---
license: apache-2.0
datasets:
- kinetics-700-2020
---
# Perceiver IO for multimodal autoencoding
Perceiver IO model trained on [Kinetics-700-2020](https://arxiv.org/abs/2010.10864) for auto-encoding videos that consist of images, audio and a class label. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
The goal of multimodal autoencoding is to learn a model that can accurately reconstruct multimodal inputs in the presence of a bottleneck induced by an architecture.
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For multimodal autoencoding, the output contains the reconstructions of the 3 modalities: images, audio and the class label.
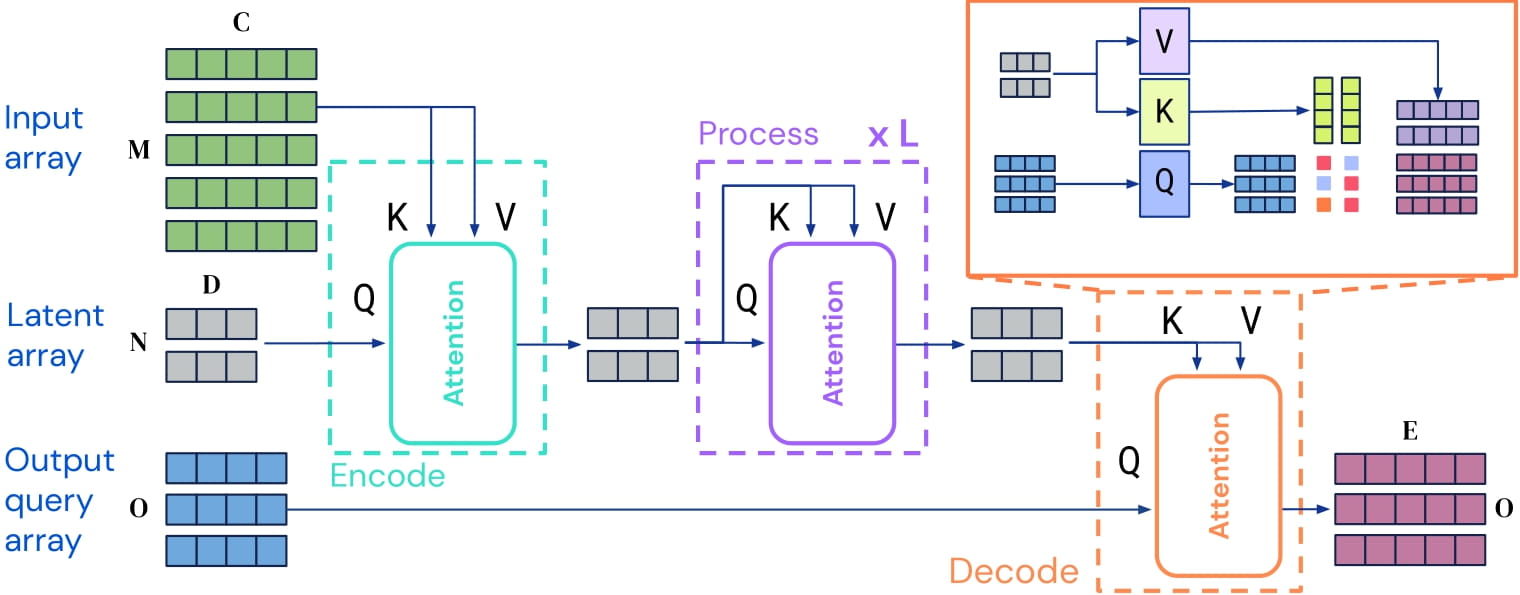 Perceiver IO architecture.
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model by padding the inputs (images, audio, class label) with modality-specific embeddings and serialize all of them into a 2D input array (i.e. concatenate along the time dimension). Decoding the final hidden states of the latents is done by using queries containing Fourier-based position embeddings (for video and audio) and modality embeddings.
## Intended uses & limitations
You can use the raw model for multimodal autoencoding. Note that by masking the class label during evaluation, the auto-encoding model becomes a video classifier.
See the [model hub](https://huggingface.co/models search=deepmind/perceiver) to look for other versions on a task that may interest you.
### How to use
We refer to the [tutorial notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Perceiver/Perceiver_for_Multimodal_Autoencoding.ipynb) regarding using the Perceiver for multimodal autoencoding.
## Training data
This model was trained on [Kinetics-700-200](https://arxiv.org/abs/2010.10864), a dataset consisting of videos that belong to one of 700 classes.
## Training procedure
### Preprocessing
The authors train on 16 frames at 224x224 resolution, preprocessed into 50k 4x4 patches as well as 30k raw audio samples, patched into a total of 1920 16-dimensional vectors and one 700-dimensional one-hot representation of the class label.
### Pretraining
Hyperparameter details can be found in Appendix F of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
For evaluation results, we refer to table 5 of the [paper](https://arxiv.org/abs/2107.14795).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Perceiver IO architecture.
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model by padding the inputs (images, audio, class label) with modality-specific embeddings and serialize all of them into a 2D input array (i.e. concatenate along the time dimension). Decoding the final hidden states of the latents is done by using queries containing Fourier-based position embeddings (for video and audio) and modality embeddings.
## Intended uses & limitations
You can use the raw model for multimodal autoencoding. Note that by masking the class label during evaluation, the auto-encoding model becomes a video classifier.
See the [model hub](https://huggingface.co/models search=deepmind/perceiver) to look for other versions on a task that may interest you.
### How to use
We refer to the [tutorial notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Perceiver/Perceiver_for_Multimodal_Autoencoding.ipynb) regarding using the Perceiver for multimodal autoencoding.
## Training data
This model was trained on [Kinetics-700-200](https://arxiv.org/abs/2010.10864), a dataset consisting of videos that belong to one of 700 classes.
## Training procedure
### Preprocessing
The authors train on 16 frames at 224x224 resolution, preprocessed into 50k 4x4 patches as well as 30k raw audio samples, patched into a total of 1920 16-dimensional vectors and one 700-dimensional one-hot representation of the class label.
### Pretraining
Hyperparameter details can be found in Appendix F of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
For evaluation results, we refer to table 5 of the [paper](https://arxiv.org/abs/2107.14795).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```