Update: following the release of OpenAI's Whisper large-v3, an updated distil-large-v3 model was published. This distil-large-v3 model surpasses the performance of the distil-large-v2 model, with no architecture changes and better support for sequential long-form generation. Thus, it is recommended that the distil-large-v3 model is used in-place of the large-v2 model.
**Note:** Distil-Whisper is currently only available for English speech recognition. We are working with the community
to distill Whisper on other languages. If you are interested in distilling Whisper in your language, check out the
provided [training code](https://github.com/huggingface/distil-whisper/tree/main/training). We will update the
[Distil-Whisper repository](https://github.com/huggingface/distil-whisper/) with multilingual checkpoints when ready!
## Usage
Distil-Whisper is supported in Hugging Face 🤗 Transformers from version 4.35 onwards. To run the model, first
install the latest version of the Transformers library. For this example, we'll also install 🤗 Datasets to load toy
audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
```
### Short-Form Transcription
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe short-form audio files (< 30-seconds) as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```diff
- result = pipe(sample)
+ result = pipe("audio.mp3")
```
### Long-Form Transcription
Distil-Whisper uses a chunked algorithm to transcribe long-form audio files (> 30-seconds). In practice, this chunked long-form algorithm
is 9x faster than the sequential algorithm proposed by OpenAI in the Whisper paper (see Table 7 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430)).
To enable chunking, pass the `chunk_length_s` parameter to the `pipeline`. For Distil-Whisper, a chunk length of 15-seconds
is optimal. To activate batching, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
### Speculative Decoding
Distil-Whisper can be used as an assistant model to Whisper for [speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding).
Speculative decoding mathematically ensures the exact same outputs as Whisper are obtained while being 2 times faster.
This makes it the perfect drop-in replacement for existing Whisper pipelines, since the same outputs are guaranteed.
In the following code-snippet, we load the assistant Distil-Whisper model standalone to the main Whisper pipeline. We then
specify it as the "assistant model" for generation:
```python
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
## Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Distil-Whisper which we cover in the following.
### Flash Attention
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2) if your GPU allows for it.
To do so, you first need to install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
and then all you have to do is to pass `use_flash_attention_2=True` to `from_pretrained`:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
```
### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of [BetterTransformers](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#bettertransformer).
To do so, you first need to install optimum:
```
pip install --upgrade optimum
```
And then convert your model to a "BetterTransformer" model before using it:
```diff
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
```
### Running Distil-Whisper in `openai-whisper`
To use the model in the original Whisper format, first ensure you have the [`openai-whisper`](https://pypi.org/project/openai-whisper/) package installed:
```bash
pip install --upgrade openai-whisper
```
The following code-snippet demonstrates how to transcribe a sample file from the LibriSpeech dataset loaded using
🤗 Datasets:
```python
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from whisper import load_model, transcribe
distil_large_v2 = hf_hub_download(repo_id="distil-whisper/distil-large-v2", filename="original-model.bin")
model = load_model(distil_large_v2)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["array"]
sample = torch.from_numpy(sample).float()
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
```
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
pred_out = transcribe(model, audio="audio.mp3")
```
### Whisper.cpp
Distil-Whisper can be run from the [Whisper.cpp](https://github.com/ggerganov/whisper.cpp) repository with the original
sequential long-form transcription algorithm. In a [provisional benchmark](https://github.com/ggerganov/whisper.cpp/pull/1424#issuecomment-1793513399)
on Mac M1, `distil-large-v2` is 2x faster than `large-v2`, while performing to within 0.1% WER over long-form audio.
Note that future releases of Distil-Whisper will target faster CPU inference more! By distilling smaller encoders, we
aim to achieve similar speed-ups to what we obtain on GPU.
Steps for getting started:
1. Clone the Whisper.cpp repository:
```
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
```
2. Download the ggml weights for `distil-medium.en` from the Hugging Face Hub:
```bash
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='distil-whisper/distil-large-v2', filename='ggml-large-32-2.en.bin', local_dir='./models')"
```
Note that if you do not have the `huggingface_hub` package installed, you can also download the weights with `wget`:
```bash
wget https://huggingface.co/distil-whisper/distil-large-v2/resolve/main/ggml-large-32-2.en.bin -P ./models
```
3. Run inference using the provided sample audio:
```bash
make -j && ./main -m models/ggml-large-32-2.en.bin -f samples/jfk.wav
```
### Transformers.js
```js
import { pipeline } from '@xenova/transformers';
let transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-large-v2');
let url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
let output = await transcriber(url);
// { text: " And so, my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
```
See the [docs](https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.AutomaticSpeechRecognitionPipeline) for more information.
*Note:* Due to the large model size, we recommend running this model server-side with [Node.js](https://huggingface.co/docs/transformers.js/guides/node-audio-processing) (instead of in-browser).
### Candle
Through an integration with Hugging Face [Candle](https://github.com/huggingface/candle/tree/main) 🕯️, Distil-Whisper is
now available in the Rust library 🦀
Benefit from:
* Optimised CPU backend with optional MKL support for x86 and Accelerate for Macs
* CUDA backend for efficiently running on GPUs, multiple GPU distribution via NCCL
* WASM support: run Distil-Whisper in a browser
Steps for getting started:
1. Install [`candle-core`](https://github.com/huggingface/candle/tree/main/candle-core) as explained [here](https://huggingface.github.io/candle/guide/installation.html)
2. Clone the `candle` repository locally:
```
git clone https://github.com/huggingface/candle.git
```
3. Enter the example directory for [Whisper](https://github.com/huggingface/candle/tree/main/candle-examples/examples/whisper):
```
cd candle/candle-examples/examples/whisper
```
4. Run an example:
```
cargo run --example whisper --release -- --model distil-large-v2
```
5. To specify your own audio file, add the `--input` flag:
```
cargo run --example whisper --release -- --model distil-large-v2 --input audio.wav
```
### 8bit & 4bit Quantization
Coming soon ...
### Whisper.cpp
Coming soon ...
## Model Details
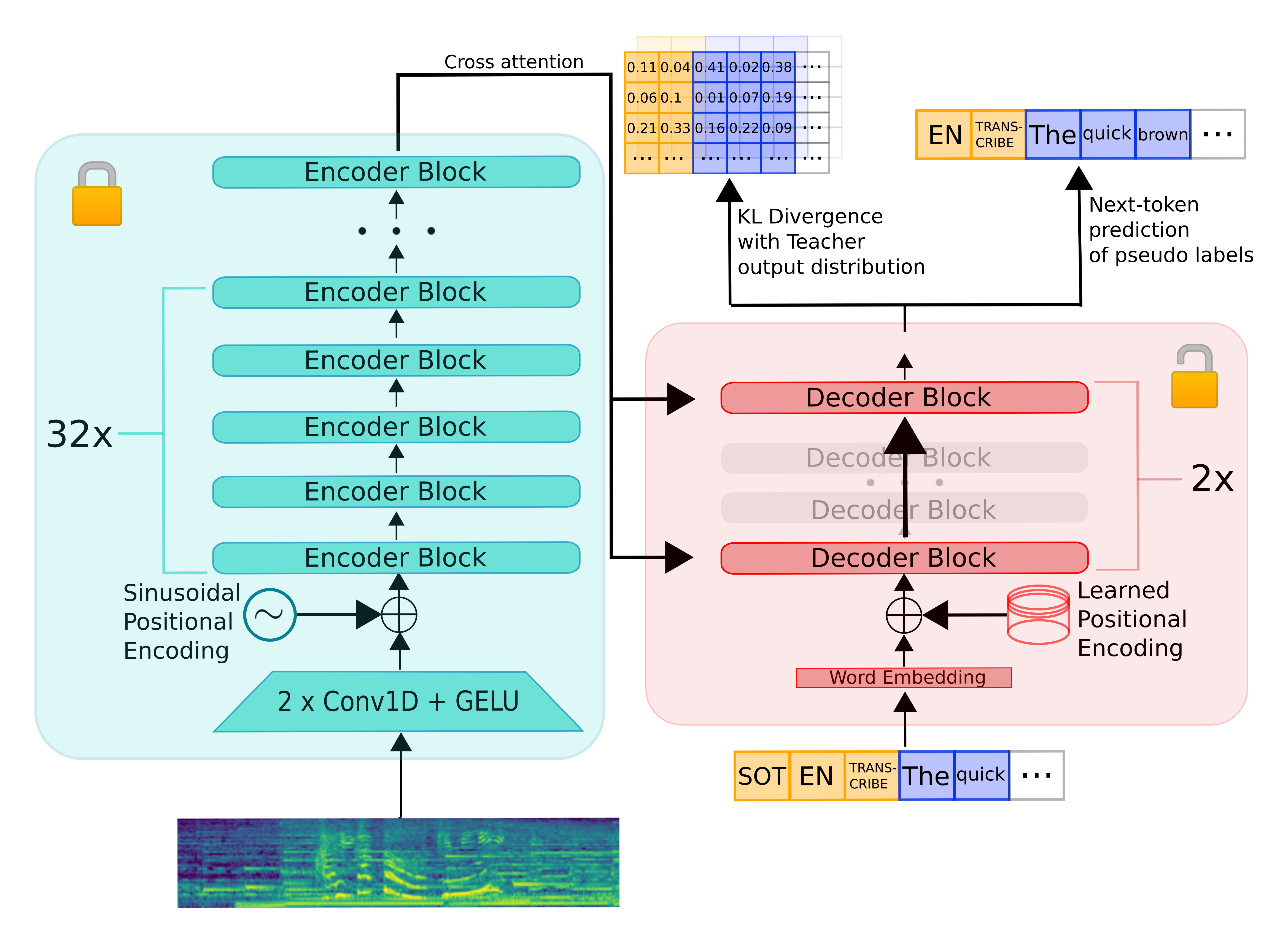
Distil-Whisper inherits the encoder-decoder architecture from Whisper. The encoder maps a sequence of speech vector
inputs to a sequence of hidden-state vectors. The decoder auto-regressively predicts text tokens, conditional on all
previous tokens and the encoder hidden-states. Consequently, the encoder is only run forward once, whereas the decoder
is run as many times as the number of tokens generated. In practice, this means the decoder accounts for over 90% of
total inference time. Thus, to optimise for latency, the focus should be on minimising the inference time of the decoder.
To distill the Whisper model, we reduce the number of decoder layers while keeping the encoder fixed.
The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training.
The student's decoder consists of only two decoder layers, which are initialised from the first and last decoder layer of
the teacher (shown in red). All other decoder layers of the teacher are discarded. The model is then trained on a weighted sum
of the KL divergence and pseudo-label loss terms.