
html_url
stringlengths 51
51
| title
stringlengths 6
280
| comments
stringlengths 67
24.7k
| body
stringlengths 51
36.2k
⌀ | comment_length
int64 16
1.45k
| text
stringlengths 159
38.3k
|
|---|---|---|---|---|---|
https://github.com/huggingface/datasets/issues/3760 | Unable to view the Gradio flagged call back dataset | The problem was resolved by deleted the dataset and creating new one with similar name and then clicking on flag button. | ## Dataset viewer issue for '*savtadepth-flags*'
**Link:** *[savtadepth-flags](https://huggingface.co/datasets/kingabzpro/savtadepth-flags)*
*with the Gradio 2.8.1 the dataset viers stopped working. I tried to add values manually but its not working. The dataset is also not showing the link with the app https://huggingface.co/spaces/kingabzpro/savtadepth.*
Am I the one who added this dataset ? Yes
| 21 | Unable to view the Gradio flagged call back dataset
## Dataset viewer issue for '*savtadepth-flags*'
**Link:** *[savtadepth-flags](https://huggingface.co/datasets/kingabzpro/savtadepth-flags)*
*with the Gradio 2.8.1 the dataset viers stopped working. I tried to add values manually but its not working. The dataset is also not showing the link with the app https://huggingface.co/spaces/kingabzpro/savtadepth.*
Am I the one who added this dataset ? Yes
The problem was resolved by deleted the dataset and creating new one with similar name and then clicking on flag button. |
https://github.com/huggingface/datasets/issues/3758 | head_qa file missing | We usually find issues with files hosted at Google Drive...
In this case we download the Google Drive Virus scan warning instead of the data file. | ## Describe the bug
A file for the `head_qa` dataset is missing (https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t/HEAD_EN/train_HEAD_EN.json)
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("head_qa", name="en")
```
## Expected results
The dataset should be loaded
## Actual results
```
Downloading and preparing dataset head_qa/en (download: 75.69 MiB, generated: 2.69 MiB, post-processed: Unknown size, total: 78.38 MiB) to /home/slesage/.cache/huggingface/datasets/head_qa/en/1.1.0/583ab408e8baf54aab378c93715fadc4d8aa51b393e27c3484a877e2ac0278e9...
Downloading data: 2.21kB [00:00, 2.05MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/load.py", line 1729, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 594, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 665, in _download_and_prepare
verify_checksums(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t']
```
## Environment info
- `datasets` version: 1.18.4.dev0
- Platform: Linux-5.11.0-1028-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| 26 | head_qa file missing
## Describe the bug
A file for the `head_qa` dataset is missing (https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t/HEAD_EN/train_HEAD_EN.json)
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("head_qa", name="en")
```
## Expected results
The dataset should be loaded
## Actual results
```
Downloading and preparing dataset head_qa/en (download: 75.69 MiB, generated: 2.69 MiB, post-processed: Unknown size, total: 78.38 MiB) to /home/slesage/.cache/huggingface/datasets/head_qa/en/1.1.0/583ab408e8baf54aab378c93715fadc4d8aa51b393e27c3484a877e2ac0278e9...
Downloading data: 2.21kB [00:00, 2.05MB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/load.py", line 1729, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 594, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 665, in _download_and_prepare
verify_checksums(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t']
```
## Environment info
- `datasets` version: 1.18.4.dev0
- Platform: Linux-5.11.0-1028-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
We usually find issues with files hosted at Google Drive...
In this case we download the Google Drive Virus scan warning instead of the data file. |
https://github.com/huggingface/datasets/issues/3756 | Images get decoded when using `map()` with `input_columns` argument on a dataset | Hi! If I'm not mistaken, this behavior is intentional, but I agree it could be more intuitive.
@albertvillanova Do you remember why you decided not to decode columns in the `Audio` feature PR when `input_columns` is not `None`? IMO we should decode those columns, and we don't even have to use lazy structures here because the user explicitly requires them in the map transform.
cc @lhoestq for visibility | ## Describe the bug
The `datasets.features.Image` feature class decodes image data by default. Expectedly, when indexing a dataset or using the `map()` method, images are returned as PIL Image instances.
However, when calling `map()` and setting a specific data column with the `input_columns` argument, the image data is passed as raw byte representation to the mapping function.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchvision import transforms
from PIL.Image import Image
dataset = load_dataset('mnist', split='train')
def transform_all_columns(example):
# example['image'] is encoded as PIL Image
assert isinstance(example['image'], Image)
return example
def transform_image_column(image):
# image is decoded here and represented as raw bytes
assert isinstance(image, Image)
return image
# single-sample dataset for debugging purposes
dev = dataset.select([0])
dev.map(transform_all_columns)
dev.map(transform_image_column, input_columns='image')
```
## Expected results
Image data should be passed in decoded form, i.e. as PIL Image objects to the mapping function unless the `decode` attribute on the image feature is set to `False`.
## Actual results
The mapping function receives images as raw byte data.
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-49-generic-x86_64-with-glibc2.32
- Python version: 3.8.0b4
- PyArrow version: 7.0.0
| 68 | Images get decoded when using `map()` with `input_columns` argument on a dataset
## Describe the bug
The `datasets.features.Image` feature class decodes image data by default. Expectedly, when indexing a dataset or using the `map()` method, images are returned as PIL Image instances.
However, when calling `map()` and setting a specific data column with the `input_columns` argument, the image data is passed as raw byte representation to the mapping function.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchvision import transforms
from PIL.Image import Image
dataset = load_dataset('mnist', split='train')
def transform_all_columns(example):
# example['image'] is encoded as PIL Image
assert isinstance(example['image'], Image)
return example
def transform_image_column(image):
# image is decoded here and represented as raw bytes
assert isinstance(image, Image)
return image
# single-sample dataset for debugging purposes
dev = dataset.select([0])
dev.map(transform_all_columns)
dev.map(transform_image_column, input_columns='image')
```
## Expected results
Image data should be passed in decoded form, i.e. as PIL Image objects to the mapping function unless the `decode` attribute on the image feature is set to `False`.
## Actual results
The mapping function receives images as raw byte data.
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-49-generic-x86_64-with-glibc2.32
- Python version: 3.8.0b4
- PyArrow version: 7.0.0
Hi! If I'm not mistaken, this behavior is intentional, but I agree it could be more intuitive.
@albertvillanova Do you remember why you decided not to decode columns in the `Audio` feature PR when `input_columns` is not `None`? IMO we should decode those columns, and we don't even have to use lazy structures here because the user explicitly requires them in the map transform.
cc @lhoestq for visibility |
https://github.com/huggingface/datasets/issues/3756 | Images get decoded when using `map()` with `input_columns` argument on a dataset | I think I excluded to decorate the function when `input_columns` were passed as a quick fix for some non-passing tests:
- https://github.com/huggingface/datasets/pull/2324/commits/9d7c3e8fa53e23ec636859b4407eeec904b1b3f9
That PR was quite complex and I decided to focus on the main feature requests, leaving refinements for subsequent PRs.
Note that when `input_columns` are passed, the signature of the function is effectively changed, while the decorated function expects an item (whether an example or a batch) as first arg (which is not the case when passing `input_columns`.
I agree we should consider supporting the case when `input_columns` are passed. | ## Describe the bug
The `datasets.features.Image` feature class decodes image data by default. Expectedly, when indexing a dataset or using the `map()` method, images are returned as PIL Image instances.
However, when calling `map()` and setting a specific data column with the `input_columns` argument, the image data is passed as raw byte representation to the mapping function.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchvision import transforms
from PIL.Image import Image
dataset = load_dataset('mnist', split='train')
def transform_all_columns(example):
# example['image'] is encoded as PIL Image
assert isinstance(example['image'], Image)
return example
def transform_image_column(image):
# image is decoded here and represented as raw bytes
assert isinstance(image, Image)
return image
# single-sample dataset for debugging purposes
dev = dataset.select([0])
dev.map(transform_all_columns)
dev.map(transform_image_column, input_columns='image')
```
## Expected results
Image data should be passed in decoded form, i.e. as PIL Image objects to the mapping function unless the `decode` attribute on the image feature is set to `False`.
## Actual results
The mapping function receives images as raw byte data.
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-49-generic-x86_64-with-glibc2.32
- Python version: 3.8.0b4
- PyArrow version: 7.0.0
| 92 | Images get decoded when using `map()` with `input_columns` argument on a dataset
## Describe the bug
The `datasets.features.Image` feature class decodes image data by default. Expectedly, when indexing a dataset or using the `map()` method, images are returned as PIL Image instances.
However, when calling `map()` and setting a specific data column with the `input_columns` argument, the image data is passed as raw byte representation to the mapping function.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchvision import transforms
from PIL.Image import Image
dataset = load_dataset('mnist', split='train')
def transform_all_columns(example):
# example['image'] is encoded as PIL Image
assert isinstance(example['image'], Image)
return example
def transform_image_column(image):
# image is decoded here and represented as raw bytes
assert isinstance(image, Image)
return image
# single-sample dataset for debugging purposes
dev = dataset.select([0])
dev.map(transform_all_columns)
dev.map(transform_image_column, input_columns='image')
```
## Expected results
Image data should be passed in decoded form, i.e. as PIL Image objects to the mapping function unless the `decode` attribute on the image feature is set to `False`.
## Actual results
The mapping function receives images as raw byte data.
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-49-generic-x86_64-with-glibc2.32
- Python version: 3.8.0b4
- PyArrow version: 7.0.0
I think I excluded to decorate the function when `input_columns` were passed as a quick fix for some non-passing tests:
- https://github.com/huggingface/datasets/pull/2324/commits/9d7c3e8fa53e23ec636859b4407eeec904b1b3f9
That PR was quite complex and I decided to focus on the main feature requests, leaving refinements for subsequent PRs.
Note that when `input_columns` are passed, the signature of the function is effectively changed, while the decorated function expects an item (whether an example or a batch) as first arg (which is not the case when passing `input_columns`.
I agree we should consider supporting the case when `input_columns` are passed. |
https://github.com/huggingface/datasets/issues/3755 | Cannot preview dataset | Thanks for reporting. The dataset viewer depends on some backend treatments, and for now, they might take some hours to get processed. We're working on improving it. | ## Dataset viewer issue for '*rubrix/news*'
**Link:https://huggingface.co/datasets/rubrix/news** *link to the dataset viewer page*
Cannot see the dataset preview:
```
Status code: 400
Exception: Status400Error
Message: Not found. Cache is waiting to be refreshed.
```
Am I the one who added this dataset ? No
| 27 | Cannot preview dataset
## Dataset viewer issue for '*rubrix/news*'
**Link:https://huggingface.co/datasets/rubrix/news** *link to the dataset viewer page*
Cannot see the dataset preview:
```
Status code: 400
Exception: Status400Error
Message: Not found. Cache is waiting to be refreshed.
```
Am I the one who added this dataset ? No
Thanks for reporting. The dataset viewer depends on some backend treatments, and for now, they might take some hours to get processed. We're working on improving it. |
https://github.com/huggingface/datasets/issues/3753 | Expanding streaming capabilities | Cool ! `filter` will be very useful. There can be a filter that you can apply on a streaming dataset:
```python
load_dataset(..., streaming=True).filter(lambda x: x["lang"] == "sw")
```
Otherwise if you want to apply a filter on the source files that are going to be used for streaming, the logic has to be impIemented directly in the dataset script, or if there's no dataset script this can be done with pattern matching
```python
load_dataset(..., lang="sw") # if the dataset script supports this parameter
load_dataset(..., data_files="data/lang=sw/*") # if there's no dataset script, but only data files
```
--------------
Here are also some additional ideas of API to convert from iterable to map-style dataset:
```python
on_disk_dataset = streaming_dataset.to_disk()
on_disk_dataset = streaming_dataset.to_disk(path="path/to/my/dataset/dir")
in_memory_dataset = streaming_dataset.take(100).to_memory() # to experiment without having to write files
```
--------------
Finally regarding `push_to_hub`, we can replace `batch_size` by `shard_size` (same API as for on-disk datasets). The default is 500MB per file
Let me know what you think ! | Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova | 160 | Expanding streaming capabilities
Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova
Cool ! `filter` will be very useful. There can be a filter that you can apply on a streaming dataset:
```python
load_dataset(..., streaming=True).filter(lambda x: x["lang"] == "sw")
```
Otherwise if you want to apply a filter on the source files that are going to be used for streaming, the logic has to be impIemented directly in the dataset script, or if there's no dataset script this can be done with pattern matching
```python
load_dataset(..., lang="sw") # if the dataset script supports this parameter
load_dataset(..., data_files="data/lang=sw/*") # if there's no dataset script, but only data files
```
--------------
Here are also some additional ideas of API to convert from iterable to map-style dataset:
```python
on_disk_dataset = streaming_dataset.to_disk()
on_disk_dataset = streaming_dataset.to_disk(path="path/to/my/dataset/dir")
in_memory_dataset = streaming_dataset.take(100).to_memory() # to experiment without having to write files
```
--------------
Finally regarding `push_to_hub`, we can replace `batch_size` by `shard_size` (same API as for on-disk datasets). The default is 500MB per file
Let me know what you think ! |
https://github.com/huggingface/datasets/issues/3753 | Expanding streaming capabilities | Regarding conversion, I'd also ask for some kind of equivalent to `save_to_disk` for an `IterableDataset`.
Similarly to the streaming to hub idea, my use case would be to define a sequence of dataset transforms via `.map()`, using an `IterableDataset` as the input (so processing could start without doing whole download up-front), but streaming the resultant processed dataset just to disk. | Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova | 60 | Expanding streaming capabilities
Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova
Regarding conversion, I'd also ask for some kind of equivalent to `save_to_disk` for an `IterableDataset`.
Similarly to the streaming to hub idea, my use case would be to define a sequence of dataset transforms via `.map()`, using an `IterableDataset` as the input (so processing could start without doing whole download up-front), but streaming the resultant processed dataset just to disk. |
https://github.com/huggingface/datasets/issues/3753 | Expanding streaming capabilities | That makes sense @athewsey , thanks for the suggestion :)
Maybe instead of the `to_disk` we could simply have `save_to_disk` instead:
```python
streaming_dataset.save_to_disk("path/to/my/dataset/dir")
on_disk_dataset = load_from_disk("path/to/my/dataset/dir")
in_memory_dataset = Dataset.from_list(list(streaming_dataset.take(100))) # to experiment without having to write files
``` | Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova | 38 | Expanding streaming capabilities
Some ideas for a few features that could be useful when working with large datasets in streaming mode.
## `filter` for `IterableDataset`
Adding filtering to streaming datasets would be useful in several scenarios:
- filter a dataset with many languages for a subset of languages
- filter a dataset for specific licenses
- other custom logic to get a subset
The only way to achieve this at the moment is I think through writing a custom loading script and implementing filters there.
## `IterableDataset` to `Dataset` conversion
In combination with the above filter a functionality to "play" the whole stream would be useful. The motivation is that often one might filter the dataset to get a manageable size for experimentation. In that case streaming mode is no longer necessary as the filtered dataset is small enough and it would be useful to be able to play through the whole stream to create a normal `Dataset` with all its benefits.
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(lambda x: x["lang"]="fr")
ds_filter = ds_filter.stream() # here the `IterableDataset` is converted to a `Dataset`
```
Naturally, this could be expanded with `stream(n=1000)` which creates a `Dataset` with the first `n` elements similar to `take`.
## Stream to the Hub
While streaming allows to use a dataset as is without saving the whole dataset on the local machine it is currently not possible to process a dataset and add it to the hub. The only way to do this is by downloading the full dataset and saving the processed dataset again before pushing them to the hub. The API could looks something like:
```python
ds = load_dataset("some_large_dataset", streaming=True)
ds_filter = ds.filter(some_filter_func)
ds_processed = ds_filter.map(some_processing_func)
ds_processed.push_to_hub("new_better_dataset", batch_size=100_000)
```
Under the hood this could be done by processing and aggregating `batch_size` elements and then pushing that batch as a single file to the hub. With this functionality one could process and create TB scale datasets while only requiring size of `batch_size` local disk space.
cc @lhoestq @albertvillanova
That makes sense @athewsey , thanks for the suggestion :)
Maybe instead of the `to_disk` we could simply have `save_to_disk` instead:
```python
streaming_dataset.save_to_disk("path/to/my/dataset/dir")
on_disk_dataset = load_from_disk("path/to/my/dataset/dir")
in_memory_dataset = Dataset.from_list(list(streaming_dataset.take(100))) # to experiment without having to write files
``` |
https://github.com/huggingface/datasets/issues/3739 | Pubmed dataset does not work in streaming mode | Thanks for reporting, @abhi-mosaic (related to #3655).
Please note that `xml.etree.ElementTree.parse` already supports streaming:
- #3476
No need to refactor to use `open`/`xopen`. Is is enough with importing the package `as ET` (instead of `as etree`). | ## Describe the bug
Trying to use the `pubmed` dataset with `streaming=True` fails.
## Steps to reproduce the bug
```python
import datasets
pubmed_train = datasets.load_dataset('pubmed', split='train', streaming=True)
print (next(iter(pubmed_train)))
```
## Expected results
I would expect to see the first training sample from the pubmed dataset.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 367, in __iter__
for key, example in self._iter():
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 364, in _iter
yield from ex_iterable
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
for key, example in self.generate_examples_fn(**self.kwargs):
File "/Users/abhinav/.cache/huggingface/modules/datasets_modules/datasets/pubmed/9715addf10c42a7877a2149ae0c5f2fddabefc775cd1bd9b03ac3f012b86ce46/pubmed.py", line 373, in _generate_examples
tree = etree.parse(filename)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 1202, in parse
tree.parse(source, parser)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 584, in parse
source = open(source, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'gzip://pubmed21n0001.xml::ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0001.xml.gz'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
## Comments
The error looks like an issue with `open` vs. `xopen` inside the `xml` package. It looks like it's trying to open the remote source URL, which has been edited with prefix `gzip://...`.
Maybe there can be an explicit `xopen` before passing the raw data to `etree`, something like:
```python
# Before
tree = etree.parse(filename)
root = tree.getroot()
# After
with xopen(filename) as f:
data_str = f.read()
root = etree.fromstring(data_str)
``` | 36 | Pubmed dataset does not work in streaming mode
## Describe the bug
Trying to use the `pubmed` dataset with `streaming=True` fails.
## Steps to reproduce the bug
```python
import datasets
pubmed_train = datasets.load_dataset('pubmed', split='train', streaming=True)
print (next(iter(pubmed_train)))
```
## Expected results
I would expect to see the first training sample from the pubmed dataset.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 367, in __iter__
for key, example in self._iter():
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 364, in _iter
yield from ex_iterable
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
for key, example in self.generate_examples_fn(**self.kwargs):
File "/Users/abhinav/.cache/huggingface/modules/datasets_modules/datasets/pubmed/9715addf10c42a7877a2149ae0c5f2fddabefc775cd1bd9b03ac3f012b86ce46/pubmed.py", line 373, in _generate_examples
tree = etree.parse(filename)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 1202, in parse
tree.parse(source, parser)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 584, in parse
source = open(source, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'gzip://pubmed21n0001.xml::ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0001.xml.gz'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
## Comments
The error looks like an issue with `open` vs. `xopen` inside the `xml` package. It looks like it's trying to open the remote source URL, which has been edited with prefix `gzip://...`.
Maybe there can be an explicit `xopen` before passing the raw data to `etree`, something like:
```python
# Before
tree = etree.parse(filename)
root = tree.getroot()
# After
with xopen(filename) as f:
data_str = f.read()
root = etree.fromstring(data_str)
```
Thanks for reporting, @abhi-mosaic (related to #3655).
Please note that `xml.etree.ElementTree.parse` already supports streaming:
- #3476
No need to refactor to use `open`/`xopen`. Is is enough with importing the package `as ET` (instead of `as etree`). |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | Note that we might change the heuristic and create a different config per file, at least in that case. | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 19 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
Note that we might change the heuristic and create a different config per file, at least in that case. |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | Hi @severo, thanks for reporting.
Yes, this happens because when non-streaming, a cast of all data is done in order to "concatenate" it all into a single dataset (thus the error), while this casting is not done while yielding item by item in streaming mode.
Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema? | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 74 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
Hi @severo, thanks for reporting.
Yes, this happens because when non-streaming, a cast of all data is done in order to "concatenate" it all into a single dataset (thus the error), while this casting is not done while yielding item by item in streaming mode.
Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema? |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | Why do we want to concatenate the files? Is it the expected behavior for most datasets that lack a script and dataset info? | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 23 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
Why do we want to concatenate the files? Is it the expected behavior for most datasets that lack a script and dataset info? |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | These files are two different dataset configurations since they don't share the same schema.
IMO the streaming mode should fail in this case, as @albertvillanova said.
There is one challenge though: inferring the schema from the first example is not robust enough in the general case - especially if some fields are nullable. I guess we can at least make sure that no new columns are added | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 67 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
These files are two different dataset configurations since they don't share the same schema.
IMO the streaming mode should fail in this case, as @albertvillanova said.
There is one challenge though: inferring the schema from the first example is not robust enough in the general case - especially if some fields are nullable. I guess we can at least make sure that no new columns are added |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | OK. So, if we make the streaming also fail, the dataset https://huggingface.co/datasets/huggingface/transformers-metadata will never be [viewable](https://github.com/huggingface/datasets-preview-backend/issues/144) (be it using streaming or fallback to downloading the files), right?
| See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 27 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
OK. So, if we make the streaming also fail, the dataset https://huggingface.co/datasets/huggingface/transformers-metadata will never be [viewable](https://github.com/huggingface/datasets-preview-backend/issues/144) (be it using streaming or fallback to downloading the files), right?
|
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | Yes, until we have a way for the user to specify explicitly that those two files are different configurations.
We can maybe have some rule to detect this automatically, maybe checking the first line of each file ? That would mean that for dataset of 10,000+ files we would have to verify every single one of them just to know if there is one ore more configurations, so I'm not sure if this is a good idea | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 77 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
Yes, until we have a way for the user to specify explicitly that those two files are different configurations.
We can maybe have some rule to detect this automatically, maybe checking the first line of each file ? That would mean that for dataset of 10,000+ files we would have to verify every single one of them just to know if there is one ore more configurations, so I'm not sure if this is a good idea |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | i think requiring the user to specify that those two files are different configurations is in that case perfectly reasonable.
(Maybe at some point we could however detect this type of case and prompt them to define a config mapping etc) | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 41 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
i think requiring the user to specify that those two files are different configurations is in that case perfectly reasonable.
(Maybe at some point we could however detect this type of case and prompt them to define a config mapping etc) |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | OK, so, before closing the issue, what do you think should be done?
> Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?
or nothing? | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 45 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
OK, so, before closing the issue, what do you think should be done?
> Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?
or nothing? |
https://github.com/huggingface/datasets/issues/3738 | For data-only datasets, streaming and non-streaming don't behave the same | We should at least raise an error if a new sample has column names that are missing, or if it has extra columns. No need to check for the type for now.
I'm in favor of having an error especially because we want to avoid silent issues as much as possible - i.e. when something goes wrong (when schemas don't match or some data are missing) and no errors/warnings are raised.
Consistency between streaming and non-streaming is also important. | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | 79 | For data-only datasets, streaming and non-streaming don't behave the same
See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
```
We should at least raise an error if a new sample has column names that are missing, or if it has extra columns. No need to check for the type for now.
I'm in favor of having an error especially because we want to avoid silent issues as much as possible - i.e. when something goes wrong (when schemas don't match or some data are missing) and no errors/warnings are raised.
Consistency between streaming and non-streaming is also important. |
https://github.com/huggingface/datasets/issues/3735 | Performance of `datasets` at scale | The most surprising part to me is the saving time. Wondering if it could be due to compression (`ParquetWriter` uses SNAPPY compression by default; it can be turned off with `to_parquet(..., compression=None)`). | # Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
| 32 | Performance of `datasets` at scale
# Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
The most surprising part to me is the saving time. Wondering if it could be due to compression (`ParquetWriter` uses SNAPPY compression by default; it can be turned off with `to_parquet(..., compression=None)`). |
https://github.com/huggingface/datasets/issues/3735 | Performance of `datasets` at scale | +1 to what @mariosasko mentioned. Also, @lvwerra did you parallelize `to_parquet` using similar approach in #2747? (we used multiprocessing at the shard level). I'm working on a similar PR to add multi_proc in `to_parquet` which might give you further speed up.
Stas benchmarked his approach and mine in this [gist](https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c) for `lama` dataset when we were working on adding multi_proc support for `to_json`. | # Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
| 63 | Performance of `datasets` at scale
# Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
+1 to what @mariosasko mentioned. Also, @lvwerra did you parallelize `to_parquet` using similar approach in #2747? (we used multiprocessing at the shard level). I'm working on a similar PR to add multi_proc in `to_parquet` which might give you further speed up.
Stas benchmarked his approach and mine in this [gist](https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c) for `lama` dataset when we were working on adding multi_proc support for `to_json`. |
https://github.com/huggingface/datasets/issues/3735 | Performance of `datasets` at scale | @mariosasko I did not turn it off but I can try the next time - I have to run the pipeline again, anyway.
@bhavitvyamalik Yes, I also sharded the dataset and used multiprocessing to save each shard. I'll have a closer look at your approach, too. | # Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
| 46 | Performance of `datasets` at scale
# Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
@mariosasko I did not turn it off but I can try the next time - I have to run the pipeline again, anyway.
@bhavitvyamalik Yes, I also sharded the dataset and used multiprocessing to save each shard. I'll have a closer look at your approach, too. |
https://github.com/huggingface/datasets/issues/3730 | Checksum Error when loading multi-news dataset | Thanks for reporting @byw2.
We are fixing it.
In the meantime, you can load the dataset by passing `ignore_verifications=True`:
```python
dataset = load_dataset("multi_news", ignore_verifications=True) | ## Describe the bug
When using the load_dataset function from datasets module to load the Multi-News dataset, does not load the dataset but throws Checksum Error instead.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("multi_news")
```
## Expected results
Should download and load Multi-News dataset.
## Actual results
Throws the following error and cannot load data successfully:
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1vRY2wM6rlOZrf9exGTm5pXj5ExlVwJ0C']
```
Could this issue please be looked at? Thanks! | 24 | Checksum Error when loading multi-news dataset
## Describe the bug
When using the load_dataset function from datasets module to load the Multi-News dataset, does not load the dataset but throws Checksum Error instead.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("multi_news")
```
## Expected results
Should download and load Multi-News dataset.
## Actual results
Throws the following error and cannot load data successfully:
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1vRY2wM6rlOZrf9exGTm5pXj5ExlVwJ0C']
```
Could this issue please be looked at? Thanks!
Thanks for reporting @byw2.
We are fixing it.
In the meantime, you can load the dataset by passing `ignore_verifications=True`:
```python
dataset = load_dataset("multi_news", ignore_verifications=True) |
https://github.com/huggingface/datasets/issues/3729 | Wrong number of examples when loading a text dataset | Hi @kg-nlp, thanks for reporting.
That is weird... I guess we would need some sample data file where this behavior appears to reproduce the bug for further investigation... | ## Describe the bug
when I use load_dataset to read a txt file I find that the number of the samples is incorrect
## Steps to reproduce the bug
```
fr = open('train.txt','r',encoding='utf-8').readlines()
print(len(fr)) # 1199637
datasets = load_dataset('text', data_files={'train': ['train.txt']}, streaming=False)
print(len(datasets['train'])) # 1199649
```
I also use command line operation to verify it
```
$ wc -l train.txt
1199637 train.txt
```
## Expected results
please fix that issue
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.3
- Platform:windows&linux
- Python version:3.7
- PyArrow version:6.0.1
| 28 | Wrong number of examples when loading a text dataset
## Describe the bug
when I use load_dataset to read a txt file I find that the number of the samples is incorrect
## Steps to reproduce the bug
```
fr = open('train.txt','r',encoding='utf-8').readlines()
print(len(fr)) # 1199637
datasets = load_dataset('text', data_files={'train': ['train.txt']}, streaming=False)
print(len(datasets['train'])) # 1199649
```
I also use command line operation to verify it
```
$ wc -l train.txt
1199637 train.txt
```
## Expected results
please fix that issue
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.3
- Platform:windows&linux
- Python version:3.7
- PyArrow version:6.0.1
Hi @kg-nlp, thanks for reporting.
That is weird... I guess we would need some sample data file where this behavior appears to reproduce the bug for further investigation... |
https://github.com/huggingface/datasets/issues/3729 | Wrong number of examples when loading a text dataset | ok, I found the reason why that two results are not same.
there is /u2029 in the text, the datasets will split sentence according to the /u2029,but when I use open function will not do that .
so I want to know which function shell do that
thanks | ## Describe the bug
when I use load_dataset to read a txt file I find that the number of the samples is incorrect
## Steps to reproduce the bug
```
fr = open('train.txt','r',encoding='utf-8').readlines()
print(len(fr)) # 1199637
datasets = load_dataset('text', data_files={'train': ['train.txt']}, streaming=False)
print(len(datasets['train'])) # 1199649
```
I also use command line operation to verify it
```
$ wc -l train.txt
1199637 train.txt
```
## Expected results
please fix that issue
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.3
- Platform:windows&linux
- Python version:3.7
- PyArrow version:6.0.1
| 48 | Wrong number of examples when loading a text dataset
## Describe the bug
when I use load_dataset to read a txt file I find that the number of the samples is incorrect
## Steps to reproduce the bug
```
fr = open('train.txt','r',encoding='utf-8').readlines()
print(len(fr)) # 1199637
datasets = load_dataset('text', data_files={'train': ['train.txt']}, streaming=False)
print(len(datasets['train'])) # 1199649
```
I also use command line operation to verify it
```
$ wc -l train.txt
1199637 train.txt
```
## Expected results
please fix that issue
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.3
- Platform:windows&linux
- Python version:3.7
- PyArrow version:6.0.1
ok, I found the reason why that two results are not same.
there is /u2029 in the text, the datasets will split sentence according to the /u2029,but when I use open function will not do that .
so I want to know which function shell do that
thanks |
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | Hi @aasem, thanks for reporting.
Please note that currently Commom Voice is hosted on our Hub as a community dataset by the Mozilla Foundation. See all Common Voice versions here: https://huggingface.co/mozilla-foundation
Maybe we should add an explaining note in our "legacy" Common Voice canonical script? What do you think @lhoestq @mariosasko ? | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 52 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
Hi @aasem, thanks for reporting.
Please note that currently Commom Voice is hosted on our Hub as a community dataset by the Mozilla Foundation. See all Common Voice versions here: https://huggingface.co/mozilla-foundation
Maybe we should add an explaining note in our "legacy" Common Voice canonical script? What do you think @lhoestq @mariosasko ? |
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | Thank you, @albertvillanova, for the quick response. I am not sure about the exact flow but I guess adding the following lines under the `_Languages` dictionary definition in [common_voice.py](https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py) might resolve the issue. I guess the dataset is recently made available so the file needs updating.
```
"ur": {
"Language": "Urdu",
"Date": "2022-01-19",
"Size": "68 MB",
"Version": "ur_3h_2022-01-19",
"Validated_Hr_Total": 1,
"Overall_Hr_Total": 3,
"Number_Of_Voice": 48,
},
```
| Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 66 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
Thank you, @albertvillanova, for the quick response. I am not sure about the exact flow but I guess adding the following lines under the `_Languages` dictionary definition in [common_voice.py](https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py) might resolve the issue. I guess the dataset is recently made available so the file needs updating.
```
"ur": {
"Language": "Urdu",
"Date": "2022-01-19",
"Size": "68 MB",
"Version": "ur_3h_2022-01-19",
"Validated_Hr_Total": 1,
"Overall_Hr_Total": 3,
"Number_Of_Voice": 48,
},
```
|
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | @aasem for compliance reasons, we are no longer updating the `common_voice.py` script.
We agreed with Mozilla Foundation to use their community datasets instead, which will ask you to accept their terms of use:
```
You need to share your contact information to access this dataset.
This repository is publicly accessible, but you have to register to access its content — don't worry, it's just one click!
By clicking on “Access repository” below, you accept that your contact information (email address and username) can be shared with the repository authors. This will let the authors get in touch for instance if some parts of the repository's contents need to be taken down for licensing reasons.
By clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the Common Voice dataset.
You will immediately be granted access to the contents of the dataset.
```
In order to use e.g. their Common Voice dataset version 8.0, please:
- First visit their dataset page: https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0
- Accept their term of use by clicking "Access repository"
- You can then load their dataset with:
```python
load_dataset("mozilla-foundation/common_voice_8_0", "ur", split="train+validation")
``` | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 192 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
@aasem for compliance reasons, we are no longer updating the `common_voice.py` script.
We agreed with Mozilla Foundation to use their community datasets instead, which will ask you to accept their terms of use:
```
You need to share your contact information to access this dataset.
This repository is publicly accessible, but you have to register to access its content — don't worry, it's just one click!
By clicking on “Access repository” below, you accept that your contact information (email address and username) can be shared with the repository authors. This will let the authors get in touch for instance if some parts of the repository's contents need to be taken down for licensing reasons.
By clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the Common Voice dataset.
You will immediately be granted access to the contents of the dataset.
```
In order to use e.g. their Common Voice dataset version 8.0, please:
- First visit their dataset page: https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0
- Accept their term of use by clicking "Access repository"
- You can then load their dataset with:
```python
load_dataset("mozilla-foundation/common_voice_8_0", "ur", split="train+validation")
``` |
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | @albertvillanova
>Maybe we should add an explaining note in our "legacy" Common Voice canonical script?
Yes, I agree we should have a deprecation notice in the canonical script to redirect users to the new script. | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 35 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
@albertvillanova
>Maybe we should add an explaining note in our "legacy" Common Voice canonical script?
Yes, I agree we should have a deprecation notice in the canonical script to redirect users to the new script. |
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | @albertvillanova,
I now get the following error after downloading my access token from the huggingface and passing it to `load_dataset` call:
`AttributeError: 'DownloadManager' object has no attribute 'download_config'`
Any quick pointer on how it might be resolved? | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 37 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
@albertvillanova,
I now get the following error after downloading my access token from the huggingface and passing it to `load_dataset` call:
`AttributeError: 'DownloadManager' object has no attribute 'download_config'`
Any quick pointer on how it might be resolved? |
https://github.com/huggingface/datasets/issues/3720 | Builder Configuration Update Required on Common Voice Dataset | @aasem What version of `datasets` are you using? We renamed that attribute from `_download_config` to `download_conig` fairly recently, so updating to the newest version should resolve the issue:
```
pip install -U datasets
``` | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| 34 | Builder Configuration Update Required on Common Voice Dataset
Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
@aasem What version of `datasets` are you using? We renamed that attribute from `_download_config` to `download_conig` fairly recently, so updating to the newest version should resolve the issue:
```
pip install -U datasets
``` |
https://github.com/huggingface/datasets/issues/3717 | wrong condition in `Features ClassLabel encode_example` | Hi @Tudyx,
Please note that in Python, the boolean NOT operator (`not`) has lower precedence than comparison operators (`<=`, `<`), thus the expression you mention is equivalent to:
```python
not (-1 <= example_data < self.num_classes)
```
Also note that as expected, the exception is raised if:
- `example_data < -1`
- or `example_data >= self.num_classes`
The raise of the exception is expected when `example_data` equals 4 and `self.num_classes` equals 4 too. | ## Describe the bug
The `encode_example` function in *features.py* seems to have a wrong condition.
```python
if not -1 <= example_data < self.num_classes:
raise ValueError(f"Class label {example_data:d} greater than configured num_classes {self.num_classes}")
```
## Expected results
The `not - 1` condition change the result of the condition. For instance, if `example_data` equals 4 and ` self.num_classes` equals 4 too, `example_data < self.num_classes` will give `False` as expected . But if i add the `not - 1` condition, `not -1 <= example_data < self.num_classes` will give `True` and raise an exception.
## Environment info
- `datasets` version: 1.18.3
- Python version: 3.8.10
- PyArrow version: 7.00
| 71 | wrong condition in `Features ClassLabel encode_example`
## Describe the bug
The `encode_example` function in *features.py* seems to have a wrong condition.
```python
if not -1 <= example_data < self.num_classes:
raise ValueError(f"Class label {example_data:d} greater than configured num_classes {self.num_classes}")
```
## Expected results
The `not - 1` condition change the result of the condition. For instance, if `example_data` equals 4 and ` self.num_classes` equals 4 too, `example_data < self.num_classes` will give `False` as expected . But if i add the `not - 1` condition, `not -1 <= example_data < self.num_classes` will give `True` and raise an exception.
## Environment info
- `datasets` version: 1.18.3
- Python version: 3.8.10
- PyArrow version: 7.00
Hi @Tudyx,
Please note that in Python, the boolean NOT operator (`not`) has lower precedence than comparison operators (`<=`, `<`), thus the expression you mention is equivalent to:
```python
not (-1 <= example_data < self.num_classes)
```
Also note that as expected, the exception is raised if:
- `example_data < -1`
- or `example_data >= self.num_classes`
The raise of the exception is expected when `example_data` equals 4 and `self.num_classes` equals 4 too. |
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | Hi ! Note that it does `block_size *= 2` until `block_size > len(batch)`, so it doesn't loop indefinitely. What do you mean by "get stuck indefinitely" then ? Is this the actual call to `paj.read_json` that hangs ?
> increasing the `chunksize` argument decreases the chance of getting stuck
Could you share the values of chunksize that you're using to observe this ? And maybe the order of magnitude of number of bytes per line of JSON ? | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 78 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
Hi ! Note that it does `block_size *= 2` until `block_size > len(batch)`, so it doesn't loop indefinitely. What do you mean by "get stuck indefinitely" then ? Is this the actual call to `paj.read_json` that hangs ?
> increasing the `chunksize` argument decreases the chance of getting stuck
Could you share the values of chunksize that you're using to observe this ? And maybe the order of magnitude of number of bytes per line of JSON ? |
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | To clarify, I don't think it loops indefinitely but the `paj.read_json` gets stuck after the first try. That's why I think it could be an issue with a lock somewhere.
Using `load_dataset(..., chunksize=40<<20)` worked without errors. | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 36 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
To clarify, I don't think it loops indefinitely but the `paj.read_json` gets stuck after the first try. That's why I think it could be an issue with a lock somewhere.
Using `load_dataset(..., chunksize=40<<20)` worked without errors. |
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | @lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.
```
train_dataset = datasets.load_dataset("json",
data_files=corpus_jsonl_path,
keep_in_memory=False,
cache_dir=model_args.cache_dir,
streaming=False)
train_dataset.set_transform(psg_parse_fn)
```
| ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 49 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
@lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.
```
train_dataset = datasets.load_dataset("json",
data_files=corpus_jsonl_path,
keep_in_memory=False,
cache_dir=model_args.cache_dir,
streaming=False)
train_dataset.set_transform(psg_parse_fn)
```
|
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | I couldn't I think your problem is unrelated to this issue @memray
Indeed this issue discusses a bug when doing `load_dataset`, while your case has to do with the dataloader in a multiprocessing setup. Can you open a new issue and provide more details (share your env and what psg_parse_fn does) ? | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 52 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
I couldn't I think your problem is unrelated to this issue @memray
Indeed this issue discusses a bug when doing `load_dataset`, while your case has to do with the dataloader in a multiprocessing setup. Can you open a new issue and provide more details (share your env and what psg_parse_fn does) ? |
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | I also encountered a similar issue when loading a 190GB dataset of jsonl files (255 files with less than 1Gb) where it got stuck for over 20h at tables generation (fig below), increasing the `chunksize` with `load_dataset(..., chunksize=40<<20)` fixed the issue
<img width="560" alt="image" src="https://user-images.githubusercontent.com/44069155/195605603-548a106e-7ad3-4269-8cdd-2ad3e975bf16.png">
| ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 45 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
I also encountered a similar issue when loading a 190GB dataset of jsonl files (255 files with less than 1Gb) where it got stuck for over 20h at tables generation (fig below), increasing the `chunksize` with `load_dataset(..., chunksize=40<<20)` fixed the issue
<img width="560" alt="image" src="https://user-images.githubusercontent.com/44069155/195605603-548a106e-7ad3-4269-8cdd-2ad3e975bf16.png">
|
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | > @lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.
>
> ```
> train_dataset = datasets.load_dataset("json",
> data_files=corpus_jsonl_path,
> keep_in_memory=False,
> cache_dir=model_args.cache_dir,
> streaming=False)
> train_dataset.set_transform(psg_parse_fn)
> ```
In case people also get this problem, I found a way to fix it by adding `persistent_workers=True` when initializing DataLoader, like:
`train_loader = DataLoader(
train_dataset,
batch_size=self._train_batch_size,
sampler=train_sampler,
collate_fn=data_collator,
num_workers=self.args.dataloader_num_workers,
persistent_workers=True
)`
The error was `CUDA error: initialization error Exception raised from insert_events at ../c10/cuda/CUDACachingAllocator.cpp:1266` after the 1st epoch, I guess it's because the data_loader worker is killed after each epoch and the data supply is cut off. This error only occurs when num_workers>1.
| ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 132 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
> @lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.
>
> ```
> train_dataset = datasets.load_dataset("json",
> data_files=corpus_jsonl_path,
> keep_in_memory=False,
> cache_dir=model_args.cache_dir,
> streaming=False)
> train_dataset.set_transform(psg_parse_fn)
> ```
In case people also get this problem, I found a way to fix it by adding `persistent_workers=True` when initializing DataLoader, like:
`train_loader = DataLoader(
train_dataset,
batch_size=self._train_batch_size,
sampler=train_sampler,
collate_fn=data_collator,
num_workers=self.args.dataloader_num_workers,
persistent_workers=True
)`
The error was `CUDA error: initialization error Exception raised from insert_events at ../c10/cuda/CUDACachingAllocator.cpp:1266` after the 1st epoch, I guess it's because the data_loader worker is killed after each epoch and the data supply is cut off. This error only occurs when num_workers>1.
|
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | I can confirm the issue using datasets (2.12.0) with the following code and Accelerate (0.20.3) env:
````
trainDataloader = DataLoader(trainSplit, batch_size=args.train_batch_size, shuffle=True)
evalDataloader = DataLoader(validSplit, batch_size=args.valid_batch_size) // Here is where it gets stuck.
````
````
- `Accelerate` version: 0.20.3
- Platform: Linux-5.4.0-150-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Numpy version: 1.24.3
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- PyTorch XPU available: False
- System RAM: 503.28 GB
- GPU type: Tesla V100-SXM2-32GB
- `Accelerate` default config:
- compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: fp16
- use_cpu: False
- num_processes: 2
- machine_rank: 0
- num_machines: 1
- gpu_ids: 0,1
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
````
Notable that with Accelerate configured for one GPU only, **it doesn't get stuck.**
The suggestion made by @memray worked in my case. This is how it was applied:
````
trainDataloader = DataLoader(trainSplit, batch_size=args.train_batch_size, shuffle=True, num_workers=2, persistent_workers=True)
evalDataloader = DataLoader(validSplit, batch_size=args.valid_batch_size, num_workers=2, persistent_workers=True)
````
| ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 164 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
I can confirm the issue using datasets (2.12.0) with the following code and Accelerate (0.20.3) env:
````
trainDataloader = DataLoader(trainSplit, batch_size=args.train_batch_size, shuffle=True)
evalDataloader = DataLoader(validSplit, batch_size=args.valid_batch_size) // Here is where it gets stuck.
````
````
- `Accelerate` version: 0.20.3
- Platform: Linux-5.4.0-150-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Numpy version: 1.24.3
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- PyTorch XPU available: False
- System RAM: 503.28 GB
- GPU type: Tesla V100-SXM2-32GB
- `Accelerate` default config:
- compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: fp16
- use_cpu: False
- num_processes: 2
- machine_rank: 0
- num_machines: 1
- gpu_ids: 0,1
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
````
Notable that with Accelerate configured for one GPU only, **it doesn't get stuck.**
The suggestion made by @memray worked in my case. This is how it was applied:
````
trainDataloader = DataLoader(trainSplit, batch_size=args.train_batch_size, shuffle=True, num_workers=2, persistent_workers=True)
evalDataloader = DataLoader(validSplit, batch_size=args.valid_batch_size, num_workers=2, persistent_workers=True)
````
|
https://github.com/huggingface/datasets/issues/3708 | Loading JSON gets stuck with many workers/threads | I think your issue is related to `accelerate`, feel free to open an issue there: https://github.com/huggingface/accelerate/issues
`Dataset` objects generally work fine with the torch DataLoader, idk what `accelerate` does that could make it get stuck. | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| 35 | Loading JSON gets stuck with many workers/threads
## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
I think your issue is related to `accelerate`, feel free to open an issue there: https://github.com/huggingface/accelerate/issues
`Dataset` objects generally work fine with the torch DataLoader, idk what `accelerate` does that could make it get stuck. |
https://github.com/huggingface/datasets/issues/3707 | `.select`: unexpected behavior with `indices` | Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).
@albertvillanova @lhoestq wdyt? | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
| 42 | `.select`: unexpected behavior with `indices`
## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).
@albertvillanova @lhoestq wdyt? |
https://github.com/huggingface/datasets/issues/3707 | `.select`: unexpected behavior with `indices` | I agree. I think `index % len(dset)` was used to support negative indices.
I think this needs to be fixed in `datasets.formatting.formatting._check_valid_index_key` if I'm not mistaken | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
| 26 | `.select`: unexpected behavior with `indices`
## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
I agree. I think `index % len(dset)` was used to support negative indices.
I think this needs to be fixed in `datasets.formatting.formatting._check_valid_index_key` if I'm not mistaken |
https://github.com/huggingface/datasets/issues/3706 | Unable to load dataset 'big_patent' | Hi @ankitk2109,
Have you tried passing the split name with the keyword `split=`? See e.g. an example in our Quick Start docs: https://huggingface.co/docs/datasets/quickstart.html#load-the-dataset-and-model
```python
ds = load_dataset("big_patent", "d", split="validation") | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| 29 | Unable to load dataset 'big_patent'
## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
Hi @ankitk2109,
Have you tried passing the split name with the keyword `split=`? See e.g. an example in our Quick Start docs: https://huggingface.co/docs/datasets/quickstart.html#load-the-dataset-and-model
```python
ds = load_dataset("big_patent", "d", split="validation") |
https://github.com/huggingface/datasets/issues/3706 | Unable to load dataset 'big_patent' | Hi @albertvillanova,
Thanks for your response.
Yes, I tried the `split='validation'` as well. But getting the same issue. | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| 18 | Unable to load dataset 'big_patent'
## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
Hi @albertvillanova,
Thanks for your response.
Yes, I tried the `split='validation'` as well. But getting the same issue. |
https://github.com/huggingface/datasets/issues/3706 | Unable to load dataset 'big_patent' | I'm sorry, but I can't reproduce your problem:
```python
In [5]: ds = load_dataset("big_patent", "d", split="validation")
Downloading and preparing dataset big_patent/d (download: 6.01 GiB, generated: 169.61 MiB, post-processed: Unknown size, total: 6.17 GiB) to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c...
Downloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6.45G/6.45G [27:36<00:00, 3.89MB/s]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [03:18<00:00, 66.08s/it]
Dataset big_patent downloaded and prepared to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c. Subsequent calls will reuse this data.
In [6]: ds
Out[6]:
Dataset({
features: ['description', 'abstract'],
num_rows: 565
})
| ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| 72 | Unable to load dataset 'big_patent'
## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
I'm sorry, but I can't reproduce your problem:
```python
In [5]: ds = load_dataset("big_patent", "d", split="validation")
Downloading and preparing dataset big_patent/d (download: 6.01 GiB, generated: 169.61 MiB, post-processed: Unknown size, total: 6.17 GiB) to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c...
Downloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6.45G/6.45G [27:36<00:00, 3.89MB/s]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [03:18<00:00, 66.08s/it]
Dataset big_patent downloaded and prepared to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c. Subsequent calls will reuse this data.
In [6]: ds
Out[6]:
Dataset({
features: ['description', 'abstract'],
num_rows: 565
})
|
https://github.com/huggingface/datasets/issues/3706 | Unable to load dataset 'big_patent' | Maybe you had a connection issue while downloading the file and this was corrupted?
Our cache system uses the file you downloaded first time.
If so, you could try forcing redownload of the file with:
```python
ds = load_dataset("big_patent", "d", split="validation", download_mode="force_redownload") | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| 42 | Unable to load dataset 'big_patent'
## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
Maybe you had a connection issue while downloading the file and this was corrupted?
Our cache system uses the file you downloaded first time.
If so, you could try forcing redownload of the file with:
```python
ds = load_dataset("big_patent", "d", split="validation", download_mode="force_redownload") |
https://github.com/huggingface/datasets/issues/3706 | Unable to load dataset 'big_patent' | I am able to download the dataset with ``` download_mode="force_redownload"```. As you mentioned it was an issue with the cached version which was failed earlier due to a network issue. I am closing the issue now, once again thank you. | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| 40 | Unable to load dataset 'big_patent'
## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
I am able to download the dataset with ``` download_mode="force_redownload"```. As you mentioned it was an issue with the cached version which was failed earlier due to a network issue. I am closing the issue now, once again thank you. |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Hi @adrianeboyd, thanks for reporting.
There is indeed a bug in that community dataset:
Line:
```python
metadata_and_text_files = list(zip(metadata_files, text_files))
```
should be replaced with
```python
metadata_and_text_files = list(zip(sorted(metadata_files), sorted(text_files)))
```
I am going to contact their owners (https://huggingface.co/oscar-corpus) in order to inform them about the bug.
I keep you informed. | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 51 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Hi @adrianeboyd, thanks for reporting.
There is indeed a bug in that community dataset:
Line:
```python
metadata_and_text_files = list(zip(metadata_files, text_files))
```
should be replaced with
```python
metadata_and_text_files = list(zip(sorted(metadata_files), sorted(text_files)))
```
I am going to contact their owners (https://huggingface.co/oscar-corpus) in order to inform them about the bug.
I keep you informed. |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | That fix is part of it, but it's clearly not the only issue.
I also already contacted the OSCAR creators, but I reported it here because it looked like huggingface members were the main authors in the git history. Is there a better place to have reported this? | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 48 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
That fix is part of it, but it's clearly not the only issue.
I also already contacted the OSCAR creators, but I reported it here because it looked like huggingface members were the main authors in the git history. Is there a better place to have reported this? |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Hello,
We've had an issue that could be linked to this one here: https://github.com/oscar-corpus/corpus/issues/15.
I have been spot checking the source (`.txt`/`.jsonl`) files for a while, and have not found issues, especially in the start/end of corpora (but I conceed that more integration testing would be necessary on our side).
The text and metadata files are designed to be used in sync (with `lang_part_n.txt` and `lang_meta_part_n.jsonl` working together), while staying independent from part to part, so that anyone could randomly choose a part and work with it.
The fix @albertvillanova proposed should fix the problem, as the parts will be in sync again.
Let me know if you need help or more details, I'd be glad to help! | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 118 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Hello,
We've had an issue that could be linked to this one here: https://github.com/oscar-corpus/corpus/issues/15.
I have been spot checking the source (`.txt`/`.jsonl`) files for a while, and have not found issues, especially in the start/end of corpora (but I conceed that more integration testing would be necessary on our side).
The text and metadata files are designed to be used in sync (with `lang_part_n.txt` and `lang_meta_part_n.jsonl` working together), while staying independent from part to part, so that anyone could randomly choose a part and work with it.
The fix @albertvillanova proposed should fix the problem, as the parts will be in sync again.
Let me know if you need help or more details, I'd be glad to help! |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | I'm happy to move the discussion to the other repo!
Merely sorting the files only **maybe** fixes the processing of the first part. If the first part contains non-unix newlines, it will still be misaligned/truncated, and all the following parts will be truncated with incorrect text offsets and metadata due the offset and newline bugs. | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 55 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
I'm happy to move the discussion to the other repo!
Merely sorting the files only **maybe** fixes the processing of the first part. If the first part contains non-unix newlines, it will still be misaligned/truncated, and all the following parts will be truncated with incorrect text offsets and metadata due the offset and newline bugs. |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Hi @Uinelj, This is a total noobs question but how can I integrate that bugfix into my code? I reinstalled the datasets library this time from source. Should that have fixed the issue? I am still facing the misalignment issue. Do I need to download the dataset from scratch? | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 49 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Hi @Uinelj, This is a total noobs question but how can I integrate that bugfix into my code? I reinstalled the datasets library this time from source. Should that have fixed the issue? I am still facing the misalignment issue. Do I need to download the dataset from scratch? |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Sorry @norakassner for the late reply.
There are indeed several issues creating the misalignment, as @adrianeboyd cleverly pointed out:
- https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/3cd7e95aa1799b73c5ea8afc3989635f3e19b86b fixed one of them
- but there are still others to be fixed | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 34 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Sorry @norakassner for the late reply.
There are indeed several issues creating the misalignment, as @adrianeboyd cleverly pointed out:
- https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/3cd7e95aa1799b73c5ea8afc3989635f3e19b86b fixed one of them
- but there are still others to be fixed |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Normally, the issues should be fixed now:
- Fix offset initialization for each file: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/1ad9b7bfe00798a9258a923b887bb1c8d732b833
- Disable default universal newline support: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/0c2f307d3167f03632f502af361ac6c3c393f510
Feel free to reopen if you find additional misalignments/truncations.
CC: @adrianeboyd @norakassner @Uinelj | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 35 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Normally, the issues should be fixed now:
- Fix offset initialization for each file: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/1ad9b7bfe00798a9258a923b887bb1c8d732b833
- Disable default universal newline support: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/0c2f307d3167f03632f502af361ac6c3c393f510
Feel free to reopen if you find additional misalignments/truncations.
CC: @adrianeboyd @norakassner @Uinelj |
https://github.com/huggingface/datasets/issues/3704 | OSCAR-2109 datasets are misaligned and truncated | Thanks for the updates!
The purist in me would still like to have the rstrip not strip additional characters from the original text (unicode whitespace mainly in practice, I think), but the differences are extremely small in practice and it doesn't actually matter for my current task:
```python
text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip("\n")
``` | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | 56 | OSCAR-2109 datasets are misaligned and truncated
## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data.
Thanks for the updates!
The purist in me would still like to have the rstrip not strip additional characters from the original text (unicode whitespace mainly in practice, I think), but the differences are extremely small in practice and it doesn't actually matter for my current task:
```python
text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip("\n")
``` |
https://github.com/huggingface/datasets/issues/3703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue. | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| 26 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue. |
https://github.com/huggingface/datasets/issues/3703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | > Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.
I installed seqeval, but still reported the same error. That's too bad.
| hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| 39 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
> Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.
I installed seqeval, but still reported the same error. That's too bad.
|
https://github.com/huggingface/datasets/issues/3703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | > > Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.
> > I installed seqeval, but still reported the same error. That's too bad.
Same issue here. What should I do to fix this error? Please help! Thank you. | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| 57 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
> > Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.
> > I installed seqeval, but still reported the same error. That's too bad.
Same issue here. What should I do to fix this error? Please help! Thank you. |
https://github.com/huggingface/datasets/issues/3703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | I tried to install **seqeval** package through anaconda instead of pip:
`conda install -c conda-forge seqeval`
It worked for me! | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| 20 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
I tried to install **seqeval** package through anaconda instead of pip:
`conda install -c conda-forge seqeval`
It worked for me! |
https://github.com/huggingface/datasets/issues/3700 | Unable to load a dataset | Hi! `load_dataset` is intended to be used to load a canonical dataset (`wikipedia`), a packaged dataset (`csv`, `json`, ...) or a dataset hosted on the Hub. For local datasets saved with `save_to_disk("path/to/dataset")`, use `load_from_disk("path/to/dataset")`. | ## Describe the bug
Unable to load a dataset from Huggingface that I have just saved.
## Steps to reproduce the bug
On Google colab
`! pip install datasets `
`from datasets import load_dataset`
`my_path = "wiki_dataset"`
`dataset = load_dataset('wikipedia', "20200501.fr")`
`dataset.save_to_disk(my_path)`
`dataset = load_dataset(my_path)`
## Expected results
Loading the dataset
## Actual results
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: null
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: string
to
{'builder_name': Value(dtype='string', id=None), 'citation': Value(dtype='string', id=None), 'config_name': Value(dtype='string', id=None), 'dataset_size': Value(dtype='int64', id=None), 'description': Value(dtype='string', id=None), 'download_checksums': {}, 'download_size': Value(dtype='int64', id=None), 'features': {'title': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}, 'text': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'post_processed': Value(dtype='null', id=None), 'post_processing_size': Value(dtype='null', id=None), 'size_in_bytes': Value(dtype='int64', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='string', id=None)}}, 'supervised_keys': Value(dtype='null', id=None), 'task_templates': Value(dtype='null', id=None), 'version': {'version_str': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'major': Value(dtype='int64', id=None), 'minor': Value(dtype='int64', id=None), 'patch': Value(dtype='int64', id=None)}}
because column names don't match
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
| 34 | Unable to load a dataset
## Describe the bug
Unable to load a dataset from Huggingface that I have just saved.
## Steps to reproduce the bug
On Google colab
`! pip install datasets `
`from datasets import load_dataset`
`my_path = "wiki_dataset"`
`dataset = load_dataset('wikipedia', "20200501.fr")`
`dataset.save_to_disk(my_path)`
`dataset = load_dataset(my_path)`
## Expected results
Loading the dataset
## Actual results
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: null
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: string
to
{'builder_name': Value(dtype='string', id=None), 'citation': Value(dtype='string', id=None), 'config_name': Value(dtype='string', id=None), 'dataset_size': Value(dtype='int64', id=None), 'description': Value(dtype='string', id=None), 'download_checksums': {}, 'download_size': Value(dtype='int64', id=None), 'features': {'title': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}, 'text': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'post_processed': Value(dtype='null', id=None), 'post_processing_size': Value(dtype='null', id=None), 'size_in_bytes': Value(dtype='int64', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='string', id=None)}}, 'supervised_keys': Value(dtype='null', id=None), 'task_templates': Value(dtype='null', id=None), 'version': {'version_str': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'major': Value(dtype='int64', id=None), 'minor': Value(dtype='int64', id=None), 'patch': Value(dtype='int64', id=None)}}
because column names don't match
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
Hi! `load_dataset` is intended to be used to load a canonical dataset (`wikipedia`), a packaged dataset (`csv`, `json`, ...) or a dataset hosted on the Hub. For local datasets saved with `save_to_disk("path/to/dataset")`, use `load_from_disk("path/to/dataset")`. |
https://github.com/huggingface/datasets/issues/3688 | Pyarrow version error | Hi @Zaker237, thanks for reporting.
This is weird: the error you get is only thrown if the installed pyarrow version is less than 3.0.0.
Could you please check that you install pyarrow in the same Python virtual environment where you installed datasets?
From the Python command line (or terminal) where you get the error, please type:
```
import pyarrow
print(pyarrow.__version__)
import datasets
print(datasets.__version__)
``` | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
| 64 | Pyarrow version error
## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
Hi @Zaker237, thanks for reporting.
This is weird: the error you get is only thrown if the installed pyarrow version is less than 3.0.0.
Could you please check that you install pyarrow in the same Python virtual environment where you installed datasets?
From the Python command line (or terminal) where you get the error, please type:
```
import pyarrow
print(pyarrow.__version__)
import datasets
print(datasets.__version__)
``` |
https://github.com/huggingface/datasets/issues/3688 | Pyarrow version error | hi @albertvillanova i try yesterday to create a new python environement with python 7 and try it on the environement and it worked. so i think that the error was not the package but may be jupyter notebook on conda. still yet i'm not yet sure but it worked in an environment created with venv | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
| 55 | Pyarrow version error
## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
hi @albertvillanova i try yesterday to create a new python environement with python 7 and try it on the environement and it worked. so i think that the error was not the package but may be jupyter notebook on conda. still yet i'm not yet sure but it worked in an environment created with venv |
https://github.com/huggingface/datasets/issues/3688 | Pyarrow version error | OK, thanks @Zaker237 for your feedback.
I close this issue then. Please, feel free to reopen it if the problem arises again. | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
| 22 | Pyarrow version error
## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
OK, thanks @Zaker237 for your feedback.
I close this issue then. Please, feel free to reopen it if the problem arises again. |
https://github.com/huggingface/datasets/issues/3687 | Can't get the text data when calling to_tf_dataset | You are correct that `to_tf_dataset` only handles numerical columns right now, yes, though this is a limitation we might remove in future! The main reason we do this is that our models mostly do not include the tokenizer as a model layer, because it's very difficult to compile some of them in TF. So the "normal" Huggingface workflow is to first tokenize your dataset, and then pass tokenized tensors to the model.
For your use case, would you prefer to pass strings to the model, and use some text processing layers instead of the built-in tokenizers? | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| 96 | Can't get the text data when calling to_tf_dataset
I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
You are correct that `to_tf_dataset` only handles numerical columns right now, yes, though this is a limitation we might remove in future! The main reason we do this is that our models mostly do not include the tokenizer as a model layer, because it's very difficult to compile some of them in TF. So the "normal" Huggingface workflow is to first tokenize your dataset, and then pass tokenized tensors to the model.
For your use case, would you prefer to pass strings to the model, and use some text processing layers instead of the built-in tokenizers? |
https://github.com/huggingface/datasets/issues/3687 | Can't get the text data when calling to_tf_dataset | Thanks for the quick follow-up to my issue.
For my use-case, instead of the built-in tokenizers I wanted to use the `TextVectorization` layer to map from strings to integers. To achieve this, I came up with the following solution:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
import tensorflow as tf
import string
import re
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
#some hyper-parameters for the text-to-integer mapping
max_features = 20000
embedding_dim = 128
sequence_length = 210
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst", "default")
#adapt the vectorization layer on train data only
vectorize_layer.adapt(dataset["train"].to_dict(batched=False)["sentence"])
def prepare_features(text, label):
text = tf.expand_dims(text, -1)
return {"vectorized_text": vectorize_layer(text)[0], "label": tf.expand_dims(label, axis=-1)}
encoded_dataset = dataset.map(lambda example: prepare_features(example["sentence"], example["label"]), batched=False)
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
return tf.strings.regex_replace(
lowercase, f"[{re.escape(string.punctuation)}]", ""
)
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode="int",
output_sequence_length=sequence_length,
)
train_dataset = encoded_dataset["train"].to_tf_dataset(columns=['vectorized_text'], label_cols=["label"],
shuffle=True, batch_size=1, collate_fn=data_collator).unbatch()
#similar for the other sub-sets
```
Since the strings would have been mapped to integers or floats at some point, it's no drawback that this mapping is done early in the process.
For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float. For now, this can be done by calling `to_dict`. | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| 212 | Can't get the text data when calling to_tf_dataset
I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
Thanks for the quick follow-up to my issue.
For my use-case, instead of the built-in tokenizers I wanted to use the `TextVectorization` layer to map from strings to integers. To achieve this, I came up with the following solution:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
import tensorflow as tf
import string
import re
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
#some hyper-parameters for the text-to-integer mapping
max_features = 20000
embedding_dim = 128
sequence_length = 210
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst", "default")
#adapt the vectorization layer on train data only
vectorize_layer.adapt(dataset["train"].to_dict(batched=False)["sentence"])
def prepare_features(text, label):
text = tf.expand_dims(text, -1)
return {"vectorized_text": vectorize_layer(text)[0], "label": tf.expand_dims(label, axis=-1)}
encoded_dataset = dataset.map(lambda example: prepare_features(example["sentence"], example["label"]), batched=False)
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
return tf.strings.regex_replace(
lowercase, f"[{re.escape(string.punctuation)}]", ""
)
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode="int",
output_sequence_length=sequence_length,
)
train_dataset = encoded_dataset["train"].to_tf_dataset(columns=['vectorized_text'], label_cols=["label"],
shuffle=True, batch_size=1, collate_fn=data_collator).unbatch()
#similar for the other sub-sets
```
Since the strings would have been mapped to integers or floats at some point, it's no drawback that this mapping is done early in the process.
For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float. For now, this can be done by calling `to_dict`. |
https://github.com/huggingface/datasets/issues/3687 | Can't get the text data when calling to_tf_dataset | > For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float.
Yes, I agree, so let's keep this issue open. | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| 44 | Can't get the text data when calling to_tf_dataset
I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
> For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float.
Yes, I agree, so let's keep this issue open. |
https://github.com/huggingface/datasets/issues/3687 | Can't get the text data when calling to_tf_dataset | Going to close this now - methods like `to_tf_dataset` and `prepare_tf_dataset` now support string data, and have done for a while! If anyone sees this and is encountering issues with string data in those methods, please file a new issue! | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| 40 | Can't get the text data when calling to_tf_dataset
I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
Going to close this now - methods like `to_tf_dataset` and `prepare_tf_dataset` now support string data, and have done for a while! If anyone sees this and is encountering issues with string data in those methods, please file a new issue! |
https://github.com/huggingface/datasets/issues/3686 | `Translation` features cannot be `flatten`ed | Thanks for reporting, @SBrandeis! Some additional feature types that don't behave as expected when flattened: `Audio`, `Image` and `TranslationVariableLanguages` | ## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train[:10]")
print(dataset.features)
# {'translation': Translation(languages=['en', 'fr'], id=None)}
print(dataset[0])
# {'translation': {'en': 'Vaccination against hepatitis C is not yet available.', 'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
dataset.flatten()
```
## Expected results
`dataset.flatten` should flatten the `Translation` column as if it were a dict of `Value("string")`
```python
dataset[0]
# {'translation.en': 'Vaccination against hepatitis C is not yet available.', 'translation.fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.' }
dataset.features
# {'translation.en': Value("string"), 'translation.fr': Value("string")}
```
## Actual results
```python
In [31]: dset.flatten()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-bb88eb5276ee> in <module>
----> 1 dset.flatten()
[...]\site-packages\datasets\fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
[...]\site-packages\datasets\arrow_dataset.py in flatten(self, new_fingerprint, max_depth)
1294 break
1295 dataset.info.features = self.features.flatten(max_depth=max_depth)
-> 1296 dataset._data = update_metadata_with_features(dataset._data, dataset.features)
1297 logger.info(f'Flattened dataset from depth {depth} to depth {1 if depth + 1 < max_depth else "unknown"}.')
1298 dataset._fingerprint = new_fingerprint
[...]\site-packages\datasets\arrow_dataset.py in update_metadata_with_features(table, features)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
[...]\site-packages\datasets\arrow_dataset.py in <dictcomp>(.0)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
KeyError: 'translation.en'
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.10
- PyArrow version: 3.0.0
| 19 | `Translation` features cannot be `flatten`ed
## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train[:10]")
print(dataset.features)
# {'translation': Translation(languages=['en', 'fr'], id=None)}
print(dataset[0])
# {'translation': {'en': 'Vaccination against hepatitis C is not yet available.', 'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
dataset.flatten()
```
## Expected results
`dataset.flatten` should flatten the `Translation` column as if it were a dict of `Value("string")`
```python
dataset[0]
# {'translation.en': 'Vaccination against hepatitis C is not yet available.', 'translation.fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.' }
dataset.features
# {'translation.en': Value("string"), 'translation.fr': Value("string")}
```
## Actual results
```python
In [31]: dset.flatten()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-bb88eb5276ee> in <module>
----> 1 dset.flatten()
[...]\site-packages\datasets\fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
[...]\site-packages\datasets\arrow_dataset.py in flatten(self, new_fingerprint, max_depth)
1294 break
1295 dataset.info.features = self.features.flatten(max_depth=max_depth)
-> 1296 dataset._data = update_metadata_with_features(dataset._data, dataset.features)
1297 logger.info(f'Flattened dataset from depth {depth} to depth {1 if depth + 1 < max_depth else "unknown"}.')
1298 dataset._fingerprint = new_fingerprint
[...]\site-packages\datasets\arrow_dataset.py in update_metadata_with_features(table, features)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
[...]\site-packages\datasets\arrow_dataset.py in <dictcomp>(.0)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
KeyError: 'translation.en'
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.10
- PyArrow version: 3.0.0
Thanks for reporting, @SBrandeis! Some additional feature types that don't behave as expected when flattened: `Audio`, `Image` and `TranslationVariableLanguages` |
https://github.com/huggingface/datasets/issues/3679 | Download datasets from a private hub | Hi ! For information one can set the environment variable `HF_ENDPOINT` (default is `https://huggingface.co`) if they want to use a private hub.
We may need to coordinate with the other libraries to have a consistent way of changing the hub endpoint | In the context of a private hub deployment, customers would like to use load_dataset() to load datasets from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature.
The obvious workaround is to clone the repo first and then load it from local storage, but this adds an extra step. It'd be great to have the same experience regardless of where the hub is hosted.
The same issue exists with the transformers library and the CLI. I'm going to create issues there as well, and I'll reference them below. | 41 | Download datasets from a private hub
In the context of a private hub deployment, customers would like to use load_dataset() to load datasets from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature.
The obvious workaround is to clone the repo first and then load it from local storage, but this adds an extra step. It'd be great to have the same experience regardless of where the hub is hosted.
The same issue exists with the transformers library and the CLI. I'm going to create issues there as well, and I'll reference them below.
Hi ! For information one can set the environment variable `HF_ENDPOINT` (default is `https://huggingface.co`) if they want to use a private hub.
We may need to coordinate with the other libraries to have a consistent way of changing the hub endpoint |
https://github.com/huggingface/datasets/issues/3677 | Discovery cannot be streamed anymore | Seems like a regression from https://github.com/huggingface/datasets/pull/2843
Or maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected
| ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| 26 | Discovery cannot be streamed anymore
## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
Seems like a regression from https://github.com/huggingface/datasets/pull/2843
Or maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected
|
https://github.com/huggingface/datasets/issues/3677 | Discovery cannot be streamed anymore | Hi @severo, thanks for reporting.
Some servers do not support HTTP range requests, and those are required to stream some file formats (like ZIP in this case).
Let me try to propose a workaround. | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| 34 | Discovery cannot be streamed anymore
## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
Hi @severo, thanks for reporting.
Some servers do not support HTTP range requests, and those are required to stream some file formats (like ZIP in this case).
Let me try to propose a workaround. |
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | It looks like this is because of this behavior in pyarrow:
```python
import pyarrow as pa
arr = pa.array([None, [0]])
reconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)
print(reconstructed_arr.to_pylist())
# [[], [0]]
```
It seems that `arr.offsets` can reconstruct the array properly, but an offsets array with null values can:
```python
fixed_offsets = pa.array([None, 0, 1])
fixed_arr = pa.ListArray.from_arrays(fixed_offsets, arr.values)
print(fixed_arr.to_pylist())
# [None, [0]]
print(arr.offsets.to_pylist())
# [0, 0, 1]
print(fixed_offsets.to_pylist())
# [None, 0, 1]
```
EDIT: this is because `arr.offsets` is not enough to reconstruct the array, we also need the validity bitmap | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 89 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
It looks like this is because of this behavior in pyarrow:
```python
import pyarrow as pa
arr = pa.array([None, [0]])
reconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)
print(reconstructed_arr.to_pylist())
# [[], [0]]
```
It seems that `arr.offsets` can reconstruct the array properly, but an offsets array with null values can:
```python
fixed_offsets = pa.array([None, 0, 1])
fixed_arr = pa.ListArray.from_arrays(fixed_offsets, arr.values)
print(fixed_arr.to_pylist())
# [None, [0]]
print(arr.offsets.to_pylist())
# [0, 0, 1]
print(fixed_offsets.to_pylist())
# [None, 0, 1]
```
EDIT: this is because `arr.offsets` is not enough to reconstruct the array, we also need the validity bitmap |
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | The offsets don't have nulls because they don't include the validity bitmap from `arr.buffers()[0]`, which is used to say which values are null and which values are non-null.
Though the validity bitmap also seems to be wrong:
```python
bin(int(arr.buffers()[0].hex(), 16))
# '0b10'
# it should be 0b110 - 1 corresponds to non-null and 0 corresponds to null, if you take the bits in reverse order
```
So apparently I can't even create the fixed offsets array using this.
If I understand correctly it's always missing the 1 on the left, so I can add it manually as a hack to fix the issue until this is fixed in pyarrow EDIT: actually it may be more complicated than that
EDIT2: actuall it's right, it corresponds to the validity bitmap of the array of logical length 2. So if we use the offsets array, the values array, and this validity bitmap it should be possible to reconstruct the array properly | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 158 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
The offsets don't have nulls because they don't include the validity bitmap from `arr.buffers()[0]`, which is used to say which values are null and which values are non-null.
Though the validity bitmap also seems to be wrong:
```python
bin(int(arr.buffers()[0].hex(), 16))
# '0b10'
# it should be 0b110 - 1 corresponds to non-null and 0 corresponds to null, if you take the bits in reverse order
```
So apparently I can't even create the fixed offsets array using this.
If I understand correctly it's always missing the 1 on the left, so I can add it manually as a hack to fix the issue until this is fixed in pyarrow EDIT: actually it may be more complicated than that
EDIT2: actuall it's right, it corresponds to the validity bitmap of the array of logical length 2. So if we use the offsets array, the values array, and this validity bitmap it should be possible to reconstruct the array properly |
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | FYI the behavior is the same with:
- `datasets` version: 1.18.3
- Platform: Linux-5.8.0-50-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.11
- PyArrow version: 6.0.1
but not with:
- `datasets` version: 1.8.0
- Platform: Linux-4.18.0-305.40.2.el8_4.x86_64-x86_64-with-redhat-8.4-Ootpa
- Python version: 3.7.11
- PyArrow version: 3.0.0
i.e. it outputs:
```py
0 [None, [0]]
1 [None, [0]]
2 [None, [0]]
3 [None, [0]]
```
| Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 57 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
FYI the behavior is the same with:
- `datasets` version: 1.18.3
- Platform: Linux-5.8.0-50-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.11
- PyArrow version: 6.0.1
but not with:
- `datasets` version: 1.8.0
- Platform: Linux-4.18.0-305.40.2.el8_4.x86_64-x86_64-with-redhat-8.4-Ootpa
- Python version: 3.7.11
- PyArrow version: 3.0.0
i.e. it outputs:
```py
0 [None, [0]]
1 [None, [0]]
2 [None, [0]]
3 [None, [0]]
```
|
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | Thanks for the insights @PaulLerner !
I found a way to workaround this issue for the code example presented in this issue.
Note that empty lists will still appear when you explicitly `cast` a list of lists that contain None values like [None, [0]] to a new feature type (e.g. to change the integer precision). In this case it will show a warning that it happened. If you don't cast anything, then the None values will be kept as expected.
Let me know what you think ! | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 87 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
Thanks for the insights @PaulLerner !
I found a way to workaround this issue for the code example presented in this issue.
Note that empty lists will still appear when you explicitly `cast` a list of lists that contain None values like [None, [0]] to a new feature type (e.g. to change the integer precision). In this case it will show a warning that it happened. If you don't cast anything, then the None values will be kept as expected.
Let me know what you think ! |
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | Hi! I feel like I’m missing something in your answer, *what* is the workaround? Is it fixed in some `datasets` version? | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 21 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
Hi! I feel like I’m missing something in your answer, *what* is the workaround? Is it fixed in some `datasets` version? |
https://github.com/huggingface/datasets/issues/3676 | `None` replaced by `[]` after first batch in map | `pa.ListArray.from_arrays` returns empty lists instead of None values. The workaround I added inside `datasets` simply consists in not using `pa.ListArray.from_arrays` :)
Once this PR [here ](https://github.com/huggingface/datasets/pull/4282)is merged, we'll release a new version of `datasets` that currectly returns the None values in the case described in this issue
EDIT: released :) but let's keep this issue open because it might happen again if users change the integer precision for example | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | 69 | `None` replaced by `[]` after first batch in map
Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger
`pa.ListArray.from_arrays` returns empty lists instead of None values. The workaround I added inside `datasets` simply consists in not using `pa.ListArray.from_arrays` :)
Once this PR [here ](https://github.com/huggingface/datasets/pull/4282)is merged, we'll release a new version of `datasets` that currectly returns the None values in the case described in this issue
EDIT: released :) but let's keep this issue open because it might happen again if users change the integer precision for example |
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But
1. maybe it's the wrong default
2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).
| ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 43 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But
1. maybe it's the wrong default
2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).
|
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | Hi @severo,
Thanks for clarifying.
I think this default is a bit counterintuitive for the user. However, this is a personal opinion that might not be general. I think it is nice to have the actual (non-encoded) labels in the viewer. On the other hand, it would be nice to match what the user sees with what they get when they download a dataset. I don't know - I can see the difficulty of choosing a default :)
Maybe having non-encoded labels as a default can be useful?
Anyway, I think the issue has been addressed. Thanks a lot for your super-quick answer!
| ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 103 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
Hi @severo,
Thanks for clarifying.
I think this default is a bit counterintuitive for the user. However, this is a personal opinion that might not be general. I think it is nice to have the actual (non-encoded) labels in the viewer. On the other hand, it would be nice to match what the user sees with what they get when they download a dataset. I don't know - I can see the difficulty of choosing a default :)
Maybe having non-encoded labels as a default can be useful?
Anyway, I think the issue has been addressed. Thanks a lot for your super-quick answer!
|
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | Thanks for the 👍 in https://github.com/huggingface/datasets/issues/3673#issuecomment-1029008349 @mariosasko @gary149 @pietrolesci, but as I proposed various solutions, it's not clear to me which you prefer. Could you write your preferences as a comment?
_(note for myself: one idea per comment in the future)_ | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 41 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
Thanks for the 👍 in https://github.com/huggingface/datasets/issues/3673#issuecomment-1029008349 @mariosasko @gary149 @pietrolesci, but as I proposed various solutions, it's not clear to me which you prefer. Could you write your preferences as a comment?
_(note for myself: one idea per comment in the future)_ |
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | As I am working with seq2seq, I prefer having the label in string form rather than numeric. So the viewer is fine and the underlying dataset should be "decoded" (from int to str). In this way, the user does not have to search for a mapping `int -> original name` (even though is trivial to find, I reckon). Also, encoding labels is rather easy.
I hope this is useful | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 69 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
As I am working with seq2seq, I prefer having the label in string form rather than numeric. So the viewer is fine and the underlying dataset should be "decoded" (from int to str). In this way, the user does not have to search for a mapping `int -> original name` (even though is trivial to find, I reckon). Also, encoding labels is rather easy.
I hope this is useful |
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | I like the idea of "0 (neutral)". The label name can even be greyed to make it clear that it's not part of the actual item in the dataset, it's just the meaning. | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 33 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
I like the idea of "0 (neutral)". The label name can even be greyed to make it clear that it's not part of the actual item in the dataset, it's just the meaning. |
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | Proposals by @gary149. Which one do you prefer? Please vote with the thumbs
- 👍

- 👎
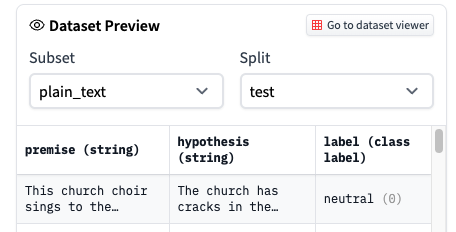
| ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 20 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
Proposals by @gary149. Which one do you prefer? Please vote with the thumbs
- 👍

- 👎

|
https://github.com/huggingface/datasets/issues/3673 | `load_dataset("snli")` is different from dataset viewer | It's [live](https://huggingface.co/datasets/glue/viewer/cola/train):
<img width="1126" alt="Capture d’écran 2022-02-14 à 10 26 03" src="https://user-images.githubusercontent.com/1676121/153836716-25f6205b-96af-42d8-880a-7c09cb24c420.png">
Thanks all for the help to improve the UI! | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| 21 | `load_dataset("snli")` is different from dataset viewer
## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
It's [live](https://huggingface.co/datasets/glue/viewer/cola/train):
<img width="1126" alt="Capture d’écran 2022-02-14 à 10 26 03" src="https://user-images.githubusercontent.com/1676121/153836716-25f6205b-96af-42d8-880a-7c09cb24c420.png">
Thanks all for the help to improve the UI! |
https://github.com/huggingface/datasets/issues/3668 | Couldn't cast array of type string error with cast_column | Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.
If you manage to share a reproducible code example that would be perfect | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
but get error:
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
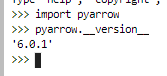
| 38 | Couldn't cast array of type string error with cast_column
## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.
If you manage to share a reproducible code example that would be perfect |
https://github.com/huggingface/datasets/issues/3668 | Couldn't cast array of type string error with cast_column | Hi,
I think my team mate got this solved. Clolsing it for now and will reopen if I experience this again.
Thanks :) | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

| 23 | Couldn't cast array of type string error with cast_column
## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

Hi,
I think my team mate got this solved. Clolsing it for now and will reopen if I experience this again.
Thanks :) |
https://github.com/huggingface/datasets/issues/3668 | Couldn't cast array of type string error with cast_column | Hi @R4ZZ3,
If it is not too much of a bother, can you please help me how to resolve this error? I am exactly getting the same error where I am going as per the documentation guideline:
`my_audio_dataset = my_audio_dataset.cast_column("audio_paths", Audio())`
where `"audio_paths"` is a dataset column (feature) having strings of absolute paths to mp3 files of the dataset.
| ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

| 59 | Couldn't cast array of type string error with cast_column
## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

Hi @R4ZZ3,
If it is not too much of a bother, can you please help me how to resolve this error? I am exactly getting the same error where I am going as per the documentation guideline:
`my_audio_dataset = my_audio_dataset.cast_column("audio_paths", Audio())`
where `"audio_paths"` is a dataset column (feature) having strings of absolute paths to mp3 files of the dataset.
|
https://github.com/huggingface/datasets/issues/3668 | Couldn't cast array of type string error with cast_column | I was having the same issue with this code:
```
dataset = dataset.map(
lambda batch: {"full_path" : os.path.join(self.data_path, batch["path"])},
num_procs = 4
)
my_audio_dataset = dataset.cast_column("full_path", Audio(sampling_rate=16_000))
```
Removing the "num_procs" argument fixed it somehow.
Using a mac with m1 chip | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

| 41 | Couldn't cast array of type string error with cast_column
## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method

but get error:

## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)

- Python version: 3.8.8
- PyArrow version:

I was having the same issue with this code:
```
dataset = dataset.map(
lambda batch: {"full_path" : os.path.join(self.data_path, batch["path"])},
num_procs = 4
)
my_audio_dataset = dataset.cast_column("full_path", Audio(sampling_rate=16_000))
```
Removing the "num_procs" argument fixed it somehow.
Using a mac with m1 chip |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | Having talked to @lhoestq, I see that this feature is no longer supported.
I really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audio files automatically, but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files - e.g. `common_voice` doesn't work anymore in a TF training script. Note this worked perfectly fine before making the change (think it was done [here](https://github.com/huggingface/datasets/pull/3290) no?)
IMO, it's really important to think about a solution here and I strongly favor to make a difference here between loading a dataset in streaming mode and in non-streaming mode, so that in non-streaming mode the actual downloaded file is displayed. It's really crucial for people to be able to analyse the original files IMO when the dataset is not downloaded in streaming mode.
There are the following reasons why it is paramount to have access to the **original** audio file in my opinion (in non-streaming mode):
- There are a wide variety of different libraries to load audio data with varying support on different platforms. For me it was quite clear that there is simply to single good library to load audio files for all platforms - so we have to leave the option to the user to decide which loading to use.
- We had support for audio datasets a long time before streaming audio was possible. There were quite some versions where we advertised **everywhere** to load the audio from the path name (and there are many places where we still do even though it's not possible anymore). To give some examples:
- Official example of TF Wav2Vec2: https://github.com/huggingface/transformers/blob/f427e750490b486944cc9be3c99834ad5cf78b57/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py#L1423 Wav2Vec2 is as important for speech as BERT is for NLP - so it's **very** important. The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment. Same goes for Flax.
- The most downloaded non-nlp checkpoint: https://huggingface.co/facebook/wav2vec2-base-960h#usage has a usage example which doesn't work anymore with the current datasets implementation. I'll update this now, but we have >1000 wav2vec2 checkpoints on the Hub and we can't update all the model cards.
=> This is a big breaking change with no current solution. For `transformers` breaking changes are one of the biggest complaints.
- Similar to this we also shouldn't assume that there is only one resampling method for Audio. I think it's good to have one offered automatically by `datasets`, but we have to leave the user the freedom to choose her/his own resampling as well. Resampling can take very different filtering windows and other parameters which are currently somewhat hardcoded in `datasets`, which users might very well want to change.
=> IMO, it's a **very** big priority to again have the correct absolute path in non-streaming mode. The other solution of providing a path-like object derived from the bytes stocked in the `.array` file is not nearly as user-friendly, but better than nothing. | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 522 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
Having talked to @lhoestq, I see that this feature is no longer supported.
I really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audio files automatically, but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files - e.g. `common_voice` doesn't work anymore in a TF training script. Note this worked perfectly fine before making the change (think it was done [here](https://github.com/huggingface/datasets/pull/3290) no?)
IMO, it's really important to think about a solution here and I strongly favor to make a difference here between loading a dataset in streaming mode and in non-streaming mode, so that in non-streaming mode the actual downloaded file is displayed. It's really crucial for people to be able to analyse the original files IMO when the dataset is not downloaded in streaming mode.
There are the following reasons why it is paramount to have access to the **original** audio file in my opinion (in non-streaming mode):
- There are a wide variety of different libraries to load audio data with varying support on different platforms. For me it was quite clear that there is simply to single good library to load audio files for all platforms - so we have to leave the option to the user to decide which loading to use.
- We had support for audio datasets a long time before streaming audio was possible. There were quite some versions where we advertised **everywhere** to load the audio from the path name (and there are many places where we still do even though it's not possible anymore). To give some examples:
- Official example of TF Wav2Vec2: https://github.com/huggingface/transformers/blob/f427e750490b486944cc9be3c99834ad5cf78b57/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py#L1423 Wav2Vec2 is as important for speech as BERT is for NLP - so it's **very** important. The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment. Same goes for Flax.
- The most downloaded non-nlp checkpoint: https://huggingface.co/facebook/wav2vec2-base-960h#usage has a usage example which doesn't work anymore with the current datasets implementation. I'll update this now, but we have >1000 wav2vec2 checkpoints on the Hub and we can't update all the model cards.
=> This is a big breaking change with no current solution. For `transformers` breaking changes are one of the biggest complaints.
- Similar to this we also shouldn't assume that there is only one resampling method for Audio. I think it's good to have one offered automatically by `datasets`, but we have to leave the user the freedom to choose her/his own resampling as well. Resampling can take very different filtering windows and other parameters which are currently somewhat hardcoded in `datasets`, which users might very well want to change.
=> IMO, it's a **very** big priority to again have the correct absolute path in non-streaming mode. The other solution of providing a path-like object derived from the bytes stocked in the `.array` file is not nearly as user-friendly, but better than nothing. |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | Agree that we need to have access to the original sound files. Few days ago I was looking for these original files because I suspected there is bug in the audio resampling (confirmed in https://github.com/huggingface/datasets/issues/3662) and I want to do my own resampling to workaround the bug, which is now not possible anymore due to the unavailability of the original files. | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 61 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
Agree that we need to have access to the original sound files. Few days ago I was looking for these original files because I suspected there is bug in the audio resampling (confirmed in https://github.com/huggingface/datasets/issues/3662) and I want to do my own resampling to workaround the bug, which is now not possible anymore due to the unavailability of the original files. |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | @patrickvonplaten
> The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing
Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?
> The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment
I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 (https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627).
Your concern is reasonable, but there are situations where we can only serve bytes (see https://github.com/huggingface/datasets/pull/3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column("audio", Audio(decode=False))`).
| ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 180 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
@patrickvonplaten
> The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing
Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?
> The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment
I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 (https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627).
Your concern is reasonable, but there are situations where we can only serve bytes (see https://github.com/huggingface/datasets/pull/3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column("audio", Audio(decode=False))`).
|
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | Related to this discussion: in https://github.com/huggingface/datasets/pull/3664#issuecomment-1031866858 I propose how we could change `iter_archive` to work for streaming and also return local paths (as it used too !). I'd love your opinions on this | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 33 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
Related to this discussion: in https://github.com/huggingface/datasets/pull/3664#issuecomment-1031866858 I propose how we could change `iter_archive` to work for streaming and also return local paths (as it used too !). I'd love your opinions on this |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | > @patrickvonplaten
>
> > The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing
>
> Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?
Yes!
>
> > The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment
>
> I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 ([#3667 (comment)](https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627)).
> Your concern is reasonable, but there are situations where we can only serve bytes (see #3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column("audio", Audio(decode=False))`).
Yes this might be, but I highly doubt that `soundfile` is the go-to library for audio then. @anton-l and I have tried out a bunch of different audio loading libraries (`soundfile`, `librosa`, `torchaudio`, pure `ffmpeg`, `audioread`, ...). One thing that was pretty clear to me is that there is just no "de-facto standard" library and they all have pros and cons. None of the libraries really supports "batch"-ed audio loading. Some depend on PyTorch. `torchaudio` is 100x faster (really!) than `librosa's` fallback on MP3. `torchaudio` often has problems with multi-proessing, ... Also we should keep in mind that resampling is similarly not as simple as reading a text file. It's a pretty complex signal processing transform and people very well might want to use special filters, etc...at the moment we just hard-code `torchaudio's` or `librosa's` default filter when doing resampling.
=> All this to say that we **should definitely** care about whether we rely on local paths or bytes IMO. We don't want to loose all users that are forced to use `datasets` decoding or resampling or have to built a very much not intuitive way of loading bytes into a numpy array. It's much more intuitive to be able to inspect a local file. I feel pretty strongly about this and am happy to also jump on a call. Keeping libraries flexible and lean as well as exposing internals is very important IMO (this philosophy has worked quite well so far with Transformers).
| ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 436 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
> @patrickvonplaten
>
> > The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing
>
> Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?
Yes!
>
> > The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment
>
> I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 ([#3667 (comment)](https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627)).
> Your concern is reasonable, but there are situations where we can only serve bytes (see #3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column("audio", Audio(decode=False))`).
Yes this might be, but I highly doubt that `soundfile` is the go-to library for audio then. @anton-l and I have tried out a bunch of different audio loading libraries (`soundfile`, `librosa`, `torchaudio`, pure `ffmpeg`, `audioread`, ...). One thing that was pretty clear to me is that there is just no "de-facto standard" library and they all have pros and cons. None of the libraries really supports "batch"-ed audio loading. Some depend on PyTorch. `torchaudio` is 100x faster (really!) than `librosa's` fallback on MP3. `torchaudio` often has problems with multi-proessing, ... Also we should keep in mind that resampling is similarly not as simple as reading a text file. It's a pretty complex signal processing transform and people very well might want to use special filters, etc...at the moment we just hard-code `torchaudio's` or `librosa's` default filter when doing resampling.
=> All this to say that we **should definitely** care about whether we rely on local paths or bytes IMO. We don't want to loose all users that are forced to use `datasets` decoding or resampling or have to built a very much not intuitive way of loading bytes into a numpy array. It's much more intuitive to be able to inspect a local file. I feel pretty strongly about this and am happy to also jump on a call. Keeping libraries flexible and lean as well as exposing internals is very important IMO (this philosophy has worked quite well so far with Transformers).
|
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | From https://github.com/huggingface/datasets/pull/3736 the Common Voice dataset now gives access to the local audio files as before | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 16 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
From https://github.com/huggingface/datasets/pull/3736 the Common Voice dataset now gives access to the local audio files as before |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).
Regardless of whether it is a breaking change, however, I don't see the other arguments.
> but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files
I don't exactly understand this. Why not?
Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?
But even if you just provide the raw bytes to TF, on TF you could just use sth like `tfio.audio.decode_mp3` or `tf.audio.decode_ogg` or `tfio.audio.decode_flac`?
> There are the following reasons why it is paramount to have access to the original audio file in my opinion ...
I don't really understand the arguments (despite that it maybe breaks existing code). You anyway have the original audio files but it is just embedded in the dataset? I don't really know about any library which cannot also load the audio from memory (i.e. from the dataset).
Btw, on librosa being slow for decoding audio files, I saw that as well, so we have this comment RETURNN:
> Don't use librosa.load which internally uses audioread which would use Gstreamer as a backend which has multiple issues:
> https://github.com/beetbox/audioread/issues/62
> https://github.com/beetbox/audioread/issues/63
> Instead, use PySoundFile (soundfile), which is also faster. See here for discussions:
> https://github.com/beetbox/audioread/issues/64
> https://github.com/librosa/librosa/issues/681
Resampling is also a separate aspect, which is also less straightforward and with different compromises between speed and quality. So there the different tradeoffs and different implementations can make a difference.
However, I don't see how this is related to the question whether there should be the raw bytes inside the dataset or as separate local files.
| ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 336 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).
Regardless of whether it is a breaking change, however, I don't see the other arguments.
> but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files
I don't exactly understand this. Why not?
Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?
But even if you just provide the raw bytes to TF, on TF you could just use sth like `tfio.audio.decode_mp3` or `tf.audio.decode_ogg` or `tfio.audio.decode_flac`?
> There are the following reasons why it is paramount to have access to the original audio file in my opinion ...
I don't really understand the arguments (despite that it maybe breaks existing code). You anyway have the original audio files but it is just embedded in the dataset? I don't really know about any library which cannot also load the audio from memory (i.e. from the dataset).
Btw, on librosa being slow for decoding audio files, I saw that as well, so we have this comment RETURNN:
> Don't use librosa.load which internally uses audioread which would use Gstreamer as a backend which has multiple issues:
> https://github.com/beetbox/audioread/issues/62
> https://github.com/beetbox/audioread/issues/63
> Instead, use PySoundFile (soundfile), which is also faster. See here for discussions:
> https://github.com/beetbox/audioread/issues/64
> https://github.com/librosa/librosa/issues/681
Resampling is also a separate aspect, which is also less straightforward and with different compromises between speed and quality. So there the different tradeoffs and different implementations can make a difference.
However, I don't see how this is related to the question whether there should be the raw bytes inside the dataset or as separate local files.
|
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | Thanks for your comments here @albertz - cool to get your input!
Answering a bit here between the lines:
> I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).
>
> Regardless of whether it is a breaking change, however, I don't see the other arguments.
>
> > but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files
>
> I don't exactly understand this. Why not?
> Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?
The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.
So for TF and Flax it's important that users can load audio files or bytes they way the want to - this might become less important if we find (or make) a good library with few dependencies that is fast for all kinds of platforms / use cases.
Now the question is whether it's better to store audio data as a path to a file or as raw bytes I guess.\
My main arguments for storing the audio data as a path to a file is pretty much all about users experience - I don't really expect our users to understand the inner workings of datasets:
- 1. It's not straightforward to know which function to use to decode it - not all `load_audio(...)` or `read_audio(...)` work on raw bytes. E.g. Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes . There are also some functions of other libraries which only work on files which would require the user to save the bytes as a file first before being able to load it.
- 2. It's difficult to see which format the bytes are coming from (mp3, ogg, ...) - guess this could be remedied by adding the format to each sample though
- 3. It is a bit scary IMO to see raw bytes for users. Overall, I think it's better to leave the data in it's raw form as this way it's much easier for people to play around with the audio files, less need to read docs because people don't worry about what happened to the audio files (are the bytes already resampled?)
But the argument that the audio should be loadable directly from memory is good - haven't thought about this too much.
I guess it's still very much possible for the user to do this:
```python
def save_as_bytes:
batch["bytes"] = read_in_bytes_from_file(batch["file"])\
os.remove(batch["file"])
ds = ds.map(save_as_bytes)
ds.save_to_disk(...)
```
Guess the question is more a bit about what should be the default case? | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 561 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
Thanks for your comments here @albertz - cool to get your input!
Answering a bit here between the lines:
> I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).
>
> Regardless of whether it is a breaking change, however, I don't see the other arguments.
>
> > but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files
>
> I don't exactly understand this. Why not?
> Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?
The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.
So for TF and Flax it's important that users can load audio files or bytes they way the want to - this might become less important if we find (or make) a good library with few dependencies that is fast for all kinds of platforms / use cases.
Now the question is whether it's better to store audio data as a path to a file or as raw bytes I guess.\
My main arguments for storing the audio data as a path to a file is pretty much all about users experience - I don't really expect our users to understand the inner workings of datasets:
- 1. It's not straightforward to know which function to use to decode it - not all `load_audio(...)` or `read_audio(...)` work on raw bytes. E.g. Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes . There are also some functions of other libraries which only work on files which would require the user to save the bytes as a file first before being able to load it.
- 2. It's difficult to see which format the bytes are coming from (mp3, ogg, ...) - guess this could be remedied by adding the format to each sample though
- 3. It is a bit scary IMO to see raw bytes for users. Overall, I think it's better to leave the data in it's raw form as this way it's much easier for people to play around with the audio files, less need to read docs because people don't worry about what happened to the audio files (are the bytes already resampled?)
But the argument that the audio should be loadable directly from memory is good - haven't thought about this too much.
I guess it's still very much possible for the user to do this:
```python
def save_as_bytes:
batch["bytes"] = read_in_bytes_from_file(batch["file"])\
os.remove(batch["file"])
ds = ds.map(save_as_bytes)
ds.save_to_disk(...)
```
Guess the question is more a bit about what should be the default case? |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | > The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.
But how is this relevant for this issue here? I thought this issue here is about having the (correct) path in the dataset or having raw bytes in the dataset.
How did TF users use it at all then? Or they just do not use on-the-fly decoding? I did not even notice this problem (maybe because I had `torchaudio` installed). But what do they use instead?
But as I outlined before, they could just use `tfio.audio.decode_flac` and co, where it would be more natural if you already provide the raw bytes.
> Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes
I was not really familiar with `torchaudio`. It seems that they really don't provide an easy/direct API to operate on raw bytes. Which is very strange and unfortunate because as far as I can see, all the underlying backend libraries (e.g. soundfile) easily allow that. So I would say that this is the fault of `torchaudio` then. But despite, if you anyway use `torchaudio` with `soundfile` backend, why not just use `soundfile` directly. It's very simple to use and crossplatform.
But ok, now we are just discussing how to handle the on-the-fly decoding. I still think this is a separate issue and having raw bytes in the dataset instead of local files should just be fine as well.
> It is a bit scary IMO to see raw bytes for users.
I think nobody who writes code is scared by seeing the raw bytes content of a binary file. :)
> I guess it's still very much possible for the user to do this:
>
> ```python
> def save_as_bytes:
> batch["bytes"] = read_in_bytes_from_file(batch["file"])\
> os.remove(batch["file"])
>
> ds = ds.map(save_as_bytes)
>
> ds.save_to_disk(...)
> ```
In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this `map` is not needed anymore and `save_to_disk` could do it automatically (maybe via some option)?
> Guess the question is more a bit about what should be the default case?
Yea this is up to you. I'm happy as long as we can get it the way we want easily and this is a well supported use case. :)
| ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 435 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
> The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.
But how is this relevant for this issue here? I thought this issue here is about having the (correct) path in the dataset or having raw bytes in the dataset.
How did TF users use it at all then? Or they just do not use on-the-fly decoding? I did not even notice this problem (maybe because I had `torchaudio` installed). But what do they use instead?
But as I outlined before, they could just use `tfio.audio.decode_flac` and co, where it would be more natural if you already provide the raw bytes.
> Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes
I was not really familiar with `torchaudio`. It seems that they really don't provide an easy/direct API to operate on raw bytes. Which is very strange and unfortunate because as far as I can see, all the underlying backend libraries (e.g. soundfile) easily allow that. So I would say that this is the fault of `torchaudio` then. But despite, if you anyway use `torchaudio` with `soundfile` backend, why not just use `soundfile` directly. It's very simple to use and crossplatform.
But ok, now we are just discussing how to handle the on-the-fly decoding. I still think this is a separate issue and having raw bytes in the dataset instead of local files should just be fine as well.
> It is a bit scary IMO to see raw bytes for users.
I think nobody who writes code is scared by seeing the raw bytes content of a binary file. :)
> I guess it's still very much possible for the user to do this:
>
> ```python
> def save_as_bytes:
> batch["bytes"] = read_in_bytes_from_file(batch["file"])\
> os.remove(batch["file"])
>
> ds = ds.map(save_as_bytes)
>
> ds.save_to_disk(...)
> ```
In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this `map` is not needed anymore and `save_to_disk` could do it automatically (maybe via some option)?
> Guess the question is more a bit about what should be the default case?
Yea this is up to you. I'm happy as long as we can get it the way we want easily and this is a well supported use case. :)
|
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | > In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this map is not needed anymore and save_to_disk could do it automatically (maybe via some option)?
Yes! Should be super easy now see discussion here: https://github.com/rwth-i6/i6_core/issues/257#issuecomment-1105494468
Thanks for the super useful input :-) | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 39 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
> In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this map is not needed anymore and save_to_disk could do it automatically (maybe via some option)?
Yes! Should be super easy now see discussion here: https://github.com/rwth-i6/i6_core/issues/257#issuecomment-1105494468
Thanks for the super useful input :-) |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2) | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 22 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2) |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | > Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)
It appears downgrading to torchaudio 0.11.0 fixed this problem. | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 32 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
> Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)
It appears downgrading to torchaudio 0.11.0 fixed this problem. |
https://github.com/huggingface/datasets/issues/3663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | @patrickvonplaten @lhoestq @polinaeterna I was unable to load audio from Common Voice using 🤗 with the current version of torchaudio, but downgrading to torchaudio 0.11.0 fixed it. This is probably more of a torch problem than a Hugging Face problem. | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| 40 | [Audio] Path of Common Voice cannot be used for audio loading anymore
## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
@patrickvonplaten @lhoestq @polinaeterna I was unable to load audio from Common Voice using 🤗 with the current version of torchaudio, but downgrading to torchaudio 0.11.0 fixed it. This is probably more of a torch problem than a Hugging Face problem. |