
State-of-the-art bilingual open-sourced Math reasoning LLMs.
A **solver**, **prover**, **verifier**, **augmentor**.
[💻 Github](https://github.com/InternLM/InternLM-Math) [🤗 Demo](https://huggingface.co/spaces/internlm/internlm2-math-7b) [🤗 Checkpoints](https://huggingface.co/internlm/internlm2-math-7b) [](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B) [

ModelScope](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)
# News
- [2024.01.29] We add checkpoints from ModelScope. Tech report is on the way!
- [2024.01.26] We add checkpoints from OpenXLab, which ease Chinese users to download!
# Introduction
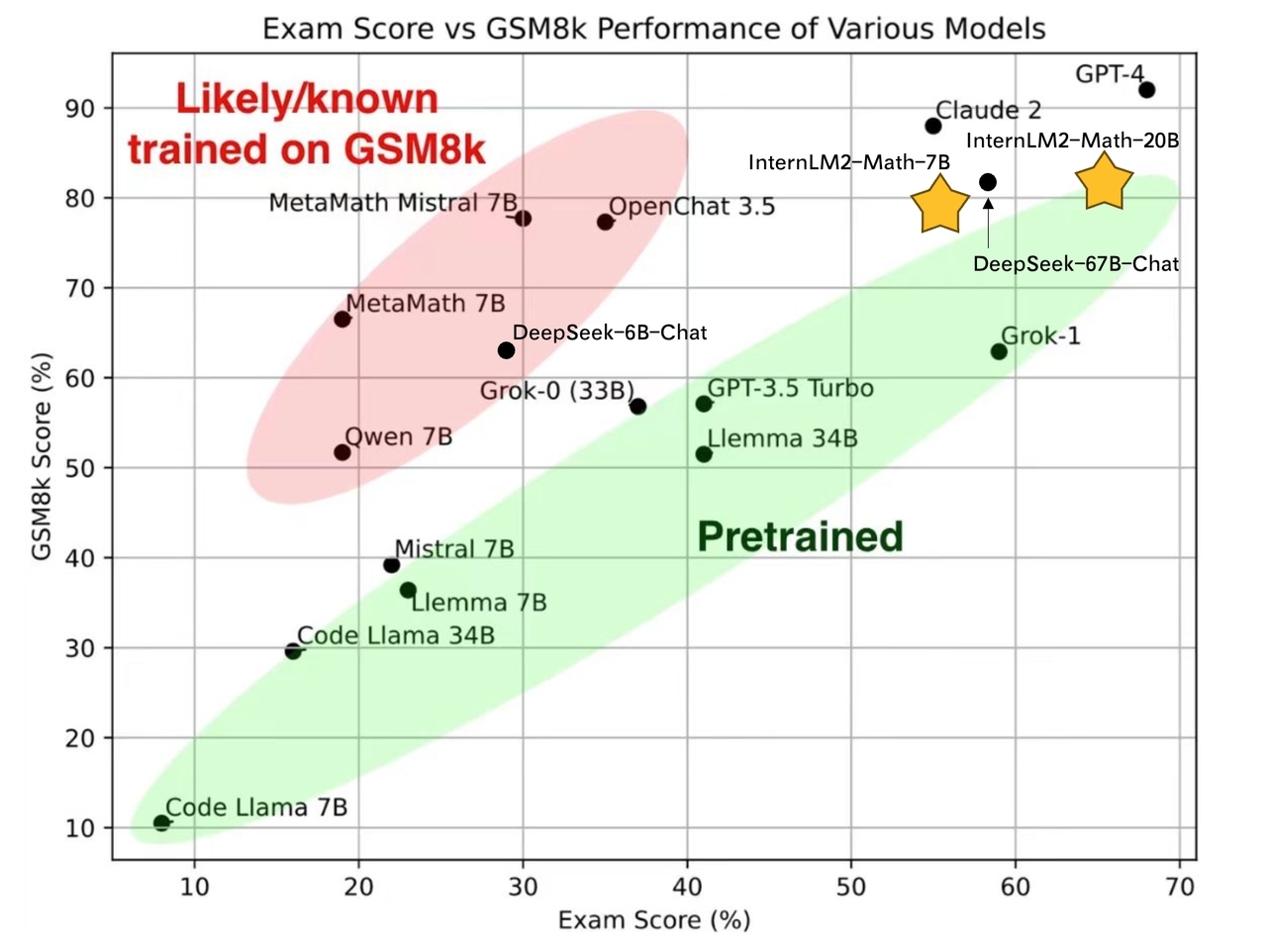
- **7B and 20B Chinese and English Math LMs with better than ChatGPT performances.** InternLM2-Math are continued pretrained from InternLM2-Base with ~100B high quality math-related tokens and SFT with ~2M bilingual math supervised data. We apply minhash and exact number match to decontaminate possible test set leakage.
- **Add Lean as a support language for math problem solving and math theorem proving.** We are exploring combining Lean 3 with InternLM-Math for verifiable math reasoning. InternLM-Math can generate Lean codes for simple math reasoning tasks like GSM8K or provide possible proof tactics based on Lean states.
- **Also can be viewed as a reward model, which supports the Outcome/Process/Lean Reward Model.** We supervise InternLM2-Math with various types of reward modeling data, to make InternLM2-Math can also verify chain-of-thought processes. We also add the ability to convert a chain-of-thought process into Lean 3 code.
- **A Math LM Augment Helper** and **Code Interpreter**. InternLM2-Math can help augment math reasoning problems and solve them using the code interpreter which makes you generate synthesis data quicker!
# Models
**InternLM2-Math-Base-7B** and **InternLM2-Math-Base-20B** are pretrained checkpoints. **InternLM2-Math-7B** and **InternLM2-Math-20B** are SFT checkpoints.
| Model |Model Type | Transformers(HF) |OpenXLab| ModelScope | Release Date |
|---|---|---|---|---|---|
| **InternLM2-Math-Base-7B** | Base| [🤗internlm/internlm2-math-base-7b](https://huggingface.co/internlm/internlm2-math-base-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-7B)| [