Language models in RL
LMs encode useful knowledge for agents
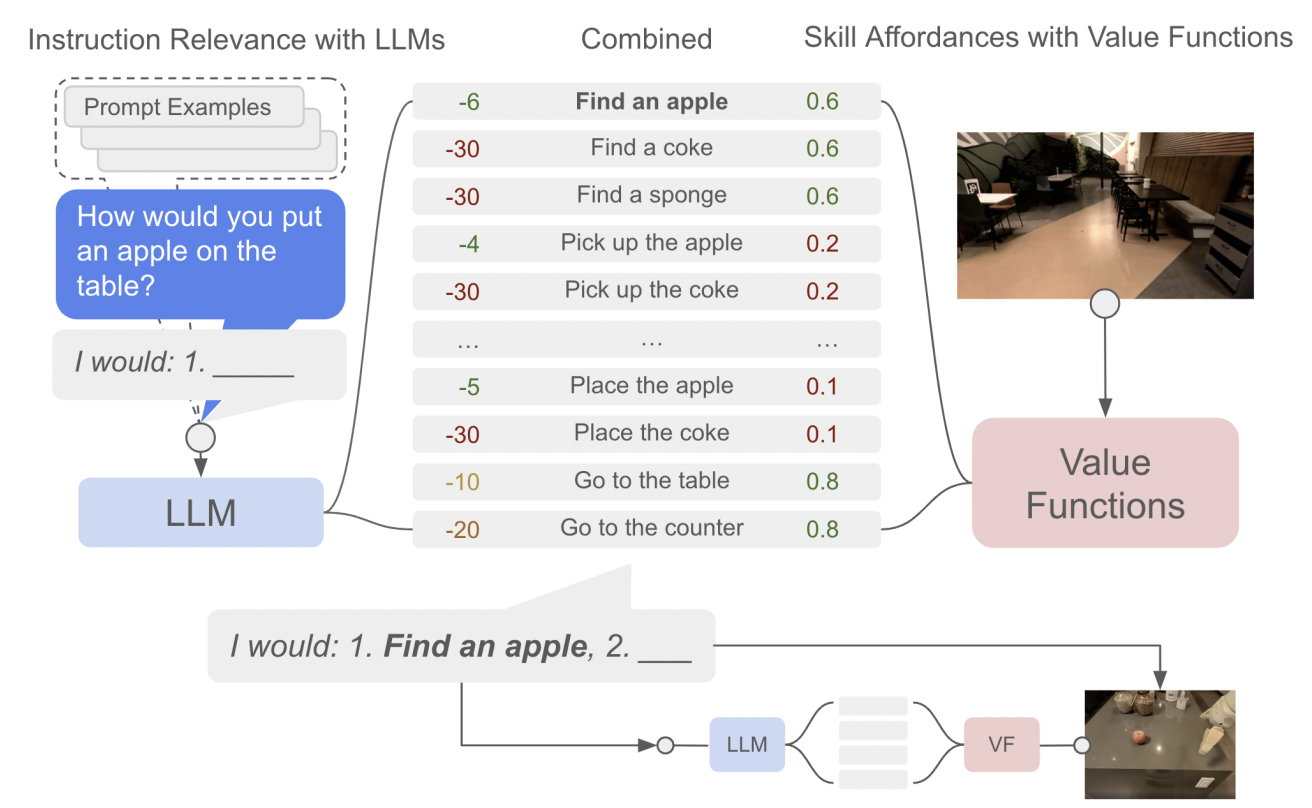
Language models (LMs) can exhibit impressive abilities when manipulating text such as question-answering or even step-by-step reasoning. Additionally, their training on massive text corpora allowed them to encode various types of knowledge including abstract ones about the physical rules of our world (for instance what is possible to do with an object, what happens when one rotates an object…).
A natural question recently studied was whether such knowledge could benefit agents such as robots when trying to solve everyday tasks. And while these works showed interesting results, the proposed agents lacked any learning method. This limitation prevents these agent from adapting to the environment (e.g. fixing wrong knowledge) or learning new skills.
LMs and RL
There is therefore a potential synergy between LMs which can bring knowledge about the world, and RL which can align and correct this knowledge by interacting with an environment. It is especially interesting from a RL point-of-view as the RL field mostly relies on the Tabula-rasa setup where everything is learned from scratch by the agent leading to:
1) Sample inefficiency
2) Unexpected behaviors from humans’ eyes
As a first attempt, the paper “Grounding Large Language Models with Online Reinforcement Learning” tackled the problem of adapting or aligning a LM to a textual environment using PPO. They showed that the knowledge encoded in the LM lead to a fast adaptation to the environment (opening avenues for sample efficient RL agents) but also that such knowledge allowed the LM to better generalize to new tasks once aligned.
Another direction studied in “Guiding Pretraining in Reinforcement Learning with Large Language Models” was to keep the LM frozen but leverage its knowledge to guide an RL agent’s exploration. Such a method allows the RL agent to be guided towards human-meaningful and plausibly useful behaviors without requiring a human in the loop during training.
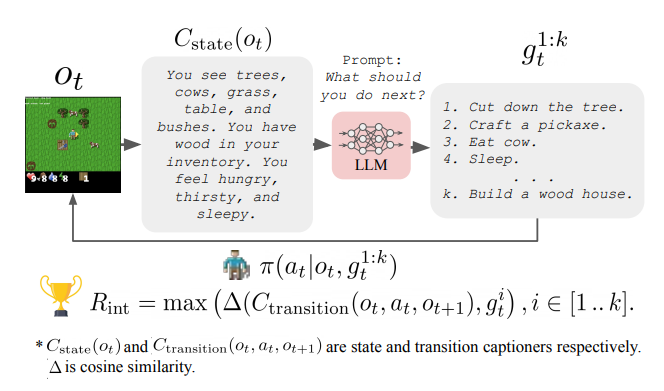
Several limitations make these works still very preliminary such as the need to convert the agent’s observation to text before giving it to a LM as well as the compute cost of interacting with very large LMs.
Further reading
For more information we recommend you check out the following resources:
- Google Research, 2022 & beyond: Robotics
- Pre-Trained Language Models for Interactive Decision-Making
- Grounding Large Language Models with Online Reinforcement Learning
- Guiding Pretraining in Reinforcement Learning with Large Language Models
Author
This section was written by Clément Romac