
id
int64 959M
2.55B
| title
stringlengths 3
133
| body
stringlengths 1
65.5k
⌀ | description
stringlengths 5
65.6k
| state
stringclasses 2
values | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | user
stringclasses 174
values |
|---|---|---|---|---|---|---|---|---|
1,632,594,586 | Dataset Viewer issue for j-krzywdziak/test | ### Link
https://huggingface.co/datasets/j-krzywdziak/test
### Description
Hi, recently I am having a problem with dataset viewer. I cannot get the preview of audio files in my dataset. I am getting this error :
ERROR: type should be audio, got [ { "src": "https://datasets-server.huggingface.co/assets/j-krzywdziak/test/--/Test Dataset/test/2/audio/audio.mp3", "type": "audio/mpeg" }, { "src": "https://datasets-server.huggingface.co/assets/j-krzywdziak/test/--/Test Dataset/test/2/audio/audio.wav", "type": "audio/wav" } ]
Audio files are zipped and are in wav format. Anyone have any idea?
https://discuss.huggingface.co/t/audio-files-view-error/31624
<img width="1021" alt="Capture d’écran 2023-03-20 à 18 51 25" src="https://user-images.githubusercontent.com/1676121/226425185-e765d2ac-e61b-46ee-8d75-e0a9b78ae4b0.png">
| Dataset Viewer issue for j-krzywdziak/test: ### Link
https://huggingface.co/datasets/j-krzywdziak/test
### Description
Hi, recently I am having a problem with dataset viewer. I cannot get the preview of audio files in my dataset. I am getting this error :
ERROR: type should be audio, got [ { "src": "https://datasets-server.huggingface.co/assets/j-krzywdziak/test/--/Test Dataset/test/2/audio/audio.mp3", "type": "audio/mpeg" }, { "src": "https://datasets-server.huggingface.co/assets/j-krzywdziak/test/--/Test Dataset/test/2/audio/audio.wav", "type": "audio/wav" } ]
Audio files are zipped and are in wav format. Anyone have any idea?
https://discuss.huggingface.co/t/audio-files-view-error/31624
<img width="1021" alt="Capture d’écran 2023-03-20 à 18 51 25" src="https://user-images.githubusercontent.com/1676121/226425185-e765d2ac-e61b-46ee-8d75-e0a9b78ae4b0.png">
| closed | 2023-03-20T17:51:32Z | 2023-06-01T06:22:37Z | 2023-06-01T06:22:37Z | severo |
1,632,580,742 | Change the limit of started jobs? all kinds -> per kind | Currently, the `QUEUE_MAX_JOBS_PER_NAMESPACE` parameter limits the number of started jobs for the same namespace (user or organization). Maybe we should enforce this limit **per job kind** instead of **globally**. | Change the limit of started jobs? all kinds -> per kind: Currently, the `QUEUE_MAX_JOBS_PER_NAMESPACE` parameter limits the number of started jobs for the same namespace (user or organization). Maybe we should enforce this limit **per job kind** instead of **globally**. | closed | 2023-03-20T17:40:45Z | 2023-04-29T15:03:57Z | 2023-04-29T15:03:57Z | severo |
1,632,576,244 | Kill a job after a maximum duration? | The heartbeat already allows to detect if a job has crashed and to generate an error in that case. But some jobs can take forever, while not crashing. Should we set a maximum duration for the jobs, in order to save resources and free the queue? I imagine that we could automatically kill a job that takes more than 20 minutes to run, and insert an error in the cache. | Kill a job after a maximum duration?: The heartbeat already allows to detect if a job has crashed and to generate an error in that case. But some jobs can take forever, while not crashing. Should we set a maximum duration for the jobs, in order to save resources and free the queue? I imagine that we could automatically kill a job that takes more than 20 minutes to run, and insert an error in the cache. | closed | 2023-03-20T17:37:35Z | 2023-03-23T13:16:33Z | 2023-03-23T13:16:33Z | severo |
1,632,567,717 | check if /splits-name-from-streaming is necessary before processing it | If /splits-name-from-dataset-info already exists and is successful, /splits-name-from-streaming can be skipped.
I'm not sure if we should:
- copy the result
- or generate an error (something like "SkippedError")
| check if /splits-name-from-streaming is necessary before processing it: If /splits-name-from-dataset-info already exists and is successful, /splits-name-from-streaming can be skipped.
I'm not sure if we should:
- copy the result
- or generate an error (something like "SkippedError")
| closed | 2023-03-20T17:31:57Z | 2023-03-30T19:20:46Z | 2023-03-30T19:20:46Z | severo |
1,632,078,030 | Config-level dataset info | Will solve https://github.com/huggingface/datasets-server/issues/864
Part of https://github.com/huggingface/datasets-server/issues/735
I preserved the old name (without leading "/") for dataset-level step - `"dataset-info"` and named config-level step `"config-info"` because `"dataset-dataset-info"` and `"config-dataset-info"` look a bit silly to me but I don't have a strong opinion here, let me know what you think.
`config-info` result format is dict with info, `dataset-info` result format remained the same (dict[config_name, infos]), like this:
* `config-info`
```
dataset_info: {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
}
```
* `dataset-info`
```
dataset_info: {
"config_1": {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
},
"config_2": {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
},
}
```
I'm not sure why CI is broken. | Config-level dataset info: Will solve https://github.com/huggingface/datasets-server/issues/864
Part of https://github.com/huggingface/datasets-server/issues/735
I preserved the old name (without leading "/") for dataset-level step - `"dataset-info"` and named config-level step `"config-info"` because `"dataset-dataset-info"` and `"config-dataset-info"` look a bit silly to me but I don't have a strong opinion here, let me know what you think.
`config-info` result format is dict with info, `dataset-info` result format remained the same (dict[config_name, infos]), like this:
* `config-info`
```
dataset_info: {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
}
```
* `dataset-info`
```
dataset_info: {
"config_1": {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
},
"config_2": {
"description": "_DESCRIPTION",
"citation": "_CITATION",
"homepage": "_HOMEPAGE",
...
},
}
```
I'm not sure why CI is broken. | closed | 2023-03-20T13:07:46Z | 2023-03-23T18:43:30Z | 2023-03-23T18:40:34Z | polinaeterna |
1,631,680,898 | feat: 🎸 reduce the number of allowed jobs for one namespace | Currently, 20 jobs are only for one namespace, blocking all the other users/datasets (220 waiting jobs). Also: moving config-names to the list of "light" jobs (even if it's not as light as the other ones, it's quick because it only creates the dataset builder. | feat: 🎸 reduce the number of allowed jobs for one namespace: Currently, 20 jobs are only for one namespace, blocking all the other users/datasets (220 waiting jobs). Also: moving config-names to the list of "light" jobs (even if it's not as light as the other ones, it's quick because it only creates the dataset builder. | closed | 2023-03-20T09:06:48Z | 2023-03-20T09:41:50Z | 2023-03-20T09:11:41Z | severo |
1,631,631,612 | Dataset Viewer issue for bigscience/P3 of config 'super_glue_cb_GPT_3_style' | ### Link
https://huggingface.co/datasets/bigscience/P3
### Description
The dataset viewer is not working for dataset bigscience/P3.
Error details:
The dataset preview of this split is not available.
Job runner crashed while running this job (missing heartbeats).
```
Error code: JobRunnerCrashedError
```
| Dataset Viewer issue for bigscience/P3 of config 'super_glue_cb_GPT_3_style': ### Link
https://huggingface.co/datasets/bigscience/P3
### Description
The dataset viewer is not working for dataset bigscience/P3.
Error details:
The dataset preview of this split is not available.
Job runner crashed while running this job (missing heartbeats).
```
Error code: JobRunnerCrashedError
```
| closed | 2023-03-20T08:34:26Z | 2023-03-24T12:42:04Z | 2023-03-24T09:46:45Z | VoiceBeer |
1,630,950,775 | Dataset Viewer issue for shainaraza/clinical_bias | ### Link
https://huggingface.co/datasets/shainaraza/clinical_bias
### Description
The dataset viewer is not working for dataset shainaraza/clinical_bias.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for shainaraza/clinical_bias: ### Link
https://huggingface.co/datasets/shainaraza/clinical_bias
### Description
The dataset viewer is not working for dataset shainaraza/clinical_bias.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-19T13:52:25Z | 2023-04-19T07:56:43Z | 2023-04-19T07:56:43Z | shainaraza |
1,630,750,083 | Dataset Viewer issue for Zexuan/soc_data | ### Link
https://huggingface.co/datasets/Zexuan/soc_data
### Description
The dataset viewer is not working for dataset Zexuan/soc_data.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for Zexuan/soc_data: ### Link
https://huggingface.co/datasets/Zexuan/soc_data
### Description
The dataset viewer is not working for dataset Zexuan/soc_data.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-19T02:43:01Z | 2023-03-20T09:33:37Z | 2023-03-20T09:33:36Z | lzxlll |
1,630,361,681 | Dataset Viewer issue for Crapp/sadQuotes | ### Link
https://huggingface.co/datasets/Crapp/sadQuotes
### Description
The dataset viewer is not working for dataset Crapp/sadQuotes.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for Crapp/sadQuotes: ### Link
https://huggingface.co/datasets/Crapp/sadQuotes
### Description
The dataset viewer is not working for dataset Crapp/sadQuotes.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-18T15:05:36Z | 2023-03-20T09:40:41Z | 2023-03-20T09:40:40Z | crapptrapp |
1,629,924,485 | Dataset Viewer issue for vhug/xorder_dish_dataset | ### Link
https://huggingface.co/datasets/vhug/xorder_dish_dataset
### Description
The dataset viewer is not working for dataset vhug/xorder_dish_dataset.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for vhug/xorder_dish_dataset: ### Link
https://huggingface.co/datasets/vhug/xorder_dish_dataset
### Description
The dataset viewer is not working for dataset vhug/xorder_dish_dataset.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-17T21:00:27Z | 2023-03-20T10:15:49Z | 2023-03-20T10:15:48Z | v-prgmr |
1,629,552,190 | feat: 🎸 authenticate webhooks sent by the Hub | The authentication is done with a shared secret passed in X-Webhook-Secret header. If not trusted, a log is recorded and only add/update are taken into account. I.e. move and delete required the sender to be trusted. Also: before, requests were sent to the Hub to check if the dataset was supported by the datasets-server. Now, we always create the job, and it's its responsibility to check the dataset is supported. This way: a valid webhook should always be taken into account. See #950 for antecedents. | feat: 🎸 authenticate webhooks sent by the Hub: The authentication is done with a shared secret passed in X-Webhook-Secret header. If not trusted, a log is recorded and only add/update are taken into account. I.e. move and delete required the sender to be trusted. Also: before, requests were sent to the Hub to check if the dataset was supported by the datasets-server. Now, we always create the job, and it's its responsibility to check the dataset is supported. This way: a valid webhook should always be taken into account. See #950 for antecedents. | closed | 2023-03-17T15:56:13Z | 2023-03-20T09:41:40Z | 2023-03-20T08:51:23Z | severo |
1,629,088,743 | feat: 🎸 reduce log level to INFO in prod | Investigation on #950 has finished, we can reduce the log level | feat: 🎸 reduce log level to INFO in prod: Investigation on #950 has finished, we can reduce the log level | closed | 2023-03-17T10:42:47Z | 2023-03-17T10:46:15Z | 2023-03-17T10:43:15Z | severo |
1,629,075,191 | Dataset Viewer issue for orkg/SciQA | ### Link
https://huggingface.co/datasets/orkg/SciQA
### Description
Hi,
I'm trying to upload my dataset to the hub, and it seems everything is working when using the data via the python package, however, the dataset viewer is not working for dataset orkg/SciQA.
Error details:
```
Error code: ResponseNotFound
```
| Dataset Viewer issue for orkg/SciQA: ### Link
https://huggingface.co/datasets/orkg/SciQA
### Description
Hi,
I'm trying to upload my dataset to the hub, and it seems everything is working when using the data via the python package, however, the dataset viewer is not working for dataset orkg/SciQA.
Error details:
```
Error code: ResponseNotFound
```
| closed | 2023-03-17T10:32:41Z | 2023-03-17T10:56:05Z | 2023-03-17T10:54:29Z | YaserJaradeh |
1,629,074,641 | feat: 🎸 increase the timeout to Hub from 200ms to 1.5s | null | feat: 🎸 increase the timeout to Hub from 200ms to 1.5s: | closed | 2023-03-17T10:32:15Z | 2023-03-17T10:42:22Z | 2023-03-17T10:32:40Z | severo |
1,629,060,310 | feat: 🎸 add logs in case of error in /webhook | these errors should not occur, and we should be alerted when it's the case. | feat: 🎸 add logs in case of error in /webhook: these errors should not occur, and we should be alerted when it's the case. | closed | 2023-03-17T10:21:24Z | 2023-03-17T10:26:58Z | 2023-03-17T10:23:44Z | severo |
1,629,030,908 | More than half of the received webhooks are ignored! | An exception is raised (400 is returned) and thus the update jobs are not created, leading to many outdated dataset viewers on the Hub. | More than half of the received webhooks are ignored!: An exception is raised (400 is returned) and thus the update jobs are not created, leading to many outdated dataset viewers on the Hub. | closed | 2023-03-17T10:02:10Z | 2023-03-17T10:42:09Z | 2023-03-17T10:42:08Z | severo |
1,628,985,528 | An error in a step should be propagated in the dependent steps | See https://github.com/huggingface/datasets-server/issues/948:
- the entries of "/first-rows" should have been deleted because the upstream jobs are errors and we cannot get the list of splits.
- the entry of "/dataset-info" should be an error, since the result of "/parquet-and-dataset-info" is an error, and both are at dataset level.
- etc.
I think we have to review the logic of what occurs in case of error, to have a coherent status for the cache of a dataset. | An error in a step should be propagated in the dependent steps: See https://github.com/huggingface/datasets-server/issues/948:
- the entries of "/first-rows" should have been deleted because the upstream jobs are errors and we cannot get the list of splits.
- the entry of "/dataset-info" should be an error, since the result of "/parquet-and-dataset-info" is an error, and both are at dataset level.
- etc.
I think we have to review the logic of what occurs in case of error, to have a coherent status for the cache of a dataset. | closed | 2023-03-17T09:30:01Z | 2023-04-28T08:58:03Z | 2023-04-28T08:58:03Z | severo |
1,628,964,722 | Add dataset,config,split to /admin/dataset-status | The report on https://huggingface.co/datasets/mweiss/fashion_mnist_corrupted is missing information about the configs and splits (in first rows in particular):
```json
{
"/config-names": {
"cached_responses": [
{
"http_status": 200,
"error_code": null,
"job_runner_version": 1,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": 1.0
}
],
"jobs": []
},
"/split-names-from-streaming": {
"cached_responses": [
{
"http_status": 500,
"error_code": "SplitNamesFromStreamingError",
"job_runner_version": 2,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"/splits": {
"cached_responses": [
{
"http_status": 500,
"error_code": "SplitsNamesError",
"job_runner_version": 2,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"/first-rows": {
"cached_responses": [
{
"http_status": 501,
"error_code": "JobRunnerCrashedError",
"job_runner_version": 2,
"dataset_git_revision": "6a4780f015ba3159709d35c7777ca8b83e30b3cd",
"progress": null
},
{
"http_status": 500,
"error_code": "StreamingRowsError",
"job_runner_version": 2,
"dataset_git_revision": "6a4780f015ba3159709d35c7777ca8b83e30b3cd",
"progress": null
}
],
"jobs": []
},
"/parquet-and-dataset-info": {
"cached_responses": [
{
"http_status": 500,
"error_code": "UnexpectedError",
"job_runner_version": 1,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"config-parquet": { "cached_responses": [], "jobs": [] },
"dataset-parquet": { "cached_responses": [], "jobs": [] },
"/dataset-info": {
"cached_responses": [
{
"http_status": 200,
"error_code": null,
"job_runner_version": 1,
"dataset_git_revision": "f0f97726ff1c5fcabaf48a458818dcde3967d728",
"progress": 1.0
}
],
"jobs": []
},
"/split-names-from-dataset-info": { "cached_responses": [], "jobs": [] },
"config-size": { "cached_responses": [], "jobs": [] },
"dataset-size": { "cached_responses": [], "jobs": [] },
"dataset-split-names-from-streaming": { "cached_responses": [], "jobs": [] },
"dataset-split-names-from-dataset-info": {
"cached_responses": [],
"jobs": []
}
}
```
We could add `dataset`, `config` and `split` to each cache response | Add dataset,config,split to /admin/dataset-status: The report on https://huggingface.co/datasets/mweiss/fashion_mnist_corrupted is missing information about the configs and splits (in first rows in particular):
```json
{
"/config-names": {
"cached_responses": [
{
"http_status": 200,
"error_code": null,
"job_runner_version": 1,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": 1.0
}
],
"jobs": []
},
"/split-names-from-streaming": {
"cached_responses": [
{
"http_status": 500,
"error_code": "SplitNamesFromStreamingError",
"job_runner_version": 2,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"/splits": {
"cached_responses": [
{
"http_status": 500,
"error_code": "SplitsNamesError",
"job_runner_version": 2,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"/first-rows": {
"cached_responses": [
{
"http_status": 501,
"error_code": "JobRunnerCrashedError",
"job_runner_version": 2,
"dataset_git_revision": "6a4780f015ba3159709d35c7777ca8b83e30b3cd",
"progress": null
},
{
"http_status": 500,
"error_code": "StreamingRowsError",
"job_runner_version": 2,
"dataset_git_revision": "6a4780f015ba3159709d35c7777ca8b83e30b3cd",
"progress": null
}
],
"jobs": []
},
"/parquet-and-dataset-info": {
"cached_responses": [
{
"http_status": 500,
"error_code": "UnexpectedError",
"job_runner_version": 1,
"dataset_git_revision": "705573226dc92bd56883d3882d62b1b9bb6b2d73",
"progress": null
}
],
"jobs": []
},
"config-parquet": { "cached_responses": [], "jobs": [] },
"dataset-parquet": { "cached_responses": [], "jobs": [] },
"/dataset-info": {
"cached_responses": [
{
"http_status": 200,
"error_code": null,
"job_runner_version": 1,
"dataset_git_revision": "f0f97726ff1c5fcabaf48a458818dcde3967d728",
"progress": 1.0
}
],
"jobs": []
},
"/split-names-from-dataset-info": { "cached_responses": [], "jobs": [] },
"config-size": { "cached_responses": [], "jobs": [] },
"dataset-size": { "cached_responses": [], "jobs": [] },
"dataset-split-names-from-streaming": { "cached_responses": [], "jobs": [] },
"dataset-split-names-from-dataset-info": {
"cached_responses": [],
"jobs": []
}
}
```
We could add `dataset`, `config` and `split` to each cache response | closed | 2023-03-17T09:15:02Z | 2023-04-11T11:44:49Z | 2023-04-11T11:44:49Z | severo |
1,628,963,555 | TEST: DO NOT MERGE | only for test | TEST: DO NOT MERGE: only for test | closed | 2023-03-17T09:14:10Z | 2023-03-17T09:22:12Z | 2023-03-17T09:19:26Z | rtrompier |
1,627,918,334 | Dataset Viewer issue for domro11/lectures | ### Link
https://huggingface.co/datasets/domro11/lectures
### Description
The dataset viewer is not working for dataset domro11/lectures.
Error details:
```
Error code: ResponseNotReady
```
Furthermore not able to incorporate dataset wtih streamlit app as ask for a need to differentiate between train and test | Dataset Viewer issue for domro11/lectures: ### Link
https://huggingface.co/datasets/domro11/lectures
### Description
The dataset viewer is not working for dataset domro11/lectures.
Error details:
```
Error code: ResponseNotReady
```
Furthermore not able to incorporate dataset wtih streamlit app as ask for a need to differentiate between train and test | closed | 2023-03-16T17:03:11Z | 2023-03-17T09:00:13Z | 2023-03-17T09:00:12Z | dominikroser |
1,627,787,717 | Adding ligth worker | Given the new job runners/ job types: `dataset-split-names-from-streaming and dataset-split-names-from-dataset-info`, we will move them to be processed in a dedicated "light" worker with 2 pods. | Adding ligth worker: Given the new job runners/ job types: `dataset-split-names-from-streaming and dataset-split-names-from-dataset-info`, we will move them to be processed in a dedicated "light" worker with 2 pods. | closed | 2023-03-16T15:52:33Z | 2023-03-17T16:47:07Z | 2023-03-17T16:43:26Z | AndreaFrancis |
1,627,698,468 | Try to fix the e2e tests in the CI | null | Try to fix the e2e tests in the CI: | closed | 2023-03-16T15:02:43Z | 2023-03-16T15:28:39Z | 2023-03-16T15:25:41Z | severo |
1,627,571,137 | Aggregated JobRunners: Look for pending job if cache does not exist and create one if not | For aggregated JobRunners like https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset/split_names_from_streaming.py https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset_parquet.py and https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset_size.py, we get the list of configs and iterate them to get the partial response. If no cache is found, we append it to a "pending" list. In that case we should look for pending Jobs in status WAITING/STARTED and if it does not exist, create a new Job.
See thread https://github.com/huggingface/datasets-server/pull/936#discussion_r1138298762 for more details | Aggregated JobRunners: Look for pending job if cache does not exist and create one if not: For aggregated JobRunners like https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset/split_names_from_streaming.py https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset_parquet.py and https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runners/dataset_size.py, we get the list of configs and iterate them to get the partial response. If no cache is found, we append it to a "pending" list. In that case we should look for pending Jobs in status WAITING/STARTED and if it does not exist, create a new Job.
See thread https://github.com/huggingface/datasets-server/pull/936#discussion_r1138298762 for more details | closed | 2023-03-16T14:07:59Z | 2023-05-12T07:54:10Z | 2023-05-12T07:54:10Z | AndreaFrancis |
1,627,227,798 | Github Dataset not Downloaded | ### Link
https://huggingface.co/datasets/mweiss/fashion_mnist_corrupted
### Description
```
Error code: StreamingRowsError
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: 'https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy'
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 570, in compute_first_rows_response
rows = get_rows(
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 161, in decorator
return func(*args, **kwargs)
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 217, in get_rows
rows_plus_one = list(itertools.islice(ds, rows_max_number + 1))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 937, in __iter__
for key, example in ex_iterable:
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 113, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/tmp/modules-cache/datasets_modules/datasets/mweiss--fashion_mnist_corrupted/eb400b17b13bc9eff3632e537102d6486ced9893ea148a5b41c8eca38b36f7ce/fashion_mnist_corrupted.py", line 120, in _generate_examples
images = np.load(filepath[0])
File "/src/services/worker/.venv/lib/python3.9/site-packages/numpy/lib/npyio.py", line 407, in load
fid = stack.enter_context(open(os_fspath(file), "rb"))
FileNotFoundError: [Errno 2] No such file or directory: 'https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy'
```
I am not sure about the root cause of this error. After all, the url [https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy](https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy) is correct.
Does huggingface-server somehow block github urls? Or are you aware that huggingface requests get blocked by github? | Github Dataset not Downloaded: ### Link
https://huggingface.co/datasets/mweiss/fashion_mnist_corrupted
### Description
```
Error code: StreamingRowsError
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: 'https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy'
Traceback: Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 570, in compute_first_rows_response
rows = get_rows(
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 161, in decorator
return func(*args, **kwargs)
File "/src/services/worker/src/worker/job_runners/first_rows.py", line 217, in get_rows
rows_plus_one = list(itertools.islice(ds, rows_max_number + 1))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 937, in __iter__
for key, example in ex_iterable:
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 113, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/tmp/modules-cache/datasets_modules/datasets/mweiss--fashion_mnist_corrupted/eb400b17b13bc9eff3632e537102d6486ced9893ea148a5b41c8eca38b36f7ce/fashion_mnist_corrupted.py", line 120, in _generate_examples
images = np.load(filepath[0])
File "/src/services/worker/.venv/lib/python3.9/site-packages/numpy/lib/npyio.py", line 407, in load
fid = stack.enter_context(open(os_fspath(file), "rb"))
FileNotFoundError: [Errno 2] No such file or directory: 'https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy'
```
I am not sure about the root cause of this error. After all, the url [https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy](https://github.com/testingautomated-usi/fashion-mnist-c/raw/v1.0.0/generated/npy/fmnist-c-train.npy) is correct.
Does huggingface-server somehow block github urls? Or are you aware that huggingface requests get blocked by github? | closed | 2023-03-16T11:00:09Z | 2023-03-17T13:48:02Z | 2023-03-17T13:48:01Z | MiWeiss |
1,627,058,293 | ci: 🎡 use the public key of the CI Hub | Note that it would not change anything because we don't e2e test the Hub sending a request to the datasets-server... | ci: 🎡 use the public key of the CI Hub: Note that it would not change anything because we don't e2e test the Hub sending a request to the datasets-server... | closed | 2023-03-16T09:35:09Z | 2023-03-16T13:38:08Z | 2023-03-16T13:35:22Z | severo |
1,627,039,398 | Revert log increase | This PR reduces the log level to INFO. To be merged after the investigation is done. See https://github.com/huggingface/datasets-server/pull/939 | Revert log increase: This PR reduces the log level to INFO. To be merged after the investigation is done. See https://github.com/huggingface/datasets-server/pull/939 | closed | 2023-03-16T09:24:26Z | 2023-03-16T10:20:20Z | 2023-03-16T10:17:05Z | severo |
1,627,035,255 | Increase logs to debug jwt issue | null | Increase logs to debug jwt issue: | closed | 2023-03-16T09:22:03Z | 2023-03-16T09:42:12Z | 2023-03-16T09:39:13Z | severo |
1,626,913,494 | Dataset Viewer issue for bookcorpus | ### Link
https://huggingface.co/datasets/bookcorpus
### Description
The dataset viewer is not working for dataset bookcorpus.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for bookcorpus: ### Link
https://huggingface.co/datasets/bookcorpus
### Description
The dataset viewer is not working for dataset bookcorpus.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-16T07:59:11Z | 2023-03-20T14:03:45Z | 2023-03-20T14:03:44Z | HungOm |
1,626,334,087 | dataset-level split names from dataset info | Second part of https://github.com/huggingface/datasets-server/issues/734
Splits will be based on:
dataset-split-names-from-streaming (https://github.com/huggingface/datasets-server/pull/936))
dataset-split-names-from-dataset-info (This PR) | dataset-level split names from dataset info: Second part of https://github.com/huggingface/datasets-server/issues/734
Splits will be based on:
dataset-split-names-from-streaming (https://github.com/huggingface/datasets-server/pull/936))
dataset-split-names-from-dataset-info (This PR) | closed | 2023-03-15T21:49:26Z | 2023-03-16T15:03:18Z | 2023-03-16T14:34:41Z | AndreaFrancis |
1,625,871,738 | dataset-level split names from streaming | First part of https://github.com/huggingface/datasets-server/issues/734
Splits will be based on:
- dataset-split-names-from-streaming (This PR)
- dataset-split-names-from-dataset-info (Will send in another PR) | dataset-level split names from streaming: First part of https://github.com/huggingface/datasets-server/issues/734
Splits will be based on:
- dataset-split-names-from-streaming (This PR)
- dataset-split-names-from-dataset-info (Will send in another PR) | closed | 2023-03-15T16:35:03Z | 2023-03-16T14:08:11Z | 2023-03-16T14:01:58Z | AndreaFrancis |
1,625,485,909 | Error: not found on existing datasets | https://datasets-server.huggingface.co/size?dataset=severo/glue
https://datasets-server.huggingface.co/size?dataset=severo/danish-wit
-> `{"error":"Not found."}`
While it should be: `{"error":"The server is busier than usual and the response is not ready yet. Please retry later."}` if the cache does not exist, then the successful answer.
| Error: not found on existing datasets: https://datasets-server.huggingface.co/size?dataset=severo/glue
https://datasets-server.huggingface.co/size?dataset=severo/danish-wit
-> `{"error":"Not found."}`
While it should be: `{"error":"The server is busier than usual and the response is not ready yet. Please retry later."}` if the cache does not exist, then the successful answer.
| closed | 2023-03-15T13:00:46Z | 2023-05-12T07:52:36Z | 2023-05-12T07:52:35Z | severo |
1,625,431,042 | Support bypass jwt on authorization header? | Internal conversation: https://huggingface.slack.com/archives/C04L6P8KNQ5/p1678874819105149?thread_ts=1678874751.420079&cid=C04L6P8KNQ5
The `x-api-key` header does not describe very well that it should contain a JWT, and it's not standard.
Maybe support passing the authentication bypass JWT (#898) via the `authorization` header instead.
As the `authorization` header is already used with Hub users/app tokens, we could check if the token starts with `hf_` to discriminate:
- Hub token: `Authorization: Bearer hf_app_abcdef...`
- JWT: `Authorization: Bearer aaaabbbb...`
Another option: a prefix such as `jwt:` could be appended to the JWT: `Authorization: Bearer jwt:aaaabbbb...`
| Support bypass jwt on authorization header?: Internal conversation: https://huggingface.slack.com/archives/C04L6P8KNQ5/p1678874819105149?thread_ts=1678874751.420079&cid=C04L6P8KNQ5
The `x-api-key` header does not describe very well that it should contain a JWT, and it's not standard.
Maybe support passing the authentication bypass JWT (#898) via the `authorization` header instead.
As the `authorization` header is already used with Hub users/app tokens, we could check if the token starts with `hf_` to discriminate:
- Hub token: `Authorization: Bearer hf_app_abcdef...`
- JWT: `Authorization: Bearer aaaabbbb...`
Another option: a prefix such as `jwt:` could be appended to the JWT: `Authorization: Bearer jwt:aaaabbbb...`
| closed | 2023-03-15T12:27:06Z | 2023-08-17T16:13:53Z | 2023-08-17T16:13:53Z | severo |
1,625,147,817 | fix: 🐛 take the algorithm into account in config | null | fix: 🐛 take the algorithm into account in config: | closed | 2023-03-15T09:49:32Z | 2023-03-15T09:56:36Z | 2023-03-15T09:54:16Z | severo |
1,625,095,985 | refactor: 💡 fix type of the public key: str, not Any | null | refactor: 💡 fix type of the public key: str, not Any: | closed | 2023-03-15T09:23:23Z | 2023-03-15T09:48:50Z | 2023-03-15T09:46:10Z | severo |
1,623,933,537 | Config-level parquet | Created `config-parquet` and `dataset-parquet` jobs, and removing the old `/parquet` job.
The `/parquet` endpoints uses the two new jobs.
Close https://github.com/huggingface/datasets-server/issues/865 | Config-level parquet: Created `config-parquet` and `dataset-parquet` jobs, and removing the old `/parquet` job.
The `/parquet` endpoints uses the two new jobs.
Close https://github.com/huggingface/datasets-server/issues/865 | closed | 2023-03-14T17:03:22Z | 2023-03-15T11:06:15Z | 2023-03-15T11:03:48Z | lhoestq |
1,623,757,222 | Don't cancel CI jobs on main | Currently, if two commits are pushed to main quickly, some actions are canceled in the first commit, leading to a red cross. I think we want to be have the full CI on every push to main, so we should ensure the actions are not canceled in that case.
<img width="774" alt="Capture d’écran 2023-03-14 à 16 43 42" src="https://user-images.githubusercontent.com/1676121/225057195-ed86230f-a306-47a5-8208-5f7f3414f46e.png">
| Don't cancel CI jobs on main: Currently, if two commits are pushed to main quickly, some actions are canceled in the first commit, leading to a red cross. I think we want to be have the full CI on every push to main, so we should ensure the actions are not canceled in that case.
<img width="774" alt="Capture d’écran 2023-03-14 à 16 43 42" src="https://user-images.githubusercontent.com/1676121/225057195-ed86230f-a306-47a5-8208-5f7f3414f46e.png">
| closed | 2023-03-14T15:46:01Z | 2023-06-14T12:13:41Z | 2023-06-14T12:13:41Z | severo |
1,623,546,901 | Fix jwt decoding | The algorithm was not passed to the decoding function. | Fix jwt decoding: The algorithm was not passed to the decoding function. | closed | 2023-03-14T14:00:54Z | 2023-03-14T14:51:59Z | 2023-03-14T14:48:52Z | severo |
1,622,704,025 | Dataset Viewer issue for ethers/avril15s02-datasets | ### Link
https://huggingface.co/datasets/ethers/avril15s02-datasets
### Description
The dataset viewer is not working for dataset ethers/avril15s02-datasets.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for ethers/avril15s02-datasets: ### Link
https://huggingface.co/datasets/ethers/avril15s02-datasets
### Description
The dataset viewer is not working for dataset ethers/avril15s02-datasets.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-14T04:31:40Z | 2023-03-14T08:26:30Z | 2023-03-14T08:26:30Z | 0xdigiscore |
1,622,290,010 | Remove worker version | In PR https://github.com/huggingface/datasets-server/pull/916, `job_runner_version` new field was created in order to version `JobRunner` with int instead of string. Now that we have all the logic depending on the new field `worker_version` is no more needed. | Remove worker version: In PR https://github.com/huggingface/datasets-server/pull/916, `job_runner_version` new field was created in order to version `JobRunner` with int instead of string. Now that we have all the logic depending on the new field `worker_version` is no more needed. | closed | 2023-03-13T21:26:46Z | 2023-03-14T15:40:17Z | 2023-03-14T15:37:33Z | AndreaFrancis |
1,621,923,597 | Config-level size | I added `config-size` job and using #909 I implemented the fan-in `dataset-size` job.
I remember there was a discussion to name it `dataset--size` at one point. Not the biggest fan but lmk
It also returns `size: {...}` and not `sizes: {...}` as before. | Config-level size: I added `config-size` job and using #909 I implemented the fan-in `dataset-size` job.
I remember there was a discussion to name it `dataset--size` at one point. Not the biggest fan but lmk
It also returns `size: {...}` and not `sizes: {...}` as before. | closed | 2023-03-13T17:20:12Z | 2023-03-14T15:38:53Z | 2023-03-14T15:36:11Z | lhoestq |
1,621,764,470 | Fix access to gated datasets, and forbid access to private datasets! | null | Fix access to gated datasets, and forbid access to private datasets!: | closed | 2023-03-13T15:48:04Z | 2023-03-13T19:51:16Z | 2023-03-13T19:48:44Z | severo |
1,621,511,534 | Support webhook version 3? | The Hub provides different formats for the webhooks. The current version, used in the public feature (https://huggingface.co/docs/hub/webhooks) is version 3. Maybe we should support version 3 soon. | Support webhook version 3?: The Hub provides different formats for the webhooks. The current version, used in the public feature (https://huggingface.co/docs/hub/webhooks) is version 3. Maybe we should support version 3 soon. | closed | 2023-03-13T13:39:59Z | 2023-04-21T15:03:54Z | 2023-04-21T15:03:54Z | severo |
1,621,500,919 | Don't rebuild dev images | To improve the local dev environment and let us iterate quicker:
1. I created `dev.Dockerfile` for the admin and api services
2. I improved the dev-docker-compose to use volumes for libcommon, admin and api
3. I removed a step in the `Dockerfile`s
that was unecessarilly reinstalling python (and possibly at another version than 3.9.15)
4. I updated poetry (1.3.2 can't install `torch` in a linux container on mac m2) and fixed the `tensorflow` dependency to have it working locally on a mac with amd chip (this impacts the dev images but also the prod images, but I think it's ok, it was introduced in https://github.com/huggingface/datasets-server/pull/823)
With those changes I don't need to rebuild images anymore when changing code in libcommon/admin/api/worker etc.
The image is rebuilt only when the dependencies change. | Don't rebuild dev images: To improve the local dev environment and let us iterate quicker:
1. I created `dev.Dockerfile` for the admin and api services
2. I improved the dev-docker-compose to use volumes for libcommon, admin and api
3. I removed a step in the `Dockerfile`s
that was unecessarilly reinstalling python (and possibly at another version than 3.9.15)
4. I updated poetry (1.3.2 can't install `torch` in a linux container on mac m2) and fixed the `tensorflow` dependency to have it working locally on a mac with amd chip (this impacts the dev images but also the prod images, but I think it's ok, it was introduced in https://github.com/huggingface/datasets-server/pull/823)
With those changes I don't need to rebuild images anymore when changing code in libcommon/admin/api/worker etc.
The image is rebuilt only when the dependencies change. | closed | 2023-03-13T13:33:33Z | 2023-03-13T18:03:23Z | 2023-03-13T18:00:42Z | lhoestq |
1,620,006,550 | Dataset Viewer issue for gsdf/EasyNegative | ### Link
https://huggingface.co/datasets/gsdf/EasyNegative
### Description
The dataset viewer is not working for dataset gsdf/EasyNegative.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for gsdf/EasyNegative: ### Link
https://huggingface.co/datasets/gsdf/EasyNegative
### Description
The dataset viewer is not working for dataset gsdf/EasyNegative.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-11T13:36:53Z | 2023-03-11T18:05:25Z | 2023-03-11T18:05:25Z | Usonw |
1,619,431,821 | refactor the `hub_datasets` fixture | It makes no sense to have to create N repos on the hub just to be able to run one test locally. It takes forever for nothing, and I always have to comment most of them to debug.
All the repos used for fixtures should be separated. | refactor the `hub_datasets` fixture: It makes no sense to have to create N repos on the hub just to be able to run one test locally. It takes forever for nothing, and I always have to comment most of them to debug.
All the repos used for fixtures should be separated. | closed | 2023-03-10T18:31:41Z | 2023-06-15T20:53:35Z | 2023-06-15T20:53:34Z | lhoestq |
1,619,333,128 | Fix gated (gated=True -> gated="auto") | this should fix the CI | Fix gated (gated=True -> gated="auto"): this should fix the CI | closed | 2023-03-10T17:22:50Z | 2023-03-11T18:56:58Z | 2023-03-10T18:40:47Z | lhoestq |
1,619,328,433 | Fix gated (gated=True -> gated="auto") | this should fix the CI | Fix gated (gated=True -> gated="auto"): this should fix the CI | closed | 2023-03-10T17:18:37Z | 2023-03-10T17:24:46Z | 2023-03-10T17:21:36Z | lhoestq |
1,618,710,583 | Revert "feat: 🎸 change log level to DEBUG (#917)" | This reverts commit 6643f943619a6b8c2b4449c12eafc883db1873fe.
Do not merge or deploy while the investigation is not finished. | Revert "feat: 🎸 change log level to DEBUG (#917)": This reverts commit 6643f943619a6b8c2b4449c12eafc883db1873fe.
Do not merge or deploy while the investigation is not finished. | closed | 2023-03-10T10:16:23Z | 2023-03-10T11:40:37Z | 2023-03-10T11:37:41Z | severo |
1,618,649,988 | feat: 🎸 change log level to DEBUG | also set the log level for requests to DEBUG. To investigate https://github.com/huggingface/datasets-server/issues/877. This commit should then be reverted. | feat: 🎸 change log level to DEBUG: also set the log level for requests to DEBUG. To investigate https://github.com/huggingface/datasets-server/issues/877. This commit should then be reverted. | closed | 2023-03-10T09:35:40Z | 2023-03-10T10:15:37Z | 2023-03-10T10:13:15Z | severo |
1,618,140,604 | Change worker_version to int job_runner_version | According to conversation on https://github.com/huggingface/datasets-server/pull/912, worker_version needs to be an int value.
I renamed worker_version to job_runner_version as suggested in a comment in https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runner.py#L315 to keep consistency between class name and field.
| Change worker_version to int job_runner_version: According to conversation on https://github.com/huggingface/datasets-server/pull/912, worker_version needs to be an int value.
I renamed worker_version to job_runner_version as suggested in a comment in https://github.com/huggingface/datasets-server/blob/main/services/worker/src/worker/job_runner.py#L315 to keep consistency between class name and field.
| closed | 2023-03-09T23:34:51Z | 2023-03-13T20:37:11Z | 2023-03-13T20:34:14Z | AndreaFrancis |
1,617,545,385 | Add some profiling | null | Add some profiling: | closed | 2023-03-09T16:11:14Z | 2023-03-09T19:02:35Z | 2023-03-09T18:59:54Z | severo |
1,617,367,920 | Add "context" label to filter the metrics on the endpoint | null | Add "context" label to filter the metrics on the endpoint: | closed | 2023-03-09T14:29:45Z | 2023-03-09T16:43:48Z | 2023-03-09T16:41:03Z | severo |
1,616,889,732 | Use pydantic, or msgspec, for validation+serialization+OpenAPI spec generation | See https://docs.pydantic.dev (https://docs.pydantic.dev/usage/settings/ for the config)
Alternative: https://jcristharif.com/msgspec/
Usages:
- validate query parameters in API endpoints
- validate data fetched from the database (we do it manually, in case some data are malformed)
- serialize the API responses to JSON (we use orjson)
- generate JSON schema (ie OpenAPI spec) from code
- use constraints in validation (>0, etc) | Use pydantic, or msgspec, for validation+serialization+OpenAPI spec generation: See https://docs.pydantic.dev (https://docs.pydantic.dev/usage/settings/ for the config)
Alternative: https://jcristharif.com/msgspec/
Usages:
- validate query parameters in API endpoints
- validate data fetched from the database (we do it manually, in case some data are malformed)
- serialize the API responses to JSON (we use orjson)
- generate JSON schema (ie OpenAPI spec) from code
- use constraints in validation (>0, etc) | closed | 2023-03-09T10:23:52Z | 2024-02-08T11:00:39Z | 2024-02-08T11:00:39Z | severo |
1,616,070,540 | Refresh when cache is outdated because of job_runner_version | Given that we had a new version for `/split-names-from-streaming,` we need to refresh the outdated cache records because some records have a specific format and other with higher version have another one.
Previous context was: https://github.com/huggingface/datasets-server/pull/880
Based on comments, there should be a `K8s Job` that appends a new `dataset server Job` by each cache outdated based on job_runner_version field. | Refresh when cache is outdated because of job_runner_version: Given that we had a new version for `/split-names-from-streaming,` we need to refresh the outdated cache records because some records have a specific format and other with higher version have another one.
Previous context was: https://github.com/huggingface/datasets-server/pull/880
Based on comments, there should be a `K8s Job` that appends a new `dataset server Job` by each cache outdated based on job_runner_version field. | closed | 2023-03-08T22:53:19Z | 2023-03-20T19:48:20Z | 2023-03-20T19:45:12Z | AndreaFrancis |
1,615,381,670 | Instrument api service | null | Instrument api service: | closed | 2023-03-08T14:35:55Z | 2023-03-09T10:12:50Z | 2023-03-09T10:10:19Z | severo |
1,615,374,106 | Add timeout to calls to hub | Add a timeout of 200ms on requests to /ask-access and /dataset-info when done from the API service. We already to it for the calls to /auth-check. Only used in the API service, not in the workers or the admin service for now. | Add timeout to calls to hub: Add a timeout of 200ms on requests to /ask-access and /dataset-info when done from the API service. We already to it for the calls to /auth-check. Only used in the API service, not in the workers or the admin service for now. | closed | 2023-03-08T14:30:50Z | 2023-03-08T15:50:51Z | 2023-03-08T15:48:05Z | severo |
1,615,346,521 | Add partial cache entries for fan-in jobs | Following discussion in https://github.com/huggingface/datasets-server/pull/900
I don't have a strong opinion on the name of the key we should store between "partial", "completeness" or others.
Therefore feel free to recommend another name or value type if you have better ideas.
I just like "partial" better because by default a job is not partial, so we just need to specify it when needed.
EDIT: actually switched yo 'progress' - a value between 0. and 1. (with 1. = complete) | Add partial cache entries for fan-in jobs: Following discussion in https://github.com/huggingface/datasets-server/pull/900
I don't have a strong opinion on the name of the key we should store between "partial", "completeness" or others.
Therefore feel free to recommend another name or value type if you have better ideas.
I just like "partial" better because by default a job is not partial, so we just need to specify it when needed.
EDIT: actually switched yo 'progress' - a value between 0. and 1. (with 1. = complete) | closed | 2023-03-08T14:12:55Z | 2023-03-13T09:55:01Z | 2023-03-13T09:52:31Z | lhoestq |
1,613,870,350 | `/parquet-and-dataset-info` is processing datasets bigger than 5GB | e.g. right now it's processing https://huggingface.co/datasets/madrylab/imagenet-star/tree/main
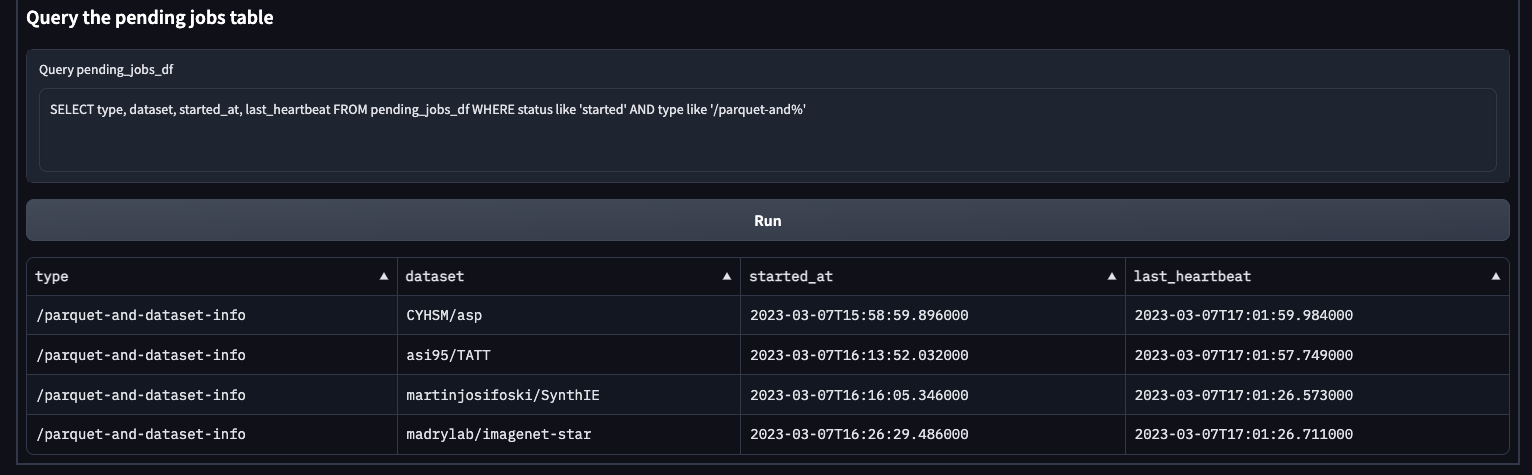
Though I checked and `PARQUET_AND_DATASET_INFO_MAX_DATASET_SIZE` is defined by
```
parquetAndDatasetInfo:
maxDatasetSize: "5_000_000_000"
``` | `/parquet-and-dataset-info` is processing datasets bigger than 5GB: e.g. right now it's processing https://huggingface.co/datasets/madrylab/imagenet-star/tree/main

Though I checked and `PARQUET_AND_DATASET_INFO_MAX_DATASET_SIZE` is defined by
```
parquetAndDatasetInfo:
maxDatasetSize: "5_000_000_000"
``` | closed | 2023-03-07T17:10:33Z | 2023-06-09T15:21:14Z | 2023-06-09T15:04:05Z | lhoestq |
1,613,832,578 | Dataset Viewer issue for Yusuf5/OpenCaselist | ### Link
https://huggingface.co/datasets/Yusuf5/OpenCaselist
### Description
The dataset viewer is not working for dataset Yusuf5/OpenCaselist.
Error details:
```
Error code: ResponseNotReady
```
NOTE: This is a 40GB CSV file, of several million debate documents. It's a follow up to DebateSum
https://huggingface.co/datasets/Hellisotherpeople/DebateSum | Dataset Viewer issue for Yusuf5/OpenCaselist: ### Link
https://huggingface.co/datasets/Yusuf5/OpenCaselist
### Description
The dataset viewer is not working for dataset Yusuf5/OpenCaselist.
Error details:
```
Error code: ResponseNotReady
```
NOTE: This is a 40GB CSV file, of several million debate documents. It's a follow up to DebateSum
https://huggingface.co/datasets/Hellisotherpeople/DebateSum | closed | 2023-03-07T16:47:07Z | 2023-03-08T09:36:23Z | 2023-03-08T09:36:23Z | Hellisotherpeople |
1,613,724,485 | Chart split-names-from-dataset-info Fix duplicated name | null | Chart split-names-from-dataset-info Fix duplicated name: | closed | 2023-03-07T15:47:51Z | 2023-03-07T15:55:12Z | 2023-03-07T15:52:14Z | AndreaFrancis |
1,613,591,230 | fix: chart dependencies | null | fix: chart dependencies: | closed | 2023-03-07T14:35:10Z | 2023-03-08T09:38:56Z | 2023-03-07T14:51:03Z | rtrompier |
1,613,487,341 | Adding deploy for missing JobRunners in chart | We have two new JobRunners name:
- /split-names-from-streaming -> It was previously /split-names, but it was renamed
- /split-names-from-dataset-info -> It is a new JobRunner which is supposed to have a similar workload as /dataset-info or /parquet | Adding deploy for missing JobRunners in chart: We have two new JobRunners name:
- /split-names-from-streaming -> It was previously /split-names, but it was renamed
- /split-names-from-dataset-info -> It is a new JobRunner which is supposed to have a similar workload as /dataset-info or /parquet | closed | 2023-03-07T13:43:47Z | 2023-03-08T09:05:26Z | 2023-03-07T15:37:47Z | AndreaFrancis |
1,613,003,698 | Dataset Viewer issue for mc4 | ### Link
https://huggingface.co/datasets/mc4
### Description
The dataset viewer is not working for dataset mc4.
When I tried to look into subsets of the mc4 dataset I got the following error:
Error details:
```
Error code: ClientConnectionError
The dataset preview is not available for this dataset.
```
| Dataset Viewer issue for mc4: ### Link
https://huggingface.co/datasets/mc4
### Description
The dataset viewer is not working for dataset mc4.
When I tried to look into subsets of the mc4 dataset I got the following error:
Error details:
```
Error code: ClientConnectionError
The dataset preview is not available for this dataset.
```
| closed | 2023-03-07T09:00:03Z | 2023-03-08T09:34:55Z | 2023-03-08T09:34:46Z | yonikremer |
1,613,002,859 | Dataset Viewer issue for mc4 | ### Link
https://huggingface.co/datasets/mc4
### Description
The dataset viewer is not working for dataset mc4.
When I tried to look into subsets of the mc4 dataset I got the following error:
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for mc4: ### Link
https://huggingface.co/datasets/mc4
### Description
The dataset viewer is not working for dataset mc4.
When I tried to look into subsets of the mc4 dataset I got the following error:
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-07T08:59:33Z | 2023-03-08T09:33:49Z | 2023-03-08T09:33:49Z | yonikremer |
1,612,840,157 | Dataset Viewer issue for bridgeconn/snow-mountain | ### Link
https://huggingface.co/datasets/bridgeconn/snow-mountain
### Description
The dataset viewer is not working for dataset bridgeconn/snow-mountain.
Error details:
```
Error code: JobRunnerCrashedError
```
| Dataset Viewer issue for bridgeconn/snow-mountain: ### Link
https://huggingface.co/datasets/bridgeconn/snow-mountain
### Description
The dataset viewer is not working for dataset bridgeconn/snow-mountain.
Error details:
```
Error code: JobRunnerCrashedError
```
| closed | 2023-03-07T06:58:00Z | 2023-03-21T09:26:39Z | 2023-03-21T09:22:54Z | anjalyjayakrishnan |
1,612,371,547 | WIP - Adding dataset--split-names aggregation worker | For https://github.com/huggingface/datasets-server/issues/734 we need a way to compute /splits based the new worker's cache /split-names-from-streaming and /split-names-from-dataset-info.
The new worker name will be `dataset--split-names` (Following new nomenclature https://github.com/huggingface/datasets-server/issues/867).
This is a WIP to achieve a new more robust response for /splits.
Depends on https://github.com/huggingface/datasets-server/pull/909
Pending tasks:
- [ ] Unit test for new worker
| WIP - Adding dataset--split-names aggregation worker: For https://github.com/huggingface/datasets-server/issues/734 we need a way to compute /splits based the new worker's cache /split-names-from-streaming and /split-names-from-dataset-info.
The new worker name will be `dataset--split-names` (Following new nomenclature https://github.com/huggingface/datasets-server/issues/867).
This is a WIP to achieve a new more robust response for /splits.
Depends on https://github.com/huggingface/datasets-server/pull/909
Pending tasks:
- [ ] Unit test for new worker
| closed | 2023-03-06T23:08:05Z | 2023-03-15T13:17:14Z | 2023-03-15T13:14:36Z | AndreaFrancis |
1,611,917,713 | Dataset Viewer issue for hendrycks/ethics | ### Link
https://huggingface.co/datasets/hendrycks/ethics
### Description
The dataset viewer is not working for dataset hendrycks/ethics.
Error details:
```
Error code: ResponseNotReady
```
How do I debug this? | Dataset Viewer issue for hendrycks/ethics: ### Link
https://huggingface.co/datasets/hendrycks/ethics
### Description
The dataset viewer is not working for dataset hendrycks/ethics.
Error details:
```
Error code: ResponseNotReady
```
How do I debug this? | closed | 2023-03-06T17:41:15Z | 2023-03-07T18:02:24Z | 2023-03-07T18:02:24Z | xksteven |
1,611,913,522 | Add jwt to bypass auth | Alternative to https://github.com/huggingface/datasets-server/pull/897, corresponding to option 2 in https://github.com/huggingface/datasets-server/issues/877#issuecomment-1456474625 | Add jwt to bypass auth: Alternative to https://github.com/huggingface/datasets-server/pull/897, corresponding to option 2 in https://github.com/huggingface/datasets-server/issues/877#issuecomment-1456474625 | closed | 2023-03-06T17:38:24Z | 2023-03-13T19:38:35Z | 2023-03-13T19:36:02Z | severo |
1,611,848,651 | fix: 🐛 add a mechanism with shared secret to bypass auth check | Option 1 in
https://github.com/huggingface/datasets-server/issues/877#issuecomment-1456474625. | fix: 🐛 add a mechanism with shared secret to bypass auth check: Option 1 in
https://github.com/huggingface/datasets-server/issues/877#issuecomment-1456474625. | closed | 2023-03-06T16:59:57Z | 2023-03-09T10:11:43Z | 2023-03-09T10:11:36Z | severo |
1,611,462,553 | feat: 🎸 add timeout when requesting Hub authentication check | Set to 200ms by default and in production. See #877 | feat: 🎸 add timeout when requesting Hub authentication check: Set to 200ms by default and in production. See #877 | closed | 2023-03-06T13:45:13Z | 2023-03-08T09:17:27Z | 2023-03-08T09:14:53Z | severo |
1,611,116,467 | ci: update dependencies before lint | null | ci: update dependencies before lint: | closed | 2023-03-06T10:35:21Z | 2023-03-06T20:58:44Z | 2023-03-06T20:56:07Z | rtrompier |
1,611,112,977 | Dataset Viewer issue for prasertkhajusrokar/hack5-FFT | ### Link
https://huggingface.co/datasets/prasertkhajusrokar/hack5-FFT
### Description
The dataset viewer is not working for dataset prasertkhajusrokar/hack5-FFT.
Error details:
```
Error code: ResponseNotReady
```
| Dataset Viewer issue for prasertkhajusrokar/hack5-FFT: ### Link
https://huggingface.co/datasets/prasertkhajusrokar/hack5-FFT
### Description
The dataset viewer is not working for dataset prasertkhajusrokar/hack5-FFT.
Error details:
```
Error code: ResponseNotReady
```
| closed | 2023-03-06T10:32:58Z | 2023-03-20T14:10:17Z | 2023-03-20T14:10:17Z | prasertkhajusrokar |
1,610,994,108 | fix: 🐛 ensure the dataset parameter is provided in endpoints | All the endpoints require the dataset parameter, at least, for the moment. The auth_check and the get_cache_entry_from_steps methods require dataset to be a string (None is not supported) and we have to check before that it's the case. | fix: 🐛 ensure the dataset parameter is provided in endpoints: All the endpoints require the dataset parameter, at least, for the moment. The auth_check and the get_cache_entry_from_steps methods require dataset to be a string (None is not supported) and we have to check before that it's the case. | closed | 2023-03-06T09:22:44Z | 2023-03-06T13:09:35Z | 2023-03-06T13:06:52Z | severo |
1,610,793,850 | Dataset Viewer issue for hendrycks_test | ### Link
https://huggingface.co/datasets/hendrycks_test
### Description
The dataset viewer is not working for dataset hendrycks_test.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for hendrycks_test: ### Link
https://huggingface.co/datasets/hendrycks_test
### Description
The dataset viewer is not working for dataset hendrycks_test.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-06T07:03:30Z | 2023-03-06T09:11:49Z | 2023-03-06T09:11:02Z | shiyujiaaaa |
1,608,746,289 | Store /valid and /is-valid in the cache | Pre-computing /is-valid (for each dataset) and /valid (for all the datasets) and storing the responses in that cache would help reduce the latency of these endpoints and the compute load on the API service. They are the only two endpoints that are calculated on the fly.
Another benefit: it would remove the particular field `required_by_dataset_viewer` in https://github.com/huggingface/datasets-server/blob/main/libs/libcommon/src/libcommon/processing_graph.py because the same property could be defined as dependencies between processing steps:
- /is-valid would depend on /splits and /first-rows
- /valid would depend on /is-valid
Note that we would have to add a value to [InputType](https://github.com/huggingface/datasets-server/blob/0539fbd1950bfbe89605ddd40db1aaebfc757438/libs/libcommon/src/libcommon/processing_graph.py#L10) for /valid. None? Optional?
Thanks, @AndreaFrancis, for the discussion that allowed rethinking this part.
---
- [x] create `dataset-is-valid` https://github.com/huggingface/datasets-server/pull/1032
- [ ] create `valid`
- [ ] add `none` in InputType, and make the `dataset` parameter optional where it makes sense (it is currently mandatory nearly everywhere in the code)
- [ ] add the `valid` step
- [ ] deploy and fill the cache. Done for `is-valid`
- [ ] switch the /valid and /is-valid endpoints. PR for `is-valid`: https://github.com/huggingface/datasets-server/pull/1160 | Store /valid and /is-valid in the cache: Pre-computing /is-valid (for each dataset) and /valid (for all the datasets) and storing the responses in that cache would help reduce the latency of these endpoints and the compute load on the API service. They are the only two endpoints that are calculated on the fly.
Another benefit: it would remove the particular field `required_by_dataset_viewer` in https://github.com/huggingface/datasets-server/blob/main/libs/libcommon/src/libcommon/processing_graph.py because the same property could be defined as dependencies between processing steps:
- /is-valid would depend on /splits and /first-rows
- /valid would depend on /is-valid
Note that we would have to add a value to [InputType](https://github.com/huggingface/datasets-server/blob/0539fbd1950bfbe89605ddd40db1aaebfc757438/libs/libcommon/src/libcommon/processing_graph.py#L10) for /valid. None? Optional?
Thanks, @AndreaFrancis, for the discussion that allowed rethinking this part.
---
- [x] create `dataset-is-valid` https://github.com/huggingface/datasets-server/pull/1032
- [ ] create `valid`
- [ ] add `none` in InputType, and make the `dataset` parameter optional where it makes sense (it is currently mandatory nearly everywhere in the code)
- [ ] add the `valid` step
- [ ] deploy and fill the cache. Done for `is-valid`
- [ ] switch the /valid and /is-valid endpoints. PR for `is-valid`: https://github.com/huggingface/datasets-server/pull/1160 | closed | 2023-03-03T14:30:42Z | 2023-08-22T20:19:36Z | 2023-08-22T20:15:46Z | severo |
1,608,443,541 | Allow to use service nodeport | More info here : https://github.com/huggingface/private-hub-package/issues/24
| Allow to use service nodeport: More info here : https://github.com/huggingface/private-hub-package/issues/24
| closed | 2023-03-03T11:14:51Z | 2023-03-06T10:30:39Z | 2023-03-06T10:28:03Z | rtrompier |
1,608,419,848 | Fix gauge metrics in api and admin services | The API and admin services run using uvicorn with multiple workers. We set the `PROMETHEUS_MULTIPROC_DIR` environment variable (to `/tmp`), as described in https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn, which allows every worker to write in a dedicated file. See, for example, the content of `/tmp` for one of the pods of the admin service:
<img width="831" alt="Capture d’écran 2023-03-03 à 11 53 32" src="https://user-images.githubusercontent.com/1676121/222702335-3fd14920-757d-4b0d-bc10-a83451fd75f5.png">
Each of the nine workers has its file for every metric type: `counter`, `gauge_all`, `gauge_liveall`, `histogram`.
But, as described in https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn, the "live" gauge metrics are special: they should only count the live workers, and to do that, the files starting with `gauge_live` [should be deleted](https://github.com/prometheus/client_python/blob/30f83196ac1f1a1a2626da9d724d83955aff79b1/prometheus_client/multiprocess.py#L157) on a worker child exit. But we don't do it, since uvicorn does not allow to call a specific function on child exit.
Two solutions:
- [run the services with gunicorn](https://www.uvicorn.org/deployment/)
- or, avoid using "live" gauges.
| Fix gauge metrics in api and admin services: The API and admin services run using uvicorn with multiple workers. We set the `PROMETHEUS_MULTIPROC_DIR` environment variable (to `/tmp`), as described in https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn, which allows every worker to write in a dedicated file. See, for example, the content of `/tmp` for one of the pods of the admin service:
<img width="831" alt="Capture d’écran 2023-03-03 à 11 53 32" src="https://user-images.githubusercontent.com/1676121/222702335-3fd14920-757d-4b0d-bc10-a83451fd75f5.png">
Each of the nine workers has its file for every metric type: `counter`, `gauge_all`, `gauge_liveall`, `histogram`.
But, as described in https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn, the "live" gauge metrics are special: they should only count the live workers, and to do that, the files starting with `gauge_live` [should be deleted](https://github.com/prometheus/client_python/blob/30f83196ac1f1a1a2626da9d724d83955aff79b1/prometheus_client/multiprocess.py#L157) on a worker child exit. But we don't do it, since uvicorn does not allow to call a specific function on child exit.
Two solutions:
- [run the services with gunicorn](https://www.uvicorn.org/deployment/)
- or, avoid using "live" gauges.
| open | 2023-03-03T10:56:22Z | 2024-06-19T14:06:56Z | null | severo |
1,608,240,758 | feat: 🎸 add an index to the jobs collection | proposed by mongo atlas
<img width="1121" alt="Capture d’écran 2023-03-03 à 10 08 30" src="https://user-images.githubusercontent.com/1676121/222680591-1b2d14f3-6a9d-4937-888b-cb6756ba04c8.png">
| feat: 🎸 add an index to the jobs collection: proposed by mongo atlas
<img width="1121" alt="Capture d’écran 2023-03-03 à 10 08 30" src="https://user-images.githubusercontent.com/1676121/222680591-1b2d14f3-6a9d-4937-888b-cb6756ba04c8.png">
| closed | 2023-03-03T09:15:09Z | 2023-03-03T09:52:39Z | 2023-03-03T09:42:40Z | severo |
1,607,609,417 | Adding field in processing step to support aggregations at worker level | In https://github.com/huggingface/datasets-server/issues/734 and https://github.com/huggingface/datasets-server/issues/755 we need to create a new worker that will compute splits based on split names by config see comment https://github.com/huggingface/datasets-server/issues/755#issuecomment-1428236340 .
I added a new field on processing step so that we can define the aggregation level.
e.g:
For /splits endpoint we will have two different responses based on query params:
-` ?dataset=...config=...` Respond with processing steps `[/split-names-from-streaming, /split-names-from-dataset-info] `
- `?dataset= ` Respond with two new processing steps` [/dataset-split-names-from-streaming, /dataset-split-names-from-dataset-info] `
`/dataset-split-names-from-streaming` depends on `/split-names-from-streaming`
`/split-names-from-streaming` input type is `config` and in db its granularity is dataset and config but we only need one record in the db for `/dataset-split-names-from-streaming` that will summarize the previous entries.
For the specific case of /dataset-split-names-from-streaming new worker, there will exist a new Job after /split-names-from-streaming but there will exist only 1 record for /dataset-split-names-from-streaming that will be updated N times.
If processing step is "config" but aggregation level is "dataset" one Job in the Queue per config but the result will be only one record in Cache.
| Adding field in processing step to support aggregations at worker level: In https://github.com/huggingface/datasets-server/issues/734 and https://github.com/huggingface/datasets-server/issues/755 we need to create a new worker that will compute splits based on split names by config see comment https://github.com/huggingface/datasets-server/issues/755#issuecomment-1428236340 .
I added a new field on processing step so that we can define the aggregation level.
e.g:
For /splits endpoint we will have two different responses based on query params:
-` ?dataset=...config=...` Respond with processing steps `[/split-names-from-streaming, /split-names-from-dataset-info] `
- `?dataset= ` Respond with two new processing steps` [/dataset-split-names-from-streaming, /dataset-split-names-from-dataset-info] `
`/dataset-split-names-from-streaming` depends on `/split-names-from-streaming`
`/split-names-from-streaming` input type is `config` and in db its granularity is dataset and config but we only need one record in the db for `/dataset-split-names-from-streaming` that will summarize the previous entries.
For the specific case of /dataset-split-names-from-streaming new worker, there will exist a new Job after /split-names-from-streaming but there will exist only 1 record for /dataset-split-names-from-streaming that will be updated N times.
If processing step is "config" but aggregation level is "dataset" one Job in the Queue per config but the result will be only one record in Cache.
| closed | 2023-03-02T22:26:51Z | 2023-03-03T14:35:10Z | 2023-03-03T14:32:03Z | AndreaFrancis |
1,606,811,201 | feat: 🎸 reduce the requests (and limits) in k8s resources | It's required for the api/admin services which were absolutely over-provisioned. And for the workers: we reduce a lot for now, since most of the datasets don't require that quantity of RAM, and we now manage the failed jobs due to OOm. We will work on a strategy to relaunch these jobs on "big" workers (to be done) | feat: 🎸 reduce the requests (and limits) in k8s resources: It's required for the api/admin services which were absolutely over-provisioned. And for the workers: we reduce a lot for now, since most of the datasets don't require that quantity of RAM, and we now manage the failed jobs due to OOm. We will work on a strategy to relaunch these jobs on "big" workers (to be done) | closed | 2023-03-02T13:29:01Z | 2023-03-02T14:06:52Z | 2023-03-02T14:04:15Z | severo |
1,606,713,432 | Publish /healthcheck again | <strike>It is needed by argocd</strike>
<img width="143" alt="Capture d’écran 2023-03-02 à 13 22 09" src="https://user-images.githubusercontent.com/1676121/222427779-9e56ddc4-b40e-4334-b6fb-5712f8df7b92.png">
It is needed by the ALB
It's defined at https://github.com/huggingface/datasets-server/blob/fb48ed36cd41b13fba88b6b18072faf1bbd1fb62/chart/env/prod.yaml#L125 | Publish /healthcheck again: <strike>It is needed by argocd</strike>
<img width="143" alt="Capture d’écran 2023-03-02 à 13 22 09" src="https://user-images.githubusercontent.com/1676121/222427779-9e56ddc4-b40e-4334-b6fb-5712f8df7b92.png">
It is needed by the ALB
It's defined at https://github.com/huggingface/datasets-server/blob/fb48ed36cd41b13fba88b6b18072faf1bbd1fb62/chart/env/prod.yaml#L125 | closed | 2023-03-02T12:23:40Z | 2023-03-02T12:49:31Z | 2023-03-02T12:44:55Z | severo |
1,606,605,717 | chore: 🤖 use other nodes for the workers | null | chore: 🤖 use other nodes for the workers: | closed | 2023-03-02T11:12:22Z | 2023-03-02T11:18:42Z | 2023-03-02T11:15:18Z | severo |
1,606,465,607 | feat: 🎸 add an index | Recommended by the managed mongo database service
<img width="1076" alt="Capture d’écran 2023-03-02 à 10 39 45" src="https://user-images.githubusercontent.com/1676121/222391301-2b9b2261-6601-4ac4-b9bf-cb36fa95f486.png"> | feat: 🎸 add an index: Recommended by the managed mongo database service
<img width="1076" alt="Capture d’écran 2023-03-02 à 10 39 45" src="https://user-images.githubusercontent.com/1676121/222391301-2b9b2261-6601-4ac4-b9bf-cb36fa95f486.png"> | closed | 2023-03-02T09:42:25Z | 2023-03-03T09:15:40Z | 2023-03-02T14:24:33Z | severo |
1,606,039,462 | Unsafe warning issue for poloclub/diffusiondb | ### Link
https://huggingface.co/datasets/poloclub/diffusiondb
### Description
Hello 👋, we have seen the below warning on [our dataset](https://huggingface.co/datasets/poloclub/diffusiondb) on hugging face. The flagged file is a [zip file](https://huggingface.co/datasets/poloclub/diffusiondb/blob/main/images/part-000989.zip).
```
Virus: Multios.Backdoor.Msfvenom_Payload-9951536-0
```

This zip file only contains 1000 images and a json file. I don't think there is any security concern among these files. I tried to (1) re-load and re-export all images using PIL and (2) re-zip and re-upload this particular file in [this commit](https://huggingface.co/datasets/poloclub/diffusiondb/commit/527749109c86eda3c82027143e45964e75cbf772). However, the same error comes back again 😭.
Do you have any suggestions on how to fix it please? Thank you!
| Unsafe warning issue for poloclub/diffusiondb: ### Link
https://huggingface.co/datasets/poloclub/diffusiondb
### Description
Hello 👋, we have seen the below warning on [our dataset](https://huggingface.co/datasets/poloclub/diffusiondb) on hugging face. The flagged file is a [zip file](https://huggingface.co/datasets/poloclub/diffusiondb/blob/main/images/part-000989.zip).
```
Virus: Multios.Backdoor.Msfvenom_Payload-9951536-0
```

This zip file only contains 1000 images and a json file. I don't think there is any security concern among these files. I tried to (1) re-load and re-export all images using PIL and (2) re-zip and re-upload this particular file in [this commit](https://huggingface.co/datasets/poloclub/diffusiondb/commit/527749109c86eda3c82027143e45964e75cbf772). However, the same error comes back again 😭.
Do you have any suggestions on how to fix it please? Thank you!
| closed | 2023-03-02T03:18:08Z | 2023-11-20T15:05:02Z | 2023-11-20T15:05:02Z | xiaohk |
1,605,956,753 | Dataset Viewer issue for fka/awesome-chatgpt-prompts | ### Link
https://huggingface.co/datasets/fka/awesome-chatgpt-prompts
### Description
The dataset viewer is not working for dataset fka/awesome-chatgpt-prompts.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for fka/awesome-chatgpt-prompts: ### Link
https://huggingface.co/datasets/fka/awesome-chatgpt-prompts
### Description
The dataset viewer is not working for dataset fka/awesome-chatgpt-prompts.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-02T01:23:56Z | 2023-03-02T08:31:53Z | 2023-03-02T08:31:53Z | AI-wangzeyu |
1,605,787,225 | WIP - Adding new admin enpoint to refresh outdated cache | Since #879 increased the workers version but we have existing records in dev/prod, we need a way to process the cache again given a specific processing step.
This solution will get the current version and will append a new Job for every cache entry with a `worker_version` minor than the current worker version.
Pending:
- [ ] Tests | WIP - Adding new admin enpoint to refresh outdated cache : Since #879 increased the workers version but we have existing records in dev/prod, we need a way to process the cache again given a specific processing step.
This solution will get the current version and will append a new Job for every cache entry with a `worker_version` minor than the current worker version.
Pending:
- [ ] Tests | closed | 2023-03-01T22:45:57Z | 2023-03-02T15:02:33Z | 2023-03-02T14:49:22Z | AndreaFrancis |
1,605,383,387 | Increase version of workers /split-names from streaming and dataset info | As per PR https://github.com/huggingface/datasets-server/pull/878, worker versions should have been increased | Increase version of workers /split-names from streaming and dataset info: As per PR https://github.com/huggingface/datasets-server/pull/878, worker versions should have been increased | closed | 2023-03-01T17:32:12Z | 2023-03-02T08:32:30Z | 2023-03-01T17:47:32Z | AndreaFrancis |
1,605,245,319 | Renaming split-names response to splits | Fix content response name in split_names_from_streaming and split_names_from_dataset_info from "split_names" to "splits" so that it is consistent with the response of splits worker | Renaming split-names response to splits: Fix content response name in split_names_from_streaming and split_names_from_dataset_info from "split_names" to "splits" so that it is consistent with the response of splits worker | closed | 2023-03-01T16:02:38Z | 2023-03-01T16:31:36Z | 2023-03-01T16:28:42Z | AndreaFrancis |
1,604,882,787 | Reduce the endpoints response time | Many issues (like https://github.com/huggingface/datasets-server/issues/876) are created with `Error code: ClientConnectionError`. They are due to the Hub backend timing out when requesting a response from the datasets server.
We monitor the endpoints' response time at (internal) https://grafana.huggingface.tech/d/i7gwsO5Vz/global-view | Reduce the endpoints response time: Many issues (like https://github.com/huggingface/datasets-server/issues/876) are created with `Error code: ClientConnectionError`. They are due to the Hub backend timing out when requesting a response from the datasets server.
We monitor the endpoints' response time at (internal) https://grafana.huggingface.tech/d/i7gwsO5Vz/global-view | closed | 2023-03-01T12:29:23Z | 2023-03-15T09:37:44Z | 2023-03-14T15:17:41Z | severo |
1,604,852,606 | Dataset Viewer issue for Matthijs/cmu-arctic-xvectors | ### Link
https://huggingface.co/datasets/Matthijs/cmu-arctic-xvectors
### Description
The dataset viewer is not working for dataset Matthijs/cmu-arctic-xvectors.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for Matthijs/cmu-arctic-xvectors: ### Link
https://huggingface.co/datasets/Matthijs/cmu-arctic-xvectors
### Description
The dataset viewer is not working for dataset Matthijs/cmu-arctic-xvectors.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-03-01T12:08:40Z | 2023-03-01T12:29:58Z | 2023-03-01T12:29:58Z | p1sa |
1,604,705,760 | Random rows | Add a new endpoint: `/rows`
Parameters: `dataset`, `config`, `split`, `offset` and `limit`.
It returns a list of `limit` rows of the split, from row idx=`offset`, by fetching them from the parquet files published on the Hub.
Replaces #687 | Random rows: Add a new endpoint: `/rows`
Parameters: `dataset`, `config`, `split`, `offset` and `limit`.
It returns a list of `limit` rows of the split, from row idx=`offset`, by fetching them from the parquet files published on the Hub.
Replaces #687 | closed | 2023-03-01T10:36:13Z | 2023-03-27T08:30:52Z | 2023-03-27T08:27:35Z | severo |
1,604,618,244 | feat: 🎸 reduce a lot the resources used in production | nearly all the jobs should be managed by the generic worker. We still reserve two workers for each job type (for now) | feat: 🎸 reduce a lot the resources used in production: nearly all the jobs should be managed by the generic worker. We still reserve two workers for each job type (for now) | closed | 2023-03-01T09:44:36Z | 2023-03-01T09:50:33Z | 2023-03-01T09:48:04Z | severo |
1,604,574,233 | fix: 🐛 manage duplicates in cache entries migration | null | fix: 🐛 manage duplicates in cache entries migration: | closed | 2023-03-01T09:15:28Z | 2023-03-01T09:21:32Z | 2023-03-01T09:19:01Z | severo |
1,603,964,352 | Dataset Viewer issue for docred | ### Link
https://huggingface.co/datasets/docred
### Description
The dataset viewer is not working for dataset docred.
Error details:
```
Error code: ClientConnectionError
```
| Dataset Viewer issue for docred: ### Link
https://huggingface.co/datasets/docred
### Description
The dataset viewer is not working for dataset docred.
Error details:
```
Error code: ClientConnectionError
```
| closed | 2023-02-28T23:20:54Z | 2023-03-01T12:30:14Z | 2023-03-01T12:30:13Z | ArchchanaKugathasan |
1,603,729,730 | fix: 🐛 set the list of supported job types as a csv string | not a python list! fixes #870 | fix: 🐛 set the list of supported job types as a csv string: not a python list! fixes #870 | closed | 2023-02-28T20:05:36Z | 2023-02-28T20:11:49Z | 2023-02-28T20:09:22Z | severo |
1,603,725,065 | Empty list of processing steps is not parsed correctly | Instead of allowing all the types of processing steps, it seems to be considered as the list of one element, called `'[]'`
Logs:
```
DEBUG: 2023-02-28 19:56:54,650 - root - looking for a job to start, among the following types: ['[]']
DEBUG: 2023-02-28 19:56:54,650 - root - Getting next waiting job for priority Priority.NORMAL, among types ['[]']
``` | Empty list of processing steps is not parsed correctly: Instead of allowing all the types of processing steps, it seems to be considered as the list of one element, called `'[]'`
Logs:
```
DEBUG: 2023-02-28 19:56:54,650 - root - looking for a job to start, among the following types: ['[]']
DEBUG: 2023-02-28 19:56:54,650 - root - Getting next waiting job for priority Priority.NORMAL, among types ['[]']
``` | closed | 2023-02-28T20:02:08Z | 2023-02-28T20:09:23Z | 2023-02-28T20:09:23Z | severo |
1,603,361,324 | ci: 🎡 add missing step to get the source code | null | ci: 🎡 add missing step to get the source code: | closed | 2023-02-28T16:07:23Z | 2023-02-28T16:18:27Z | 2023-02-28T16:15:26Z | severo |
1,602,727,787 | Add doc, simplify docker, update chart | - add doc on how to setup the TMPDIR environment variable
- simplify docker compose
- update chart to use the four new environment variables
- upgrade some minor dependencies
(sorry, it's a mix of too many things, should have been various PRs) | Add doc, simplify docker, update chart: - add doc on how to setup the TMPDIR environment variable
- simplify docker compose
- update chart to use the four new environment variables
- upgrade some minor dependencies
(sorry, it's a mix of too many things, should have been various PRs) | closed | 2023-02-28T10:06:07Z | 2023-02-28T14:50:48Z | 2023-02-28T14:48:18Z | severo |
1,601,605,808 | Change nomenclature of processing steps | Until now, every public endpoint (ie /splits) was associated with one job and one type of cache entry. But that’s no more the case:
- the response can be computed using two concurrent methods (streaming vs normal, for example), and the first successful response is returned
- the response can be computed at config level (/split-names) then aggregated at dataset level
It’s the occasion to rethink a bit the name of the steps, job types and cache kinds.
For now, every processing step has only one associated job type and cache kind, so we use the same for these three. But it’s no more related to the public API endpoint.
- First change: remove the initial slash (`/step` → `step`)
- Second change: to make it easier to think about, we can include the “level” at which the response is computed in the name of the step (`step` → `dataset-step`)
With these rules, after renaming and implementing some pending issues (https://github.com/huggingface/datasets-server/issues/735) we would end with the following set of processing steps and public endpoints:
Public endpoint | Dataset-level steps | Config-level steps | Split-level steps
-- | -- | -- | --
| `dataset-config-names` | |
`/splits` | `dataset-split-names` | `config-split-names-from-streaming`, `config-split-names-from-dataset-info` | |
`/first-rows` | | | `split-first-rows-from-streaming`, `split-first-rows-from-parquet` | | |
| | `config-parquet-and-dataset-info` |
`/parquet` | `dataset-parquet` | `config-parquet` |
`/dataset-info` | `dataset-dataset-info` | `config-dataset-info` |
`/sizes` | `dataset-sizes` | `config-sizes` |
<p>Also: every cached response would be accessible through: <code>/admin/cache/[step name]</code>, e.g. <code>/admin/cache/config-parquet-and-dataset-info?dataset=x&config=y</code></p>
| Change nomenclature of processing steps: Until now, every public endpoint (ie /splits) was associated with one job and one type of cache entry. But that’s no more the case:
- the response can be computed using two concurrent methods (streaming vs normal, for example), and the first successful response is returned
- the response can be computed at config level (/split-names) then aggregated at dataset level
It’s the occasion to rethink a bit the name of the steps, job types and cache kinds.
For now, every processing step has only one associated job type and cache kind, so we use the same for these three. But it’s no more related to the public API endpoint.
- First change: remove the initial slash (`/step` → `step`)
- Second change: to make it easier to think about, we can include the “level” at which the response is computed in the name of the step (`step` → `dataset-step`)
With these rules, after renaming and implementing some pending issues (https://github.com/huggingface/datasets-server/issues/735) we would end with the following set of processing steps and public endpoints:
Public endpoint | Dataset-level steps | Config-level steps | Split-level steps
-- | -- | -- | --
| `dataset-config-names` | |
`/splits` | `dataset-split-names` | `config-split-names-from-streaming`, `config-split-names-from-dataset-info` | |
`/first-rows` | | | `split-first-rows-from-streaming`, `split-first-rows-from-parquet` | | |
| | `config-parquet-and-dataset-info` |
`/parquet` | `dataset-parquet` | `config-parquet` |
`/dataset-info` | `dataset-dataset-info` | `config-dataset-info` |
`/sizes` | `dataset-sizes` | `config-sizes` |
<p>Also: every cached response would be accessible through: <code>/admin/cache/[step name]</code>, e.g. <code>/admin/cache/config-parquet-and-dataset-info?dataset=x&config=y</code></p>
| closed | 2023-02-27T17:17:29Z | 2023-06-02T15:53:02Z | 2023-06-02T15:53:01Z | severo |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.