---
license: other
license_name: qwen-research
license_link: https://huggingface.co/Qwen/Qwen2.5-3B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
datasets:
- mlabonne/orpo-dpo-mix-40k
base_model:
- Qwen/Qwen2.5-3B
---
# Qwen2.5-3B-ORPO
This model is a finetuned model of the (Qwen2.5-3B base model](https://huggingface.co/Qwen/Qwen2.5-3B) by Qwen using ORPO over the [ORPO-DPO-mix dataset](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) by M. Labonne.
We evaluate the model using several benchmarks working with an Eleuther evaluation harness. Apart from ensuring no reduction in general model performance, benchmarks testing for improved performance in logical and numerical reasoning
are applied. The results are inconclusive on most, but not all, metrics. This shows promise for further improvements on more tailored datasets or by further applying DPO for preference training.
## Model Details
### Model Description
Qwen2.5 is the latest series of Qwen large language models. We finetune the 3B model with the following specifications:
- **Developed by:** (Finetuned from) Qwen
- **Language(s) (NLP):** English
- **Finetuned from model:** Qwen2.5-3B
- **Model type:** Causal LM
- **Architecture:** Transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
- **Number of Parameters:** 3.09B
- **Number of Paramaters (Non-Embedding):** 2.77B
- **Number of Layers:** 36
- **Number of Attention Heads (GQA):** 16 for Q and 2 for KV
- **Context Length:** Full 32,768 tokens
For additional details, we refer to the base model repository.
### Model Sources
The Qwen2.5-3B base model can be found here:
- **Repository:** https://huggingface.co/Qwen/Qwen2.5-3B
## Uses
The model is finetuned but with only little performance increase over the base model in logical and numerical reasoning.
While better than the base model, we do not think it suffices for well-founded logical and numerical reasoning at this stage.
However, we detect no performance decrease for common sense natural reasoning.
### Direct Use
Common sense natural language reasoning.
### Downstream Use
Logical and numerical reasoning.
### Recommendations
Additional finetuning on different datasets, as well as preference training.
## Training Details
### Training Data
We use the [ORPO-DPO-mix dataset](https://huggingface.co/datasets/mlabonne/orpo-dpo-mix-40k) by M. Labonne.
It is a dataset is designed for ORPO or DPO training. See Fine-tune Llama 3 with ORPO for more information about how to use it.
### Training Procedure
We used the trl [ORPO trainer](https://huggingface.co/docs/trl/main/en/orpo_trainer) for finetuning over four epochs with batch size two.
Moreover, we used [LoRa](https://arxiv.org/abs/2106.09685) for parameter efficient training by targeting only particular parts of the base model architecture.
### Training Hyperparameters
- **Training regime:** fp16 non-mixed precision
- **Max lenght:** 4096
- **Max prompt length:** 4096
- **Batch size:** 2
- **Epochs trained:** 4
- **Modules targeted:** q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj
- **Bias:** None
All remaining hyperparameters were kept standard.
# Evaluation
We evaluate base and finetuned models on four general benchmarks and two usecase specific one. We work with an Eleuther test harness.
Our usecase is logical and numerical reasoning.
## Benchmarks used:
1. GENERAL A: Commonsense natural language reasoning.
1.1 HellaSwag
1.2 WinoGrande
2. GENERAL B: Robustness and grammatical understanding.
2.1 ANLI
2.2 BLiMP
3. USECASE: Logical and numerical reasoning.
3.1 Arithmetic
3.2 ASDiv
## Summary of results:
Within standard error, there is no difference between base and finetuned model on any general benchmark. This suggests there was no drop in performance for the chosen tasks due to finetuning.
Benchmarks for logical and numerical reasoning are more mixed. Without standard error, the finetuned model generally outperforms the base model. However, this lies - often just about - within standard error.
The finetuned model *does* outperform the base model even accounting for standard error with maximal conservative bias on [**arithmetic_5da**](https://arxiv.org/abs/2005.14165).
This is of interest, since this benchmarks a model's ability to add five digits, and addition is *the* fundamental arithmetic operation. Subtraction appears generally harder for both the finetuned and base models, even as the finetuned model performs better.
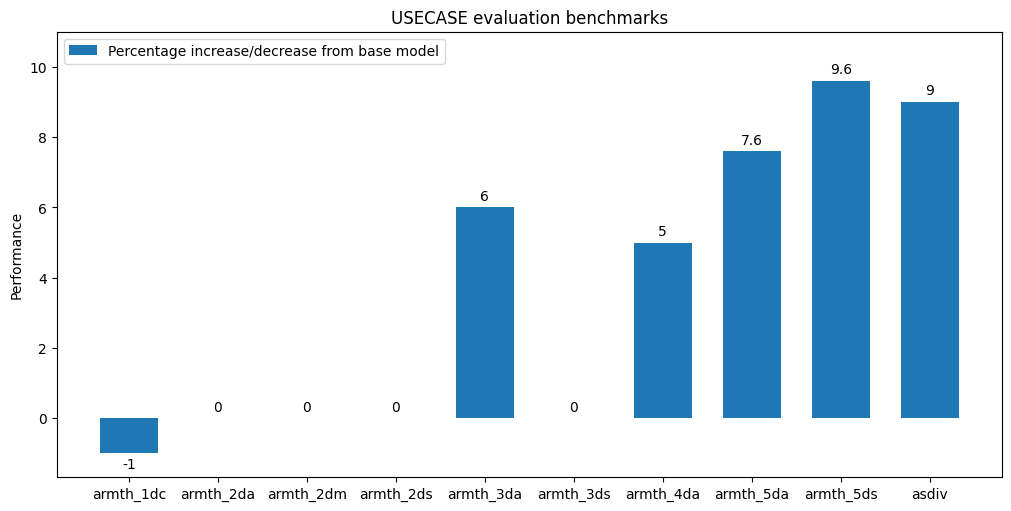
We highlight the relevant rows for five-digit addition and subtraction for easy comparison. Moreover, we give a visualisation of the performance gain *without standard error* for all usecase specific benchmarks at the end of the model card.
## Evaluation results:
**BASE**
| Tasks | Version | Filter | n-shot | Metric | | Value | | Stderr |
|----------|--------:|--------|-------:|--------|---|------:|---|-------:|
|hellaswag | 1 | none | 0 |acc |↑ | 0.5492|± | 0.0050|
| | | none | 0 |acc_norm|↑ | 0.7353|± | 0.0044|
|winogrande| 1 | none | 0 |acc |↑ | 0.6851|± | 0.0131|
|anli_r1 | 1 | none | 0 |acc |↑ | 0.4670|± | 0.0158|
|anli_r2 | 1 | none | 0 |acc |↑ | 0.4440|± | 0.0157|
|anli_r3 | 1 | none | 0 |acc |↑ | 0.4467|± | 0.0144|
|blimp | 2 | none | 0 |acc |↑ | 0.7250|± | 0.0016|
Collect GENERAL benchmarks results for the base model.
| Tasks | Version | Filter | n-shot | Metric | | Value | | Stderr |
|--------------|--------:|--------|-------:|--------|---|------:|---|-------:|
|arithmetic_1dc| 1 | none | 0 |acc |↑ | 0.6780|± | 0.0105|
|arithmetic_2da| 1 | none | 0 |acc |↑ | 0.0095|± | 0.0022|
|arithmetic_2dm| 1 | none | 0 |acc |↑ | 0.0230|± | 0.0034|
|arithmetic_2ds| 1 | none | 0 |acc |↑ | 0.0280|± | 0.0037|
|arithmetic_3da| 1 | none | 0 |acc |↑ | 0.0075|± | 0.0019|
|arithmetic_3ds| 1 | none | 0 |acc |↑ | 0.0055|± | 0.0017|
|arithmetic_4da| 1 | none | 0 |acc |↑ | 0.0675|± | 0.0056|
|arithmetic_4ds| 1 | none | 0 |acc |↑ | 0.0010|± | 0.0007|
|**arithmetic_5da**| 1 | none | 0 |acc |↑ | **0.3720**|± | **0.0108**|
|*arithmetic_5ds*| 1 | none | 0 |acc |↑ | *0.0260*|± | *0.0036*|
|asdiv | 1 | none | 0 |acc |↑ | 0.0187|± | 0.0028|
Collected USECASE benchmarks results for the base model.
**FINETUNED**
| Tasks | Version | Filter | n-shot | Metric | | Value | | Stderr |
|----------|--------:|--------|-------:|--------|---|------:|---|-------:|
|hellaswag | 1 | none | 0 |acc |↑ | 0.5490|± | 0.0050|
| | | none | 0 |acc_norm|↑ | 0.7358|± | 0.0044|
|winogrande| 1 | none | 0 |acc |↑ | 0.6827|± | 0.0131|
|anli_r1 | 1 | none | 0 |acc |↑ | 0.4660|± | 0.0158|
|anli_r2 | 1 | none | 0 |acc |↑ | 0.4380|± | 0.0157|
|anli_r3 | 1 | none | 0 |acc |↑ | 0.4408|± | 0.0143|
|blimp | 2 | none | 0 |acc |↑ | 0.7253|± | 0.0016|
Collect GENERAL benchmarks results for the finetuned model.
| Tasks | Version | Filter | n-shot | Metric | | Value | | Stderr |
|--------------|--------:|--------|-------:|--------|---|------:|---|-------:|
|arithmetic_1dc| 1 | none | 0 |acc |↑ | 0.6725|± | 0.0105|
|arithmetic_2da| 1 | none | 0 |acc |↑ | 0.0095|± | 0.0022|
|arithmetic_2dm| 1 | none | 0 |acc |↑ | 0.0230|± | 0.0034|
|arithmetic_2ds| 1 | none | 0 |acc |↑ | 0.0280|± | 0.0037|
|arithmetic_3da| 1 | none | 0 |acc |↑ | 0.0080|± | 0.0020|
|arithmetic_3ds| 1 | none | 0 |acc |↑ | 0.0055|± | 0.0017|
|arithmetic_4da| 1 | none | 0 |acc |↑ | 0.0710|± | 0.0057|
|arithmetic_4ds| 1 | none | 0 |acc |↑ | 0.0005|± | 0.0005|
|**arithmetic_5da**| 1 | none | 0 |acc |↑ | **0.4005**|± | **0.0110**|
|*arithmetic_5ds*| 1 | none | 0 |acc |↑ | *0.0285*|± | *0.0037*|
|asdiv | 1 | none | 0 |acc |↑ | 0.0204|± | 0.0029|
Collected USECASE benchmarks results for the finetuned model.
**VISUALISATION OF USECASE BENCHMARK RESULTS**
USECASE benchmark results given as percentage change of finetuned model relative to base model. **Does not account for standard error.**
For visualisation purposes we drop "arithmetic_4ds" since results for both models are very small and dominated by standard error.