---
tags:
- text-to-image
- stable-diffusion
language:
- en
library_name: diffusers
---
# IP-Adapter-FaceID Model Card
[**Project Page**](https://ip-adapter.github.io) **|** [**Paper (ArXiv)**](https://arxiv.org/abs/2308.06721) **|** [**Code**](https://github.com/tencent-ailab/IP-Adapter)
---
## Introduction
An experimental version of IP-Adapter-FaceID: we use face ID embedding from a face recognition model instead of CLIP image embedding, additionally, we use LoRA to improve ID consistency. IP-Adapter-FaceID can generate various style images conditioned on a face with only text prompts.
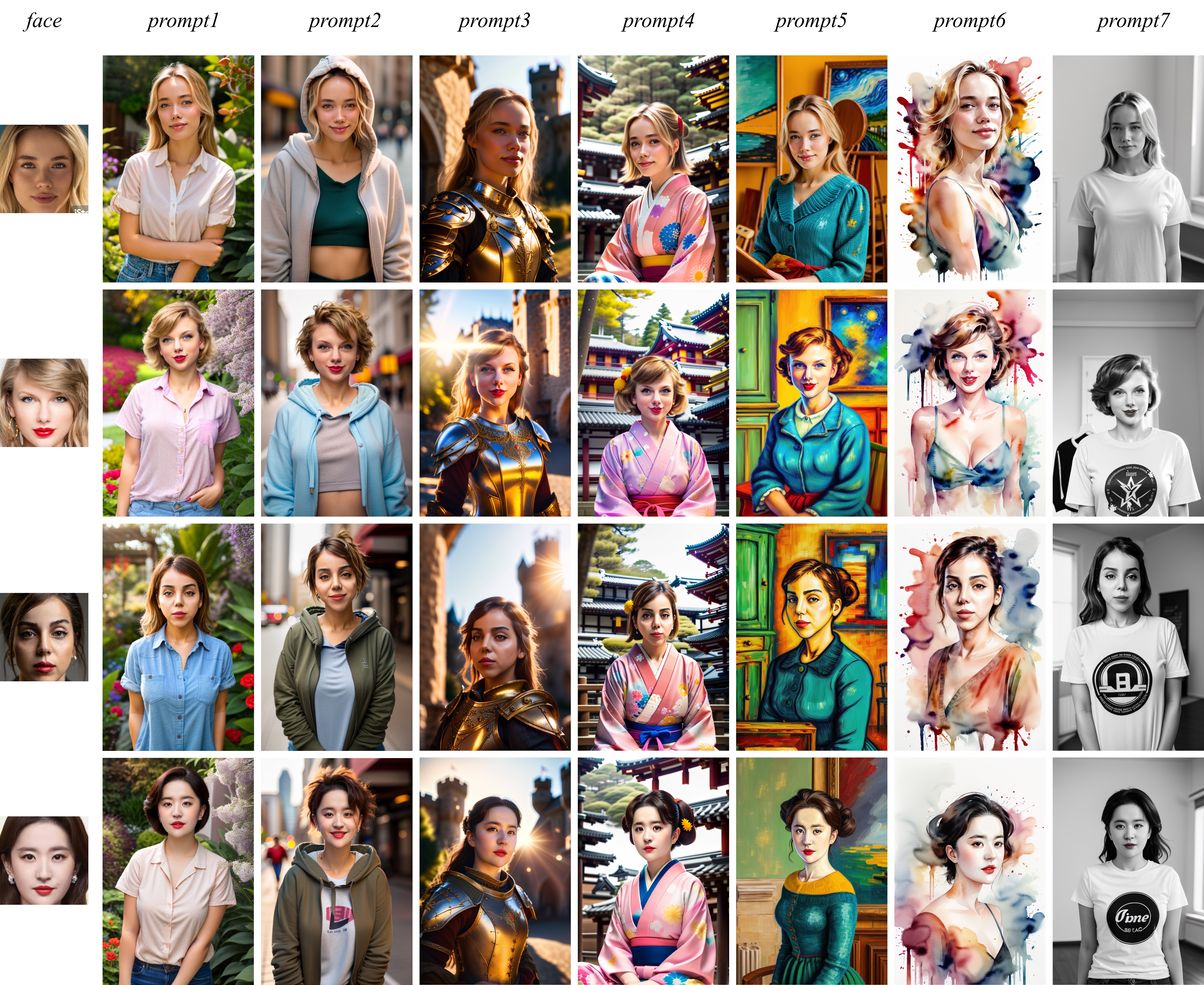
**Update 2023/12/27**:
IP-Adapter-FaceID-Plus: face ID embedding (for face ID) + CLIP image embedding (for face structure)

**Update 2023/12/28**:
IP-Adapter-FaceID-PlusV2: face ID embedding (for face ID) + controllable CLIP image embedding (for face structure)
You can adjust the weight of the face structure to get different generation!

**Update 2024/01/04**:
IP-Adapter-FaceID-SDXL: An experimental SDXL version of IP-Adapter-FaceID

## Usage
### IP-Adapter-FaceID
Firstly, you should use [insightface](https://github.com/deepinsight/insightface) to extract face ID embedding:
```python
import cv2
from insightface.app import FaceAnalysis
import torch
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.imread("person.jpg")
faces = app.get(image)
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
```
Then, you can generate images conditioned on the face embeddings:
```python
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler, AutoencoderKL
from PIL import Image
from ip_adapter.ip_adapter_faceid import IPAdapterFaceID
base_model_path = "SG161222/Realistic_Vision_V4.0_noVAE"
vae_model_path = "stabilityai/sd-vae-ft-mse"
ip_ckpt = "ip-adapter-faceid_sd15.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
vae = AutoencoderKL.from_pretrained(vae_model_path).to(dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
vae=vae,
feature_extractor=None,
safety_checker=None
)
# load ip-adapter
ip_model = IPAdapterFaceID(pipe, ip_ckpt, device)
# generate image
prompt = "photo of a woman in red dress in a garden"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality, blurry"
images = ip_model.generate(
prompt=prompt, negative_prompt=negative_prompt, faceid_embeds=faceid_embeds, num_samples=4, width=512, height=768, num_inference_steps=30, seed=2023
)
```
### IP-Adapter-FaceID-SDXL
Firstly, you should use [insightface](https://github.com/deepinsight/insightface) to extract face ID embedding:
```python
import cv2
from insightface.app import FaceAnalysis
import torch
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.imread("person.jpg")
faces = app.get(image)
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
```
Then, you can generate images conditioned on the face embeddings:
```python
import torch
from diffusers import StableDiffusionXLPipeline, DDIMScheduler
from PIL import Image
from ip_adapter.ip_adapter_faceid import IPAdapterFaceIDXL
base_model_path = "SG161222/RealVisXL_V3.0"
ip_ckpt = "ip-adapter-faceid_sdxl.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
pipe = StableDiffusionXLPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
add_watermarker=False,
)
# load ip-adapter
ip_model = IPAdapterFaceIDXL(pipe, ip_ckpt, device)
# generate image
prompt = "A closeup shot of a beautiful Asian teenage girl in a white dress wearing small silver earrings in the garden, under the soft morning light"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality, blurry"
images = ip_model.generate(
prompt=prompt, negative_prompt=negative_prompt, faceid_embeds=faceid_embeds, num_samples=2,
width=1024, height=1024,
num_inference_steps=30, guidance_scale=7.5, seed=2023
)
```
### IP-Adapter-FaceID-Plus
Firstly, you should use [insightface](https://github.com/deepinsight/insightface) to extract face ID embedding and face image:
```python
import cv2
from insightface.app import FaceAnalysis
from insightface.utils import face_align
import torch
app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
image = cv2.imread("person.jpg")
faces = app.get(image)
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
face_image = face_align.norm_crop(image, landmark=faces[0].kps, image_size=224) # you can also segment the face
```
Then, you can generate images conditioned on the face embeddings:
```python
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler, AutoencoderKL
from PIL import Image
from ip_adapter.ip_adapter_faceid import IPAdapterFaceIDPlus
v2 = False
base_model_path = "SG161222/Realistic_Vision_V4.0_noVAE"
vae_model_path = "stabilityai/sd-vae-ft-mse"
image_encoder_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
ip_ckpt = "ip-adapter-faceid-plus_sd15.bin" if not v2 else "ip-adapter-faceid-plusv2_sd15.bin"
device = "cuda"
noise_scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
vae = AutoencoderKL.from_pretrained(vae_model_path).to(dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
scheduler=noise_scheduler,
vae=vae,
feature_extractor=None,
safety_checker=None
)
# load ip-adapter
ip_model = IPAdapterFaceIDPlus(pipe, image_encoder_path, ip_ckpt, device)
# generate image
prompt = "photo of a woman in red dress in a garden"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality, blurry"
images = ip_model.generate(
prompt=prompt, negative_prompt=negative_prompt, face_image=face_image, faceid_embeds=faceid_embeds, shortcut=v2, s_scale=1.0,
num_samples=4, width=512, height=768, num_inference_steps=30, seed=2023
)
```
## Limitations and Bias
- The model does not achieve perfect photorealism and ID consistency.
- The generalization of the model is limited due to limitations of the training data, base model and face recognition model.
## Non-commercial use
**This model is released exclusively for research purposes and is not intended for commercial use.**