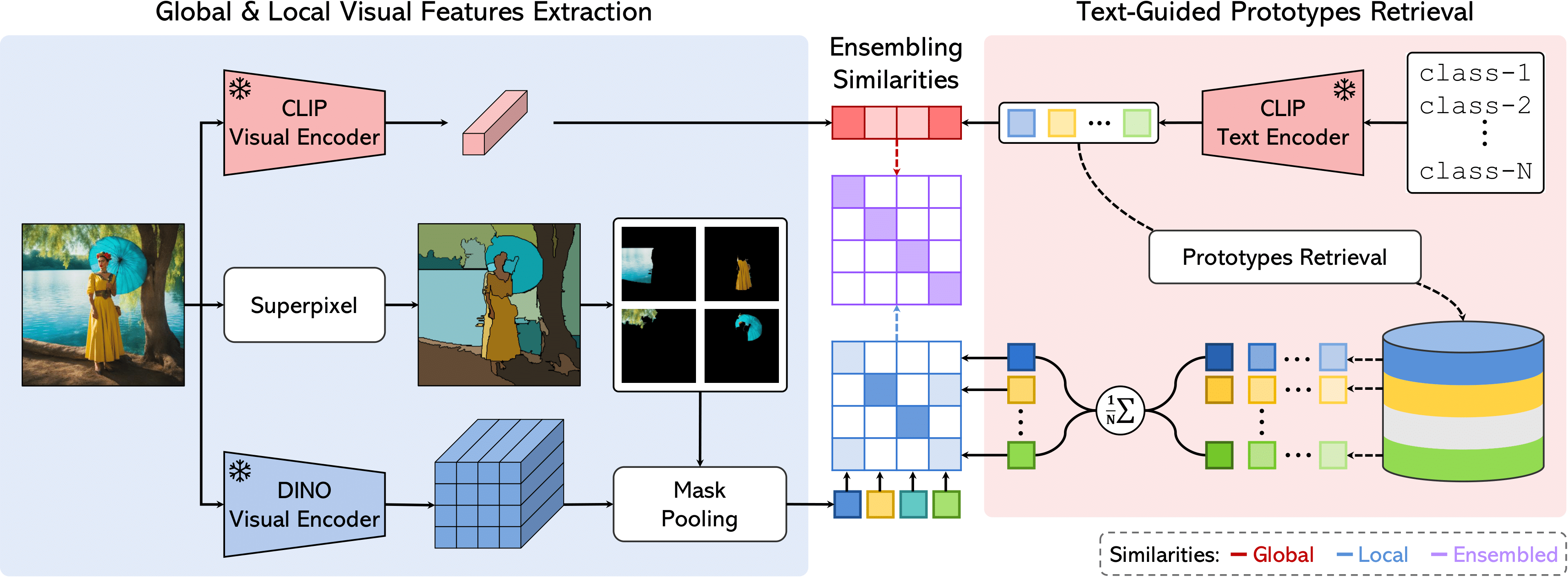
FreeDA: Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation (CVPR 2024)
[Project Page](https://aimagelab.github.io/freeda/) | [Paper](https://arxiv.org/abs/2404.06542) | [Code](https://github.com/aimagelab/freeda)