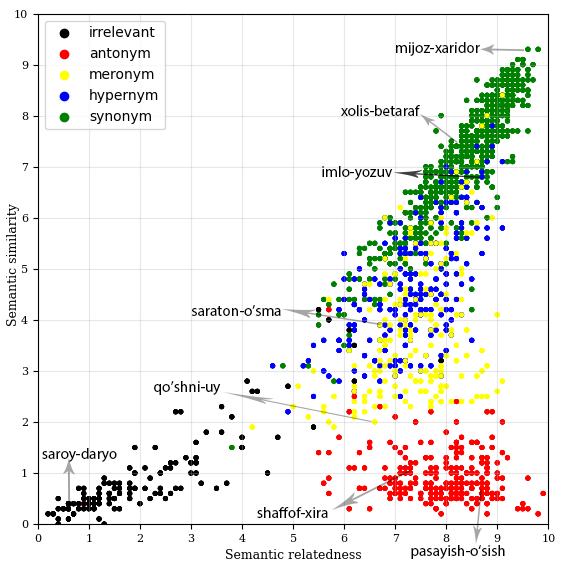
We present a semantic model evaluation dataset: SimRelUz - a collection of similarity and relatedness scores of word pairs for Uzbek language. The dataset consists of more than a thousand pairs of words carefully selected based on their morphological features, occurrence frequency, semantic relation, as well as annotated by eleven native Uzbek speakers from different age groups and gender. Additionally, we also present a web-based tool to annotate similarity and relatedness scores. We also share the code to generate the scatter-plot to visualize word-pairs in a vector space.