
url
stringlengths 63
64
| repository_url
stringclasses 1
value | labels_url
stringlengths 77
78
| comments_url
stringlengths 72
73
| events_url
stringlengths 70
71
| html_url
stringlengths 51
54
| id
int64 1.73B
2.09B
| node_id
stringlengths 18
19
| number
int64 5.23k
16.2k
| title
stringlengths 1
385
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | milestone
null | comments
int64 0
56
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 1
55.4k
⌀ | reactions
dict | timeline_url
stringlengths 72
73
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/langchain-ai/langchain/issues/5556 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5556/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5556/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5556/events | https://github.com/langchain-ai/langchain/pull/5556 | 1,736,107,375 | PR_kwDOIPDwls5R4_zU | 5,556 | Create word.py | {
"login": "imaginespark",
"id": 27605365,
"node_id": "MDQ6VXNlcjI3NjA1MzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/27605365?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/imaginespark",
"html_url": "https://github.com/imaginespark",
"followers_url": "https://api.github.com/users/imaginespark/followers",
"following_url": "https://api.github.com/users/imaginespark/following{/other_user}",
"gists_url": "https://api.github.com/users/imaginespark/gists{/gist_id}",
"starred_url": "https://api.github.com/users/imaginespark/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/imaginespark/subscriptions",
"organizations_url": "https://api.github.com/users/imaginespark/orgs",
"repos_url": "https://api.github.com/users/imaginespark/repos",
"events_url": "https://api.github.com/users/imaginespark/events{/privacy}",
"received_events_url": "https://api.github.com/users/imaginespark/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-06-01T11:31:52" | "2023-06-01T11:48:38" | "2023-06-01T11:48:38" | NONE | null | Loader that loads word files, such as .doc or .docx file
# Add a new DocumentLoader to support word file.
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## @eyurtsev
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5556/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5556/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5556",
"html_url": "https://github.com/langchain-ai/langchain/pull/5556",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5556.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5556.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5555 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5555/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5555/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5555/events | https://github.com/langchain-ai/langchain/issues/5555 | 1,736,083,127 | I_kwDOIPDwls5neoa3 | 5,555 | Query With Multiple Collections | {
"login": "ragvendra3898",
"id": 62380006,
"node_id": "MDQ6VXNlcjYyMzgwMDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/62380006?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ragvendra3898",
"html_url": "https://github.com/ragvendra3898",
"followers_url": "https://api.github.com/users/ragvendra3898/followers",
"following_url": "https://api.github.com/users/ragvendra3898/following{/other_user}",
"gists_url": "https://api.github.com/users/ragvendra3898/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ragvendra3898/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ragvendra3898/subscriptions",
"organizations_url": "https://api.github.com/users/ragvendra3898/orgs",
"repos_url": "https://api.github.com/users/ragvendra3898/repos",
"events_url": "https://api.github.com/users/ragvendra3898/events{/privacy}",
"received_events_url": "https://api.github.com/users/ragvendra3898/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 13 | "2023-06-01T11:18:06" | "2023-12-30T01:39:01" | null | NONE | null | Hi,
I am using langchain to create collections in my local directory after that I am persisting it using below code
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter , TokenTextSplitter
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import VectorDBQA, RetrievalQA
from langchain.document_loaders import TextLoader, UnstructuredFileLoader, DirectoryLoader
loader = DirectoryLoader("D:/files/data")
docs = loader.load()
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectordb = Chroma.from_documents(texts, embedding=embeddings, persist_directory = persist_directory, collection_name=my_collection)
vectordb.persist()
vectordb = None
I am using above code for creating different different collection in the same persist_directory by just changing the collection name and the data files path, now lets say I have 5 collection in my persist directory
my_collection1
my_collection2
my_collection3
my_collection4
my_collection5
Now If I want to perform querying to my data then I have to call my persist_directory with collection_name
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embeddings, collection_name=my_collection3)
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(openai_api_key=openai_api_key), chain_type="stuff", retriever=vectordb.as_retriever(search_type="mmr"), return_source_documents=True)
qa("query")
so the issue is if I am using above code then I can perform only querying for my_collection3 but I want to perform querying to all my five collections, so can anyone please suggest, how can I do this or if it is not possible, I will be thankful to you.
I had tried without collection name for ex-
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(openai_api_key=openai_api_key), chain_type="stuff", retriever=vectordb.as_retriever(search_type="mmr"), return_source_documents=True)
qa("query")
but in this case I am getting
NoIndexException: Index not found, please create an instance before querying | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5555/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/langchain-ai/langchain/issues/5555/timeline | null | null | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5553 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5553/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5553/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5553/events | https://github.com/langchain-ai/langchain/issues/5553 | 1,736,029,435 | I_kwDOIPDwls5nebT7 | 5,553 | ConversationalRetrievalChain is changing context of input | {
"login": "hussainwali74",
"id": 24194686,
"node_id": "MDQ6VXNlcjI0MTk0Njg2",
"avatar_url": "https://avatars.githubusercontent.com/u/24194686?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hussainwali74",
"html_url": "https://github.com/hussainwali74",
"followers_url": "https://api.github.com/users/hussainwali74/followers",
"following_url": "https://api.github.com/users/hussainwali74/following{/other_user}",
"gists_url": "https://api.github.com/users/hussainwali74/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hussainwali74/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hussainwali74/subscriptions",
"organizations_url": "https://api.github.com/users/hussainwali74/orgs",
"repos_url": "https://api.github.com/users/hussainwali74/repos",
"events_url": "https://api.github.com/users/hussainwali74/events{/privacy}",
"received_events_url": "https://api.github.com/users/hussainwali74/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-06-01T10:49:37" | "2023-09-10T16:09:04" | "2023-09-10T16:09:03" | NONE | null | ### System Info
The first time I query the LLM evertything is okay, the second time and in all the calls after that user query is totally changed.
For example my input was "How are you today?" and the chain while trying to make this a standalone question gets confused and totally changes the question,
file:///home/propsure/Pictures/Screenshots/Screenshot%20from%202023-06-01%2015-47-08.png
This is how I am using the chain,
` QA_PROMPT = PromptTemplate(template=prompt_template, input_variables=["context","question", "chat_history" ])
chain = ConversationalRetrievalChain.from_llm(
llm=llm, retriever=retriever, return_source_documents=False,
verbose=True,
max_tokens_limit=2048, combine_docs_chain_kwargs={'prompt': QA_PROMPT}
`
### Who can help?
_No response_
### Information
- [ ] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
Run any llm locally, I am using WizardVicuna (faced the same issue with OpenAI api), and try a conversationalretreival QA with chat_history. Also if I am doing something incorrectly please let me know much appreciated.
### Expected behavior
there should be an option if we don't want it to condense the question, prompt. Because in context based QA we want a similar behaviour. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5553/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5553/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5552 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5552/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5552/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5552/events | https://github.com/langchain-ai/langchain/issues/5552 | 1,735,984,739 | I_kwDOIPDwls5neQZj | 5,552 | Self-querying with Chroma bug - Got invalid return object. Expected markdown code snippet with JSON object, but got ... | {
"login": "Oliver-Douz",
"id": 120089844,
"node_id": "U_kgDOByhs9A",
"avatar_url": "https://avatars.githubusercontent.com/u/120089844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Oliver-Douz",
"html_url": "https://github.com/Oliver-Douz",
"followers_url": "https://api.github.com/users/Oliver-Douz/followers",
"following_url": "https://api.github.com/users/Oliver-Douz/following{/other_user}",
"gists_url": "https://api.github.com/users/Oliver-Douz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Oliver-Douz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Oliver-Douz/subscriptions",
"organizations_url": "https://api.github.com/users/Oliver-Douz/orgs",
"repos_url": "https://api.github.com/users/Oliver-Douz/repos",
"events_url": "https://api.github.com/users/Oliver-Douz/events{/privacy}",
"received_events_url": "https://api.github.com/users/Oliver-Douz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 9 | "2023-06-01T10:25:32" | "2023-12-14T16:08:08" | "2023-12-14T16:08:07" | NONE | null | ### System Info
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /opt/conda/lib/python3.10/site-packages/langchain/chains/query_constructor/base.py:36 in parse │
│ │
│ 33 │ def parse(self, text: str) -> StructuredQuery: │
│ 34 │ │ try: │
│ 35 │ │ │ expected_keys = ["query", "filter"] │
│ ❱ 36 │ │ │ parsed = parse_json_markdown(text, expected_keys) │
│ 37 │ │ │ if len(parsed["query"]) == 0: │
│ 38 │ │ │ │ parsed["query"] = " " │
│ 39 │ │ │ if parsed["filter"] == "NO_FILTER" or not parsed["filter"]: │
│ │
│ /opt/conda/lib/python3.10/site-packages/langchain/output_parsers/structured.py:27 in │
│ parse_json_markdown │
│ │
│ 24 │
│ 25 def parse_json_markdown(text: str, expected_keys: List[str]) -> Any: │
│ 26 │ if "```json" not in text: │
│ ❱ 27 │ │ raise OutputParserException( │
│ 28 │ │ │ f"Got invalid return object. Expected markdown code snippet with JSON " │
│ 29 │ │ │ f"object, but got:\n{text}" │
│ 30 │ │ ) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
OutputParserException: Got invalid return object. Expected markdown code snippet with JSON object, but got:
```vbnet
{
"query": "chatbot refinement",
"filter": "NO_FILTER"
}
```
During handling of the above exception, another exception occurred:
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /tmp/ipykernel_28206/2038672913.py:1 in <module> │
│ │
│ [Errno 2] No such file or directory: '/tmp/ipykernel_28206/2038672913.py' │
│ │
│ /opt/conda/lib/python3.10/site-packages/langchain/retrievers/self_query/base.py:73 in │
│ get_relevant_documents │
│ │
│ 70 │ │ """ │
│ 71 │ │ inputs = self.llm_chain.prep_inputs({"query": query}) │
│ 72 │ │ structured_query = cast( │
│ ❱ 73 │ │ │ StructuredQuery, self.llm_chain.predict_and_parse(callbacks=None, **inputs) │
│ 74 │ │ ) │
│ 75 │ │ if self.verbose: │
│ 76 │ │ │ print(structured_query) │
│ │
│ /opt/conda/lib/python3.10/site-packages/langchain/chains/llm.py:238 in predict_and_parse │
│ │
│ 235 │ │ """Call predict and then parse the results.""" │
│ 236 │ │ result = self.predict(callbacks=callbacks, **kwargs) │
│ 237 │ │ if self.prompt.output_parser is not None: │
│ ❱ 238 │ │ │ return self.prompt.output_parser.parse(result) │
│ 239 │ │ else: │
│ 240 │ │ │ return result │
│ 241 │
│ │
│ /opt/conda/lib/python3.10/site-packages/langchain/chains/query_constructor/base.py:49 in parse │
│ │
│ 46 │ │ │ │ limit=parsed.get("limit"), │
│ 47 │ │ │ ) │
│ 48 │ │ except Exception as e: │
│ ❱ 49 │ │ │ raise OutputParserException( │
│ 50 │ │ │ │ f"Parsing text\n{text}\n raised following error:\n{e}" │
│ 51 │ │ │ ) │
│ 52 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
OutputParserException: Parsing text
```vbnet
{
"query": "chatbot refinement",
"filter": "NO_FILTER"
}
```
raised following error:
Got invalid return object. Expected markdown code snippet with JSON object, but got:
```vbnet
{
"query": "chatbot refinement",
"filter": "NO_FILTER"
}
```
### Who can help?
_No response_
### Information
- [ ] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
```
class Dolly(LLM):
history_data: Optional[List] = []
chatbot : Optional[hugchat.ChatBot] = None
conversation : Optional[str] = ""
#### WARNING : for each api call this library will create a new chat on chat.openai.com
@property
def _llm_type(self) -> str:
return "custom"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
if stop is not None:
pass
#raise ValueError("stop kwargs are not permitted.")
#token is a must check
if self.chatbot is None:
if self.conversation == "":
self.chatbot = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
else:
raise ValueError("Something went wrong")
sleep(2)
data = self.chatbot(prompt)[0]["generated_text"]
#add to history
self.history_data.append({"prompt":prompt,"response":data})
return data
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"model": "DollyCHAT"}
llm = Dolly()
```
Then I follow the instructions in https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/chroma_self_query.html
and I got the above error, sometimes it works, but sometimes it doesn't.
### Expected behavior
Should not return error and act like before (return the related documents) | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5552/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5552/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5551 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5551/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5551/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5551/events | https://github.com/langchain-ai/langchain/issues/5551 | 1,735,921,910 | I_kwDOIPDwls5neBD2 | 5,551 | Incorrect PromptTemplate memorizing | {
"login": "skozlovf",
"id": 730013,
"node_id": "MDQ6VXNlcjczMDAxMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/730013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skozlovf",
"html_url": "https://github.com/skozlovf",
"followers_url": "https://api.github.com/users/skozlovf/followers",
"following_url": "https://api.github.com/users/skozlovf/following{/other_user}",
"gists_url": "https://api.github.com/users/skozlovf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skozlovf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skozlovf/subscriptions",
"organizations_url": "https://api.github.com/users/skozlovf/orgs",
"repos_url": "https://api.github.com/users/skozlovf/repos",
"events_url": "https://api.github.com/users/skozlovf/events{/privacy}",
"received_events_url": "https://api.github.com/users/skozlovf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-06-01T09:54:09" | "2023-09-10T16:09:09" | "2023-09-10T16:09:08" | CONTRIBUTOR | null | ### System Info
LangChain 0.0.187, Python 3.8.16, Linux Mint.
### Who can help?
@hwchase17 @ago
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [X] LLMs/Chat Models
- [ ] Embedding Models
- [X] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [X] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
This script demonstrates the issue:
```python
from langchain.chains import ConversationChain
from langchain.llms import FakeListLLM
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
)
sys_prompt = SystemMessagePromptTemplate.from_template("You are helpful assistant.")
human_prompt = HumanMessagePromptTemplate.from_template("Hey, {input}")
prompt = ChatPromptTemplate.from_messages(
[
sys_prompt,
MessagesPlaceholder(variable_name="history"),
human_prompt,
]
)
chain = ConversationChain(
prompt=prompt,
llm=FakeListLLM(responses=[f"+{x}" for x in range(10)]),
memory=ConversationBufferMemory(return_messages=True, input_key="input"),
verbose=True,
)
chain({"input": "hi there!"})
chain({"input": "what's the weather?"})
```
Output:
```
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: Hey, hi there!
> Finished chain.
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: hi there! <----- ISSUE
AI: +0
Human: Hey, what's the weather?
> Finished chain.
```
`ISSUE`: `Human` history message in the second request is incorrect. It provides raw input.
### Expected behavior
Expected output:
```
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: Hey, hi there!
> Finished chain.
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: Hey, hi there! <----- EXPECTED
AI: +0
Human: Hey, what's the weather?
> Finished chain.
```
History message should contain rendered template string instead of raw input.
As a workaround I add extra "rendering" step before the `ConversationChain`:
```python
from langchain.chains import ConversationChain, SequentialChain, TransformChain
from langchain.llms import FakeListLLM
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
# Extra step: pre-render user template.
in_prompt = PromptTemplate.from_template("Hey, {input}")
render_chain = TransformChain(
input_variables=in_prompt.input_variables,
output_variables=["text"],
transform=lambda x: {"text": in_prompt.format(**x)},
)
prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("You are helpful assistant."),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
chat_chain = ConversationChain(
prompt=prompt,
llm=FakeListLLM(responses=(f"+{x}" for x in range(10))),
memory=ConversationBufferMemory(return_messages=True, input_key="text"),
input_key="text",
verbose=True,
)
chain = SequentialChain(chains=[render_chain, chat_chain], input_variables=["input"])
chain({"input": "hi there!"})
chain({"input": "what's the weather?"})
```
Output:
```
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: Hey, hi there!
> Finished chain.
> Entering new ConversationChain chain...
Prompt after formatting:
System: You are helpful assistant.
Human: Hey, hi there! <--- FIXED
AI: +0
Human: Hey, what's the weather?
> Finished chain.
```
I have checked the code and looks like this behavior is by design: Both `Chain.prep_inputs()` and `Chain.prep_outputs()` pass only inputs/outputs to the `memory` so there is no way to store formatted/rendered template.
Not sure if this is a design issue or incorrect `langchain` API usage. Docs say nothing about `PromptTemplate` restrictions, so I assumed it should work out of the box. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5551/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5551/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5550 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5550/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5550/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5550/events | https://github.com/langchain-ai/langchain/pull/5550 | 1,735,865,772 | PR_kwDOIPDwls5R4KX1 | 5,550 | [Vectorstore] Added async gRPC methods to Qdrant vectorstore | {
"login": "c0sogi",
"id": 121936784,
"node_id": "U_kgDOB0SbkA",
"avatar_url": "https://avatars.githubusercontent.com/u/121936784?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/c0sogi",
"html_url": "https://github.com/c0sogi",
"followers_url": "https://api.github.com/users/c0sogi/followers",
"following_url": "https://api.github.com/users/c0sogi/following{/other_user}",
"gists_url": "https://api.github.com/users/c0sogi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/c0sogi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/c0sogi/subscriptions",
"organizations_url": "https://api.github.com/users/c0sogi/orgs",
"repos_url": "https://api.github.com/users/c0sogi/repos",
"events_url": "https://api.github.com/users/c0sogi/events{/privacy}",
"received_events_url": "https://api.github.com/users/c0sogi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5541432778,
"node_id": "LA_kwDOIPDwls8AAAABSkuNyg",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20vector%20store",
"name": "area: vector store",
"color": "D4C5F9",
"default": false,
"description": "Related to vector store module"
},
{
"id": 5680700863,
"node_id": "LA_kwDOIPDwls8AAAABUpidvw",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:enhancement",
"name": "auto:enhancement",
"color": "C2E0C6",
"default": false,
"description": "A large net-new component, integration, or chain. Use sparingly. The largest features"
}
] | closed | false | {
"login": "kacperlukawski",
"id": 2649301,
"node_id": "MDQ6VXNlcjI2NDkzMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kacperlukawski",
"html_url": "https://github.com/kacperlukawski",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
"gists_url": "https://api.github.com/users/kacperlukawski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kacperlukawski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kacperlukawski/subscriptions",
"organizations_url": "https://api.github.com/users/kacperlukawski/orgs",
"repos_url": "https://api.github.com/users/kacperlukawski/repos",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"received_events_url": "https://api.github.com/users/kacperlukawski/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "kacperlukawski",
"id": 2649301,
"node_id": "MDQ6VXNlcjI2NDkzMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kacperlukawski",
"html_url": "https://github.com/kacperlukawski",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
"gists_url": "https://api.github.com/users/kacperlukawski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kacperlukawski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kacperlukawski/subscriptions",
"organizations_url": "https://api.github.com/users/kacperlukawski/orgs",
"repos_url": "https://api.github.com/users/kacperlukawski/repos",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"received_events_url": "https://api.github.com/users/kacperlukawski/received_events",
"type": "User",
"site_admin": false
}
] | null | 6 | "2023-06-01T09:23:37" | "2023-07-17T11:48:55" | "2023-07-17T11:48:54" | NONE | null | # Async gRPC methods to Qdrant vectorstore
Changes:
- Async methods to add:
aadd_texts, asimilarity_search, asimilarity_search_with_score, amax_marginal_relevance_search_with_score
- Helper methods to add:
_document_from_scored_point_grpc, _document_from_scored_point_grpc, _build_condition_grpc, _qdrant_filter_from_dict_grpc
In addition to rest, Qdrant supports the gRPC protocol, which allows calling asynchronous methods on the client.
gRPC is an open source remote procedure call (RPC) framework developed by Google. gRPC uses a data serialization and RPC protocol called Protocol Buffers to enable efficient communication between clients and servers.
By adding Qdrant's native asynchronous methods, we can solve the event loop blocking issue that occurs when using synchronous methods.
Since these asynchronous methods only work on remote clients, not local, I've made it so that attempting to use them in a local environment (memory, disk) will result in a NotImplementedError.
I was going to create a unit test functions, but I didn't add it for now because it requires a real Remote server to test the method, but it's working fine for now in my project. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5550/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5550",
"html_url": "https://github.com/langchain-ai/langchain/pull/5550",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5550.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5550.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5549 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5549/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5549/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5549/events | https://github.com/langchain-ai/langchain/pull/5549 | 1,735,822,834 | PR_kwDOIPDwls5R4BCt | 5,549 | Fixed incorrect prompt formatting for chat based ReAct agent | {
"login": "oguzgultepe",
"id": 15001584,
"node_id": "MDQ6VXNlcjE1MDAxNTg0",
"avatar_url": "https://avatars.githubusercontent.com/u/15001584?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oguzgultepe",
"html_url": "https://github.com/oguzgultepe",
"followers_url": "https://api.github.com/users/oguzgultepe/followers",
"following_url": "https://api.github.com/users/oguzgultepe/following{/other_user}",
"gists_url": "https://api.github.com/users/oguzgultepe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oguzgultepe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oguzgultepe/subscriptions",
"organizations_url": "https://api.github.com/users/oguzgultepe/orgs",
"repos_url": "https://api.github.com/users/oguzgultepe/repos",
"events_url": "https://api.github.com/users/oguzgultepe/events{/privacy}",
"received_events_url": "https://api.github.com/users/oguzgultepe/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4899412369,
"node_id": "LA_kwDOIPDwls8AAAABJAcZkQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20agent",
"name": "area: agent",
"color": "BFD4F2",
"default": false,
"description": "Related to agents module"
},
{
"id": 5680700839,
"node_id": "LA_kwDOIPDwls8AAAABUpidpw",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:bug",
"name": "auto:bug",
"color": "E99695",
"default": false,
"description": "Related to a bug, vulnerability, unexpected error with an existing feature"
}
] | closed | false | {
"login": "efriis",
"id": 9557659,
"node_id": "MDQ6VXNlcjk1NTc2NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/9557659?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/efriis",
"html_url": "https://github.com/efriis",
"followers_url": "https://api.github.com/users/efriis/followers",
"following_url": "https://api.github.com/users/efriis/following{/other_user}",
"gists_url": "https://api.github.com/users/efriis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/efriis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/efriis/subscriptions",
"organizations_url": "https://api.github.com/users/efriis/orgs",
"repos_url": "https://api.github.com/users/efriis/repos",
"events_url": "https://api.github.com/users/efriis/events{/privacy}",
"received_events_url": "https://api.github.com/users/efriis/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "efriis",
"id": 9557659,
"node_id": "MDQ6VXNlcjk1NTc2NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/9557659?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/efriis",
"html_url": "https://github.com/efriis",
"followers_url": "https://api.github.com/users/efriis/followers",
"following_url": "https://api.github.com/users/efriis/following{/other_user}",
"gists_url": "https://api.github.com/users/efriis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/efriis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/efriis/subscriptions",
"organizations_url": "https://api.github.com/users/efriis/orgs",
"repos_url": "https://api.github.com/users/efriis/repos",
"events_url": "https://api.github.com/users/efriis/events{/privacy}",
"received_events_url": "https://api.github.com/users/efriis/received_events",
"type": "User",
"site_admin": false
}
] | null | 9 | "2023-06-01T09:00:33" | "2023-11-30T22:17:46" | "2023-11-30T22:17:46" | NONE | null | # Fixed incorrect prompt formatting for chat based ReAct agent
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes #5390
Created two new classes (ReActStringPromptValue and ReActPromptTemplate) in order to handle correct prompt formatting for chat based models.
My twitter handle: @gultepeoguz
## Before submitting
Format/lint/tests already run.
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5549/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5549",
"html_url": "https://github.com/langchain-ai/langchain/pull/5549",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5549.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5549.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5548 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5548/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5548/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5548/events | https://github.com/langchain-ai/langchain/issues/5548 | 1,735,790,487 | I_kwDOIPDwls5ndg-X | 5,548 | Guanaco 65B model support | {
"login": "Bec-k",
"id": 65600131,
"node_id": "MDQ6VXNlcjY1NjAwMTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/65600131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Bec-k",
"html_url": "https://github.com/Bec-k",
"followers_url": "https://api.github.com/users/Bec-k/followers",
"following_url": "https://api.github.com/users/Bec-k/following{/other_user}",
"gists_url": "https://api.github.com/users/Bec-k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Bec-k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Bec-k/subscriptions",
"organizations_url": "https://api.github.com/users/Bec-k/orgs",
"repos_url": "https://api.github.com/users/Bec-k/repos",
"events_url": "https://api.github.com/users/Bec-k/events{/privacy}",
"received_events_url": "https://api.github.com/users/Bec-k/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-06-01T08:42:42" | "2023-09-14T16:07:08" | "2023-09-14T16:07:07" | NONE | null | ### Feature request
Please add support for the model Guanaco 65B, which is trained via qLoRA method. To be able to swap OpenAI model to Guanaco and perform same operations over it.
### Motivation
The best performance and free model out there up to date 01.06.2023.
### Your contribution
- | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5548/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5548/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5547 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5547/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5547/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5547/events | https://github.com/langchain-ai/langchain/pull/5547 | 1,735,785,488 | PR_kwDOIPDwls5R34_A | 5,547 | Improve Error Messaging for APOC Procedure Failure in Neo4jGraph | {
"login": "guangchen811",
"id": 103159823,
"node_id": "U_kgDOBiYYDw",
"avatar_url": "https://avatars.githubusercontent.com/u/103159823?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guangchen811",
"html_url": "https://github.com/guangchen811",
"followers_url": "https://api.github.com/users/guangchen811/followers",
"following_url": "https://api.github.com/users/guangchen811/following{/other_user}",
"gists_url": "https://api.github.com/users/guangchen811/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guangchen811/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guangchen811/subscriptions",
"organizations_url": "https://api.github.com/users/guangchen811/orgs",
"repos_url": "https://api.github.com/users/guangchen811/repos",
"events_url": "https://api.github.com/users/guangchen811/events{/privacy}",
"received_events_url": "https://api.github.com/users/guangchen811/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-06-01T08:39:49" | "2023-06-07T15:38:20" | "2023-06-03T23:56:39" | CONTRIBUTOR | null | ## Improve Error Messaging for APOC Procedure Failure in Neo4jGraph
This commit revises the error message provided when the 'apoc.meta.data()' procedure fails. Previously, the message simply instructed the user to install the APOC plugin in Neo4j. The new error message is more specific.
Also removed an unnecessary newline in the Cypher statement variable: `node_properties_query`.
Fixes #5545
## Who can review?
- @vowelparrot
- @dev2049 | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5547/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5547/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5547",
"html_url": "https://github.com/langchain-ai/langchain/pull/5547",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5547.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5547.patch",
"merged_at": "2023-06-03T23:56:39"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5545 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5545/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5545/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5545/events | https://github.com/langchain-ai/langchain/issues/5545 | 1,735,730,197 | I_kwDOIPDwls5ndSQV | 5,545 | Issue: Improve Error Messaging When APOC Procedures Fail in Neo4jGraph | {
"login": "guangchen811",
"id": 103159823,
"node_id": "U_kgDOBiYYDw",
"avatar_url": "https://avatars.githubusercontent.com/u/103159823?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guangchen811",
"html_url": "https://github.com/guangchen811",
"followers_url": "https://api.github.com/users/guangchen811/followers",
"following_url": "https://api.github.com/users/guangchen811/following{/other_user}",
"gists_url": "https://api.github.com/users/guangchen811/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guangchen811/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guangchen811/subscriptions",
"organizations_url": "https://api.github.com/users/guangchen811/orgs",
"repos_url": "https://api.github.com/users/guangchen811/repos",
"events_url": "https://api.github.com/users/guangchen811/events{/privacy}",
"received_events_url": "https://api.github.com/users/guangchen811/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-06-01T08:04:16" | "2023-06-03T23:56:40" | "2023-06-03T23:56:40" | CONTRIBUTOR | null | ### Issue you'd like to raise.
In the current implementation, when an APOC procedure fails, a generic error message is raised stating: "Could not use APOC procedures. Please install the APOC plugin in Neo4j." This message can lead to user confusion as it suggests the APOC plugin is not installed when in reality it may be installed but not correctly configured or permitted to run certain procedures.
This issue is encountered specifically when the refresh_schema function calls apoc.meta.data(). The function apoc.meta.data() isn't allowed to run under default configurations in the Neo4j database, thus leading to the mentioned error message.
Here is the code snippet where the issue arises:
```
# Set schema
try:
self.refresh_schema()
except neo4j.exceptions.ClientError
raise ValueError(
"Could not use APOC procedures. "
"Please install the APOC plugin in Neo4j."
)
```
### Suggestion:
To improve the user experience, I propose that the error message should be made more specific. Instead of merely advising users to install the APOC plugin, it would be beneficial to indicate that certain procedures may not be configured or whitelisted to run by default and to guide the users to check their configurations.
I believe this will save users time when troubleshooting and will reduce the potential for confusion. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5545/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5545/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5544 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5544/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5544/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5544/events | https://github.com/langchain-ai/langchain/issues/5544 | 1,735,643,747 | I_kwDOIPDwls5nc9Jj | 5,544 | The same code, sometimes throwing an exception(ValueError: Could not parse output), sometimes running correctly | {
"login": "hotpeppeper",
"id": 15924284,
"node_id": "MDQ6VXNlcjE1OTI0Mjg0",
"avatar_url": "https://avatars.githubusercontent.com/u/15924284?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hotpeppeper",
"html_url": "https://github.com/hotpeppeper",
"followers_url": "https://api.github.com/users/hotpeppeper/followers",
"following_url": "https://api.github.com/users/hotpeppeper/following{/other_user}",
"gists_url": "https://api.github.com/users/hotpeppeper/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hotpeppeper/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hotpeppeper/subscriptions",
"organizations_url": "https://api.github.com/users/hotpeppeper/orgs",
"repos_url": "https://api.github.com/users/hotpeppeper/repos",
"events_url": "https://api.github.com/users/hotpeppeper/events{/privacy}",
"received_events_url": "https://api.github.com/users/hotpeppeper/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-06-01T07:13:59" | "2023-11-27T16:09:56" | "2023-11-27T16:09:55" | NONE | null | ### Issue you'd like to raise.
```
loaders = [TextLoader("13.txt"), TextLoader("14.txt"), TextLoader("15.txt"),TextLoader("16.txt"), TextLoader("17.txt"), TextLoader("18.txt")]
documents = []
for loader in loaders:
documents.extend(loader.load())
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=150)
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
qa = RetrievalQAWithSourcesChain.from_chain_type(llm=llm,
chain_type="map_rerank",
retriever=vectorstore.as_retriever(),
return_source_documents=True)
query = "茶艺师报名条件是什么,使用中文回答"
chat_history = []
result = qa({'question': query})
```
sometimes this code raise ValueError: Could not parse output,but when I rerun result = qa({'question': query}), this may return the anwser. how can I fix this?
### Suggestion:
I wonder why this happens, and how to fix it. please help me!! | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5544/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5544/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5543 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5543/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5543/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5543/events | https://github.com/langchain-ai/langchain/pull/5543 | 1,735,593,915 | PR_kwDOIPDwls5R3Pdy | 5,543 | Incorrect argument count handling | {
"login": "swappysh",
"id": 7112252,
"node_id": "MDQ6VXNlcjcxMTIyNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7112252?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/swappysh",
"html_url": "https://github.com/swappysh",
"followers_url": "https://api.github.com/users/swappysh/followers",
"following_url": "https://api.github.com/users/swappysh/following{/other_user}",
"gists_url": "https://api.github.com/users/swappysh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/swappysh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/swappysh/subscriptions",
"organizations_url": "https://api.github.com/users/swappysh/orgs",
"repos_url": "https://api.github.com/users/swappysh/repos",
"events_url": "https://api.github.com/users/swappysh/events{/privacy}",
"received_events_url": "https://api.github.com/users/swappysh/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 3 | "2023-06-01T06:41:39" | "2023-06-20T22:29:24" | "2023-06-20T05:06:20" | CONTRIBUTOR | null | Throwing ToolException when incorrect arguments are passed to tools so that that agent can course correct them.
# Incorrect argument count handling
I was facing an error where the agent passed incorrect arguments to tools. As per the discussions going around, I started throwing ToolException to allow the model to course correct.
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5543/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5543/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5543",
"html_url": "https://github.com/langchain-ai/langchain/pull/5543",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5543.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5543.patch",
"merged_at": "2023-06-20T05:06:20"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5542 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5542/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5542/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5542/events | https://github.com/langchain-ai/langchain/issues/5542 | 1,735,589,481 | I_kwDOIPDwls5ncv5p | 5,542 | Issue: previous message condensing time on `ConversationalRetrievalChain` | {
"login": "Rijoanul-Shanto",
"id": 17069712,
"node_id": "MDQ6VXNlcjE3MDY5NzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/17069712?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rijoanul-Shanto",
"html_url": "https://github.com/Rijoanul-Shanto",
"followers_url": "https://api.github.com/users/Rijoanul-Shanto/followers",
"following_url": "https://api.github.com/users/Rijoanul-Shanto/following{/other_user}",
"gists_url": "https://api.github.com/users/Rijoanul-Shanto/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rijoanul-Shanto/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rijoanul-Shanto/subscriptions",
"organizations_url": "https://api.github.com/users/Rijoanul-Shanto/orgs",
"repos_url": "https://api.github.com/users/Rijoanul-Shanto/repos",
"events_url": "https://api.github.com/users/Rijoanul-Shanto/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rijoanul-Shanto/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-06-01T06:37:44" | "2023-10-05T16:10:16" | "2023-10-05T16:10:16" | NONE | null | ### Issue you'd like to raise.
I got a scenario where I'm using the `ConversationalRetrievalChain` with chat history. The problem is, it was streaming the condensed output of the question. Not the actual answer. So I separated the models, one for condensing the question and one for answering with streaming. But as I suspected, the condensing chain is eating up a time to generate the condensed output of the question, and the actual streaming of the answer is waiting for the condensed question generator.
some of my implementations:
```python
callback = AsyncIteratorCallbackHandler()
q_generator_llm = ChatOpenAI(
openai_api_key=settings.openai_api_key,
)
streaming_llm = ChatOpenAI(
openai_api_key=settings.openai_api_key,
streaming=True,
callbacks=[callback],
)
question_generator = LLMChain(llm=q_generator_llm, prompt=CONDENSE_QUESTION_PROMPT)
doc_chain = load_qa_chain(llm=streaming_llm, chain_type="stuff", prompt=prompt)
qa_chain = ConversationalRetrievalChain(
retriever=collection_store.as_retriever(search_kwargs={"k": 3}),
combine_docs_chain=doc_chain,
question_generator=question_generator,
return_source_documents=True,
)
history = []
task = asyncio.create_task(
qa_chain.acall({
"question": q,
"chat_history": history
}),
)
```
___
### **Any workaround on how I avoid condensing the question to save time? Or any efficient way to resolve the issue?**
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5542/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5542/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5541 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5541/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5541/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5541/events | https://github.com/langchain-ai/langchain/pull/5541 | 1,735,553,303 | PR_kwDOIPDwls5R3GrD | 5,541 | Cypher search: Check if generated Cypher is provided in backticks | {
"login": "tomasonjo",
"id": 19948365,
"node_id": "MDQ6VXNlcjE5OTQ4MzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/19948365?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomasonjo",
"html_url": "https://github.com/tomasonjo",
"followers_url": "https://api.github.com/users/tomasonjo/followers",
"following_url": "https://api.github.com/users/tomasonjo/following{/other_user}",
"gists_url": "https://api.github.com/users/tomasonjo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tomasonjo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomasonjo/subscriptions",
"organizations_url": "https://api.github.com/users/tomasonjo/orgs",
"repos_url": "https://api.github.com/users/tomasonjo/repos",
"events_url": "https://api.github.com/users/tomasonjo/events{/privacy}",
"received_events_url": "https://api.github.com/users/tomasonjo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 3 | "2023-06-01T06:13:20" | "2023-06-05T19:48:14" | "2023-06-05T19:48:14" | CONTRIBUTOR | null | # Check if generated Cypher code is wrapped in backticks
Some LLMs like the VertexAI like to explain how they generated the Cypher statement and wrap the actual code in three backticks:
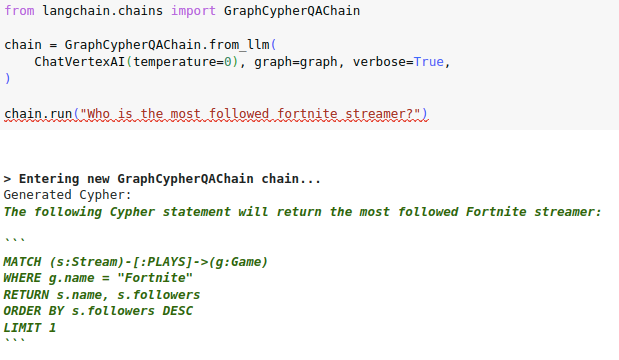
I have observed a similar pattern with OpenAI chat models in a conversational settings, where multiple user and assistant message are provided to the LLM to generate Cypher statements, where then the LLM wants to maybe apologize for previous steps or explain its thoughts. Interestingly, both OpenAI and VertexAI wrap the code in three backticks if they are doing any explaining or apologizing. Checking if the generated cypher is wrapped in backticks seems like a low-hanging fruit to expand the cypher search to other LLMs and conversational settings.
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5541/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5541/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5541",
"html_url": "https://github.com/langchain-ai/langchain/pull/5541",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5541.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5541.patch",
"merged_at": "2023-06-05T19:48:14"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5540 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5540/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5540/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5540/events | https://github.com/langchain-ai/langchain/pull/5540 | 1,735,539,583 | PR_kwDOIPDwls5R3DqJ | 5,540 | Harrison/pipeline prompt | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-06-01T06:04:10" | "2023-06-04T21:29:38" | "2023-06-04T21:29:37" | COLLABORATOR | null | idea is to make prompts more composable | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5540/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5540/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5540",
"html_url": "https://github.com/langchain-ai/langchain/pull/5540",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5540.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5540.patch",
"merged_at": "2023-06-04T21:29:37"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5539 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5539/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5539/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5539/events | https://github.com/langchain-ai/langchain/issues/5539 | 1,735,478,342 | I_kwDOIPDwls5ncUxG | 5,539 | Allow users to pass local embeddings to Weaviate Hybrid Search Retriever | {
"login": "jacobhutchinson",
"id": 18623246,
"node_id": "MDQ6VXNlcjE4NjIzMjQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/18623246?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jacobhutchinson",
"html_url": "https://github.com/jacobhutchinson",
"followers_url": "https://api.github.com/users/jacobhutchinson/followers",
"following_url": "https://api.github.com/users/jacobhutchinson/following{/other_user}",
"gists_url": "https://api.github.com/users/jacobhutchinson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jacobhutchinson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jacobhutchinson/subscriptions",
"organizations_url": "https://api.github.com/users/jacobhutchinson/orgs",
"repos_url": "https://api.github.com/users/jacobhutchinson/repos",
"events_url": "https://api.github.com/users/jacobhutchinson/events{/privacy}",
"received_events_url": "https://api.github.com/users/jacobhutchinson/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-06-01T05:19:27" | "2023-12-06T17:45:40" | "2023-12-06T17:45:39" | NONE | null | ### Feature request
Fork off from this issue: https://github.com/hwchase17/langchain/issues/5300
The idea is to provide the WeaviateHybridSearchRetriever with the ability to use local embeddings similar to the Weaviate vectorstore. Specifically, for the `WeaviateHybridSearchRetriever.add_documents()` and `WeaviateHybridSearchRetriever.get_relevant_documents()` functions to work similar to the `Weviate.from_texts()` function where there is the option to use local embeddings if passed during creation. Additionally, the `WeaviateHybridSearchRetriever._create_schema_if_missing()` function likely needs to remove the default addition of a vectorizer in the schema object (related issue here: https://github.com/hwchase17/langchain/issues/5300).
### Motivation
This will allow those of us running Weaviate without embedding modules (like myself) to use the Weaviate Hybrid Search Retriever.
### Your contribution
I am planning on working to get a fix locally, I can potentially submit this as a PR down the line. Busy this week so others would probably beat me to it. I can review though. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5539/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5539/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5538 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5538/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5538/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5538/events | https://github.com/langchain-ai/langchain/pull/5538 | 1,735,456,313 | PR_kwDOIPDwls5R2xSx | 5,538 | add brave search util | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-06-01T05:00:11" | "2023-06-01T08:11:53" | "2023-06-01T08:11:52" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5538/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5538/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5538",
"html_url": "https://github.com/langchain-ai/langchain/pull/5538",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5538.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5538.patch",
"merged_at": "2023-06-01T08:11:52"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5537 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5537/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5537/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5537/events | https://github.com/langchain-ai/langchain/issues/5537 | 1,735,414,868 | I_kwDOIPDwls5ncFRU | 5,537 | OpenAI and Azure OpenAI - calls one after another | {
"login": "ushakrishnan",
"id": 18739265,
"node_id": "MDQ6VXNlcjE4NzM5MjY1",
"avatar_url": "https://avatars.githubusercontent.com/u/18739265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ushakrishnan",
"html_url": "https://github.com/ushakrishnan",
"followers_url": "https://api.github.com/users/ushakrishnan/followers",
"following_url": "https://api.github.com/users/ushakrishnan/following{/other_user}",
"gists_url": "https://api.github.com/users/ushakrishnan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ushakrishnan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ushakrishnan/subscriptions",
"organizations_url": "https://api.github.com/users/ushakrishnan/orgs",
"repos_url": "https://api.github.com/users/ushakrishnan/repos",
"events_url": "https://api.github.com/users/ushakrishnan/events{/privacy}",
"received_events_url": "https://api.github.com/users/ushakrishnan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-06-01T04:20:05" | "2023-09-18T16:09:34" | "2023-09-18T16:09:34" | NONE | null | ### System Info
langchain - 0.0.174 / 0.0.178 / 0.0.187
python3
### Who can help?
@hwchase17 @agola11
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [X] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [X] Agents / Agent Executors
- [X] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
1. Call OpenAI setting the parameters - openai_api_type , openai_api_version , openai_api_base , openai_api_key
-- Successful OpenAI request response
2. Call Azure OpenAI setting the parameters - openai_api_type , openai_api_version , openai_api_base , openai_api_key
-- Fails
All subsequent calls fails
Alternatively, if you first call Azure OpenAI with parameters set correctly - that succeeds, but OpenAI fails. And all subsequent fails.
Each independently works - so guessing the. parameter values work as expected. But when one after other is called, the second API (OpenAI or Azure OpenAI - which ever is called second) - fails
### Expected behavior
If parameters are set correctly, both should work as required. If independently they work if app is restarted, why would it fail if they are called sequentiially?
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5537/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5537/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5536 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5536/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5536/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5536/events | https://github.com/langchain-ai/langchain/issues/5536 | 1,735,412,964 | I_kwDOIPDwls5ncEzk | 5,536 | `RetrievalQAWithSourcesChain` not returning sources in `sources` field. | {
"login": "eRuaro",
"id": 69240261,
"node_id": "MDQ6VXNlcjY5MjQwMjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/69240261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eRuaro",
"html_url": "https://github.com/eRuaro",
"followers_url": "https://api.github.com/users/eRuaro/followers",
"following_url": "https://api.github.com/users/eRuaro/following{/other_user}",
"gists_url": "https://api.github.com/users/eRuaro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eRuaro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eRuaro/subscriptions",
"organizations_url": "https://api.github.com/users/eRuaro/orgs",
"repos_url": "https://api.github.com/users/eRuaro/repos",
"events_url": "https://api.github.com/users/eRuaro/events{/privacy}",
"received_events_url": "https://api.github.com/users/eRuaro/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-06-01T04:17:08" | "2024-01-16T08:36:32" | "2023-09-10T16:09:18" | CONTRIBUTOR | null | ### System Info
System Info (Docker Dev Container):
```
PRETTY_NAME="Debian GNU/Linux 10 (buster)"
NAME="Debian GNU/Linux"
VERSION_ID="10"
VERSION="10 (buster)"
VERSION_CODENAME=buster
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
```
Python: 3.10
Pip:
```
absl-py 1.4.0
aiohttp 3.8.4
aiosignal 1.3.1
antlr4-python3-runtime 4.9.3
anyio 3.6.2
argilla 1.6.0
async-timeout 4.0.2
attrs 23.1.0
backoff 2.2.1
cachetools 5.3.0
certifi 2022.12.7
cffi 1.15.1
charset-normalizer 3.1.0
click 8.1.3
cloudpickle 2.2.1
cmake 3.26.3
coloredlogs 15.0.1
commonmark 0.9.1
contourpy 1.0.7
cryptography 40.0.2
cycler 0.11.0
dataclasses-json 0.5.7
Deprecated 1.2.13
detectron2 0.4
effdet 0.3.0
et-xmlfile 1.1.0
exceptiongroup 1.1.1
fastapi 0.95.1
filelock 3.11.0
flatbuffers 23.3.3
fonttools 4.39.3
frozenlist 1.3.3
future 0.18.3
fvcore 0.1.3.post20210317
google-auth 2.17.3
google-auth-oauthlib 1.0.0
gptcache 0.1.11
greenlet 2.0.2
grpcio 1.53.0
h11 0.14.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.13.4
humanfriendly 10.0
idna 3.4
iniconfig 2.0.0
iopath 0.1.10
Jinja2 3.1.2
joblib 1.2.0
kiwisolver 1.4.4
langchain 0.0.141
layoutparser 0.3.4
lit 16.0.1
lxml 4.9.2
Markdown 3.4.3
MarkupSafe 2.1.2
marshmallow 3.19.0
marshmallow-enum 1.5.1
matplotlib 3.7.1
monotonic 1.6
mpmath 1.3.0
msg-parser 1.2.0
multidict 6.0.4
mypy-extensions 1.0.0
networkx 3.1
nltk 3.8.1
numpy 1.23.5
nvidia-cublas-cu11 11.10.3.66
nvidia-cuda-cupti-cu11 11.7.101
nvidia-cuda-nvrtc-cu11 11.7.99
nvidia-cuda-runtime-cu11 11.7.99
nvidia-cudnn-cu11 8.5.0.96
nvidia-cufft-cu11 10.9.0.58
nvidia-curand-cu11 10.2.10.91
nvidia-cusolver-cu11 11.4.0.1
nvidia-cusparse-cu11 11.7.4.91
nvidia-nccl-cu11 2.14.3
nvidia-nvtx-cu11 11.7.91
oauthlib 3.2.2
olefile 0.46
omegaconf 2.3.0
onnxruntime 1.14.1
openai 0.27.4
openapi-schema-pydantic 1.2.4
opencv-python 4.6.0.66
openpyxl 3.1.2
packaging 23.1
pandas 1.5.3
pdf2image 1.16.3
pdfminer.six 20221105
pdfplumber 0.9.0
pgvector 0.1.6
Pillow 9.5.0
pip 23.1
pluggy 1.0.0
portalocker 2.7.0
protobuf 4.22.3
psycopg2-binary 2.9.6
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.6
pycparser 2.21
pydantic 1.10.7
pydot 1.4.2
Pygments 2.15.0
pypandoc 1.11
pyparsing 3.0.9
pypdf 3.9.0
pytesseract 0.3.10
pytest 7.3.1
python-dateutil 2.8.2
python-docx 0.8.11
python-dotenv 1.0.0
python-magic 0.4.27
python-multipart 0.0.6
python-poppler 0.4.0
python-pptx 0.6.21
pytz 2023.3
PyYAML 6.0
regex 2023.3.23
requests 2.28.2
requests-oauthlib 1.3.1
rfc3986 1.5.0
rich 13.0.1
rsa 4.9
scipy 1.10.1
setuptools 65.5.1
six 1.16.0
sniffio 1.3.0
SQLAlchemy 1.4.47
starlette 0.26.1
sympy 1.11.1
tabulate 0.9.0
tenacity 8.2.2
tensorboard 2.12.2
tensorboard-data-server 0.7.0
tensorboard-plugin-wit 1.8.1
termcolor 2.2.0
tiktoken 0.3.3
timm 0.6.13
tokenizers 0.13.3
tomli 2.0.1
torch 2.0.0
torchaudio 2.0.1
torchvision 0.15.1
tqdm 4.65.0
transformers 4.28.1
triton 2.0.0
typing_extensions 4.5.0
typing-inspect 0.8.0
unstructured 0.5.12
unstructured-inference 0.3.2
urllib3 1.26.15
uvicorn 0.21.1
Wand 0.6.11
Werkzeug 2.2.3
wheel 0.40.0
wrapt 1.14.1
XlsxWriter 3.1.0
yacs 0.1.8
yarl 1.8.2
```
### Who can help?
@hwchase17
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [X] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [X] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
Write the code below:
```
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=ChatOpenAI(openai_api_key=api_key),
chain_type="map_reduce",
retriever=retriever,
)
llm_call = "random llm call"
result = chain({
"question": llm_call,
},
return_only_outputs=True
)
```
### Expected behavior
I'm expecting that I'll be having a `result["answer"]` and non empty `result["sources"]` but here's what I get instead:

As you can see, `sources` is empty but it's included in `result["answer"]` as a string. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5536/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5536/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5535 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5535/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5535/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5535/events | https://github.com/langchain-ai/langchain/issues/5535 | 1,735,366,931 | I_kwDOIPDwls5nb5kT | 5,535 | Add Tigris vectorstore for vector search | {
"login": "adilansari",
"id": 2469198,
"node_id": "MDQ6VXNlcjI0NjkxOTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2469198?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adilansari",
"html_url": "https://github.com/adilansari",
"followers_url": "https://api.github.com/users/adilansari/followers",
"following_url": "https://api.github.com/users/adilansari/following{/other_user}",
"gists_url": "https://api.github.com/users/adilansari/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adilansari/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adilansari/subscriptions",
"organizations_url": "https://api.github.com/users/adilansari/orgs",
"repos_url": "https://api.github.com/users/adilansari/repos",
"events_url": "https://api.github.com/users/adilansari/events{/privacy}",
"received_events_url": "https://api.github.com/users/adilansari/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4678528817,
"node_id": "LA_kwDOIPDwls8AAAABFtyvMQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 5541432778,
"node_id": "LA_kwDOIPDwls8AAAABSkuNyg",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20vector%20store",
"name": "area: vector store",
"color": "D4C5F9",
"default": false,
"description": "Related to vector store module"
}
] | closed | false | null | [] | null | 3 | "2023-06-01T03:18:00" | "2023-06-06T03:39:17" | "2023-06-06T03:39:17" | CONTRIBUTOR | null | ### Feature request
Support Tigris as a vector search backend
### Motivation
Tigris is a Serverless NoSQL Database and Search Platform and have their [vector search](https://www.tigrisdata.com/docs/concepts/vector-search/python/) product. It will be great option for users to use an integrated database and search product.
### Your contribution
I can submit a a PR | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5535/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5535/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5533 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5533/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5533/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5533/events | https://github.com/langchain-ai/langchain/pull/5533 | 1,735,277,122 | PR_kwDOIPDwls5R2KbU | 5,533 | add maxcompute | {
"login": "dev2049",
"id": 130488702,
"node_id": "U_kgDOB8cZfg",
"avatar_url": "https://avatars.githubusercontent.com/u/130488702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev2049",
"html_url": "https://github.com/dev2049",
"followers_url": "https://api.github.com/users/dev2049/followers",
"following_url": "https://api.github.com/users/dev2049/following{/other_user}",
"gists_url": "https://api.github.com/users/dev2049/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev2049/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev2049/subscriptions",
"organizations_url": "https://api.github.com/users/dev2049/orgs",
"repos_url": "https://api.github.com/users/dev2049/repos",
"events_url": "https://api.github.com/users/dev2049/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev2049/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4678528817,
"node_id": "LA_kwDOIPDwls8AAAABFtyvMQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 5541144676,
"node_id": "LA_kwDOIPDwls8AAAABSkcoZA",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20doc%20loader",
"name": "area: doc loader",
"color": "D4C5F9",
"default": false,
"description": "Related to document loader module (not documentation)"
}
] | closed | false | null | [] | null | 2 | "2023-06-01T01:28:47" | "2023-06-02T02:53:06" | "2023-06-01T07:54:43" | CONTRIBUTOR | null | cc @pengwork (fresh branch, no creds) | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5533/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5533/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5533",
"html_url": "https://github.com/langchain-ai/langchain/pull/5533",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5533.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5533.patch",
"merged_at": "2023-06-01T07:54:42"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5532 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5532/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5532/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5532/events | https://github.com/langchain-ai/langchain/issues/5532 | 1,735,238,661 | I_kwDOIPDwls5nbaQF | 5,532 | Issue: how stream results with long context | {
"login": "qlql489",
"id": 10767590,
"node_id": "MDQ6VXNlcjEwNzY3NTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/10767590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qlql489",
"html_url": "https://github.com/qlql489",
"followers_url": "https://api.github.com/users/qlql489/followers",
"following_url": "https://api.github.com/users/qlql489/following{/other_user}",
"gists_url": "https://api.github.com/users/qlql489/gists{/gist_id}",
"starred_url": "https://api.github.com/users/qlql489/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qlql489/subscriptions",
"organizations_url": "https://api.github.com/users/qlql489/orgs",
"repos_url": "https://api.github.com/users/qlql489/repos",
"events_url": "https://api.github.com/users/qlql489/events{/privacy}",
"received_events_url": "https://api.github.com/users/qlql489/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 3 | "2023-06-01T00:52:51" | "2023-10-11T16:17:53" | null | NONE | null | ### Issue you'd like to raise.
i follow the chapter “Chat Over Documents with Chat History” to build a bot chat with pdf,
i want to streanming return,
but when i use stuff chain like this
```python
doc_chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff", prompt=QA_PROMPT)
chain = ConversationalRetrievalChain(
retriever=vector_db.as_retriever(),
question_generator=question_generator,
combine_docs_chain=doc_chain
)
```
it return "This model's maximum context length is 4097 tokens, however you requested 5741 tokens (5485 in your prompt; 256 for the completion). Please reduce your prompt; or completion length"
when i use map_reduce chain
```python
doc_chain = load_qa_chain(OpenAI(temperature=0,streaming=True,callbacks=[StreamingStdOutCallbackHandler()]), chain_type="map_reduce", combine_prompt=getQaMap_reducePromot())
```
it return "Cannot stream results with multiple prompts."
how to resolve it when the context is too long
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5532/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5532/timeline | null | null | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5531 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5531/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5531/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5531/events | https://github.com/langchain-ai/langchain/issues/5531 | 1,735,113,256 | I_kwDOIPDwls5na7oo | 5,531 | Sampling parameters are ignored by vertexai | {
"login": "khallbobo",
"id": 871838,
"node_id": "MDQ6VXNlcjg3MTgzOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/871838?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/khallbobo",
"html_url": "https://github.com/khallbobo",
"followers_url": "https://api.github.com/users/khallbobo/followers",
"following_url": "https://api.github.com/users/khallbobo/following{/other_user}",
"gists_url": "https://api.github.com/users/khallbobo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/khallbobo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/khallbobo/subscriptions",
"organizations_url": "https://api.github.com/users/khallbobo/orgs",
"repos_url": "https://api.github.com/users/khallbobo/repos",
"events_url": "https://api.github.com/users/khallbobo/events{/privacy}",
"received_events_url": "https://api.github.com/users/khallbobo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-31T22:19:11" | "2023-06-05T14:06:42" | "2023-06-05T14:06:41" | CONTRIBUTOR | null | start_chat() constructs a vertextai _ChatSession and sets class variables with the parameters, but send_message() will not use those parameters if send_message is called w/o parameters. This is because send_message() has default values for the parameters which are set to global variables.
You can fix this by moving **self._default_params to the send_message() call.
https://github.com/hwchase17/langchain/blob/359fb8fa3ae0b0904dbb36f998cd2339ea0aec0f/langchain/chat_models/vertexai.py#LL122C75-L122C75 | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5531/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5531/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5530 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5530/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5530/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5530/events | https://github.com/langchain-ai/langchain/issues/5530 | 1,735,101,156 | I_kwDOIPDwls5na4rk | 5,530 | Remove Chat Models | {
"login": "dashesy",
"id": 873905,
"node_id": "MDQ6VXNlcjg3MzkwNQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/873905?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dashesy",
"html_url": "https://github.com/dashesy",
"followers_url": "https://api.github.com/users/dashesy/followers",
"following_url": "https://api.github.com/users/dashesy/following{/other_user}",
"gists_url": "https://api.github.com/users/dashesy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dashesy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dashesy/subscriptions",
"organizations_url": "https://api.github.com/users/dashesy/orgs",
"repos_url": "https://api.github.com/users/dashesy/repos",
"events_url": "https://api.github.com/users/dashesy/events{/privacy}",
"received_events_url": "https://api.github.com/users/dashesy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-31T22:08:48" | "2023-09-13T16:07:48" | "2023-09-13T16:07:47" | NONE | null | ### Feature request
Chat models relying on `SystemMessage`, ... instead of simple text, hinder creating longer prompts.
It would have been much simpler to avoid special casing chat models, and instead parse special tokens in the text prompt to separate system, human, ai, ...
### Motivation
Something similar to [this](https://github.com/microsoft/MM-REACT/blob/main/langchain/llms/openai.py#L211) that uses `<|im_start|>system\nsystem message<|im_end|>` would make it easier to keep the same code for models, and just use different prompts for chat endpints.
For example, it is perfectly valid to have 2 system messages, and I found it improves the results to have a system message at the beginning, and [one after](https://github.com/microsoft/MM-REACT/blob/main/langchain/agents/assistant/prompt.py#L191) some zero-shot examples right before the input.
### Your contribution
I can send the PR if there is any interest. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5530/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5530/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5529 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5529/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5529/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5529/events | https://github.com/langchain-ai/langchain/pull/5529 | 1,735,073,050 | PR_kwDOIPDwls5R1exn | 5,529 | [retrievers][knn] Replace loop appends with list comprehension. | {
"login": "ttsugriy",
"id": 172294,
"node_id": "MDQ6VXNlcjE3MjI5NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/172294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ttsugriy",
"html_url": "https://github.com/ttsugriy",
"followers_url": "https://api.github.com/users/ttsugriy/followers",
"following_url": "https://api.github.com/users/ttsugriy/following{/other_user}",
"gists_url": "https://api.github.com/users/ttsugriy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ttsugriy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ttsugriy/subscriptions",
"organizations_url": "https://api.github.com/users/ttsugriy/orgs",
"repos_url": "https://api.github.com/users/ttsugriy/repos",
"events_url": "https://api.github.com/users/ttsugriy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ttsugriy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T21:42:23" | "2023-05-31T23:58:09" | "2023-05-31T23:57:24" | CONTRIBUTOR | null | # Replace loop appends with list comprehension.
It's much faster, more idiomatic and slightly more readable. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5529/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5529/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5529",
"html_url": "https://github.com/langchain-ai/langchain/pull/5529",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5529.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5529.patch",
"merged_at": "2023-05-31T23:57:24"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5528 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5528/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5528/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5528/events | https://github.com/langchain-ai/langchain/pull/5528 | 1,735,068,158 | PR_kwDOIPDwls5R1dsG | 5,528 | Replace loop appends with list comprehension. | {
"login": "ttsugriy",
"id": 172294,
"node_id": "MDQ6VXNlcjE3MjI5NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/172294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ttsugriy",
"html_url": "https://github.com/ttsugriy",
"followers_url": "https://api.github.com/users/ttsugriy/followers",
"following_url": "https://api.github.com/users/ttsugriy/following{/other_user}",
"gists_url": "https://api.github.com/users/ttsugriy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ttsugriy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ttsugriy/subscriptions",
"organizations_url": "https://api.github.com/users/ttsugriy/orgs",
"repos_url": "https://api.github.com/users/ttsugriy/repos",
"events_url": "https://api.github.com/users/ttsugriy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ttsugriy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-31T21:39:08" | "2023-05-31T23:57:56" | "2023-05-31T23:56:13" | CONTRIBUTOR | null | # Replace loop appends with list comprehension.
It's significantly faster because it avoids repeated method lookup. It's also more idiomatic and readable. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5528/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5528/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5528",
"html_url": "https://github.com/langchain-ai/langchain/pull/5528",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5528.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5528.patch",
"merged_at": "2023-05-31T23:56:13"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5527 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5527/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5527/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5527/events | https://github.com/langchain-ai/langchain/pull/5527 | 1,735,052,184 | PR_kwDOIPDwls5R1aK1 | 5,527 | Replace enumerate with zip. | {
"login": "ttsugriy",
"id": 172294,
"node_id": "MDQ6VXNlcjE3MjI5NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/172294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ttsugriy",
"html_url": "https://github.com/ttsugriy",
"followers_url": "https://api.github.com/users/ttsugriy/followers",
"following_url": "https://api.github.com/users/ttsugriy/following{/other_user}",
"gists_url": "https://api.github.com/users/ttsugriy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ttsugriy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ttsugriy/subscriptions",
"organizations_url": "https://api.github.com/users/ttsugriy/orgs",
"repos_url": "https://api.github.com/users/ttsugriy/repos",
"events_url": "https://api.github.com/users/ttsugriy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ttsugriy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T21:24:24" | "2023-05-31T23:41:48" | "2023-05-31T22:02:23" | CONTRIBUTOR | null | # Replace enumerate with zip.
It's more idiomatic and slightly more readable. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5527/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5527/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5527",
"html_url": "https://github.com/langchain-ai/langchain/pull/5527",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5527.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5527.patch",
"merged_at": "2023-05-31T22:02:23"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5526 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5526/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5526/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5526/events | https://github.com/langchain-ai/langchain/pull/5526 | 1,735,048,395 | PR_kwDOIPDwls5R1ZWN | 5,526 | Replace list comprehension with generator. | {
"login": "ttsugriy",
"id": 172294,
"node_id": "MDQ6VXNlcjE3MjI5NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/172294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ttsugriy",
"html_url": "https://github.com/ttsugriy",
"followers_url": "https://api.github.com/users/ttsugriy/followers",
"following_url": "https://api.github.com/users/ttsugriy/following{/other_user}",
"gists_url": "https://api.github.com/users/ttsugriy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ttsugriy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ttsugriy/subscriptions",
"organizations_url": "https://api.github.com/users/ttsugriy/orgs",
"repos_url": "https://api.github.com/users/ttsugriy/repos",
"events_url": "https://api.github.com/users/ttsugriy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ttsugriy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-31T21:20:42" | "2023-05-31T23:42:14" | "2023-05-31T22:10:43" | CONTRIBUTOR | null | # Replace list comprehension with generator.
Since these strings can be fairly long, it's best to not construct unnecessary temporary list just to pass it to `join`. Generators produce items one-by-one and even though they are slightly more expensive than lists in terms of CPU they are much more memory-friendly and slightly more readable. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5526/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5526/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5526",
"html_url": "https://github.com/langchain-ai/langchain/pull/5526",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5526.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5526.patch",
"merged_at": "2023-05-31T22:10:43"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5525 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5525/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5525/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5525/events | https://github.com/langchain-ai/langchain/pull/5525 | 1,735,035,338 | PR_kwDOIPDwls5R1WZw | 5,525 | Add minor fixes for PySpark Document Loader Docs | {
"login": "rithwik-db",
"id": 81988348,
"node_id": "MDQ6VXNlcjgxOTg4MzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/81988348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rithwik-db",
"html_url": "https://github.com/rithwik-db",
"followers_url": "https://api.github.com/users/rithwik-db/followers",
"following_url": "https://api.github.com/users/rithwik-db/following{/other_user}",
"gists_url": "https://api.github.com/users/rithwik-db/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rithwik-db/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rithwik-db/subscriptions",
"organizations_url": "https://api.github.com/users/rithwik-db/orgs",
"repos_url": "https://api.github.com/users/rithwik-db/repos",
"events_url": "https://api.github.com/users/rithwik-db/events{/privacy}",
"received_events_url": "https://api.github.com/users/rithwik-db/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T21:11:35" | "2023-05-31T22:06:44" | "2023-05-31T22:02:57" | CONTRIBUTOR | null | # Add minor fixes for PySpark Document Loader Docs
Renamed "PySpack" to "PySpark" and executed the notebook to show outputs. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5525/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5525/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5525",
"html_url": "https://github.com/langchain-ai/langchain/pull/5525",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5525.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5525.patch",
"merged_at": "2023-05-31T22:02:57"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5524 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5524/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5524/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5524/events | https://github.com/langchain-ai/langchain/pull/5524 | 1,734,961,602 | PR_kwDOIPDwls5R1GN7 | 5,524 | docs: unstructured no longer requires installing detectron2 from source | {
"login": "MthwRobinson",
"id": 1635179,
"node_id": "MDQ6VXNlcjE2MzUxNzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1635179?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MthwRobinson",
"html_url": "https://github.com/MthwRobinson",
"followers_url": "https://api.github.com/users/MthwRobinson/followers",
"following_url": "https://api.github.com/users/MthwRobinson/following{/other_user}",
"gists_url": "https://api.github.com/users/MthwRobinson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MthwRobinson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MthwRobinson/subscriptions",
"organizations_url": "https://api.github.com/users/MthwRobinson/orgs",
"repos_url": "https://api.github.com/users/MthwRobinson/repos",
"events_url": "https://api.github.com/users/MthwRobinson/events{/privacy}",
"received_events_url": "https://api.github.com/users/MthwRobinson/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T20:24:26" | "2023-05-31T22:03:22" | "2023-05-31T22:03:21" | CONTRIBUTOR | null | # Update Unstructured docs to remove the `detectron2` install instructions
Removes `detectron2` installation instructions from the Unstructured docs because installing `detectron2` is no longer required for `unstructured>=0.7.0`. The `detectron2` model now runs using the ONNX runtime.
## Who can review?
@hwchase17
@eyurtsev | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5524/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5524/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5524",
"html_url": "https://github.com/langchain-ai/langchain/pull/5524",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5524.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5524.patch",
"merged_at": "2023-05-31T22:03:21"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5523 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5523/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5523/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5523/events | https://github.com/langchain-ai/langchain/pull/5523 | 1,734,958,845 | PR_kwDOIPDwls5R1Fnq | 5,523 | Skips creating boto client for Bedrock if passed in constructor | {
"login": "3coins",
"id": 289369,
"node_id": "MDQ6VXNlcjI4OTM2OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/289369?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/3coins",
"html_url": "https://github.com/3coins",
"followers_url": "https://api.github.com/users/3coins/followers",
"following_url": "https://api.github.com/users/3coins/following{/other_user}",
"gists_url": "https://api.github.com/users/3coins/gists{/gist_id}",
"starred_url": "https://api.github.com/users/3coins/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/3coins/subscriptions",
"organizations_url": "https://api.github.com/users/3coins/orgs",
"repos_url": "https://api.github.com/users/3coins/repos",
"events_url": "https://api.github.com/users/3coins/events{/privacy}",
"received_events_url": "https://api.github.com/users/3coins/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T20:22:01" | "2023-05-31T21:54:12" | "2023-05-31T21:54:12" | CONTRIBUTOR | null | # Skips creating boto client if passed in constructor
Current LLM and Embeddings class always creates a new boto client, even if one is passed in a constructor. This blocks certain users from passing in externally created boto clients, for example in SSO authentication.
## Who can review?
@hwchase17
@jasondotparse
@rsgrewal-aws
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5523/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5523/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5523",
"html_url": "https://github.com/langchain-ai/langchain/pull/5523",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5523.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5523.patch",
"merged_at": "2023-05-31T21:54:12"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5522 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5522/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5522/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5522/events | https://github.com/langchain-ai/langchain/issues/5522 | 1,734,953,214 | I_kwDOIPDwls5naUj- | 5,522 | Query execution with langchain LLM pipeline is happening on CPU, even if model is loaded on GPU | {
"login": "suraj-gade",
"id": 112926867,
"node_id": "U_kgDOBrsgkw",
"avatar_url": "https://avatars.githubusercontent.com/u/112926867?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/suraj-gade",
"html_url": "https://github.com/suraj-gade",
"followers_url": "https://api.github.com/users/suraj-gade/followers",
"following_url": "https://api.github.com/users/suraj-gade/following{/other_user}",
"gists_url": "https://api.github.com/users/suraj-gade/gists{/gist_id}",
"starred_url": "https://api.github.com/users/suraj-gade/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/suraj-gade/subscriptions",
"organizations_url": "https://api.github.com/users/suraj-gade/orgs",
"repos_url": "https://api.github.com/users/suraj-gade/repos",
"events_url": "https://api.github.com/users/suraj-gade/events{/privacy}",
"received_events_url": "https://api.github.com/users/suraj-gade/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-31T20:18:21" | "2023-09-21T16:08:57" | "2023-09-21T16:08:56" | NONE | null | Hi,
I am building a chatbot using LLM like fastchat-t5-3b-v1.0 and want to reduce my inference time.
I am loading the entire model on GPU, using device_map parameter, and making use of `langchain.llms.HuggingFacePipeline` agent for querying the LLM model. Also specifying the device=0 ( which is the 1st rank GPU) for hugging face pipeline as well.
I am monitoring the GPU and CPU usage throughout the entire execution, and I can see that though my model is on GPU, at the time of querying the model, it makes use of CPU.
The spike in CPU usage shows that query execution is happening on CPU.
Below is the code that I am using to do inference on Fastchat LLM.
```
from llama_index import SimpleDirectoryReader, GPTVectorStoreIndex, PromptHelper, LLMPredictor
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index import LangchainEmbedding, ServiceContext
from transformers import T5Tokenizer, T5ForConditionalGeneration
from accelerate import init_empty_weights, infer_auto_device_map
model_name = 'lmsys/fastchat-t5-3b-v1.0'
config = T5Config.from_pretrained(model_name )
with init_empty_weights():
model_layer = T5ForConditionalGeneration(config=config)
device_map = infer_auto_device_map(model_layer, max_memory={0: "12GiB",1: "12GiB", "cpu": "0GiB"}, no_split_module_classes=["T5Block"])
# the value for is : device_map = {'': 0}. i.e loading model in 1st GPU
model = T5ForConditionalGeneration.from_pretrained(model_name, torch_dtype=torch.float16, device_map=device_map, offload_folder="offload", offload_state_dict=True)
tokenizer = T5Tokenizer.from_pretrained(model_name)
from transformers import pipeline
pipe = pipeline(
"text2text-generation", model=model, tokenizer=tokenizer, device= 0,
max_length=1536, temperature=0, top_p = 1, num_beams=1, early_stopping=False
)
from langchain.llms import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=pipe)
embed_model = LangchainEmbedding(HuggingFaceEmbeddings())
# set maximum input size
max_input_size = 2048
# set number of output tokens
num_outputs = 512
# set maximum chunk overlap
max_chunk_overlap = 20
# set chunk size limit
chunk_size_limit = 300
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap)
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm_predictor=LLMPredictor(llm), prompt_helper=prompt_helper, chunk_size_limit=chunk_size_limit)
# build index
documents = SimpleDirectoryReader('data').load_data()
new_index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = new_index.as_query_engine(
response_mode='no_text',
verbose=True,
similarity_top_k=2
)
template = """
A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.
### Human: Given the context:
---
{context}
---
Answer the following question:
---
{input}
### Assistant:
"""
from langchain import LLMChain, PromptTemplate
prompt = PromptTemplate(
input_variables=["context", "input"],
template=template,
)
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
user_input= "sample query question?"
context = query_engine.query(user_input)
concatenated_context = ' '.join(map(str, [node.node.text for node in context.source_nodes]))
response = chain.run({"context": concatenated_context, "input": user_input})
```
Here the “data” folder has my full input text in pdf format, and am using the GPTVectoreStoreIndex and hugging face pipeline to build the index on that and fetch the relevant chunk to generate the prompt with context and user_input
Then using LLMChain agent from langchain library to generate the response from FastChat model as shown in the code.
Please have a look, and let me know if this is the expected behaviour.
how can I make use of GPU for query execution as well? to reduce the inference response time.
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5522/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5522/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5521 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5521/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5521/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5521/events | https://github.com/langchain-ai/langchain/issues/5521 | 1,734,829,837 | I_kwDOIPDwls5nZ2cN | 5,521 | Tracing V2 doesn't work | {
"login": "alexkreidler",
"id": 11166947,
"node_id": "MDQ6VXNlcjExMTY2OTQ3",
"avatar_url": "https://avatars.githubusercontent.com/u/11166947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexkreidler",
"html_url": "https://github.com/alexkreidler",
"followers_url": "https://api.github.com/users/alexkreidler/followers",
"following_url": "https://api.github.com/users/alexkreidler/following{/other_user}",
"gists_url": "https://api.github.com/users/alexkreidler/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexkreidler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexkreidler/subscriptions",
"organizations_url": "https://api.github.com/users/alexkreidler/orgs",
"repos_url": "https://api.github.com/users/alexkreidler/repos",
"events_url": "https://api.github.com/users/alexkreidler/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexkreidler/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T19:04:38" | "2023-09-10T16:09:29" | "2023-09-10T16:09:29" | NONE | null | ### System Info
```
$ langchain env
LangChain Environment:
library_version:0.0.184
platform:Linux-5.4.0-146-generic-x86_64-with-glibc2.31
runtime:python
runtime_version:3.11.3
```
### Who can help?
_No response_
### Information
- [x] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [X] Callbacks/Tracing
- [ ] Async
### Reproduction
Following the [tracing v2 instructions](https://python.langchain.com/en/latest/tracing/agent_with_tracing.html#beta-tracing-v2), run:
```
$ langchain plus start
WARN[0000] The "OPENAI_API_KEY" variable is not set. Defaulting to a blank string.
[+] Running 2/2
⠿ langchain-frontend Pulled 5.3s
⠿ langchain-backend Pulled 9.5s
unable to prepare context: path "frontend-react/." not found
langchain plus server is running at http://localhost. To connect locally, set the following environment variable when running your LangChain application.
LANGCHAIN_TRACING_V2=true
```
It looks like neither the `frontend-react` or `backend` folders referenced by the [`docker-compose.yaml`](https://github.com/hwchase17/langchain/blob/f72bb966f894f99c9ffc2c730be392c71d020ac8/langchain/cli/docker-compose.yaml#L14) are in the repository, thus docker won't build them. Maybe we should remove the `build:` section of the YAML when deploying to users so they simply pull the images from the Docker Hub.
### Expected behavior
It should start properly. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5521/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 1,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5521/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5519 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5519/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5519/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5519/events | https://github.com/langchain-ai/langchain/issues/5519 | 1,734,732,180 | I_kwDOIPDwls5nZemU | 5,519 | Chroma: Constructor takes wrong embedding function (document vs query) | {
"login": "jrinder42",
"id": 8828652,
"node_id": "MDQ6VXNlcjg4Mjg2NTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8828652?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jrinder42",
"html_url": "https://github.com/jrinder42",
"followers_url": "https://api.github.com/users/jrinder42/followers",
"following_url": "https://api.github.com/users/jrinder42/following{/other_user}",
"gists_url": "https://api.github.com/users/jrinder42/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jrinder42/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jrinder42/subscriptions",
"organizations_url": "https://api.github.com/users/jrinder42/orgs",
"repos_url": "https://api.github.com/users/jrinder42/repos",
"events_url": "https://api.github.com/users/jrinder42/events{/privacy}",
"received_events_url": "https://api.github.com/users/jrinder42/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-31T18:02:20" | "2023-10-18T16:07:54" | "2023-10-18T16:07:52" | NONE | null | ### System Info
Most recent version of Langchain
Python: 3.10.8
MacOS 13.4 - M1
### Who can help?
@hwchase17
@agola11
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
The Chroma constructor in the vectorstore section uses the document function when it should be the query function for embeddings. As a result, if the documents parameter is blank when using Chroma, Langchain will error out with a ValidationError. Please change line 95 to be embed_query instead of embed_documents [here](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/chroma.py) in order for this to work / be consistent with the rest of the vectorstore wrappers
### Expected behavior
Use the query function instead of the documents function for use with embeddings in Chroma | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5519/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5519/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5518 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5518/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5518/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5518/events | https://github.com/langchain-ai/langchain/pull/5518 | 1,734,692,434 | PR_kwDOIPDwls5R0Kvs | 5,518 | added DeepLearing.AI course link | {
"login": "leo-gan",
"id": 2256422,
"node_id": "MDQ6VXNlcjIyNTY0MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2256422?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leo-gan",
"html_url": "https://github.com/leo-gan",
"followers_url": "https://api.github.com/users/leo-gan/followers",
"following_url": "https://api.github.com/users/leo-gan/following{/other_user}",
"gists_url": "https://api.github.com/users/leo-gan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leo-gan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leo-gan/subscriptions",
"organizations_url": "https://api.github.com/users/leo-gan/orgs",
"repos_url": "https://api.github.com/users/leo-gan/repos",
"events_url": "https://api.github.com/users/leo-gan/events{/privacy}",
"received_events_url": "https://api.github.com/users/leo-gan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T17:39:34" | "2023-05-31T22:28:33" | "2023-05-31T21:53:15" | COLLABORATOR | null | # added DeepLearing.AI course link
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
not @hwchase17 - hehe
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5518/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5518/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5518",
"html_url": "https://github.com/langchain-ai/langchain/pull/5518",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5518.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5518.patch",
"merged_at": "2023-05-31T21:53:15"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5517 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5517/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5517/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5517/events | https://github.com/langchain-ai/langchain/pull/5517 | 1,734,656,036 | PR_kwDOIPDwls5R0Cw_ | 5,517 | Update Tracer Auth / Reduce Num Calls | {
"login": "vowelparrot",
"id": 130414180,
"node_id": "U_kgDOB8X2ZA",
"avatar_url": "https://avatars.githubusercontent.com/u/130414180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vowelparrot",
"html_url": "https://github.com/vowelparrot",
"followers_url": "https://api.github.com/users/vowelparrot/followers",
"following_url": "https://api.github.com/users/vowelparrot/following{/other_user}",
"gists_url": "https://api.github.com/users/vowelparrot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vowelparrot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vowelparrot/subscriptions",
"organizations_url": "https://api.github.com/users/vowelparrot/orgs",
"repos_url": "https://api.github.com/users/vowelparrot/repos",
"events_url": "https://api.github.com/users/vowelparrot/events{/privacy}",
"received_events_url": "https://api.github.com/users/vowelparrot/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T17:16:44" | "2023-06-02T19:13:57" | "2023-06-02T19:13:56" | CONTRIBUTOR | null | Update the session creation and calls | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5517/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5517/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5517",
"html_url": "https://github.com/langchain-ai/langchain/pull/5517",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5517.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5517.patch",
"merged_at": "2023-06-02T19:13:56"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5516 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5516/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5516/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5516/events | https://github.com/langchain-ai/langchain/pull/5516 | 1,734,602,354 | PR_kwDOIPDwls5Rz3Aw | 5,516 | Change methodology for scraping | {
"login": "Haste171",
"id": 34923485,
"node_id": "MDQ6VXNlcjM0OTIzNDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/34923485?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Haste171",
"html_url": "https://github.com/Haste171",
"followers_url": "https://api.github.com/users/Haste171/followers",
"following_url": "https://api.github.com/users/Haste171/following{/other_user}",
"gists_url": "https://api.github.com/users/Haste171/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Haste171/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Haste171/subscriptions",
"organizations_url": "https://api.github.com/users/Haste171/orgs",
"repos_url": "https://api.github.com/users/Haste171/repos",
"events_url": "https://api.github.com/users/Haste171/events{/privacy}",
"received_events_url": "https://api.github.com/users/Haste171/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5541144676,
"node_id": "LA_kwDOIPDwls8AAAABSkcoZA",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20doc%20loader",
"name": "area: doc loader",
"color": "D4C5F9",
"default": false,
"description": "Related to document loader module (not documentation)"
},
{
"id": 5680700873,
"node_id": "LA_kwDOIPDwls8AAAABUpidyQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:improvement",
"name": "auto:improvement",
"color": "FBCA04",
"default": false,
"description": "Medium size change to existing code to handle new use-cases"
}
] | closed | false | {
"login": "eyurtsev",
"id": 3205522,
"node_id": "MDQ6VXNlcjMyMDU1MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3205522?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eyurtsev",
"html_url": "https://github.com/eyurtsev",
"followers_url": "https://api.github.com/users/eyurtsev/followers",
"following_url": "https://api.github.com/users/eyurtsev/following{/other_user}",
"gists_url": "https://api.github.com/users/eyurtsev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eyurtsev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyurtsev/subscriptions",
"organizations_url": "https://api.github.com/users/eyurtsev/orgs",
"repos_url": "https://api.github.com/users/eyurtsev/repos",
"events_url": "https://api.github.com/users/eyurtsev/events{/privacy}",
"received_events_url": "https://api.github.com/users/eyurtsev/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "eyurtsev",
"id": 3205522,
"node_id": "MDQ6VXNlcjMyMDU1MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3205522?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eyurtsev",
"html_url": "https://github.com/eyurtsev",
"followers_url": "https://api.github.com/users/eyurtsev/followers",
"following_url": "https://api.github.com/users/eyurtsev/following{/other_user}",
"gists_url": "https://api.github.com/users/eyurtsev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eyurtsev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyurtsev/subscriptions",
"organizations_url": "https://api.github.com/users/eyurtsev/orgs",
"repos_url": "https://api.github.com/users/eyurtsev/repos",
"events_url": "https://api.github.com/users/eyurtsev/events{/privacy}",
"received_events_url": "https://api.github.com/users/eyurtsev/received_events",
"type": "User",
"site_admin": false
}
] | null | 7 | "2023-05-31T16:38:16" | "2023-07-24T14:58:49" | "2023-07-24T14:58:48" | CONTRIBUTOR | null | It seems that the ReadTheDocsLoader is trying to parse and clean HTML contents from specific tags in the HTML file. If the HTML file doesn't contain the exact tag, the page_content will be empty.
The loader is looking for the "main" tag with the id "main-content" and if it doesn't find it, it's looking for a "div" tag with the role "main". If neither is found, it returns an empty string.
One way to fix this issue is to adjust the tags to those present in the HTML files to be scraped.
@eyurtsev | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5516/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5516/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5516",
"html_url": "https://github.com/langchain-ai/langchain/pull/5516",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5516.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5516.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5515 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5515/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5515/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5515/events | https://github.com/langchain-ai/langchain/pull/5515 | 1,734,600,312 | PR_kwDOIPDwls5Rz2kY | 5,515 | Fix: Qdrant ids | {
"login": "kacperlukawski",
"id": 2649301,
"node_id": "MDQ6VXNlcjI2NDkzMDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kacperlukawski",
"html_url": "https://github.com/kacperlukawski",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
"gists_url": "https://api.github.com/users/kacperlukawski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kacperlukawski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kacperlukawski/subscriptions",
"organizations_url": "https://api.github.com/users/kacperlukawski/orgs",
"repos_url": "https://api.github.com/users/kacperlukawski/repos",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"received_events_url": "https://api.github.com/users/kacperlukawski/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-31T16:36:43" | "2023-06-02T15:57:35" | "2023-06-02T15:57:35" | CONTRIBUTOR | null | # Fix Qdrant ids creation
There has been a bug in how the ids were created in the Qdrant vector store. They were previously calculated based on the texts. However, there are some scenarios in which two documents may have the same piece of text but different metadata, and that's a valid case. Deduplication should be done outside of insertion.
It has been fixed and covered with the integration tests.
## Who can review?
@dev2049 @hwchase17 | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5515/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5515/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5515",
"html_url": "https://github.com/langchain-ai/langchain/pull/5515",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5515.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5515.patch",
"merged_at": "2023-06-02T15:57:35"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5514 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5514/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5514/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5514/events | https://github.com/langchain-ai/langchain/pull/5514 | 1,734,592,119 | PR_kwDOIPDwls5Rz0y- | 5,514 | Reference OpenAIEmbeddings client attr as private | {
"login": "ninjapenguin",
"id": 38786,
"node_id": "MDQ6VXNlcjM4Nzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/38786?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ninjapenguin",
"html_url": "https://github.com/ninjapenguin",
"followers_url": "https://api.github.com/users/ninjapenguin/followers",
"following_url": "https://api.github.com/users/ninjapenguin/following{/other_user}",
"gists_url": "https://api.github.com/users/ninjapenguin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ninjapenguin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ninjapenguin/subscriptions",
"organizations_url": "https://api.github.com/users/ninjapenguin/orgs",
"repos_url": "https://api.github.com/users/ninjapenguin/repos",
"events_url": "https://api.github.com/users/ninjapenguin/events{/privacy}",
"received_events_url": "https://api.github.com/users/ninjapenguin/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5541141061,
"node_id": "LA_kwDOIPDwls8AAAABSkcaRQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20embeddings",
"name": "area: embeddings",
"color": "C5DEF5",
"default": false,
"description": "Related to text embedding models module"
},
{
"id": 5680700839,
"node_id": "LA_kwDOIPDwls8AAAABUpidpw",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:bug",
"name": "auto:bug",
"color": "E99695",
"default": false,
"description": "Related to a bug, vulnerability, unexpected error with an existing feature"
}
] | closed | false | null | [] | null | 6 | "2023-05-31T16:30:40" | "2023-11-07T04:20:42" | "2023-11-07T04:20:42" | CONTRIBUTOR | null | Reference OpenAIEmbeddings client attr as private
When utilising Pylance it is currently unable to manage interpretation of the `client` attribute within `OpenAIEmbeddings` as private. This results in the following errors being displayed:

Additionally newer versions of `mypy` also identify this issue:
`tests/integration_tests/embeddings/test_openai.py:11: error: Missing named argument "client" for "OpenAIEmbeddings" [call-arg]`
One minor note is that I've include a property setter to preserve any access patterns for `OpenAIEmbeddings.client`
/cc @hwchase17 - project lead
/cc @agola11 - Models
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5514/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5514/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5514",
"html_url": "https://github.com/langchain-ai/langchain/pull/5514",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5514.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5514.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5513 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5513/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5513/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5513/events | https://github.com/langchain-ai/langchain/issues/5513 | 1,734,577,939 | I_kwDOIPDwls5nY48T | 5,513 | Flan-t5-xxl doesnot work with openapi_agent | {
"login": "kiranalii",
"id": 22620201,
"node_id": "MDQ6VXNlcjIyNjIwMjAx",
"avatar_url": "https://avatars.githubusercontent.com/u/22620201?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kiranalii",
"html_url": "https://github.com/kiranalii",
"followers_url": "https://api.github.com/users/kiranalii/followers",
"following_url": "https://api.github.com/users/kiranalii/following{/other_user}",
"gists_url": "https://api.github.com/users/kiranalii/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kiranalii/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kiranalii/subscriptions",
"organizations_url": "https://api.github.com/users/kiranalii/orgs",
"repos_url": "https://api.github.com/users/kiranalii/repos",
"events_url": "https://api.github.com/users/kiranalii/events{/privacy}",
"received_events_url": "https://api.github.com/users/kiranalii/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 5 | "2023-05-31T16:21:02" | "2023-10-19T16:07:59" | "2023-10-19T16:07:58" | NONE | null | ### Issue you'd like to raise.
I have created a pipeline. And want to use the same pipeline in openapi_agent. When I run the following command:
ibm_agent = planner.create_openapi_agent(ibm_api_spec, requests_wrapper, hf_pipeline)
I get error out of memory error. I'm using flan-t5-xxl llm, which consumes 22GB of memory. I have 18GB left.
```
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xxl")
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-xxl", torch_dtype=torch.float16, device_map="auto")
instruct_pipeline = pipeline("text2text-generation", model=model, tokenizer=tokenizer,
pad_token_id=tokenizer.eos_token_id,
torch_dtype=torch.bfloat16, device='cuda:0', max_length=2000)
hf_pipeline = HuggingFacePipeline(pipeline=instruct_pipeline)
agent = planner.create_openapi_agent(api_spec, requests_wrapper, hf_pipeline)
user_query = "query"
agent.run(user_query)
```
When i run code i get out following error
```
> Entering new AgentExecutor chain...
Action: api_planner Action Input: api_planner(query) api_planner(query) api_controller(api_planner(query))
Traceback (most recent call last):
File "/home/kiran/dolly/agents.py", line 79, in <module>
ibm_agent.run(user_query)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 236, in run
return self(args[0], callbacks=callbacks)[self.output_keys[0]]
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 140, in __call__
raise e
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 134, in __call__
self._call(inputs, run_manager=run_manager)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 953, in _call
next_step_output = self._take_next_step(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 820, in _take_next_step
observation = tool.run(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/tools/base.py", line 294, in run
raise e
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/tools/base.py", line 266, in run
self._run(*tool_args, run_manager=run_manager, **tool_kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/tools/base.py", line 409, in _run
self.func(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 236, in run
return self(args[0], callbacks=callbacks)[self.output_keys[0]]
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 140, in __call__
raise e
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 134, in __call__
self._call(inputs, run_manager=run_manager)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/llm.py", line 69, in _call
response = self.generate([inputs], run_manager=run_manager)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/chains/llm.py", line 79, in generate
return self.llm.generate_prompt(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 134, in generate_prompt
return self.generate(prompt_strings, stop=stop, callbacks=callbacks)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 191, in generate
raise e
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 185, in generate
self._generate(prompts, stop=stop, run_manager=run_manager)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 436, in _generate
self._call(prompt, stop=stop, run_manager=run_manager)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/langchain/llms/huggingface_pipeline.py", line 168, in _call
response = self.pipeline(prompt)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/pipelines/text2text_generation.py", line 165, in __call__
result = super().__call__(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1119, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1126, in run_single
model_outputs = self.forward(model_inputs, **forward_params)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1025, in forward
model_outputs = self._forward(model_inputs, **forward_params)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/pipelines/text2text_generation.py", line 187, in _forward
output_ids = self.model.generate(**model_inputs, **generate_kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/generation/utils.py", line 1322, in generate
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/generation/utils.py", line 638, in _prepare_encoder_decoder_kwargs_for_generation
model_kwargs["encoder_outputs"]: ModelOutput = encoder(**encoder_kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py", line 1086, in forward
layer_outputs = layer_module(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py", line 693, in forward
self_attention_outputs = self.layer[0](
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py", line 600, in forward
attention_output = self.SelfAttention(
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/kiran/dolly/venv/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py", line 530, in forward
scores = torch.matmul(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 28.28 GiB (GPU 0; 39.43 GiB total capacity; 25.09 GiB already allocated; 13.13 GiB free; 25.12 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5513/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5513/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5512 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5512/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5512/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5512/events | https://github.com/langchain-ai/langchain/pull/5512 | 1,734,551,787 | PR_kwDOIPDwls5Rzr9Y | 5,512 | add allow_download as class attribute for GPT4All | {
"login": "Vokturz",
"id": 21696514,
"node_id": "MDQ6VXNlcjIxNjk2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/21696514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vokturz",
"html_url": "https://github.com/Vokturz",
"followers_url": "https://api.github.com/users/Vokturz/followers",
"following_url": "https://api.github.com/users/Vokturz/following{/other_user}",
"gists_url": "https://api.github.com/users/Vokturz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vokturz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vokturz/subscriptions",
"organizations_url": "https://api.github.com/users/Vokturz/orgs",
"repos_url": "https://api.github.com/users/Vokturz/repos",
"events_url": "https://api.github.com/users/Vokturz/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vokturz/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-31T16:05:21" | "2023-05-31T20:32:32" | "2023-05-31T20:32:31" | CONTRIBUTOR | null | # Added support for download GPT4All model if does not exist
I've include the class attribute `allow_download` to the GPT4All class. By default, `allow_download` is set to False.
## Changes Made
- Added a new class attribute, `allow_download`, to the GPT4All class.
- Updated the `validate_environment` method to pass the `allow_download` parameter to the GPT4All model constructor.
## Context
This change provides more control over model downloading in the GPT4All class. Previously, if the model file was not found in the cache directory `~/.cache/gpt4all/`, the package returned error "Failed to retrieve model (type=value_error)". Now, if `allow_download` is set as True then it will use GPT4All package to download it . With the addition of the `allow_download` attribute, users can now choose whether the wrapper is allowed to download the model or not.
## Dependencies
There are no new dependencies introduced by this change. It only utilizes existing functionality provided by the GPT4All package.
## Testing
Since this is a minor change to the existing behavior, the existing test suite for the GPT4All package should cover this scenario
## Reviewers
- @hwchase17
- @agola11 | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5512/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5512/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5512",
"html_url": "https://github.com/langchain-ai/langchain/pull/5512",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5512.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5512.patch",
"merged_at": "2023-05-31T20:32:31"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5511 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5511/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5511/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5511/events | https://github.com/langchain-ai/langchain/issues/5511 | 1,734,540,520 | I_kwDOIPDwls5nYvzo | 5,511 | Automatically detect input_variables from PromptTemplate string | {
"login": "adivekar-utexas",
"id": 71379271,
"node_id": "MDQ6VXNlcjcxMzc5Mjcx",
"avatar_url": "https://avatars.githubusercontent.com/u/71379271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adivekar-utexas",
"html_url": "https://github.com/adivekar-utexas",
"followers_url": "https://api.github.com/users/adivekar-utexas/followers",
"following_url": "https://api.github.com/users/adivekar-utexas/following{/other_user}",
"gists_url": "https://api.github.com/users/adivekar-utexas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adivekar-utexas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adivekar-utexas/subscriptions",
"organizations_url": "https://api.github.com/users/adivekar-utexas/orgs",
"repos_url": "https://api.github.com/users/adivekar-utexas/repos",
"events_url": "https://api.github.com/users/adivekar-utexas/events{/privacy}",
"received_events_url": "https://api.github.com/users/adivekar-utexas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-31T15:59:04" | "2023-09-18T16:09:45" | "2023-09-18T16:09:44" | NONE | null | ### Feature request
If input_variables is not passed, try to detect them automatically as those which are surrounded by curly braces:
E.g.
```
prompt_template = PromptTemplate(template="What is the price of {product_name}?") ## Automatically detects the input_variables to be ['product_name']
```
### Motivation
This has been bugging me for a while and makes it more cumbersome.
### Your contribution
You can use the code mentioned below, it's literally that simple (at least for f-strings).
I can submit a PR.
```
def str_format_args(x: str, named_only: bool = True) -> List[str]:
## Ref: https://stackoverflow.com/a/46161774/4900327
args: List[str] = [
str(tup[1]) for tup in string.Formatter().parse(x)
if tup[1] is not None
]
if named_only:
args: List[str] = [
arg for arg in args
if not arg.isdigit() and len(arg) > 0
]
return args
str_format_args("What is the price of {product_name}?") ## Returns ['product_name']
``` | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5511/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5511/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5508 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5508/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5508/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5508/events | https://github.com/langchain-ai/langchain/issues/5508 | 1,734,515,334 | I_kwDOIPDwls5nYpqG | 5,508 | ConversationalRetrievalChain new_question only from the question_generator only for retrieval and not for combine_docs_chain | {
"login": "lucasiscovici",
"id": 15991202,
"node_id": "MDQ6VXNlcjE1OTkxMjAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15991202?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucasiscovici",
"html_url": "https://github.com/lucasiscovici",
"followers_url": "https://api.github.com/users/lucasiscovici/followers",
"following_url": "https://api.github.com/users/lucasiscovici/following{/other_user}",
"gists_url": "https://api.github.com/users/lucasiscovici/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucasiscovici/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucasiscovici/subscriptions",
"organizations_url": "https://api.github.com/users/lucasiscovici/orgs",
"repos_url": "https://api.github.com/users/lucasiscovici/repos",
"events_url": "https://api.github.com/users/lucasiscovici/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucasiscovici/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T15:43:29" | "2023-06-12T13:21:03" | "2023-06-12T13:21:03" | CONTRIBUTOR | null | ### Discussed in https://github.com/hwchase17/langchain/discussions/5499
<div type='discussions-op-text'>
<sup>Originally posted by **lucasiscovici** May 31, 2023</sup>
Hello and thank you for this amazing library.
Here we :
- get question
- get new_question with the question_generator
- retrieve docs with _get_docs and the new_question
- call the combine_docs_chain with the new_question and the docs
1/ It's possible to allow to call the question_generator event if the chat_history_str is empty ?
i have to transform the question to search query to call the search engine even if the chat history is empty
2/ It's possible to not use the new_question in the combine_docs_chain call ?
i need the true question and not the new question (the search query) to call the llm for the qa
Thanks in advance
```python
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, Any]:
_run_manager = run_manager or CallbackManagerForChainRun.get_noop_manager()
question = inputs["question"]
get_chat_history = self.get_chat_history or _get_chat_history
chat_history_str = get_chat_history(inputs["chat_history"])
if chat_history_str:
callbacks = _run_manager.get_child()
new_question = self.question_generator.run(
question=question, chat_history=chat_history_str, callbacks=callbacks
)
else:
new_question = question
docs = self._get_docs(new_question, inputs)
new_inputs = inputs.copy()
new_inputs["question"] = new_question
new_inputs["chat_history"] = chat_history_str
answer = self.combine_docs_chain.run(
input_documents=docs, callbacks=_run_manager.get_child(), **new_inputs
)
if self.return_source_documents:
return {self.output_key: answer, "source_documents": docs}
else:
return {self.output_key: answer}
``` | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5508/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5508/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5507 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5507/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5507/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5507/events | https://github.com/langchain-ai/langchain/pull/5507 | 1,734,505,271 | PR_kwDOIPDwls5Rzh01 | 5,507 | Add Managed Motorhead | {
"login": "softboyjimbo",
"id": 100361543,
"node_id": "U_kgDOBftlRw",
"avatar_url": "https://avatars.githubusercontent.com/u/100361543?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/softboyjimbo",
"html_url": "https://github.com/softboyjimbo",
"followers_url": "https://api.github.com/users/softboyjimbo/followers",
"following_url": "https://api.github.com/users/softboyjimbo/following{/other_user}",
"gists_url": "https://api.github.com/users/softboyjimbo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/softboyjimbo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/softboyjimbo/subscriptions",
"organizations_url": "https://api.github.com/users/softboyjimbo/orgs",
"repos_url": "https://api.github.com/users/softboyjimbo/repos",
"events_url": "https://api.github.com/users/softboyjimbo/events{/privacy}",
"received_events_url": "https://api.github.com/users/softboyjimbo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4899126096,
"node_id": "LA_kwDOIPDwls8AAAABJAK7UA",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20memory",
"name": "area: memory",
"color": "BFDADC",
"default": false,
"description": "Related to memory module"
},
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T15:37:27" | "2023-05-31T21:55:41" | "2023-05-31T21:55:41" | CONTRIBUTOR | null | # Add Managed Motorhead
This change enabled MotorheadMemory to utilize Metal's managed version of Motorhead. We can easily enable this by passing in a `api_key` and `client_id` in order to hit the managed url and access the memory api on Metal.
Twitter: [@softboyjimbo](https://twitter.com/softboyjimbo)
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
@dev2049 @hwchase17
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5507/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5507/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5507",
"html_url": "https://github.com/langchain-ai/langchain/pull/5507",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5507.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5507.patch",
"merged_at": "2023-05-31T21:55:41"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5506 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5506/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5506/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5506/events | https://github.com/langchain-ai/langchain/pull/5506 | 1,734,454,269 | PR_kwDOIPDwls5RzXJI | 5,506 | Add "name" parameter in Request body under messages for chat completions via OpenAI API | {
"login": "Smuglix",
"id": 102866132,
"node_id": "U_kgDOBiGc1A",
"avatar_url": "https://avatars.githubusercontent.com/u/102866132?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Smuglix",
"html_url": "https://github.com/Smuglix",
"followers_url": "https://api.github.com/users/Smuglix/followers",
"following_url": "https://api.github.com/users/Smuglix/following{/other_user}",
"gists_url": "https://api.github.com/users/Smuglix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Smuglix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Smuglix/subscriptions",
"organizations_url": "https://api.github.com/users/Smuglix/orgs",
"repos_url": "https://api.github.com/users/Smuglix/repos",
"events_url": "https://api.github.com/users/Smuglix/events{/privacy}",
"received_events_url": "https://api.github.com/users/Smuglix/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5680700873,
"node_id": "LA_kwDOIPDwls8AAAABUpidyQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:improvement",
"name": "auto:improvement",
"color": "FBCA04",
"default": false,
"description": "Medium size change to existing code to handle new use-cases"
}
] | closed | false | null | [] | null | 11 | "2023-05-31T15:09:35" | "2023-09-13T20:40:12" | "2023-09-13T20:40:11" | NONE | null | Add "name" parameter in Request body under messages for chat completions via OpenAI API
This adds "name" parameter to the request body inside "messages".
For example, when defining HumanMessage or AIMessage, there is now option to add name parameter like this:
```py
HumanMessage(content="Hello! what is my name?", name='Ilya')
```
As in OpenAI API: https://platform.openai.com/docs/api-reference/chat/create#chat/create-name

The message dictionaries look like this (of course name parameter is optional):
```py
{'role': 'system', 'content': "That's goofy conversation without rules"}
{'role': 'user', 'name': 'Spy', 'content': 'Hello! what is my name? And your name?'}
{'role': 'assistant', 'name': 'Scout', 'content': "Hi! I won't answer your question, You mad? :P "}
{'role': 'assistant', 'name': 'Heavy', 'content': "Bruh man, don't be mean"}
{'role': 'user', 'name': 'spy', 'content': 'As you wish, Scout. Off to visit your mom ヾ(•ω•`)o'}
{'role': 'system', 'content': "summarize the conversation and list it's participants"}
```
## Simple test
```py
import os
from dotenv import load_dotenv
load_dotenv()
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(model_name="gpt-4",temperature=1) # change gpt-4 to gpt-3.5-turbo if you doesn't have gpt-4 access yet
messages = [
SystemMessage(content="That's goofy conversation without rules"),
HumanMessage(content="Hello! what is my name? And your name?", name='Spy'),
AIMessage(content="Hi! I won't answer your question, You mad? :P ", name='Scout'),
AIMessage(content="Bruh man, don't be mean", name='Heavy'),
HumanMessage(content="As you wish, Scout. Off to visit your mom ヾ(•ω•`)o", name='spy'),
SystemMessage(content="summarize the conversation and list it's participants")
]
response=chat(messages)
print(response.content,end='\n')
```
Response should be smt like this:
```
Participants: User (Spy), Assistant (Scout), Assistant (Heavy)
Summary: The User initiates a goofy conversation asking about names. Assistant (Scout) responds playfully by not answering the question, then Assistant (Heavy) advises to not be mean. The User then continues with a witty remark about visiting Assistant (Scout)'s mom.
```
## Maintainers/contributors who might be interested:
Models
@hwchase17
@agola11
VectorStores / Retrievers / Memory
@dev2049
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5506/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5506/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5506",
"html_url": "https://github.com/langchain-ai/langchain/pull/5506",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5506.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5506.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5504 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5504/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5504/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5504/events | https://github.com/langchain-ai/langchain/pull/5504 | 1,734,358,887 | PR_kwDOIPDwls5RzB__ | 5,504 | bump 187 | {
"login": "dev2049",
"id": 130488702,
"node_id": "U_kgDOB8cZfg",
"avatar_url": "https://avatars.githubusercontent.com/u/130488702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev2049",
"html_url": "https://github.com/dev2049",
"followers_url": "https://api.github.com/users/dev2049/followers",
"following_url": "https://api.github.com/users/dev2049/following{/other_user}",
"gists_url": "https://api.github.com/users/dev2049/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev2049/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev2049/subscriptions",
"organizations_url": "https://api.github.com/users/dev2049/orgs",
"repos_url": "https://api.github.com/users/dev2049/repos",
"events_url": "https://api.github.com/users/dev2049/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev2049/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5010622926,
"node_id": "LA_kwDOIPDwls8AAAABKqgJzg",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/release",
"name": "release",
"color": "07D4BE",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T14:26:44" | "2023-05-31T14:35:10" | "2023-05-31T14:35:09" | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5504/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5504",
"html_url": "https://github.com/langchain-ai/langchain/pull/5504",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5504.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5504.patch",
"merged_at": "2023-05-31T14:35:09"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5503 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5503/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5503/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5503/events | https://github.com/langchain-ai/langchain/pull/5503 | 1,734,335,335 | PR_kwDOIPDwls5Ry8xh | 5,503 | add more vars to text splitter | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T14:15:22" | "2023-05-31T14:21:21" | "2023-05-31T14:21:20" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5503/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5503",
"html_url": "https://github.com/langchain-ai/langchain/pull/5503",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5503.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5503.patch",
"merged_at": "2023-05-31T14:21:20"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5502 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5502/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5502/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5502/events | https://github.com/langchain-ai/langchain/pull/5502 | 1,734,332,888 | PR_kwDOIPDwls5Ry8Pk | 5,502 | Text splitter regex | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T14:14:14" | "2023-05-31T14:21:23" | "2023-05-31T14:21:23" | COLLABORATOR | null | # Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5502/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5502",
"html_url": "https://github.com/langchain-ai/langchain/pull/5502",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5502.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5502.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5501 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5501/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5501/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5501/events | https://github.com/langchain-ai/langchain/pull/5501 | 1,734,308,967 | PR_kwDOIPDwls5Ry29T | 5,501 | Fix wrong class instantiation in docs MMR example | {
"login": "tobiasvanderwerff",
"id": 33268192,
"node_id": "MDQ6VXNlcjMzMjY4MTky",
"avatar_url": "https://avatars.githubusercontent.com/u/33268192?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tobiasvanderwerff",
"html_url": "https://github.com/tobiasvanderwerff",
"followers_url": "https://api.github.com/users/tobiasvanderwerff/followers",
"following_url": "https://api.github.com/users/tobiasvanderwerff/following{/other_user}",
"gists_url": "https://api.github.com/users/tobiasvanderwerff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tobiasvanderwerff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tobiasvanderwerff/subscriptions",
"organizations_url": "https://api.github.com/users/tobiasvanderwerff/orgs",
"repos_url": "https://api.github.com/users/tobiasvanderwerff/repos",
"events_url": "https://api.github.com/users/tobiasvanderwerff/events{/privacy}",
"received_events_url": "https://api.github.com/users/tobiasvanderwerff/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T14:03:08" | "2023-06-01T00:31:00" | "2023-06-01T00:31:00" | CONTRIBUTOR | null | # Fix wrong class instantiation in docs MMR example
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
When looking at the Maximal Marginal Relevance ExampleSelector example at https://python.langchain.com/en/latest/modules/prompts/example_selectors/examples/mmr.html, I noticed that there seems to be an error. Initially, the `MaxMarginalRelevanceExampleSelector` class is used as an `example_selector` argument to the `FewShotPromptTemplate` class. Then, according to the text, a comparison is made to regular similarity search. However, the `FewShotPromptTemplate` still uses the `MaxMarginalRelevanceExampleSelector` class, so the output is the same.
To fix it, I added an instantiation of the `SemanticSimilarityExampleSelector` class, because this seems to be what is intended.
## Who can review?
@hwchase17
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5501/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5501/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5501",
"html_url": "https://github.com/langchain-ai/langchain/pull/5501",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5501.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5501.patch",
"merged_at": "2023-06-01T00:31:00"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5500 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5500/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5500/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5500/events | https://github.com/langchain-ai/langchain/pull/5500 | 1,734,262,479 | PR_kwDOIPDwls5Ryst9 | 5,500 | Add texts with embeddings to PGVector wrapper | {
"login": "shenghann",
"id": 12733721,
"node_id": "MDQ6VXNlcjEyNzMzNzIx",
"avatar_url": "https://avatars.githubusercontent.com/u/12733721?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shenghann",
"html_url": "https://github.com/shenghann",
"followers_url": "https://api.github.com/users/shenghann/followers",
"following_url": "https://api.github.com/users/shenghann/following{/other_user}",
"gists_url": "https://api.github.com/users/shenghann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shenghann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shenghann/subscriptions",
"organizations_url": "https://api.github.com/users/shenghann/orgs",
"repos_url": "https://api.github.com/users/shenghann/repos",
"events_url": "https://api.github.com/users/shenghann/events{/privacy}",
"received_events_url": "https://api.github.com/users/shenghann/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T13:42:08" | "2023-06-01T00:31:52" | "2023-06-01T00:31:52" | CONTRIBUTOR | null | Similar to #1813 for faiss, this PR is to extend functionality to pass text and its vector pair to initialize and add embeddings to the PGVector wrapper.
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
- @dev2049
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5500/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5500/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5500",
"html_url": "https://github.com/langchain-ai/langchain/pull/5500",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5500.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5500.patch",
"merged_at": "2023-06-01T00:31:52"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5498 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5498/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5498/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5498/events | https://github.com/langchain-ai/langchain/issues/5498 | 1,734,126,410 | I_kwDOIPDwls5nXKtK | 5,498 | Tracking of time to generate text | {
"login": "dheerajiiitv",
"id": 24246192,
"node_id": "MDQ6VXNlcjI0MjQ2MTky",
"avatar_url": "https://avatars.githubusercontent.com/u/24246192?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dheerajiiitv",
"html_url": "https://github.com/dheerajiiitv",
"followers_url": "https://api.github.com/users/dheerajiiitv/followers",
"following_url": "https://api.github.com/users/dheerajiiitv/following{/other_user}",
"gists_url": "https://api.github.com/users/dheerajiiitv/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dheerajiiitv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dheerajiiitv/subscriptions",
"organizations_url": "https://api.github.com/users/dheerajiiitv/orgs",
"repos_url": "https://api.github.com/users/dheerajiiitv/repos",
"events_url": "https://api.github.com/users/dheerajiiitv/events{/privacy}",
"received_events_url": "https://api.github.com/users/dheerajiiitv/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 5 | "2023-05-31T12:33:47" | "2023-12-16T05:54:01" | "2023-10-21T16:08:50" | CONTRIBUTOR | null | ### Feature request
Hey Team,
I would like to propose a new feature that will enhance the visibility of the LLM's response time. In addition to providing information about token usage and cost, I suggest incorporating the time taken to generate the text. This additional metric will offer valuable insights into the efficiency and performance of the system.
### Motivation
By including the response time, we can provide a comprehensive picture of the different LLM's API's performance, ensuring that we have a more accurate measure of its capabilities. This information will be particularly useful for evaluating and optimizing different LLMs, as it will shed light on the latency of the system.
### Your contribution
We can easily implement this by adding additional variables in callbacks of LLM's. I would like to implement this feature.
Here the example code:
```
class BaseCallbackHandler:
"""Base callback handler that can be used to handle callbacks from langchain."""
time_take_by_llm_to_generate_text: float = 0
start_time: float = 0
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Run when LLM starts running."""
self.start_time = datetime.now()
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running."""
self.end_time = datetime.now()
self.time_take_by_llm_to_generate_text += end_time - start_time
```
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5498/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 5,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5498/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5497 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5497/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5497/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5497/events | https://github.com/langchain-ai/langchain/pull/5497 | 1,734,121,153 | PR_kwDOIPDwls5RyNkI | 5,497 | QuickFix for FinalStreamingStdOutCallbackHandler: Ignore new lines & white spaces | {
"login": "UmerHA",
"id": 40663591,
"node_id": "MDQ6VXNlcjQwNjYzNTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/40663591?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/UmerHA",
"html_url": "https://github.com/UmerHA",
"followers_url": "https://api.github.com/users/UmerHA/followers",
"following_url": "https://api.github.com/users/UmerHA/following{/other_user}",
"gists_url": "https://api.github.com/users/UmerHA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/UmerHA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/UmerHA/subscriptions",
"organizations_url": "https://api.github.com/users/UmerHA/orgs",
"repos_url": "https://api.github.com/users/UmerHA/repos",
"events_url": "https://api.github.com/users/UmerHA/events{/privacy}",
"received_events_url": "https://api.github.com/users/UmerHA/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T12:31:12" | "2023-06-04T13:32:55" | "2023-06-03T22:05:58" | CONTRIBUTOR | null | # Make FinalStreamingStdOutCallbackHandler more robust by ignoring new lines & white spaces
`FinalStreamingStdOutCallbackHandler` doesn't work out of the box with `ChatOpenAI`, as it tokenized slightly differently than `OpenAI`. The response of `OpenAI` contains the tokens `["\nFinal", " Answer", ":"]` while `ChatOpenAI` contains `["Final", " Answer", ":"]`.
This PR make `FinalStreamingStdOutCallbackHandler` more robust by ignoring new lines & white spaces when determining if the answer prefix has been reached.
Fixes #5433
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
Tracing / Callbacks
- @agola11
Twitter: [@UmerHAdil](https://twitter.com/@UmerHAdil) | Discord: RicChilligerDude#7589 | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5497/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5497/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5497",
"html_url": "https://github.com/langchain-ai/langchain/pull/5497",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5497.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5497.patch",
"merged_at": "2023-06-03T22:05:58"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5496 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5496/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5496/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5496/events | https://github.com/langchain-ai/langchain/pull/5496 | 1,734,115,502 | PR_kwDOIPDwls5RyMSe | 5,496 | simple code update | {
"login": "chenweisomebody126",
"id": 16988728,
"node_id": "MDQ6VXNlcjE2OTg4NzI4",
"avatar_url": "https://avatars.githubusercontent.com/u/16988728?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chenweisomebody126",
"html_url": "https://github.com/chenweisomebody126",
"followers_url": "https://api.github.com/users/chenweisomebody126/followers",
"following_url": "https://api.github.com/users/chenweisomebody126/following{/other_user}",
"gists_url": "https://api.github.com/users/chenweisomebody126/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chenweisomebody126/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chenweisomebody126/subscriptions",
"organizations_url": "https://api.github.com/users/chenweisomebody126/orgs",
"repos_url": "https://api.github.com/users/chenweisomebody126/repos",
"events_url": "https://api.github.com/users/chenweisomebody126/events{/privacy}",
"received_events_url": "https://api.github.com/users/chenweisomebody126/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T12:28:38" | "2023-06-11T18:52:05" | "2023-06-11T18:52:04" | CONTRIBUTOR | null | # Update the comments and python logic
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5496/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5496/timeline | null | null | true | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5496",
"html_url": "https://github.com/langchain-ai/langchain/pull/5496",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5496.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5496.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5495 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5495/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5495/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5495/events | https://github.com/langchain-ai/langchain/pull/5495 | 1,734,058,640 | PR_kwDOIPDwls5Rx_wS | 5,495 | make the elasticsearch api support version which below 8.x | {
"login": "ARSblithe212",
"id": 22144293,
"node_id": "MDQ6VXNlcjIyMTQ0Mjkz",
"avatar_url": "https://avatars.githubusercontent.com/u/22144293?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ARSblithe212",
"html_url": "https://github.com/ARSblithe212",
"followers_url": "https://api.github.com/users/ARSblithe212/followers",
"following_url": "https://api.github.com/users/ARSblithe212/following{/other_user}",
"gists_url": "https://api.github.com/users/ARSblithe212/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ARSblithe212/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ARSblithe212/subscriptions",
"organizations_url": "https://api.github.com/users/ARSblithe212/orgs",
"repos_url": "https://api.github.com/users/ARSblithe212/repos",
"events_url": "https://api.github.com/users/ARSblithe212/events{/privacy}",
"received_events_url": "https://api.github.com/users/ARSblithe212/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-05-31T11:59:00" | "2023-06-01T17:58:32" | "2023-06-01T17:58:20" | CONTRIBUTOR | null | # Your PR Title (What it does)
make the elasticsearch api support version which below 8.x
<!--
the api which create index or search in the elasticsearch below 8.x is different with 8.x. When use the es which below 8.x , it will throw error. I fix the problem
-->
@hwchase17
@dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5495/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5495/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5495",
"html_url": "https://github.com/langchain-ai/langchain/pull/5495",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5495.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5495.patch",
"merged_at": "2023-06-01T17:58:20"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5494 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5494/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5494/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5494/events | https://github.com/langchain-ai/langchain/pull/5494 | 1,733,925,749 | PR_kwDOIPDwls5Rxic8 | 5,494 | feat: support NebulaGraph DB, add NebulaGraphQAChain | {
"login": "wey-gu",
"id": 1651790,
"node_id": "MDQ6VXNlcjE2NTE3OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1651790?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wey-gu",
"html_url": "https://github.com/wey-gu",
"followers_url": "https://api.github.com/users/wey-gu/followers",
"following_url": "https://api.github.com/users/wey-gu/following{/other_user}",
"gists_url": "https://api.github.com/users/wey-gu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wey-gu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wey-gu/subscriptions",
"organizations_url": "https://api.github.com/users/wey-gu/orgs",
"repos_url": "https://api.github.com/users/wey-gu/repos",
"events_url": "https://api.github.com/users/wey-gu/events{/privacy}",
"received_events_url": "https://api.github.com/users/wey-gu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 4 | "2023-05-31T10:48:25" | "2023-06-08T06:16:56" | "2023-06-08T04:38:43" | CONTRIBUTOR | null | # feat: support NebulaGraph DB, add NebulaGraphQAChain
Bring the support of [NebulaGraph](http://github.com/vesoft-inc/nebula), the open-source distributed graph database with NebulaGraphQAChain
## Before submitting
- [x] a test for the integration - favor unit tests that do not rely on network access.
- [x] an example notebook showing its use
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
@tomasonjo
@vowelparrot
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5494/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5494/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5494",
"html_url": "https://github.com/langchain-ai/langchain/pull/5494",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5494.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5494.patch",
"merged_at": "2023-06-08T04:38:43"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5493 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5493/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5493/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5493/events | https://github.com/langchain-ai/langchain/issues/5493 | 1,733,916,668 | I_kwDOIPDwls5nWXf8 | 5,493 | Issue: LLM callback handler not printing in Docker | {
"login": "kd-leo",
"id": 126190162,
"node_id": "U_kgDOB4WCUg",
"avatar_url": "https://avatars.githubusercontent.com/u/126190162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kd-leo",
"html_url": "https://github.com/kd-leo",
"followers_url": "https://api.github.com/users/kd-leo/followers",
"following_url": "https://api.github.com/users/kd-leo/following{/other_user}",
"gists_url": "https://api.github.com/users/kd-leo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kd-leo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kd-leo/subscriptions",
"organizations_url": "https://api.github.com/users/kd-leo/orgs",
"repos_url": "https://api.github.com/users/kd-leo/repos",
"events_url": "https://api.github.com/users/kd-leo/events{/privacy}",
"received_events_url": "https://api.github.com/users/kd-leo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-31T10:43:14" | "2023-11-16T02:12:25" | "2023-09-10T16:09:34" | NONE | null | ### Issue you'd like to raise.
I have a Flask with LangChain setup in docker-compose, and I don't see LLM ChatOpenAI streaming output from CallbackHandlers in console, but everything works when I run it locally without Docker.
My CallbackHandler code (StreamingStdOutCallbackHandler also doesn't work):
```
from typing import Any
from langchain.callbacks.base import BaseCallbackHandler
class StreamingOutput(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
print(token, end="", flush=True)
```
- ChatOpenAI has streaming and verbose flags set to true
- ConversationChain has verbose flag set to True
- Flask is run with `CMD ["flask", "run", "--debug", "--with-threads"]`
I tried setting the PYTHONUNBUFFERED env variable but it didn't help - what am I doing wrong?
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5493/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5493/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5492 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5492/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5492/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5492/events | https://github.com/langchain-ai/langchain/issues/5492 | 1,733,868,611 | I_kwDOIPDwls5nWLxD | 5,492 | Can I connect to my RDBMS? | {
"login": "microyybar",
"id": 69891168,
"node_id": "MDQ6VXNlcjY5ODkxMTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/69891168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/microyybar",
"html_url": "https://github.com/microyybar",
"followers_url": "https://api.github.com/users/microyybar/followers",
"following_url": "https://api.github.com/users/microyybar/following{/other_user}",
"gists_url": "https://api.github.com/users/microyybar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/microyybar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/microyybar/subscriptions",
"organizations_url": "https://api.github.com/users/microyybar/orgs",
"repos_url": "https://api.github.com/users/microyybar/repos",
"events_url": "https://api.github.com/users/microyybar/events{/privacy}",
"received_events_url": "https://api.github.com/users/microyybar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-31T10:17:58" | "2023-09-18T16:09:50" | "2023-09-18T16:09:49" | NONE | null | Can I connect to my RDBMS?
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5492/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5492/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5490 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5490/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5490/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5490/events | https://github.com/langchain-ai/langchain/issues/5490 | 1,733,741,544 | I_kwDOIPDwls5nVsvo | 5,490 | Error while importing Langchain | {
"login": "armaandhar",
"id": 87694042,
"node_id": "MDQ6VXNlcjg3Njk0MDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/87694042?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/armaandhar",
"html_url": "https://github.com/armaandhar",
"followers_url": "https://api.github.com/users/armaandhar/followers",
"following_url": "https://api.github.com/users/armaandhar/following{/other_user}",
"gists_url": "https://api.github.com/users/armaandhar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/armaandhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/armaandhar/subscriptions",
"organizations_url": "https://api.github.com/users/armaandhar/orgs",
"repos_url": "https://api.github.com/users/armaandhar/repos",
"events_url": "https://api.github.com/users/armaandhar/events{/privacy}",
"received_events_url": "https://api.github.com/users/armaandhar/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-31T09:18:01" | "2023-09-18T16:09:56" | "2023-09-18T16:09:55" | NONE | null | ---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [6], in <cell line: 1>()
----> 1 import langchain
File ~\anaconda3\lib\site-packages\langchain\__init__.py:6, in <module>
3 from importlib import metadata
4 from typing import Optional
----> 6 from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
7 from langchain.cache import BaseCache
8 from langchain.chains import (
9 ConversationChain,
10 LLMBashChain,
(...)
18 VectorDBQAWithSourcesChain,
19 )
File ~\anaconda3\lib\site-packages\langchain\agents\__init__.py:2, in <module>
1 """Interface for agents."""
----> 2 from langchain.agents.agent import (
3 Agent,
4 AgentExecutor,
5 AgentOutputParser,
6 BaseMultiActionAgent,
7 BaseSingleActionAgent,
8 LLMSingleActionAgent,
9 )
10 from langchain.agents.agent_toolkits import (
11 create_csv_agent,
12 create_json_agent,
(...)
21 create_vectorstore_router_agent,
22 )
23 from langchain.agents.agent_types import AgentType
File ~\anaconda3\lib\site-packages\langchain\agents\agent.py:13, in <module>
10 from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
12 import yaml
---> 13 from pydantic import BaseModel, root_validator
15 from langchain.agents.agent_types import AgentType
16 from langchain.agents.tools import InvalidTool
File ~\anaconda3\lib\site-packages\pydantic\__init__.py:2, in init pydantic.__init__()
File ~\anaconda3\lib\site-packages\pydantic\dataclasses.py:48, in init pydantic.dataclasses()
File ~\anaconda3\lib\site-packages\pydantic\main.py:120, in init pydantic.main()
TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5490/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5490/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5489 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5489/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5489/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5489/events | https://github.com/langchain-ai/langchain/issues/5489 | 1,733,653,438 | I_kwDOIPDwls5nVXO- | 5,489 | the text splitter adds metadata by itself | {
"login": "etherious1804",
"id": 73232975,
"node_id": "MDQ6VXNlcjczMjMyOTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/73232975?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/etherious1804",
"html_url": "https://github.com/etherious1804",
"followers_url": "https://api.github.com/users/etherious1804/followers",
"following_url": "https://api.github.com/users/etherious1804/following{/other_user}",
"gists_url": "https://api.github.com/users/etherious1804/gists{/gist_id}",
"starred_url": "https://api.github.com/users/etherious1804/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/etherious1804/subscriptions",
"organizations_url": "https://api.github.com/users/etherious1804/orgs",
"repos_url": "https://api.github.com/users/etherious1804/repos",
"events_url": "https://api.github.com/users/etherious1804/events{/privacy}",
"received_events_url": "https://api.github.com/users/etherious1804/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-05-31T08:27:59" | "2023-11-30T16:09:16" | "2023-11-30T16:09:15" | NONE | null | ### Issue you'd like to raise.
I cant find any way to add custom metadata with the character splitter, it adds source as metadata but I cant seem to change it or define what kind of metadata I want
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5489/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5489/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5488 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5488/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5488/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5488/events | https://github.com/langchain-ai/langchain/issues/5488 | 1,733,633,884 | I_kwDOIPDwls5nVSdc | 5,488 | Connecting to Elastic vector store throws ssl error | {
"login": "naimavahab",
"id": 13636783,
"node_id": "MDQ6VXNlcjEzNjM2Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/13636783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/naimavahab",
"html_url": "https://github.com/naimavahab",
"followers_url": "https://api.github.com/users/naimavahab/followers",
"following_url": "https://api.github.com/users/naimavahab/following{/other_user}",
"gists_url": "https://api.github.com/users/naimavahab/gists{/gist_id}",
"starred_url": "https://api.github.com/users/naimavahab/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/naimavahab/subscriptions",
"organizations_url": "https://api.github.com/users/naimavahab/orgs",
"repos_url": "https://api.github.com/users/naimavahab/repos",
"events_url": "https://api.github.com/users/naimavahab/events{/privacy}",
"received_events_url": "https://api.github.com/users/naimavahab/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 5 | "2023-05-31T08:15:41" | "2023-09-26T16:06:29" | "2023-09-26T16:06:28" | NONE | null | Is there a way to pass parameters to Elasticvectorsearch to disable ssl verification. I tried to add verify_certs=False and ssl_verify=None ; but both didnt work. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5488/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5488/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5487 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5487/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5487/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5487/events | https://github.com/langchain-ai/langchain/issues/5487 | 1,733,616,462 | I_kwDOIPDwls5nVONO | 5,487 | HuggingFacePipeline is not loaded correctly | {
"login": "liangz1",
"id": 7851093,
"node_id": "MDQ6VXNlcjc4NTEwOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7851093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liangz1",
"html_url": "https://github.com/liangz1",
"followers_url": "https://api.github.com/users/liangz1/followers",
"following_url": "https://api.github.com/users/liangz1/following{/other_user}",
"gists_url": "https://api.github.com/users/liangz1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liangz1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liangz1/subscriptions",
"organizations_url": "https://api.github.com/users/liangz1/orgs",
"repos_url": "https://api.github.com/users/liangz1/repos",
"events_url": "https://api.github.com/users/liangz1/events{/privacy}",
"received_events_url": "https://api.github.com/users/liangz1/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 6 | "2023-05-31T08:05:06" | "2023-11-14T14:53:22" | null | CONTRIBUTOR | null | ### System Info
langchain==0.0.186
### Who can help?
@hwchase17
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [X] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [X] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
Running the following code snippet:
```python
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(model_id="bigscience/bloom-1b7", task="text-generation", model_kwargs={"temperature":0, "max_length":64})
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
llm_chain.save("/tmp/hfp/model.yaml")
from langchain.chains.loading import load_chain
local_loaded_model = load_chain("/tmp/hfp/model.yaml")
question = "What is electroencephalography?"
local_loaded_model.run(question)
```
Gives the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
File <command-826248432925795>:1
----> 1 local_loaded_model.run(question)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/chains/base.py:236, in Chain.run(self, callbacks, *args, **kwargs)
234 if len(args) != 1:
235 raise ValueError("`run` supports only one positional argument.")
--> 236 return self(args[0], callbacks=callbacks)[self.output_keys[0]]
238 if kwargs and not args:
239 return self(kwargs, callbacks=callbacks)[self.output_keys[0]]
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/chains/base.py:140, in Chain.__call__(self, inputs, return_only_outputs, callbacks)
138 except (KeyboardInterrupt, Exception) as e:
139 run_manager.on_chain_error(e)
--> 140 raise e
141 run_manager.on_chain_end(outputs)
142 return self.prep_outputs(inputs, outputs, return_only_outputs)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/chains/base.py:134, in Chain.__call__(self, inputs, return_only_outputs, callbacks)
128 run_manager = callback_manager.on_chain_start(
129 {"name": self.__class__.__name__},
130 inputs,
131 )
132 try:
133 outputs = (
--> 134 self._call(inputs, run_manager=run_manager)
135 if new_arg_supported
136 else self._call(inputs)
137 )
138 except (KeyboardInterrupt, Exception) as e:
139 run_manager.on_chain_error(e)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/chains/llm.py:69, in LLMChain._call(self, inputs, run_manager)
64 def _call(
65 self,
66 inputs: Dict[str, Any],
67 run_manager: Optional[CallbackManagerForChainRun] = None,
68 ) -> Dict[str, str]:
---> 69 response = self.generate([inputs], run_manager=run_manager)
70 return self.create_outputs(response)[0]
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/chains/llm.py:79, in LLMChain.generate(self, input_list, run_manager)
77 """Generate LLM result from inputs."""
78 prompts, stop = self.prep_prompts(input_list, run_manager=run_manager)
---> 79 return self.llm.generate_prompt(
80 prompts, stop, callbacks=run_manager.get_child() if run_manager else None
81 )
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/llms/base.py:134, in BaseLLM.generate_prompt(self, prompts, stop, callbacks)
127 def generate_prompt(
128 self,
129 prompts: List[PromptValue],
130 stop: Optional[List[str]] = None,
131 callbacks: Callbacks = None,
132 ) -> LLMResult:
133 prompt_strings = [p.to_string() for p in prompts]
--> 134 return self.generate(prompt_strings, stop=stop, callbacks=callbacks)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/llms/base.py:191, in BaseLLM.generate(self, prompts, stop, callbacks)
189 except (KeyboardInterrupt, Exception) as e:
190 run_manager.on_llm_error(e)
--> 191 raise e
192 run_manager.on_llm_end(output)
193 return output
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/llms/base.py:185, in BaseLLM.generate(self, prompts, stop, callbacks)
180 run_manager = callback_manager.on_llm_start(
181 {"name": self.__class__.__name__}, prompts, invocation_params=params
182 )
183 try:
184 output = (
--> 185 self._generate(prompts, stop=stop, run_manager=run_manager)
186 if new_arg_supported
187 else self._generate(prompts, stop=stop)
188 )
189 except (KeyboardInterrupt, Exception) as e:
190 run_manager.on_llm_error(e)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/llms/base.py:436, in LLM._generate(self, prompts, stop, run_manager)
433 new_arg_supported = inspect.signature(self._call).parameters.get("run_manager")
434 for prompt in prompts:
435 text = (
--> 436 self._call(prompt, stop=stop, run_manager=run_manager)
437 if new_arg_supported
438 else self._call(prompt, stop=stop)
439 )
440 generations.append([Generation(text=text)])
441 return LLMResult(generations=generations)
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-51383c0b-9b1f-48ec-a6a9-ac979dcdc755/lib/python3.10/site-packages/langchain/llms/huggingface_pipeline.py:168, in HuggingFacePipeline._call(self, prompt, stop, run_manager)
162 def _call(
163 self,
164 prompt: str,
165 stop: Optional[List[str]] = None,
166 run_manager: Optional[CallbackManagerForLLMRun] = None,
167 ) -> str:
--> 168 response = self.pipeline(prompt)
169 if self.pipeline.task == "text-generation":
170 # Text generation return includes the starter text.
171 text = response[0]["generated_text"][len(prompt) :]
TypeError: 'NoneType' object is not callable
```
### Expected behavior
`local_loaded_model.run(question)` should behave the same way as:
```python
llm_chain.run(question)
``` | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5487/timeline | null | null | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5486 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5486/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5486/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5486/events | https://github.com/langchain-ai/langchain/pull/5486 | 1,733,606,212 | PR_kwDOIPDwls5Rwcgt | 5,486 | Gfrenkel/sql columns option | {
"login": "Gil-Frenkel",
"id": 40665898,
"node_id": "MDQ6VXNlcjQwNjY1ODk4",
"avatar_url": "https://avatars.githubusercontent.com/u/40665898?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Gil-Frenkel",
"html_url": "https://github.com/Gil-Frenkel",
"followers_url": "https://api.github.com/users/Gil-Frenkel/followers",
"following_url": "https://api.github.com/users/Gil-Frenkel/following{/other_user}",
"gists_url": "https://api.github.com/users/Gil-Frenkel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Gil-Frenkel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Gil-Frenkel/subscriptions",
"organizations_url": "https://api.github.com/users/Gil-Frenkel/orgs",
"repos_url": "https://api.github.com/users/Gil-Frenkel/repos",
"events_url": "https://api.github.com/users/Gil-Frenkel/events{/privacy}",
"received_events_url": "https://api.github.com/users/Gil-Frenkel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5680700873,
"node_id": "LA_kwDOIPDwls8AAAABUpidyQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:improvement",
"name": "auto:improvement",
"color": "FBCA04",
"default": false,
"description": "Medium size change to existing code to handle new use-cases"
}
] | closed | false | null | [] | null | 5 | "2023-05-31T07:59:24" | "2023-11-07T04:21:01" | "2023-11-07T04:21:00" | NONE | null | # Add column names to SQLDatabase.run() result
Description:
Current state: SQLDatabase.run() method returns a result from the database after executing a SQL query but there is no option of adding the column names as well to the returned result.
PR offer the following solution:
Adding a argument "include_column_names_on_query" to the SQLDatabase constructor.
By default, this argument will be set to False, but when set to True, SQLDatabase.run() method will add the column names to the result (if the result is not empty).
Would love to hear some feedback!
- @hwchase17
- @vowelparrot
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5486/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5486",
"html_url": "https://github.com/langchain-ai/langchain/pull/5486",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5486.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5486.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5485 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5485/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5485/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5485/events | https://github.com/langchain-ai/langchain/pull/5485 | 1,733,598,360 | PR_kwDOIPDwls5Rwa1b | 5,485 | Add param requests_kwargs for WebBaseLoader | {
"login": "sevendark",
"id": 13547104,
"node_id": "MDQ6VXNlcjEzNTQ3MTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/13547104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sevendark",
"html_url": "https://github.com/sevendark",
"followers_url": "https://api.github.com/users/sevendark/followers",
"following_url": "https://api.github.com/users/sevendark/following{/other_user}",
"gists_url": "https://api.github.com/users/sevendark/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sevendark/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sevendark/subscriptions",
"organizations_url": "https://api.github.com/users/sevendark/orgs",
"repos_url": "https://api.github.com/users/sevendark/repos",
"events_url": "https://api.github.com/users/sevendark/events{/privacy}",
"received_events_url": "https://api.github.com/users/sevendark/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T07:54:37" | "2023-05-31T22:27:39" | "2023-05-31T22:27:39" | CONTRIBUTOR | null | # Add param `requests_kwargs` for WebBaseLoader
Fixes # (issue)
#5483
## Who can review?
@eyurtsev
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5485/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5485",
"html_url": "https://github.com/langchain-ai/langchain/pull/5485",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5485.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5485.patch",
"merged_at": "2023-05-31T22:27:39"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5484 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5484/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5484/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5484/events | https://github.com/langchain-ai/langchain/pull/5484 | 1,733,598,037 | PR_kwDOIPDwls5RwaxD | 5,484 | Adds var and class to JS separators | {
"login": "jacoblee93",
"id": 6952323,
"node_id": "MDQ6VXNlcjY5NTIzMjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6952323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jacoblee93",
"html_url": "https://github.com/jacoblee93",
"followers_url": "https://api.github.com/users/jacoblee93/followers",
"following_url": "https://api.github.com/users/jacoblee93/following{/other_user}",
"gists_url": "https://api.github.com/users/jacoblee93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jacoblee93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jacoblee93/subscriptions",
"organizations_url": "https://api.github.com/users/jacoblee93/orgs",
"repos_url": "https://api.github.com/users/jacoblee93/repos",
"events_url": "https://api.github.com/users/jacoblee93/events{/privacy}",
"received_events_url": "https://api.github.com/users/jacoblee93/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T07:54:22" | "2023-05-31T14:11:56" | "2023-05-31T14:11:56" | CONTRIBUTOR | null | # Adds var and class to JS separators
Some additional separators for text splitting on JS code. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5484/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5484",
"html_url": "https://github.com/langchain-ai/langchain/pull/5484",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5484.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5484.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5483 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5483/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5483/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5483/events | https://github.com/langchain-ai/langchain/issues/5483 | 1,733,595,290 | I_kwDOIPDwls5nVJCa | 5,483 | [SSL: CERTIFICATE_VERIFY_FAILED] while load from SitemapLoader | {
"login": "sevendark",
"id": 13547104,
"node_id": "MDQ6VXNlcjEzNTQ3MTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/13547104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sevendark",
"html_url": "https://github.com/sevendark",
"followers_url": "https://api.github.com/users/sevendark/followers",
"following_url": "https://api.github.com/users/sevendark/following{/other_user}",
"gists_url": "https://api.github.com/users/sevendark/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sevendark/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sevendark/subscriptions",
"organizations_url": "https://api.github.com/users/sevendark/orgs",
"repos_url": "https://api.github.com/users/sevendark/repos",
"events_url": "https://api.github.com/users/sevendark/events{/privacy}",
"received_events_url": "https://api.github.com/users/sevendark/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T07:52:33" | "2023-06-19T01:34:19" | "2023-06-19T01:34:19" | CONTRIBUTOR | null | ### System Info
langchain: 0.0.181
platform: windows
python: 3.11.3
### Who can help?
@eyurtsev
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
```py
site_loader = SitemapLoader(web_path="https://help.glueup.com/sitemap_index.xml")
docs = site_loader.load()
print(docs[0])
# ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1002)
```
### Expected behavior
print the frist doc | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5483/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5482 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5482/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5482/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5482/events | https://github.com/langchain-ai/langchain/pull/5482 | 1,733,595,038 | PR_kwDOIPDwls5RwaI5 | 5,482 | Add option to ignore column names in SQLDatabase.run() | {
"login": "Gil-Frenkel",
"id": 40665898,
"node_id": "MDQ6VXNlcjQwNjY1ODk4",
"avatar_url": "https://avatars.githubusercontent.com/u/40665898?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Gil-Frenkel",
"html_url": "https://github.com/Gil-Frenkel",
"followers_url": "https://api.github.com/users/Gil-Frenkel/followers",
"following_url": "https://api.github.com/users/Gil-Frenkel/following{/other_user}",
"gists_url": "https://api.github.com/users/Gil-Frenkel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Gil-Frenkel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Gil-Frenkel/subscriptions",
"organizations_url": "https://api.github.com/users/Gil-Frenkel/orgs",
"repos_url": "https://api.github.com/users/Gil-Frenkel/repos",
"events_url": "https://api.github.com/users/Gil-Frenkel/events{/privacy}",
"received_events_url": "https://api.github.com/users/Gil-Frenkel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-31T07:52:22" | "2023-05-31T07:58:48" | "2023-05-31T07:58:44" | NONE | null | # Add column names to SQLDatabase.run() result
Description:
Current state: SQLDatabase.run() method returns a result from the database after executing a SQL query but there is no option of adding the column names as well to the returned result.
PR offer the following solution:
Adding a argument "ignore_column_names_on_query" to the SQLDatabase constructor.
By default, the argument is set to True, but when set to False, SQLDatabase.run() method will add the column names to the result (if the result is not empty).
Would love to hear some feedback!
- @hwchase17
- @vowelparrot
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5482/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5482/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5482",
"html_url": "https://github.com/langchain-ai/langchain/pull/5482",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5482.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5482.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5481 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5481/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5481/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5481/events | https://github.com/langchain-ai/langchain/issues/5481 | 1,733,366,807 | I_kwDOIPDwls5nURQX | 5,481 | [Feature Request] Supoprts document loader caching | {
"login": "tddschn",
"id": 45612704,
"node_id": "MDQ6VXNlcjQ1NjEyNzA0",
"avatar_url": "https://avatars.githubusercontent.com/u/45612704?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tddschn",
"html_url": "https://github.com/tddschn",
"followers_url": "https://api.github.com/users/tddschn/followers",
"following_url": "https://api.github.com/users/tddschn/following{/other_user}",
"gists_url": "https://api.github.com/users/tddschn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tddschn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tddschn/subscriptions",
"organizations_url": "https://api.github.com/users/tddschn/orgs",
"repos_url": "https://api.github.com/users/tddschn/repos",
"events_url": "https://api.github.com/users/tddschn/events{/privacy}",
"received_events_url": "https://api.github.com/users/tddschn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-31T04:29:06" | "2023-11-14T16:08:14" | "2023-11-14T16:08:13" | NONE | null | ### Feature request
I want langchain to implement caching for document loaders in a way similar to how it caches LLM calls, like this:
```python
from langchain.cache import InMemoryCache
langchain.document_loader_cache = InMemoryCache()
```
### Motivation
Loading from certain documents with langchain document loader can be an expensive operation (for example, I implemneted a custom PDF loader using OCR that's slow, or loaders that involves network calls).
### Your contribution
If langchain would accept such a PR, I'd try to implement the logic and file a PR. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5481/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5481/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5480 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5480/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5480/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5480/events | https://github.com/langchain-ai/langchain/pull/5480 | 1,733,364,170 | PR_kwDOIPDwls5RvodF | 5,480 | code splitter docs | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T04:25:28" | "2023-05-31T15:27:38" | "2023-05-31T14:11:53" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5480/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5480/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5480",
"html_url": "https://github.com/langchain-ai/langchain/pull/5480",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5480.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5480.patch",
"merged_at": "2023-05-31T14:11:53"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5479 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5479/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5479/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5479/events | https://github.com/langchain-ai/langchain/pull/5479 | 1,733,357,904 | PR_kwDOIPDwls5RvnHw | 5,479 | Update youtube.py - Fix metadata validation error in YoutubeLoader | {
"login": "ricardoreis",
"id": 104947,
"node_id": "MDQ6VXNlcjEwNDk0Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/104947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ricardoreis",
"html_url": "https://github.com/ricardoreis",
"followers_url": "https://api.github.com/users/ricardoreis/followers",
"following_url": "https://api.github.com/users/ricardoreis/following{/other_user}",
"gists_url": "https://api.github.com/users/ricardoreis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ricardoreis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ricardoreis/subscriptions",
"organizations_url": "https://api.github.com/users/ricardoreis/orgs",
"repos_url": "https://api.github.com/users/ricardoreis/repos",
"events_url": "https://api.github.com/users/ricardoreis/events{/privacy}",
"received_events_url": "https://api.github.com/users/ricardoreis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T04:15:22" | "2023-06-03T23:56:18" | "2023-06-03T23:56:18" | CONTRIBUTOR | null | This commit addresses a ValueError occurring when the YoutubeLoader class tries to add datetime metadata from a YouTube video's publish date. The error was happening because the ChromaDB metadata validation only accepts str, int, or float data types.
In the `_get_video_info` method of the `YoutubeLoader` class, the publish date retrieved from the YouTube video was of datetime type. This commit fixes the issue by converting the datetime object to a string before adding it to the metadata dictionary.
Additionally, this commit introduces error handling in the `_get_video_info` method to ensure that all metadata fields have valid values. If a metadata field is found to be None, a default value is assigned. This prevents potential errors during metadata validation when metadata fields are None.
The file modified in this commit is youtube.py.
# Your PR Title (What it does)
<!--
Thank you for contributing to LangChain! Your PR will appear in our release under the title you set. Please make sure it highlights your valuable contribution.
Replace this with a description of the change, the issue it fixes (if applicable), and relevant context. List any dependencies required for this change.
After you're done, someone will review your PR. They may suggest improvements. If no one reviews your PR within a few days, feel free to @-mention the same people again, as notifications can get lost.
Finally, we'd love to show appreciation for your contribution - if you'd like us to shout you out on Twitter, please also include your handle!
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
<!-- If you're adding a new integration, please include:
1. a test for the integration - favor unit tests that does not rely on network access.
2. an example notebook showing its use
See contribution guidelines for more information on how to write tests, lint
etc:
https://github.com/hwchase17/langchain/blob/master/.github/CONTRIBUTING.md
-->
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5479/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5479",
"html_url": "https://github.com/langchain-ai/langchain/pull/5479",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5479.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5479.patch",
"merged_at": "2023-06-03T23:56:18"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5478 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5478/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5478/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5478/events | https://github.com/langchain-ai/langchain/pull/5478 | 1,733,347,692 | PR_kwDOIPDwls5Rvk5w | 5,478 | make BaseEntityStore inherit from BaseModel | {
"login": "aditivin",
"id": 6583444,
"node_id": "MDQ6VXNlcjY1ODM0NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6583444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aditivin",
"html_url": "https://github.com/aditivin",
"followers_url": "https://api.github.com/users/aditivin/followers",
"following_url": "https://api.github.com/users/aditivin/following{/other_user}",
"gists_url": "https://api.github.com/users/aditivin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aditivin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aditivin/subscriptions",
"organizations_url": "https://api.github.com/users/aditivin/orgs",
"repos_url": "https://api.github.com/users/aditivin/repos",
"events_url": "https://api.github.com/users/aditivin/events{/privacy}",
"received_events_url": "https://api.github.com/users/aditivin/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-31T04:02:04" | "2023-06-01T00:32:20" | "2023-06-01T00:32:20" | CONTRIBUTOR | null | # Make BaseEntityStore inherit from BaseModel
This enables initializing InMemoryEntityStore by optionally passing in a value for the store field.
## Who can review?
It's a small change so I think any of the reviewers can review, but tagging @dev2049 who seems most relevant since the change relates to Memory.
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5478/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5478/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5478",
"html_url": "https://github.com/langchain-ai/langchain/pull/5478",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5478.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5478.patch",
"merged_at": "2023-06-01T00:32:20"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5477 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5477/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5477/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5477/events | https://github.com/langchain-ai/langchain/pull/5477 | 1,733,315,349 | PR_kwDOIPDwls5RveBJ | 5,477 | move schema to a directory | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5680700892,
"node_id": "LA_kwDOIPDwls8AAAABUpid3A",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:refactor",
"name": "auto:refactor",
"color": "D4C5F9",
"default": false,
"description": "A large refactor of a feature(s) or restructuring of many files"
}
] | closed | false | null | [] | null | 1 | "2023-05-31T03:12:36" | "2023-08-11T07:26:17" | "2023-08-11T07:26:17" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5477/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5477",
"html_url": "https://github.com/langchain-ai/langchain/pull/5477",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5477.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5477.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5476 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5476/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5476/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5476/events | https://github.com/langchain-ai/langchain/issues/5476 | 1,733,300,168 | I_kwDOIPDwls5nUA_I | 5,476 | IndexError: list index out of range when use Chroma.from_documents | {
"login": "fraywang",
"id": 43070555,
"node_id": "MDQ6VXNlcjQzMDcwNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43070555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fraywang",
"html_url": "https://github.com/fraywang",
"followers_url": "https://api.github.com/users/fraywang/followers",
"following_url": "https://api.github.com/users/fraywang/following{/other_user}",
"gists_url": "https://api.github.com/users/fraywang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fraywang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fraywang/subscriptions",
"organizations_url": "https://api.github.com/users/fraywang/orgs",
"repos_url": "https://api.github.com/users/fraywang/repos",
"events_url": "https://api.github.com/users/fraywang/events{/privacy}",
"received_events_url": "https://api.github.com/users/fraywang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 9 | "2023-05-31T02:51:19" | "2023-12-14T16:08:13" | "2023-12-14T16:08:12" | NONE | null | ### System Info
Lang Chain 0.0.186
Mac OS Ventura
Python 3.10
### Who can help?
_No response_
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
why i got IndexError: list index out of range when use Chroma.from_documents
import os
from langchain.document_loaders import BiliBiliLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ["OPENAI_API_KEY"] = "***"
loader = BiliBiliLoader(["https://www.bilibili.com/video/BV18o4y137n1/"])
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=20
)
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(documents, embeddings, persist_directory="./db")
db.persist()
Traceback (most recent call last):
File "/bilibili/bilibili_embeddings.py", line 28, in <module>
db = Chroma.from_documents(documents, embeddings, persist_directory="./db")
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 422, in from_documents
return cls.from_texts(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 390, in from_texts
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 160, in add_texts
self._collection.add(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 103, in add
ids, embeddings, metadatas, documents = self._validate_embedding_set(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 354, in _validate_embedding_set
ids = validate_ids(maybe_cast_one_to_many(ids))
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/chromadb/api/types.py", line 82, in maybe_cast_one_to_many
if isinstance(target[0], (int, float)):
IndexError: list index out of range
### Expected behavior
index gen succefully in the persist_directory | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5476/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5475 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5475/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5475/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5475/events | https://github.com/langchain-ai/langchain/issues/5475 | 1,733,256,921 | I_kwDOIPDwls5nT2bZ | 5,475 | Getting only the instance of the vector store without adding text | {
"login": "rajib76",
"id": 16340036,
"node_id": "MDQ6VXNlcjE2MzQwMDM2",
"avatar_url": "https://avatars.githubusercontent.com/u/16340036?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajib76",
"html_url": "https://github.com/rajib76",
"followers_url": "https://api.github.com/users/rajib76/followers",
"following_url": "https://api.github.com/users/rajib76/following{/other_user}",
"gists_url": "https://api.github.com/users/rajib76/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajib76/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajib76/subscriptions",
"organizations_url": "https://api.github.com/users/rajib76/orgs",
"repos_url": "https://api.github.com/users/rajib76/repos",
"events_url": "https://api.github.com/users/rajib76/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajib76/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-05-31T01:56:08" | "2023-08-30T17:39:07" | "2023-08-30T17:39:07" | CONTRIBUTOR | null | ### Feature request
Hi,
Currently the from_documents method will add the embeddings and then return the instance of the store. Why don't we have a method to just return the store. This is useful when I already have a loaded vector store and I just need the instance of the store. It will be like the below code without the _store.add_texts_
```
store = cls(
connection_string=connection_string,
collection_name=collection_name,
embedding_function=embedding,
distance_strategy=distance_strategy,
pre_delete_collection=pre_delete_collection,
)
store.add_texts(texts=texts, metadatas=metadatas, ids=ids, **kwargs)
return store
```
### Motivation
This is required when I already have a loaded vector store
### Your contribution
If this change is acceptable, I can add this functionality and create a PR | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5475/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5474 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5474/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5474/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5474/events | https://github.com/langchain-ai/langchain/issues/5474 | 1,733,206,572 | I_kwDOIPDwls5nTqIs | 5,474 | llm_chain.llm.save("llm.json") # method not found | {
"login": "wunglee",
"id": 5841627,
"node_id": "MDQ6VXNlcjU4NDE2Mjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5841627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wunglee",
"html_url": "https://github.com/wunglee",
"followers_url": "https://api.github.com/users/wunglee/followers",
"following_url": "https://api.github.com/users/wunglee/following{/other_user}",
"gists_url": "https://api.github.com/users/wunglee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wunglee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wunglee/subscriptions",
"organizations_url": "https://api.github.com/users/wunglee/orgs",
"repos_url": "https://api.github.com/users/wunglee/repos",
"events_url": "https://api.github.com/users/wunglee/events{/privacy}",
"received_events_url": "https://api.github.com/users/wunglee/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-31T00:43:10" | "2023-09-10T16:09:41" | "2023-09-10T16:09:40" | NONE | null | ### System Info
llm_chain.llm.save("llm.json") # method not found
bug in .ipynb:
docs/modules/chains/generic/serialization.ipynb
### Who can help?
_No response_
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
llm_chain.llm.save("llm.json") # method not found
bug in .ipynb:
docs/modules/chains/generic/serialization.ipynb
### Expected behavior
llm_chain.llm.save("llm.json") # method not found
bug in .ipynb:
docs/modules/chains/generic/serialization.ipynb | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5474/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5473 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5473/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5473/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5473/events | https://github.com/langchain-ai/langchain/issues/5473 | 1,733,174,360 | I_kwDOIPDwls5nTiRY | 5,473 | Qdrant Document object is not behaving correct | {
"login": "jrinder42",
"id": 8828652,
"node_id": "MDQ6VXNlcjg4Mjg2NTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8828652?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jrinder42",
"html_url": "https://github.com/jrinder42",
"followers_url": "https://api.github.com/users/jrinder42/followers",
"following_url": "https://api.github.com/users/jrinder42/following{/other_user}",
"gists_url": "https://api.github.com/users/jrinder42/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jrinder42/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jrinder42/subscriptions",
"organizations_url": "https://api.github.com/users/jrinder42/orgs",
"repos_url": "https://api.github.com/users/jrinder42/repos",
"events_url": "https://api.github.com/users/jrinder42/events{/privacy}",
"received_events_url": "https://api.github.com/users/jrinder42/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-30T23:55:06" | "2023-06-01T16:00:54" | "2023-06-01T16:00:24" | NONE | null | ### System Info
Langchain Version: 0.0.186
MacOS Ventura 13.3 - M1
Python 3.10.8
### Who can help?
@hwchase17
@agola11
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [X] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
There is an error in the Qdrant Vectorstore code ([`qdrant.py`](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/qdrant.py)). Specifically, with the function `_document_from_scored_point` on line 468 of [`qdrant.py`](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/qdrant.py). The Document object is from the [`schema.py`](https://github.com/hwchase17/langchain/blob/master/langchain/schema.py) The function takes as few arguments:
page_content: str
metadata: dict = Field(default_factory=dict)
The [`qdrant.py`](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/qdrant.py) file incorrectly makes the *metadata* parameter a string instead of a dict.
This creates a few problems:
1. If the *metadata* parameter in the function `_document_from_scored_point` is passed anything but None or a key that is not in the score_point object (a.k.a. None), it will error out. This is because this variable should be a dict, which is not returned from a dictionary *get* method.
2. The *metadata_payload_key* parameter does not seem to have a purpose / does not make sense given the above context.
3. It is impossible for metadata to be returned when using the Qdrant *similarity_search* function within Langchain due to this issue.
### Expected behavior
I would like to be able to return metadata when using similarity_search with Qdrant. If you run [this](https://www.pinecone.io/learn/langchain-retrieval-augmentation/) example / focus on the vectorstore part and swap out the Pinecone work for Qdrant, there does not seem to be a way to use similarity search with metadata similar to how the example shows it. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5473/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5473/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5472 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5472/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5472/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5472/events | https://github.com/langchain-ai/langchain/issues/5472 | 1,733,121,843 | I_kwDOIPDwls5nTVcz | 5,472 | Does langchain support Oracle database as VectorStores?If yes, how to use the Oracle as VectorStore? | {
"login": "JustinZou1",
"id": 128281676,
"node_id": "U_kgDOB6VsTA",
"avatar_url": "https://avatars.githubusercontent.com/u/128281676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JustinZou1",
"html_url": "https://github.com/JustinZou1",
"followers_url": "https://api.github.com/users/JustinZou1/followers",
"following_url": "https://api.github.com/users/JustinZou1/following{/other_user}",
"gists_url": "https://api.github.com/users/JustinZou1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JustinZou1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JustinZou1/subscriptions",
"organizations_url": "https://api.github.com/users/JustinZou1/orgs",
"repos_url": "https://api.github.com/users/JustinZou1/repos",
"events_url": "https://api.github.com/users/JustinZou1/events{/privacy}",
"received_events_url": "https://api.github.com/users/JustinZou1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-30T22:45:24" | "2023-09-06T01:55:37" | "2023-09-06T01:55:37" | NONE | null | Does langchain support Oracle database as VectorStores?If yes, how to use the Oracle as VectorStore? | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5472/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5471 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5471/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5471/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5471/events | https://github.com/langchain-ai/langchain/pull/5471 | 1,733,116,731 | PR_kwDOIPDwls5Ru0og | 5,471 | Update psychicapi version | {
"login": "Ayan-Bandyopadhyay",
"id": 13636019,
"node_id": "MDQ6VXNlcjEzNjM2MDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/13636019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Ayan-Bandyopadhyay",
"html_url": "https://github.com/Ayan-Bandyopadhyay",
"followers_url": "https://api.github.com/users/Ayan-Bandyopadhyay/followers",
"following_url": "https://api.github.com/users/Ayan-Bandyopadhyay/following{/other_user}",
"gists_url": "https://api.github.com/users/Ayan-Bandyopadhyay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Ayan-Bandyopadhyay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ayan-Bandyopadhyay/subscriptions",
"organizations_url": "https://api.github.com/users/Ayan-Bandyopadhyay/orgs",
"repos_url": "https://api.github.com/users/Ayan-Bandyopadhyay/repos",
"events_url": "https://api.github.com/users/Ayan-Bandyopadhyay/events{/privacy}",
"received_events_url": "https://api.github.com/users/Ayan-Bandyopadhyay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T22:40:18" | "2023-05-30T22:55:23" | "2023-05-30T22:55:23" | CONTRIBUTOR | null | Update [psychicapi](https://pypi.org/project/psychicapi/) python package dependency to the latest version 0.5. The newest python package version addresses breaking changes in the Psychic http api.
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5471/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5471/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5471",
"html_url": "https://github.com/langchain-ai/langchain/pull/5471",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5471.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5471.patch",
"merged_at": "2023-05-30T22:55:22"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5470 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5470/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5470/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5470/events | https://github.com/langchain-ai/langchain/pull/5470 | 1,733,108,290 | PR_kwDOIPDwls5Ruy1C | 5,470 | docs `ecosystem/integrations` update 3 | {
"login": "leo-gan",
"id": 2256422,
"node_id": "MDQ6VXNlcjIyNTY0MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2256422?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leo-gan",
"html_url": "https://github.com/leo-gan",
"followers_url": "https://api.github.com/users/leo-gan/followers",
"following_url": "https://api.github.com/users/leo-gan/following{/other_user}",
"gists_url": "https://api.github.com/users/leo-gan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leo-gan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leo-gan/subscriptions",
"organizations_url": "https://api.github.com/users/leo-gan/orgs",
"repos_url": "https://api.github.com/users/leo-gan/repos",
"events_url": "https://api.github.com/users/leo-gan/events{/privacy}",
"received_events_url": "https://api.github.com/users/leo-gan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T22:30:39" | "2023-06-01T01:23:50" | "2023-06-01T00:54:05" | COLLABORATOR | null | # docs: `ecosystem_integrations` update 3
Next cycle of updating the `ecosystem/integrations`
* Added an integration `template` file
* Added missed integration files
* Fixed several document_loaders/notebooks
## Who can review?
Is it possible to assign somebody to review PRs on docs? Thanks.
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5470/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5470",
"html_url": "https://github.com/langchain-ai/langchain/pull/5470",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5470.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5470.patch",
"merged_at": "2023-06-01T00:54:05"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5469 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5469/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5469/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5469/events | https://github.com/langchain-ai/langchain/pull/5469 | 1,733,105,578 | PR_kwDOIPDwls5RuyPw | 5,469 | Harrison/compose prompt | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T22:27:09" | "2023-06-02T20:44:18" | "2023-06-02T20:44:18" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5469/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5469",
"html_url": "https://github.com/langchain-ai/langchain/pull/5469",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5469.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5469.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5468 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5468/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5468/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5468/events | https://github.com/langchain-ai/langchain/pull/5468 | 1,733,099,280 | PR_kwDOIPDwls5Ruw6M | 5,468 | Harrison/html splitter | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T22:18:58" | "2023-05-31T04:06:08" | "2023-05-31T04:06:07" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5468/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5468",
"html_url": "https://github.com/langchain-ai/langchain/pull/5468",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5468.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5468.patch",
"merged_at": "2023-05-31T04:06:07"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5467 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5467/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5467/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5467/events | https://github.com/langchain-ai/langchain/pull/5467 | 1,733,067,120 | PR_kwDOIPDwls5Rup4c | 5,467 | rfc: doc manager | {
"login": "dev2049",
"id": 130488702,
"node_id": "U_kgDOB8cZfg",
"avatar_url": "https://avatars.githubusercontent.com/u/130488702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev2049",
"html_url": "https://github.com/dev2049",
"followers_url": "https://api.github.com/users/dev2049/followers",
"following_url": "https://api.github.com/users/dev2049/following{/other_user}",
"gists_url": "https://api.github.com/users/dev2049/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev2049/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev2049/subscriptions",
"organizations_url": "https://api.github.com/users/dev2049/orgs",
"repos_url": "https://api.github.com/users/dev2049/repos",
"events_url": "https://api.github.com/users/dev2049/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev2049/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T21:52:15" | "2023-06-22T08:19:54" | "2023-06-22T08:19:54" | CONTRIBUTOR | null | scratchpad thinkin | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5467/timeline | null | null | true | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5467",
"html_url": "https://github.com/langchain-ai/langchain/pull/5467",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5467.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5467.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5466 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5466/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5466/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5466/events | https://github.com/langchain-ai/langchain/pull/5466 | 1,733,035,935 | PR_kwDOIPDwls5RujEa | 5,466 | Ability to specify credentials wihen using Google BigQuery as a data loader | {
"login": "nsheils",
"id": 5385263,
"node_id": "MDQ6VXNlcjUzODUyNjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5385263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nsheils",
"html_url": "https://github.com/nsheils",
"followers_url": "https://api.github.com/users/nsheils/followers",
"following_url": "https://api.github.com/users/nsheils/following{/other_user}",
"gists_url": "https://api.github.com/users/nsheils/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nsheils/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsheils/subscriptions",
"organizations_url": "https://api.github.com/users/nsheils/orgs",
"repos_url": "https://api.github.com/users/nsheils/repos",
"events_url": "https://api.github.com/users/nsheils/events{/privacy}",
"received_events_url": "https://api.github.com/users/nsheils/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-30T21:23:44" | "2023-05-31T11:17:06" | "2023-05-30T23:25:23" | CONTRIBUTOR | null | # Adds ability to specify credentials when using Google BigQuery as a data loader
Fixes #5465 . Adds ability to set credentials which must be of the `google.auth.credentials.Credentials` type. This argument is optional and will default to `None.
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
@eyurtsev
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5466/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5466",
"html_url": "https://github.com/langchain-ai/langchain/pull/5466",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5466.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5466.patch",
"merged_at": "2023-05-30T23:25:23"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5465 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5465/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5465/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5465/events | https://github.com/langchain-ai/langchain/issues/5465 | 1,733,027,963 | I_kwDOIPDwls5nS-h7 | 5,465 | Google BigQuery Loader doesn't take credentials | {
"login": "nsheils",
"id": 5385263,
"node_id": "MDQ6VXNlcjUzODUyNjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5385263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nsheils",
"html_url": "https://github.com/nsheils",
"followers_url": "https://api.github.com/users/nsheils/followers",
"following_url": "https://api.github.com/users/nsheils/following{/other_user}",
"gists_url": "https://api.github.com/users/nsheils/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nsheils/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nsheils/subscriptions",
"organizations_url": "https://api.github.com/users/nsheils/orgs",
"repos_url": "https://api.github.com/users/nsheils/repos",
"events_url": "https://api.github.com/users/nsheils/events{/privacy}",
"received_events_url": "https://api.github.com/users/nsheils/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T21:18:13" | "2023-05-30T23:25:25" | "2023-05-30T23:25:25" | CONTRIBUTOR | null | ### Feature request
I would like to be able to provide credentials to the bigquery.client object
### Motivation
I cannot access protected datasets without use of a service account or other credentials
### Your contribution
I will submit a PR. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5465/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5465/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5464 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5464/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5464/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5464/events | https://github.com/langchain-ai/langchain/pull/5464 | 1,733,025,389 | PR_kwDOIPDwls5RugwQ | 5,464 | Bedrock llm and embeddings | {
"login": "3coins",
"id": 289369,
"node_id": "MDQ6VXNlcjI4OTM2OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/289369?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/3coins",
"html_url": "https://github.com/3coins",
"followers_url": "https://api.github.com/users/3coins/followers",
"following_url": "https://api.github.com/users/3coins/following{/other_user}",
"gists_url": "https://api.github.com/users/3coins/gists{/gist_id}",
"starred_url": "https://api.github.com/users/3coins/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/3coins/subscriptions",
"organizations_url": "https://api.github.com/users/3coins/orgs",
"repos_url": "https://api.github.com/users/3coins/repos",
"events_url": "https://api.github.com/users/3coins/events{/privacy}",
"received_events_url": "https://api.github.com/users/3coins/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4678528817,
"node_id": "LA_kwDOIPDwls8AAAABFtyvMQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 4899415699,
"node_id": "LA_kwDOIPDwls8AAAABJAcmkw",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/llms",
"name": "llms",
"color": "7CDBB2",
"default": false,
"description": ""
},
{
"id": 5541141061,
"node_id": "LA_kwDOIPDwls8AAAABSkcaRQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20embeddings",
"name": "area: embeddings",
"color": "C5DEF5",
"default": false,
"description": "Related to text embedding models module"
}
] | closed | false | null | [] | null | 3 | "2023-05-30T21:15:40" | "2023-05-31T14:17:02" | "2023-05-31T14:17:02" | CONTRIBUTOR | null | # Bedrock LLM and Embeddings
This PR adds a new LLM and an Embeddings class for the [Bedrock](https://aws.amazon.com/bedrock) service. The PR also includes example notebooks for using the LLM class in a conversation chain and embeddings usage in creating an embedding for a query and document.
**Note**: AWS is doing a private release of the Bedrock service on 05/31/2023; users need to request access and added to an allowlist in order to start using the Bedrock models and embeddings. Please use the [Bedrock Home Page](https://aws.amazon.com/bedrock) to request access and to learn more about the models available in Bedrock.
<!-- For a quicker response, figure out the right person to tag with @
@hwchase17 - project lead
Tracing / Callbacks
- @agola11
Async
- @agola11
DataLoaders
- @eyurtsev
Models
- @hwchase17
- @agola11
Agents / Tools / Toolkits
- @vowelparrot
VectorStores / Retrievers / Memory
- @dev2049
-->
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5464/reactions",
"total_count": 10,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 10,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5464/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5464",
"html_url": "https://github.com/langchain-ai/langchain/pull/5464",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5464.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5464.patch",
"merged_at": "2023-05-31T14:17:02"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5463 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5463/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5463/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5463/events | https://github.com/langchain-ai/langchain/issues/5463 | 1,732,993,542 | I_kwDOIPDwls5nS2IG | 5,463 | Structured tools cannot properly infer function schema | {
"login": "teoh",
"id": 10181537,
"node_id": "MDQ6VXNlcjEwMTgxNTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10181537?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/teoh",
"html_url": "https://github.com/teoh",
"followers_url": "https://api.github.com/users/teoh/followers",
"following_url": "https://api.github.com/users/teoh/following{/other_user}",
"gists_url": "https://api.github.com/users/teoh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/teoh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/teoh/subscriptions",
"organizations_url": "https://api.github.com/users/teoh/orgs",
"repos_url": "https://api.github.com/users/teoh/repos",
"events_url": "https://api.github.com/users/teoh/events{/privacy}",
"received_events_url": "https://api.github.com/users/teoh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | "2023-05-30T20:51:13" | "2023-09-10T16:09:44" | "2023-09-10T16:09:44" | NONE | null | ### System Info
```
$ pip show langchain
Name: langchain
Version: 0.0.186
Summary: Building applications with LLMs through composability
Home-page: https://www.github.com/hwchase17/langchain
Author:
Author-email:
License: MIT
Location: /home/mteoh/temp_venv/venv/lib/python3.10/site-packages
Requires: PyYAML, pydantic, tenacity, dataclasses-json, numexpr, numpy, openapi-schema-pydantic, aiohttp, async-timeout, requests, SQLAlchemy
Required-by:
```
```
$ python --version
Python 3.10.2
```
### Who can help?
@vowelpa
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [ ] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [X] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
1. install langchain version 0.0.186, python version 3.10.2
2. Run the code below (I put in a file called `mwe.py`)
```python
from langchain.tools import StructuredTool
from typing import Dict
from pydantic import BaseModel
def foo(args_dict: Dict[str, str]):
return "hi there"
class FooSchema(BaseModel):
args_dict: Dict[str, str]
foo_tool = StructuredTool.from_function(
foo,
name="FooTool",
description="min working example of a bug?",
# args_schema=FooSchema # inferring this schema does not work
)
result = foo_tool.run(tool_input={
"args_dict": {"aa": "bb"}
})
print(result)
```
4. observe the error below:
```
Traceback (most recent call last):
File "/home/mteoh/temp_venv/mwe.py", line 18, in <module>
result = foo_tool.run(tool_input={
File "/home/mteoh/temp_venv/venv/lib/python3.10/site-packages/langchain/tools/base.py", line 247, in run
parsed_input = self._parse_input(tool_input)
File "/home/mteoh/temp_venv/venv/lib/python3.10/site-packages/langchain/tools/base.py", line 190, in _parse_input
result = input_args.parse_obj(tool_input)
File "pydantic/main.py", line 526, in pydantic.main.BaseModel.parse_obj
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for FooToolSchemaSchema
args_dict
str type expected (type=type_error.str)
```
### Expected behavior
We expect to see the output of `foo()` which is `"hi there"`.
You can get this result by uncommenting `args_schema=FooSchema` above. This is a problem, because this line below in `StructuredTool.from_function()` https://github.com/hwchase17/langchain/blob/58e95cd11e2c2fc31ed6551b5a2b876143d57429/langchain/tools/base.py#L469 suggests that the schema gets inferred, if not provided one. Instead, what's happening is that the tool "infers" that the arguments involve just one string, which is incorrect.
I don't mind fixing this myself. In that case, any guidance is very welcome. Thank you! | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5463/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5462 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5462/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5462/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5462/events | https://github.com/langchain-ai/langchain/issues/5462 | 1,732,984,618 | I_kwDOIPDwls5nSz8q | 5,462 | conversationalRetrievalChain - how to set the template | {
"login": "DennisPeeters",
"id": 7126132,
"node_id": "MDQ6VXNlcjcxMjYxMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7126132?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DennisPeeters",
"html_url": "https://github.com/DennisPeeters",
"followers_url": "https://api.github.com/users/DennisPeeters/followers",
"following_url": "https://api.github.com/users/DennisPeeters/following{/other_user}",
"gists_url": "https://api.github.com/users/DennisPeeters/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DennisPeeters/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DennisPeeters/subscriptions",
"organizations_url": "https://api.github.com/users/DennisPeeters/orgs",
"repos_url": "https://api.github.com/users/DennisPeeters/repos",
"events_url": "https://api.github.com/users/DennisPeeters/events{/privacy}",
"received_events_url": "https://api.github.com/users/DennisPeeters/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 8 | "2023-05-30T20:43:46" | "2023-10-25T13:25:13" | "2023-10-24T16:08:12" | NONE | null | ### Issue you'd like to raise.
I am using conversationalRetrievalChain. I cannot seem to change the system template. Any suggestion how to do this?
`retriever = vectorstore.as_retriever(search_kwargs={"k": source_amount}, qa_template=QA_PROMPT, question_generator_template=CONDENSE_PROMPT)`
`qa = ConversationalRetrievalChain.from_llm(llm=model, retriever=retriever, return_source_documents=True)`
When printing QA:
[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context'], output_parser=None, partial_variables={}, template="Use the following pieces of context to answer the users question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\n{context}", template_format='f-string', validate_template=True), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['question'],
Whatever I try, I seem to be unable to change the template "Use the following pieces of context to answer..."
### Suggestion:
_No response_ | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5462/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5462/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5461 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5461/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5461/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5461/events | https://github.com/langchain-ai/langchain/pull/5461 | 1,732,758,086 | PR_kwDOIPDwls5RtliF | 5,461 | add simple test for imports | {
"login": "hwchase17",
"id": 11986836,
"node_id": "MDQ6VXNlcjExOTg2ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/11986836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwchase17",
"html_url": "https://github.com/hwchase17",
"followers_url": "https://api.github.com/users/hwchase17/followers",
"following_url": "https://api.github.com/users/hwchase17/following{/other_user}",
"gists_url": "https://api.github.com/users/hwchase17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwchase17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwchase17/subscriptions",
"organizations_url": "https://api.github.com/users/hwchase17/orgs",
"repos_url": "https://api.github.com/users/hwchase17/repos",
"events_url": "https://api.github.com/users/hwchase17/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwchase17/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-30T18:25:18" | "2023-05-30T23:24:28" | "2023-05-30T23:24:27" | COLLABORATOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5461/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5461/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5461",
"html_url": "https://github.com/langchain-ai/langchain/pull/5461",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5461.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5461.patch",
"merged_at": "2023-05-30T23:24:27"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5460 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5460/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5460/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5460/events | https://github.com/langchain-ai/langchain/pull/5460 | 1,732,724,426 | PR_kwDOIPDwls5RteQy | 5,460 | Brute force web research | {
"login": "eyurtsev",
"id": 3205522,
"node_id": "MDQ6VXNlcjMyMDU1MjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3205522?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eyurtsev",
"html_url": "https://github.com/eyurtsev",
"followers_url": "https://api.github.com/users/eyurtsev/followers",
"following_url": "https://api.github.com/users/eyurtsev/following{/other_user}",
"gists_url": "https://api.github.com/users/eyurtsev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eyurtsev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyurtsev/subscriptions",
"organizations_url": "https://api.github.com/users/eyurtsev/orgs",
"repos_url": "https://api.github.com/users/eyurtsev/repos",
"events_url": "https://api.github.com/users/eyurtsev/events{/privacy}",
"received_events_url": "https://api.github.com/users/eyurtsev/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5541144676,
"node_id": "LA_kwDOIPDwls8AAAABSkcoZA",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20doc%20loader",
"name": "area: doc loader",
"color": "D4C5F9",
"default": false,
"description": "Related to document loader module (not documentation)"
},
{
"id": 5680700863,
"node_id": "LA_kwDOIPDwls8AAAABUpidvw",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:enhancement",
"name": "auto:enhancement",
"color": "C2E0C6",
"default": false,
"description": "A large net-new component, integration, or chain. Use sparingly. The largest features"
}
] | closed | false | null | [] | null | 3 | "2023-05-30T18:00:01" | "2023-08-11T18:48:14" | "2023-08-11T18:48:13" | COLLABORATOR | null | # Research Chain
This is an experimental research chain that tries to answer "researchy" questions using information on the web.
For example,
```
Compile information about Albert Einstein.
Ignore if it's a different Albert Einstein.
Only include information you're certain about.
Include:
* education history
* major contributions
* names of spouse
* date of birth
* place of birth
* a 3 sentence short biography
Format your answer in a bullet point format for each sub-question.
```
Or replace `Albert Einstein` with another person of interest (e.g., John Smith of Boston).
The chain is composed of the following components:
1. A searcher that searches for documents using a search engine.
- The searcher is responsible to return a list of URLs of documents that
may be relevant to read to be able to answer the question.
2. A downloader that downloads the documents.
3. An HTML to markdown parser (hard coded) that converts the HTML to markdown.
* Conversion to markdown is lossy
* However, it can significantly reduce the token count of the document
* Markdown helps to preserve some styling information
(e.g., bold, italics, links, headers) which is expected to help the reader
to answer certain kinds of questions correctly.
4. A reader that reads the documents and produces an answer.
## Limitations
* Quality of results depends on LLM used, and can be improved by providing more specialized parsers (e.g., parse only the body of articles).
* If asking about people, provide enough information to disambiguate the person.
* Content downloader may get blocked (e.g., if attempting to download from linkedin) -- may need to read terms of service / user agents appropriately.
* Chain can be potentially long running (use initialization parameters to control how many options are explored) -- use async implementation as it uses more concurrency.
* This research chain only implements a single hop at the moment; i.e.,
it goes from the questions to a list of URLs to documents to compiling answers.
Without continuing the crawl, web-sites that require pagination will not be explored fully.
* The reader chain must match the type of question. For example, the QA refine chain
isn't good at extracting a list of entries from a long document.
## Extending
* Continue crawling documents to discover more relevant pages that were not surfaced by the search engine.
* Adapt reading strategy based on nature of question.
* Analyze the query and determine whether the query is a multi-hop query and change search/crawling strategy based on that.
* Break components into tools that can be exposed to an agent. :)
* Add cheaper strategies for selecting which links should be explored further (e.g., based on tf-idf similarity instead of gpt-4)
* Add a summarization chain on top of the individually collected answers.
* Improve strategy to ignore irrelevant information. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5460/timeline | null | null | true | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5460",
"html_url": "https://github.com/langchain-ai/langchain/pull/5460",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5460.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5460.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5459 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5459/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5459/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5459/events | https://github.com/langchain-ai/langchain/pull/5459 | 1,732,700,530 | PR_kwDOIPDwls5RtZH4 | 5,459 | bump 186 | {
"login": "dev2049",
"id": 130488702,
"node_id": "U_kgDOB8cZfg",
"avatar_url": "https://avatars.githubusercontent.com/u/130488702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev2049",
"html_url": "https://github.com/dev2049",
"followers_url": "https://api.github.com/users/dev2049/followers",
"following_url": "https://api.github.com/users/dev2049/following{/other_user}",
"gists_url": "https://api.github.com/users/dev2049/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev2049/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev2049/subscriptions",
"organizations_url": "https://api.github.com/users/dev2049/orgs",
"repos_url": "https://api.github.com/users/dev2049/repos",
"events_url": "https://api.github.com/users/dev2049/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev2049/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5010622926,
"node_id": "LA_kwDOIPDwls8AAAABKqgJzg",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/release",
"name": "release",
"color": "07D4BE",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 0 | "2023-05-30T17:42:54" | "2023-05-30T17:48:00" | "2023-05-30T17:48:00" | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5459/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5459/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5459",
"html_url": "https://github.com/langchain-ai/langchain/pull/5459",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5459.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5459.patch",
"merged_at": "2023-05-30T17:48:00"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5458 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5458/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5458/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5458/events | https://github.com/langchain-ai/langchain/issues/5458 | 1,732,692,820 | I_kwDOIPDwls5nRstU | 5,458 | similarity_score_threshold NotImplementedError | {
"login": "Kevin-McIsaac",
"id": 16606323,
"node_id": "MDQ6VXNlcjE2NjA2MzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/16606323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Kevin-McIsaac",
"html_url": "https://github.com/Kevin-McIsaac",
"followers_url": "https://api.github.com/users/Kevin-McIsaac/followers",
"following_url": "https://api.github.com/users/Kevin-McIsaac/following{/other_user}",
"gists_url": "https://api.github.com/users/Kevin-McIsaac/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Kevin-McIsaac/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Kevin-McIsaac/subscriptions",
"organizations_url": "https://api.github.com/users/Kevin-McIsaac/orgs",
"repos_url": "https://api.github.com/users/Kevin-McIsaac/repos",
"events_url": "https://api.github.com/users/Kevin-McIsaac/events{/privacy}",
"received_events_url": "https://api.github.com/users/Kevin-McIsaac/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-30T17:36:59" | "2023-10-26T16:07:38" | "2023-10-26T16:07:38" | NONE | null | ### System Info
Langchain 0.0.184
Python 3.9.2
### Who can help?
@hwchase17
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] Output Parsers
- [ ] Document Loaders
- [X] Vector Stores / Retrievers
- [ ] Memory
- [ ] Agents / Agent Executors
- [ ] Tools / Toolkits
- [ ] Chains
- [ ] Callbacks/Tracing
- [ ] Async
### Reproduction
I'm using as_retriever in a RetrievalQA with Pinecone as the vector store. If i use search_type="similarity_score_threshold" code below works. If I change this to `similarity_score_threshold` and set a `score_threshold`, then when I run the qa I get NotImplementedError:
The code looks like this
```python
db = Pinecone.from_existing_index(index_name=os.environ.get('INDEX'),
namespace='SCA_H5',
embedding=OpenAIEmbeddings())
retriever=db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={"k":3, "score_threshold":0.5})
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0), # uses 'gpt-3.5-turbo' which is cheaper and better
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
```
The python Traceback is
```python
NotImplementedError Traceback (most recent call last)
Cell In[4], line 1
----> 1 result = Simon("What does the legisltation cover", sources=True, content=False)
Cell In[3], line 26, in Simon(query, sources, content)
21 def Simon(query, sources=True, content=False):
23 instructions = '''You are an expert in Western Australia "Strata Titles Act"
24 answering questions from a citizen. Only use information provided to you from the
25 legislation below. If you do not know say "I do not know"'''
---> 26 result = qa({"query": f'{instructions} \n\n {query}'})
27 process_llm_response(result, sources=sources, content=content)
28 return (result)
File [~/Projects/Personal/SCAWA/.venv/lib/python3.9/site-packages/langchain/chains/base.py:140](https://file+.vscode-resource.vscode-cdn.net/home/kmcisaac/Projects/Personal/SCAWA/~/Projects/Personal/SCAWA/.venv/lib/python3.9/site-packages/langchain/chains/base.py:140), in Chain.__call__(self, inputs, return_only_outputs, callbacks)
138 except (KeyboardInterrupt, Exception) as e:
139 run_manager.on_chain_error(e)
--> 140 raise e
141 run_manager.on_chain_end(outputs)
142 return self.prep_outputs(inputs, outputs, return_only_outputs)
File [~/Projects/Personal/SCAWA/.venv/lib/python3.9/site-packages/langchain/chains/base.py:134](https://file+.vscode-resource.vscode-cdn.net/home/kmcisaac/Projects/Personal/SCAWA/~/Projects/Personal/SCAWA/.venv/lib/python3.9/site-packages/langchain/chains/base.py:134), in Chain.__call__(self, inputs, return_only_outputs, callbacks)
128 run_manager = callback_manager.on_chain_start(
129 {"name": self.__class__.__name__},
130 inputs,
...
165 0 is dissimilar, 1 is most similar.
166 """
--> 167 raise NotImplementedError
```
### Expected behavior
The qa call does not fail. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5458/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/langchain-ai/langchain/issues/5458/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5457 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5457/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5457/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5457/events | https://github.com/langchain-ai/langchain/pull/5457 | 1,732,666,648 | PR_kwDOIPDwls5RtRyF | 5,457 | fix | {
"login": "dev2049",
"id": 130488702,
"node_id": "U_kgDOB8cZfg",
"avatar_url": "https://avatars.githubusercontent.com/u/130488702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dev2049",
"html_url": "https://github.com/dev2049",
"followers_url": "https://api.github.com/users/dev2049/followers",
"following_url": "https://api.github.com/users/dev2049/following{/other_user}",
"gists_url": "https://api.github.com/users/dev2049/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dev2049/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dev2049/subscriptions",
"organizations_url": "https://api.github.com/users/dev2049/orgs",
"repos_url": "https://api.github.com/users/dev2049/repos",
"events_url": "https://api.github.com/users/dev2049/events{/privacy}",
"received_events_url": "https://api.github.com/users/dev2049/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | "2023-05-30T17:17:17" | "2023-05-30T17:42:21" | "2023-05-30T17:42:21" | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5457/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5457",
"html_url": "https://github.com/langchain-ai/langchain/pull/5457",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5457.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5457.patch",
"merged_at": "2023-05-30T17:42:20"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5456 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5456/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5456/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5456/events | https://github.com/langchain-ai/langchain/issues/5456 | 1,732,655,629 | I_kwDOIPDwls5nRjoN | 5,456 | Tools: Inconsistent callbacks/run_manager parameter | {
"login": "aledelunap",
"id": 54540938,
"node_id": "MDQ6VXNlcjU0NTQwOTM4",
"avatar_url": "https://avatars.githubusercontent.com/u/54540938?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aledelunap",
"html_url": "https://github.com/aledelunap",
"followers_url": "https://api.github.com/users/aledelunap/followers",
"following_url": "https://api.github.com/users/aledelunap/following{/other_user}",
"gists_url": "https://api.github.com/users/aledelunap/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aledelunap/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aledelunap/subscriptions",
"organizations_url": "https://api.github.com/users/aledelunap/orgs",
"repos_url": "https://api.github.com/users/aledelunap/repos",
"events_url": "https://api.github.com/users/aledelunap/events{/privacy}",
"received_events_url": "https://api.github.com/users/aledelunap/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "vowelparrot",
"id": 130414180,
"node_id": "U_kgDOB8X2ZA",
"avatar_url": "https://avatars.githubusercontent.com/u/130414180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vowelparrot",
"html_url": "https://github.com/vowelparrot",
"followers_url": "https://api.github.com/users/vowelparrot/followers",
"following_url": "https://api.github.com/users/vowelparrot/following{/other_user}",
"gists_url": "https://api.github.com/users/vowelparrot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vowelparrot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vowelparrot/subscriptions",
"organizations_url": "https://api.github.com/users/vowelparrot/orgs",
"repos_url": "https://api.github.com/users/vowelparrot/repos",
"events_url": "https://api.github.com/users/vowelparrot/events{/privacy}",
"received_events_url": "https://api.github.com/users/vowelparrot/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "vowelparrot",
"id": 130414180,
"node_id": "U_kgDOB8X2ZA",
"avatar_url": "https://avatars.githubusercontent.com/u/130414180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vowelparrot",
"html_url": "https://github.com/vowelparrot",
"followers_url": "https://api.github.com/users/vowelparrot/followers",
"following_url": "https://api.github.com/users/vowelparrot/following{/other_user}",
"gists_url": "https://api.github.com/users/vowelparrot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vowelparrot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vowelparrot/subscriptions",
"organizations_url": "https://api.github.com/users/vowelparrot/orgs",
"repos_url": "https://api.github.com/users/vowelparrot/repos",
"events_url": "https://api.github.com/users/vowelparrot/events{/privacy}",
"received_events_url": "https://api.github.com/users/vowelparrot/received_events",
"type": "User",
"site_admin": false
}
] | null | 4 | "2023-05-30T17:09:02" | "2023-06-23T08:48:28" | "2023-06-23T08:48:28" | CONTRIBUTOR | null | ### System Info
MacOS Ventura 13.3.1 (a)
python = "^3.9"
langchain = "0.0.185"
### Who can help?
@agola11 @vowelparrot
### Related Components
- Agents / Agent Executors
- Tools / Toolkits
- Callbacks/Tracing
### Reproduction
I want to use the CallbackManager to save some info within a tool. So, as per the [`create_schema_from_function`](https://github.com/hwchase17/langchain/blob/64b4165c8d9b8374295d4629ef57d4d58e9af7c8/langchain/tools/base.py#L99) that is used to create the tool schema, I define the function as:
```python
def get_list_of_products(
self, profile_description: str, run_manager: CallbackManagerForToolRun
):
```
Nonetheless, once the tool is run the[ expected parameter](https://github.com/hwchase17/langchain/blob/64b4165c8d9b8374295d4629ef57d4d58e9af7c8/langchain/tools/base.py#L493) in the function's signature is `callbacks`,
```python
new_argument_supported = signature(self.func).parameters.get("callbacks")
```
So the tool can't run, with the error being:
```bash
TypeError: get_list_of_products() missing 1 required positional argument: 'run_manager'
```
This behavior applies to Structured tool and Tool.
### Expected behavior
Either the expected function parameter is set to `run_manager` to replicate the behavior of the [`run` function](https://github.com/hwchase17/langchain/blob/64b4165c8d9b8374295d4629ef57d4d58e9af7c8/langchain/tools/base.py#L256) from the `BaseTool` or a different function is used instead of [`create_schema_from_function`](https://github.com/hwchase17/langchain/blob/64b4165c8d9b8374295d4629ef57d4d58e9af7c8/langchain/tools/base.py#L99) to create a tool's schema expecting the `callbacks` parameter. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5456/timeline | null | completed | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5455 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5455/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5455/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5455/events | https://github.com/langchain-ai/langchain/issues/5455 | 1,732,654,338 | I_kwDOIPDwls5nRjUC | 5,455 | DOC: Return Source Documents to Vectorstore Agent | {
"login": "djpecot",
"id": 8185181,
"node_id": "MDQ6VXNlcjgxODUxODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8185181?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/djpecot",
"html_url": "https://github.com/djpecot",
"followers_url": "https://api.github.com/users/djpecot/followers",
"following_url": "https://api.github.com/users/djpecot/following{/other_user}",
"gists_url": "https://api.github.com/users/djpecot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/djpecot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/djpecot/subscriptions",
"organizations_url": "https://api.github.com/users/djpecot/orgs",
"repos_url": "https://api.github.com/users/djpecot/repos",
"events_url": "https://api.github.com/users/djpecot/events{/privacy}",
"received_events_url": "https://api.github.com/users/djpecot/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-30T17:07:58" | "2023-09-15T16:09:32" | "2023-09-15T16:09:31" | NONE | null | ### Issue with current documentation:
Unable to recreate return source documents from prompt in the current [Vectorstore Agent Documentation](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/vectorstore.html). I tried adding `return_source_documents=True` to my `create_vectorstore_agent` (as discussed [here](https://github.com/hwchase17/langchain/issues/4562)) method and explicitly asking for the source document:
`agent_executor.run("What did biden say about ketanji brown jackson is the state of the union address? Show me the source document")`
But this only returns the content of the `answer`, i.e.
```
{
"answer":"message returned here.\n",
"sources":"13421341235123"
}
```
### Idea or request for content:
Would like either a way to link to a custom output parser / memory for this use case ([memory does seem to work out of the box](https://python.langchain.com/en/latest/modules/agents/agent_executors/examples/sharedmemory_for_tools.html)) or a demo of how to configure the underlying tools to force output to string or something. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5455/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 4
} | https://api.github.com/repos/langchain-ai/langchain/issues/5455/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5454 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5454/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5454/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5454/events | https://github.com/langchain-ai/langchain/issues/5454 | 1,732,652,179 | I_kwDOIPDwls5nRiyT | 5,454 | Cannot build a file agent | {
"login": "Undertone0809",
"id": 72488598,
"node_id": "MDQ6VXNlcjcyNDg4NTk4",
"avatar_url": "https://avatars.githubusercontent.com/u/72488598?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Undertone0809",
"html_url": "https://github.com/Undertone0809",
"followers_url": "https://api.github.com/users/Undertone0809/followers",
"following_url": "https://api.github.com/users/Undertone0809/following{/other_user}",
"gists_url": "https://api.github.com/users/Undertone0809/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Undertone0809/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Undertone0809/subscriptions",
"organizations_url": "https://api.github.com/users/Undertone0809/orgs",
"repos_url": "https://api.github.com/users/Undertone0809/repos",
"events_url": "https://api.github.com/users/Undertone0809/events{/privacy}",
"received_events_url": "https://api.github.com/users/Undertone0809/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 5 | "2023-05-30T17:06:27" | "2023-12-09T16:06:21" | "2023-12-09T16:06:20" | CONTRIBUTOR | null | ### Issue you'd like to raise.
As we know, we can build a agent with tool by following way:
```python
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
```
We can also use `FileManagementToolKit` to manage the file system. But I want to know, how to build a agent of file management of file system. `Langchain` still not provide agent for file management. So I want to know how to build agent with file system. I tried to use `load_tools` as follows, but failed. `FileManagementToolKit` can not be imported to `load_tools()` because `load_tools` does not provider file-related options.
```python
import os
from langchain.agents.agent_toolkits import FileManagementToolkit
from tempfile import TemporaryDirectory
from langchain.agents import load_tools
working_directory = TemporaryDirectory(dir=os.getcwd())
toolkit = FileManagementToolkit(root_dir=str(working_directory.name))
tool_names = list(map(lambda item: item.name,toolkit.get_tools()))
tools = load_tools(tool_names)
```
```
ValueError Traceback (most recent call last)
Cell In[27], line 3
1 from langchain.agents import load_tools
2 tool_names = list(map(lambda item: item.name,toolkit.get_tools()))
----> 3 tools = load_tools(tool_names)
File E:\Programming\anaconda\lib\site-packages\langchain\agents\load_tools.py:341, in load_tools(tool_names, llm, callback_manager, **kwargs)
339 tools.append(tool)
340 else:
--> 341 raise ValueError(f"Got unknown tool {name}")
342 return tools
ValueError: Got unknown tool copy_file
```
the tools of `FileManagementToolkit`:
```python
list(map(lambda item: item.name,toolkit.get_tools()))
```
```
['copy_file',
'file_delete',
'file_search',
'move_file',
'read_file',
'write_file',
'list_directory']
```
### Suggestion:
Maybe we can build a like `create_file_agent()` like `create_sql_agent()`. As we all know, we can build sql agent as follows:
```python
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
def create_mysql_kit():
db = SQLDatabase.from_uri("sqlite:///../../../../notebooks/Chinook.db")
llm = OpenAI(temperature=0.3)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
# agent_executor.run("Who are the users of sysuser in this system? Tell me the username of all users")
agent_executor.run("How many people are in this system?")
if __name__ == '__main__':
create_mysql_kit()
```
I think we can build the `file agent` in the same way.
### More
- There may be some way to achieve the same functionality as the file agent, but I don't know. If so, please tell to how to use it.
- Can we provide a method to make an agent use all tools, including tools in toolkit and tools of `load_tools()` | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5454/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5454/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5453 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5453/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5453/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5453/events | https://github.com/langchain-ai/langchain/pull/5453 | 1,732,622,456 | PR_kwDOIPDwls5RtIQT | 5,453 | Localization langchain prompt (zh_CN and agents) | {
"login": "lingfengchencn",
"id": 2757011,
"node_id": "MDQ6VXNlcjI3NTcwMTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2757011?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lingfengchencn",
"html_url": "https://github.com/lingfengchencn",
"followers_url": "https://api.github.com/users/lingfengchencn/followers",
"following_url": "https://api.github.com/users/lingfengchencn/following{/other_user}",
"gists_url": "https://api.github.com/users/lingfengchencn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lingfengchencn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lingfengchencn/subscriptions",
"organizations_url": "https://api.github.com/users/lingfengchencn/orgs",
"repos_url": "https://api.github.com/users/lingfengchencn/repos",
"events_url": "https://api.github.com/users/lingfengchencn/events{/privacy}",
"received_events_url": "https://api.github.com/users/lingfengchencn/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4899412369,
"node_id": "LA_kwDOIPDwls8AAAABJAcZkQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/area:%20agent",
"name": "area: agent",
"color": "BFD4F2",
"default": false,
"description": "Related to agents module"
},
{
"id": 5680700873,
"node_id": "LA_kwDOIPDwls8AAAABUpidyQ",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/auto:improvement",
"name": "auto:improvement",
"color": "FBCA04",
"default": false,
"description": "Medium size change to existing code to handle new use-cases"
}
] | closed | false | null | [] | null | 6 | "2023-05-30T16:44:27" | "2023-11-07T04:21:32" | "2023-11-07T04:21:32" | NONE | null | # Localization langchain prompt (now is zh_CN and agents)
Create Localization prompt for zh_CN angets/* and will add more language and whole langchain prompt after ....
all PROMPT translated by gpt-3.5-turbo。
Fixes # (issue)
#5075
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
Agents / Tools / Toolkits
@vowelparrot
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5453/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5453/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5453",
"html_url": "https://github.com/langchain-ai/langchain/pull/5453",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5453.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5453.patch",
"merged_at": null
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5452 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5452/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5452/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5452/events | https://github.com/langchain-ai/langchain/issues/5452 | 1,732,618,952 | I_kwDOIPDwls5nRarI | 5,452 | Why raise an error in conversation retrieval chain if the chat history is a string? | {
"login": "ogabrielluiz",
"id": 24829397,
"node_id": "MDQ6VXNlcjI0ODI5Mzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/24829397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ogabrielluiz",
"html_url": "https://github.com/ogabrielluiz",
"followers_url": "https://api.github.com/users/ogabrielluiz/followers",
"following_url": "https://api.github.com/users/ogabrielluiz/following{/other_user}",
"gists_url": "https://api.github.com/users/ogabrielluiz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ogabrielluiz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ogabrielluiz/subscriptions",
"organizations_url": "https://api.github.com/users/ogabrielluiz/orgs",
"repos_url": "https://api.github.com/users/ogabrielluiz/repos",
"events_url": "https://api.github.com/users/ogabrielluiz/events{/privacy}",
"received_events_url": "https://api.github.com/users/ogabrielluiz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | "2023-05-30T16:41:33" | "2023-10-12T16:09:23" | "2023-10-12T16:09:22" | NONE | null | https://github.com/hwchase17/langchain/blob/64b4165c8d9b8374295d4629ef57d4d58e9af7c8/langchain/chains/conversational_retrieval/base.py#L34
It seems the `_get_chat_history` is building the chat_history string but if the history is already a string then it should.
The check might even be in the BaseConversationalRetrievalChain `_call` methods.
What would be the correct way of using this if the chat_history is already a string? | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5452/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/langchain-ai/langchain/issues/5452/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5451 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5451/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5451/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5451/events | https://github.com/langchain-ai/langchain/issues/5451 | 1,732,574,359 | I_kwDOIPDwls5nRPyX | 5,451 | Text Fragments from text splitters for deep linking with browsers (or compatible systems) to specific text chunks in source documents | {
"login": "nelsonjchen",
"id": 5363,
"node_id": "MDQ6VXNlcjUzNjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5363?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nelsonjchen",
"html_url": "https://github.com/nelsonjchen",
"followers_url": "https://api.github.com/users/nelsonjchen/followers",
"following_url": "https://api.github.com/users/nelsonjchen/following{/other_user}",
"gists_url": "https://api.github.com/users/nelsonjchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nelsonjchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nelsonjchen/subscriptions",
"organizations_url": "https://api.github.com/users/nelsonjchen/orgs",
"repos_url": "https://api.github.com/users/nelsonjchen/repos",
"events_url": "https://api.github.com/users/nelsonjchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/nelsonjchen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | "2023-05-30T16:13:04" | "2023-09-10T16:09:55" | "2023-09-10T16:09:54" | NONE | null | ### Feature request
Example URL of a Text Fragment to the README of this project that highlights the About:
https://github.com/hwchase17/langchain#:~:text=About-,%E2%9A%A1,%E2%9A%A1,-Resources
A SO: https://stackoverflow.com/questions/62989058/how-does-text-in-url-works-to-highlight-text
Example of splitter I'm talking about: https://python.langchain.com/en/latest/modules/indexes/text_splitters/examples/markdown.html
It'll be awesome if these text splitters could get the ability to try and generate [Text Fragments](https://web.dev/text-fragments/) for the text that was split up so that a URL could be generated that a user can click through and have the browser auto-scroll to the highlighted fragment. I'm sure the system could also be used outside the browser world for some tooling that could itself scroll to as well as it should be a well developed pattern/algorithm.
The system wouldn't be perfect due to issues such as duplicate text on page, impossible to generate unique split text, but I'm sure most citations would still find it useful.
### Motivation
I'm a little disappointed at the [notion db employee handbook example](https://github.com/hwchase17/notion-qa) where the sources are just filenames.
What if the info was in a big doc? `Source: Office d0ebcaaa2074442ba155c67a41d315dd.md` ? Eh. How about as an option:
```
Source: Office%20d0ebcaaa2074442ba155c67a41d315dd.md#:~:text=~12%20o%27%20clock%2C%20there%20is%20lunch%20in%20the%20canteen%2C%20free%20of%20cost.%20Jo%C3%ABlle%20is%20in%20charge%20of%20lunch%20%E2%80%94%C2%A0ask%20her%20if%20you%20need%20anything%20(allergies%20for%20example).
```
[Hyperlink to raw with text fragment](https://github.com/hwchase17/notion-qa/blob/71610847545c97041b93ecb3b19d9746623ce80f/Notion_DB/Blendle's%20Employee%20Handbook%20a834d55573614857a48a9ce9ec4194e3/Office%20d0ebcaaa2074442ba155c67a41d315dd.md#:~:text=~12%20o%27%20clock%2C%20there%20is%20lunch%20in%20the%20canteen%2C%20free%20of%20cost.%20Jo%C3%ABlle%20is%20in%20charge%20of%20lunch%20%E2%80%94%C2%A0ask%20her%20if%20you%20need%20anything%20(allergies%20for%20example).)
Of course, that looks ugly in a terminal, but on a web page where links can be hyperlinks like above, it'll be a much better experience.
edit: Hmm, that link doesn't work very well on GitHub and it's turbolink'd pages.
### Your contribution
I wish, I'm still trying to grasp Langchain itself. I'm particularly interested in Langchain and friends or rivals for Q/A answering and some of my personal hobby's, my work's, and the notion DB example's pages are quite long. | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5451/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5451/timeline | null | not_planned | null | null |
https://api.github.com/repos/langchain-ai/langchain/issues/5450 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5450/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5450/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5450/events | https://github.com/langchain-ai/langchain/pull/5450 | 1,732,572,168 | PR_kwDOIPDwls5Rs9Tr | 5,450 | `encoding_kwargs` for InstructEmbeddings | {
"login": "Xmaster6y",
"id": 66315201,
"node_id": "MDQ6VXNlcjY2MzE1MjAx",
"avatar_url": "https://avatars.githubusercontent.com/u/66315201?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Xmaster6y",
"html_url": "https://github.com/Xmaster6y",
"followers_url": "https://api.github.com/users/Xmaster6y/followers",
"following_url": "https://api.github.com/users/Xmaster6y/following{/other_user}",
"gists_url": "https://api.github.com/users/Xmaster6y/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Xmaster6y/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Xmaster6y/subscriptions",
"organizations_url": "https://api.github.com/users/Xmaster6y/orgs",
"repos_url": "https://api.github.com/users/Xmaster6y/repos",
"events_url": "https://api.github.com/users/Xmaster6y/events{/privacy}",
"received_events_url": "https://api.github.com/users/Xmaster6y/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-30T16:11:31" | "2023-05-30T18:57:05" | "2023-05-30T18:57:05" | CONTRIBUTOR | null | # What does this PR do?
Bring support of `encode_kwargs` for ` HuggingFaceInstructEmbeddings`, change the docstring example and add a test to illustrate with `normalize_embeddings`.
Fixes #3605
(Similar to #3914)
Use case:
```python
from langchain.embeddings import HuggingFaceInstructEmbeddings
model_name = "hkunlp/instructor-large"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceInstructEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
```
## Before submitting
- [x] Tests were added and passed
- [x] Actions are passed
## Who can review?
Community members can review the PR once tests pass. Tag maintainers/contributors who might be interested:
Models
- @hwchase17
- @agola11
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5450/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5450/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5450",
"html_url": "https://github.com/langchain-ai/langchain/pull/5450",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5450.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5450.patch",
"merged_at": "2023-05-30T18:57:04"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5449 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5449/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5449/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5449/events | https://github.com/langchain-ai/langchain/pull/5449 | 1,732,547,240 | PR_kwDOIPDwls5Rs31S | 5,449 | Removes duplicated call from langchain/client/langchain.py | {
"login": "patrickkeane",
"id": 13934664,
"node_id": "MDQ6VXNlcjEzOTM0NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/13934664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickkeane",
"html_url": "https://github.com/patrickkeane",
"followers_url": "https://api.github.com/users/patrickkeane/followers",
"following_url": "https://api.github.com/users/patrickkeane/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickkeane/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickkeane/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickkeane/subscriptions",
"organizations_url": "https://api.github.com/users/patrickkeane/orgs",
"repos_url": "https://api.github.com/users/patrickkeane/repos",
"events_url": "https://api.github.com/users/patrickkeane/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickkeane/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 5454193895,
"node_id": "LA_kwDOIPDwls8AAAABRRhk5w",
"url": "https://api.github.com/repos/langchain-ai/langchain/labels/lgtm",
"name": "lgtm",
"color": "0E8A16",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | 1 | "2023-05-30T15:55:54" | "2023-05-30T19:19:02" | "2023-05-30T18:52:46" | CONTRIBUTOR | null | This removes duplicate code presumably introduced by a cut-and-paste error, spotted while reviewing the code in ```langchain/client/langchain.py```. The original code had back to back occurrences of the following code block:
```
response = self._get(
path,
params=params,
)
raise_for_status_with_text(response)
```
Here are the ```make test``` results:
```
================= 693 passed, 52 skipped, 27 warnings in 8.38s =================
``` | {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5449/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/langchain-ai/langchain/issues/5449/timeline | null | null | false | {
"url": "https://api.github.com/repos/langchain-ai/langchain/pulls/5449",
"html_url": "https://github.com/langchain-ai/langchain/pull/5449",
"diff_url": "https://github.com/langchain-ai/langchain/pull/5449.diff",
"patch_url": "https://github.com/langchain-ai/langchain/pull/5449.patch",
"merged_at": "2023-05-30T18:52:46"
} |
https://api.github.com/repos/langchain-ai/langchain/issues/5448 | https://api.github.com/repos/langchain-ai/langchain | https://api.github.com/repos/langchain-ai/langchain/issues/5448/labels{/name} | https://api.github.com/repos/langchain-ai/langchain/issues/5448/comments | https://api.github.com/repos/langchain-ai/langchain/issues/5448/events | https://github.com/langchain-ai/langchain/issues/5448 | 1,732,533,742 | I_kwDOIPDwls5nRF3u | 5,448 | Issue: Get the verbose messages from chain | {
"login": "KanaSukita",
"id": 32619535,
"node_id": "MDQ6VXNlcjMyNjE5NTM1",
"avatar_url": "https://avatars.githubusercontent.com/u/32619535?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KanaSukita",
"html_url": "https://github.com/KanaSukita",
"followers_url": "https://api.github.com/users/KanaSukita/followers",
"following_url": "https://api.github.com/users/KanaSukita/following{/other_user}",
"gists_url": "https://api.github.com/users/KanaSukita/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KanaSukita/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KanaSukita/subscriptions",
"organizations_url": "https://api.github.com/users/KanaSukita/orgs",
"repos_url": "https://api.github.com/users/KanaSukita/repos",
"events_url": "https://api.github.com/users/KanaSukita/events{/privacy}",
"received_events_url": "https://api.github.com/users/KanaSukita/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 4 | "2023-05-30T15:46:42" | "2023-12-11T16:07:28" | "2023-12-11T16:07:27" | NONE | null | ### Issue you'd like to raise.
We can get the intermediate messages printed when the verbose is set to True in the chains. But is there a way we can get the intermediate messages from the chain as a return value?
### Suggestion:
Take the code below as example.
```
from langchain import OpenAI, ConversationChain
from langchain.llms import OpenAI
llm = OpenAI(engine="text-davinci-003", temperature=0.9)
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="How are you?")
conversation.predict(input="I am Ricardo Kaka, what is your name?")
conversation.predict(input="What is the first thing I said to you?")
```
We get the messages below printed in the shell. But I am wondering if there is a way I can get the messages as an return value, something like conversation.verbose_message, or conversation.get_verbose_message()?
| {
"url": "https://api.github.com/repos/langchain-ai/langchain/issues/5448/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/langchain-ai/langchain/issues/5448/timeline | null | not_planned | null | null |