---
license: cc-by-4.0
tags:
- vision
- nougat
pipeline_tag: image-to-text
---
# Nougat model, small-sized version
Nougat model trained on PDF-to-markdown. It was introduced in the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Blecher et al. and first released in [this repository](https://github.com/facebookresearch/nougat/tree/main).
Disclaimer: The team releasing Nougat did not write a model card for this model so this model card has been written by the Hugging Face team.
Note: this model corresponds to the "0.1.0-small" version of the original repository.
## Model description
Nougat is a [Donut](https://huggingface.co/docs/transformers/model_doc/donut) model trained to transcribe scientific PDFs into an easy-to-use markdown format. The model consists of a Swin Transformer as vision encoder, and an mBART model as text decoder.
The model is trained to autoregressively predict the markdown given only the pixels of the PDF image as input.
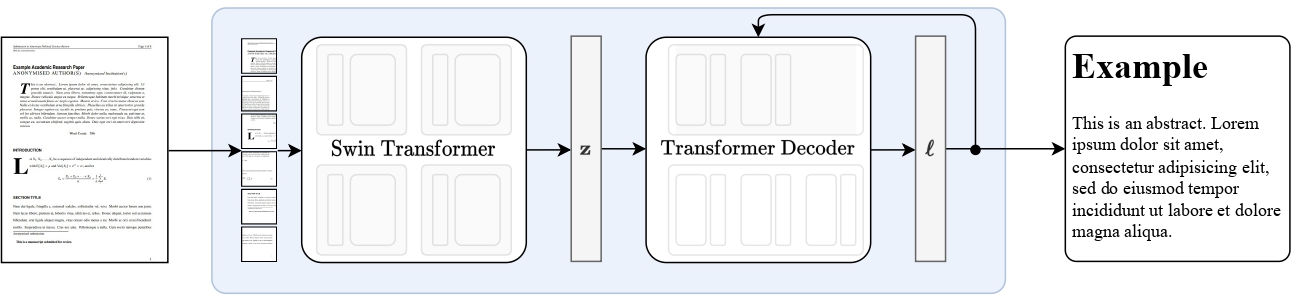 Nougat high-level overview. Taken from the original paper.
## Intended uses & limitations
You can use the raw model for transcribing a PDF into Markdown. See the [model hub](https://huggingface.co/models?search=nougat) to look for other
fine-tuned versions that may interest you.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/nougat).
### BibTeX entry and citation info
```bibtex
@misc{blecher2023nougat,
title={Nougat: Neural Optical Understanding for Academic Documents},
author={Lukas Blecher and Guillem Cucurull and Thomas Scialom and Robert Stojnic},
year={2023},
eprint={2308.13418},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
Nougat high-level overview. Taken from the original paper.
## Intended uses & limitations
You can use the raw model for transcribing a PDF into Markdown. See the [model hub](https://huggingface.co/models?search=nougat) to look for other
fine-tuned versions that may interest you.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/nougat).
### BibTeX entry and citation info
```bibtex
@misc{blecher2023nougat,
title={Nougat: Neural Optical Understanding for Academic Documents},
author={Lukas Blecher and Guillem Cucurull and Thomas Scialom and Robert Stojnic},
year={2023},
eprint={2308.13418},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```