+ raise FileNotFoundError(f'{self.prefix}{p} does not exist')
+ im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
+ # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
+ assert im_files, f'{self.prefix}No images found in {img_path}'
+ except Exception as e:
+ raise FileNotFoundError(f'{self.prefix}Error loading data from {img_path}\n{HELP_URL}') from e
+ if self.fraction < 1:
+ im_files = im_files[:round(len(im_files) * self.fraction)]
+ return im_files
+
+ def update_labels(self, include_class: Optional[list]):
+ """include_class, filter labels to include only these classes (optional)."""
+ include_class_array = np.array(include_class).reshape(1, -1)
+ for i in range(len(self.labels)):
+ if include_class is not None:
+ cls = self.labels[i]['cls']
+ bboxes = self.labels[i]['bboxes']
+ segments = self.labels[i]['segments']
+ keypoints = self.labels[i]['keypoints']
+ j = (cls == include_class_array).any(1)
+ self.labels[i]['cls'] = cls[j]
+ self.labels[i]['bboxes'] = bboxes[j]
+ if segments:
+ self.labels[i]['segments'] = [segments[si] for si, idx in enumerate(j) if idx]
+ if keypoints is not None:
+ self.labels[i]['keypoints'] = keypoints[j]
+ if self.single_cls:
+ self.labels[i]['cls'][:, 0] = 0
+
+ def load_image(self, i):
+ """Loads 1 image from dataset index 'i', returns (im, resized hw)."""
+ im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
+ if im is None: # not cached in RAM
+ if fn.exists(): # load npy
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ if im is None:
+ raise FileNotFoundError(f'Image Not Found {f}')
+ h0, w0 = im.shape[:2] # orig hw
+ r = self.imgsz / max(h0, w0) # ratio
+ if r != 1: # if sizes are not equal
+ interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
+ im = cv2.resize(im, (min(math.ceil(w0 * r), self.imgsz), min(math.ceil(h0 * r), self.imgsz)),
+ interpolation=interp)
+
+ # Add to buffer if training with augmentations
+ if self.augment:
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
+ self.buffer.append(i)
+ if len(self.buffer) >= self.max_buffer_length:
+ j = self.buffer.pop(0)
+ self.ims[j], self.im_hw0[j], self.im_hw[j] = None, None, None
+
+ return im, (h0, w0), im.shape[:2]
+
+ return self.ims[i], self.im_hw0[i], self.im_hw[i]
+
+ def cache_images(self, cache):
+ """Cache images to memory or disk."""
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
+ fcn = self.cache_images_to_disk if cache == 'disk' else self.load_image
+ with ThreadPool(NUM_THREADS) as pool:
+ results = pool.imap(fcn, range(self.ni))
+ pbar = tqdm(enumerate(results), total=self.ni, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
+ for i, x in pbar:
+ if cache == 'disk':
+ b += self.npy_files[i].stat().st_size
+ else: # 'ram'
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
+ b += self.ims[i].nbytes
+ pbar.desc = f'{self.prefix}Caching images ({b / gb:.1f}GB {cache})'
+ pbar.close()
+
+ def cache_images_to_disk(self, i):
+ """Saves an image as an *.npy file for faster loading."""
+ f = self.npy_files[i]
+ if not f.exists():
+ np.save(f.as_posix(), cv2.imread(self.im_files[i]))
+
+ def check_cache_ram(self, safety_margin=0.5):
+ """Check image caching requirements vs available memory."""
+ b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
+ n = min(self.ni, 30) # extrapolate from 30 random images
+ for _ in range(n):
+ im = cv2.imread(random.choice(self.im_files)) # sample image
+ ratio = self.imgsz / max(im.shape[0], im.shape[1]) # max(h, w) # ratio
+ b += im.nbytes * ratio ** 2
+ mem_required = b * self.ni / n * (1 + safety_margin) # GB required to cache dataset into RAM
+ mem = psutil.virtual_memory()
+ cache = mem_required < mem.available # to cache or not to cache, that is the question
+ if not cache:
+ LOGGER.info(f'{self.prefix}{mem_required / gb:.1f}GB RAM required to cache images '
+ f'with {int(safety_margin * 100)}% safety margin but only '
+ f'{mem.available / gb:.1f}/{mem.total / gb:.1f}GB available, '
+ f"{'caching images ✅' if cache else 'not caching images ⚠️'}")
+ return cache
+
+ def set_rectangle(self):
+ """Sets the shape of bounding boxes for YOLO detections as rectangles."""
+ bi = np.floor(np.arange(self.ni) / self.batch_size).astype(int) # batch index
+ nb = bi[-1] + 1 # number of batches
+
+ s = np.array([x.pop('shape') for x in self.labels]) # hw
+ ar = s[:, 0] / s[:, 1] # aspect ratio
+ irect = ar.argsort()
+ self.im_files = [self.im_files[i] for i in irect]
+ self.labels = [self.labels[i] for i in irect]
+ ar = ar[irect]
+
+ # Set training image shapes
+ shapes = [[1, 1]] * nb
+ for i in range(nb):
+ ari = ar[bi == i]
+ mini, maxi = ari.min(), ari.max()
+ if maxi < 1:
+ shapes[i] = [maxi, 1]
+ elif mini > 1:
+ shapes[i] = [1, 1 / mini]
+
+ self.batch_shapes = np.ceil(np.array(shapes) * self.imgsz / self.stride + self.pad).astype(int) * self.stride
+ self.batch = bi # batch index of image
+
+ def __getitem__(self, index):
+ """Returns transformed label information for given index."""
+ return self.transforms(self.get_image_and_label(index))
+
+ def get_image_and_label(self, index):
+ """Get and return label information from the dataset."""
+ label = deepcopy(self.labels[index]) # requires deepcopy() https://github.com/ultralytics/ultralytics/pull/1948
+ label.pop('shape', None) # shape is for rect, remove it
+ label['img'], label['ori_shape'], label['resized_shape'] = self.load_image(index)
+ label['ratio_pad'] = (label['resized_shape'][0] / label['ori_shape'][0],
+ label['resized_shape'][1] / label['ori_shape'][1]) # for evaluation
+ if self.rect:
+ label['rect_shape'] = self.batch_shapes[self.batch[index]]
+ return self.update_labels_info(label)
+
+ def __len__(self):
+ """Returns the length of the labels list for the dataset."""
+ return len(self.labels)
+
+ def update_labels_info(self, label):
+ """custom your label format here."""
+ return label
+
+ def build_transforms(self, hyp=None):
+ """Users can custom augmentations here
+ like:
+ if self.augment:
+ # Training transforms
+ return Compose([])
+ else:
+ # Val transforms
+ return Compose([])
+ """
+ raise NotImplementedError
+
+ def get_labels(self):
+ """Users can custom their own format here.
+ Make sure your output is a list with each element like below:
+ dict(
+ im_file=im_file,
+ shape=shape, # format: (height, width)
+ cls=cls,
+ bboxes=bboxes, # xywh
+ segments=segments, # xy
+ keypoints=keypoints, # xy
+ normalized=True, # or False
+ bbox_format="xyxy", # or xywh, ltwh
+ )
+ """
+ raise NotImplementedError
diff --git a/STPoseNet/ultralytics/data/build.py b/STPoseNet/ultralytics/data/build.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d40e5a0a7386c03bb8927a32ae8dfaae19a348d
--- /dev/null
+++ b/STPoseNet/ultralytics/data/build.py
@@ -0,0 +1,171 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+import random
+from pathlib import Path
+
+import numpy as np
+import torch
+from PIL import Image
+from torch.utils.data import dataloader, distributed
+
+from ultralytics.data.loaders import (LOADERS, LoadImages, LoadPilAndNumpy, LoadScreenshots, LoadStreams, LoadTensor,
+ SourceTypes, autocast_list)
+from ultralytics.data.utils import IMG_FORMATS, VID_FORMATS
+from ultralytics.utils import RANK, colorstr
+from ultralytics.utils.checks import check_file
+
+from .dataset import YOLODataset
+from .utils import PIN_MEMORY
+
+
+class InfiniteDataLoader(dataloader.DataLoader):
+ """Dataloader that reuses workers. Uses same syntax as vanilla DataLoader."""
+
+ def __init__(self, *args, **kwargs):
+ """Dataloader that infinitely recycles workers, inherits from DataLoader."""
+ super().__init__(*args, **kwargs)
+ object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
+ self.iterator = super().__iter__()
+
+ def __len__(self):
+ """Returns the length of the batch sampler's sampler."""
+ return len(self.batch_sampler.sampler)
+
+ def __iter__(self):
+ """Creates a sampler that repeats indefinitely."""
+ for _ in range(len(self)):
+ yield next(self.iterator)
+
+ def reset(self):
+ """Reset iterator.
+ This is useful when we want to modify settings of dataset while training.
+ """
+ self.iterator = self._get_iterator()
+
+
+class _RepeatSampler:
+ """
+ Sampler that repeats forever.
+
+ Args:
+ sampler (Dataset.sampler): The sampler to repeat.
+ """
+
+ def __init__(self, sampler):
+ """Initializes an object that repeats a given sampler indefinitely."""
+ self.sampler = sampler
+
+ def __iter__(self):
+ """Iterates over the 'sampler' and yields its contents."""
+ while True:
+ yield from iter(self.sampler)
+
+
+def seed_worker(worker_id): # noqa
+ """Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader."""
+ worker_seed = torch.initial_seed() % 2 ** 32
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
+
+
+def build_yolo_dataset(cfg, img_path, batch, data, mode='train', rect=False, stride=32):
+ """Build YOLO Dataset"""
+ return YOLODataset(
+ img_path=img_path,
+ imgsz=cfg.imgsz,
+ batch_size=batch,
+ augment=mode == 'train', # augmentation
+ hyp=cfg, # TODO: probably add a get_hyps_from_cfg function
+ rect=cfg.rect or rect, # rectangular batches
+ cache=cfg.cache or None,
+ single_cls=cfg.single_cls or False,
+ stride=int(stride),
+ pad=0.0 if mode == 'train' else 0.5,
+ prefix=colorstr(f'{mode}: '),
+ use_segments=cfg.task == 'segment',
+ use_keypoints=cfg.task == 'pose',
+ classes=cfg.classes,
+ data=data,
+ fraction=cfg.fraction if mode == 'train' else 1.0)
+
+
+def build_dataloader(dataset, batch, workers, shuffle=True, rank=-1):
+ """Return an InfiniteDataLoader or DataLoader for training or validation set."""
+ batch = min(batch, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch if batch > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + RANK)
+ return InfiniteDataLoader(dataset=dataset,
+ batch_size=batch,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=PIN_MEMORY,
+ collate_fn=getattr(dataset, 'collate_fn', None),
+ worker_init_fn=seed_worker,
+ generator=generator)
+
+
+def check_source(source):
+ """Check source type and return corresponding flag values."""
+ webcam, screenshot, from_img, in_memory, tensor = False, False, False, False, False
+ if isinstance(source, (str, int, Path)): # int for local usb camera
+ source = str(source)
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('https://', 'http://', 'rtsp://', 'rtmp://'))
+ webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
+ screenshot = source.lower() == 'screen'
+ if is_url and is_file:
+ source = check_file(source) # download
+ elif isinstance(source, LOADERS):
+ in_memory = True
+ elif isinstance(source, (list, tuple)):
+ source = autocast_list(source) # convert all list elements to PIL or np arrays
+ from_img = True
+ elif isinstance(source, (Image.Image, np.ndarray)):
+ from_img = True
+ elif isinstance(source, torch.Tensor):
+ tensor = True
+ else:
+ raise TypeError('Unsupported image type. For supported types see https://docs.ultralytics.com/modes/predict')
+
+ return source, webcam, screenshot, from_img, in_memory, tensor
+
+
+def load_inference_source(source=None, imgsz=640, vid_stride=1, stream_buffer=False):
+ """
+ Loads an inference source for object detection and applies necessary transformations.
+
+ Args:
+ source (str, Path, Tensor, PIL.Image, np.ndarray): The input source for inference.
+ imgsz (int, optional): The size of the image for inference. Default is 640.
+ vid_stride (int, optional): The frame interval for video sources. Default is 1.
+ stream_buffer (bool, optional): Determined whether stream frames will be buffered. Default is False.
+
+ Returns:
+ dataset (Dataset): A dataset object for the specified input source.
+ """
+ source, webcam, screenshot, from_img, in_memory, tensor = check_source(source)
+ source_type = source.source_type if in_memory else SourceTypes(webcam, screenshot, from_img, tensor)
+
+ # Dataloader
+ if tensor:
+ dataset = LoadTensor(source)
+ elif in_memory:
+ dataset = source
+ elif webcam:
+ dataset = LoadStreams(source, imgsz=imgsz, vid_stride=vid_stride, stream_buffer=stream_buffer)
+ elif screenshot:
+ dataset = LoadScreenshots(source, imgsz=imgsz)
+ elif from_img:
+ dataset = LoadPilAndNumpy(source, imgsz=imgsz)
+ else:
+ dataset = LoadImages(source, imgsz=imgsz, vid_stride=vid_stride)
+
+ # Attach source types to the dataset
+ setattr(dataset, 'source_type', source_type)
+
+ return dataset
diff --git a/STPoseNet/ultralytics/data/converter.py b/STPoseNet/ultralytics/data/converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbcbb2cfee783cd013adf8f4eb50366ba913a5fa
--- /dev/null
+++ b/STPoseNet/ultralytics/data/converter.py
@@ -0,0 +1,297 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import json
+import shutil
+from collections import defaultdict
+from pathlib import Path
+
+import cv2
+import numpy as np
+from tqdm import tqdm
+
+
+def coco91_to_coco80_class():
+ """Converts 91-index COCO class IDs to 80-index COCO class IDs.
+
+ Returns:
+ (list): A list of 91 class IDs where the index represents the 80-index class ID and the value is the
+ corresponding 91-index class ID.
+ """
+ return [
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, None, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, None, 24, 25, None,
+ None, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, None, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
+ 51, 52, 53, 54, 55, 56, 57, 58, 59, None, 60, None, None, 61, None, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72,
+ None, 73, 74, 75, 76, 77, 78, 79, None]
+
+
+def coco80_to_coco91_class(): #
+ """
+ Converts 80-index (val2014) to 91-index (paper).
+ For details see https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/.
+
+ Example:
+ ```python
+ import numpy as np
+
+ a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
+ b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
+ x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
+ x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
+ ```
+ """
+ return [
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
+ 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
+ 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
+
+
+def convert_coco(labels_dir='../coco/annotations/', use_segments=False, use_keypoints=False, cls91to80=True):
+ """Converts COCO dataset annotations to a format suitable for training YOLOv5 models.
+
+ Args:
+ labels_dir (str, optional): Path to directory containing COCO dataset annotation files.
+ use_segments (bool, optional): Whether to include segmentation masks in the output.
+ use_keypoints (bool, optional): Whether to include keypoint annotations in the output.
+ cls91to80 (bool, optional): Whether to map 91 COCO class IDs to the corresponding 80 COCO class IDs.
+
+ Example:
+ ```python
+ from ultralytics.data.converter import convert_coco
+
+ convert_coco('../datasets/coco/annotations/', use_segments=True, use_keypoints=False, cls91to80=True)
+ ```
+
+ Output:
+ Generates output files in the specified output directory.
+ """
+
+ # Create dataset directory
+ save_dir = Path('yolo_labels')
+ if save_dir.exists():
+ shutil.rmtree(save_dir) # delete dir
+ for p in save_dir / 'labels', save_dir / 'images':
+ p.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Convert classes
+ coco80 = coco91_to_coco80_class()
+
+ # Import json
+ for json_file in sorted(Path(labels_dir).resolve().glob('*.json')):
+ fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder name
+ fn.mkdir(parents=True, exist_ok=True)
+ with open(json_file) as f:
+ data = json.load(f)
+
+ # Create image dict
+ images = {f'{x["id"]:d}': x for x in data['images']}
+ # Create image-annotations dict
+ imgToAnns = defaultdict(list)
+ for ann in data['annotations']:
+ imgToAnns[ann['image_id']].append(ann)
+
+ # Write labels file
+ for img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {json_file}'):
+ img = images[f'{img_id:d}']
+ h, w, f = img['height'], img['width'], img['file_name']
+
+ bboxes = []
+ segments = []
+ keypoints = []
+ for ann in anns:
+ if ann['iscrowd']:
+ continue
+ # The COCO box format is [top left x, top left y, width, height]
+ box = np.array(ann['bbox'], dtype=np.float64)
+ box[:2] += box[2:] / 2 # xy top-left corner to center
+ box[[0, 2]] /= w # normalize x
+ box[[1, 3]] /= h # normalize y
+ if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
+ continue
+
+ cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # class
+ box = [cls] + box.tolist()
+ if box not in bboxes:
+ bboxes.append(box)
+ if use_segments and ann.get('segmentation') is not None:
+ if len(ann['segmentation']) == 0:
+ segments.append([])
+ continue
+ elif len(ann['segmentation']) > 1:
+ s = merge_multi_segment(ann['segmentation'])
+ s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()
+ else:
+ s = [j for i in ann['segmentation'] for j in i] # all segments concatenated
+ s = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()
+ s = [cls] + s
+ if s not in segments:
+ segments.append(s)
+ if use_keypoints and ann.get('keypoints') is not None:
+ keypoints.append(box + (np.array(ann['keypoints']).reshape(-1, 3) /
+ np.array([w, h, 1])).reshape(-1).tolist())
+
+ # Write
+ with open((fn / f).with_suffix('.txt'), 'a') as file:
+ for i in range(len(bboxes)):
+ if use_keypoints:
+ line = *(keypoints[i]), # cls, box, keypoints
+ else:
+ line = *(segments[i]
+ if use_segments and len(segments[i]) > 0 else bboxes[i]), # cls, box or segments
+ file.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def convert_dota_to_yolo_obb(dota_root_path: str):
+ """
+ Converts DOTA dataset annotations to YOLO OBB (Oriented Bounding Box) format.
+
+ The function processes images in the 'train' and 'val' folders of the DOTA dataset. For each image, it reads the
+ associated label from the original labels directory and writes new labels in YOLO OBB format to a new directory.
+
+ Args:
+ dota_root_path (str): The root directory path of the DOTA dataset.
+
+ Example:
+ ```python
+ from ultralytics.data.converter import convert_dota_to_yolo_obb
+
+ convert_dota_to_yolo_obb('path/to/DOTA')
+ ```
+
+ Notes:
+ The directory structure assumed for the DOTA dataset:
+ - DOTA
+ - images
+ - train
+ - val
+ - labels
+ - train_original
+ - val_original
+
+ After the function execution, the new labels will be saved in:
+ - DOTA
+ - labels
+ - train
+ - val
+ """
+ dota_root_path = Path(dota_root_path)
+
+ # Class names to indices mapping
+ class_mapping = {
+ 'plane': 0,
+ 'ship': 1,
+ 'storage-tank': 2,
+ 'baseball-diamond': 3,
+ 'tennis-court': 4,
+ 'basketball-court': 5,
+ 'ground-track-field': 6,
+ 'harbor': 7,
+ 'bridge': 8,
+ 'large-vehicle': 9,
+ 'small-vehicle': 10,
+ 'helicopter': 11,
+ 'roundabout': 12,
+ 'soccer ball-field': 13,
+ 'swimming-pool': 14,
+ 'container-crane': 15,
+ 'airport': 16,
+ 'helipad': 17}
+
+ def convert_label(image_name, image_width, image_height, orig_label_dir, save_dir):
+ orig_label_path = orig_label_dir / f'{image_name}.txt'
+ save_path = save_dir / f'{image_name}.txt'
+
+ with orig_label_path.open('r') as f, save_path.open('w') as g:
+ lines = f.readlines()
+ for line in lines:
+ parts = line.strip().split()
+ if len(parts) < 9:
+ continue
+ class_name = parts[8]
+ class_idx = class_mapping[class_name]
+ coords = [float(p) for p in parts[:8]]
+ normalized_coords = [
+ coords[i] / image_width if i % 2 == 0 else coords[i] / image_height for i in range(8)]
+ formatted_coords = ['{:.6g}'.format(coord) for coord in normalized_coords]
+ g.write(f"{class_idx} {' '.join(formatted_coords)}\n")
+
+ for phase in ['train', 'val']:
+ image_dir = dota_root_path / 'images' / phase
+ orig_label_dir = dota_root_path / 'labels' / f'{phase}_original'
+ save_dir = dota_root_path / 'labels' / phase
+
+ save_dir.mkdir(parents=True, exist_ok=True)
+
+ image_paths = list(image_dir.iterdir())
+ for image_path in tqdm(image_paths, desc=f'Processing {phase} images'):
+ if image_path.suffix != '.png':
+ continue
+ image_name_without_ext = image_path.stem
+ img = cv2.imread(str(image_path))
+ h, w = img.shape[:2]
+ convert_label(image_name_without_ext, w, h, orig_label_dir, save_dir)
+
+
+def min_index(arr1, arr2):
+ """
+ Find a pair of indexes with the shortest distance between two arrays of 2D points.
+
+ Args:
+ arr1 (np.array): A NumPy array of shape (N, 2) representing N 2D points.
+ arr2 (np.array): A NumPy array of shape (M, 2) representing M 2D points.
+
+ Returns:
+ (tuple): A tuple containing the indexes of the points with the shortest distance in arr1 and arr2 respectively.
+ """
+ dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)
+ return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
+
+
+def merge_multi_segment(segments):
+ """
+ Merge multiple segments into one list by connecting the coordinates with the minimum distance between each segment.
+ This function connects these coordinates with a thin line to merge all segments into one.
+
+ Args:
+ segments (List[List]): Original segmentations in COCO's JSON file.
+ Each element is a list of coordinates, like [segmentation1, segmentation2,...].
+
+ Returns:
+ s (List[np.ndarray]): A list of connected segments represented as NumPy arrays.
+ """
+ s = []
+ segments = [np.array(i).reshape(-1, 2) for i in segments]
+ idx_list = [[] for _ in range(len(segments))]
+
+ # record the indexes with min distance between each segment
+ for i in range(1, len(segments)):
+ idx1, idx2 = min_index(segments[i - 1], segments[i])
+ idx_list[i - 1].append(idx1)
+ idx_list[i].append(idx2)
+
+ # use two round to connect all the segments
+ for k in range(2):
+ # forward connection
+ if k == 0:
+ for i, idx in enumerate(idx_list):
+ # middle segments have two indexes
+ # reverse the index of middle segments
+ if len(idx) == 2 and idx[0] > idx[1]:
+ idx = idx[::-1]
+ segments[i] = segments[i][::-1, :]
+
+ segments[i] = np.roll(segments[i], -idx[0], axis=0)
+ segments[i] = np.concatenate([segments[i], segments[i][:1]])
+ # deal with the first segment and the last one
+ if i in [0, len(idx_list) - 1]:
+ s.append(segments[i])
+ else:
+ idx = [0, idx[1] - idx[0]]
+ s.append(segments[i][idx[0]:idx[1] + 1])
+
+ else:
+ for i in range(len(idx_list) - 1, -1, -1):
+ if i not in [0, len(idx_list) - 1]:
+ idx = idx_list[i]
+ nidx = abs(idx[1] - idx[0])
+ s.append(segments[i][nidx:])
+ return s
diff --git a/STPoseNet/ultralytics/data/dataset.py b/STPoseNet/ultralytics/data/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..515c4823b96e44ce37f8b27ed382c34dc893100e
--- /dev/null
+++ b/STPoseNet/ultralytics/data/dataset.py
@@ -0,0 +1,327 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+import contextlib
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+import torchvision
+from tqdm import tqdm
+
+from ultralytics.utils import LOCAL_RANK, NUM_THREADS, TQDM_BAR_FORMAT, colorstr, is_dir_writeable
+
+from .augment import Compose, Format, Instances, LetterBox, classify_albumentations, classify_transforms, v8_transforms
+from .base import BaseDataset
+from .utils import HELP_URL, LOGGER, get_hash, img2label_paths, verify_image, verify_image_label
+
+# Ultralytics dataset *.cache version, >= 1.0.0 for YOLOv8
+DATASET_CACHE_VERSION = '1.0.3'
+
+
+class YOLODataset(BaseDataset):
+ """
+ Dataset class for loading object detection and/or segmentation labels in YOLO format.
+
+ Args:
+ data (dict, optional): A dataset YAML dictionary. Defaults to None.
+ use_segments (bool, optional): If True, segmentation masks are used as labels. Defaults to False.
+ use_keypoints (bool, optional): If True, keypoints are used as labels. Defaults to False.
+
+ Returns:
+ (torch.utils.data.Dataset): A PyTorch dataset object that can be used for training an object detection model.
+ """
+
+ def __init__(self, *args, data=None, use_segments=False, use_keypoints=False, **kwargs):
+ self.use_segments = use_segments
+ self.use_keypoints = use_keypoints
+ self.data = data
+ assert not (self.use_segments and self.use_keypoints), 'Can not use both segments and keypoints.'
+ super().__init__(*args, **kwargs)
+
+ def cache_labels(self, path=Path('./labels.cache')):
+ """Cache dataset labels, check images and read shapes.
+ Args:
+ path (Path): path where to save the cache file (default: Path('./labels.cache')).
+ Returns:
+ (dict): labels.
+ """
+ x = {'labels': []}
+ nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
+ desc = f'{self.prefix}Scanning {path.parent / path.stem}...'
+ total = len(self.im_files)
+ nkpt, ndim = self.data.get('kpt_shape', (0, 0))
+ if self.use_keypoints and (nkpt <= 0 or ndim not in (2, 3)):
+ raise ValueError("'kpt_shape' in data.yaml missing or incorrect. Should be a list with [number of "
+ "keypoints, number of dims (2 for x,y or 3 for x,y,visible)], i.e. 'kpt_shape: [17, 3]'")
+ with ThreadPool(NUM_THREADS) as pool:
+ results = pool.imap(func=verify_image_label,
+ iterable=zip(self.im_files, self.label_files, repeat(self.prefix),
+ repeat(self.use_keypoints), repeat(len(self.data['names'])), repeat(nkpt),
+ repeat(ndim)))
+ pbar = tqdm(results, desc=desc, total=total, bar_format=TQDM_BAR_FORMAT)
+ for im_file, lb, shape, segments, keypoint, nm_f, nf_f, ne_f, nc_f, msg in pbar:
+ nm += nm_f
+ nf += nf_f
+ ne += ne_f
+ nc += nc_f
+ if im_file:
+ x['labels'].append(
+ dict(
+ im_file=im_file,
+ shape=shape,
+ cls=lb[:, 0:1], # n, 1
+ bboxes=lb[:, 1:], # n, 4
+ segments=segments,
+ keypoints=keypoint,
+ normalized=True,
+ bbox_format='xywh'))
+ if msg:
+ msgs.append(msg)
+ pbar.desc = f'{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt'
+ pbar.close()
+
+ if msgs:
+ LOGGER.info('\n'.join(msgs))
+ if nf == 0:
+ LOGGER.warning(f'{self.prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}')
+ x['hash'] = get_hash(self.label_files + self.im_files)
+ x['results'] = nf, nm, ne, nc, len(self.im_files)
+ x['msgs'] = msgs # warnings
+ save_dataset_cache_file(self.prefix, path, x)
+ return x
+
+ def get_labels(self):
+ """Returns dictionary of labels for YOLO training."""
+ self.label_files = img2label_paths(self.im_files)
+ cache_path = Path(self.label_files[0]).parent.with_suffix('.cache')
+ try:
+ cache, exists = load_dataset_cache_file(cache_path), True # attempt to load a *.cache file
+ assert cache['version'] == DATASET_CACHE_VERSION # matches current version
+ assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
+ except (FileNotFoundError, AssertionError, AttributeError):
+ cache, exists = self.cache_labels(cache_path), False # run cache ops
+
+ # Display cache
+ nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
+ if exists and LOCAL_RANK in (-1, 0):
+ d = f'Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt'
+ tqdm(None, desc=self.prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display results
+ if cache['msgs']:
+ LOGGER.info('\n'.join(cache['msgs'])) # display warnings
+
+ # Read cache
+ [cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
+ labels = cache['labels']
+ if not labels:
+ LOGGER.warning(f'WARNING ⚠️ No images found in {cache_path}, training may not work correctly. {HELP_URL}')
+ self.im_files = [lb['im_file'] for lb in labels] # update im_files
+
+ # Check if the dataset is all boxes or all segments
+ lengths = ((len(lb['cls']), len(lb['bboxes']), len(lb['segments'])) for lb in labels)
+ len_cls, len_boxes, len_segments = (sum(x) for x in zip(*lengths))
+ if len_segments and len_boxes != len_segments:
+ LOGGER.warning(
+ f'WARNING ⚠️ Box and segment counts should be equal, but got len(segments) = {len_segments}, '
+ f'len(boxes) = {len_boxes}. To resolve this only boxes will be used and all segments will be removed. '
+ 'To avoid this please supply either a detect or segment dataset, not a detect-segment mixed dataset.')
+ for lb in labels:
+ lb['segments'] = []
+ if len_cls == 0:
+ LOGGER.warning(f'WARNING ⚠️ No labels found in {cache_path}, training may not work correctly. {HELP_URL}')
+ return labels
+
+ def build_transforms(self, hyp=None):
+ """Builds and appends transforms to the list."""
+ if self.augment:
+ hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0
+ hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0
+ transforms = v8_transforms(self, self.imgsz, hyp)
+ else:
+ transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), scaleup=False)])
+ transforms.append(
+ Format(bbox_format='xywh',
+ normalize=True,
+ return_mask=self.use_segments,
+ return_keypoint=self.use_keypoints,
+ batch_idx=True,
+ mask_ratio=hyp.mask_ratio,
+ mask_overlap=hyp.overlap_mask))
+ return transforms
+
+ def close_mosaic(self, hyp):
+ """Sets mosaic, copy_paste and mixup options to 0.0 and builds transformations."""
+ hyp.mosaic = 0.0 # set mosaic ratio=0.0
+ hyp.copy_paste = 0.0 # keep the same behavior as previous v8 close-mosaic
+ hyp.mixup = 0.0 # keep the same behavior as previous v8 close-mosaic
+ self.transforms = self.build_transforms(hyp)
+
+ def update_labels_info(self, label):
+ """custom your label format here."""
+ # NOTE: cls is not with bboxes now, classification and semantic segmentation need an independent cls label
+ # we can make it also support classification and semantic segmentation by add or remove some dict keys there.
+ bboxes = label.pop('bboxes')
+ segments = label.pop('segments')
+ keypoints = label.pop('keypoints', None)
+ bbox_format = label.pop('bbox_format')
+ normalized = label.pop('normalized')
+ label['instances'] = Instances(bboxes, segments, keypoints, bbox_format=bbox_format, normalized=normalized)
+ return label
+
+ @staticmethod
+ def collate_fn(batch):
+ """Collates data samples into batches."""
+ new_batch = {}
+ keys = batch[0].keys()
+ values = list(zip(*[list(b.values()) for b in batch]))
+ for i, k in enumerate(keys):
+ value = values[i]
+ if k == 'img':
+ value = torch.stack(value, 0)
+ if k in ['masks', 'keypoints', 'bboxes', 'cls']:
+ value = torch.cat(value, 0)
+ new_batch[k] = value
+ new_batch['batch_idx'] = list(new_batch['batch_idx'])
+ for i in range(len(new_batch['batch_idx'])):
+ new_batch['batch_idx'][i] += i # add target image index for build_targets()
+ new_batch['batch_idx'] = torch.cat(new_batch['batch_idx'], 0)
+ return new_batch
+
+
+# Classification dataloaders -------------------------------------------------------------------------------------------
+class ClassificationDataset(torchvision.datasets.ImageFolder):
+ """
+ YOLO Classification Dataset.
+
+ Args:
+ root (str): Dataset path.
+
+ Attributes:
+ cache_ram (bool): True if images should be cached in RAM, False otherwise.
+ cache_disk (bool): True if images should be cached on disk, False otherwise.
+ samples (list): List of samples containing file, index, npy, and im.
+ torch_transforms (callable): torchvision transforms applied to the dataset.
+ album_transforms (callable, optional): Albumentations transforms applied to the dataset if augment is True.
+ """
+
+ def __init__(self, root, args, augment=False, cache=False, prefix=''):
+ """
+ Initialize YOLO object with root, image size, augmentations, and cache settings.
+
+ Args:
+ root (str): Dataset path.
+ args (Namespace): Argument parser containing dataset related settings.
+ augment (bool, optional): True if dataset should be augmented, False otherwise. Defaults to False.
+ cache (bool | str | optional): Cache setting, can be True, False, 'ram' or 'disk'. Defaults to False.
+ """
+ super().__init__(root=root)
+ if augment and args.fraction < 1.0: # reduce training fraction
+ self.samples = self.samples[:round(len(self.samples) * args.fraction)]
+ self.prefix = colorstr(f'{prefix}: ') if prefix else ''
+ self.cache_ram = cache is True or cache == 'ram'
+ self.cache_disk = cache == 'disk'
+ self.samples = self.verify_images() # filter out bad images
+ self.samples = [list(x) + [Path(x[0]).with_suffix('.npy'), None] for x in self.samples] # file, index, npy, im
+ self.torch_transforms = classify_transforms(args.imgsz)
+ self.album_transforms = classify_albumentations(
+ augment=augment,
+ size=args.imgsz,
+ scale=(1.0 - args.scale, 1.0), # (0.08, 1.0)
+ hflip=args.fliplr,
+ vflip=args.flipud,
+ hsv_h=args.hsv_h, # HSV-Hue augmentation (fraction)
+ hsv_s=args.hsv_s, # HSV-Saturation augmentation (fraction)
+ hsv_v=args.hsv_v, # HSV-Value augmentation (fraction)
+ mean=(0.0, 0.0, 0.0), # IMAGENET_MEAN
+ std=(1.0, 1.0, 1.0), # IMAGENET_STD
+ auto_aug=False) if augment else None
+
+ def __getitem__(self, i):
+ """Returns subset of data and targets corresponding to given indices."""
+ f, j, fn, im = self.samples[i] # filename, index, filename.with_suffix('.npy'), image
+ if self.cache_ram and im is None:
+ im = self.samples[i][3] = cv2.imread(f)
+ elif self.cache_disk:
+ if not fn.exists(): # load npy
+ np.save(fn.as_posix(), cv2.imread(f))
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ if self.album_transforms:
+ sample = self.album_transforms(image=cv2.cvtColor(im, cv2.COLOR_BGR2RGB))['image']
+ else:
+ sample = self.torch_transforms(im)
+ return {'img': sample, 'cls': j}
+
+ def __len__(self) -> int:
+ return len(self.samples)
+
+ def verify_images(self):
+ """Verify all images in dataset."""
+ desc = f'{self.prefix}Scanning {self.root}...'
+ path = Path(self.root).with_suffix('.cache') # *.cache file path
+
+ with contextlib.suppress(FileNotFoundError, AssertionError, AttributeError):
+ cache = load_dataset_cache_file(path) # attempt to load a *.cache file
+ assert cache['version'] == DATASET_CACHE_VERSION # matches current version
+ assert cache['hash'] == get_hash([x[0] for x in self.samples]) # identical hash
+ nf, nc, n, samples = cache.pop('results') # found, missing, empty, corrupt, total
+ if LOCAL_RANK in (-1, 0):
+ d = f'{desc} {nf} images, {nc} corrupt'
+ tqdm(None, desc=d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT)
+ if cache['msgs']:
+ LOGGER.info('\n'.join(cache['msgs'])) # display warnings
+ return samples
+
+ # Run scan if *.cache retrieval failed
+ nf, nc, msgs, samples, x = 0, 0, [], [], {}
+ with ThreadPool(NUM_THREADS) as pool:
+ results = pool.imap(func=verify_image, iterable=zip(self.samples, repeat(self.prefix)))
+ pbar = tqdm(results, desc=desc, total=len(self.samples), bar_format=TQDM_BAR_FORMAT)
+ for sample, nf_f, nc_f, msg in pbar:
+ if nf_f:
+ samples.append(sample)
+ if msg:
+ msgs.append(msg)
+ nf += nf_f
+ nc += nc_f
+ pbar.desc = f'{desc} {nf} images, {nc} corrupt'
+ pbar.close()
+ if msgs:
+ LOGGER.info('\n'.join(msgs))
+ x['hash'] = get_hash([x[0] for x in self.samples])
+ x['results'] = nf, nc, len(samples), samples
+ x['msgs'] = msgs # warnings
+ save_dataset_cache_file(self.prefix, path, x)
+ return samples
+
+
+def load_dataset_cache_file(path):
+ """Load an Ultralytics *.cache dictionary from path."""
+ import gc
+ gc.disable() # reduce pickle load time https://github.com/ultralytics/ultralytics/pull/1585
+ cache = np.load(str(path), allow_pickle=True).item() # load dict
+ gc.enable()
+ return cache
+
+
+def save_dataset_cache_file(prefix, path, x):
+ """Save an Ultralytics dataset *.cache dictionary x to path."""
+ x['version'] = DATASET_CACHE_VERSION # add cache version
+ if is_dir_writeable(path.parent):
+ if path.exists():
+ path.unlink() # remove *.cache file if exists
+ np.save(str(path), x) # save cache for next time
+ path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
+ LOGGER.info(f'{prefix}New cache created: {path}')
+ else:
+ LOGGER.warning(f'{prefix}WARNING ⚠️ Cache directory {path.parent} is not writeable, cache not saved.')
+
+
+# TODO: support semantic segmentation
+class SemanticDataset(BaseDataset):
+
+ def __init__(self):
+ """Initialize a SemanticDataset object."""
+ super().__init__()
diff --git a/STPoseNet/ultralytics/data/loaders.py b/STPoseNet/ultralytics/data/loaders.py
new file mode 100644
index 0000000000000000000000000000000000000000..66565964902d521c17de07242b5a06289997a4af
--- /dev/null
+++ b/STPoseNet/ultralytics/data/loaders.py
@@ -0,0 +1,412 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import glob
+import math
+import os
+import time
+from dataclasses import dataclass
+from pathlib import Path
+from threading import Thread
+from urllib.parse import urlparse
+
+import cv2
+import numpy as np
+import requests
+import torch
+from PIL import Image
+
+from ultralytics.data.utils import IMG_FORMATS, VID_FORMATS
+from ultralytics.utils import LOGGER, is_colab, is_kaggle, ops
+from ultralytics.utils.checks import check_requirements
+
+
+@dataclass
+class SourceTypes:
+ webcam: bool = False
+ screenshot: bool = False
+ from_img: bool = False
+ tensor: bool = False
+
+
+class LoadStreams:
+ """YOLOv8 streamloader, i.e. `yolo predict source='rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`."""
+
+ def __init__(self, sources='file.streams', imgsz=640, vid_stride=1, stream_buffer=False):
+ """Initialize instance variables and check for consistent input stream shapes."""
+ torch.backends.cudnn.benchmark = True # faster for fixed-size inference
+ self.stream_buffer = stream_buffer # buffer input streams
+ self.running = True # running flag for Thread
+ self.mode = 'stream'
+ self.imgsz = imgsz
+ self.vid_stride = vid_stride # video frame-rate stride
+ sources = Path(sources).read_text().rsplit() if os.path.isfile(sources) else [sources]
+ n = len(sources)
+ self.sources = [ops.clean_str(x) for x in sources] # clean source names for later
+ self.imgs, self.fps, self.frames, self.threads, self.shape = [[]] * n, [0] * n, [0] * n, [None] * n, [None] * n
+ self.caps = [None] * n # video capture objects
+ for i, s in enumerate(sources): # index, source
+ # Start thread to read frames from video stream
+ st = f'{i + 1}/{n}: {s}... '
+ if urlparse(s).hostname in ('www.youtube.com', 'youtube.com', 'youtu.be'): # if source is YouTube video
+ # YouTube format i.e. 'https://www.youtube.com/watch?v=Zgi9g1ksQHc' or 'https://youtu.be/Zgi9g1ksQHc'
+ s = get_best_youtube_url(s)
+ s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
+ if s == 0 and (is_colab() or is_kaggle()):
+ raise NotImplementedError("'source=0' webcam not supported in Colab and Kaggle notebooks. "
+ "Try running 'source=0' in a local environment.")
+ self.caps[i] = cv2.VideoCapture(s) # store video capture object
+ if not self.caps[i].isOpened():
+ raise ConnectionError(f'{st}Failed to open {s}')
+ w = int(self.caps[i].get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(self.caps[i].get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = self.caps[i].get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
+ self.frames[i] = max(int(self.caps[i].get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float(
+ 'inf') # infinite stream fallback
+ self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
+
+ success, im = self.caps[i].read() # guarantee first frame
+ if not success or im is None:
+ raise ConnectionError(f'{st}Failed to read images from {s}')
+ self.imgs[i].append(im)
+ self.shape[i] = im.shape
+ self.threads[i] = Thread(target=self.update, args=([i, self.caps[i], s]), daemon=True)
+ LOGGER.info(f'{st}Success ✅ ({self.frames[i]} frames of shape {w}x{h} at {self.fps[i]:.2f} FPS)')
+ self.threads[i].start()
+ LOGGER.info('') # newline
+
+ # Check for common shapes
+ self.bs = self.__len__()
+
+ def update(self, i, cap, stream):
+ """Read stream `i` frames in daemon thread."""
+ n, f = 0, self.frames[i] # frame number, frame array
+ while self.running and cap.isOpened() and n < (f - 1):
+ # Only read a new frame if the buffer is empty
+ if not self.imgs[i] or not self.stream_buffer:
+ n += 1
+ cap.grab() # .read() = .grab() followed by .retrieve()
+ if n % self.vid_stride == 0:
+ success, im = cap.retrieve()
+ if not success:
+ im = np.zeros(self.shape[i], dtype=np.uint8)
+ LOGGER.warning('WARNING ⚠️ Video stream unresponsive, please check your IP camera connection.')
+ cap.open(stream) # re-open stream if signal was lost
+ self.imgs[i].append(im) # add image to buffer
+ else:
+ time.sleep(0.01) # wait until the buffer is empty
+
+ def close(self):
+ """Close stream loader and release resources."""
+ self.running = False # stop flag for Thread
+ for thread in self.threads:
+ if thread.is_alive():
+ thread.join(timeout=5) # Add timeout
+ for cap in self.caps: # Iterate through the stored VideoCapture objects
+ try:
+ cap.release() # release video capture
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ Could not release VideoCapture object: {e}')
+ cv2.destroyAllWindows()
+
+ def __iter__(self):
+ """Iterates through YOLO image feed and re-opens unresponsive streams."""
+ self.count = -1
+ return self
+
+ def __next__(self):
+ """Returns source paths, transformed and original images for processing."""
+ self.count += 1
+
+ # Wait until a frame is available in each buffer
+ while not all(self.imgs):
+ if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
+ self.close()
+ raise StopIteration
+ time.sleep(1 / min(self.fps))
+
+ # Get and remove the next frame from imgs buffer
+ if self.stream_buffer:
+ images = [x.pop(0) for x in self.imgs]
+ else:
+ # Get the latest frame, and clear the rest from the imgs buffer
+ images = []
+ for x in self.imgs:
+ images.append(x.pop(-1) if x else None)
+ x.clear()
+
+ return self.sources, images, None, ''
+
+ def __len__(self):
+ """Return the length of the sources object."""
+ return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
+
+
+class LoadScreenshots:
+ """YOLOv8 screenshot dataloader, i.e. `yolo predict source=screen`."""
+
+ def __init__(self, source, imgsz=640):
+ """source = [screen_number left top width height] (pixels)."""
+ check_requirements('mss')
+ import mss # noqa
+
+ source, *params = source.split()
+ self.screen, left, top, width, height = 0, None, None, None, None # default to full screen 0
+ if len(params) == 1:
+ self.screen = int(params[0])
+ elif len(params) == 4:
+ left, top, width, height = (int(x) for x in params)
+ elif len(params) == 5:
+ self.screen, left, top, width, height = (int(x) for x in params)
+ self.imgsz = imgsz
+ self.mode = 'stream'
+ self.frame = 0
+ self.sct = mss.mss()
+ self.bs = 1
+
+ # Parse monitor shape
+ monitor = self.sct.monitors[self.screen]
+ self.top = monitor['top'] if top is None else (monitor['top'] + top)
+ self.left = monitor['left'] if left is None else (monitor['left'] + left)
+ self.width = width or monitor['width']
+ self.height = height or monitor['height']
+ self.monitor = {'left': self.left, 'top': self.top, 'width': self.width, 'height': self.height}
+
+ def __iter__(self):
+ """Returns an iterator of the object."""
+ return self
+
+ def __next__(self):
+ """mss screen capture: get raw pixels from the screen as np array."""
+ im0 = np.asarray(self.sct.grab(self.monitor))[:, :, :3] # BGRA to BGR
+ s = f'screen {self.screen} (LTWH): {self.left},{self.top},{self.width},{self.height}: '
+
+ self.frame += 1
+ return [str(self.screen)], [im0], None, s # screen, img, vid_cap, string
+
+
+class LoadImages:
+ """YOLOv8 image/video dataloader, i.e. `yolo predict source=image.jpg/vid.mp4`."""
+
+ def __init__(self, path, imgsz=640, vid_stride=1):
+ """Initialize the Dataloader and raise FileNotFoundError if file not found."""
+ parent = None
+ if isinstance(path, str) and Path(path).suffix == '.txt': # *.txt file with img/vid/dir on each line
+ parent = Path(path).parent
+ path = Path(path).read_text().splitlines() # list of sources
+ files = []
+ for p in sorted(path) if isinstance(path, (list, tuple)) else [path]:
+ a = str(Path(p).absolute()) # do not use .resolve() https://github.com/ultralytics/ultralytics/issues/2912
+ if '*' in a:
+ files.extend(sorted(glob.glob(a, recursive=True))) # glob
+ elif os.path.isdir(a):
+ files.extend(sorted(glob.glob(os.path.join(a, '*.*')))) # dir
+ elif os.path.isfile(a):
+ files.append(a) # files (absolute or relative to CWD)
+ elif parent and (parent / p).is_file():
+ files.append(str((parent / p).absolute())) # files (relative to *.txt file parent)
+ else:
+ raise FileNotFoundError(f'{p} does not exist')
+
+ images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
+ videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
+ ni, nv = len(images), len(videos)
+
+ self.imgsz = imgsz
+ self.files = images + videos
+ self.nf = ni + nv # number of files
+ self.video_flag = [False] * ni + [True] * nv
+ self.mode = 'image'
+ self.vid_stride = vid_stride # video frame-rate stride
+ self.bs = 1
+ if any(videos):
+ self._new_video(videos[0]) # new video
+ else:
+ self.cap = None
+ if self.nf == 0:
+ raise FileNotFoundError(f'No images or videos found in {p}. '
+ f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}')
+
+ def __iter__(self):
+ """Returns an iterator object for VideoStream or ImageFolder."""
+ self.count = 0
+ return self
+
+ def __next__(self):
+ """Return next image, path and metadata from dataset."""
+ if self.count == self.nf:
+ raise StopIteration
+ path = self.files[self.count]
+
+ if self.video_flag[self.count]:
+ # Read video
+ self.mode = 'video'
+ for _ in range(self.vid_stride):
+ self.cap.grab()
+ success, im0 = self.cap.retrieve()
+ while not success:
+ self.count += 1
+ self.cap.release()
+ if self.count == self.nf: # last video
+ raise StopIteration
+ path = self.files[self.count]
+ self._new_video(path)
+ success, im0 = self.cap.read()
+
+ self.frame += 1
+ # im0 = self._cv2_rotate(im0) # for use if cv2 autorotation is False
+ s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
+
+ else:
+ # Read image
+ self.count += 1
+ im0 = cv2.imread(path) # BGR
+ if im0 is None:
+ raise FileNotFoundError(f'Image Not Found {path}')
+ s = f'image {self.count}/{self.nf} {path}: '
+
+ return [path], [im0], self.cap, s
+
+ def _new_video(self, path):
+ """Create a new video capture object."""
+ self.frame = 0
+ self.cap = cv2.VideoCapture(path)
+ self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT) / self.vid_stride)
+
+ def __len__(self):
+ """Returns the number of files in the object."""
+ return self.nf # number of files
+
+
+class LoadPilAndNumpy:
+
+ def __init__(self, im0, imgsz=640):
+ """Initialize PIL and Numpy Dataloader."""
+ if not isinstance(im0, list):
+ im0 = [im0]
+ self.paths = [getattr(im, 'filename', f'image{i}.jpg') for i, im in enumerate(im0)]
+ self.im0 = [self._single_check(im) for im in im0]
+ self.imgsz = imgsz
+ self.mode = 'image'
+ # Generate fake paths
+ self.bs = len(self.im0)
+
+ @staticmethod
+ def _single_check(im):
+ """Validate and format an image to numpy array."""
+ assert isinstance(im, (Image.Image, np.ndarray)), f'Expected PIL/np.ndarray image type, but got {type(im)}'
+ if isinstance(im, Image.Image):
+ if im.mode != 'RGB':
+ im = im.convert('RGB')
+ im = np.asarray(im)[:, :, ::-1]
+ im = np.ascontiguousarray(im) # contiguous
+ return im
+
+ def __len__(self):
+ """Returns the length of the 'im0' attribute."""
+ return len(self.im0)
+
+ def __next__(self):
+ """Returns batch paths, images, processed images, None, ''."""
+ if self.count == 1: # loop only once as it's batch inference
+ raise StopIteration
+ self.count += 1
+ return self.paths, self.im0, None, ''
+
+ def __iter__(self):
+ """Enables iteration for class LoadPilAndNumpy."""
+ self.count = 0
+ return self
+
+
+class LoadTensor:
+
+ def __init__(self, im0) -> None:
+ self.im0 = self._single_check(im0)
+ self.bs = self.im0.shape[0]
+ self.mode = 'image'
+ self.paths = [getattr(im, 'filename', f'image{i}.jpg') for i, im in enumerate(im0)]
+
+ @staticmethod
+ def _single_check(im, stride=32):
+ """Validate and format an image to torch.Tensor."""
+ s = f'WARNING ⚠️ torch.Tensor inputs should be BCHW i.e. shape(1, 3, 640, 640) ' \
+ f'divisible by stride {stride}. Input shape{tuple(im.shape)} is incompatible.'
+ if len(im.shape) != 4:
+ if len(im.shape) != 3:
+ raise ValueError(s)
+ LOGGER.warning(s)
+ im = im.unsqueeze(0)
+ if im.shape[2] % stride or im.shape[3] % stride:
+ raise ValueError(s)
+ if im.max() > 1.0:
+ LOGGER.warning(f'WARNING ⚠️ torch.Tensor inputs should be normalized 0.0-1.0 but max value is {im.max()}. '
+ f'Dividing input by 255.')
+ im = im.float() / 255.0
+
+ return im
+
+ def __iter__(self):
+ """Returns an iterator object."""
+ self.count = 0
+ return self
+
+ def __next__(self):
+ """Return next item in the iterator."""
+ if self.count == 1:
+ raise StopIteration
+ self.count += 1
+ return self.paths, self.im0, None, ''
+
+ def __len__(self):
+ """Returns the batch size."""
+ return self.bs
+
+
+def autocast_list(source):
+ """
+ Merges a list of source of different types into a list of numpy arrays or PIL images
+ """
+ files = []
+ for im in source:
+ if isinstance(im, (str, Path)): # filename or uri
+ files.append(Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im))
+ elif isinstance(im, (Image.Image, np.ndarray)): # PIL or np Image
+ files.append(im)
+ else:
+ raise TypeError(f'type {type(im).__name__} is not a supported Ultralytics prediction source type. \n'
+ f'See https://docs.ultralytics.com/modes/predict for supported source types.')
+
+ return files
+
+
+LOADERS = LoadStreams, LoadPilAndNumpy, LoadImages, LoadScreenshots # tuple
+
+
+def get_best_youtube_url(url, use_pafy=False):
+ """
+ Retrieves the URL of the best quality MP4 video stream from a given YouTube video.
+
+ This function uses the pafy or yt_dlp library to extract the video info from YouTube. It then finds the highest
+ quality MP4 format that has video codec but no audio codec, and returns the URL of this video stream.
+
+ Args:
+ url (str): The URL of the YouTube video.
+ use_pafy (bool): Use the pafy package, default=True, otherwise use yt_dlp package.
+
+ Returns:
+ (str): The URL of the best quality MP4 video stream, or None if no suitable stream is found.
+ """
+ if use_pafy:
+ check_requirements(('pafy', 'youtube_dl==2020.12.2'))
+ import pafy # noqa
+ return pafy.new(url).getbestvideo(preftype='mp4').url
+ else:
+ check_requirements('yt-dlp')
+ import yt_dlp
+ with yt_dlp.YoutubeDL({'quiet': True}) as ydl:
+ info_dict = ydl.extract_info(url, download=False) # extract info
+ for f in reversed(info_dict.get('formats', [])): # reversed because best is usually last
+ # Find a format with video codec, no audio, *.mp4 extension at least 1920x1080 size
+ good_size = (f.get('width') or 0) >= 1920 or (f.get('height') or 0) >= 1080
+ if good_size and f['vcodec'] != 'none' and f['acodec'] == 'none' and f['ext'] == 'mp4':
+ return f.get('url')
diff --git a/STPoseNet/ultralytics/data/scripts/download_weights.sh b/STPoseNet/ultralytics/data/scripts/download_weights.sh
new file mode 100644
index 0000000000000000000000000000000000000000..87db31fe1e673146b0dbe2c3a318a01b709b7c14
--- /dev/null
+++ b/STPoseNet/ultralytics/data/scripts/download_weights.sh
@@ -0,0 +1,18 @@
+#!/bin/bash
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Download latest models from https://github.com/ultralytics/assets/releases
+# Example usage: bash ultralytics/data/scripts/download_weights.sh
+# parent
+# └── weights
+# ├── yolov8n.pt ← downloads here
+# ├── yolov8s.pt
+# └── ...
+
+python - < 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
+ assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
+ if im.format.lower() in ('jpg', 'jpeg'):
+ with open(im_file, 'rb') as f:
+ f.seek(-2, 2)
+ if f.read() != b'\xff\xd9': # corrupt JPEG
+ ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
+ msg = f'{prefix}WARNING ⚠️ {im_file}: corrupt JPEG restored and saved'
+ nf = 1
+ except Exception as e:
+ nc = 1
+ msg = f'{prefix}WARNING ⚠️ {im_file}: ignoring corrupt image/label: {e}'
+ return (im_file, cls), nf, nc, msg
+
+
+def verify_image_label(args):
+ """Verify one image-label pair."""
+ im_file, lb_file, prefix, keypoint, num_cls, nkpt, ndim = args
+ # Number (missing, found, empty, corrupt), message, segments, keypoints
+ nm, nf, ne, nc, msg, segments, keypoints = 0, 0, 0, 0, '', [], None
+ try:
+ # Verify images
+ im = Image.open(im_file)
+ im.verify() # PIL verify
+ shape = exif_size(im) # image size
+ shape = (shape[1], shape[0]) # hw
+ assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
+ assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
+ if im.format.lower() in ('jpg', 'jpeg'):
+ with open(im_file, 'rb') as f:
+ f.seek(-2, 2)
+ if f.read() != b'\xff\xd9': # corrupt JPEG
+ ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
+ msg = f'{prefix}WARNING ⚠️ {im_file}: corrupt JPEG restored and saved'
+
+ # Verify labels
+ if os.path.isfile(lb_file):
+ nf = 1 # label found
+ with open(lb_file) as f:
+ lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
+ if any(len(x) > 6 for x in lb) and (not keypoint): # is segment
+ classes = np.array([x[0] for x in lb], dtype=np.float32)
+ segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
+ lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
+ lb = np.array(lb, dtype=np.float32)
+ nl = len(lb)
+ if nl:
+ if keypoint:
+ assert lb.shape[1] == (5 + nkpt * ndim), f'labels require {(5 + nkpt * ndim)} columns each'
+ assert (lb[:, 5::ndim] <= 1).all(), 'non-normalized or out of bounds coordinate labels'
+ assert (lb[:, 6::ndim] <= 1).all(), 'non-normalized or out of bounds coordinate labels'
+ else:
+ assert lb.shape[1] == 5, f'labels require 5 columns, {lb.shape[1]} columns detected'
+ assert (lb[:, 1:] <= 1).all(), \
+ f'non-normalized or out of bounds coordinates {lb[:, 1:][lb[:, 1:] > 1]}'
+ assert (lb >= 0).all(), f'negative label values {lb[lb < 0]}'
+ # All labels
+ max_cls = int(lb[:, 0].max()) # max label count
+ assert max_cls <= num_cls, \
+ f'Label class {max_cls} exceeds dataset class count {num_cls}. ' \
+ f'Possible class labels are 0-{num_cls - 1}'
+ _, i = np.unique(lb, axis=0, return_index=True)
+ if len(i) < nl: # duplicate row check
+ lb = lb[i] # remove duplicates
+ if segments:
+ segments = [segments[x] for x in i]
+ msg = f'{prefix}WARNING ⚠️ {im_file}: {nl - len(i)} duplicate labels removed'
+ else:
+ ne = 1 # label empty
+ lb = np.zeros((0, (5 + nkpt * ndim)), dtype=np.float32) if keypoint else np.zeros(
+ (0, 5), dtype=np.float32)
+ else:
+ nm = 1 # label missing
+ lb = np.zeros((0, (5 + nkpt * ndim)), dtype=np.float32) if keypoint else np.zeros((0, 5), dtype=np.float32)
+ if keypoint:
+ keypoints = lb[:, 5:].reshape(-1, nkpt, ndim)
+ if ndim == 2:
+ kpt_mask = np.where((keypoints[..., 0] < 0) | (keypoints[..., 1] < 0), 0.0, 1.0).astype(np.float32)
+ keypoints = np.concatenate([keypoints, kpt_mask[..., None]], axis=-1) # (nl, nkpt, 3)
+ lb = lb[:, :5]
+ return im_file, lb, shape, segments, keypoints, nm, nf, ne, nc, msg
+ except Exception as e:
+ nc = 1
+ msg = f'{prefix}WARNING ⚠️ {im_file}: ignoring corrupt image/label: {e}'
+ return [None, None, None, None, None, nm, nf, ne, nc, msg]
+
+
+def polygon2mask(imgsz, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ imgsz (tuple): The image size.
+ polygons (list[np.ndarray]): [N, M], N is the number of polygons, M is the number of points(Be divided by 2).
+ color (int): color
+ downsample_ratio (int): downsample ratio
+ """
+ mask = np.zeros(imgsz, dtype=np.uint8)
+ polygons = np.asarray(polygons, dtype=np.int32)
+ polygons = polygons.reshape((polygons.shape[0], -1, 2))
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (imgsz[0] // downsample_ratio, imgsz[1] // downsample_ratio)
+ # NOTE: fillPoly first then resize is trying to keep the same way of loss calculation when mask-ratio=1.
+ return cv2.resize(mask, (nw, nh))
+
+
+def polygons2masks(imgsz, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ imgsz (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M], N is number of polygons, M is number of points (M % 2 = 0)
+ color (int): color
+ downsample_ratio (int): downsample ratio
+ """
+ return np.array([polygon2mask(imgsz, [x.reshape(-1)], color, downsample_ratio) for x in polygons])
+
+
+def polygons2masks_overlap(imgsz, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((imgsz[0] // downsample_ratio, imgsz[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(imgsz, [segments[si].reshape(-1)], downsample_ratio=downsample_ratio, color=1)
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
+
+
+def check_det_dataset(dataset, autodownload=True):
+ """
+ Download, verify, and/or unzip a dataset if not found locally.
+
+ This function checks the availability of a specified dataset, and if not found, it has the option to download and
+ unzip the dataset. It then reads and parses the accompanying YAML data, ensuring key requirements are met and also
+ resolves paths related to the dataset.
+
+ Args:
+ dataset (str): Path to the dataset or dataset descriptor (like a YAML file).
+ autodownload (bool, optional): Whether to automatically download the dataset if not found. Defaults to True.
+
+ Returns:
+ (dict): Parsed dataset information and paths.
+ """
+
+ data = check_file(dataset)
+
+ # Download (optional)
+ extract_dir = ''
+ if isinstance(data, (str, Path)) and (zipfile.is_zipfile(data) or is_tarfile(data)):
+ new_dir = safe_download(data, dir=DATASETS_DIR, unzip=True, delete=False, curl=False)
+ data = next((DATASETS_DIR / new_dir).rglob('*.yaml'))
+ extract_dir, autodownload = data.parent, False
+
+ # Read YAML (optional)
+ if isinstance(data, (str, Path)):
+ data = yaml_load(data, append_filename=True) # dictionary
+
+ # Checks
+ for k in 'train', 'val':
+ if k not in data:
+ if k == 'val' and 'validation' in data:
+ LOGGER.info("WARNING ⚠️ renaming data YAML 'validation' key to 'val' to match YOLO format.")
+ data['val'] = data.pop('validation') # replace 'validation' key with 'val' key
+ else:
+ raise SyntaxError(
+ emojis(f"{dataset} '{k}:' key missing ❌.\n'train' and 'val' are required in all data YAMLs."))
+ if 'names' not in data and 'nc' not in data:
+ raise SyntaxError(emojis(f"{dataset} key missing ❌.\n either 'names' or 'nc' are required in all data YAMLs."))
+ if 'names' in data and 'nc' in data and len(data['names']) != data['nc']:
+ raise SyntaxError(emojis(f"{dataset} 'names' length {len(data['names'])} and 'nc: {data['nc']}' must match."))
+ if 'names' not in data:
+ data['names'] = [f'class_{i}' for i in range(data['nc'])]
+ else:
+ data['nc'] = len(data['names'])
+
+ data['names'] = check_class_names(data['names'])
+
+ # Resolve paths
+ path = Path(extract_dir or data.get('path') or Path(data.get('yaml_file', '')).parent) # dataset root
+
+ if not path.is_absolute():
+ path = (DATASETS_DIR / path).resolve()
+ data['path'] = path # download scripts
+ for k in 'train', 'val', 'test':
+ if data.get(k): # prepend path
+ if isinstance(data[k], str):
+ x = (path / data[k]).resolve()
+ if not x.exists() and data[k].startswith('../'):
+ x = (path / data[k][3:]).resolve()
+ data[k] = str(x)
+ else:
+ data[k] = [str((path / x).resolve()) for x in data[k]]
+
+ # Parse YAML
+ train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
+ if val:
+ val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
+ if not all(x.exists() for x in val):
+ name = clean_url(dataset) # dataset name with URL auth stripped
+ m = f"\nDataset '{name}' images not found ⚠️, missing path '{[x for x in val if not x.exists()][0]}'"
+ if s and autodownload:
+ LOGGER.warning(m)
+ else:
+ m += f"\nNote dataset download directory is '{DATASETS_DIR}'. You can update this in '{SETTINGS_YAML}'"
+ raise FileNotFoundError(m)
+ t = time.time()
+ r = None # success
+ if s.startswith('http') and s.endswith('.zip'): # URL
+ safe_download(url=s, dir=DATASETS_DIR, delete=True)
+ elif s.startswith('bash '): # bash script
+ LOGGER.info(f'Running {s} ...')
+ r = os.system(s)
+ else: # python script
+ exec(s, {'yaml': data})
+ dt = f'({round(time.time() - t, 1)}s)'
+ s = f"success ✅ {dt}, saved to {colorstr('bold', DATASETS_DIR)}" if r in (0, None) else f'failure {dt} ❌'
+ LOGGER.info(f'Dataset download {s}\n')
+ check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf') # download fonts
+
+ return data # dictionary
+
+
+def check_cls_dataset(dataset: str, split=''):
+ """
+ Checks a classification dataset such as Imagenet.
+
+ This function accepts a `dataset` name and attempts to retrieve the corresponding dataset information.
+ If the dataset is not found locally, it attempts to download the dataset from the internet and save it locally.
+
+ Args:
+ dataset (str): The name of the dataset.
+ split (str, optional): The split of the dataset. Either 'val', 'test', or ''. Defaults to ''.
+
+ Returns:
+ (dict): A dictionary containing the following keys:
+ - 'train' (Path): The directory path containing the training set of the dataset.
+ - 'val' (Path): The directory path containing the validation set of the dataset.
+ - 'test' (Path): The directory path containing the test set of the dataset.
+ - 'nc' (int): The number of classes in the dataset.
+ - 'names' (dict): A dictionary of class names in the dataset.
+ """
+
+ dataset = Path(dataset)
+ data_dir = (dataset if dataset.is_dir() else (DATASETS_DIR / dataset)).resolve()
+ if not data_dir.is_dir():
+ LOGGER.warning(f'\nDataset not found ⚠️, missing path {data_dir}, attempting download...')
+ t = time.time()
+ if str(dataset) == 'imagenet':
+ subprocess.run(f"bash {ROOT / 'data/scripts/get_imagenet.sh'}", shell=True, check=True)
+ else:
+ url = f'https://github.com/ultralytics/yolov5/releases/download/v1.0/{dataset}.zip'
+ download(url, dir=data_dir.parent)
+ s = f"Dataset download success ✅ ({time.time() - t:.1f}s), saved to {colorstr('bold', data_dir)}\n"
+ LOGGER.info(s)
+ train_set = data_dir / 'train'
+ val_set = data_dir / 'val' if (data_dir / 'val').exists() else data_dir / 'validation' if (
+ data_dir / 'validation').exists() else None # data/test or data/val
+ test_set = data_dir / 'test' if (data_dir / 'test').exists() else None # data/val or data/test
+ if split == 'val' and not val_set:
+ LOGGER.warning("WARNING ⚠️ Dataset 'split=val' not found, using 'split=test' instead.")
+ elif split == 'test' and not test_set:
+ LOGGER.warning("WARNING ⚠️ Dataset 'split=test' not found, using 'split=val' instead.")
+
+ nc = len([x for x in (data_dir / 'train').glob('*') if x.is_dir()]) # number of classes
+ names = [x.name for x in (data_dir / 'train').iterdir() if x.is_dir()] # class names list
+ names = dict(enumerate(sorted(names)))
+
+ # Print to console
+ for k, v in {'train': train_set, 'val': val_set, 'test': test_set}.items():
+ prefix = f'{colorstr(f"{k}:")} {v}...'
+ if v is None:
+ LOGGER.info(prefix)
+ else:
+ files = [path for path in v.rglob('*.*') if path.suffix[1:].lower() in IMG_FORMATS]
+ nf = len(files) # number of files
+ nd = len({file.parent for file in files}) # number of directories
+ if nf == 0:
+ if k == 'train':
+ raise FileNotFoundError(emojis(f"{dataset} '{k}:' no training images found ❌ "))
+ else:
+ LOGGER.warning(f'{prefix} found {nf} images in {nd} classes: WARNING ⚠️ no images found')
+ elif nd != nc:
+ LOGGER.warning(f'{prefix} found {nf} images in {nd} classes: ERROR ❌️ requires {nc} classes, not {nd}')
+ else:
+ LOGGER.info(f'{prefix} found {nf} images in {nd} classes ✅ ')
+
+ return {'train': train_set, 'val': val_set or test_set, 'test': test_set or val_set, 'nc': nc, 'names': names}
+
+
+class HUBDatasetStats:
+ """
+ A class for generating HUB dataset JSON and `-hub` dataset directory.
+
+ Args:
+ path (str): Path to data.yaml or data.zip (with data.yaml inside data.zip). Default is 'coco128.yaml'.
+ task (str): Dataset task. Options are 'detect', 'segment', 'pose', 'classify'. Default is 'detect'.
+ autodownload (bool): Attempt to download dataset if not found locally. Default is False.
+
+ Example:
+ Download *.zip files from i.e. https://github.com/ultralytics/hub/raw/main/example_datasets/coco8.zip.
+ ```python
+ from ultralytics.data.utils import HUBDatasetStats
+
+ stats = HUBDatasetStats('path/to/coco8.zip', task='detect') # detect dataset
+ stats = HUBDatasetStats('path/to/coco8-seg.zip', task='segment') # segment dataset
+ stats = HUBDatasetStats('path/to/coco8-pose.zip', task='pose') # pose dataset
+ stats.get_json(save=False)
+ stats.process_images()
+ ```
+ """
+
+ def __init__(self, path='coco128.yaml', task='detect', autodownload=False):
+ """Initialize class."""
+ path = Path(path).resolve()
+ LOGGER.info(f'Starting HUB dataset checks for {path}....')
+ zipped, data_dir, yaml_path = self._unzip(path)
+ try:
+ # data = yaml_load(check_yaml(yaml_path)) # data dict
+ data = check_det_dataset(yaml_path, autodownload) # data dict
+ if zipped:
+ data['path'] = data_dir
+ except Exception as e:
+ raise Exception('error/HUB/dataset_stats/yaml_load') from e
+
+ self.hub_dir = Path(str(data['path']) + '-hub')
+ self.im_dir = self.hub_dir / 'images'
+ self.im_dir.mkdir(parents=True, exist_ok=True) # makes /images
+ self.stats = {'nc': len(data['names']), 'names': list(data['names'].values())} # statistics dictionary
+ self.data = data
+ self.task = task # detect, segment, pose, classify
+
+ @staticmethod
+ def _find_yaml(dir):
+ """Return data.yaml file."""
+ files = list(dir.glob('*.yaml')) or list(dir.rglob('*.yaml')) # try root level first and then recursive
+ assert files, f"No *.yaml file found in '{dir.resolve()}'"
+ if len(files) > 1:
+ files = [f for f in files if f.stem == dir.stem] # prefer *.yaml files that match dir name
+ assert len(files) == 1, f"Expected 1 *.yaml file in '{dir.resolve()}', but found {len(files)}.\n{files}"
+ return files[0]
+
+ def _unzip(self, path):
+ """Unzip data.zip."""
+ if not str(path).endswith('.zip'): # path is data.yaml
+ return False, None, path
+ unzip_dir = unzip_file(path, path=path.parent)
+ assert unzip_dir.is_dir(), f'Error unzipping {path}, {unzip_dir} not found. ' \
+ f'path/to/abc.zip MUST unzip to path/to/abc/'
+ return True, str(unzip_dir), self._find_yaml(unzip_dir) # zipped, data_dir, yaml_path
+
+ def _hub_ops(self, f):
+ """Saves a compressed image for HUB previews."""
+ compress_one_image(f, self.im_dir / Path(f).name) # save to dataset-hub
+
+ def get_json(self, save=False, verbose=False):
+ """Return dataset JSON for Ultralytics HUB."""
+ from ultralytics.data import YOLODataset # ClassificationDataset
+
+ def _round(labels):
+ """Update labels to integer class and 4 decimal place floats."""
+ if self.task == 'detect':
+ coordinates = labels['bboxes']
+ elif self.task == 'segment':
+ coordinates = [x.flatten() for x in labels['segments']]
+ elif self.task == 'pose':
+ n = labels['keypoints'].shape[0]
+ coordinates = np.concatenate((labels['bboxes'], labels['keypoints'].reshape(n, -1)), 1)
+ else:
+ raise ValueError('Undefined dataset task.')
+ zipped = zip(labels['cls'], coordinates)
+ return [[int(c[0]), *(round(float(x), 4) for x in points)] for c, points in zipped]
+
+ for split in 'train', 'val', 'test':
+ self.stats[split] = None # predefine
+ path = self.data.get(split)
+
+ # Check split
+ if path is None: # no split
+ continue
+ files = [f for f in Path(path).rglob('*.*') if f.suffix[1:].lower() in IMG_FORMATS] # image files in split
+ if not files: # no images
+ continue
+
+ # Get dataset statistics
+ dataset = YOLODataset(img_path=self.data[split],
+ data=self.data,
+ use_segments=self.task == 'segment',
+ use_keypoints=self.task == 'pose')
+ x = np.array([
+ np.bincount(label['cls'].astype(int).flatten(), minlength=self.data['nc'])
+ for label in tqdm(dataset.labels, total=len(dataset), desc='Statistics')]) # shape(128x80)
+ self.stats[split] = {
+ 'instance_stats': {
+ 'total': int(x.sum()),
+ 'per_class': x.sum(0).tolist()},
+ 'image_stats': {
+ 'total': len(dataset),
+ 'unlabelled': int(np.all(x == 0, 1).sum()),
+ 'per_class': (x > 0).sum(0).tolist()},
+ 'labels': [{
+ Path(k).name: _round(v)} for k, v in zip(dataset.im_files, dataset.labels)]}
+
+ # Save, print and return
+ if save:
+ stats_path = self.hub_dir / 'stats.json'
+ LOGGER.info(f'Saving {stats_path.resolve()}...')
+ with open(stats_path, 'w') as f:
+ json.dump(self.stats, f) # save stats.json
+ if verbose:
+ LOGGER.info(json.dumps(self.stats, indent=2, sort_keys=False))
+ return self.stats
+
+ def process_images(self):
+ """Compress images for Ultralytics HUB."""
+ from ultralytics.data import YOLODataset # ClassificationDataset
+
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ continue
+ dataset = YOLODataset(img_path=self.data[split], data=self.data)
+ with ThreadPool(NUM_THREADS) as pool:
+ for _ in tqdm(pool.imap(self._hub_ops, dataset.im_files), total=len(dataset), desc=f'{split} images'):
+ pass
+ LOGGER.info(f'Done. All images saved to {self.im_dir}')
+ return self.im_dir
+
+
+def compress_one_image(f, f_new=None, max_dim=1920, quality=50):
+ """
+ Compresses a single image file to reduced size while preserving its aspect ratio and quality using either the
+ Python Imaging Library (PIL) or OpenCV library. If the input image is smaller than the maximum dimension, it will
+ not be resized.
+
+ Args:
+ f (str): The path to the input image file.
+ f_new (str, optional): The path to the output image file. If not specified, the input file will be overwritten.
+ max_dim (int, optional): The maximum dimension (width or height) of the output image. Default is 1920 pixels.
+ quality (int, optional): The image compression quality as a percentage. Default is 50%.
+
+ Example:
+ ```python
+ from pathlib import Path
+ from ultralytics.data.utils import compress_one_image
+
+ for f in Path('path/to/dataset').rglob('*.jpg'):
+ compress_one_image(f)
+ ```
+ """
+
+ try: # use PIL
+ im = Image.open(f)
+ r = max_dim / max(im.height, im.width) # ratio
+ if r < 1.0: # image too large
+ im = im.resize((int(im.width * r), int(im.height * r)))
+ im.save(f_new or f, 'JPEG', quality=quality, optimize=True) # save
+ except Exception as e: # use OpenCV
+ LOGGER.info(f'WARNING ⚠️ HUB ops PIL failure {f}: {e}')
+ im = cv2.imread(f)
+ im_height, im_width = im.shape[:2]
+ r = max_dim / max(im_height, im_width) # ratio
+ if r < 1.0: # image too large
+ im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_AREA)
+ cv2.imwrite(str(f_new or f), im)
+
+
+def autosplit(path=DATASETS_DIR / 'coco8/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
+ """
+ Automatically split a dataset into train/val/test splits and save the resulting splits into autosplit_*.txt files.
+
+ Args:
+ path (Path, optional): Path to images directory. Defaults to DATASETS_DIR / 'coco8/images'.
+ weights (list | tuple, optional): Train, validation, and test split fractions. Defaults to (0.9, 0.1, 0.0).
+ annotated_only (bool, optional): If True, only images with an associated txt file are used. Defaults to False.
+
+ Example:
+ ```python
+ from ultralytics.data.utils import autosplit
+
+ autosplit()
+ ```
+ """
+
+ path = Path(path) # images dir
+ files = sorted(x for x in path.rglob('*.*') if x.suffix[1:].lower() in IMG_FORMATS) # image files only
+ n = len(files) # number of files
+ random.seed(0) # for reproducibility
+ indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
+
+ txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
+ for x in txt:
+ if (path.parent / x).exists():
+ (path.parent / x).unlink() # remove existing
+
+ LOGGER.info(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
+ for i, img in tqdm(zip(indices, files), total=n):
+ if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
+ with open(path.parent / txt[i], 'a') as f:
+ f.write(f'./{img.relative_to(path.parent).as_posix()}' + '\n') # add image to txt file
diff --git a/STPoseNet/ultralytics/engine/__init__.py b/STPoseNet/ultralytics/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/STPoseNet/ultralytics/engine/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e89b38b11b6fb4218fe39330737460f7d46914c3
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/exporter.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/exporter.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eed63f4c0834ad6d37cb3072fa4b42f1df31f2b4
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/exporter.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7e71d41395979ee5f442ac4b8263b4a1081a390
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/predictor.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/predictor.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2106fea0e539dc18ce97cfe0bb604faaf8915951
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/predictor.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/results.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/results.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ee5acf64f9f14aa9f5fadeb829a167562f631b75
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/results.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/trainer.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/trainer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9eca0128f7324b96355dff6f9f74708caaec3106
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/trainer.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/__pycache__/validator.cpython-38.pyc b/STPoseNet/ultralytics/engine/__pycache__/validator.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bb7318131c9bc5ad6b8115a1def3e225e775c8f8
Binary files /dev/null and b/STPoseNet/ultralytics/engine/__pycache__/validator.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/engine/exporter.py b/STPoseNet/ultralytics/engine/exporter.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe648e6cdc78ffa9deb55d827761b9ef7bc335d
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/exporter.py
@@ -0,0 +1,985 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Export a YOLOv8 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
+
+Format | `format=argument` | Model
+--- | --- | ---
+PyTorch | - | yolov8n.pt
+TorchScript | `torchscript` | yolov8n.torchscript
+ONNX | `onnx` | yolov8n.onnx
+OpenVINO | `openvino` | yolov8n_openvino_model/
+TensorRT | `engine` | yolov8n.engine
+CoreML | `coreml` | yolov8n.mlpackage
+TensorFlow SavedModel | `saved_model` | yolov8n_saved_model/
+TensorFlow GraphDef | `pb` | yolov8n.pb
+TensorFlow Lite | `tflite` | yolov8n.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov8n_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov8n_web_model/
+PaddlePaddle | `paddle` | yolov8n_paddle_model/
+ncnn | `ncnn` | yolov8n_ncnn_model/
+
+Requirements:
+ $ pip install "ultralytics[export]"
+
+Python:
+ from ultralytics import YOLO
+ model = YOLO('yolov8n.pt')
+ results = model.export(format='onnx')
+
+CLI:
+ $ yolo mode=export model=yolov8n.pt format=onnx
+
+Inference:
+ $ yolo predict model=yolov8n.pt # PyTorch
+ yolov8n.torchscript # TorchScript
+ yolov8n.onnx # ONNX Runtime or OpenCV DNN with dnn=True
+ yolov8n_openvino_model # OpenVINO
+ yolov8n.engine # TensorRT
+ yolov8n.mlpackage # CoreML (macOS-only)
+ yolov8n_saved_model # TensorFlow SavedModel
+ yolov8n.pb # TensorFlow GraphDef
+ yolov8n.tflite # TensorFlow Lite
+ yolov8n_edgetpu.tflite # TensorFlow Edge TPU
+ yolov8n_paddle_model # PaddlePaddle
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov8n_web_model public/yolov8n_web_model
+ $ npm start
+"""
+import json
+import os
+import shutil
+import subprocess
+import time
+import warnings
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import torch
+
+from ultralytics.cfg import get_cfg
+from ultralytics.nn.autobackend import check_class_names
+from ultralytics.nn.modules import C2f, Detect, RTDETRDecoder
+from ultralytics.nn.tasks import DetectionModel, SegmentationModel
+from ultralytics.utils import (ARM64, DEFAULT_CFG, LINUX, LOGGER, MACOS, ROOT, WINDOWS, __version__, callbacks,
+ colorstr, get_default_args, yaml_save)
+from ultralytics.utils.checks import check_imgsz, check_requirements, check_version
+from ultralytics.utils.downloads import attempt_download_asset, get_github_assets
+from ultralytics.utils.files import file_size, spaces_in_path
+from ultralytics.utils.ops import Profile
+from ultralytics.utils.torch_utils import get_latest_opset, select_device, smart_inference_mode
+
+
+def export_formats():
+ """YOLOv8 export formats."""
+ import pandas
+ x = [
+ ['PyTorch', '-', '.pt', True, True],
+ ['TorchScript', 'torchscript', '.torchscript', True, True],
+ ['ONNX', 'onnx', '.onnx', True, True],
+ ['OpenVINO', 'openvino', '_openvino_model', True, False],
+ ['TensorRT', 'engine', '.engine', False, True],
+ ['CoreML', 'coreml', '.mlpackage', True, False],
+ ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
+ ['TensorFlow GraphDef', 'pb', '.pb', True, True],
+ ['TensorFlow Lite', 'tflite', '.tflite', True, False],
+ ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', True, False],
+ ['TensorFlow.js', 'tfjs', '_web_model', True, False],
+ ['PaddlePaddle', 'paddle', '_paddle_model', True, True],
+ ['ncnn', 'ncnn', '_ncnn_model', True, True], ]
+ return pandas.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
+
+
+def gd_outputs(gd):
+ """TensorFlow GraphDef model output node names."""
+ name_list, input_list = [], []
+ for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDef
+ name_list.append(node.name)
+ input_list.extend(node.input)
+ return sorted(f'{x}:0' for x in list(set(name_list) - set(input_list)) if not x.startswith('NoOp'))
+
+
+def try_export(inner_func):
+ """YOLOv8 export decorator, i..e @try_export."""
+ inner_args = get_default_args(inner_func)
+
+ def outer_func(*args, **kwargs):
+ """Export a model."""
+ prefix = inner_args['prefix']
+ try:
+ with Profile() as dt:
+ f, model = inner_func(*args, **kwargs)
+ LOGGER.info(f"{prefix} export success ✅ {dt.t:.1f}s, saved as '{f}' ({file_size(f):.1f} MB)")
+ return f, model
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
+ raise e
+
+ return outer_func
+
+
+class Exporter:
+ """
+ A class for exporting a model.
+
+ Attributes:
+ args (SimpleNamespace): Configuration for the exporter.
+ callbacks (list, optional): List of callback functions. Defaults to None.
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """
+ Initializes the Exporter class.
+
+ Args:
+ cfg (str, optional): Path to a configuration file. Defaults to DEFAULT_CFG.
+ overrides (dict, optional): Configuration overrides. Defaults to None.
+ _callbacks (list, optional): List of callback functions. Defaults to None.
+ """
+ self.args = get_cfg(cfg, overrides)
+ self.callbacks = _callbacks or callbacks.get_default_callbacks()
+ callbacks.add_integration_callbacks(self)
+
+ @smart_inference_mode()
+ def __call__(self, model=None):
+ """Returns list of exported files/dirs after running callbacks."""
+ self.run_callbacks('on_export_start')
+ t = time.time()
+ format = self.args.format.lower() # to lowercase
+ if format in ('tensorrt', 'trt'): # 'engine' aliases
+ format = 'engine'
+ if format in ('mlmodel', 'mlpackage', 'mlprogram', 'apple', 'ios'): # 'coreml' aliases
+ format = 'coreml'
+ fmts = tuple(export_formats()['Argument'][1:]) # available export formats
+ flags = [x == format for x in fmts]
+ if sum(flags) != 1:
+ raise ValueError(f"Invalid export format='{format}'. Valid formats are {fmts}")
+ jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, ncnn = flags # export booleans
+
+ # Device
+ if format == 'engine' and self.args.device is None:
+ LOGGER.warning('WARNING ⚠️ TensorRT requires GPU export, automatically assigning device=0')
+ self.args.device = '0'
+ self.device = select_device('cpu' if self.args.device is None else self.args.device)
+
+ # Checks
+ model.names = check_class_names(model.names)
+ if self.args.half and onnx and self.device.type == 'cpu':
+ LOGGER.warning('WARNING ⚠️ half=True only compatible with GPU export, i.e. use device=0')
+ self.args.half = False
+ assert not self.args.dynamic, 'half=True not compatible with dynamic=True, i.e. use only one.'
+ self.imgsz = check_imgsz(self.args.imgsz, stride=model.stride, min_dim=2) # check image size
+ if self.args.optimize:
+ assert not ncnn, "optimize=True not compatible with format='ncnn', i.e. use optimize=False"
+ assert self.device.type == 'cpu', "optimize=True not compatible with cuda devices, i.e. use device='cpu'"
+ if edgetpu and not LINUX:
+ raise SystemError('Edge TPU export only supported on Linux. See https://coral.ai/docs/edgetpu/compiler/')
+
+ # Input
+ im = torch.zeros(self.args.batch, 3, *self.imgsz).to(self.device)
+ file = Path(
+ getattr(model, 'pt_path', None) or getattr(model, 'yaml_file', None) or model.yaml.get('yaml_file', ''))
+ if file.suffix in ('.yaml', '.yml'):
+ file = Path(file.name)
+
+ # Update model
+ model = deepcopy(model).to(self.device)
+ for p in model.parameters():
+ p.requires_grad = False
+ model.eval()
+ model.float()
+ model = model.fuse()
+ for m in model.modules():
+ if isinstance(m, (Detect, RTDETRDecoder)): # Segment and Pose use Detect base class
+ m.dynamic = self.args.dynamic
+ m.export = True
+ m.format = self.args.format
+ elif isinstance(m, C2f) and not any((saved_model, pb, tflite, edgetpu, tfjs)):
+ # EdgeTPU does not support FlexSplitV while split provides cleaner ONNX graph
+ m.forward = m.forward_split
+
+ y = None
+ for _ in range(2):
+ y = model(im) # dry runs
+ if self.args.half and (engine or onnx) and self.device.type != 'cpu':
+ im, model = im.half(), model.half() # to FP16
+
+ # Filter warnings
+ warnings.filterwarnings('ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
+ warnings.filterwarnings('ignore', category=UserWarning) # suppress shape prim::Constant missing ONNX warning
+ warnings.filterwarnings('ignore', category=DeprecationWarning) # suppress CoreML np.bool deprecation warning
+
+ # Assign
+ self.im = im
+ self.model = model
+ self.file = file
+ self.output_shape = tuple(y.shape) if isinstance(y, torch.Tensor) else \
+ tuple(tuple(x.shape if isinstance(x, torch.Tensor) else []) for x in y)
+ self.pretty_name = Path(self.model.yaml.get('yaml_file', self.file)).stem.replace('yolo', 'YOLO')
+ data = model.args['data'] if hasattr(model, 'args') and isinstance(model.args, dict) else ''
+ description = f'Ultralytics {self.pretty_name} model {f"trained on {data}" if data else ""}'
+ self.metadata = {
+ 'description': description,
+ 'author': 'Ultralytics',
+ 'license': 'AGPL-3.0 https://ultralytics.com/license',
+ 'date': datetime.now().isoformat(),
+ 'version': __version__,
+ 'stride': int(max(model.stride)),
+ 'task': model.task,
+ 'batch': self.args.batch,
+ 'imgsz': self.imgsz,
+ 'names': model.names} # model metadata
+ if model.task == 'pose':
+ self.metadata['kpt_shape'] = model.model[-1].kpt_shape
+
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from '{file}' with input shape {tuple(im.shape)} BCHW and "
+ f'output shape(s) {self.output_shape} ({file_size(file):.1f} MB)')
+
+ # Exports
+ f = [''] * len(fmts) # exported filenames
+ if jit or ncnn: # TorchScript
+ f[0], _ = self.export_torchscript()
+ if engine: # TensorRT required before ONNX
+ f[1], _ = self.export_engine()
+ if onnx or xml: # OpenVINO requires ONNX
+ f[2], _ = self.export_onnx()
+ if xml: # OpenVINO
+ f[3], _ = self.export_openvino()
+ if coreml: # CoreML
+ f[4], _ = self.export_coreml()
+ if any((saved_model, pb, tflite, edgetpu, tfjs)): # TensorFlow formats
+ self.args.int8 |= edgetpu
+ f[5], keras_model = self.export_saved_model()
+ if pb or tfjs: # pb prerequisite to tfjs
+ f[6], _ = self.export_pb(keras_model=keras_model)
+ if tflite:
+ f[7], _ = self.export_tflite(keras_model=keras_model, nms=False, agnostic_nms=self.args.agnostic_nms)
+ if edgetpu:
+ f[8], _ = self.export_edgetpu(tflite_model=Path(f[5]) / f'{self.file.stem}_full_integer_quant.tflite')
+ if tfjs:
+ f[9], _ = self.export_tfjs()
+ if paddle: # PaddlePaddle
+ f[10], _ = self.export_paddle()
+ if ncnn: # ncnn
+ f[11], _ = self.export_ncnn()
+
+ # Finish
+ f = [str(x) for x in f if x] # filter out '' and None
+ if any(f):
+ f = str(Path(f[-1]))
+ square = self.imgsz[0] == self.imgsz[1]
+ s = '' if square else f"WARNING ⚠️ non-PyTorch val requires square images, 'imgsz={self.imgsz}' will not " \
+ f"work. Use export 'imgsz={max(self.imgsz)}' if val is required."
+ imgsz = self.imgsz[0] if square else str(self.imgsz)[1:-1].replace(' ', '')
+ predict_data = f'data={data}' if model.task == 'segment' and format == 'pb' else ''
+ LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f'\nPredict: yolo predict task={model.task} model={f} imgsz={imgsz} {predict_data}'
+ f'\nValidate: yolo val task={model.task} model={f} imgsz={imgsz} data={data} {s}'
+ f'\nVisualize: https://netron.app')
+
+ self.run_callbacks('on_export_end')
+ return f # return list of exported files/dirs
+
+ @try_export
+ def export_torchscript(self, prefix=colorstr('TorchScript:')):
+ """YOLOv8 TorchScript model export."""
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = self.file.with_suffix('.torchscript')
+
+ ts = torch.jit.trace(self.model, self.im, strict=False)
+ extra_files = {'config.txt': json.dumps(self.metadata)} # torch._C.ExtraFilesMap()
+ if self.args.optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
+ LOGGER.info(f'{prefix} optimizing for mobile...')
+ from torch.utils.mobile_optimizer import optimize_for_mobile
+ optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
+ else:
+ ts.save(str(f), _extra_files=extra_files)
+ return f, None
+
+ @try_export
+ def export_onnx(self, prefix=colorstr('ONNX:')):
+ """YOLOv8 ONNX export."""
+ requirements = ['onnx>=1.12.0']
+ if self.args.simplify:
+ requirements += ['onnxsim>=0.4.33', 'onnxruntime-gpu' if torch.cuda.is_available() else 'onnxruntime']
+ check_requirements(requirements)
+ import onnx # noqa
+
+ opset_version = self.args.opset or get_latest_opset()
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__} opset {opset_version}...')
+ f = str(self.file.with_suffix('.onnx'))
+
+ output_names = ['output0', 'output1'] if isinstance(self.model, SegmentationModel) else ['output0']
+ dynamic = self.args.dynamic
+ if dynamic:
+ dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
+ if isinstance(self.model, SegmentationModel):
+ dynamic['output0'] = {0: 'batch', 2: 'anchors'} # shape(1, 116, 8400)
+ dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
+ elif isinstance(self.model, DetectionModel):
+ dynamic['output0'] = {0: 'batch', 2: 'anchors'} # shape(1, 84, 8400)
+
+ torch.onnx.export(
+ self.model.cpu() if dynamic else self.model, # dynamic=True only compatible with cpu
+ self.im.cpu() if dynamic else self.im,
+ f,
+ verbose=False,
+ opset_version=opset_version,
+ do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
+ input_names=['images'],
+ output_names=output_names,
+ dynamic_axes=dynamic or None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ # onnx.checker.check_model(model_onnx) # check onnx model
+
+ # Simplify
+ if self.args.simplify:
+ try:
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
+ # subprocess.run(f'onnxsim "{f}" "{f}"', shell=True)
+ model_onnx, check = onnxsim.simplify(model_onnx)
+ assert check, 'Simplified ONNX model could not be validated'
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+
+ # Metadata
+ for k, v in self.metadata.items():
+ meta = model_onnx.metadata_props.add()
+ meta.key, meta.value = k, str(v)
+
+ onnx.save(model_onnx, f)
+ return f, model_onnx
+
+ @try_export
+ def export_openvino(self, prefix=colorstr('OpenVINO:')):
+ """YOLOv8 OpenVINO export."""
+ check_requirements('openvino-dev>=2023.0') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ import openvino.runtime as ov # noqa
+ from openvino.tools import mo # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with openvino {ov.__version__}...')
+ f = str(self.file).replace(self.file.suffix, f'_openvino_model{os.sep}')
+ f_onnx = self.file.with_suffix('.onnx')
+ f_ov = str(Path(f) / self.file.with_suffix('.xml').name)
+
+ ov_model = mo.convert_model(f_onnx,
+ model_name=self.pretty_name,
+ framework='onnx',
+ compress_to_fp16=self.args.half) # export
+
+ # Set RT info
+ ov_model.set_rt_info('YOLOv8', ['model_info', 'model_type'])
+ ov_model.set_rt_info(True, ['model_info', 'reverse_input_channels'])
+ ov_model.set_rt_info(114, ['model_info', 'pad_value'])
+ ov_model.set_rt_info([255.0], ['model_info', 'scale_values'])
+ ov_model.set_rt_info(self.args.iou, ['model_info', 'iou_threshold'])
+ ov_model.set_rt_info([v.replace(' ', '_') for k, v in sorted(self.model.names.items())],
+ ['model_info', 'labels'])
+ if self.model.task != 'classify':
+ ov_model.set_rt_info('fit_to_window_letterbox', ['model_info', 'resize_type'])
+
+ ov.serialize(ov_model, f_ov) # save
+ yaml_save(Path(f) / 'metadata.yaml', self.metadata) # add metadata.yaml
+ return f, None
+
+ @try_export
+ def export_paddle(self, prefix=colorstr('PaddlePaddle:')):
+ """YOLOv8 Paddle export."""
+ check_requirements(('paddlepaddle', 'x2paddle'))
+ import x2paddle # noqa
+ from x2paddle.convert import pytorch2paddle # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with X2Paddle {x2paddle.__version__}...')
+ f = str(self.file).replace(self.file.suffix, f'_paddle_model{os.sep}')
+
+ pytorch2paddle(module=self.model, save_dir=f, jit_type='trace', input_examples=[self.im]) # export
+ yaml_save(Path(f) / 'metadata.yaml', self.metadata) # add metadata.yaml
+ return f, None
+
+ @try_export
+ def export_ncnn(self, prefix=colorstr('ncnn:')):
+ """
+ YOLOv8 ncnn export using PNNX https://github.com/pnnx/pnnx.
+ """
+ check_requirements('git+https://github.com/Tencent/ncnn.git' if ARM64 else 'ncnn') # requires ncnn
+ import ncnn # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with ncnn {ncnn.__version__}...')
+ f = Path(str(self.file).replace(self.file.suffix, f'_ncnn_model{os.sep}'))
+ f_ts = self.file.with_suffix('.torchscript')
+
+ pnnx_filename = 'pnnx.exe' if WINDOWS else 'pnnx'
+ if Path(pnnx_filename).is_file():
+ pnnx = pnnx_filename
+ elif (ROOT / pnnx_filename).is_file():
+ pnnx = ROOT / pnnx_filename
+ else:
+ LOGGER.warning(
+ f'{prefix} WARNING ⚠️ PNNX not found. Attempting to download binary file from '
+ 'https://github.com/pnnx/pnnx/.\nNote PNNX Binary file must be placed in current working directory '
+ f'or in {ROOT}. See PNNX repo for full installation instructions.')
+ _, assets = get_github_assets(repo='pnnx/pnnx', retry=True)
+ system = 'macos' if MACOS else 'ubuntu' if LINUX else 'windows' # operating system
+ asset = [x for x in assets if system in x][0] if assets else \
+ f'https://github.com/pnnx/pnnx/releases/download/20230816/pnnx-20230816-{system}.zip' # fallback
+ asset = attempt_download_asset(asset, repo='pnnx/pnnx', release='latest')
+ unzip_dir = Path(asset).with_suffix('')
+ pnnx = ROOT / pnnx_filename # new location
+ (unzip_dir / pnnx_filename).rename(pnnx) # move binary to ROOT
+ shutil.rmtree(unzip_dir) # delete unzip dir
+ Path(asset).unlink() # delete zip
+ pnnx.chmod(0o777) # set read, write, and execute permissions for everyone
+
+ use_ncnn = True
+ ncnn_args = [
+ f'ncnnparam={f / "model.ncnn.param"}',
+ f'ncnnbin={f / "model.ncnn.bin"}',
+ f'ncnnpy={f / "model_ncnn.py"}', ] if use_ncnn else []
+
+ use_pnnx = False
+ pnnx_args = [
+ f'pnnxparam={f / "model.pnnx.param"}',
+ f'pnnxbin={f / "model.pnnx.bin"}',
+ f'pnnxpy={f / "model_pnnx.py"}',
+ f'pnnxonnx={f / "model.pnnx.onnx"}', ] if use_pnnx else []
+
+ cmd = [
+ str(pnnx),
+ str(f_ts),
+ *ncnn_args,
+ *pnnx_args,
+ f'fp16={int(self.args.half)}',
+ f'device={self.device.type}',
+ f'inputshape="{[self.args.batch, 3, *self.imgsz]}"', ]
+ f.mkdir(exist_ok=True) # make ncnn_model directory
+ LOGGER.info(f"{prefix} running '{' '.join(cmd)}'")
+ subprocess.run(cmd, check=True)
+ for f_debug in 'debug.bin', 'debug.param', 'debug2.bin', 'debug2.param': # remove debug files
+ Path(f_debug).unlink(missing_ok=True)
+
+ yaml_save(f / 'metadata.yaml', self.metadata) # add metadata.yaml
+ return str(f), None
+
+ @try_export
+ def export_coreml(self, prefix=colorstr('CoreML:')):
+ """YOLOv8 CoreML export."""
+ mlmodel = self.args.format.lower() == 'mlmodel' # legacy *.mlmodel export format requested
+ check_requirements('coremltools>=6.0,<=6.2' if mlmodel else 'coremltools>=7.0.b1')
+ import coremltools as ct # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = self.file.with_suffix('.mlmodel' if mlmodel else '.mlpackage')
+ if f.is_dir():
+ shutil.rmtree(f)
+
+ bias = [0.0, 0.0, 0.0]
+ scale = 1 / 255
+ classifier_config = None
+ if self.model.task == 'classify':
+ classifier_config = ct.ClassifierConfig(list(self.model.names.values())) if self.args.nms else None
+ model = self.model
+ elif self.model.task == 'detect':
+ model = IOSDetectModel(self.model, self.im) if self.args.nms else self.model
+ else:
+ if self.args.nms:
+ LOGGER.warning(f"{prefix} WARNING ⚠️ 'nms=True' is only available for Detect models like 'yolov8n.pt'.")
+ # TODO CoreML Segment and Pose model pipelining
+ model = self.model
+
+ ts = torch.jit.trace(model.eval(), self.im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts,
+ inputs=[ct.ImageType('image', shape=self.im.shape, scale=scale, bias=bias)],
+ classifier_config=classifier_config,
+ convert_to='neuralnetwork' if mlmodel else 'mlprogram')
+ bits, mode = (8, 'kmeans') if self.args.int8 else (16, 'linear') if self.args.half else (32, None)
+ if bits < 32:
+ if 'kmeans' in mode:
+ check_requirements('scikit-learn') # scikit-learn package required for k-means quantization
+ if mlmodel:
+ ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
+ elif bits == 8: # mlprogram already quantized to FP16
+ import coremltools.optimize.coreml as cto
+ op_config = cto.OpPalettizerConfig(mode='kmeans', nbits=bits, weight_threshold=512)
+ config = cto.OptimizationConfig(global_config=op_config)
+ ct_model = cto.palettize_weights(ct_model, config=config)
+ if self.args.nms and self.model.task == 'detect':
+ if mlmodel:
+ import platform
+
+ # coremltools<=6.2 NMS export requires Python<3.11
+ check_version(platform.python_version(), '<3.11', name='Python ', hard=True)
+ weights_dir = None
+ else:
+ ct_model.save(str(f)) # save otherwise weights_dir does not exist
+ weights_dir = str(f / 'Data/com.apple.CoreML/weights')
+ ct_model = self._pipeline_coreml(ct_model, weights_dir=weights_dir)
+
+ m = self.metadata # metadata dict
+ ct_model.short_description = m.pop('description')
+ ct_model.author = m.pop('author')
+ ct_model.license = m.pop('license')
+ ct_model.version = m.pop('version')
+ ct_model.user_defined_metadata.update({k: str(v) for k, v in m.items()})
+ try:
+ ct_model.save(str(f)) # save *.mlpackage
+ except Exception as e:
+ LOGGER.warning(
+ f'{prefix} WARNING ⚠️ CoreML export to *.mlpackage failed ({e}), reverting to *.mlmodel export. '
+ f'Known coremltools Python 3.11 and Windows bugs https://github.com/apple/coremltools/issues/1928.')
+ f = f.with_suffix('.mlmodel')
+ ct_model.save(str(f))
+ return f, ct_model
+
+ @try_export
+ def export_engine(self, prefix=colorstr('TensorRT:')):
+ """YOLOv8 TensorRT export https://developer.nvidia.com/tensorrt."""
+ assert self.im.device.type != 'cpu', "export running on CPU but must be on GPU, i.e. use 'device=0'"
+ try:
+ import tensorrt as trt # noqa
+ except ImportError:
+ if LINUX:
+ check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
+ import tensorrt as trt # noqa
+
+ check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
+ self.args.simplify = True
+ f_onnx, _ = self.export_onnx()
+
+ LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
+ assert Path(f_onnx).exists(), f'failed to export ONNX file: {f_onnx}'
+ f = self.file.with_suffix('.engine') # TensorRT engine file
+ logger = trt.Logger(trt.Logger.INFO)
+ if self.args.verbose:
+ logger.min_severity = trt.Logger.Severity.VERBOSE
+
+ builder = trt.Builder(logger)
+ config = builder.create_builder_config()
+ config.max_workspace_size = self.args.workspace * 1 << 30
+ # config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
+
+ flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
+ network = builder.create_network(flag)
+ parser = trt.OnnxParser(network, logger)
+ if not parser.parse_from_file(f_onnx):
+ raise RuntimeError(f'failed to load ONNX file: {f_onnx}')
+
+ inputs = [network.get_input(i) for i in range(network.num_inputs)]
+ outputs = [network.get_output(i) for i in range(network.num_outputs)]
+ for inp in inputs:
+ LOGGER.info(f'{prefix} input "{inp.name}" with shape{inp.shape} {inp.dtype}')
+ for out in outputs:
+ LOGGER.info(f'{prefix} output "{out.name}" with shape{out.shape} {out.dtype}')
+
+ if self.args.dynamic:
+ shape = self.im.shape
+ if shape[0] <= 1:
+ LOGGER.warning(f"{prefix} WARNING ⚠️ 'dynamic=True' model requires max batch size, i.e. 'batch=16'")
+ profile = builder.create_optimization_profile()
+ for inp in inputs:
+ profile.set_shape(inp.name, (1, *shape[1:]), (max(1, shape[0] // 2), *shape[1:]), shape)
+ config.add_optimization_profile(profile)
+
+ LOGGER.info(
+ f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and self.args.half else 32} engine as {f}')
+ if builder.platform_has_fast_fp16 and self.args.half:
+ config.set_flag(trt.BuilderFlag.FP16)
+
+ # Write file
+ with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
+ # Metadata
+ meta = json.dumps(self.metadata)
+ t.write(len(meta).to_bytes(4, byteorder='little', signed=True))
+ t.write(meta.encode())
+ # Model
+ t.write(engine.serialize())
+
+ return f, None
+
+ @try_export
+ def export_saved_model(self, prefix=colorstr('TensorFlow SavedModel:')):
+ """YOLOv8 TensorFlow SavedModel export."""
+ cuda = torch.cuda.is_available()
+ try:
+ import tensorflow as tf # noqa
+ except ImportError:
+ check_requirements(f"tensorflow{'-macos' if MACOS else '-aarch64' if ARM64 else '' if cuda else '-cpu'}")
+ import tensorflow as tf # noqa
+ check_requirements(
+ ('onnx', 'onnx2tf>=1.15.4', 'sng4onnx>=1.0.1', 'onnxsim>=0.4.33', 'onnx_graphsurgeon>=0.3.26',
+ 'tflite_support', 'onnxruntime-gpu' if cuda else 'onnxruntime'),
+ cmds='--extra-index-url https://pypi.ngc.nvidia.com') # onnx_graphsurgeon only on NVIDIA
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = Path(str(self.file).replace(self.file.suffix, '_saved_model'))
+ if f.is_dir():
+ import shutil
+ shutil.rmtree(f) # delete output folder
+
+ # Export to ONNX
+ self.args.simplify = True
+ f_onnx, _ = self.export_onnx()
+
+ # Export to TF
+ tmp_file = f / 'tmp_tflite_int8_calibration_images.npy' # int8 calibration images file
+ if self.args.int8:
+ verbosity = '--verbosity info'
+ if self.args.data:
+ import numpy as np
+
+ from ultralytics.data.dataset import YOLODataset
+ from ultralytics.data.utils import check_det_dataset
+
+ # Generate calibration data for integer quantization
+ LOGGER.info(f"{prefix} collecting INT8 calibration images from 'data={self.args.data}'")
+ data = check_det_dataset(self.args.data)
+ dataset = YOLODataset(data['val'], data=data, imgsz=self.imgsz[0], augment=False)
+ images = []
+ n_images = 100 # maximum number of images
+ for n, batch in enumerate(dataset):
+ if n >= n_images:
+ break
+ im = batch['img'].permute(1, 2, 0)[None] # list to nparray, CHW to BHWC
+ images.append(im)
+ f.mkdir()
+ images = torch.cat(images, 0).float()
+ # mean = images.view(-1, 3).mean(0) # imagenet mean [123.675, 116.28, 103.53]
+ # std = images.view(-1, 3).std(0) # imagenet std [58.395, 57.12, 57.375]
+ np.save(str(tmp_file), images.numpy()) # BHWC
+ int8 = f'-oiqt -qt per-tensor -cind images "{tmp_file}" "[[[[0, 0, 0]]]]" "[[[[255, 255, 255]]]]"'
+ else:
+ int8 = '-oiqt -qt per-tensor'
+ else:
+ verbosity = '--non_verbose'
+ int8 = ''
+
+ cmd = f'onnx2tf -i "{f_onnx}" -o "{f}" -nuo {verbosity} {int8}'.strip()
+ LOGGER.info(f"{prefix} running '{cmd}'")
+ subprocess.run(cmd, shell=True)
+ yaml_save(f / 'metadata.yaml', self.metadata) # add metadata.yaml
+
+ # Remove/rename TFLite models
+ if self.args.int8:
+ tmp_file.unlink(missing_ok=True)
+ for file in f.rglob('*_dynamic_range_quant.tflite'):
+ file.rename(file.with_name(file.stem.replace('_dynamic_range_quant', '_int8') + file.suffix))
+ for file in f.rglob('*_integer_quant_with_int16_act.tflite'):
+ file.unlink() # delete extra fp16 activation TFLite files
+
+ # Add TFLite metadata
+ for file in f.rglob('*.tflite'):
+ f.unlink() if 'quant_with_int16_act.tflite' in str(f) else self._add_tflite_metadata(file)
+
+ return str(f), tf.saved_model.load(f, tags=None, options=None) # load saved_model as Keras model
+
+ @try_export
+ def export_pb(self, keras_model, prefix=colorstr('TensorFlow GraphDef:')):
+ """YOLOv8 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow."""
+ import tensorflow as tf # noqa
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = self.file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+ return f, None
+
+ @try_export
+ def export_tflite(self, keras_model, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
+ """YOLOv8 TensorFlow Lite export."""
+ import tensorflow as tf # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ saved_model = Path(str(self.file).replace(self.file.suffix, '_saved_model'))
+ if self.args.int8:
+ f = saved_model / f'{self.file.stem}_int8.tflite' # fp32 in/out
+ elif self.args.half:
+ f = saved_model / f'{self.file.stem}_float16.tflite' # fp32 in/out
+ else:
+ f = saved_model / f'{self.file.stem}_float32.tflite'
+ return str(f), None
+
+ @try_export
+ def export_edgetpu(self, tflite_model='', prefix=colorstr('Edge TPU:')):
+ """YOLOv8 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/."""
+ LOGGER.warning(f'{prefix} WARNING ⚠️ Edge TPU known bug https://github.com/ultralytics/ultralytics/issues/1185')
+
+ cmd = 'edgetpu_compiler --version'
+ help_url = 'https://coral.ai/docs/edgetpu/compiler/'
+ assert LINUX, f'export only supported on Linux. See {help_url}'
+ if subprocess.run(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, shell=True).returncode != 0:
+ LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
+ sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
+ for c in (
+ 'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
+ 'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
+ 'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
+ subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
+ ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
+
+ LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
+ f = str(tflite_model).replace('.tflite', '_edgetpu.tflite') # Edge TPU model
+
+ cmd = f'edgetpu_compiler -s -d -k 10 --out_dir "{Path(f).parent}" "{tflite_model}"'
+ LOGGER.info(f"{prefix} running '{cmd}'")
+ subprocess.run(cmd, shell=True)
+ self._add_tflite_metadata(f)
+ return f, None
+
+ @try_export
+ def export_tfjs(self, prefix=colorstr('TensorFlow.js:')):
+ """YOLOv8 TensorFlow.js export."""
+ check_requirements('tensorflowjs')
+ import tensorflow as tf
+ import tensorflowjs as tfjs # noqa
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(self.file).replace(self.file.suffix, '_web_model') # js dir
+ f_pb = str(self.file.with_suffix('.pb')) # *.pb path
+
+ gd = tf.Graph().as_graph_def() # TF GraphDef
+ with open(f_pb, 'rb') as file:
+ gd.ParseFromString(file.read())
+ outputs = ','.join(gd_outputs(gd))
+ LOGGER.info(f'\n{prefix} output node names: {outputs}')
+
+ with spaces_in_path(f_pb) as fpb_, spaces_in_path(f) as f_: # exporter can not handle spaces in path
+ cmd = f'tensorflowjs_converter --input_format=tf_frozen_model --output_node_names={outputs} "{fpb_}" "{f_}"'
+ LOGGER.info(f"{prefix} running '{cmd}'")
+ subprocess.run(cmd, shell=True)
+
+ if ' ' in str(f):
+ LOGGER.warning(f"{prefix} WARNING ⚠️ your model may not work correctly with spaces in path '{f}'.")
+
+ # f_json = Path(f) / 'model.json' # *.json path
+ # with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ # subst = re.sub(
+ # r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ # r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ # r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ # r'"Identity.?.?": {"name": "Identity.?.?"}}}',
+ # r'{"outputs": {"Identity": {"name": "Identity"}, '
+ # r'"Identity_1": {"name": "Identity_1"}, '
+ # r'"Identity_2": {"name": "Identity_2"}, '
+ # r'"Identity_3": {"name": "Identity_3"}}}',
+ # f_json.read_text(),
+ # )
+ # j.write(subst)
+ yaml_save(Path(f) / 'metadata.yaml', self.metadata) # add metadata.yaml
+ return f, None
+
+ def _add_tflite_metadata(self, file):
+ """Add metadata to *.tflite models per https://www.tensorflow.org/lite/models/convert/metadata."""
+ from tflite_support import flatbuffers # noqa
+ from tflite_support import metadata as _metadata # noqa
+ from tflite_support import metadata_schema_py_generated as _metadata_fb # noqa
+
+ # Create model info
+ model_meta = _metadata_fb.ModelMetadataT()
+ model_meta.name = self.metadata['description']
+ model_meta.version = self.metadata['version']
+ model_meta.author = self.metadata['author']
+ model_meta.license = self.metadata['license']
+
+ # Label file
+ tmp_file = Path(file).parent / 'temp_meta.txt'
+ with open(tmp_file, 'w') as f:
+ f.write(str(self.metadata))
+
+ label_file = _metadata_fb.AssociatedFileT()
+ label_file.name = tmp_file.name
+ label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
+
+ # Create input info
+ input_meta = _metadata_fb.TensorMetadataT()
+ input_meta.name = 'image'
+ input_meta.description = 'Input image to be detected.'
+ input_meta.content = _metadata_fb.ContentT()
+ input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
+ input_meta.content.contentProperties.colorSpace = _metadata_fb.ColorSpaceType.RGB
+ input_meta.content.contentPropertiesType = _metadata_fb.ContentProperties.ImageProperties
+
+ # Create output info
+ output1 = _metadata_fb.TensorMetadataT()
+ output1.name = 'output'
+ output1.description = 'Coordinates of detected objects, class labels, and confidence score'
+ output1.associatedFiles = [label_file]
+ if self.model.task == 'segment':
+ output2 = _metadata_fb.TensorMetadataT()
+ output2.name = 'output'
+ output2.description = 'Mask protos'
+ output2.associatedFiles = [label_file]
+
+ # Create subgraph info
+ subgraph = _metadata_fb.SubGraphMetadataT()
+ subgraph.inputTensorMetadata = [input_meta]
+ subgraph.outputTensorMetadata = [output1, output2] if self.model.task == 'segment' else [output1]
+ model_meta.subgraphMetadata = [subgraph]
+
+ b = flatbuffers.Builder(0)
+ b.Finish(model_meta.Pack(b), _metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
+ metadata_buf = b.Output()
+
+ populator = _metadata.MetadataPopulator.with_model_file(str(file))
+ populator.load_metadata_buffer(metadata_buf)
+ populator.load_associated_files([str(tmp_file)])
+ populator.populate()
+ tmp_file.unlink()
+
+ def _pipeline_coreml(self, model, weights_dir=None, prefix=colorstr('CoreML Pipeline:')):
+ """YOLOv8 CoreML pipeline."""
+ import coremltools as ct # noqa
+
+ LOGGER.info(f'{prefix} starting pipeline with coremltools {ct.__version__}...')
+ _, _, h, w = list(self.im.shape) # BCHW
+
+ # Output shapes
+ spec = model.get_spec()
+ out0, out1 = iter(spec.description.output)
+ if MACOS:
+ from PIL import Image
+ img = Image.new('RGB', (w, h)) # w=192, h=320
+ out = model.predict({'image': img})
+ out0_shape = out[out0.name].shape # (3780, 80)
+ out1_shape = out[out1.name].shape # (3780, 4)
+ else: # linux and windows can not run model.predict(), get sizes from PyTorch model output y
+ out0_shape = self.output_shape[2], self.output_shape[1] - 4 # (3780, 80)
+ out1_shape = self.output_shape[2], 4 # (3780, 4)
+
+ # Checks
+ names = self.metadata['names']
+ nx, ny = spec.description.input[0].type.imageType.width, spec.description.input[0].type.imageType.height
+ _, nc = out0_shape # number of anchors, number of classes
+ # _, nc = out0.type.multiArrayType.shape
+ assert len(names) == nc, f'{len(names)} names found for nc={nc}' # check
+
+ # Define output shapes (missing)
+ out0.type.multiArrayType.shape[:] = out0_shape # (3780, 80)
+ out1.type.multiArrayType.shape[:] = out1_shape # (3780, 4)
+ # spec.neuralNetwork.preprocessing[0].featureName = '0'
+
+ # Flexible input shapes
+ # from coremltools.models.neural_network import flexible_shape_utils
+ # s = [] # shapes
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(320, 192))
+ # s.append(flexible_shape_utils.NeuralNetworkImageSize(640, 384)) # (height, width)
+ # flexible_shape_utils.add_enumerated_image_sizes(spec, feature_name='image', sizes=s)
+ # r = flexible_shape_utils.NeuralNetworkImageSizeRange() # shape ranges
+ # r.add_height_range((192, 640))
+ # r.add_width_range((192, 640))
+ # flexible_shape_utils.update_image_size_range(spec, feature_name='image', size_range=r)
+
+ # Print
+ # print(spec.description)
+
+ # Model from spec
+ model = ct.models.MLModel(spec, weights_dir=weights_dir)
+
+ # 3. Create NMS protobuf
+ nms_spec = ct.proto.Model_pb2.Model()
+ nms_spec.specificationVersion = 5
+ for i in range(2):
+ decoder_output = model._spec.description.output[i].SerializeToString()
+ nms_spec.description.input.add()
+ nms_spec.description.input[i].ParseFromString(decoder_output)
+ nms_spec.description.output.add()
+ nms_spec.description.output[i].ParseFromString(decoder_output)
+
+ nms_spec.description.output[0].name = 'confidence'
+ nms_spec.description.output[1].name = 'coordinates'
+
+ output_sizes = [nc, 4]
+ for i in range(2):
+ ma_type = nms_spec.description.output[i].type.multiArrayType
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[0].lowerBound = 0
+ ma_type.shapeRange.sizeRanges[0].upperBound = -1
+ ma_type.shapeRange.sizeRanges.add()
+ ma_type.shapeRange.sizeRanges[1].lowerBound = output_sizes[i]
+ ma_type.shapeRange.sizeRanges[1].upperBound = output_sizes[i]
+ del ma_type.shape[:]
+
+ nms = nms_spec.nonMaximumSuppression
+ nms.confidenceInputFeatureName = out0.name # 1x507x80
+ nms.coordinatesInputFeatureName = out1.name # 1x507x4
+ nms.confidenceOutputFeatureName = 'confidence'
+ nms.coordinatesOutputFeatureName = 'coordinates'
+ nms.iouThresholdInputFeatureName = 'iouThreshold'
+ nms.confidenceThresholdInputFeatureName = 'confidenceThreshold'
+ nms.iouThreshold = 0.45
+ nms.confidenceThreshold = 0.25
+ nms.pickTop.perClass = True
+ nms.stringClassLabels.vector.extend(names.values())
+ nms_model = ct.models.MLModel(nms_spec)
+
+ # 4. Pipeline models together
+ pipeline = ct.models.pipeline.Pipeline(input_features=[('image', ct.models.datatypes.Array(3, ny, nx)),
+ ('iouThreshold', ct.models.datatypes.Double()),
+ ('confidenceThreshold', ct.models.datatypes.Double())],
+ output_features=['confidence', 'coordinates'])
+ pipeline.add_model(model)
+ pipeline.add_model(nms_model)
+
+ # Correct datatypes
+ pipeline.spec.description.input[0].ParseFromString(model._spec.description.input[0].SerializeToString())
+ pipeline.spec.description.output[0].ParseFromString(nms_model._spec.description.output[0].SerializeToString())
+ pipeline.spec.description.output[1].ParseFromString(nms_model._spec.description.output[1].SerializeToString())
+
+ # Update metadata
+ pipeline.spec.specificationVersion = 5
+ pipeline.spec.description.metadata.userDefined.update({
+ 'IoU threshold': str(nms.iouThreshold),
+ 'Confidence threshold': str(nms.confidenceThreshold)})
+
+ # Save the model
+ model = ct.models.MLModel(pipeline.spec, weights_dir=weights_dir)
+ model.input_description['image'] = 'Input image'
+ model.input_description['iouThreshold'] = f'(optional) IOU threshold override (default: {nms.iouThreshold})'
+ model.input_description['confidenceThreshold'] = \
+ f'(optional) Confidence threshold override (default: {nms.confidenceThreshold})'
+ model.output_description['confidence'] = 'Boxes × Class confidence (see user-defined metadata "classes")'
+ model.output_description['coordinates'] = 'Boxes × [x, y, width, height] (relative to image size)'
+ LOGGER.info(f'{prefix} pipeline success')
+ return model
+
+ def add_callback(self, event: str, callback):
+ """
+ Appends the given callback.
+ """
+ self.callbacks[event].append(callback)
+
+ def run_callbacks(self, event: str):
+ """Execute all callbacks for a given event."""
+ for callback in self.callbacks.get(event, []):
+ callback(self)
+
+
+class IOSDetectModel(torch.nn.Module):
+ """Wrap an Ultralytics YOLO model for Apple iOS CoreML export."""
+
+ def __init__(self, model, im):
+ """Initialize the IOSDetectModel class with a YOLO model and example image."""
+ super().__init__()
+ _, _, h, w = im.shape # batch, channel, height, width
+ self.model = model
+ self.nc = len(model.names) # number of classes
+ if w == h:
+ self.normalize = 1.0 / w # scalar
+ else:
+ self.normalize = torch.tensor([1.0 / w, 1.0 / h, 1.0 / w, 1.0 / h]) # broadcast (slower, smaller)
+
+ def forward(self, x):
+ """Normalize predictions of object detection model with input size-dependent factors."""
+ xywh, cls = self.model(x)[0].transpose(0, 1).split((4, self.nc), 1)
+ return cls, xywh * self.normalize # confidence (3780, 80), coordinates (3780, 4)
diff --git a/STPoseNet/ultralytics/engine/model.py b/STPoseNet/ultralytics/engine/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..97a49bd7360939d83ab3fdf6493fcdf2ebc8d91d
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/model.py
@@ -0,0 +1,435 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import inspect
+import sys
+from pathlib import Path
+from typing import Union
+
+from ultralytics.cfg import TASK2DATA, get_cfg, get_save_dir
+from ultralytics.hub.utils import HUB_WEB_ROOT
+from ultralytics.nn.tasks import attempt_load_one_weight, guess_model_task, nn, yaml_model_load
+from ultralytics.utils import ASSETS, DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, RANK, callbacks, emojis, yaml_load
+from ultralytics.utils.checks import check_file, check_imgsz, check_pip_update_available, check_yaml
+from ultralytics.utils.downloads import GITHUB_ASSETS_STEMS
+from ultralytics.utils.torch_utils import smart_inference_mode
+
+
+class Model:
+ """
+ A base model class to unify apis for all the models.
+
+ Args:
+ model (str, Path): Path to the model file to load or create.
+ task (Any, optional): Task type for the YOLO model. Defaults to None.
+
+ Attributes:
+ predictor (Any): The predictor object.
+ model (Any): The model object.
+ trainer (Any): The trainer object.
+ task (str): The type of model task.
+ ckpt (Any): The checkpoint object if the model loaded from *.pt file.
+ cfg (str): The model configuration if loaded from *.yaml file.
+ ckpt_path (str): The checkpoint file path.
+ overrides (dict): Overrides for the trainer object.
+ metrics (Any): The data for metrics.
+
+ Methods:
+ __call__(source=None, stream=False, **kwargs):
+ Alias for the predict method.
+ _new(cfg:str, verbose:bool=True) -> None:
+ Initializes a new model and infers the task type from the model definitions.
+ _load(weights:str, task:str='') -> None:
+ Initializes a new model and infers the task type from the model head.
+ _check_is_pytorch_model() -> None:
+ Raises TypeError if the model is not a PyTorch model.
+ reset() -> None:
+ Resets the model modules.
+ info(verbose:bool=False) -> None:
+ Logs the model info.
+ fuse() -> None:
+ Fuses the model for faster inference.
+ predict(source=None, stream=False, **kwargs) -> List[ultralytics.engine.results.Results]:
+ Performs prediction using the YOLO model.
+
+ Returns:
+ list(ultralytics.engine.results.Results): The prediction results.
+ """
+
+ def __init__(self, model: Union[str, Path] = 'yolov8n.pt', task=None) -> None:
+ """
+ Initializes the YOLO model.
+
+ Args:
+ model (Union[str, Path], optional): Path or name of the model to load or create. Defaults to 'yolov8n.pt'.
+ task (Any, optional): Task type for the YOLO model. Defaults to None.
+ """
+ self.callbacks = callbacks.get_default_callbacks()
+ self.predictor = None # reuse predictor
+ self.model = None # model object
+ self.trainer = None # trainer object
+ self.ckpt = None # if loaded from *.pt
+ self.cfg = None # if loaded from *.yaml
+ self.ckpt_path = None
+ self.overrides = {} # overrides for trainer object
+ self.metrics = None # validation/training metrics
+ self.session = None # HUB session
+ self.task = task # task type
+ model = str(model).strip() # strip spaces
+
+ # Check if Ultralytics HUB model from https://hub.ultralytics.com
+ if self.is_hub_model(model):
+ from ultralytics.hub.session import HUBTrainingSession
+ self.session = HUBTrainingSession(model)
+ model = self.session.model_file
+
+ # Load or create new YOLO model
+ suffix = Path(model).suffix
+ if not suffix and Path(model).stem in GITHUB_ASSETS_STEMS:
+ model, suffix = Path(model).with_suffix('.pt'), '.pt' # add suffix, i.e. yolov8n -> yolov8n.pt
+ if suffix in ('.yaml', '.yml'):
+ self._new(model, task)
+ else:
+ self._load(model, task)
+
+ def __call__(self, source=None, stream=False, **kwargs):
+ """Calls the 'predict' function with given arguments to perform object detection."""
+ return self.predict(source, stream, **kwargs)
+
+ @staticmethod
+ def is_hub_model(model):
+ """Check if the provided model is a HUB model."""
+ return any((
+ model.startswith(f'{HUB_WEB_ROOT}/models/'), # i.e. https://hub.ultralytics.com/models/MODEL_ID
+ [len(x) for x in model.split('_')] == [42, 20], # APIKEY_MODELID
+ len(model) == 20 and not Path(model).exists() and all(x not in model for x in './\\'))) # MODELID
+
+ def _new(self, cfg: str, task=None, model=None, verbose=True):
+ """
+ Initializes a new model and infers the task type from the model definitions.
+
+ Args:
+ cfg (str): model configuration file
+ task (str | None): model task
+ model (BaseModel): Customized model.
+ verbose (bool): display model info on load
+ """
+ cfg_dict = yaml_model_load(cfg)
+ self.cfg = cfg
+ self.task = task or guess_model_task(cfg_dict)
+ self.model = (model or self.smart_load('model'))(cfg_dict, verbose=verbose and RANK == -1) # build model
+ self.overrides['model'] = self.cfg
+ self.overrides['task'] = self.task
+
+ # Below added to allow export from YAMLs
+ args = {**DEFAULT_CFG_DICT, **self.overrides} # combine model and default args, preferring model args
+ self.model.args = {k: v for k, v in args.items() if k in DEFAULT_CFG_KEYS} # attach args to model
+ self.model.task = self.task
+
+ def _load(self, weights: str, task=None):
+ """
+ Initializes a new model and infers the task type from the model head.
+
+ Args:
+ weights (str): model checkpoint to be loaded
+ task (str | None): model task
+ """
+ suffix = Path(weights).suffix
+ if suffix == '.pt':
+ self.model, self.ckpt = attempt_load_one_weight(weights)
+ self.task = self.model.args['task']
+ self.overrides = self.model.args = self._reset_ckpt_args(self.model.args)
+ self.ckpt_path = self.model.pt_path
+ else:
+ weights = check_file(weights)
+ self.model, self.ckpt = weights, None
+ self.task = task or guess_model_task(weights)
+ self.ckpt_path = weights
+ self.overrides['model'] = weights
+ self.overrides['task'] = self.task
+
+ def _check_is_pytorch_model(self):
+ """
+ Raises TypeError is model is not a PyTorch model
+ """
+ pt_str = isinstance(self.model, (str, Path)) and Path(self.model).suffix == '.pt'
+ pt_module = isinstance(self.model, nn.Module)
+ if not (pt_module or pt_str):
+ raise TypeError(f"model='{self.model}' must be a *.pt PyTorch model, but is a different type. "
+ f'PyTorch models can be used to train, val, predict and export, i.e. '
+ f"'yolo export model=yolov8n.pt', but exported formats like ONNX, TensorRT etc. only "
+ f"support 'predict' and 'val' modes, i.e. 'yolo predict model=yolov8n.onnx'.")
+
+ @smart_inference_mode()
+ def reset_weights(self):
+ """
+ Resets the model modules parameters to randomly initialized values, losing all training information.
+ """
+ self._check_is_pytorch_model()
+ for m in self.model.modules():
+ if hasattr(m, 'reset_parameters'):
+ m.reset_parameters()
+ for p in self.model.parameters():
+ p.requires_grad = True
+ return self
+
+ @smart_inference_mode()
+ def load(self, weights='yolov8n.pt'):
+ """
+ Transfers parameters with matching names and shapes from 'weights' to model.
+ """
+ self._check_is_pytorch_model()
+ if isinstance(weights, (str, Path)):
+ weights, self.ckpt = attempt_load_one_weight(weights)
+ self.model.load(weights)
+ return self
+
+ def info(self, detailed=False, verbose=True):
+ """
+ Logs model info.
+
+ Args:
+ detailed (bool): Show detailed information about model.
+ verbose (bool): Controls verbosity.
+ """
+ self._check_is_pytorch_model()
+ return self.model.info(detailed=detailed, verbose=verbose)
+
+ def fuse(self):
+ """Fuse PyTorch Conv2d and BatchNorm2d layers."""
+ self._check_is_pytorch_model()
+ self.model.fuse()
+
+ @smart_inference_mode()
+ def predict(self, source=None, stream=False, predictor=None, **kwargs):
+ """
+ Perform prediction using the YOLO model.
+
+ Args:
+ source (str | int | PIL | np.ndarray): The source of the image to make predictions on.
+ Accepts all source types accepted by the YOLO model.
+ stream (bool): Whether to stream the predictions or not. Defaults to False.
+ predictor (BasePredictor): Customized predictor.
+ **kwargs : Additional keyword arguments passed to the predictor.
+ Check the 'configuration' section in the documentation for all available options.
+
+ Returns:
+ (List[ultralytics.engine.results.Results]): The prediction results.
+ """
+ if source is None:
+ source = ASSETS
+ LOGGER.warning(f"WARNING ⚠️ 'source' is missing. Using 'source={source}'.")
+
+ is_cli = (sys.argv[0].endswith('yolo') or sys.argv[0].endswith('ultralytics')) and any(
+ x in sys.argv for x in ('predict', 'track', 'mode=predict', 'mode=track'))
+
+ custom = {'conf': 0.25, 'save': is_cli} # method defaults
+ args = {**self.overrides, **custom, **kwargs, 'mode': 'predict'} # highest priority args on the right
+ prompts = args.pop('prompts', None) # for SAM-type models
+
+ if not self.predictor:
+ self.predictor = (predictor or self.smart_load('predictor'))(overrides=args, _callbacks=self.callbacks)
+ self.predictor.setup_model(model=self.model, verbose=is_cli)
+ else: # only update args if predictor is already setup
+ self.predictor.args = get_cfg(self.predictor.args, args)
+ if 'project' in args or 'name' in args:
+ self.predictor.save_dir = get_save_dir(self.predictor.args)
+ if prompts and hasattr(self.predictor, 'set_prompts'): # for SAM-type models
+ self.predictor.set_prompts(prompts)
+ return self.predictor.predict_cli(source=source) if is_cli else self.predictor(source=source, stream=stream)
+
+ def track(self, source=None, stream=False, persist=False, **kwargs):
+ """
+ Perform object tracking on the input source using the registered trackers.
+
+ Args:
+ source (str, optional): The input source for object tracking. Can be a file path or a video stream.
+ stream (bool, optional): Whether the input source is a video stream. Defaults to False.
+ persist (bool, optional): Whether to persist the trackers if they already exist. Defaults to False.
+ **kwargs (optional): Additional keyword arguments for the tracking process.
+
+ Returns:
+ (List[ultralytics.engine.results.Results]): The tracking results.
+ """
+ if not hasattr(self.predictor, 'trackers'):
+ from ultralytics.trackers import register_tracker
+ register_tracker(self, persist)
+ # ByteTrack-based method needs low confidence predictions as input
+ kwargs['conf'] = kwargs.get('conf') or 0.1
+ kwargs['mode'] = 'track'
+ return self.predict(source=source, stream=stream, **kwargs)
+
+ @smart_inference_mode()
+ def val(self, validator=None, **kwargs):
+ """
+ Validate a model on a given dataset.
+
+ Args:
+ validator (BaseValidator): Customized validator.
+ **kwargs : Any other args accepted by the validators. To see all args check 'configuration' section in docs
+ """
+ custom = {'rect': True} # method defaults
+ args = {**self.overrides, **custom, **kwargs, 'mode': 'val'} # highest priority args on the right
+ args['imgsz'] = check_imgsz(args['imgsz'], max_dim=1)
+
+ validator = (validator or self.smart_load('validator'))(args=args, _callbacks=self.callbacks)
+ validator(model=self.model)
+ self.metrics = validator.metrics
+ return validator.metrics
+
+ @smart_inference_mode()
+ def benchmark(self, **kwargs):
+ """
+ Benchmark a model on all export formats.
+
+ Args:
+ **kwargs : Any other args accepted by the validators. To see all args check 'configuration' section in docs
+ """
+ self._check_is_pytorch_model()
+ from ultralytics.utils.benchmarks import benchmark
+
+ custom = {'verbose': False} # method defaults
+ args = {**DEFAULT_CFG_DICT, **self.model.args, **custom, **kwargs, 'mode': 'benchmark'}
+ return benchmark(
+ model=self,
+ data=kwargs.get('data'), # if no 'data' argument passed set data=None for default datasets
+ imgsz=args['imgsz'],
+ half=args['half'],
+ int8=args['int8'],
+ device=args['device'],
+ verbose=kwargs.get('verbose'))
+
+ def export(self, **kwargs):
+ """
+ Export model.
+
+ Args:
+ **kwargs : Any other args accepted by the Exporter. To see all args check 'configuration' section in docs.
+ """
+ self._check_is_pytorch_model()
+ from .exporter import Exporter
+
+ custom = {'imgsz': self.model.args['imgsz'], 'batch': 1, 'data': None, 'verbose': False} # method defaults
+ args = {**self.overrides, **custom, **kwargs, 'mode': 'export'} # highest priority args on the right
+ return Exporter(overrides=args, _callbacks=self.callbacks)(model=self.model)
+
+ def train(self, trainer=None, **kwargs):
+ """
+ Trains the model on a given dataset.
+
+ Args:
+ trainer (BaseTrainer, optional): Customized trainer.
+ **kwargs (Any): Any number of arguments representing the training configuration.
+ """
+ self._check_is_pytorch_model()
+ if self.session: # Ultralytics HUB session
+ if any(kwargs):
+ LOGGER.warning('WARNING ⚠️ using HUB training arguments, ignoring local training arguments.')
+ kwargs = self.session.train_args
+ check_pip_update_available()
+
+ overrides = yaml_load(check_yaml(kwargs['cfg'])) if kwargs.get('cfg') else self.overrides
+ custom = {'data': TASK2DATA[self.task]} # method defaults
+ args = {**overrides, **custom, **kwargs, 'mode': 'train'} # highest priority args on the right
+ if args.get('resume'):
+ args['resume'] = self.ckpt_path
+
+ self.trainer = (trainer or self.smart_load('trainer'))(overrides=args, _callbacks=self.callbacks)
+ if not args.get('resume'): # manually set model only if not resuming
+ self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
+ self.model = self.trainer.model
+ self.trainer.hub_session = self.session # attach optional HUB session
+ self.trainer.train()
+ # Update model and cfg after training
+ if RANK in (-1, 0):
+ self.model, _ = attempt_load_one_weight(str(self.trainer.best))
+ self.overrides = self.model.args
+ self.metrics = getattr(self.trainer.validator, 'metrics', None) # TODO: no metrics returned by DDP
+ return self.metrics
+
+ def tune(self, use_ray=False, iterations=10, *args, **kwargs):
+ """
+ Runs hyperparameter tuning, optionally using Ray Tune. See ultralytics.utils.tuner.run_ray_tune for Args.
+
+ Returns:
+ (dict): A dictionary containing the results of the hyperparameter search.
+ """
+ self._check_is_pytorch_model()
+ if use_ray:
+ from ultralytics.utils.tuner import run_ray_tune
+ return run_ray_tune(self, max_samples=iterations, *args, **kwargs)
+ else:
+ from .tuner import Tuner
+
+ custom = {} # method defaults
+ args = {**self.overrides, **custom, **kwargs, 'mode': 'export'} # highest priority args on the right
+ return Tuner(args=args, _callbacks=self.callbacks)(model=self.model, iterations=iterations)
+
+ def to(self, device):
+ """
+ Sends the model to the given device.
+
+ Args:
+ device (str): device
+ """
+ self._check_is_pytorch_model()
+ self.model.to(device)
+ return self
+
+ @property
+ def names(self):
+ """Returns class names of the loaded model."""
+ return self.model.names if hasattr(self.model, 'names') else None
+
+ @property
+ def device(self):
+ """Returns device if PyTorch model."""
+ return next(self.model.parameters()).device if isinstance(self.model, nn.Module) else None
+
+ @property
+ def transforms(self):
+ """Returns transform of the loaded model."""
+ return self.model.transforms if hasattr(self.model, 'transforms') else None
+
+ def add_callback(self, event: str, func):
+ """Add a callback."""
+ self.callbacks[event].append(func)
+
+ def clear_callback(self, event: str):
+ """Clear all event callbacks."""
+ self.callbacks[event] = []
+
+ @staticmethod
+ def _reset_ckpt_args(args):
+ """Reset arguments when loading a PyTorch model."""
+ include = {'imgsz', 'data', 'task', 'single_cls'} # only remember these arguments when loading a PyTorch model
+ return {k: v for k, v in args.items() if k in include}
+
+ def _reset_callbacks(self):
+ """Reset all registered callbacks."""
+ for event in callbacks.default_callbacks.keys():
+ self.callbacks[event] = [callbacks.default_callbacks[event][0]]
+
+ def __getattr__(self, attr):
+ """Raises error if object has no requested attribute."""
+ name = self.__class__.__name__
+ raise AttributeError(f"'{name}' object has no attribute '{attr}'. See valid attributes below.\n{self.__doc__}")
+
+ def smart_load(self, key):
+ """Load model/trainer/validator/predictor."""
+ try:
+ return self.task_map[self.task][key]
+ except Exception as e:
+ name = self.__class__.__name__
+ mode = inspect.stack()[1][3] # get the function name.
+ raise NotImplementedError(
+ emojis(f"WARNING ⚠️ '{name}' model does not support '{mode}' mode for '{self.task}' task yet.")) from e
+
+ @property
+ def task_map(self):
+ """
+ Map head to model, trainer, validator, and predictor classes.
+
+ Returns:
+ task_map (dict): The map of model task to mode classes.
+ """
+ raise NotImplementedError('Please provide task map for your model!')
diff --git a/STPoseNet/ultralytics/engine/predictor.py b/STPoseNet/ultralytics/engine/predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..96c2646903f62b9487a292634af793f2492c2641
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/predictor.py
@@ -0,0 +1,646 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Run prediction on images, videos, directories, globs, YouTube, webcam, streams, etc.
+
+Usage - sources:
+ $ yolo mode=predict model=yolov8n.pt source=0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ screen # screenshot
+ path/ # directory
+ list.txt # list of images
+ list.streams # list of streams
+ 'path/*.jpg' # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ yolo mode=predict model=yolov8n.pt # PyTorch
+ yolov8n.torchscript # TorchScript
+ yolov8n.onnx # ONNX Runtime or OpenCV DNN with dnn=True
+ yolov8n_openvino_model # OpenVINO
+ yolov8n.engine # TensorRT
+ yolov8n.mlpackage # CoreML (macOS-only)
+ yolov8n_saved_model # TensorFlow SavedModel
+ yolov8n.pb # TensorFlow GraphDef
+ yolov8n.tflite # TensorFlow Lite
+ yolov8n_edgetpu.tflite # TensorFlow Edge TPU
+ yolov8n_paddle_model # PaddlePaddle
+"""
+import platform
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+import copy
+
+from ultralytics.cfg import get_cfg, get_save_dir
+from ultralytics.data import load_inference_source
+from ultralytics.data.augment import LetterBox, classify_transforms
+from ultralytics.nn.autobackend import AutoBackend
+from ultralytics.utils import DEFAULT_CFG, LOGGER, MACOS, WINDOWS, callbacks, colorstr, ops
+from ultralytics.utils.checks import check_imgsz, check_imshow
+from ultralytics.utils.files import increment_path
+from ultralytics.utils.torch_utils import select_device, smart_inference_mode
+
+STREAM_WARNING = """
+ WARNING ⚠️ stream/video/webcam/dir predict source will accumulate results in RAM unless `stream=True` is passed,
+ causing potential out-of-memory errors for large sources or long-running streams/videos.
+
+ Example:
+ results = model(source=..., stream=True) # generator of Results objects
+ for r in results:
+ boxes = r.boxes # Boxes object for bbox outputs
+ masks = r.masks # Masks object for segment masks outputs
+ probs = r.probs # Class probabilities for classification outputs
+"""
+
+margin_coefficient = 0.9
+
+
+class BasePredictor:
+ """
+ BasePredictor
+
+ A base class for creating predictors.
+
+ Attributes:
+ args (SimpleNamespace): Configuration for the predictor.
+ save_dir (Path): Directory to save results.
+ done_warmup (bool): Whether the predictor has finished setup.
+ model (nn.Module): Model used for prediction.
+ data (dict): Data configuration.
+ device (torch.device): Device used for prediction.
+ dataset (Dataset): Dataset used for prediction.
+ vid_path (str): Path to video file.
+ vid_writer (cv2.VideoWriter): Video writer for saving video output.
+ data_path (str): Path to data.
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """
+ Initializes the BasePredictor class.
+
+ Args:
+ cfg (str, optional): Path to a configuration file. Defaults to DEFAULT_CFG.
+ overrides (dict, optional): Configuration overrides. Defaults to None.
+ """
+ self.args = get_cfg(cfg, overrides)
+ self.save_dir = get_save_dir(self.args)
+ if self.args.conf is None:
+ self.args.conf = 0.25 # default conf=0.25
+ self.done_warmup = False
+ if self.args.show:
+ self.args.show = check_imshow(warn=True)
+
+ # Usable if setup is done
+ self.model = None
+ self.data = self.args.data # data_dict
+ self.imgsz = None
+ self.device = None
+ self.dataset = None
+ self.vid_path, self.vid_writer = None, None
+ self.plotted_img = None
+ self.data_path = None
+ self.source_type = None
+ self.batch = None
+ self.results = None
+ self.results_min = None
+ self.transforms = None
+ self.callbacks = _callbacks or callbacks.get_default_callbacks()
+ self.txt_path = None
+
+ # kalman
+ self.kalman_p_last = np.zeros((3, 2))
+ self.kalman_last = np.zeros((3, 2))
+ self.kal_kp = np.zeros((3, 2))
+
+ callbacks.add_integration_callbacks(self)
+
+ def preprocess(self, im):
+ """Prepares input image before inference.
+
+ Args:
+ im (torch.Tensor | List(np.ndarray)): BCHW for tensor, [(HWC) x B] for list.
+ """
+ not_tensor = not isinstance(im, torch.Tensor)
+ if not_tensor:
+ im = np.stack(self.pre_transform(im))
+ im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
+ im = np.ascontiguousarray(im) # contiguous
+ im = torch.from_numpy(im)
+
+ img = im.to(self.device)
+ img = img.half() if self.model.fp16 else img.float() # uint8 to fp16/32
+ if not_tensor:
+ img /= 255 # 0 - 255 to 0.0 - 1.0
+ return img
+
+ def inference(self, im, *args, **kwargs):
+ visualize = increment_path(self.save_dir / Path(self.batch[0][0]).stem,
+ mkdir=True) if self.args.visualize and (not self.source_type.tensor) else False
+ return self.model(im, augment=self.args.augment, visualize=visualize)
+
+ def pre_transform(self, im):
+ """
+ Pre-transform input image before inference.
+
+ Args:
+ im (List(np.ndarray)): (N, 3, h, w) for tensor, [(h, w, 3) x N] for list.
+
+ Returns:
+ (list): A list of transformed images.
+ """
+ same_shapes = all(x.shape == im[0].shape for x in im)
+ auto = same_shapes and self.model.pt
+ return [LetterBox(self.imgsz, auto=auto, stride=self.model.stride)(image=x) for x in im]
+
+ def write_results(self, idx, results, batch):
+ """Write inference results to a file or directory."""
+ p, im, _ = batch
+ log_string = ''
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ if self.source_type.webcam or self.source_type.from_img or self.source_type.tensor: # batch_size >= 1
+ log_string += f'{idx}: '
+ frame = self.dataset.count
+ else:
+ frame = getattr(self.dataset, 'frame', 0)
+ self.data_path = p
+ txt_id = ''
+ if frame <= 9999999999:
+ txt_id = '' + str(frame)
+ if frame <= 999999999:
+ txt_id = '0' + str(frame)
+ if frame <= 99999999:
+ txt_id = '00' + str(frame)
+ if frame <= 9999999:
+ txt_id = '000' + str(frame)
+ if frame <= 999999:
+ txt_id = '0000' + str(frame)
+ if frame <= 99999:
+ txt_id = '00000' + str(frame)
+ if frame <= 9999:
+ txt_id = '000000' + str(frame)
+ if frame <= 999:
+ txt_id = '0000000' + str(frame)
+ if frame <= 99:
+ txt_id = '00000000' + str(frame)
+ if frame <= 9:
+ txt_id = '000000000' + str(frame)
+
+ self.txt_path = str(self.save_dir / 'labels' / p.stem) + ('' if self.dataset.mode == 'image' else f'_{txt_id}')
+ log_string += '%gx%g ' % im.shape[2:] # print string
+ result = results[idx]
+ log_string += result.verbose()
+
+ if self.args.save or self.args.show: # Add bbox to image
+ plot_args = {
+ 'line_width': self.args.line_width,
+ 'boxes': self.args.boxes,
+ 'conf': self.args.show_conf,
+ 'labels': self.args.show_labels}
+ if not self.args.retina_masks:
+ plot_args['im_gpu'] = im[idx]
+ self.plotted_img = result.plot(**plot_args)
+ # Write
+ if self.args.save_txt:
+ result.save_txt(f'{self.txt_path}.txt', save_conf=self.args.save_conf)
+ if self.args.save_crop:
+ result.save_crop(save_dir=self.save_dir / 'crops',
+ file_name=self.data_path.stem + ('' if self.dataset.mode == 'image' else f'_{frame}'))
+
+ return log_string
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Post-processes predictions for an image and returns them."""
+ return preds
+
+ def __call__(self, source=None, model=None, stream=False, *args, **kwargs):
+ """Performs inference on an image or stream."""
+ self.stream = stream
+ if stream:
+ return self.stream_inference(source, model, *args, **kwargs)
+ else:
+ return list(self.stream_inference(source, model, *args, **kwargs)) # merge list of Result into one
+
+ def predict_cli(self, source=None, model=None):
+ """Method used for CLI prediction. It uses always generator as outputs as not required by CLI mode."""
+ gen = self.stream_inference(source, model)
+ for _ in gen: # running CLI inference without accumulating any outputs (do not modify)
+ pass
+
+ def setup_source(self, source):
+ """Sets up source and inference mode."""
+ self.imgsz = check_imgsz(self.args.imgsz, stride=self.model.stride, min_dim=2) # check image size
+ self.transforms = getattr(self.model.model, 'transforms', classify_transforms(
+ self.imgsz[0])) if self.args.task == 'classify' else None
+ self.dataset = load_inference_source(source=source,
+ imgsz=self.imgsz,
+ vid_stride=self.args.vid_stride,
+ stream_buffer=self.args.stream_buffer)
+ self.source_type = self.dataset.source_type
+ if not getattr(self, 'stream', True) and (self.dataset.mode == 'stream' or # streams
+ len(self.dataset) > 1000 or # images
+ any(getattr(self.dataset, 'video_flag', [False]))): # videos
+ LOGGER.warning(STREAM_WARNING)
+ self.vid_path, self.vid_writer = [None] * self.dataset.bs, [None] * self.dataset.bs
+
+ def kalman(self, R = 0.0542, Q = 0.018):
+ x_mid = self.kalman_last
+ p_mid = self.kalman_p_last + Q
+ kg = p_mid / (p_mid + R) # 测量的越不准,越应将R值增大。
+ x_now = x_mid + kg * (self.kal_kp - x_mid)
+ p_now = (1 - kg) * p_mid
+ self.kalman_p_last = p_now
+ self.kalman_last = x_now
+ self.kal_kp = x_now
+
+ @smart_inference_mode()
+ def stream_inference(self, source=None, model=None, *args, **kwargs):
+ """Streams real-time inference on camera feed and saves results to file."""
+ if self.args.verbose:
+ LOGGER.info('')
+
+ # Setup model
+ if not self.model:
+ self.setup_model(model)
+
+ # Setup source every time predict is called
+ self.setup_source(source if source is not None else self.args.source)
+
+ # Check if save_dir/ label file exists
+ if self.args.save or self.args.save_txt:
+ (self.save_dir / 'labels' if self.args.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True)
+
+ # Warmup model
+ if not self.done_warmup:
+ self.model.warmup(imgsz=(1 if self.model.pt or self.model.triton else self.dataset.bs, 3, *self.imgsz))
+ self.done_warmup = True
+
+ self.seen, self.windows, self.batch, profilers = 0, [], None, (ops.Profile(), ops.Profile(), ops.Profile())
+ self.run_callbacks('on_predict_start')
+
+ for batch in self.dataset:
+ self.run_callbacks('on_predict_batch_start')
+ self.batch = batch
+ path, im0s, vid_cap, s = batch
+ pre_type = s.split('1', 1)
+
+ if pre_type[0] == str('video '):
+ frame = int(s.split('(')[1].split('/')[0])
+ # 第一次识别,确定初始位置
+ if frame == 1:
+ # Preprocess
+ with profilers[0]:
+ im = self.preprocess(im0s)
+
+ # Inference
+ with profilers[1]:
+ preds = self.inference(im, *args, **kwargs)
+
+ # Postprocess
+ with profilers[2]:
+ self.results = self.postprocess(preds, im, im0s)
+
+ result = copy.deepcopy(self.results)
+ new_boxes = copy.deepcopy(self.results[0].boxes.data).cpu().numpy()
+ likelihoods = new_boxes[:, -2]
+ likelihood_ = 0
+ for i, likelihood in enumerate(likelihoods):
+ if likelihood > likelihood_:
+ likelihood_ = likelihood
+ result[0].boxes = self.results[0].boxes[i, :]
+ result[0].keypoints = self.results[0].keypoints[i, :, :]
+ self.results = result
+
+ kalman_kps = result[0].keypoints[0, :, :2].cpu().numpy().data
+
+ self.kal_kp[0, :] = kalman_kps[0, 0, :]
+ self.kal_kp[1, :] = kalman_kps[0, 1, :]
+ self.kal_kp[2, :] = kalman_kps[0, 2, :]
+
+ self.kalman_p_last[0, :] = kalman_kps[0, 0, :]
+ self.kalman_p_last[1, :] = kalman_kps[0, 1, :]
+ self.kalman_p_last[2, :] = kalman_kps[0, 2, :]
+ self.kalman()
+
+ img_size = copy.deepcopy(self.results[0].orig_shape)
+ last_box = result[0].boxes.xywh
+
+ min_img = [[(last_box[0, 0] - margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3]).cpu().numpy()],
+ [(last_box[0, 0] + margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] + margin_coefficient * last_box[0, 3]).cpu().numpy()]]
+ min_img = np.array(min_img).astype(np.int16)
+ for i in range(2):
+ if min_img[i, 0] > img_size[1]:
+ min_img[i, 0] = img_size[1]
+ for i in range(2):
+ if min_img[i, 1] > img_size[0]:
+ min_img[i, 1] = img_size[0]
+
+ self.run_callbacks('on_predict_postprocess_end')
+
+ # 跟随识别
+ if frame > 1:
+ im1s = copy.deepcopy(im0s)
+ im1s = [np.array(im1s[0])[min_img[0, 1]:min_img[1, 1]+1, min_img[0, 0]:min_img[1, 0]+1, :]]
+
+ # Preprocess
+ with profilers[0]:
+ im = self.preprocess(im1s)
+
+ # Inference
+ with profilers[1]:
+ preds = self.inference(im, *args, **kwargs)
+
+ # Postprocess
+ with profilers[2]:
+ self.results = self.postprocess(preds, im, im1s)
+ result = copy.deepcopy(self.results)
+
+ likelihoods = copy.deepcopy(self.results[0].boxes.data).cpu().numpy()[:, -2]
+ likelihood_ = 0
+ for i, likelihood in enumerate(likelihoods):
+ if likelihood > likelihood_:
+ likelihood_ = likelihood
+ result[0].boxes = self.results[0].boxes[i, :]
+ result[0].keypoints = self.results[0].keypoints[i, :, :]
+
+ kalman_kps = result[0].keypoints[0, :, :2].cpu().numpy().data
+ if kalman_kps.shape[1] == 3:
+ self.kalman_p_last[0, :] = kalman_kps[0, 0, :]
+ self.kalman_p_last[1, :] = kalman_kps[0, 1, :]
+ self.kalman_p_last[2, :] = kalman_kps[0, 2, :]
+ self.kalman()
+
+ # if likelihood_ >= 0.9:
+ result, last_box = self.tf_img_min(last_box, result, im0s[0])
+
+ self.results = result
+
+ min_img = [[(last_box[0, 0] - margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3]).cpu().numpy()],
+ [(last_box[0, 0] + margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] + margin_coefficient * last_box[0, 3]).cpu().numpy()]]
+ min_img = np.array(min_img).astype(np.int16)
+
+ for i in range(2):
+ if min_img[i, 0] > img_size[1]:
+ min_img[i, 0] = img_size[1]
+ for i in range(2):
+ if min_img[i, 1] > img_size[0]:
+ min_img[i, 1] = img_size[0]
+
+ if likelihood_ < 0.9:
+ # Preprocess
+ with profilers[0]:
+ im = self.preprocess(im0s)
+
+ # Inference
+ with profilers[1]:
+ preds = self.inference(im, *args, **kwargs)
+
+ # Postprocess
+ with profilers[2]:
+ self.results = self.postprocess(preds, im, im0s)
+
+ result = copy.deepcopy(self.results)
+ new_boxes = copy.deepcopy(self.results[0].boxes.data).cpu().numpy()
+ likelihoods = new_boxes[:, -2]
+ likelihood_ = 0
+ for i, likelihood in enumerate(likelihoods):
+ if likelihood > likelihood_:
+ likelihood_ = likelihood
+ result[0].boxes = self.results[0].boxes[i, :]
+ result[0].keypoints = self.results[0].keypoints[i, :, :]
+ self.results = result
+
+ if likelihood_ < 0.3:
+ kp = self.kal_kp
+ kp = torch.tensor(kp).to(torch.device('cuda'))
+
+ self.results[0].keypoints[:, :, :2][0][0] = kp[0]
+ self.results[0].keypoints[:, :, :2][0][1] = kp[1]
+ self.results[0].keypoints[:, :, :2][0][2] = kp[2]
+
+ img_size = copy.deepcopy(self.results[0].orig_shape)
+ last_box = result[0].boxes.xywh
+
+ min_img = [[(last_box[0, 0] - margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3]).cpu().numpy()],
+ [(last_box[0, 0] + margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] + margin_coefficient * last_box[0, 3]).cpu().numpy()]]
+ min_img = np.array(min_img).astype(np.int16)
+ for i in range(2):
+ if min_img[i, 0] > img_size[1]:
+ min_img[i, 0] = img_size[1]
+ for i in range(2):
+ if min_img[i, 1] > img_size[0]:
+ min_img[i, 1] = img_size[0]
+
+ else:
+ img_size = copy.deepcopy(self.results[0].orig_shape)
+ last_box = result[0].boxes.xywh
+
+ min_img = [[(last_box[0, 0] - margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3]).cpu().numpy()],
+ [(last_box[0, 0] + margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] + margin_coefficient * last_box[0, 3]).cpu().numpy()]]
+ min_img = np.array(min_img).astype(np.int16)
+ for i in range(2):
+ if min_img[i, 0] > img_size[1]:
+ min_img[i, 0] = img_size[1]
+ for i in range(2):
+ if min_img[i, 1] > img_size[0]:
+ min_img[i, 1] = img_size[0]
+ else:
+ # Preprocess
+ with profilers[0]:
+ im = self.preprocess(im0s)
+
+ # Inference
+ with profilers[1]:
+ preds = self.inference(im, *args, **kwargs)
+
+ # Postprocess
+ with profilers[2]:
+ self.results = self.postprocess(preds, im, im0s)
+
+ result = copy.deepcopy(self.results)
+ new_boxes = copy.deepcopy(self.results[0].boxes.data).cpu().numpy()
+ likelihoods = new_boxes[:, -2]
+ likelihood_ = 0
+ for i, likelihood in enumerate(likelihoods):
+ if likelihood > likelihood_:
+ likelihood_ = likelihood
+ result[0].boxes = self.results[0].boxes[i, :]
+ result[0].keypoints = self.results[0].keypoints[i, :, :]
+ self.results = result
+
+ kalman_kps = result[0].keypoints[0, :, :2].cpu().numpy().data
+
+ self.kal_kp[0, :] = kalman_kps[0, 0, :]
+ self.kal_kp[1, :] = kalman_kps[0, 1, :]
+ self.kal_kp[2, :] = kalman_kps[0, 2, :]
+
+ self.kalman_p_last[0, :] = kalman_kps[0, 0, :]
+ self.kalman_p_last[1, :] = kalman_kps[0, 1, :]
+ self.kalman_p_last[2, :] = kalman_kps[0, 2, :]
+ self.kalman()
+
+ img_size = copy.deepcopy(self.results[0].orig_shape)
+ last_box = result[0].boxes.xywh
+
+ min_img = [[(last_box[0, 0] - margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3]).cpu().numpy()],
+ [(last_box[0, 0] + margin_coefficient * last_box[0, 2]).cpu().numpy(),
+ (last_box[0, 1] + margin_coefficient * last_box[0, 3]).cpu().numpy()]]
+ min_img = np.array(min_img).astype(np.int16)
+ for i in range(2):
+ if min_img[i, 0] > img_size[1]:
+ min_img[i, 0] = img_size[1]
+ for i in range(2):
+ if min_img[i, 1] > img_size[0]:
+ min_img[i, 1] = img_size[0]
+
+ self.run_callbacks('on_predict_postprocess_end')
+
+ # 训练或识别单张图片
+ else:
+
+ # Preprocess
+ with profilers[0]:
+ im = self.preprocess(im0s)
+
+ # Inference
+ with profilers[1]:
+ preds = self.inference(im, *args, **kwargs)
+
+ # Postprocess
+ with profilers[2]:
+ self.results = self.postprocess(preds, im, im0s)
+ self.run_callbacks('on_predict_postprocess_end')
+
+ # Visualize, save, write results
+ n = len(im0s)
+ for i in range(n):
+ self.seen += 1
+ self.results[i].speed = {
+ 'preprocess': profilers[0].dt * 1E3 / n,
+ 'inference': profilers[1].dt * 1E3 / n,
+ 'postprocess': profilers[2].dt * 1E3 / n}
+ p, im0 = path[i], None if self.source_type.tensor else im0s[i].copy()
+ p = Path(p)
+
+ if self.args.verbose or self.args.save or self.args.save_txt or self.args.show:
+ s += self.write_results(i, self.results, (p, im, im0))
+ if self.args.save or self.args.save_txt:
+ self.results[i].save_dir = self.save_dir.__str__()
+ if self.args.show and self.plotted_img is not None:
+ self.show(p)
+ if self.args.save and self.plotted_img is not None:
+ self.save_preds(vid_cap, i, str(self.save_dir / p.name))
+
+ self.run_callbacks('on_predict_batch_end')
+ yield from self.results
+
+ # Print time (inference-only)
+ if self.args.verbose:
+ LOGGER.info(f'{s}{profilers[1].dt * 1E3:.1f}ms')
+
+ # Release assets
+ if isinstance(self.vid_writer[-1], cv2.VideoWriter):
+ self.vid_writer[-1].release() # release final video writer
+
+ # Print results
+ if self.args.verbose and self.seen:
+ t = tuple(x.t / self.seen * 1E3 for x in profilers) # speeds per image
+ LOGGER.info(f'Speed: %.1fms preprocess, %.1fms inference, %.1fms postprocess per image at shape '
+ f'{(1, 3, *im.shape[2:])}' % t)
+ if self.args.save or self.args.save_txt or self.args.save_crop:
+ nl = len(list(self.save_dir.glob('labels/*.txt'))) # number of labels
+ s = f"\n{nl} label{'s' * (nl > 1)} saved to {self.save_dir / 'labels'}" if self.args.save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', self.save_dir)}{s}")
+
+ self.run_callbacks('on_predict_end')
+
+ def setup_model(self, model, verbose=True):
+ """Initialize YOLO model with given parameters and set it to evaluation mode."""
+ self.model = AutoBackend(model or self.args.model,
+ device=select_device(self.args.device, verbose=verbose),
+ dnn=self.args.dnn,
+ data=self.args.data,
+ fp16=self.args.half,
+ fuse=True,
+ verbose=verbose)
+
+ self.device = self.model.device # update device
+ self.args.half = self.model.fp16 # update half
+ self.model.eval()
+
+ def show(self, p):
+ """Display an image in a window using OpenCV imshow()."""
+ im0 = self.plotted_img
+ if platform.system() == 'Linux' and p not in self.windows:
+ self.windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ cv2.waitKey(500 if self.batch[3].startswith('image') else 1) # 1 millisecond
+
+ def save_preds(self, vid_cap, idx, save_path):
+ """Save video predictions as mp4 at specified path."""
+ im0 = self.plotted_img
+ # Save imgs
+ if self.dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if self.vid_path[idx] != save_path: # new video
+ self.vid_path[idx] = save_path
+ if isinstance(self.vid_writer[idx], cv2.VideoWriter):
+ self.vid_writer[idx].release() # release previous video writer
+ if vid_cap: # video
+ fps = int(vid_cap.get(cv2.CAP_PROP_FPS)) # integer required, floats produce error in MP4 codec
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ suffix, fourcc = ('.mp4', 'avc1') if MACOS else ('.avi', 'WMV2') if WINDOWS else ('.avi', 'MJPG')
+ save_path = str(Path(save_path).with_suffix(suffix))
+ self.vid_writer[idx] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))
+ self.vid_writer[idx].write(im0)
+
+ def tf_img_min(self, last_box, result, img):
+ img_size = [img.shape[0], img.shape[1]]
+ tf_set = [(last_box[0, 0] - margin_coefficient * last_box[0, 2]),
+ (last_box[0, 1] - margin_coefficient * last_box[0, 3])]
+
+ result[0].boxes.data[0, 0] = result[0].boxes.data[0, 0] + tf_set[0]
+ result[0].boxes.data[0, 1] = result[0].boxes.data[0, 1] + tf_set[1]
+ result[0].boxes.data[0, 2] = result[0].boxes.data[0, 2] + tf_set[0]
+ result[0].boxes.data[0, 3] = result[0].boxes.data[0, 3] + tf_set[1]
+ result[0].boxes.orig_shape = img_size
+
+ for i in range(3):
+ result[0].keypoints.data[0, i, 0] = result[0].keypoints.data[0, i, 0] + tf_set[0]
+ result[0].keypoints.data[0, i, 1] = result[0].keypoints.data[0, i, 1] + tf_set[1]
+ result[0].keypoints.orig_shape = img_size
+
+ result[0].orig_img = img
+ result[0].orig_shape = img_size
+
+ return result, result[0].boxes.xywh
+
+ def run_callbacks(self, event: str):
+ """Runs all registered callbacks for a specific event."""
+ for callback in self.callbacks.get(event, []):
+ callback(self)
+
+ def add_callback(self, event: str, func):
+ """
+ Add callback
+ """
+ self.callbacks[event].append(func)
diff --git a/STPoseNet/ultralytics/engine/results.py b/STPoseNet/ultralytics/engine/results.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba805e3885438844adf55b6d10788787f785592f
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/results.py
@@ -0,0 +1,726 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Ultralytics Results, Boxes and Masks classes for handling inference results
+
+Usage: See https://docs.ultralytics.com/modes/predict/
+"""
+
+from copy import deepcopy
+from functools import lru_cache
+from pathlib import Path
+
+import numpy as np
+import torch
+
+from ultralytics.data.augment import LetterBox
+from ultralytics.utils import LOGGER, SimpleClass, deprecation_warn, ops
+from ultralytics.utils.plotting import Annotator, colors, save_one_box
+
+
+class BaseTensor(SimpleClass):
+ """
+ Base tensor class with additional methods for easy manipulation and device handling.
+ """
+
+ def __init__(self, data, orig_shape) -> None:
+ """Initialize BaseTensor with data and original shape.
+
+ Args:
+ data (torch.Tensor | np.ndarray): Predictions, such as bboxes, masks and keypoints.
+ orig_shape (tuple): Original shape of image.
+ """
+ assert isinstance(data, (torch.Tensor, np.ndarray))
+ self.data = data
+ self.orig_shape = orig_shape
+
+ @property
+ def shape(self):
+ """Return the shape of the data tensor."""
+ return self.data.shape
+
+ def cpu(self):
+ """Return a copy of the tensor on CPU memory."""
+ return self if isinstance(self.data, np.ndarray) else self.__class__(self.data.cpu(), self.orig_shape)
+
+ def numpy(self):
+ """Return a copy of the tensor as a numpy array."""
+ return self if isinstance(self.data, np.ndarray) else self.__class__(self.data.numpy(), self.orig_shape)
+
+ def cuda(self):
+ """Return a copy of the tensor on GPU memory."""
+ return self.__class__(torch.as_tensor(self.data).cuda(), self.orig_shape)
+
+ def to(self, *args, **kwargs):
+ """Return a copy of the tensor with the specified device and dtype."""
+ return self.__class__(torch.as_tensor(self.data).to(*args, **kwargs), self.orig_shape)
+
+ def __len__(self): # override len(results)
+ """Return the length of the data tensor."""
+ return len(self.data)
+
+ def __getitem__(self, idx):
+ """Return a BaseTensor with the specified index of the data tensor."""
+ return self.__class__(self.data[idx], self.orig_shape)
+
+
+class Results(SimpleClass):
+ """
+ A class for storing and manipulating inference results.
+
+ Args:
+ orig_img (numpy.ndarray): The original image as a numpy array.
+ path (str): The path to the image file.
+ names (dict): A dictionary of class names.
+ boxes (torch.tensor, optional): A 2D tensor of bounding box coordinates for each detection.
+ masks (torch.tensor, optional): A 3D tensor of detection masks, where each mask is a binary image.
+ probs (torch.tensor, optional): A 1D tensor of probabilities of each class for classification task.
+ keypoints (List[List[float]], optional): A list of detected keypoints for each object.
+
+ Attributes:
+ orig_img (numpy.ndarray): The original image as a numpy array.
+ orig_shape (tuple): The original image shape in (height, width) format.
+ boxes (Boxes, optional): A Boxes object containing the detection bounding boxes.
+ masks (Masks, optional): A Masks object containing the detection masks.
+ probs (Probs, optional): A Probs object containing probabilities of each class for classification task.
+ keypoints (Keypoints, optional): A Keypoints object containing detected keypoints for each object.
+ speed (dict): A dictionary of preprocess, inference, and postprocess speeds in milliseconds per image.
+ names (dict): A dictionary of class names.
+ path (str): The path to the image file.
+ _keys (tuple): A tuple of attribute names for non-empty attributes.
+ """
+
+ def __init__(self, orig_img, path, names, boxes=None, masks=None, probs=None, keypoints=None, min_flag=None) -> None:
+ """Initialize the Results class."""
+ self.orig_img = orig_img
+ self.orig_shape = orig_img.shape[:2]
+ self.boxes = Boxes(boxes, self.orig_shape) if boxes is not None else None # native size boxes
+ self.masks = Masks(masks, self.orig_shape) if masks is not None else None # native size or imgsz masks
+ self.probs = Probs(probs) if probs is not None else None
+ self.keypoints = Keypoints(keypoints, self.orig_shape) if keypoints is not None else None
+ self.speed = {'preprocess': None, 'inference': None, 'postprocess': None} # milliseconds per image
+ self.names = names
+ self.path = path
+ self.save_dir = None
+ self._keys = 'boxes', 'masks', 'probs', 'keypoints'
+
+ def __getitem__(self, idx):
+ """Return a Results object for the specified index."""
+ return self._apply('__getitem__', idx)
+
+ def __len__(self):
+ """Return the number of detections in the Results object."""
+ for k in self._keys:
+ v = getattr(self, k)
+ if v is not None:
+ return len(v)
+
+ def update(self, boxes=None, masks=None, probs=None):
+ """Update the boxes, masks, and probs attributes of the Results object."""
+ if boxes is not None:
+ ops.clip_boxes(boxes, self.orig_shape) # clip boxes
+ self.boxes = Boxes(boxes, self.orig_shape)
+ if masks is not None:
+ self.masks = Masks(masks, self.orig_shape)
+ if probs is not None:
+ self.probs = probs
+
+ def _apply(self, fn, *args, **kwargs):
+ r = self.new()
+ for k in self._keys:
+ v = getattr(self, k)
+ if v is not None:
+ setattr(r, k, getattr(v, fn)(*args, **kwargs))
+ return r
+
+ def cpu(self):
+ """Return a copy of the Results object with all tensors on CPU memory."""
+ return self._apply('cpu')
+
+ def numpy(self):
+ """Return a copy of the Results object with all tensors as numpy arrays."""
+ return self._apply('numpy')
+
+ def cuda(self):
+ """Return a copy of the Results object with all tensors on GPU memory."""
+ return self._apply('cuda')
+
+ def to(self, *args, **kwargs):
+ """Return a copy of the Results object with tensors on the specified device and dtype."""
+ return self._apply('to', *args, **kwargs)
+
+ def new(self):
+ """Return a new Results object with the same image, path, and names."""
+ return Results(orig_img=self.orig_img, path=self.path, names=self.names)
+
+ def plot(
+ self,
+ conf=True,
+ line_width=None,
+ font_size=None,
+ font='Arial.ttf',
+ pil=False,
+ img=None,
+ im_gpu=None,
+ kpt_radius=5,
+ kpt_line=True,
+ labels=True,
+ boxes=True,
+ masks=True,
+ probs=True,
+ **kwargs # deprecated args TODO: remove support in 8.2
+ ):
+ """
+ Plots the detection results on an input RGB image. Accepts a numpy array (cv2) or a PIL Image.
+
+ Args:
+ conf (bool): Whether to plot the detection confidence score.
+ line_width (float, optional): The line width of the bounding boxes. If None, it is scaled to the image size.
+ font_size (float, optional): The font size of the text. If None, it is scaled to the image size.
+ font (str): The font to use for the text.
+ pil (bool): Whether to return the image as a PIL Image.
+ img (numpy.ndarray): Plot to another image. if not, plot to original image.
+ im_gpu (torch.Tensor): Normalized image in gpu with shape (1, 3, 640, 640), for faster mask plotting.
+ kpt_radius (int, optional): Radius of the drawn keypoints. Default is 5.
+ kpt_line (bool): Whether to draw lines connecting keypoints.
+ labels (bool): Whether to plot the label of bounding boxes.
+ boxes (bool): Whether to plot the bounding boxes.
+ masks (bool): Whether to plot the masks.
+ probs (bool): Whether to plot classification probability
+
+ Returns:
+ (numpy.ndarray): A numpy array of the annotated image.
+
+ Example:
+ ```python
+ from PIL import Image
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ results = model('bus.jpg') # results list
+ for r in results:
+ im_array = r.plot() # plot a BGR numpy array of predictions
+ im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
+ im.show() # show image
+ im.save('results.jpg') # save image
+ ```
+ """
+ if img is None and isinstance(self.orig_img, torch.Tensor):
+ img = (self.orig_img[0].detach().permute(1, 2, 0).cpu().contiguous() * 255).to(torch.uint8).numpy()
+
+ # Deprecation warn TODO: remove in 8.2
+ if 'show_conf' in kwargs:
+ deprecation_warn('show_conf', 'conf')
+ conf = kwargs['show_conf']
+ assert isinstance(conf, bool), '`show_conf` should be of boolean type, i.e, show_conf=True/False'
+
+ if 'line_thickness' in kwargs:
+ deprecation_warn('line_thickness', 'line_width')
+ line_width = kwargs['line_thickness']
+ assert isinstance(line_width, int), '`line_width` should be of int type, i.e, line_width=3'
+
+ names = self.names
+ pred_boxes, show_boxes = self.boxes, boxes
+ pred_masks, show_masks = self.masks, masks
+ pred_probs, show_probs = self.probs, probs
+ annotator = Annotator(
+ deepcopy(self.orig_img if img is None else img),
+ line_width,
+ font_size,
+ font,
+ pil or (pred_probs is not None and show_probs), # Classify tasks default to pil=True
+ example=names)
+
+ # Plot Segment results
+ if pred_masks and show_masks:
+ if im_gpu is None:
+ img = LetterBox(pred_masks.shape[1:])(image=annotator.result())
+ im_gpu = torch.as_tensor(img, dtype=torch.float16, device=pred_masks.data.device).permute(
+ 2, 0, 1).flip(0).contiguous() / 255
+ idx = pred_boxes.cls if pred_boxes else range(len(pred_masks))
+ annotator.masks(pred_masks.data, colors=[colors(x, True) for x in idx], im_gpu=im_gpu)
+
+ # Plot Detect results
+ if pred_boxes and show_boxes:
+ for d in reversed(pred_boxes):
+ c, conf, id = int(d.cls), float(d.conf) if conf else None, None if d.id is None else int(d.id.item())
+ name = ('' if id is None else f'id:{id} ') + names[c]
+ label = (f'{name} {conf:.2f}' if conf else name) if labels else None
+ annotator.box_label(d.xyxy.squeeze(), label, color=colors(c, True))
+
+ # Plot Classify results
+ if pred_probs is not None and show_probs:
+ text = ',\n'.join(f'{names[j] if names else j} {pred_probs.data[j]:.2f}' for j in pred_probs.top5)
+ x = round(self.orig_shape[0] * 0.03)
+ annotator.text([x, x], text, txt_color=(255, 255, 255)) # TODO: allow setting colors
+
+ # Plot Pose results
+ if self.keypoints is not None:
+ for k in reversed(self.keypoints.data):
+ annotator.kpts(k, self.orig_shape, radius=kpt_radius, kpt_line=kpt_line)
+
+ return annotator.result()
+
+ def verbose(self):
+ """
+ Return log string for each task.
+ """
+ log_string = ''
+ probs = self.probs
+ boxes = self.boxes
+ if len(self) == 0:
+ return log_string if probs is not None else f'{log_string}(no detections), '
+ if probs is not None:
+ log_string += f"{', '.join(f'{self.names[j]} {probs.data[j]:.2f}' for j in probs.top5)}, "
+ if boxes:
+ for c in boxes.cls.unique():
+ n = (boxes.cls == c).sum() # detections per class
+ log_string += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, "
+ return log_string
+
+ def save_txt(self, txt_file, save_conf=False):
+ """
+ Save predictions into txt file.
+
+ Args:
+ txt_file (str): txt file path.
+ save_conf (bool): save confidence score or not.
+ """
+ boxes = self.boxes
+ masks = self.masks
+ probs = self.probs
+ kpts = self.keypoints
+ texts = []
+ if probs is not None:
+ # Classify
+ [texts.append(f'{probs.data[j]:.2f} {self.names[j]}') for j in probs.top5]
+ elif boxes:
+ # Detect/segment/pose
+ for j, d in enumerate(boxes):
+ c, conf, id = int(d.cls), float(d.conf), None if d.id is None else int(d.id.item())
+ line = (c, *d.xywhn.view(-1))
+ if masks:
+ seg = masks[j].xyn[0].copy().reshape(-1) # reversed mask.xyn, (n,2) to (n*2)
+ line = (c, *seg)
+ if kpts is not None:
+ kpt = torch.cat((kpts[j].xyn, kpts[j].conf[..., None]), 2) if kpts[j].has_visible else kpts[j].xyn
+ line += (*kpt.reshape(-1).tolist(), )
+ line += (conf, ) * save_conf + (() if id is None else (id, ))
+ texts.append(('%g ' * len(line)).rstrip() % line)
+
+ if texts:
+ Path(txt_file).parent.mkdir(parents=True, exist_ok=True) # make directory
+ with open(txt_file, 'a') as f:
+ f.writelines(text + '\n' for text in texts)
+
+ def save_crop(self, save_dir, file_name=Path('im.jpg')):
+ """
+ Save cropped predictions to `save_dir/cls/file_name.jpg`.
+
+ Args:
+ save_dir (str | pathlib.Path): Save path.
+ file_name (str | pathlib.Path): File name.
+ """
+ if self.probs is not None:
+ LOGGER.warning('WARNING ⚠️ Classify task do not support `save_crop`.')
+ return
+ for d in self.boxes:
+ save_one_box(d.xyxy,
+ self.orig_img.copy(),
+ file=Path(save_dir) / self.names[int(d.cls)] / f'{Path(file_name).stem}.jpg',
+ BGR=True)
+
+ def tojson(self, normalize=False):
+ """Convert the object to JSON format."""
+ if self.probs is not None:
+ LOGGER.warning('Warning: Classify task do not support `tojson` yet.')
+ return
+
+ import json
+
+ # Create list of detection dictionaries
+ results = []
+ data = self.boxes.data.cpu().tolist()
+ h, w = self.orig_shape if normalize else (1, 1)
+ for i, row in enumerate(data): # xyxy, track_id if tracking, conf, class_id
+ box = {'x1': row[0] / w, 'y1': row[1] / h, 'x2': row[2] / w, 'y2': row[3] / h}
+ conf = row[-2]
+ class_id = int(row[-1])
+ name = self.names[class_id]
+ result = {'name': name, 'class': class_id, 'confidence': conf, 'box': box}
+ if self.boxes.is_track:
+ result['track_id'] = int(row[-3]) # track ID
+ if self.masks:
+ x, y = self.masks.xy[i][:, 0], self.masks.xy[i][:, 1] # numpy array
+ result['segments'] = {'x': (x / w).tolist(), 'y': (y / h).tolist()}
+ if self.keypoints is not None:
+ x, y, visible = self.keypoints[i].data[0].cpu().unbind(dim=1) # torch Tensor
+ result['keypoints'] = {'x': (x / w).tolist(), 'y': (y / h).tolist(), 'visible': visible.tolist()}
+ results.append(result)
+
+ # Convert detections to JSON
+ return json.dumps(results, indent=2)
+
+
+class Boxes(BaseTensor):
+ """
+ A class for storing and manipulating detection boxes.
+
+ Args:
+ boxes (torch.Tensor | numpy.ndarray): A tensor or numpy array containing the detection boxes,
+ with shape (num_boxes, 6) or (num_boxes, 7). The last two columns contain confidence and class values.
+ If present, the third last column contains track IDs.
+ orig_shape (tuple): Original image size, in the format (height, width).
+
+ Attributes:
+ xyxy (torch.Tensor | numpy.ndarray): The boxes in xyxy format.
+ conf (torch.Tensor | numpy.ndarray): The confidence values of the boxes.
+ cls (torch.Tensor | numpy.ndarray): The class values of the boxes.
+ id (torch.Tensor | numpy.ndarray): The track IDs of the boxes (if available).
+ xywh (torch.Tensor | numpy.ndarray): The boxes in xywh format.
+ xyxyn (torch.Tensor | numpy.ndarray): The boxes in xyxy format normalized by original image size.
+ xywhn (torch.Tensor | numpy.ndarray): The boxes in xywh format normalized by original image size.
+ data (torch.Tensor): The raw bboxes tensor (alias for `boxes`).
+
+ Methods:
+ cpu(): Move the object to CPU memory.
+ numpy(): Convert the object to a numpy array.
+ cuda(): Move the object to CUDA memory.
+ to(*args, **kwargs): Move the object to the specified device.
+ """
+
+ def __init__(self, boxes, orig_shape) -> None:
+ """Initialize the Boxes class."""
+ if boxes.ndim == 1:
+ boxes = boxes[None, :]
+ n = boxes.shape[-1]
+ assert n in (6, 7), f'expected `n` in [6, 7], but got {n}' # xyxy, track_id, conf, cls
+ super().__init__(boxes, orig_shape)
+ self.is_track = n == 7
+ self.orig_shape = orig_shape
+
+ @property
+ def xyxy(self):
+ """Return the boxes in xyxy format."""
+ return self.data[:, :4]
+
+ @property
+ def conf(self):
+ """Return the confidence values of the boxes."""
+ return self.data[:, -2]
+
+ @property
+ def cls(self):
+ """Return the class values of the boxes."""
+ return self.data[:, -1]
+
+ @property
+ def id(self):
+ """Return the track IDs of the boxes (if available)."""
+ return self.data[:, -3] if self.is_track else None
+
+ @property
+ @lru_cache(maxsize=2) # maxsize 1 should suffice
+ def xywh(self):
+ """Return the boxes in xywh format."""
+ return ops.xyxy2xywh(self.xyxy)
+
+ @property
+ @lru_cache(maxsize=2)
+ def xyxyn(self):
+ """Return the boxes in xyxy format normalized by original image size."""
+ xyxy = self.xyxy.clone() if isinstance(self.xyxy, torch.Tensor) else np.copy(self.xyxy)
+ xyxy[..., [0, 2]] /= self.orig_shape[1]
+ xyxy[..., [1, 3]] /= self.orig_shape[0]
+ return xyxy
+
+ @property
+ @lru_cache(maxsize=2)
+ def xywhn(self):
+ """Return the boxes in xywh format normalized by original image size."""
+ xywh = ops.xyxy2xywh(self.xyxy)
+ xywh[..., [0, 2]] /= self.orig_shape[1]
+ xywh[..., [1, 3]] /= self.orig_shape[0]
+ return xywh
+
+ @property
+ def boxes(self):
+ """Return the raw bboxes tensor (deprecated)."""
+ LOGGER.warning("WARNING ⚠️ 'Boxes.boxes' is deprecated. Use 'Boxes.data' instead.")
+ return self.data
+
+
+class Boxes_min(BaseTensor):
+ """
+ A class for storing and manipulating detection boxes.
+
+ Args:
+ boxes (torch.Tensor | numpy.ndarray): A tensor or numpy array containing the detection boxes,
+ with shape (num_boxes, 6) or (num_boxes, 7). The last two columns contain confidence and class values.
+ If present, the third last column contains track IDs.
+ orig_shape (tuple): Original image size, in the format (height, width).
+
+ Attributes:
+ xyxy (torch.Tensor | numpy.ndarray): The boxes in xyxy format.
+ conf (torch.Tensor | numpy.ndarray): The confidence values of the boxes.
+ cls (torch.Tensor | numpy.ndarray): The class values of the boxes.
+ id (torch.Tensor | numpy.ndarray): The track IDs of the boxes (if available).
+ xywh (torch.Tensor | numpy.ndarray): The boxes in xywh format.
+ xyxyn (torch.Tensor | numpy.ndarray): The boxes in xyxy format normalized by original image size.
+ xywhn (torch.Tensor | numpy.ndarray): The boxes in xywh format normalized by original image size.
+ data (torch.Tensor): The raw bboxes tensor (alias for `boxes`).
+
+ Methods:
+ cpu(): Move the object to CPU memory.
+ numpy(): Convert the object to a numpy array.
+ cuda(): Move the object to CUDA memory.
+ to(*args, **kwargs): Move the object to the specified device.
+ """
+
+ def __init__(self, boxes, orig_shape) -> None:
+ """Initialize the Boxes class."""
+ if boxes.ndim == 1:
+ boxes = boxes[None, :]
+ n = boxes.shape[-1]
+ assert n in (6, 7), f'expected `n` in [6, 7], but got {n}' # xyxy, track_id, conf, cls
+ super().__init__(boxes, orig_shape)
+ self.is_track = n == 7
+ self.orig_shape = orig_shape
+
+ @property
+ def xyxy(self):
+ """Return the boxes in xyxy format."""
+ return self.data[:, :4]
+
+ @property
+ def conf(self):
+ """Return the confidence values of the boxes."""
+ return self.data[:, -2]
+
+ @property
+ def cls(self):
+ """Return the class values of the boxes."""
+ return self.data[:, -1]
+
+ @property
+ def id(self):
+ """Return the track IDs of the boxes (if available)."""
+ return self.data[:, -3] if self.is_track else None
+
+ @property
+ @lru_cache(maxsize=2) # maxsize 1 should suffice
+ def xywh(self):
+ """Return the boxes in xywh format."""
+ return ops.xyxy2xywh(self.xyxy)
+
+ @property
+ @lru_cache(maxsize=2)
+ def xyxyn(self):
+ """Return the boxes in xyxy format normalized by original image size."""
+ xyxy = self.xyxy.clone() if isinstance(self.xyxy, torch.Tensor) else np.copy(self.xyxy)
+ xyxy[..., [0, 2]] /= self.orig_shape[1]
+ xyxy[..., [1, 3]] /= self.orig_shape[0]
+ return xyxy
+
+ @property
+ @lru_cache(maxsize=2)
+ def xywhn(self):
+ """Return the boxes in xywh format normalized by original image size."""
+ xywh = ops.xyxy2xywh(self.xyxy)
+ xywh[..., [0, 2]] /= self.orig_shape[1]
+ xywh[..., [1, 3]] /= self.orig_shape[0]
+ return xywh
+
+ @property
+ def boxes(self):
+ """Return the raw bboxes tensor (deprecated)."""
+ LOGGER.warning("WARNING ⚠️ 'Boxes.boxes' is deprecated. Use 'Boxes.data' instead.")
+ return self.data
+
+
+class Masks(BaseTensor):
+ """
+ A class for storing and manipulating detection masks.
+
+ Attributes:
+ segments (list): Deprecated property for segments (normalized).
+ xy (list): A list of segments in pixel coordinates.
+ xyn (list): A list of normalized segments.
+
+ Methods:
+ cpu(): Returns the masks tensor on CPU memory.
+ numpy(): Returns the masks tensor as a numpy array.
+ cuda(): Returns the masks tensor on GPU memory.
+ to(device, dtype): Returns the masks tensor with the specified device and dtype.
+ """
+
+ def __init__(self, masks, orig_shape) -> None:
+ """Initialize the Masks class with the given masks tensor and original image shape."""
+ if masks.ndim == 2:
+ masks = masks[None, :]
+ super().__init__(masks, orig_shape)
+
+ @property
+ @lru_cache(maxsize=1)
+ def segments(self):
+ """Return segments (normalized). Deprecated; use xyn property instead."""
+ LOGGER.warning(
+ "WARNING ⚠️ 'Masks.segments' is deprecated. Use 'Masks.xyn' for segments (normalized) and 'Masks.xy' for segments (pixels) instead."
+ )
+ return self.xyn
+
+ @property
+ @lru_cache(maxsize=1)
+ def xyn(self):
+ """Return normalized segments."""
+ return [
+ ops.scale_coords(self.data.shape[1:], x, self.orig_shape, normalize=True)
+ for x in ops.masks2segments(self.data)]
+
+ @property
+ @lru_cache(maxsize=1)
+ def xy(self):
+ """Return segments in pixel coordinates."""
+ return [
+ ops.scale_coords(self.data.shape[1:], x, self.orig_shape, normalize=False)
+ for x in ops.masks2segments(self.data)]
+
+ @property
+ def masks(self):
+ """Return the raw masks tensor. Deprecated; use data attribute instead."""
+ LOGGER.warning("WARNING ⚠️ 'Masks.masks' is deprecated. Use 'Masks.data' instead.")
+ return self.data
+
+
+class Keypoints(BaseTensor):
+ """
+ A class for storing and manipulating detection keypoints.
+
+ Attributes:
+ xy (torch.Tensor): A collection of keypoints containing x, y coordinates for each detection.
+ xyn (torch.Tensor): A normalized version of xy with coordinates in the range [0, 1].
+ conf (torch.Tensor): Confidence values associated with keypoints if available, otherwise None.
+
+ Methods:
+ cpu(): Returns a copy of the keypoints tensor on CPU memory.
+ numpy(): Returns a copy of the keypoints tensor as a numpy array.
+ cuda(): Returns a copy of the keypoints tensor on GPU memory.
+ to(device, dtype): Returns a copy of the keypoints tensor with the specified device and dtype.
+ """
+
+ def __init__(self, keypoints, orig_shape) -> None:
+ """Initializes the Keypoints object with detection keypoints and original image size."""
+ if keypoints.ndim == 2:
+ keypoints = keypoints[None, :]
+ super().__init__(keypoints, orig_shape)
+ self.has_visible = self.data.shape[-1] == 3
+
+ @property
+ @lru_cache(maxsize=1)
+ def xy(self):
+ """Returns x, y coordinates of keypoints."""
+ return self.data[..., :2]
+
+ @property
+ @lru_cache(maxsize=1)
+ def xyn(self):
+ """Returns normalized x, y coordinates of keypoints."""
+ xy = self.xy.clone() if isinstance(self.xy, torch.Tensor) else np.copy(self.xy)
+ xy[..., 0] /= self.orig_shape[1]
+ xy[..., 1] /= self.orig_shape[0]
+ return xy
+
+ @property
+ @lru_cache(maxsize=1)
+ def conf(self):
+ """Returns confidence values of keypoints if available, else None."""
+ return self.data[..., 2] if self.has_visible else None
+
+
+class Keypoints_min(BaseTensor):
+ """
+ A class for storing and manipulating detection keypoints.
+
+ Attributes:
+ xy (torch.Tensor): A collection of keypoints containing x, y coordinates for each detection.
+ xyn (torch.Tensor): A normalized version of xy with coordinates in the range [0, 1].
+ conf (torch.Tensor): Confidence values associated with keypoints if available, otherwise None.
+
+ Methods:
+ cpu(): Returns a copy of the keypoints tensor on CPU memory.
+ numpy(): Returns a copy of the keypoints tensor as a numpy array.
+ cuda(): Returns a copy of the keypoints tensor on GPU memory.
+ to(device, dtype): Returns a copy of the keypoints tensor with the specified device and dtype.
+ """
+
+ def __init__(self, keypoints, orig_shape) -> None:
+ """Initializes the Keypoints object with detection keypoints and original image size."""
+ if keypoints.ndim == 2:
+ keypoints = keypoints[None, :]
+ super().__init__(keypoints, orig_shape)
+ self.has_visible = self.data.shape[-1] == 3
+
+ @property
+ @lru_cache(maxsize=1)
+ def xy(self):
+ """Returns x, y coordinates of keypoints."""
+ return self.data[..., :2]
+
+ @property
+ @lru_cache(maxsize=1)
+ def xyn(self):
+ """Returns normalized x, y coordinates of keypoints."""
+ xy = self.xy.clone() if isinstance(self.xy, torch.Tensor) else np.copy(self.xy)
+ xy[..., 0] /= self.orig_shape[1]
+ xy[..., 1] /= self.orig_shape[0]
+ return xy
+
+ @property
+ @lru_cache(maxsize=1)
+ def conf(self):
+ """Returns confidence values of keypoints if available, else None."""
+ return self.data[..., 2] if self.has_visible else None
+
+
+class Probs(BaseTensor):
+ """
+ A class for storing and manipulating classification predictions.
+
+ Attributes:
+ top1 (int): Index of the top 1 class.
+ top5 (list[int]): Indices of the top 5 classes.
+ top1conf (torch.Tensor): Confidence of the top 1 class.
+ top5conf (torch.Tensor): Confidences of the top 5 classes.
+
+ Methods:
+ cpu(): Returns a copy of the probs tensor on CPU memory.
+ numpy(): Returns a copy of the probs tensor as a numpy array.
+ cuda(): Returns a copy of the probs tensor on GPU memory.
+ to(): Returns a copy of the probs tensor with the specified device and dtype.
+ """
+
+ def __init__(self, probs, orig_shape=None) -> None:
+ super().__init__(probs, orig_shape)
+
+ @property
+ @lru_cache(maxsize=1)
+ def top1(self):
+ """Return the index of top 1."""
+ return int(self.data.argmax())
+
+ @property
+ @lru_cache(maxsize=1)
+ def top5(self):
+ """Return the indices of top 5."""
+ return (-self.data).argsort(0)[:5].tolist() # this way works with both torch and numpy.
+
+ @property
+ @lru_cache(maxsize=1)
+ def top1conf(self):
+ """Return the confidence of top 1."""
+ return self.data[self.top1]
+
+ @property
+ @lru_cache(maxsize=1)
+ def top5conf(self):
+ """Return the confidences of top 5."""
+ return self.data[self.top5]
diff --git a/STPoseNet/ultralytics/engine/trainer.py b/STPoseNet/ultralytics/engine/trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..6fb5f8bdc9b7f16e996d465941c8a376db43ea32
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/trainer.py
@@ -0,0 +1,690 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Train a model on a dataset
+
+Usage:
+ $ yolo mode=train model=yolov8n.pt data=coco128.yaml imgsz=640 epochs=100 batch=16
+"""
+
+import math
+import os
+import subprocess
+import time
+import warnings
+from copy import deepcopy
+from datetime import datetime, timedelta
+from pathlib import Path
+
+import numpy as np
+import torch
+from torch import distributed as dist
+from torch import nn, optim
+from torch.cuda import amp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from tqdm import tqdm
+
+from ultralytics.cfg import get_cfg, get_save_dir
+from ultralytics.data.utils import check_cls_dataset, check_det_dataset
+from ultralytics.nn.tasks import attempt_load_one_weight, attempt_load_weights
+from ultralytics.utils import (DEFAULT_CFG, LOGGER, RANK, TQDM_BAR_FORMAT, __version__, callbacks, clean_url, colorstr,
+ emojis, yaml_save)
+from ultralytics.utils.autobatch import check_train_batch_size
+from ultralytics.utils.checks import check_amp, check_file, check_imgsz, print_args
+from ultralytics.utils.dist import ddp_cleanup, generate_ddp_command
+from ultralytics.utils.files import get_latest_run
+from ultralytics.utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, init_seeds, one_cycle, select_device,
+ strip_optimizer)
+
+
+class BaseTrainer:
+ """
+ BaseTrainer
+
+ A base class for creating trainers.
+
+ Attributes:
+ args (SimpleNamespace): Configuration for the trainer.
+ check_resume (method): Method to check if training should be resumed from a saved checkpoint.
+ validator (BaseValidator): Validator instance.
+ model (nn.Module): Model instance.
+ callbacks (defaultdict): Dictionary of callbacks.
+ save_dir (Path): Directory to save results.
+ wdir (Path): Directory to save weights.
+ last (Path): Path to the last checkpoint.
+ best (Path): Path to the best checkpoint.
+ save_period (int): Save checkpoint every x epochs (disabled if < 1).
+ batch_size (int): Batch size for training.
+ epochs (int): Number of epochs to train for.
+ start_epoch (int): Starting epoch for training.
+ device (torch.device): Device to use for training.
+ amp (bool): Flag to enable AMP (Automatic Mixed Precision).
+ scaler (amp.GradScaler): Gradient scaler for AMP.
+ data (str): Path to data.
+ trainset (torch.utils.data.Dataset): Training dataset.
+ testset (torch.utils.data.Dataset): Testing dataset.
+ ema (nn.Module): EMA (Exponential Moving Average) of the model.
+ lf (nn.Module): Loss function.
+ scheduler (torch.optim.lr_scheduler._LRScheduler): Learning rate scheduler.
+ best_fitness (float): The best fitness value achieved.
+ fitness (float): Current fitness value.
+ loss (float): Current loss value.
+ tloss (float): Total loss value.
+ loss_names (list): List of loss names.
+ csv (Path): Path to results CSV file.
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """
+ Initializes the BaseTrainer class.
+
+ Args:
+ cfg (str, optional): Path to a configuration file. Defaults to DEFAULT_CFG.
+ overrides (dict, optional): Configuration overrides. Defaults to None.
+ """
+ self.args = get_cfg(cfg, overrides)
+ self.check_resume(overrides)
+ self.device = select_device(self.args.device, self.args.batch)
+ self.validator = None
+ self.model = None
+ self.metrics = None
+ self.plots = {}
+ init_seeds(self.args.seed + 1 + RANK, deterministic=self.args.deterministic)
+
+ # Dirs
+ self.save_dir = get_save_dir(self.args)
+ self.wdir = self.save_dir / 'weights' # weights dir
+ if RANK in (-1, 0):
+ self.wdir.mkdir(parents=True, exist_ok=True) # make dir
+ self.args.save_dir = str(self.save_dir)
+ yaml_save(self.save_dir / 'args.yaml', vars(self.args)) # save run args
+ self.last, self.best = self.wdir / 'last.pt', self.wdir / 'best.pt' # checkpoint paths
+ self.save_period = self.args.save_period
+
+ self.batch_size = self.args.batch
+ self.epochs = self.args.epochs
+ self.start_epoch = 0
+ if RANK == -1:
+ print_args(vars(self.args))
+
+ # Device
+ if self.device.type == 'cpu':
+ self.args.workers = 0 # faster CPU training as time dominated by inference, not dataloading
+
+ # Model and Dataset
+ self.model = self.args.model
+ try:
+ if self.args.task == 'classify':
+ self.data = check_cls_dataset(self.args.data)
+ elif self.args.data.split('.')[-1] in ('yaml', 'yml') or self.args.task in ('detect', 'segment'):
+ self.data = check_det_dataset(self.args.data)
+ if 'yaml_file' in self.data:
+ self.args.data = self.data['yaml_file'] # for validating 'yolo train data=url.zip' usage
+ except Exception as e:
+ raise RuntimeError(emojis(f"Dataset '{clean_url(self.args.data)}' error ❌ {e}")) from e
+
+ self.trainset, self.testset = self.get_dataset(self.data)
+ self.ema = None
+
+ # Optimization utils init
+ self.lf = None
+ self.scheduler = None
+
+ # Epoch level metrics
+ self.best_fitness = None
+ self.fitness = None
+ self.loss = None
+ self.tloss = None
+ self.loss_names = ['Loss']
+ self.csv = self.save_dir / 'results.csv'
+ self.plot_idx = [0, 1, 2]
+
+ # Callbacks
+ self.callbacks = _callbacks or callbacks.get_default_callbacks()
+ if RANK in (-1, 0):
+ callbacks.add_integration_callbacks(self)
+
+ def add_callback(self, event: str, callback):
+ """
+ Appends the given callback.
+ """
+ self.callbacks[event].append(callback)
+
+ def set_callback(self, event: str, callback):
+ """
+ Overrides the existing callbacks with the given callback.
+ """
+ self.callbacks[event] = [callback]
+
+ def run_callbacks(self, event: str):
+ """Run all existing callbacks associated with a particular event."""
+ for callback in self.callbacks.get(event, []):
+ callback(self)
+
+ def train(self):
+ """Allow device='', device=None on Multi-GPU systems to default to device=0."""
+ if isinstance(self.args.device, str) and len(self.args.device): # i.e. device='0' or device='0,1,2,3'
+ world_size = len(self.args.device.split(','))
+ elif isinstance(self.args.device, (tuple, list)): # i.e. device=[0, 1, 2, 3] (multi-GPU from CLI is list)
+ world_size = len(self.args.device)
+ elif torch.cuda.is_available(): # i.e. device=None or device='' or device=number
+ world_size = 1 # default to device 0
+ else: # i.e. device='cpu' or 'mps'
+ world_size = 0
+
+ # Run subprocess if DDP training, else train normally
+ if world_size > 1 and 'LOCAL_RANK' not in os.environ:
+ # Argument checks
+ if self.args.rect:
+ LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with Multi-GPU training, setting 'rect=False'")
+ self.args.rect = False
+ if self.args.batch == -1:
+ LOGGER.warning("WARNING ⚠️ 'batch=-1' for AutoBatch is incompatible with Multi-GPU training, setting "
+ "default 'batch=16'")
+ self.args.batch = 16
+
+ # Command
+ cmd, file = generate_ddp_command(world_size, self)
+ try:
+ LOGGER.info(f'{colorstr("DDP:")} debug command {" ".join(cmd)}')
+ subprocess.run(cmd, check=True)
+ except Exception as e:
+ raise e
+ finally:
+ ddp_cleanup(self, str(file))
+
+ else:
+ self._do_train(world_size)
+
+ def _setup_ddp(self, world_size):
+ """Initializes and sets the DistributedDataParallel parameters for training."""
+ torch.cuda.set_device(RANK)
+ self.device = torch.device('cuda', RANK)
+ # LOGGER.info(f'DDP info: RANK {RANK}, WORLD_SIZE {world_size}, DEVICE {self.device}')
+ os.environ['NCCL_BLOCKING_WAIT'] = '1' # set to enforce timeout
+ dist.init_process_group(
+ 'nccl' if dist.is_nccl_available() else 'gloo',
+ timeout=timedelta(seconds=10800), # 3 hours
+ rank=RANK,
+ world_size=world_size)
+
+ def _setup_train(self, world_size):
+ """
+ Builds dataloaders and optimizer on correct rank process.
+ """
+
+ # Model
+ self.run_callbacks('on_pretrain_routine_start')
+ ckpt = self.setup_model()
+ self.model = self.model.to(self.device)
+ self.set_model_attributes()
+
+ # Freeze layers
+ freeze_list = self.args.freeze if isinstance(
+ self.args.freeze, list) else range(self.args.freeze) if isinstance(self.args.freeze, int) else []
+ always_freeze_names = ['.dfl'] # always freeze these layers
+ freeze_layer_names = [f'model.{x}.' for x in freeze_list] + always_freeze_names
+ for k, v in self.model.named_parameters():
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze_layer_names):
+ LOGGER.info(f"Freezing layer '{k}'")
+ v.requires_grad = False
+ elif not v.requires_grad:
+ LOGGER.info(f"WARNING ⚠️ setting 'requires_grad=True' for frozen layer '{k}'. "
+ 'See ultralytics.engine.trainer for customization of frozen layers.')
+ v.requires_grad = True
+
+ # Check AMP
+ self.amp = torch.tensor(self.args.amp).to(self.device) # True or False
+ if self.amp and RANK in (-1, 0): # Single-GPU and DDP
+ callbacks_backup = callbacks.default_callbacks.copy() # backup callbacks as check_amp() resets them
+ self.amp = torch.tensor(check_amp(self.model), device=self.device)
+ callbacks.default_callbacks = callbacks_backup # restore callbacks
+ if RANK > -1 and world_size > 1: # DDP
+ dist.broadcast(self.amp, src=0) # broadcast the tensor from rank 0 to all other ranks (returns None)
+ self.amp = bool(self.amp) # as boolean
+ self.scaler = amp.GradScaler(enabled=self.amp)
+ if world_size > 1:
+ self.model = DDP(self.model, device_ids=[RANK])
+
+ # Check imgsz
+ gs = max(int(self.model.stride.max() if hasattr(self.model, 'stride') else 32), 32) # grid size (max stride)
+ self.args.imgsz = check_imgsz(self.args.imgsz, stride=gs, floor=gs, max_dim=1)
+
+ # Batch size
+ if self.batch_size == -1:
+ if RANK == -1: # single-GPU only, estimate best batch size
+ self.args.batch = self.batch_size = check_train_batch_size(self.model, self.args.imgsz, self.amp)
+
+ # Dataloaders
+ batch_size = self.batch_size // max(world_size, 1)
+ self.train_loader = self.get_dataloader(self.trainset, batch_size=batch_size, rank=RANK, mode='train')
+ if RANK in (-1, 0):
+ self.test_loader = self.get_dataloader(self.testset, batch_size=batch_size * 2, rank=-1, mode='val')
+ self.validator = self.get_validator()
+ metric_keys = self.validator.metrics.keys + self.label_loss_items(prefix='val')
+ self.metrics = dict(zip(metric_keys, [0] * len(metric_keys))) # TODO: init metrics for plot_results()?
+ self.ema = ModelEMA(self.model)
+ if self.args.plots:
+ self.plot_training_labels()
+
+ # Optimizer
+ self.accumulate = max(round(self.args.nbs / self.batch_size), 1) # accumulate loss before optimizing
+ weight_decay = self.args.weight_decay * self.batch_size * self.accumulate / self.args.nbs # scale weight_decay
+ iterations = math.ceil(len(self.train_loader.dataset) / max(self.batch_size, self.args.nbs)) * self.epochs
+ self.optimizer = self.build_optimizer(model=self.model,
+ name=self.args.optimizer,
+ lr=self.args.lr0,
+ momentum=self.args.momentum,
+ decay=weight_decay,
+ iterations=iterations)
+ # Scheduler
+ if self.args.cos_lr:
+ self.lf = one_cycle(1, self.args.lrf, self.epochs) # cosine 1->hyp['lrf']
+ else:
+ self.lf = lambda x: (1 - x / self.epochs) * (1.0 - self.args.lrf) + self.args.lrf # linear
+ self.scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=self.lf)
+ self.stopper, self.stop = EarlyStopping(patience=self.args.patience), False
+ self.resume_training(ckpt)
+ self.scheduler.last_epoch = self.start_epoch - 1 # do not move
+ self.run_callbacks('on_pretrain_routine_end')
+
+ def _do_train(self, world_size=1):
+ """Train completed, evaluate and plot if specified by arguments."""
+ if world_size > 1:
+ self._setup_ddp(world_size)
+ self._setup_train(world_size)
+
+ self.epoch_time = None
+ self.epoch_time_start = time.time()
+ self.train_time_start = time.time()
+ nb = len(self.train_loader) # number of batches
+ nw = max(round(self.args.warmup_epochs * nb), 100) if self.args.warmup_epochs > 0 else -1 # warmup iterations
+ last_opt_step = -1
+ self.run_callbacks('on_train_start')
+ LOGGER.info(f'Image sizes {self.args.imgsz} train, {self.args.imgsz} val\n'
+ f'Using {self.train_loader.num_workers * (world_size or 1)} dataloader workers\n'
+ f"Logging results to {colorstr('bold', self.save_dir)}\n"
+ f'Starting training for {self.epochs} epochs...')
+ if self.args.close_mosaic:
+ base_idx = (self.epochs - self.args.close_mosaic) * nb
+ self.plot_idx.extend([base_idx, base_idx + 1, base_idx + 2])
+ epoch = self.epochs # predefine for resume fully trained model edge cases
+ for epoch in range(self.start_epoch, self.epochs):
+ self.epoch = epoch
+ self.run_callbacks('on_train_epoch_start')
+ self.model.train()
+ if RANK != -1:
+ self.train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(self.train_loader)
+ # Update dataloader attributes (optional)
+ if epoch == (self.epochs - self.args.close_mosaic):
+ LOGGER.info('Closing dataloader mosaic')
+ if hasattr(self.train_loader.dataset, 'mosaic'):
+ self.train_loader.dataset.mosaic = False
+ if hasattr(self.train_loader.dataset, 'close_mosaic'):
+ self.train_loader.dataset.close_mosaic(hyp=self.args)
+ self.train_loader.reset()
+
+ if RANK in (-1, 0):
+ LOGGER.info(self.progress_string())
+ pbar = tqdm(enumerate(self.train_loader), total=nb, bar_format=TQDM_BAR_FORMAT)
+ self.tloss = None
+ self.optimizer.zero_grad()
+ for i, batch in pbar:
+ self.run_callbacks('on_train_batch_start')
+ # Warmup
+ ni = i + nb * epoch
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ self.accumulate = max(1, np.interp(ni, xi, [1, self.args.nbs / self.batch_size]).round())
+ for j, x in enumerate(self.optimizer.param_groups):
+ # Bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(
+ ni, xi, [self.args.warmup_bias_lr if j == 0 else 0.0, x['initial_lr'] * self.lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [self.args.warmup_momentum, self.args.momentum])
+
+ # Forward
+ with torch.cuda.amp.autocast(self.amp):
+ batch = self.preprocess_batch(batch)
+ self.loss, self.loss_items = self.model(batch)
+ if RANK != -1:
+ self.loss *= world_size
+ self.tloss = (self.tloss * i + self.loss_items) / (i + 1) if self.tloss is not None \
+ else self.loss_items
+
+ # Backward
+ self.scaler.scale(self.loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= self.accumulate:
+ self.optimizer_step()
+ last_opt_step = ni
+
+ # Log
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ loss_len = self.tloss.shape[0] if len(self.tloss.size()) else 1
+ losses = self.tloss if loss_len > 1 else torch.unsqueeze(self.tloss, 0)
+ if RANK in (-1, 0):
+ pbar.set_description(
+ ('%11s' * 2 + '%11.4g' * (2 + loss_len)) %
+ (f'{epoch + 1}/{self.epochs}', mem, *losses, batch['cls'].shape[0], batch['img'].shape[-1]))
+ self.run_callbacks('on_batch_end')
+ if self.args.plots and ni in self.plot_idx:
+ self.plot_training_samples(batch, ni)
+
+ self.run_callbacks('on_train_batch_end')
+
+ self.lr = {f'lr/pg{ir}': x['lr'] for ir, x in enumerate(self.optimizer.param_groups)} # for loggers
+
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress 'Detected lr_scheduler.step() before optimizer.step()'
+ self.scheduler.step()
+ self.run_callbacks('on_train_epoch_end')
+
+ if RANK in (-1, 0):
+
+ # Validation
+ self.ema.update_attr(self.model, include=['yaml', 'nc', 'args', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == self.epochs) or self.stopper.possible_stop
+
+ if self.args.val or final_epoch:
+ self.metrics, self.fitness = self.validate()
+ self.save_metrics(metrics={**self.label_loss_items(self.tloss), **self.metrics, **self.lr})
+ self.stop = self.stopper(epoch + 1, self.fitness)
+
+ # Save model
+ if self.args.save or (epoch + 1 == self.epochs):
+ self.save_model()
+ self.run_callbacks('on_model_save')
+
+ tnow = time.time()
+ self.epoch_time = tnow - self.epoch_time_start
+ self.epoch_time_start = tnow
+ self.run_callbacks('on_fit_epoch_end')
+ torch.cuda.empty_cache() # clears GPU vRAM at end of epoch, can help with out of memory errors
+
+ # Early Stopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [self.stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ self.stop = broadcast_list[0]
+ if self.stop:
+ break # must break all DDP ranks
+
+ if RANK in (-1, 0):
+ # Do final val with best.pt
+ LOGGER.info(f'\n{epoch - self.start_epoch + 1} epochs completed in '
+ f'{(time.time() - self.train_time_start) / 3600:.3f} hours.')
+ self.final_eval()
+ if self.args.plots:
+ self.plot_metrics()
+ self.run_callbacks('on_train_end')
+ torch.cuda.empty_cache()
+ self.run_callbacks('teardown')
+
+ def save_model(self):
+ """Save model checkpoints based on various conditions."""
+ ckpt = {
+ 'epoch': self.epoch,
+ 'best_fitness': self.best_fitness,
+ 'model': deepcopy(de_parallel(self.model)).half(),
+ 'ema': deepcopy(self.ema.ema).half(),
+ 'updates': self.ema.updates,
+ 'optimizer': self.optimizer.state_dict(),
+ 'train_args': vars(self.args), # save as dict
+ 'date': datetime.now().isoformat(),
+ 'version': __version__}
+
+ # Use dill (if exists) to serialize the lambda functions where pickle does not do this
+ try:
+ import dill as pickle
+ except ImportError:
+ import pickle
+
+ # Save last, best and delete
+ torch.save(ckpt, self.last, pickle_module=pickle)
+ if self.best_fitness == self.fitness:
+ torch.save(ckpt, self.best, pickle_module=pickle)
+ if (self.epoch > 0) and (self.save_period > 0) and (self.epoch % self.save_period == 0):
+ torch.save(ckpt, self.wdir / f'epoch{self.epoch}.pt', pickle_module=pickle)
+ del ckpt
+
+ @staticmethod
+ def get_dataset(data):
+ """
+ Get train, val path from data dict if it exists. Returns None if data format is not recognized.
+ """
+ return data['train'], data.get('val') or data.get('test')
+
+ def setup_model(self):
+ """
+ load/create/download model for any task.
+ """
+ if isinstance(self.model, torch.nn.Module): # if model is loaded beforehand. No setup needed
+ return
+
+ model, weights = self.model, None
+ ckpt = None
+ if str(model).endswith('.pt'):
+ weights, ckpt = attempt_load_one_weight(model)
+ cfg = ckpt['model'].yaml
+ else:
+ cfg = model
+ self.model = self.get_model(cfg=cfg, weights=weights, verbose=RANK == -1) # calls Model(cfg, weights)
+ return ckpt
+
+ def optimizer_step(self):
+ """Perform a single step of the training optimizer with gradient clipping and EMA update."""
+ self.scaler.unscale_(self.optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=10.0) # clip gradients
+ self.scaler.step(self.optimizer)
+ self.scaler.update()
+ self.optimizer.zero_grad()
+ if self.ema:
+ self.ema.update(self.model)
+
+ def preprocess_batch(self, batch):
+ """
+ Allows custom preprocessing model inputs and ground truths depending on task type.
+ """
+ return batch
+
+ def validate(self):
+ """
+ Runs validation on test set using self.validator. The returned dict is expected to contain "fitness" key.
+ """
+ metrics = self.validator(self)
+ fitness = metrics.pop('fitness', -self.loss.detach().cpu().numpy()) # use loss as fitness measure if not found
+ if not self.best_fitness or self.best_fitness < fitness:
+ self.best_fitness = fitness
+ return metrics, fitness
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Get model and raise NotImplementedError for loading cfg files."""
+ raise NotImplementedError("This task trainer doesn't support loading cfg files")
+
+ def get_validator(self):
+ """Returns a NotImplementedError when the get_validator function is called."""
+ raise NotImplementedError('get_validator function not implemented in trainer')
+
+ def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
+ """
+ Returns dataloader derived from torch.data.Dataloader.
+ """
+ raise NotImplementedError('get_dataloader function not implemented in trainer')
+
+ def build_dataset(self, img_path, mode='train', batch=None):
+ """Build dataset"""
+ raise NotImplementedError('build_dataset function not implemented in trainer')
+
+ def label_loss_items(self, loss_items=None, prefix='train'):
+ """
+ Returns a loss dict with labelled training loss items tensor
+ """
+ # Not needed for classification but necessary for segmentation & detection
+ return {'loss': loss_items} if loss_items is not None else ['loss']
+
+ def set_model_attributes(self):
+ """
+ To set or update model parameters before training.
+ """
+ self.model.names = self.data['names']
+
+ def build_targets(self, preds, targets):
+ """Builds target tensors for training YOLO model."""
+ pass
+
+ def progress_string(self):
+ """Returns a string describing training progress."""
+ return ''
+
+ # TODO: may need to put these following functions into callback
+ def plot_training_samples(self, batch, ni):
+ """Plots training samples during YOLOv5 training."""
+ pass
+
+ def plot_training_labels(self):
+ """Plots training labels for YOLO model."""
+ pass
+
+ def save_metrics(self, metrics):
+ """Saves training metrics to a CSV file."""
+ keys, vals = list(metrics.keys()), list(metrics.values())
+ n = len(metrics) + 1 # number of cols
+ s = '' if self.csv.exists() else (('%23s,' * n % tuple(['epoch'] + keys)).rstrip(',') + '\n') # header
+ with open(self.csv, 'a') as f:
+ f.write(s + ('%23.5g,' * n % tuple([self.epoch + 1] + vals)).rstrip(',') + '\n')
+
+ def plot_metrics(self):
+ """Plot and display metrics visually."""
+ pass
+
+ def on_plot(self, name, data=None):
+ """Registers plots (e.g. to be consumed in callbacks)"""
+ path = Path(name)
+ self.plots[path] = {'data': data, 'timestamp': time.time()}
+
+ def final_eval(self):
+ """Performs final evaluation and validation for object detection YOLO model."""
+ for f in self.last, self.best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is self.best:
+ LOGGER.info(f'\nValidating {f}...')
+ self.metrics = self.validator(model=f)
+ self.metrics.pop('fitness', None)
+ self.run_callbacks('on_fit_epoch_end')
+
+ def check_resume(self, overrides):
+ """Check if resume checkpoint exists and update arguments accordingly."""
+ resume = self.args.resume
+ if resume:
+ try:
+ exists = isinstance(resume, (str, Path)) and Path(resume).exists()
+ last = Path(check_file(resume) if exists else get_latest_run())
+
+ # Check that resume data YAML exists, otherwise strip to force re-download of dataset
+ ckpt_args = attempt_load_weights(last).args
+ if not Path(ckpt_args['data']).exists():
+ ckpt_args['data'] = self.args.data
+
+ resume = True
+ self.args = get_cfg(ckpt_args)
+ self.args.model = str(last) # reinstate model
+ for k in 'imgsz', 'batch': # allow arg updates to reduce memory on resume if crashed due to CUDA OOM
+ if k in overrides:
+ setattr(self.args, k, overrides[k])
+
+ except Exception as e:
+ raise FileNotFoundError('Resume checkpoint not found. Please pass a valid checkpoint to resume from, '
+ "i.e. 'yolo train resume model=path/to/last.pt'") from e
+ self.resume = resume
+
+ def resume_training(self, ckpt):
+ """Resume YOLO training from given epoch and best fitness."""
+ if ckpt is None:
+ return
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ self.optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if self.ema and ckpt.get('ema'):
+ self.ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ self.ema.updates = ckpt['updates']
+ if self.resume:
+ assert start_epoch > 0, \
+ f'{self.args.model} training to {self.epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without resuming, i.e. 'yolo train model={self.args.model}'"
+ LOGGER.info(
+ f'Resuming training from {self.args.model} from epoch {start_epoch + 1} to {self.epochs} total epochs')
+ if self.epochs < start_epoch:
+ LOGGER.info(
+ f"{self.model} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {self.epochs} more epochs.")
+ self.epochs += ckpt['epoch'] # finetune additional epochs
+ self.best_fitness = best_fitness
+ self.start_epoch = start_epoch
+ if start_epoch > (self.epochs - self.args.close_mosaic):
+ LOGGER.info('Closing dataloader mosaic')
+ if hasattr(self.train_loader.dataset, 'mosaic'):
+ self.train_loader.dataset.mosaic = False
+ if hasattr(self.train_loader.dataset, 'close_mosaic'):
+ self.train_loader.dataset.close_mosaic(hyp=self.args)
+
+ def build_optimizer(self, model, name='auto', lr=0.001, momentum=0.9, decay=1e-5, iterations=1e5):
+ """
+ Constructs an optimizer for the given model, based on the specified optimizer name, learning rate,
+ momentum, weight decay, and number of iterations.
+
+ Args:
+ model (torch.nn.Module): The model for which to build an optimizer.
+ name (str, optional): The name of the optimizer to use. If 'auto', the optimizer is selected
+ based on the number of iterations. Default: 'auto'.
+ lr (float, optional): The learning rate for the optimizer. Default: 0.001.
+ momentum (float, optional): The momentum factor for the optimizer. Default: 0.9.
+ decay (float, optional): The weight decay for the optimizer. Default: 1e-5.
+ iterations (float, optional): The number of iterations, which determines the optimizer if
+ name is 'auto'. Default: 1e5.
+
+ Returns:
+ (torch.optim.Optimizer): The constructed optimizer.
+ """
+
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ if name == 'auto':
+ nc = getattr(model, 'nc', 10) # number of classes
+ lr_fit = round(0.002 * 5 / (4 + nc), 6) # lr0 fit equation to 6 decimal places
+ name, lr, momentum = ('SGD', 0.01, 0.9) if iterations > 10000 else ('AdamW', lr_fit, 0.9)
+ self.args.warmup_bias_lr = 0.0 # no higher than 0.01 for Adam
+
+ for module_name, module in model.named_modules():
+ for param_name, param in module.named_parameters(recurse=False):
+ fullname = f'{module_name}.{param_name}' if module_name else param_name
+ if 'bias' in fullname: # bias (no decay)
+ g[2].append(param)
+ elif isinstance(module, bn): # weight (no decay)
+ g[1].append(param)
+ else: # weight (with decay)
+ g[0].append(param)
+
+ if name in ('Adam', 'Adamax', 'AdamW', 'NAdam', 'RAdam'):
+ optimizer = getattr(optim, name, optim.Adam)(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(
+ f"Optimizer '{name}' not found in list of available optimizers "
+ f'[Adam, AdamW, NAdam, RAdam, RMSProp, SGD, auto].'
+ 'To request support for addition optimizers please visit https://github.com/ultralytics/ultralytics.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(
+ f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}, momentum={momentum}) with parameter groups "
+ f'{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias(decay=0.0)')
+ return optimizer
diff --git a/STPoseNet/ultralytics/engine/tuner.py b/STPoseNet/ultralytics/engine/tuner.py
new file mode 100644
index 0000000000000000000000000000000000000000..5865c18c556d43c6ba398cb1d7c569b3aabab766
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/tuner.py
@@ -0,0 +1,183 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+This module provides functionalities for hyperparameter tuning of the Ultralytics YOLO models for object detection,
+instance segmentation, image classification, pose estimation, and multi-object tracking.
+
+Hyperparameter tuning is the process of systematically searching for the optimal set of hyperparameters
+that yield the best model performance. This is particularly crucial in deep learning models like YOLO,
+where small changes in hyperparameters can lead to significant differences in model accuracy and efficiency.
+
+Example:
+ Tune hyperparameters for YOLOv8n on COCO8 at imgsz=640 and epochs=30 for 300 tuning iterations.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.tune(data='coco8.yaml', imgsz=640, epochs=100, iterations=10)
+ ```
+"""
+import random
+import time
+
+import numpy as np
+
+from ultralytics import YOLO
+from ultralytics.cfg import get_cfg, get_save_dir
+from ultralytics.utils import DEFAULT_CFG, LOGGER, callbacks, colorstr, yaml_print, yaml_save
+
+
+class Tuner:
+ """
+ Class responsible for hyperparameter tuning of YOLO models.
+
+ The class evolves YOLO model hyperparameters over a given number of iterations
+ by mutating them according to the search space and retraining the model to evaluate their performance.
+
+ Attributes:
+ space (dict): Hyperparameter search space containing bounds and scaling factors for mutation.
+ tune_dir (Path): Directory where evolution logs and results will be saved.
+ evolve_csv (Path): Path to the CSV file where evolution logs are saved.
+
+ Methods:
+ _mutate(hyp: dict) -> dict:
+ Mutates the given hyperparameters within the bounds specified in `self.space`.
+
+ __call__():
+ Executes the hyperparameter evolution across multiple iterations.
+
+ Example:
+ Tune hyperparameters for YOLOv8n on COCO8 at imgsz=640 and epochs=30 for 300 tuning iterations.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.tune(data='coco8.yaml', imgsz=640, epochs=100, iterations=10)
+ ```
+ """
+
+ def __init__(self, args=DEFAULT_CFG, _callbacks=None):
+ """
+ Initialize the Tuner with configurations.
+
+ Args:
+ args (dict, optional): Configuration for hyperparameter evolution.
+ """
+ self.args = get_cfg(overrides=args)
+ self.space = {
+ # 'optimizer': tune.choice(['SGD', 'Adam', 'AdamW', 'NAdam', 'RAdam', 'RMSProp']),
+ 'lr0': (1e-5, 1e-1),
+ 'lrf': (0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (0.0, 0.001), # optimizer weight decay 5e-4
+ 'warmup_epochs': (0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (0.0, 0.95), # warmup initial momentum
+ 'box': (0.02, 0.2), # box loss gain
+ 'cls': (0.2, 4.0), # cls loss gain (scale with pixels)
+ 'hsv_h': (0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (0.0, 0.9), # image scale (+/- gain)
+ 'shear': (0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (0.0, 1.0), # image mixup (probability)
+ 'mixup': (0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (0.0, 1.0)} # segment copy-paste (probability)
+ self.tune_dir = get_save_dir(self.args, name='tune')
+ self.evolve_csv = self.tune_dir / 'evolve.csv'
+ self.callbacks = _callbacks or callbacks.get_default_callbacks()
+ callbacks.add_integration_callbacks(self)
+ LOGGER.info(f"Initialized Tuner instance with 'tune_dir={self.tune_dir}'.")
+
+ def _mutate(self, parent='single', n=5, mutation=0.8, sigma=0.6, return_best=False):
+ """
+ Mutates the hyperparameters based on bounds and scaling factors specified in `self.space`.
+
+ Args:
+ parent (str): Parent selection method: 'single' or 'weighted'.
+ n (int): Number of parents to consider.
+ mutation (float): Probability of a parameter mutation in any given iteration.
+ sigma (float): Standard deviation for Gaussian random number generator.
+
+ Returns:
+ (dict): A dictionary containing mutated hyperparameters.
+ """
+ if self.evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ x = np.loadtxt(self.evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ fitness = x[:, 0] # first column
+ n = min(n, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness)][:n] # top n mutations
+ if return_best:
+ return {k: float(x[0, i + 1]) for i, k in enumerate(self.space.keys())}
+ fitness = x[:, 0] # first column
+ w = fitness - fitness.min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ r = np.random # method
+ r.seed(int(time.time()))
+ g = np.array([self.space[k][0] for k in self.space.keys()]) # gains 0-1
+ ng = len(self.space)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (r.random(ng) < mutation) * r.randn(ng) * r.random() * sigma + 1).clip(0.3, 3.0)
+ hyp = {k: float(x[i + 1] * v[i]) for i, k in enumerate(self.space.keys())}
+ else:
+ hyp = {k: getattr(self.args, k) for k in self.space.keys()}
+
+ # Constrain to limits
+ for k, v in self.space.items():
+ hyp[k] = max(hyp[k], v[0]) # lower limit
+ hyp[k] = min(hyp[k], v[1]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ return hyp
+
+ def __call__(self, model=None, iterations=10, prefix=colorstr('Tuner:')):
+ """
+ Executes the hyperparameter evolution process when the Tuner instance is called.
+
+ This method iterates through the number of iterations, performing the following steps in each iteration:
+ 1. Load the existing hyperparameters or initialize new ones.
+ 2. Mutate the hyperparameters using the `mutate` method.
+ 3. Train a YOLO model with the mutated hyperparameters.
+ 4. Log the fitness score and mutated hyperparameters to a CSV file.
+
+ Args:
+ model (YOLO): A pre-initialized YOLO model to be used for training.
+ iterations (int): The number of generations to run the evolution for.
+
+ Note:
+ The method utilizes the `self.evolve_csv` Path object to read and log hyperparameters and fitness scores.
+ Ensure this path is set correctly in the Tuner instance.
+ """
+
+ self.tune_dir.mkdir(parents=True, exist_ok=True)
+ for i in range(iterations):
+ # Mutate hyperparameters
+ mutated_hyp = self._mutate()
+ LOGGER.info(f'{prefix} Starting iteration {i + 1}/{iterations} with hyperparameters: {mutated_hyp}')
+
+ # Initialize and train YOLOv8 model
+ model = YOLO('yolov8n.pt')
+ train_args = {**vars(self.args), **mutated_hyp}
+ results = model.train(**train_args)
+
+ # Save results and mutated_hyp to evolve_csv
+ headers = '' if self.evolve_csv.exists() else (','.join(['fitness_score'] + list(self.space.keys())) + '\n')
+ log_row = [results.fitness] + [mutated_hyp[k] for k in self.space.keys()]
+ with open(self.evolve_csv, 'a') as f:
+ f.write(headers + ','.join(map(str, log_row)) + '\n')
+
+ LOGGER.info(f'{prefix} All iterations complete. Results saved to {colorstr("bold", self.tune_dir)}')
+ best_hyp = self._mutate(return_best=True) # best hyps
+ yaml_save(self.tune_dir / 'best.yaml', best_hyp)
+ yaml_print(self.tune_dir / 'best.yaml')
diff --git a/STPoseNet/ultralytics/engine/validator.py b/STPoseNet/ultralytics/engine/validator.py
new file mode 100644
index 0000000000000000000000000000000000000000..e445368ca5f88f80b8bb6b09bca02149dde38a93
--- /dev/null
+++ b/STPoseNet/ultralytics/engine/validator.py
@@ -0,0 +1,318 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Check a model's accuracy on a test or val split of a dataset.
+
+Usage:
+ $ yolo mode=val model=yolov8n.pt data=coco128.yaml imgsz=640
+
+Usage - formats:
+ $ yolo mode=val model=yolov8n.pt # PyTorch
+ yolov8n.torchscript # TorchScript
+ yolov8n.onnx # ONNX Runtime or OpenCV DNN with dnn=True
+ yolov8n_openvino_model # OpenVINO
+ yolov8n.engine # TensorRT
+ yolov8n.mlpackage # CoreML (macOS-only)
+ yolov8n_saved_model # TensorFlow SavedModel
+ yolov8n.pb # TensorFlow GraphDef
+ yolov8n.tflite # TensorFlow Lite
+ yolov8n_edgetpu.tflite # TensorFlow Edge TPU
+ yolov8n_paddle_model # PaddlePaddle
+"""
+import json
+import time
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+from ultralytics.cfg import get_cfg, get_save_dir
+from ultralytics.data.utils import check_cls_dataset, check_det_dataset
+from ultralytics.nn.autobackend import AutoBackend
+from ultralytics.utils import LOGGER, TQDM_BAR_FORMAT, callbacks, colorstr, emojis
+from ultralytics.utils.checks import check_imgsz
+from ultralytics.utils.ops import Profile
+from ultralytics.utils.torch_utils import de_parallel, select_device, smart_inference_mode
+
+
+class BaseValidator:
+ """
+ BaseValidator
+
+ A base class for creating validators.
+
+ Attributes:
+ args (SimpleNamespace): Configuration for the validator.
+ dataloader (DataLoader): Dataloader to use for validation.
+ pbar (tqdm): Progress bar to update during validation.
+ model (nn.Module): Model to validate.
+ data (dict): Data dictionary.
+ device (torch.device): Device to use for validation.
+ batch_i (int): Current batch index.
+ training (bool): Whether the model is in training mode.
+ names (dict): Class names.
+ seen: Records the number of images seen so far during validation.
+ stats: Placeholder for statistics during validation.
+ confusion_matrix: Placeholder for a confusion matrix.
+ nc: Number of classes.
+ iouv: (torch.Tensor): IoU thresholds from 0.50 to 0.95 in spaces of 0.05.
+ jdict (dict): Dictionary to store JSON validation results.
+ speed (dict): Dictionary with keys 'preprocess', 'inference', 'loss', 'postprocess' and their respective
+ batch processing times in milliseconds.
+ save_dir (Path): Directory to save results.
+ plots (dict): Dictionary to store plots for visualization.
+ callbacks (dict): Dictionary to store various callback functions.
+ """
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """
+ Initializes a BaseValidator instance.
+
+ Args:
+ dataloader (torch.utils.data.DataLoader): Dataloader to be used for validation.
+ save_dir (Path, optional): Directory to save results.
+ pbar (tqdm.tqdm): Progress bar for displaying progress.
+ args (SimpleNamespace): Configuration for the validator.
+ _callbacks (dict): Dictionary to store various callback functions.
+ """
+ self.args = get_cfg(overrides=args)
+ self.dataloader = dataloader
+ self.pbar = pbar
+ self.model = None
+ self.data = None
+ self.device = None
+ self.batch_i = None
+ self.training = True
+ self.names = None
+ self.seen = None
+ self.stats = None
+ self.confusion_matrix = None
+ self.nc = None
+ self.iouv = None
+ self.jdict = None
+ self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0}
+
+ self.save_dir = save_dir or get_save_dir(self.args)
+ (self.save_dir / 'labels' if self.args.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True)
+ if self.args.conf is None:
+ self.args.conf = 0.001 # default conf=0.001
+
+ self.plots = {}
+ self.callbacks = _callbacks or callbacks.get_default_callbacks()
+
+ @smart_inference_mode()
+ def __call__(self, trainer=None, model=None):
+ """
+ Supports validation of a pre-trained model if passed or a model being trained
+ if trainer is passed (trainer gets priority).
+ """
+ self.training = trainer is not None
+ augment = self.args.augment and (not self.training)
+ if self.training:
+ self.device = trainer.device
+ self.data = trainer.data
+ model = trainer.ema.ema or trainer.model
+ self.args.half = self.device.type != 'cpu' # force FP16 val during training
+ model = model.half() if self.args.half else model.float()
+ self.model = model
+ self.loss = torch.zeros_like(trainer.loss_items, device=trainer.device)
+ self.args.plots = trainer.stopper.possible_stop or (trainer.epoch == trainer.epochs - 1)
+ model.eval()
+ else:
+ callbacks.add_integration_callbacks(self)
+ self.run_callbacks('on_val_start')
+ model = AutoBackend(model or self.args.model,
+ device=select_device(self.args.device, self.args.batch),
+ dnn=self.args.dnn,
+ data=self.args.data,
+ fp16=self.args.half)
+ self.model = model
+ self.device = model.device # update device
+ self.args.half = model.fp16 # update half
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_imgsz(self.args.imgsz, stride=stride)
+ if engine:
+ self.args.batch = model.batch_size
+ elif not pt and not jit:
+ self.args.batch = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing batch=1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ if isinstance(self.args.data, str) and self.args.data.split('.')[-1] in ('yaml', 'yml'):
+ self.data = check_det_dataset(self.args.data)
+ elif self.args.task == 'classify':
+ self.data = check_cls_dataset(self.args.data, split=self.args.split)
+ else:
+ raise FileNotFoundError(emojis(f"Dataset '{self.args.data}' for task={self.args.task} not found ❌"))
+
+ if self.device.type == 'cpu':
+ self.args.workers = 0 # faster CPU val as time dominated by inference, not dataloading
+ if not pt:
+ self.args.rect = False
+ self.dataloader = self.dataloader or self.get_dataloader(self.data.get(self.args.split), self.args.batch)
+
+ model.eval()
+ model.warmup(imgsz=(1 if pt else self.args.batch, 3, imgsz, imgsz)) # warmup
+
+ dt = Profile(), Profile(), Profile(), Profile()
+ n_batches = len(self.dataloader)
+ desc = self.get_desc()
+ # NOTE: keeping `not self.training` in tqdm will eliminate pbar after segmentation evaluation during training,
+ # which may affect classification task since this arg is in yolov5/classify/val.py.
+ # bar = tqdm(self.dataloader, desc, n_batches, not self.training, bar_format=TQDM_BAR_FORMAT)
+ bar = tqdm(self.dataloader, desc, n_batches, bar_format=TQDM_BAR_FORMAT)
+ self.init_metrics(de_parallel(model))
+ self.jdict = [] # empty before each val
+ for batch_i, batch in enumerate(bar):
+ self.run_callbacks('on_val_batch_start')
+ self.batch_i = batch_i
+ # Preprocess
+ with dt[0]:
+ batch = self.preprocess(batch)
+
+ # Inference
+ with dt[1]:
+ preds = model(batch['img'], augment=augment)
+
+ # Loss
+ with dt[2]:
+ if self.training:
+ self.loss += model.loss(batch, preds)[1]
+
+ # Postprocess
+ with dt[3]:
+ preds = self.postprocess(preds)
+
+ self.update_metrics(preds, batch)
+ if self.args.plots and batch_i < 3:
+ self.plot_val_samples(batch, batch_i)
+ self.plot_predictions(batch, preds, batch_i)
+
+ self.run_callbacks('on_val_batch_end')
+ stats = self.get_stats()
+ self.check_stats(stats)
+ self.speed = dict(zip(self.speed.keys(), (x.t / len(self.dataloader.dataset) * 1E3 for x in dt)))
+ self.finalize_metrics()
+ self.print_results()
+ self.run_callbacks('on_val_end')
+ if self.training:
+ model.float()
+ results = {**stats, **trainer.label_loss_items(self.loss.cpu() / len(self.dataloader), prefix='val')}
+ return {k: round(float(v), 5) for k, v in results.items()} # return results as 5 decimal place floats
+ else:
+ LOGGER.info('Speed: %.1fms preprocess, %.1fms inference, %.1fms loss, %.1fms postprocess per image' %
+ tuple(self.speed.values()))
+ if self.args.save_json and self.jdict:
+ with open(str(self.save_dir / 'predictions.json'), 'w') as f:
+ LOGGER.info(f'Saving {f.name}...')
+ json.dump(self.jdict, f) # flatten and save
+ stats = self.eval_json(stats) # update stats
+ if self.args.plots or self.args.save_json:
+ LOGGER.info(f"Results saved to {colorstr('bold', self.save_dir)}")
+ return stats
+
+ def match_predictions(self, pred_classes, true_classes, iou):
+ """
+ Matches predictions to ground truth objects (pred_classes, true_classes) using IoU.
+
+ Args:
+ pred_classes (torch.Tensor): Predicted class indices of shape(N,).
+ true_classes (torch.Tensor): Target class indices of shape(M,).
+ iou (torch.Tensor): An NxM tensor containing the pairwise IoU values for predictions and ground of truth
+
+ Returns:
+ (torch.Tensor): Correct tensor of shape(N,10) for 10 IoU thresholds.
+ """
+ correct = np.zeros((pred_classes.shape[0], self.iouv.shape[0])).astype(bool)
+ correct_class = true_classes[:, None] == pred_classes
+ for i, iouv in enumerate(self.iouv):
+ x = torch.nonzero(iou.ge(iouv) & correct_class) # IoU > threshold and classes match
+ if x.shape[0]:
+ # Concatenate [label, detect, iou]
+ matches = torch.cat((x, iou[x[:, 0], x[:, 1]].unsqueeze(1)), 1).cpu().numpy()
+ if x.shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=pred_classes.device)
+
+ def add_callback(self, event: str, callback):
+ """Appends the given callback."""
+ self.callbacks[event].append(callback)
+
+ def run_callbacks(self, event: str):
+ """Runs all callbacks associated with a specified event."""
+ for callback in self.callbacks.get(event, []):
+ callback(self)
+
+ def get_dataloader(self, dataset_path, batch_size):
+ """Get data loader from dataset path and batch size."""
+ raise NotImplementedError('get_dataloader function not implemented for this validator')
+
+ def build_dataset(self, img_path):
+ """Build dataset"""
+ raise NotImplementedError('build_dataset function not implemented in validator')
+
+ def preprocess(self, batch):
+ """Preprocesses an input batch."""
+ return batch
+
+ def postprocess(self, preds):
+ """Describes and summarizes the purpose of 'postprocess()' but no details mentioned."""
+ return preds
+
+ def init_metrics(self, model):
+ """Initialize performance metrics for the YOLO model."""
+ pass
+
+ def update_metrics(self, preds, batch):
+ """Updates metrics based on predictions and batch."""
+ pass
+
+ def finalize_metrics(self, *args, **kwargs):
+ """Finalizes and returns all metrics."""
+ pass
+
+ def get_stats(self):
+ """Returns statistics about the model's performance."""
+ return {}
+
+ def check_stats(self, stats):
+ """Checks statistics."""
+ pass
+
+ def print_results(self):
+ """Prints the results of the model's predictions."""
+ pass
+
+ def get_desc(self):
+ """Get description of the YOLO model."""
+ pass
+
+ @property
+ def metric_keys(self):
+ """Returns the metric keys used in YOLO training/validation."""
+ return []
+
+ def on_plot(self, name, data=None):
+ """Registers plots (e.g. to be consumed in callbacks)"""
+ path = Path(name)
+ self.plots[path] = {'data': data, 'timestamp': time.time()}
+
+ # TODO: may need to put these following functions into callback
+ def plot_val_samples(self, batch, ni):
+ """Plots validation samples during training."""
+ pass
+
+ def plot_predictions(self, batch, preds, ni):
+ """Plots YOLO model predictions on batch images."""
+ pass
+
+ def pred_to_json(self, preds, batch):
+ """Convert predictions to JSON format."""
+ pass
+
+ def eval_json(self, stats):
+ """Evaluate and return JSON format of prediction statistics."""
+ pass
diff --git a/STPoseNet/ultralytics/hub/__init__.py b/STPoseNet/ultralytics/hub/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..daed439c2224843d6021861ba50c40c486e944a8
--- /dev/null
+++ b/STPoseNet/ultralytics/hub/__init__.py
@@ -0,0 +1,100 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import requests
+
+from ultralytics.data.utils import HUBDatasetStats
+from ultralytics.hub.auth import Auth
+from ultralytics.hub.utils import HUB_API_ROOT, HUB_WEB_ROOT, PREFIX
+from ultralytics.utils import LOGGER, SETTINGS
+
+
+def login(api_key=''):
+ """
+ Log in to the Ultralytics HUB API using the provided API key.
+
+ Args:
+ api_key (str, optional): May be an API key or a combination API key and model ID, i.e. key_id
+
+ Example:
+ ```python
+ from ultralytics import hub
+
+ hub.login('API_KEY')
+ ```
+ """
+ Auth(api_key, verbose=True)
+
+
+def logout():
+ """
+ Log out of Ultralytics HUB by removing the API key from the settings file. To log in again, use 'yolo hub login'.
+
+ Example:
+ ```python
+ from ultralytics import hub
+
+ hub.logout()
+ ```
+ """
+ SETTINGS['api_key'] = ''
+ SETTINGS.save()
+ LOGGER.info(f"{PREFIX}logged out ✅. To log in again, use 'yolo hub login'.")
+
+
+def reset_model(model_id=''):
+ """Reset a trained model to an untrained state."""
+ r = requests.post(f'{HUB_API_ROOT}/model-reset', json={'apiKey': Auth().api_key, 'modelId': model_id})
+ if r.status_code == 200:
+ LOGGER.info(f'{PREFIX}Model reset successfully')
+ return
+ LOGGER.warning(f'{PREFIX}Model reset failure {r.status_code} {r.reason}')
+
+
+def export_fmts_hub():
+ """Returns a list of HUB-supported export formats."""
+ from ultralytics.engine.exporter import export_formats
+ return list(export_formats()['Argument'][1:]) + ['ultralytics_tflite', 'ultralytics_coreml']
+
+
+def export_model(model_id='', format='torchscript'):
+ """Export a model to all formats."""
+ assert format in export_fmts_hub(), f"Unsupported export format '{format}', valid formats are {export_fmts_hub()}"
+ r = requests.post(f'{HUB_API_ROOT}/v1/models/{model_id}/export',
+ json={'format': format},
+ headers={'x-api-key': Auth().api_key})
+ assert r.status_code == 200, f'{PREFIX}{format} export failure {r.status_code} {r.reason}'
+ LOGGER.info(f'{PREFIX}{format} export started ✅')
+
+
+def get_export(model_id='', format='torchscript'):
+ """Get an exported model dictionary with download URL."""
+ assert format in export_fmts_hub(), f"Unsupported export format '{format}', valid formats are {export_fmts_hub()}"
+ r = requests.post(f'{HUB_API_ROOT}/get-export',
+ json={
+ 'apiKey': Auth().api_key,
+ 'modelId': model_id,
+ 'format': format})
+ assert r.status_code == 200, f'{PREFIX}{format} get_export failure {r.status_code} {r.reason}'
+ return r.json()
+
+
+def check_dataset(path='', task='detect'):
+ """
+ Function for error-checking HUB dataset Zip file before upload. It checks a dataset for errors before it is
+ uploaded to the HUB. Usage examples are given below.
+
+ Args:
+ path (str, optional): Path to data.zip (with data.yaml inside data.zip). Defaults to ''.
+ task (str, optional): Dataset task. Options are 'detect', 'segment', 'pose', 'classify'. Defaults to 'detect'.
+
+ Example:
+ ```python
+ from ultralytics.hub import check_dataset
+
+ check_dataset('path/to/coco8.zip', task='detect') # detect dataset
+ check_dataset('path/to/coco8-seg.zip', task='segment') # segment dataset
+ check_dataset('path/to/coco8-pose.zip', task='pose') # pose dataset
+ ```
+ """
+ HUBDatasetStats(path=path, task=task).get_json()
+ LOGGER.info(f'Checks completed correctly ✅. Upload this dataset to {HUB_WEB_ROOT}/datasets/.')
diff --git a/STPoseNet/ultralytics/hub/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/hub/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..059f2320d847620c4f693d97bb9b50dc858c2897
Binary files /dev/null and b/STPoseNet/ultralytics/hub/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/hub/__pycache__/auth.cpython-38.pyc b/STPoseNet/ultralytics/hub/__pycache__/auth.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2b8f5d9ee753679944f51712c9bb1bab9e79a7c2
Binary files /dev/null and b/STPoseNet/ultralytics/hub/__pycache__/auth.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/hub/__pycache__/utils.cpython-38.pyc b/STPoseNet/ultralytics/hub/__pycache__/utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1a3b09edf7a85f81ee024df996e30b55f5a49f17
Binary files /dev/null and b/STPoseNet/ultralytics/hub/__pycache__/utils.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/hub/auth.py b/STPoseNet/ultralytics/hub/auth.py
new file mode 100644
index 0000000000000000000000000000000000000000..9963d79c0903650645ad166bfe4261d62faf1330
--- /dev/null
+++ b/STPoseNet/ultralytics/hub/auth.py
@@ -0,0 +1,119 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import requests
+
+from ultralytics.hub.utils import HUB_API_ROOT, HUB_WEB_ROOT, PREFIX, request_with_credentials
+from ultralytics.utils import LOGGER, SETTINGS, emojis, is_colab
+
+API_KEY_URL = f'{HUB_WEB_ROOT}/settings?tab=api+keys'
+
+
+class Auth:
+ id_token = api_key = model_key = False
+
+ def __init__(self, api_key='', verbose=False):
+ """
+ Initialize the Auth class with an optional API key.
+
+ Args:
+ api_key (str, optional): May be an API key or a combination API key and model ID, i.e. key_id
+ """
+ # Split the input API key in case it contains a combined key_model and keep only the API key part
+ api_key = api_key.split('_')[0]
+
+ # Set API key attribute as value passed or SETTINGS API key if none passed
+ self.api_key = api_key or SETTINGS.get('api_key', '')
+
+ # If an API key is provided
+ if self.api_key:
+ # If the provided API key matches the API key in the SETTINGS
+ if self.api_key == SETTINGS.get('api_key'):
+ # Log that the user is already logged in
+ if verbose:
+ LOGGER.info(f'{PREFIX}Authenticated ✅')
+ return
+ else:
+ # Attempt to authenticate with the provided API key
+ success = self.authenticate()
+ # If the API key is not provided and the environment is a Google Colab notebook
+ elif is_colab():
+ # Attempt to authenticate using browser cookies
+ success = self.auth_with_cookies()
+ else:
+ # Request an API key
+ success = self.request_api_key()
+
+ # Update SETTINGS with the new API key after successful authentication
+ if success:
+ SETTINGS.update({'api_key': self.api_key})
+ # Log that the new login was successful
+ if verbose:
+ LOGGER.info(f'{PREFIX}New authentication successful ✅')
+ elif verbose:
+ LOGGER.info(f'{PREFIX}Retrieve API key from {API_KEY_URL}')
+
+ def request_api_key(self, max_attempts=3):
+ """
+ Prompt the user to input their API key. Returns the model ID.
+ """
+ import getpass
+ for attempts in range(max_attempts):
+ LOGGER.info(f'{PREFIX}Login. Attempt {attempts + 1} of {max_attempts}')
+ input_key = getpass.getpass(f'Enter API key from {API_KEY_URL} ')
+ self.api_key = input_key.split('_')[0] # remove model id if present
+ if self.authenticate():
+ return True
+ raise ConnectionError(emojis(f'{PREFIX}Failed to authenticate ❌'))
+
+ def authenticate(self) -> bool:
+ """
+ Attempt to authenticate with the server using either id_token or API key.
+
+ Returns:
+ bool: True if authentication is successful, False otherwise.
+ """
+ try:
+ if header := self.get_auth_header():
+ r = requests.post(f'{HUB_API_ROOT}/v1/auth', headers=header)
+ if not r.json().get('success', False):
+ raise ConnectionError('Unable to authenticate.')
+ return True
+ raise ConnectionError('User has not authenticated locally.')
+ except ConnectionError:
+ self.id_token = self.api_key = False # reset invalid
+ LOGGER.warning(f'{PREFIX}Invalid API key ⚠️')
+ return False
+
+ def auth_with_cookies(self) -> bool:
+ """
+ Attempt to fetch authentication via cookies and set id_token.
+ User must be logged in to HUB and running in a supported browser.
+
+ Returns:
+ bool: True if authentication is successful, False otherwise.
+ """
+ if not is_colab():
+ return False # Currently only works with Colab
+ try:
+ authn = request_with_credentials(f'{HUB_API_ROOT}/v1/auth/auto')
+ if authn.get('success', False):
+ self.id_token = authn.get('data', {}).get('idToken', None)
+ self.authenticate()
+ return True
+ raise ConnectionError('Unable to fetch browser authentication details.')
+ except ConnectionError:
+ self.id_token = False # reset invalid
+ return False
+
+ def get_auth_header(self):
+ """
+ Get the authentication header for making API requests.
+
+ Returns:
+ (dict): The authentication header if id_token or API key is set, None otherwise.
+ """
+ if self.id_token:
+ return {'authorization': f'Bearer {self.id_token}'}
+ elif self.api_key:
+ return {'x-api-key': self.api_key}
+ # else returns None
diff --git a/STPoseNet/ultralytics/hub/session.py b/STPoseNet/ultralytics/hub/session.py
new file mode 100644
index 0000000000000000000000000000000000000000..595de2977775c0fe3e320edb92a85e4dcc8f520d
--- /dev/null
+++ b/STPoseNet/ultralytics/hub/session.py
@@ -0,0 +1,190 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import signal
+import sys
+from pathlib import Path
+from time import sleep
+
+import requests
+
+from ultralytics.hub.utils import HUB_API_ROOT, HUB_WEB_ROOT, PREFIX, smart_request
+from ultralytics.utils import LOGGER, __version__, checks, emojis, is_colab, threaded
+from ultralytics.utils.errors import HUBModelError
+
+AGENT_NAME = f'python-{__version__}-colab' if is_colab() else f'python-{__version__}-local'
+
+
+class HUBTrainingSession:
+ """
+ HUB training session for Ultralytics HUB YOLO models. Handles model initialization, heartbeats, and checkpointing.
+
+ Args:
+ url (str): Model identifier used to initialize the HUB training session.
+
+ Attributes:
+ agent_id (str): Identifier for the instance communicating with the server.
+ model_id (str): Identifier for the YOLOv5 model being trained.
+ model_url (str): URL for the model in Ultralytics HUB.
+ api_url (str): API URL for the model in Ultralytics HUB.
+ auth_header (dict): Authentication header for the Ultralytics HUB API requests.
+ rate_limits (dict): Rate limits for different API calls (in seconds).
+ timers (dict): Timers for rate limiting.
+ metrics_queue (dict): Queue for the model's metrics.
+ model (dict): Model data fetched from Ultralytics HUB.
+ alive (bool): Indicates if the heartbeat loop is active.
+ """
+
+ def __init__(self, url):
+ """
+ Initialize the HUBTrainingSession with the provided model identifier.
+
+ Args:
+ url (str): Model identifier used to initialize the HUB training session.
+ It can be a URL string or a model key with specific format.
+
+ Raises:
+ ValueError: If the provided model identifier is invalid.
+ ConnectionError: If connecting with global API key is not supported.
+ """
+
+ from ultralytics.hub.auth import Auth
+
+ # Parse input
+ if url.startswith(f'{HUB_WEB_ROOT}/models/'):
+ url = url.split(f'{HUB_WEB_ROOT}/models/')[-1]
+ if [len(x) for x in url.split('_')] == [42, 20]:
+ key, model_id = url.split('_')
+ elif len(url) == 20:
+ key, model_id = '', url
+ else:
+ raise HUBModelError(f"model='{url}' not found. Check format is correct, i.e. "
+ f"model='{HUB_WEB_ROOT}/models/MODEL_ID' and try again.")
+
+ # Authorize
+ auth = Auth(key)
+ self.agent_id = None # identifies which instance is communicating with server
+ self.model_id = model_id
+ self.model_url = f'{HUB_WEB_ROOT}/models/{model_id}'
+ self.api_url = f'{HUB_API_ROOT}/v1/models/{model_id}'
+ self.auth_header = auth.get_auth_header()
+ self.rate_limits = {'metrics': 3.0, 'ckpt': 900.0, 'heartbeat': 300.0} # rate limits (seconds)
+ self.timers = {} # rate limit timers (seconds)
+ self.metrics_queue = {} # metrics queue
+ self.model = self._get_model()
+ self.alive = True
+ self._start_heartbeat() # start heartbeats
+ self._register_signal_handlers()
+ LOGGER.info(f'{PREFIX}View model at {self.model_url} 🚀')
+
+ def _register_signal_handlers(self):
+ """Register signal handlers for SIGTERM and SIGINT signals to gracefully handle termination."""
+ signal.signal(signal.SIGTERM, self._handle_signal)
+ signal.signal(signal.SIGINT, self._handle_signal)
+
+ def _handle_signal(self, signum, frame):
+ """
+ Handle kill signals and prevent heartbeats from being sent on Colab after termination.
+ This method does not use frame, it is included as it is passed by signal.
+ """
+ if self.alive is True:
+ LOGGER.info(f'{PREFIX}Kill signal received! ❌')
+ self._stop_heartbeat()
+ sys.exit(signum)
+
+ def _stop_heartbeat(self):
+ """Terminate the heartbeat loop."""
+ self.alive = False
+
+ def upload_metrics(self):
+ """Upload model metrics to Ultralytics HUB."""
+ payload = {'metrics': self.metrics_queue.copy(), 'type': 'metrics'}
+ smart_request('post', self.api_url, json=payload, headers=self.auth_header, code=2)
+
+ def _get_model(self):
+ """Fetch and return model data from Ultralytics HUB."""
+ api_url = f'{HUB_API_ROOT}/v1/models/{self.model_id}'
+
+ try:
+ response = smart_request('get', api_url, headers=self.auth_header, thread=False, code=0)
+ data = response.json().get('data', None)
+
+ if data.get('status', None) == 'trained':
+ raise ValueError(emojis(f'Model is already trained and uploaded to {self.model_url} 🚀'))
+
+ if not data.get('data', None):
+ raise ValueError('Dataset may still be processing. Please wait a minute and try again.') # RF fix
+ self.model_id = data['id']
+
+ if data['status'] == 'new': # new model to start training
+ self.train_args = {
+ # TODO: deprecate 'batch_size' key for 'batch' in 3Q23
+ 'batch': data['batch' if ('batch' in data) else 'batch_size'],
+ 'epochs': data['epochs'],
+ 'imgsz': data['imgsz'],
+ 'patience': data['patience'],
+ 'device': data['device'],
+ 'cache': data['cache'],
+ 'data': data['data']}
+ self.model_file = data.get('cfg') or data.get('weights') # cfg for pretrained=False
+ self.model_file = checks.check_yolov5u_filename(self.model_file, verbose=False) # YOLOv5->YOLOv5u
+ elif data['status'] == 'training': # existing model to resume training
+ self.train_args = {'data': data['data'], 'resume': True}
+ self.model_file = data['resume']
+
+ return data
+ except requests.exceptions.ConnectionError as e:
+ raise ConnectionRefusedError('ERROR: The HUB server is not online. Please try again later.') from e
+ except Exception:
+ raise
+
+ def upload_model(self, epoch, weights, is_best=False, map=0.0, final=False):
+ """
+ Upload a model checkpoint to Ultralytics HUB.
+
+ Args:
+ epoch (int): The current training epoch.
+ weights (str): Path to the model weights file.
+ is_best (bool): Indicates if the current model is the best one so far.
+ map (float): Mean average precision of the model.
+ final (bool): Indicates if the model is the final model after training.
+ """
+ if Path(weights).is_file():
+ with open(weights, 'rb') as f:
+ file = f.read()
+ else:
+ LOGGER.warning(f'{PREFIX}WARNING ⚠️ Model upload issue. Missing model {weights}.')
+ file = None
+ url = f'{self.api_url}/upload'
+ # url = 'http://httpbin.org/post' # for debug
+ data = {'epoch': epoch}
+ if final:
+ data.update({'type': 'final', 'map': map})
+ smart_request('post',
+ url,
+ data=data,
+ files={'best.pt': file},
+ headers=self.auth_header,
+ retry=10,
+ timeout=3600,
+ thread=False,
+ progress=True,
+ code=4)
+ else:
+ data.update({'type': 'epoch', 'isBest': bool(is_best)})
+ smart_request('post', url, data=data, files={'last.pt': file}, headers=self.auth_header, code=3)
+
+ @threaded
+ def _start_heartbeat(self):
+ """Begin a threaded heartbeat loop to report the agent's status to Ultralytics HUB."""
+ while self.alive:
+ r = smart_request('post',
+ f'{HUB_API_ROOT}/v1/agent/heartbeat/models/{self.model_id}',
+ json={
+ 'agent': AGENT_NAME,
+ 'agentId': self.agent_id},
+ headers=self.auth_header,
+ retry=0,
+ code=5,
+ thread=False) # already in a thread
+ self.agent_id = r.json().get('data', {}).get('agentId', None)
+ sleep(self.rate_limits['heartbeat'])
diff --git a/STPoseNet/ultralytics/hub/utils.py b/STPoseNet/ultralytics/hub/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..e469987aed9bed32ac84f96c75a4f3483b712c49
--- /dev/null
+++ b/STPoseNet/ultralytics/hub/utils.py
@@ -0,0 +1,223 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+import platform
+import random
+import sys
+import threading
+import time
+from pathlib import Path
+
+import requests
+from tqdm import tqdm
+
+from ultralytics.utils import (ENVIRONMENT, LOGGER, ONLINE, RANK, SETTINGS, TESTS_RUNNING, TQDM_BAR_FORMAT, TryExcept,
+ __version__, colorstr, get_git_origin_url, is_colab, is_git_dir, is_pip_package)
+from ultralytics.utils.downloads import GITHUB_ASSETS_NAMES
+
+PREFIX = colorstr('Ultralytics HUB: ')
+HELP_MSG = 'If this issue persists please visit https://github.com/ultralytics/hub/issues for assistance.'
+HUB_API_ROOT = os.environ.get('ULTRALYTICS_HUB_API', 'https://api.ultralytics.com')
+HUB_WEB_ROOT = os.environ.get('ULTRALYTICS_HUB_WEB', 'https://hub.ultralytics.com')
+
+
+def request_with_credentials(url: str) -> any:
+ """
+ Make an AJAX request with cookies attached in a Google Colab environment.
+
+ Args:
+ url (str): The URL to make the request to.
+
+ Returns:
+ (any): The response data from the AJAX request.
+
+ Raises:
+ OSError: If the function is not run in a Google Colab environment.
+ """
+ if not is_colab():
+ raise OSError('request_with_credentials() must run in a Colab environment')
+ from google.colab import output # noqa
+ from IPython import display # noqa
+ display.display(
+ display.Javascript("""
+ window._hub_tmp = new Promise((resolve, reject) => {
+ const timeout = setTimeout(() => reject("Failed authenticating existing browser session"), 5000)
+ fetch("%s", {
+ method: 'POST',
+ credentials: 'include'
+ })
+ .then((response) => resolve(response.json()))
+ .then((json) => {
+ clearTimeout(timeout);
+ }).catch((err) => {
+ clearTimeout(timeout);
+ reject(err);
+ });
+ });
+ """ % url))
+ return output.eval_js('_hub_tmp')
+
+
+def requests_with_progress(method, url, **kwargs):
+ """
+ Make an HTTP request using the specified method and URL, with an optional progress bar.
+
+ Args:
+ method (str): The HTTP method to use (e.g. 'GET', 'POST').
+ url (str): The URL to send the request to.
+ **kwargs (dict): Additional keyword arguments to pass to the underlying `requests.request` function.
+
+ Returns:
+ (requests.Response): The response object from the HTTP request.
+
+ Note:
+ If 'progress' is set to True, the progress bar will display the download progress
+ for responses with a known content length.
+ """
+ progress = kwargs.pop('progress', False)
+ if not progress:
+ return requests.request(method, url, **kwargs)
+ response = requests.request(method, url, stream=True, **kwargs)
+ total = int(response.headers.get('content-length', 0)) # total size
+ try:
+ pbar = tqdm(total=total, unit='B', unit_scale=True, unit_divisor=1024, bar_format=TQDM_BAR_FORMAT)
+ for data in response.iter_content(chunk_size=1024):
+ pbar.update(len(data))
+ pbar.close()
+ except requests.exceptions.ChunkedEncodingError: # avoid 'Connection broken: IncompleteRead' warnings
+ response.close()
+ return response
+
+
+def smart_request(method, url, retry=3, timeout=30, thread=True, code=-1, verbose=True, progress=False, **kwargs):
+ """
+ Makes an HTTP request using the 'requests' library, with exponential backoff retries up to a specified timeout.
+
+ Args:
+ method (str): The HTTP method to use for the request. Choices are 'post' and 'get'.
+ url (str): The URL to make the request to.
+ retry (int, optional): Number of retries to attempt before giving up. Default is 3.
+ timeout (int, optional): Timeout in seconds after which the function will give up retrying. Default is 30.
+ thread (bool, optional): Whether to execute the request in a separate daemon thread. Default is True.
+ code (int, optional): An identifier for the request, used for logging purposes. Default is -1.
+ verbose (bool, optional): A flag to determine whether to print out to console or not. Default is True.
+ progress (bool, optional): Whether to show a progress bar during the request. Default is False.
+ **kwargs (dict): Keyword arguments to be passed to the requests function specified in method.
+
+ Returns:
+ (requests.Response): The HTTP response object. If the request is executed in a separate thread, returns None.
+ """
+ retry_codes = (408, 500) # retry only these codes
+
+ @TryExcept(verbose=verbose)
+ def func(func_method, func_url, **func_kwargs):
+ """Make HTTP requests with retries and timeouts, with optional progress tracking."""
+ r = None # response
+ t0 = time.time() # initial time for timer
+ for i in range(retry + 1):
+ if (time.time() - t0) > timeout:
+ break
+ r = requests_with_progress(func_method, func_url, **func_kwargs) # i.e. get(url, data, json, files)
+ if r.status_code < 300: # return codes in the 2xx range are generally considered "good" or "successful"
+ break
+ try:
+ m = r.json().get('message', 'No JSON message.')
+ except AttributeError:
+ m = 'Unable to read JSON.'
+ if i == 0:
+ if r.status_code in retry_codes:
+ m += f' Retrying {retry}x for {timeout}s.' if retry else ''
+ elif r.status_code == 429: # rate limit
+ h = r.headers # response headers
+ m = f"Rate limit reached ({h['X-RateLimit-Remaining']}/{h['X-RateLimit-Limit']}). " \
+ f"Please retry after {h['Retry-After']}s."
+ if verbose:
+ LOGGER.warning(f'{PREFIX}{m} {HELP_MSG} ({r.status_code} #{code})')
+ if r.status_code not in retry_codes:
+ return r
+ time.sleep(2 ** i) # exponential standoff
+ return r
+
+ args = method, url
+ kwargs['progress'] = progress
+ if thread:
+ threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True).start()
+ else:
+ return func(*args, **kwargs)
+
+
+class Events:
+ """
+ A class for collecting anonymous event analytics. Event analytics are enabled when sync=True in settings and
+ disabled when sync=False. Run 'yolo settings' to see and update settings YAML file.
+
+ Attributes:
+ url (str): The URL to send anonymous events.
+ rate_limit (float): The rate limit in seconds for sending events.
+ metadata (dict): A dictionary containing metadata about the environment.
+ enabled (bool): A flag to enable or disable Events based on certain conditions.
+ """
+
+ url = 'https://www.google-analytics.com/mp/collect?measurement_id=G-X8NCJYTQXM&api_secret=QLQrATrNSwGRFRLE-cbHJw'
+
+ def __init__(self):
+ """
+ Initializes the Events object with default values for events, rate_limit, and metadata.
+ """
+ self.events = [] # events list
+ self.rate_limit = 60.0 # rate limit (seconds)
+ self.t = 0.0 # rate limit timer (seconds)
+ self.metadata = {
+ 'cli': Path(sys.argv[0]).name == 'yolo',
+ 'install': 'git' if is_git_dir() else 'pip' if is_pip_package() else 'other',
+ 'python': '.'.join(platform.python_version_tuple()[:2]), # i.e. 3.10
+ 'version': __version__,
+ 'env': ENVIRONMENT,
+ 'session_id': round(random.random() * 1E15),
+ 'engagement_time_msec': 1000}
+ self.enabled = \
+ SETTINGS['sync'] and \
+ RANK in (-1, 0) and \
+ not TESTS_RUNNING and \
+ ONLINE and \
+ (is_pip_package() or get_git_origin_url() == 'https://github.com/ultralytics/ultralytics.git')
+
+ def __call__(self, cfg):
+ """
+ Attempts to add a new event to the events list and send events if the rate limit is reached.
+
+ Args:
+ cfg (IterableSimpleNamespace): The configuration object containing mode and task information.
+ """
+ if not self.enabled:
+ # Events disabled, do nothing
+ return
+
+ # Attempt to add to events
+ if len(self.events) < 25: # Events list limited to 25 events (drop any events past this)
+ params = {
+ **self.metadata, 'task': cfg.task,
+ 'model': cfg.model if cfg.model in GITHUB_ASSETS_NAMES else 'custom'}
+ if cfg.mode == 'export':
+ params['format'] = cfg.format
+ self.events.append({'name': cfg.mode, 'params': params})
+
+ # Check rate limit
+ t = time.time()
+ if (t - self.t) < self.rate_limit:
+ # Time is under rate limiter, wait to send
+ return
+
+ # Time is over rate limiter, send now
+ data = {'client_id': SETTINGS['uuid'], 'events': self.events} # SHA-256 anonymized UUID hash and events list
+
+ # POST equivalent to requests.post(self.url, json=data)
+ smart_request('post', self.url, json=data, retry=0, verbose=False)
+
+ # Reset events and rate limit timer
+ self.events = []
+ self.t = t
+
+
+# Run below code on hub/utils init -------------------------------------------------------------------------------------
+events = Events()
diff --git a/STPoseNet/ultralytics/models/__init__.py b/STPoseNet/ultralytics/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e96f893e96912c653501cc360bb22c0e672e4b72
--- /dev/null
+++ b/STPoseNet/ultralytics/models/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .rtdetr import RTDETR
+from .sam import SAM
+from .yolo import YOLO
+
+__all__ = 'YOLO', 'RTDETR', 'SAM' # allow simpler import
diff --git a/STPoseNet/ultralytics/models/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b478b647a9a52ae2da3dd70440ad76a27059d5a
Binary files /dev/null and b/STPoseNet/ultralytics/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__init__.py b/STPoseNet/ultralytics/models/fastsam/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f47772fd5eec97ea6776d7fdee00a9ea79dac17
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/__init__.py
@@ -0,0 +1,8 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .model import FastSAM
+from .predict import FastSAMPredictor
+from .prompt import FastSAMPrompt
+from .val import FastSAMValidator
+
+__all__ = 'FastSAMPredictor', 'FastSAM', 'FastSAMPrompt', 'FastSAMValidator'
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0e62b4d15c237a96c9e4964752136352c9731f21
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..044ba43e808316bead3db1896bbda0b7f9d14bca
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eb1549b2fac46a8e8c1b7b7931876fbac119edcb
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/prompt.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/prompt.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1784a0cf4cd9cbbba22bf0c166cf9ad30c819020
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/prompt.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/utils.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6c9bb617c467dc40768cbded2ed8d292573d8f34
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/utils.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/fastsam/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b756487e8ded031a828b7d2a717bfc00e4d83a5
Binary files /dev/null and b/STPoseNet/ultralytics/models/fastsam/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/fastsam/model.py b/STPoseNet/ultralytics/models/fastsam/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1895fc6264226bfac142c39bb1974ef228d3ce7
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/model.py
@@ -0,0 +1,33 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from pathlib import Path
+
+from ultralytics.engine.model import Model
+
+from .predict import FastSAMPredictor
+from .val import FastSAMValidator
+
+
+class FastSAM(Model):
+ """
+ FastSAM model interface.
+
+ Example:
+ ```python
+ from ultralytics import FastSAM
+
+ model = FastSAM('last.pt')
+ results = model.predict('ultralytics/assets/bus.jpg')
+ ```
+ """
+
+ def __init__(self, model='FastSAM-x.pt'):
+ """Call the __init__ method of the parent class (YOLO) with the updated default model"""
+ if str(model) == 'FastSAM.pt':
+ model = 'FastSAM-x.pt'
+ assert Path(model).suffix not in ('.yaml', '.yml'), 'FastSAM models only support pre-trained models.'
+ super().__init__(model=model, task='segment')
+
+ @property
+ def task_map(self):
+ return {'segment': {'predictor': FastSAMPredictor, 'validator': FastSAMValidator}}
diff --git a/STPoseNet/ultralytics/models/fastsam/predict.py b/STPoseNet/ultralytics/models/fastsam/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c9cb21c0d7d5e84d196de5363ad82507fb0e598
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/predict.py
@@ -0,0 +1,50 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.engine.results import Results
+from ultralytics.models.fastsam.utils import bbox_iou
+from ultralytics.models.yolo.detect.predict import DetectionPredictor
+from ultralytics.utils import DEFAULT_CFG, ops
+
+
+class FastSAMPredictor(DetectionPredictor):
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ super().__init__(cfg, overrides, _callbacks)
+ self.args.task = 'segment'
+
+ def postprocess(self, preds, img, orig_imgs):
+ p = ops.non_max_suppression(preds[0],
+ self.args.conf,
+ self.args.iou,
+ agnostic=self.args.agnostic_nms,
+ max_det=self.args.max_det,
+ nc=len(self.model.names),
+ classes=self.args.classes)
+ full_box = torch.zeros_like(p[0][0])
+ full_box[2], full_box[3], full_box[4], full_box[6:] = img.shape[3], img.shape[2], 1.0, 1.0
+ full_box = full_box.view(1, -1)
+ critical_iou_index = bbox_iou(full_box[0][:4], p[0][:, :4], iou_thres=0.9, image_shape=img.shape[2:])
+ if critical_iou_index.numel() != 0:
+ full_box[0][4] = p[0][critical_iou_index][:, 4]
+ full_box[0][6:] = p[0][critical_iou_index][:, 6:]
+ p[0][critical_iou_index] = full_box
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
+ for i, pred in enumerate(p):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ img_path = self.batch[0][i]
+ if not len(pred): # save empty boxes
+ masks = None
+ elif self.args.retina_masks:
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ masks = ops.process_mask_native(proto[i], pred[:, 6:], pred[:, :4], orig_img.shape[:2]) # HWC
+ else:
+ masks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWC
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6], masks=masks))
+ return results
diff --git a/STPoseNet/ultralytics/models/fastsam/prompt.py b/STPoseNet/ultralytics/models/fastsam/prompt.py
new file mode 100644
index 0000000000000000000000000000000000000000..3bdc9448e740e5f1e4d75c6368bb42cc9ed26655
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/prompt.py
@@ -0,0 +1,301 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+from PIL import Image
+
+from ultralytics.utils import LOGGER
+
+
+class FastSAMPrompt:
+
+ def __init__(self, img_path, results, device='cuda') -> None:
+ # self.img_path = img_path
+ self.device = device
+ self.results = results
+ self.img_path = str(img_path)
+ self.ori_img = cv2.imread(self.img_path)
+
+ # Import and assign clip
+ try:
+ import clip # for linear_assignment
+ except ImportError:
+ from ultralytics.utils.checks import check_requirements
+ check_requirements('git+https://github.com/openai/CLIP.git')
+ import clip
+ self.clip = clip
+
+ @staticmethod
+ def _segment_image(image, bbox):
+ image_array = np.array(image)
+ segmented_image_array = np.zeros_like(image_array)
+ x1, y1, x2, y2 = bbox
+ segmented_image_array[y1:y2, x1:x2] = image_array[y1:y2, x1:x2]
+ segmented_image = Image.fromarray(segmented_image_array)
+ black_image = Image.new('RGB', image.size, (255, 255, 255))
+ # transparency_mask = np.zeros_like((), dtype=np.uint8)
+ transparency_mask = np.zeros((image_array.shape[0], image_array.shape[1]), dtype=np.uint8)
+ transparency_mask[y1:y2, x1:x2] = 255
+ transparency_mask_image = Image.fromarray(transparency_mask, mode='L')
+ black_image.paste(segmented_image, mask=transparency_mask_image)
+ return black_image
+
+ @staticmethod
+ def _format_results(result, filter=0):
+ annotations = []
+ n = len(result.masks.data)
+ for i in range(n):
+ mask = result.masks.data[i] == 1.0
+ if torch.sum(mask) >= filter:
+ annotation = {
+ 'id': i,
+ 'segmentation': mask.cpu().numpy(),
+ 'bbox': result.boxes.data[i],
+ 'score': result.boxes.conf[i]}
+ annotation['area'] = annotation['segmentation'].sum()
+ annotations.append(annotation)
+ return annotations
+
+ @staticmethod
+ def _get_bbox_from_mask(mask):
+ mask = mask.astype(np.uint8)
+ contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
+ x1, y1, w, h = cv2.boundingRect(contours[0])
+ x2, y2 = x1 + w, y1 + h
+ if len(contours) > 1:
+ for b in contours:
+ x_t, y_t, w_t, h_t = cv2.boundingRect(b)
+ # 将多个bbox合并成一个
+ x1 = min(x1, x_t)
+ y1 = min(y1, y_t)
+ x2 = max(x2, x_t + w_t)
+ y2 = max(y2, y_t + h_t)
+ return [x1, y1, x2, y2]
+
+ def plot(self,
+ annotations,
+ output,
+ bbox=None,
+ points=None,
+ point_label=None,
+ mask_random_color=True,
+ better_quality=True,
+ retina=False,
+ with_countouers=True):
+ if isinstance(annotations[0], dict):
+ annotations = [annotation['segmentation'] for annotation in annotations]
+ if isinstance(annotations, torch.Tensor):
+ annotations = annotations.cpu().numpy()
+ result_name = os.path.basename(self.img_path)
+ image = self.ori_img
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
+ original_h = image.shape[0]
+ original_w = image.shape[1]
+ # for macOS only
+ # plt.switch_backend('TkAgg')
+ fig = plt.figure(figsize=(original_w / 100, original_h / 100))
+ # Add subplot with no margin.
+ plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
+ plt.margins(0, 0)
+ plt.gca().xaxis.set_major_locator(plt.NullLocator())
+ plt.gca().yaxis.set_major_locator(plt.NullLocator())
+
+ plt.imshow(image)
+ if better_quality:
+ for i, mask in enumerate(annotations):
+ mask = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8))
+ annotations[i] = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8))
+ self.fast_show_mask(
+ annotations,
+ plt.gca(),
+ random_color=mask_random_color,
+ bbox=bbox,
+ points=points,
+ pointlabel=point_label,
+ retinamask=retina,
+ target_height=original_h,
+ target_width=original_w,
+ )
+
+ if with_countouers:
+ contour_all = []
+ temp = np.zeros((original_h, original_w, 1))
+ for i, mask in enumerate(annotations):
+ if isinstance(mask, dict):
+ mask = mask['segmentation']
+ annotation = mask.astype(np.uint8)
+ if not retina:
+ annotation = cv2.resize(
+ annotation,
+ (original_w, original_h),
+ interpolation=cv2.INTER_NEAREST,
+ )
+ contours, hierarchy = cv2.findContours(annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
+ contour_all.extend(iter(contours))
+ cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2)
+ color = np.array([0 / 255, 0 / 255, 1.0, 0.8])
+ contour_mask = temp / 255 * color.reshape(1, 1, -1)
+ plt.imshow(contour_mask)
+
+ save_path = Path(output) / result_name
+ save_path.parent.mkdir(exist_ok=True, parents=True)
+ plt.axis('off')
+ fig.savefig(save_path)
+ LOGGER.info(f'Saved to {save_path.absolute()}')
+
+ # CPU post process
+ @staticmethod
+ def fast_show_mask(
+ annotation,
+ ax,
+ random_color=False,
+ bbox=None,
+ points=None,
+ pointlabel=None,
+ retinamask=True,
+ target_height=960,
+ target_width=960,
+ ):
+ n, h, w = annotation.shape # batch, height, width
+
+ areas = np.sum(annotation, axis=(1, 2))
+ annotation = annotation[np.argsort(areas)]
+
+ index = (annotation != 0).argmax(axis=0)
+ if random_color:
+ color = np.random.random((n, 1, 1, 3))
+ else:
+ color = np.ones((n, 1, 1, 3)) * np.array([30 / 255, 144 / 255, 1.0])
+ transparency = np.ones((n, 1, 1, 1)) * 0.6
+ visual = np.concatenate([color, transparency], axis=-1)
+ mask_image = np.expand_dims(annotation, -1) * visual
+
+ show = np.zeros((h, w, 4))
+ h_indices, w_indices = np.meshgrid(np.arange(h), np.arange(w), indexing='ij')
+ indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
+
+ show[h_indices, w_indices, :] = mask_image[indices]
+ if bbox is not None:
+ x1, y1, x2, y2 = bbox
+ ax.add_patch(plt.Rectangle((x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor='b', linewidth=1))
+ # Draw point
+ if points is not None:
+ plt.scatter(
+ [point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
+ [point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
+ s=20,
+ c='y',
+ )
+ plt.scatter(
+ [point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
+ [point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
+ s=20,
+ c='m',
+ )
+
+ if not retinamask:
+ show = cv2.resize(show, (target_width, target_height), interpolation=cv2.INTER_NEAREST)
+ ax.imshow(show)
+
+ @torch.no_grad()
+ def retrieve(self, model, preprocess, elements, search_text: str, device) -> int:
+ preprocessed_images = [preprocess(image).to(device) for image in elements]
+ tokenized_text = self.clip.tokenize([search_text]).to(device)
+ stacked_images = torch.stack(preprocessed_images)
+ image_features = model.encode_image(stacked_images)
+ text_features = model.encode_text(tokenized_text)
+ image_features /= image_features.norm(dim=-1, keepdim=True)
+ text_features /= text_features.norm(dim=-1, keepdim=True)
+ probs = 100.0 * image_features @ text_features.T
+ return probs[:, 0].softmax(dim=0)
+
+ def _crop_image(self, format_results):
+
+ image = Image.fromarray(cv2.cvtColor(self.ori_img, cv2.COLOR_BGR2RGB))
+ ori_w, ori_h = image.size
+ annotations = format_results
+ mask_h, mask_w = annotations[0]['segmentation'].shape
+ if ori_w != mask_w or ori_h != mask_h:
+ image = image.resize((mask_w, mask_h))
+ cropped_boxes = []
+ cropped_images = []
+ not_crop = []
+ filter_id = []
+ for _, mask in enumerate(annotations):
+ if np.sum(mask['segmentation']) <= 100:
+ filter_id.append(_)
+ continue
+ bbox = self._get_bbox_from_mask(mask['segmentation']) # mask 的 bbox
+ cropped_boxes.append(self._segment_image(image, bbox)) # 保存裁剪的图片
+ cropped_images.append(bbox) # 保存裁剪的图片的bbox
+
+ return cropped_boxes, cropped_images, not_crop, filter_id, annotations
+
+ def box_prompt(self, bbox):
+
+ assert (bbox[2] != 0 and bbox[3] != 0)
+ masks = self.results[0].masks.data
+ target_height = self.ori_img.shape[0]
+ target_width = self.ori_img.shape[1]
+ h = masks.shape[1]
+ w = masks.shape[2]
+ if h != target_height or w != target_width:
+ bbox = [
+ int(bbox[0] * w / target_width),
+ int(bbox[1] * h / target_height),
+ int(bbox[2] * w / target_width),
+ int(bbox[3] * h / target_height), ]
+ bbox[0] = max(round(bbox[0]), 0)
+ bbox[1] = max(round(bbox[1]), 0)
+ bbox[2] = min(round(bbox[2]), w)
+ bbox[3] = min(round(bbox[3]), h)
+
+ # IoUs = torch.zeros(len(masks), dtype=torch.float32)
+ bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
+
+ masks_area = torch.sum(masks[:, bbox[1]:bbox[3], bbox[0]:bbox[2]], dim=(1, 2))
+ orig_masks_area = torch.sum(masks, dim=(1, 2))
+
+ union = bbox_area + orig_masks_area - masks_area
+ IoUs = masks_area / union
+ max_iou_index = torch.argmax(IoUs)
+
+ return np.array([masks[max_iou_index].cpu().numpy()])
+
+ def point_prompt(self, points, pointlabel): # numpy 处理
+
+ masks = self._format_results(self.results[0], 0)
+ target_height = self.ori_img.shape[0]
+ target_width = self.ori_img.shape[1]
+ h = masks[0]['segmentation'].shape[0]
+ w = masks[0]['segmentation'].shape[1]
+ if h != target_height or w != target_width:
+ points = [[int(point[0] * w / target_width), int(point[1] * h / target_height)] for point in points]
+ onemask = np.zeros((h, w))
+ for i, annotation in enumerate(masks):
+ mask = annotation['segmentation'] if isinstance(annotation, dict) else annotation
+ for i, point in enumerate(points):
+ if mask[point[1], point[0]] == 1 and pointlabel[i] == 1:
+ onemask += mask
+ if mask[point[1], point[0]] == 1 and pointlabel[i] == 0:
+ onemask -= mask
+ onemask = onemask >= 1
+ return np.array([onemask])
+
+ def text_prompt(self, text):
+ format_results = self._format_results(self.results[0], 0)
+ cropped_boxes, cropped_images, not_crop, filter_id, annotations = self._crop_image(format_results)
+ clip_model, preprocess = self.clip.load('ViT-B/32', device=self.device)
+ scores = self.retrieve(clip_model, preprocess, cropped_boxes, text, device=self.device)
+ max_idx = scores.argsort()
+ max_idx = max_idx[-1]
+ max_idx += sum(np.array(filter_id) <= int(max_idx))
+ return np.array([annotations[max_idx]['segmentation']])
+
+ def everything_prompt(self):
+ return self.results[0].masks.data
diff --git a/STPoseNet/ultralytics/models/fastsam/utils.py b/STPoseNet/ultralytics/models/fastsam/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..e99fd623d9525c474e96b392d36f6c1cb084fd08
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/utils.py
@@ -0,0 +1,67 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+
+def adjust_bboxes_to_image_border(boxes, image_shape, threshold=20):
+ """
+ Adjust bounding boxes to stick to image border if they are within a certain threshold.
+
+ Args:
+ boxes (torch.Tensor): (n, 4)
+ image_shape (tuple): (height, width)
+ threshold (int): pixel threshold
+
+ Returns:
+ adjusted_boxes (torch.Tensor): adjusted bounding boxes
+ """
+
+ # Image dimensions
+ h, w = image_shape
+
+ # Adjust boxes
+ boxes[boxes[:, 0] < threshold, 0] = 0 # x1
+ boxes[boxes[:, 1] < threshold, 1] = 0 # y1
+ boxes[boxes[:, 2] > w - threshold, 2] = w # x2
+ boxes[boxes[:, 3] > h - threshold, 3] = h # y2
+ return boxes
+
+
+def bbox_iou(box1, boxes, iou_thres=0.9, image_shape=(640, 640), raw_output=False):
+ """
+ Compute the Intersection-Over-Union of a bounding box with respect to an array of other bounding boxes.
+
+ Args:
+ box1 (torch.Tensor): (4, )
+ boxes (torch.Tensor): (n, 4)
+ iou_thres (float): IoU threshold
+ image_shape (tuple): (height, width)
+ raw_output (bool): If True, return the raw IoU values instead of the indices
+
+ Returns:
+ high_iou_indices (torch.Tensor): Indices of boxes with IoU > thres
+ """
+ boxes = adjust_bboxes_to_image_border(boxes, image_shape)
+ # obtain coordinates for intersections
+ x1 = torch.max(box1[0], boxes[:, 0])
+ y1 = torch.max(box1[1], boxes[:, 1])
+ x2 = torch.min(box1[2], boxes[:, 2])
+ y2 = torch.min(box1[3], boxes[:, 3])
+
+ # compute the area of intersection
+ intersection = (x2 - x1).clamp(0) * (y2 - y1).clamp(0)
+
+ # compute the area of both individual boxes
+ box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1])
+ box2_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
+
+ # compute the area of union
+ union = box1_area + box2_area - intersection
+
+ # compute the IoU
+ iou = intersection / union # Should be shape (n, )
+ if raw_output:
+ return 0 if iou.numel() == 0 else iou
+
+ # return indices of boxes with IoU > thres
+ return torch.nonzero(iou > iou_thres).flatten()
diff --git a/STPoseNet/ultralytics/models/fastsam/val.py b/STPoseNet/ultralytics/models/fastsam/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa25e49ff38e0138b760ab005946adc92abab258
--- /dev/null
+++ b/STPoseNet/ultralytics/models/fastsam/val.py
@@ -0,0 +1,14 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.models.yolo.segment import SegmentationValidator
+from ultralytics.utils.metrics import SegmentMetrics
+
+
+class FastSAMValidator(SegmentationValidator):
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """Initialize SegmentationValidator and set task to 'segment', metrics to SegmentMetrics."""
+ super().__init__(dataloader, save_dir, pbar, args, _callbacks)
+ self.args.task = 'segment'
+ self.args.plots = False # disable ConfusionMatrix and other plots to avoid errors
+ self.metrics = SegmentMetrics(save_dir=self.save_dir, on_plot=self.on_plot)
diff --git a/STPoseNet/ultralytics/models/nas/__init__.py b/STPoseNet/ultralytics/models/nas/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..eec3837d492b08db2c8be6a033b7f3870dd6e0df
--- /dev/null
+++ b/STPoseNet/ultralytics/models/nas/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .model import NAS
+from .predict import NASPredictor
+from .val import NASValidator
+
+__all__ = 'NASPredictor', 'NASValidator', 'NAS'
diff --git a/STPoseNet/ultralytics/models/nas/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/nas/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d4feaaf858b1811555fc855d390848685c19ff6e
Binary files /dev/null and b/STPoseNet/ultralytics/models/nas/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/nas/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/models/nas/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..92f4ec128df2c207248c6229f5300b133c2e2784
Binary files /dev/null and b/STPoseNet/ultralytics/models/nas/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/nas/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/nas/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3fa3086bef3d9e7a4f30dfcf4e3ce1bf8ac36150
Binary files /dev/null and b/STPoseNet/ultralytics/models/nas/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/nas/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/nas/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8be7d67c261bff447138d6df25c9c3456b69a2d7
Binary files /dev/null and b/STPoseNet/ultralytics/models/nas/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/nas/model.py b/STPoseNet/ultralytics/models/nas/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f848cc4bff1ed5e93fb498cb3d15d1de274e8b46
--- /dev/null
+++ b/STPoseNet/ultralytics/models/nas/model.py
@@ -0,0 +1,61 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+YOLO-NAS model interface.
+
+Example:
+ ```python
+ from ultralytics import NAS
+
+ model = NAS('yolo_nas_s')
+ results = model.predict('ultralytics/assets/bus.jpg')
+ ```
+"""
+
+from pathlib import Path
+
+import torch
+
+from ultralytics.engine.model import Model
+from ultralytics.utils.torch_utils import model_info, smart_inference_mode
+
+from .predict import NASPredictor
+from .val import NASValidator
+
+
+class NAS(Model):
+
+ def __init__(self, model='yolo_nas_s.pt') -> None:
+ assert Path(model).suffix not in ('.yaml', '.yml'), 'YOLO-NAS models only support pre-trained models.'
+ super().__init__(model, task='detect')
+
+ @smart_inference_mode()
+ def _load(self, weights: str, task: str):
+ # Load or create new NAS model
+ import super_gradients
+ suffix = Path(weights).suffix
+ if suffix == '.pt':
+ self.model = torch.load(weights)
+ elif suffix == '':
+ self.model = super_gradients.training.models.get(weights, pretrained_weights='coco')
+ # Standardize model
+ self.model.fuse = lambda verbose=True: self.model
+ self.model.stride = torch.tensor([32])
+ self.model.names = dict(enumerate(self.model._class_names))
+ self.model.is_fused = lambda: False # for info()
+ self.model.yaml = {} # for info()
+ self.model.pt_path = weights # for export()
+ self.model.task = 'detect' # for export()
+
+ def info(self, detailed=False, verbose=True):
+ """
+ Logs model info.
+
+ Args:
+ detailed (bool): Show detailed information about model.
+ verbose (bool): Controls verbosity.
+ """
+ return model_info(self.model, detailed=detailed, verbose=verbose, imgsz=640)
+
+ @property
+ def task_map(self):
+ return {'detect': {'predictor': NASPredictor, 'validator': NASValidator}}
diff --git a/STPoseNet/ultralytics/models/nas/predict.py b/STPoseNet/ultralytics/models/nas/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..b29d2dc244be07319797bd4c0cb5eb32a4a2df36
--- /dev/null
+++ b/STPoseNet/ultralytics/models/nas/predict.py
@@ -0,0 +1,34 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.engine.predictor import BasePredictor
+from ultralytics.engine.results import Results
+from ultralytics.utils import ops
+
+
+class NASPredictor(BasePredictor):
+
+ def postprocess(self, preds_in, img, orig_imgs):
+ """Postprocess predictions and returns a list of Results objects."""
+
+ # Cat boxes and class scores
+ boxes = ops.xyxy2xywh(preds_in[0][0])
+ preds = torch.cat((boxes, preds_in[0][1]), -1).permute(0, 2, 1)
+
+ preds = ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ agnostic=self.args.agnostic_nms,
+ max_det=self.args.max_det,
+ classes=self.args.classes)
+
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, pred in enumerate(preds):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ img_path = self.batch[0][i]
+ results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
+ return results
diff --git a/STPoseNet/ultralytics/models/nas/val.py b/STPoseNet/ultralytics/models/nas/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c39171a31d174f3a562c207d5d9afbc2c181e18
--- /dev/null
+++ b/STPoseNet/ultralytics/models/nas/val.py
@@ -0,0 +1,24 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.models.yolo.detect import DetectionValidator
+from ultralytics.utils import ops
+
+__all__ = ['NASValidator']
+
+
+class NASValidator(DetectionValidator):
+
+ def postprocess(self, preds_in):
+ """Apply Non-maximum suppression to prediction outputs."""
+ boxes = ops.xyxy2xywh(preds_in[0][0])
+ preds = torch.cat((boxes, preds_in[0][1]), -1).permute(0, 2, 1)
+ return ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ labels=self.lb,
+ multi_label=False,
+ agnostic=self.args.single_cls,
+ max_det=self.args.max_det,
+ max_time_img=0.5)
diff --git a/STPoseNet/ultralytics/models/rtdetr/__init__.py b/STPoseNet/ultralytics/models/rtdetr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d12115616a9e637857da368d5ace3098bbb96d1
--- /dev/null
+++ b/STPoseNet/ultralytics/models/rtdetr/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .model import RTDETR
+from .predict import RTDETRPredictor
+from .val import RTDETRValidator
+
+__all__ = 'RTDETRPredictor', 'RTDETRValidator', 'RTDETR'
diff --git a/STPoseNet/ultralytics/models/rtdetr/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/rtdetr/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84b2ad40040670f09328cce452c882bccf482ac9
Binary files /dev/null and b/STPoseNet/ultralytics/models/rtdetr/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/rtdetr/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/models/rtdetr/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2bf1bba553cb1e053d783fb7836c35b25286d106
Binary files /dev/null and b/STPoseNet/ultralytics/models/rtdetr/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/rtdetr/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/rtdetr/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9aa4184b12205c9b2cd668e2f8f8b91a99128b5c
Binary files /dev/null and b/STPoseNet/ultralytics/models/rtdetr/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/rtdetr/__pycache__/train.cpython-38.pyc b/STPoseNet/ultralytics/models/rtdetr/__pycache__/train.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cd3f87914f65a3aff4954b0f41d4170f97740ddc
Binary files /dev/null and b/STPoseNet/ultralytics/models/rtdetr/__pycache__/train.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/rtdetr/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/rtdetr/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ba1807d8c99ad189ddbd2e1a674ff88a2c28c83d
Binary files /dev/null and b/STPoseNet/ultralytics/models/rtdetr/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/rtdetr/model.py b/STPoseNet/ultralytics/models/rtdetr/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c20d72f6435fadd96f81a87161c71c3bebe49d13
--- /dev/null
+++ b/STPoseNet/ultralytics/models/rtdetr/model.py
@@ -0,0 +1,30 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+RT-DETR model interface
+"""
+from ultralytics.engine.model import Model
+from ultralytics.nn.tasks import RTDETRDetectionModel
+
+from .predict import RTDETRPredictor
+from .train import RTDETRTrainer
+from .val import RTDETRValidator
+
+
+class RTDETR(Model):
+ """
+ RTDETR model interface.
+ """
+
+ def __init__(self, model='rtdetr-l.pt') -> None:
+ if model and model.split('.')[-1] not in ('pt', 'yaml', 'yml'):
+ raise NotImplementedError('RT-DETR only supports creating from *.pt file or *.yaml file.')
+ super().__init__(model=model, task='detect')
+
+ @property
+ def task_map(self):
+ return {
+ 'detect': {
+ 'predictor': RTDETRPredictor,
+ 'validator': RTDETRValidator,
+ 'trainer': RTDETRTrainer,
+ 'model': RTDETRDetectionModel}}
diff --git a/STPoseNet/ultralytics/models/rtdetr/predict.py b/STPoseNet/ultralytics/models/rtdetr/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..2415a4501326ceb98474383bc9780ec208e5ec99
--- /dev/null
+++ b/STPoseNet/ultralytics/models/rtdetr/predict.py
@@ -0,0 +1,85 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.data.augment import LetterBox
+from ultralytics.engine.predictor import BasePredictor
+from ultralytics.engine.results import Results
+from ultralytics.utils import ops
+
+
+class RTDETRPredictor(BasePredictor):
+ """
+ A class extending the BasePredictor class for prediction based on an RT-DETR detection model.
+
+ Example:
+ ```python
+ from ultralytics.utils import ASSETS
+ from ultralytics.models.rtdetr import RTDETRPredictor
+
+ args = dict(model='rtdetr-l.pt', source=ASSETS)
+ predictor = RTDETRPredictor(overrides=args)
+ predictor.predict_cli()
+ ```
+ """
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Postprocess predictions and returns a list of Results objects."""
+ nd = preds[0].shape[-1]
+ bboxes, scores = preds[0].split((4, nd - 4), dim=-1)
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, bbox in enumerate(bboxes): # (300, 4)
+ bbox = ops.xywh2xyxy(bbox)
+ score, cls = scores[i].max(-1, keepdim=True) # (300, 1)
+ idx = score.squeeze(-1) > self.args.conf # (300, )
+ if self.args.classes is not None:
+ idx = (cls == torch.tensor(self.args.classes, device=cls.device)).any(1) & idx
+ pred = torch.cat([bbox, score, cls], dim=-1)[idx] # filter
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ oh, ow = orig_img.shape[:2]
+ if is_list:
+ pred[..., [0, 2]] *= ow
+ pred[..., [1, 3]] *= oh
+ img_path = self.batch[0][i]
+ results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred, min_flag=self.min_flag))
+ return results
+
+ # """Postprocess predictions and returns a list of Results objects."""
+ # nd = preds[0].shape[-1]
+ # bboxes, scores = preds[0].split((4, nd - 4), dim=-1)
+ # results = []
+ # is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ # likelihood_ = 0
+ # for i, bbox in enumerate(bboxes): # (300, 4)
+ # bbox = ops.xywh2xyxy(bbox)
+ # score, cls = scores[i].max(-1, keepdim=True) # (300, 1)
+ # idx = score.squeeze(-1) > self.args.conf # (300, )
+ # if self.args.classes is not None:
+ # idx = (cls == torch.tensor(self.args.classes, device=cls.device)).any(1) & idx
+ # pred = torch.cat([bbox, score, cls], dim=-1)[idx] # filter
+ # orig_img = orig_imgs[i] if is_list else orig_imgs
+ # oh, ow = orig_img.shape[:2]
+ # if is_list:
+ # pred[..., [0, 2]] *= ow
+ # pred[..., [1, 3]] *= oh
+ # img_path = self.batch[0][i]
+ # result = Results(orig_img, path=img_path, names=self.model.names, boxes=pred, min_flag=self.min_flag)
+ # likelihood = result.boxes[-2]
+ # if likelihood > likelihood_:
+ # likelihood_ = likelihood
+ # results = result
+ # return results
+
+ def pre_transform(self, im):
+ """Pre-transform input image before inference.
+
+ Args:
+ im (List(np.ndarray)): (N, 3, h, w) for tensor, [(h, w, 3) x N] for list.
+
+ Notes: The size must be square(640) and scaleFilled.
+
+ Returns:
+ (list): A list of transformed imgs.
+ """
+ return [LetterBox(self.imgsz, auto=False, scaleFill=True)(image=x) for x in im]
diff --git a/STPoseNet/ultralytics/models/rtdetr/train.py b/STPoseNet/ultralytics/models/rtdetr/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e586683d0cf3b03f08fdbf8072242e715895da7
--- /dev/null
+++ b/STPoseNet/ultralytics/models/rtdetr/train.py
@@ -0,0 +1,72 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from copy import copy
+
+import torch
+
+from ultralytics.models.yolo.detect import DetectionTrainer
+from ultralytics.nn.tasks import RTDETRDetectionModel
+from ultralytics.utils import RANK, colorstr
+
+from .val import RTDETRDataset, RTDETRValidator
+
+
+class RTDETRTrainer(DetectionTrainer):
+ """
+ A class extending the DetectionTrainer class for training based on an RT-DETR detection model.
+
+ Notes:
+ - F.grid_sample used in rt-detr does not support the `deterministic=True` argument.
+ - AMP training can lead to NaN outputs and may produce errors during bipartite graph matching.
+
+ Example:
+ ```python
+ from ultralytics.models.rtdetr.train import RTDETRTrainer
+
+ args = dict(model='rtdetr-l.yaml', data='coco8.yaml', imgsz=640, epochs=3)
+ trainer = RTDETRTrainer(overrides=args)
+ trainer.train()
+ ```
+ """
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Return a YOLO detection model."""
+ model = RTDETRDetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
+ if weights:
+ model.load(weights)
+ return model
+
+ def build_dataset(self, img_path, mode='val', batch=None):
+ """Build RTDETR Dataset
+
+ Args:
+ img_path (str): Path to the folder containing images.
+ mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode.
+ batch (int, optional): Size of batches, this is for `rect`. Defaults to None.
+ """
+ return RTDETRDataset(
+ img_path=img_path,
+ imgsz=self.args.imgsz,
+ batch_size=batch,
+ augment=mode == 'train', # no augmentation
+ hyp=self.args,
+ rect=False, # no rect
+ cache=self.args.cache or None,
+ prefix=colorstr(f'{mode}: '),
+ data=self.data)
+
+ def get_validator(self):
+ """Returns a DetectionValidator for RTDETR model validation."""
+ self.loss_names = 'giou_loss', 'cls_loss', 'l1_loss'
+ return RTDETRValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
+
+ def preprocess_batch(self, batch):
+ """Preprocesses a batch of images by scaling and converting to float."""
+ batch = super().preprocess_batch(batch)
+ bs = len(batch['img'])
+ batch_idx = batch['batch_idx']
+ gt_bbox, gt_class = [], []
+ for i in range(bs):
+ gt_bbox.append(batch['bboxes'][batch_idx == i].to(batch_idx.device))
+ gt_class.append(batch['cls'][batch_idx == i].to(device=batch_idx.device, dtype=torch.long))
+ return batch
diff --git a/STPoseNet/ultralytics/models/rtdetr/val.py b/STPoseNet/ultralytics/models/rtdetr/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..69c23d08d891758699c6954ec0cd8d9b610be4ed
--- /dev/null
+++ b/STPoseNet/ultralytics/models/rtdetr/val.py
@@ -0,0 +1,164 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+
+from ultralytics.data import YOLODataset
+from ultralytics.data.augment import Compose, Format, v8_transforms
+from ultralytics.models.yolo.detect import DetectionValidator
+from ultralytics.utils import colorstr, ops
+
+__all__ = 'RTDETRValidator', # tuple or list
+
+
+# TODO: Temporarily RT-DETR does not need padding.
+class RTDETRDataset(YOLODataset):
+
+ def __init__(self, *args, data=None, **kwargs):
+ super().__init__(*args, data=data, use_segments=False, use_keypoints=False, **kwargs)
+
+ # NOTE: add stretch version load_image for rtdetr mosaic
+ def load_image(self, i):
+ """Loads 1 image from dataset index 'i', returns (im, resized hw)."""
+ im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
+ if im is None: # not cached in RAM
+ if fn.exists(): # load npy
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ if im is None:
+ raise FileNotFoundError(f'Image Not Found {f}')
+ h0, w0 = im.shape[:2] # orig hw
+ im = cv2.resize(im, (self.imgsz, self.imgsz), interpolation=cv2.INTER_LINEAR)
+
+ # Add to buffer if training with augmentations
+ if self.augment:
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
+ self.buffer.append(i)
+ if len(self.buffer) >= self.max_buffer_length:
+ j = self.buffer.pop(0)
+ self.ims[j], self.im_hw0[j], self.im_hw[j] = None, None, None
+
+ return im, (h0, w0), im.shape[:2]
+
+ return self.ims[i], self.im_hw0[i], self.im_hw[i]
+
+ def build_transforms(self, hyp=None):
+ """Temporary, only for evaluation."""
+ if self.augment:
+ hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0
+ hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0
+ transforms = v8_transforms(self, self.imgsz, hyp, stretch=True)
+ else:
+ # transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), auto=False, scaleFill=True)])
+ transforms = Compose([])
+ transforms.append(
+ Format(bbox_format='xywh',
+ normalize=True,
+ return_mask=self.use_segments,
+ return_keypoint=self.use_keypoints,
+ batch_idx=True,
+ mask_ratio=hyp.mask_ratio,
+ mask_overlap=hyp.overlap_mask))
+ return transforms
+
+
+class RTDETRValidator(DetectionValidator):
+ """
+ A class extending the DetectionValidator class for validation based on an RT-DETR detection model.
+
+ Example:
+ ```python
+ from ultralytics.models.rtdetr import RTDETRValidator
+
+ args = dict(model='rtdetr-l.pt', data='coco8.yaml')
+ validator = RTDETRValidator(args=args)
+ validator()
+ ```
+ """
+
+ def build_dataset(self, img_path, mode='val', batch=None):
+ """
+ Build an RTDETR Dataset.
+
+ Args:
+ img_path (str): Path to the folder containing images.
+ mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode.
+ batch (int, optional): Size of batches, this is for `rect`. Defaults to None.
+ """
+ return RTDETRDataset(
+ img_path=img_path,
+ imgsz=self.args.imgsz,
+ batch_size=batch,
+ augment=False, # no augmentation
+ hyp=self.args,
+ rect=False, # no rect
+ cache=self.args.cache or None,
+ prefix=colorstr(f'{mode}: '),
+ data=self.data)
+
+ def postprocess(self, preds):
+ """Apply Non-maximum suppression to prediction outputs."""
+ bs, _, nd = preds[0].shape
+ bboxes, scores = preds[0].split((4, nd - 4), dim=-1)
+ bboxes *= self.args.imgsz
+ outputs = [torch.zeros((0, 6), device=bboxes.device)] * bs
+ for i, bbox in enumerate(bboxes): # (300, 4)
+ bbox = ops.xywh2xyxy(bbox)
+ score, cls = scores[i].max(-1) # (300, )
+ # Do not need threshold for evaluation as only got 300 boxes here.
+ # idx = score > self.args.conf
+ pred = torch.cat([bbox, score[..., None], cls[..., None]], dim=-1) # filter
+ # sort by confidence to correctly get internal metrics.
+ pred = pred[score.argsort(descending=True)]
+ outputs[i] = pred # [idx]
+
+ return outputs
+
+ def update_metrics(self, preds, batch):
+ """Metrics."""
+ for si, pred in enumerate(preds):
+ idx = batch['batch_idx'] == si
+ cls = batch['cls'][idx]
+ bbox = batch['bboxes'][idx]
+ nl, npr = cls.shape[0], pred.shape[0] # number of labels, predictions
+ shape = batch['ori_shape'][si]
+ correct_bboxes = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ self.seen += 1
+
+ if npr == 0:
+ if nl:
+ self.stats.append((correct_bboxes, *torch.zeros((2, 0), device=self.device), cls.squeeze(-1)))
+ if self.args.plots:
+ self.confusion_matrix.process_batch(detections=None, labels=cls.squeeze(-1))
+ continue
+
+ # Predictions
+ if self.args.single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ predn[..., [0, 2]] *= shape[1] / self.args.imgsz # native-space pred
+ predn[..., [1, 3]] *= shape[0] / self.args.imgsz # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = ops.xywh2xyxy(bbox) # target boxes
+ tbox[..., [0, 2]] *= shape[1] # native-space pred
+ tbox[..., [1, 3]] *= shape[0] # native-space pred
+ labelsn = torch.cat((cls, tbox), 1) # native-space labels
+ # NOTE: To get correct metrics, the inputs of `_process_batch` should always be float32 type.
+ correct_bboxes = self._process_batch(predn.float(), labelsn)
+ # TODO: maybe remove these `self.` arguments as they already are member variable
+ if self.args.plots:
+ self.confusion_matrix.process_batch(predn, labelsn)
+ self.stats.append((correct_bboxes, pred[:, 4], pred[:, 5], cls.squeeze(-1))) # (conf, pcls, tcls)
+
+ # Save
+ if self.args.save_json:
+ self.pred_to_json(predn, batch['im_file'][si])
+ if self.args.save_txt:
+ file = self.save_dir / 'labels' / f'{Path(batch["im_file"][si]).stem}.txt'
+ self.save_one_txt(predn, self.args.save_conf, shape, file)
diff --git a/STPoseNet/ultralytics/models/sam/__init__.py b/STPoseNet/ultralytics/models/sam/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..35f4efa86ac2c4d960d64ca275b87059ab609bda
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/__init__.py
@@ -0,0 +1,8 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .model import SAM
+from .predict import Predictor
+
+# from .build import build_sam
+
+__all__ = 'SAM', 'Predictor' # tuple or list
diff --git a/STPoseNet/ultralytics/models/sam/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d0798de3e65c7167550972f435b8233440b23522
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/__pycache__/amg.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/__pycache__/amg.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..17be57fd4dbb82aa34e0176c76ad7c06aa2ea82b
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/__pycache__/amg.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/__pycache__/build.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/__pycache__/build.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ef6959da7b0e79452a50b63b74fb56232c4b499b
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/__pycache__/build.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a3ba9fcc129fba3f92e6d550603a367ee597e3ee
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bf196c5ff4f3a6de1dd865a637a252a22008f2e8
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/amg.py b/STPoseNet/ultralytics/models/sam/amg.py
new file mode 100644
index 0000000000000000000000000000000000000000..f251fe4e073b0be1b2d47b6cdf65044cc2949df3
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/amg.py
@@ -0,0 +1,180 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import math
+from itertools import product
+from typing import Any, Generator, List, Tuple
+
+import numpy as np
+import torch
+
+
+def is_box_near_crop_edge(boxes: torch.Tensor,
+ crop_box: List[int],
+ orig_box: List[int],
+ atol: float = 20.0) -> torch.Tensor:
+ """Return a boolean tensor indicating if boxes are near the crop edge."""
+ crop_box_torch = torch.as_tensor(crop_box, dtype=torch.float, device=boxes.device)
+ orig_box_torch = torch.as_tensor(orig_box, dtype=torch.float, device=boxes.device)
+ boxes = uncrop_boxes_xyxy(boxes, crop_box).float()
+ near_crop_edge = torch.isclose(boxes, crop_box_torch[None, :], atol=atol, rtol=0)
+ near_image_edge = torch.isclose(boxes, orig_box_torch[None, :], atol=atol, rtol=0)
+ near_crop_edge = torch.logical_and(near_crop_edge, ~near_image_edge)
+ return torch.any(near_crop_edge, dim=1)
+
+
+def batch_iterator(batch_size: int, *args) -> Generator[List[Any], None, None]:
+ """Yield batches of data from the input arguments."""
+ assert args and all(len(a) == len(args[0]) for a in args), 'Batched iteration must have same-size inputs.'
+ n_batches = len(args[0]) // batch_size + int(len(args[0]) % batch_size != 0)
+ for b in range(n_batches):
+ yield [arg[b * batch_size:(b + 1) * batch_size] for arg in args]
+
+
+def calculate_stability_score(masks: torch.Tensor, mask_threshold: float, threshold_offset: float) -> torch.Tensor:
+ """
+ Computes the stability score for a batch of masks. The stability
+ score is the IoU between the binary masks obtained by thresholding
+ the predicted mask logits at high and low values.
+ """
+ # One mask is always contained inside the other.
+ # Save memory by preventing unnecessary cast to torch.int64
+ intersections = ((masks > (mask_threshold + threshold_offset)).sum(-1, dtype=torch.int16).sum(-1,
+ dtype=torch.int32))
+ unions = ((masks > (mask_threshold - threshold_offset)).sum(-1, dtype=torch.int16).sum(-1, dtype=torch.int32))
+ return intersections / unions
+
+
+def build_point_grid(n_per_side: int) -> np.ndarray:
+ """Generate a 2D grid of evenly spaced points in the range [0,1]x[0,1]."""
+ offset = 1 / (2 * n_per_side)
+ points_one_side = np.linspace(offset, 1 - offset, n_per_side)
+ points_x = np.tile(points_one_side[None, :], (n_per_side, 1))
+ points_y = np.tile(points_one_side[:, None], (1, n_per_side))
+ return np.stack([points_x, points_y], axis=-1).reshape(-1, 2)
+
+
+def build_all_layer_point_grids(n_per_side: int, n_layers: int, scale_per_layer: int) -> List[np.ndarray]:
+ """Generate point grids for all crop layers."""
+ return [build_point_grid(int(n_per_side / (scale_per_layer ** i))) for i in range(n_layers + 1)]
+
+
+def generate_crop_boxes(im_size: Tuple[int, ...], n_layers: int,
+ overlap_ratio: float) -> Tuple[List[List[int]], List[int]]:
+ """Generates a list of crop boxes of different sizes. Each layer has (2**i)**2 boxes for the ith layer."""
+ crop_boxes, layer_idxs = [], []
+ im_h, im_w = im_size
+ short_side = min(im_h, im_w)
+
+ # Original image
+ crop_boxes.append([0, 0, im_w, im_h])
+ layer_idxs.append(0)
+
+ def crop_len(orig_len, n_crops, overlap):
+ """Crops bounding boxes to the size of the input image."""
+ return int(math.ceil((overlap * (n_crops - 1) + orig_len) / n_crops))
+
+ for i_layer in range(n_layers):
+ n_crops_per_side = 2 ** (i_layer + 1)
+ overlap = int(overlap_ratio * short_side * (2 / n_crops_per_side))
+
+ crop_w = crop_len(im_w, n_crops_per_side, overlap)
+ crop_h = crop_len(im_h, n_crops_per_side, overlap)
+
+ crop_box_x0 = [int((crop_w - overlap) * i) for i in range(n_crops_per_side)]
+ crop_box_y0 = [int((crop_h - overlap) * i) for i in range(n_crops_per_side)]
+
+ # Crops in XYWH format
+ for x0, y0 in product(crop_box_x0, crop_box_y0):
+ box = [x0, y0, min(x0 + crop_w, im_w), min(y0 + crop_h, im_h)]
+ crop_boxes.append(box)
+ layer_idxs.append(i_layer + 1)
+
+ return crop_boxes, layer_idxs
+
+
+def uncrop_boxes_xyxy(boxes: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
+ """Uncrop bounding boxes by adding the crop box offset."""
+ x0, y0, _, _ = crop_box
+ offset = torch.tensor([[x0, y0, x0, y0]], device=boxes.device)
+ # Check if boxes has a channel dimension
+ if len(boxes.shape) == 3:
+ offset = offset.unsqueeze(1)
+ return boxes + offset
+
+
+def uncrop_points(points: torch.Tensor, crop_box: List[int]) -> torch.Tensor:
+ """Uncrop points by adding the crop box offset."""
+ x0, y0, _, _ = crop_box
+ offset = torch.tensor([[x0, y0]], device=points.device)
+ # Check if points has a channel dimension
+ if len(points.shape) == 3:
+ offset = offset.unsqueeze(1)
+ return points + offset
+
+
+def uncrop_masks(masks: torch.Tensor, crop_box: List[int], orig_h: int, orig_w: int) -> torch.Tensor:
+ """Uncrop masks by padding them to the original image size."""
+ x0, y0, x1, y1 = crop_box
+ if x0 == 0 and y0 == 0 and x1 == orig_w and y1 == orig_h:
+ return masks
+ # Coordinate transform masks
+ pad_x, pad_y = orig_w - (x1 - x0), orig_h - (y1 - y0)
+ pad = (x0, pad_x - x0, y0, pad_y - y0)
+ return torch.nn.functional.pad(masks, pad, value=0)
+
+
+def remove_small_regions(mask: np.ndarray, area_thresh: float, mode: str) -> Tuple[np.ndarray, bool]:
+ """Remove small disconnected regions or holes in a mask, returning the mask and a modification indicator."""
+ import cv2 # type: ignore
+
+ assert mode in {'holes', 'islands'}
+ correct_holes = mode == 'holes'
+ working_mask = (correct_holes ^ mask).astype(np.uint8)
+ n_labels, regions, stats, _ = cv2.connectedComponentsWithStats(working_mask, 8)
+ sizes = stats[:, -1][1:] # Row 0 is background label
+ small_regions = [i + 1 for i, s in enumerate(sizes) if s < area_thresh]
+ if not small_regions:
+ return mask, False
+ fill_labels = [0] + small_regions
+ if not correct_holes:
+ # If every region is below threshold, keep largest
+ fill_labels = [i for i in range(n_labels) if i not in fill_labels] or [int(np.argmax(sizes)) + 1]
+ mask = np.isin(regions, fill_labels)
+ return mask, True
+
+
+def batched_mask_to_box(masks: torch.Tensor) -> torch.Tensor:
+ """
+ Calculates boxes in XYXY format around masks. Return [0,0,0,0] for
+ an empty mask. For input shape C1xC2x...xHxW, the output shape is C1xC2x...x4.
+ """
+ # torch.max below raises an error on empty inputs, just skip in this case
+ if torch.numel(masks) == 0:
+ return torch.zeros(*masks.shape[:-2], 4, device=masks.device)
+
+ # Normalize shape to CxHxW
+ shape = masks.shape
+ h, w = shape[-2:]
+ masks = masks.flatten(0, -3) if len(shape) > 2 else masks.unsqueeze(0)
+ # Get top and bottom edges
+ in_height, _ = torch.max(masks, dim=-1)
+ in_height_coords = in_height * torch.arange(h, device=in_height.device)[None, :]
+ bottom_edges, _ = torch.max(in_height_coords, dim=-1)
+ in_height_coords = in_height_coords + h * (~in_height)
+ top_edges, _ = torch.min(in_height_coords, dim=-1)
+
+ # Get left and right edges
+ in_width, _ = torch.max(masks, dim=-2)
+ in_width_coords = in_width * torch.arange(w, device=in_width.device)[None, :]
+ right_edges, _ = torch.max(in_width_coords, dim=-1)
+ in_width_coords = in_width_coords + w * (~in_width)
+ left_edges, _ = torch.min(in_width_coords, dim=-1)
+
+ # If the mask is empty the right edge will be to the left of the left edge.
+ # Replace these boxes with [0, 0, 0, 0]
+ empty_filter = (right_edges < left_edges) | (bottom_edges < top_edges)
+ out = torch.stack([left_edges, top_edges, right_edges, bottom_edges], dim=-1)
+ out = out * (~empty_filter).unsqueeze(-1)
+
+ # Return to original shape
+ return out.reshape(*shape[:-2], 4) if len(shape) > 2 else out[0]
diff --git a/STPoseNet/ultralytics/models/sam/build.py b/STPoseNet/ultralytics/models/sam/build.py
new file mode 100644
index 0000000000000000000000000000000000000000..21da265c4d44da9740bac35415ef4a8358203fcb
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/build.py
@@ -0,0 +1,158 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from functools import partial
+
+import torch
+
+from ultralytics.utils.downloads import attempt_download_asset
+
+from .modules.decoders import MaskDecoder
+from .modules.encoders import ImageEncoderViT, PromptEncoder
+from .modules.sam import Sam
+from .modules.tiny_encoder import TinyViT
+from .modules.transformer import TwoWayTransformer
+
+
+def build_sam_vit_h(checkpoint=None):
+ """Build and return a Segment Anything Model (SAM) h-size model."""
+ return _build_sam(
+ encoder_embed_dim=1280,
+ encoder_depth=32,
+ encoder_num_heads=16,
+ encoder_global_attn_indexes=[7, 15, 23, 31],
+ checkpoint=checkpoint,
+ )
+
+
+def build_sam_vit_l(checkpoint=None):
+ """Build and return a Segment Anything Model (SAM) l-size model."""
+ return _build_sam(
+ encoder_embed_dim=1024,
+ encoder_depth=24,
+ encoder_num_heads=16,
+ encoder_global_attn_indexes=[5, 11, 17, 23],
+ checkpoint=checkpoint,
+ )
+
+
+def build_sam_vit_b(checkpoint=None):
+ """Build and return a Segment Anything Model (SAM) b-size model."""
+ return _build_sam(
+ encoder_embed_dim=768,
+ encoder_depth=12,
+ encoder_num_heads=12,
+ encoder_global_attn_indexes=[2, 5, 8, 11],
+ checkpoint=checkpoint,
+ )
+
+
+def build_mobile_sam(checkpoint=None):
+ """Build and return Mobile Segment Anything Model (Mobile-SAM)."""
+ return _build_sam(
+ encoder_embed_dim=[64, 128, 160, 320],
+ encoder_depth=[2, 2, 6, 2],
+ encoder_num_heads=[2, 4, 5, 10],
+ encoder_global_attn_indexes=None,
+ mobile_sam=True,
+ checkpoint=checkpoint,
+ )
+
+
+def _build_sam(encoder_embed_dim,
+ encoder_depth,
+ encoder_num_heads,
+ encoder_global_attn_indexes,
+ checkpoint=None,
+ mobile_sam=False):
+ """Builds the selected SAM model architecture."""
+ prompt_embed_dim = 256
+ image_size = 1024
+ vit_patch_size = 16
+ image_embedding_size = image_size // vit_patch_size
+ image_encoder = (TinyViT(
+ img_size=1024,
+ in_chans=3,
+ num_classes=1000,
+ embed_dims=encoder_embed_dim,
+ depths=encoder_depth,
+ num_heads=encoder_num_heads,
+ window_sizes=[7, 7, 14, 7],
+ mlp_ratio=4.0,
+ drop_rate=0.0,
+ drop_path_rate=0.0,
+ use_checkpoint=False,
+ mbconv_expand_ratio=4.0,
+ local_conv_size=3,
+ layer_lr_decay=0.8,
+ ) if mobile_sam else ImageEncoderViT(
+ depth=encoder_depth,
+ embed_dim=encoder_embed_dim,
+ img_size=image_size,
+ mlp_ratio=4,
+ norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
+ num_heads=encoder_num_heads,
+ patch_size=vit_patch_size,
+ qkv_bias=True,
+ use_rel_pos=True,
+ global_attn_indexes=encoder_global_attn_indexes,
+ window_size=14,
+ out_chans=prompt_embed_dim,
+ ))
+ sam = Sam(
+ image_encoder=image_encoder,
+ prompt_encoder=PromptEncoder(
+ embed_dim=prompt_embed_dim,
+ image_embedding_size=(image_embedding_size, image_embedding_size),
+ input_image_size=(image_size, image_size),
+ mask_in_chans=16,
+ ),
+ mask_decoder=MaskDecoder(
+ num_multimask_outputs=3,
+ transformer=TwoWayTransformer(
+ depth=2,
+ embedding_dim=prompt_embed_dim,
+ mlp_dim=2048,
+ num_heads=8,
+ ),
+ transformer_dim=prompt_embed_dim,
+ iou_head_depth=3,
+ iou_head_hidden_dim=256,
+ ),
+ pixel_mean=[123.675, 116.28, 103.53],
+ pixel_std=[58.395, 57.12, 57.375],
+ )
+ if checkpoint is not None:
+ checkpoint = attempt_download_asset(checkpoint)
+ with open(checkpoint, 'rb') as f:
+ state_dict = torch.load(f)
+ sam.load_state_dict(state_dict)
+ sam.eval()
+ # sam.load_state_dict(torch.load(checkpoint), strict=True)
+ # sam.eval()
+ return sam
+
+
+sam_model_map = {
+ 'sam_h.pt': build_sam_vit_h,
+ 'sam_l.pt': build_sam_vit_l,
+ 'sam_b.pt': build_sam_vit_b,
+ 'mobile_sam.pt': build_mobile_sam, }
+
+
+def build_sam(ckpt='sam_b.pt'):
+ """Build a SAM model specified by ckpt."""
+ model_builder = None
+ for k in sam_model_map.keys():
+ if ckpt.endswith(k):
+ model_builder = sam_model_map.get(k)
+
+ if not model_builder:
+ raise FileNotFoundError(f'{ckpt} is not a supported sam model. Available models are: \n {sam_model_map.keys()}')
+
+ return model_builder(ckpt)
diff --git a/STPoseNet/ultralytics/models/sam/model.py b/STPoseNet/ultralytics/models/sam/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ca35011f7fe0a99a3b9796425e26ffbef05c731
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/model.py
@@ -0,0 +1,51 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+SAM model interface
+"""
+
+from pathlib import Path
+
+from ultralytics.engine.model import Model
+from ultralytics.utils.torch_utils import model_info
+
+from .build import build_sam
+from .predict import Predictor
+
+
+class SAM(Model):
+ """
+ SAM model interface.
+ """
+
+ def __init__(self, model='sam_b.pt') -> None:
+ if model and Path(model).suffix not in ('.pt', '.pth'):
+ raise NotImplementedError('SAM prediction requires pre-trained *.pt or *.pth model.')
+ super().__init__(model=model, task='segment')
+
+ def _load(self, weights: str, task=None):
+ self.model = build_sam(weights)
+
+ def predict(self, source, stream=False, bboxes=None, points=None, labels=None, **kwargs):
+ """Predicts and returns segmentation masks for given image or video source."""
+ overrides = dict(conf=0.25, task='segment', mode='predict', imgsz=1024)
+ kwargs.update(overrides)
+ prompts = dict(bboxes=bboxes, points=points, labels=labels)
+ return super().predict(source, stream, prompts=prompts, **kwargs)
+
+ def __call__(self, source=None, stream=False, bboxes=None, points=None, labels=None, **kwargs):
+ """Calls the 'predict' function with given arguments to perform object detection."""
+ return self.predict(source, stream, bboxes, points, labels, **kwargs)
+
+ def info(self, detailed=False, verbose=True):
+ """
+ Logs model info.
+
+ Args:
+ detailed (bool): Show detailed information about model.
+ verbose (bool): Controls verbosity.
+ """
+ return model_info(self.model, detailed=detailed, verbose=verbose)
+
+ @property
+ def task_map(self):
+ return {'segment': {'predictor': Predictor}}
diff --git a/STPoseNet/ultralytics/models/sam/modules/__init__.py b/STPoseNet/ultralytics/models/sam/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e68dc12245afb4f72ba5f7c1227df74613a427d
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/__init__.py
@@ -0,0 +1 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..080c4c92dc47da32c4493a715be2fa341fbffd46
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/decoders.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/decoders.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..de3b09e8dec6f343cafe95ec30ba1c01b05350f9
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/decoders.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/encoders.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/encoders.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..29da41323660e9972f637e97fffed18e9b10e377
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/encoders.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/sam.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/sam.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ae9b09b0ec1015e902a4f6397102159bf56d274
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/sam.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/tiny_encoder.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/tiny_encoder.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..241995a66aa78e52066128323d5adc780c64e150
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/tiny_encoder.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/__pycache__/transformer.cpython-38.pyc b/STPoseNet/ultralytics/models/sam/modules/__pycache__/transformer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..61ea487e4a96748b2639ba1823ec9c077e09661b
Binary files /dev/null and b/STPoseNet/ultralytics/models/sam/modules/__pycache__/transformer.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/sam/modules/decoders.py b/STPoseNet/ultralytics/models/sam/modules/decoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c64a7e42451d29f513de69d62c7deb0b72549d2
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/decoders.py
@@ -0,0 +1,159 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from typing import List, Tuple, Type
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from ultralytics.nn.modules import LayerNorm2d
+
+
+class MaskDecoder(nn.Module):
+
+ def __init__(
+ self,
+ *,
+ transformer_dim: int,
+ transformer: nn.Module,
+ num_multimask_outputs: int = 3,
+ activation: Type[nn.Module] = nn.GELU,
+ iou_head_depth: int = 3,
+ iou_head_hidden_dim: int = 256,
+ ) -> None:
+ """
+ Predicts masks given an image and prompt embeddings, using a transformer architecture.
+
+ Args:
+ transformer_dim (int): the channel dimension of the transformer module
+ transformer (nn.Module): the transformer used to predict masks
+ num_multimask_outputs (int): the number of masks to predict when disambiguating masks
+ activation (nn.Module): the type of activation to use when upscaling masks
+ iou_head_depth (int): the depth of the MLP used to predict mask quality
+ iou_head_hidden_dim (int): the hidden dimension of the MLP used to predict mask quality
+ """
+ super().__init__()
+ self.transformer_dim = transformer_dim
+ self.transformer = transformer
+
+ self.num_multimask_outputs = num_multimask_outputs
+
+ self.iou_token = nn.Embedding(1, transformer_dim)
+ self.num_mask_tokens = num_multimask_outputs + 1
+ self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
+
+ self.output_upscaling = nn.Sequential(
+ nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
+ LayerNorm2d(transformer_dim // 4),
+ activation(),
+ nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
+ activation(),
+ )
+ self.output_hypernetworks_mlps = nn.ModuleList([
+ MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) for _ in range(self.num_mask_tokens)])
+
+ self.iou_prediction_head = MLP(transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth)
+
+ def forward(
+ self,
+ image_embeddings: torch.Tensor,
+ image_pe: torch.Tensor,
+ sparse_prompt_embeddings: torch.Tensor,
+ dense_prompt_embeddings: torch.Tensor,
+ multimask_output: bool,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Predict masks given image and prompt embeddings.
+
+ Args:
+ image_embeddings (torch.Tensor): the embeddings from the image encoder
+ image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
+ sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
+ dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
+ multimask_output (bool): Whether to return multiple masks or a single mask.
+
+ Returns:
+ torch.Tensor: batched predicted masks
+ torch.Tensor: batched predictions of mask quality
+ """
+ masks, iou_pred = self.predict_masks(
+ image_embeddings=image_embeddings,
+ image_pe=image_pe,
+ sparse_prompt_embeddings=sparse_prompt_embeddings,
+ dense_prompt_embeddings=dense_prompt_embeddings,
+ )
+
+ # Select the correct mask or masks for output
+ mask_slice = slice(1, None) if multimask_output else slice(0, 1)
+ masks = masks[:, mask_slice, :, :]
+ iou_pred = iou_pred[:, mask_slice]
+
+ # Prepare output
+ return masks, iou_pred
+
+ def predict_masks(
+ self,
+ image_embeddings: torch.Tensor,
+ image_pe: torch.Tensor,
+ sparse_prompt_embeddings: torch.Tensor,
+ dense_prompt_embeddings: torch.Tensor,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Predicts masks. See 'forward' for more details."""
+ # Concatenate output tokens
+ output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
+ output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
+ tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
+
+ # Expand per-image data in batch direction to be per-mask
+ src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
+ src = src + dense_prompt_embeddings
+ pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
+ b, c, h, w = src.shape
+
+ # Run the transformer
+ hs, src = self.transformer(src, pos_src, tokens)
+ iou_token_out = hs[:, 0, :]
+ mask_tokens_out = hs[:, 1:(1 + self.num_mask_tokens), :]
+
+ # Upscale mask embeddings and predict masks using the mask tokens
+ src = src.transpose(1, 2).view(b, c, h, w)
+ upscaled_embedding = self.output_upscaling(src)
+ hyper_in_list: List[torch.Tensor] = [
+ self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]) for i in range(self.num_mask_tokens)]
+ hyper_in = torch.stack(hyper_in_list, dim=1)
+ b, c, h, w = upscaled_embedding.shape
+ masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
+
+ # Generate mask quality predictions
+ iou_pred = self.iou_prediction_head(iou_token_out)
+
+ return masks, iou_pred
+
+
+class MLP(nn.Module):
+ """
+ Lightly adapted from
+ https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py
+ """
+
+ def __init__(
+ self,
+ input_dim: int,
+ hidden_dim: int,
+ output_dim: int,
+ num_layers: int,
+ sigmoid_output: bool = False,
+ ) -> None:
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+ self.sigmoid_output = sigmoid_output
+
+ def forward(self, x):
+ """Executes feedforward within the neural network module and applies activation."""
+ for i, layer in enumerate(self.layers):
+ x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ if self.sigmoid_output:
+ x = torch.sigmoid(x)
+ return x
diff --git a/STPoseNet/ultralytics/models/sam/modules/encoders.py b/STPoseNet/ultralytics/models/sam/modules/encoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb9352f970fb81441ce9b3c8bdc5f5282aacd639
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/encoders.py
@@ -0,0 +1,568 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from typing import Any, Optional, Tuple, Type
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ultralytics.nn.modules import LayerNorm2d, MLPBlock
+
+
+# This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py # noqa
+class ImageEncoderViT(nn.Module):
+
+ def __init__(
+ self,
+ img_size: int = 1024,
+ patch_size: int = 16,
+ in_chans: int = 3,
+ embed_dim: int = 768,
+ depth: int = 12,
+ num_heads: int = 12,
+ mlp_ratio: float = 4.0,
+ out_chans: int = 256,
+ qkv_bias: bool = True,
+ norm_layer: Type[nn.Module] = nn.LayerNorm,
+ act_layer: Type[nn.Module] = nn.GELU,
+ use_abs_pos: bool = True,
+ use_rel_pos: bool = False,
+ rel_pos_zero_init: bool = True,
+ window_size: int = 0,
+ global_attn_indexes: Tuple[int, ...] = (),
+ ) -> None:
+ """
+ Args:
+ img_size (int): Input image size.
+ patch_size (int): Patch size.
+ in_chans (int): Number of input image channels.
+ embed_dim (int): Patch embedding dimension.
+ depth (int): Depth of ViT.
+ num_heads (int): Number of attention heads in each ViT block.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool): If True, add a learnable bias to query, key, value.
+ norm_layer (nn.Module): Normalization layer.
+ act_layer (nn.Module): Activation layer.
+ use_abs_pos (bool): If True, use absolute positional embeddings.
+ use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
+ rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
+ window_size (int): Window size for window attention blocks.
+ global_attn_indexes (list): Indexes for blocks using global attention.
+ """
+ super().__init__()
+ self.img_size = img_size
+
+ self.patch_embed = PatchEmbed(
+ kernel_size=(patch_size, patch_size),
+ stride=(patch_size, patch_size),
+ in_chans=in_chans,
+ embed_dim=embed_dim,
+ )
+
+ self.pos_embed: Optional[nn.Parameter] = None
+ if use_abs_pos:
+ # Initialize absolute positional embedding with pretrain image size.
+ self.pos_embed = nn.Parameter(torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim))
+
+ self.blocks = nn.ModuleList()
+ for i in range(depth):
+ block = Block(
+ dim=embed_dim,
+ num_heads=num_heads,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ norm_layer=norm_layer,
+ act_layer=act_layer,
+ use_rel_pos=use_rel_pos,
+ rel_pos_zero_init=rel_pos_zero_init,
+ window_size=window_size if i not in global_attn_indexes else 0,
+ input_size=(img_size // patch_size, img_size // patch_size),
+ )
+ self.blocks.append(block)
+
+ self.neck = nn.Sequential(
+ nn.Conv2d(
+ embed_dim,
+ out_chans,
+ kernel_size=1,
+ bias=False,
+ ),
+ LayerNorm2d(out_chans),
+ nn.Conv2d(
+ out_chans,
+ out_chans,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ ),
+ LayerNorm2d(out_chans),
+ )
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = self.patch_embed(x)
+ if self.pos_embed is not None:
+ x = x + self.pos_embed
+ for blk in self.blocks:
+ x = blk(x)
+ return self.neck(x.permute(0, 3, 1, 2))
+
+
+class PromptEncoder(nn.Module):
+
+ def __init__(
+ self,
+ embed_dim: int,
+ image_embedding_size: Tuple[int, int],
+ input_image_size: Tuple[int, int],
+ mask_in_chans: int,
+ activation: Type[nn.Module] = nn.GELU,
+ ) -> None:
+ """
+ Encodes prompts for input to SAM's mask decoder.
+
+ Args:
+ embed_dim (int): The prompts' embedding dimension
+ image_embedding_size (tuple(int, int)): The spatial size of the
+ image embedding, as (H, W).
+ input_image_size (int): The padded size of the image as input
+ to the image encoder, as (H, W).
+ mask_in_chans (int): The number of hidden channels used for
+ encoding input masks.
+ activation (nn.Module): The activation to use when encoding
+ input masks.
+ """
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.input_image_size = input_image_size
+ self.image_embedding_size = image_embedding_size
+ self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
+
+ self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
+ point_embeddings = [nn.Embedding(1, embed_dim) for _ in range(self.num_point_embeddings)]
+ self.point_embeddings = nn.ModuleList(point_embeddings)
+ self.not_a_point_embed = nn.Embedding(1, embed_dim)
+
+ self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
+ self.mask_downscaling = nn.Sequential(
+ nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
+ LayerNorm2d(mask_in_chans // 4),
+ activation(),
+ nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
+ LayerNorm2d(mask_in_chans),
+ activation(),
+ nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
+ )
+ self.no_mask_embed = nn.Embedding(1, embed_dim)
+
+ def get_dense_pe(self) -> torch.Tensor:
+ """
+ Returns the positional encoding used to encode point prompts,
+ applied to a dense set of points the shape of the image encoding.
+
+ Returns:
+ torch.Tensor: Positional encoding with shape 1x(embed_dim)x(embedding_h)x(embedding_w)
+ """
+ return self.pe_layer(self.image_embedding_size).unsqueeze(0)
+
+ def _embed_points(
+ self,
+ points: torch.Tensor,
+ labels: torch.Tensor,
+ pad: bool,
+ ) -> torch.Tensor:
+ """Embeds point prompts."""
+ points = points + 0.5 # Shift to center of pixel
+ if pad:
+ padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
+ padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
+ points = torch.cat([points, padding_point], dim=1)
+ labels = torch.cat([labels, padding_label], dim=1)
+ point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
+ point_embedding[labels == -1] = 0.0
+ point_embedding[labels == -1] += self.not_a_point_embed.weight
+ point_embedding[labels == 0] += self.point_embeddings[0].weight
+ point_embedding[labels == 1] += self.point_embeddings[1].weight
+ return point_embedding
+
+ def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
+ """Embeds box prompts."""
+ boxes = boxes + 0.5 # Shift to center of pixel
+ coords = boxes.reshape(-1, 2, 2)
+ corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
+ corner_embedding[:, 0, :] += self.point_embeddings[2].weight
+ corner_embedding[:, 1, :] += self.point_embeddings[3].weight
+ return corner_embedding
+
+ def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
+ """Embeds mask inputs."""
+ return self.mask_downscaling(masks)
+
+ def _get_batch_size(
+ self,
+ points: Optional[Tuple[torch.Tensor, torch.Tensor]],
+ boxes: Optional[torch.Tensor],
+ masks: Optional[torch.Tensor],
+ ) -> int:
+ """
+ Gets the batch size of the output given the batch size of the input prompts.
+ """
+ if points is not None:
+ return points[0].shape[0]
+ elif boxes is not None:
+ return boxes.shape[0]
+ elif masks is not None:
+ return masks.shape[0]
+ else:
+ return 1
+
+ def _get_device(self) -> torch.device:
+ return self.point_embeddings[0].weight.device
+
+ def forward(
+ self,
+ points: Optional[Tuple[torch.Tensor, torch.Tensor]],
+ boxes: Optional[torch.Tensor],
+ masks: Optional[torch.Tensor],
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Embeds different types of prompts, returning both sparse and dense embeddings.
+
+ Args:
+ points (tuple(torch.Tensor, torch.Tensor), None): point coordinates and labels to embed.
+ boxes (torch.Tensor, None): boxes to embed
+ masks (torch.Tensor, None): masks to embed
+
+ Returns:
+ torch.Tensor: sparse embeddings for the points and boxes, with shape BxNx(embed_dim), where N is determined
+ by the number of input points and boxes.
+ torch.Tensor: dense embeddings for the masks, in the shape Bx(embed_dim)x(embed_H)x(embed_W)
+ """
+ bs = self._get_batch_size(points, boxes, masks)
+ sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
+ if points is not None:
+ coords, labels = points
+ point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
+ sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
+ if boxes is not None:
+ box_embeddings = self._embed_boxes(boxes)
+ sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
+
+ if masks is not None:
+ dense_embeddings = self._embed_masks(masks)
+ else:
+ dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1,
+ 1).expand(bs, -1, self.image_embedding_size[0],
+ self.image_embedding_size[1])
+
+ return sparse_embeddings, dense_embeddings
+
+
+class PositionEmbeddingRandom(nn.Module):
+ """
+ Positional encoding using random spatial frequencies.
+ """
+
+ def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
+ super().__init__()
+ if scale is None or scale <= 0.0:
+ scale = 1.0
+ self.register_buffer('positional_encoding_gaussian_matrix', scale * torch.randn((2, num_pos_feats)))
+
+ # Set non-deterministic for forward() error 'cumsum_cuda_kernel does not have a deterministic implementation'
+ torch.use_deterministic_algorithms(False)
+ torch.backends.cudnn.deterministic = False
+
+ def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
+ """Positionally encode points that are normalized to [0,1]."""
+ # assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
+ coords = 2 * coords - 1
+ coords = coords @ self.positional_encoding_gaussian_matrix
+ coords = 2 * np.pi * coords
+ # outputs d_1 x ... x d_n x C shape
+ return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
+
+ def forward(self, size: Tuple[int, int]) -> torch.Tensor:
+ """Generate positional encoding for a grid of the specified size."""
+ h, w = size
+ device: Any = self.positional_encoding_gaussian_matrix.device
+ grid = torch.ones((h, w), device=device, dtype=torch.float32)
+ y_embed = grid.cumsum(dim=0) - 0.5
+ x_embed = grid.cumsum(dim=1) - 0.5
+ y_embed = y_embed / h
+ x_embed = x_embed / w
+
+ pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
+ return pe.permute(2, 0, 1) # C x H x W
+
+ def forward_with_coords(self, coords_input: torch.Tensor, image_size: Tuple[int, int]) -> torch.Tensor:
+ """Positionally encode points that are not normalized to [0,1]."""
+ coords = coords_input.clone()
+ coords[:, :, 0] = coords[:, :, 0] / image_size[1]
+ coords[:, :, 1] = coords[:, :, 1] / image_size[0]
+ return self._pe_encoding(coords.to(torch.float)) # B x N x C
+
+
+class Block(nn.Module):
+ """Transformer blocks with support of window attention and residual propagation blocks"""
+
+ def __init__(
+ self,
+ dim: int,
+ num_heads: int,
+ mlp_ratio: float = 4.0,
+ qkv_bias: bool = True,
+ norm_layer: Type[nn.Module] = nn.LayerNorm,
+ act_layer: Type[nn.Module] = nn.GELU,
+ use_rel_pos: bool = False,
+ rel_pos_zero_init: bool = True,
+ window_size: int = 0,
+ input_size: Optional[Tuple[int, int]] = None,
+ ) -> None:
+ """
+ Args:
+ dim (int): Number of input channels.
+ num_heads (int): Number of attention heads in each ViT block.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool): If True, add a learnable bias to query, key, value.
+ norm_layer (nn.Module): Normalization layer.
+ act_layer (nn.Module): Activation layer.
+ use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
+ rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
+ window_size (int): Window size for window attention blocks. If it equals 0, then
+ use global attention.
+ input_size (tuple(int, int), None): Input resolution for calculating the relative
+ positional parameter size.
+ """
+ super().__init__()
+ self.norm1 = norm_layer(dim)
+ self.attn = Attention(
+ dim,
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ use_rel_pos=use_rel_pos,
+ rel_pos_zero_init=rel_pos_zero_init,
+ input_size=input_size if window_size == 0 else (window_size, window_size),
+ )
+
+ self.norm2 = norm_layer(dim)
+ self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
+
+ self.window_size = window_size
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ shortcut = x
+ x = self.norm1(x)
+ # Window partition
+ if self.window_size > 0:
+ H, W = x.shape[1], x.shape[2]
+ x, pad_hw = window_partition(x, self.window_size)
+
+ x = self.attn(x)
+ # Reverse window partition
+ if self.window_size > 0:
+ x = window_unpartition(x, self.window_size, pad_hw, (H, W))
+
+ x = shortcut + x
+ return x + self.mlp(self.norm2(x))
+
+
+class Attention(nn.Module):
+ """Multi-head Attention block with relative position embeddings."""
+
+ def __init__(
+ self,
+ dim: int,
+ num_heads: int = 8,
+ qkv_bias: bool = True,
+ use_rel_pos: bool = False,
+ rel_pos_zero_init: bool = True,
+ input_size: Optional[Tuple[int, int]] = None,
+ ) -> None:
+ """
+ Args:
+ dim (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool): If True, add a learnable bias to query, key, value.
+ rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
+ input_size (tuple(int, int), None): Input resolution for calculating the relative
+ positional parameter size.
+ """
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = head_dim ** -0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj = nn.Linear(dim, dim)
+
+ self.use_rel_pos = use_rel_pos
+ if self.use_rel_pos:
+ assert (input_size is not None), 'Input size must be provided if using relative positional encoding.'
+ # initialize relative positional embeddings
+ self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
+ self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ B, H, W, _ = x.shape
+ # qkv with shape (3, B, nHead, H * W, C)
+ qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
+ # q, k, v with shape (B * nHead, H * W, C)
+ q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
+
+ attn = (q * self.scale) @ k.transpose(-2, -1)
+
+ if self.use_rel_pos:
+ attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
+
+ attn = attn.softmax(dim=-1)
+ x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
+ return self.proj(x)
+
+
+def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:
+ """
+ Partition into non-overlapping windows with padding if needed.
+ Args:
+ x (tensor): input tokens with [B, H, W, C].
+ window_size (int): window size.
+
+ Returns:
+ windows: windows after partition with [B * num_windows, window_size, window_size, C].
+ (Hp, Wp): padded height and width before partition
+ """
+ B, H, W, C = x.shape
+
+ pad_h = (window_size - H % window_size) % window_size
+ pad_w = (window_size - W % window_size) % window_size
+ if pad_h > 0 or pad_w > 0:
+ x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
+ Hp, Wp = H + pad_h, W + pad_w
+
+ x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
+ return windows, (Hp, Wp)
+
+
+def window_unpartition(windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int],
+ hw: Tuple[int, int]) -> torch.Tensor:
+ """
+ Window unpartition into original sequences and removing padding.
+ Args:
+ windows (tensor): input tokens with [B * num_windows, window_size, window_size, C].
+ window_size (int): window size.
+ pad_hw (Tuple): padded height and width (Hp, Wp).
+ hw (Tuple): original height and width (H, W) before padding.
+
+ Returns:
+ x: unpartitioned sequences with [B, H, W, C].
+ """
+ Hp, Wp = pad_hw
+ H, W = hw
+ B = windows.shape[0] // (Hp * Wp // window_size // window_size)
+ x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
+
+ if Hp > H or Wp > W:
+ x = x[:, :H, :W, :].contiguous()
+ return x
+
+
+def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
+ """
+ Get relative positional embeddings according to the relative positions of
+ query and key sizes.
+ Args:
+ q_size (int): size of query q.
+ k_size (int): size of key k.
+ rel_pos (Tensor): relative position embeddings (L, C).
+
+ Returns:
+ Extracted positional embeddings according to relative positions.
+ """
+ max_rel_dist = int(2 * max(q_size, k_size) - 1)
+ # Interpolate rel pos if needed.
+ if rel_pos.shape[0] != max_rel_dist:
+ # Interpolate rel pos.
+ rel_pos_resized = F.interpolate(
+ rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
+ size=max_rel_dist,
+ mode='linear',
+ )
+ rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
+ else:
+ rel_pos_resized = rel_pos
+
+ # Scale the coords with short length if shapes for q and k are different.
+ q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
+ k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
+ relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
+
+ return rel_pos_resized[relative_coords.long()]
+
+
+def add_decomposed_rel_pos(
+ attn: torch.Tensor,
+ q: torch.Tensor,
+ rel_pos_h: torch.Tensor,
+ rel_pos_w: torch.Tensor,
+ q_size: Tuple[int, int],
+ k_size: Tuple[int, int],
+) -> torch.Tensor:
+ """
+ Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
+ https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950
+ Args:
+ attn (Tensor): attention map.
+ q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C).
+ rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis.
+ rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis.
+ q_size (Tuple): spatial sequence size of query q with (q_h, q_w).
+ k_size (Tuple): spatial sequence size of key k with (k_h, k_w).
+
+ Returns:
+ attn (Tensor): attention map with added relative positional embeddings.
+ """
+ q_h, q_w = q_size
+ k_h, k_w = k_size
+ Rh = get_rel_pos(q_h, k_h, rel_pos_h)
+ Rw = get_rel_pos(q_w, k_w, rel_pos_w)
+
+ B, _, dim = q.shape
+ r_q = q.reshape(B, q_h, q_w, dim)
+ rel_h = torch.einsum('bhwc,hkc->bhwk', r_q, Rh)
+ rel_w = torch.einsum('bhwc,wkc->bhwk', r_q, Rw)
+
+ attn = (attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]).view(
+ B, q_h * q_w, k_h * k_w)
+
+ return attn
+
+
+class PatchEmbed(nn.Module):
+ """
+ Image to Patch Embedding.
+ """
+
+ def __init__(
+ self,
+ kernel_size: Tuple[int, int] = (16, 16),
+ stride: Tuple[int, int] = (16, 16),
+ padding: Tuple[int, int] = (0, 0),
+ in_chans: int = 3,
+ embed_dim: int = 768,
+ ) -> None:
+ """
+ Args:
+ kernel_size (Tuple): kernel size of the projection layer.
+ stride (Tuple): stride of the projection layer.
+ padding (Tuple): padding size of the projection layer.
+ in_chans (int): Number of input image channels.
+ embed_dim (int): Patch embedding dimension.
+ """
+ super().__init__()
+
+ self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ return self.proj(x).permute(0, 2, 3, 1) # B C H W -> B H W C
diff --git a/STPoseNet/ultralytics/models/sam/modules/sam.py b/STPoseNet/ultralytics/models/sam/modules/sam.py
new file mode 100644
index 0000000000000000000000000000000000000000..5649920cd8dec635ecfa369ccce71b7eb6ae59e9
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/sam.py
@@ -0,0 +1,49 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+from typing import List
+
+import torch
+from torch import nn
+
+from .decoders import MaskDecoder
+from .encoders import ImageEncoderViT, PromptEncoder
+
+
+class Sam(nn.Module):
+ mask_threshold: float = 0.0
+ image_format: str = 'RGB'
+
+ def __init__(
+ self,
+ image_encoder: ImageEncoderViT,
+ prompt_encoder: PromptEncoder,
+ mask_decoder: MaskDecoder,
+ pixel_mean: List[float] = (123.675, 116.28, 103.53),
+ pixel_std: List[float] = (58.395, 57.12, 57.375)
+ ) -> None:
+ """
+ SAM predicts object masks from an image and input prompts.
+
+ Note:
+ All forward() operations moved to SAMPredictor.
+
+ Args:
+ image_encoder (ImageEncoderViT): The backbone used to encode the image into image embeddings that allow for
+ efficient mask prediction.
+ prompt_encoder (PromptEncoder): Encodes various types of input prompts.
+ mask_decoder (MaskDecoder): Predicts masks from the image embeddings and encoded prompts.
+ pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
+ pixel_std (list(float)): Std values for normalizing pixels in the input image.
+ """
+ super().__init__()
+ self.image_encoder = image_encoder
+ self.prompt_encoder = prompt_encoder
+ self.mask_decoder = mask_decoder
+ self.register_buffer('pixel_mean', torch.Tensor(pixel_mean).view(-1, 1, 1), False)
+ self.register_buffer('pixel_std', torch.Tensor(pixel_std).view(-1, 1, 1), False)
diff --git a/STPoseNet/ultralytics/models/sam/modules/tiny_encoder.py b/STPoseNet/ultralytics/models/sam/modules/tiny_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca8de50b759421279c2e6e7577939b9c7927a465
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/tiny_encoder.py
@@ -0,0 +1,582 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+# --------------------------------------------------------
+# TinyViT Model Architecture
+# Copyright (c) 2022 Microsoft
+# Adapted from LeViT and Swin Transformer
+# LeViT: (https://github.com/facebookresearch/levit)
+# Swin: (https://github.com/microsoft/swin-transformer)
+# Build the TinyViT Model
+# --------------------------------------------------------
+
+import itertools
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+
+from ultralytics.utils.instance import to_2tuple
+
+
+class Conv2d_BN(torch.nn.Sequential):
+
+ def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1, groups=1, bn_weight_init=1):
+ super().__init__()
+ self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))
+ bn = torch.nn.BatchNorm2d(b)
+ torch.nn.init.constant_(bn.weight, bn_weight_init)
+ torch.nn.init.constant_(bn.bias, 0)
+ self.add_module('bn', bn)
+
+
+class PatchEmbed(nn.Module):
+
+ def __init__(self, in_chans, embed_dim, resolution, activation):
+ super().__init__()
+ img_size: Tuple[int, int] = to_2tuple(resolution)
+ self.patches_resolution = (img_size[0] // 4, img_size[1] // 4)
+ self.num_patches = self.patches_resolution[0] * self.patches_resolution[1]
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+ n = embed_dim
+ self.seq = nn.Sequential(
+ Conv2d_BN(in_chans, n // 2, 3, 2, 1),
+ activation(),
+ Conv2d_BN(n // 2, n, 3, 2, 1),
+ )
+
+ def forward(self, x):
+ return self.seq(x)
+
+
+class MBConv(nn.Module):
+
+ def __init__(self, in_chans, out_chans, expand_ratio, activation, drop_path):
+ super().__init__()
+ self.in_chans = in_chans
+ self.hidden_chans = int(in_chans * expand_ratio)
+ self.out_chans = out_chans
+
+ self.conv1 = Conv2d_BN(in_chans, self.hidden_chans, ks=1)
+ self.act1 = activation()
+
+ self.conv2 = Conv2d_BN(self.hidden_chans, self.hidden_chans, ks=3, stride=1, pad=1, groups=self.hidden_chans)
+ self.act2 = activation()
+
+ self.conv3 = Conv2d_BN(self.hidden_chans, out_chans, ks=1, bn_weight_init=0.0)
+ self.act3 = activation()
+
+ # NOTE: `DropPath` is needed only for training.
+ # self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.drop_path = nn.Identity()
+
+ def forward(self, x):
+ shortcut = x
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ x = self.act2(x)
+ x = self.conv3(x)
+ x = self.drop_path(x)
+ x += shortcut
+ return self.act3(x)
+
+
+class PatchMerging(nn.Module):
+
+ def __init__(self, input_resolution, dim, out_dim, activation):
+ super().__init__()
+
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.out_dim = out_dim
+ self.act = activation()
+ self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
+ stride_c = 1 if out_dim in [320, 448, 576] else 2
+ self.conv2 = Conv2d_BN(out_dim, out_dim, 3, stride_c, 1, groups=out_dim)
+ self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
+
+ def forward(self, x):
+ if x.ndim == 3:
+ H, W = self.input_resolution
+ B = len(x)
+ # (B, C, H, W)
+ x = x.view(B, H, W, -1).permute(0, 3, 1, 2)
+
+ x = self.conv1(x)
+ x = self.act(x)
+
+ x = self.conv2(x)
+ x = self.act(x)
+ x = self.conv3(x)
+ return x.flatten(2).transpose(1, 2)
+
+
+class ConvLayer(nn.Module):
+
+ def __init__(
+ self,
+ dim,
+ input_resolution,
+ depth,
+ activation,
+ drop_path=0.,
+ downsample=None,
+ use_checkpoint=False,
+ out_dim=None,
+ conv_expand_ratio=4.,
+ ):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ MBConv(
+ dim,
+ dim,
+ conv_expand_ratio,
+ activation,
+ drop_path[i] if isinstance(drop_path, list) else drop_path,
+ ) for i in range(depth)])
+
+ # patch merging layer
+ self.downsample = None if downsample is None else downsample(
+ input_resolution, dim=dim, out_dim=out_dim, activation=activation)
+
+ def forward(self, x):
+ for blk in self.blocks:
+ x = checkpoint.checkpoint(blk, x) if self.use_checkpoint else blk(x)
+ return x if self.downsample is None else self.downsample(x)
+
+
+class Mlp(nn.Module):
+
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.norm = nn.LayerNorm(in_features)
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.act = act_layer()
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.norm(x)
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ return self.drop(x)
+
+
+class Attention(torch.nn.Module):
+
+ def __init__(
+ self,
+ dim,
+ key_dim,
+ num_heads=8,
+ attn_ratio=4,
+ resolution=(14, 14),
+ ):
+ super().__init__()
+ # (h, w)
+ assert isinstance(resolution, tuple) and len(resolution) == 2
+ self.num_heads = num_heads
+ self.scale = key_dim ** -0.5
+ self.key_dim = key_dim
+ self.nh_kd = nh_kd = key_dim * num_heads
+ self.d = int(attn_ratio * key_dim)
+ self.dh = int(attn_ratio * key_dim) * num_heads
+ self.attn_ratio = attn_ratio
+ h = self.dh + nh_kd * 2
+
+ self.norm = nn.LayerNorm(dim)
+ self.qkv = nn.Linear(dim, h)
+ self.proj = nn.Linear(self.dh, dim)
+
+ points = list(itertools.product(range(resolution[0]), range(resolution[1])))
+ N = len(points)
+ attention_offsets = {}
+ idxs = []
+ for p1 in points:
+ for p2 in points:
+ offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
+ if offset not in attention_offsets:
+ attention_offsets[offset] = len(attention_offsets)
+ idxs.append(attention_offsets[offset])
+ self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets)))
+ self.register_buffer('attention_bias_idxs', torch.LongTensor(idxs).view(N, N), persistent=False)
+
+ @torch.no_grad()
+ def train(self, mode=True):
+ super().train(mode)
+ if mode and hasattr(self, 'ab'):
+ del self.ab
+ else:
+ self.ab = self.attention_biases[:, self.attention_bias_idxs]
+
+ def forward(self, x): # x (B,N,C)
+ B, N, _ = x.shape
+
+ # Normalization
+ x = self.norm(x)
+
+ qkv = self.qkv(x)
+ # (B, N, num_heads, d)
+ q, k, v = qkv.view(B, N, self.num_heads, -1).split([self.key_dim, self.key_dim, self.d], dim=3)
+ # (B, num_heads, N, d)
+ q = q.permute(0, 2, 1, 3)
+ k = k.permute(0, 2, 1, 3)
+ v = v.permute(0, 2, 1, 3)
+ self.ab = self.ab.to(self.attention_biases.device)
+
+ attn = ((q @ k.transpose(-2, -1)) * self.scale +
+ (self.attention_biases[:, self.attention_bias_idxs] if self.training else self.ab))
+ attn = attn.softmax(dim=-1)
+ x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
+ return self.proj(x)
+
+
+class TinyViTBlock(nn.Module):
+ """
+ TinyViT Block.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int, int]): Input resolution.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ drop (float, optional): Dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ local_conv_size (int): the kernel size of the convolution between Attention and MLP. Default: 3
+ activation (torch.nn): the activation function. Default: nn.GELU
+ """
+
+ def __init__(
+ self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ mlp_ratio=4.,
+ drop=0.,
+ drop_path=0.,
+ local_conv_size=3,
+ activation=nn.GELU,
+ ):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ assert window_size > 0, 'window_size must be greater than 0'
+ self.window_size = window_size
+ self.mlp_ratio = mlp_ratio
+
+ # NOTE: `DropPath` is needed only for training.
+ # self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.drop_path = nn.Identity()
+
+ assert dim % num_heads == 0, 'dim must be divisible by num_heads'
+ head_dim = dim // num_heads
+
+ window_resolution = (window_size, window_size)
+ self.attn = Attention(dim, head_dim, num_heads, attn_ratio=1, resolution=window_resolution)
+
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ mlp_activation = activation
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=mlp_activation, drop=drop)
+
+ pad = local_conv_size // 2
+ self.local_conv = Conv2d_BN(dim, dim, ks=local_conv_size, stride=1, pad=pad, groups=dim)
+
+ def forward(self, x):
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, 'input feature has wrong size'
+ res_x = x
+ if H == self.window_size and W == self.window_size:
+ x = self.attn(x)
+ else:
+ x = x.view(B, H, W, C)
+ pad_b = (self.window_size - H % self.window_size) % self.window_size
+ pad_r = (self.window_size - W % self.window_size) % self.window_size
+ padding = pad_b > 0 or pad_r > 0
+
+ if padding:
+ x = F.pad(x, (0, 0, 0, pad_r, 0, pad_b))
+
+ pH, pW = H + pad_b, W + pad_r
+ nH = pH // self.window_size
+ nW = pW // self.window_size
+ # window partition
+ x = x.view(B, nH, self.window_size, nW, self.window_size,
+ C).transpose(2, 3).reshape(B * nH * nW, self.window_size * self.window_size, C)
+ x = self.attn(x)
+ # window reverse
+ x = x.view(B, nH, nW, self.window_size, self.window_size, C).transpose(2, 3).reshape(B, pH, pW, C)
+
+ if padding:
+ x = x[:, :H, :W].contiguous()
+
+ x = x.view(B, L, C)
+
+ x = res_x + self.drop_path(x)
+
+ x = x.transpose(1, 2).reshape(B, C, H, W)
+ x = self.local_conv(x)
+ x = x.view(B, C, L).transpose(1, 2)
+
+ return x + self.drop_path(self.mlp(x))
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, ' \
+ f'window_size={self.window_size}, mlp_ratio={self.mlp_ratio}'
+
+
+class BasicLayer(nn.Module):
+ """
+ A basic TinyViT layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ drop (float, optional): Dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ local_conv_size (int): the kernel size of the depthwise convolution between attention and MLP. Default: 3
+ activation (torch.nn): the activation function. Default: nn.GELU
+ out_dim (int | optional): the output dimension of the layer. Default: None
+ """
+
+ def __init__(
+ self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ drop=0.,
+ drop_path=0.,
+ downsample=None,
+ use_checkpoint=False,
+ local_conv_size=3,
+ activation=nn.GELU,
+ out_dim=None,
+ ):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ TinyViTBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ drop=drop,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ local_conv_size=local_conv_size,
+ activation=activation,
+ ) for i in range(depth)])
+
+ # patch merging layer
+ self.downsample = None if downsample is None else downsample(
+ input_resolution, dim=dim, out_dim=out_dim, activation=activation)
+
+ def forward(self, x):
+ for blk in self.blocks:
+ x = checkpoint.checkpoint(blk, x) if self.use_checkpoint else blk(x)
+ return x if self.downsample is None else self.downsample(x)
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}'
+
+
+class LayerNorm2d(nn.Module):
+
+ def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(num_channels))
+ self.bias = nn.Parameter(torch.zeros(num_channels))
+ self.eps = eps
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ u = x.mean(1, keepdim=True)
+ s = (x - u).pow(2).mean(1, keepdim=True)
+ x = (x - u) / torch.sqrt(s + self.eps)
+ return self.weight[:, None, None] * x + self.bias[:, None, None]
+
+
+class TinyViT(nn.Module):
+
+ def __init__(
+ self,
+ img_size=224,
+ in_chans=3,
+ num_classes=1000,
+ embed_dims=[96, 192, 384, 768],
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_sizes=[7, 7, 14, 7],
+ mlp_ratio=4.,
+ drop_rate=0.,
+ drop_path_rate=0.1,
+ use_checkpoint=False,
+ mbconv_expand_ratio=4.0,
+ local_conv_size=3,
+ layer_lr_decay=1.0,
+ ):
+ super().__init__()
+ self.img_size = img_size
+ self.num_classes = num_classes
+ self.depths = depths
+ self.num_layers = len(depths)
+ self.mlp_ratio = mlp_ratio
+
+ activation = nn.GELU
+
+ self.patch_embed = PatchEmbed(in_chans=in_chans,
+ embed_dim=embed_dims[0],
+ resolution=img_size,
+ activation=activation)
+
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # stochastic depth
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+
+ # build layers
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ kwargs = dict(
+ dim=embed_dims[i_layer],
+ input_resolution=(patches_resolution[0] // (2 ** (i_layer - 1 if i_layer == 3 else i_layer)),
+ patches_resolution[1] // (2 ** (i_layer - 1 if i_layer == 3 else i_layer))),
+ # input_resolution=(patches_resolution[0] // (2 ** i_layer),
+ # patches_resolution[1] // (2 ** i_layer)),
+ depth=depths[i_layer],
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
+ downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
+ use_checkpoint=use_checkpoint,
+ out_dim=embed_dims[min(i_layer + 1,
+ len(embed_dims) - 1)],
+ activation=activation,
+ )
+ if i_layer == 0:
+ layer = ConvLayer(conv_expand_ratio=mbconv_expand_ratio, **kwargs)
+ else:
+ layer = BasicLayer(num_heads=num_heads[i_layer],
+ window_size=window_sizes[i_layer],
+ mlp_ratio=self.mlp_ratio,
+ drop=drop_rate,
+ local_conv_size=local_conv_size,
+ **kwargs)
+ self.layers.append(layer)
+
+ # Classifier head
+ self.norm_head = nn.LayerNorm(embed_dims[-1])
+ self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
+
+ # init weights
+ self.apply(self._init_weights)
+ self.set_layer_lr_decay(layer_lr_decay)
+ self.neck = nn.Sequential(
+ nn.Conv2d(
+ embed_dims[-1],
+ 256,
+ kernel_size=1,
+ bias=False,
+ ),
+ LayerNorm2d(256),
+ nn.Conv2d(
+ 256,
+ 256,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ ),
+ LayerNorm2d(256),
+ )
+
+ def set_layer_lr_decay(self, layer_lr_decay):
+ decay_rate = layer_lr_decay
+
+ # layers -> blocks (depth)
+ depth = sum(self.depths)
+ lr_scales = [decay_rate ** (depth - i - 1) for i in range(depth)]
+
+ def _set_lr_scale(m, scale):
+ for p in m.parameters():
+ p.lr_scale = scale
+
+ self.patch_embed.apply(lambda x: _set_lr_scale(x, lr_scales[0]))
+ i = 0
+ for layer in self.layers:
+ for block in layer.blocks:
+ block.apply(lambda x: _set_lr_scale(x, lr_scales[i]))
+ i += 1
+ if layer.downsample is not None:
+ layer.downsample.apply(lambda x: _set_lr_scale(x, lr_scales[i - 1]))
+ assert i == depth
+ for m in [self.norm_head, self.head]:
+ m.apply(lambda x: _set_lr_scale(x, lr_scales[-1]))
+
+ for k, p in self.named_parameters():
+ p.param_name = k
+
+ def _check_lr_scale(m):
+ for p in m.parameters():
+ assert hasattr(p, 'lr_scale'), p.param_name
+
+ self.apply(_check_lr_scale)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ # NOTE: This initialization is needed only for training.
+ # trunc_normal_(m.weight, std=.02)
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'attention_biases'}
+
+ def forward_features(self, x):
+ # x: (N, C, H, W)
+ x = self.patch_embed(x)
+
+ x = self.layers[0](x)
+ start_i = 1
+
+ for i in range(start_i, len(self.layers)):
+ layer = self.layers[i]
+ x = layer(x)
+ B, _, C = x.size()
+ x = x.view(B, 64, 64, C)
+ x = x.permute(0, 3, 1, 2)
+ return self.neck(x)
+
+ def forward(self, x):
+ return self.forward_features(x)
diff --git a/STPoseNet/ultralytics/models/sam/modules/transformer.py b/STPoseNet/ultralytics/models/sam/modules/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..f925538b6bfaa0131caddb94645603de0a4f1ebb
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/modules/transformer.py
@@ -0,0 +1,230 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import math
+from typing import Tuple, Type
+
+import torch
+from torch import Tensor, nn
+
+from ultralytics.nn.modules import MLPBlock
+
+
+class TwoWayTransformer(nn.Module):
+
+ def __init__(
+ self,
+ depth: int,
+ embedding_dim: int,
+ num_heads: int,
+ mlp_dim: int,
+ activation: Type[nn.Module] = nn.ReLU,
+ attention_downsample_rate: int = 2,
+ ) -> None:
+ """
+ A transformer decoder that attends to an input image using
+ queries whose positional embedding is supplied.
+
+ Args:
+ depth (int): number of layers in the transformer
+ embedding_dim (int): the channel dimension for the input embeddings
+ num_heads (int): the number of heads for multihead attention. Must
+ divide embedding_dim
+ mlp_dim (int): the channel dimension internal to the MLP block
+ activation (nn.Module): the activation to use in the MLP block
+ """
+ super().__init__()
+ self.depth = depth
+ self.embedding_dim = embedding_dim
+ self.num_heads = num_heads
+ self.mlp_dim = mlp_dim
+ self.layers = nn.ModuleList()
+
+ for i in range(depth):
+ self.layers.append(
+ TwoWayAttentionBlock(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ mlp_dim=mlp_dim,
+ activation=activation,
+ attention_downsample_rate=attention_downsample_rate,
+ skip_first_layer_pe=(i == 0),
+ ))
+
+ self.final_attn_token_to_image = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)
+ self.norm_final_attn = nn.LayerNorm(embedding_dim)
+
+ def forward(
+ self,
+ image_embedding: Tensor,
+ image_pe: Tensor,
+ point_embedding: Tensor,
+ ) -> Tuple[Tensor, Tensor]:
+ """
+ Args:
+ image_embedding (torch.Tensor): image to attend to. Should be shape B x embedding_dim x h x w for any h and w.
+ image_pe (torch.Tensor): the positional encoding to add to the image. Must have same shape as image_embedding.
+ point_embedding (torch.Tensor): the embedding to add to the query points.
+ Must have shape B x N_points x embedding_dim for any N_points.
+
+ Returns:
+ (torch.Tensor): the processed point_embedding
+ (torch.Tensor): the processed image_embedding
+ """
+ # BxCxHxW -> BxHWxC == B x N_image_tokens x C
+ bs, c, h, w = image_embedding.shape
+ image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
+ image_pe = image_pe.flatten(2).permute(0, 2, 1)
+
+ # Prepare queries
+ queries = point_embedding
+ keys = image_embedding
+
+ # Apply transformer blocks and final layernorm
+ for layer in self.layers:
+ queries, keys = layer(
+ queries=queries,
+ keys=keys,
+ query_pe=point_embedding,
+ key_pe=image_pe,
+ )
+
+ # Apply the final attention layer from the points to the image
+ q = queries + point_embedding
+ k = keys + image_pe
+ attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
+ queries = queries + attn_out
+ queries = self.norm_final_attn(queries)
+
+ return queries, keys
+
+
+class TwoWayAttentionBlock(nn.Module):
+
+ def __init__(
+ self,
+ embedding_dim: int,
+ num_heads: int,
+ mlp_dim: int = 2048,
+ activation: Type[nn.Module] = nn.ReLU,
+ attention_downsample_rate: int = 2,
+ skip_first_layer_pe: bool = False,
+ ) -> None:
+ """
+ A transformer block with four layers: (1) self-attention of sparse inputs, (2) cross attention of sparse
+ inputs to dense inputs, (3) mlp block on sparse inputs, and (4) cross attention of dense inputs to sparse
+ inputs.
+
+ Args:
+ embedding_dim (int): the channel dimension of the embeddings
+ num_heads (int): the number of heads in the attention layers
+ mlp_dim (int): the hidden dimension of the mlp block
+ activation (nn.Module): the activation of the mlp block
+ skip_first_layer_pe (bool): skip the PE on the first layer
+ """
+ super().__init__()
+ self.self_attn = Attention(embedding_dim, num_heads)
+ self.norm1 = nn.LayerNorm(embedding_dim)
+
+ self.cross_attn_token_to_image = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)
+ self.norm2 = nn.LayerNorm(embedding_dim)
+
+ self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
+ self.norm3 = nn.LayerNorm(embedding_dim)
+
+ self.norm4 = nn.LayerNorm(embedding_dim)
+ self.cross_attn_image_to_token = Attention(embedding_dim, num_heads, downsample_rate=attention_downsample_rate)
+
+ self.skip_first_layer_pe = skip_first_layer_pe
+
+ def forward(self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor) -> Tuple[Tensor, Tensor]:
+ """Apply self-attention and cross-attention to queries and keys and return the processed embeddings."""
+
+ # Self attention block
+ if self.skip_first_layer_pe:
+ queries = self.self_attn(q=queries, k=queries, v=queries)
+ else:
+ q = queries + query_pe
+ attn_out = self.self_attn(q=q, k=q, v=queries)
+ queries = queries + attn_out
+ queries = self.norm1(queries)
+
+ # Cross attention block, tokens attending to image embedding
+ q = queries + query_pe
+ k = keys + key_pe
+ attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
+ queries = queries + attn_out
+ queries = self.norm2(queries)
+
+ # MLP block
+ mlp_out = self.mlp(queries)
+ queries = queries + mlp_out
+ queries = self.norm3(queries)
+
+ # Cross attention block, image embedding attending to tokens
+ q = queries + query_pe
+ k = keys + key_pe
+ attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
+ keys = keys + attn_out
+ keys = self.norm4(keys)
+
+ return queries, keys
+
+
+class Attention(nn.Module):
+ """
+ An attention layer that allows for downscaling the size of the embedding after projection to queries, keys, and
+ values.
+ """
+
+ def __init__(
+ self,
+ embedding_dim: int,
+ num_heads: int,
+ downsample_rate: int = 1,
+ ) -> None:
+ super().__init__()
+ self.embedding_dim = embedding_dim
+ self.internal_dim = embedding_dim // downsample_rate
+ self.num_heads = num_heads
+ assert self.internal_dim % num_heads == 0, 'num_heads must divide embedding_dim.'
+
+ self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
+ self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
+ self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
+ self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
+
+ def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
+ """Separate the input tensor into the specified number of attention heads."""
+ b, n, c = x.shape
+ x = x.reshape(b, n, num_heads, c // num_heads)
+ return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
+
+ def _recombine_heads(self, x: Tensor) -> Tensor:
+ """Recombine the separated attention heads into a single tensor."""
+ b, n_heads, n_tokens, c_per_head = x.shape
+ x = x.transpose(1, 2)
+ return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
+
+ def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
+ """Compute the attention output given the input query, key, and value tensors."""
+
+ # Input projections
+ q = self.q_proj(q)
+ k = self.k_proj(k)
+ v = self.v_proj(v)
+
+ # Separate into heads
+ q = self._separate_heads(q, self.num_heads)
+ k = self._separate_heads(k, self.num_heads)
+ v = self._separate_heads(v, self.num_heads)
+
+ # Attention
+ _, _, _, c_per_head = q.shape
+ attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
+ attn = attn / math.sqrt(c_per_head)
+ attn = torch.softmax(attn, dim=-1)
+
+ # Get output
+ out = attn @ v
+ out = self._recombine_heads(out)
+ return self.out_proj(out)
diff --git a/STPoseNet/ultralytics/models/sam/predict.py b/STPoseNet/ultralytics/models/sam/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1c3b481d80ac5da401720c20af1823ec563db58
--- /dev/null
+++ b/STPoseNet/ultralytics/models/sam/predict.py
@@ -0,0 +1,404 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torchvision
+
+from ultralytics.data.augment import LetterBox
+from ultralytics.engine.predictor import BasePredictor
+from ultralytics.engine.results import Results
+from ultralytics.utils import DEFAULT_CFG, ops
+from ultralytics.utils.torch_utils import select_device
+
+from .amg import (batch_iterator, batched_mask_to_box, build_all_layer_point_grids, calculate_stability_score,
+ generate_crop_boxes, is_box_near_crop_edge, remove_small_regions, uncrop_boxes_xyxy, uncrop_masks)
+from .build import build_sam
+
+
+class Predictor(BasePredictor):
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ if overrides is None:
+ overrides = {}
+ overrides.update(dict(task='segment', mode='predict', imgsz=1024))
+ super().__init__(cfg, overrides, _callbacks)
+ # SAM needs retina_masks=True, or the results would be a mess.
+ self.args.retina_masks = True
+ # Args for set_image
+ self.im = None
+ self.features = None
+ # Args for set_prompts
+ self.prompts = {}
+ # Args for segment everything
+ self.segment_all = False
+
+ def preprocess(self, im):
+ """Prepares input image before inference.
+
+ Args:
+ im (torch.Tensor | List(np.ndarray)): BCHW for tensor, [(HWC) x B] for list.
+ """
+ if self.im is not None:
+ return self.im
+ not_tensor = not isinstance(im, torch.Tensor)
+ if not_tensor:
+ im = np.stack(self.pre_transform(im))
+ im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
+ im = np.ascontiguousarray(im) # contiguous
+ im = torch.from_numpy(im)
+
+ img = im.to(self.device)
+ img = img.half() if self.model.fp16 else img.float() # uint8 to fp16/32
+ if not_tensor:
+ img = (img - self.mean) / self.std
+ return img
+
+ def pre_transform(self, im):
+ """
+ Pre-transform input image before inference.
+
+ Args:
+ im (List(np.ndarray)): (N, 3, h, w) for tensor, [(h, w, 3) x N] for list.
+
+ Returns:
+ (list): A list of transformed images.
+ """
+ assert len(im) == 1, 'SAM model has not supported batch inference yet!'
+ return [LetterBox(self.args.imgsz, auto=False, center=False)(image=x) for x in im]
+
+ def inference(self, im, bboxes=None, points=None, labels=None, masks=None, multimask_output=False, *args, **kwargs):
+ """
+ Predict masks for the given input prompts, using the currently set image.
+
+ Args:
+ im (torch.Tensor): The preprocessed image, (N, C, H, W).
+ bboxes (np.ndarray | List, None): (N, 4), in XYXY format.
+ points (np.ndarray | List, None): (N, 2), Each point is in (X,Y) in pixels.
+ labels (np.ndarray | List, None): (N, ), labels for the point prompts.
+ 1 indicates a foreground point and 0 indicates a background point.
+ masks (np.ndarray, None): A low resolution mask input to the model, typically
+ coming from a previous prediction iteration. Has form (N, H, W), where
+ for SAM, H=W=256.
+ multimask_output (bool): If true, the model will return three masks.
+ For ambiguous input prompts (such as a single click), this will often
+ produce better masks than a single prediction. If only a single
+ mask is needed, the model's predicted quality score can be used
+ to select the best mask. For non-ambiguous prompts, such as multiple
+ input prompts, multimask_output=False can give better results.
+
+ Returns:
+ (np.ndarray): The output masks in CxHxW format, where C is the
+ number of masks, and (H, W) is the original image size.
+ (np.ndarray): An array of length C containing the model's
+ predictions for the quality of each mask.
+ (np.ndarray): An array of shape CxHxW, where C is the number
+ of masks and H=W=256. These low resolution logits can be passed to
+ a subsequent iteration as mask input.
+ """
+ # Get prompts from self.prompts first
+ bboxes = self.prompts.pop('bboxes', bboxes)
+ points = self.prompts.pop('points', points)
+ masks = self.prompts.pop('masks', masks)
+ if all(i is None for i in [bboxes, points, masks]):
+ return self.generate(im, *args, **kwargs)
+ return self.prompt_inference(im, bboxes, points, labels, masks, multimask_output)
+
+ def prompt_inference(self, im, bboxes=None, points=None, labels=None, masks=None, multimask_output=False):
+ """
+ Predict masks for the given input prompts, using the currently set image.
+
+ Args:
+ im (torch.Tensor): The preprocessed image, (N, C, H, W).
+ bboxes (np.ndarray | List, None): (N, 4), in XYXY format.
+ points (np.ndarray | List, None): (N, 2), Each point is in (X,Y) in pixels.
+ labels (np.ndarray | List, None): (N, ), labels for the point prompts.
+ 1 indicates a foreground point and 0 indicates a background point.
+ masks (np.ndarray, None): A low resolution mask input to the model, typically
+ coming from a previous prediction iteration. Has form (N, H, W), where
+ for SAM, H=W=256.
+ multimask_output (bool): If true, the model will return three masks.
+ For ambiguous input prompts (such as a single click), this will often
+ produce better masks than a single prediction. If only a single
+ mask is needed, the model's predicted quality score can be used
+ to select the best mask. For non-ambiguous prompts, such as multiple
+ input prompts, multimask_output=False can give better results.
+
+ Returns:
+ (np.ndarray): The output masks in CxHxW format, where C is the
+ number of masks, and (H, W) is the original image size.
+ (np.ndarray): An array of length C containing the model's
+ predictions for the quality of each mask.
+ (np.ndarray): An array of shape CxHxW, where C is the number
+ of masks and H=W=256. These low resolution logits can be passed to
+ a subsequent iteration as mask input.
+ """
+ features = self.model.image_encoder(im) if self.features is None else self.features
+
+ src_shape, dst_shape = self.batch[1][0].shape[:2], im.shape[2:]
+ r = 1.0 if self.segment_all else min(dst_shape[0] / src_shape[0], dst_shape[1] / src_shape[1])
+ # Transform input prompts
+ if points is not None:
+ points = torch.as_tensor(points, dtype=torch.float32, device=self.device)
+ points = points[None] if points.ndim == 1 else points
+ # Assuming labels are all positive if users don't pass labels.
+ if labels is None:
+ labels = np.ones(points.shape[0])
+ labels = torch.as_tensor(labels, dtype=torch.int32, device=self.device)
+ points *= r
+ # (N, 2) --> (N, 1, 2), (N, ) --> (N, 1)
+ points, labels = points[:, None, :], labels[:, None]
+ if bboxes is not None:
+ bboxes = torch.as_tensor(bboxes, dtype=torch.float32, device=self.device)
+ bboxes = bboxes[None] if bboxes.ndim == 1 else bboxes
+ bboxes *= r
+ if masks is not None:
+ masks = torch.as_tensor(masks, dtype=torch.float32, device=self.device).unsqueeze(1)
+
+ points = (points, labels) if points is not None else None
+ # Embed prompts
+ sparse_embeddings, dense_embeddings = self.model.prompt_encoder(
+ points=points,
+ boxes=bboxes,
+ masks=masks,
+ )
+
+ # Predict masks
+ pred_masks, pred_scores = self.model.mask_decoder(
+ image_embeddings=features,
+ image_pe=self.model.prompt_encoder.get_dense_pe(),
+ sparse_prompt_embeddings=sparse_embeddings,
+ dense_prompt_embeddings=dense_embeddings,
+ multimask_output=multimask_output,
+ )
+
+ # (N, d, H, W) --> (N*d, H, W), (N, d) --> (N*d, )
+ # `d` could be 1 or 3 depends on `multimask_output`.
+ return pred_masks.flatten(0, 1), pred_scores.flatten(0, 1)
+
+ def generate(self,
+ im,
+ crop_n_layers=0,
+ crop_overlap_ratio=512 / 1500,
+ crop_downscale_factor=1,
+ point_grids=None,
+ points_stride=32,
+ points_batch_size=64,
+ conf_thres=0.88,
+ stability_score_thresh=0.95,
+ stability_score_offset=0.95,
+ crop_nms_thresh=0.7):
+ """Segment the whole image.
+
+ Args:
+ im (torch.Tensor): The preprocessed image, (N, C, H, W).
+ crop_n_layers (int): If >0, mask prediction will be run again on
+ crops of the image. Sets the number of layers to run, where each
+ layer has 2**i_layer number of image crops.
+ crop_overlap_ratio (float): Sets the degree to which crops overlap.
+ In the first crop layer, crops will overlap by this fraction of
+ the image length. Later layers with more crops scale down this overlap.
+ crop_downscale_factor (int): The number of points-per-side
+ sampled in layer n is scaled down by crop_n_points_downscale_factor**n.
+ point_grids (list(np.ndarray), None): A list over explicit grids
+ of points used for sampling, normalized to [0,1]. The nth grid in the
+ list is used in the nth crop layer. Exclusive with points_per_side.
+ points_stride (int, None): The number of points to be sampled
+ along one side of the image. The total number of points is
+ points_per_side**2. If None, 'point_grids' must provide explicit
+ point sampling.
+ points_batch_size (int): Sets the number of points run simultaneously
+ by the model. Higher numbers may be faster but use more GPU memory.
+ conf_thres (float): A filtering threshold in [0,1], using the
+ model's predicted mask quality.
+ stability_score_thresh (float): A filtering threshold in [0,1], using
+ the stability of the mask under changes to the cutoff used to binarize
+ the model's mask predictions.
+ stability_score_offset (float): The amount to shift the cutoff when
+ calculated the stability score.
+ crop_nms_thresh (float): The box IoU cutoff used by non-maximal
+ suppression to filter duplicate masks between different crops.
+ """
+ self.segment_all = True
+ ih, iw = im.shape[2:]
+ crop_regions, layer_idxs = generate_crop_boxes((ih, iw), crop_n_layers, crop_overlap_ratio)
+ if point_grids is None:
+ point_grids = build_all_layer_point_grids(
+ points_stride,
+ crop_n_layers,
+ crop_downscale_factor,
+ )
+ pred_masks, pred_scores, pred_bboxes, region_areas = [], [], [], []
+ for crop_region, layer_idx in zip(crop_regions, layer_idxs):
+ x1, y1, x2, y2 = crop_region
+ w, h = x2 - x1, y2 - y1
+ area = torch.tensor(w * h, device=im.device)
+ points_scale = np.array([[w, h]]) # w, h
+ # Crop image and interpolate to input size
+ crop_im = F.interpolate(im[..., y1:y2, x1:x2], (ih, iw), mode='bilinear', align_corners=False)
+ # (num_points, 2)
+ points_for_image = point_grids[layer_idx] * points_scale
+ crop_masks, crop_scores, crop_bboxes = [], [], []
+ for (points, ) in batch_iterator(points_batch_size, points_for_image):
+ pred_mask, pred_score = self.prompt_inference(crop_im, points=points, multimask_output=True)
+ # Interpolate predicted masks to input size
+ pred_mask = F.interpolate(pred_mask[None], (h, w), mode='bilinear', align_corners=False)[0]
+ idx = pred_score > conf_thres
+ pred_mask, pred_score = pred_mask[idx], pred_score[idx]
+
+ stability_score = calculate_stability_score(pred_mask, self.model.mask_threshold,
+ stability_score_offset)
+ idx = stability_score > stability_score_thresh
+ pred_mask, pred_score = pred_mask[idx], pred_score[idx]
+ # Bool type is much more memory-efficient.
+ pred_mask = pred_mask > self.model.mask_threshold
+ # (N, 4)
+ pred_bbox = batched_mask_to_box(pred_mask).float()
+ keep_mask = ~is_box_near_crop_edge(pred_bbox, crop_region, [0, 0, iw, ih])
+ if not torch.all(keep_mask):
+ pred_bbox, pred_mask, pred_score = pred_bbox[keep_mask], pred_mask[keep_mask], pred_score[keep_mask]
+
+ crop_masks.append(pred_mask)
+ crop_bboxes.append(pred_bbox)
+ crop_scores.append(pred_score)
+
+ # Do nms within this crop
+ crop_masks = torch.cat(crop_masks)
+ crop_bboxes = torch.cat(crop_bboxes)
+ crop_scores = torch.cat(crop_scores)
+ keep = torchvision.ops.nms(crop_bboxes, crop_scores, self.args.iou) # NMS
+ crop_bboxes = uncrop_boxes_xyxy(crop_bboxes[keep], crop_region)
+ crop_masks = uncrop_masks(crop_masks[keep], crop_region, ih, iw)
+ crop_scores = crop_scores[keep]
+
+ pred_masks.append(crop_masks)
+ pred_bboxes.append(crop_bboxes)
+ pred_scores.append(crop_scores)
+ region_areas.append(area.expand(len(crop_masks)))
+
+ pred_masks = torch.cat(pred_masks)
+ pred_bboxes = torch.cat(pred_bboxes)
+ pred_scores = torch.cat(pred_scores)
+ region_areas = torch.cat(region_areas)
+
+ # Remove duplicate masks between crops
+ if len(crop_regions) > 1:
+ scores = 1 / region_areas
+ keep = torchvision.ops.nms(pred_bboxes, scores, crop_nms_thresh)
+ pred_masks, pred_bboxes, pred_scores = pred_masks[keep], pred_bboxes[keep], pred_scores[keep]
+
+ return pred_masks, pred_scores, pred_bboxes
+
+ def setup_model(self, model, verbose=True):
+ """Set up YOLO model with specified thresholds and device."""
+ device = select_device(self.args.device, verbose=verbose)
+ if model is None:
+ model = build_sam(self.args.model)
+ model.eval()
+ self.model = model.to(device)
+ self.device = device
+ self.mean = torch.tensor([123.675, 116.28, 103.53]).view(-1, 1, 1).to(device)
+ self.std = torch.tensor([58.395, 57.12, 57.375]).view(-1, 1, 1).to(device)
+ # TODO: Temporary settings for compatibility
+ self.model.pt = False
+ self.model.triton = False
+ self.model.stride = 32
+ self.model.fp16 = False
+ self.done_warmup = True
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Post-processes inference output predictions to create detection masks for objects."""
+ # (N, 1, H, W), (N, 1)
+ pred_masks, pred_scores = preds[:2]
+ pred_bboxes = preds[2] if self.segment_all else None
+ names = dict(enumerate(str(i) for i in range(len(pred_masks))))
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, masks in enumerate([pred_masks]):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ if pred_bboxes is not None:
+ pred_bboxes = ops.scale_boxes(img.shape[2:], pred_bboxes.float(), orig_img.shape, padding=False)
+ cls = torch.arange(len(pred_masks), dtype=torch.int32, device=pred_masks.device)
+ pred_bboxes = torch.cat([pred_bboxes, pred_scores[:, None], cls[:, None]], dim=-1)
+
+ masks = ops.scale_masks(masks[None].float(), orig_img.shape[:2], padding=False)[0]
+ masks = masks > self.model.mask_threshold # to bool
+ img_path = self.batch[0][i]
+ results.append(Results(orig_img, path=img_path, names=names, masks=masks, boxes=pred_bboxes))
+ # Reset segment-all mode.
+ self.segment_all = False
+ return results
+
+ def setup_source(self, source):
+ """Sets up source and inference mode."""
+ if source is not None:
+ super().setup_source(source)
+
+ def set_image(self, image):
+ """Set image in advance.
+ Args:
+
+ image (str | np.ndarray): image file path or np.ndarray image by cv2.
+ """
+ if self.model is None:
+ model = build_sam(self.args.model)
+ self.setup_model(model)
+ self.setup_source(image)
+ assert len(self.dataset) == 1, '`set_image` only supports setting one image!'
+ for batch in self.dataset:
+ im = self.preprocess(batch[1])
+ self.features = self.model.image_encoder(im)
+ self.im = im
+ break
+
+ def set_prompts(self, prompts):
+ """Set prompts in advance."""
+ self.prompts = prompts
+
+ def reset_image(self):
+ self.im = None
+ self.features = None
+
+ @staticmethod
+ def remove_small_regions(masks, min_area=0, nms_thresh=0.7):
+ """
+ Removes small disconnected regions and holes in masks, then reruns
+ box NMS to remove any new duplicates. Requires open-cv as a dependency.
+
+ Args:
+ masks (torch.Tensor): Masks, (N, H, W).
+ min_area (int): Minimum area threshold.
+ nms_thresh (float): NMS threshold.
+ Returns:
+ new_masks (torch.Tensor): New Masks, (N, H, W).
+ keep (List[int]): The indices of the new masks, which can be used to filter
+ the corresponding boxes.
+ """
+ if len(masks) == 0:
+ return masks
+
+ # Filter small disconnected regions and holes
+ new_masks = []
+ scores = []
+ for mask in masks:
+ mask = mask.cpu().numpy().astype(np.uint8)
+ mask, changed = remove_small_regions(mask, min_area, mode='holes')
+ unchanged = not changed
+ mask, changed = remove_small_regions(mask, min_area, mode='islands')
+ unchanged = unchanged and not changed
+
+ new_masks.append(torch.as_tensor(mask).unsqueeze(0))
+ # Give score=0 to changed masks and score=1 to unchanged masks
+ # so NMS will prefer ones that didn't need postprocessing
+ scores.append(float(unchanged))
+
+ # Recalculate boxes and remove any new duplicates
+ new_masks = torch.cat(new_masks, dim=0)
+ boxes = batched_mask_to_box(new_masks)
+ keep = torchvision.ops.nms(
+ boxes.float(),
+ torch.as_tensor(scores),
+ nms_thresh,
+ )
+
+ return new_masks[keep].to(device=masks.device, dtype=masks.dtype), keep
diff --git a/STPoseNet/ultralytics/models/utils/__init__.py b/STPoseNet/ultralytics/models/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e68dc12245afb4f72ba5f7c1227df74613a427d
--- /dev/null
+++ b/STPoseNet/ultralytics/models/utils/__init__.py
@@ -0,0 +1 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
diff --git a/STPoseNet/ultralytics/models/utils/loss.py b/STPoseNet/ultralytics/models/utils/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f95e5f0bf9d32d22cb5677dd1e8bff923525fa9
--- /dev/null
+++ b/STPoseNet/ultralytics/models/utils/loss.py
@@ -0,0 +1,296 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ultralytics.utils.loss import FocalLoss, VarifocalLoss
+from ultralytics.utils.metrics import bbox_iou
+
+from .ops import HungarianMatcher
+
+
+class DETRLoss(nn.Module):
+
+ def __init__(self,
+ nc=80,
+ loss_gain=None,
+ aux_loss=True,
+ use_fl=True,
+ use_vfl=False,
+ use_uni_match=False,
+ uni_match_ind=0):
+ """
+ DETR loss function.
+
+ Args:
+ nc (int): The number of classes.
+ loss_gain (dict): The coefficient of loss.
+ aux_loss (bool): If 'aux_loss = True', loss at each decoder layer are to be used.
+ use_vfl (bool): Use VarifocalLoss or not.
+ use_uni_match (bool): Whether to use a fixed layer to assign labels for auxiliary branch.
+ uni_match_ind (int): The fixed indices of a layer.
+ """
+ super().__init__()
+
+ if loss_gain is None:
+ loss_gain = {'class': 1, 'bbox': 5, 'giou': 2, 'no_object': 0.1, 'mask': 1, 'dice': 1}
+ self.nc = nc
+ self.matcher = HungarianMatcher(cost_gain={'class': 2, 'bbox': 5, 'giou': 2})
+ self.loss_gain = loss_gain
+ self.aux_loss = aux_loss
+ self.fl = FocalLoss() if use_fl else None
+ self.vfl = VarifocalLoss() if use_vfl else None
+
+ self.use_uni_match = use_uni_match
+ self.uni_match_ind = uni_match_ind
+ self.device = None
+
+ def _get_loss_class(self, pred_scores, targets, gt_scores, num_gts, postfix=''):
+ # logits: [b, query, num_classes], gt_class: list[[n, 1]]
+ name_class = f'loss_class{postfix}'
+ bs, nq = pred_scores.shape[:2]
+ # one_hot = F.one_hot(targets, self.nc + 1)[..., :-1] # (bs, num_queries, num_classes)
+ one_hot = torch.zeros((bs, nq, self.nc + 1), dtype=torch.int64, device=targets.device)
+ one_hot.scatter_(2, targets.unsqueeze(-1), 1)
+ one_hot = one_hot[..., :-1]
+ gt_scores = gt_scores.view(bs, nq, 1) * one_hot
+
+ if self.fl:
+ if num_gts and self.vfl:
+ loss_cls = self.vfl(pred_scores, gt_scores, one_hot)
+ else:
+ loss_cls = self.fl(pred_scores, one_hot.float())
+ loss_cls /= max(num_gts, 1) / nq
+ else:
+ loss_cls = nn.BCEWithLogitsLoss(reduction='none')(pred_scores, gt_scores).mean(1).sum() # YOLO CLS loss
+
+ return {name_class: loss_cls.squeeze() * self.loss_gain['class']}
+
+ def _get_loss_bbox(self, pred_bboxes, gt_bboxes, postfix=''):
+ # boxes: [b, query, 4], gt_bbox: list[[n, 4]]
+ name_bbox = f'loss_bbox{postfix}'
+ name_giou = f'loss_giou{postfix}'
+
+ loss = {}
+ if len(gt_bboxes) == 0:
+ loss[name_bbox] = torch.tensor(0., device=self.device)
+ loss[name_giou] = torch.tensor(0., device=self.device)
+ return loss
+
+ loss[name_bbox] = self.loss_gain['bbox'] * F.l1_loss(pred_bboxes, gt_bboxes, reduction='sum') / len(gt_bboxes)
+ loss[name_giou] = 1.0 - bbox_iou(pred_bboxes, gt_bboxes, xywh=True, GIoU=True)
+ loss[name_giou] = loss[name_giou].sum() / len(gt_bboxes)
+ loss[name_giou] = self.loss_gain['giou'] * loss[name_giou]
+ return {k: v.squeeze() for k, v in loss.items()}
+
+ def _get_loss_mask(self, masks, gt_mask, match_indices, postfix=''):
+ # masks: [b, query, h, w], gt_mask: list[[n, H, W]]
+ name_mask = f'loss_mask{postfix}'
+ name_dice = f'loss_dice{postfix}'
+
+ loss = {}
+ if sum(len(a) for a in gt_mask) == 0:
+ loss[name_mask] = torch.tensor(0., device=self.device)
+ loss[name_dice] = torch.tensor(0., device=self.device)
+ return loss
+
+ num_gts = len(gt_mask)
+ src_masks, target_masks = self._get_assigned_bboxes(masks, gt_mask, match_indices)
+ src_masks = F.interpolate(src_masks.unsqueeze(0), size=target_masks.shape[-2:], mode='bilinear')[0]
+ # TODO: torch does not have `sigmoid_focal_loss`, but it's not urgent since we don't use mask branch for now.
+ loss[name_mask] = self.loss_gain['mask'] * F.sigmoid_focal_loss(src_masks, target_masks,
+ torch.tensor([num_gts], dtype=torch.float32))
+ loss[name_dice] = self.loss_gain['dice'] * self._dice_loss(src_masks, target_masks, num_gts)
+ return loss
+
+ @staticmethod
+ def _dice_loss(inputs, targets, num_gts):
+ inputs = F.sigmoid(inputs)
+ inputs = inputs.flatten(1)
+ targets = targets.flatten(1)
+ numerator = 2 * (inputs * targets).sum(1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_gts
+
+ def _get_loss_aux(self,
+ pred_bboxes,
+ pred_scores,
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ match_indices=None,
+ postfix='',
+ masks=None,
+ gt_mask=None):
+ """Get auxiliary losses"""
+ # NOTE: loss class, bbox, giou, mask, dice
+ loss = torch.zeros(5 if masks is not None else 3, device=pred_bboxes.device)
+ if match_indices is None and self.use_uni_match:
+ match_indices = self.matcher(pred_bboxes[self.uni_match_ind],
+ pred_scores[self.uni_match_ind],
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ masks=masks[self.uni_match_ind] if masks is not None else None,
+ gt_mask=gt_mask)
+ for i, (aux_bboxes, aux_scores) in enumerate(zip(pred_bboxes, pred_scores)):
+ aux_masks = masks[i] if masks is not None else None
+ loss_ = self._get_loss(aux_bboxes,
+ aux_scores,
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ masks=aux_masks,
+ gt_mask=gt_mask,
+ postfix=postfix,
+ match_indices=match_indices)
+ loss[0] += loss_[f'loss_class{postfix}']
+ loss[1] += loss_[f'loss_bbox{postfix}']
+ loss[2] += loss_[f'loss_giou{postfix}']
+ # if masks is not None and gt_mask is not None:
+ # loss_ = self._get_loss_mask(aux_masks, gt_mask, match_indices, postfix)
+ # loss[3] += loss_[f'loss_mask{postfix}']
+ # loss[4] += loss_[f'loss_dice{postfix}']
+
+ loss = {
+ f'loss_class_aux{postfix}': loss[0],
+ f'loss_bbox_aux{postfix}': loss[1],
+ f'loss_giou_aux{postfix}': loss[2]}
+ # if masks is not None and gt_mask is not None:
+ # loss[f'loss_mask_aux{postfix}'] = loss[3]
+ # loss[f'loss_dice_aux{postfix}'] = loss[4]
+ return loss
+
+ @staticmethod
+ def _get_index(match_indices):
+ batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(match_indices)])
+ src_idx = torch.cat([src for (src, _) in match_indices])
+ dst_idx = torch.cat([dst for (_, dst) in match_indices])
+ return (batch_idx, src_idx), dst_idx
+
+ def _get_assigned_bboxes(self, pred_bboxes, gt_bboxes, match_indices):
+ pred_assigned = torch.cat([
+ t[I] if len(I) > 0 else torch.zeros(0, t.shape[-1], device=self.device)
+ for t, (I, _) in zip(pred_bboxes, match_indices)])
+ gt_assigned = torch.cat([
+ t[J] if len(J) > 0 else torch.zeros(0, t.shape[-1], device=self.device)
+ for t, (_, J) in zip(gt_bboxes, match_indices)])
+ return pred_assigned, gt_assigned
+
+ def _get_loss(self,
+ pred_bboxes,
+ pred_scores,
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ masks=None,
+ gt_mask=None,
+ postfix='',
+ match_indices=None):
+ """Get losses"""
+ if match_indices is None:
+ match_indices = self.matcher(pred_bboxes,
+ pred_scores,
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ masks=masks,
+ gt_mask=gt_mask)
+
+ idx, gt_idx = self._get_index(match_indices)
+ pred_bboxes, gt_bboxes = pred_bboxes[idx], gt_bboxes[gt_idx]
+
+ bs, nq = pred_scores.shape[:2]
+ targets = torch.full((bs, nq), self.nc, device=pred_scores.device, dtype=gt_cls.dtype)
+ targets[idx] = gt_cls[gt_idx]
+
+ gt_scores = torch.zeros([bs, nq], device=pred_scores.device)
+ if len(gt_bboxes):
+ gt_scores[idx] = bbox_iou(pred_bboxes.detach(), gt_bboxes, xywh=True).squeeze(-1)
+
+ loss = {}
+ loss.update(self._get_loss_class(pred_scores, targets, gt_scores, len(gt_bboxes), postfix))
+ loss.update(self._get_loss_bbox(pred_bboxes, gt_bboxes, postfix))
+ # if masks is not None and gt_mask is not None:
+ # loss.update(self._get_loss_mask(masks, gt_mask, match_indices, postfix))
+ return loss
+
+ def forward(self, pred_bboxes, pred_scores, batch, postfix='', **kwargs):
+ """
+ Args:
+ pred_bboxes (torch.Tensor): [l, b, query, 4]
+ pred_scores (torch.Tensor): [l, b, query, num_classes]
+ batch (dict): A dict includes:
+ gt_cls (torch.Tensor) with shape [num_gts, ],
+ gt_bboxes (torch.Tensor): [num_gts, 4],
+ gt_groups (List(int)): a list of batch size length includes the number of gts of each image.
+ postfix (str): postfix of loss name.
+ """
+ self.device = pred_bboxes.device
+ match_indices = kwargs.get('match_indices', None)
+ gt_cls, gt_bboxes, gt_groups = batch['cls'], batch['bboxes'], batch['gt_groups']
+
+ total_loss = self._get_loss(pred_bboxes[-1],
+ pred_scores[-1],
+ gt_bboxes,
+ gt_cls,
+ gt_groups,
+ postfix=postfix,
+ match_indices=match_indices)
+
+ if self.aux_loss:
+ total_loss.update(
+ self._get_loss_aux(pred_bboxes[:-1], pred_scores[:-1], gt_bboxes, gt_cls, gt_groups, match_indices,
+ postfix))
+
+ return total_loss
+
+
+class RTDETRDetectionLoss(DETRLoss):
+
+ def forward(self, preds, batch, dn_bboxes=None, dn_scores=None, dn_meta=None):
+ pred_bboxes, pred_scores = preds
+ total_loss = super().forward(pred_bboxes, pred_scores, batch)
+
+ if dn_meta is not None:
+ dn_pos_idx, dn_num_group = dn_meta['dn_pos_idx'], dn_meta['dn_num_group']
+ assert len(batch['gt_groups']) == len(dn_pos_idx)
+
+ # Denoising match indices
+ match_indices = self.get_dn_match_indices(dn_pos_idx, dn_num_group, batch['gt_groups'])
+
+ # Compute denoising training loss
+ dn_loss = super().forward(dn_bboxes, dn_scores, batch, postfix='_dn', match_indices=match_indices)
+ total_loss.update(dn_loss)
+ else:
+ total_loss.update({f'{k}_dn': torch.tensor(0., device=self.device) for k in total_loss.keys()})
+
+ return total_loss
+
+ @staticmethod
+ def get_dn_match_indices(dn_pos_idx, dn_num_group, gt_groups):
+ """
+ Get the match indices for denoising.
+
+ Args:
+ dn_pos_idx (List[torch.Tensor]): A list includes positive indices of denoising.
+ dn_num_group (int): The number of groups of denoising.
+ gt_groups (List(int)): a list of batch size length includes the number of gts of each image.
+
+ Returns:
+ dn_match_indices (List(tuple)): Matched indices.
+ """
+ dn_match_indices = []
+ idx_groups = torch.as_tensor([0, *gt_groups[:-1]]).cumsum_(0)
+ for i, num_gt in enumerate(gt_groups):
+ if num_gt > 0:
+ gt_idx = torch.arange(end=num_gt, dtype=torch.long) + idx_groups[i]
+ gt_idx = gt_idx.repeat(dn_num_group)
+ assert len(dn_pos_idx[i]) == len(gt_idx), 'Expected the same length, '
+ f'but got {len(dn_pos_idx[i])} and {len(gt_idx)} respectively.'
+ dn_match_indices.append((dn_pos_idx[i], gt_idx))
+ else:
+ dn_match_indices.append((torch.zeros([0], dtype=torch.long), torch.zeros([0], dtype=torch.long)))
+ return dn_match_indices
diff --git a/STPoseNet/ultralytics/models/utils/ops.py b/STPoseNet/ultralytics/models/utils/ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..e7f829b613fec7585fd2d152fbf93f94983610c8
--- /dev/null
+++ b/STPoseNet/ultralytics/models/utils/ops.py
@@ -0,0 +1,260 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from scipy.optimize import linear_sum_assignment
+
+from ultralytics.utils.metrics import bbox_iou
+from ultralytics.utils.ops import xywh2xyxy, xyxy2xywh
+
+
+class HungarianMatcher(nn.Module):
+ """
+ A module implementing the HungarianMatcher, which is a differentiable module to solve the assignment problem in
+ an end-to-end fashion.
+
+ HungarianMatcher performs optimal assignment over predicted and ground truth bounding boxes using a cost function
+ that considers classification scores, bounding box coordinates, and optionally, mask predictions.
+
+ Attributes:
+ cost_gain (dict): Dictionary of cost coefficients for different components: 'class', 'bbox', 'giou', 'mask', and 'dice'.
+ use_fl (bool): Indicates whether to use Focal Loss for the classification cost calculation.
+ with_mask (bool): Indicates whether the model makes mask predictions.
+ num_sample_points (int): The number of sample points used in mask cost calculation.
+ alpha (float): The alpha factor in Focal Loss calculation.
+ gamma (float): The gamma factor in Focal Loss calculation.
+
+ Methods:
+ forward(pred_bboxes, pred_scores, gt_bboxes, gt_cls, gt_groups, masks=None, gt_mask=None): Computes the assignment
+ between predictions and ground truths for a batch.
+ _cost_mask(bs, num_gts, masks=None, gt_mask=None): Computes the mask cost and dice cost if masks are predicted.
+ """
+
+ def __init__(self, cost_gain=None, use_fl=True, with_mask=False, num_sample_points=12544, alpha=0.25, gamma=2.0):
+ super().__init__()
+ if cost_gain is None:
+ cost_gain = {'class': 1, 'bbox': 5, 'giou': 2, 'mask': 1, 'dice': 1}
+ self.cost_gain = cost_gain
+ self.use_fl = use_fl
+ self.with_mask = with_mask
+ self.num_sample_points = num_sample_points
+ self.alpha = alpha
+ self.gamma = gamma
+
+ def forward(self, pred_bboxes, pred_scores, gt_bboxes, gt_cls, gt_groups, masks=None, gt_mask=None):
+ """
+ Forward pass for HungarianMatcher. This function computes costs based on prediction and ground truth
+ (classification cost, L1 cost between boxes and GIoU cost between boxes) and finds the optimal matching
+ between predictions and ground truth based on these costs.
+
+ Args:
+ pred_bboxes (Tensor): Predicted bounding boxes with shape [batch_size, num_queries, 4].
+ pred_scores (Tensor): Predicted scores with shape [batch_size, num_queries, num_classes].
+ gt_cls (torch.Tensor): Ground truth classes with shape [num_gts, ].
+ gt_bboxes (torch.Tensor): Ground truth bounding boxes with shape [num_gts, 4].
+ gt_groups (List[int]): List of length equal to batch size, containing the number of ground truths for
+ each image.
+ masks (Tensor, optional): Predicted masks with shape [batch_size, num_queries, height, width].
+ Defaults to None.
+ gt_mask (List[Tensor], optional): List of ground truth masks, each with shape [num_masks, Height, Width].
+ Defaults to None.
+
+ Returns:
+ (List[Tuple[Tensor, Tensor]]): A list of size batch_size, each element is a tuple (index_i, index_j), where:
+ - index_i is the tensor of indices of the selected predictions (in order)
+ - index_j is the tensor of indices of the corresponding selected ground truth targets (in order)
+ For each batch element, it holds:
+ len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
+ """
+
+ bs, nq, nc = pred_scores.shape
+
+ if sum(gt_groups) == 0:
+ return [(torch.tensor([], dtype=torch.long), torch.tensor([], dtype=torch.long)) for _ in range(bs)]
+
+ # We flatten to compute the cost matrices in a batch
+ # [batch_size * num_queries, num_classes]
+ pred_scores = pred_scores.detach().view(-1, nc)
+ pred_scores = F.sigmoid(pred_scores) if self.use_fl else F.softmax(pred_scores, dim=-1)
+ # [batch_size * num_queries, 4]
+ pred_bboxes = pred_bboxes.detach().view(-1, 4)
+
+ # Compute the classification cost
+ pred_scores = pred_scores[:, gt_cls]
+ if self.use_fl:
+ neg_cost_class = (1 - self.alpha) * (pred_scores ** self.gamma) * (-(1 - pred_scores + 1e-8).log())
+ pos_cost_class = self.alpha * ((1 - pred_scores) ** self.gamma) * (-(pred_scores + 1e-8).log())
+ cost_class = pos_cost_class - neg_cost_class
+ else:
+ cost_class = -pred_scores
+
+ # Compute the L1 cost between boxes
+ cost_bbox = (pred_bboxes.unsqueeze(1) - gt_bboxes.unsqueeze(0)).abs().sum(-1) # (bs*num_queries, num_gt)
+
+ # Compute the GIoU cost between boxes, (bs*num_queries, num_gt)
+ cost_giou = 1.0 - bbox_iou(pred_bboxes.unsqueeze(1), gt_bboxes.unsqueeze(0), xywh=True, GIoU=True).squeeze(-1)
+
+ # Final cost matrix
+ C = self.cost_gain['class'] * cost_class + \
+ self.cost_gain['bbox'] * cost_bbox + \
+ self.cost_gain['giou'] * cost_giou
+ # Compute the mask cost and dice cost
+ if self.with_mask:
+ C += self._cost_mask(bs, gt_groups, masks, gt_mask)
+
+ C = C.view(bs, nq, -1).cpu()
+ indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(gt_groups, -1))]
+ gt_groups = torch.as_tensor([0, *gt_groups[:-1]]).cumsum_(0)
+ # (idx for queries, idx for gt)
+ return [(torch.tensor(i, dtype=torch.long), torch.tensor(j, dtype=torch.long) + gt_groups[k])
+ for k, (i, j) in enumerate(indices)]
+
+ def _cost_mask(self, bs, num_gts, masks=None, gt_mask=None):
+ assert masks is not None and gt_mask is not None, 'Make sure the input has `mask` and `gt_mask`'
+ # all masks share the same set of points for efficient matching
+ sample_points = torch.rand([bs, 1, self.num_sample_points, 2])
+ sample_points = 2.0 * sample_points - 1.0
+
+ out_mask = F.grid_sample(masks.detach(), sample_points, align_corners=False).squeeze(-2)
+ out_mask = out_mask.flatten(0, 1)
+
+ tgt_mask = torch.cat(gt_mask).unsqueeze(1)
+ sample_points = torch.cat([a.repeat(b, 1, 1, 1) for a, b in zip(sample_points, num_gts) if b > 0])
+ tgt_mask = F.grid_sample(tgt_mask, sample_points, align_corners=False).squeeze([1, 2])
+
+ with torch.cuda.amp.autocast(False):
+ # binary cross entropy cost
+ pos_cost_mask = F.binary_cross_entropy_with_logits(out_mask, torch.ones_like(out_mask), reduction='none')
+ neg_cost_mask = F.binary_cross_entropy_with_logits(out_mask, torch.zeros_like(out_mask), reduction='none')
+ cost_mask = torch.matmul(pos_cost_mask, tgt_mask.T) + torch.matmul(neg_cost_mask, 1 - tgt_mask.T)
+ cost_mask /= self.num_sample_points
+
+ # dice cost
+ out_mask = F.sigmoid(out_mask)
+ numerator = 2 * torch.matmul(out_mask, tgt_mask.T)
+ denominator = out_mask.sum(-1, keepdim=True) + tgt_mask.sum(-1).unsqueeze(0)
+ cost_dice = 1 - (numerator + 1) / (denominator + 1)
+
+ C = self.cost_gain['mask'] * cost_mask + self.cost_gain['dice'] * cost_dice
+ return C
+
+
+def get_cdn_group(batch,
+ num_classes,
+ num_queries,
+ class_embed,
+ num_dn=100,
+ cls_noise_ratio=0.5,
+ box_noise_scale=1.0,
+ training=False):
+ """
+ Get contrastive denoising training group. This function creates a contrastive denoising training group with
+ positive and negative samples from the ground truths (gt). It applies noise to the class labels and bounding
+ box coordinates, and returns the modified labels, bounding boxes, attention mask and meta information.
+
+ Args:
+ batch (dict): A dict that includes 'gt_cls' (torch.Tensor with shape [num_gts, ]), 'gt_bboxes'
+ (torch.Tensor with shape [num_gts, 4]), 'gt_groups' (List(int)) which is a list of batch size length
+ indicating the number of gts of each image.
+ num_classes (int): Number of classes.
+ num_queries (int): Number of queries.
+ class_embed (torch.Tensor): Embedding weights to map class labels to embedding space.
+ num_dn (int, optional): Number of denoising. Defaults to 100.
+ cls_noise_ratio (float, optional): Noise ratio for class labels. Defaults to 0.5.
+ box_noise_scale (float, optional): Noise scale for bounding box coordinates. Defaults to 1.0.
+ training (bool, optional): If it's in training mode. Defaults to False.
+
+ Returns:
+ (Tuple[Optional[Tensor], Optional[Tensor], Optional[Tensor], Optional[Dict]]): The modified class embeddings,
+ bounding boxes, attention mask and meta information for denoising. If not in training mode or 'num_dn'
+ is less than or equal to 0, the function returns None for all elements in the tuple.
+ """
+
+ if (not training) or num_dn <= 0:
+ return None, None, None, None
+ gt_groups = batch['gt_groups']
+ total_num = sum(gt_groups)
+ max_nums = max(gt_groups)
+ if max_nums == 0:
+ return None, None, None, None
+
+ num_group = num_dn // max_nums
+ num_group = 1 if num_group == 0 else num_group
+ # pad gt to max_num of a batch
+ bs = len(gt_groups)
+ gt_cls = batch['cls'] # (bs*num, )
+ gt_bbox = batch['bboxes'] # bs*num, 4
+ b_idx = batch['batch_idx']
+
+ # each group has positive and negative queries.
+ dn_cls = gt_cls.repeat(2 * num_group) # (2*num_group*bs*num, )
+ dn_bbox = gt_bbox.repeat(2 * num_group, 1) # 2*num_group*bs*num, 4
+ dn_b_idx = b_idx.repeat(2 * num_group).view(-1) # (2*num_group*bs*num, )
+
+ # positive and negative mask
+ # (bs*num*num_group, ), the second total_num*num_group part as negative samples
+ neg_idx = torch.arange(total_num * num_group, dtype=torch.long, device=gt_bbox.device) + num_group * total_num
+
+ if cls_noise_ratio > 0:
+ # half of bbox prob
+ mask = torch.rand(dn_cls.shape) < (cls_noise_ratio * 0.5)
+ idx = torch.nonzero(mask).squeeze(-1)
+ # randomly put a new one here
+ new_label = torch.randint_like(idx, 0, num_classes, dtype=dn_cls.dtype, device=dn_cls.device)
+ dn_cls[idx] = new_label
+
+ if box_noise_scale > 0:
+ known_bbox = xywh2xyxy(dn_bbox)
+
+ diff = (dn_bbox[..., 2:] * 0.5).repeat(1, 2) * box_noise_scale # 2*num_group*bs*num, 4
+
+ rand_sign = torch.randint_like(dn_bbox, 0, 2) * 2.0 - 1.0
+ rand_part = torch.rand_like(dn_bbox)
+ rand_part[neg_idx] += 1.0
+ rand_part *= rand_sign
+ known_bbox += rand_part * diff
+ known_bbox.clip_(min=0.0, max=1.0)
+ dn_bbox = xyxy2xywh(known_bbox)
+ dn_bbox = inverse_sigmoid(dn_bbox)
+
+ # total denoising queries
+ num_dn = int(max_nums * 2 * num_group)
+ # class_embed = torch.cat([class_embed, torch.zeros([1, class_embed.shape[-1]], device=class_embed.device)])
+ dn_cls_embed = class_embed[dn_cls] # bs*num * 2 * num_group, 256
+ padding_cls = torch.zeros(bs, num_dn, dn_cls_embed.shape[-1], device=gt_cls.device)
+ padding_bbox = torch.zeros(bs, num_dn, 4, device=gt_bbox.device)
+
+ map_indices = torch.cat([torch.tensor(range(num), dtype=torch.long) for num in gt_groups])
+ pos_idx = torch.stack([map_indices + max_nums * i for i in range(num_group)], dim=0)
+
+ map_indices = torch.cat([map_indices + max_nums * i for i in range(2 * num_group)])
+ padding_cls[(dn_b_idx, map_indices)] = dn_cls_embed
+ padding_bbox[(dn_b_idx, map_indices)] = dn_bbox
+
+ tgt_size = num_dn + num_queries
+ attn_mask = torch.zeros([tgt_size, tgt_size], dtype=torch.bool)
+ # match query cannot see the reconstruct
+ attn_mask[num_dn:, :num_dn] = True
+ # reconstruct cannot see each other
+ for i in range(num_group):
+ if i == 0:
+ attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
+ if i == num_group - 1:
+ attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * i * 2] = True
+ else:
+ attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
+ attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * 2 * i] = True
+ dn_meta = {
+ 'dn_pos_idx': [p.reshape(-1) for p in pos_idx.cpu().split(list(gt_groups), dim=1)],
+ 'dn_num_group': num_group,
+ 'dn_num_split': [num_dn, num_queries]}
+
+ return padding_cls.to(class_embed.device), padding_bbox.to(class_embed.device), attn_mask.to(
+ class_embed.device), dn_meta
+
+
+def inverse_sigmoid(x, eps=1e-6):
+ """Inverse sigmoid function."""
+ x = x.clip(min=0., max=1.)
+ return torch.log(x / (1 - x + eps) + eps)
diff --git a/STPoseNet/ultralytics/models/yolo/__init__.py b/STPoseNet/ultralytics/models/yolo/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c66e37627d3ddb22bc59ce84c26297f23508a38c
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.models.yolo import classify, detect, pose, segment
+
+from .model import YOLO
+
+__all__ = 'classify', 'segment', 'detect', 'pose', 'YOLO'
diff --git a/STPoseNet/ultralytics/models/yolo/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..405939d31971036fabe9facfaf1ed0a0b87f33ca
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/__pycache__/model.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/__pycache__/model.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ad8a614b7f2da8428541c4c9a2eb49c5fe6f5c1f
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/__pycache__/model.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/classify/__init__.py b/STPoseNet/ultralytics/models/yolo/classify/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..33d72e68eb7604c8ecd617b7ec906a498d57429a
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/classify/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.models.yolo.classify.predict import ClassificationPredictor
+from ultralytics.models.yolo.classify.train import ClassificationTrainer
+from ultralytics.models.yolo.classify.val import ClassificationValidator
+
+__all__ = 'ClassificationPredictor', 'ClassificationTrainer', 'ClassificationValidator'
diff --git a/STPoseNet/ultralytics/models/yolo/classify/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ef512757dd7725237207fd4f9f99ae765b007e32
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/classify/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..197c33d5baede24063a318878790e002c0a878c0
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/classify/__pycache__/train.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/train.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f2586e76623c12c00458222b74fa553c3e58e978
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/train.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/classify/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..86732f16cd988f678cc047aad90e3dddfe1c7fd9
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/classify/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/classify/predict.py b/STPoseNet/ultralytics/models/yolo/classify/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..18815137ce7eed1158a0cc966dd537c92e9b1490
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/classify/predict.py
@@ -0,0 +1,47 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.engine.predictor import BasePredictor
+from ultralytics.engine.results import Results
+from ultralytics.utils import DEFAULT_CFG
+
+
+class ClassificationPredictor(BasePredictor):
+ """
+ A class extending the BasePredictor class for prediction based on a classification model.
+
+ Notes:
+ - Torchvision classification models can also be passed to the 'model' argument, i.e. model='resnet18'.
+
+ Example:
+ ```python
+ from ultralytics.utils import ASSETS
+ from ultralytics.models.yolo.classify import ClassificationPredictor
+
+ args = dict(model='yolov8n-cls.pt', source=ASSETS)
+ predictor = ClassificationPredictor(overrides=args)
+ predictor.predict_cli()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ super().__init__(cfg, overrides, _callbacks)
+ self.args.task = 'classify'
+
+ def preprocess(self, img):
+ """Converts input image to model-compatible data type."""
+ if not isinstance(img, torch.Tensor):
+ img = torch.stack([self.transforms(im) for im in img], dim=0)
+ img = (img if isinstance(img, torch.Tensor) else torch.from_numpy(img)).to(self.model.device)
+ return img.half() if self.model.fp16 else img.float() # uint8 to fp16/32
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Post-processes predictions to return Results objects."""
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, pred in enumerate(preds):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ img_path = self.batch[0][i]
+ results.append(Results(orig_img, path=img_path, names=self.model.names, probs=pred))
+ return results
diff --git a/STPoseNet/ultralytics/models/yolo/classify/train.py b/STPoseNet/ultralytics/models/yolo/classify/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9393ac6537fe1bfe565972592044b7b0938995e
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/classify/train.py
@@ -0,0 +1,150 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+import torchvision
+
+from ultralytics.data import ClassificationDataset, build_dataloader
+from ultralytics.engine.trainer import BaseTrainer
+from ultralytics.models import yolo
+from ultralytics.nn.tasks import ClassificationModel, attempt_load_one_weight
+from ultralytics.utils import DEFAULT_CFG, LOGGER, RANK, colorstr
+from ultralytics.utils.plotting import plot_images, plot_results
+from ultralytics.utils.torch_utils import is_parallel, strip_optimizer, torch_distributed_zero_first
+
+
+class ClassificationTrainer(BaseTrainer):
+ """
+ A class extending the BaseTrainer class for training based on a classification model.
+
+ Notes:
+ - Torchvision classification models can also be passed to the 'model' argument, i.e. model='resnet18'.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.classify import ClassificationTrainer
+
+ args = dict(model='yolov8n-cls.pt', data='imagenet10', epochs=3)
+ trainer = ClassificationTrainer(overrides=args)
+ trainer.train()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """Initialize a ClassificationTrainer object with optional configuration overrides and callbacks."""
+ if overrides is None:
+ overrides = {}
+ overrides['task'] = 'classify'
+ if overrides.get('imgsz') is None:
+ overrides['imgsz'] = 224
+ super().__init__(cfg, overrides, _callbacks)
+
+ def set_model_attributes(self):
+ """Set the YOLO model's class names from the loaded dataset."""
+ self.model.names = self.data['names']
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Returns a modified PyTorch model configured for training YOLO."""
+ model = ClassificationModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
+ if weights:
+ model.load(weights)
+
+ for m in model.modules():
+ if not self.args.pretrained and hasattr(m, 'reset_parameters'):
+ m.reset_parameters()
+ if isinstance(m, torch.nn.Dropout) and self.args.dropout:
+ m.p = self.args.dropout # set dropout
+ for p in model.parameters():
+ p.requires_grad = True # for training
+ return model
+
+ def setup_model(self):
+ """load/create/download model for any task"""
+ if isinstance(self.model, torch.nn.Module): # if model is loaded beforehand. No setup needed
+ return
+
+ model, ckpt = str(self.model), None
+ # Load a YOLO model locally, from torchvision, or from Ultralytics assets
+ if model.endswith('.pt'):
+ self.model, ckpt = attempt_load_one_weight(model, device='cpu')
+ for p in self.model.parameters():
+ p.requires_grad = True # for training
+ elif model.split('.')[-1] in ('yaml', 'yml'):
+ self.model = self.get_model(cfg=model)
+ elif model in torchvision.models.__dict__:
+ self.model = torchvision.models.__dict__[model](weights='IMAGENET1K_V1' if self.args.pretrained else None)
+ else:
+ FileNotFoundError(f'ERROR: model={model} not found locally or online. Please check model name.')
+ ClassificationModel.reshape_outputs(self.model, self.data['nc'])
+
+ return ckpt
+
+ def build_dataset(self, img_path, mode='train', batch=None):
+ return ClassificationDataset(root=img_path, args=self.args, augment=mode == 'train', prefix=mode)
+
+ def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
+ """Returns PyTorch DataLoader with transforms to preprocess images for inference."""
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = self.build_dataset(dataset_path, mode)
+
+ loader = build_dataloader(dataset, batch_size, self.args.workers, rank=rank)
+ # Attach inference transforms
+ if mode != 'train':
+ if is_parallel(self.model):
+ self.model.module.transforms = loader.dataset.torch_transforms
+ else:
+ self.model.transforms = loader.dataset.torch_transforms
+ return loader
+
+ def preprocess_batch(self, batch):
+ """Preprocesses a batch of images and classes."""
+ batch['img'] = batch['img'].to(self.device)
+ batch['cls'] = batch['cls'].to(self.device)
+ return batch
+
+ def progress_string(self):
+ """Returns a formatted string showing training progress."""
+ return ('\n' + '%11s' * (4 + len(self.loss_names))) % \
+ ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
+
+ def get_validator(self):
+ """Returns an instance of ClassificationValidator for validation."""
+ self.loss_names = ['loss']
+ return yolo.classify.ClassificationValidator(self.test_loader, self.save_dir)
+
+ def label_loss_items(self, loss_items=None, prefix='train'):
+ """
+ Returns a loss dict with labelled training loss items tensor. Not needed for classification but necessary for
+ segmentation & detection
+ """
+ keys = [f'{prefix}/{x}' for x in self.loss_names]
+ if loss_items is None:
+ return keys
+ loss_items = [round(float(loss_items), 5)]
+ return dict(zip(keys, loss_items))
+
+ def plot_metrics(self):
+ """Plots metrics from a CSV file."""
+ plot_results(file=self.csv, classify=True, on_plot=self.on_plot) # save results.png
+
+ def final_eval(self):
+ """Evaluate trained model and save validation results."""
+ for f in self.last, self.best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ # TODO: validate best.pt after training completes
+ # if f is self.best:
+ # LOGGER.info(f'\nValidating {f}...')
+ # self.validator.args.save_json = True
+ # self.metrics = self.validator(model=f)
+ # self.metrics.pop('fitness', None)
+ # self.run_callbacks('on_fit_epoch_end')
+ LOGGER.info(f"Results saved to {colorstr('bold', self.save_dir)}")
+
+ def plot_training_samples(self, batch, ni):
+ """Plots training samples with their annotations."""
+ plot_images(
+ images=batch['img'],
+ batch_idx=torch.arange(len(batch['img'])),
+ cls=batch['cls'].view(-1), # warning: use .view(), not .squeeze() for Classify models
+ fname=self.save_dir / f'train_batch{ni}.jpg',
+ on_plot=self.on_plot)
diff --git a/STPoseNet/ultralytics/models/yolo/classify/val.py b/STPoseNet/ultralytics/models/yolo/classify/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..80606292d471811a123385d556dbfbcba6684dc5
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/classify/val.py
@@ -0,0 +1,109 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+
+from ultralytics.data import ClassificationDataset, build_dataloader
+from ultralytics.engine.validator import BaseValidator
+from ultralytics.utils import LOGGER
+from ultralytics.utils.metrics import ClassifyMetrics, ConfusionMatrix
+from ultralytics.utils.plotting import plot_images
+
+
+class ClassificationValidator(BaseValidator):
+ """
+ A class extending the BaseValidator class for validation based on a classification model.
+
+ Notes:
+ - Torchvision classification models can also be passed to the 'model' argument, i.e. model='resnet18'.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.classify import ClassificationValidator
+
+ args = dict(model='yolov8n-cls.pt', data='imagenet10')
+ validator = ClassificationValidator(args=args)
+ validator()
+ ```
+ """
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """Initializes ClassificationValidator instance with args, dataloader, save_dir, and progress bar."""
+ super().__init__(dataloader, save_dir, pbar, args, _callbacks)
+ self.targets = None
+ self.pred = None
+ self.args.task = 'classify'
+ self.metrics = ClassifyMetrics()
+
+ def get_desc(self):
+ """Returns a formatted string summarizing classification metrics."""
+ return ('%22s' + '%11s' * 2) % ('classes', 'top1_acc', 'top5_acc')
+
+ def init_metrics(self, model):
+ """Initialize confusion matrix, class names, and top-1 and top-5 accuracy."""
+ self.names = model.names
+ self.nc = len(model.names)
+ self.confusion_matrix = ConfusionMatrix(nc=self.nc, task='classify')
+ self.pred = []
+ self.targets = []
+
+ def preprocess(self, batch):
+ """Preprocesses input batch and returns it."""
+ batch['img'] = batch['img'].to(self.device, non_blocking=True)
+ batch['img'] = batch['img'].half() if self.args.half else batch['img'].float()
+ batch['cls'] = batch['cls'].to(self.device)
+ return batch
+
+ def update_metrics(self, preds, batch):
+ """Updates running metrics with model predictions and batch targets."""
+ n5 = min(len(self.model.names), 5)
+ self.pred.append(preds.argsort(1, descending=True)[:, :n5])
+ self.targets.append(batch['cls'])
+
+ def finalize_metrics(self, *args, **kwargs):
+ """Finalizes metrics of the model such as confusion_matrix and speed."""
+ self.confusion_matrix.process_cls_preds(self.pred, self.targets)
+ if self.args.plots:
+ for normalize in True, False:
+ self.confusion_matrix.plot(save_dir=self.save_dir,
+ names=self.names.values(),
+ normalize=normalize,
+ on_plot=self.on_plot)
+ self.metrics.speed = self.speed
+ self.metrics.confusion_matrix = self.confusion_matrix
+
+ def get_stats(self):
+ """Returns a dictionary of metrics obtained by processing targets and predictions."""
+ self.metrics.process(self.targets, self.pred)
+ return self.metrics.results_dict
+
+ def build_dataset(self, img_path):
+ return ClassificationDataset(root=img_path, args=self.args, augment=False, prefix=self.args.split)
+
+ def get_dataloader(self, dataset_path, batch_size):
+ """Builds and returns a data loader for classification tasks with given parameters."""
+ dataset = self.build_dataset(dataset_path)
+ return build_dataloader(dataset, batch_size, self.args.workers, rank=-1)
+
+ def print_results(self):
+ """Prints evaluation metrics for YOLO object detection model."""
+ pf = '%22s' + '%11.3g' * len(self.metrics.keys) # print format
+ LOGGER.info(pf % ('all', self.metrics.top1, self.metrics.top5))
+
+ def plot_val_samples(self, batch, ni):
+ """Plot validation image samples."""
+ plot_images(
+ images=batch['img'],
+ batch_idx=torch.arange(len(batch['img'])),
+ cls=batch['cls'].view(-1), # warning: use .view(), not .squeeze() for Classify models
+ fname=self.save_dir / f'val_batch{ni}_labels.jpg',
+ names=self.names,
+ on_plot=self.on_plot)
+
+ def plot_predictions(self, batch, preds, ni):
+ """Plots predicted bounding boxes on input images and saves the result."""
+ plot_images(batch['img'],
+ batch_idx=torch.arange(len(batch['img'])),
+ cls=torch.argmax(preds, dim=1),
+ fname=self.save_dir / f'val_batch{ni}_pred.jpg',
+ names=self.names,
+ on_plot=self.on_plot) # pred
diff --git a/STPoseNet/ultralytics/models/yolo/detect/__init__.py b/STPoseNet/ultralytics/models/yolo/detect/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..20fc0c4898246bdce2d2b68bab43a2a6259fc45f
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/detect/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .predict import DetectionPredictor
+from .train import DetectionTrainer
+from .val import DetectionValidator
+
+__all__ = 'DetectionPredictor', 'DetectionTrainer', 'DetectionValidator'
diff --git a/STPoseNet/ultralytics/models/yolo/detect/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fe03248b5d843331edb66548e7848d87ec1dceb9
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/detect/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..583fbd23ae5ddd4490c671e85a91792e3deb5b72
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/detect/__pycache__/train.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/train.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ea205de70b4a34cfa3d22dd457aa241f41c77c14
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/train.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/detect/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..408ba649127a483ee6ef8e667e81e919ce83a2ef
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/detect/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/detect/predict.py b/STPoseNet/ultralytics/models/yolo/detect/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdf3e176c50af539780003dd4c78cf9223cfb7d5
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/detect/predict.py
@@ -0,0 +1,40 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.engine.predictor import BasePredictor
+from ultralytics.engine.results import Results
+from ultralytics.utils import ops
+
+
+class DetectionPredictor(BasePredictor):
+ """
+ A class extending the BasePredictor class for prediction based on a detection model.
+
+ Example:
+ ```python
+ from ultralytics.utils import ASSETS
+ from ultralytics.models.yolo.detect import DetectionPredictor
+
+ args = dict(model='yolov8n.pt', source=ASSETS)
+ predictor = DetectionPredictor(overrides=args)
+ predictor.predict_cli()
+ ```
+ """
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Post-processes predictions and returns a list of Results objects."""
+ preds = ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ agnostic=self.args.agnostic_nms,
+ max_det=self.args.max_det,
+ classes=self.args.classes)
+
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, pred in enumerate(preds):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ img_path = self.batch[0][i]
+ results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
+ return results
diff --git a/STPoseNet/ultralytics/models/yolo/detect/train.py b/STPoseNet/ultralytics/models/yolo/detect/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..56d9243cfe7847a42772bd2c5504397ae19f9368
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/detect/train.py
@@ -0,0 +1,116 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from copy import copy
+
+import numpy as np
+
+from ultralytics.data import build_dataloader, build_yolo_dataset
+from ultralytics.engine.trainer import BaseTrainer
+from ultralytics.models import yolo
+from ultralytics.nn.tasks import DetectionModel
+from ultralytics.utils import LOGGER, RANK
+from ultralytics.utils.plotting import plot_images, plot_labels, plot_results
+from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
+
+
+class DetectionTrainer(BaseTrainer):
+ """
+ A class extending the BaseTrainer class for training based on a detection model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.detect import DetectionTrainer
+
+ args = dict(model='yolov8n.pt', data='coco8.yaml', epochs=3)
+ trainer = DetectionTrainer(overrides=args)
+ trainer.train()
+ ```
+ """
+
+ def build_dataset(self, img_path, mode='train', batch=None):
+ """
+ Build YOLO Dataset.
+
+ Args:
+ img_path (str): Path to the folder containing images.
+ mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode.
+ batch (int, optional): Size of batches, this is for `rect`. Defaults to None.
+ """
+ gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
+ return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
+
+ def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
+ """Construct and return dataloader."""
+ assert mode in ['train', 'val']
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = self.build_dataset(dataset_path, mode, batch_size)
+ shuffle = mode == 'train'
+ if getattr(dataset, 'rect', False) and shuffle:
+ LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
+ shuffle = False
+ workers = self.args.workers if mode == 'train' else self.args.workers * 2
+ return build_dataloader(dataset, batch_size, workers, shuffle, rank) # return dataloader
+
+ def preprocess_batch(self, batch):
+ """Preprocesses a batch of images by scaling and converting to float."""
+ batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
+ return batch
+
+ def set_model_attributes(self):
+ """nl = de_parallel(self.model).model[-1].nl # number of detection layers (to scale hyps)."""
+ # self.args.box *= 3 / nl # scale to layers
+ # self.args.cls *= self.data["nc"] / 80 * 3 / nl # scale to classes and layers
+ # self.args.cls *= (self.args.imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ self.model.nc = self.data['nc'] # attach number of classes to model
+ self.model.names = self.data['names'] # attach class names to model
+ self.model.args = self.args # attach hyperparameters to model
+ # TODO: self.model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Return a YOLO detection model."""
+ model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
+ if weights:
+ model.load(weights)
+ return model
+
+ def get_validator(self):
+ """Returns a DetectionValidator for YOLO model validation."""
+ self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
+ return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
+
+ def label_loss_items(self, loss_items=None, prefix='train'):
+ """
+ Returns a loss dict with labelled training loss items tensor. Not needed for classification but necessary for
+ segmentation & detection
+ """
+ keys = [f'{prefix}/{x}' for x in self.loss_names]
+ if loss_items is not None:
+ loss_items = [round(float(x), 5) for x in loss_items] # convert tensors to 5 decimal place floats
+ return dict(zip(keys, loss_items))
+ else:
+ return keys
+
+ def progress_string(self):
+ """Returns a formatted string of training progress with epoch, GPU memory, loss, instances and size."""
+ return ('\n' + '%11s' *
+ (4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
+
+ def plot_training_samples(self, batch, ni):
+ """Plots training samples with their annotations."""
+ plot_images(images=batch['img'],
+ batch_idx=batch['batch_idx'],
+ cls=batch['cls'].squeeze(-1),
+ bboxes=batch['bboxes'],
+ paths=batch['im_file'],
+ fname=self.save_dir / f'train_batch{ni}.jpg',
+ on_plot=self.on_plot)
+
+ def plot_metrics(self):
+ """Plots metrics from a CSV file."""
+ plot_results(file=self.csv, on_plot=self.on_plot) # save results.png
+
+ def plot_training_labels(self):
+ """Create a labeled training plot of the YOLO model."""
+ boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
+ cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
+ plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
diff --git a/STPoseNet/ultralytics/models/yolo/detect/val.py b/STPoseNet/ultralytics/models/yolo/detect/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9f84ae8a5e0c69987ffcfb8bc6cdb30dcb3dafb
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/detect/val.py
@@ -0,0 +1,268 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+from pathlib import Path
+
+import numpy as np
+import torch
+
+from ultralytics.data import build_dataloader, build_yolo_dataset, converter
+from ultralytics.engine.validator import BaseValidator
+from ultralytics.utils import LOGGER, ops
+from ultralytics.utils.checks import check_requirements
+from ultralytics.utils.metrics import ConfusionMatrix, DetMetrics, box_iou
+from ultralytics.utils.plotting import output_to_target, plot_images
+from ultralytics.utils.torch_utils import de_parallel
+
+
+class DetectionValidator(BaseValidator):
+ """
+ A class extending the BaseValidator class for validation based on a detection model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.detect import DetectionValidator
+
+ args = dict(model='yolov8n.pt', data='coco8.yaml')
+ validator = DetectionValidator(args=args)
+ validator()
+ ```
+ """
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """Initialize detection model with necessary variables and settings."""
+ super().__init__(dataloader, save_dir, pbar, args, _callbacks)
+ self.nt_per_class = None
+ self.is_coco = False
+ self.class_map = None
+ self.args.task = 'detect'
+ self.metrics = DetMetrics(save_dir=self.save_dir, on_plot=self.on_plot)
+ self.iouv = torch.linspace(0.5, 0.95, 10) # iou vector for mAP@0.5:0.95
+ self.niou = self.iouv.numel()
+ self.lb = [] # for autolabelling
+
+ def preprocess(self, batch):
+ """Preprocesses batch of images for YOLO training."""
+ batch['img'] = batch['img'].to(self.device, non_blocking=True)
+ batch['img'] = (batch['img'].half() if self.args.half else batch['img'].float()) / 255
+ for k in ['batch_idx', 'cls', 'bboxes']:
+ batch[k] = batch[k].to(self.device)
+
+ if self.args.save_hybrid:
+ height, width = batch['img'].shape[2:]
+ nb = len(batch['img'])
+ bboxes = batch['bboxes'] * torch.tensor((width, height, width, height), device=self.device)
+ self.lb = [
+ torch.cat([batch['cls'][batch['batch_idx'] == i], bboxes[batch['batch_idx'] == i]], dim=-1)
+ for i in range(nb)] if self.args.save_hybrid else [] # for autolabelling
+
+ return batch
+
+ def init_metrics(self, model):
+ """Initialize evaluation metrics for YOLO."""
+ val = self.data.get(self.args.split, '') # validation path
+ self.is_coco = isinstance(val, str) and 'coco' in val and val.endswith(f'{os.sep}val2017.txt') # is COCO
+ self.class_map = converter.coco80_to_coco91_class() if self.is_coco else list(range(1000))
+ self.args.save_json |= self.is_coco and not self.training # run on final val if training COCO
+ self.names = model.names
+ self.nc = len(model.names)
+ self.metrics.names = self.names
+ self.metrics.plot = self.args.plots
+ self.confusion_matrix = ConfusionMatrix(nc=self.nc)
+ self.seen = 0
+ self.jdict = []
+ self.stats = []
+
+ def get_desc(self):
+ """Return a formatted string summarizing class metrics of YOLO model."""
+ return ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'Box(P', 'R', 'mAP50', 'mAP50-95)')
+
+ def postprocess(self, preds):
+ """Apply Non-maximum suppression to prediction outputs."""
+ return ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ labels=self.lb,
+ multi_label=True,
+ agnostic=self.args.single_cls,
+ max_det=self.args.max_det)
+
+ def update_metrics(self, preds, batch):
+ """Metrics."""
+ for si, pred in enumerate(preds):
+ idx = batch['batch_idx'] == si
+ cls = batch['cls'][idx]
+ bbox = batch['bboxes'][idx]
+ nl, npr = cls.shape[0], pred.shape[0] # number of labels, predictions
+ shape = batch['ori_shape'][si]
+ correct_bboxes = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ self.seen += 1
+
+ if npr == 0:
+ if nl:
+ self.stats.append((correct_bboxes, *torch.zeros((2, 0), device=self.device), cls.squeeze(-1)))
+ if self.args.plots:
+ self.confusion_matrix.process_batch(detections=None, labels=cls.squeeze(-1))
+ continue
+
+ # Predictions
+ if self.args.single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ ops.scale_boxes(batch['img'][si].shape[1:], predn[:, :4], shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space pred
+
+ # Evaluate
+ if nl:
+ height, width = batch['img'].shape[2:]
+ tbox = ops.xywh2xyxy(bbox) * torch.tensor(
+ (width, height, width, height), device=self.device) # target boxes
+ ops.scale_boxes(batch['img'][si].shape[1:], tbox, shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space labels
+ labelsn = torch.cat((cls, tbox), 1) # native-space labels
+ correct_bboxes = self._process_batch(predn, labelsn)
+ # TODO: maybe remove these `self.` arguments as they already are member variable
+ if self.args.plots:
+ self.confusion_matrix.process_batch(predn, labelsn)
+ self.stats.append((correct_bboxes, pred[:, 4], pred[:, 5], cls.squeeze(-1))) # (conf, pcls, tcls)
+
+ # Save
+ if self.args.save_json:
+ self.pred_to_json(predn, batch['im_file'][si])
+ if self.args.save_txt:
+ file = self.save_dir / 'labels' / f'{Path(batch["im_file"][si]).stem}.txt'
+ self.save_one_txt(predn, self.args.save_conf, shape, file)
+
+ def finalize_metrics(self, *args, **kwargs):
+ """Set final values for metrics speed and confusion matrix."""
+ self.metrics.speed = self.speed
+ self.metrics.confusion_matrix = self.confusion_matrix
+
+ def get_stats(self):
+ """Returns metrics statistics and results dictionary."""
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*self.stats)] # to numpy
+ if len(stats) and stats[0].any():
+ self.metrics.process(*stats)
+ self.nt_per_class = np.bincount(stats[-1].astype(int), minlength=self.nc) # number of targets per class
+ return self.metrics.results_dict
+
+ def print_results(self):
+ """Prints training/validation set metrics per class."""
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * len(self.metrics.keys) # print format
+ LOGGER.info(pf % ('all', self.seen, self.nt_per_class.sum(), *self.metrics.mean_results()))
+ if self.nt_per_class.sum() == 0:
+ LOGGER.warning(
+ f'WARNING ⚠️ no labels found in {self.args.task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if self.args.verbose and not self.training and self.nc > 1 and len(self.stats):
+ for i, c in enumerate(self.metrics.ap_class_index):
+ LOGGER.info(pf % (self.names[c], self.seen, self.nt_per_class[c], *self.metrics.class_result(i)))
+
+ if self.args.plots:
+ for normalize in True, False:
+ self.confusion_matrix.plot(save_dir=self.save_dir,
+ names=self.names.values(),
+ normalize=normalize,
+ on_plot=self.on_plot)
+
+ def _process_batch(self, detections, labels):
+ """
+ Return correct prediction matrix.
+
+ Args:
+ detections (torch.Tensor): Tensor of shape [N, 6] representing detections.
+ Each detection is of the format: x1, y1, x2, y2, conf, class.
+ labels (torch.Tensor): Tensor of shape [M, 5] representing labels.
+ Each label is of the format: class, x1, y1, x2, y2.
+
+ Returns:
+ (torch.Tensor): Correct prediction matrix of shape [N, 10] for 10 IoU levels.
+ """
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ return self.match_predictions(detections[:, 5], labels[:, 0], iou)
+
+ def build_dataset(self, img_path, mode='val', batch=None):
+ """
+ Build YOLO Dataset.
+
+ Args:
+ img_path (str): Path to the folder containing images.
+ mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode.
+ batch (int, optional): Size of batches, this is for `rect`. Defaults to None.
+ """
+ gs = max(int(de_parallel(self.model).stride if self.model else 0), 32)
+ return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, stride=gs)
+
+ def get_dataloader(self, dataset_path, batch_size):
+ """Construct and return dataloader."""
+ dataset = self.build_dataset(dataset_path, batch=batch_size, mode='val')
+ return build_dataloader(dataset, batch_size, self.args.workers, shuffle=False, rank=-1) # return dataloader
+
+ def plot_val_samples(self, batch, ni):
+ """Plot validation image samples."""
+ plot_images(batch['img'],
+ batch['batch_idx'],
+ batch['cls'].squeeze(-1),
+ batch['bboxes'],
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_labels.jpg',
+ names=self.names,
+ on_plot=self.on_plot)
+
+ def plot_predictions(self, batch, preds, ni):
+ """Plots predicted bounding boxes on input images and saves the result."""
+ plot_images(batch['img'],
+ *output_to_target(preds, max_det=self.args.max_det),
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_pred.jpg',
+ names=self.names,
+ on_plot=self.on_plot) # pred
+
+ def save_one_txt(self, predn, save_conf, shape, file):
+ """Save YOLO detections to a txt file in normalized coordinates in a specific format."""
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (ops.xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ def pred_to_json(self, predn, filename):
+ """Serialize YOLO predictions to COCO json format."""
+ stem = Path(filename).stem
+ image_id = int(stem) if stem.isnumeric() else stem
+ box = ops.xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ self.jdict.append({
+ 'image_id': image_id,
+ 'category_id': self.class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+ def eval_json(self, stats):
+ """Evaluates YOLO output in JSON format and returns performance statistics."""
+ if self.args.save_json and self.is_coco and len(self.jdict):
+ anno_json = self.data['path'] / 'annotations/instances_val2017.json' # annotations
+ pred_json = self.save_dir / 'predictions.json' # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP using {pred_json} and {anno_json}...')
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO # noqa
+ from pycocotools.cocoeval import COCOeval # noqa
+
+ for x in anno_json, pred_json:
+ assert x.is_file(), f'{x} file not found'
+ anno = COCO(str(anno_json)) # init annotations api
+ pred = anno.loadRes(str(pred_json)) # init predictions api (must pass string, not Path)
+ eval = COCOeval(anno, pred, 'bbox')
+ if self.is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in self.dataloader.dataset.im_files] # images to eval
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ stats[self.metrics.keys[-1]], stats[self.metrics.keys[-2]] = eval.stats[:2] # update mAP50-95 and mAP50
+ except Exception as e:
+ LOGGER.warning(f'pycocotools unable to run: {e}')
+ return stats
diff --git a/STPoseNet/ultralytics/models/yolo/model.py b/STPoseNet/ultralytics/models/yolo/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..b85d46bdb84fe5fa38e6aae671dbc292d3592f59
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/model.py
@@ -0,0 +1,36 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.engine.model import Model
+from ultralytics.models import yolo # noqa
+from ultralytics.nn.tasks import ClassificationModel, DetectionModel, PoseModel, SegmentationModel
+
+
+class YOLO(Model):
+ """
+ YOLO (You Only Look Once) object detection model.
+ """
+
+ @property
+ def task_map(self):
+ """Map head to model, trainer, validator, and predictor classes"""
+ return {
+ 'classify': {
+ 'model': ClassificationModel,
+ 'trainer': yolo.classify.ClassificationTrainer,
+ 'validator': yolo.classify.ClassificationValidator,
+ 'predictor': yolo.classify.ClassificationPredictor, },
+ 'detect': {
+ 'model': DetectionModel,
+ 'trainer': yolo.detect.DetectionTrainer,
+ 'validator': yolo.detect.DetectionValidator,
+ 'predictor': yolo.detect.DetectionPredictor, },
+ 'segment': {
+ 'model': SegmentationModel,
+ 'trainer': yolo.segment.SegmentationTrainer,
+ 'validator': yolo.segment.SegmentationValidator,
+ 'predictor': yolo.segment.SegmentationPredictor, },
+ 'pose': {
+ 'model': PoseModel,
+ 'trainer': yolo.pose.PoseTrainer,
+ 'validator': yolo.pose.PoseValidator,
+ 'predictor': yolo.pose.PosePredictor, }, }
diff --git a/STPoseNet/ultralytics/models/yolo/pose/__init__.py b/STPoseNet/ultralytics/models/yolo/pose/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a79f0f34e79de36f0ce645d340cc85582ce613e
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/pose/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .predict import PosePredictor
+from .train import PoseTrainer
+from .val import PoseValidator
+
+__all__ = 'PoseTrainer', 'PoseValidator', 'PosePredictor'
diff --git a/STPoseNet/ultralytics/models/yolo/pose/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..359d15767e07ba0c9f5aa3c3cf47eb8dd67eb21a
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/pose/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7203875bd73cff26dc872cb1e50b9e1c7fd2d52d
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/pose/__pycache__/train.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/train.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..833b5d5e9104b906668908fafe47efc471bd4030
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/train.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/pose/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b5043cb861c13cd8759eb20c58848e5a3537f30
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/pose/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/pose/predict.py b/STPoseNet/ultralytics/models/yolo/pose/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf89fb1a9db9cdd0f03c03b58743787b8296b463
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/pose/predict.py
@@ -0,0 +1,50 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.engine.results import Results
+from ultralytics.models.yolo.detect.predict import DetectionPredictor
+from ultralytics.utils import DEFAULT_CFG, LOGGER, ops
+
+
+class PosePredictor(DetectionPredictor):
+ """
+ A class extending the DetectionPredictor class for prediction based on a pose model.
+
+ Example:
+ ```python
+ from ultralytics.utils import ASSETS
+ from ultralytics.models.yolo.pose import PosePredictor
+
+ args = dict(model='yolov8n-pose.pt', source=ASSETS)
+ predictor = PosePredictor(overrides=args)
+ predictor.predict_cli()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ super().__init__(cfg, overrides, _callbacks)
+ self.args.task = 'pose'
+ if isinstance(self.args.device, str) and self.args.device.lower() == 'mps':
+ LOGGER.warning("WARNING ⚠️ Apple MPS known Pose bug. Recommend 'device=cpu' for Pose models. "
+ 'See https://github.com/ultralytics/ultralytics/issues/4031.')
+
+ def postprocess(self, preds, img, orig_imgs):
+ """Return detection results for a given input image or list of images."""
+ preds = ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ agnostic=self.args.agnostic_nms,
+ max_det=self.args.max_det,
+ classes=self.args.classes,
+ nc=len(self.model.names))
+
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ for i, pred in enumerate(preds):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape).round()
+ pred_kpts = pred[:, 6:].view(len(pred), *self.model.kpt_shape) if len(pred) else pred[:, 6:]
+ pred_kpts = ops.scale_coords(img.shape[2:], pred_kpts, orig_img.shape)
+ img_path = self.batch[0][i]
+ results.append(
+ Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6], keypoints=pred_kpts))
+ return results
diff --git a/STPoseNet/ultralytics/models/yolo/pose/train.py b/STPoseNet/ultralytics/models/yolo/pose/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d4f4e0d49ea39d9603c6571c704355f5ac6a6ac
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/pose/train.py
@@ -0,0 +1,73 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from copy import copy
+
+from ultralytics.models import yolo
+from ultralytics.nn.tasks import PoseModel
+from ultralytics.utils import DEFAULT_CFG, LOGGER
+from ultralytics.utils.plotting import plot_images, plot_results
+
+
+class PoseTrainer(yolo.detect.DetectionTrainer):
+ """
+ A class extending the DetectionTrainer class for training based on a pose model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.pose import PoseTrainer
+
+ args = dict(model='yolov8n-pose.pt', data='coco8-pose.yaml', epochs=3)
+ trainer = PoseTrainer(overrides=args)
+ trainer.train()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """Initialize a PoseTrainer object with specified configurations and overrides."""
+ if overrides is None:
+ overrides = {}
+ overrides['task'] = 'pose'
+ super().__init__(cfg, overrides, _callbacks)
+
+ if isinstance(self.args.device, str) and self.args.device.lower() == 'mps':
+ LOGGER.warning("WARNING ⚠️ Apple MPS known Pose bug. Recommend 'device=cpu' for Pose models. "
+ 'See https://github.com/ultralytics/ultralytics/issues/4031.')
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Get pose estimation model with specified configuration and weights."""
+ model = PoseModel(cfg, ch=3, nc=self.data['nc'], data_kpt_shape=self.data['kpt_shape'], verbose=verbose)
+ if weights:
+ model.load(weights)
+
+ return model
+
+ def set_model_attributes(self):
+ """Sets keypoints shape attribute of PoseModel."""
+ super().set_model_attributes()
+ self.model.kpt_shape = self.data['kpt_shape']
+
+ def get_validator(self):
+ """Returns an instance of the PoseValidator class for validation."""
+ self.loss_names = 'box_loss', 'pose_loss', 'kobj_loss', 'cls_loss', 'dfl_loss'
+ return yolo.pose.PoseValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
+
+ def plot_training_samples(self, batch, ni):
+ """Plot a batch of training samples with annotated class labels, bounding boxes, and keypoints."""
+ images = batch['img']
+ kpts = batch['keypoints']
+ cls = batch['cls'].squeeze(-1)
+ bboxes = batch['bboxes']
+ paths = batch['im_file']
+ batch_idx = batch['batch_idx']
+ plot_images(images,
+ batch_idx,
+ cls,
+ bboxes,
+ kpts=kpts,
+ paths=paths,
+ fname=self.save_dir / f'train_batch{ni}.jpg',
+ on_plot=self.on_plot)
+
+ def plot_metrics(self):
+ """Plots training/val metrics."""
+ plot_results(file=self.csv, pose=True, on_plot=self.on_plot) # save results.png
diff --git a/STPoseNet/ultralytics/models/yolo/pose/val.py b/STPoseNet/ultralytics/models/yolo/pose/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8ebf57edb0f143d0a43020a2557f57f73b2f9c7
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/pose/val.py
@@ -0,0 +1,215 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from pathlib import Path
+
+import numpy as np
+import torch
+
+from ultralytics.models.yolo.detect import DetectionValidator
+from ultralytics.utils import LOGGER, ops
+from ultralytics.utils.checks import check_requirements
+from ultralytics.utils.metrics import OKS_SIGMA, PoseMetrics, box_iou, kpt_iou
+from ultralytics.utils.plotting import output_to_target, plot_images
+
+
+class PoseValidator(DetectionValidator):
+ """
+ A class extending the DetectionValidator class for validation based on a pose model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.pose import PoseValidator
+
+ args = dict(model='yolov8n-pose.pt', data='coco8-pose.yaml')
+ validator = PoseValidator(args=args)
+ validator()
+ ```
+ """
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """Initialize a 'PoseValidator' object with custom parameters and assigned attributes."""
+ super().__init__(dataloader, save_dir, pbar, args, _callbacks)
+ self.sigma = None
+ self.kpt_shape = None
+ self.args.task = 'pose'
+ self.metrics = PoseMetrics(save_dir=self.save_dir, on_plot=self.on_plot)
+ if isinstance(self.args.device, str) and self.args.device.lower() == 'mps':
+ LOGGER.warning("WARNING ⚠️ Apple MPS known Pose bug. Recommend 'device=cpu' for Pose models. "
+ 'See https://github.com/ultralytics/ultralytics/issues/4031.')
+
+ def preprocess(self, batch):
+ """Preprocesses the batch by converting the 'keypoints' data into a float and moving it to the device."""
+ batch = super().preprocess(batch)
+ batch['keypoints'] = batch['keypoints'].to(self.device).float()
+ return batch
+
+ def get_desc(self):
+ """Returns description of evaluation metrics in string format."""
+ return ('%22s' + '%11s' * 10) % ('Class', 'Images', 'Instances', 'Box(P', 'R', 'mAP50', 'mAP50-95)', 'Pose(P',
+ 'R', 'mAP50', 'mAP50-95)')
+
+ def postprocess(self, preds):
+ """Apply non-maximum suppression and return detections with high confidence scores."""
+ return ops.non_max_suppression(preds,
+ self.args.conf,
+ self.args.iou,
+ labels=self.lb,
+ multi_label=True,
+ agnostic=self.args.single_cls,
+ max_det=self.args.max_det,
+ nc=self.nc)
+
+ def init_metrics(self, model):
+ """Initiate pose estimation metrics for YOLO model."""
+ super().init_metrics(model)
+ self.kpt_shape = self.data['kpt_shape']
+ is_pose = self.kpt_shape == [17, 3]
+ nkpt = self.kpt_shape[0]
+ self.sigma = OKS_SIGMA if is_pose else np.ones(nkpt) / nkpt
+
+ def update_metrics(self, preds, batch):
+ """Metrics."""
+ for si, pred in enumerate(preds):
+ idx = batch['batch_idx'] == si
+ cls = batch['cls'][idx]
+ bbox = batch['bboxes'][idx]
+ kpts = batch['keypoints'][idx]
+ nl, npr = cls.shape[0], pred.shape[0] # number of labels, predictions
+ nk = kpts.shape[1] # number of keypoints
+ shape = batch['ori_shape'][si]
+ correct_kpts = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ correct_bboxes = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ self.seen += 1
+
+ if npr == 0:
+ if nl:
+ self.stats.append((correct_bboxes, correct_kpts, *torch.zeros(
+ (2, 0), device=self.device), cls.squeeze(-1)))
+ if self.args.plots:
+ self.confusion_matrix.process_batch(detections=None, labels=cls.squeeze(-1))
+ continue
+
+ # Predictions
+ if self.args.single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ ops.scale_boxes(batch['img'][si].shape[1:], predn[:, :4], shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space pred
+ pred_kpts = predn[:, 6:].view(npr, nk, -1)
+ ops.scale_coords(batch['img'][si].shape[1:], pred_kpts, shape, ratio_pad=batch['ratio_pad'][si])
+
+ # Evaluate
+ if nl:
+ height, width = batch['img'].shape[2:]
+ tbox = ops.xywh2xyxy(bbox) * torch.tensor(
+ (width, height, width, height), device=self.device) # target boxes
+ ops.scale_boxes(batch['img'][si].shape[1:], tbox, shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space labels
+ tkpts = kpts.clone()
+ tkpts[..., 0] *= width
+ tkpts[..., 1] *= height
+ tkpts = ops.scale_coords(batch['img'][si].shape[1:], tkpts, shape, ratio_pad=batch['ratio_pad'][si])
+ labelsn = torch.cat((cls, tbox), 1) # native-space labels
+ correct_bboxes = self._process_batch(predn[:, :6], labelsn)
+ correct_kpts = self._process_batch(predn[:, :6], labelsn, pred_kpts, tkpts)
+ if self.args.plots:
+ self.confusion_matrix.process_batch(predn, labelsn)
+
+ # Append correct_masks, correct_boxes, pconf, pcls, tcls
+ self.stats.append((correct_bboxes, correct_kpts, pred[:, 4], pred[:, 5], cls.squeeze(-1)))
+
+ # Save
+ if self.args.save_json:
+ self.pred_to_json(predn, batch['im_file'][si])
+ # if self.args.save_txt:
+ # save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+
+ def _process_batch(self, detections, labels, pred_kpts=None, gt_kpts=None):
+ """
+ Return correct prediction matrix.
+
+ Args:
+ detections (torch.Tensor): Tensor of shape [N, 6] representing detections.
+ Each detection is of the format: x1, y1, x2, y2, conf, class.
+ labels (torch.Tensor): Tensor of shape [M, 5] representing labels.
+ Each label is of the format: class, x1, y1, x2, y2.
+ pred_kpts (torch.Tensor, optional): Tensor of shape [N, 51] representing predicted keypoints.
+ 51 corresponds to 17 keypoints each with 3 values.
+ gt_kpts (torch.Tensor, optional): Tensor of shape [N, 51] representing ground truth keypoints.
+
+ Returns:
+ torch.Tensor: Correct prediction matrix of shape [N, 10] for 10 IoU levels.
+ """
+ if pred_kpts is not None and gt_kpts is not None:
+ # `0.53` is from https://github.com/jin-s13/xtcocoapi/blob/master/xtcocotools/cocoeval.py#L384
+ area = ops.xyxy2xywh(labels[:, 1:])[:, 2:].prod(1) * 0.53
+ iou = kpt_iou(gt_kpts, pred_kpts, sigma=self.sigma, area=area)
+ else: # boxes
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ return self.match_predictions(detections[:, 5], labels[:, 0], iou)
+
+ def plot_val_samples(self, batch, ni):
+ """Plots and saves validation set samples with predicted bounding boxes and keypoints."""
+ plot_images(batch['img'],
+ batch['batch_idx'],
+ batch['cls'].squeeze(-1),
+ batch['bboxes'],
+ kpts=batch['keypoints'],
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_labels.jpg',
+ names=self.names,
+ on_plot=self.on_plot)
+
+ def plot_predictions(self, batch, preds, ni):
+ """Plots predictions for YOLO model."""
+ pred_kpts = torch.cat([p[:, 6:].view(-1, *self.kpt_shape) for p in preds], 0)
+ plot_images(batch['img'],
+ *output_to_target(preds, max_det=self.args.max_det),
+ kpts=pred_kpts,
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_pred.jpg',
+ names=self.names,
+ on_plot=self.on_plot) # pred
+
+ def pred_to_json(self, predn, filename):
+ """Converts YOLO predictions to COCO JSON format."""
+ stem = Path(filename).stem
+ image_id = int(stem) if stem.isnumeric() else stem
+ box = ops.xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ self.jdict.append({
+ 'image_id': image_id,
+ 'category_id': self.class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'keypoints': p[6:],
+ 'score': round(p[4], 5)})
+
+ def eval_json(self, stats):
+ """Evaluates object detection model using COCO JSON format."""
+ if self.args.save_json and self.is_coco and len(self.jdict):
+ anno_json = self.data['path'] / 'annotations/person_keypoints_val2017.json' # annotations
+ pred_json = self.save_dir / 'predictions.json' # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP using {pred_json} and {anno_json}...')
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO # noqa
+ from pycocotools.cocoeval import COCOeval # noqa
+
+ for x in anno_json, pred_json:
+ assert x.is_file(), f'{x} file not found'
+ anno = COCO(str(anno_json)) # init annotations api
+ pred = anno.loadRes(str(pred_json)) # init predictions api (must pass string, not Path)
+ for i, eval in enumerate([COCOeval(anno, pred, 'bbox'), COCOeval(anno, pred, 'keypoints')]):
+ if self.is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in self.dataloader.dataset.im_files] # im to eval
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ idx = i * 4 + 2
+ stats[self.metrics.keys[idx + 1]], stats[
+ self.metrics.keys[idx]] = eval.stats[:2] # update mAP50-95 and mAP50
+ except Exception as e:
+ LOGGER.warning(f'pycocotools unable to run: {e}')
+ return stats
diff --git a/STPoseNet/ultralytics/models/yolo/segment/__init__.py b/STPoseNet/ultralytics/models/yolo/segment/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c84a570e9a274b21fcf0bb50294344261483061c
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/segment/__init__.py
@@ -0,0 +1,7 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .predict import SegmentationPredictor
+from .train import SegmentationTrainer
+from .val import SegmentationValidator
+
+__all__ = 'SegmentationPredictor', 'SegmentationTrainer', 'SegmentationValidator'
diff --git a/STPoseNet/ultralytics/models/yolo/segment/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ada261424bb56a964c856ab7630dc42958b7a63
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/segment/__pycache__/predict.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/predict.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11810a5910ec6e98a8837d42f9fd79b68b859256
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/predict.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/segment/__pycache__/train.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/train.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..96769845659b322dbcd9991e60dcf03f1e3ac03c
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/train.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/segment/__pycache__/val.cpython-38.pyc b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/val.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b28a7282745b5b1a3c4f139db764ecd5fb620c75
Binary files /dev/null and b/STPoseNet/ultralytics/models/yolo/segment/__pycache__/val.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/models/yolo/segment/predict.py b/STPoseNet/ultralytics/models/yolo/segment/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d650a1a3ccab9e89870d2a717f8e62be09823f5
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/segment/predict.py
@@ -0,0 +1,52 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.engine.results import Results
+from ultralytics.models.yolo.detect.predict import DetectionPredictor
+from ultralytics.utils import DEFAULT_CFG, ops
+
+
+class SegmentationPredictor(DetectionPredictor):
+ """
+ A class extending the DetectionPredictor class for prediction based on a segmentation model.
+
+ Example:
+ ```python
+ from ultralytics.utils import ASSETS
+ from ultralytics.models.yolo.segment import SegmentationPredictor
+
+ args = dict(model='yolov8n-seg.pt', source=ASSETS)
+ predictor = SegmentationPredictor(overrides=args)
+ predictor.predict_cli()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ super().__init__(cfg, overrides, _callbacks)
+ self.args.task = 'segment'
+
+ def postprocess(self, preds, img, orig_imgs):
+ p = ops.non_max_suppression(preds[0],
+ self.args.conf,
+ self.args.iou,
+ agnostic=self.args.agnostic_nms,
+ max_det=self.args.max_det,
+ nc=len(self.model.names),
+ classes=self.args.classes)
+ results = []
+ is_list = isinstance(orig_imgs, list) # input images are a list, not a torch.Tensor
+ proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
+ for i, pred in enumerate(p):
+ orig_img = orig_imgs[i] if is_list else orig_imgs
+ img_path = self.batch[0][i]
+ if not len(pred): # save empty boxes
+ masks = None
+ elif self.args.retina_masks:
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ masks = ops.process_mask_native(proto[i], pred[:, 6:], pred[:, :4], orig_img.shape[:2]) # HWC
+ else:
+ masks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWC
+ if is_list:
+ pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
+ results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred[:, :6], masks=masks))
+ return results
diff --git a/STPoseNet/ultralytics/models/yolo/segment/train.py b/STPoseNet/ultralytics/models/yolo/segment/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..b290192cd1eeb70501c85e3f9fb4566d70ad4a23
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/segment/train.py
@@ -0,0 +1,58 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from copy import copy
+
+from ultralytics.models import yolo
+from ultralytics.nn.tasks import SegmentationModel
+from ultralytics.utils import DEFAULT_CFG, RANK
+from ultralytics.utils.plotting import plot_images, plot_results
+
+
+class SegmentationTrainer(yolo.detect.DetectionTrainer):
+ """
+ A class extending the DetectionTrainer class for training based on a segmentation model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.segment import SegmentationTrainer
+
+ args = dict(model='yolov8n-seg.pt', data='coco8-seg.yaml', epochs=3)
+ trainer = SegmentationTrainer(overrides=args)
+ trainer.train()
+ ```
+ """
+
+ def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
+ """Initialize a SegmentationTrainer object with given arguments."""
+ if overrides is None:
+ overrides = {}
+ overrides['task'] = 'segment'
+ super().__init__(cfg, overrides, _callbacks)
+
+ def get_model(self, cfg=None, weights=None, verbose=True):
+ """Return SegmentationModel initialized with specified config and weights."""
+ model = SegmentationModel(cfg, ch=3, nc=self.data['nc'], verbose=verbose and RANK == -1)
+ if weights:
+ model.load(weights)
+
+ return model
+
+ def get_validator(self):
+ """Return an instance of SegmentationValidator for validation of YOLO model."""
+ self.loss_names = 'box_loss', 'seg_loss', 'cls_loss', 'dfl_loss'
+ return yolo.segment.SegmentationValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
+
+ def plot_training_samples(self, batch, ni):
+ """Creates a plot of training sample images with labels and box coordinates."""
+ plot_images(batch['img'],
+ batch['batch_idx'],
+ batch['cls'].squeeze(-1),
+ batch['bboxes'],
+ batch['masks'],
+ paths=batch['im_file'],
+ fname=self.save_dir / f'train_batch{ni}.jpg',
+ on_plot=self.on_plot)
+
+ def plot_metrics(self):
+ """Plots training/val metrics."""
+ plot_results(file=self.csv, segment=True, on_plot=self.on_plot) # save results.png
diff --git a/STPoseNet/ultralytics/models/yolo/segment/val.py b/STPoseNet/ultralytics/models/yolo/segment/val.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a2acb41a1bf50e5f914a54e7b095700abe632aa
--- /dev/null
+++ b/STPoseNet/ultralytics/models/yolo/segment/val.py
@@ -0,0 +1,247 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+from ultralytics.models.yolo.detect import DetectionValidator
+from ultralytics.utils import LOGGER, NUM_THREADS, ops
+from ultralytics.utils.checks import check_requirements
+from ultralytics.utils.metrics import SegmentMetrics, box_iou, mask_iou
+from ultralytics.utils.plotting import output_to_target, plot_images
+
+
+class SegmentationValidator(DetectionValidator):
+ """
+ A class extending the DetectionValidator class for validation based on a segmentation model.
+
+ Example:
+ ```python
+ from ultralytics.models.yolo.segment import SegmentationValidator
+
+ args = dict(model='yolov8n-seg.pt', data='coco8-seg.yaml')
+ validator = SegmentationValidator(args=args)
+ validator()
+ ```
+ """
+
+ def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
+ """Initialize SegmentationValidator and set task to 'segment', metrics to SegmentMetrics."""
+ super().__init__(dataloader, save_dir, pbar, args, _callbacks)
+ self.plot_masks = None
+ self.process = None
+ self.args.task = 'segment'
+ self.metrics = SegmentMetrics(save_dir=self.save_dir, on_plot=self.on_plot)
+
+ def preprocess(self, batch):
+ """Preprocesses batch by converting masks to float and sending to device."""
+ batch = super().preprocess(batch)
+ batch['masks'] = batch['masks'].to(self.device).float()
+ return batch
+
+ def init_metrics(self, model):
+ """Initialize metrics and select mask processing function based on save_json flag."""
+ super().init_metrics(model)
+ self.plot_masks = []
+ if self.args.save_json:
+ check_requirements('pycocotools>=2.0.6')
+ self.process = ops.process_mask_upsample # more accurate
+ else:
+ self.process = ops.process_mask # faster
+
+ def get_desc(self):
+ """Return a formatted description of evaluation metrics."""
+ return ('%22s' + '%11s' * 10) % ('Class', 'Images', 'Instances', 'Box(P', 'R', 'mAP50', 'mAP50-95)', 'Mask(P',
+ 'R', 'mAP50', 'mAP50-95)')
+
+ def postprocess(self, preds):
+ """Post-processes YOLO predictions and returns output detections with proto."""
+ p = ops.non_max_suppression(preds[0],
+ self.args.conf,
+ self.args.iou,
+ labels=self.lb,
+ multi_label=True,
+ agnostic=self.args.single_cls,
+ max_det=self.args.max_det,
+ nc=self.nc)
+ proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
+ return p, proto
+
+ def update_metrics(self, preds, batch):
+ """Metrics."""
+ for si, (pred, proto) in enumerate(zip(preds[0], preds[1])):
+ idx = batch['batch_idx'] == si
+ cls = batch['cls'][idx]
+ bbox = batch['bboxes'][idx]
+ nl, npr = cls.shape[0], pred.shape[0] # number of labels, predictions
+ shape = batch['ori_shape'][si]
+ correct_masks = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ correct_bboxes = torch.zeros(npr, self.niou, dtype=torch.bool, device=self.device) # init
+ self.seen += 1
+
+ if npr == 0:
+ if nl:
+ self.stats.append((correct_bboxes, correct_masks, *torch.zeros(
+ (2, 0), device=self.device), cls.squeeze(-1)))
+ if self.args.plots:
+ self.confusion_matrix.process_batch(detections=None, labels=cls.squeeze(-1))
+ continue
+
+ # Masks
+ midx = [si] if self.args.overlap_mask else idx
+ gt_masks = batch['masks'][midx]
+ pred_masks = self.process(proto, pred[:, 6:], pred[:, :4], shape=batch['img'][si].shape[1:])
+
+ # Predictions
+ if self.args.single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ ops.scale_boxes(batch['img'][si].shape[1:], predn[:, :4], shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space pred
+
+ # Evaluate
+ if nl:
+ height, width = batch['img'].shape[2:]
+ tbox = ops.xywh2xyxy(bbox) * torch.tensor(
+ (width, height, width, height), device=self.device) # target boxes
+ ops.scale_boxes(batch['img'][si].shape[1:], tbox, shape,
+ ratio_pad=batch['ratio_pad'][si]) # native-space labels
+ labelsn = torch.cat((cls, tbox), 1) # native-space labels
+ correct_bboxes = self._process_batch(predn, labelsn)
+ # TODO: maybe remove these `self.` arguments as they already are member variable
+ correct_masks = self._process_batch(predn,
+ labelsn,
+ pred_masks,
+ gt_masks,
+ overlap=self.args.overlap_mask,
+ masks=True)
+ if self.args.plots:
+ self.confusion_matrix.process_batch(predn, labelsn)
+
+ # Append correct_masks, correct_boxes, pconf, pcls, tcls
+ self.stats.append((correct_bboxes, correct_masks, pred[:, 4], pred[:, 5], cls.squeeze(-1)))
+
+ pred_masks = torch.as_tensor(pred_masks, dtype=torch.uint8)
+ if self.args.plots and self.batch_i < 3:
+ self.plot_masks.append(pred_masks[:15].cpu()) # filter top 15 to plot
+
+ # Save
+ if self.args.save_json:
+ pred_masks = ops.scale_image(pred_masks.permute(1, 2, 0).contiguous().cpu().numpy(),
+ shape,
+ ratio_pad=batch['ratio_pad'][si])
+ self.pred_to_json(predn, batch['im_file'][si], pred_masks)
+ # if self.args.save_txt:
+ # save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+
+ def finalize_metrics(self, *args, **kwargs):
+ """Sets speed and confusion matrix for evaluation metrics."""
+ self.metrics.speed = self.speed
+ self.metrics.confusion_matrix = self.confusion_matrix
+
+ def _process_batch(self, detections, labels, pred_masks=None, gt_masks=None, overlap=False, masks=False):
+ """
+ Return correct prediction matrix
+
+ Args:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ if masks:
+ if overlap:
+ nl = len(labels)
+ index = torch.arange(nl, device=gt_masks.device).view(nl, 1, 1) + 1
+ gt_masks = gt_masks.repeat(nl, 1, 1) # shape(1,640,640) -> (n,640,640)
+ gt_masks = torch.where(gt_masks == index, 1.0, 0.0)
+ if gt_masks.shape[1:] != pred_masks.shape[1:]:
+ gt_masks = F.interpolate(gt_masks[None], pred_masks.shape[1:], mode='bilinear', align_corners=False)[0]
+ gt_masks = gt_masks.gt_(0.5)
+ iou = mask_iou(gt_masks.view(gt_masks.shape[0], -1), pred_masks.view(pred_masks.shape[0], -1))
+ else: # boxes
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ return self.match_predictions(detections[:, 5], labels[:, 0], iou)
+
+ def plot_val_samples(self, batch, ni):
+ """Plots validation samples with bounding box labels."""
+ plot_images(batch['img'],
+ batch['batch_idx'],
+ batch['cls'].squeeze(-1),
+ batch['bboxes'],
+ batch['masks'],
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_labels.jpg',
+ names=self.names,
+ on_plot=self.on_plot)
+
+ def plot_predictions(self, batch, preds, ni):
+ """Plots batch predictions with masks and bounding boxes."""
+ plot_images(
+ batch['img'],
+ *output_to_target(preds[0], max_det=15), # not set to self.args.max_det due to slow plotting speed
+ torch.cat(self.plot_masks, dim=0) if len(self.plot_masks) else self.plot_masks,
+ paths=batch['im_file'],
+ fname=self.save_dir / f'val_batch{ni}_pred.jpg',
+ names=self.names,
+ on_plot=self.on_plot) # pred
+ self.plot_masks.clear()
+
+ def pred_to_json(self, predn, filename, pred_masks):
+ """Save one JSON result."""
+ # Example result = {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ from pycocotools.mask import encode # noqa
+
+ def single_encode(x):
+ """Encode predicted masks as RLE and append results to jdict."""
+ rle = encode(np.asarray(x[:, :, None], order='F', dtype='uint8'))[0]
+ rle['counts'] = rle['counts'].decode('utf-8')
+ return rle
+
+ stem = Path(filename).stem
+ image_id = int(stem) if stem.isnumeric() else stem
+ box = ops.xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ pred_masks = np.transpose(pred_masks, (2, 0, 1))
+ with ThreadPool(NUM_THREADS) as pool:
+ rles = pool.map(single_encode, pred_masks)
+ for i, (p, b) in enumerate(zip(predn.tolist(), box.tolist())):
+ self.jdict.append({
+ 'image_id': image_id,
+ 'category_id': self.class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5),
+ 'segmentation': rles[i]})
+
+ def eval_json(self, stats):
+ """Return COCO-style object detection evaluation metrics."""
+ if self.args.save_json and self.is_coco and len(self.jdict):
+ anno_json = self.data['path'] / 'annotations/instances_val2017.json' # annotations
+ pred_json = self.save_dir / 'predictions.json' # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP using {pred_json} and {anno_json}...')
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO # noqa
+ from pycocotools.cocoeval import COCOeval # noqa
+
+ for x in anno_json, pred_json:
+ assert x.is_file(), f'{x} file not found'
+ anno = COCO(str(anno_json)) # init annotations api
+ pred = anno.loadRes(str(pred_json)) # init predictions api (must pass string, not Path)
+ for i, eval in enumerate([COCOeval(anno, pred, 'bbox'), COCOeval(anno, pred, 'segm')]):
+ if self.is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in self.dataloader.dataset.im_files] # im to eval
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ idx = i * 4 + 2
+ stats[self.metrics.keys[idx + 1]], stats[
+ self.metrics.keys[idx]] = eval.stats[:2] # update mAP50-95 and mAP50
+ except Exception as e:
+ LOGGER.warning(f'pycocotools unable to run: {e}')
+ return stats
diff --git a/STPoseNet/ultralytics/nn/__init__.py b/STPoseNet/ultralytics/nn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9889b7ef218a106eade7e56f381a66c27c53b7c3
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/__init__.py
@@ -0,0 +1,9 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .tasks import (BaseModel, ClassificationModel, DetectionModel, SegmentationModel, attempt_load_one_weight,
+ attempt_load_weights, guess_model_scale, guess_model_task, parse_model, torch_safe_load,
+ yaml_model_load)
+
+__all__ = ('attempt_load_one_weight', 'attempt_load_weights', 'parse_model', 'yaml_model_load', 'guess_model_task',
+ 'guess_model_scale', 'torch_safe_load', 'DetectionModel', 'SegmentationModel', 'ClassificationModel',
+ 'BaseModel')
diff --git a/STPoseNet/ultralytics/nn/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/nn/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..64851a85a28af1e3a1df1afbbde8323171318d2c
Binary files /dev/null and b/STPoseNet/ultralytics/nn/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/__pycache__/autobackend.cpython-38.pyc b/STPoseNet/ultralytics/nn/__pycache__/autobackend.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d9da1e5d9ecb2b44acba0ddc56468b17c70a53be
Binary files /dev/null and b/STPoseNet/ultralytics/nn/__pycache__/autobackend.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/__pycache__/tasks.cpython-38.pyc b/STPoseNet/ultralytics/nn/__pycache__/tasks.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2bbaefe104f8825a40eeb131a87eab9c87536cc3
Binary files /dev/null and b/STPoseNet/ultralytics/nn/__pycache__/tasks.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/autobackend.py b/STPoseNet/ultralytics/nn/autobackend.py
new file mode 100644
index 0000000000000000000000000000000000000000..9010815bf11b57761e03e0b3979c5e061700406e
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/autobackend.py
@@ -0,0 +1,497 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import ast
+import contextlib
+import json
+import platform
+import zipfile
+from collections import OrderedDict, namedtuple
+from pathlib import Path
+from urllib.parse import urlparse
+
+import cv2
+import numpy as np
+import torch
+import torch.nn as nn
+from PIL import Image
+
+from ultralytics.utils import ARM64, LINUX, LOGGER, ROOT, yaml_load
+from ultralytics.utils.checks import check_requirements, check_suffix, check_version, check_yaml
+from ultralytics.utils.downloads import attempt_download_asset, is_url
+
+
+def check_class_names(names):
+ """Check class names. Map imagenet class codes to human-readable names if required. Convert lists to dicts."""
+ if isinstance(names, list): # names is a list
+ names = dict(enumerate(names)) # convert to dict
+ if isinstance(names, dict):
+ # Convert 1) string keys to int, i.e. '0' to 0, and non-string values to strings, i.e. True to 'True'
+ names = {int(k): str(v) for k, v in names.items()}
+ n = len(names)
+ if max(names.keys()) >= n:
+ raise KeyError(f'{n}-class dataset requires class indices 0-{n - 1}, but you have invalid class indices '
+ f'{min(names.keys())}-{max(names.keys())} defined in your dataset YAML.')
+ if isinstance(names[0], str) and names[0].startswith('n0'): # imagenet class codes, i.e. 'n01440764'
+ map = yaml_load(ROOT / 'cfg/datasets/ImageNet.yaml')['map'] # human-readable names
+ names = {k: map[v] for k, v in names.items()}
+ return names
+
+
+class AutoBackend(nn.Module):
+
+ def __init__(self,
+ weights='yolov8n.pt',
+ device=torch.device('cpu'),
+ dnn=False,
+ data=None,
+ fp16=False,
+ fuse=True,
+ verbose=True):
+ """
+ MultiBackend class for python inference on various platforms using Ultralytics YOLO.
+
+ Args:
+ weights (str): The path to the weights file. Default: 'yolov8n.pt'
+ device (torch.device): The device to run the model on.
+ dnn (bool): Use OpenCV DNN module for inference if True, defaults to False.
+ data (str | Path | optional): Additional data.yaml file for class names.
+ fp16 (bool): If True, use half precision. Default: False
+ fuse (bool): Whether to fuse the model or not. Default: True
+ verbose (bool): Whether to run in verbose mode or not. Default: True
+
+ Supported formats and their naming conventions:
+ | Format | Suffix |
+ |-----------------------|------------------|
+ | PyTorch | *.pt |
+ | TorchScript | *.torchscript |
+ | ONNX Runtime | *.onnx |
+ | ONNX OpenCV DNN | *.onnx dnn=True |
+ | OpenVINO | *.xml |
+ | CoreML | *.mlpackage |
+ | TensorRT | *.engine |
+ | TensorFlow SavedModel | *_saved_model |
+ | TensorFlow GraphDef | *.pb |
+ | TensorFlow Lite | *.tflite |
+ | TensorFlow Edge TPU | *_edgetpu.tflite |
+ | PaddlePaddle | *_paddle_model |
+ | ncnn | *_ncnn_model |
+ """
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ nn_module = isinstance(weights, torch.nn.Module)
+ pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, ncnn, triton = \
+ self._model_type(w)
+ fp16 &= pt or jit or onnx or xml or engine or nn_module or triton # FP16
+ nhwc = coreml or saved_model or pb or tflite or edgetpu # BHWC formats (vs torch BCWH)
+ stride = 32 # default stride
+ model, metadata = None, None
+
+ # Set device
+ cuda = torch.cuda.is_available() and device.type != 'cpu' # use CUDA
+ if cuda and not any([nn_module, pt, jit, engine]): # GPU dataloader formats
+ device = torch.device('cpu')
+ cuda = False
+
+ # Download if not local
+ if not (pt or triton or nn_module):
+ w = attempt_download_asset(w)
+
+ # Load model
+ if nn_module: # in-memory PyTorch model
+ model = weights.to(device)
+ model = model.fuse(verbose=verbose) if fuse else model
+ if hasattr(model, 'kpt_shape'):
+ kpt_shape = model.kpt_shape # pose-only
+ stride = max(int(model.stride.max()), 32) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ model.half() if fp16 else model.float()
+ self.model = model # explicitly assign for to(), cpu(), cuda(), half()
+ pt = True
+ elif pt: # PyTorch
+ from ultralytics.nn.tasks import attempt_load_weights
+ model = attempt_load_weights(weights if isinstance(weights, list) else w,
+ device=device,
+ inplace=True,
+ fuse=fuse)
+ if hasattr(model, 'kpt_shape'):
+ kpt_shape = model.kpt_shape # pose-only
+ stride = max(int(model.stride.max()), 32) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ model.half() if fp16 else model.float()
+ self.model = model # explicitly assign for to(), cpu(), cuda(), half()
+ elif jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files, map_location=device)
+ model.half() if fp16 else model.float()
+ if extra_files['config.txt']: # load metadata dict
+ metadata = json.loads(extra_files['config.txt'], object_hook=lambda x: dict(x.items()))
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements('opencv-python>=4.5.4')
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
+ import onnxruntime
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
+ session = onnxruntime.InferenceSession(w, providers=providers)
+ output_names = [x.name for x in session.get_outputs()]
+ metadata = session.get_modelmeta().custom_metadata_map # metadata
+ elif xml: # OpenVINO
+ LOGGER.info(f'Loading {w} for OpenVINO inference...')
+ check_requirements('openvino>=2023.0') # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ from openvino.runtime import Core, Layout, get_batch # noqa
+ core = Core()
+ w = Path(w)
+ if not w.is_file(): # if not *.xml
+ w = next(w.glob('*.xml')) # get *.xml file from *_openvino_model dir
+ ov_model = core.read_model(model=str(w), weights=w.with_suffix('.bin'))
+ if ov_model.get_parameters()[0].get_layout().empty:
+ ov_model.get_parameters()[0].set_layout(Layout('NCHW'))
+ batch_dim = get_batch(ov_model)
+ if batch_dim.is_static:
+ batch_size = batch_dim.get_length()
+ ov_compiled_model = core.compile_model(ov_model, device_name='AUTO') # AUTO selects best available device
+ metadata = w.parent / 'metadata.yaml'
+ elif engine: # TensorRT
+ LOGGER.info(f'Loading {w} for TensorRT inference...')
+ try:
+ import tensorrt as trt # noqa https://developer.nvidia.com/nvidia-tensorrt-download
+ except ImportError:
+ if LINUX:
+ check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
+ import tensorrt as trt # noqa
+ check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
+ if device.type == 'cpu':
+ device = torch.device('cuda:0')
+ Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
+ logger = trt.Logger(trt.Logger.INFO)
+ # Read file
+ with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
+ meta_len = int.from_bytes(f.read(4), byteorder='little') # read metadata length
+ metadata = json.loads(f.read(meta_len).decode('utf-8')) # read metadata
+ model = runtime.deserialize_cuda_engine(f.read()) # read engine
+ context = model.create_execution_context()
+ bindings = OrderedDict()
+ output_names = []
+ fp16 = False # default updated below
+ dynamic = False
+ for i in range(model.num_bindings):
+ name = model.get_binding_name(i)
+ dtype = trt.nptype(model.get_binding_dtype(i))
+ if model.binding_is_input(i):
+ if -1 in tuple(model.get_binding_shape(i)): # dynamic
+ dynamic = True
+ context.set_binding_shape(i, tuple(model.get_profile_shape(0, i)[2]))
+ if dtype == np.float16:
+ fp16 = True
+ else: # output
+ output_names.append(name)
+ shape = tuple(context.get_binding_shape(i))
+ im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)
+ bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))
+ binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
+ batch_size = bindings['images'].shape[0] # if dynamic, this is instead max batch size
+ elif coreml: # CoreML
+ LOGGER.info(f'Loading {w} for CoreML inference...')
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ metadata = dict(model.user_defined_metadata)
+ elif saved_model: # TF SavedModel
+ LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
+ import tensorflow as tf
+ keras = False # assume TF1 saved_model
+ model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
+ metadata = Path(w) / 'metadata.yaml'
+ elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
+ import tensorflow as tf
+
+ from ultralytics.engine.exporter import gd_outputs
+
+ def wrap_frozen_graph(gd, inputs, outputs):
+ """Wrap frozen graphs for deployment."""
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=''), []) # wrapped
+ ge = x.graph.as_graph_element
+ return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
+
+ gd = tf.Graph().as_graph_def() # TF GraphDef
+ with open(w, 'rb') as f:
+ gd.ParseFromString(f.read())
+ frozen_func = wrap_frozen_graph(gd, inputs='x:0', outputs=gd_outputs(gd))
+ elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
+ from tflite_runtime.interpreter import Interpreter, load_delegate
+ except ImportError:
+ import tensorflow as tf
+ Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate
+ if edgetpu: # TF Edge TPU https://coral.ai/software/#edgetpu-runtime
+ LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
+ delegate = {
+ 'Linux': 'libedgetpu.so.1',
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
+ else: # TFLite
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ # Load metadata
+ with contextlib.suppress(zipfile.BadZipFile):
+ with zipfile.ZipFile(w, 'r') as model:
+ meta_file = model.namelist()[0]
+ metadata = ast.literal_eval(model.read(meta_file).decode('utf-8'))
+ elif tfjs: # TF.js
+ raise NotImplementedError('YOLOv8 TF.js inference is not currently supported.')
+ elif paddle: # PaddlePaddle
+ LOGGER.info(f'Loading {w} for PaddlePaddle inference...')
+ check_requirements('paddlepaddle-gpu' if cuda else 'paddlepaddle')
+ import paddle.inference as pdi # noqa
+ w = Path(w)
+ if not w.is_file(): # if not *.pdmodel
+ w = next(w.rglob('*.pdmodel')) # get *.pdmodel file from *_paddle_model dir
+ config = pdi.Config(str(w), str(w.with_suffix('.pdiparams')))
+ if cuda:
+ config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0)
+ predictor = pdi.create_predictor(config)
+ input_handle = predictor.get_input_handle(predictor.get_input_names()[0])
+ output_names = predictor.get_output_names()
+ metadata = w.parents[1] / 'metadata.yaml'
+ elif ncnn: # ncnn
+ LOGGER.info(f'Loading {w} for ncnn inference...')
+ check_requirements('git+https://github.com/Tencent/ncnn.git' if ARM64 else 'ncnn') # requires ncnn
+ import ncnn as pyncnn
+ net = pyncnn.Net()
+ net.opt.use_vulkan_compute = cuda
+ w = Path(w)
+ if not w.is_file(): # if not *.param
+ w = next(w.glob('*.param')) # get *.param file from *_ncnn_model dir
+ net.load_param(str(w))
+ net.load_model(str(w.with_suffix('.bin')))
+ metadata = w.parent / 'metadata.yaml'
+ elif triton: # NVIDIA Triton Inference Server
+ """TODO
+ check_requirements('tritonclient[all]')
+ from utils.triton import TritonRemoteModel
+ model = TritonRemoteModel(url=w)
+ nhwc = model.runtime.startswith("tensorflow")
+ """
+ raise NotImplementedError('Triton Inference Server is not currently supported.')
+ else:
+ from ultralytics.engine.exporter import export_formats
+ raise TypeError(f"model='{w}' is not a supported model format. "
+ 'See https://docs.ultralytics.com/modes/predict for help.'
+ f'\n\n{export_formats()}')
+
+ # Load external metadata YAML
+ if isinstance(metadata, (str, Path)) and Path(metadata).exists():
+ metadata = yaml_load(metadata)
+ if metadata:
+ for k, v in metadata.items():
+ if k in ('stride', 'batch'):
+ metadata[k] = int(v)
+ elif k in ('imgsz', 'names', 'kpt_shape') and isinstance(v, str):
+ metadata[k] = eval(v)
+ stride = metadata['stride']
+ task = metadata['task']
+ batch = metadata['batch']
+ imgsz = metadata['imgsz']
+ names = metadata['names']
+ kpt_shape = metadata.get('kpt_shape')
+ elif not (pt or triton or nn_module):
+ LOGGER.warning(f"WARNING ⚠️ Metadata not found for 'model={weights}'")
+
+ # Check names
+ if 'names' not in locals(): # names missing
+ names = self._apply_default_class_names(data)
+ names = check_class_names(names)
+
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False):
+ """
+ Runs inference on the YOLOv8 MultiBackend model.
+
+ Args:
+ im (torch.Tensor): The image tensor to perform inference on.
+ augment (bool): whether to perform data augmentation during inference, defaults to False
+ visualize (bool): whether to visualize the output predictions, defaults to False
+
+ Returns:
+ (tuple): Tuple containing the raw output tensor, and processed output for visualization (if visualize=True)
+ """
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.fp16 and im.dtype != torch.float16:
+ im = im.half() # to FP16
+ if self.nhwc:
+ im = im.permute(0, 2, 3, 1) # torch BCHW to numpy BHWC shape(1,320,192,3)
+
+ if self.pt or self.nn_module: # PyTorch
+ y = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)
+ elif self.jit: # TorchScript
+ y = self.model(im)
+ elif self.dnn: # ONNX OpenCV DNN
+ im = im.cpu().numpy() # torch to numpy
+ self.net.setInput(im)
+ y = self.net.forward()
+ elif self.onnx: # ONNX Runtime
+ im = im.cpu().numpy() # torch to numpy
+ y = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})
+ elif self.xml: # OpenVINO
+ im = im.cpu().numpy() # FP32
+ y = list(self.ov_compiled_model(im).values())
+ elif self.engine: # TensorRT
+ if self.dynamic and im.shape != self.bindings['images'].shape:
+ i = self.model.get_binding_index('images')
+ self.context.set_binding_shape(i, im.shape) # reshape if dynamic
+ self.bindings['images'] = self.bindings['images']._replace(shape=im.shape)
+ for name in self.output_names:
+ i = self.model.get_binding_index(name)
+ self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))
+ s = self.bindings['images'].shape
+ assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
+ self.binding_addrs['images'] = int(im.data_ptr())
+ self.context.execute_v2(list(self.binding_addrs.values()))
+ y = [self.bindings[x].data for x in sorted(self.output_names)]
+ elif self.coreml: # CoreML
+ im = im[0].cpu().numpy()
+ im_pil = Image.fromarray((im * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.BILINEAR)
+ y = self.model.predict({'image': im_pil}) # coordinates are xywh normalized
+ if 'confidence' in y:
+ raise TypeError('Ultralytics only supports inference of non-pipelined CoreML models exported with '
+ f"'nms=False', but 'model={w}' has an NMS pipeline created by an 'nms=True' export.")
+ # TODO: CoreML NMS inference handling
+ # from ultralytics.utils.ops import xywh2xyxy
+ # box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ # conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float32)
+ # y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ elif len(y) == 1: # classification model
+ y = list(y.values())
+ elif len(y) == 2: # segmentation model
+ y = list(reversed(y.values())) # reversed for segmentation models (pred, proto)
+ elif self.paddle: # PaddlePaddle
+ im = im.cpu().numpy().astype(np.float32)
+ self.input_handle.copy_from_cpu(im)
+ self.predictor.run()
+ y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names]
+ elif self.ncnn: # ncnn
+ mat_in = self.pyncnn.Mat(im[0].cpu().numpy())
+ ex = self.net.create_extractor()
+ input_names, output_names = self.net.input_names(), self.net.output_names()
+ ex.input(input_names[0], mat_in)
+ y = []
+ for output_name in output_names:
+ mat_out = self.pyncnn.Mat()
+ ex.extract(output_name, mat_out)
+ y.append(np.array(mat_out)[None])
+ elif self.triton: # NVIDIA Triton Inference Server
+ y = self.model(im)
+ else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
+ im = im.cpu().numpy()
+ if self.saved_model: # SavedModel
+ y = self.model(im, training=False) if self.keras else self.model(im)
+ if not isinstance(y, list):
+ y = [y]
+ elif self.pb: # GraphDef
+ y = self.frozen_func(x=self.tf.constant(im))
+ if len(y) == 2 and len(self.names) == 999: # segments and names not defined
+ ip, ib = (0, 1) if len(y[0].shape) == 4 else (1, 0) # index of protos, boxes
+ nc = y[ib].shape[1] - y[ip].shape[3] - 4 # y = (1, 160, 160, 32), (1, 116, 8400)
+ self.names = {i: f'class{i}' for i in range(nc)}
+ else: # Lite or Edge TPU
+ details = self.input_details[0]
+ integer = details['dtype'] in (np.int8, np.int16) # is TFLite quantized int8 or int16 model
+ if integer:
+ scale, zero_point = details['quantization']
+ im = (im / scale + zero_point).astype(details['dtype']) # de-scale
+ self.interpreter.set_tensor(details['index'], im)
+ self.interpreter.invoke()
+ y = []
+ for output in self.output_details:
+ x = self.interpreter.get_tensor(output['index'])
+ if integer:
+ scale, zero_point = output['quantization']
+ x = (x.astype(np.float32) - zero_point) * scale # re-scale
+ if x.ndim > 2: # if task is not classification
+ # Denormalize xywh by image size. See https://github.com/ultralytics/ultralytics/pull/1695
+ # xywh are normalized in TFLite/EdgeTPU to mitigate quantization error of integer models
+ x[:, [0, 2]] *= w
+ x[:, [1, 3]] *= h
+ y.append(x)
+ # TF segment fixes: export is reversed vs ONNX export and protos are transposed
+ if len(y) == 2: # segment with (det, proto) output order reversed
+ if len(y[1].shape) != 4:
+ y = list(reversed(y)) # should be y = (1, 116, 8400), (1, 160, 160, 32)
+ y[1] = np.transpose(y[1], (0, 3, 1, 2)) # should be y = (1, 116, 8400), (1, 32, 160, 160)
+ y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]
+
+ # for x in y:
+ # print(type(x), len(x)) if isinstance(x, (list, tuple)) else print(type(x), x.shape) # debug shapes
+ if isinstance(y, (list, tuple)):
+ return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]
+ else:
+ return self.from_numpy(y)
+
+ def from_numpy(self, x):
+ """
+ Convert a numpy array to a tensor.
+
+ Args:
+ x (np.ndarray): The array to be converted.
+
+ Returns:
+ (torch.Tensor): The converted tensor
+ """
+ return torch.tensor(x).to(self.device) if isinstance(x, np.ndarray) else x
+
+ def warmup(self, imgsz=(1, 3, 640, 640)):
+ """
+ Warm up the model by running one forward pass with a dummy input.
+
+ Args:
+ imgsz (tuple): The shape of the dummy input tensor in the format (batch_size, channels, height, width)
+
+ Returns:
+ (None): This method runs the forward pass and don't return any value
+ """
+ warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.triton, self.nn_module
+ if any(warmup_types) and (self.device.type != 'cpu' or self.triton):
+ im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
+ for _ in range(2 if self.jit else 1): #
+ self.forward(im) # warmup
+
+ @staticmethod
+ def _apply_default_class_names(data):
+ """Applies default class names to an input YAML file or returns numerical class names."""
+ with contextlib.suppress(Exception):
+ return yaml_load(check_yaml(data))['names']
+ return {i: f'class{i}' for i in range(999)} # return default if above errors
+
+ @staticmethod
+ def _model_type(p='path/to/model.pt'):
+ """
+ This function takes a path to a model file and returns the model type
+
+ Args:
+ p: path to the model file. Defaults to path/to/model.pt
+ """
+ # Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
+ # types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]
+ from ultralytics.engine.exporter import export_formats
+ sf = list(export_formats().Suffix) # export suffixes
+ if not is_url(p, check=False) and not isinstance(p, str):
+ check_suffix(p, sf) # checks
+ name = Path(p).name
+ types = [s in name for s in sf]
+ types[5] |= name.endswith('.mlmodel') # retain support for older Apple CoreML *.mlmodel formats
+ types[8] &= not types[9] # tflite &= not edgetpu
+ if any(types):
+ triton = False
+ else:
+ url = urlparse(p) # if url may be Triton inference server
+ triton = all([any(s in url.scheme for s in ['http', 'grpc']), url.netloc])
+ return types + [triton]
diff --git a/STPoseNet/ultralytics/nn/modules/__init__.py b/STPoseNet/ultralytics/nn/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6dc6c4423631e70146cf1db223e03a3873dec5c
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/__init__.py
@@ -0,0 +1,29 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Ultralytics modules. Visualize with:
+
+from ultralytics.nn.modules import *
+import torch
+import os
+
+x = torch.ones(1, 128, 40, 40)
+m = Conv(128, 128)
+f = f'{m._get_name()}.onnx'
+torch.onnx.export(m, x, f)
+os.system(f'onnxsim {f} {f} && open {f}')
+"""
+
+from .block import (C1, C2, C3, C3TR, DFL, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, GhostBottleneck,
+ HGBlock, HGStem, Proto, RepC3)
+from .conv import (CBAM, ChannelAttention, Concat, Conv, Conv2, ConvTranspose, DWConv, DWConvTranspose2d, Focus,
+ GhostConv, LightConv, RepConv, SpatialAttention)
+from .head import Classify, Detect, Pose, RTDETRDecoder, Segment
+from .transformer import (AIFI, MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer, LayerNorm2d,
+ MLPBlock, MSDeformAttn, TransformerBlock, TransformerEncoderLayer, TransformerLayer)
+
+__all__ = ('Conv', 'Conv2', 'LightConv', 'RepConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus',
+ 'GhostConv', 'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'TransformerLayer',
+ 'TransformerBlock', 'MLPBlock', 'LayerNorm2d', 'DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3',
+ 'C2f', 'C3x', 'C3TR', 'C3Ghost', 'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'Detect',
+ 'Segment', 'Pose', 'Classify', 'TransformerEncoderLayer', 'RepC3', 'RTDETRDecoder', 'AIFI',
+ 'DeformableTransformerDecoder', 'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP')
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a720853047c9c4d356384d650f36f996676b7064
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/block.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/block.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d296c8ad05d596ebc3d6198f1dba1d6a4aeeff71
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/block.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/conv.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/conv.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8047e6026e030830abb914ae38644bfd367d55ec
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/conv.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/head.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/head.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2518ef65138c8cbf83c01da48303acab47944090
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/head.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/transformer.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/transformer.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6b47c9ae444970833b1ef69c9db4d8efc164c79c
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/transformer.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/__pycache__/utils.cpython-38.pyc b/STPoseNet/ultralytics/nn/modules/__pycache__/utils.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..caf7a87e5647d2c09c1bd13c7bad5f10ccbe3613
Binary files /dev/null and b/STPoseNet/ultralytics/nn/modules/__pycache__/utils.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/nn/modules/block.py b/STPoseNet/ultralytics/nn/modules/block.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8183d84ded75aba806fa01335c36934875722ca
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/block.py
@@ -0,0 +1,304 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Block modules
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .conv import Conv, DWConv, GhostConv, LightConv, RepConv
+from .transformer import TransformerBlock
+
+__all__ = ('DFL', 'HGBlock', 'HGStem', 'SPP', 'SPPF', 'C1', 'C2', 'C3', 'C2f', 'C3x', 'C3TR', 'C3Ghost',
+ 'GhostBottleneck', 'Bottleneck', 'BottleneckCSP', 'Proto', 'RepC3')
+
+
+class DFL(nn.Module):
+ """
+ Integral module of Distribution Focal Loss (DFL).
+ Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
+ """
+
+ def __init__(self, c1=16):
+ """Initialize a convolutional layer with a given number of input channels."""
+ super().__init__()
+ self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
+ x = torch.arange(c1, dtype=torch.float)
+ self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
+ self.c1 = c1
+
+ def forward(self, x):
+ """Applies a transformer layer on input tensor 'x' and returns a tensor."""
+ b, c, a = x.shape # batch, channels, anchors
+ return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
+ # return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
+
+
+class Proto(nn.Module):
+ """YOLOv8 mask Proto module for segmentation models."""
+
+ def __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of masks
+ super().__init__()
+ self.cv1 = Conv(c1, c_, k=3)
+ self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True) # nn.Upsample(scale_factor=2, mode='nearest')
+ self.cv2 = Conv(c_, c_, k=3)
+ self.cv3 = Conv(c_, c2)
+
+ def forward(self, x):
+ """Performs a forward pass through layers using an upsampled input image."""
+ return self.cv3(self.cv2(self.upsample(self.cv1(x))))
+
+
+class HGStem(nn.Module):
+ """StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
+ """
+
+ def __init__(self, c1, cm, c2):
+ super().__init__()
+ self.stem1 = Conv(c1, cm, 3, 2, act=nn.ReLU())
+ self.stem2a = Conv(cm, cm // 2, 2, 1, 0, act=nn.ReLU())
+ self.stem2b = Conv(cm // 2, cm, 2, 1, 0, act=nn.ReLU())
+ self.stem3 = Conv(cm * 2, cm, 3, 2, act=nn.ReLU())
+ self.stem4 = Conv(cm, c2, 1, 1, act=nn.ReLU())
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
+
+ def forward(self, x):
+ """Forward pass of a PPHGNetV2 backbone layer."""
+ x = self.stem1(x)
+ x = F.pad(x, [0, 1, 0, 1])
+ x2 = self.stem2a(x)
+ x2 = F.pad(x2, [0, 1, 0, 1])
+ x2 = self.stem2b(x2)
+ x1 = self.pool(x)
+ x = torch.cat([x1, x2], dim=1)
+ x = self.stem3(x)
+ x = self.stem4(x)
+ return x
+
+
+class HGBlock(nn.Module):
+ """HG_Block of PPHGNetV2 with 2 convolutions and LightConv.
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
+ """
+
+ def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=nn.ReLU()):
+ super().__init__()
+ block = LightConv if lightconv else Conv
+ self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
+ self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # squeeze conv
+ self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # excitation conv
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ """Forward pass of a PPHGNetV2 backbone layer."""
+ y = [x]
+ y.extend(m(y[-1]) for m in self.m)
+ y = self.ec(self.sc(torch.cat(y, 1)))
+ return y + x if self.add else y
+
+
+class SPP(nn.Module):
+ """Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729."""
+
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ """Initialize the SPP layer with input/output channels and pooling kernel sizes."""
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ """Forward pass of the SPP layer, performing spatial pyramid pooling."""
+ x = self.cv1(x)
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ """Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
+
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ """Forward pass through Ghost Convolution block."""
+ x = self.cv1(x)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
+
+
+class C1(nn.Module):
+ """CSP Bottleneck with 1 convolution."""
+
+ def __init__(self, c1, c2, n=1): # ch_in, ch_out, number
+ super().__init__()
+ self.cv1 = Conv(c1, c2, 1, 1)
+ self.m = nn.Sequential(*(Conv(c2, c2, 3) for _ in range(n)))
+
+ def forward(self, x):
+ """Applies cross-convolutions to input in the C3 module."""
+ y = self.cv1(x)
+ return self.m(y) + y
+
+
+class C2(nn.Module):
+ """CSP Bottleneck with 2 convolutions."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ self.c = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, 2 * self.c, 1, 1)
+ self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)
+ # self.attention = ChannelAttention(2 * self.c) # or SpatialAttention()
+ self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ """Forward pass through the CSP bottleneck with 2 convolutions."""
+ a, b = self.cv1(x).chunk(2, 1)
+ return self.cv2(torch.cat((self.m(a), b), 1))
+
+
+class C2f(nn.Module):
+ """Faster Implementation of CSP Bottleneck with 2 convolutions."""
+
+ def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ self.c = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, 2 * self.c, 1, 1)
+ self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
+ self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
+
+ def forward(self, x):
+ """Forward pass through C2f layer."""
+ y = list(self.cv1(x).chunk(2, 1))
+ y.extend(m(y[-1]) for m in self.m)
+ return self.cv2(torch.cat(y, 1))
+
+ def forward_split(self, x):
+ """Forward pass using split() instead of chunk()."""
+ y = list(self.cv1(x).split((self.c, self.c), 1))
+ y.extend(m(y[-1]) for m in self.m)
+ return self.cv2(torch.cat(y, 1))
+
+
+class C3(nn.Module):
+ """CSP Bottleneck with 3 convolutions."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ """Forward pass through the CSP bottleneck with 2 convolutions."""
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
+
+
+class C3x(C3):
+ """C3 module with cross-convolutions."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ """Initialize C3TR instance and set default parameters."""
+ super().__init__(c1, c2, n, shortcut, g, e)
+ self.c_ = int(c2 * e)
+ self.m = nn.Sequential(*(Bottleneck(self.c_, self.c_, shortcut, g, k=((1, 3), (3, 1)), e=1) for _ in range(n)))
+
+
+class RepC3(nn.Module):
+ """Rep C3."""
+
+ def __init__(self, c1, c2, n=3, e=1.0):
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c2, 1, 1)
+ self.cv2 = Conv(c1, c2, 1, 1)
+ self.m = nn.Sequential(*[RepConv(c_, c_) for _ in range(n)])
+ self.cv3 = Conv(c_, c2, 1, 1) if c_ != c2 else nn.Identity()
+
+ def forward(self, x):
+ """Forward pass of RT-DETR neck layer."""
+ return self.cv3(self.m(self.cv1(x)) + self.cv2(x))
+
+
+class C3TR(C3):
+ """C3 module with TransformerBlock()."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ """Initialize C3Ghost module with GhostBottleneck()."""
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3Ghost(C3):
+ """C3 module with GhostBottleneck()."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ """Initialize 'SPP' module with various pooling sizes for spatial pyramid pooling."""
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class GhostBottleneck(nn.Module):
+ """Ghost Bottleneck https://github.com/huawei-noah/ghostnet."""
+
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(
+ GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
+ act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ """Applies skip connection and concatenation to input tensor."""
+ return self.conv(x) + self.shortcut(x)
+
+
+class Bottleneck(nn.Module):
+ """Standard bottleneck."""
+
+ def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, k[0], 1)
+ self.cv2 = Conv(c_, c2, k[1], 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ """'forward()' applies the YOLOv5 FPN to input data."""
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ """CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks."""
+
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ """Applies a CSP bottleneck with 3 convolutions."""
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
diff --git a/STPoseNet/ultralytics/nn/modules/conv.py b/STPoseNet/ultralytics/nn/modules/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..77e99c009e42772b6a9fba0a068d0ddb9b7bd4bf
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/conv.py
@@ -0,0 +1,294 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Convolution modules
+"""
+
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+__all__ = ('Conv', 'Conv2', 'LightConv', 'DWConv', 'DWConvTranspose2d', 'ConvTranspose', 'Focus', 'GhostConv',
+ 'ChannelAttention', 'SpatialAttention', 'CBAM', 'Concat', 'RepConv')
+
+
+def autopad(k, p=None, d=1): # kernel, padding, dilation
+ """Pad to 'same' shape outputs."""
+ if d > 1:
+ k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
+ default_act = nn.SiLU() # default activation
+
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
+ """Initialize Conv layer with given arguments including activation."""
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
+
+ def forward(self, x):
+ """Apply convolution, batch normalization and activation to input tensor."""
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ """Perform transposed convolution of 2D data."""
+ return self.act(self.conv(x))
+
+
+class Conv2(Conv):
+ """Simplified RepConv module with Conv fusing."""
+
+ def __init__(self, c1, c2, k=3, s=1, p=None, g=1, d=1, act=True):
+ """Initialize Conv layer with given arguments including activation."""
+ super().__init__(c1, c2, k, s, p, g=g, d=d, act=act)
+ self.cv2 = nn.Conv2d(c1, c2, 1, s, autopad(1, p, d), groups=g, dilation=d, bias=False) # add 1x1 conv
+
+ def forward(self, x):
+ """Apply convolution, batch normalization and activation to input tensor."""
+ return self.act(self.bn(self.conv(x) + self.cv2(x)))
+
+ def forward_fuse(self, x):
+ """Apply fused convolution, batch normalization and activation to input tensor."""
+ return self.act(self.bn(self.conv(x)))
+
+ def fuse_convs(self):
+ """Fuse parallel convolutions."""
+ w = torch.zeros_like(self.conv.weight.data)
+ i = [x // 2 for x in w.shape[2:]]
+ w[:, :, i[0]:i[0] + 1, i[1]:i[1] + 1] = self.cv2.weight.data.clone()
+ self.conv.weight.data += w
+ self.__delattr__('cv2')
+ self.forward = self.forward_fuse
+
+
+class LightConv(nn.Module):
+ """Light convolution with args(ch_in, ch_out, kernel).
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
+ """
+
+ def __init__(self, c1, c2, k=1, act=nn.ReLU()):
+ """Initialize Conv layer with given arguments including activation."""
+ super().__init__()
+ self.conv1 = Conv(c1, c2, 1, act=False)
+ self.conv2 = DWConv(c2, c2, k, act=act)
+
+ def forward(self, x):
+ """Apply 2 convolutions to input tensor."""
+ return self.conv2(self.conv1(x))
+
+
+class DWConv(Conv):
+ """Depth-wise convolution."""
+
+ def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
+
+
+class DWConvTranspose2d(nn.ConvTranspose2d):
+ """Depth-wise transpose convolution."""
+
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
+ super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
+
+
+class ConvTranspose(nn.Module):
+ """Convolution transpose 2d layer."""
+ default_act = nn.SiLU() # default activation
+
+ def __init__(self, c1, c2, k=2, s=2, p=0, bn=True, act=True):
+ """Initialize ConvTranspose2d layer with batch normalization and activation function."""
+ super().__init__()
+ self.conv_transpose = nn.ConvTranspose2d(c1, c2, k, s, p, bias=not bn)
+ self.bn = nn.BatchNorm2d(c2) if bn else nn.Identity()
+ self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
+
+ def forward(self, x):
+ """Applies transposed convolutions, batch normalization and activation to input."""
+ return self.act(self.bn(self.conv_transpose(x)))
+
+ def forward_fuse(self, x):
+ """Applies activation and convolution transpose operation to input."""
+ return self.act(self.conv_transpose(x))
+
+
+class Focus(nn.Module):
+ """Focus wh information into c-space."""
+
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ """Ghost Convolution https://github.com/huawei-noah/ghostnet."""
+
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act=act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)
+
+ def forward(self, x):
+ """Forward propagation through a Ghost Bottleneck layer with skip connection."""
+ y = self.cv1(x)
+ return torch.cat((y, self.cv2(y)), 1)
+
+
+class RepConv(nn.Module):
+ """
+ RepConv is a basic rep-style block, including training and deploy status. This module is used in RT-DETR.
+ Based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
+ """
+ default_act = nn.SiLU() # default activation
+
+ def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
+ super().__init__()
+ assert k == 3 and p == 1
+ self.g = g
+ self.c1 = c1
+ self.c2 = c2
+ self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
+
+ self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
+ self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
+ self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
+
+ def forward_fuse(self, x):
+ """Forward process"""
+ return self.act(self.conv(x))
+
+ def forward(self, x):
+ """Forward process"""
+ id_out = 0 if self.bn is None else self.bn(x)
+ return self.act(self.conv1(x) + self.conv2(x) + id_out)
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
+ kernelid, biasid = self._fuse_bn_tensor(self.bn)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, Conv):
+ kernel = branch.conv.weight
+ running_mean = branch.bn.running_mean
+ running_var = branch.bn.running_var
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn.eps
+ elif isinstance(branch, nn.BatchNorm2d):
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.c1 // self.g
+ kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.c1):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
+ kernel = self.id_tensor
+ running_mean = branch.running_mean
+ running_var = branch.running_var
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch.eps
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape(-1, 1, 1, 1)
+ return kernel * t, beta - running_mean * gamma / std
+
+ def fuse_convs(self):
+ if hasattr(self, 'conv'):
+ return
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
+ out_channels=self.conv1.conv.out_channels,
+ kernel_size=self.conv1.conv.kernel_size,
+ stride=self.conv1.conv.stride,
+ padding=self.conv1.conv.padding,
+ dilation=self.conv1.conv.dilation,
+ groups=self.conv1.conv.groups,
+ bias=True).requires_grad_(False)
+ self.conv.weight.data = kernel
+ self.conv.bias.data = bias
+ for para in self.parameters():
+ para.detach_()
+ self.__delattr__('conv1')
+ self.__delattr__('conv2')
+ if hasattr(self, 'nm'):
+ self.__delattr__('nm')
+ if hasattr(self, 'bn'):
+ self.__delattr__('bn')
+ if hasattr(self, 'id_tensor'):
+ self.__delattr__('id_tensor')
+
+
+class ChannelAttention(nn.Module):
+ """Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
+
+ def __init__(self, channels: int) -> None:
+ super().__init__()
+ self.pool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
+ self.act = nn.Sigmoid()
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ return x * self.act(self.fc(self.pool(x)))
+
+
+class SpatialAttention(nn.Module):
+ """Spatial-attention module."""
+
+ def __init__(self, kernel_size=7):
+ """Initialize Spatial-attention module with kernel size argument."""
+ super().__init__()
+ assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
+ padding = 3 if kernel_size == 7 else 1
+ self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
+ self.act = nn.Sigmoid()
+
+ def forward(self, x):
+ """Apply channel and spatial attention on input for feature recalibration."""
+ return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
+
+
+class CBAM(nn.Module):
+ """Convolutional Block Attention Module."""
+
+ def __init__(self, c1, kernel_size=7): # ch_in, kernels
+ super().__init__()
+ self.channel_attention = ChannelAttention(c1)
+ self.spatial_attention = SpatialAttention(kernel_size)
+
+ def forward(self, x):
+ """Applies the forward pass through C1 module."""
+ return self.spatial_attention(self.channel_attention(x))
+
+
+class Concat(nn.Module):
+ """Concatenate a list of tensors along dimension."""
+
+ def __init__(self, dimension=1):
+ """Concatenates a list of tensors along a specified dimension."""
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ """Forward pass for the YOLOv8 mask Proto module."""
+ return torch.cat(x, self.d)
diff --git a/STPoseNet/ultralytics/nn/modules/head.py b/STPoseNet/ultralytics/nn/modules/head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b02eb3c6406542ad3e84a8ab24fc9b2128a4dee
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/head.py
@@ -0,0 +1,362 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Model head modules
+"""
+
+import math
+
+import torch
+import torch.nn as nn
+from torch.nn.init import constant_, xavier_uniform_
+
+from ultralytics.utils.tal import TORCH_1_10, dist2bbox, make_anchors
+
+from .block import DFL, Proto
+from .conv import Conv
+from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer
+from .utils import bias_init_with_prob, linear_init_
+
+__all__ = 'Detect', 'Segment', 'Pose', 'Classify', 'RTDETRDecoder'
+
+
+class Detect(nn.Module):
+ """YOLOv8 Detect head for detection models."""
+ dynamic = False # force grid reconstruction
+ export = False # export mode
+ shape = None
+ anchors = torch.empty(0) # init
+ strides = torch.empty(0) # init
+
+ def __init__(self, nc=80, ch=()): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.nl = len(ch) # number of detection layers
+ self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
+ self.no = nc + self.reg_max * 4 # number of outputs per anchor
+ self.stride = torch.zeros(self.nl) # strides computed during build
+ c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
+ self.cv2 = nn.ModuleList(
+ nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
+ self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
+ self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
+
+ def forward(self, x):
+ """Concatenates and returns predicted bounding boxes and class probabilities."""
+ shape = x[0].shape # BCHW
+ for i in range(self.nl):
+ x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
+ if self.training:
+ return x
+ elif self.dynamic or self.shape != shape:
+ self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
+ self.shape = shape
+
+ x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
+ if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
+ box = x_cat[:, :self.reg_max * 4]
+ cls = x_cat[:, self.reg_max * 4:]
+ else:
+ box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
+ dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
+
+ if self.export and self.format in ('tflite', 'edgetpu'):
+ # Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:
+ # https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309
+ # See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695
+ img_h = shape[2] * self.stride[0]
+ img_w = shape[3] * self.stride[0]
+ img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
+ dbox /= img_size
+
+ y = torch.cat((dbox, cls.sigmoid()), 1)
+ return y if self.export else (y, x)
+
+ def bias_init(self):
+ """Initialize Detect() biases, WARNING: requires stride availability."""
+ m = self # self.model[-1] # Detect() module
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
+ # ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
+ for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
+ a[-1].bias.data[:] = 1.0 # box
+ b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
+
+
+class Segment(Detect):
+ """YOLOv8 Segment head for segmentation models."""
+
+ def __init__(self, nc=80, nm=32, npr=256, ch=()):
+ """Initialize the YOLO model attributes such as the number of masks, prototypes, and the convolution layers."""
+ super().__init__(nc, ch)
+ self.nm = nm # number of masks
+ self.npr = npr # number of protos
+ self.proto = Proto(ch[0], self.npr, self.nm) # protos
+ self.detect = Detect.forward
+
+ c4 = max(ch[0] // 4, self.nm)
+ self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)
+
+ def forward(self, x):
+ """Return model outputs and mask coefficients if training, otherwise return outputs and mask coefficients."""
+ p = self.proto(x[0]) # mask protos
+ bs = p.shape[0] # batch size
+
+ mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
+ x = self.detect(self, x)
+ if self.training:
+ return x, mc, p
+ return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
+
+
+class Pose(Detect):
+ """YOLOv8 Pose head for keypoints models."""
+
+ def __init__(self, nc=80, kpt_shape=(17, 3), ch=()):
+ """Initialize YOLO network with default parameters and Convolutional Layers."""
+ super().__init__(nc, ch)
+ self.kpt_shape = kpt_shape # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+ self.nk = kpt_shape[0] * kpt_shape[1] # number of keypoints total
+ self.detect = Detect.forward
+
+ c4 = max(ch[0] // 4, self.nk)
+ self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nk, 1)) for x in ch)
+
+ def forward(self, x):
+ """Perform forward pass through YOLO model and return predictions."""
+ bs = x[0].shape[0] # batch size
+ kpt = torch.cat([self.cv4[i](x[i]).view(bs, self.nk, -1) for i in range(self.nl)], -1) # (bs, 17*3, h*w)
+ x = self.detect(self, x)
+ if self.training:
+ return x, kpt
+ pred_kpt = self.kpts_decode(bs, kpt)
+ return torch.cat([x, pred_kpt], 1) if self.export else (torch.cat([x[0], pred_kpt], 1), (x[1], kpt))
+
+ def kpts_decode(self, bs, kpts):
+ """Decodes keypoints."""
+ ndim = self.kpt_shape[1]
+ if self.export: # required for TFLite export to avoid 'PLACEHOLDER_FOR_GREATER_OP_CODES' bug
+ y = kpts.view(bs, *self.kpt_shape, -1)
+ a = (y[:, :, :2] * 2.0 + (self.anchors - 0.5)) * self.strides
+ if ndim == 3:
+ a = torch.cat((a, y[:, :, 2:3].sigmoid()), 2)
+ return a.view(bs, self.nk, -1)
+ else:
+ y = kpts.clone()
+ if ndim == 3:
+ y[:, 2::3].sigmoid_() # inplace sigmoid
+ y[:, 0::ndim] = (y[:, 0::ndim] * 2.0 + (self.anchors[0] - 0.5)) * self.strides
+ y[:, 1::ndim] = (y[:, 1::ndim] * 2.0 + (self.anchors[1] - 0.5)) * self.strides
+ return y
+
+
+class Classify(nn.Module):
+ """YOLOv8 classification head, i.e. x(b,c1,20,20) to x(b,c2)."""
+
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ c_ = 1280 # efficientnet_b0 size
+ self.conv = Conv(c1, c_, k, s, p, g)
+ self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
+ self.drop = nn.Dropout(p=0.0, inplace=True)
+ self.linear = nn.Linear(c_, c2) # to x(b,c2)
+
+ def forward(self, x):
+ """Performs a forward pass of the YOLO model on input image data."""
+ if isinstance(x, list):
+ x = torch.cat(x, 1)
+ x = self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
+ return x if self.training else x.softmax(1)
+
+
+class RTDETRDecoder(nn.Module):
+ export = False # export mode
+
+ def __init__(
+ self,
+ nc=80,
+ ch=(512, 1024, 2048),
+ hd=256, # hidden dim
+ nq=300, # num queries
+ ndp=4, # num decoder points
+ nh=8, # num head
+ ndl=6, # num decoder layers
+ d_ffn=1024, # dim of feedforward
+ dropout=0.,
+ act=nn.ReLU(),
+ eval_idx=-1,
+ # training args
+ nd=100, # num denoising
+ label_noise_ratio=0.5,
+ box_noise_scale=1.0,
+ learnt_init_query=False):
+ super().__init__()
+ self.hidden_dim = hd
+ self.nhead = nh
+ self.nl = len(ch) # num level
+ self.nc = nc
+ self.num_queries = nq
+ self.num_decoder_layers = ndl
+
+ # backbone feature projection
+ self.input_proj = nn.ModuleList(nn.Sequential(nn.Conv2d(x, hd, 1, bias=False), nn.BatchNorm2d(hd)) for x in ch)
+ # NOTE: simplified version but it's not consistent with .pt weights.
+ # self.input_proj = nn.ModuleList(Conv(x, hd, act=False) for x in ch)
+
+ # Transformer module
+ decoder_layer = DeformableTransformerDecoderLayer(hd, nh, d_ffn, dropout, act, self.nl, ndp)
+ self.decoder = DeformableTransformerDecoder(hd, decoder_layer, ndl, eval_idx)
+
+ # denoising part
+ self.denoising_class_embed = nn.Embedding(nc, hd)
+ self.num_denoising = nd
+ self.label_noise_ratio = label_noise_ratio
+ self.box_noise_scale = box_noise_scale
+
+ # decoder embedding
+ self.learnt_init_query = learnt_init_query
+ if learnt_init_query:
+ self.tgt_embed = nn.Embedding(nq, hd)
+ self.query_pos_head = MLP(4, 2 * hd, hd, num_layers=2)
+
+ # encoder head
+ self.enc_output = nn.Sequential(nn.Linear(hd, hd), nn.LayerNorm(hd))
+ self.enc_score_head = nn.Linear(hd, nc)
+ self.enc_bbox_head = MLP(hd, hd, 4, num_layers=3)
+
+ # decoder head
+ self.dec_score_head = nn.ModuleList([nn.Linear(hd, nc) for _ in range(ndl)])
+ self.dec_bbox_head = nn.ModuleList([MLP(hd, hd, 4, num_layers=3) for _ in range(ndl)])
+
+ self._reset_parameters()
+
+ def forward(self, x, batch=None):
+ from ultralytics.models.utils.ops import get_cdn_group
+
+ # input projection and embedding
+ feats, shapes = self._get_encoder_input(x)
+
+ # prepare denoising training
+ dn_embed, dn_bbox, attn_mask, dn_meta = \
+ get_cdn_group(batch,
+ self.nc,
+ self.num_queries,
+ self.denoising_class_embed.weight,
+ self.num_denoising,
+ self.label_noise_ratio,
+ self.box_noise_scale,
+ self.training)
+
+ embed, refer_bbox, enc_bboxes, enc_scores = \
+ self._get_decoder_input(feats, shapes, dn_embed, dn_bbox)
+
+ # decoder
+ dec_bboxes, dec_scores = self.decoder(embed,
+ refer_bbox,
+ feats,
+ shapes,
+ self.dec_bbox_head,
+ self.dec_score_head,
+ self.query_pos_head,
+ attn_mask=attn_mask)
+ x = dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta
+ if self.training:
+ return x
+ # (bs, 300, 4+nc)
+ y = torch.cat((dec_bboxes.squeeze(0), dec_scores.squeeze(0).sigmoid()), -1)
+ return y if self.export else (y, x)
+
+ def _generate_anchors(self, shapes, grid_size=0.05, dtype=torch.float32, device='cpu', eps=1e-2):
+ anchors = []
+ for i, (h, w) in enumerate(shapes):
+ sy = torch.arange(end=h, dtype=dtype, device=device)
+ sx = torch.arange(end=w, dtype=dtype, device=device)
+ grid_y, grid_x = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
+ grid_xy = torch.stack([grid_x, grid_y], -1) # (h, w, 2)
+
+ valid_WH = torch.tensor([h, w], dtype=dtype, device=device)
+ grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH # (1, h, w, 2)
+ wh = torch.ones_like(grid_xy, dtype=dtype, device=device) * grid_size * (2.0 ** i)
+ anchors.append(torch.cat([grid_xy, wh], -1).view(-1, h * w, 4)) # (1, h*w, 4)
+
+ anchors = torch.cat(anchors, 1) # (1, h*w*nl, 4)
+ valid_mask = ((anchors > eps) * (anchors < 1 - eps)).all(-1, keepdim=True) # 1, h*w*nl, 1
+ anchors = torch.log(anchors / (1 - anchors))
+ anchors = anchors.masked_fill(~valid_mask, float('inf'))
+ return anchors, valid_mask
+
+ def _get_encoder_input(self, x):
+ # get projection features
+ x = [self.input_proj[i](feat) for i, feat in enumerate(x)]
+ # get encoder inputs
+ feats = []
+ shapes = []
+ for feat in x:
+ h, w = feat.shape[2:]
+ # [b, c, h, w] -> [b, h*w, c]
+ feats.append(feat.flatten(2).permute(0, 2, 1))
+ # [nl, 2]
+ shapes.append([h, w])
+
+ # [b, h*w, c]
+ feats = torch.cat(feats, 1)
+ return feats, shapes
+
+ def _get_decoder_input(self, feats, shapes, dn_embed=None, dn_bbox=None):
+ bs = len(feats)
+ # prepare input for decoder
+ anchors, valid_mask = self._generate_anchors(shapes, dtype=feats.dtype, device=feats.device)
+ features = self.enc_output(valid_mask * feats) # bs, h*w, 256
+
+ enc_outputs_scores = self.enc_score_head(features) # (bs, h*w, nc)
+
+ # query selection
+ # (bs, num_queries)
+ topk_ind = torch.topk(enc_outputs_scores.max(-1).values, self.num_queries, dim=1).indices.view(-1)
+ # (bs, num_queries)
+ batch_ind = torch.arange(end=bs, dtype=topk_ind.dtype).unsqueeze(-1).repeat(1, self.num_queries).view(-1)
+
+ # (bs, num_queries, 256)
+ top_k_features = features[batch_ind, topk_ind].view(bs, self.num_queries, -1)
+ # (bs, num_queries, 4)
+ top_k_anchors = anchors[:, topk_ind].view(bs, self.num_queries, -1)
+
+ # dynamic anchors + static content
+ refer_bbox = self.enc_bbox_head(top_k_features) + top_k_anchors
+
+ enc_bboxes = refer_bbox.sigmoid()
+ if dn_bbox is not None:
+ refer_bbox = torch.cat([dn_bbox, refer_bbox], 1)
+ enc_scores = enc_outputs_scores[batch_ind, topk_ind].view(bs, self.num_queries, -1)
+
+ embeddings = self.tgt_embed.weight.unsqueeze(0).repeat(bs, 1, 1) if self.learnt_init_query else top_k_features
+ if self.training:
+ refer_bbox = refer_bbox.detach()
+ if not self.learnt_init_query:
+ embeddings = embeddings.detach()
+ if dn_embed is not None:
+ embeddings = torch.cat([dn_embed, embeddings], 1)
+
+ return embeddings, refer_bbox, enc_bboxes, enc_scores
+
+ # TODO
+ def _reset_parameters(self):
+ # class and bbox head init
+ bias_cls = bias_init_with_prob(0.01) / 80 * self.nc
+ # NOTE: the weight initialization in `linear_init_` would cause NaN when training with custom datasets.
+ # linear_init_(self.enc_score_head)
+ constant_(self.enc_score_head.bias, bias_cls)
+ constant_(self.enc_bbox_head.layers[-1].weight, 0.)
+ constant_(self.enc_bbox_head.layers[-1].bias, 0.)
+ for cls_, reg_ in zip(self.dec_score_head, self.dec_bbox_head):
+ # linear_init_(cls_)
+ constant_(cls_.bias, bias_cls)
+ constant_(reg_.layers[-1].weight, 0.)
+ constant_(reg_.layers[-1].bias, 0.)
+
+ linear_init_(self.enc_output[0])
+ xavier_uniform_(self.enc_output[0].weight)
+ if self.learnt_init_query:
+ xavier_uniform_(self.tgt_embed.weight)
+ xavier_uniform_(self.query_pos_head.layers[0].weight)
+ xavier_uniform_(self.query_pos_head.layers[1].weight)
+ for layer in self.input_proj:
+ xavier_uniform_(layer[0].weight)
diff --git a/STPoseNet/ultralytics/nn/modules/transformer.py b/STPoseNet/ultralytics/nn/modules/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a51d2cb716ff0b31a9ad1a98bc761cf8f70e79c
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/transformer.py
@@ -0,0 +1,375 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Transformer modules
+"""
+
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.init import constant_, xavier_uniform_
+
+from .conv import Conv
+from .utils import _get_clones, inverse_sigmoid, multi_scale_deformable_attn_pytorch
+
+__all__ = ('TransformerEncoderLayer', 'TransformerLayer', 'TransformerBlock', 'MLPBlock', 'LayerNorm2d', 'AIFI',
+ 'DeformableTransformerDecoder', 'DeformableTransformerDecoderLayer', 'MSDeformAttn', 'MLP')
+
+
+class TransformerEncoderLayer(nn.Module):
+ """Transformer Encoder."""
+
+ def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
+ super().__init__()
+ from ...utils.torch_utils import TORCH_1_9
+ if not TORCH_1_9:
+ raise ModuleNotFoundError(
+ 'TransformerEncoderLayer() requires torch>=1.9 to use nn.MultiheadAttention(batch_first=True).')
+ self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True)
+ # Implementation of Feedforward model
+ self.fc1 = nn.Linear(c1, cm)
+ self.fc2 = nn.Linear(cm, c1)
+
+ self.norm1 = nn.LayerNorm(c1)
+ self.norm2 = nn.LayerNorm(c1)
+ self.dropout = nn.Dropout(dropout)
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+
+ self.act = act
+ self.normalize_before = normalize_before
+
+ def with_pos_embed(self, tensor, pos=None):
+ """Add position embeddings if given."""
+ return tensor if pos is None else tensor + pos
+
+ def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
+ q = k = self.with_pos_embed(src, pos)
+ src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
+ src = src + self.dropout1(src2)
+ src = self.norm1(src)
+ src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
+ src = src + self.dropout2(src2)
+ return self.norm2(src)
+
+ def forward_pre(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
+ src2 = self.norm1(src)
+ q = k = self.with_pos_embed(src2, pos)
+ src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
+ src = src + self.dropout1(src2)
+ src2 = self.norm2(src)
+ src2 = self.fc2(self.dropout(self.act(self.fc1(src2))))
+ return src + self.dropout2(src2)
+
+ def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
+ """Forward propagates the input through the encoder module."""
+ if self.normalize_before:
+ return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
+ return self.forward_post(src, src_mask, src_key_padding_mask, pos)
+
+
+class AIFI(TransformerEncoderLayer):
+
+ def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
+ super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
+
+ def forward(self, x):
+ c, h, w = x.shape[1:]
+ pos_embed = self.build_2d_sincos_position_embedding(w, h, c)
+ # flatten [B, C, H, W] to [B, HxW, C]
+ x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
+ return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
+
+ @staticmethod
+ def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.):
+ grid_w = torch.arange(int(w), dtype=torch.float32)
+ grid_h = torch.arange(int(h), dtype=torch.float32)
+ grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')
+ assert embed_dim % 4 == 0, \
+ 'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
+ pos_dim = embed_dim // 4
+ omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
+ omega = 1. / (temperature ** omega)
+
+ out_w = grid_w.flatten()[..., None] @ omega[None]
+ out_h = grid_h.flatten()[..., None] @ omega[None]
+
+ return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]
+
+
+class TransformerLayer(nn.Module):
+ """Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)."""
+
+ def __init__(self, c, num_heads):
+ """Initializes a self-attention mechanism using linear transformations and multi-head attention."""
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ """Apply a transformer block to the input x and return the output."""
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ return self.fc2(self.fc1(x)) + x
+
+
+class TransformerBlock(nn.Module):
+ """Vision Transformer https://arxiv.org/abs/2010.11929."""
+
+ def __init__(self, c1, c2, num_heads, num_layers):
+ """Initialize a Transformer module with position embedding and specified number of heads and layers."""
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ """Forward propagates the input through the bottleneck module."""
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class MLPBlock(nn.Module):
+
+ def __init__(self, embedding_dim, mlp_dim, act=nn.GELU):
+ super().__init__()
+ self.lin1 = nn.Linear(embedding_dim, mlp_dim)
+ self.lin2 = nn.Linear(mlp_dim, embedding_dim)
+ self.act = act()
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ return self.lin2(self.act(self.lin1(x)))
+
+
+class MLP(nn.Module):
+ """ Very simple multi-layer perceptron (also called FFN)"""
+
+ def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x):
+ for i, layer in enumerate(self.layers):
+ x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+class LayerNorm2d(nn.Module):
+ """
+ LayerNorm2d module from https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py
+ https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119
+ """
+
+ def __init__(self, num_channels, eps=1e-6):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(num_channels))
+ self.bias = nn.Parameter(torch.zeros(num_channels))
+ self.eps = eps
+
+ def forward(self, x):
+ u = x.mean(1, keepdim=True)
+ s = (x - u).pow(2).mean(1, keepdim=True)
+ x = (x - u) / torch.sqrt(s + self.eps)
+ return self.weight[:, None, None] * x + self.bias[:, None, None]
+
+
+class MSDeformAttn(nn.Module):
+ """
+ Original Multi-Scale Deformable Attention Module.
+ https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/modules/ms_deform_attn.py
+ """
+
+ def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
+ super().__init__()
+ if d_model % n_heads != 0:
+ raise ValueError(f'd_model must be divisible by n_heads, but got {d_model} and {n_heads}')
+ _d_per_head = d_model // n_heads
+ # you'd better set _d_per_head to a power of 2 which is more efficient in our CUDA implementation
+ assert _d_per_head * n_heads == d_model, '`d_model` must be divisible by `n_heads`'
+
+ self.im2col_step = 64
+
+ self.d_model = d_model
+ self.n_levels = n_levels
+ self.n_heads = n_heads
+ self.n_points = n_points
+
+ self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
+ self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
+ self.value_proj = nn.Linear(d_model, d_model)
+ self.output_proj = nn.Linear(d_model, d_model)
+
+ self._reset_parameters()
+
+ def _reset_parameters(self):
+ constant_(self.sampling_offsets.weight.data, 0.)
+ thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
+ grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
+ grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(
+ 1, self.n_levels, self.n_points, 1)
+ for i in range(self.n_points):
+ grid_init[:, :, i, :] *= i + 1
+ with torch.no_grad():
+ self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
+ constant_(self.attention_weights.weight.data, 0.)
+ constant_(self.attention_weights.bias.data, 0.)
+ xavier_uniform_(self.value_proj.weight.data)
+ constant_(self.value_proj.bias.data, 0.)
+ xavier_uniform_(self.output_proj.weight.data)
+ constant_(self.output_proj.bias.data, 0.)
+
+ def forward(self, query, refer_bbox, value, value_shapes, value_mask=None):
+ """
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
+ Args:
+ query (torch.Tensor): [bs, query_length, C]
+ refer_bbox (torch.Tensor): [bs, query_length, n_levels, 2], range in [0, 1], top-left (0,0),
+ bottom-right (1, 1), including padding area
+ value (torch.Tensor): [bs, value_length, C]
+ value_shapes (List): [n_levels, 2], [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
+ value_mask (Tensor): [bs, value_length], True for non-padding elements, False for padding elements
+
+ Returns:
+ output (Tensor): [bs, Length_{query}, C]
+ """
+ bs, len_q = query.shape[:2]
+ len_v = value.shape[1]
+ assert sum(s[0] * s[1] for s in value_shapes) == len_v
+
+ value = self.value_proj(value)
+ if value_mask is not None:
+ value = value.masked_fill(value_mask[..., None], float(0))
+ value = value.view(bs, len_v, self.n_heads, self.d_model // self.n_heads)
+ sampling_offsets = self.sampling_offsets(query).view(bs, len_q, self.n_heads, self.n_levels, self.n_points, 2)
+ attention_weights = self.attention_weights(query).view(bs, len_q, self.n_heads, self.n_levels * self.n_points)
+ attention_weights = F.softmax(attention_weights, -1).view(bs, len_q, self.n_heads, self.n_levels, self.n_points)
+ # N, Len_q, n_heads, n_levels, n_points, 2
+ num_points = refer_bbox.shape[-1]
+ if num_points == 2:
+ offset_normalizer = torch.as_tensor(value_shapes, dtype=query.dtype, device=query.device).flip(-1)
+ add = sampling_offsets / offset_normalizer[None, None, None, :, None, :]
+ sampling_locations = refer_bbox[:, :, None, :, None, :] + add
+ elif num_points == 4:
+ add = sampling_offsets / self.n_points * refer_bbox[:, :, None, :, None, 2:] * 0.5
+ sampling_locations = refer_bbox[:, :, None, :, None, :2] + add
+ else:
+ raise ValueError(f'Last dim of reference_points must be 2 or 4, but got {num_points}.')
+ output = multi_scale_deformable_attn_pytorch(value, value_shapes, sampling_locations, attention_weights)
+ return self.output_proj(output)
+
+
+class DeformableTransformerDecoderLayer(nn.Module):
+ """
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
+ https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/deformable_transformer.py
+ """
+
+ def __init__(self, d_model=256, n_heads=8, d_ffn=1024, dropout=0., act=nn.ReLU(), n_levels=4, n_points=4):
+ super().__init__()
+
+ # self attention
+ self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
+ self.dropout1 = nn.Dropout(dropout)
+ self.norm1 = nn.LayerNorm(d_model)
+
+ # cross attention
+ self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
+ self.dropout2 = nn.Dropout(dropout)
+ self.norm2 = nn.LayerNorm(d_model)
+
+ # ffn
+ self.linear1 = nn.Linear(d_model, d_ffn)
+ self.act = act
+ self.dropout3 = nn.Dropout(dropout)
+ self.linear2 = nn.Linear(d_ffn, d_model)
+ self.dropout4 = nn.Dropout(dropout)
+ self.norm3 = nn.LayerNorm(d_model)
+
+ @staticmethod
+ def with_pos_embed(tensor, pos):
+ return tensor if pos is None else tensor + pos
+
+ def forward_ffn(self, tgt):
+ tgt2 = self.linear2(self.dropout3(self.act(self.linear1(tgt))))
+ tgt = tgt + self.dropout4(tgt2)
+ return self.norm3(tgt)
+
+ def forward(self, embed, refer_bbox, feats, shapes, padding_mask=None, attn_mask=None, query_pos=None):
+ # self attention
+ q = k = self.with_pos_embed(embed, query_pos)
+ tgt = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), embed.transpose(0, 1),
+ attn_mask=attn_mask)[0].transpose(0, 1)
+ embed = embed + self.dropout1(tgt)
+ embed = self.norm1(embed)
+
+ # cross attention
+ tgt = self.cross_attn(self.with_pos_embed(embed, query_pos), refer_bbox.unsqueeze(2), feats, shapes,
+ padding_mask)
+ embed = embed + self.dropout2(tgt)
+ embed = self.norm2(embed)
+
+ # ffn
+ return self.forward_ffn(embed)
+
+
+class DeformableTransformerDecoder(nn.Module):
+ """
+ https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
+ """
+
+ def __init__(self, hidden_dim, decoder_layer, num_layers, eval_idx=-1):
+ super().__init__()
+ self.layers = _get_clones(decoder_layer, num_layers)
+ self.num_layers = num_layers
+ self.hidden_dim = hidden_dim
+ self.eval_idx = eval_idx if eval_idx >= 0 else num_layers + eval_idx
+
+ def forward(
+ self,
+ embed, # decoder embeddings
+ refer_bbox, # anchor
+ feats, # image features
+ shapes, # feature shapes
+ bbox_head,
+ score_head,
+ pos_mlp,
+ attn_mask=None,
+ padding_mask=None):
+ output = embed
+ dec_bboxes = []
+ dec_cls = []
+ last_refined_bbox = None
+ refer_bbox = refer_bbox.sigmoid()
+ for i, layer in enumerate(self.layers):
+ output = layer(output, refer_bbox, feats, shapes, padding_mask, attn_mask, pos_mlp(refer_bbox))
+
+ bbox = bbox_head[i](output)
+ refined_bbox = torch.sigmoid(bbox + inverse_sigmoid(refer_bbox))
+
+ if self.training:
+ dec_cls.append(score_head[i](output))
+ if i == 0:
+ dec_bboxes.append(refined_bbox)
+ else:
+ dec_bboxes.append(torch.sigmoid(bbox + inverse_sigmoid(last_refined_bbox)))
+ elif i == self.eval_idx:
+ dec_cls.append(score_head[i](output))
+ dec_bboxes.append(refined_bbox)
+ break
+
+ last_refined_bbox = refined_bbox
+ refer_bbox = refined_bbox.detach() if self.training else refined_bbox
+
+ return torch.stack(dec_bboxes), torch.stack(dec_cls)
diff --git a/STPoseNet/ultralytics/nn/modules/utils.py b/STPoseNet/ultralytics/nn/modules/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8636dc479d242e982fb969a313f7fd786cc3107
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/modules/utils.py
@@ -0,0 +1,78 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Module utils
+"""
+
+import copy
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.init import uniform_
+
+__all__ = 'multi_scale_deformable_attn_pytorch', 'inverse_sigmoid'
+
+
+def _get_clones(module, n):
+ return nn.ModuleList([copy.deepcopy(module) for _ in range(n)])
+
+
+def bias_init_with_prob(prior_prob=0.01):
+ """initialize conv/fc bias value according to a given probability value."""
+ return float(-np.log((1 - prior_prob) / prior_prob)) # return bias_init
+
+
+def linear_init_(module):
+ bound = 1 / math.sqrt(module.weight.shape[0])
+ uniform_(module.weight, -bound, bound)
+ if hasattr(module, 'bias') and module.bias is not None:
+ uniform_(module.bias, -bound, bound)
+
+
+def inverse_sigmoid(x, eps=1e-5):
+ x = x.clamp(min=0, max=1)
+ x1 = x.clamp(min=eps)
+ x2 = (1 - x).clamp(min=eps)
+ return torch.log(x1 / x2)
+
+
+def multi_scale_deformable_attn_pytorch(value: torch.Tensor, value_spatial_shapes: torch.Tensor,
+ sampling_locations: torch.Tensor,
+ attention_weights: torch.Tensor) -> torch.Tensor:
+ """
+ Multi-scale deformable attention.
+ https://github.com/IDEA-Research/detrex/blob/main/detrex/layers/multi_scale_deform_attn.py
+ """
+
+ bs, _, num_heads, embed_dims = value.shape
+ _, num_queries, num_heads, num_levels, num_points, _ = sampling_locations.shape
+ value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
+ sampling_grids = 2 * sampling_locations - 1
+ sampling_value_list = []
+ for level, (H_, W_) in enumerate(value_spatial_shapes):
+ # bs, H_*W_, num_heads, embed_dims ->
+ # bs, H_*W_, num_heads*embed_dims ->
+ # bs, num_heads*embed_dims, H_*W_ ->
+ # bs*num_heads, embed_dims, H_, W_
+ value_l_ = (value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_))
+ # bs, num_queries, num_heads, num_points, 2 ->
+ # bs, num_heads, num_queries, num_points, 2 ->
+ # bs*num_heads, num_queries, num_points, 2
+ sampling_grid_l_ = sampling_grids[:, :, :, level].transpose(1, 2).flatten(0, 1)
+ # bs*num_heads, embed_dims, num_queries, num_points
+ sampling_value_l_ = F.grid_sample(value_l_,
+ sampling_grid_l_,
+ mode='bilinear',
+ padding_mode='zeros',
+ align_corners=False)
+ sampling_value_list.append(sampling_value_l_)
+ # (bs, num_queries, num_heads, num_levels, num_points) ->
+ # (bs, num_heads, num_queries, num_levels, num_points) ->
+ # (bs, num_heads, 1, num_queries, num_levels*num_points)
+ attention_weights = attention_weights.transpose(1, 2).reshape(bs * num_heads, 1, num_queries,
+ num_levels * num_points)
+ output = ((torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(
+ bs, num_heads * embed_dims, num_queries))
+ return output.transpose(1, 2).contiguous()
diff --git a/STPoseNet/ultralytics/nn/tasks.py b/STPoseNet/ultralytics/nn/tasks.py
new file mode 100644
index 0000000000000000000000000000000000000000..24153d244c50fe1a8d2a4fdaf5fadcc78a6d7a3e
--- /dev/null
+++ b/STPoseNet/ultralytics/nn/tasks.py
@@ -0,0 +1,792 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+
+from ultralytics.nn.modules import (AIFI, C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x,
+ Classify, Concat, Conv, Conv2, ConvTranspose, Detect, DWConv, DWConvTranspose2d,
+ Focus, GhostBottleneck, GhostConv, HGBlock, HGStem, Pose, RepC3, RepConv,
+ RTDETRDecoder, Segment)
+from ultralytics.utils import DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, colorstr, emojis, yaml_load
+from ultralytics.utils.checks import check_requirements, check_suffix, check_yaml
+from ultralytics.utils.loss import v8ClassificationLoss, v8DetectionLoss, v8PoseLoss, v8SegmentationLoss
+from ultralytics.utils.plotting import feature_visualization
+from ultralytics.utils.torch_utils import (fuse_conv_and_bn, fuse_deconv_and_bn, initialize_weights, intersect_dicts,
+ make_divisible, model_info, scale_img, time_sync)
+
+try:
+ import thop
+except ImportError:
+ thop = None
+
+
+class BaseModel(nn.Module):
+ """
+ The BaseModel class serves as a base class for all the models in the Ultralytics YOLO family.
+ """
+
+ def forward(self, x, *args, **kwargs):
+ """
+ Forward pass of the model on a single scale.
+ Wrapper for `_forward_once` method.
+
+ Args:
+ x (torch.Tensor | dict): The input image tensor or a dict including image tensor and gt labels.
+
+ Returns:
+ (torch.Tensor): The output of the network.
+ """
+ if isinstance(x, dict): # for cases of training and validating while training.
+ return self.loss(x, *args, **kwargs)
+ return self.predict(x, *args, **kwargs)
+
+ def predict(self, x, profile=False, visualize=False, augment=False):
+ """
+ Perform a forward pass through the network.
+
+ Args:
+ x (torch.Tensor): The input tensor to the model.
+ profile (bool): Print the computation time of each layer if True, defaults to False.
+ visualize (bool): Save the feature maps of the model if True, defaults to False.
+ augment (bool): Augment image during prediction, defaults to False.
+
+ Returns:
+ (torch.Tensor): The last output of the model.
+ """
+ if augment:
+ return self._predict_augment(x)
+ return self._predict_once(x, profile, visualize)
+
+ def _predict_once(self, x, profile=False, visualize=False):
+ """
+ Perform a forward pass through the network.
+
+ Args:
+ x (torch.Tensor): The input tensor to the model.
+ profile (bool): Print the computation time of each layer if True, defaults to False.
+ visualize (bool): Save the feature maps of the model if True, defaults to False.
+
+ Returns:
+ (torch.Tensor): The last output of the model.
+ """
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _predict_augment(self, x):
+ """Perform augmentations on input image x and return augmented inference."""
+ LOGGER.warning(f'WARNING ⚠️ {self.__class__.__name__} does not support augmented inference yet. '
+ f'Reverting to single-scale inference instead.')
+ return self._predict_once(x)
+
+ def _profile_one_layer(self, m, x, dt):
+ """
+ Profile the computation time and FLOPs of a single layer of the model on a given input.
+ Appends the results to the provided list.
+
+ Args:
+ m (nn.Module): The layer to be profiled.
+ x (torch.Tensor): The input data to the layer.
+ dt (list): A list to store the computation time of the layer.
+
+ Returns:
+ None
+ """
+ c = m == self.model[-1] and isinstance(x, list) # is final layer list, copy input as inplace fix
+ flops = thop.profile(m, inputs=[x.copy() if c else x], verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
+ LOGGER.info(f'{dt[-1]:10.2f} {flops:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def fuse(self, verbose=True):
+ """
+ Fuse the `Conv2d()` and `BatchNorm2d()` layers of the model into a single layer, in order to improve the
+ computation efficiency.
+
+ Returns:
+ (nn.Module): The fused model is returned.
+ """
+ if not self.is_fused():
+ for m in self.model.modules():
+ if isinstance(m, (Conv, Conv2, DWConv)) and hasattr(m, 'bn'):
+ if isinstance(m, Conv2):
+ m.fuse_convs()
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ if isinstance(m, ConvTranspose) and hasattr(m, 'bn'):
+ m.conv_transpose = fuse_deconv_and_bn(m.conv_transpose, m.bn)
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ if isinstance(m, RepConv):
+ m.fuse_convs()
+ m.forward = m.forward_fuse # update forward
+ self.info(verbose=verbose)
+
+ return self
+
+ def is_fused(self, thresh=10):
+ """
+ Check if the model has less than a certain threshold of BatchNorm layers.
+
+ Args:
+ thresh (int, optional): The threshold number of BatchNorm layers. Default is 10.
+
+ Returns:
+ (bool): True if the number of BatchNorm layers in the model is less than the threshold, False otherwise.
+ """
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ return sum(isinstance(v, bn) for v in self.modules()) < thresh # True if < 'thresh' BatchNorm layers in model
+
+ def info(self, detailed=False, verbose=True, imgsz=640):
+ """
+ Prints model information
+
+ Args:
+ detailed (bool): if True, prints out detailed information about the model. Defaults to False
+ verbose (bool): if True, prints out the model information. Defaults to False
+ imgsz (int): the size of the image that the model will be trained on. Defaults to 640
+ """
+ return model_info(self, detailed=detailed, verbose=verbose, imgsz=imgsz)
+
+ def _apply(self, fn):
+ """
+ Applies a function to all the tensors in the model that are not parameters or registered buffers.
+
+ Args:
+ fn (function): the function to apply to the model
+
+ Returns:
+ A model that is a Detect() object.
+ """
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment)):
+ m.stride = fn(m.stride)
+ m.anchors = fn(m.anchors)
+ m.strides = fn(m.strides)
+ return self
+
+ def load(self, weights, verbose=True):
+ """
+ Load the weights into the model.
+
+ Args:
+ weights (dict | torch.nn.Module): The pre-trained weights to be loaded.
+ verbose (bool, optional): Whether to log the transfer progress. Defaults to True.
+ """
+ model = weights['model'] if isinstance(weights, dict) else weights # torchvision models are not dicts
+ csd = model.float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, self.state_dict()) # intersect
+ self.load_state_dict(csd, strict=False) # load
+ if verbose:
+ LOGGER.info(f'Transferred {len(csd)}/{len(self.model.state_dict())} items from pretrained weights')
+
+ def loss(self, batch, preds=None):
+ """
+ Compute loss
+
+ Args:
+ batch (dict): Batch to compute loss on
+ preds (torch.Tensor | List[torch.Tensor]): Predictions.
+ """
+ if not hasattr(self, 'criterion'):
+ self.criterion = self.init_criterion()
+
+ preds = self.forward(batch['img']) if preds is None else preds
+ return self.criterion(preds, batch)
+
+ def init_criterion(self):
+ raise NotImplementedError('compute_loss() needs to be implemented by task heads')
+
+
+class DetectionModel(BaseModel):
+ """YOLOv8 detection model."""
+
+ def __init__(self, cfg='yolov8n.yaml', ch=3, nc=None, verbose=True): # model, input channels, number of classes
+ super().__init__()
+ self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override YAML value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist
+ self.names = {i: f'{i}' for i in range(self.yaml['nc'])} # default names dict
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides
+ m = self.model[-1] # Detect()
+ if isinstance(m, (Detect, Segment, Pose)):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Pose)) else self.forward(x)
+ m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
+ self.stride = m.stride
+ m.bias_init() # only run once
+ else:
+ self.stride = torch.Tensor([32]) # default stride for i.e. RTDETR
+
+ # Init weights, biases
+ initialize_weights(self)
+ if verbose:
+ self.info()
+ LOGGER.info('')
+
+ def _predict_augment(self, x):
+ """Perform augmentations on input image x and return augmented inference and train outputs."""
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = super().predict(xi)[0] # forward
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, -1), None # augmented inference, train
+
+ @staticmethod
+ def _descale_pred(p, flips, scale, img_size, dim=1):
+ """De-scale predictions following augmented inference (inverse operation)."""
+ p[:, :4] /= scale # de-scale
+ x, y, wh, cls = p.split((1, 1, 2, p.shape[dim] - 4), dim)
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ return torch.cat((x, y, wh, cls), dim)
+
+ def _clip_augmented(self, y):
+ """Clip YOLOv5 augmented inference tails."""
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[-1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][..., :-i] # large
+ i = (y[-1].shape[-1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][..., i:] # small
+ return y
+
+ def init_criterion(self):
+ return v8DetectionLoss(self)
+
+
+class SegmentationModel(DetectionModel):
+ """YOLOv8 segmentation model."""
+
+ def __init__(self, cfg='yolov8n-seg.yaml', ch=3, nc=None, verbose=True):
+ """Initialize YOLOv8 segmentation model with given config and parameters."""
+ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
+
+ def init_criterion(self):
+ return v8SegmentationLoss(self)
+
+
+class PoseModel(DetectionModel):
+ """YOLOv8 pose model."""
+
+ def __init__(self, cfg='yolov8n-pose.yaml', ch=3, nc=None, data_kpt_shape=(None, None), verbose=True):
+ """Initialize YOLOv8 Pose model."""
+ if not isinstance(cfg, dict):
+ cfg = yaml_model_load(cfg) # load model YAML
+ if any(data_kpt_shape) and list(data_kpt_shape) != list(cfg['kpt_shape']):
+ LOGGER.info(f"Overriding model.yaml kpt_shape={cfg['kpt_shape']} with kpt_shape={data_kpt_shape}")
+ cfg['kpt_shape'] = data_kpt_shape
+ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
+
+ def init_criterion(self):
+ return v8PoseLoss(self)
+
+
+class ClassificationModel(BaseModel):
+ """YOLOv8 classification model."""
+
+ def __init__(self, cfg='yolov8n-cls.yaml', ch=3, nc=None, verbose=True):
+ """Init ClassificationModel with YAML, channels, number of classes, verbose flag."""
+ super().__init__()
+ self._from_yaml(cfg, ch, nc, verbose)
+
+ def _from_yaml(self, cfg, ch, nc, verbose):
+ """Set YOLOv8 model configurations and define the model architecture."""
+ self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override YAML value
+ elif not nc and not self.yaml.get('nc', None):
+ raise ValueError('nc not specified. Must specify nc in model.yaml or function arguments.')
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist
+ self.stride = torch.Tensor([1]) # no stride constraints
+ self.names = {i: f'{i}' for i in range(self.yaml['nc'])} # default names dict
+ self.info()
+
+ @staticmethod
+ def reshape_outputs(model, nc):
+ """Update a TorchVision classification model to class count 'n' if required."""
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLO Classify() head
+ if m.linear.out_features != nc:
+ m.linear = nn.Linear(m.linear.in_features, nc)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != nc:
+ setattr(model, name, nn.Linear(m.in_features, nc))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != nc:
+ m[i] = nn.Linear(m[i].in_features, nc)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != nc:
+ m[i] = nn.Conv2d(m[i].in_channels, nc, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+ def init_criterion(self):
+ """Compute the classification loss between predictions and true labels."""
+ return v8ClassificationLoss()
+
+
+class RTDETRDetectionModel(DetectionModel):
+
+ def __init__(self, cfg='rtdetr-l.yaml', ch=3, nc=None, verbose=True):
+ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
+
+ def init_criterion(self):
+ """Compute the classification loss between predictions and true labels."""
+ from ultralytics.models.utils.loss import RTDETRDetectionLoss
+
+ return RTDETRDetectionLoss(nc=self.nc, use_vfl=True)
+
+ def loss(self, batch, preds=None):
+ if not hasattr(self, 'criterion'):
+ self.criterion = self.init_criterion()
+
+ img = batch['img']
+ # NOTE: preprocess gt_bbox and gt_labels to list.
+ bs = len(img)
+ batch_idx = batch['batch_idx']
+ gt_groups = [(batch_idx == i).sum().item() for i in range(bs)]
+ targets = {
+ 'cls': batch['cls'].to(img.device, dtype=torch.long).view(-1),
+ 'bboxes': batch['bboxes'].to(device=img.device),
+ 'batch_idx': batch_idx.to(img.device, dtype=torch.long).view(-1),
+ 'gt_groups': gt_groups}
+
+ preds = self.predict(img, batch=targets) if preds is None else preds
+ dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta = preds if self.training else preds[1]
+ if dn_meta is None:
+ dn_bboxes, dn_scores = None, None
+ else:
+ dn_bboxes, dec_bboxes = torch.split(dec_bboxes, dn_meta['dn_num_split'], dim=2)
+ dn_scores, dec_scores = torch.split(dec_scores, dn_meta['dn_num_split'], dim=2)
+
+ dec_bboxes = torch.cat([enc_bboxes.unsqueeze(0), dec_bboxes]) # (7, bs, 300, 4)
+ dec_scores = torch.cat([enc_scores.unsqueeze(0), dec_scores])
+
+ loss = self.criterion((dec_bboxes, dec_scores),
+ targets,
+ dn_bboxes=dn_bboxes,
+ dn_scores=dn_scores,
+ dn_meta=dn_meta)
+ # NOTE: There are like 12 losses in RTDETR, backward with all losses but only show the main three losses.
+ return sum(loss.values()), torch.as_tensor([loss[k].detach() for k in ['loss_giou', 'loss_class', 'loss_bbox']],
+ device=img.device)
+
+ def predict(self, x, profile=False, visualize=False, batch=None, augment=False):
+ """
+ Perform a forward pass through the network.
+
+ Args:
+ x (torch.Tensor): The input tensor to the model
+ profile (bool): Print the computation time of each layer if True, defaults to False.
+ visualize (bool): Save the feature maps of the model if True, defaults to False
+ batch (dict): A dict including gt boxes and labels from dataloader.
+
+ Returns:
+ (torch.Tensor): The last output of the model.
+ """
+ y, dt = [], [] # outputs
+ for m in self.model[:-1]: # except the head part
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ head = self.model[-1]
+ x = head([y[j] for j in head.f], batch) # head inference
+ return x
+
+
+class Ensemble(nn.ModuleList):
+ """Ensemble of models."""
+
+ def __init__(self):
+ """Initialize an ensemble of models."""
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ """Function generates the YOLOv5 network's final layer."""
+ y = [module(x, augment, profile, visualize)[0] for module in self]
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 2) # nms ensemble, y shape(B, HW, C)
+ return y, None # inference, train output
+
+
+# Functions ------------------------------------------------------------------------------------------------------------
+
+
+@contextlib.contextmanager
+def temporary_modules(modules=None):
+ """
+ Context manager for temporarily adding or modifying modules in Python's module cache (`sys.modules`).
+
+ This function can be used to change the module paths during runtime. It's useful when refactoring code,
+ where you've moved a module from one location to another, but you still want to support the old import
+ paths for backwards compatibility.
+
+ Args:
+ modules (dict, optional): A dictionary mapping old module paths to new module paths.
+
+ Example:
+ ```python
+ with temporary_modules({'old.module.path': 'new.module.path'}):
+ import old.module.path # this will now import new.module.path
+ ```
+
+ Note:
+ The changes are only in effect inside the context manager and are undone once the context manager exits.
+ Be aware that directly manipulating `sys.modules` can lead to unpredictable results, especially in larger
+ applications or libraries. Use this function with caution.
+ """
+ if not modules:
+ modules = {}
+
+ import importlib
+ import sys
+ try:
+ # Set modules in sys.modules under their old name
+ for old, new in modules.items():
+ sys.modules[old] = importlib.import_module(new)
+
+ yield
+ finally:
+ # Remove the temporary module paths
+ for old in modules:
+ if old in sys.modules:
+ del sys.modules[old]
+
+
+def torch_safe_load(weight):
+ """
+ This function attempts to load a PyTorch model with the torch.load() function. If a ModuleNotFoundError is raised,
+ it catches the error, logs a warning message, and attempts to install the missing module via the
+ check_requirements() function. After installation, the function again attempts to load the model using torch.load().
+
+ Args:
+ weight (str): The file path of the PyTorch model.
+
+ Returns:
+ (dict): The loaded PyTorch model.
+ """
+ from ultralytics.utils.downloads import attempt_download_asset
+
+ check_suffix(file=weight, suffix='.pt')
+ file = attempt_download_asset(weight) # search online if missing locally
+ try:
+ with temporary_modules({
+ 'ultralytics.yolo.utils': 'ultralytics.utils',
+ 'ultralytics.yolo.v8': 'ultralytics.models.yolo',
+ 'ultralytics.yolo.data': 'ultralytics.data'}): # for legacy 8.0 Classify and Pose models
+ return torch.load(file, map_location='cpu'), file # load
+
+ except ModuleNotFoundError as e: # e.name is missing module name
+ if e.name == 'models':
+ raise TypeError(
+ emojis(f'ERROR ❌️ {weight} appears to be an Ultralytics YOLOv5 model originally trained '
+ f'with https://github.com/ultralytics/yolov5.\nThis model is NOT forwards compatible with '
+ f'YOLOv8 at https://github.com/ultralytics/ultralytics.'
+ f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to "
+ f"run a command with an official YOLOv8 model, i.e. 'yolo predict model=yolov8n.pt'")) from e
+ LOGGER.warning(f"WARNING ⚠️ {weight} appears to require '{e.name}', which is not in ultralytics requirements."
+ f"\nAutoInstall will run now for '{e.name}' but this feature will be removed in the future."
+ f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to "
+ f"run a command with an official YOLOv8 model, i.e. 'yolo predict model=yolov8n.pt'")
+ check_requirements(e.name) # install missing module
+
+ return torch.load(file, map_location='cpu'), file # load
+
+
+def attempt_load_weights(weights, device=None, inplace=True, fuse=False):
+ """Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a."""
+
+ ensemble = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt, w = torch_safe_load(w) # load ckpt
+ args = {**DEFAULT_CFG_DICT, **ckpt['train_args']} if 'train_args' in ckpt else None # combined args
+ model = (ckpt.get('ema') or ckpt['model']).to(device).float() # FP32 model
+
+ # Model compatibility updates
+ model.args = args # attach args to model
+ model.pt_path = w # attach *.pt file path to model
+ model.task = guess_model_task(model)
+ if not hasattr(model, 'stride'):
+ model.stride = torch.tensor([32.])
+
+ # Append
+ ensemble.append(model.fuse().eval() if fuse and hasattr(model, 'fuse') else model.eval()) # model in eval mode
+
+ # Module updates
+ for m in ensemble.modules():
+ t = type(m)
+ if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment):
+ m.inplace = inplace
+ elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ # Return model
+ if len(ensemble) == 1:
+ return ensemble[-1]
+
+ # Return ensemble
+ LOGGER.info(f'Ensemble created with {weights}\n')
+ for k in 'names', 'nc', 'yaml':
+ setattr(ensemble, k, getattr(ensemble[0], k))
+ ensemble.stride = ensemble[torch.argmax(torch.tensor([m.stride.max() for m in ensemble])).int()].stride
+ assert all(ensemble[0].nc == m.nc for m in ensemble), f'Models differ in class counts {[m.nc for m in ensemble]}'
+ return ensemble
+
+
+def attempt_load_one_weight(weight, device=None, inplace=True, fuse=False):
+ """Loads a single model weights."""
+ ckpt, weight = torch_safe_load(weight) # load ckpt
+ args = {**DEFAULT_CFG_DICT, **(ckpt.get('train_args', {}))} # combine model and default args, preferring model args
+ model = (ckpt.get('ema') or ckpt['model']).to(device).float() # FP32 model
+
+ # Model compatibility updates
+ model.args = {k: v for k, v in args.items() if k in DEFAULT_CFG_KEYS} # attach args to model
+ model.pt_path = weight # attach *.pt file path to model
+ model.task = guess_model_task(model)
+ if not hasattr(model, 'stride'):
+ model.stride = torch.tensor([32.])
+
+ model = model.fuse().eval() if fuse and hasattr(model, 'fuse') else model.eval() # model in eval mode
+
+ # Module updates
+ for m in model.modules():
+ t = type(m)
+ if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment):
+ m.inplace = inplace
+ elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ # Return model and ckpt
+ return model, ckpt
+
+
+def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
+ """Parse a YOLO model.yaml dictionary into a PyTorch model."""
+ import ast
+
+ # Args
+ max_channels = float('inf')
+ nc, act, scales = (d.get(x) for x in ('nc', 'activation', 'scales'))
+ depth, width, kpt_shape = (d.get(x, 1.0) for x in ('depth_multiple', 'width_multiple', 'kpt_shape'))
+ if scales:
+ scale = d.get('scale')
+ if not scale:
+ scale = tuple(scales.keys())[0]
+ LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
+ depth, width, max_channels = scales[scale]
+
+ if act:
+ Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
+ if verbose:
+ LOGGER.info(f"{colorstr('activation:')} {act}") # print
+
+ if verbose:
+ LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
+ ch = [ch]
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
+ for j, a in enumerate(args):
+ if isinstance(a, str):
+ with contextlib.suppress(ValueError):
+ args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
+
+ n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
+ if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
+ BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3):
+ c1, c2 = ch[f], args[0]
+ if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
+ c2 = make_divisible(min(c2, max_channels) * width, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3):
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is AIFI:
+ args = [ch[f], *args]
+ elif m in (HGStem, HGBlock):
+ c1, cm, c2 = ch[f], args[0], args[1]
+ args = [c1, cm, c2, *args[2:]]
+ if m is HGBlock:
+ args.insert(4, n) # number of repeats
+ n = 1
+
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ elif m in (Detect, Segment, Pose):
+ args.append([ch[x] for x in f])
+ if m is Segment:
+ args[2] = make_divisible(min(args[2], max_channels) * width, 8)
+ elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
+ args.insert(1, [ch[x] for x in f])
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ m.np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, type
+ if verbose:
+ LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+def yaml_model_load(path):
+ """Load a YOLOv8 model from a YAML file."""
+ import re
+
+ path = Path(path)
+ if path.stem in (f'yolov{d}{x}6' for x in 'nsmlx' for d in (5, 8)):
+ new_stem = re.sub(r'(\d+)([nslmx])6(.+)?$', r'\1\2-p6\3', path.stem)
+ LOGGER.warning(f'WARNING ⚠️ Ultralytics YOLO P6 models now use -p6 suffix. Renaming {path.stem} to {new_stem}.')
+ path = path.with_name(new_stem + path.suffix)
+
+ unified_path = re.sub(r'(\d+)([nslmx])(.+)?$', r'\1\3', str(path)) # i.e. yolov8x.yaml -> yolov8.yaml
+ yaml_file = check_yaml(unified_path, hard=False) or check_yaml(path)
+ d = yaml_load(yaml_file) # model dict
+ d['scale'] = guess_model_scale(path)
+ d['yaml_file'] = str(path)
+ return d
+
+
+def guess_model_scale(model_path):
+ """
+ Takes a path to a YOLO model's YAML file as input and extracts the size character of the model's scale.
+ The function uses regular expression matching to find the pattern of the model scale in the YAML file name,
+ which is denoted by n, s, m, l, or x. The function returns the size character of the model scale as a string.
+
+ Args:
+ model_path (str | Path): The path to the YOLO model's YAML file.
+
+ Returns:
+ (str): The size character of the model's scale, which can be n, s, m, l, or x.
+ """
+ with contextlib.suppress(AttributeError):
+ import re
+ return re.search(r'yolov\d+([nslmx])', Path(model_path).stem).group(1) # n, s, m, l, or x
+ return ''
+
+
+def guess_model_task(model):
+ """
+ Guess the task of a PyTorch model from its architecture or configuration.
+
+ Args:
+ model (nn.Module | dict): PyTorch model or model configuration in YAML format.
+
+ Returns:
+ (str): Task of the model ('detect', 'segment', 'classify', 'pose').
+
+ Raises:
+ SyntaxError: If the task of the model could not be determined.
+ """
+
+ def cfg2task(cfg):
+ """Guess from YAML dictionary."""
+ m = cfg['head'][-1][-2].lower() # output module name
+ if m in ('classify', 'classifier', 'cls', 'fc'):
+ return 'classify'
+ if m == 'detect':
+ return 'detect'
+ if m == 'segment':
+ return 'segment'
+ if m == 'pose':
+ return 'pose'
+
+ # Guess from model cfg
+ if isinstance(model, dict):
+ with contextlib.suppress(Exception):
+ return cfg2task(model)
+
+ # Guess from PyTorch model
+ if isinstance(model, nn.Module): # PyTorch model
+ for x in 'model.args', 'model.model.args', 'model.model.model.args':
+ with contextlib.suppress(Exception):
+ return eval(x)['task']
+ for x in 'model.yaml', 'model.model.yaml', 'model.model.model.yaml':
+ with contextlib.suppress(Exception):
+ return cfg2task(eval(x))
+
+ for m in model.modules():
+ if isinstance(m, Detect):
+ return 'detect'
+ elif isinstance(m, Segment):
+ return 'segment'
+ elif isinstance(m, Classify):
+ return 'classify'
+ elif isinstance(m, Pose):
+ return 'pose'
+
+ # Guess from model filename
+ if isinstance(model, (str, Path)):
+ model = Path(model)
+ if '-seg' in model.stem or 'segment' in model.parts:
+ return 'segment'
+ elif '-cls' in model.stem or 'classify' in model.parts:
+ return 'classify'
+ elif '-pose' in model.stem or 'pose' in model.parts:
+ return 'pose'
+ elif 'detect' in model.parts:
+ return 'detect'
+
+ # Unable to determine task from model
+ LOGGER.warning("WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. "
+ "Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.")
+ return 'detect' # assume detect
diff --git a/STPoseNet/ultralytics/trackers/README.md b/STPoseNet/ultralytics/trackers/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..843bd2245fb6ba4d277264d1a52240bfa80feb80
--- /dev/null
+++ b/STPoseNet/ultralytics/trackers/README.md
@@ -0,0 +1,86 @@
+# Tracker
+
+## Supported Trackers
+
+- [x] ByteTracker
+- [x] BoT-SORT
+
+## Usage
+
+### python interface:
+
+You can use the Python interface to track objects using the YOLO model.
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt") # or a segmentation model .i.e yolov8n-seg.pt
+model.track(
+ source="video/streams",
+ stream=True,
+ tracker="botsort.yaml", # or 'bytetrack.yaml'
+ show=True,
+)
+```
+
+You can get the IDs of the tracked objects using the following code:
+
+```python
+from ultralytics import YOLO
+
+model = YOLO("yolov8n.pt")
+
+for result in model.track(source="video.mp4"):
+ print(
+ result.boxes.id.cpu().numpy().astype(int)
+ ) # this will print the IDs of the tracked objects in the frame
+```
+
+If you want to use the tracker with a folder of images or when you loop on the video frames, you should use the `persist` parameter to tell the model that these frames are related to each other so the IDs will be fixed for the same objects. Otherwise, the IDs will be different in each frame because in each loop, the model creates a new object for tracking, but the `persist` parameter makes it use the same object for tracking.
+
+```python
+import cv2
+from ultralytics import YOLO
+
+cap = cv2.VideoCapture("video.mp4")
+model = YOLO("yolov8n.pt")
+while True:
+ ret, frame = cap.read()
+ if not ret:
+ break
+ results = model.track(frame, persist=True)
+ boxes = results[0].boxes.xyxy.cpu().numpy().astype(int)
+ ids = results[0].boxes.id.cpu().numpy().astype(int)
+ for box, id in zip(boxes, ids):
+ cv2.rectangle(frame, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
+ cv2.putText(
+ frame,
+ f"Id {id}",
+ (box[0], box[1]),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 1,
+ (0, 0, 255),
+ 2,
+ )
+ cv2.imshow("frame", frame)
+ if cv2.waitKey(1) & 0xFF == ord("q"):
+ break
+```
+
+## Change tracker parameters
+
+You can change the tracker parameters by eding the `tracker.yaml` file which is located in the ultralytics/cfg/trackers folder.
+
+## Command Line Interface (CLI)
+
+You can also use the command line interface to track objects using the YOLO model.
+
+```bash
+yolo detect track source=... tracker=...
+yolo segment track source=... tracker=...
+yolo pose track source=... tracker=...
+```
+
+By default, trackers will use the configuration in `ultralytics/cfg/trackers`.
+We also support using a modified tracker config file. Please refer to the tracker config files
+in `ultralytics/cfg/trackers`.(pixels) | mAPvalCPU ONNX{gpu} TensorRT(M) | FLOPs(B) |'
+ separator = '|-------------|---------------------|--------------------|------------------------------|-----------------------------------|------------------|-----------------|'
+
+ print(f'\n\n{header}')
+ print(separator)
+ for row in table_rows:
+ print(row)
diff --git a/STPoseNet/ultralytics/utils/callbacks/__init__.py b/STPoseNet/ultralytics/utils/callbacks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ad4ad6e7b4726d5c8405a217ab2a3cf9cb3440d
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/__init__.py
@@ -0,0 +1,5 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from .base import add_integration_callbacks, default_callbacks, get_default_callbacks
+
+__all__ = 'add_integration_callbacks', 'default_callbacks', 'get_default_callbacks'
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/__init__.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a971f3f39fbd69fbb9588df73df6a9c1d83c4fea
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/__init__.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/base.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/base.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a08e1d49b783cade5e0267ddacc55934f6eb6415
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/base.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/clearml.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/clearml.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3d4c5d7eb69904fb5dd42d75b6fcdc54b079e2d9
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/clearml.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/comet.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/comet.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a4efe0623ec2ca671f4df61c0e6f01e5449b6070
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/comet.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/dvc.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/dvc.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..281665859d8830cf6fa4abe49d9fb0f16024ff1f
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/dvc.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/hub.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/hub.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6192f92659c88c907ca2c3f7cb6ff076887edd66
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/hub.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/mlflow.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/mlflow.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6092ae9c5a5799ed487a8f4ebde52bf308c41b87
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/mlflow.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/neptune.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/neptune.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ce0e4261fb26fe38263dddb69cfe92310370b69a
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/neptune.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/raytune.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/raytune.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..14faa70d213f7f34f6b0423e99ca74b86c4e89ee
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/raytune.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/tensorboard.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/tensorboard.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7473f25d0047ec43629b8339a435255cea0f7580
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/tensorboard.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/__pycache__/wb.cpython-38.pyc b/STPoseNet/ultralytics/utils/callbacks/__pycache__/wb.cpython-38.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aad9a6957d476b2094b95f545164e9d9a123974c
Binary files /dev/null and b/STPoseNet/ultralytics/utils/callbacks/__pycache__/wb.cpython-38.pyc differ
diff --git a/STPoseNet/ultralytics/utils/callbacks/base.py b/STPoseNet/ultralytics/utils/callbacks/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b1734798ffb760f92c9ea098e996d4637b082ea
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/base.py
@@ -0,0 +1,212 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Base callbacks
+"""
+
+from collections import defaultdict
+from copy import deepcopy
+
+# Trainer callbacks ----------------------------------------------------------------------------------------------------
+
+
+def on_pretrain_routine_start(trainer):
+ """Called before the pretraining routine starts."""
+ pass
+
+
+def on_pretrain_routine_end(trainer):
+ """Called after the pretraining routine ends."""
+ pass
+
+
+def on_train_start(trainer):
+ """Called when the training starts."""
+ pass
+
+
+def on_train_epoch_start(trainer):
+ """Called at the start of each training epoch."""
+ pass
+
+
+def on_train_batch_start(trainer):
+ """Called at the start of each training batch."""
+ pass
+
+
+def optimizer_step(trainer):
+ """Called when the optimizer takes a step."""
+ pass
+
+
+def on_before_zero_grad(trainer):
+ """Called before the gradients are set to zero."""
+ pass
+
+
+def on_train_batch_end(trainer):
+ """Called at the end of each training batch."""
+ pass
+
+
+def on_train_epoch_end(trainer):
+ """Called at the end of each training epoch."""
+ pass
+
+
+def on_fit_epoch_end(trainer):
+ """Called at the end of each fit epoch (train + val)."""
+ pass
+
+
+def on_model_save(trainer):
+ """Called when the model is saved."""
+ pass
+
+
+def on_train_end(trainer):
+ """Called when the training ends."""
+ pass
+
+
+def on_params_update(trainer):
+ """Called when the model parameters are updated."""
+ pass
+
+
+def teardown(trainer):
+ """Called during the teardown of the training process."""
+ pass
+
+
+# Validator callbacks --------------------------------------------------------------------------------------------------
+
+
+def on_val_start(validator):
+ """Called when the validation starts."""
+ pass
+
+
+def on_val_batch_start(validator):
+ """Called at the start of each validation batch."""
+ pass
+
+
+def on_val_batch_end(validator):
+ """Called at the end of each validation batch."""
+ pass
+
+
+def on_val_end(validator):
+ """Called when the validation ends."""
+ pass
+
+
+# Predictor callbacks --------------------------------------------------------------------------------------------------
+
+
+def on_predict_start(predictor):
+ """Called when the prediction starts."""
+ pass
+
+
+def on_predict_batch_start(predictor):
+ """Called at the start of each prediction batch."""
+ pass
+
+
+def on_predict_batch_end(predictor):
+ """Called at the end of each prediction batch."""
+ pass
+
+
+def on_predict_postprocess_end(predictor):
+ """Called after the post-processing of the prediction ends."""
+ pass
+
+
+def on_predict_end(predictor):
+ """Called when the prediction ends."""
+ pass
+
+
+# Exporter callbacks ---------------------------------------------------------------------------------------------------
+
+
+def on_export_start(exporter):
+ """Called when the model export starts."""
+ pass
+
+
+def on_export_end(exporter):
+ """Called when the model export ends."""
+ pass
+
+
+default_callbacks = {
+ # Run in trainer
+ 'on_pretrain_routine_start': [on_pretrain_routine_start],
+ 'on_pretrain_routine_end': [on_pretrain_routine_end],
+ 'on_train_start': [on_train_start],
+ 'on_train_epoch_start': [on_train_epoch_start],
+ 'on_train_batch_start': [on_train_batch_start],
+ 'optimizer_step': [optimizer_step],
+ 'on_before_zero_grad': [on_before_zero_grad],
+ 'on_train_batch_end': [on_train_batch_end],
+ 'on_train_epoch_end': [on_train_epoch_end],
+ 'on_fit_epoch_end': [on_fit_epoch_end], # fit = train + val
+ 'on_model_save': [on_model_save],
+ 'on_train_end': [on_train_end],
+ 'on_params_update': [on_params_update],
+ 'teardown': [teardown],
+
+ # Run in validator
+ 'on_val_start': [on_val_start],
+ 'on_val_batch_start': [on_val_batch_start],
+ 'on_val_batch_end': [on_val_batch_end],
+ 'on_val_end': [on_val_end],
+
+ # Run in predictor
+ 'on_predict_start': [on_predict_start],
+ 'on_predict_batch_start': [on_predict_batch_start],
+ 'on_predict_postprocess_end': [on_predict_postprocess_end],
+ 'on_predict_batch_end': [on_predict_batch_end],
+ 'on_predict_end': [on_predict_end],
+
+ # Run in exporter
+ 'on_export_start': [on_export_start],
+ 'on_export_end': [on_export_end]}
+
+
+def get_default_callbacks():
+ """
+ Return a copy of the default_callbacks dictionary with lists as default values.
+
+ Returns:
+ (defaultdict): A defaultdict with keys from default_callbacks and empty lists as default values.
+ """
+ return defaultdict(list, deepcopy(default_callbacks))
+
+
+def add_integration_callbacks(instance):
+ """
+ Add integration callbacks from various sources to the instance's callbacks.
+
+ Args:
+ instance (Trainer, Predictor, Validator, Exporter): An object with a 'callbacks' attribute that is a dictionary
+ of callback lists.
+ """
+ from .clearml import callbacks as clearml_cb
+ from .comet import callbacks as comet_cb
+ from .dvc import callbacks as dvc_cb
+ from .hub import callbacks as hub_cb
+ from .mlflow import callbacks as mlflow_cb
+ from .neptune import callbacks as neptune_cb
+ from .raytune import callbacks as tune_cb
+ from .tensorboard import callbacks as tensorboard_cb
+ from .wb import callbacks as wb_cb
+
+ for x in clearml_cb, comet_cb, hub_cb, mlflow_cb, neptune_cb, tune_cb, tensorboard_cb, wb_cb, dvc_cb:
+ for k, v in x.items():
+ if v not in instance.callbacks[k]: # prevent duplicate callbacks addition
+ instance.callbacks[k].append(v) # callback[name].append(func)
diff --git a/STPoseNet/ultralytics/utils/callbacks/clearml.py b/STPoseNet/ultralytics/utils/callbacks/clearml.py
new file mode 100644
index 0000000000000000000000000000000000000000..5460aca61ed4f18a176275633f12f9ce23551357
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/clearml.py
@@ -0,0 +1,139 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import re
+
+import matplotlib.image as mpimg
+import matplotlib.pyplot as plt
+
+from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+try:
+ import clearml
+ from clearml import Task
+ from clearml.binding.frameworks.pytorch_bind import PatchPyTorchModelIO
+ from clearml.binding.matplotlib_bind import PatchedMatplotlib
+
+ assert hasattr(clearml, '__version__') # verify package is not directory
+ assert not TESTS_RUNNING # do not log pytest
+ assert SETTINGS['clearml'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ clearml = None
+
+
+def _log_debug_samples(files, title='Debug Samples') -> None:
+ """
+ Log files (images) as debug samples in the ClearML task.
+
+ Args:
+ files (list): A list of file paths in PosixPath format.
+ title (str): A title that groups together images with the same values.
+ """
+ if task := Task.current_task():
+ for f in files:
+ if f.exists():
+ it = re.search(r'_batch(\d+)', f.name)
+ iteration = int(it.groups()[0]) if it else 0
+ task.get_logger().report_image(title=title,
+ series=f.name.replace(it.group(), ''),
+ local_path=str(f),
+ iteration=iteration)
+
+
+def _log_plot(title, plot_path) -> None:
+ """
+ Log an image as a plot in the plot section of ClearML.
+
+ Args:
+ title (str): The title of the plot.
+ plot_path (str): The path to the saved image file.
+ """
+ img = mpimg.imread(plot_path)
+ fig = plt.figure()
+ ax = fig.add_axes([0, 0, 1, 1], frameon=False, aspect='auto', xticks=[], yticks=[]) # no ticks
+ ax.imshow(img)
+
+ Task.current_task().get_logger().report_matplotlib_figure(title=title,
+ series='',
+ figure=fig,
+ report_interactive=False)
+
+
+def on_pretrain_routine_start(trainer):
+ """Runs at start of pretraining routine; initializes and connects/ logs task to ClearML."""
+ try:
+ if task := Task.current_task():
+ # Make sure the automatic pytorch and matplotlib bindings are disabled!
+ # We are logging these plots and model files manually in the integration
+ PatchPyTorchModelIO.update_current_task(None)
+ PatchedMatplotlib.update_current_task(None)
+ else:
+ task = Task.init(project_name=trainer.args.project or 'YOLOv8',
+ task_name=trainer.args.name,
+ tags=['YOLOv8'],
+ output_uri=True,
+ reuse_last_task_id=False,
+ auto_connect_frameworks={
+ 'pytorch': False,
+ 'matplotlib': False})
+ LOGGER.warning('ClearML Initialized a new task. If you want to run remotely, '
+ 'please add clearml-init and connect your arguments before initializing YOLO.')
+ task.connect(vars(trainer.args), name='General')
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ ClearML installed but not initialized correctly, not logging this run. {e}')
+
+
+def on_train_epoch_end(trainer):
+ """Logs debug samples for the first epoch of YOLO training and report current training progress."""
+ if task := Task.current_task():
+ # Log debug samples
+ if trainer.epoch == 1:
+ _log_debug_samples(sorted(trainer.save_dir.glob('train_batch*.jpg')), 'Mosaic')
+ # Report the current training progress
+ for k, v in trainer.validator.metrics.results_dict.items():
+ task.get_logger().report_scalar('train', k, v, iteration=trainer.epoch)
+
+
+def on_fit_epoch_end(trainer):
+ """Reports model information to logger at the end of an epoch."""
+ if task := Task.current_task():
+ # You should have access to the validation bboxes under jdict
+ task.get_logger().report_scalar(title='Epoch Time',
+ series='Epoch Time',
+ value=trainer.epoch_time,
+ iteration=trainer.epoch)
+ if trainer.epoch == 0:
+ for k, v in model_info_for_loggers(trainer).items():
+ task.get_logger().report_single_value(k, v)
+
+
+def on_val_end(validator):
+ """Logs validation results including labels and predictions."""
+ if Task.current_task():
+ # Log val_labels and val_pred
+ _log_debug_samples(sorted(validator.save_dir.glob('val*.jpg')), 'Validation')
+
+
+def on_train_end(trainer):
+ """Logs final model and its name on training completion."""
+ if task := Task.current_task():
+ # Log final results, CM matrix + PR plots
+ files = [
+ 'results.png', 'confusion_matrix.png', 'confusion_matrix_normalized.png',
+ *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(trainer.save_dir / f) for f in files if (trainer.save_dir / f).exists()] # filter
+ for f in files:
+ _log_plot(title=f.stem, plot_path=f)
+ # Report final metrics
+ for k, v in trainer.validator.metrics.results_dict.items():
+ task.get_logger().report_single_value(k, v)
+ # Log the final model
+ task.update_output_model(model_path=str(trainer.best), model_name=trainer.args.name, auto_delete_file=False)
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_train_epoch_end': on_train_epoch_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_val_end': on_val_end,
+ 'on_train_end': on_train_end} if clearml else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/comet.py b/STPoseNet/ultralytics/utils/callbacks/comet.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6f6c4038b894eafebfdfb7d8635da11ccc50c84
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/comet.py
@@ -0,0 +1,369 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+from pathlib import Path
+
+from ultralytics.utils import LOGGER, RANK, SETTINGS, TESTS_RUNNING, ops
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+try:
+ import comet_ml
+
+ assert not TESTS_RUNNING # do not log pytest
+ assert hasattr(comet_ml, '__version__') # verify package is not directory
+ assert SETTINGS['comet'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ comet_ml = None
+
+# Ensures certain logging functions only run for supported tasks
+COMET_SUPPORTED_TASKS = ['detect']
+
+# Names of plots created by YOLOv8 that are logged to Comet
+EVALUATION_PLOT_NAMES = 'F1_curve', 'P_curve', 'R_curve', 'PR_curve', 'confusion_matrix'
+LABEL_PLOT_NAMES = 'labels', 'labels_correlogram'
+
+_comet_image_prediction_count = 0
+
+
+def _get_comet_mode():
+ return os.getenv('COMET_MODE', 'online')
+
+
+def _get_comet_model_name():
+ return os.getenv('COMET_MODEL_NAME', 'YOLOv8')
+
+
+def _get_eval_batch_logging_interval():
+ return int(os.getenv('COMET_EVAL_BATCH_LOGGING_INTERVAL', 1))
+
+
+def _get_max_image_predictions_to_log():
+ return int(os.getenv('COMET_MAX_IMAGE_PREDICTIONS', 100))
+
+
+def _scale_confidence_score(score):
+ scale = float(os.getenv('COMET_MAX_CONFIDENCE_SCORE', 100.0))
+ return score * scale
+
+
+def _should_log_confusion_matrix():
+ return os.getenv('COMET_EVAL_LOG_CONFUSION_MATRIX', 'false').lower() == 'true'
+
+
+def _should_log_image_predictions():
+ return os.getenv('COMET_EVAL_LOG_IMAGE_PREDICTIONS', 'true').lower() == 'true'
+
+
+def _get_experiment_type(mode, project_name):
+ """Return an experiment based on mode and project name."""
+ if mode == 'offline':
+ return comet_ml.OfflineExperiment(project_name=project_name)
+
+ return comet_ml.Experiment(project_name=project_name)
+
+
+def _create_experiment(args):
+ """Ensures that the experiment object is only created in a single process during distributed training."""
+ if RANK not in (-1, 0):
+ return
+ try:
+ comet_mode = _get_comet_mode()
+ _project_name = os.getenv('COMET_PROJECT_NAME', args.project)
+ experiment = _get_experiment_type(comet_mode, _project_name)
+ experiment.log_parameters(vars(args))
+ experiment.log_others({
+ 'eval_batch_logging_interval': _get_eval_batch_logging_interval(),
+ 'log_confusion_matrix_on_eval': _should_log_confusion_matrix(),
+ 'log_image_predictions': _should_log_image_predictions(),
+ 'max_image_predictions': _get_max_image_predictions_to_log(), })
+ experiment.log_other('Created from', 'yolov8')
+
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ Comet installed but not initialized correctly, not logging this run. {e}')
+
+
+def _fetch_trainer_metadata(trainer):
+ """Returns metadata for YOLO training including epoch and asset saving status."""
+ curr_epoch = trainer.epoch + 1
+
+ train_num_steps_per_epoch = len(trainer.train_loader.dataset) // trainer.batch_size
+ curr_step = curr_epoch * train_num_steps_per_epoch
+ final_epoch = curr_epoch == trainer.epochs
+
+ save = trainer.args.save
+ save_period = trainer.args.save_period
+ save_interval = curr_epoch % save_period == 0
+ save_assets = save and save_period > 0 and save_interval and not final_epoch
+
+ return dict(
+ curr_epoch=curr_epoch,
+ curr_step=curr_step,
+ save_assets=save_assets,
+ final_epoch=final_epoch,
+ )
+
+
+def _scale_bounding_box_to_original_image_shape(box, resized_image_shape, original_image_shape, ratio_pad):
+ """YOLOv8 resizes images during training and the label values
+ are normalized based on this resized shape. This function rescales the
+ bounding box labels to the original image shape.
+ """
+
+ resized_image_height, resized_image_width = resized_image_shape
+
+ # Convert normalized xywh format predictions to xyxy in resized scale format
+ box = ops.xywhn2xyxy(box, h=resized_image_height, w=resized_image_width)
+ # Scale box predictions from resized image scale back to original image scale
+ box = ops.scale_boxes(resized_image_shape, box, original_image_shape, ratio_pad)
+ # Convert bounding box format from xyxy to xywh for Comet logging
+ box = ops.xyxy2xywh(box)
+ # Adjust xy center to correspond top-left corner
+ box[:2] -= box[2:] / 2
+ box = box.tolist()
+
+ return box
+
+
+def _format_ground_truth_annotations_for_detection(img_idx, image_path, batch, class_name_map=None):
+ """Format ground truth annotations for detection."""
+ indices = batch['batch_idx'] == img_idx
+ bboxes = batch['bboxes'][indices]
+ if len(bboxes) == 0:
+ LOGGER.debug(f'COMET WARNING: Image: {image_path} has no bounding boxes labels')
+ return None
+
+ cls_labels = batch['cls'][indices].squeeze(1).tolist()
+ if class_name_map:
+ cls_labels = [str(class_name_map[label]) for label in cls_labels]
+
+ original_image_shape = batch['ori_shape'][img_idx]
+ resized_image_shape = batch['resized_shape'][img_idx]
+ ratio_pad = batch['ratio_pad'][img_idx]
+
+ data = []
+ for box, label in zip(bboxes, cls_labels):
+ box = _scale_bounding_box_to_original_image_shape(box, resized_image_shape, original_image_shape, ratio_pad)
+ data.append({
+ 'boxes': [box],
+ 'label': f'gt_{label}',
+ 'score': _scale_confidence_score(1.0), })
+
+ return {'name': 'ground_truth', 'data': data}
+
+
+def _format_prediction_annotations_for_detection(image_path, metadata, class_label_map=None):
+ """Format YOLO predictions for object detection visualization."""
+ stem = image_path.stem
+ image_id = int(stem) if stem.isnumeric() else stem
+
+ predictions = metadata.get(image_id)
+ if not predictions:
+ LOGGER.debug(f'COMET WARNING: Image: {image_path} has no bounding boxes predictions')
+ return None
+
+ data = []
+ for prediction in predictions:
+ boxes = prediction['bbox']
+ score = _scale_confidence_score(prediction['score'])
+ cls_label = prediction['category_id']
+ if class_label_map:
+ cls_label = str(class_label_map[cls_label])
+
+ data.append({'boxes': [boxes], 'label': cls_label, 'score': score})
+
+ return {'name': 'prediction', 'data': data}
+
+
+def _fetch_annotations(img_idx, image_path, batch, prediction_metadata_map, class_label_map):
+ """Join the ground truth and prediction annotations if they exist."""
+ ground_truth_annotations = _format_ground_truth_annotations_for_detection(img_idx, image_path, batch,
+ class_label_map)
+ prediction_annotations = _format_prediction_annotations_for_detection(image_path, prediction_metadata_map,
+ class_label_map)
+
+ annotations = [
+ annotation for annotation in [ground_truth_annotations, prediction_annotations] if annotation is not None]
+ return [annotations] if annotations else None
+
+
+def _create_prediction_metadata_map(model_predictions):
+ """Create metadata map for model predictions by groupings them based on image ID."""
+ pred_metadata_map = {}
+ for prediction in model_predictions:
+ pred_metadata_map.setdefault(prediction['image_id'], [])
+ pred_metadata_map[prediction['image_id']].append(prediction)
+
+ return pred_metadata_map
+
+
+def _log_confusion_matrix(experiment, trainer, curr_step, curr_epoch):
+ """Log the confusion matrix to Comet experiment."""
+ conf_mat = trainer.validator.confusion_matrix.matrix
+ names = list(trainer.data['names'].values()) + ['background']
+ experiment.log_confusion_matrix(
+ matrix=conf_mat,
+ labels=names,
+ max_categories=len(names),
+ epoch=curr_epoch,
+ step=curr_step,
+ )
+
+
+def _log_images(experiment, image_paths, curr_step, annotations=None):
+ """Logs images to the experiment with optional annotations."""
+ if annotations:
+ for image_path, annotation in zip(image_paths, annotations):
+ experiment.log_image(image_path, name=image_path.stem, step=curr_step, annotations=annotation)
+
+ else:
+ for image_path in image_paths:
+ experiment.log_image(image_path, name=image_path.stem, step=curr_step)
+
+
+def _log_image_predictions(experiment, validator, curr_step):
+ """Logs predicted boxes for a single image during training."""
+ global _comet_image_prediction_count
+
+ task = validator.args.task
+ if task not in COMET_SUPPORTED_TASKS:
+ return
+
+ jdict = validator.jdict
+ if not jdict:
+ return
+
+ predictions_metadata_map = _create_prediction_metadata_map(jdict)
+ dataloader = validator.dataloader
+ class_label_map = validator.names
+
+ batch_logging_interval = _get_eval_batch_logging_interval()
+ max_image_predictions = _get_max_image_predictions_to_log()
+
+ for batch_idx, batch in enumerate(dataloader):
+ if (batch_idx + 1) % batch_logging_interval != 0:
+ continue
+
+ image_paths = batch['im_file']
+ for img_idx, image_path in enumerate(image_paths):
+ if _comet_image_prediction_count >= max_image_predictions:
+ return
+
+ image_path = Path(image_path)
+ annotations = _fetch_annotations(
+ img_idx,
+ image_path,
+ batch,
+ predictions_metadata_map,
+ class_label_map,
+ )
+ _log_images(
+ experiment,
+ [image_path],
+ curr_step,
+ annotations=annotations,
+ )
+ _comet_image_prediction_count += 1
+
+
+def _log_plots(experiment, trainer):
+ """Logs evaluation plots and label plots for the experiment."""
+ plot_filenames = [trainer.save_dir / f'{plots}.png' for plots in EVALUATION_PLOT_NAMES]
+ _log_images(experiment, plot_filenames, None)
+
+ label_plot_filenames = [trainer.save_dir / f'{labels}.jpg' for labels in LABEL_PLOT_NAMES]
+ _log_images(experiment, label_plot_filenames, None)
+
+
+def _log_model(experiment, trainer):
+ """Log the best-trained model to Comet.ml."""
+ model_name = _get_comet_model_name()
+ experiment.log_model(
+ model_name,
+ file_or_folder=str(trainer.best),
+ file_name='best.pt',
+ overwrite=True,
+ )
+
+
+def on_pretrain_routine_start(trainer):
+ """Creates or resumes a CometML experiment at the start of a YOLO pre-training routine."""
+ experiment = comet_ml.get_global_experiment()
+ is_alive = getattr(experiment, 'alive', False)
+ if not experiment or not is_alive:
+ _create_experiment(trainer.args)
+
+
+def on_train_epoch_end(trainer):
+ """Log metrics and save batch images at the end of training epochs."""
+ experiment = comet_ml.get_global_experiment()
+ if not experiment:
+ return
+
+ metadata = _fetch_trainer_metadata(trainer)
+ curr_epoch = metadata['curr_epoch']
+ curr_step = metadata['curr_step']
+
+ experiment.log_metrics(
+ trainer.label_loss_items(trainer.tloss, prefix='train'),
+ step=curr_step,
+ epoch=curr_epoch,
+ )
+
+ if curr_epoch == 1:
+ _log_images(experiment, trainer.save_dir.glob('train_batch*.jpg'), curr_step)
+
+
+def on_fit_epoch_end(trainer):
+ """Logs model assets at the end of each epoch."""
+ experiment = comet_ml.get_global_experiment()
+ if not experiment:
+ return
+
+ metadata = _fetch_trainer_metadata(trainer)
+ curr_epoch = metadata['curr_epoch']
+ curr_step = metadata['curr_step']
+ save_assets = metadata['save_assets']
+
+ experiment.log_metrics(trainer.metrics, step=curr_step, epoch=curr_epoch)
+ experiment.log_metrics(trainer.lr, step=curr_step, epoch=curr_epoch)
+ if curr_epoch == 1:
+ experiment.log_metrics(model_info_for_loggers(trainer), step=curr_step, epoch=curr_epoch)
+
+ if not save_assets:
+ return
+
+ _log_model(experiment, trainer)
+ if _should_log_confusion_matrix():
+ _log_confusion_matrix(experiment, trainer, curr_step, curr_epoch)
+ if _should_log_image_predictions():
+ _log_image_predictions(experiment, trainer.validator, curr_step)
+
+
+def on_train_end(trainer):
+ """Perform operations at the end of training."""
+ experiment = comet_ml.get_global_experiment()
+ if not experiment:
+ return
+
+ metadata = _fetch_trainer_metadata(trainer)
+ curr_epoch = metadata['curr_epoch']
+ curr_step = metadata['curr_step']
+ plots = trainer.args.plots
+
+ _log_model(experiment, trainer)
+ if plots:
+ _log_plots(experiment, trainer)
+
+ _log_confusion_matrix(experiment, trainer, curr_step, curr_epoch)
+ _log_image_predictions(experiment, trainer.validator, curr_step)
+ experiment.end()
+
+ global _comet_image_prediction_count
+ _comet_image_prediction_count = 0
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_train_epoch_end': on_train_epoch_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_train_end': on_train_end} if comet_ml else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/dvc.py b/STPoseNet/ultralytics/utils/callbacks/dvc.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf7498bf39b815965b18f4f2577d9fe264d5f5dc
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/dvc.py
@@ -0,0 +1,140 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+import re
+from pathlib import Path
+
+import pkg_resources as pkg
+
+from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+try:
+ from importlib.metadata import version
+
+ import dvclive
+
+ assert not TESTS_RUNNING # do not log pytest
+ assert SETTINGS['dvc'] is True # verify integration is enabled
+
+ ver = version('dvclive')
+ if pkg.parse_version(ver) < pkg.parse_version('2.11.0'):
+ LOGGER.debug(f'DVCLive is detected but version {ver} is incompatible (>=2.11 required).')
+ dvclive = None # noqa: F811
+except (ImportError, AssertionError, TypeError):
+ dvclive = None
+
+# DVCLive logger instance
+live = None
+_processed_plots = {}
+
+# `on_fit_epoch_end` is called on final validation (probably need to be fixed)
+# for now this is the way we distinguish final evaluation of the best model vs
+# last epoch validation
+_training_epoch = False
+
+
+def _log_images(path, prefix=''):
+ if live:
+ name = path.name
+
+ # Group images by batch to enable sliders in UI
+ if m := re.search(r'_batch(\d+)', name):
+ ni = m[1]
+ new_stem = re.sub(r'_batch(\d+)', '_batch', path.stem)
+ name = (Path(new_stem) / ni).with_suffix(path.suffix)
+
+ live.log_image(os.path.join(prefix, name), path)
+
+
+def _log_plots(plots, prefix=''):
+ for name, params in plots.items():
+ timestamp = params['timestamp']
+ if _processed_plots.get(name) != timestamp:
+ _log_images(name, prefix)
+ _processed_plots[name] = timestamp
+
+
+def _log_confusion_matrix(validator):
+ targets = []
+ preds = []
+ matrix = validator.confusion_matrix.matrix
+ names = list(validator.names.values())
+ if validator.confusion_matrix.task == 'detect':
+ names += ['background']
+
+ for ti, pred in enumerate(matrix.T.astype(int)):
+ for pi, num in enumerate(pred):
+ targets.extend([names[ti]] * num)
+ preds.extend([names[pi]] * num)
+
+ live.log_sklearn_plot('confusion_matrix', targets, preds, name='cf.json', normalized=True)
+
+
+def on_pretrain_routine_start(trainer):
+ try:
+ global live
+ live = dvclive.Live(save_dvc_exp=True, cache_images=True)
+ LOGGER.info(
+ f'DVCLive is detected and auto logging is enabled (can be disabled in the {SETTINGS.file} with `dvc: false`).'
+ )
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ DVCLive installed but not initialized correctly, not logging this run. {e}')
+
+
+def on_pretrain_routine_end(trainer):
+ _log_plots(trainer.plots, 'train')
+
+
+def on_train_start(trainer):
+ if live:
+ live.log_params(trainer.args)
+
+
+def on_train_epoch_start(trainer):
+ global _training_epoch
+ _training_epoch = True
+
+
+def on_fit_epoch_end(trainer):
+ global _training_epoch
+ if live and _training_epoch:
+ all_metrics = {**trainer.label_loss_items(trainer.tloss, prefix='train'), **trainer.metrics, **trainer.lr}
+ for metric, value in all_metrics.items():
+ live.log_metric(metric, value)
+
+ if trainer.epoch == 0:
+ for metric, value in model_info_for_loggers(trainer).items():
+ live.log_metric(metric, value, plot=False)
+
+ _log_plots(trainer.plots, 'train')
+ _log_plots(trainer.validator.plots, 'val')
+
+ live.next_step()
+ _training_epoch = False
+
+
+def on_train_end(trainer):
+ if live:
+ # At the end log the best metrics. It runs validator on the best model internally.
+ all_metrics = {**trainer.label_loss_items(trainer.tloss, prefix='train'), **trainer.metrics, **trainer.lr}
+ for metric, value in all_metrics.items():
+ live.log_metric(metric, value, plot=False)
+
+ _log_plots(trainer.plots, 'val')
+ _log_plots(trainer.validator.plots, 'val')
+ _log_confusion_matrix(trainer.validator)
+
+ if trainer.best.exists():
+ live.log_artifact(trainer.best, copy=True, type='model')
+
+ live.end()
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_pretrain_routine_end': on_pretrain_routine_end,
+ 'on_train_start': on_train_start,
+ 'on_train_epoch_start': on_train_epoch_start,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_train_end': on_train_end} if dvclive else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/hub.py b/STPoseNet/ultralytics/utils/callbacks/hub.py
new file mode 100644
index 0000000000000000000000000000000000000000..fba5a6b57817836e09e1e398e1a85426316ee64a
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/hub.py
@@ -0,0 +1,87 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import json
+from time import time
+
+from ultralytics.hub.utils import HUB_WEB_ROOT, PREFIX, events
+from ultralytics.utils import LOGGER, SETTINGS
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+
+def on_pretrain_routine_end(trainer):
+ """Logs info before starting timer for upload rate limit."""
+ session = getattr(trainer, 'hub_session', None)
+ if session:
+ # Start timer for upload rate limit
+ LOGGER.info(f'{PREFIX}View model at {HUB_WEB_ROOT}/models/{session.model_id} 🚀')
+ session.timers = {'metrics': time(), 'ckpt': time()} # start timer on session.rate_limit
+
+
+def on_fit_epoch_end(trainer):
+ """Uploads training progress metrics at the end of each epoch."""
+ session = getattr(trainer, 'hub_session', None)
+ if session:
+ # Upload metrics after val end
+ all_plots = {**trainer.label_loss_items(trainer.tloss, prefix='train'), **trainer.metrics}
+ if trainer.epoch == 0:
+ all_plots = {**all_plots, **model_info_for_loggers(trainer)}
+ session.metrics_queue[trainer.epoch] = json.dumps(all_plots)
+ if time() - session.timers['metrics'] > session.rate_limits['metrics']:
+ session.upload_metrics()
+ session.timers['metrics'] = time() # reset timer
+ session.metrics_queue = {} # reset queue
+
+
+def on_model_save(trainer):
+ """Saves checkpoints to Ultralytics HUB with rate limiting."""
+ session = getattr(trainer, 'hub_session', None)
+ if session:
+ # Upload checkpoints with rate limiting
+ is_best = trainer.best_fitness == trainer.fitness
+ if time() - session.timers['ckpt'] > session.rate_limits['ckpt']:
+ LOGGER.info(f'{PREFIX}Uploading checkpoint {HUB_WEB_ROOT}/models/{session.model_id}')
+ session.upload_model(trainer.epoch, trainer.last, is_best)
+ session.timers['ckpt'] = time() # reset timer
+
+
+def on_train_end(trainer):
+ """Upload final model and metrics to Ultralytics HUB at the end of training."""
+ session = getattr(trainer, 'hub_session', None)
+ if session:
+ # Upload final model and metrics with exponential standoff
+ LOGGER.info(f'{PREFIX}Syncing final model...')
+ session.upload_model(trainer.epoch, trainer.best, map=trainer.metrics.get('metrics/mAP50-95(B)', 0), final=True)
+ session.alive = False # stop heartbeats
+ LOGGER.info(f'{PREFIX}Done ✅\n'
+ f'{PREFIX}View model at {HUB_WEB_ROOT}/models/{session.model_id} 🚀')
+
+
+def on_train_start(trainer):
+ """Run events on train start."""
+ events(trainer.args)
+
+
+def on_val_start(validator):
+ """Runs events on validation start."""
+ events(validator.args)
+
+
+def on_predict_start(predictor):
+ """Run events on predict start."""
+ events(predictor.args)
+
+
+def on_export_start(exporter):
+ """Run events on export start."""
+ events(exporter.args)
+
+
+callbacks = {
+ 'on_pretrain_routine_end': on_pretrain_routine_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_model_save': on_model_save,
+ 'on_train_end': on_train_end,
+ 'on_train_start': on_train_start,
+ 'on_val_start': on_val_start,
+ 'on_predict_start': on_predict_start,
+ 'on_export_start': on_export_start} if SETTINGS['hub'] is True else {} # verify enabled
diff --git a/STPoseNet/ultralytics/utils/callbacks/mlflow.py b/STPoseNet/ultralytics/utils/callbacks/mlflow.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3256d6f03c90af9fb3edc19fef4d9ec61dc563c
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/mlflow.py
@@ -0,0 +1,71 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+import re
+from pathlib import Path
+
+from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING, colorstr
+
+try:
+ import mlflow
+
+ assert not TESTS_RUNNING # do not log pytest
+ assert hasattr(mlflow, '__version__') # verify package is not directory
+ assert SETTINGS['mlflow'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ mlflow = None
+
+
+def on_pretrain_routine_end(trainer):
+ """Logs training parameters to MLflow."""
+ global mlflow, run, experiment_name
+
+ if os.environ.get('MLFLOW_TRACKING_URI') is None:
+ mlflow = None
+
+ if mlflow:
+ mlflow_location = os.environ['MLFLOW_TRACKING_URI'] # "http://192.168.xxx.xxx:5000"
+ mlflow.set_tracking_uri(mlflow_location)
+
+ experiment_name = os.environ.get('MLFLOW_EXPERIMENT_NAME') or trainer.args.project or '/Shared/YOLOv8'
+ run_name = os.environ.get('MLFLOW_RUN') or trainer.args.name
+ experiment = mlflow.get_experiment_by_name(experiment_name)
+ if experiment is None:
+ mlflow.create_experiment(experiment_name)
+ mlflow.set_experiment(experiment_name)
+
+ prefix = colorstr('MLFlow: ')
+ try:
+ run, active_run = mlflow, mlflow.active_run()
+ if not active_run:
+ active_run = mlflow.start_run(experiment_id=experiment.experiment_id, run_name=run_name)
+ LOGGER.info(f'{prefix}Using run_id({active_run.info.run_id}) at {mlflow_location}')
+ run.log_params(vars(trainer.model.args))
+ except Exception as err:
+ LOGGER.error(f'{prefix}Failing init - {repr(err)}')
+ LOGGER.warning(f'{prefix}Continuing without Mlflow')
+
+
+def on_fit_epoch_end(trainer):
+ """Logs training metrics to Mlflow."""
+ if mlflow:
+ metrics_dict = {f"{re.sub('[()]', '', k)}": float(v) for k, v in trainer.metrics.items()}
+ run.log_metrics(metrics=metrics_dict, step=trainer.epoch)
+
+
+def on_train_end(trainer):
+ """Called at end of train loop to log model artifact info."""
+ if mlflow:
+ root_dir = Path(__file__).resolve().parents[3]
+ run.log_artifact(trainer.last)
+ run.log_artifact(trainer.best)
+ run.pyfunc.log_model(artifact_path=experiment_name,
+ code_path=[str(root_dir)],
+ artifacts={'model_path': str(trainer.save_dir)},
+ python_model=run.pyfunc.PythonModel())
+
+
+callbacks = {
+ 'on_pretrain_routine_end': on_pretrain_routine_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_train_end': on_train_end} if mlflow else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/neptune.py b/STPoseNet/ultralytics/utils/callbacks/neptune.py
new file mode 100644
index 0000000000000000000000000000000000000000..f72a63b25803fcc031235ef1905eb97a0362d08f
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/neptune.py
@@ -0,0 +1,104 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import matplotlib.image as mpimg
+import matplotlib.pyplot as plt
+
+from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+try:
+ import neptune
+ from neptune.types import File
+
+ assert not TESTS_RUNNING # do not log pytest
+ assert hasattr(neptune, '__version__')
+ assert SETTINGS['neptune'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ neptune = None
+
+run = None # NeptuneAI experiment logger instance
+
+
+def _log_scalars(scalars, step=0):
+ """Log scalars to the NeptuneAI experiment logger."""
+ if run:
+ for k, v in scalars.items():
+ run[k].append(value=v, step=step)
+
+
+def _log_images(imgs_dict, group=''):
+ """Log scalars to the NeptuneAI experiment logger."""
+ if run:
+ for k, v in imgs_dict.items():
+ run[f'{group}/{k}'].upload(File(v))
+
+
+def _log_plot(title, plot_path):
+ """Log plots to the NeptuneAI experiment logger."""
+ """
+ Log image as plot in the plot section of NeptuneAI
+
+ arguments:
+ title (str) Title of the plot
+ plot_path (PosixPath or str) Path to the saved image file
+ """
+ img = mpimg.imread(plot_path)
+ fig = plt.figure()
+ ax = fig.add_axes([0, 0, 1, 1], frameon=False, aspect='auto', xticks=[], yticks=[]) # no ticks
+ ax.imshow(img)
+ run[f'Plots/{title}'].upload(fig)
+
+
+def on_pretrain_routine_start(trainer):
+ """Callback function called before the training routine starts."""
+ try:
+ global run
+ run = neptune.init_run(project=trainer.args.project or 'YOLOv8', name=trainer.args.name, tags=['YOLOv8'])
+ run['Configuration/Hyperparameters'] = {k: '' if v is None else v for k, v in vars(trainer.args).items()}
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ NeptuneAI installed but not initialized correctly, not logging this run. {e}')
+
+
+def on_train_epoch_end(trainer):
+ """Callback function called at end of each training epoch."""
+ _log_scalars(trainer.label_loss_items(trainer.tloss, prefix='train'), trainer.epoch + 1)
+ _log_scalars(trainer.lr, trainer.epoch + 1)
+ if trainer.epoch == 1:
+ _log_images({f.stem: str(f) for f in trainer.save_dir.glob('train_batch*.jpg')}, 'Mosaic')
+
+
+def on_fit_epoch_end(trainer):
+ """Callback function called at end of each fit (train+val) epoch."""
+ if run and trainer.epoch == 0:
+ run['Configuration/Model'] = model_info_for_loggers(trainer)
+ _log_scalars(trainer.metrics, trainer.epoch + 1)
+
+
+def on_val_end(validator):
+ """Callback function called at end of each validation."""
+ if run:
+ # Log val_labels and val_pred
+ _log_images({f.stem: str(f) for f in validator.save_dir.glob('val*.jpg')}, 'Validation')
+
+
+def on_train_end(trainer):
+ """Callback function called at end of training."""
+ if run:
+ # Log final results, CM matrix + PR plots
+ files = [
+ 'results.png', 'confusion_matrix.png', 'confusion_matrix_normalized.png',
+ *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(trainer.save_dir / f) for f in files if (trainer.save_dir / f).exists()] # filter
+ for f in files:
+ _log_plot(title=f.stem, plot_path=f)
+ # Log the final model
+ run[f'weights/{trainer.args.name or trainer.args.task}/{str(trainer.best.name)}'].upload(File(str(
+ trainer.best)))
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_train_epoch_end': on_train_epoch_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_val_end': on_val_end,
+ 'on_train_end': on_train_end} if neptune else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/raytune.py b/STPoseNet/ultralytics/utils/callbacks/raytune.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ca1d2b3c29a42ef6b895c0c7d69bef8d151c129
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/raytune.py
@@ -0,0 +1,24 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.utils import SETTINGS
+
+try:
+ import ray
+ from ray import tune
+ from ray.air import session
+
+ assert SETTINGS['raytune'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ tune = None
+
+
+def on_fit_epoch_end(trainer):
+ """Sends training metrics to Ray Tune at end of each epoch."""
+ if ray.tune.is_session_enabled():
+ metrics = trainer.metrics
+ metrics['epoch'] = trainer.epoch
+ session.report(metrics)
+
+
+callbacks = {
+ 'on_fit_epoch_end': on_fit_epoch_end, } if tune else {}
diff --git a/STPoseNet/ultralytics/utils/callbacks/tensorboard.py b/STPoseNet/ultralytics/utils/callbacks/tensorboard.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cd5708bb51fe6d26114b5fc7c436548c7d6f26d
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/tensorboard.py
@@ -0,0 +1,75 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING, colorstr
+
+try:
+ from torch.utils.tensorboard import SummaryWriter
+
+ assert not TESTS_RUNNING # do not log pytest
+ assert SETTINGS['tensorboard'] is True # verify integration is enabled
+
+# TypeError for handling 'Descriptors cannot not be created directly.' protobuf errors in Windows
+except (ImportError, AssertionError, TypeError):
+ SummaryWriter = None
+
+WRITER = None # TensorBoard SummaryWriter instance
+
+
+def _log_scalars(scalars, step=0):
+ """Logs scalar values to TensorBoard."""
+ if WRITER:
+ for k, v in scalars.items():
+ WRITER.add_scalar(k, v, step)
+
+
+def _log_tensorboard_graph(trainer):
+ """Log model graph to TensorBoard."""
+ try:
+ import warnings
+
+ from ultralytics.utils.torch_utils import de_parallel, torch
+
+ imgsz = trainer.args.imgsz
+ imgsz = (imgsz, imgsz) if isinstance(imgsz, int) else imgsz
+ p = next(trainer.model.parameters()) # for device, type
+ im = torch.zeros((1, 3, *imgsz), device=p.device, dtype=p.dtype) # input image (must be zeros, not empty)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore', category=UserWarning) # suppress jit trace warning
+ WRITER.add_graph(torch.jit.trace(de_parallel(trainer.model), im, strict=False), [])
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ TensorBoard graph visualization failure {e}')
+
+
+def on_pretrain_routine_start(trainer):
+ """Initialize TensorBoard logging with SummaryWriter."""
+ if SummaryWriter:
+ try:
+ global WRITER
+ WRITER = SummaryWriter(str(trainer.save_dir))
+ prefix = colorstr('TensorBoard: ')
+ LOGGER.info(f"{prefix}Start with 'tensorboard --logdir {trainer.save_dir}', view at http://localhost:6006/")
+ except Exception as e:
+ LOGGER.warning(f'WARNING ⚠️ TensorBoard not initialized correctly, not logging this run. {e}')
+
+
+def on_train_start(trainer):
+ """Log TensorBoard graph."""
+ if WRITER:
+ _log_tensorboard_graph(trainer)
+
+
+def on_batch_end(trainer):
+ """Logs scalar statistics at the end of a training batch."""
+ _log_scalars(trainer.label_loss_items(trainer.tloss, prefix='train'), trainer.epoch + 1)
+
+
+def on_fit_epoch_end(trainer):
+ """Logs epoch metrics at end of training epoch."""
+ _log_scalars(trainer.metrics, trainer.epoch + 1)
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_train_start': on_train_start,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_batch_end': on_batch_end}
diff --git a/STPoseNet/ultralytics/utils/callbacks/wb.py b/STPoseNet/ultralytics/utils/callbacks/wb.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a8ee242670a832032f4ff54dfd46d11c693bfde
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/callbacks/wb.py
@@ -0,0 +1,62 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.utils import SETTINGS, TESTS_RUNNING
+from ultralytics.utils.torch_utils import model_info_for_loggers
+
+try:
+ import wandb as wb
+
+ assert hasattr(wb, '__version__')
+ assert not TESTS_RUNNING # do not log pytest
+ assert SETTINGS['wandb'] is True # verify integration is enabled
+except (ImportError, AssertionError):
+ wb = None
+
+_processed_plots = {}
+
+
+def _log_plots(plots, step):
+ for name, params in plots.items():
+ timestamp = params['timestamp']
+ if _processed_plots.get(name) != timestamp:
+ wb.run.log({name.stem: wb.Image(str(name))}, step=step)
+ _processed_plots[name] = timestamp
+
+
+def on_pretrain_routine_start(trainer):
+ """Initiate and start project if module is present."""
+ wb.run or wb.init(project=trainer.args.project or 'YOLOv8', name=trainer.args.name, config=vars(trainer.args))
+
+
+def on_fit_epoch_end(trainer):
+ """Logs training metrics and model information at the end of an epoch."""
+ wb.run.log(trainer.metrics, step=trainer.epoch + 1)
+ _log_plots(trainer.plots, step=trainer.epoch + 1)
+ _log_plots(trainer.validator.plots, step=trainer.epoch + 1)
+ if trainer.epoch == 0:
+ wb.run.log(model_info_for_loggers(trainer), step=trainer.epoch + 1)
+
+
+def on_train_epoch_end(trainer):
+ """Log metrics and save images at the end of each training epoch."""
+ wb.run.log(trainer.label_loss_items(trainer.tloss, prefix='train'), step=trainer.epoch + 1)
+ wb.run.log(trainer.lr, step=trainer.epoch + 1)
+ if trainer.epoch == 1:
+ _log_plots(trainer.plots, step=trainer.epoch + 1)
+
+
+def on_train_end(trainer):
+ """Save the best model as an artifact at end of training."""
+ _log_plots(trainer.validator.plots, step=trainer.epoch + 1)
+ _log_plots(trainer.plots, step=trainer.epoch + 1)
+ art = wb.Artifact(type='model', name=f'run_{wb.run.id}_model')
+ if trainer.best.exists():
+ art.add_file(trainer.best)
+ wb.run.log_artifact(art, aliases=['best'])
+
+
+callbacks = {
+ 'on_pretrain_routine_start': on_pretrain_routine_start,
+ 'on_train_epoch_end': on_train_epoch_end,
+ 'on_fit_epoch_end': on_fit_epoch_end,
+ 'on_train_end': on_train_end} if wb else {}
diff --git a/STPoseNet/ultralytics/utils/checks.py b/STPoseNet/ultralytics/utils/checks.py
new file mode 100644
index 0000000000000000000000000000000000000000..28cad0dc722861a304c85c102cb18840b2e7413d
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/checks.py
@@ -0,0 +1,538 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+import contextlib
+import glob
+import inspect
+import math
+import os
+import platform
+import re
+import shutil
+import subprocess
+import time
+from pathlib import Path
+from typing import Optional
+
+import cv2
+import numpy as np
+import pkg_resources as pkg
+import psutil
+import requests
+import torch
+from matplotlib import font_manager
+
+from ultralytics.utils import (ASSETS, AUTOINSTALL, LINUX, LOGGER, ONLINE, ROOT, USER_CONFIG_DIR, ThreadingLocked,
+ TryExcept, clean_url, colorstr, downloads, emojis, is_colab, is_docker, is_jupyter,
+ is_kaggle, is_online, is_pip_package, url2file)
+
+
+def is_ascii(s) -> bool:
+ """
+ Check if a string is composed of only ASCII characters.
+
+ Args:
+ s (str): String to be checked.
+
+ Returns:
+ bool: True if the string is composed only of ASCII characters, False otherwise.
+ """
+ # Convert list, tuple, None, etc. to string
+ s = str(s)
+
+ # Check if the string is composed of only ASCII characters
+ return all(ord(c) < 128 for c in s)
+
+
+def check_imgsz(imgsz, stride=32, min_dim=1, max_dim=2, floor=0):
+ """
+ Verify image size is a multiple of the given stride in each dimension. If the image size is not a multiple of the
+ stride, update it to the nearest multiple of the stride that is greater than or equal to the given floor value.
+
+ Args:
+ imgsz (int | cList[int]): Image size.
+ stride (int): Stride value.
+ min_dim (int): Minimum number of dimensions.
+ max_dim (int): Maximum number of dimensions.
+ floor (int): Minimum allowed value for image size.
+
+ Returns:
+ (List[int]): Updated image size.
+ """
+ # Convert stride to integer if it is a tensor
+ stride = int(stride.max() if isinstance(stride, torch.Tensor) else stride)
+
+ # Convert image size to list if it is an integer
+ if isinstance(imgsz, int):
+ imgsz = [imgsz]
+ elif isinstance(imgsz, (list, tuple)):
+ imgsz = list(imgsz)
+ else:
+ raise TypeError(f"'imgsz={imgsz}' is of invalid type {type(imgsz).__name__}. "
+ f"Valid imgsz types are int i.e. 'imgsz=640' or list i.e. 'imgsz=[640,640]'")
+
+ # Apply max_dim
+ if len(imgsz) > max_dim:
+ msg = "'train' and 'val' imgsz must be an integer, while 'predict' and 'export' imgsz may be a [h, w] list " \
+ "or an integer, i.e. 'yolo export imgsz=640,480' or 'yolo export imgsz=640'"
+ if max_dim != 1:
+ raise ValueError(f'imgsz={imgsz} is not a valid image size. {msg}')
+ LOGGER.warning(f"WARNING ⚠️ updating to 'imgsz={max(imgsz)}'. {msg}")
+ imgsz = [max(imgsz)]
+ # Make image size a multiple of the stride
+ sz = [max(math.ceil(x / stride) * stride, floor) for x in imgsz]
+
+ # Print warning message if image size was updated
+ if sz != imgsz:
+ LOGGER.warning(f'WARNING ⚠️ imgsz={imgsz} must be multiple of max stride {stride}, updating to {sz}')
+
+ # Add missing dimensions if necessary
+ sz = [sz[0], sz[0]] if min_dim == 2 and len(sz) == 1 else sz[0] if min_dim == 1 and len(sz) == 1 else sz
+
+ return sz
+
+
+def check_version(current: str = '0.0.0',
+ required: str = '0.0.0',
+ name: str = 'version ',
+ hard: bool = False,
+ verbose: bool = False) -> bool:
+ """
+ Check current version against the required version or range.
+
+ Args:
+ current (str): Current version.
+ required (str): Required version or range (in pip-style format).
+ name (str): Name to be used in warning message.
+ hard (bool): If True, raise an AssertionError if the requirement is not met.
+ verbose (bool): If True, print warning message if requirement is not met.
+
+ Returns:
+ (bool): True if requirement is met, False otherwise.
+
+ Example:
+ # check if current version is exactly 22.04
+ check_version(current='22.04', required='==22.04')
+
+ # check if current version is greater than or equal to 22.04
+ check_version(current='22.10', required='22.04') # assumes '>=' inequality if none passed
+
+ # check if current version is less than or equal to 22.04
+ check_version(current='22.04', required='<=22.04')
+
+ # check if current version is between 20.04 (inclusive) and 22.04 (exclusive)
+ check_version(current='21.10', required='>20.04,<22.04')
+ """
+ current = pkg.parse_version(current)
+ constraints = re.findall(r'([<>!=]{1,2}\s*\d+\.\d+)', required) or [f'>={required}']
+
+ result = True
+ for constraint in constraints:
+ op, version = re.match(r'([<>!=]{1,2})\s*(\d+\.\d+)', constraint).groups()
+ version = pkg.parse_version(version)
+ if op == '==' and current != version:
+ result = False
+ elif op == '!=' and current == version:
+ result = False
+ elif op == '>=' and not (current >= version):
+ result = False
+ elif op == '<=' and not (current <= version):
+ result = False
+ elif op == '>' and not (current > version):
+ result = False
+ elif op == '<' and not (current < version):
+ result = False
+ if not result:
+ warning_message = f'WARNING ⚠️ {name}{required} is required, but {name}{current} is currently installed'
+ if hard:
+ raise ModuleNotFoundError(emojis(warning_message)) # assert version requirements met
+ if verbose:
+ LOGGER.warning(warning_message)
+ return result
+
+
+def check_latest_pypi_version(package_name='ultralytics'):
+ """
+ Returns the latest version of a PyPI package without downloading or installing it.
+
+ Parameters:
+ package_name (str): The name of the package to find the latest version for.
+
+ Returns:
+ (str): The latest version of the package.
+ """
+ with contextlib.suppress(Exception):
+ requests.packages.urllib3.disable_warnings() # Disable the InsecureRequestWarning
+ response = requests.get(f'https://pypi.org/pypi/{package_name}/json', timeout=3)
+ if response.status_code == 200:
+ return response.json()['info']['version']
+
+
+def check_pip_update_available():
+ """
+ Checks if a new version of the ultralytics package is available on PyPI.
+
+ Returns:
+ (bool): True if an update is available, False otherwise.
+ """
+ if ONLINE and is_pip_package():
+ with contextlib.suppress(Exception):
+ from ultralytics import __version__
+ latest = check_latest_pypi_version()
+ if pkg.parse_version(__version__) < pkg.parse_version(latest): # update is available
+ LOGGER.info(f'New https://pypi.org/project/ultralytics/{latest} available 😃 '
+ f"Update with 'pip install -U ultralytics'")
+ return True
+ return False
+
+
+@ThreadingLocked()
+def check_font(font='Arial.ttf'):
+ """
+ Find font locally or download to user's configuration directory if it does not already exist.
+
+ Args:
+ font (str): Path or name of font.
+
+ Returns:
+ file (Path): Resolved font file path.
+ """
+ name = Path(font).name
+
+ # Check USER_CONFIG_DIR
+ file = USER_CONFIG_DIR / name
+ if file.exists():
+ return file
+
+ # Check system fonts
+ matches = [s for s in font_manager.findSystemFonts() if font in s]
+ if any(matches):
+ return matches[0]
+
+ # Download to USER_CONFIG_DIR if missing
+ url = f'https://ultralytics.com/assets/{name}'
+ if downloads.is_url(url):
+ downloads.safe_download(url=url, file=file)
+ return file
+
+
+def check_python(minimum: str = '3.8.0') -> bool:
+ """
+ Check current python version against the required minimum version.
+
+ Args:
+ minimum (str): Required minimum version of python.
+
+ Returns:
+ None
+ """
+ return check_version(platform.python_version(), minimum, name='Python ', hard=True)
+
+
+@TryExcept()
+def check_requirements(requirements=ROOT.parent / 'requirements.txt', exclude=(), install=True, cmds=''):
+ """
+ Check if installed dependencies meet YOLOv8 requirements and attempt to auto-update if needed.
+
+ Args:
+ requirements (Union[Path, str, List[str]]): Path to a requirements.txt file, a single package requirement as a
+ string, or a list of package requirements as strings.
+ exclude (Tuple[str]): Tuple of package names to exclude from checking.
+ install (bool): If True, attempt to auto-update packages that don't meet requirements.
+ cmds (str): Additional commands to pass to the pip install command when auto-updating.
+
+ Example:
+ ```python
+ from ultralytics.utils.checks import check_requirements
+
+ # Check a requirements.txt file
+ check_requirements('path/to/requirements.txt')
+
+ # Check a single package
+ check_requirements('ultralytics>=8.0.0')
+
+ # Check multiple packages
+ check_requirements(['numpy', 'ultralytics>=8.0.0'])
+ ```
+ """
+ prefix = colorstr('red', 'bold', 'requirements:')
+ check_python() # check python version
+ check_torchvision() # check torch-torchvision compatibility
+ if isinstance(requirements, Path): # requirements.txt file
+ file = requirements.resolve()
+ assert file.exists(), f'{prefix} {file} not found, check failed.'
+ with file.open() as f:
+ requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
+ elif isinstance(requirements, str):
+ requirements = [requirements]
+
+ pkgs = []
+ for r in requirements:
+ r_stripped = r.split('/')[-1].replace('.git', '') # replace git+https://org/repo.git -> 'repo'
+ try:
+ pkg.require(r_stripped) # exception if requirements not met
+ except pkg.DistributionNotFound:
+ try: # attempt to import (slower but more accurate)
+ import importlib
+ importlib.import_module(next(pkg.parse_requirements(r_stripped)).name)
+ except ImportError:
+ pkgs.append(r)
+ except pkg.VersionConflict:
+ pkgs.append(r)
+
+ s = ' '.join(f'"{x}"' for x in pkgs) # console string
+ if s:
+ if install and AUTOINSTALL: # check environment variable
+ n = len(pkgs) # number of packages updates
+ LOGGER.info(f"{prefix} Ultralytics requirement{'s' * (n > 1)} {pkgs} not found, attempting AutoUpdate...")
+ try:
+ t = time.time()
+ assert is_online(), 'AutoUpdate skipped (offline)'
+ LOGGER.info(subprocess.check_output(f'pip install --no-cache {s} {cmds}', shell=True).decode())
+ dt = time.time() - t
+ LOGGER.info(
+ f"{prefix} AutoUpdate success ✅ {dt:.1f}s, installed {n} package{'s' * (n > 1)}: {pkgs}\n"
+ f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n")
+ except Exception as e:
+ LOGGER.warning(f'{prefix} ❌ {e}')
+ return False
+ else:
+ return False
+
+ return True
+
+
+def check_torchvision():
+ """
+ Checks the installed versions of PyTorch and Torchvision to ensure they're compatible.
+
+ This function checks the installed versions of PyTorch and Torchvision, and warns if they're incompatible according
+ to the provided compatibility table based on https://github.com/pytorch/vision#installation. The
+ compatibility table is a dictionary where the keys are PyTorch versions and the values are lists of compatible
+ Torchvision versions.
+ """
+
+ import torchvision
+
+ # Compatibility table
+ compatibility_table = {'2.0': ['0.15'], '1.13': ['0.14'], '1.12': ['0.13']}
+
+ # Extract only the major and minor versions
+ v_torch = '.'.join(torch.__version__.split('+')[0].split('.')[:2])
+ v_torchvision = '.'.join(torchvision.__version__.split('+')[0].split('.')[:2])
+
+ if v_torch in compatibility_table:
+ compatible_versions = compatibility_table[v_torch]
+ if all(pkg.parse_version(v_torchvision) != pkg.parse_version(v) for v in compatible_versions):
+ print(f'WARNING ⚠️ torchvision=={v_torchvision} is incompatible with torch=={v_torch}.\n'
+ f"Run 'pip install torchvision=={compatible_versions[0]}' to fix torchvision or "
+ "'pip install -U torch torchvision' to update both.\n"
+ 'For a full compatibility table see https://github.com/pytorch/vision#installation')
+
+
+def check_suffix(file='yolov8n.pt', suffix='.pt', msg=''):
+ """Check file(s) for acceptable suffix."""
+ if file and suffix:
+ if isinstance(suffix, str):
+ suffix = (suffix, )
+ for f in file if isinstance(file, (list, tuple)) else [file]:
+ s = Path(f).suffix.lower().strip() # file suffix
+ if len(s):
+ assert s in suffix, f'{msg}{f} acceptable suffix is {suffix}, not {s}'
+
+
+def check_yolov5u_filename(file: str, verbose: bool = True):
+ """Replace legacy YOLOv5 filenames with updated YOLOv5u filenames."""
+ if 'yolov3' in file or 'yolov5' in file:
+ if 'u.yaml' in file:
+ file = file.replace('u.yaml', '.yaml') # i.e. yolov5nu.yaml -> yolov5n.yaml
+ elif '.pt' in file and 'u' not in file:
+ original_file = file
+ file = re.sub(r'(.*yolov5([nsmlx]))\.pt', '\\1u.pt', file) # i.e. yolov5n.pt -> yolov5nu.pt
+ file = re.sub(r'(.*yolov5([nsmlx])6)\.pt', '\\1u.pt', file) # i.e. yolov5n6.pt -> yolov5n6u.pt
+ file = re.sub(r'(.*yolov3(|-tiny|-spp))\.pt', '\\1u.pt', file) # i.e. yolov3-spp.pt -> yolov3-sppu.pt
+ if file != original_file and verbose:
+ LOGGER.info(
+ f"PRO TIP 💡 Replace 'model={original_file}' with new 'model={file}'.\nYOLOv5 'u' models are "
+ f'trained with https://github.com/ultralytics/ultralytics and feature improved performance vs '
+ f'standard YOLOv5 models trained with https://github.com/ultralytics/yolov5.\n')
+ return file
+
+
+def check_file(file, suffix='', download=True, hard=True):
+ """Search/download file (if necessary) and return path."""
+ check_suffix(file, suffix) # optional
+ file = str(file).strip() # convert to string and strip spaces
+ file = check_yolov5u_filename(file) # yolov5n -> yolov5nu
+ if not file or ('://' not in file and Path(file).exists()): # exists ('://' check required in Windows Python<3.10)
+ return file
+ elif download and file.lower().startswith(('https://', 'http://', 'rtsp://', 'rtmp://')): # download
+ url = file # warning: Pathlib turns :// -> :/
+ file = url2file(file) # '%2F' to '/', split https://url.com/file.txt?auth
+ if Path(file).exists():
+ LOGGER.info(f'Found {clean_url(url)} locally at {file}') # file already exists
+ else:
+ downloads.safe_download(url=url, file=file, unzip=False)
+ return file
+ else: # search
+ files = glob.glob(str(ROOT / 'cfg' / '**' / file), recursive=True) # find file
+ if not files and hard:
+ raise FileNotFoundError(f"'{file}' does not exist")
+ elif len(files) > 1 and hard:
+ raise FileNotFoundError(f"Multiple files match '{file}', specify exact path: {files}")
+ return files[0] if len(files) else [] # return file
+
+
+def check_yaml(file, suffix=('.yaml', '.yml'), hard=True):
+ """Search/download YAML file (if necessary) and return path, checking suffix."""
+ return check_file(file, suffix, hard=hard)
+
+
+def check_imshow(warn=False):
+ """Check if environment supports image displays."""
+ try:
+ if LINUX:
+ assert 'DISPLAY' in os.environ and not is_docker() and not is_colab() and not is_kaggle()
+ cv2.imshow('test', np.zeros((8, 8, 3), dtype=np.uint8)) # show a small 8-pixel image
+ cv2.waitKey(1)
+ cv2.destroyAllWindows()
+ cv2.waitKey(1)
+ return True
+ except Exception as e:
+ if warn:
+ LOGGER.warning(f'WARNING ⚠️ Environment does not support cv2.imshow() or PIL Image.show()\n{e}')
+ return False
+
+
+def check_yolo(verbose=True, device=''):
+ """Return a human-readable YOLO software and hardware summary."""
+ from ultralytics.utils.torch_utils import select_device
+
+ if is_jupyter():
+ if check_requirements('wandb', install=False):
+ os.system('pip uninstall -y wandb') # uninstall wandb: unwanted account creation prompt with infinite hang
+ if is_colab():
+ shutil.rmtree('sample_data', ignore_errors=True) # remove colab /sample_data directory
+
+ if verbose:
+ # System info
+ gib = 1 << 30 # bytes per GiB
+ ram = psutil.virtual_memory().total
+ total, used, free = shutil.disk_usage('/')
+ s = f'({os.cpu_count()} CPUs, {ram / gib:.1f} GB RAM, {(total - free) / gib:.1f}/{total / gib:.1f} GB disk)'
+ with contextlib.suppress(Exception): # clear display if ipython is installed
+ from IPython import display
+ display.clear_output()
+ else:
+ s = ''
+
+ select_device(device=device, newline=False)
+ LOGGER.info(f'Setup complete ✅ {s}')
+
+
+def check_amp(model):
+ """
+ This function checks the PyTorch Automatic Mixed Precision (AMP) functionality of a YOLOv8 model.
+ If the checks fail, it means there are anomalies with AMP on the system that may cause NaN losses or zero-mAP
+ results, so AMP will be disabled during training.
+
+ Args:
+ model (nn.Module): A YOLOv8 model instance.
+
+ Example:
+ ```python
+ from ultralytics import YOLO
+ from ultralytics.utils.checks import check_amp
+
+ model = YOLO('yolov8n.pt').model.cuda()
+ check_amp(model)
+ ```
+
+ Returns:
+ (bool): Returns True if the AMP functionality works correctly with YOLOv8 model, else False.
+ """
+ device = next(model.parameters()).device # get model device
+ if device.type in ('cpu', 'mps'):
+ return False # AMP only used on CUDA devices
+
+ def amp_allclose(m, im):
+ """All close FP32 vs AMP results."""
+ a = m(im, device=device, verbose=False)[0].boxes.data # FP32 inference
+ with torch.cuda.amp.autocast(True):
+ b = m(im, device=device, verbose=False)[0].boxes.data # AMP inference
+ del m
+ return a.shape == b.shape and torch.allclose(a, b.float(), atol=0.5) # close to 0.5 absolute tolerance
+
+ im = ASSETS / 'bus.jpg' # image to check
+ prefix = colorstr('AMP: ')
+ LOGGER.info(f'{prefix}running Automatic Mixed Precision (AMP) checks with YOLOv8n...')
+ warning_msg = "Setting 'amp=True'. If you experience zero-mAP or NaN losses you can disable AMP with amp=False."
+ try:
+ from ultralytics import YOLO
+ assert amp_allclose(YOLO('yolov8n.pt'), im)
+ LOGGER.info(f'{prefix}checks passed ✅')
+ except ConnectionError:
+ LOGGER.warning(f'{prefix}checks skipped ⚠️, offline and unable to download YOLOv8n. {warning_msg}')
+ except (AttributeError, ModuleNotFoundError):
+ LOGGER.warning(
+ f'{prefix}checks skipped ⚠️. Unable to load YOLOv8n due to possible Ultralytics package modifications. {warning_msg}'
+ )
+ except AssertionError:
+ LOGGER.warning(f'{prefix}checks failed ❌. Anomalies were detected with AMP on your system that may lead to '
+ f'NaN losses or zero-mAP results, so AMP will be disabled during training.')
+ return False
+ return True
+
+
+def git_describe(path=ROOT): # path must be a directory
+ """Return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe."""
+ with contextlib.suppress(Exception):
+ return subprocess.check_output(f'git -C {path} describe --tags --long --always', shell=True).decode()[:-1]
+ return ''
+
+
+def print_args(args: Optional[dict] = None, show_file=True, show_func=False):
+ """Print function arguments (optional args dict)."""
+
+ def strip_auth(v):
+ """Clean longer Ultralytics HUB URLs by stripping potential authentication information."""
+ return clean_url(v) if (isinstance(v, str) and v.startswith('http') and len(v) > 100) else v
+
+ x = inspect.currentframe().f_back # previous frame
+ file, _, func, _, _ = inspect.getframeinfo(x)
+ if args is None: # get args automatically
+ args, _, _, frm = inspect.getargvalues(x)
+ args = {k: v for k, v in frm.items() if k in args}
+ try:
+ file = Path(file).resolve().relative_to(ROOT).with_suffix('')
+ except ValueError:
+ file = Path(file).stem
+ s = (f'{file}: ' if show_file else '') + (f'{func}: ' if show_func else '')
+ LOGGER.info(colorstr(s) + ', '.join(f'{k}={strip_auth(v)}' for k, v in args.items()))
+
+
+def cuda_device_count() -> int:
+ """Get the number of NVIDIA GPUs available in the environment.
+
+ Returns:
+ (int): The number of NVIDIA GPUs available.
+ """
+ try:
+ # Run the nvidia-smi command and capture its output
+ output = subprocess.check_output(['nvidia-smi', '--query-gpu=count', '--format=csv,noheader,nounits'],
+ encoding='utf-8')
+
+ # Take the first line and strip any leading/trailing white space
+ first_line = output.strip().split('\n')[0]
+
+ return int(first_line)
+ except (subprocess.CalledProcessError, FileNotFoundError, ValueError):
+ # If the command fails, nvidia-smi is not found, or output is not an integer, assume no GPUs are available
+ return 0
+
+
+def cuda_is_available() -> bool:
+ """Check if CUDA is available in the environment.
+
+ Returns:
+ (bool): True if one or more NVIDIA GPUs are available, False otherwise.
+ """
+ return cuda_device_count() > 0
diff --git a/STPoseNet/ultralytics/utils/dist.py b/STPoseNet/ultralytics/utils/dist.py
new file mode 100644
index 0000000000000000000000000000000000000000..11900985ac5e3bc309eb72485a9b33777614717d
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/dist.py
@@ -0,0 +1,67 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import os
+import re
+import shutil
+import socket
+import sys
+import tempfile
+from pathlib import Path
+
+from . import USER_CONFIG_DIR
+from .torch_utils import TORCH_1_9
+
+
+def find_free_network_port() -> int:
+ """Finds a free port on localhost.
+
+ It is useful in single-node training when we don't want to connect to a real main node but have to set the
+ `MASTER_PORT` environment variable.
+ """
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(('127.0.0.1', 0))
+ return s.getsockname()[1] # port
+
+
+def generate_ddp_file(trainer):
+ """Generates a DDP file and returns its file name."""
+ module, name = f'{trainer.__class__.__module__}.{trainer.__class__.__name__}'.rsplit('.', 1)
+
+ content = f'''overrides = {vars(trainer.args)} \nif __name__ == "__main__":
+ from {module} import {name}
+ from ultralytics.utils import DEFAULT_CFG_DICT
+
+ cfg = DEFAULT_CFG_DICT.copy()
+ cfg.update(save_dir='') # handle the extra key 'save_dir'
+ trainer = {name}(cfg=cfg, overrides=overrides)
+ trainer.train()'''
+ (USER_CONFIG_DIR / 'DDP').mkdir(exist_ok=True)
+ with tempfile.NamedTemporaryFile(prefix='_temp_',
+ suffix=f'{id(trainer)}.py',
+ mode='w+',
+ encoding='utf-8',
+ dir=USER_CONFIG_DIR / 'DDP',
+ delete=False) as file:
+ file.write(content)
+ return file.name
+
+
+def generate_ddp_command(world_size, trainer):
+ """Generates and returns command for distributed training."""
+ import __main__ # noqa local import to avoid https://github.com/Lightning-AI/lightning/issues/15218
+ if not trainer.resume:
+ shutil.rmtree(trainer.save_dir) # remove the save_dir
+ file = str(Path(sys.argv[0]).resolve())
+ safe_pattern = re.compile(r'^[a-zA-Z0-9_. /\\-]{1,128}$') # allowed characters and maximum of 100 characters
+ if not (safe_pattern.match(file) and Path(file).exists() and file.endswith('.py')): # using CLI
+ file = generate_ddp_file(trainer)
+ dist_cmd = 'torch.distributed.run' if TORCH_1_9 else 'torch.distributed.launch'
+ port = find_free_network_port()
+ cmd = [sys.executable, '-m', dist_cmd, '--nproc_per_node', f'{world_size}', '--master_port', f'{port}', file]
+ return cmd, file
+
+
+def ddp_cleanup(trainer, file):
+ """Delete temp file if created."""
+ if f'{id(trainer)}.py' in file: # if temp_file suffix in file
+ os.remove(file)
diff --git a/STPoseNet/ultralytics/utils/downloads.py b/STPoseNet/ultralytics/utils/downloads.py
new file mode 100644
index 0000000000000000000000000000000000000000..b088562ea481b259a538282a15f46e285f5735f8
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/downloads.py
@@ -0,0 +1,399 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+import re
+import shutil
+import subprocess
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from urllib import parse, request
+
+import requests
+import torch
+from tqdm import tqdm
+
+from ultralytics.utils import LOGGER, TQDM_BAR_FORMAT, checks, clean_url, emojis, is_online, url2file
+
+# Define Ultralytics GitHub assets maintained at https://github.com/ultralytics/assets
+GITHUB_ASSETS_REPO = 'ultralytics/assets'
+GITHUB_ASSETS_NAMES = [f'yolov8{k}{suffix}.pt' for k in 'nsmlx' for suffix in ('', '6', '-cls', '-seg', '-pose')] + \
+ [f'yolov5{k}u.pt' for k in 'nsmlx'] + \
+ [f'yolov3{k}u.pt' for k in ('', '-spp', '-tiny')] + \
+ [f'yolo_nas_{k}.pt' for k in 'sml'] + \
+ [f'sam_{k}.pt' for k in 'bl'] + \
+ [f'FastSAM-{k}.pt' for k in 'sx'] + \
+ [f'rtdetr-{k}.pt' for k in 'lx'] + \
+ ['mobile_sam.pt']
+GITHUB_ASSETS_STEMS = [Path(k).stem for k in GITHUB_ASSETS_NAMES]
+
+
+def is_url(url, check=True):
+ """Check if string is URL and check if URL exists."""
+ with contextlib.suppress(Exception):
+ url = str(url)
+ result = parse.urlparse(url)
+ assert all([result.scheme, result.netloc]) # check if is url
+ if check:
+ with request.urlopen(url) as response:
+ return response.getcode() == 200 # check if exists online
+ return True
+ return False
+
+
+def delete_dsstore(path, files_to_delete=('.DS_Store', '__MACOSX')):
+ """
+ Deletes all ".DS_store" files under a specified directory.
+
+ Args:
+ path (str, optional): The directory path where the ".DS_store" files should be deleted.
+ files_to_delete (tuple): The files to be deleted.
+
+ Example:
+ ```python
+ from ultralytics.utils.downloads import delete_dsstore
+
+ delete_dsstore('path/to/dir')
+ ```
+
+ Note:
+ ".DS_store" files are created by the Apple operating system and contain metadata about folders and files. They
+ are hidden system files and can cause issues when transferring files between different operating systems.
+ """
+ # Delete Apple .DS_store files
+ for file in files_to_delete:
+ matches = list(Path(path).rglob(file))
+ LOGGER.info(f'Deleting {file} files: {matches}')
+ for f in matches:
+ f.unlink()
+
+
+def zip_directory(directory, compress=True, exclude=('.DS_Store', '__MACOSX'), progress=True):
+ """
+ Zips the contents of a directory, excluding files containing strings in the exclude list.
+ The resulting zip file is named after the directory and placed alongside it.
+
+ Args:
+ directory (str | Path): The path to the directory to be zipped.
+ compress (bool): Whether to compress the files while zipping. Default is True.
+ exclude (tuple, optional): A tuple of filename strings to be excluded. Defaults to ('.DS_Store', '__MACOSX').
+ progress (bool, optional): Whether to display a progress bar. Defaults to True.
+
+ Returns:
+ (Path): The path to the resulting zip file.
+
+ Example:
+ ```python
+ from ultralytics.utils.downloads import zip_directory
+
+ file = zip_directory('path/to/dir')
+ ```
+ """
+ from zipfile import ZIP_DEFLATED, ZIP_STORED, ZipFile
+
+ delete_dsstore(directory)
+ directory = Path(directory)
+ if not directory.is_dir():
+ raise FileNotFoundError(f"Directory '{directory}' does not exist.")
+
+ # Unzip with progress bar
+ files_to_zip = [f for f in directory.rglob('*') if f.is_file() and all(x not in f.name for x in exclude)]
+ zip_file = directory.with_suffix('.zip')
+ compression = ZIP_DEFLATED if compress else ZIP_STORED
+ with ZipFile(zip_file, 'w', compression) as f:
+ for file in tqdm(files_to_zip,
+ desc=f'Zipping {directory} to {zip_file}...',
+ unit='file',
+ disable=not progress,
+ bar_format=TQDM_BAR_FORMAT):
+ f.write(file, file.relative_to(directory))
+
+ return zip_file # return path to zip file
+
+
+def unzip_file(file, path=None, exclude=('.DS_Store', '__MACOSX'), exist_ok=False, progress=True):
+ """
+ Unzips a *.zip file to the specified path, excluding files containing strings in the exclude list.
+
+ If the zipfile does not contain a single top-level directory, the function will create a new
+ directory with the same name as the zipfile (without the extension) to extract its contents.
+ If a path is not provided, the function will use the parent directory of the zipfile as the default path.
+
+ Args:
+ file (str): The path to the zipfile to be extracted.
+ path (str, optional): The path to extract the zipfile to. Defaults to None.
+ exclude (tuple, optional): A tuple of filename strings to be excluded. Defaults to ('.DS_Store', '__MACOSX').
+ exist_ok (bool, optional): Whether to overwrite existing contents if they exist. Defaults to False.
+ progress (bool, optional): Whether to display a progress bar. Defaults to True.
+
+ Raises:
+ BadZipFile: If the provided file does not exist or is not a valid zipfile.
+
+ Returns:
+ (Path): The path to the directory where the zipfile was extracted.
+
+ Example:
+ ```python
+ from ultralytics.utils.downloads import unzip_file
+
+ dir = unzip_file('path/to/file.zip')
+ ```
+ """
+ from zipfile import BadZipFile, ZipFile, is_zipfile
+
+ if not (Path(file).exists() and is_zipfile(file)):
+ raise BadZipFile(f"File '{file}' does not exist or is a bad zip file.")
+ if path is None:
+ path = Path(file).parent # default path
+
+ # Unzip the file contents
+ with ZipFile(file) as zipObj:
+ files = [f for f in zipObj.namelist() if all(x not in f for x in exclude)]
+ top_level_dirs = {Path(f).parts[0] for f in files}
+
+ if len(top_level_dirs) > 1 or not files[0].endswith('/'): # zip has multiple files at top level
+ path = extract_path = Path(path) / Path(file).stem # i.e. ../datasets/coco8
+ else: # zip has 1 top-level directory
+ extract_path = path # i.e. ../datasets
+ path = Path(path) / list(top_level_dirs)[0] # i.e. ../datasets/coco8
+
+ # Check if destination directory already exists and contains files
+ if path.exists() and any(path.iterdir()) and not exist_ok:
+ # If it exists and is not empty, return the path without unzipping
+ LOGGER.info(f'Skipping {file} unzip (already unzipped)')
+ return path
+
+ for f in tqdm(files,
+ desc=f'Unzipping {file} to {Path(path).resolve()}...',
+ unit='file',
+ disable=not progress,
+ bar_format=TQDM_BAR_FORMAT):
+ zipObj.extract(f, path=extract_path)
+
+ return path # return unzip dir
+
+
+def check_disk_space(url='https://ultralytics.com/assets/coco128.zip', sf=1.5, hard=True):
+ """
+ Check if there is sufficient disk space to download and store a file.
+
+ Args:
+ url (str, optional): The URL to the file. Defaults to 'https://ultralytics.com/assets/coco128.zip'.
+ sf (float, optional): Safety factor, the multiplier for the required free space. Defaults to 2.0.
+ hard (bool, optional): Whether to throw an error or not on insufficient disk space. Defaults to True.
+
+ Returns:
+ (bool): True if there is sufficient disk space, False otherwise.
+ """
+ with contextlib.suppress(Exception):
+ gib = 1 << 30 # bytes per GiB
+ data = int(requests.head(url).headers['Content-Length']) / gib # file size (GB)
+ total, used, free = (x / gib for x in shutil.disk_usage('/')) # bytes
+ if data * sf < free:
+ return True # sufficient space
+
+ # Insufficient space
+ text = (f'WARNING ⚠️ Insufficient free disk space {free:.1f} GB < {data * sf:.3f} GB required, '
+ f'Please free {data * sf - free:.1f} GB additional disk space and try again.')
+ if hard:
+ raise MemoryError(text)
+ LOGGER.warning(text)
+ return False
+
+ return True
+
+
+def get_google_drive_file_info(link):
+ """
+ Retrieves the direct download link and filename for a shareable Google Drive file link.
+
+ Args:
+ link (str): The shareable link of the Google Drive file.
+
+ Returns:
+ (str): Direct download URL for the Google Drive file.
+ (str): Original filename of the Google Drive file. If filename extraction fails, returns None.
+
+ Example:
+ ```python
+ from ultralytics.utils.downloads import get_google_drive_file_info
+
+ link = "https://drive.google.com/file/d/1cqT-cJgANNrhIHCrEufUYhQ4RqiWG_lJ/view?usp=drive_link"
+ url, filename = get_google_drive_file_info(link)
+ ```
+ """
+ file_id = link.split('/d/')[1].split('/view')[0]
+ drive_url = f'https://drive.google.com/uc?export=download&id={file_id}'
+ filename = None
+
+ # Start session
+ with requests.Session() as session:
+ response = session.get(drive_url, stream=True)
+ if 'quota exceeded' in str(response.content.lower()):
+ raise ConnectionError(
+ emojis(f'❌ Google Drive file download quota exceeded. '
+ f'Please try again later or download this file manually at {link}.'))
+ for k, v in response.cookies.items():
+ if k.startswith('download_warning'):
+ drive_url += f'&confirm={v}' # v is token
+ cd = response.headers.get('content-disposition')
+ if cd:
+ filename = re.findall('filename="(.+)"', cd)[0]
+ return drive_url, filename
+
+
+def safe_download(url,
+ file=None,
+ dir=None,
+ unzip=True,
+ delete=False,
+ curl=False,
+ retry=3,
+ min_bytes=1E0,
+ progress=True):
+ """
+ Downloads files from a URL, with options for retrying, unzipping, and deleting the downloaded file.
+
+ Args:
+ url (str): The URL of the file to be downloaded.
+ file (str, optional): The filename of the downloaded file.
+ If not provided, the file will be saved with the same name as the URL.
+ dir (str, optional): The directory to save the downloaded file.
+ If not provided, the file will be saved in the current working directory.
+ unzip (bool, optional): Whether to unzip the downloaded file. Default: True.
+ delete (bool, optional): Whether to delete the downloaded file after unzipping. Default: False.
+ curl (bool, optional): Whether to use curl command line tool for downloading. Default: False.
+ retry (int, optional): The number of times to retry the download in case of failure. Default: 3.
+ min_bytes (float, optional): The minimum number of bytes that the downloaded file should have, to be considered
+ a successful download. Default: 1E0.
+ progress (bool, optional): Whether to display a progress bar during the download. Default: True.
+ """
+
+ # Check if the URL is a Google Drive link
+ gdrive = 'drive.google.com' in url
+ if gdrive:
+ url, file = get_google_drive_file_info(url)
+
+ f = dir / (file if gdrive else url2file(url)) if dir else Path(file) # URL converted to filename
+ if '://' not in str(url) and Path(url).is_file(): # URL exists ('://' check required in Windows Python<3.10)
+ f = Path(url) # filename
+ elif not f.is_file(): # URL and file do not exist
+ assert dir or file, 'dir or file required for download'
+ desc = f"Downloading {url if gdrive else clean_url(url)} to '{f}'"
+ LOGGER.info(f'{desc}...')
+ f.parent.mkdir(parents=True, exist_ok=True) # make directory if missing
+ check_disk_space(url)
+ for i in range(retry + 1):
+ try:
+ if curl or i > 0: # curl download with retry, continue
+ s = 'sS' * (not progress) # silent
+ r = subprocess.run(['curl', '-#', f'-{s}L', url, '-o', f, '--retry', '3', '-C', '-']).returncode
+ assert r == 0, f'Curl return value {r}'
+ else: # urllib download
+ method = 'torch'
+ if method == 'torch':
+ torch.hub.download_url_to_file(url, f, progress=progress)
+ else:
+ with request.urlopen(url) as response, tqdm(total=int(response.getheader('Content-Length', 0)),
+ desc=desc,
+ disable=not progress,
+ unit='B',
+ unit_scale=True,
+ unit_divisor=1024,
+ bar_format=TQDM_BAR_FORMAT) as pbar:
+ with open(f, 'wb') as f_opened:
+ for data in response:
+ f_opened.write(data)
+ pbar.update(len(data))
+
+ if f.exists():
+ if f.stat().st_size > min_bytes:
+ break # success
+ f.unlink() # remove partial downloads
+ except Exception as e:
+ if i == 0 and not is_online():
+ raise ConnectionError(emojis(f'❌ Download failure for {url}. Environment is not online.')) from e
+ elif i >= retry:
+ raise ConnectionError(emojis(f'❌ Download failure for {url}. Retry limit reached.')) from e
+ LOGGER.warning(f'⚠️ Download failure, retrying {i + 1}/{retry} {url}...')
+
+ if unzip and f.exists() and f.suffix in ('', '.zip', '.tar', '.gz'):
+ from zipfile import is_zipfile
+
+ unzip_dir = dir or f.parent # unzip to dir if provided else unzip in place
+ if is_zipfile(f):
+ unzip_dir = unzip_file(file=f, path=unzip_dir, progress=progress) # unzip
+ elif f.suffix in ('.tar', '.gz'):
+ LOGGER.info(f'Unzipping {f} to {unzip_dir.resolve()}...')
+ subprocess.run(['tar', 'xf' if f.suffix == '.tar' else 'xfz', f, '--directory', unzip_dir], check=True)
+ if delete:
+ f.unlink() # remove zip
+ return unzip_dir
+
+
+def get_github_assets(repo='ultralytics/assets', version='latest', retry=False):
+ """Return GitHub repo tag and assets (i.e. ['yolov8n.pt', 'yolov8s.pt', ...])."""
+ if version != 'latest':
+ version = f'tags/{version}' # i.e. tags/v6.2
+ url = f'https://api.github.com/repos/{repo}/releases/{version}'
+ r = requests.get(url) # github api
+ if r.status_code != 200 and r.reason != 'rate limit exceeded' and retry: # failed and not 403 rate limit exceeded
+ r = requests.get(url) # try again
+ if r.status_code != 200:
+ LOGGER.warning(f'⚠️ GitHub assets check failure for {url}: {r.status_code} {r.reason}')
+ return '', []
+ data = r.json()
+ return data['tag_name'], [x['name'] for x in data['assets']] # tag, assets
+
+
+def attempt_download_asset(file, repo='ultralytics/assets', release='v0.0.0'):
+ """Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v6.2', etc."""
+ from ultralytics.utils import SETTINGS # scoped for circular import
+
+ # YOLOv3/5u updates
+ file = str(file)
+ file = checks.check_yolov5u_filename(file)
+ file = Path(file.strip().replace("'", ''))
+ if file.exists():
+ return str(file)
+ elif (SETTINGS['weights_dir'] / file).exists():
+ return str(SETTINGS['weights_dir'] / file)
+ else:
+ # URL specified
+ name = Path(parse.unquote(str(file))).name # decode '%2F' to '/' etc.
+ if str(file).startswith(('http:/', 'https:/')): # download
+ url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
+ file = url2file(name) # parse authentication https://url.com/file.txt?auth...
+ if Path(file).is_file():
+ LOGGER.info(f'Found {clean_url(url)} locally at {file}') # file already exists
+ else:
+ safe_download(url=url, file=file, min_bytes=1E5)
+
+ elif repo == GITHUB_ASSETS_REPO and name in GITHUB_ASSETS_NAMES:
+ safe_download(url=f'https://github.com/{repo}/releases/download/{release}/{name}', file=file, min_bytes=1E5)
+
+ else:
+ tag, assets = get_github_assets(repo, release)
+ if not assets:
+ tag, assets = get_github_assets(repo) # latest release
+ if name in assets:
+ safe_download(url=f'https://github.com/{repo}/releases/download/{tag}/{name}', file=file, min_bytes=1E5)
+
+ return str(file)
+
+
+def download(url, dir=Path.cwd(), unzip=True, delete=False, curl=False, threads=1, retry=3):
+ """Downloads and unzips files concurrently if threads > 1, else sequentially."""
+ dir = Path(dir)
+ dir.mkdir(parents=True, exist_ok=True) # make directory
+ if threads > 1:
+ with ThreadPool(threads) as pool:
+ pool.map(
+ lambda x: safe_download(
+ url=x[0], dir=x[1], unzip=unzip, delete=delete, curl=curl, retry=retry, progress=threads <= 1),
+ zip(url, repeat(dir)))
+ pool.close()
+ pool.join()
+ else:
+ for u in [url] if isinstance(url, (str, Path)) else url:
+ safe_download(url=u, dir=dir, unzip=unzip, delete=delete, curl=curl, retry=retry)
diff --git a/STPoseNet/ultralytics/utils/errors.py b/STPoseNet/ultralytics/utils/errors.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a764318683c4c5547bf82b6d66d1a87350dadc5
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/errors.py
@@ -0,0 +1,10 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from ultralytics.utils import emojis
+
+
+class HUBModelError(Exception):
+
+ def __init__(self, message='Model not found. Please check model URL and try again.'):
+ """Create an exception for when a model is not found."""
+ super().__init__(emojis(message))
diff --git a/STPoseNet/ultralytics/utils/files.py b/STPoseNet/ultralytics/utils/files.py
new file mode 100644
index 0000000000000000000000000000000000000000..0102c4b6a81fc81e9b47c79eff183cf64c9e1938
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/files.py
@@ -0,0 +1,147 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+import glob
+import os
+import shutil
+import tempfile
+from contextlib import contextmanager
+from datetime import datetime
+from pathlib import Path
+
+
+class WorkingDirectory(contextlib.ContextDecorator):
+ """Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager."""
+
+ def __init__(self, new_dir):
+ """Sets the working directory to 'new_dir' upon instantiation."""
+ self.dir = new_dir # new dir
+ self.cwd = Path.cwd().resolve() # current dir
+
+ def __enter__(self):
+ """Changes the current directory to the specified directory."""
+ os.chdir(self.dir)
+
+ def __exit__(self, exc_type, exc_val, exc_tb): # noqa
+ """Restore the current working directory on context exit."""
+ os.chdir(self.cwd)
+
+
+@contextmanager
+def spaces_in_path(path):
+ """
+ Context manager to handle paths with spaces in their names.
+ If a path contains spaces, it replaces them with underscores, copies the file/directory to the new path,
+ executes the context code block, then copies the file/directory back to its original location.
+
+ Args:
+ path (str | Path): The original path.
+
+ Yields:
+ (Path): Temporary path with spaces replaced by underscores if spaces were present, otherwise the original path.
+
+ Example:
+ ```python
+ with ultralytics.utils.files import spaces_in_path
+
+ with spaces_in_path('/path/with spaces') as new_path:
+ # your code here
+ ```
+ """
+
+ # If path has spaces, replace them with underscores
+ if ' ' in str(path):
+ string = isinstance(path, str) # input type
+ path = Path(path)
+
+ # Create a temporary directory and construct the new path
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tmp_path = Path(tmp_dir) / path.name.replace(' ', '_')
+
+ # Copy file/directory
+ if path.is_dir():
+ # tmp_path.mkdir(parents=True, exist_ok=True)
+ shutil.copytree(path, tmp_path)
+ elif path.is_file():
+ tmp_path.parent.mkdir(parents=True, exist_ok=True)
+ shutil.copy2(path, tmp_path)
+
+ try:
+ # Yield the temporary path
+ yield str(tmp_path) if string else tmp_path
+
+ finally:
+ # Copy file/directory back
+ if tmp_path.is_dir():
+ shutil.copytree(tmp_path, path, dirs_exist_ok=True)
+ elif tmp_path.is_file():
+ shutil.copy2(tmp_path, path) # Copy back the file
+
+ else:
+ # If there are no spaces, just yield the original path
+ yield path
+
+
+def increment_path(path, exist_ok=False, sep='', mkdir=False):
+ """
+ Increments a file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
+
+ If the path exists and exist_ok is not set to True, the path will be incremented by appending a number and sep to
+ the end of the path. If the path is a file, the file extension will be preserved. If the path is a directory, the
+ number will be appended directly to the end of the path. If mkdir is set to True, the path will be created as a
+ directory if it does not already exist.
+
+ Args:
+ path (str, pathlib.Path): Path to increment.
+ exist_ok (bool, optional): If True, the path will not be incremented and returned as-is. Defaults to False.
+ sep (str, optional): Separator to use between the path and the incrementation number. Defaults to ''.
+ mkdir (bool, optional): Create a directory if it does not exist. Defaults to False.
+
+ Returns:
+ (pathlib.Path): Incremented path.
+ """
+ path = Path(path) # os-agnostic
+ if path.exists() and not exist_ok:
+ path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
+
+ # Method 1
+ for n in range(2, 9999):
+ p = f'{path}{sep}{n}{suffix}' # increment path
+ if not os.path.exists(p): #
+ break
+ path = Path(p)
+
+ if mkdir:
+ path.mkdir(parents=True, exist_ok=True) # make directory
+
+ return path
+
+
+def file_age(path=__file__):
+ """Return days since last file update."""
+ dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
+ return dt.days # + dt.seconds / 86400 # fractional days
+
+
+def file_date(path=__file__):
+ """Return human-readable file modification date, i.e. '2021-3-26'."""
+ t = datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def file_size(path):
+ """Return file/dir size (MB)."""
+ if isinstance(path, (str, Path)):
+ mb = 1 << 20 # bytes to MiB (1024 ** 2)
+ path = Path(path)
+ if path.is_file():
+ return path.stat().st_size / mb
+ elif path.is_dir():
+ return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
+ return 0.0
+
+
+def get_latest_run(search_dir='.'):
+ """Return path to most recent 'last.pt' in /runs (i.e. to --resume from)."""
+ last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
+ return max(last_list, key=os.path.getctime) if last_list else ''
diff --git a/STPoseNet/ultralytics/utils/instance.py b/STPoseNet/ultralytics/utils/instance.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e2e4380985c5d64cdc972bc822e5d80e70d9e99
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/instance.py
@@ -0,0 +1,370 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from collections import abc
+from itertools import repeat
+from numbers import Number
+from typing import List
+
+import numpy as np
+
+from .ops import ltwh2xywh, ltwh2xyxy, resample_segments, xywh2ltwh, xywh2xyxy, xyxy2ltwh, xyxy2xywh
+
+
+def _ntuple(n):
+ """From PyTorch internals."""
+
+ def parse(x):
+ """Parse bounding boxes format between XYWH and LTWH."""
+ return x if isinstance(x, abc.Iterable) else tuple(repeat(x, n))
+
+ return parse
+
+
+to_2tuple = _ntuple(2)
+to_4tuple = _ntuple(4)
+
+# `xyxy` means left top and right bottom
+# `xywh` means center x, center y and width, height(YOLO format)
+# `ltwh` means left top and width, height(COCO format)
+_formats = ['xyxy', 'xywh', 'ltwh']
+
+__all__ = 'Bboxes', # tuple or list
+
+
+class Bboxes:
+ """Bounding Boxes class. Only numpy variables are supported."""
+
+ def __init__(self, bboxes, format='xyxy') -> None:
+ assert format in _formats, f'Invalid bounding box format: {format}, format must be one of {_formats}'
+ bboxes = bboxes[None, :] if bboxes.ndim == 1 else bboxes
+ assert bboxes.ndim == 2
+ assert bboxes.shape[1] == 4
+ self.bboxes = bboxes
+ self.format = format
+ # self.normalized = normalized
+
+ def convert(self, format):
+ """Converts bounding box format from one type to another."""
+ assert format in _formats, f'Invalid bounding box format: {format}, format must be one of {_formats}'
+ if self.format == format:
+ return
+ elif self.format == 'xyxy':
+ func = xyxy2xywh if format == 'xywh' else xyxy2ltwh
+ elif self.format == 'xywh':
+ func = xywh2xyxy if format == 'xyxy' else xywh2ltwh
+ else:
+ func = ltwh2xyxy if format == 'xyxy' else ltwh2xywh
+ self.bboxes = func(self.bboxes)
+ self.format = format
+
+ def areas(self):
+ """Return box areas."""
+ self.convert('xyxy')
+ return (self.bboxes[:, 2] - self.bboxes[:, 0]) * (self.bboxes[:, 3] - self.bboxes[:, 1])
+
+ # def denormalize(self, w, h):
+ # if not self.normalized:
+ # return
+ # assert (self.bboxes <= 1.0).all()
+ # self.bboxes[:, 0::2] *= w
+ # self.bboxes[:, 1::2] *= h
+ # self.normalized = False
+ #
+ # def normalize(self, w, h):
+ # if self.normalized:
+ # return
+ # assert (self.bboxes > 1.0).any()
+ # self.bboxes[:, 0::2] /= w
+ # self.bboxes[:, 1::2] /= h
+ # self.normalized = True
+
+ def mul(self, scale):
+ """
+ Args:
+ scale (tuple | list | int): the scale for four coords.
+ """
+ if isinstance(scale, Number):
+ scale = to_4tuple(scale)
+ assert isinstance(scale, (tuple, list))
+ assert len(scale) == 4
+ self.bboxes[:, 0] *= scale[0]
+ self.bboxes[:, 1] *= scale[1]
+ self.bboxes[:, 2] *= scale[2]
+ self.bboxes[:, 3] *= scale[3]
+
+ def add(self, offset):
+ """
+ Args:
+ offset (tuple | list | int): the offset for four coords.
+ """
+ if isinstance(offset, Number):
+ offset = to_4tuple(offset)
+ assert isinstance(offset, (tuple, list))
+ assert len(offset) == 4
+ self.bboxes[:, 0] += offset[0]
+ self.bboxes[:, 1] += offset[1]
+ self.bboxes[:, 2] += offset[2]
+ self.bboxes[:, 3] += offset[3]
+
+ def __len__(self):
+ """Return the number of boxes."""
+ return len(self.bboxes)
+
+ @classmethod
+ def concatenate(cls, boxes_list: List['Bboxes'], axis=0) -> 'Bboxes':
+ """
+ Concatenate a list of Bboxes objects into a single Bboxes object.
+
+ Args:
+ boxes_list (List[Bboxes]): A list of Bboxes objects to concatenate.
+ axis (int, optional): The axis along which to concatenate the bounding boxes.
+ Defaults to 0.
+
+ Returns:
+ Bboxes: A new Bboxes object containing the concatenated bounding boxes.
+
+ Note:
+ The input should be a list or tuple of Bboxes objects.
+ """
+ assert isinstance(boxes_list, (list, tuple))
+ if not boxes_list:
+ return cls(np.empty(0))
+ assert all(isinstance(box, Bboxes) for box in boxes_list)
+
+ if len(boxes_list) == 1:
+ return boxes_list[0]
+ return cls(np.concatenate([b.bboxes for b in boxes_list], axis=axis))
+
+ def __getitem__(self, index) -> 'Bboxes':
+ """
+ Retrieve a specific bounding box or a set of bounding boxes using indexing.
+
+ Args:
+ index (int, slice, or np.ndarray): The index, slice, or boolean array to select
+ the desired bounding boxes.
+
+ Returns:
+ Bboxes: A new Bboxes object containing the selected bounding boxes.
+
+ Raises:
+ AssertionError: If the indexed bounding boxes do not form a 2-dimensional matrix.
+
+ Note:
+ When using boolean indexing, make sure to provide a boolean array with the same
+ length as the number of bounding boxes.
+ """
+ if isinstance(index, int):
+ return Bboxes(self.bboxes[index].view(1, -1))
+ b = self.bboxes[index]
+ assert b.ndim == 2, f'Indexing on Bboxes with {index} failed to return a matrix!'
+ return Bboxes(b)
+
+
+class Instances:
+
+ def __init__(self, bboxes, segments=None, keypoints=None, bbox_format='xywh', normalized=True) -> None:
+ """
+ Args:
+ bboxes (ndarray): bboxes with shape [N, 4].
+ segments (list | ndarray): segments.
+ keypoints (ndarray): keypoints(x, y, visible) with shape [N, 17, 3].
+ """
+ if segments is None:
+ segments = []
+ self._bboxes = Bboxes(bboxes=bboxes, format=bbox_format)
+ self.keypoints = keypoints
+ self.normalized = normalized
+
+ if len(segments) > 0:
+ # list[np.array(1000, 2)] * num_samples
+ segments = resample_segments(segments)
+ # (N, 1000, 2)
+ segments = np.stack(segments, axis=0)
+ else:
+ segments = np.zeros((0, 1000, 2), dtype=np.float32)
+ self.segments = segments
+
+ def convert_bbox(self, format):
+ """Convert bounding box format."""
+ self._bboxes.convert(format=format)
+
+ @property
+ def bbox_areas(self):
+ """Calculate the area of bounding boxes."""
+ return self._bboxes.areas()
+
+ def scale(self, scale_w, scale_h, bbox_only=False):
+ """this might be similar with denormalize func but without normalized sign."""
+ self._bboxes.mul(scale=(scale_w, scale_h, scale_w, scale_h))
+ if bbox_only:
+ return
+ self.segments[..., 0] *= scale_w
+ self.segments[..., 1] *= scale_h
+ if self.keypoints is not None:
+ self.keypoints[..., 0] *= scale_w
+ self.keypoints[..., 1] *= scale_h
+
+ def denormalize(self, w, h):
+ """Denormalizes boxes, segments, and keypoints from normalized coordinates."""
+ if not self.normalized:
+ return
+ self._bboxes.mul(scale=(w, h, w, h))
+ self.segments[..., 0] *= w
+ self.segments[..., 1] *= h
+ if self.keypoints is not None:
+ self.keypoints[..., 0] *= w
+ self.keypoints[..., 1] *= h
+ self.normalized = False
+
+ def normalize(self, w, h):
+ """Normalize bounding boxes, segments, and keypoints to image dimensions."""
+ if self.normalized:
+ return
+ self._bboxes.mul(scale=(1 / w, 1 / h, 1 / w, 1 / h))
+ self.segments[..., 0] /= w
+ self.segments[..., 1] /= h
+ if self.keypoints is not None:
+ self.keypoints[..., 0] /= w
+ self.keypoints[..., 1] /= h
+ self.normalized = True
+
+ def add_padding(self, padw, padh):
+ """Handle rect and mosaic situation."""
+ assert not self.normalized, 'you should add padding with absolute coordinates.'
+ self._bboxes.add(offset=(padw, padh, padw, padh))
+ self.segments[..., 0] += padw
+ self.segments[..., 1] += padh
+ if self.keypoints is not None:
+ self.keypoints[..., 0] += padw
+ self.keypoints[..., 1] += padh
+
+ def __getitem__(self, index) -> 'Instances':
+ """
+ Retrieve a specific instance or a set of instances using indexing.
+
+ Args:
+ index (int, slice, or np.ndarray): The index, slice, or boolean array to select
+ the desired instances.
+
+ Returns:
+ Instances: A new Instances object containing the selected bounding boxes,
+ segments, and keypoints if present.
+
+ Note:
+ When using boolean indexing, make sure to provide a boolean array with the same
+ length as the number of instances.
+ """
+ segments = self.segments[index] if len(self.segments) else self.segments
+ keypoints = self.keypoints[index] if self.keypoints is not None else None
+ bboxes = self.bboxes[index]
+ bbox_format = self._bboxes.format
+ return Instances(
+ bboxes=bboxes,
+ segments=segments,
+ keypoints=keypoints,
+ bbox_format=bbox_format,
+ normalized=self.normalized,
+ )
+
+ def flipud(self, h):
+ """Flips the coordinates of bounding boxes, segments, and keypoints vertically."""
+ if self._bboxes.format == 'xyxy':
+ y1 = self.bboxes[:, 1].copy()
+ y2 = self.bboxes[:, 3].copy()
+ self.bboxes[:, 1] = h - y2
+ self.bboxes[:, 3] = h - y1
+ else:
+ self.bboxes[:, 1] = h - self.bboxes[:, 1]
+ self.segments[..., 1] = h - self.segments[..., 1]
+ if self.keypoints is not None:
+ self.keypoints[..., 1] = h - self.keypoints[..., 1]
+
+ def fliplr(self, w):
+ """Reverses the order of the bounding boxes and segments horizontally."""
+ if self._bboxes.format == 'xyxy':
+ x1 = self.bboxes[:, 0].copy()
+ x2 = self.bboxes[:, 2].copy()
+ self.bboxes[:, 0] = w - x2
+ self.bboxes[:, 2] = w - x1
+ else:
+ self.bboxes[:, 0] = w - self.bboxes[:, 0]
+ self.segments[..., 0] = w - self.segments[..., 0]
+ if self.keypoints is not None:
+ self.keypoints[..., 0] = w - self.keypoints[..., 0]
+
+ def clip(self, w, h):
+ """Clips bounding boxes, segments, and keypoints values to stay within image boundaries."""
+ ori_format = self._bboxes.format
+ self.convert_bbox(format='xyxy')
+ self.bboxes[:, [0, 2]] = self.bboxes[:, [0, 2]].clip(0, w)
+ self.bboxes[:, [1, 3]] = self.bboxes[:, [1, 3]].clip(0, h)
+ if ori_format != 'xyxy':
+ self.convert_bbox(format=ori_format)
+ self.segments[..., 0] = self.segments[..., 0].clip(0, w)
+ self.segments[..., 1] = self.segments[..., 1].clip(0, h)
+ if self.keypoints is not None:
+ self.keypoints[..., 0] = self.keypoints[..., 0].clip(0, w)
+ self.keypoints[..., 1] = self.keypoints[..., 1].clip(0, h)
+
+ def remove_zero_area_boxes(self):
+ """Remove zero-area boxes, i.e. after clipping some boxes may have zero width or height. This removes them."""
+ good = self.bbox_areas > 0
+ if not all(good):
+ self._bboxes = self._bboxes[good]
+ if len(self.segments):
+ self.segments = self.segments[good]
+ if self.keypoints is not None:
+ self.keypoints = self.keypoints[good]
+ return good
+
+ def update(self, bboxes, segments=None, keypoints=None):
+ """Updates instance variables."""
+ self._bboxes = Bboxes(bboxes, format=self._bboxes.format)
+ if segments is not None:
+ self.segments = segments
+ if keypoints is not None:
+ self.keypoints = keypoints
+
+ def __len__(self):
+ """Return the length of the instance list."""
+ return len(self.bboxes)
+
+ @classmethod
+ def concatenate(cls, instances_list: List['Instances'], axis=0) -> 'Instances':
+ """
+ Concatenates a list of Instances objects into a single Instances object.
+
+ Args:
+ instances_list (List[Instances]): A list of Instances objects to concatenate.
+ axis (int, optional): The axis along which the arrays will be concatenated. Defaults to 0.
+
+ Returns:
+ Instances: A new Instances object containing the concatenated bounding boxes,
+ segments, and keypoints if present.
+
+ Note:
+ The `Instances` objects in the list should have the same properties, such as
+ the format of the bounding boxes, whether keypoints are present, and if the
+ coordinates are normalized.
+ """
+ assert isinstance(instances_list, (list, tuple))
+ if not instances_list:
+ return cls(np.empty(0))
+ assert all(isinstance(instance, Instances) for instance in instances_list)
+
+ if len(instances_list) == 1:
+ return instances_list[0]
+
+ use_keypoint = instances_list[0].keypoints is not None
+ bbox_format = instances_list[0]._bboxes.format
+ normalized = instances_list[0].normalized
+
+ cat_boxes = np.concatenate([ins.bboxes for ins in instances_list], axis=axis)
+ cat_segments = np.concatenate([b.segments for b in instances_list], axis=axis)
+ cat_keypoints = np.concatenate([b.keypoints for b in instances_list], axis=axis) if use_keypoint else None
+ return cls(cat_boxes, cat_segments, cat_keypoints, bbox_format, normalized)
+
+ @property
+ def bboxes(self):
+ """Return bounding boxes."""
+ return self._bboxes.bboxes
diff --git a/STPoseNet/ultralytics/utils/loss.py b/STPoseNet/ultralytics/utils/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..1da0586c843347ed93dd1aa1eb500dc47ef84c13
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/loss.py
@@ -0,0 +1,392 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ultralytics.utils.metrics import OKS_SIGMA
+from ultralytics.utils.ops import crop_mask, xywh2xyxy, xyxy2xywh
+from ultralytics.utils.tal import TaskAlignedAssigner, dist2bbox, make_anchors
+
+from .metrics import bbox_iou
+from .tal import bbox2dist
+
+
+class VarifocalLoss(nn.Module):
+ """Varifocal loss by Zhang et al. https://arxiv.org/abs/2008.13367."""
+
+ def __init__(self):
+ """Initialize the VarifocalLoss class."""
+ super().__init__()
+
+ def forward(self, pred_score, gt_score, label, alpha=0.75, gamma=2.0):
+ """Computes varfocal loss."""
+ weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
+ with torch.cuda.amp.autocast(enabled=False):
+ loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction='none') *
+ weight).mean(1).sum()
+ return loss
+
+
+# Losses
+class FocalLoss(nn.Module):
+ """Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)."""
+
+ def __init__(self, ):
+ super().__init__()
+
+ def forward(self, pred, label, gamma=1.5, alpha=0.25):
+ """Calculates and updates confusion matrix for object detection/classification tasks."""
+ loss = F.binary_cross_entropy_with_logits(pred, label, reduction='none')
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = pred.sigmoid() # prob from logits
+ p_t = label * pred_prob + (1 - label) * (1 - pred_prob)
+ modulating_factor = (1.0 - p_t) ** gamma
+ loss *= modulating_factor
+ if alpha > 0:
+ alpha_factor = label * alpha + (1 - label) * (1 - alpha)
+ loss *= alpha_factor
+ return loss.mean(1).sum()
+
+
+class BboxLoss(nn.Module):
+
+ def __init__(self, reg_max, use_dfl=False):
+ """Initialize the BboxLoss module with regularization maximum and DFL settings."""
+ super().__init__()
+ self.reg_max = reg_max
+ self.use_dfl = use_dfl
+
+ def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
+ """IoU loss."""
+ weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
+ iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
+ loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
+
+ # DFL loss
+ if self.use_dfl:
+ target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
+ loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
+ loss_dfl = loss_dfl.sum() / target_scores_sum
+ else:
+ loss_dfl = torch.tensor(0.0).to(pred_dist.device)
+
+ return loss_iou, loss_dfl
+
+ @staticmethod
+ def _df_loss(pred_dist, target):
+ """Return sum of left and right DFL losses."""
+ # Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
+ tl = target.long() # target left
+ tr = tl + 1 # target right
+ wl = tr - target # weight left
+ wr = 1 - wl # weight right
+ return (F.cross_entropy(pred_dist, tl.view(-1), reduction='none').view(tl.shape) * wl +
+ F.cross_entropy(pred_dist, tr.view(-1), reduction='none').view(tl.shape) * wr).mean(-1, keepdim=True)
+
+
+class KeypointLoss(nn.Module):
+
+ def __init__(self, sigmas) -> None:
+ super().__init__()
+ self.sigmas = sigmas
+
+ def forward(self, pred_kpts, gt_kpts, kpt_mask, area):
+ """Calculates keypoint loss factor and Euclidean distance loss for predicted and actual keypoints."""
+ d = (pred_kpts[..., 0] - gt_kpts[..., 0]) ** 2 + (pred_kpts[..., 1] - gt_kpts[..., 1]) ** 2
+ kpt_loss_factor = (torch.sum(kpt_mask != 0) + torch.sum(kpt_mask == 0)) / (torch.sum(kpt_mask != 0) + 1e-9)
+ # e = d / (2 * (area * self.sigmas) ** 2 + 1e-9) # from formula
+ e = d / (2 * self.sigmas) ** 2 / (area + 1e-9) / 2 # from cocoeval
+ return kpt_loss_factor * ((1 - torch.exp(-e)) * kpt_mask).mean()
+
+
+# Criterion class for computing Detection training losses
+class v8DetectionLoss:
+
+ def __init__(self, model): # model must be de-paralleled
+
+ device = next(model.parameters()).device # get model device
+ h = model.args # hyperparameters
+
+ m = model.model[-1] # Detect() module
+ self.bce = nn.BCEWithLogitsLoss(reduction='none')
+ self.hyp = h
+ self.stride = m.stride # model strides
+ self.nc = m.nc # number of classes
+ self.no = m.no
+ self.reg_max = m.reg_max
+ self.device = device
+
+ self.use_dfl = m.reg_max > 1
+
+ self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
+ self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)
+ self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
+
+ def preprocess(self, targets, batch_size, scale_tensor):
+ """Preprocesses the target counts and matches with the input batch size to output a tensor."""
+ if targets.shape[0] == 0:
+ out = torch.zeros(batch_size, 0, 5, device=self.device)
+ else:
+ i = targets[:, 0] # image index
+ _, counts = i.unique(return_counts=True)
+ counts = counts.to(dtype=torch.int32)
+ out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
+ for j in range(batch_size):
+ matches = i == j
+ n = matches.sum()
+ if n:
+ out[j, :n] = targets[matches, 1:]
+ out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
+ return out
+
+ def bbox_decode(self, anchor_points, pred_dist):
+ """Decode predicted object bounding box coordinates from anchor points and distribution."""
+ if self.use_dfl:
+ b, a, c = pred_dist.shape # batch, anchors, channels
+ pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
+ # pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
+ # pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
+ return dist2bbox(pred_dist, anchor_points, xywh=False)
+
+ def __call__(self, preds, batch):
+ """Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""
+ loss = torch.zeros(3, device=self.device) # box, cls, dfl
+ feats = preds[1] if isinstance(preds, tuple) else preds
+ pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
+ (self.reg_max * 4, self.nc), 1)
+
+ pred_scores = pred_scores.permute(0, 2, 1).contiguous()
+ pred_distri = pred_distri.permute(0, 2, 1).contiguous()
+
+ dtype = pred_scores.dtype
+ batch_size = pred_scores.shape[0]
+ imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
+ anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
+
+ # targets
+ targets = torch.cat((batch['batch_idx'].view(-1, 1), batch['cls'].view(-1, 1), batch['bboxes']), 1)
+ targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
+ gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
+ mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
+
+ # pboxes
+ pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
+
+ _, target_bboxes, target_scores, fg_mask, _ = self.assigner(
+ pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
+ anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
+
+ target_scores_sum = max(target_scores.sum(), 1)
+
+ # cls loss
+ # loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
+ loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
+
+ # bbox loss
+ if fg_mask.sum():
+ target_bboxes /= stride_tensor
+ loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,
+ target_scores_sum, fg_mask)
+
+ loss[0] *= self.hyp.box # box gain
+ loss[1] *= self.hyp.cls # cls gain
+ loss[2] *= self.hyp.dfl # dfl gain
+
+ return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
+
+
+# Criterion class for computing training losses
+class v8SegmentationLoss(v8DetectionLoss):
+
+ def __init__(self, model): # model must be de-paralleled
+ super().__init__(model)
+ self.nm = model.model[-1].nm # number of masks
+ self.overlap = model.args.overlap_mask
+
+ def __call__(self, preds, batch):
+ """Calculate and return the loss for the YOLO model."""
+ loss = torch.zeros(4, device=self.device) # box, cls, dfl
+ feats, pred_masks, proto = preds if len(preds) == 3 else preds[1]
+ batch_size, _, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
+ (self.reg_max * 4, self.nc), 1)
+
+ # b, grids, ..
+ pred_scores = pred_scores.permute(0, 2, 1).contiguous()
+ pred_distri = pred_distri.permute(0, 2, 1).contiguous()
+ pred_masks = pred_masks.permute(0, 2, 1).contiguous()
+
+ dtype = pred_scores.dtype
+ imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
+ anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
+
+ # targets
+ try:
+ batch_idx = batch['batch_idx'].view(-1, 1)
+ targets = torch.cat((batch_idx, batch['cls'].view(-1, 1), batch['bboxes']), 1)
+ targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
+ gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
+ mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
+ except RuntimeError as e:
+ raise TypeError('ERROR ❌ segment dataset incorrectly formatted or not a segment dataset.\n'
+ "This error can occur when incorrectly training a 'segment' model on a 'detect' dataset, "
+ "i.e. 'yolo train model=yolov8n-seg.pt data=coco128.yaml'.\nVerify your dataset is a "
+ "correctly formatted 'segment' dataset using 'data=coco128-seg.yaml' "
+ 'as an example.\nSee https://docs.ultralytics.com/tasks/segment/ for help.') from e
+
+ # pboxes
+ pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
+
+ _, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(
+ pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
+ anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
+
+ target_scores_sum = max(target_scores.sum(), 1)
+
+ # cls loss
+ # loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
+ loss[2] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
+
+ if fg_mask.sum():
+ # bbox loss
+ loss[0], loss[3] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes / stride_tensor,
+ target_scores, target_scores_sum, fg_mask)
+ # masks loss
+ masks = batch['masks'].to(self.device).float()
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]
+
+ for i in range(batch_size):
+ if fg_mask[i].sum():
+ mask_idx = target_gt_idx[i][fg_mask[i]]
+ if self.overlap:
+ gt_mask = torch.where(masks[[i]] == (mask_idx + 1).view(-1, 1, 1), 1.0, 0.0)
+ else:
+ gt_mask = masks[batch_idx.view(-1) == i][mask_idx]
+ xyxyn = target_bboxes[i][fg_mask[i]] / imgsz[[1, 0, 1, 0]]
+ marea = xyxy2xywh(xyxyn)[:, 2:].prod(1)
+ mxyxy = xyxyn * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device)
+ loss[1] += self.single_mask_loss(gt_mask, pred_masks[i][fg_mask[i]], proto[i], mxyxy, marea) # seg
+
+ # WARNING: lines below prevents Multi-GPU DDP 'unused gradient' PyTorch errors, do not remove
+ else:
+ loss[1] += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan loss
+
+ # WARNING: lines below prevent Multi-GPU DDP 'unused gradient' PyTorch errors, do not remove
+ else:
+ loss[1] += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan loss
+
+ loss[0] *= self.hyp.box # box gain
+ loss[1] *= self.hyp.box / batch_size # seg gain
+ loss[2] *= self.hyp.cls # cls gain
+ loss[3] *= self.hyp.dfl # dfl gain
+
+ return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ """Mask loss for one image."""
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n, 32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+
+# Criterion class for computing training losses
+class v8PoseLoss(v8DetectionLoss):
+
+ def __init__(self, model): # model must be de-paralleled
+ super().__init__(model)
+ self.kpt_shape = model.model[-1].kpt_shape
+ self.bce_pose = nn.BCEWithLogitsLoss()
+ is_pose = self.kpt_shape == [17, 3]
+ nkpt = self.kpt_shape[0] # number of keypoints
+ sigmas = torch.from_numpy(OKS_SIGMA).to(self.device) if is_pose else torch.ones(nkpt, device=self.device) / nkpt
+ self.keypoint_loss = KeypointLoss(sigmas=sigmas)
+
+ def __call__(self, preds, batch):
+ """Calculate the total loss and detach it."""
+ loss = torch.zeros(5, device=self.device) # box, cls, dfl, kpt_location, kpt_visibility
+ feats, pred_kpts = preds if isinstance(preds[0], list) else preds[1]
+ pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
+ (self.reg_max * 4, self.nc), 1)
+
+ # b, grids, ..
+ pred_scores = pred_scores.permute(0, 2, 1).contiguous()
+ pred_distri = pred_distri.permute(0, 2, 1).contiguous()
+ pred_kpts = pred_kpts.permute(0, 2, 1).contiguous()
+
+ dtype = pred_scores.dtype
+ imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
+ anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
+
+ # targets
+ batch_size = pred_scores.shape[0]
+ batch_idx = batch['batch_idx'].view(-1, 1)
+ targets = torch.cat((batch_idx, batch['cls'].view(-1, 1), batch['bboxes']), 1)
+ targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
+ gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
+ mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
+
+ # pboxes
+ pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
+ pred_kpts = self.kpts_decode(anchor_points, pred_kpts.view(batch_size, -1, *self.kpt_shape)) # (b, h*w, 17, 3)
+
+ _, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(
+ pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
+ anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
+
+ target_scores_sum = max(target_scores.sum(), 1)
+
+ # cls loss
+ # loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
+ loss[3] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
+
+ # bbox loss
+ if fg_mask.sum():
+ target_bboxes /= stride_tensor
+ loss[0], loss[4] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,
+ target_scores_sum, fg_mask)
+ keypoints = batch['keypoints'].to(self.device).float().clone()
+ keypoints[..., 0] *= imgsz[1]
+ keypoints[..., 1] *= imgsz[0]
+ for i in range(batch_size):
+ if fg_mask[i].sum():
+ idx = target_gt_idx[i][fg_mask[i]]
+ gt_kpt = keypoints[batch_idx.view(-1) == i][idx] # (n, 51)
+ gt_kpt[..., 0] /= stride_tensor[fg_mask[i]]
+ gt_kpt[..., 1] /= stride_tensor[fg_mask[i]]
+ area = xyxy2xywh(target_bboxes[i][fg_mask[i]])[:, 2:].prod(1, keepdim=True)
+ pred_kpt = pred_kpts[i][fg_mask[i]]
+ kpt_mask = gt_kpt[..., 2] != 0
+ loss[1] += self.keypoint_loss(pred_kpt, gt_kpt, kpt_mask, area) # pose loss
+ # kpt_score loss
+ if pred_kpt.shape[-1] == 3:
+ loss[2] += self.bce_pose(pred_kpt[..., 2], kpt_mask.float()) # keypoint obj loss
+
+ loss[0] *= self.hyp.box # box gain
+ loss[1] *= self.hyp.pose / batch_size # pose gain
+ loss[2] *= self.hyp.kobj / batch_size # kobj gain
+ loss[3] *= self.hyp.cls # cls gain
+ loss[4] *= self.hyp.dfl # dfl gain
+
+ return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
+
+ def kpts_decode(self, anchor_points, pred_kpts):
+ """Decodes predicted keypoints to image coordinates."""
+ y = pred_kpts.clone()
+ y[..., :2] *= 2.0
+ y[..., 0] += anchor_points[:, [0]] - 0.5
+ y[..., 1] += anchor_points[:, [1]] - 0.5
+ return y
+
+
+class v8ClassificationLoss:
+
+ def __call__(self, preds, batch):
+ """Compute the classification loss between predictions and true labels."""
+ loss = torch.nn.functional.cross_entropy(preds, batch['cls'], reduction='sum') / 64
+ loss_items = loss.detach()
+ return loss, loss_items
diff --git a/STPoseNet/ultralytics/utils/metrics.py b/STPoseNet/ultralytics/utils/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..028e45f054b9f2e556f23e61121ba8149da9deb4
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/metrics.py
@@ -0,0 +1,969 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Model validation metrics
+"""
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from ultralytics.utils import LOGGER, SimpleClass, TryExcept, plt_settings
+
+OKS_SIGMA = np.array([.26, .25, .25, .35, .35, .79, .79, .72, .72, .62, .62, 1.07, 1.07, .87, .87, .89, .89]) / 10.0
+
+
+def bbox_ioa(box1, box2, iou=False, eps=1e-7):
+ """
+ Calculate the intersection over box2 area given box1 and box2. Boxes are in x1y1x2y2 format.
+
+ Args:
+ box1 (np.array): A numpy array of shape (n, 4) representing n bounding boxes.
+ box2 (np.array): A numpy array of shape (m, 4) representing m bounding boxes.
+ iou (bool): Calculate the standard iou if True else return inter_area/box2_area.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
+
+ Returns:
+ (np.array): A numpy array of shape (n, m) representing the intersection over box2 area.
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.T
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2[:, None], b2_x2) - np.maximum(b1_x1[:, None], b2_x1)).clip(0) * \
+ (np.minimum(b1_y2[:, None], b2_y2) - np.maximum(b1_y1[:, None], b2_y1)).clip(0)
+
+ # box2 area
+ area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
+ if iou:
+ box1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
+ area = area + box1_area[:, None] - inter_area
+
+ # Intersection over box2 area
+ return inter_area / (area + eps)
+
+
+def box_iou(box1, box2, eps=1e-7):
+ """
+ Calculate intersection-over-union (IoU) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Based on https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+
+ Args:
+ box1 (torch.Tensor): A tensor of shape (N, 4) representing N bounding boxes.
+ box2 (torch.Tensor): A tensor of shape (M, 4) representing M bounding boxes.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
+
+ Returns:
+ (torch.Tensor): An NxM tensor containing the pairwise IoU values for every element in box1 and box2.
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp_(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ """
+ Calculate Intersection over Union (IoU) of box1(1, 4) to box2(n, 4).
+
+ Args:
+ box1 (torch.Tensor): A tensor representing a single bounding box with shape (1, 4).
+ box2 (torch.Tensor): A tensor representing n bounding boxes with shape (n, 4).
+ xywh (bool, optional): If True, input boxes are in (x, y, w, h) format. If False, input boxes are in
+ (x1, y1, x2, y2) format. Defaults to True.
+ GIoU (bool, optional): If True, calculate Generalized IoU. Defaults to False.
+ DIoU (bool, optional): If True, calculate Distance IoU. Defaults to False.
+ CIoU (bool, optional): If True, calculate Complete IoU. Defaults to False.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
+
+ Returns:
+ (torch.Tensor): IoU, GIoU, DIoU, or CIoU values depending on the specified flags.
+ """
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+
+ # Intersection area
+ inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \
+ (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
+ ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ Calculate masks IoU.
+
+ Args:
+ mask1 (torch.Tensor): A tensor of shape (N, n) where N is the number of ground truth objects and n is the
+ product of image width and height.
+ mask2 (torch.Tensor): A tensor of shape (M, n) where M is the number of predicted objects and n is the
+ product of image width and height.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
+
+ Returns:
+ (torch.Tensor): A tensor of shape (N, M) representing masks IoU.
+ """
+ intersection = torch.matmul(mask1, mask2.T).clamp_(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def kpt_iou(kpt1, kpt2, area, sigma, eps=1e-7):
+ """
+ Calculate Object Keypoint Similarity (OKS).
+
+ Args:
+ kpt1 (torch.Tensor): A tensor of shape (N, 17, 3) representing ground truth keypoints.
+ kpt2 (torch.Tensor): A tensor of shape (M, 17, 3) representing predicted keypoints.
+ area (torch.Tensor): A tensor of shape (N,) representing areas from ground truth.
+ sigma (list): A list containing 17 values representing keypoint scales.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
+
+ Returns:
+ (torch.Tensor): A tensor of shape (N, M) representing keypoint similarities.
+ """
+ d = (kpt1[:, None, :, 0] - kpt2[..., 0]) ** 2 + (kpt1[:, None, :, 1] - kpt2[..., 1]) ** 2 # (N, M, 17)
+ sigma = torch.tensor(sigma, device=kpt1.device, dtype=kpt1.dtype) # (17, )
+ kpt_mask = kpt1[..., 2] != 0 # (N, 17)
+ e = d / (2 * sigma) ** 2 / (area[:, None, None] + eps) / 2 # from cocoeval
+ # e = d / ((area[None, :, None] + eps) * sigma) ** 2 / 2 # from formula
+ return (torch.exp(-e) * kpt_mask[:, None]).sum(-1) / (kpt_mask.sum(-1)[:, None] + eps)
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class ConfusionMatrix:
+ """
+ A class for calculating and updating a confusion matrix for object detection and classification tasks.
+
+ Attributes:
+ task (str): The type of task, either 'detect' or 'classify'.
+ matrix (np.array): The confusion matrix, with dimensions depending on the task.
+ nc (int): The number of classes.
+ conf (float): The confidence threshold for detections.
+ iou_thres (float): The Intersection over Union threshold.
+ """
+
+ def __init__(self, nc, conf=0.25, iou_thres=0.45, task='detect'):
+ """Initialize attributes for the YOLO model."""
+ self.task = task
+ self.matrix = np.zeros((nc + 1, nc + 1)) if self.task == 'detect' else np.zeros((nc, nc))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_cls_preds(self, preds, targets):
+ """
+ Update confusion matrix for classification task
+
+ Args:
+ preds (Array[N, min(nc,5)]): Predicted class labels.
+ targets (Array[N, 1]): Ground truth class labels.
+ """
+ preds, targets = torch.cat(preds)[:, 0], torch.cat(targets)
+ for p, t in zip(preds.cpu().numpy(), targets.cpu().numpy()):
+ self.matrix[p][t] += 1
+
+ def process_batch(self, detections, labels):
+ """
+ Update confusion matrix for object detection task.
+
+ Args:
+ detections (Array[N, 6]): Detected bounding boxes and their associated information.
+ Each row should contain (x1, y1, x2, y2, conf, class).
+ labels (Array[M, 5]): Ground truth bounding boxes and their associated class labels.
+ Each row should contain (class, x1, y1, x2, y2).
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def matrix(self):
+ """Returns the confusion matrix."""
+ return self.matrix
+
+ def tp_fp(self):
+ """Returns true positives and false positives."""
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return (tp[:-1], fp[:-1]) if self.task == 'detect' else (tp, fp) # remove background class if task=detect
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ @plt_settings()
+ def plot(self, normalize=True, save_dir='', names=(), on_plot=None):
+ """
+ Plot the confusion matrix using seaborn and save it to a file.
+
+ Args:
+ normalize (bool): Whether to normalize the confusion matrix.
+ save_dir (str): Directory where the plot will be saved.
+ names (tuple): Names of classes, used as labels on the plot.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered.
+ """
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (list(names) + ['background']) if labels else 'auto'
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ 'size': 8},
+ cmap='Blues',
+ fmt='.2f' if normalize else '.0f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ title = 'Confusion Matrix' + ' Normalized' * normalize
+ ax.set_xlabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title(title)
+ plot_fname = Path(save_dir) / f'{title.lower().replace(" ", "_")}.png'
+ fig.savefig(plot_fname, dpi=250)
+ plt.close(fig)
+ if on_plot:
+ on_plot(plot_fname)
+
+ def print(self):
+ """
+ Print the confusion matrix to the console.
+ """
+ for i in range(self.nc + 1):
+ LOGGER.info(' '.join(map(str, self.matrix[i])))
+
+
+def smooth(y, f=0.05):
+ """Box filter of fraction f."""
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+@plt_settings()
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=(), on_plot=None):
+ """Plots a precision-recall curve."""
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+ if on_plot:
+ on_plot(save_dir)
+
+
+@plt_settings()
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric', on_plot=None):
+ """Plots a metric-confidence curve."""
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc='upper left')
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+ if on_plot:
+ on_plot(save_dir)
+
+
+def compute_ap(recall, precision):
+ """
+ Compute the average precision (AP) given the recall and precision curves.
+
+ Args:
+ recall (list): The recall curve.
+ precision (list): The precision curve.
+
+ Returns:
+ (float): Average precision.
+ (np.ndarray): Precision envelope curve.
+ (np.ndarray): Modified recall curve with sentinel values added at the beginning and end.
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x-axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+def ap_per_class(tp,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ on_plot=None,
+ save_dir=Path(),
+ names=(),
+ eps=1e-16,
+ prefix=''):
+ """
+ Computes the average precision per class for object detection evaluation.
+
+ Args:
+ tp (np.ndarray): Binary array indicating whether the detection is correct (True) or not (False).
+ conf (np.ndarray): Array of confidence scores of the detections.
+ pred_cls (np.ndarray): Array of predicted classes of the detections.
+ target_cls (np.ndarray): Array of true classes of the detections.
+ plot (bool, optional): Whether to plot PR curves or not. Defaults to False.
+ on_plot (func, optional): A callback to pass plots path and data when they are rendered. Defaults to None.
+ save_dir (Path, optional): Directory to save the PR curves. Defaults to an empty path.
+ names (tuple, optional): Tuple of class names to plot PR curves. Defaults to an empty tuple.
+ eps (float, optional): A small value to avoid division by zero. Defaults to 1e-16.
+ prefix (str, optional): A prefix string for saving the plot files. Defaults to an empty string.
+
+ Returns:
+ (tuple): A tuple of six arrays and one array of unique classes, where:
+ tp (np.ndarray): True positive counts for each class.
+ fp (np.ndarray): False positive counts for each class.
+ p (np.ndarray): Precision values at each confidence threshold.
+ r (np.ndarray): Recall values at each confidence threshold.
+ f1 (np.ndarray): F1-score values at each confidence threshold.
+ ap (np.ndarray): Average precision for each class at different IoU thresholds.
+ unique_classes (np.ndarray): An array of unique classes that have data.
+
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, save_dir / f'{prefix}PR_curve.png', names, on_plot=on_plot)
+ plot_mc_curve(px, f1, save_dir / f'{prefix}F1_curve.png', names, ylabel='F1', on_plot=on_plot)
+ plot_mc_curve(px, p, save_dir / f'{prefix}P_curve.png', names, ylabel='Precision', on_plot=on_plot)
+ plot_mc_curve(px, r, save_dir / f'{prefix}R_curve.png', names, ylabel='Recall', on_plot=on_plot)
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+class Metric(SimpleClass):
+ """
+ Class for computing evaluation metrics for YOLOv8 model.
+
+ Attributes:
+ p (list): Precision for each class. Shape: (nc,).
+ r (list): Recall for each class. Shape: (nc,).
+ f1 (list): F1 score for each class. Shape: (nc,).
+ all_ap (list): AP scores for all classes and all IoU thresholds. Shape: (nc, 10).
+ ap_class_index (list): Index of class for each AP score. Shape: (nc,).
+ nc (int): Number of classes.
+
+ Methods:
+ ap50(): AP at IoU threshold of 0.5 for all classes. Returns: List of AP scores. Shape: (nc,) or [].
+ ap(): AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: List of AP scores. Shape: (nc,) or [].
+ mp(): Mean precision of all classes. Returns: Float.
+ mr(): Mean recall of all classes. Returns: Float.
+ map50(): Mean AP at IoU threshold of 0.5 for all classes. Returns: Float.
+ map75(): Mean AP at IoU threshold of 0.75 for all classes. Returns: Float.
+ map(): Mean AP at IoU thresholds from 0.5 to 0.95 for all classes. Returns: Float.
+ mean_results(): Mean of results, returns mp, mr, map50, map.
+ class_result(i): Class-aware result, returns p[i], r[i], ap50[i], ap[i].
+ maps(): mAP of each class. Returns: Array of mAP scores, shape: (nc,).
+ fitness(): Model fitness as a weighted combination of metrics. Returns: Float.
+ update(results): Update metric attributes with new evaluation results.
+ """
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+ self.nc = 0
+
+ @property
+ def ap50(self):
+ """
+ Returns the Average Precision (AP) at an IoU threshold of 0.5 for all classes.
+
+ Returns:
+ (np.ndarray, list): Array of shape (nc,) with AP50 values per class, or an empty list if not available.
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """
+ Returns the Average Precision (AP) at an IoU threshold of 0.5-0.95 for all classes.
+
+ Returns:
+ (np.ndarray, list): Array of shape (nc,) with AP50-95 values per class, or an empty list if not available.
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """
+ Returns the Mean Precision of all classes.
+
+ Returns:
+ (float): The mean precision of all classes.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """
+ Returns the Mean Recall of all classes.
+
+ Returns:
+ (float): The mean recall of all classes.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """
+ Returns the mean Average Precision (mAP) at an IoU threshold of 0.5.
+
+ Returns:
+ (float): The mAP50 at an IoU threshold of 0.5.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map75(self):
+ """
+ Returns the mean Average Precision (mAP) at an IoU threshold of 0.75.
+
+ Returns:
+ (float): The mAP50 at an IoU threshold of 0.75.
+ """
+ return self.all_ap[:, 5].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """
+ Returns the mean Average Precision (mAP) over IoU thresholds of 0.5 - 0.95 in steps of 0.05.
+
+ Returns:
+ (float): The mAP over IoU thresholds of 0.5 - 0.95 in steps of 0.05.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map."""
+ return [self.mp, self.mr, self.map50, self.map]
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]."""
+ return self.p[i], self.r[i], self.ap50[i], self.ap[i]
+
+ @property
+ def maps(self):
+ """mAP of each class."""
+ maps = np.zeros(self.nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def fitness(self):
+ """Model fitness as a weighted combination of metrics."""
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (np.array(self.mean_results()) * w).sum()
+
+ def update(self, results):
+ """
+ Args:
+ results (tuple): A tuple of (p, r, ap, f1, ap_class)
+ """
+ self.p, self.r, self.f1, self.all_ap, self.ap_class_index = results
+
+
+class DetMetrics(SimpleClass):
+ """
+ This class is a utility class for computing detection metrics such as precision, recall, and mean average precision
+ (mAP) of an object detection model.
+
+ Args:
+ save_dir (Path): A path to the directory where the output plots will be saved. Defaults to current directory.
+ plot (bool): A flag that indicates whether to plot precision-recall curves for each class. Defaults to False.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered. Defaults to None.
+ names (tuple of str): A tuple of strings that represents the names of the classes. Defaults to an empty tuple.
+
+ Attributes:
+ save_dir (Path): A path to the directory where the output plots will be saved.
+ plot (bool): A flag that indicates whether to plot the precision-recall curves for each class.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered.
+ names (tuple of str): A tuple of strings that represents the names of the classes.
+ box (Metric): An instance of the Metric class for storing the results of the detection metrics.
+ speed (dict): A dictionary for storing the execution time of different parts of the detection process.
+
+ Methods:
+ process(tp, conf, pred_cls, target_cls): Updates the metric results with the latest batch of predictions.
+ keys: Returns a list of keys for accessing the computed detection metrics.
+ mean_results: Returns a list of mean values for the computed detection metrics.
+ class_result(i): Returns a list of values for the computed detection metrics for a specific class.
+ maps: Returns a dictionary of mean average precision (mAP) values for different IoU thresholds.
+ fitness: Computes the fitness score based on the computed detection metrics.
+ ap_class_index: Returns a list of class indices sorted by their average precision (AP) values.
+ results_dict: Returns a dictionary that maps detection metric keys to their computed values.
+ """
+
+ def __init__(self, save_dir=Path('.'), plot=False, on_plot=None, names=()) -> None:
+ self.save_dir = save_dir
+ self.plot = plot
+ self.on_plot = on_plot
+ self.names = names
+ self.box = Metric()
+ self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0}
+
+ def process(self, tp, conf, pred_cls, target_cls):
+ """Process predicted results for object detection and update metrics."""
+ results = ap_per_class(tp,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=self.plot,
+ save_dir=self.save_dir,
+ names=self.names,
+ on_plot=self.on_plot)[2:]
+ self.box.nc = len(self.names)
+ self.box.update(results)
+
+ @property
+ def keys(self):
+ """Returns a list of keys for accessing specific metrics."""
+ return ['metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)']
+
+ def mean_results(self):
+ """Calculate mean of detected objects & return precision, recall, mAP50, and mAP50-95."""
+ return self.box.mean_results()
+
+ def class_result(self, i):
+ """Return the result of evaluating the performance of an object detection model on a specific class."""
+ return self.box.class_result(i)
+
+ @property
+ def maps(self):
+ """Returns mean Average Precision (mAP) scores per class."""
+ return self.box.maps
+
+ @property
+ def fitness(self):
+ """Returns the fitness of box object."""
+ return self.box.fitness()
+
+ @property
+ def ap_class_index(self):
+ """Returns the average precision index per class."""
+ return self.box.ap_class_index
+
+ @property
+ def results_dict(self):
+ """Returns dictionary of computed performance metrics and statistics."""
+ return dict(zip(self.keys + ['fitness'], self.mean_results() + [self.fitness]))
+
+
+class SegmentMetrics(SimpleClass):
+ """
+ Calculates and aggregates detection and segmentation metrics over a given set of classes.
+
+ Args:
+ save_dir (Path): Path to the directory where the output plots should be saved. Default is the current directory.
+ plot (bool): Whether to save the detection and segmentation plots. Default is False.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered. Defaults to None.
+ names (list): List of class names. Default is an empty list.
+
+ Attributes:
+ save_dir (Path): Path to the directory where the output plots should be saved.
+ plot (bool): Whether to save the detection and segmentation plots.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered.
+ names (list): List of class names.
+ box (Metric): An instance of the Metric class to calculate box detection metrics.
+ seg (Metric): An instance of the Metric class to calculate mask segmentation metrics.
+ speed (dict): Dictionary to store the time taken in different phases of inference.
+
+ Methods:
+ process(tp_m, tp_b, conf, pred_cls, target_cls): Processes metrics over the given set of predictions.
+ mean_results(): Returns the mean of the detection and segmentation metrics over all the classes.
+ class_result(i): Returns the detection and segmentation metrics of class `i`.
+ maps: Returns the mean Average Precision (mAP) scores for IoU thresholds ranging from 0.50 to 0.95.
+ fitness: Returns the fitness scores, which are a single weighted combination of metrics.
+ ap_class_index: Returns the list of indices of classes used to compute Average Precision (AP).
+ results_dict: Returns the dictionary containing all the detection and segmentation metrics and fitness score.
+ """
+
+ def __init__(self, save_dir=Path('.'), plot=False, on_plot=None, names=()) -> None:
+ self.save_dir = save_dir
+ self.plot = plot
+ self.on_plot = on_plot
+ self.names = names
+ self.box = Metric()
+ self.seg = Metric()
+ self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0}
+
+ def process(self, tp_b, tp_m, conf, pred_cls, target_cls):
+ """
+ Processes the detection and segmentation metrics over the given set of predictions.
+
+ Args:
+ tp_b (list): List of True Positive boxes.
+ tp_m (list): List of True Positive masks.
+ conf (list): List of confidence scores.
+ pred_cls (list): List of predicted classes.
+ target_cls (list): List of target classes.
+ """
+
+ results_mask = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=self.plot,
+ on_plot=self.on_plot,
+ save_dir=self.save_dir,
+ names=self.names,
+ prefix='Mask')[2:]
+ self.seg.nc = len(self.names)
+ self.seg.update(results_mask)
+ results_box = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=self.plot,
+ on_plot=self.on_plot,
+ save_dir=self.save_dir,
+ names=self.names,
+ prefix='Box')[2:]
+ self.box.nc = len(self.names)
+ self.box.update(results_box)
+
+ @property
+ def keys(self):
+ """Returns a list of keys for accessing metrics."""
+ return [
+ 'metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)',
+ 'metrics/precision(M)', 'metrics/recall(M)', 'metrics/mAP50(M)', 'metrics/mAP50-95(M)']
+
+ def mean_results(self):
+ """Return the mean metrics for bounding box and segmentation results."""
+ return self.box.mean_results() + self.seg.mean_results()
+
+ def class_result(self, i):
+ """Returns classification results for a specified class index."""
+ return self.box.class_result(i) + self.seg.class_result(i)
+
+ @property
+ def maps(self):
+ """Returns mAP scores for object detection and semantic segmentation models."""
+ return self.box.maps + self.seg.maps
+
+ @property
+ def fitness(self):
+ """Get the fitness score for both segmentation and bounding box models."""
+ return self.seg.fitness() + self.box.fitness()
+
+ @property
+ def ap_class_index(self):
+ """Boxes and masks have the same ap_class_index."""
+ return self.box.ap_class_index
+
+ @property
+ def results_dict(self):
+ """Returns results of object detection model for evaluation."""
+ return dict(zip(self.keys + ['fitness'], self.mean_results() + [self.fitness]))
+
+
+class PoseMetrics(SegmentMetrics):
+ """
+ Calculates and aggregates detection and pose metrics over a given set of classes.
+
+ Args:
+ save_dir (Path): Path to the directory where the output plots should be saved. Default is the current directory.
+ plot (bool): Whether to save the detection and segmentation plots. Default is False.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered. Defaults to None.
+ names (list): List of class names. Default is an empty list.
+
+ Attributes:
+ save_dir (Path): Path to the directory where the output plots should be saved.
+ plot (bool): Whether to save the detection and segmentation plots.
+ on_plot (func): An optional callback to pass plots path and data when they are rendered.
+ names (list): List of class names.
+ box (Metric): An instance of the Metric class to calculate box detection metrics.
+ pose (Metric): An instance of the Metric class to calculate mask segmentation metrics.
+ speed (dict): Dictionary to store the time taken in different phases of inference.
+
+ Methods:
+ process(tp_m, tp_b, conf, pred_cls, target_cls): Processes metrics over the given set of predictions.
+ mean_results(): Returns the mean of the detection and segmentation metrics over all the classes.
+ class_result(i): Returns the detection and segmentation metrics of class `i`.
+ maps: Returns the mean Average Precision (mAP) scores for IoU thresholds ranging from 0.50 to 0.95.
+ fitness: Returns the fitness scores, which are a single weighted combination of metrics.
+ ap_class_index: Returns the list of indices of classes used to compute Average Precision (AP).
+ results_dict: Returns the dictionary containing all the detection and segmentation metrics and fitness score.
+ """
+
+ def __init__(self, save_dir=Path('.'), plot=False, on_plot=None, names=()) -> None:
+ super().__init__(save_dir, plot, names)
+ self.save_dir = save_dir
+ self.plot = plot
+ self.on_plot = on_plot
+ self.names = names
+ self.box = Metric()
+ self.pose = Metric()
+ self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0}
+
+ def process(self, tp_b, tp_p, conf, pred_cls, target_cls):
+ """
+ Processes the detection and pose metrics over the given set of predictions.
+
+ Args:
+ tp_b (list): List of True Positive boxes.
+ tp_p (list): List of True Positive keypoints.
+ conf (list): List of confidence scores.
+ pred_cls (list): List of predicted classes.
+ target_cls (list): List of target classes.
+ """
+
+ results_pose = ap_per_class(tp_p,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=self.plot,
+ on_plot=self.on_plot,
+ save_dir=self.save_dir,
+ names=self.names,
+ prefix='Pose')[2:]
+ self.pose.nc = len(self.names)
+ self.pose.update(results_pose)
+ results_box = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=self.plot,
+ on_plot=self.on_plot,
+ save_dir=self.save_dir,
+ names=self.names,
+ prefix='Box')[2:]
+ self.box.nc = len(self.names)
+ self.box.update(results_box)
+
+ @property
+ def keys(self):
+ """Returns list of evaluation metric keys."""
+ return [
+ 'metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)',
+ 'metrics/precision(P)', 'metrics/recall(P)', 'metrics/mAP50(P)', 'metrics/mAP50-95(P)']
+
+ def mean_results(self):
+ """Return the mean results of box and pose."""
+ return self.box.mean_results() + self.pose.mean_results()
+
+ def class_result(self, i):
+ """Return the class-wise detection results for a specific class i."""
+ return self.box.class_result(i) + self.pose.class_result(i)
+
+ @property
+ def maps(self):
+ """Returns the mean average precision (mAP) per class for both box and pose detections."""
+ return self.box.maps + self.pose.maps
+
+ @property
+ def fitness(self):
+ """Computes classification metrics and speed using the `targets` and `pred` inputs."""
+ return self.pose.fitness() + self.box.fitness()
+
+
+class ClassifyMetrics(SimpleClass):
+ """
+ Class for computing classification metrics including top-1 and top-5 accuracy.
+
+ Attributes:
+ top1 (float): The top-1 accuracy.
+ top5 (float): The top-5 accuracy.
+ speed (Dict[str, float]): A dictionary containing the time taken for each step in the pipeline.
+
+ Properties:
+ fitness (float): The fitness of the model, which is equal to top-5 accuracy.
+ results_dict (Dict[str, Union[float, str]]): A dictionary containing the classification metrics and fitness.
+ keys (List[str]): A list of keys for the results_dict.
+
+ Methods:
+ process(targets, pred): Processes the targets and predictions to compute classification metrics.
+ """
+
+ def __init__(self) -> None:
+ self.top1 = 0
+ self.top5 = 0
+ self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0}
+
+ def process(self, targets, pred):
+ """Target classes and predicted classes."""
+ pred, targets = torch.cat(pred), torch.cat(targets)
+ correct = (targets[:, None] == pred).float()
+ acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
+ self.top1, self.top5 = acc.mean(0).tolist()
+
+ @property
+ def fitness(self):
+ """Returns mean of top-1 and top-5 accuracies as fitness score."""
+ return (self.top1 + self.top5) / 2
+
+ @property
+ def results_dict(self):
+ """Returns a dictionary with model's performance metrics and fitness score."""
+ return dict(zip(self.keys + ['fitness'], [self.top1, self.top5, self.fitness]))
+
+ @property
+ def keys(self):
+ """Returns a list of keys for the results_dict property."""
+ return ['metrics/accuracy_top1', 'metrics/accuracy_top5']
diff --git a/STPoseNet/ultralytics/utils/ops.py b/STPoseNet/ultralytics/utils/ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c90906cee0c5a2de7d7b92f8c86acc79dec0f33
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/ops.py
@@ -0,0 +1,784 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+import math
+import re
+import time
+
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torchvision
+
+from ultralytics.utils import LOGGER
+
+
+class Profile(contextlib.ContextDecorator):
+ """
+ YOLOv8 Profile class. Use as a decorator with @Profile() or as a context manager with 'with Profile():'.
+
+ Example:
+ ```python
+ from ultralytics.utils.ops import Profile
+
+ with Profile() as dt:
+ pass # slow operation here
+
+ print(dt) # prints "Elapsed time is 9.5367431640625e-07 s"
+ ```
+ """
+
+ def __init__(self, t=0.0):
+ """
+ Initialize the Profile class.
+
+ Args:
+ t (float): Initial time. Defaults to 0.0.
+ """
+ self.t = t
+ self.cuda = torch.cuda.is_available()
+
+ def __enter__(self):
+ """Start timing."""
+ self.start = self.time()
+ return self
+
+ def __exit__(self, type, value, traceback): # noqa
+ """Stop timing."""
+ self.dt = self.time() - self.start # delta-time
+ self.t += self.dt # accumulate dt
+
+ def __str__(self):
+ return f'Elapsed time is {self.t} s'
+
+ def time(self):
+ """Get current time."""
+ if self.cuda:
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def segment2box(segment, width=640, height=640):
+ """
+ Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy).
+
+ Args:
+ segment (torch.Tensor): the segment label
+ width (int): the width of the image. Defaults to 640
+ height (int): The height of the image. Defaults to 640
+
+ Returns:
+ (np.ndarray): the minimum and maximum x and y values of the segment.
+ """
+ # Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
+ x, y = segment.T # segment xy
+ inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
+ x, y, = x[inside], y[inside]
+ return np.array([x.min(), y.min(), x.max(), y.max()], dtype=segment.dtype) if any(x) else np.zeros(
+ 4, dtype=segment.dtype) # xyxy
+
+
+def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None, padding=True):
+ """
+ Rescales bounding boxes (in the format of xyxy) from the shape of the image they were originally specified in
+ (img1_shape) to the shape of a different image (img0_shape).
+
+ Args:
+ img1_shape (tuple): The shape of the image that the bounding boxes are for, in the format of (height, width).
+ boxes (torch.Tensor): the bounding boxes of the objects in the image, in the format of (x1, y1, x2, y2)
+ img0_shape (tuple): the shape of the target image, in the format of (height, width).
+ ratio_pad (tuple): a tuple of (ratio, pad) for scaling the boxes. If not provided, the ratio and pad will be
+ calculated based on the size difference between the two images.
+ padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
+ rescaling.
+
+ Returns:
+ boxes (torch.Tensor): The scaled bounding boxes, in the format of (x1, y1, x2, y2)
+ """
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = round((img1_shape[1] - img0_shape[1] * gain) / 2 - 0.1), round(
+ (img1_shape[0] - img0_shape[0] * gain) / 2 - 0.1) # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ if padding:
+ boxes[..., [0, 2]] -= pad[0] # x padding
+ boxes[..., [1, 3]] -= pad[1] # y padding
+ boxes[..., :4] /= gain
+ clip_boxes(boxes, img0_shape)
+ return boxes
+
+
+def make_divisible(x, divisor):
+ """
+ Returns the nearest number that is divisible by the given divisor.
+
+ Args:
+ x (int): The number to make divisible.
+ divisor (int | torch.Tensor): The divisor.
+
+ Returns:
+ (int): The nearest number divisible by the divisor.
+ """
+ if isinstance(divisor, torch.Tensor):
+ divisor = int(divisor.max()) # to int
+ return math.ceil(x / divisor) * divisor
+
+
+def non_max_suppression(
+ prediction,
+ conf_thres=0.25,
+ iou_thres=0.45,
+ classes=None,
+ agnostic=False,
+ multi_label=False,
+ labels=(),
+ max_det=300,
+ nc=0, # number of classes (optional)
+ max_time_img=0.05,
+ max_nms=30000,
+ max_wh=7680,
+):
+ """
+ Perform non-maximum suppression (NMS) on a set of boxes, with support for masks and multiple labels per box.
+
+ Args:
+ prediction (torch.Tensor): A tensor of shape (batch_size, num_classes + 4 + num_masks, num_boxes)
+ containing the predicted boxes, classes, and masks. The tensor should be in the format
+ output by a model, such as YOLO.
+ conf_thres (float): The confidence threshold below which boxes will be filtered out.
+ Valid values are between 0.0 and 1.0.
+ iou_thres (float): The IoU threshold below which boxes will be filtered out during NMS.
+ Valid values are between 0.0 and 1.0.
+ classes (List[int]): A list of class indices to consider. If None, all classes will be considered.
+ agnostic (bool): If True, the model is agnostic to the number of classes, and all
+ classes will be considered as one.
+ multi_label (bool): If True, each box may have multiple labels.
+ labels (List[List[Union[int, float, torch.Tensor]]]): A list of lists, where each inner
+ list contains the apriori labels for a given image. The list should be in the format
+ output by a dataloader, with each label being a tuple of (class_index, x1, y1, x2, y2).
+ max_det (int): The maximum number of boxes to keep after NMS.
+ nc (int, optional): The number of classes output by the model. Any indices after this will be considered masks.
+ max_time_img (float): The maximum time (seconds) for processing one image.
+ max_nms (int): The maximum number of boxes into torchvision.ops.nms().
+ max_wh (int): The maximum box width and height in pixels
+
+ Returns:
+ (List[torch.Tensor]): A list of length batch_size, where each element is a tensor of
+ shape (num_boxes, 6 + num_masks) containing the kept boxes, with columns
+ (x1, y1, x2, y2, confidence, class, mask1, mask2, ...).
+ """
+
+ # Checks
+ assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
+ assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
+ if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
+ prediction = prediction[0] # select only inference output
+
+ device = prediction.device
+ mps = 'mps' in device.type # Apple MPS
+ if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
+ prediction = prediction.cpu()
+ bs = prediction.shape[0] # batch size
+ nc = nc or (prediction.shape[1] - 4) # number of classes
+ nm = prediction.shape[1] - nc - 4
+ mi = 4 + nc # mask start index
+ xc = prediction[:, 4:mi].amax(1) > conf_thres # candidates
+
+ # Settings
+ # min_wh = 2 # (pixels) minimum box width and height
+ time_limit = 0.5 + max_time_img * bs # seconds to quit after
+ multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
+
+ prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
+ prediction[..., :4] = xywh2xyxy(prediction[..., :4]) # xywh to xyxy
+
+ t = time.time()
+ output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
+ for xi, x in enumerate(prediction): # image index, image inference
+ # Apply constraints
+ # x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
+ x = x[xc[xi]] # confidence
+
+ # Cat apriori labels if autolabelling
+ if labels and len(labels[xi]):
+ lb = labels[xi]
+ v = torch.zeros((len(lb), nc + nm + 4), device=x.device)
+ v[:, :4] = xywh2xyxy(lb[:, 1:5]) # box
+ v[range(len(lb)), lb[:, 0].long() + 4] = 1.0 # cls
+ x = torch.cat((x, v), 0)
+
+ # If none remain process next image
+ if not x.shape[0]:
+ continue
+
+ # Detections matrix nx6 (xyxy, conf, cls)
+ box, cls, mask = x.split((4, nc, nm), 1)
+
+ if multi_label:
+ i, j = torch.where(cls > conf_thres)
+ x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
+ else: # best class only
+ conf, j = cls.max(1, keepdim=True)
+ x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
+
+ # Filter by class
+ if classes is not None:
+ x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
+
+ # Check shape
+ n = x.shape[0] # number of boxes
+ if not n: # no boxes
+ continue
+ if n > max_nms: # excess boxes
+ x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
+
+ # Batched NMS
+ c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
+ boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
+ i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
+ i = i[:max_det] # limit detections
+
+ # # Experimental
+ # merge = False # use merge-NMS
+ # if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
+ # # Update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
+ # from .metrics import box_iou
+ # iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
+ # weights = iou * scores[None] # box weights
+ # x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
+ # redundant = True # require redundant detections
+ # if redundant:
+ # i = i[iou.sum(1) > 1] # require redundancy
+
+ output[xi] = x[i]
+ if mps:
+ output[xi] = output[xi].to(device)
+ if (time.time() - t) > time_limit:
+ LOGGER.warning(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
+ break # time limit exceeded
+
+ return output
+
+
+def clip_boxes(boxes, shape):
+ """
+ Takes a list of bounding boxes and a shape (height, width) and clips the bounding boxes to the shape.
+
+ Args:
+ boxes (torch.Tensor): the bounding boxes to clip
+ shape (tuple): the shape of the image
+ """
+ if isinstance(boxes, torch.Tensor): # faster individually
+ boxes[..., 0].clamp_(0, shape[1]) # x1
+ boxes[..., 1].clamp_(0, shape[0]) # y1
+ boxes[..., 2].clamp_(0, shape[1]) # x2
+ boxes[..., 3].clamp_(0, shape[0]) # y2
+ else: # np.array (faster grouped)
+ boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
+ boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
+
+
+def clip_coords(coords, shape):
+ """
+ Clip line coordinates to the image boundaries.
+
+ Args:
+ coords (torch.Tensor | numpy.ndarray): A list of line coordinates.
+ shape (tuple): A tuple of integers representing the size of the image in the format (height, width).
+
+ Returns:
+ (None): The function modifies the input `coordinates` in place, by clipping each coordinate to the image boundaries.
+ """
+ if isinstance(coords, torch.Tensor): # faster individually
+ coords[..., 0].clamp_(0, shape[1]) # x
+ coords[..., 1].clamp_(0, shape[0]) # y
+ else: # np.array (faster grouped)
+ coords[..., 0] = coords[..., 0].clip(0, shape[1]) # x
+ coords[..., 1] = coords[..., 1].clip(0, shape[0]) # y
+
+
+def scale_image(masks, im0_shape, ratio_pad=None):
+ """
+ Takes a mask, and resizes it to the original image size
+
+ Args:
+ masks (np.ndarray): resized and padded masks/images, [h, w, num]/[h, w, 3].
+ im0_shape (tuple): the original image shape
+ ratio_pad (tuple): the ratio of the padding to the original image.
+
+ Returns:
+ masks (torch.Tensor): The masks that are being returned.
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ im1_shape = masks.shape
+ if im1_shape[:2] == im0_shape[:2]:
+ return masks
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+
+ return masks
+
+
+def xyxy2xywh(x):
+ """
+ Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height) format where (x1, y1) is the
+ top-left corner and (x2, y2) is the bottom-right corner.
+
+ Args:
+ x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height) format.
+ """
+ assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
+ y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
+ y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
+ y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
+ y[..., 2] = x[..., 2] - x[..., 0] # width
+ y[..., 3] = x[..., 3] - x[..., 1] # height
+ return y
+
+
+def xywh2xyxy(x):
+ """
+ Convert bounding box coordinates from (x, y, width, height) format to (x1, y1, x2, y2) format where (x1, y1) is the
+ top-left corner and (x2, y2) is the bottom-right corner.
+
+ Args:
+ x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x, y, width, height) format.
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in (x1, y1, x2, y2) format.
+ """
+ assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
+ y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
+ dw = x[..., 2] / 2 # half-width
+ dh = x[..., 3] / 2 # half-height
+ y[..., 0] = x[..., 0] - dw # top left x
+ y[..., 1] = x[..., 1] - dh # top left y
+ y[..., 2] = x[..., 0] + dw # bottom right x
+ y[..., 3] = x[..., 1] + dh # bottom right y
+ return y
+
+
+def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
+ """
+ Convert normalized bounding box coordinates to pixel coordinates.
+
+ Args:
+ x (np.ndarray | torch.Tensor): The bounding box coordinates.
+ w (int): Width of the image. Defaults to 640
+ h (int): Height of the image. Defaults to 640
+ padw (int): Padding width. Defaults to 0
+ padh (int): Padding height. Defaults to 0
+ Returns:
+ y (np.ndarray | torch.Tensor): The coordinates of the bounding box in the format [x1, y1, x2, y2] where
+ x1,y1 is the top-left corner, x2,y2 is the bottom-right corner of the bounding box.
+ """
+ assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
+ y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
+ y[..., 0] = w * (x[..., 0] - x[..., 2] / 2) + padw # top left x
+ y[..., 1] = h * (x[..., 1] - x[..., 3] / 2) + padh # top left y
+ y[..., 2] = w * (x[..., 0] + x[..., 2] / 2) + padw # bottom right x
+ y[..., 3] = h * (x[..., 1] + x[..., 3] / 2) + padh # bottom right y
+ return y
+
+
+def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
+ """
+ Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height, normalized) format.
+ x, y, width and height are normalized to image dimensions
+
+ Args:
+ x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
+ w (int): The width of the image. Defaults to 640
+ h (int): The height of the image. Defaults to 640
+ clip (bool): If True, the boxes will be clipped to the image boundaries. Defaults to False
+ eps (float): The minimum value of the box's width and height. Defaults to 0.0
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height, normalized) format
+ """
+ if clip:
+ clip_boxes(x, (h - eps, w - eps)) # warning: inplace clip
+ assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
+ y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
+ y[..., 0] = ((x[..., 0] + x[..., 2]) / 2) / w # x center
+ y[..., 1] = ((x[..., 1] + x[..., 3]) / 2) / h # y center
+ y[..., 2] = (x[..., 2] - x[..., 0]) / w # width
+ y[..., 3] = (x[..., 3] - x[..., 1]) / h # height
+ return y
+
+
+def xywh2ltwh(x):
+ """
+ Convert the bounding box format from [x, y, w, h] to [x1, y1, w, h], where x1, y1 are the top-left coordinates.
+
+ Args:
+ x (np.ndarray | torch.Tensor): The input tensor with the bounding box coordinates in the xywh format
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in the xyltwh format
+ """
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
+ y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
+ return y
+
+
+def xyxy2ltwh(x):
+ """
+ Convert nx4 bounding boxes from [x1, y1, x2, y2] to [x1, y1, w, h], where xy1=top-left, xy2=bottom-right
+
+ Args:
+ x (np.ndarray | torch.Tensor): The input tensor with the bounding boxes coordinates in the xyxy format
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in the xyltwh format.
+ """
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 2] = x[..., 2] - x[..., 0] # width
+ y[..., 3] = x[..., 3] - x[..., 1] # height
+ return y
+
+
+def ltwh2xywh(x):
+ """
+ Convert nx4 boxes from [x1, y1, w, h] to [x, y, w, h] where xy1=top-left, xy=center
+
+ Args:
+ x (torch.Tensor): the input tensor
+
+ Returns:
+ y (np.ndarray | torch.Tensor): The bounding box coordinates in the xywh format.
+ """
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 0] = x[..., 0] + x[..., 2] / 2 # center x
+ y[..., 1] = x[..., 1] + x[..., 3] / 2 # center y
+ return y
+
+
+def xyxyxyxy2xywhr(corners):
+ """
+ Convert batched Oriented Bounding Boxes (OBB) from [xy1, xy2, xy3, xy4] to [xywh, rotation].
+
+ Args:
+ corners (numpy.ndarray | torch.Tensor): Input corners of shape (n, 8).
+
+ Returns:
+ (numpy.ndarray | torch.Tensor): Converted data in [cx, cy, w, h, rotation] format of shape (n, 5).
+ """
+ is_numpy = isinstance(corners, np.ndarray)
+ atan2, sqrt = (np.arctan2, np.sqrt) if is_numpy else (torch.atan2, torch.sqrt)
+
+ x1, y1, x2, y2, x3, y3, x4, y4 = corners.T
+ cx = (x1 + x3) / 2
+ cy = (y1 + y3) / 2
+ dx21 = x2 - x1
+ dy21 = y2 - y1
+
+ w = sqrt(dx21 ** 2 + dy21 ** 2)
+ h = sqrt((x2 - x3) ** 2 + (y2 - y3) ** 2)
+
+ rotation = atan2(-dy21, dx21)
+ rotation *= 180.0 / math.pi # radians to degrees
+
+ return np.vstack((cx, cy, w, h, rotation)).T if is_numpy else torch.stack((cx, cy, w, h, rotation), dim=1)
+
+
+def xywhr2xyxyxyxy(center):
+ """
+ Convert batched Oriented Bounding Boxes (OBB) from [xywh, rotation] to [xy1, xy2, xy3, xy4].
+
+ Args:
+ center (numpy.ndarray | torch.Tensor): Input data in [cx, cy, w, h, rotation] format of shape (n, 5).
+
+ Returns:
+ (numpy.ndarray | torch.Tensor): Converted corner points of shape (n, 8).
+ """
+ is_numpy = isinstance(center, np.ndarray)
+ cos, sin = (np.cos, np.sin) if is_numpy else (torch.cos, torch.sin)
+
+ cx, cy, w, h, rotation = center.T
+ rotation *= math.pi / 180.0 # degrees to radians
+
+ dx = w / 2
+ dy = h / 2
+
+ cos_rot = cos(rotation)
+ sin_rot = sin(rotation)
+ dx_cos_rot = dx * cos_rot
+ dx_sin_rot = dx * sin_rot
+ dy_cos_rot = dy * cos_rot
+ dy_sin_rot = dy * sin_rot
+
+ x1 = cx - dx_cos_rot - dy_sin_rot
+ y1 = cy + dx_sin_rot - dy_cos_rot
+ x2 = cx + dx_cos_rot - dy_sin_rot
+ y2 = cy - dx_sin_rot - dy_cos_rot
+ x3 = cx + dx_cos_rot + dy_sin_rot
+ y3 = cy - dx_sin_rot + dy_cos_rot
+ x4 = cx - dx_cos_rot + dy_sin_rot
+ y4 = cy + dx_sin_rot + dy_cos_rot
+
+ return np.vstack((x1, y1, x2, y2, x3, y3, x4, y4)).T if is_numpy else torch.stack(
+ (x1, y1, x2, y2, x3, y3, x4, y4), dim=1)
+
+
+def ltwh2xyxy(x):
+ """
+ It converts the bounding box from [x1, y1, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+
+ Args:
+ x (np.ndarray | torch.Tensor): the input image
+
+ Returns:
+ y (np.ndarray | torch.Tensor): the xyxy coordinates of the bounding boxes.
+ """
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[..., 2] = x[..., 2] + x[..., 0] # width
+ y[..., 3] = x[..., 3] + x[..., 1] # height
+ return y
+
+
+def segments2boxes(segments):
+ """
+ It converts segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
+
+ Args:
+ segments (list): list of segments, each segment is a list of points, each point is a list of x, y coordinates
+
+ Returns:
+ (np.ndarray): the xywh coordinates of the bounding boxes.
+ """
+ boxes = []
+ for s in segments:
+ x, y = s.T # segment xy
+ boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
+ return xyxy2xywh(np.array(boxes)) # cls, xywh
+
+
+def resample_segments(segments, n=1000):
+ """
+ Inputs a list of segments (n,2) and returns a list of segments (n,2) up-sampled to n points each.
+
+ Args:
+ segments (list): a list of (n,2) arrays, where n is the number of points in the segment.
+ n (int): number of points to resample the segment to. Defaults to 1000
+
+ Returns:
+ segments (list): the resampled segments.
+ """
+ for i, s in enumerate(segments):
+ s = np.concatenate((s, s[0:1, :]), axis=0)
+ x = np.linspace(0, len(s) - 1, n)
+ xp = np.arange(len(s))
+ segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)],
+ dtype=np.float32).reshape(2, -1).T # segment xy
+ return segments
+
+
+def crop_mask(masks, boxes):
+ """
+ It takes a mask and a bounding box, and returns a mask that is cropped to the bounding box.
+
+ Args:
+ masks (torch.Tensor): [n, h, w] tensor of masks
+ boxes (torch.Tensor): [n, 4] tensor of bbox coordinates in relative point form
+
+ Returns:
+ (torch.Tensor): The masks are being cropped to the bounding box.
+ """
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(n,1,1)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,1,w)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(1,h,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Takes the output of the mask head, and applies the mask to the bounding boxes. This produces masks of higher
+ quality but is slower.
+
+ Args:
+ protos (torch.Tensor): [mask_dim, mask_h, mask_w]
+ masks_in (torch.Tensor): [n, mask_dim], n is number of masks after nms
+ bboxes (torch.Tensor): [n, 4], n is number of masks after nms
+ shape (tuple): the size of the input image (h,w)
+
+ Returns:
+ (torch.Tensor): The upsampled masks.
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Apply masks to bounding boxes using the output of the mask head.
+
+ Args:
+ protos (torch.Tensor): A tensor of shape [mask_dim, mask_h, mask_w].
+ masks_in (torch.Tensor): A tensor of shape [n, mask_dim], where n is the number of masks after NMS.
+ bboxes (torch.Tensor): A tensor of shape [n, 4], where n is the number of masks after NMS.
+ shape (tuple): A tuple of integers representing the size of the input image in the format (h, w).
+ upsample (bool): A flag to indicate whether to upsample the mask to the original image size. Default is False.
+
+ Returns:
+ (torch.Tensor): A binary mask tensor of shape [n, h, w], where n is the number of masks after NMS, and h and w
+ are the height and width of the input image. The mask is applied to the bounding boxes.
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask_native(protos, masks_in, bboxes, shape):
+ """
+ It takes the output of the mask head, and crops it after upsampling to the bounding boxes.
+
+ Args:
+ protos (torch.Tensor): [mask_dim, mask_h, mask_w]
+ masks_in (torch.Tensor): [n, mask_dim], n is number of masks after nms
+ bboxes (torch.Tensor): [n, 4], n is number of masks after nms
+ shape (tuple): the size of the input image (h,w)
+
+ Returns:
+ masks (torch.Tensor): The returned masks with dimensions [h, w, n]
+ """
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = scale_masks(masks[None], shape)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def scale_masks(masks, shape, padding=True):
+ """
+ Rescale segment masks to shape.
+
+ Args:
+ masks (torch.Tensor): (N, C, H, W).
+ shape (tuple): Height and width.
+ padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
+ rescaling.
+ """
+ mh, mw = masks.shape[2:]
+ gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
+ pad = [mw - shape[1] * gain, mh - shape[0] * gain] # wh padding
+ if padding:
+ pad[0] /= 2
+ pad[1] /= 2
+ top, left = (int(pad[1]), int(pad[0])) if padding else (0, 0) # y, x
+ bottom, right = (int(mh - pad[1]), int(mw - pad[0]))
+ masks = masks[..., top:bottom, left:right]
+
+ masks = F.interpolate(masks, shape, mode='bilinear', align_corners=False) # NCHW
+ return masks
+
+
+def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None, normalize=False, padding=True):
+ """
+ Rescale segment coordinates (xy) from img1_shape to img0_shape
+
+ Args:
+ img1_shape (tuple): The shape of the image that the coords are from.
+ coords (torch.Tensor): the coords to be scaled of shape n,2.
+ img0_shape (tuple): the shape of the image that the segmentation is being applied to.
+ ratio_pad (tuple): the ratio of the image size to the padded image size.
+ normalize (bool): If True, the coordinates will be normalized to the range [0, 1]. Defaults to False.
+ padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
+ rescaling.
+
+ Returns:
+ coords (torch.Tensor): The scaled coordinates.
+ """
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ if padding:
+ coords[..., 0] -= pad[0] # x padding
+ coords[..., 1] -= pad[1] # y padding
+ coords[..., 0] /= gain
+ coords[..., 1] /= gain
+ clip_coords(coords, img0_shape)
+ if normalize:
+ coords[..., 0] /= img0_shape[1] # width
+ coords[..., 1] /= img0_shape[0] # height
+ return coords
+
+
+def masks2segments(masks, strategy='largest'):
+ """
+ It takes a list of masks(n,h,w) and returns a list of segments(n,xy)
+
+ Args:
+ masks (torch.Tensor): the output of the model, which is a tensor of shape (batch_size, 160, 160)
+ strategy (str): 'concat' or 'largest'. Defaults to largest
+
+ Returns:
+ segments (List): list of segment masks
+ """
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
+
+
+def clean_str(s):
+ """
+ Cleans a string by replacing special characters with underscore _
+
+ Args:
+ s (str): a string needing special characters replaced
+
+ Returns:
+ (str): a string with special characters replaced by an underscore _
+ """
+ return re.sub(pattern='[|@#!¡·$€%&()=?¿^*;:,¨´><+]', repl='_', string=s)
diff --git a/STPoseNet/ultralytics/utils/patches.py b/STPoseNet/ultralytics/utils/patches.py
new file mode 100644
index 0000000000000000000000000000000000000000..a145763947a256eac9954e5a3f378f1141248c9a
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/patches.py
@@ -0,0 +1,75 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+"""
+Monkey patches to update/extend functionality of existing functions
+"""
+
+from pathlib import Path
+
+import cv2
+import numpy as np
+import torch
+
+# OpenCV Multilanguage-friendly functions ------------------------------------------------------------------------------
+_imshow = cv2.imshow # copy to avoid recursion errors
+
+
+def imread(filename: str, flags: int = cv2.IMREAD_COLOR):
+ """Read an image from a file.
+
+ Args:
+ filename (str): Path to the file to read.
+ flags (int, optional): Flag that can take values of cv2.IMREAD_*. Defaults to cv2.IMREAD_COLOR.
+
+ Returns:
+ (np.ndarray): The read image.
+ """
+ return cv2.imdecode(np.fromfile(filename, np.uint8), flags)
+
+
+def imwrite(filename: str, img: np.ndarray, params=None):
+ """Write an image to a file.
+
+ Args:
+ filename (str): Path to the file to write.
+ img (np.ndarray): Image to write.
+ params (list of ints, optional): Additional parameters. See OpenCV documentation.
+
+ Returns:
+ (bool): True if the file was written, False otherwise.
+ """
+ try:
+ cv2.imencode(Path(filename).suffix, img, params)[1].tofile(filename)
+ return True
+ except Exception:
+ return False
+
+
+def imshow(winname: str, mat: np.ndarray):
+ """Displays an image in the specified window.
+
+ Args:
+ winname (str): Name of the window.
+ mat (np.ndarray): Image to be shown.
+ """
+ _imshow(winname.encode('unicode_escape').decode(), mat)
+
+
+# PyTorch functions ----------------------------------------------------------------------------------------------------
+_torch_save = torch.save # copy to avoid recursion errors
+
+
+def torch_save(*args, **kwargs):
+ """Use dill (if exists) to serialize the lambda functions where pickle does not do this.
+
+ Args:
+ *args (tuple): Positional arguments to pass to torch.save.
+ **kwargs (dict): Keyword arguments to pass to torch.save.
+ """
+ try:
+ import dill as pickle # noqa
+ except ImportError:
+ import pickle
+
+ if 'pickle_module' not in kwargs:
+ kwargs['pickle_module'] = pickle # noqa
+ return _torch_save(*args, **kwargs)
diff --git a/STPoseNet/ultralytics/utils/plotting.py b/STPoseNet/ultralytics/utils/plotting.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ad79e20c6d2a427b14966034c096b847226fa16
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/plotting.py
@@ -0,0 +1,592 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import contextlib
+import math
+import warnings
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+from PIL import Image, ImageDraw, ImageFont
+from PIL import __version__ as pil_version
+
+from ultralytics.utils import LOGGER, TryExcept, plt_settings, threaded
+
+from .checks import check_font, check_version, is_ascii
+from .files import increment_path
+from .ops import clip_boxes, scale_image, xywh2xyxy, xyxy2xywh
+
+
+class Colors:
+ """
+ Ultralytics default color palette https://ultralytics.com/.
+
+ This class provides methods to work with the Ultralytics color palette, including converting hex color codes to
+ RGB values.
+
+ Attributes:
+ palette (list of tuple): List of RGB color values.
+ n (int): The number of colors in the palette.
+ pose_palette (np.array): A specific color palette array with dtype np.uint8.
+ """
+
+ def __init__(self):
+ """Initialize colors as hex = matplotlib.colors.TABLEAU_COLORS.values()."""
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+ self.pose_palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102], [230, 230, 0], [255, 153, 255],
+ [153, 204, 255], [255, 102, 255], [255, 51, 255], [102, 178, 255], [51, 153, 255],
+ [255, 153, 153], [255, 102, 102], [255, 51, 51], [153, 255, 153], [102, 255, 102],
+ [51, 255, 51], [0, 255, 0], [0, 0, 255], [255, 0, 0], [255, 255, 255]],
+ dtype=np.uint8)
+
+ def __call__(self, i, bgr=False):
+ """Converts hex color codes to RGB values."""
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h):
+ """Converts hex color codes to RGB values (i.e. default PIL order)."""
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+class Annotator:
+ """
+ Ultralytics Annotator for train/val mosaics and JPGs and predictions annotations.
+
+ Attributes:
+ im (Image.Image or numpy array): The image to annotate.
+ pil (bool): Whether to use PIL or cv2 for drawing annotations.
+ font (ImageFont.truetype or ImageFont.load_default): Font used for text annotations.
+ lw (float): Line width for drawing.
+ skeleton (List[List[int]]): Skeleton structure for keypoints.
+ limb_color (List[int]): Color palette for limbs.
+ kpt_color (List[int]): Color palette for keypoints.
+ """
+
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ """Initialize the Annotator class with image and line width along with color palette for keypoints and limbs."""
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ try:
+ font = check_font('Arial.Unicode.ttf' if non_ascii else font)
+ size = font_size or max(round(sum(self.im.size) / 2 * 0.035), 12)
+ self.font = ImageFont.truetype(str(font), size)
+ except Exception:
+ self.font = ImageFont.load_default()
+ # Deprecation fix for w, h = getsize(string) -> _, _, w, h = getbox(string)
+ if check_version(pil_version, '9.2.0'):
+ self.font.getsize = lambda x: self.font.getbbox(x)[2:4] # text width, height
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+ # Pose
+ self.skeleton = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8], [7, 9],
+ [8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]
+
+ self.limb_color = colors.pose_palette[[9, 9, 9, 9, 7, 7, 7, 0, 0, 0, 0, 0, 16, 16, 16, 16, 16, 16, 16]]
+ self.kpt_color = colors.pose_palette[[16, 16, 16, 16, 16, 0, 0, 0, 0, 0, 0, 9, 9, 9, 9, 9, 9]]
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ """Add one xyxy box to image with label."""
+ if isinstance(box, torch.Tensor):
+ box = box.tolist()
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu, alpha=0.5, retina_masks=False):
+ """
+ Plot masks on image.
+
+ Args:
+ masks (tensor): Predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): Colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): Image is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): Mask transparency: 0.0 fully transparent, 1.0 opaque
+ retina_masks (bool): Whether to use high resolution masks or not. Defaults to False.
+ """
+ if self.pil:
+ # Convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ if im_gpu.device != masks.device:
+ im_gpu = im_gpu.to(masks.device)
+ colors = torch.tensor(colors, device=masks.device, dtype=torch.float32) / 255.0 # shape(n,3)
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = masks_color.max(dim=0).values # shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255)
+ im_mask_np = im_mask.byte().cpu().numpy()
+ self.im[:] = im_mask_np if retina_masks else scale_image(im_mask_np, self.im.shape)
+ if self.pil:
+ # Convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def kpts(self, kpts, shape=(640, 640), radius=5, kpt_line=True):
+ """
+ Plot keypoints on the image.
+
+ Args:
+ kpts (tensor): Predicted keypoints with shape [17, 3]. Each keypoint has (x, y, confidence).
+ shape (tuple): Image shape as a tuple (h, w), where h is the height and w is the width.
+ radius (int, optional): Radius of the drawn keypoints. Default is 5.
+ kpt_line (bool, optional): If True, the function will draw lines connecting keypoints
+ for human pose. Default is True.
+
+ Note: `kpt_line=True` currently only supports human pose plotting.
+ """
+ if self.pil:
+ # Convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ nkpt, ndim = kpts.shape
+ is_pose = nkpt == 17 and ndim == 3
+ kpt_line &= is_pose # `kpt_line=True` for now only supports human pose plotting
+ for i, k in enumerate(kpts):
+ color_k = [int(x) for x in self.kpt_color[i]] if is_pose else colors(i)
+ x_coord, y_coord = k[0], k[1]
+ if x_coord % shape[1] != 0 and y_coord % shape[0] != 0:
+ if len(k) == 3:
+ conf = k[2]
+ if conf < 0.5:
+ continue
+ cv2.circle(self.im, (int(x_coord), int(y_coord)), radius, color_k, -1, lineType=cv2.LINE_AA)
+
+ if kpt_line:
+ ndim = kpts.shape[-1]
+ for i, sk in enumerate(self.skeleton):
+ pos1 = (int(kpts[(sk[0] - 1), 0]), int(kpts[(sk[0] - 1), 1]))
+ pos2 = (int(kpts[(sk[1] - 1), 0]), int(kpts[(sk[1] - 1), 1]))
+ if ndim == 3:
+ conf1 = kpts[(sk[0] - 1), 2]
+ conf2 = kpts[(sk[1] - 1), 2]
+ if conf1 < 0.5 or conf2 < 0.5:
+ continue
+ if pos1[0] % shape[1] == 0 or pos1[1] % shape[0] == 0 or pos1[0] < 0 or pos1[1] < 0:
+ continue
+ if pos2[0] % shape[1] == 0 or pos2[1] % shape[0] == 0 or pos2[0] < 0 or pos2[1] < 0:
+ continue
+ cv2.line(self.im, pos1, pos2, [int(x) for x in self.limb_color[i]], thickness=2, lineType=cv2.LINE_AA)
+ if self.pil:
+ # Convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ """Add rectangle to image (PIL-only)."""
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top', box_style=False):
+ """Adds text to an image using PIL or cv2."""
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ if self.pil:
+ if box_style:
+ w, h = self.font.getsize(text)
+ self.draw.rectangle((xy[0], xy[1], xy[0] + w + 1, xy[1] + h + 1), fill=txt_color)
+ # Using `txt_color` for background and draw fg with white color
+ txt_color = (255, 255, 255)
+ if '\n' in text:
+ lines = text.split('\n')
+ _, h = self.font.getsize(text)
+ for line in lines:
+ self.draw.text(xy, line, fill=txt_color, font=self.font)
+ xy[1] += h
+ else:
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+ else:
+ if box_style:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(text, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = xy[1] - h >= 3
+ p2 = xy[0] + w, xy[1] - h - 3 if outside else xy[1] + h + 3
+ cv2.rectangle(self.im, xy, p2, txt_color, -1, cv2.LINE_AA) # filled
+ # Using `txt_color` for background and draw fg with white color
+ txt_color = (255, 255, 255)
+ tf = max(self.lw - 1, 1) # font thickness
+ cv2.putText(self.im, text, xy, 0, self.lw / 3, txt_color, thickness=tf, lineType=cv2.LINE_AA)
+
+ def fromarray(self, im):
+ """Update self.im from a numpy array."""
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ """Return annotated image as array."""
+ return np.asarray(self.im)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+@plt_settings()
+def plot_labels(boxes, cls, names=(), save_dir=Path(''), on_plot=None):
+ """Plot training labels including class histograms and box statistics."""
+ import pandas as pd
+ import seaborn as sn
+
+ # Filter matplotlib>=3.7.2 warning
+ warnings.filterwarnings('ignore', category=UserWarning, message='The figure layout has changed to tight')
+
+ # Plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ nc = int(cls.max() + 1) # number of classes
+ boxes = boxes[:1000000] # limit to 1M boxes
+ x = pd.DataFrame(boxes, columns=['x', 'y', 'width', 'height'])
+
+ # Seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # Matplotlib labels
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(cls, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # Rectangles
+ boxes[:, 0:2] = 0.5 # center
+ boxes = xywh2xyxy(boxes) * 1000
+ img = Image.fromarray(np.ones((1000, 1000, 3), dtype=np.uint8) * 255)
+ for cls, box in zip(cls[:500], boxes[:500]):
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ fname = save_dir / 'labels.jpg'
+ plt.savefig(fname, dpi=200)
+ plt.close()
+ if on_plot:
+ on_plot(fname)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ """Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop.
+
+ This function takes a bounding box and an image, and then saves a cropped portion of the image according
+ to the bounding box. Optionally, the crop can be squared, and the function allows for gain and padding
+ adjustments to the bounding box.
+
+ Args:
+ xyxy (torch.Tensor or list): A tensor or list representing the bounding box in xyxy format.
+ im (numpy.ndarray): The input image.
+ file (Path, optional): The path where the cropped image will be saved. Defaults to 'im.jpg'.
+ gain (float, optional): A multiplicative factor to increase the size of the bounding box. Defaults to 1.02.
+ pad (int, optional): The number of pixels to add to the width and height of the bounding box. Defaults to 10.
+ square (bool, optional): If True, the bounding box will be transformed into a square. Defaults to False.
+ BGR (bool, optional): If True, the image will be saved in BGR format, otherwise in RGB. Defaults to False.
+ save (bool, optional): If True, the cropped image will be saved to disk. Defaults to True.
+
+ Returns:
+ (numpy.ndarray): The cropped image.
+
+ Example:
+ ```python
+ from ultralytics.utils.plotting import save_one_box
+
+ xyxy = [50, 50, 150, 150]
+ im = cv2.imread('image.jpg')
+ cropped_im = save_one_box(xyxy, im, file='cropped.jpg', square=True)
+ ```
+ """
+
+ if not isinstance(xyxy, torch.Tensor): # may be list
+ xyxy = torch.stack(xyxy)
+ b = xyxy2xywh(xyxy.view(-1, 4)) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
+
+
+@threaded
+def plot_images(images,
+ batch_idx,
+ cls,
+ bboxes=np.zeros(0, dtype=np.float32),
+ masks=np.zeros(0, dtype=np.uint8),
+ kpts=np.zeros((0, 51), dtype=np.float32),
+ paths=None,
+ fname='images.jpg',
+ names=None,
+ on_plot=None):
+ """Plot image grid with labels."""
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(cls, torch.Tensor):
+ cls = cls.cpu().numpy()
+ if isinstance(bboxes, torch.Tensor):
+ bboxes = bboxes.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+ if isinstance(kpts, torch.Tensor):
+ kpts = kpts.cpu().numpy()
+ if isinstance(batch_idx, torch.Tensor):
+ batch_idx = batch_idx.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(cls) > 0:
+ idx = batch_idx == i
+ classes = cls[idx].astype('int')
+
+ if len(bboxes):
+ boxes = xywh2xyxy(bboxes[idx, :4]).T
+ labels = bboxes.shape[1] == 4 # labels if no conf column
+ conf = None if labels else bboxes[idx, 4] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ c = classes[j]
+ color = colors(c)
+ c = names.get(c, c) if names else c
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{c}' if labels else f'{c} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ elif len(classes):
+ for c in classes:
+ color = colors(c)
+ c = names.get(c, c) if names else c
+ annotator.text((x, y), f'{c}', txt_color=color, box_style=True)
+
+ # Plot keypoints
+ if len(kpts):
+ kpts_ = kpts[idx].copy()
+ if len(kpts_):
+ if kpts_[..., 0].max() <= 1.01 or kpts_[..., 1].max() <= 1.01: # if normalized with tolerance .01
+ kpts_[..., 0] *= w # scale to pixels
+ kpts_[..., 1] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ kpts_ *= scale
+ kpts_[..., 0] += x
+ kpts_[..., 1] += y
+ for j in range(len(kpts_)):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ annotator.kpts(kpts_[j])
+
+ # Plot masks
+ if len(masks):
+ if idx.shape[0] == masks.shape[0]: # overlap_masks=False
+ image_masks = masks[idx]
+ else: # overlap_masks=True
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = idx.sum()
+ index = np.arange(nl).reshape((nl, 1, 1)) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+ if on_plot:
+ on_plot(fname)
+
+
+@plt_settings()
+def plot_results(file='path/to/results.csv', dir='', segment=False, pose=False, classify=False, on_plot=None):
+ """
+ Plot training results from results CSV file.
+
+ Example:
+ ```python
+ from ultralytics.utils.plotting import plot_results
+
+ plot_results('path/to/results.csv')
+ ```
+ """
+ import pandas as pd
+ from scipy.ndimage import gaussian_filter1d
+ save_dir = Path(file).parent if file else Path(dir)
+ if classify:
+ fig, ax = plt.subplots(2, 2, figsize=(6, 6), tight_layout=True)
+ index = [1, 4, 2, 3]
+ elif segment:
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ index = [1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]
+ elif pose:
+ fig, ax = plt.subplots(2, 9, figsize=(21, 6), tight_layout=True)
+ index = [1, 2, 3, 4, 5, 6, 7, 10, 11, 14, 15, 16, 17, 18, 8, 9, 12, 13]
+ else:
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ index = [1, 2, 3, 4, 5, 8, 9, 10, 6, 7]
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate(index):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8) # actual results
+ ax[i].plot(x, gaussian_filter1d(y, sigma=3), ':', label='smooth', linewidth=2) # smoothing line
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.warning(f'WARNING: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fname = save_dir / 'results.png'
+ fig.savefig(fname, dpi=200)
+ plt.close()
+ if on_plot:
+ on_plot(fname)
+
+
+def output_to_target(output, max_det=300):
+ """Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting."""
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ targets = torch.cat(targets, 0).numpy()
+ return targets[:, 0], targets[:, 1], targets[:, 2:]
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ Visualize feature maps of a given model module during inference.
+
+ Args:
+ x (torch.Tensor): Features to be visualized.
+ module_type (str): Module type.
+ stage (int): Module stage within the model.
+ n (int, optional): Maximum number of feature maps to plot. Defaults to 32.
+ save_dir (Path, optional): Directory to save results. Defaults to Path('runs/detect/exp').
+ """
+ for m in ['Detect', 'Pose', 'Segment']:
+ if m in module_type:
+ return
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
diff --git a/STPoseNet/ultralytics/utils/tal.py b/STPoseNet/ultralytics/utils/tal.py
new file mode 100644
index 0000000000000000000000000000000000000000..87f4579156c1dc19ef8ff51f96e83e54c00a9086
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/tal.py
@@ -0,0 +1,279 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import torch
+import torch.nn as nn
+
+from .checks import check_version
+from .metrics import bbox_iou
+
+TORCH_1_10 = check_version(torch.__version__, '1.10.0')
+
+
+def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
+ """
+ Select the positive anchor center in gt.
+
+ Args:
+ xy_centers (Tensor): shape(h*w, 4)
+ gt_bboxes (Tensor): shape(b, n_boxes, 4)
+
+ Returns:
+ (Tensor): shape(b, n_boxes, h*w)
+ """
+ n_anchors = xy_centers.shape[0]
+ bs, n_boxes, _ = gt_bboxes.shape
+ lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
+ bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
+ # return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)
+ return bbox_deltas.amin(3).gt_(eps)
+
+
+def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
+ """
+ If an anchor box is assigned to multiple gts, the one with the highest IoI will be selected.
+
+ Args:
+ mask_pos (Tensor): shape(b, n_max_boxes, h*w)
+ overlaps (Tensor): shape(b, n_max_boxes, h*w)
+
+ Returns:
+ target_gt_idx (Tensor): shape(b, h*w)
+ fg_mask (Tensor): shape(b, h*w)
+ mask_pos (Tensor): shape(b, n_max_boxes, h*w)
+ """
+ # (b, n_max_boxes, h*w) -> (b, h*w)
+ fg_mask = mask_pos.sum(-2)
+ if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
+ mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
+ max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
+
+ is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
+ is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
+
+ mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
+ fg_mask = mask_pos.sum(-2)
+ # Find each grid serve which gt(index)
+ target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
+ return target_gt_idx, fg_mask, mask_pos
+
+
+class TaskAlignedAssigner(nn.Module):
+ """
+ A task-aligned assigner for object detection.
+
+ This class assigns ground-truth (gt) objects to anchors based on the task-aligned metric,
+ which combines both classification and localization information.
+
+ Attributes:
+ topk (int): The number of top candidates to consider.
+ num_classes (int): The number of object classes.
+ alpha (float): The alpha parameter for the classification component of the task-aligned metric.
+ beta (float): The beta parameter for the localization component of the task-aligned metric.
+ eps (float): A small value to prevent division by zero.
+ """
+
+ def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):
+ """Initialize a TaskAlignedAssigner object with customizable hyperparameters."""
+ super().__init__()
+ self.topk = topk
+ self.num_classes = num_classes
+ self.bg_idx = num_classes
+ self.alpha = alpha
+ self.beta = beta
+ self.eps = eps
+
+ @torch.no_grad()
+ def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
+ """
+ Compute the task-aligned assignment.
+ Reference https://github.com/Nioolek/PPYOLOE_pytorch/blob/master/ppyoloe/assigner/tal_assigner.py
+
+ Args:
+ pd_scores (Tensor): shape(bs, num_total_anchors, num_classes)
+ pd_bboxes (Tensor): shape(bs, num_total_anchors, 4)
+ anc_points (Tensor): shape(num_total_anchors, 2)
+ gt_labels (Tensor): shape(bs, n_max_boxes, 1)
+ gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)
+ mask_gt (Tensor): shape(bs, n_max_boxes, 1)
+
+ Returns:
+ target_labels (Tensor): shape(bs, num_total_anchors)
+ target_bboxes (Tensor): shape(bs, num_total_anchors, 4)
+ target_scores (Tensor): shape(bs, num_total_anchors, num_classes)
+ fg_mask (Tensor): shape(bs, num_total_anchors)
+ target_gt_idx (Tensor): shape(bs, num_total_anchors)
+ """
+ self.bs = pd_scores.size(0)
+ self.n_max_boxes = gt_bboxes.size(1)
+
+ if self.n_max_boxes == 0:
+ device = gt_bboxes.device
+ return (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device), torch.zeros_like(pd_bboxes).to(device),
+ torch.zeros_like(pd_scores).to(device), torch.zeros_like(pd_scores[..., 0]).to(device),
+ torch.zeros_like(pd_scores[..., 0]).to(device))
+
+ mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points,
+ mask_gt)
+
+ target_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
+
+ # Assigned target
+ target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
+
+ # Normalize
+ align_metric *= mask_pos
+ pos_align_metrics = align_metric.amax(axis=-1, keepdim=True) # b, max_num_obj
+ pos_overlaps = (overlaps * mask_pos).amax(axis=-1, keepdim=True) # b, max_num_obj
+ norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
+ target_scores = target_scores * norm_align_metric
+
+ return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
+
+ def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
+ """Get in_gts mask, (b, max_num_obj, h*w)."""
+ mask_in_gts = select_candidates_in_gts(anc_points, gt_bboxes)
+ # Get anchor_align metric, (b, max_num_obj, h*w)
+ align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)
+ # Get topk_metric mask, (b, max_num_obj, h*w)
+ mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())
+ # Merge all mask to a final mask, (b, max_num_obj, h*w)
+ mask_pos = mask_topk * mask_in_gts * mask_gt
+
+ return mask_pos, align_metric, overlaps
+
+ def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
+ """Compute alignment metric given predicted and ground truth bounding boxes."""
+ na = pd_bboxes.shape[-2]
+ mask_gt = mask_gt.bool() # b, max_num_obj, h*w
+ overlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device)
+ bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device)
+
+ ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 2, b, max_num_obj
+ ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # b, max_num_obj
+ ind[1] = gt_labels.squeeze(-1) # b, max_num_obj
+ # Get the scores of each grid for each gt cls
+ bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # b, max_num_obj, h*w
+
+ # (b, max_num_obj, 1, 4), (b, 1, h*w, 4)
+ pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
+ gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
+ overlaps[mask_gt] = bbox_iou(gt_boxes, pd_boxes, xywh=False, CIoU=True).squeeze(-1).clamp_(0)
+
+ align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
+ return align_metric, overlaps
+
+ def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
+ """
+ Select the top-k candidates based on the given metrics.
+
+ Args:
+ metrics (Tensor): A tensor of shape (b, max_num_obj, h*w), where b is the batch size,
+ max_num_obj is the maximum number of objects, and h*w represents the
+ total number of anchor points.
+ largest (bool): If True, select the largest values; otherwise, select the smallest values.
+ topk_mask (Tensor): An optional boolean tensor of shape (b, max_num_obj, topk), where
+ topk is the number of top candidates to consider. If not provided,
+ the top-k values are automatically computed based on the given metrics.
+
+ Returns:
+ (Tensor): A tensor of shape (b, max_num_obj, h*w) containing the selected top-k candidates.
+ """
+
+ # (b, max_num_obj, topk)
+ topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
+ if topk_mask is None:
+ topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)
+ # (b, max_num_obj, topk)
+ topk_idxs.masked_fill_(~topk_mask, 0)
+
+ # (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)
+ count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)
+ ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)
+ for k in range(self.topk):
+ # Expand topk_idxs for each value of k and add 1 at the specified positions
+ count_tensor.scatter_add_(-1, topk_idxs[:, :, k:k + 1], ones)
+ # count_tensor.scatter_add_(-1, topk_idxs, torch.ones_like(topk_idxs, dtype=torch.int8, device=topk_idxs.device))
+ # filter invalid bboxes
+ count_tensor.masked_fill_(count_tensor > 1, 0)
+
+ return count_tensor.to(metrics.dtype)
+
+ def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
+ """
+ Compute target labels, target bounding boxes, and target scores for the positive anchor points.
+
+ Args:
+ gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is the
+ batch size and max_num_obj is the maximum number of objects.
+ gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).
+ target_gt_idx (Tensor): Indices of the assigned ground truth objects for positive
+ anchor points, with shape (b, h*w), where h*w is the total
+ number of anchor points.
+ fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive
+ (foreground) anchor points.
+
+ Returns:
+ (Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:
+ - target_labels (Tensor): Shape (b, h*w), containing the target labels for
+ positive anchor points.
+ - target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxes
+ for positive anchor points.
+ - target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scores
+ for positive anchor points, where num_classes is the number
+ of object classes.
+ """
+
+ # Assigned target labels, (b, 1)
+ batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
+ target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
+ target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
+
+ # Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w)
+ target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx]
+
+ # Assigned target scores
+ target_labels.clamp_(0)
+
+ # 10x faster than F.one_hot()
+ target_scores = torch.zeros((target_labels.shape[0], target_labels.shape[1], self.num_classes),
+ dtype=torch.int64,
+ device=target_labels.device) # (b, h*w, 80)
+ target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
+
+ fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
+ target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
+
+ return target_labels, target_bboxes, target_scores
+
+
+def make_anchors(feats, strides, grid_cell_offset=0.5):
+ """Generate anchors from features."""
+ anchor_points, stride_tensor = [], []
+ assert feats is not None
+ dtype, device = feats[0].dtype, feats[0].device
+ for i, stride in enumerate(strides):
+ _, _, h, w = feats[i].shape
+ sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
+ sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
+ sy, sx = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
+ anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
+ stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
+ return torch.cat(anchor_points), torch.cat(stride_tensor)
+
+
+def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
+ """Transform distance(ltrb) to box(xywh or xyxy)."""
+ lt, rb = distance.chunk(2, dim)
+ x1y1 = anchor_points - lt
+ x2y2 = anchor_points + rb
+ if xywh:
+ c_xy = (x1y1 + x2y2) / 2
+ wh = x2y2 - x1y1
+ return torch.cat((c_xy, wh), dim) # xywh bbox
+ return torch.cat((x1y1, x2y2), dim) # xyxy bbox
+
+
+def bbox2dist(anchor_points, bbox, reg_max):
+ """Transform bbox(xyxy) to dist(ltrb)."""
+ x1y1, x2y2 = bbox.chunk(2, -1)
+ return torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1).clamp_(0, reg_max - 0.01) # dist (lt, rb)
diff --git a/STPoseNet/ultralytics/utils/torch_utils.py b/STPoseNet/ultralytics/utils/torch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..def7442b99f4684544351e5bf1b7b0ea446a1bd4
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/torch_utils.py
@@ -0,0 +1,526 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import math
+import os
+import platform
+import random
+import time
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+from typing import Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ultralytics.utils import DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, RANK, __version__
+from ultralytics.utils.checks import check_version
+
+try:
+ import thop
+except ImportError:
+ thop = None
+
+TORCH_1_9 = check_version(torch.__version__, '1.9.0')
+TORCH_2_0 = check_version(torch.__version__, '2.0.0')
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ """Decorator to make all processes in distributed training wait for each local_master to do something."""
+ initialized = torch.distributed.is_available() and torch.distributed.is_initialized()
+ if initialized and local_rank not in (-1, 0):
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if initialized and local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def smart_inference_mode():
+ """Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator."""
+
+ def decorate(fn):
+ """Applies appropriate torch decorator for inference mode based on torch version."""
+ return (torch.inference_mode if TORCH_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def get_cpu_info():
+ """Return a string with system CPU information, i.e. 'Apple M2'."""
+ import cpuinfo # pip install py-cpuinfo
+
+ k = 'brand_raw', 'hardware_raw', 'arch_string_raw' # info keys sorted by preference (not all keys always available)
+ info = cpuinfo.get_cpu_info() # info dict
+ string = info.get(k[0] if k[0] in info else k[1] if k[1] in info else k[2], 'unknown')
+ return string.replace('(R)', '').replace('CPU ', '').replace('@ ', '')
+
+
+def select_device(device='', batch=0, newline=False, verbose=True):
+ """Selects PyTorch Device. Options are device = None or 'cpu' or 0 or '0' or '0,1,2,3'."""
+ s = f'Ultralytics YOLOv{__version__} 🚀 Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).lower()
+ for remove in 'cuda:', 'none', '(', ')', '[', ']', "'", ' ':
+ device = device.replace(remove, '') # to string, 'cuda:0' -> '0' and '(0, 1)' -> '0,1'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ if device == 'cuda':
+ device = '0'
+ visible = os.environ.get('CUDA_VISIBLE_DEVICES', None)
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ if not (torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', ''))):
+ LOGGER.info(s)
+ install = 'See https://pytorch.org/get-started/locally/ for up-to-date torch install instructions if no ' \
+ 'CUDA devices are seen by torch.\n' if torch.cuda.device_count() == 0 else ''
+ raise ValueError(f"Invalid CUDA 'device={device}' requested."
+ f" Use 'device=cpu' or pass valid CUDA device(s) if available,"
+ f" i.e. 'device=0' or 'device=0,1,2,3' for Multi-GPU.\n"
+ f'\ntorch.cuda.is_available(): {torch.cuda.is_available()}'
+ f'\ntorch.cuda.device_count(): {torch.cuda.device_count()}'
+ f"\nos.environ['CUDA_VISIBLE_DEVICES']: {visible}\n"
+ f'{install}')
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch > 0 and batch % n != 0: # check batch_size is divisible by device_count
+ raise ValueError(f"'batch={batch}' must be a multiple of GPU count {n}. Try 'batch={batch // n * n}' or "
+ f"'batch={batch // n * n + n}', the nearest batch sizes evenly divisible by {n}.")
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available() and TORCH_2_0:
+ # Prefer MPS if available
+ s += f'MPS ({get_cpu_info()})\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += f'CPU ({get_cpu_info()})\n'
+ arg = 'cpu'
+
+ if verbose and RANK == -1:
+ LOGGER.info(s if newline else s.rstrip())
+ return torch.device(arg)
+
+
+def time_sync():
+ """PyTorch-accurate time."""
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def fuse_conv_and_bn(conv, bn):
+ """Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/."""
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def fuse_deconv_and_bn(deconv, bn):
+ """Fuse ConvTranspose2d() and BatchNorm2d() layers."""
+ fuseddconv = nn.ConvTranspose2d(deconv.in_channels,
+ deconv.out_channels,
+ kernel_size=deconv.kernel_size,
+ stride=deconv.stride,
+ padding=deconv.padding,
+ output_padding=deconv.output_padding,
+ dilation=deconv.dilation,
+ groups=deconv.groups,
+ bias=True).requires_grad_(False).to(deconv.weight.device)
+
+ # Prepare filters
+ w_deconv = deconv.weight.clone().view(deconv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fuseddconv.weight.copy_(torch.mm(w_bn, w_deconv).view(fuseddconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(deconv.weight.size(1), device=deconv.weight.device) if deconv.bias is None else deconv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fuseddconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fuseddconv
+
+
+def model_info(model, detailed=False, verbose=True, imgsz=640):
+ """Model information. imgsz may be int or list, i.e. imgsz=640 or imgsz=[640, 320]."""
+ if not verbose:
+ return
+ n_p = get_num_params(model) # number of parameters
+ n_g = get_num_gradients(model) # number of gradients
+ n_l = len(list(model.modules())) # number of layers
+ if detailed:
+ LOGGER.info(
+ f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ LOGGER.info('%5g %40s %9s %12g %20s %10.3g %10.3g %10s' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std(), p.dtype))
+
+ flops = get_flops(model, imgsz)
+ fused = ' (fused)' if getattr(model, 'is_fused', lambda: False)() else ''
+ fs = f', {flops:.1f} GFLOPs' if flops else ''
+ yaml_file = getattr(model, 'yaml_file', '') or getattr(model, 'yaml', {}).get('yaml_file', '')
+ model_name = Path(yaml_file).stem.replace('yolo', 'YOLO') or 'Model'
+ LOGGER.info(f'{model_name} summary{fused}: {n_l} layers, {n_p} parameters, {n_g} gradients{fs}')
+ return n_l, n_p, n_g, flops
+
+
+def get_num_params(model):
+ """Return the total number of parameters in a YOLO model."""
+ return sum(x.numel() for x in model.parameters())
+
+
+def get_num_gradients(model):
+ """Return the total number of parameters with gradients in a YOLO model."""
+ return sum(x.numel() for x in model.parameters() if x.requires_grad)
+
+
+def model_info_for_loggers(trainer):
+ """
+ Return model info dict with useful model information.
+
+ Example for YOLOv8n:
+ {'model/parameters': 3151904,
+ 'model/GFLOPs': 8.746,
+ 'model/speed_ONNX(ms)': 41.244,
+ 'model/speed_TensorRT(ms)': 3.211,
+ 'model/speed_PyTorch(ms)': 18.755}
+ """
+ if trainer.args.profile: # profile ONNX and TensorRT times
+ from ultralytics.utils.benchmarks import ProfileModels
+ results = ProfileModels([trainer.last], device=trainer.device).profile()[0]
+ results.pop('model/name')
+ else: # only return PyTorch times from most recent validation
+ results = {
+ 'model/parameters': get_num_params(trainer.model),
+ 'model/GFLOPs': round(get_flops(trainer.model), 3)}
+ results['model/speed_PyTorch(ms)'] = round(trainer.validator.speed['inference'], 3)
+ return results
+
+
+def get_flops(model, imgsz=640):
+ """Return a YOLO model's FLOPs."""
+ try:
+ model = de_parallel(model)
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1E9 * 2 if thop else 0 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ return flops * imgsz[0] / stride * imgsz[1] / stride # 640x640 GFLOPs
+ except Exception:
+ return 0
+
+
+def get_flops_with_torch_profiler(model, imgsz=640):
+ """Compute model FLOPs (thop alternative)."""
+ if TORCH_2_0:
+ model = de_parallel(model)
+ p = next(model.parameters())
+ stride = (max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32) * 2 # max stride
+ im = torch.zeros((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ with torch.profiler.profile(with_flops=True) as prof:
+ model(im)
+ flops = sum(x.flops for x in prof.key_averages()) / 1E9
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ flops = flops * imgsz[0] / stride * imgsz[1] / stride # 640x640 GFLOPs
+ return flops
+ return 0
+
+
+def initialize_weights(model):
+ """Initialize model weights to random values."""
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def make_divisible(x, divisor):
+ """Returns nearest x divisible by divisor."""
+ if isinstance(divisor, torch.Tensor):
+ divisor = int(divisor.max()) # to int
+ return math.ceil(x / divisor) * divisor
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ """Copies attributes from object 'b' to object 'a', with options to include/exclude certain attributes."""
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def get_latest_opset():
+ """Return second-most (for maturity) recently supported ONNX opset by this version of torch."""
+ return max(int(k[14:]) for k in vars(torch.onnx) if 'symbolic_opset' in k) - 1 # opset
+
+
+def intersect_dicts(da, db, exclude=()):
+ """Returns a dictionary of intersecting keys with matching shapes, excluding 'exclude' keys, using da values."""
+ return {k: v for k, v in da.items() if k in db and all(x not in k for x in exclude) and v.shape == db[k].shape}
+
+
+def is_parallel(model):
+ """Returns True if model is of type DP or DDP."""
+ return isinstance(model, (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel))
+
+
+def de_parallel(model):
+ """De-parallelize a model: returns single-GPU model if model is of type DP or DDP."""
+ return model.module if is_parallel(model) else model
+
+
+def one_cycle(y1=0.0, y2=1.0, steps=100):
+ """Returns a lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf."""
+ return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
+
+
+def init_seeds(seed=0, deterministic=False):
+ """Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html."""
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
+ # torch.backends.cudnn.benchmark = True # AutoBatch problem https://github.com/ultralytics/yolov5/issues/9287
+ if deterministic:
+ if TORCH_2_0:
+ torch.use_deterministic_algorithms(True, warn_only=True) # warn if deterministic is not possible
+ torch.backends.cudnn.deterministic = True
+ os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
+ os.environ['PYTHONHASHSEED'] = str(seed)
+ else:
+ LOGGER.warning('WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.')
+ else:
+ torch.use_deterministic_algorithms(False)
+ torch.backends.cudnn.deterministic = False
+
+
+class ModelEMA:
+ """Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ To disable EMA set the `enabled` attribute to `False`.
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ """Create EMA."""
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+ self.enabled = True
+
+ def update(self, model):
+ """Update EMA parameters."""
+ if self.enabled:
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype}, model {msd[k].dtype}'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ """Updates attributes and saves stripped model with optimizer removed."""
+ if self.enabled:
+ copy_attr(self.ema, model, include, exclude)
+
+
+def strip_optimizer(f: Union[str, Path] = 'best.pt', s: str = '') -> None:
+ """
+ Strip optimizer from 'f' to finalize training, optionally save as 's'.
+
+ Args:
+ f (str): file path to model to strip the optimizer from. Default is 'best.pt'.
+ s (str): file path to save the model with stripped optimizer to. If not provided, 'f' will be overwritten.
+
+ Returns:
+ None
+
+ Example:
+ ```python
+ from pathlib import Path
+ from ultralytics.utils.torch_utils import strip_optimizer
+
+ for f in Path('path/to/weights').rglob('*.pt'):
+ strip_optimizer(f)
+ ```
+ """
+ # Use dill (if exists) to serialize the lambda functions where pickle does not do this
+ try:
+ import dill as pickle
+ except ImportError:
+ import pickle
+
+ x = torch.load(f, map_location=torch.device('cpu'))
+ if 'model' not in x:
+ LOGGER.info(f'Skipping {f}, not a valid Ultralytics model.')
+ return
+
+ if hasattr(x['model'], 'args'):
+ x['model'].args = dict(x['model'].args) # convert from IterableSimpleNamespace to dict
+ args = {**DEFAULT_CFG_DICT, **x['train_args']} if 'train_args' in x else None # combine args
+ if x.get('ema'):
+ x['model'] = x['ema'] # replace model with ema
+ for k in 'optimizer', 'best_fitness', 'ema', 'updates': # keys
+ x[k] = None
+ x['epoch'] = -1
+ x['model'].half() # to FP16
+ for p in x['model'].parameters():
+ p.requires_grad = False
+ x['train_args'] = {k: v for k, v in args.items() if k in DEFAULT_CFG_KEYS} # strip non-default keys
+ # x['model'].args = x['train_args']
+ torch.save(x, s or f, pickle_module=pickle)
+ mb = os.path.getsize(s or f) / 1E6 # filesize
+ LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
+
+
+def profile(input, ops, n=10, device=None):
+ """
+ Ultralytics speed, memory and FLOPs profiler.
+
+ Example:
+ ```python
+ from ultralytics.utils.torch_utils import profile
+
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ ```
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ LOGGER.info(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=[x], verbose=False)[0] / 1E9 * 2 if thop else 0 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ LOGGER.info(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ LOGGER.info(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+class EarlyStopping:
+ """
+ Early stopping class that stops training when a specified number of epochs have passed without improvement.
+ """
+
+ def __init__(self, patience=50):
+ """
+ Initialize early stopping object
+
+ Args:
+ patience (int, optional): Number of epochs to wait after fitness stops improving before stopping.
+ """
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ """
+ Check whether to stop training
+
+ Args:
+ epoch (int): Current epoch of training
+ fitness (float): Fitness value of current epoch
+
+ Returns:
+ (bool): True if training should stop, False otherwise
+ """
+ if fitness is None: # check if fitness=None (happens when val=False)
+ return False
+
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `patience=300` or use `patience=0` to disable EarlyStopping.')
+ return stop
diff --git a/STPoseNet/ultralytics/utils/tuner.py b/STPoseNet/ultralytics/utils/tuner.py
new file mode 100644
index 0000000000000000000000000000000000000000..015e59664cffcc3e7388a4abb93414c3ab5b9983
--- /dev/null
+++ b/STPoseNet/ultralytics/utils/tuner.py
@@ -0,0 +1,133 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+import subprocess
+
+from ultralytics.cfg import TASK2DATA, TASK2METRIC
+from ultralytics.utils import DEFAULT_CFG_DICT, LOGGER, NUM_THREADS
+
+
+def run_ray_tune(model,
+ space: dict = None,
+ grace_period: int = 10,
+ gpu_per_trial: int = None,
+ max_samples: int = 10,
+ **train_args):
+ """
+ Runs hyperparameter tuning using Ray Tune.
+
+ Args:
+ model (YOLO): Model to run the tuner on.
+ space (dict, optional): The hyperparameter search space. Defaults to None.
+ grace_period (int, optional): The grace period in epochs of the ASHA scheduler. Defaults to 10.
+ gpu_per_trial (int, optional): The number of GPUs to allocate per trial. Defaults to None.
+ max_samples (int, optional): The maximum number of trials to run. Defaults to 10.
+ train_args (dict, optional): Additional arguments to pass to the `train()` method. Defaults to {}.
+
+ Returns:
+ (dict): A dictionary containing the results of the hyperparameter search.
+
+ Example:
+ ```python
+ from ultralytics import YOLO
+
+ # Load a YOLOv8n model
+ model = YOLO('yolov8n.pt')
+
+ # Start tuning hyperparameters for YOLOv8n training on the COCO8 dataset
+ result_grid = model.tune(data='coco8.yaml', use_ray=True)
+ ```
+ """
+ if train_args is None:
+ train_args = {}
+
+ try:
+ subprocess.run('pip install ray[tune]'.split(), check=True)
+
+ from ray import tune
+ from ray.air import RunConfig
+ from ray.air.integrations.wandb import WandbLoggerCallback
+ from ray.tune.schedulers import ASHAScheduler
+ except ImportError:
+ raise ModuleNotFoundError('Tuning hyperparameters requires Ray Tune. Install with: pip install "ray[tune]"')
+
+ try:
+ import wandb
+
+ assert hasattr(wandb, '__version__')
+ except (ImportError, AssertionError):
+ wandb = False
+
+ default_space = {
+ # 'optimizer': tune.choice(['SGD', 'Adam', 'AdamW', 'NAdam', 'RAdam', 'RMSProp']),
+ 'lr0': tune.uniform(1e-5, 1e-1),
+ 'lrf': tune.uniform(0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': tune.uniform(0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': tune.uniform(0.0, 0.001), # optimizer weight decay 5e-4
+ 'warmup_epochs': tune.uniform(0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': tune.uniform(0.0, 0.95), # warmup initial momentum
+ 'box': tune.uniform(0.02, 0.2), # box loss gain
+ 'cls': tune.uniform(0.2, 4.0), # cls loss gain (scale with pixels)
+ 'hsv_h': tune.uniform(0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': tune.uniform(0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': tune.uniform(0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': tune.uniform(0.0, 45.0), # image rotation (+/- deg)
+ 'translate': tune.uniform(0.0, 0.9), # image translation (+/- fraction)
+ 'scale': tune.uniform(0.0, 0.9), # image scale (+/- gain)
+ 'shear': tune.uniform(0.0, 10.0), # image shear (+/- deg)
+ 'perspective': tune.uniform(0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': tune.uniform(0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': tune.uniform(0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': tune.uniform(0.0, 1.0), # image mixup (probability)
+ 'mixup': tune.uniform(0.0, 1.0), # image mixup (probability)
+ 'copy_paste': tune.uniform(0.0, 1.0)} # segment copy-paste (probability)
+
+ def _tune(config):
+ """
+ Trains the YOLO model with the specified hyperparameters and additional arguments.
+
+ Args:
+ config (dict): A dictionary of hyperparameters to use for training.
+
+ Returns:
+ None.
+ """
+ model._reset_callbacks()
+ config.update(train_args)
+ model.train(**config)
+
+ # Get search space
+ if not space:
+ space = default_space
+ LOGGER.warning('WARNING ⚠️ search space not provided, using default search space.')
+
+ # Get dataset
+ data = train_args.get('data', TASK2DATA[model.task])
+ space['data'] = data
+ if 'data' not in train_args:
+ LOGGER.warning(f'WARNING ⚠️ data not provided, using default "data={data}".')
+
+ # Define the trainable function with allocated resources
+ trainable_with_resources = tune.with_resources(_tune, {'cpu': NUM_THREADS, 'gpu': gpu_per_trial or 0})
+
+ # Define the ASHA scheduler for hyperparameter search
+ asha_scheduler = ASHAScheduler(time_attr='epoch',
+ metric=TASK2METRIC[model.task],
+ mode='max',
+ max_t=train_args.get('epochs') or DEFAULT_CFG_DICT['epochs'] or 100,
+ grace_period=grace_period,
+ reduction_factor=3)
+
+ # Define the callbacks for the hyperparameter search
+ tuner_callbacks = [WandbLoggerCallback(project='YOLOv8-tune')] if wandb else []
+
+ # Create the Ray Tune hyperparameter search tuner
+ tuner = tune.Tuner(trainable_with_resources,
+ param_space=space,
+ tune_config=tune.TuneConfig(scheduler=asha_scheduler, num_samples=max_samples),
+ run_config=RunConfig(callbacks=tuner_callbacks, storage_path='./runs/tune'))
+
+ # Run the hyperparameter search
+ tuner.fit()
+
+ # Return the results of the hyperparameter search
+ return tuner.get_results()
diff --git a/STPoseNet/ultralytics/yolo/__init__.py b/STPoseNet/ultralytics/yolo/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1fa55845814759a36b040edb2cfcd930d2229f3
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/__init__.py
@@ -0,0 +1,5 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+
+from . import v8
+
+__all__ = 'v8', # tuple or list
diff --git a/STPoseNet/ultralytics/yolo/cfg/__init__.py b/STPoseNet/ultralytics/yolo/cfg/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ea5519b6ce6959f11c1fa4958f7cc39db49d498
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/cfg/__init__.py
@@ -0,0 +1,10 @@
+import importlib
+import sys
+
+from ultralytics.utils import LOGGER
+
+# Set modules in sys.modules under their old name
+sys.modules['ultralytics.yolo.cfg'] = importlib.import_module('ultralytics.cfg')
+
+LOGGER.warning("WARNING ⚠️ 'ultralytics.yolo.cfg' is deprecated since '8.0.136' and will be removed in '8.1.0'. "
+ "Please use 'ultralytics.cfg' instead.")
diff --git a/STPoseNet/ultralytics/yolo/data/__init__.py b/STPoseNet/ultralytics/yolo/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f68391ef0367a6e10b29a071baf8fbc42b64a36e
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/data/__init__.py
@@ -0,0 +1,17 @@
+import importlib
+import sys
+
+from ultralytics.utils import LOGGER
+
+# Set modules in sys.modules under their old name
+sys.modules['ultralytics.yolo.data'] = importlib.import_module('ultralytics.data')
+# This is for updating old cls models, or the way in following warning won't work.
+sys.modules['ultralytics.yolo.data.augment'] = importlib.import_module('ultralytics.data.augment')
+
+DATA_WARNING = """WARNING ⚠️ 'ultralytics.yolo.data' is deprecated since '8.0.136' and will be removed in '8.1.0'. Please use 'ultralytics.data' instead.
+Note this warning may be related to loading older models. You can update your model to current structure with:
+ import torch
+ ckpt = torch.load("model.pt") # applies to both official and custom models
+ torch.save(ckpt, "updated-model.pt")
+"""
+LOGGER.warning(DATA_WARNING)
diff --git a/STPoseNet/ultralytics/yolo/engine/__init__.py b/STPoseNet/ultralytics/yolo/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..794efcd0c31221b515611fed0ba53482e9bd23db
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/engine/__init__.py
@@ -0,0 +1,10 @@
+import importlib
+import sys
+
+from ultralytics.utils import LOGGER
+
+# Set modules in sys.modules under their old name
+sys.modules['ultralytics.yolo.engine'] = importlib.import_module('ultralytics.engine')
+
+LOGGER.warning("WARNING ⚠️ 'ultralytics.yolo.engine' is deprecated since '8.0.136' and will be removed in '8.1.0'. "
+ "Please use 'ultralytics.engine' instead.")
diff --git a/STPoseNet/ultralytics/yolo/utils/__init__.py b/STPoseNet/ultralytics/yolo/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..71557b0a7443d92f51e3c9ed31d4fda05cbeba76
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/utils/__init__.py
@@ -0,0 +1,15 @@
+import importlib
+import sys
+
+from ultralytics.utils import LOGGER
+
+# Set modules in sys.modules under their old name
+sys.modules['ultralytics.yolo.utils'] = importlib.import_module('ultralytics.utils')
+
+UTILS_WARNING = """WARNING ⚠️ 'ultralytics.yolo.utils' is deprecated since '8.0.136' and will be removed in '8.1.0'. Please use 'ultralytics.utils' instead.
+Note this warning may be related to loading older models. You can update your model to current structure with:
+ import torch
+ ckpt = torch.load("model.pt") # applies to both official and custom models
+ torch.save(ckpt, "updated-model.pt")
+"""
+LOGGER.warning(UTILS_WARNING)
diff --git a/STPoseNet/ultralytics/yolo/v8/__init__.py b/STPoseNet/ultralytics/yolo/v8/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..51adf814cdd012c1680401f43bbdef734b4a9b8b
--- /dev/null
+++ b/STPoseNet/ultralytics/yolo/v8/__init__.py
@@ -0,0 +1,10 @@
+import importlib
+import sys
+
+from ultralytics.utils import LOGGER
+
+# Set modules in sys.modules under their old name
+sys.modules['ultralytics.yolo.v8'] = importlib.import_module('ultralytics.models.yolo')
+
+LOGGER.warning("WARNING ⚠️ 'ultralytics.yolo.v8' is deprecated since '8.0.136' and will be removed in '8.1.0'. "
+ "Please use 'ultralytics.models.yolo' instead.")
 + - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
+ - **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  +
+ ## Status
+
+
+
+ ## Status
+
+