---
license: cc-by-4.0
datasets:
- Salesforce/xlam-function-calling-60k
- MadeAgents/xlam-irrelevance-7.5k
base_model:
- Qwen/Qwen2.5-0.5B-Instruct
---
# Hammer2.0-0.5b Function Calling Model
## Introduction
We're excited to release lightweight Hammer 2.0 models ([0.5B](https://huggingface.co/MadeAgents/Hammer2.0-0.5b) , [1.5B](https://huggingface.co/MadeAgents/Hammer2.0-1.5b) , [3B](https://huggingface.co/MadeAgents/Hammer2.0-3b) , and [7B](https://huggingface.co/MadeAgents/Hammer2.0-7b)) with strong function calling capability, which empower developers to build personalized, on-device agentic applications.
## Model Details
Hammer2.0 finetuned based on [Qwen 2.5 series](https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e) and [Qwen 2.5 coder series](https://huggingface.co/collections/Qwen/qwen25-coder-66eaa22e6f99801bf65b0c2f) using function masking techniques. It's trained using the [APIGen Function Calling Datasets](https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k) containing 60,000 samples, supplemented by [xlam-irrelevance-7.5k](https://huggingface.co/datasets/MadeAgents/xlam-irrelevance-7.5k) we generated. Hammer2.0 has achieved exceptional performances across numerous function calling benchmarks. For more details, please refer to [Hammer: Robust Function-Calling for On-Device Language Models via Function Masking](https://arxiv.org/abs/2410.04587) and [Hammer GitHub repository](https://github.com/MadeAgents/Hammer) .
## Evaluation
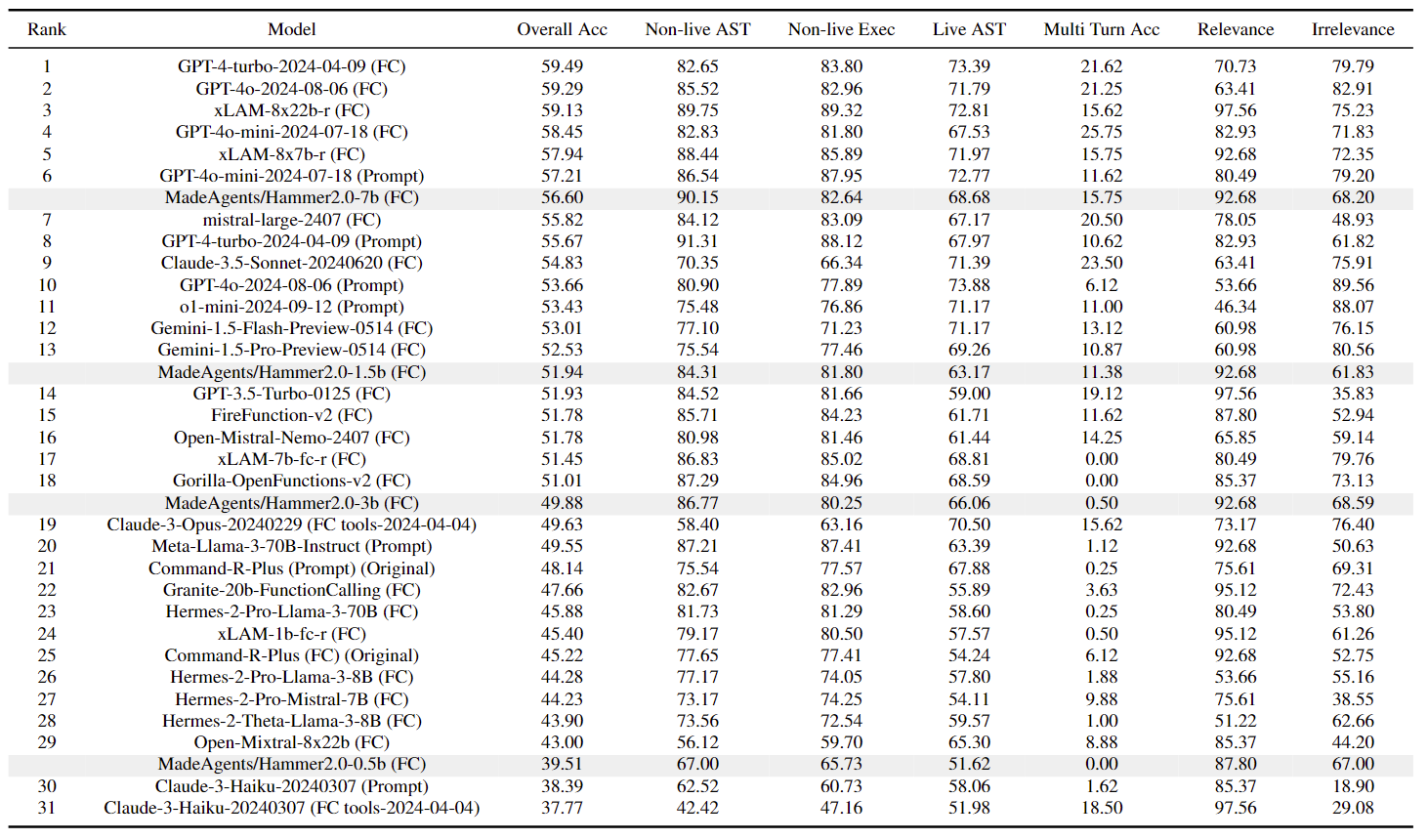
The evaluation results of Hammer 2.0 models on the Berkeley Function-Calling Leaderboard (BFCL-v3) are presented in the following table:
Our Hammer 2.0 series consistently achieves corresponding best performance at comparable scales. The 7B model outperforms most function calling enchanced models, and the 1.5B model also achieves unexpected performance.
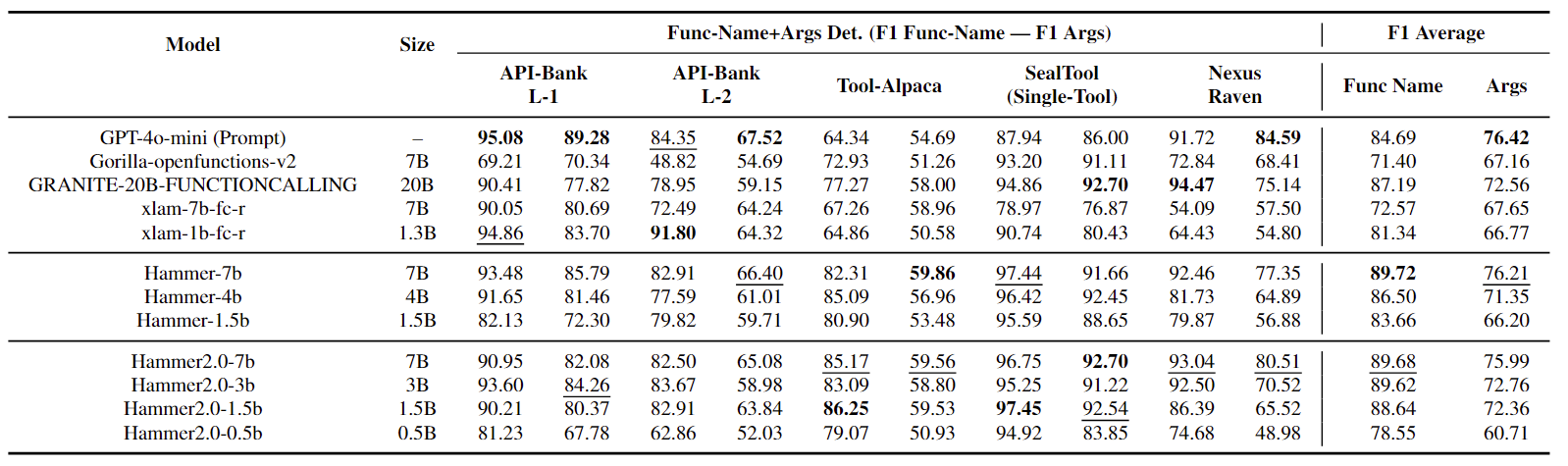
In addition, we evaluated the Hammer 2.0 models on other academic benchmarks to further demonstrate the generalization ability of our models.
Hammer 2.0 models showcase highly stable performance, suggesting the robustness of Hammer 2.0 series. In contrast, the baseline approaches display varying levels of effectiveness.
## Requiements
The code of Hammer 2.0 models have been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`.
## How to Use
This is a simple example of how to use our model.
~~~python
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MadeAgents/Hammer2.0-0.5b"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Please use our provided instruction prompt for best performance
TASK_INSTRUCTION = """You are a tool calling assistant. In order to complete the user's request, you need to select one or more appropriate tools from the following tools and fill in the correct values for the tool parameters. Your specific tasks are:
1. Make one or more function/tool calls to meet the request based on the question.
2. If none of the function can be used, point it out and refuse to answer.
3. If the given question lacks the parameters required by the function, also point it out.
"""
FORMAT_INSTRUCTION = """
The output MUST strictly adhere to the following JSON format, and NO other text MUST be included.
The example format is as follows. Please make sure the parameter type is correct. If no function call is needed, please directly output an empty list '[]'
```
[
{"name": "func_name1", "arguments": {"argument1": "value1", "argument2": "value2"}},
... (more tool calls as required)
]
```
"""
# Define the input query and available tools
query = "Where can I find live giveaways for beta access and games? And what's the weather like in New York, US?"
live_giveaways_by_type = {
"name": "live_giveaways_by_type",
"description": "Retrieve live giveaways from the GamerPower API based on the specified type.",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of giveaways to retrieve (e.g., game, loot, beta).",
"default": "game"
}
},
"required": ["type"]
}
}
get_current_weather={
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": ["location"]
}
}
get_stock_price={
"name": "get_stock_price",
"description": "Retrieves the current stock price for a given ticker symbol. The ticker symbol must be a valid symbol for a publicly traded company on a major US stock exchange like NYSE or NASDAQ. The tool will return the latest trade price in USD. It should be used when the user asks about the current or most recent price of a specific stock. It will not provide any other information about the stock or company.",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "The stock ticker symbol, e.g. AAPL for Apple Inc."
}
},
"required": ["ticker"]
}
}
def convert_to_format_tool(tools):
''''''
if isinstance(tools, dict):
format_tools = {
"name": tools["name"],
"description": tools["description"],
"parameters": tools["parameters"].get("properties", {}),
}
required = tools["parameters"].get("required", [])
for param in required:
format_tools["parameters"][param]["required"] = True
for param in format_tools["parameters"].keys():
if "default" in format_tools["parameters"][param]:
default = format_tools["parameters"][param]["default"]
format_tools["parameters"][param]["description"]+=f"default is \'{default}\'"
return format_tools
elif isinstance(tools, list):
return [convert_to_format_tool(tool) for tool in tools]
else:
return tools
# Helper function to build the input prompt for our model
def build_prompt(task_instruction: str, format_instruction: str, tools: list, query: str):
prompt = f"[BEGIN OF TASK INSTRUCTION]\n{task_instruction}\n[END OF TASK INSTRUCTION]\n\n"
prompt += f"[BEGIN OF AVAILABLE TOOLS]\n{json.dumps(tools)}\n[END OF AVAILABLE TOOLS]\n\n"
prompt += f"[BEGIN OF FORMAT INSTRUCTION]\n{format_instruction}\n[END OF FORMAT INSTRUCTION]\n\n"
prompt += f"[BEGIN OF QUERY]\n{query}\n[END OF QUERY]\n\n"
return prompt
# Build the input and start the inference
openai_format_tools = [live_giveaways_by_type, get_current_weather,get_stock_price]
format_tools = convert_to_format_tool(openai_format_tools)
content = build_prompt(TASK_INSTRUCTION, FORMAT_INSTRUCTION, format_tools, query)
messages=[
{ 'role': 'user', 'content': content}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
~~~