# JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars
## Key Messages
1. JetMoE-8B is **trained with less than $ 0.1 million**1 **cost but outperforms LLaMA2-7B from Meta AI**, who has multi-billion-dollar training resources. LLM training can be **much cheaper than people previously thought**.
2. JetMoE-8B is **fully open-sourced and academia-friendly** because:
- It **only uses public datasets** for training, and the code is open-sourced. No proprietary resource is needed.
- It **can be finetuned with very limited compute budget** (e.g., consumer-grade GPU) that most labs can afford.
3. JetMoE-8B **only has 2.2B active parameters** during inference, which drastically lowers the computational cost. Compared to a model with similar inference computation, like Gemma-2B, JetMoE-8B achieves constantly better performance.
1 We used a 96×H100 GPU cluster for 2 weeks, which cost ~$0.08 million.
Website: [https://research.myshell.ai/jetmoe](https://research.myshell.ai/jetmoe)
HuggingFace: [https://huggingface.co/jetmoe/jetmoe-8b](https://huggingface.co/jetmoe/jetmoe-8b)
Online Demo on Lepton AI: [https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat](https://www.lepton.ai/playground/chat?model=jetmoe-8b-chat)
Technical Report: [https://arxiv.org/pdf/2404.07413.pdf](https://arxiv.org/pdf/2404.07413.pdf)
## Authors
The project is contributed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ), [Zhen Guo](https://zguo0525.github.io/), [Tianle Cai](https://www.tianle.website/#/) and [Zengyi Qin](https://www.qinzy.tech/). For technical inquiries, please contact [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ). For media and collaboration inquiries, please contact [Zengyi Qin](https://www.qinzy.tech/).
## Collaboration
**If you have great ideas but need more resources (GPU, data, funding, etc.)**, welcome to contact **MyShell.ai** via [Zengyi Qin](https://www.qinzy.tech/). **MyShell.ai** is open to collaborations and are actively supporting high-quality open-source projects.
## Benchmarks
We use the same evaluation methodology as in the Open LLM leaderboard. For MBPP code benchmark, we use the same evaluation methodology as in the LLaMA2 and Deepseek-MoE paper. The results are shown below:
|Model|Activate Params|Training Tokens|Open LLM Leaderboard Avg|ARC|Hellaswag|MMLU|TruthfulQA|WinoGrande|GSM8k|MBPP|HumanEval|
|---|---|---|---|---|---|---|---|---|---|---|---|
|Shot||||25|10|5|0|5|5|3|0|
|Metric||||acc_norm|acc_norm|acc|mc2|acc|acc|Pass@1|Pass@1|
|LLaMA2-7B|7B|2T|51.0|53.1|78.6|46.9|38.8|74|14.5|20.8|12.8|
|LLaMA-13B|13B|1T|51.4|**56.2**|**80.9**|47.7|39.5|**76.2**|7.6|22.0|15.8|
|DeepseekMoE-16B|2.8B|2T|51.1|53.2|79.8|46.3|36.1|73.7|17.3|34.0|**25.0**|
|Gemma-2B|2B|2T|46.4|48.4|71.8|41.8|33.1|66.3|16.9|28.0|24.4|
|JetMoE-8B|2.2B|1.25T|**53.0**|48.7|80.5|**49.2**|**41.7**|70.2|**27.8**|**34.2**|14.6|
| Model | MT-Bench Score |
|---------------------|-----------|
| GPT-4 | 9.014 |
| GPT-3.5-turbo | 7.995 |
| Claude-v1 | 7.923 |
| **JetMoE-8B-chat** | **6.681** |
| Llama-2-13b-chat | 6.650 |
| Vicuna-13b-v1.3 | 6.413 |
| Wizardlm-13b | 6.353 |
| Llama-2-7b-chat | 6.269 |
To our surprise, despite the lower training cost and computation, JetMoE-8B performs even better than LLaMA2-7B, LLaMA-13B, and DeepseekMoE-16B. Compared to a model with similar training and inference computation, like Gemma-2B, JetMoE-8B achieves better performance.
## Model Usage
To load the models, you need install [this package](https://github.com/myshell-ai/JetMoE):
```
pip install -e .
```
Then you can load the model with the following code:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModelForSequenceClassification
from jetmoe import JetMoEForCausalLM, JetMoEConfig, JetMoEForSequenceClassification
AutoConfig.register("jetmoe", JetMoEConfig)
AutoModelForCausalLM.register(JetMoEConfig, JetMoEForCausalLM)
AutoModelForSequenceClassification.register(JetMoEConfig, JetMoEForSequenceClassification)
tokenizer = AutoTokenizer.from_pretrained('jetmoe/jetmoe-8b')
model = AutoModelForCausalLM.from_pretrained('jetmoe/jetmoe-8b')
```
## Model Details
JetMoE-8B has 24 blocks.
Each block has two MoE layers: Mixture of Attention heads (MoA) and Mixture of MLP Experts (MoE).
Each MoA and MoE layer has 8 expert, and 2 experts are activated for each input token.
It has 8 billion parameters in total and 2.2B active parameters.
JetMoE-8B is trained on 1.25T tokens from publicly available datasets, with a learning rate of 5.0 x 10-4 and a global batch-size of 4M tokens.
JetMoE Architecture
## Training Details
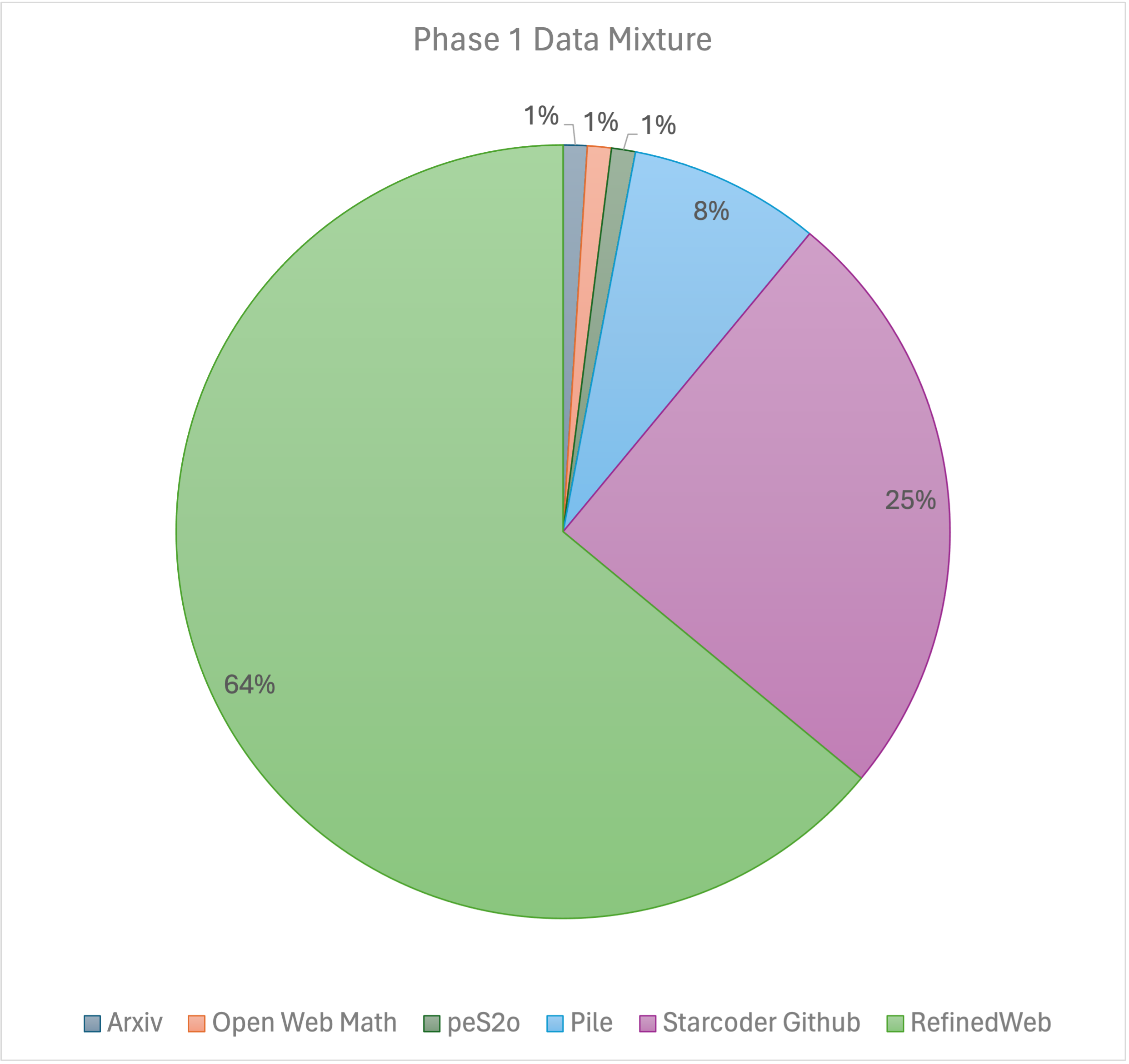
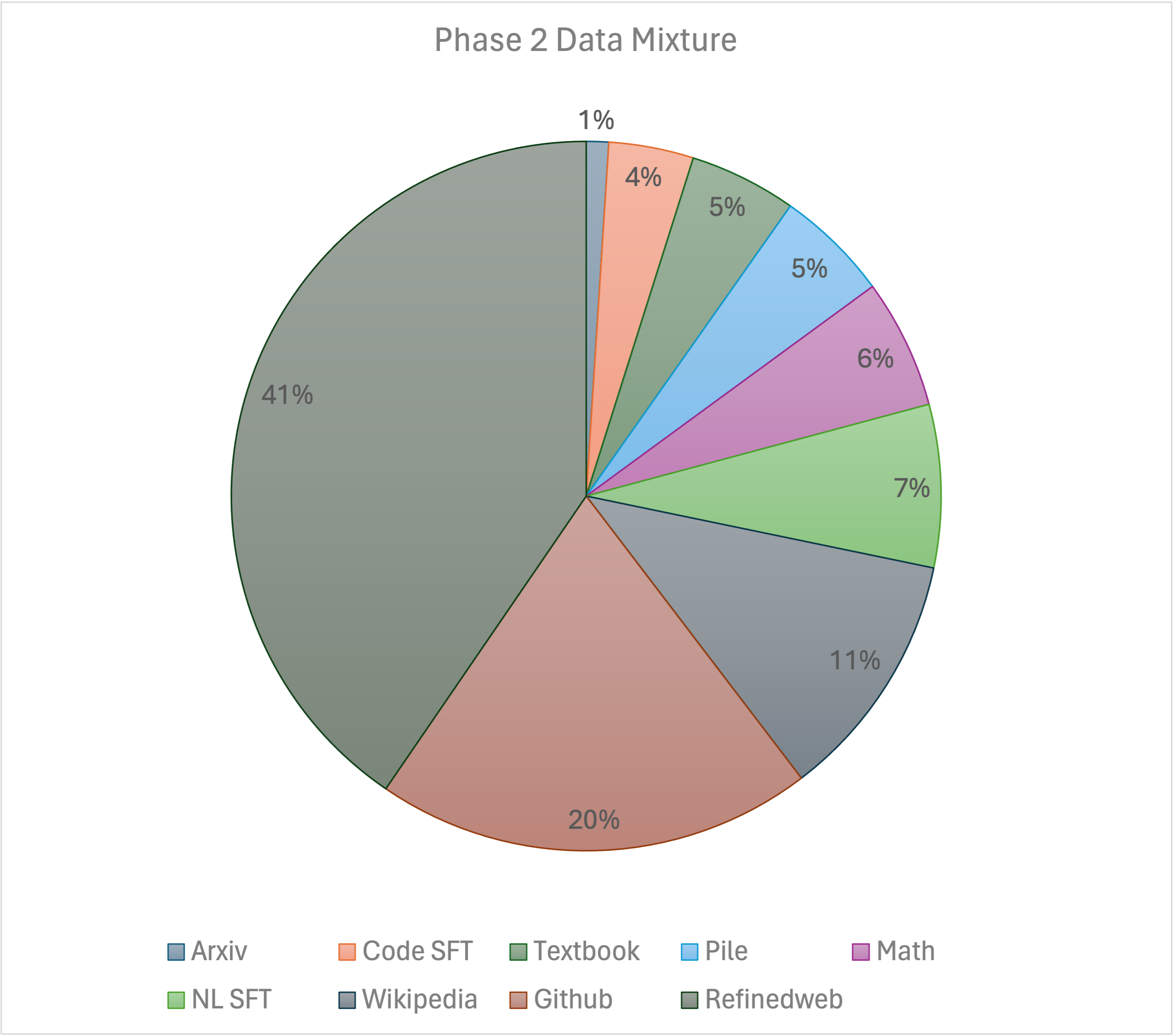
Our training recipe follows the [MiniCPM](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4)'s two-phases training method. Phase 1 uses a constant learning rate with linear warmup and is trained on 1 trillion tokens from large-scale open-source pretraining datasets, including RefinedWeb, Pile, Github data, etc. Phase 2 uses exponential learning rate decay and is trained on 250 billion tokens from phase 1 datasets and extra high-quality open-source datasets.
## Technical Report
For more details, please refer to the [JetMoE Technical Report](https://arxiv.org/abs/2404.07413).
## JetMoE Model Index
|Model|Index|
|---|---|
|JetMoE-8B-Base| [Link](https://huggingface.co/jetmoe/jetmoe-8B) |
|JetMoE-8B-SFT| [Link](https://huggingface.co/jetmoe/jetmoe-8B-sft) |
|JetMoE-8B-Chat| [Link](https://huggingface.co/jetmoe/jetmoe-8B-chat) |
## Acknowledgement
We express our gratitude to [Shengding Hu](https://shengdinghu.github.io/) for his valuable advice on the Phase 2 data mixture. We also express our gratitude to [Exabits](https://www.exabits.ai/) for their assistance in setting up the GPU clusters, and to [Lepton AI](https://www.lepton.ai/) for their support in setting up the chat demo.