diff --git "a/jsteinhardt_blog.jsonl" "b/jsteinhardt_blog.jsonl"
new file mode 100644--- /dev/null
+++ "b/jsteinhardt_blog.jsonl"
@@ -0,0 +1,39 @@
+{"text": "New new blog location\n\nI’ve switched the host of my blog to Ghost, so my blog is now located at . This is different from the previous re-hosting on my personal website, which is no longer maintained.\n\n\nFeedly users can subscribe via RSS [here](https://feedly.com/i/subscription/feed/https://bounded-regret.ghost.io/rss/). \nOr click the bottom-right subscribe button on [this](https://bounded-regret.ghost.io/) page to get e-mail notifications of new posts.\n\n", "url": "https://jsteinhardt.wordpress.com/2021/10/13/new-new-blog-location/", "title": "New new blog location", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2021-10-13T22:16:16+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "7af08cc55e69629d19952f50757a4cc3", "summary": []}
+{"text": "New blog location\n\n*[Update: This post is out of date. My blog has now moved again, to .]*\n\n\nI’ve decided to move this blog to my personal website. It’s now located here: , including all the old posts and comments, plus some new and upcoming posts :).\n\n", "url": "https://jsteinhardt.wordpress.com/2021/06/23/new-blog-location/", "title": "New blog location", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2021-06-23T23:39:11+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "130777e457a45a578fe92c25625b980b", "summary": []}
+{"text": "Sets with Small Intersection\n\nSuppose that we want to construct subsets  with the following properties:\n\n\n1.  for all \n2.  for all \n\n\nThe goal is to construct as large a family of such subsets as possible (i.e., to make  as large as possible). If 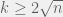, then up to constants it is not hard to show that the optimal number of sets is  (that is, the trivial construction with all sets disjoint is essentially the best we can do).\n\n\nHere I am interested in the case when . In this case I claim that we can substantially outperform the trivial construction: we can take . The proof is a very nice application of the asymmetric Lovasz Local Lemma. (Readers can refresh their memory [here](https://en.wikipedia.org/wiki/Lov%C3%A1sz_local_lemma#Asymmetric_Lov.C3.A1sz_local_lemma) on what the asymmetric LLL says.)\n\n\n**Proof.** We will take a randomized construction. For , , let  be the event that 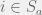. We will take the  to be independent each with probability 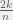. Also define the events\n\n\n![Y_{i,j,a,b} = I[i \\in S_a \\wedge j \\in S_a \\wedge i \\in S_b \\wedge j \\in S_b]](https://s0.wp.com/latex.php?latex=Y_%7Bi%2Cj%2Ca%2Cb%7D+%3D+I%5Bi+%5Cin+S_a+%5Cwedge+j+%5Cin+S_a+%5Cwedge+i+%5Cin+S_b+%5Cwedge+j+%5Cin+S_b%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\n![Z_{a} = I[|S_a| < k]](https://s0.wp.com/latex.php?latex=Z_%7Ba%7D+%3D+I%5B%7CS_a%7C+%3C+k%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nIt suffices to show that with non-zero probability, all of the  and  are false. Note that each  depends on , and each  depends on . Thus each  depends on at most  other  and  other , and each  depends on at most  of the . Also note that  and  (by the Chernoff bound). It thus suffices to find constants 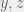 such that\n\n\n\n\n\n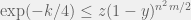\n\n\nWe will guess , , in which case the bottom inequality is approximately 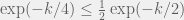 (which is satisfied for large enough , and the top inequality is approximately , which is satisfied for 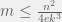 (assuming ). Hence in particular we can indeed take , as claimed.\n\n", "url": "https://jsteinhardt.wordpress.com/2017/03/17/sets-with-small-intersection/", "title": "Sets with Small Intersection", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-03-17T04:42:29+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "9674a312afb4fe19cb9b5ef08241f4fb", "summary": []}
+{"text": "Advice for Authors\n\nI’ve spent much of the last few days reading various ICML papers and I find there’s a few pieces of feedback that I give consistently across several papers. I’ve collated some of these below. As a general note, many of these are about local style rather than global structure; I think that good local style probably contributes substantially more to readability than global structure and is in general under-rated. I’m in general pretty willing to break rules about global structure (such as even having a conclusion section in the first place! though this might cause reviewers to look at your paper funny), but not to break local stylistic rules without strong reasons.\n\n\n**General Writing Advice**\n\n\n* Be precise. This isn’t about being pedantic, but about maximizing information content. Choose your words carefully so that you say what you mean to say. For instance, replace “performance” with “accuracy” or “speed” depending on what you mean.\n* Be concise. Most of us write in an overly wordy style, because it’s easy to and no one drilled it out of us. Not only does wordiness decrease readability, it wastes precious space if you have a page limit.\n* Avoid complex sentence structure. Most research is already difficult to understand and digest; there’s no reason to make it harder by having complex run-on sentences.\n* Use consistent phrasing. In general prose, we’re often told to refer to the same thing in different ways to avoid boring the reader, but in technical writing this will lead to confusion. Hopefully your actual results are interesting enough that the reader doesn’t need to be entertained by your large vocabulary.\n\n\n**Abstract**\n\n\n* There’s more than one approach to writing a good abstract, and which one you take will depend on the sort of paper you’re writing. I’ll give one approach that is good for papers presenting an unusual or unfamiliar idea to readers.\n* The first sentence / phrase should be something that all readers will agree with. The second should be something that many readers would find surprising, or wouldn’t have thought about before; but it should follow from (or at least be supported by) the first sentence. The general idea is that you need to start by warming the reader up and putting them in the right context, before they can appreciate your brilliant insight.\n* Here’s an example from my [Reified Context Models](http://jmlr.org/proceedings/papers/v37/steinhardta15.html) paper: “A classic tension exists between exact inference in a simple model and approximate inference in a complex model. The latter offers expressivity and thus accuracy, but the former provides coverage of the space, an important property for confidence estimation and learning with indirect supervision.” Note how the second sentence conveys a non-obvious claim — that coverage is important for confidence estimation as well as for indirect supervision. It’s tempting to lead with this in order to make the first sentence more punchy, but this will tend to go over reader’s heads. Imagine if the abstract had started, “In the context of inference algorithms, coverage of the space is important for confidence estimation and indirect supervision.” No one is going to understand what that means.\n\n\n**Introduction** \n\n\n* The advice in this section is most applicable to the introduction section (and maybe related work and discussion), but applies on some level to other parts of the paper as well.\n* Many authors (myself included) end up using phrases like “much recent interest” and “increasingly important” because these phrases show up frequently in academic papers, and they are vague enough to be defensible. Even though these phrases are common, they are bad writing! They are imprecise and rely on hedge words to avoid having to explain why something is interesting or important.\n* Make sure to provide context before introducing a new concept; if you suddenly start talking about “NP-hardness” or “local transformations”, you need to first explain to the reader why this is something that should be considered in the present situation.\n* Don’t beat around the bush; if the point is “A, therefore B” (where B is some good fact about your work), then say that, rather than being humble and just pointing out A.\n* Don’t make the reader wait for the payoff; spell it out in the introduction. I frequently find that I have to wait until Section 4 to find out why I should care about a paper; while I might read that far, most reviewers are going to give up about halfway through Section 1. (Okay, that was a bit of an exaggeration; they’ll probably wait until the end of Section 1 before giving up.)\n\n\n**Conclusion / Discussion**\n\n\n* I generally put in the conclusion everything that I wanted to put in the introduction, but couldn’t because readers wouldn’t be able to appreciate the context without reading the rest of the paper first. This is a relatively straightforward way to write a conclusion that isn’t just a re-hash of the introduction.\n* The conclusion can also be a good place to discuss open questions that you’d like other researchers to think about.\n* My model is that only the ~5 people most interested in your paper are going to actually read this section, so it’s worth somewhat tailoring to that audience. Unfortunately, the paper reviewers might also read this section, so you can’t tailor it too much or the reviewers might get upset if they end up not being in the target audience.\n* For theory papers, having a conclusion is completely optional (I usually skip it). In this case, open problems can go in the introduction. If you’re submitting a theory paper to NIPS or ICML, you unfortunately need a conclusion or reviewers will get upset. In my opinion, this is an instance where peer review makes the paper worse rather than better.\n\n\n**LaTeX**\n\n\n* Proper citation style: one should write “Widgets are awesome (Smith, 2001).” or “Smith (2001) shows that widgets are awesome.” but never “(Smith, 2001) shows that widgets are awesome.” You can control this in LaTeX using \\citep{} and \\citet{} if you use natbib.\n* Display equations can take up a lot of space if over-used, but at the same time, too many in-line equations can make your document hard to read. Think carefully about which equations are worth displaying, and whether your in-line equations are becoming too dense.\n* If leave a blank line after \\end{equation} or $$, you will create an extra line break in the document. This is sort of annoying because white-space isn’t supposed to matter in that way, but you can save a lot of space by remembering this.\n* DON’T use the fullpage package. I’m used to using \\usepackage{fullpage} in documents to get the margins that I want, but this will override options in many style files (including jmlr.sty which is used in machine learning).\n* \\left( and \\right) can be convenient for auto-sizing parentheses, but are often overly conservative (e.g. making parentheses too big due to serifs or subscripts). It’s fine to use \\left( and \\right) initially, but you might want to specify explicit sizes with \\big(, \\Big(, \\bigg(, etc. in the final pass.\n* When displaying a sequence of equations (e.g. with the align environment), use \\stackrel{} on any non-trivial equality or inequality statements and justify these steps immediately after the equation. See the bottom of page 6 of [this](http://www.jmlr.org/proceedings/papers/v40/Steinhardt15.pdf) paper for an example.\n* Make sure that \\label{} commands come after the \\caption{} command in a figure (rather than before), otherwise your numbering will be wrong.\n\n\n**Math**\n\n\n* When using a variable that hasn’t appeared in a while, remind the reader what it is (i.e., “the sample space 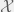” rather than “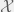“.\n* If it’s one of the main points of your work, call it a Theorem. If it’s a non-trivial conclusion that requires a somewhat involved argument (but it’s not a main point of the work), call it a Proposition. If the proof is short or routine, call it a Lemma, unless it follows directly from a Theorem you just stated, in which case call it a Corollary.\n* As a general rule there shouldn’t be more than 3 theorems in your paper (probably not more than 1). If you think this is unreasonable, consider that my [COLT 2015 paper](http://www.jmlr.org/proceedings/papers/v40/Steinhardt15.pdf) has 3 theorems across 24 pages, and my STOC 2017 paper has 2 theorems across 47 pages (not counting stating the same theorem in multiple locations).\n* If you just made a mathematical argument in the text that ended up with a non-trivial conclusion, you probably want to encapsulate it in a Proposition or Theorem. (Better yet, state the theorem before the argument so that the reader knows what you’re arguing for; although this isn’t always the best ordering.)\n", "url": "https://jsteinhardt.wordpress.com/2017/02/28/advice-for-authors/", "title": "Advice for Authors", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-02-28T01:11:50+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "3f3ca381d809cba7d7a64d49ac63f439", "summary": []}
+{"text": "Model Mis-specification and Inverse Reinforcement Learning\n\nIn my previous post, “[Latent Variables and Model Mis-specification](https://jsteinhardt.wordpress.com/2017/01/10/latent-variables-and-model-mis-specification/)”, I argued that while machine learning is good at optimizing accuracy on observed signals, it has less to say about correctly inferring the values for unobserved variables in a model. In this post I’d like to focus in on a specific context for this: inverse reinforcement learning ([Ng et al. 2000](http://ai.stanford.edu/~ang/papers/icml00-irl.pdf), [Abeel et al. 2004](http://machinelearning.wustl.edu/mlpapers/paper_files/icml2004_PieterN04.pdf), [Ziebart et al. 2008](http://www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdfhttp://www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdf), [Ho et al 2016](http://papers.nips.cc/paper/6391-generative-adversarial-imitation-learning)), where one observes the actions of an agent and wants to infer the preferences and beliefs that led to those actions. For this post, I am pleased to be joined by Owain Evans, who is an active researcher in this area and has co-authored an online [book](http://agentmodels.org/) about building models of agents (see [here](http://agentmodels.org/chapters/4-reasoning-about-agents.html) in particular for a tutorial on inverse reinforcement learning and inverse planning).\n\n\nOwain and I are particularly interested in inverse reinforcement learning (IRL) because it has been proposed (most notably by [Stuart Russell](http://papers.nips.cc/paper/6420-cooperative-inverse-reinforcement-learning)) as a method for learning human values in the context of AI safety; among other things, this would eventually involve learning and correctly implementing human values by artificial agents that are much more powerful, and act with much broader scope, than any humans alive today. While we think that overall IRL is a promising route to consider, we believe that there are also a number of non-obvious pitfalls related to performing IRL with a mis-specified model. The role of IRL in AI safety is to infer human values, which are represented by a reward function or utility function. But crucially, human values (or human reward functions) are never directly observed.\n\n\nBelow, we elaborate on these issues. We hope that by being more aware of these issues, researchers working on inverse reinforcement learning can anticipate and address the resulting failure modes. In addition, we think that considering issues caused by model mis-specification in a particular concrete context can better elucidate the general issues pointed to in the previous post on model mis-specification.\n\n\n### **Specific Pitfalls for Inverse Reinforcement Learning**\n\n\nIn “[Latent Variables and Model Mis-specification](https://jsteinhardt.wordpress.com/2017/01/10/latent-variables-and-model-mis-specification/)”, Jacob talked about *model mis-specification*, where the “true” model does not lie in the model family being considered. We encourage readers to read that post first, though we’ve also tried to make the below readable independently.\n\n\nIn the context of inverse reinforcement learning, one can see some specific problems that might arise due to model mis-specification. For instance, the following are things we could misunderstand about an agent, which would cause us to make incorrect inferences about the agent’s values:\n\n\n* The **actions** of the agent. If we believe that an agent is capable of taking a certain action, but in reality they are not, we might make strange inferences about their values (for instance, that they highly value not taking that action). Furthermore, if our data is e.g. videos of human behavior, we have an additional inference problem of recognizing actions from the frames.\n* The **information** available to the agent. If an agent has access to more information than we think it does, then a plan that seems irrational to us (from the perspective of a given reward function) might actually be optimal for reasons that we fail to appreciate. In the other direction, if an agent has less information than we think, then we might incorrectly believe that they don’t value some outcome A, even though they really only failed to obtain A due to lack of information.\n\n\n* The **long-term plans** of the agent. An agent might take many actions that are useful in accomplishing some long-term goal, but not necessarily over the time horizon that we observe the agent. Inferring correct values thus also requires inferring such long-term goals. In addition, long time horizons can make models more brittle, thereby exacerbating model mis-specification issues.\n\n\nThere are likely other sources of error as well. The general point is that, given a mis-specified model of the agent, it is easy to make incorrect inferences about an agent’s values if the optimization pressure on the learning algorithm is only towards predicting actions correctly in-sample.\n\n\nIn the remainder of this post, we will cover each of the above aspects — actions, information, and plans — in turn, giving both quantitative models and qualitative arguments for why model mis-specification for that aspect of the agent can lead to perverse beliefs and behavior. First, though, we will briefly review the definition of inverse reinforcement learning and introduce relevant notation.\n\n\n### **Inverse Reinforcement Learning: Definition and Notations**\n\n\nIn inverse reinforcement learning, we want to model an agent taking actions in a given environment. We therefore suppose that we have a **state space**  (the set of states the agent and environment can be in), an **action space**  (the set of actions the agent can take), and a **transition function** , which gives the probability of moving from state  to state  when taking action . For instance, for an AI learning to control a car, the state space would be the possible locations and orientations of the car, the action space would be the set of control signals that the AI could send to the car, and the transition function would be the dynamics model for the car. The tuple of 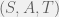 is called an 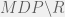, which is a Markov Decision Process without a reward function. (The 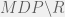 will either have a known horizon or a discount rate  but we’ll leave these out for simplicity.)\n\n\n\n\n\n*Figure 1: Diagram showing how IRL and RL are related. (Credit: Pieter Abbeel’s* [*slides*](https://people.eecs.berkeley.edu/~pabbeel/cs287-fa12/slides/inverseRL.pdf) *on IRL)* \n\n\nThe inference problem for IRL is to infer a reward function 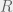 given an optimal policy  for the 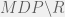 (see Figure 1). We learn about the policy  from samples 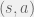 of states and the corresponding action according to  (which may be random). Typically, these samples come from a trajectory, which records the full history of the agent’s states and actions in a single episode:\n\n\n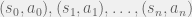\n\n\nIn the car example, this would correspond to the actions taken by an expert human driver who is demonstrating desired driving behaviour (where the actions would be recorded as the signals to the steering wheel, brake, etc.).\n\n\nGiven the 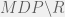 and the observed trajectory, the goal is to infer the reward function 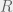. In a Bayesian framework, if we specify a prior on 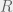 we have:\n\n\n\n\n\nThe likelihood  is just ![\\pi_R(s)[a_i]](https://s0.wp.com/latex.php?latex=%5Cpi_R%28s%29%5Ba_i%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), where  is the optimal policy under the reward function 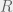. Note that computing the optimal policy given the reward is in general non-trivial; except in simple cases, we typically approximate the policy using reinforcement learning (see Figure 1). Policies are usually assumed to be noisy (e.g. using a softmax instead of deterministically taking the best action). Due to the challenges of specifying priors, computing optimal policies and integrating over reward functions, most work in IRL uses some kind of approximation to the Bayesian objective (see the references in the introduction for some examples).\n\n\n### **Recognizing Human Actions in Data**\n\n\nIRL is a promising approach to learning human values in part because of the easy availability of data. For supervised learning, humans need to produce many labeled instances specialized for a task. IRL, by contrast, is an unsupervised/semi-supervised approach where any record of human behavior is a potential data source. Facebook’s logs of user behavior provide trillions of data-points. YouTube videos, history books, and literature are a trove of data on human behavior in both actual and imagined scenarios. However, while there is lots of existing data that is informative about human preferences, we argue that exploiting this data for IRL will be a difficult, complex task with current techniques.\n\n\n*Inferring Reward Functions from Video Frames*\n\n\nAs we noted above, applications of IRL typically infer the reward function R from observed samples of the human policy . Formally, the environment is a known 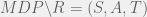 and the observations are state-action pairs, . This assumes that (a) the environment’s dynamics 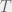 are given as part of the IRL problem, and (b) the observations are structured as “state-action” pairs. When the data comes from a human expert parking a car, these assumptions are reasonable. The states and actions of the driver can be recorded and a car simulator can be used for 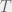. For data from YouTube videos or history books, the assumptions fail. The data is a sequence of partial observations: the transition function 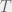 is unknown and the data does not separate out *state* and *action*. Indeed, it’s a challenging ML problem to infer human actions from text or videos.\n\n\n\n\n\n*Movie still: What actions are being performed in this situation?* ([Source](http://www.moviemoviesite.com/People/A/attenborough-richard/filmography.htm))\n\n\nAs a concrete example, suppose the data is a video of two co-pilots flying a plane. The successive frames provide only limited information about the state of the world at each time step and the frames often jump forward in time. So it’s more like a [POMDP](https://en.wikipedia.org/wiki/Partially_observable_Markov_decision_process) with a complex observation model. Moreover, the actions of each pilot need to be inferred. This is a challenging inference problem, because actions can be subtle (e.g. when a pilot nudges the controls or nods to his co-pilot).\n\n\nTo infer actions from observations, some model relating the true state-action 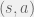 to the observed video frame must be used. But choosing any model makes substantive assumptions about how human values relate to their behavior. For example, suppose someone attacks one of the pilots and (as a reflex) he defends himself by hitting back. Is this reflexive or instinctive response (hitting the attacker) an action that is informative about the pilot’s values? Philosophers and neuroscientists might investigate this by considering the mental processes that occur before the pilot hits back. If an IRL algorithm uses an off-the-shelf action classifier, it will lock in some (contentious) assumptions about these mental processes. At the same time, an IRL algorithm cannot *learn* such a model because it never directly observes the mental processes that relate rewards to actions.\n\n\n*Inferring Policies From Video Frames*\n\n\nWhen learning a reward function via IRL, the ultimate goal is to use the reward function to guide an artificial agent’s behavior (e.g. to perform useful tasks to humans). This goal can be formalized directly, without including IRL as an intermediate step. For example, in **Apprenticeship Learning,** the goal is to learn a “good” policy for the 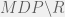 from samples of the human’s policy  (where  is assumed to approximately optimize an unknown reward function). In **Imitation Learning,** the goal is simply to learn a policy that is similar to the human’s policy.\n\n\nLike IRL, policy search techniques need to recognize an agent’s actions to infer their policy. So they have the same challenges as IRL in learning from videos or history books. Unlike IRL, policy search does not explicitly model the reward function that underlies an agent’s behavior. This leads to an additional challenge. Humans and AI systems face vastly different tasks and have different action spaces. Most actions in videos and books would never be performed by a software agent. Even when tasks are similar (e.g. humans driving in the 1930s vs. a self-driving car in 2016), it is a difficult [transfer learning](https://openreview.net/pdf?id=B16dGcqlx) problem to use human policies in one task to improve AI policies in another.\n\n\n*IRL Needs Curated Data*\n\n\nWe argued that records of human behaviour in books and videos are difficult for IRL algorithms to exploit. Data from Facebook seems more promising: we can store the state (e.g. the HTML or pixels displayed to the human) and each human action (clicks and scrolling). This extends beyond Facebook to any task that can be performed on a computer. While this covers a broad range of tasks, there are obvious limitations. Many people in the world have a limited ability to use a computer: we can’t learn about their values in this way. Moreover, some kinds of human preferences (e.g. preferences over physical activities) seem hard to learn about from behaviour on a computer.\n\n\n### **Information and Biases**\n\n\nHuman actions depend both on their preferences and their *beliefs*. The beliefs, like the preferences, are never directly observed. For narrow tasks (e.g. people choosing their favorite photos from a display), we can model humans as having full knowledge of the state (as in an [MDP](https://en.wikipedia.org/wiki/Markov_decision_process)). But for most real-world tasks, humans have limited information and their information changes over time (as in a [POMDP](https://en.wikipedia.org/wiki/Partially_observable_Markov_decision_process) or [RL](https://en.wikipedia.org/wiki/Reinforcement_learning) problem). If IRL assumes the human has full information, then the model is mis-specified and generalizing about what the human would prefer in other scenarios can be mistaken. Here are some examples:\n\n\n(1). Someone travels from their house to a cafe, which has already closed. If they are assumed to have full knowledge, then IRL would infer an alternative preference (e.g. going for a walk) rather than a preference to get a drink at the cafe.\n\n\n(2). Someone takes a drug that is widely known to be ineffective. This could be because they have a false belief that the drug is effective, or because they picked up the wrong pill, or because they take the drug for its side-effects. Each possible explanation could lead to different conclusions about preferences.\n\n\n(3). Suppose an IRL algorithm is inferring a person’s goals from key-presses on their laptop. The person repeatedly forgets their login passwords and has to reset them. This behavior is hard to capture with a POMDP-style model: humans forget some strings of characters and not others. IRL might infer that the person *intends* to repeatedly reset their passwords.\n\n\nExample (3) above arises from humans forgetting information — even if the information is only a short string of characters. This is one way in which humans systematically deviate from rational Bayesian agents. The field of psychology has documented many other deviations. Below we discuss one such deviation — *time-inconsistency* — which has been used to explain temptation, addiction and procrastination.\n\n\n*Time-inconsistency and Procrastination*\n\n\nAn IRL algorithm is inferring Alice’s preferences. In particular, the goal is to infer Alice’s preference for completing a somewhat tedious task (e.g. writing a paper) as opposed to relaxing. Alice has 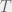 days in which she could complete the task and IRL observes her working or relaxing on each successive day.\n\n\n\n\n\n*Figure 2. MDP graph for choosing whether to “work” or “wait” (relax) on a task.* \n\n\nFormally, let R be the preference/reward Alice assigns to completing the task. Each day, Alice can “work” (receiving cost  for doing tedious work) or “wait” (cost 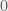). If she works, she later receives the reward 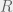 minus a tiny, linearly increasing cost (because it’s better to submit a paper earlier). Beyond the deadline at 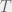, Alice cannot get the reward 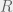. For IRL, we fix  and  and infer 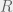.\n\n\nSuppose Alice chooses “wait” on Day 1. If she were fully rational, it follows that R (the preference for completing the task) is small compared to  (the psychological cost of doing the tedious work). In other words, Alice doesn’t care much about completing the task. Rational agents will do the task on Day 1 or never do it. Yet humans often care deeply about tasks yet leave them until the last minute (when finishing early would be optimal). Here we imagine that Alice has 9 days to complete the task and waits until the last possible day.\n\n\n\n\n\n*Figure 3: Graph showing IRL inferences for Optimal model (which is mis-specified) and Possibly Discounting Model (which includes hyperbolic discounting). On each day (**-axis) the model gets another observation of Alice’s choice. The* *-axis shows the posterior mean for* 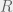 *(reward for task), where the tedious work* *.* \n\n\nFigure 3 shows results from running IRL on this problem. There is an “Optimal” model, where the agent is optimal up to an unknown level of softmax random noise (a typical assumption for IRL). There is also a “Possibly Discounting” model, where the agent is either softmax optimal or is a hyperbolic discounter (with unknown level of discounting). We do joint Bayesian inference over the completion reward 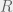, the softmax noise and (for “Possibly Discounting”) how much the agent hyperbolically discounts. The work cost  is set to 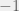. Figure 3 shows that after 6 days of observing Alice procrastinate, the “Optimal” model is very confident that Alice does not care about the task . When Alice completes the task on the last possible day, the posterior mean on R is not much more than the prior mean. By contrast, the “Possibly Discounting” model never becomes confident that Alice doesn’t care about the task. (Note that the gap between the models would be bigger for larger 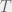. The “Optimal” model’s posterior on R shoots back to its Day-0 prior because it explains the whole action sequence as due to high softmax noise — optimal agents without noise would either do the task immediately or not at all. Full details and code are [here](http://agentmodels.org/chapters/5d-joint-inference.html).)\n\n\n### **Long-term Plans**\n\n\nAgents will often take long series of actions that generate negative utility for them in the moment in order to accomplish a long-term goal (for instance, studying every night in order to perform well on a test). Such long-term plans can make IRL more difficult for a few reasons. Here we focus on two: (1) IRL systems may not have access to the right type of data for learning about long-term goals, and (2) needing to predict long sequences of actions can make algorithms more fragile in the face of model mis-specification.\n\n\n*(1) Wrong type of data.* To make inferences based on long-term plans, it would be helpful to have coherent data about a single agent’s actions over a long period of time (so that we can e.g. see the plan unfolding). But in practice we will likely have substantially more data consisting of short snapshots of a large number of different agents (e.g. because many internet services already record user interactions, but it is uncommon for a single person to be exhaustively tracked and recorded over an extended period of time even while they are offline).\n\n\nThe former type of data (about a single representative population measured over time) is called **panel data**, while the latter type of data (about different representative populations measured at each point in time) is called **repeated cross-section data**. The differences between these two types of data is [well-studied](http://www.uio.no/studier/emner/sv/oekonomi/ECON5103/v10/undervisningsmateriale/PDAppl_17.pdf) in econometrics, and a general theme is the following: it is difficult to infer individual-level effects from cross-sectional data.\n\n\nAn easy and familiar example of this difference (albeit not in an IRL setting) can be given in terms of election campaigns. Most campaign polling is cross-sectional in nature: a different population of respondents is polled at each point in time. Suppose that Hillary Clinton gives a speech and her overall support according to cross-sectional polls increases by 2%; what can we conclude from this? Does it mean that 2% of people switched from Trump to Clinton? Or did 6% of people switch from Trump to Clinton while 4% switched from Clinton to Trump?\n\n\nAt a minimum, then, using cross-sectional data leads to a difficult disaggregation problem; for instance, different agents taking different actions at a given point in time could be due to being at different stages in the same plan, or due to having different plans, or some combination of these and other factors. Collecting demographic and other side data can help us (by allowing us to look at variation and shifts within each subpopulation), but it is unclear if this will be sufficient in general.\n\n\nOn the other hand, there are some services (such as Facebook or Google) that do have extensive data about individual users across a long period of time. However, this data has another issue: it is incomplete in a very systematic way (since it only tracks online behaviour). For instance, someone might go online most days to read course notes and Wikipedia for a class; this is data that would likely be recorded. However, it is less likely that one would have a record of that person taking the final exam, passing the class and then getting an internship based on their class performance. Of course, some pieces of this sequence would be inferable based on some people’s e-mail records, etc., but it would likely be under-represented in the data relative to the record of Wikipedia usage. In either case, some non-trivial degree of inference would be necessary to make sense of such data.\n\n\n*(2) Fragility to mis-specification.* Above we discussed why observing only short sequences of actions from an agent can make it difficult to learn about their long-term plans (and hence to reason correctly about their values). Next we discuss another potential issue — fragility to model mis-specification.\n\n\nSuppose someone spends 99 days doing a boring task to accomplish an important goal on day 100. A system that is only trying to correctly predict actions will be right 99% of the time if it predicts that the person inherently enjoys boring tasks. Of course, a system that understands the goal and how the tasks lead to the goal will be right 100% of the time, but even minor errors in its understanding could bring the accuracy back below 99%.\n\n\nThe general issue is the following: large changes in the model of the agent might only lead to small changes in the predictive accuracy of the model, and the longer the time horizon on which a goal is realized, the more this might be the case. This means that even slight mis-specifications in the model could tip the scales back in favor of a (very) incorrect reward function. A potential way of dealing with this might be to identify “important” predictions that seem closely tied to the reward function, and focus particularly on getting those predictions right (see [here](http://www.di.ens.fr/~slacoste/research/pubs/lacoste-AISTATS11-lossBayes.pdf) for a paper exploring a similar idea in the context of approximate inference).\n\n\nOne might object that this is only a problem in this toy setting; for instance, in the real world, one might look at the particular way in which someone is studying or performing some other boring task to see that it coherently leads towards some goal (in a way that would be less likely were the person to be doing something boring purely for enjoyment). In other words, correctly understanding the agent’s goals might allow for more fine-grained accurate predictions which would fare better under e.g. log-score than would an incorrect model.\n\n\nThis is a reasonable objection, but there are some historical examples of this going wrong that should give one pause. That is, there are historical instances where: (i) people expected a more complex model that seemed to get at some underlying mechanism to outperform a simpler model that ignored that mechanism, and (ii) they were wrong (the simpler model did better under log-score). The example we are most familiar with is n-gram models vs. parse trees for language modelling; the most successful language models (in terms of having the best log-score on predicting the next word given a sequence of previous words) essentially treat language as a high-order Markov chain or hidden Markov model, despite the fact that linguistic theory predicts that language should be tree-structured rather than linearly-structured. Indeed, NLP researchers have tried building language models that assume language is tree-structured, and these models perform worse, or at least do not seem to have been adopted in practice (this is true both for older discrete models and newer continuous models based on neural nets). It’s plausible that a similar issue will occur in inverse reinforcement learning, where correctly inferring plans is not enough to win out in predictive performance. The reason for the two issues might be quite similar (in language modelling, the tree structure only wins out in statistically uncommon corner cases involving long-term and/or nested dependencies, and hence getting that part of the prediction correct doesn’t help predictive accuracy much).\n\n\nThe overall point is: in the case of even slight model mis-specification, the “correct” model might actually perform worse under typical metrics such as predictive accuracy. Therefore, more careful methods of constructing a model might be necessary.\n\n\n### **Learning Values != Robustly Predicting Human Behaviour**\n\n\nThe problems with IRL described so far will result in poor performance for predicting human choices out-of-sample. For example, if someone is observed doing boring tasks for 99 days (where they only achieve the goal on Day 100), they’ll be predicted to continue doing boring tasks even when a short-cut to the goal becomes available. So even if the goal is simply to predict human behaviour (not to infer human values), mis-specification leads to bad predictions on realistic out-of-sample scenarios.\n\n\nLet’s suppose that our goal is not to predict human behaviour but to create AI systems that promote and respect human values. These goals (predicting humans and building safe AI) are distinct. Here’s an example that illustrates the difference. Consider a long-term smoker, Bob, who would continue smoking even if there were (counterfactually) a universally effective anti-smoking treatment. Maybe Bob is in denial about the health effects of smoking or Bob thinks he’ll inevitably go back to smoking whatever happens. If an AI system were assisting Bob, we might expect it to avoid promoting his smoking habit (e.g. by not offering him cigarettes at random moments). This is not paternalism, where the AI system imposes someone else’s values on Bob. The point is that even if Bob would continue smoking across many counterfactual scenarios this doesn’t mean that he places value on smoking.\n\n\nHow do we choose between the theory that Bob values smoking and the theory that he does not (but smokes anyway because of the powerful addiction)? Humans choose between these theories based on our experience with addictive behaviours and our insights into people’s preferences and values. This kind of insight can’t easily be captured as formal assumptions about a model, or even as a criterion about counterfactual generalization. (The theory that Bob values smoking *does* make accurate predictions across a wide range of counterfactuals.) Because of this, learning human values from IRL has a more profound kind of model mis-specification than the examples in Jacob’s previous post. Even in the limit of data generated from an infinite series of random counterfactual scenarios, standard IRL algorithms would not infer someone’s true values.\n\n\nPredicting human actions is neither necessary nor sufficient for learning human values. In what ways, then, are the two related? One such way stems from the premise that if someone spends more resources making a decision, the resulting decision tends to be more in keeping with their true values. For instance, someone might spend lots of time thinking about the decision, they might consult experts, or they might try out the different options in a trial period before they make the real decision. Various authors have thus suggested that people’s choices under sufficient “reflection” act as a reliable indicator of their true values. Under this view, predicting a certain kind of behaviour (choices under reflection) is sufficient for learning human values. Paul Christiano has written about [some](https://medium.com/ai-control/model-free-decisions-6e6609f5d99e#.y6gg55z3r) [proposals](https://sideways-view.com/2016/12/01/optimizing-the-news-feed/) for doing this, though we will not discuss them here (the first link is for general AI systems while the second is for newsfeeds). In general, turning these ideas into algorithms that are tractable and learn safely remains a challenging problem.\n\n\n### **Further reading**\n\n\nThere is [research](http://www.jmlr.org/papers/v12/choi11a.html) on doing IRL for agents in POMDPs. Owain and collaborators explored the effects of limited information and cognitive biases on IRL: [paper](https://arxiv.org/pdf/1512.05832), [paper](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.705.2548&rep=rep1&type=pdf), [online book](http://agentmodels.org).\n\n\nFor many environments it will not be possible to *identify* the reward function from the observed trajectories. These identification problems are related to the mis-specification problems but are not the same thing. Active learning can help with identification ([paper](https://arxiv.org/abs/1601.06569)).\n\n\nPaul Christiano raised many similar points about mis-specification in a [post](https://medium.com/ai-control/the-easy-goal-inference-problem-is-still-hard-fad030e0a876#.mb33rtxo8) on his blog.\n\n\nFor a big-picture monograph on relations between human preferences, economic utility theory and welfare/well-being, see Hausman’s [“Preference, Value, Choice and Welfare”.](https://www.amazon.com/Preference-Choice-Welfare-Daniel-Hausman/dp/1107695120)\n\n\n### **Acknowledgments**\n\n\nThanks to Sindy Li for reviewing a full draft of this post and providing many helpful comments. Thanks also to Michael Webb and Paul Christiano for doing the same on specific sections of the post.\n\n", "url": "https://jsteinhardt.wordpress.com/2017/02/07/model-mis-specification-and-inverse-reinforcement-learning/", "title": "Model Mis-specification and Inverse Reinforcement Learning", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-02-07T21:25:15+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "ae7ff499faa47ec174608acb353071c8", "summary": []}
+{"text": "Linear algebra fact\n\nHere is interesting linear algebra fact: let  be an 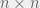 matrix and  be a vector such that . Then for any matrix , .\n\n\nThe proof is just basic algebra: 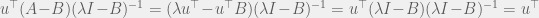.\n\n\nWhy care about this? Let’s imagine that  is a (not necessarily symmetric) stochastic matrix, so . Let  be a low-rank approximation to  (so  consists of all the large singular values, and  consists of all the small singular values). Unfortunately since  is not symmetric, this low-rank approximation doesn’t preserve the eigenvalues of  and so we need not have 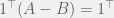. The  can be thought of as a “correction” term such that the resulting matrix is still low-rank, but we’ve preserved one of the eigenvectors of .\n\n", "url": "https://jsteinhardt.wordpress.com/2017/02/06/linear-algebra-fact/", "title": "Linear algebra fact", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-02-06T02:33:39+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "eefc78d4cc3385de7429409ee95f7f40", "summary": []}
+{"text": "Prékopa–Leindler inequality\n\nConsider the following statements:\n\n\n1. The shape with the largest volume enclosed by a given surface area is the -dimensional sphere.\n2. A marginal or sum of log-concave distributions is log-concave.\n3. Any Lipschitz function of a standard -dimensional Gaussian distribution concentrates around its mean.\n\n\nWhat do these all have in common? Despite being fairly non-trivial and deep results, they all can be proved in less than half of a page using the [Prékopa–Leindler inequality](https://en.wikipedia.org/wiki/Pr%C3%A9kopa%E2%80%93Leindler_inequality).\n\n\n(I won’t show this here, or give formal versions of the statements above, but time permitting I will do so in a later blog post.)\n\n", "url": "https://jsteinhardt.wordpress.com/2017/02/05/prekopa-leindler-inequality/", "title": "Prékopa–Leindler inequality", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-02-05T22:02:43+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "014ba3e02251aa6ba5389cabf071f444", "summary": []}
+{"text": "Latent Variables and Model Mis-specification\n\nMachine learning is very good at optimizing predictions to match an observed signal — for instance, given a dataset of input images and labels of the images (e.g. dog, cat, etc.), machine learning is very good at correctly predicting the label of a new image. However, performance can quickly break down as soon as we care about criteria other than predicting observables. There are several cases where we might care about such criteria:\n\n\n* In scientific investigations, we often care less about predicting a specific observable phenomenon, and more about what that phenomenon implies about an underlying scientific theory.\n* In economic analysis, we are most interested in what policies will lead to desirable outcomes. This requires predicting what would counterfactually happen if we were to enact the policy, which we (usually) don’t have any data about.\n* In machine learning, we may be interested in learning value functions which match human preferences (this is especially important in complex settings where it is hard to specify a satisfactory value function by hand). However, we are unlikely to observe information about the value function directly, and instead must infer it implicitly. For instance, one might infer a value function for autonomous driving by observing the actions of an expert driver.\n\n\nIn all of the above scenarios, the primary object of interest — the scientific theory, the effects of a policy, and the value function, respectively — is not part of the observed data. Instead, we can think of it as an unobserved (or “latent”) variable in the model we are using to make predictions. While we might hope that a model that makes good predictions will also place correct values on unobserved variables as well, this need not be the case in general, especially if the model is *mis-specified*.\n\n\nI am interested in latent variable inference because I think it is a potentially important sub-problem for building AI systems that behave safely and are aligned with human values. The connection is most direct for value learning, where the value function is the latent variable of interest and the fidelity with which it is learned directly impacts the well-behavedness of the system. However, one can imagine other uses as well, such as making sure that the concepts that an AI learns sufficiently match the concepts that the human designer had in mind. It will also turn out that latent variable inference is related to *counterfactual reasoning*, which has a large number of tie-ins with building safe AI systems that I will elaborate on in forthcoming posts.\n\n\nThe goal of this post is to explain why problems show up if one cares about predicting latent variables rather than observed variables, and to point to a research direction (counterfactual reasoning) that I find promising for addressing these issues. More specifically, in the remainder of this post, I will: (1) give some formal settings where we want to infer unobserved variables and explain why we can run into problems; (2) propose a possible approach to resolving these problems, based on counterfactual reasoning.\n\n\n1 Identifying Parameters in Regression Problems\n-----------------------------------------------\n\n\nSuppose that we have a regression model 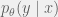, which outputs a probability distribution over  given a value for . Also suppose we are explicitly interested in identifying the “true” value of  rather than simply making good predictions about  given . For instance, we might be interested in whether smoking causes cancer, and so we care not just about predicting whether a given person will get cancer () given information about that person (), but specifically whether the coefficients in  that correspond to a history of smoking are large and positive.\n\n\nIn a typical setting, we are given data points  on which to fit a model. Most methods of training machine learning systems optimize predictive performance, i.e. they will output a parameter  that (approximately) maximizes . For instance, for a linear regression problem we have . Various more sophisticated methods might employ some form of regularization to reduce overfitting, but they are still fundamentally trying to maximize some measure of predictive accuracy, at least in the limit of infinite data.\n\n\nCall a model **well-specified** if there is some parameter  for which  matches the true distribution over , and call a model **mis-specified** if no such  exists. One can show that for well-specified models, maximizing predictive accuracy works well (modulo a number of technical conditions). In particular, maximizing  will (asymptotically, as ) lead to recovering the parameter .\n\n\nHowever, if a model is mis-specified**,** then it is not even clear what it means to correctly infer . We could declare the  maximizing predictive accuracy to be the “correct” value of , but this has issues:\n\n\n1. While  might do a good job of predicting  in the settings we’ve seen, it may not predict  well in very different settings.\n2. If we care about determining  for some scientific purpose, then good predictive accuracy may be an unsuitable metric. For instance, even though margarine consumption might [correlate well with](http://www.tylervigen.com/spurious-correlations) (and hence be a good predictor of) divorce rate, that doesn’t mean that there is a causal relationship between the two.\n\n\nThe two problems above also suggest a solution: we will say that we have done a good job of inferring a value for  if  can be used to make *good predictions in a wide variety of situations*, and not just the situation we happened to train the model on. (For the latter case of predicting causal relationships, the “wide variety of situations” should include the situation in which the relevant causal intervention is applied.)\n\n\nNote that both of the problems above are different from the typical statistical problem of overfitting. Clasically, overfitting occurs when a model is too complex relative to the amount of data at hand, but even if we have a large amount of data the problems above could occur. This is illustrated in the following graph:\n\n\n\n\n\nHere the blue line is the data we have (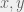), and the green line is the model we fit (with slope and intercept parametrized by ). We have more than enough data to fit a line to it. However, because the true relationship is quadratic, the best linear fit depends heavily on the distribution of the training data. If we had fit to a different part of the quadratic, we would have gotten a potentially very different result. Indeed, in this situation, there is no linear relationship that can do a good job of extrapolating to new situations, unless the domain of those new situations is restricted to the part of the quadratic that we’ve already seen.\n\n\nI will refer to the type of error in the diagram above as *mis-specification error*. Again, mis-specification error is different from error due to overfitting. Overfitting occurs when there is too little data and noise is driving the estimate of the model; in contrast, mis-specification error can occur even if there is plenty of data, and instead occurs because the best-performing model is different in different scenarios.\n\n\n**2 Structural Equation Models**\n--------------------------------\n\n\nWe will next consider a slightly subtler setting, which in economics is referred to as a *structural equation model*. In this setting we again have an output  whose distribution depends on an input , but now this relationship is mediated by an *unobserved* variable . A common example is a [discrete choice](https://en.wikipedia.org/wiki/Discrete_choice) model, where consumers make a choice among multiple goods () based on a consumer-specific utility function () that is influenced by demographic and other information about the consumer (). Natural language processing provides another source of examples: in [semantic parsing](http://www-nlp.stanford.edu/software/sempre/), we have an input utterance () and output denotation (), mediated by a latent logical form ; in [machine translation](https://en.wikipedia.org/wiki/Statistical_machine_translation), we have input and output sentences ( and ) mediated by a latent [alignment](https://en.wikipedia.org/wiki/IBM_alignment_models) ().\n\n\nSymbolically, we represent a structural equation model as a parametrized probability distribution , where we are trying to fit the parameters . Of course, we can always turn a structural equation model into a regression model by using the identity 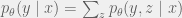, which allows us to ignore  altogether. In economics this is called a *reduced form model*. We use structural equation models if we are specifically interested in the unobserved variable  (for instance, in the examples above we are interested in the value function for each individual, or in the logical form representing the sentence’s meaning).\n\n\nIn the regression setting where we cared about identifying , it was obvious that there was no meaningful “true” value of  when the model was mis-specified. In this structural equation setting, we now care about the latent variable , which can take on a meaningful true value (e.g. the actual utility function of a given individual) even if the overall model 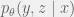 is mis-specified. It is therefore tempting to think that if we fit parameters  and use them to impute , we will have meaningful information about the actual utility functions of individual consumers. However, this is a notational sleight of hand — just because we call  “the utility function” does not make it so. The variable  need not correspond to the actual utility function of the consumer, nor does the consumer’s preferences even need to be representable by a utility function.\n\n\nWe can understand what goes wrong by consider the following procedure, which formalizes the proposal above:\n\n\n1. Find  to maximize the predictive accuracy on the observed data, , where 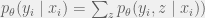. Call the result 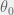.\n2. Using this value 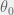, treat  as being distributed according to . On a new value  for which  is not observed, treat  as being distributed according to 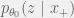.\n\n\nAs before, if the model is well-specified, one can show that such a procedure asymptotically outputs the correct probability distribution over . However, if the model is mis-specified, things can quickly go wrong. For example, suppose that  represents what choice of drink a consumer buys, and  represents consumer utility (which might be a function of the price, attributes, and quantity of the drink). Now suppose that individuals have preferences which are influenced by unmodeled covariates: for instance, a preference for cold drinks on warm days, while the input  does not have information about the outside temperature when the drink was bought. This could cause any of several effects:\n\n\n* If there is a covariate that happens to correlate with temperature in the data, then we might conclude that that covariate is predictive of preferring cold drinks.\n* We might increase our uncertainty about  to capture the unmodeled variation in .\n* We might implicitly increase uncertainty by moving utilities closer together (allowing noise or other factors to more easily change the consumer’s decision).\n\n\nIn practice we will likely have some mixture of all of these, and this will lead to systematic biases in our conclusions about the consumers’ utility functions.\n\n\nThe same problems as before arise: while we by design place probability mass on values of  that correctly predict the observation , under model mis-specification this could be due to spurious correlations or other perversities of the model. Furthermore, even though predictive performance is high on the observed data (and data similar to the observed data), there is no reason for this to continue to be the case in settings very different from the observed data, which is particularly problematic if one is considering the effects of an intervention. For instance, while inferring preferences between hot and cold drinks might seem like a silly example, the [design](http://web.stanford.edu/~jdlevin/Papers/Auctions.pdf) of [timber auctions](http://web.stanford.edu/~jdlevin/Papers/Skewing.pdf) constitutes a much more important example with a roughly similar flavour, where it is important to correctly understand the utility functions of bidders in order to predict their behaviour under alternative auction designs (the model is also more complex, allowing even more opportunities for mis-specification to cause problems).\n\n\n3 A Possible Solution: Counterfactual Reasoning\n-----------------------------------------------\n\n\nIn general, under model mis-specification we have the following problems:\n\n\n* It is often no longer meaningful to talk about the “true” value of a latent variable  (or at the very least, not one within the specified model family).\n* Even when there is a latent variable  with a well-defined meaning, the imputed distribution over  need not match reality.\n\n\nWe can make sense of both of these problems by thinking in terms of *counterfactual reasoning*. Without defining it too formally, counterfactual reasoning is the problem of making good predictions not just in the actual world, but in a wide variety of counterfactual worlds that “could” exist. (I recommend [this](http://leon.bottou.org/publications/pdf/tr-2012-09-12.pdf) paper as a good overview for machine learning researchers.)\n\n\nWhile typically machine learning models are optimized to predict well on a specific distribution, systems capable of counterfactual reasoning must make good predictions on many distributions (essentially any distribution that can be captured by a reasonable counterfactual). This stronger guarantee allows us to resolve many of the issues discussed above, while still thinking in terms of predictive performance, which historically seems to have been a successful paradigm for machine learning. In particular:\n\n\n* While we can no longer talk about the “true” value of , we can say that a value of  is a “good” value if it makes good predictions on not just a single test distribution, but many different counterfactual test distributions. This allows us to have more confidence in the generalizability of any inferences we draw based on  (for instance, if  is the coefficient vector for a regression problem, any variable with positive sign is likely to robustly correlate with the response variable for a wide variety of settings).\n* The imputed distribution over a variable  must also lead to good predictions for a wide variety of distributions. While this does not force  to match reality, it is a much stronger condition and does at least mean that any aspect of  that can be measured in some counterfactual world must correspond to reality. (For instance, any aspect of a utility function that could at least counterfactually result in a specific action would need to match reality.)\n* We will successfully predict the effects of an intervention, as long as that intervention leads to one of the counterfactual distributions considered.\n\n\n(Note that it is less clear how to actually train models to optimize counterfactual performance, since we typically won’t observe the counterfactuals! But it does at least define an end goal with good properties.)\n\n\nMany people have a strong association between the concepts of “counterfactual reasoning” and “causal reasoning”. It is important to note that these are distinct ideas; causal reasoning is a type of counterfactual reasoning (where the counterfactuals are often thought of as centered around interventions), but I think of counterfactual reasoning as any type of reasoning that involves making robustly correct statistical inferences across a wide variety of distributions. On the other hand, some people take robust statistical correlation to be the *definition* of a causal relationship, and thus do consider causal and counterfactual reasoning to be the same thing.\n\n\nI think that building machine learning systems that can do a good job of counterfactual reasoning is likely to be an important challenge, especially in cases where reliability and safety are important, and necessitates changes in how we evaluate machine learning models. In my mind, while the Turing test has many flaws, one thing it gets very right is the ability to evaluate the accuracy of counterfactual predictions (since dialogue provides the opportunity to set up counterfactual worlds via shared hypotheticals). In contrast, most existing tasks focus on repeatedly making the same type of prediction with respect to a fixed test distribution. This latter type of benchmarking is of course easier and more clear-cut, but fails to probe important aspects of our models. I think it would be very exciting to design good benchmarks that require systems to do counterfactual reasoning, and I would even be happy to [incentivize](https://jsteinhardt.wordpress.com/2016/12/31/individual-project-fund-further-details/) such work monetarily.\n\n\n**Acknowledgements**\n\n\nThanks to Michael Webb, Sindy Li, and Holden Karnofsky for providing feedback on drafts of this post. If any readers have additional feedback, please feel free to send it my way.\n\n", "url": "https://jsteinhardt.wordpress.com/2017/01/10/latent-variables-and-model-mis-specification/", "title": "Latent Variables and Model Mis-specification", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2017-01-10T02:45:46+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "e19dda5ee6f3f5f7754fa81360a2cdf1", "summary": []}
+{"text": "Individual Project Fund: Further Details\n\nIn my post on [where I plan to donate in 2016](https://jsteinhardt.wordpress.com/2016/12/28/donations-for-2016/), I said that I would set aside $2000 for funding promising projects that I come across in the next year:\n\n\n\n> The idea behind the project fund is … [to] give in a low-friction way on scales that are too small for organizations like Open Phil to think about. Moreover, it is likely good for me to develop a habit of evaluating projects I come across and thinking about whether they could benefit from additional money (either because they are funding constrained, or to incentivize an individual who is on the fence about carrying the project out). Finally, if this effort is successful, it is possible that other EAs will start to do this as well, which could magnify the overall impact. I think there is some danger that I will not be able to allocate the $2000 in the next year, in which case any leftover funds will go to next year’s donor lottery.\n> \n> \n\n\nIn this post I will give some further details about this fund. My primary goal is to give others an idea of what projects I am likely to consider funding, so that anyone who thinks they might be a good fit for this can get in contact with me. (I also expect many of the best opportunities to come from people that I meet in person but don’t necessarily read this blog, so I plan to actively look for projects throughout the year as well.)\n\n\nI am looking to fund or incentivize projects that meet several of the criteria below:\n\n\n* The project is in the area of computer science, especially one of machine learning, cyber security, algorithmic game theory, or computational social choice. [Some other areas that I would be somewhat likely to consider, in order of plausibility: economics, statistics, political science (especially international security), and biology.]\n* The project either wouldn’t happen, or would seem less worthwhile / higher-effort without the funding.\n* The organizer is someone who either I or someone I trust has an exceptionally high opinion of.\n* The project addresses a topic that I personally think is highly important. High-level areas that I tend to care about include international security, existential risk, AI safety, improving political institutions, improving scientific institutions, and helping the global poor. Technical areas that I tend to care about include reliable machine learning, machine learning and security, counterfactual reasoning, and value learning. On the other hand, if you have a project that you feel has a strong case for importance but doesn’t fit into these areas, I am interested in hearing about it.\n* It is unlikely that this project or a substantially similar project would be done by someone else at a similar level of quality. (Or, whoever else is likely to do it would instead focus on a similarly high-value project, if this one were to be taken care of.)\n* The topic pertains to a technical area that I or someone I trust has a high degree of expertise in, and can evaluate more quickly and accurately than a non-specialized funder.\n\n\nIt isn’t necessary to meet all of the criteria above, but I would probably want most things I fund to meet at least 4 of these 6.\n\n\nHere are some concrete examples of things I might fund:\n\n\n* Someone is thinking of doing a project that is undervalued (in terms of career benefits) but would be very useful. They don’t feel excited about allocating time to a non-career-relevant task but would feel more excited if getting an award of $1000 for their efforts.\n* Someone I trust is starting a new discussion group in an area that I think is important, but can’t find anyone to sponsor it, and wants money for providing food at the meetings.\n* Someone wants to do an experiment that I find valuable, but needs more compute resources than they have, and could use money for buying AWS hours.\n* Someone wants to curate a valuable dataset and needs money for hiring mechanical turkers.\n* Someone is organizing a workshop and needs money for securing a venue.\n* One project I am particularly interested in is a good survey paper at the intersection of machine learning and cyber security. If you might be interested in doing this, I would likely be willing to pay you.\n* There are likely many projects in the area of political activism that I would be interested in funding, although (due to crowdedness concerns) I have a particularly high bar for this area in terms of the criteria I laid out above.\n\n\nIf you think you might have a project that could use funding, please get in touch with me at jacob.steinhardt@gmail.com. Even if you are not sure if your project would be a good target for funding, I am very happy to talk to you about it. In addition, please feel free to comment either here or via e-mail if you have feedback on this general idea, or thoughts on types of small-project funding that I missed above.\n\n", "url": "https://jsteinhardt.wordpress.com/2016/12/31/individual-project-fund-further-details/", "title": "Individual Project Fund: Further Details", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2016-12-31T22:10:28+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "9ddf977255a2988c534758d4b282c17d", "summary": []}
+{"text": "Donations for 2016\n\nThe following explains where I plan to donate in 2016, with some of my thinking behind it. This year, I had $10,000 to allocate (the sum of my giving from 2015 and 2016, which I lumped together for tax reasons; although I think this was a mistake in retrospect, both due to discount rates and because I could have donated in January and December 2016 and still received the same tax benefits).\n\n\nTo start with the punch line: I plan to give $4000 to the [EA donor lottery](http://effective-altruism.com/ea/14d/donor_lotteries_demonstration_and_faq/), $2500 to GiveWell for discretionary granting, $2000 to be held in reserve to fund promising projects, $500 to GiveDirectly, $500 to the Carnegie Endowment (earmarked for the [Carnegie-Tsinghua Center](http://carnegietsinghua.org/)), and $500 to the [Blue Ribbon Study Panel](http://www.openphilanthropy.org/blog/suggestions-individual-donors-open-philanthropy-project-staff-2016#Blue_Ribbon_Study_Panel_on_Biodefense).\n\n\nFor those interested in donating to any of these: instructions for the EA donor lottery and the Blue Ribbon Study Panel are in the corresponding links above, and you can donate to both GiveWell and GiveDirectly at [this](https://secure.givewell.org/) page. I am looking in to whether it is possible for small donors to give to the Carnegie Endowment, and will update this page when I find out.\n\n\nAt a high level, I partitioned my giving into two categories, which are roughly (A) “help poor people right now” and (B) “improve the overall trajectory of civilization” (these are meant to be rough delineations rather than rigorous definitions). I decided to split my giving into 30% category A and 70% category B. This is because while I believe that category B is the more pressing and impactful category to address in some overall utilitarian sense, I still feel a particular moral obligation towards helping the existing poor in the world we currently live in, which I don’t feel can be discharged simply by giving more to category B. The 30-70 split is meant to represent the fact that while category B seems more important to me, category A still receives substantial weight in my moral calculus (which isn’t fully utilitarian or even consequentialist).\n\n\nThe rest of this post treats categories A and B each in turn.\n\n\n**Category A: The Global Poor**\n\n\nOut of $3000 in total, I decided to give $2500 to GiveWell for discretionary regranting (which will [likely be disbursed](http://blog.givewell.org/2016/12/19/discretionary-grant-making-and-implications-for-donor-agency/) roughly but not exactly according to [GiveWell’s recommended allocation](http://blog.givewell.org/2016/11/28/updated-top-charities-giving-season-2016/)), and $500 to some other source, with the only stipulation being that it did not exactly match GiveWell’s recommendation. The reason for this was the following: while I expect GiveWell’s recommendation to outperform any conclusion that I personally reach, I think there is substantial value in the exercise of personally thinking through where to direct my giving. A few more specific reasons:\n\n\n* Most importantly, while I think that offloading giving decisions to a trusted expert is the correct decision to maximize the impact of any individual donation, collectively it leads to a bad equilibrium where substantially fewer and less diverse brainpower is devoted to thinking about where to give. I think that giving a small but meaningful amount based on one’s own reasoning largely ameliorates this effect without losing much direct value.\n* In addition, I think it is good to build the skills to in principle think through where to direct resources, even if in practice most of the work is outsourced to a dedicated organization.\n* Finally, having a large number of individual donors check GiveWell’s work and search for alternatives creates stronger incentives for GiveWell to do a thorough job (and allows donors to have more confidence that GiveWell is doing a thorough job). While I know many GiveWell staff and believe that they would do an excellent job independently of external vetting, I still think this is good practice.\n\n\nRelated to the last point: doing this exercise gave me a better appreciation for the overall reliability, strengths, and limitations of GiveWell’s work. In general, I found that GiveWell’s work was incredibly thorough (more-so than I expected despite my high opinion of them), and moreover that they have moved substantial money beyond the publicized annual donor recommendations. An example of this is their [2016 grant to IDinsight](http://www.givewell.org/charities/IDinsight/june-2016-grant). IDinsight ended up being one of my top candidates for where to donate, such that I thought it was plausibly even better than a GiveWell top charity. However, when I looked into it further it turned out that GiveWell had already essentially filled their entire funding gap.\n\n\nI think this anecdote serves to illustrate a few things: first, as noted, GiveWell is very thorough, and does substantial work beyond what is apparent from the top charities page. Second, while GiveWell had already given to IDinsight, the grant was made in 2016. I think the same process I used would not have discovered IDinsight in 2015, but it’s possible that other processes would have. So, I think it is possible that a motivated individual could identify strong giving opportunities a year ahead of GiveWell. As a point against this, I think I am in an unusually good position to do this and still did not succeed. I also think that even if an individual identified a strong opportunity, it is unlikely that they could be *confident* that it was strong, and in most cases GiveWell’s top charities would still be better bets in expectation (but I think that merely identifying a plausibly strong giving opportunity should count as a huge success for the purposes of the overall exercise).\n\n\nTo elaborate on why my positioning might be atypically good: I already know GiveWell staff and so have some appreciation for their thinking, and I work at Stanford and have several friends in the economics department, which is one of the strongest departments in the world for Development Economics. In particular, I discussed my giving decisions extensively with a student of [Pascaline Dupas](https://web.stanford.edu/%7Epdupas/), who is one of the world experts in the areas of economics most relevant to GiveWell’s recommendations.\n\n\nBelow are specifics on organizations I looked into and where I ultimately decided to give.\n\n\n**Object-level Process and Decisions (Category A)**\n\n\nMy process for deciding where to give mostly consisted of talking to several people I trust, brainstorming and thinking things through myself, and a small amount of online research. (I think that I should likely have done substantially more online research than I ended up doing, but my thinking style tends to benefit from 1-on-1 discussions, which I also find more enjoyable.) The main types of charities that I ended up considering were:\n\n\n* GiveDirectly (direct cash transfers)\n* [IPA](http://www.poverty-action.org/)/[JPAL](https://www.povertyactionlab.org/) and similar groups (organizations that support academic research on international development)\n* [IDinsight](http://idinsight.org/) and similar groups (similar to the previous group, but explicitly tries to do the “translational work” of going from academic research to evidence-backed large-scale interventions)\n* public information campaigns (such as [Development Media International](http://www.givewell.org/charities/DMI))\n* animal welfare\n* start-ups or other small groups in the development space that might need seed funding\n* meta-charities such as [CEA](https://www.centreforeffectivealtruism.org/) that try to increase the amount of money moved to EA causes (or evidence-backed charity more generally)\n\n\nI ultimately felt unsure whether animal welfare should count in this category, and while I felt that CEA was a potentially strong candidate in terms of pure cost-effectiveness, directing funds there felt overly insular/meta to me in a way that defeated the purpose of the giving exercise. (Note: two individuals who reviewed this post encouraged me to revisit this point; as a result, next year I plan to look into CEA in more detail.)\n\n\nWhile looking into the “translational work” category, I came across one organization other than IDinsight that did work in this area and was well-regarded by at least some economists. While I was less impressed by them than I was by IDinsight, they seemed plausibly strong, and it turned out that GiveWell had not yet evaluated them. While I ended up deciding not to give to them (based on feeling that IDinsight was likely to do substantially better work in the same area) I did send GiveWell an e-mail bringing the organization to their attention.\n\n\nWhen looking into IPA, my impression was that while they have been responsible for some really good work in the past, this was primarily while they were a smaller organization, and they have now become large and bureaucratic enough that their future value will be substantially lower. However, I also found out about an individual who was running a small organization in the same space as IPA, and seemed to be doing very good work. While I was unable to offer them money for reasons related to conflict of interest, I do plan to try to find ways to direct funds to them if they are interested.\n\n\nWhile public information campaigns seem like they could a priori be very effective, briefly looking over GiveWell’s [page on DMI](http://www.givewell.org/charities/DMI) gave me the impression that GiveWell had already considered this area in a great deal of depth and prioritized other interventions for good reasons.\n\n\nI ultimately decided to give my money to GiveDirectly. While in some sense this violates the spirit of the exercise, I felt satisfied about having found at least one potentially good giving opportunity (the small IPA-like organization) even if I was unable to give to it personally, and overall felt that I had done a reasonable amount of research. Moreover, I have a strong intuition that 0% is the wrong allocation for GiveDirectly, and it wasn’t clear to me that GiveWell’s reasons for recommending 0% were strong enough to override that intuition.\n\n\nSo, overall, $2500 of my donation will go to GiveWell for discretionary re-granting, and $500 to GiveDirectly.\n\n\n**Trajectory of Civilization (Category B)**\n\n\nFirst, I plan to put $2000 into escrow for the purpose of supporting any useful small projects (specifically in the field of computer science / machine learning) that I come across in the next year. For the remaining $5000, I plan to allocate $4000 of it to the [donor lottery](http://effective-altruism.com/ea/14d/donor_lotteries_demonstration_and_faq/), $500 to the [Carnegie Endowment](http://carnegieendowment.org/), and $500 to the [Blue Ribbon Study Panel on Biodefense](http://www.openphilanthropy.org/blog/suggestions-individual-donors-open-philanthropy-project-staff-2016#Biosecurity_and_Pandemic_Preparedness_-_recommendation_by_Jaime_Yassif_). For the latter, I wanted to donate to something that improved medium-term international security, because I believe that this is an important area that is relatively under-invested in by the effective altruist community (both in terms of money and cognitive effort). Here are all of the major possibilities that I considered:\n\n\n* Donating to the Future of Humanity Institute, with funds earmarked towards their collaboration with [Allan Dafoe](https://www.fhi.ox.ac.uk/team/allan-dafoe/). I decided against this because my impression was that this particular project was not funding-constrained. (However, I am very excited by the work that Allan and his collaborators are doing, and would like to find ways to meaningfully support it.)\n* Donating to the [Carnegie Endowment](http://carnegieendowment.org/), restricted specifically to the [Carnegie-Tsinghua Center](http://carnegietsinghua.org/). My understanding is that this is one of the few western organizations working to influence China’s nuclear policy (though this is based on personal conversation and not something I have looked into myself). My intuition is that influencing Chinese nuclear policy is substantially more tractable than U.S. nuclear policy, due to far fewer people trying to do so. In addition, from looking at their website, I felt that most of the areas they worked in were important areas, which I believe to be unusual for large organizations with multiple focuses (as a contrast, for other organizations with a similar number of focus areas, I felt that roughly half of the areas were obviously orders of magnitude less important than the areas I was most excited about). I had some reservations about donating (due to their size: $30 million in revenue per year, and $300 million in assets), but I decided to donate $500 anyways because I am excited about this general type of work. (This organization was brought to my attention by Nick Beckstead; Nick notes that he doesn’t have strong opinions about this organization, primarily due to not knowing much about them.)\n* Donating to the [Blue Ribbon Study Panel](http://www.openphilanthropy.org/blog/suggestions-individual-donors-open-philanthropy-project-staff-2016#Biosecurity_and_Pandemic_Preparedness_-_recommendation_by_Jaime_Yassif_): I am basically trusting Jaime Yassif that this is a strong recommendation within the area of biodefense.\n* Donating to the ACLU: The idea here would be to decrease the probability that a President Trump seriously erodes democratic norms within the U.S. I however currently expect the ACLU to be well-funded (my understanding is that they got a flood of donations after Trump was elected).\n* Donating to the DNC or the [Obama/Holder redistricting campaign](http://www.politico.com/story/2016/10/obama-holder-redistricting-gerrymandering-229868): This is based on the idea that (1) Democrats are much better than Republicans for global stability / good U.S. policy, and (2) Republicans should be punished for helping Trump to become president. I basically agree with both, and could see myself donating to the redistricting campaign in particular in the future, but this intuitively feels less tractable/underfunded than non-partisan efforts like the Carnegie Endowment or Blue Ribbon Study Panel.\n* Creating a prize fund for incentivizing important research projects within computer science: I was originally planning to allocate $1000 to $2000 to this, based on the idea that computer science is a key field for multiple important areas (both AI safety and cyber security) and that as an expert in this field I would be in a unique position to identify useful projects relative to others in the EA community. However, after talking to several people and thinking about it myself, I decided that it was likely not tractable to provide meaningful incentives via prizes at such a small scale, and opted to instead set aside $2000 to support promising projects as I come across them.\n\n\n(As a side note: it isn’t completely clear to me whether the Carnegie Endowment accepts small donations. I plan to contact them about this, and if they do not, allocate the money to the Blue Ribbon Study Panel instead.)\n\n\nIn the remainder of this post I will briefly describe the $2000 project fund, how I plan to use it, and why I decided it was a strong giving opportunity. I also plan to describe this in more detail in a separate follow-up post. Credit goes to Owen Cotton-Barratt for suggesting this idea. In addition, one of [Paul Christiano’s blog posts](http://lesswrong.com/lw/nk0/what_is_up_with_carbon_dioxide_and_cognition_an/) inspired me to think about using prizes to incentivize research, and Holden Karnofsky further encouraged me to think along these lines.\n\n\nThe idea behind the project fund is similar to the idea behind the prize fund: I understand research in computer science better than most other EAs, and can give in a low-friction way on scales that are too small for organizations like Open Phil to think about. Moreover, it is likely good for me to develop a habit of evaluating projects I come across and thinking about whether they could benefit from additional money (either because they are funding constrained, or to incentivize an individual who is on the fence about carrying the project out). Finally, if this effort is successful, it is possible that other EAs will start to do this as well, which could magnify the overall impact. I think there is some danger that I will not be able to allocate the $2000 in the next year, in which case any leftover funds will go to next year’s donor lottery.\n\n", "url": "https://jsteinhardt.wordpress.com/2016/12/28/donations-for-2016/", "title": "Donations for 2016", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2016-12-28T04:25:44+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=1", "authors": ["jsteinhardt"], "id": "fe32c5fd056b270b0d5552afcc756261", "summary": []}
+{"text": "Thinking Outside One’s Paradigm\n\nWhen I meet someone who works in a field outside of computer science, I usually ask them a lot of questions about their field that I’m curious about. (This is still relevant even if I’ve already met someone in that field before, because it gives me an idea of the range of expert consensus; for some questions this ends up being surprisingly variable.) I often find that, as an outsider, I can think of natural-seeming questions that experts in the field haven’t thought about, because their thinking is confined by their field’s paradigm while mine is not (pessimistically, it’s instead constrained by a different paradigm, i.e. computer science).\n\n\nUsually my questions are pretty naive, and are basically what a computer scientist would think to ask based on their own biases. For instance:\n\n\n* **Neuroscience:** How much computation would it take to simulate a brain? Do our current theories of how neurons work allow us to do that even in principle?\n* **Political science:** How does the rise of powerful multinational corporations affect theories of international security (typical past theories assume that the only major powers are states)? How do we keep software companies (like Google, etc.) politically accountable? How will cyber attacks / cyber warfare affect international security?\n* **Materials science:** How much of the materials design / discovery process can be automated? What are the bottlenecks to building whatever materials we would like to? How can different research groups effectively communicate and streamline their steps for synthesizing materials?\n\n\nWhen I do this, it’s not unusual for me to end up asking questions that the other person hasn’t really thought about before. In this case, responses range from “that’s not a question that our field studies” to “I haven’t thought about this much, but let’s try to think it through on the spot”. Of course, sometimes the other person has thought about it, and sometimes my question really is just silly or ill-formed for some reason (I suspect this is true more often than I’m explicitly made aware of, since some people are too polite to point it out to me).\n\n\nI find the cases where the other person hasn’t thought about the question to be striking, because it means that I as a naive outsider can ask natural-seeming questions that haven’t been considered before by an expert in the field. I think what is going on here is that I and my interlocutor are using different paradigms (in the [Kuhnian](https://en.wikipedia.org/wiki/The_Structure_of_Scientific_Revolutions) sense) for determining what questions are worth asking in a field. But while there is a sense in which the other person’s paradigm is more trustworthy — since it arose from a consensus of experts in the relevant field — that doesn’t mean that it’s absolutely reliable. Paradigms tend to blind one to evidence or problems that don’t fit into that paradigm, and paradigm shifts in science aren’t really that rare. (In addition, many fields including machine learning don’t even have a single agreed-upon paradigm.)\n\n\nI think that as a scientist (or really, even as a citizen) it is important to be able to see outside one’s own paradigm. I currently think that I do a good job of this, but it seems to me that there’s a big danger of becoming more entrenched as I get older. Based on the above experiences, I plan to use the following test: **When someone asks me a question about my field, how often have I not thought about it before? How tempted am I to say, “That question isn’t interesting”?** If these start to become more common, then I’ll know something has gone wrong.\n\n\nA few miscellaneous observations:\n\n\n* There are several people I know who routinely have answers to whatever questions I ask. Interestingly, they tend to be considered slightly “crackpot-ish” within their field; and they might also be less successful by conventional metrics, relatively to how smart they are considered by their colleagues. I think this is a result of the fact that most academic fields over-reward progress within that field’s paradigm and under-reward progress outside of it.\n* Beyond “slightly crakpot-ish academics”, the other set of people who routinely have answers to my questions are philosophers and some people in program manager roles (this includes certain types of VCs as well).\n* I would guess that in general technical fields that overlap with the humanities are more likely to take a broad view and not get stuck in a single paradigm. For instance, I would expect political scientists to have thought about most of the political science questions I mentioned above; however, I haven’t talked to enough political scientists (or social scientists in general) to have much confidence in this.\n", "url": "https://jsteinhardt.wordpress.com/2016/12/26/thinking-outside-ones-paradigm/", "title": "Thinking Outside One’s Paradigm", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2016-12-26T17:37:45+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "014a536ccf6555c830755f8672226de3", "summary": []}
+{"text": "Two Strange Facts\n\nHere are two strange facts about matrices, which I can prove but not in a satisfying way.\n\n\n1. If  and  are symmetric matrices satisfying , then , and 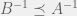, but it is NOT necessarily the case that . Is there a nice way to see why the first two properties should hold but not necessarily the third? In general, do we have 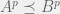 if ![p \\in [0,1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)?\n2. Given a rectangular matrix , and a set ![S \\subseteq [n]](https://s0.wp.com/latex.php?latex=S+%5Csubseteq+%5Bn%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), let  be the submatrix of  with rows in , and let  denote the nuclear norm (sum of singular values) of . Then the function 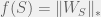 is submodular, meaning that  for all sets . In fact, this is true if we take , defined as the sum of the th powers of the singular values of , for any ![p \\in [0,2]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). The only proof I know involves trigonometric integrals and seems completely unmotivated to me. Is there any clean way of seeing why this should be true?\n\n\nIf anyone has insight into either of these, I’d be very interested!\n\n", "url": "https://jsteinhardt.wordpress.com/2016/08/25/two-strange-facts/", "title": "Two Strange Facts", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2016-08-25T06:50:00+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "9275146d8f46a74f247a1f1402c8e916", "summary": []}
+{"text": "Difficulty of Predicting the Maximum of Gaussians\n\nSuppose that we have a random variable , such that ![\\mathbb{E}[XX^{\\top}] = I_{d \\times d}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BXX%5E%7B%5Ctop%7D%5D+%3D+I_%7Bd+%5Ctimes+d%7D&bg=f0f0f0&fg=555555&s=0&c=20201002). Now take k independent Gaussian random variables , and let J be the argmax (over j in 1, …, k) of .\n\n\nIt seems that it should be very hard to predict J well, in the following sense: for any function , the expectation of ![\\mathbb{E}_{x}[q(J \\mid x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bx%7D%5Bq%28J+%5Cmid+x%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), should with high probability be very close to  (where the second probability is taken over the randomness in ). In fact, Alex Zhai and I think that the probability of the expectation exceeding 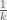 should be at most 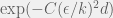 for some constant C. (We can already show this to be true where we replace  with .) I will not sketch a proof here but the idea is pretty cool, it basically uses Lipschitz concentration of Gaussian random variables.\n\n\nI’m mainly posting this problem because I think it’s pretty interesting, in case anyone else is inspired to work on it. It is closely related to the covering number of exponential families under the KL divergence, where we are interested in coverings at relatively large radii ( rather than ).\n\n", "url": "https://jsteinhardt.wordpress.com/2016/01/13/difficulty-of-predicting-the-maximum-of-gaussians/", "title": "Difficulty of Predicting the Maximum of Gaussians", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2016-01-13T05:45:15+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "96020b0d2a3445a08acbd79a0d57d201", "summary": []}
+{"text": "Maximal Maximum-Entropy Sets\n\nConsider a probability distribution 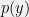 on a space . Suppose we want to construct a set 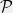 of probability distributions on  such that 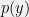 is the maximum-entropy distribution over 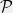:\n\n\n\n\n\nwhere ![{H(p) = \\mathbb{E}_{p}[-\\log p(y)]}](https://s0.wp.com/latex.php?latex=%7BH%28p%29+%3D+%5Cmathbb%7BE%7D_%7Bp%7D%5B-%5Clog+p%28y%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is the entropy. We call such a set a *maximum-entropy set for *. Furthermore, we would like  to be as large as possible, subject to the constraint that  is convex.\n\n\nDoes such a maximal convex maximum-entropy set  exist? That is, is there some convex set  such that  is the maximum-entropy distribution in , and for any 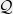 satisfying the same property, ? It turns out that the answer is yes, and there is even a simple characterization of :\n\n\n\n> **Proposition 1** *For any distribution  on , the set* \n> \n> \n> ![\\displaystyle \\mathcal{P} = \\{q \\mid \\mathbb{E}_{q}[-\\log p(y)] \\leq H(p)\\} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BP%7D+%3D+%5C%7Bq+%5Cmid+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%5Cleq+H%28p%29%5C%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n> \n> \n> is the maximal convex maximum-entropy set for .\n> \n> \n\n\nTo see why this is, first note that, clearly, , and for any  we have\n\n\n![\\displaystyle \\begin{array}{rcl} H(q) &=& \\mathbb{E}_{q}[-\\log q(y)] \\\\ &\\leq& \\mathbb{E}_{q}[-\\log p(y)] \\\\ &\\leq& H(p), \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+H%28q%29+%26%3D%26+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+q%28y%29%5D+%5C%5C+%26%5Cleq%26+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%5C%5C+%26%5Cleq%26+H%28p%29%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nso  is indeed the maximum-entropy distribution in . On the other hand, let  be any other convex set whose maximum-entropy distribution is . Then in particular, for any , we must have . Let us suppose for the sake of contradiction that 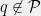, so that ![{\\mathbb{E}_{q}[-\\log p(y)] > H(p)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%3E+H%28p%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002). Then we have\n\n\n![\\displaystyle \\begin{array}{rcl} H((1-\\epsilon)p + \\epsilon q) &=& \\mathbb{E}_{(1-\\epsilon)p+\\epsilon q}[-\\log((1-\\epsilon)p(y)+\\epsilon q(y))] \\\\ &=& \\mathbb{E}_{(1-\\epsilon)p+\\epsilon q}[-\\log(p(y) + \\epsilon (q(y)-p(y))] \\\\ &=& \\mathbb{E}_{(1-\\epsilon)p+\\epsilon q}\\left[-\\log(p(y)) - \\epsilon \\frac{q(y)-p(y)}{p(y)} + \\mathcal{O}(\\epsilon^2)\\right] \\\\ &=& H(p) + \\epsilon(\\mathbb{E}_{q}[-\\log p(y)]-H(p)) - \\epsilon \\mathbb{E}_{(1-\\epsilon)p+\\epsilon q}\\left[\\frac{q(y)-p(y)}{p(y)}\\right] + \\mathcal{O}(\\epsilon^2) \\\\ &=& H(p) + \\epsilon(\\mathbb{E}_{q}[-\\log p(y)]-H(p)) - \\epsilon^2 \\mathbb{E}_{q}\\left[\\frac{q(y)-p(y)}{p(y)}\\right] + \\mathcal{O}(\\epsilon^2) \\\\ &=& H(p) + \\epsilon(\\mathbb{E}_{q}[-\\log p(y)]-H(p)) + \\mathcal{O}(\\epsilon^2). \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+H%28%281-%5Cepsilon%29p+%2B+%5Cepsilon+q%29+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5B-%5Clog%28%281-%5Cepsilon%29p%28y%29%2B%5Cepsilon+q%28y%29%29%5D+%5C%5C+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5B-%5Clog%28p%28y%29+%2B+%5Cepsilon+%28q%28y%29-p%28y%29%29%5D+%5C%5C+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5Cleft%5B-%5Clog%28p%28y%29%29+-+%5Cepsilon+%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29%5Cright%5D+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+-+%5Cepsilon+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5Cleft%5B%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D%5Cright%5D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+-+%5Cepsilon%5E2+%5Cmathbb%7BE%7D_%7Bq%7D%5Cleft%5B%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D%5Cright%5D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nSince ![{\\mathbb{E}_{q}[-\\log p(y)] - H(p) > 0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+-+H%28p%29+%3E+0%7D&bg=f0f0f0&fg=000000&s=0&c=20201002), for sufficiently small  this will exceed 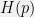, which is a contradiction. Therefore we must have  for all , and hence , so that  is indeed the maximal convex maximum-entropy set for .\n\n", "url": "https://jsteinhardt.wordpress.com/2015/09/07/maximal-maximum-entropy-sets/", "title": "Maximal Maximum-Entropy Sets", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2015-09-07T19:33:41+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "96395bc80607056f2e88557b3e26267f", "summary": []}
+{"text": "Long-Term and Short-Term Challenges to Ensuring the Safety of AI Systems\n\n#### Introduction\n\n\nThere has been much recent discussion about AI risk, meaning specifically the potential pitfalls (both short-term and long-term) that AI with improved capabilities could create for society. Discussants include AI researchers such as [Stuart Russell](https://www.cs.berkeley.edu/~russell/research/future/) and [Eric Horvitz and Tom Dietterich](https://medium.com/@tdietterich/benefits-and-risks-of-artificial-intelligence-460d288cccf3), entrepreneurs such as [Elon Musk and Bill Gates](http://lukemuehlhauser.com/musk-and-gates-on-superintelligence-and-fast-takeoff/), and research institutes such as the [Machine Intelligence Research Institute](https://intelligence.org/) (MIRI) and [Future of Humanity Institute](http://www.fhi.ox.ac.uk/research/research-areas/) (FHI); the director of the latter institute, Nick Bostrom, has even written a bestselling [book](http://www.amazon.com/Superintelligence-Dangers-Strategies-Nick-Bostrom/dp/0199678111) on this topic. Finally, ten million dollars in funding have been [earmarked](http://futureoflife.org/grants/large/initial) towards research on ensuring that AI will be safe and beneficial. Given this, I think it would be useful for AI researchers to discuss the nature and extent of risks that might be posed by increasingly capable AI systems, both short-term and long-term. As a PhD student in machine learning and artificial intelligence, this essay will describe my own views on AI risk, in the hopes of encouraging other researchers to detail their thoughts, as well.\n\n\nFor the purposes of this essay, I will define “AI” to be technology that can carry out tasks with limited or no human guidance, “advanced AI” to be technology that performs substantially more complex and domain-general tasks than are possible today, and “highly capable AI” to be technology that can outperform humans in all or almost all domains. As the primary target audience of this essay is other researchers, I have used technical terms (e.g. weakly supervised learning, inverse reinforcement learning) whenever they were useful, though I have also tried to make the essay more generally accessible when possible.\n\n\n#### Outline\n\n\nI think it is important to distinguish between two questions. First, does artificial intelligence merit the same degree of engineering safety considerations as other technologies (such as bridges)? Second, does artificial intelligence merit additional precautions, beyond those that would be considered typical? I will argue that the answer is yes to the first, even in the short term, and that current engineering methodologies in the field of machine learning do not provide even a typical level of safety or robustness. Moreover, I will argue that the answer to the second question in the long term is likely also yes — namely, that there are important ways in which highly capable artificial intelligence could pose risks which are not addressed by typical engineering concerns.\n\n\nThe point of this essay is not to be alarmist; indeed, I think that AI is likely to be net-positive for humanity. Rather, the point of this essay is to encourage a discussion about the potential pitfalls posed by artificial intelligence, since I believe that research done now can mitigate many of these pitfalls. Without such a discussion, we are unlikely to understand which pitfalls are most important or likely, and thus unable to design effective research programs to prevent them.\n\n\nA common objection to discussing risks posed by AI is that it seems somewhat early on to worry about such risks, and the discussion is likely to be more germane if we wait to have it until after the field of AI has advanced further. I think this objection is quite reasonable in the abstract; however, as I will argue below, I think we do have a reasonable understanding of at least some of the risks that AI might pose, that some of these will be realized even in the medium term, and that there are reasonable programs of research that can address these risks, which in many cases would also have the advantage of improving the usability of existing AI systems.\n\n\n#### Ordinary Engineering\n\n\nThere are many issues related to AI safety that are just a matter of good engineering methodology. For instance, we would ideally like systems that are transparent, modular, robust, and work under well-understood assumptions. Unfortunately, machine learning as a field has not developed very good methodologies for obtaining any of these things, and so this is an important issue to remedy. In other words, I think we should put at least as much thought into building an AI as we do into building a bridge.\n\n\nJust to be very clear, I do not think that machine learning researchers are bad engineers; looking at any of the open source tools such as [Torch](http://torch.ch/), [Caffe](http://caffe.berkeleyvision.org/), [MLlib](https://spark.apache.org/docs/1.1.0/mllib-guide.html), and others make it clear that many machine learning researchers are also good software engineers. Rather, I think that as a field our methodologies are not mature enough to address the specific engineering desiderata of statistical *models* (in contrast to the *algorithms* that create them). In particular, the statistical models obtained from machine learning algorithms tend to be:\n\n\n1. **Opaque**: Many machine learning models consist of hundreds of thousands of parameters, making it difficult to understand how predictions are made. Typically, practitioners resort to error analysis examining the covariates that most strongly influence each incorrect prediction. However, this is not a very sustainable long-term solution, as it requires substantial effort even for relatively narrow-domain systems.\n2. **Monolithic**: In part due to their opacity, models act as a black box, with no modularity or encapsulation of behavior. Though machine learning systems are often split into pipelines of smaller models, the lack of encapsulation can make these pipelines even harder to manage than a single large model; indeed, since machine learning models are by design optimized for a particular input distribution (i.e. whatever distribution they are trained on), we end up in a situation where “Changing Anything Changes Everything” [1].\n3. **Fragile**: As another consequence of being optimized for a particular training distribution, machine learning models can have arbitrarily poor performance when that distribution shifts. For instance, Daumé and Marcu [2] show that a named entity classifier with 92% accuracy on one dataset drops to 58% accuracy on a superficially similar dataset. Though such issues are partially addressed by work on transfer learning and domain adaptation [3], these areas are not very developed compared to supervised learning.\n4. **Poorly understood**: Beyond their fragility, understanding when a machine learning model will work is difficult. We know that a model will work if it is tested on the same distribution it is trained on, and have some extensions beyond this case (e.g. based on robust optimization [4]), but we have very little in the way of practically relevant conditions under which a model trained in one situation will work well in another situation. Although they are related, this issue differs from the opacity issue above in that it relates to making predictions about the system’s future behavior (in particular, generalization to new situations), versus understanding the internal workings of the current system.\n\n\nThat these issues plague machine learning systems is likely uncontroversial among machine learning researchers. However, in comparison to research focused on extending capabilities, very little is being done to address them. Research in this area therefore seems particularly impactful, especially given the desire to deploy machine learning systems in increasingly complex and safety-critical situations.\n\n\n#### Extraordinary Engineering\n\n\nDoes AI merit additional safety precautions, beyond those that are considered standard engineering practice in other fields? Here I am focusing only on the long-term impacts of advanced or highly capable AI systems.\n\n\nMy tentative answer is yes; there seem to be a few different ways in which AI could have bad effects, each of which seems individually unlikely but not implausible. Even if each of the risks identified so far are not likely, (i) the total risk might be large, especially if there are additional unidentified risks, and (ii) the existence of multiple “near-misses” motivates closer investigation, as it may suggest some underlying principle that makes AI risk-laden. In the sequel I will focus on so-called “global catastrophic” risks, meaning risks that could affect a large fraction of the earth’s population in a material way. I have chosen to focus on these risks because I think there is an important difference between an AI system messing up in a way that harms a few people (which would be a legal liability but perhaps should not motivate a major effort in terms of precautions) and an AI system that could cause damage on a global scale. The latter *would* justify substantial precautions, and I want to make it clear that this is the bar I am setting for myself.\n\n\nWith that in place, below are a few ways in which advanced or highly capable AI could have specific global catastrophic risks.\n\n\n**Cyber-attacks.** There are two trends which taken together make the prospect of AI-aided cyber-attacks seem worrisome. The first trend is simply the increasing prevalence of cyber-attacks; even this year we have seen Russia attack Ukraine, North Korea attack Sony, and China attack the U.S. Office of Personnel Management. Secondly, the “Internet of Things” means that an increasing number of physical devices will be connected to the internet. Assuming that software exists to autonomously control them, many internet-enabled devices such as cars could be hacked and then weaponized, leading to a decisive military advantage in a short span of time. Such an attack could be enacted by a small group of humans aided by AI technologies, which would make it hard to detect in advance. Unlike other weaponizable technology such as nuclear fission or synthetic biology, it would be very difficult to control the distribution of AI since it does not rely on any specific raw materials. Finally, note that even a team with relatively small computing resources could potentially “bootstrap” to much more computing power by first creating a botnet with which to do computations; to date, the largest botnet has spanned 30 million computers and several other botnets have exceeded 1 million.\n\n\n**Autonomous weapons.** Beyond cyber-attacks, improved autonomous robotics technology combined with ubiquitous access to miniature UAVs (“drones”) could allow both terrorists and governments to wage a particularly pernicious form of remote warfare by creating weapons that are both cheap and hard to detect or defend against (due to their small size and high maneuverability). Beyond direct malicious intent, if autonomous weapons systems or other powerful autonomous systems malfunction then they could cause a large amount of damage.\n\n\n**Mis-optimization.** A highly capable AI could acquire a large amount of power but pursue an overly narrow goal, and end up harming humans or human value while optimizing for this goal. This may seem implausible at face value, but as I will argue below, it is easier to improve AI *capabilities* than to improve AI *values*, making such a mishap possible in theory.\n\n\n**Unemployment.** It is already the case that increased automation is decreasing the number of available jobs, to the extent that some economists and policymakers are discussing what to do if the number of jobs is systematically smaller than the number of people seeking work. If AI systems allow a large number of jobs to be automated over a relatively short time period, then we may not have time to plan or implement policy solutions, and there could then be a large unemployment spike. In addition to the direct effects on the people who are unemployed, such a spike could also have indirect consequences by decreasing social stability on a global scale.\n\n\n**Opaque systems.** It is also already the case that increasingly many tasks are being delegated to autonomous systems, from trades in financial markets to aggregation of information feeds. The opacity of these systems has led to issues such as the 2010 Flash Crash and will likely lead to larger issues in the future. In the long term, as AI systems become increasingly complex, humans may lose the ability to meaningfully understand or intervene in such systems, which could lead to a loss of sovereignty if autonomous systems are employed in executive-level functions (e.g. government, economy).\n\n\nBeyond these specific risks, it seems clear that, eventually, AI will be able to outperform humans in essentially every domain. At that point, it seems doubtful that humanity will continue to have direct causal influence over its future unless specific measures are put in place to ensure this. While I do not think this day will come soon, I think it is worth thinking now about how we might meaningfully control highly capable AI systems, and I also think that many of the risks posed above (as well as others that we haven’t thought of yet) will occur on a somewhat shorter time scale.\n\n\nLet me end with some specific ways in which control of AI may be particularly difficult compared to other human-engineered systems:\n\n\n1. AI may be “agent-like”, which means that the space of possible behaviors is much larger; our intuitions about how AI will act in pursuit of a given goal may not account for this and so AI behavior could be hard to predict.\n2. Since an AI would presumably learn from experience, and will likely run at a much faster serial processing speed than humans, its capabilities may change rapidly, ruling out the usual process of trial-and-error.\n3. AI will act in a much more open-ended domain. In contrast, our existing tools for specifying the necessary properties of a system only work well in narrow domains. For instance, for a bridge, safety relates to the ability to successfully accomplish a small number of tasks (e.g. not falling over). For these, it suffices to consider well-characterized engineering properties such as tensile strength. For AI, the number of tasks we would potentially want it to perform is large, and it is unclear how to obtain a small number of well-characterized properties that would ensure safety.\n4. Existing machine learning frameworks make it very easy for AI to acquire *knowledge*, but hard to acquire *values*. For instance, while an AI’s model of reality is flexibly learned from data, its goal/utility function is hard-coded in almost all situations; an exception is some work on inverse reinforcement learning [5], but this is still a very nascent framework. Importantly, the asymmetry between knowledge (and hence capabilities) and values is fundamental, rather than simply a statement about existing technologies. This is because knowledge is something that is regularly informed by reality, whereas values are only weakly informed by reality: an AI which learns incorrect facts could notice that it makes wrong predictions, but the world might never “tell” an AI that it learned the “wrong values”. At a technical level, while many tasks in machine learning are fully supervised or at least semi-supervised, value acquisition is a weakly supervised task.\n\n\nIn summary: there are several concrete global catastrophic risks posed by highly capable AI, and there are also several reasons to believe that highly capable AI would be difficult to control. Together, these suggest to me that the control of highly capable AI systems is an important problem posing unique research challenges.\n\n\n#### Long-term Goals, Near-term Research\n\n\nAbove I presented an argument for why AI, in the long term, may require substantial precautionary efforts. Beyond this, I also believe that there is important research that can be done right now to reduce long-term AI risks. In this section I will elaborate on some specific research projects, though my list is not meant to be exhaustive.\n\n\n1. **Value learning**: In general, it seems important in the long term (and also in the short term) to design algorithms for learning values / goal systems / utility functions, rather than requiring them to be hand-coded. One framework for this is inverse reinforcement learning [5], though developing additional frameworks would also be useful.\n2. **Weakly supervised learning**: As argued above, inferring values, in contrast to beliefs, is an at most weakly supervised problem, since humans themselves are often incorrect about what they value and so any attempt to provide fully annotated training data about values would likely contain systematic errors. It may be possible to infer values indirectly through observing human actions; however, since humans often act immorally and human values change over time, current human actions are not consistent with our ideal long-term values, and so learning from actions in a naive way could lead to problems. Therefore, a better fundamental understanding of weakly supervised learning — particularly regarding guaranteed recovery of indirectly observed parameters under well-understood assumptions — seems important.\n3. **Formal specification / verification**: One way to make AI safer would be to formally specify desiderata for its behavior, and then prove that these desiderata are met. A major open challenge is to figure out how to meaningfully specify formal properties for an AI system. For instance, even if a speech transcription system did a near-perfect job of transcribing speech, it is unclear what sort of specification language one might use to state this property formally. Beyond this, though there is much existing work in formal verification, it is still extremely challenging to verify large systems.\n4. **Transparency**: To the extent that the decision-making process of an AI is transparent, it should be relatively easy to ensure that its impact will be positive. To the extent that the decision-making process is opaque, it should be relatively difficult to do so. Unfortunately, transparency seems difficult to obtain, especially for AIs that reach decisions through complex series of serial computations. Therefore, better techniques for rendering AI reasoning transparent seem important.\n5. **Strategic assessment and planning**: Better understanding of the likely impacts of AI will allow a better response. To this end, it seems valuable to map out and study specific concrete risks; for instance, better understanding ways in which machine learning could be used in cyber-attacks, or forecasting the likely effects of technology-driven unemployment, and determining useful policies around these effects. It would also be clearly useful to identify additional plausible risks beyond those of which we are currently aware. Finally, thought experiments surrounding different possible behaviors of advanced AI would help inform intuitions and point to specific technical problems. Some of these tasks are most effectively carried out by AI researchers, while others should be done in collaboration with economists, policy experts, security experts, etc.\n\n\nThe above constitute at least five concrete directions of research on which I think important progress can be made today, which would meaningfully improve the safety of advanced AI systems and which in many cases would likely have ancillary benefits in the short term, as well.\n\n\n#### Related Work\n\n\nAt a high level, while I have implicitly provided a program of research above, there are other proposed research programs as well. Perhaps the earliest proposed program is from MIRI [6], which has focused on AI alignment problems that arise even in simplified settings (e.g. with unlimited computing power or easy-to-specify goals) in hopes of later generalizing to more complex settings. The Future of Life Institute (FLI) has also published a research priorities document [7, 8] with a broader focus, including non-technical topics such as regulation of autonomous weapons and economic shifts induced by AI-based technologies. I do not necessarily endorse either document, but think that both represent a big step in the right direction. Ideally, MIRI, FLI, and others will all justify why they think their problems are worth working on and we can let the best arguments and counterarguments rise to the top. This is already happening to some extent [9, 10, 11] but I would like to see more of it, especially from academics with expertise in machine learning and AI [12, 13].\n\n\nIn addition, several specific arguments I have advanced are similar to those already advanced by others. The issue of AI-driven unemployment has been studied by Brynjolfsson and McAfee [14], and is also discussed in the FLI research document. The problem of AI pursuing narrow goals has been elaborated through Bostrom’s “paperclipping argument” [15] as well as the orthogonality thesis [16], which states that beliefs and values are independent of each other. While I disagree with the orthogonality thesis in its strongest form, the arguments presented above for the difficulty of value learning can in many cases reach similar conclusions.\n\n\nOmohundro [17] has argued that advanced agents would pursue certain instrumentally convergent drives under almost any value system, which is one way in which agent-like systems differ from systems without agency. Good [18] was the first to argue that AI capabilities could improve rapidly. Yudkowsky has argued that it would be easy for an AI to acquire power given few initial resources [19], though his example assumes the creation of advanced biotechnology.\n\n\nChristiano has argued for the value of transparent AI systems, and proposed the “advisor games” framework as a potential operationalization of transparency [20].\n\n\n#### Conclusion\n\n\nTo ensure the safety of AI systems, additional research is needed, both to meet ordinary short-term engineering desiderata as well as to make the additional precautions specific to highly capable AI systems. In both cases, there are clear programs of research that can be undertaken today, which in many cases seem to be under-researched relative to their potential societal value. I therefore think that well-directed research towards improving the safety of AI systems is a worthwhile undertaking, with the additional benefit of motivating interesting new directions of research.\n\n\n#### Acknowledgments\n\n\nThanks to Paul Christiano, Holden Karnofsky, Percy Liang, Luke Muehlhauser, Nick Beckstead, Nate Soares, and Howie Lempel for providing feedback on a draft of this essay.\n\n\n#### References\n\n\n[1] D. Sculley, et al. [*Machine Learning: The High-Interest Credit Card of Technical Debt*](http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43146.pdf). 2014. \n\n[2] Hal Daumé III and Daniel Marcu. Domain adaptation for statistical classifiers. *Journal of Artificial Intelligence Research*, pages 101–126, 2006. \n\n[3] Sinno J. Pan and Qiang Yang. A survey on transfer learning. *IEEE Transactions on Knowledge and Data Engineering*, 22(10):1345–1359, 2010. \n\n[4] Dimitris Bertsimas, David B. Brown, and Constantine Caramanis. Theory and applications of robust optimization. *SIAM Review*, 53(3):464–501, 2011. \n\n[5] Andrew Ng and Stuart Russell. Algorithms for inverse reinforcement learning. In *International Conference in Machine Learning*, pages 663–670, 2000. \n\n[6] Nate Soares and Benja Fallenstein. [*Aligning Superintelligence with Human Interests: A Technical Research Agenda*](https://intelligence.org/files/TechnicalAgenda.pdf). 2014. \n\n[7] Stuart Russell, Daniel Dewey, and Max Tegmark. [*Research priorities for robust and beneficial artificial intelligence*](http://futureoflife.org/static/data/documents/research_priorities.pdf). 2015. \n\n[8] Daniel Dewey, Stuart Russell, and Max Tegmark. [*A survey of research questions for robust and beneficial AI*](http://futureoflife.org/static/data/documents/research_survey.pdf). 2015. \n\n[9] Paul Christiano. [*The Steering Problem*](https://medium.com/ai-control/the-steering-problem-a3543e65c5c4). 2015. \n\n[10] Paul Christiano. [*Stable self-improvement as an AI safety problem*](https://medium.com/ai-control/stable-self-improvement-as-an-ai-safety-problem-46e2a44e73e). 2015. \n\n[11] Luke Muehlhauser. [*How to study superintelligence strategy*](http://lukemuehlhauser.com/some-studies-which-could-improve-our-strategic-picture-of-superintelligence/). 2014. \n\n[12] Stuart Russell. [*Of Myths and Moonshine*](http://edge.org/conversation/the-myth-of-ai#26015). 2014. \n\n[13] Tom Dietterich and Eric Horvitz. [*Benefits and Risks of Artificial Intelligence*](https://medium.com/@tdietterich/benefits-and-risks-of-artificial-intelligence-460d288cccf3). 2015. \n\n[14] Erik Brynjolfsson and Andrew McAfee. *The second machine age: work, progress, and prosperity in a time of brilliant technologies*. WW Norton & Company, 2014. \n\n[15] Nick Bostrom (2003). [*Ethical Issues in Advanced Artificial Intelligence*](http://www.nickbostrom.com/ethics/ai.html). *Cognitive, Emotive and Ethical Aspects of Decision Making in Humans and in Artificial Intelligence*. \n\n[16] Nick Bostrom. “The superintelligent will: Motivation and instrumental rationality in advanced artificial agents.” *Minds and Machines* 22.2 (2012): 71-85. \n\n[17] Stephen M. Omohundro (2008). [*The Basic AI Drives*](http://selfawaresystems.com/2007/11/30/paper-on-the-basic-ai-drives/). *Frontiers in Artificial Intelligence and Applications* (IOS Press). \n\n[18] Irving J. Good. “Speculations concerning the first ultraintelligent machine.” *Advances in computers* 6.99 (1965): 31-83. \n\n[19] Eliezer Yudkowsky. “Artificial intelligence as a positive and negative factor in global risk.” *Global catastrophic risks* 1 (2008): 303. \n\n[20] Paul Christiano. [*Advisor Games*](https://medium.com/ai-control/advisor-games-b33382fef68c). 2015.\n\n", "url": "https://jsteinhardt.wordpress.com/2015/06/24/long-term-and-short-term-challenges-to-ensuring-the-safety-of-ai-systems/", "title": "Long-Term and Short-Term Challenges to Ensuring the Safety of AI Systems", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2015-06-24T22:53:47+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "7495ccabb9d383393c48ba3c80cf2b35", "summary": []}
+{"text": "A Fervent Defense of Frequentist Statistics\n\n *[Highlights for the busy: de-bunking standard “Bayes is optimal” arguments; frequentist Solomonoff induction; and a description of the online learning framework.]*\n\n\n**Short summary.** This essay makes many points, each of which I think is worth reading, but if you are only going to understand one point I think it should be “Myth 5″ below, which describes the online learning framework as a response to the claim that frequentist methods need to make strong modeling assumptions. Among other things, online learning allows me to perform the following remarkable feat: if I’m betting on horses, and I get to place bets after watching other people bet but before seeing which horse wins the race, then I can guarantee that after a relatively small number of races, I will do almost as well overall as the best other person, even if the number of other people is very large (say, 1 billion), and their performance is correlated in complicated ways.\n\n\nIf you’re only going to understand two points, then also read about the frequentist version of Solomonoff induction, which is described in “Myth 6″.\n\n\n**Main article.** I’ve already written one essay on [Bayesian vs. frequentist statistics](http://cs.stanford.edu/~jsteinhardt/stats-essay.pdf). In that essay, I argued for a balanced, pragmatic approach in which we think of the two families of methods as a collection of tools to be used as appropriate. Since I’m currently feeling contrarian, this essay will be far less balanced and will argue explicitly against Bayesian methods and in favor of frequentist methods. I hope this will be forgiven as so much other writing goes in the opposite direction of unabashedly defending Bayes. I should note that this essay is partially inspired by some of Cosma Shalizi’s blog posts, such as [this](http://vserver1.cscs.lsa.umich.edu/~crshalizi/weblog/612.html) one.\n\n\nThis essay will start by listing a series of myths, then debunk them one-by-one. My main motivation for this is that Bayesian approaches seem to be highly popularized, to the point that one may get the impression that they are the uncontroversially superior method of doing statistics. I actually think the opposite is true: I think most statisticans would for the most part defend frequentist methods, although there are also many departments that are decidedly Bayesian (e.g. many places in England, as well as some U.S. universities like Columbia). I have a lot of respect for many of the people at these universities, such as Andrew Gelman and Philip Dawid, but I worry that many of the other proponents of Bayes (most of them non-statisticians) tend to oversell Bayesian methods or undersell alternative methodologies.\n\n\nIf you are like me from, say, two years ago, you are firmly convinced that Bayesian methods are superior and that you have knockdown arguments in favor of this. If this is the case, then I hope this essay will give you an experience that I myself found life-altering: the experience of having a way of thinking that seemed unquestionably true slowly dissolve into just one of many imperfect models of reality. This experience helped me gain more explicit appreciation for the skill of viewing the world from many different angles, and of distinguishing between a very successful paradigm and reality.\n\n\nIf you are not like me, then you may have had the experience of bringing up one of many reasonable objections to normative Bayesian epistemology, and having it shot down by one of many “standard” arguments that seem wrong but not for easy-to-articulate reasons. I hope to lend some reprieve to those of you in this camp, by providing a collection of “standard” replies to these standard arguments.\n\n\nI will start with the myths (and responses) that I think will require the least technical background and be most interesting to a general audience. Toward the end, I deal with some attacks on frequentist methods that I believe amount to technical claims that are demonstrably false; doing so involves more math. Also, I should note that for the sake of simplicity I’ve labeled everything that is non-Bayesian as a “frequentist” method, even though I think there’s actually a fair amount of variation among these methods, although also a fair amount of overlap (e.g. I’m throwing in statistical learning theory with minimax estimation, which certainly have a lot of overlap in ideas but were also in some sense developed by different communities).\n\n\n**The** **Myths:**\n\n\n* Bayesian methods are optimal.\n* Bayesian methods are optimal except for computational considerations.\n* We can deal with computational constraints simply by making approximations to Bayes.\n* The prior isn’t a big deal because Bayesians can always share likelihood ratios.\n* Frequentist methods need to assume their model is correct, or that the data are i.i.d.\n* Frequentist methods can only deal with simple models, and make arbitrary cutoffs in model complexity (aka: “I’m Bayesian because I want to do Solomonoff induction”).\n* Frequentist methods hide their assumptions while Bayesian methods make assumptions explicit.\n* Frequentist methods are fragile, Bayesian methods are robust.\n* Frequentist methods are responsible for bad science\n* Frequentist methods are unprincipled/hacky.\n* Frequentist methods have no promising approach to computationally bounded inference.\n\n\n*Myth* *1**:* *Bayesian methods are optimal.* Presumably when most people say this they are thinking of either Dutch-booking or the complete class theorem. Roughly what these say are the following:\n\n\n**Dutch-book argument:** Every coherent set of beliefs can be modeled as a subjective probability distribution. (Roughly, coherent means “unable to be Dutch-booked”.)\n\n\n**Complete class theorem:** Every non-Bayesian method is worse than some Bayesian method (in the sense of performing deterministically at least as poorly in every possible world).\n\n\nLet’s unpack both of these. My high-level argument regarding Dutch books is that I would much rather spend my time trying to correspond with reality than trying to be internally consistent. More concretely, the Dutch-book argument says that if for every bet you force me to take one side or the other, then unless I’m Bayesian there’s a collection of bets that will cause me to lose money for sure. I don’t find this very compelling. This seems analogous to the situation where there’s some quant at Jane Street, and they’re about to run code that will make thousands of dollars trading stocks, and someone comes up to them and says “Wait! You should add checks to your code to make sure that no subset of your trades will lose you money!” This just doesn’t seem worth the quant’s time, it will slow down the code substantially, and instead the quant should be writing the next program to make thousands more dollars. This is basically what dutch-booking arguments seem like to me.\n\n\nMoving on, the complete class theorem says that for any decision rule, I can do better by replacing it with *some* Bayesian decision rule. But this injunction is not useful in practice, because it doesn’t say anything about *which* decision rule I should replace it with. Of course, if you hand me a decision rule and give me infinite computational resources, then I can hand you back a Bayesian method that will perform better. But it still might not perform **well**. All the complete class theorem says is that every local optimum is Bayesan. To be a useful theory of epistemology, I need a prescription for how, in the first place, I am to arrive at a *good* decision rule, *not* just a locally optimal one. And this is something that frequentist methods do provide, to a far greater extent than Bayesian methods (for instance by using minimax decision rules such as the maximum-entropy example given later). Note also that many frequentist methods *do* correspond to a Bayesian method for some appropriately chosen prior. But the crucial point is that the frequentist *told* me how to pick a prior I would be happy with (also, many frequentist methods *don’t* correspond to a Bayesian method for any choice of prior; they nevertheless often perform quite well).\n\n\n*Myth* *2**:* *Bayesian methods are optimal except for computational considerations.* We already covered this in the previous point under the complete class theorem, but to re-iterate: **Bayesian methods are** ***locally*** **optimal,** ***not*** **global optimal. Identifying all the local optima is very different from knowing which of them is the global optimum.** I would much rather have someone hand me something that wasn’t a local optimum but was close to the global optimum, than something that was a local optimum but was far from the global optimum.\n\n\n*Myth* *3**:* *We can deal with computational constraints simply by making approximations to Bayes.* I have rarely seen this born out in practice. Here’s a challenge: suppose I give you data generated in the following way. There are a collection of vectors , , , , each with  coordinates. I generate outputs , , ,  in the following way. First I globally select  of the  coordinates uniformly at random, then I select a fixed vector  such that those  coordinates are drawn from i.i.d. Gaussians and the rest of the coordinates are zero. Now I set  (i.e.  is the dot product of  with ). You are given  and , and your job is to infer . This is a completely well-specified problem, the only task remaining is computational. I know people who have solved this problem using Bayesan methods with approximate inference. I have respect for these people, because doing so is no easy task. I think very few of them would say that “we can just approximate Bayesian updating and be fine”. (Also, this particular problem can be solved trivially with frequentist methods.)\n\n\nA particularly egregious example of this is when people talk about “computable approximations to Solomonoff induction” or “computable approximations to AIXI” as if such notions were meaningful.\n\n\n*Myth* *4**:* *the prior isn’t a big deal because Bayesians can always share likelihood ratios.* Putting aside the practical issue that there would in general be an infinite number of likelihood ratios to share, there is the larger issue that for any hypothesis , there is also the hypothesis  that matches  exactly up to now, and then predicts the opposite of  at all points in the future. You have to constrain model complexity at some point, the question is about how. To put this another way, sharing my likelihood ratios without also constraining model complexity (by focusing on a subset of all logically possible hypotheses) would be equivalent to just sharing all sensory data I’ve ever accrued in my life. To the extent that such a notion is even possible, I certainly don’t need to be a Bayesian to do such a thing.\n\n\n*Myth 5: frequentist methods need to assume their model is correct or that the data are i.i.d.* **Understanding the content of this section is the most important single insight to gain from this essay.** For some reason it’s assumed that frequentist methods need to make strong assumptions (such as Gaussianity), whereas Bayesian methods are somehow immune to this. In reality, the opposite is true. While there are many beautiful and deep frequentist formalisms that answer this, I will choose to focus on one of my favorite, which is **online learning**.\n\n\nTo explain the online learning framework, let us suppose that our data are , (x_2, y_2), \\ldots, (x_T, y_T)}\"). We don’t observe  until after making a prediction  of what  will be, and then we receive a penalty }\") based on how incorrect we were. So we can think of this as receiving prediction problems one-by-one, and in particular we make no assumptions about the relationship between the different problems; they could be i.i.d., they could be positively correlated, they could be anti-correlated, they could even be adversarially chosen.\n\n\nAs a running example, suppose that I’m betting on horses and before each race there are  other people who give me advice on which horse to bet on. I know nothing about horses, so based on this advice I’d like to devise a good betting strategy. In this case,  would be the  bets that each of the other people recommend,  would be the horse that I actually bet on, and  would be the horse that actually wins the race. Then, supposing that  (i.e., the horse I bet on actually wins), }\") is the negative of the payoff from correctly betting on that horse. Otherwise, if the horse I bet on doesn’t win, }\") is the cost I had to pay to place the bet.\n\n\nIf I’m in this setting, what guarantee can I hope for? I might ask for an algorithm that is guaranteed to make good bets — but this seems impossible unless the people advising me actually know something about horses. Or, at the very least, *one* of the people advising me knows something. Motivated by this, I define my **regret** to be the difference between my penalty and the penalty of the best of the  people (note that I only have access to the latter after all  rounds of betting). More formally, given a class  of predictors , I define\n\n\n = \\frac{1}{T} \\sum_{t=1}^T L(y_t, z_t) - \\min_{h \\in \\mathcal{M}} \\frac{1}{T} \\sum_{t=1}^T L(y_t, h(x_t))\")\n\n\nIn this case,  would have size  and the th predictor would just always follow the advice of person . The regret is then how much worse I do on average than the best expert. A remarkable fact is that, in this case, there is a strategy such that }\") shrinks at a rate of }{T}}}\"). In other words, I can have an average score within  of the best advisor after }{\\epsilon^2}}\") rounds of betting.\n\n\nOne reason that this is remarkable is that it does not depend at all on how the data are distributed; **the data could be i.i.d., positively correlated, negatively correlated, even adversarial,** and one can still construct an (adaptive) prediction rule that does almost as well as the best predictor in the family.\n\n\nTo be even more concrete, if we assume that all costs and payoffs are bounded by  per round, and that there are  people in total, then an explicit upper bound is that after  rounds, we will be within  dollars on average of the best other person. Under slightly stronger assumptions, we can do even better, for instance if the best person has an average variance of  about their mean, then the  can be replaced with .\n\n\nIt is important to note that the betting scenario is just a running example, and one can still obtain regret bounds under fairly general scenarios;  could be continuous and  could have quite general structure; the only technical assumption is that  be a convex set and that  be a convex function of . These assumptions tend to be easy to satisfy, though I have run into a few situations where they end up being problematic, mainly for computational reasons. For an -dimensional model family, typically }\") decreases at a rate of , although under additional assumptions this can be reduced to }{T}}}\"), as in the betting example above. I would consider this reduction to be one of the crowning results of modern frequentist statistics.\n\n\nYes, these guarantees sound incredibly awesome and perhaps too good to be true. They actually are that awesome, and they are actually true. The work is being done by measuring the error relative to the best model in the model family. We aren’t required to do well in an absolute sense, we just need to not do any worse than the best model. Of as long as at least one of the models in our family makes good predictions, that means we will as well. This is really what statistics is meant to be doing: you come up with everything you imagine could possibly be reasonable, and hand it to me, and then I come up with an algorithm that will figure out which of the things you handed me was most reasonable, and will do almost as well as that. As long as at least one of the things you come up with is good, then my algorithm will do well. Importantly, due to the }\") dependence on the dimension of the model family, you can actually write down extremely broad classes of models and I will still successfully sift through them.\n\n\n**Let me stress again:** regret bounds are saying that, no matter how the  and  are related, no i.i.d. assumptions anywhere in sight, we will do almost as well as any predictor  in  (in particular, almost as well as the best predictor).\n\n\n*Myth 6: frequentist methods can only deal with simple models and need to make arbitrary cutoffs in model complexity.* A naive perusal of the literature might lead one to believe that frequentists only ever consider very simple models, because many discussions center on linear and log-linear models. To dispel this, I will first note that there are just as many discussions that focus on much more general properties such as convexity and smoothness, and that can achieve comparably good bounds in many cases. But more importantly, the reason we focus so much on linear models is because **we have already reduced a large family of problems to (log-)linear regression.** The key insight, and I think one of the most important insights in all of applied mathematics, is that of **featurization**: given a *non-linear* problem, we can often embed it into a higher-dimensional *linear* problem, via a feature map  ( denotes -dimensional space, i.e. vectors of real numbers of length ). For instance, if I think that  is a polynomial (say cubic) function of , I can apply the mapping  = (1, x, x^2, x^3)}\"), and now look for a *linear* relationship between  and }\").\n\n\nThis insight extends far beyond polynomials. In combinatorial domains such as natural language, it is common to use *indicator features*: features that are  if a certain event occurs and  otherwise. For instance, I might have an indicator feature for whether two words appear consecutively in a sentence, whether two parts of speech are adjacent in a syntax tree, or for what part of speech a word has. Almost all state of the art systems in natural language processing work by solving a relatively simple regression task (typically either log-linear or max-margin) over a rich feature space (often involving hundreds of thousands or millions of features, i.e. an embedding into  or ).\n\n\nA counter-argument to the previous point could be: “Sure, you could create a high-dimensional family of models, but it’s still a *parameterized family*. I don’t want to be stuck with a parameterized family, I want my family to include all Turing machines!” Putting aside for a second the question of whether “all Turing machines” is a well-advised model choice, this is something that a frequentist approach can handle just fine, using a tool called *regularization*, which after featurization is the second most important idea in statistics.\n\n\nSpecifically, given any sufficiently quickly growing function }\"), one can show that, given  data points, there is a strategy whose average error is at most }{T}}}\") worse than *any* estimator . This can hold even if the model class  is infinite dimensional. For instance, if  consists of all probability distributions over Turing machines, and we let  denote the probability mass placed on the th Turing machine, then a valid regularizer  would be\n\n\n = \\sum_i h_i \\log(i^2 \\cdot h_i)\")\n\n\nIf we consider this, then we see that, for any probability distribution over the first  Turing machines (i.e. all Turing machines with description length ), the value of  is at most ^2) = k\\log(4)}\"). (Here we use the fact that  \\geq \\sum_i h_i \\log(i^2)}\"), since  and hence  \\leq 0}\").) **This means that, if we receive roughly  data, we will achieve error within  of the best Turing machine that has description length .**\n\n\nLet me note several things here:\n\n\n* This strategy makes no assumptions about the data being i.i.d. It doesn’t even assume that the data are computable. It just guarantees that it will perform as well as any Turing machine (or distribution over Turing machines) given the appropriate amount of data.\n* This guarantee holds for any given sufficiently smooth measurement of prediction error (the update strategy depends on the particular error measure).\n* This guarantee holds deterministically, no randomness required (although predictions may need to consist of probability distributions rather than specific points, but this is also true of Bayesian predictions).\n\n\nInterestingly, in the case that the prediction error is given by the negative log probability assigned to the truth, then the corresponding strategy that achieves the error bound is just normal Bayesian updating. But for other measurements of error, we get different update strategies. Although I haven’t worked out the math, intuitively this difference could be important if the universe is fundamentally unpredictable but our notion of error is insensitive to the unpredictable aspects.\n\n\n*Myth* *7**:* *frequentist methods hide their assumptions while* *B**ayesian methods make assumptions explicit.* I’m still not really sure where this came from. As we’ve seen numerous times so far, a very common flavor among frequentist methods is the following: I have a model class , I want to do as well as any model in ; or put another way:\n\n\n**Assumption:** At least one model in  has error at most . \n\n**Guarantee:** My method will have error at most .\n\n\nThis seems like a very explicit assumption with a very explicit guarantee. On the other hand, an argument I hear is that Bayesian methods make their assumptions explicit because they have an explicit prior. If I were to write this as an assumption and guarantee, I would write:\n\n\n**Assumption:** The data were generated from the prior. \n\n**Guarantee:** I will perform at least as well as any other method.\n\n\nWhile I agree that this is an assumption and guarantee of Bayesian methods, there are two problems that I have with drawing the conclusion that “Bayesian methods make their assumptions explicit”. The first is that it can often be very difficult to understand how a prior behaves; so while we could say “The data were generated from the prior” is an explicit assumption, it may be unclear what exactly that assumption entails. However, a bigger issue is that “The data were generated from the prior” is an assumption that very rarely holds; indeed, in many cases the underlying process is deterministic (if you’re a subjective Bayesian then this isn’t necessarily a problem, but it does certainly mean that the assumption given above doesn’t hold). So given that that assumption doesn’t hold but Bayesian methods still often perform well in practice, I would say that Bayesian methods are making some other sort of “assumption” that is far less explicit (indeed, I would be very interested in understanding what this other, more nebulous assumption might be).\n\n\n*Myth* *8**:* *frequentist methods are fragile,* *Bayesian methods are robust**.* This is another one that’s straightforwardly false. First, since frequentist methods often rest on weaker assumptions they are more robust if the assumptions don’t quite hold. Secondly, there is an entire area of robust statistics, which focuses on being robust to adversarial errors in the problem data.\n\n\n*Myth* *9**:* *frequentist methods are responsible for bad science.* I will concede that much bad science is done using frequentist statistics. But this is true only because pretty much all science is done using frequentist statistics. I’ve heard arguments that using Bayesian methods instead of frequentist methods would fix at least some of the problems with science. I don’t think this is particularly likely, as I think many of the problems come from mis-application of statistical tools or from failure to control for multiple hypotheses. If anything, Bayesian methods would exacerbate the former, because they often require more detailed modeling (although in most simple cases the difference doesn’t matter at all). I don’t think being Bayesian guards against multiple hypothesis testing. Yes, in some sense a prior “controls for multiple hypotheses”, but in general the issue is that the “multiple hypotheses” are never written down in the first place, or are written down and then discarded. One could argue that being in the habit of writing down a prior might make practitioners more likely to think about multiple hypotheses, but I’m not sure this is the first-order thing to worry about.\n\n\n*Myth 10:* *frequentist methods are unprincipled / hacky.* One of the most beautiful theoretical paradigms that I can think of is what I could call the “geometric view of statistics”. One place that does a particularly good job of show-casing this is [Shai Shalev-Shwartz’s PhD thesis](http://eprints.pascal-network.org/archive/00004161/), which was so beautiful that I cried when I read it. I’ll try (probably futilely) to convey a tiny amount of the intuition and beauty of this paradigm in the next few paragraphs, although focusing on minimax estimation, rather than online learning as in Shai’s thesis.\n\n\nThe geometric paradigm tends to emphasize a view of measurements (i.e. empirical expected values over observed data) as “noisy” linear constraints on a model family. We can control the noise by either taking few enough measurements that the total error from the noise is small (classical statistics), or by broadening the linear constraints to convex constraints (robust statistics), or by controlling the Lagrange multipliers on the constraints (regularization). One particularly beautiful result in this vein is the duality between maximum entropy and maximum likelihood. (I can already predict the Jaynesians trying to claim this result for their camp, but (i) Jaynes did not invent maximum entropy; (ii) maximum entropy is not particularly Bayesian (in the sense that frequentists use it as well); and (iii) the view on maximum entropy that I’m about to provide is different from the view given in Jaynes or by physicists in general *[edit: EHeller thinks this last claim is questionable, see discussion [here](https://jsteinhardt.wordpress.com/lw/jne/a_fervent_defense_of_frequentist_statistics/aj8g)]*.)\n\n\nTo understand the duality mentioned above, suppose that we have a probability distribution }\") and the only information we have about it is the expected value of a certain number of functions, i.e. the information that ![{\\mathbb{E}[\\phi(x)] = \\phi^*}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cphi%28x%29%5D+%3D+%5Cphi%5E%2A%7D&bg=f0f0f0&fg=000000&s=0 \"{\\mathbb{E}[\\phi(x)] = \\phi^*}\"), where the expectation is taken with respect to }\"). We are interested in constructing a probability distribution }\") such that no matter what particular value }\") takes, }\") will still make good predictions. In other words (taking }\") as our measurement of prediction accuracy) we want ![{\\mathbb{E}_{p'}[\\log q(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp%27%7D%5B%5Clog+q%28x%29%5D%7D&bg=f0f0f0&fg=000000&s=0 \"{\\mathbb{E}_{p'}[\\log q(x)]}\") to be large for all distributions  such that ![{\\mathbb{E}_{p'}[\\phi(x)] = \\phi^*}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp%27%7D%5B%5Cphi%28x%29%5D+%3D+%5Cphi%5E%2A%7D&bg=f0f0f0&fg=000000&s=0 \"{\\mathbb{E}_{p'}[\\phi(x)] = \\phi^*}\"). Using a technique called Lagrangian duality, we can both find the optimal distribution  and compute its worse-case accuracy over all  with ![{\\mathbb{E}_{p'}[\\phi(x)] = \\phi^*}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp%27%7D%5B%5Cphi%28x%29%5D+%3D+%5Cphi%5E%2A%7D&bg=f0f0f0&fg=000000&s=0 \"{\\mathbb{E}_{p'}[\\phi(x)] = \\phi^*}\"). The characterization is as follows: consider all probability distributions }\") that are proportional to )}\") for some vector , i.e.  = \\exp(\\lambda^{\\top}\\phi(x))/Z(\\lambda)}\") for some }\"). Of all of these, take the q(x) with the largest value of }\"). Then }\") will be the optimal distribution and the accuracy for *all* distributions  will be exactly }\"). Furthermore, if  is the empirical expectation given some number of samples, then one can show that }\") is propotional to the log likelihood of , which is why I say that maximum entropy and maximum likelihood are dual to each other.\n\n\nThis is a relatively simple result but it underlies a decent chunk of models used in practice.\n\n\n*Myth* *11**:* *frequentist methods have no* *promising approach to computationally bounded inference.* I would personally argue that frequentist methods are *more* promising than Bayesian methods at handling computational constraints, although computationally bounded inference is a very cutting edge area and I’m sure other experts would disagree. However, one point in favor of the frequentist approach here is that we already have some frameworks, such as the “tightening relaxations” framework discussed [here](http://people.csail.mit.edu/tommi/papers/Sontag_etal_UAI08.pdf), that provide quite elegant and rigorous ways of handling computationally intractable models.\n\n\n**References**\n\n\n(Myth 3) Sparse recovery: [Sparse recovery using sparse matrices](http://people.csail.mit.edu/indyk/survey-10.pdf) \n\n(Myth 5) Online learning: [Online learning and online convex optimization](http://www.cs.huji.ac.il/~shais/papers/OLsurvey.pdf) \n\n(Myth 8) Robust statistics: see [this](http://hunch.net/?p=197) blog post and the [two](http://www.cs.princeton.edu/~mdudik/DudikPhSc04.pdf) [linked](http://ttic.uchicago.edu/~altun/pubs/AltSmo-COLT06.pdf) papers \n\n(Myth 10) Maximum entropy duality: [Game theory, maximum entropy, minimum discrepancy and robust Bayesian decision theory](http://projecteuclid.org/euclid.aos/1091626173)\n\n", "url": "https://jsteinhardt.wordpress.com/2014/02/10/a-fervent-defense-of-frequentist-statistics/", "title": "A Fervent Defense of Frequentist Statistics", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2014-02-10T04:53:39+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "f91293f7819fb3f7b755af44f6ddad63", "summary": []}
+{"text": "Another Critique of Effective Altruism\n\nI’ve decided to branch out a bit from technical discussions and engage in, as Scott Aaronson would call it, some [metaphysical spouting](http://www.scottaaronson.com/blog/?cat=12). The topic of today is the effective altruism movement. I’m about to be relentlessly critical of it, so this is probably not the best post to read as your first introduction. Instead, read [this](http://blog.givewell.org/2013/08/13/effective-altruism/) and [this.](http://blog.givewell.org/2013/08/20/excited-altruism/) *Then* you can read what follows (but keep in mind that there are also many good things about the EA movement that I’m failing to mention here).\n\n\n\\* \\* \\*\n\n\nAnother Critique of Effective Altruism\n\n\nRecently Ben Kuhn wrote a [critique of effective altruism](http://lesswrong.com/lw/j8n/a_critique_of_effective_altruism/). I’m glad to see such self-examination taking place, but I’m also concerned that the essay did not attack some of the most serious issues I see in the effective altruist movement, so I’ve decided to write my own critique. Due to time constraints, this critique is short and incomplete. I’ve tried to bring up arguments that would make people feel uncomfortable and defensive; hopefully I’ve succeeded.\n\n\nBriefly, here are some of the major issues I have with the effective altruism movement as it currently stands:\n\n\n* Over-focus on “tried and true” and “default” options, which may both reduce actual impact and decrease exploration of new potentially high-value opportunities.\n* Over-confident claims coupled with insufficient background research.\n* Over-reliance on a small set of tools for assessing opportunities, which lead many to underestimate the value of things such as “flow-through” effects.\n\n\nThe common theme here is a subtle underlying message that simple, shallow analyses can allow one to make high-impact career and giving choices, and divest one of the need to dig further. I doubt that anyone explicitly believes this, but I do believe that this theme comes out implicitly both in arguments people make and in actions people take.\n\n\nLest this essay give a mistaken impression to the casual reader, I should note that **there are many examplary effective altruists who I feel are mostly immune to the issues above**; for instance, the [GiveWell blog](http://blog.givewell.org/) does a very good job of warning against the first and third points above, and I would recommend anyone who isn’t already to subscribe to it (and there are other examples that I’m failing to mention). But for the purposes of this essay, I will ignore this fact except for the current caveat.\n\n\n **Over-focus on “tried and true” options**\n\n\nIt seems to me that the effective altruist movement over-focuses on “tried and true” options, both in giving opportunities and in career paths. Perhaps the biggest example of this is the prevalence of “earning to give”. While this is certainly an admirable option, it should be considered as a baseline to improve upon, not a definitive answer.\n\n\nThe biggest issue with the “earning to give” path is that careers in finance and software (the two most common avenues for this) are incredibly straight-forward and secure. The two things that finance and software have in common is that there is a well-defined application process similar to the one for undergraduate admissions, and given reasonable job performance one will continue to be given promotions and raises (this probably entails working hard, but the end result is still rarely in doubt). One also gets a constant source of extrinsic positive reinforcement from the money they earn. Why do I call these things an “issue”? Because I think that these attributes encourage people to pursue these paths without looking for less obvious, less certain, but ultimately better paths. [One in six Yale graduates go into finance and consulting](http://yaledailynews.com/weekend/2011/09/30/even-artichokes-have-doubts/), seemingly due to the simplicity of applying and the easy supply of extrinsic motivation. My intuition is that this ratio is higher than an optimal society would have, even if such people commonly gave generously (and it is certainly much higher than the number of people who *enter* college planning to pursue such paths).\n\n\nContrast this with, for instance, working at a start-up. Most start-ups are low-impact, but it is undeniable that at least some have been extraordinarily high-impact, so this seems like an area that effective altruists should be considering strongly. Why aren’t there more of us at 23&me, or Coursera, or Quora, or Stripe? I think it is because these opportunities are less obvious and take more work to find, once you start working it often isn’t clear whether what you’re doing will have a positive impact or not, and your future job security is massively uncertain. There are few sources of extrinsic motivation in such a career: perhaps moreso at one of the companies mentioned above, which are reasonably established and have customers, but what about the 4-person start-up teams working in a warehouse somewhere? Some of them will go on to do great things but right now their lives must be full of anxiousness and uncertainty.\n\n\nI don’t mean to fetishize start-ups. They are just one well-known example of a potentially high-value career path that, to me, seems underexplored within the EA movement. I would argue (perhaps self-servingly) that academia is another example of such a path, with similar psychological obstacles: every 5 years or so you have the opportunity to get kicked out (e.g. applying for faculty jobs, and being up for tenure), you need to relocate regularly, few people will read your work and even fewer will praise it, and it won’t be clear whether it had a positive impact until many years down the road. And beyond the “obvious” alternatives of start-ups and academia, what of the paths that haven’t been created yet? GiveWell was revolutionary when it came about. Who will be the next GiveWell? And by this I don’t mean the next charity evaluator, but the next set of people who fundamentally alter how we view altruism.\n\n\n**Over-confident claims coupled with insufficient background research**\n\n\nThe history of effective altruism is littered with over-confident claims, many of which have later turned out to be false. In 2009, Peter Singer claimed that you could save a life for $200 (and many others repeated his claim). While the number was already questionable at the time, by 2011 we discovered that the number was completely off. Now new numbers were thrown around: from numbers still in the hundreds of dollars (GWWC’s estimate for SCI, which was later shown to be flawed) up to $1600 (GiveWell’s estimate for AMF, which GiveWell itself expected to go up, and which indeed did go up). These numbers were often cited without caveats, as well as other claims such as that the effectiveness of charities can vary by a factor of 1,000. How many people citing these numbers understood the process that generated them, or the high degree of uncertainty surrounding them, or the inaccuracy of past estimates? How many would have pointed out that saying that charities vary by a factor of 1,000 in effectiveness is by itself not very helpful, and is more a statement about how bad the bottom end is than how good the top end is?\n\n\nMore problematic than the careless bandying of numbers is the tendency toward not doing strong background research. A common pattern I see is: an effective altruist makes a bold claim, then when pressed on it offers a heuristic justification together with the claim that “[estimation is](http://80000hours.org/blog/4-estimation-is-the-best-we-have) [the best](http://80000hours.org/blog/4-estimation-is-the-best-we-have) [we have](http://80000hours.org/blog/4-estimation-is-the-best-we-have)”. This sort of argument acts as a conversation-stopper (and can also be quite annoying, which may be part of what drives some people away from effective altruism). In many of these cases, there are relatively easy opportunities to do background reading to further educate oneself about the claim being made. It can appear to an outside observer as though people are opting for the fun, easy activity (speculation) rather than the harder and more worthwhile activity (research). Again, I’m not claiming that this is people’s explicit thought process, but it does seem to be what ends up happening.\n\n\nWhy haven’t more EAs signed up for a course on global security, or tried to understand how DARPA funds projects, or learned about third-world health? I’ve heard claims that this would be too time-consuming relative to the value it provides, but this seems like a poor excuse if we want to be taken seriously as a movement (or even just want to reach consistently accurate conclusions about the world).\n\n\n**Over-reliance on a small set of tools**\n\n\nEffective altruists tend to have a lot of interest in quantitative estimates. We want to know what the best thing to do is, and we want a numerical value. This causes us to rely on scientific studies, economic reports, and Fermi estimates. It can cause us to underweight things like the competence of a particular organization, the strength of the people involved, and other “intangibles” (which are often not actually intangible but simply difficult to assign a number to). It also can cause us to over-focus on money as a unit of altruism, while often-times “it isn’t about the money”: it’s about doing the groundwork that no one is doing, or finding the opportunity that no one has found yet.\n\n\nQuantitative estimates often also tend to ignore [flow-through effects](http://blog.givewell.org/2013/05/15/flow-through-effects/): effects which are an indirect, rather than direct, result of an action (such as decreased disease in the third world contributing in the long run to increased global security). These effects are difficult to quantify but human and cultural intuition can do a reasonable job of taking them into account. As such, I often worry that effective altruists may actually be less effective than “normal” altruists. (One can point to all sorts of examples of farcical charities to claim that regular altruism sucks, but this misses the point that there are also amazing organizations out there, such as the [Simons Foundation](https://www.simonsfoundation.org/) or [HHMI](http://www.hhmi.org/), which are doing enormous amounts of good despite not subscribing to the EA philosophy.)\n\n\nWhat’s particularly worrisome is that even if we were less effective than normal altruists, we would probably still end up looking better by our own standards, which explicitly fail to account for the ways in which normal altruists might outperform us (see above). This is a problem with any paradigm, but the fact that the effective altruist community is small and insular and relies heavily on its paradigm makes us far more susceptible to it.\n\n", "url": "https://jsteinhardt.wordpress.com/2014/01/05/another-critique-of-effective-altruism/", "title": "Another Critique of Effective Altruism", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2014-01-05T09:41:20+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "ed1b896401b8c9e08dad4300d21c080a", "summary": []}
+{"text": "Convex Conditions for Strong Convexity\n\nAn important concept in online learning and convex optimization is that of *strong convexity*: a twice-differentiable function  is said to be strongly convex with respect to a norm  if\n\n\n\n\n\nfor all  (for functions that are not twice-differentiable, there is an analogous criterion in terms of the Bregman divergence). To check strong convexity, then, we basically need to check a condition on the Hessian, namely that . So, under what conditions does this hold?\n\n\nFor the  norm, the answer is easy:  if and only if  (i.e.,  is positive semidefinite). This can be shown in many ways, perhaps the easiest is by noting that .\n\n\nFor the  norm, the answer is a bit trickier but still not too complicated. Recall that we want necessary and sufficient conditions under which 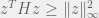. Note that this is equivalent to asking that 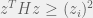 for each coordinate  of , which in turn is equivalent to 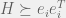 for each coordinate vector  (these are the vectors that are 1 in the th coordinate and 0 everywhere else).\n\n\nMore generally, for any norm , there exists a *dual norm*  which satisfies, among other properties, the relationship . So, in general,  is equivalent to asking that  for all  with 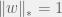. But this is in turn equivalent to asking that\n\n\n for all  such that 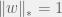.\n\n\nIn fact, it suffices to pick a subset of the  such that the convex hull consists of all  with ; this is why we were able to obtain such a clean formulation in the  case: the dual norm to  is , whose unit ball is the simplex, which is a polytope with only  vertices (namely, each of the signed unit vectors ).\n\n\nWe can also derive a simple (but computationally expensive) criterion for  strong convexity: here the dual norm is , whose unit ball is the -dimensional hypercube, with vertices given by all  vectors of the form ![[ \\pm 1 \\ \\cdots \\ \\pm 1]](https://s0.wp.com/latex.php?latex=%5B+%5Cpm+1+%5C+%5Ccdots+%5C+%5Cpm+1%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). Thus 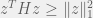 if and only if  for all  sign vectors .\n\n\nFinally, we re-examine the  case; even though the -ball is not a polytope, we were still able to obtain a very simple expression. This was because the condition  manages to capture simultaneously all dual vectors such that . We thus have the general criterion:\n\n\n**Theorem.**  for  if and only if 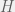 is strongly convex with respect to the norm  whose dual unit ball is the convex hull of the transformed unit balls , , where 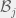 is the 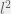 unit ball whose dimension matches the number of columns of .\n\n\n**Proof.** if and only if 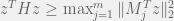. Now note that . If we define , it is then apparent that the dual norm unit ball is the convex hull of the .\n\n", "url": "https://jsteinhardt.wordpress.com/2013/12/30/linfty-strong-convexity/", "title": "Convex Conditions for Strong Convexity", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-12-30T18:14:18+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "f313558033a096054d997d3f92009035", "summary": []}
+{"text": "Convexity counterexample\n\nHere’s a fun counterexample: a function  that is jointly convex in any  of the variables, but not in all variables at once. The function is\n\n\n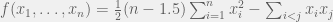\n\n\nTo see why this is, note that the Hessian of  is equal to\n\n\n![\\left[ \\begin{array}{cccc} n-1.5 & -1 & \\cdots & -1 \\\\ -1 & n-1.5 & \\cdots & -1 \\\\ \\vdots & \\vdots & \\ddots & \\vdots \\\\ -1 & -1 & \\cdots & n-1.5 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+n-1.5+%26+-1+%26+%5Ccdots+%26+-1+%5C%5C+-1+%26+n-1.5+%26+%5Ccdots+%26+-1+%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+-1+%26+-1+%26+%5Ccdots+%26+n-1.5+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nThis matrix is equal to , where  is the identity matrix and  is the all-ones matrix, which is rank 1 and whose single non-zero eigenvalue is . Therefore, this matrix has  eigenvalues of , as well as a single eigenvalue of , and hence is not positive definite.\n\n\nOn the other hand, any submatrix of size  is of the form , but where now  is only . This matrix now has  eigenvalues of , together with a single eigenvalue of , and hence is positive definite. Therefore, the Hessian is positive definite when restricted to any  variables, and hence  is convex in any  variables, but not in all  variables jointly.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/06/12/convexity-counterexample/", "title": "Convexity counterexample", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-06-12T21:04:27+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "87af47f716a785a68a7d619245691e12", "summary": []}
+{"text": "Probabilistic Abstractions I\n\n(This post represents research in progress. I may think about these concepts entirely differently a few months from now, but for my own benefit I’m trying to exposit on them in order to force myself to understand them better.)\n\n\nFor many inference tasks, especially ones with either non-linearities or non-convexities, it is common to use particle-based methods such as beam search, particle filters, sequential Monte Carlo, or Markov Chain Monte Carlo. In these methods, we approximate a distribution by a collection of samples from that distribution, then update the samples as new information is added. For instance, in beam search, if we are trying to build up a tree, we might build up a collection of  samples for the left and right subtrees, then look at all 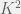 ways of combining them into the entire tree, but then downsample again to the  trees with the highest scores. This allows us to search through the exponentially large space of all trees efficiently (albeit at the cost of possibly missing high-scoring trees).\n\n\nOne major problem with such particle-based methods is diversity: the particles will tend to cluster around the highest-scoring mode, rather than exploring multiple local optima if they exist. This can be bad because it makes learning algorithms overly myopic. Another problem, especially in combinatorial domains, is difficulty of partial evaluation: if we have some training data that we are trying to fit to, and we have chosen settings of some, but not all, variables in our model, it can be difficult to know if that setting is on the right track (for instance, it can be difficult to know whether a partially-built tree is a promising candidate or not). For time-series modeling, this isn’t nearly as large of a problem, since we can evaluate against a prefix of the time series to get a good idea (this perhaps explains the success of particle filters in these domains).\n\n\nI’ve been working on a method that tries to deal with both of these problems, which I call **probabilistic abstractions**. The idea is to improve the diversity of particle-based methods by creating “fat” particles which cover multiple states at once; the reason that such fat particles help is that they allow us to first optimize for coverage (by placing down relatively large particles that cover the entire space), then later worry about more local details (by placing down many particles near promising-looking local optima).\n\n\nTo be more concrete, if we have a probability distribution over a set of random variables , then our particles will be sets obtained by specifying the values of some of the 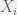 and leaving the rest to vary arbitrarily. So, for instance, if , then  might be a possible “fat” particle.\n\n\nBy choosing some number of fat particles and assigning probabilities to them, we are implicitly specifying a polytope of possible probability distributions; for instance, if our particles are 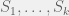, and we assign probability  to 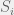, then we have the polytope of distributions 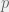 that satisfy the constraints , etc.\n\n\nGiven such a polytope, is there a way to pick a canonical representative from it? One such representative is the **maximum entropy distribution** in that polytope. This distribution has the property of minimizing the worst-case relative entropy to any other distribution within the polytope (and that worst-case relative entropy is just the entropy of the distribution).\n\n\nSuppose that we have a polytope for two independent distributions, and we want to compute the polytope for their product. This is easy — just look at the cartesian products of each particle of the first distribution with each particle of the second distribution. If each individual distribution has  particles, then the product distribution has  particles — this could be problematic computationally, so we also want a way to narrow down to a subset of the  most informative particles. These will be the  particles such that the corresponding polytope minimizes the maximum entropy of that polytope. Finding this is NP-hard in general, but I’m currently working on good heuristics for computing it.\n\n\nNext, suppose that we have a distribution on a space  and want to **apply a function**  to it. If  is a complicated function, it might be difficult to propagate the fat particles (even though it would have been easy to propagate particles composed of single points). To get around this, we need what is called a **valid abstraction** of : a function 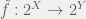 such that  for all . In this case, if we map a particle  to , our equality constraint on the mass assigned to  becomes a lower bound on the mass assigned to  — we thus still have a polytope of possible probability distributions. Depending on the exact structure of the particles (i.e. the exact way in which the different sets overlap), it may be necessary to add additional constraints to the polytope to get good performance — I feel like I have some understanding of this, but it’s something I’ll need to investigate empirically as well. It’s also interesting to note that 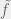 (when combined with conditioning on data, which is discussed below) allows us to assign partial credit to promising particles, which was the other property I discussed at the beginning.\n\n\nFinally, suppose that I want to **condition** on data. In this case the polytope approach doesn’t work as well, because conditioning on data can blow up the polytope by an arbitrarily large amount. Instead, we just take the maximum-entropy distribution in our polytope and treat that as our “true” distribution, then condition. I haven’t been able to make any formal statements about this procedure, but it seems to work at least somewhat reasonably. It is worth noting that conditioning may not be straightforward, since the likelihood function may not be constant across a given fat particle. To deal with this, we can replace the likelihood function by its average (which I think can be justified in terms of maximum entropy as well, although the details here are a bit hazier).\n\n\nSo, in summary, we have a notion of fat particles, which provide better coverage than point particles, and can combine them, apply functions to them, subsample them, and condition on data. This is essentially all of the operations we want to be able to apply for particle-based methods, so we in theory should now be able to implement versions of these particle-based methods that get better coverage.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/03/15/probabilistic-abstractions-i/", "title": "Probabilistic Abstractions I", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-03-15T03:45:04+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=2", "authors": ["jsteinhardt"], "id": "377601f105ddad98566e97e50f667d00", "summary": []}
+{"text": "Pairwise Independence vs. Independence\n\nFor collections of independent random variables, the Chernoff bound and related bounds give us very sharp concentration inequalities — if 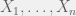 are independent, then their sum has a distribution that decays like 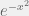. For random variables that are only pairwise independent, the strongest bound we have is Chebyshev’s inequality, which says that their sum decays like .\n\n\nThe point of this post is to construct an equality case for Chebyshev: a collection of pairwise independent random variables whose sum does not satisfy the concentration bound of Chernoff, and instead decays like .\n\n\nThe construction is as follows: let  be independent binary random variables, and for any , let 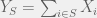, where the sum is taken mod 2. Then we can easily check that the  are pairwise independent. Now consider the random variable . If any of the  is equal to 1, then we can pair up the  by either adding or removing  from  to get the other element of the pair. If we do this, we see that  in this case. On the other hand, if all of the  are equal to 0, then  as well. Thus, with probability ,  deviates from its mean by , whereas the variance of  is . The bound on this probability form Chebyshev is , which is very close to , so this constitutes something very close to the Chebyshev equality case.\n\n\nAnyways, I just thought this was a cool example that demonstrates the difference between pairwise and full independence.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/03/13/pairwise-independence-vs-independence/", "title": "Pairwise Independence vs. Independence", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-03-13T06:53:52+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "f0078cde1f57b58b2725ebaac8ba4421", "summary": []}
+{"text": "A Fun Optimization Problem\n\nI spent the last several hours trying to come up with an efficient algorithm to the following problem:\n\n\n**Problem:** Suppose that we have a sequence of 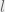 pairs of non-negative numbers 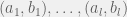 such that  and . Devise an efficient algorithm to find the  pairs  that maximize\n\n\n![\\left[\\sum_{r=1}^k a_{i_r}\\log(a_{i_r}/b_{i_r})\\right] + \\left[A-\\sum_{r=1}^k a_{i_r}\\right]\\log\\left(\\frac{A-\\sum_{r=1}^k a_{i_r}}{B-\\sum_{r=1}^k b_{i_r}}\\right).](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Csum_%7Br%3D1%7D%5Ek+a_%7Bi_r%7D%5Clog%28a_%7Bi_r%7D%2Fb_%7Bi_r%7D%29%5Cright%5D+%2B+%5Cleft%5BA-%5Csum_%7Br%3D1%7D%5Ek+a_%7Bi_r%7D%5Cright%5D%5Clog%5Cleft%28%5Cfrac%7BA-%5Csum_%7Br%3D1%7D%5Ek+a_%7Bi_r%7D%7D%7BB-%5Csum_%7Br%3D1%7D%5Ek+b_%7Bi_r%7D%7D%5Cright%29.&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\n**Commentary:** I don’t have a fully satisfactory solution to this yet, although I do think I can find an algorithm that runs in  time and finds 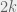 pairs that do at least  as well as the best set of  pairs. It’s possible I need to assume something like  instead of just  (and similarly for the ), although I’m happy to make that assumption.\n\n\nWhile attempting to solve this problem, I’ve managed to utilize a pretty large subset of my bag of tricks for optimization problems, so I think working on it is pretty worthwhile intellectually. It also happens to be important to my research, so if anyone comes up with a good algorithm I’d be interested to know.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/02/09/a-fun-optimization-problem/", "title": "A Fun Optimization Problem", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-02-09T06:56:29+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "1c552ffc1cf3c5480d1d4d9b31c1e6e3", "summary": []}
+{"text": "Eigenvalue Bounds\n\nWhile grading homeworks today, I came across the following bound:\n\n\n**Theorem 1:**If A and B are symmetric 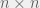 matrices with eigenvalues  and  respectively, then .\n\n\nFor such a natural-looking statement, this was surprisingly hard to prove. However, I finally came up with a proof, and it was cool enough that I felt the need to share. To prove this, we actually need two ingredients. The first is the [Cauchy Interlacing Theorem](http://en.wikipedia.org/wiki/Min-max_theorem#Cauchy_interlacing_theorem):\n\n\n**Theorem 2:**If A is an 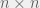 symmetric matrix and B is an  principle submatrix of A, then 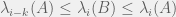, where  is the ith largest eigenvalue of X.\n\n\nAs a corollary we have:\n\n\n**Corollary 1:** For any symmetric matrix X, .\n\n\n**Proof:** The left-hand-side is just the trace of the upper-left  principle submatrix of X, whose eigenvalues are by Theorem 2 bounded by the k largest eigenvalues of X. \n\n\nThe final ingredient we will need is a sort of “majorization” inequality based on Abel summation:\n\n\n**Theorem 3:** If  and 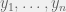 are such that  for all k (with equality when ), and 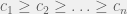, then .\n\n\n**Proof:** We have:\n\n\n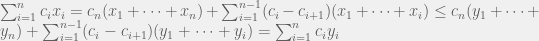\n\n\nwhere the equalities come from the [Abel summation method](http://en.wikipedia.org/wiki/Summation_by_parts). \n\n\nNow, we are finally ready to prove the original theorem:\n\n\n**Proof of Theorem 1:**First note that since the trace is invariant under similarity transforms, we can without loss of generality assume that A is diagonal, in which case we want to prove that . But by Corollary 1, we also know that  for all k. Since by assumption the 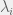 are a decreasing sequence, Theorem 3 then implies that , which is what we wanted to show. \n\n", "url": "https://jsteinhardt.wordpress.com/2013/02/05/eigenvalue-bounds/", "title": "Eigenvalue Bounds", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-02-05T06:32:11+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "2db57d5b3fd21df8e49a225e123d5f9f", "summary": []}
+{"text": "Local KL Divergence\n\nThe KL divergence is an important tool for studying the distance between two probability distributions. Formally, given two distributions  and , the KL divergence is defined as\n\n\n\n\n\nNote that . Intuitively, a small KL(p || q) means that there are few points that p assigns high probability to but that q does not. We can also think of KL(p || q) as the number of bits of information needed to update from the distribution q to the distribution p.\n\n\nSuppose that p and q are both mixtures of other distributions:  and . Can we bound  in terms of the ? In some sense this is asking to upper bound the KL divergence in terms of some more local KL divergence. It turns out this can be done:\n\n\n**Theorem:** If  and  and 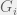 are all probability distributions, then\n\n\n.\n\n\n**Proof:** If we expand the definition, then we are trying to prove that\n\n\n\n\n\nWe will in fact show that this is true for every value of , so that it is certainly true for the integral. Using , re-write the condition for a given value of  as\n\n\n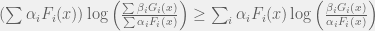\n\n\n(Note that the sign of the inequality flipped because we replaced the two expressions with their negatives.) Now, this follows by using Jensen’s inequality on the 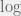 function:\n\n\n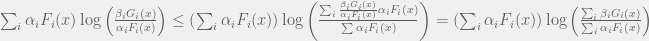\n\n\nThis proves the inequality and therefore the theorem. \n\n\n**Remark:** Intuitively, if we want to describe  in terms of , it is enough to first locate the th term in the sum and then to describe  in terms of 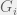. The theorem is a formalization of this intuition. In the case that 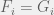, it also says that the KL divergence between two different mixtures of the same set of distributions is at most the KL divergence between the mixture weights.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/02/02/local-kl-divergence/", "title": "Local KL Divergence", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-02-02T04:27:27+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "0da79859c47dbcdb8824b17fd48dc828", "summary": []}
+{"text": "Quadratically Independent Monomials\n\nToday Arun asked me the following question:\n\n\n“Under what conditions will a set  of polynomials be quadratically independent, in the sense that  is a linearly independent set?”\n\n\nI wasn’t able to make much progress on this general question, but in the specific setting where the  are all polynomials in one variable, and we further restrict to just monomials, (i.e.  for some ), the condition is just that there are no distinct unordered pairs  such that . Arun was interested in the largest such a set could be for a given maximum degree , so we are left with the following interesting combinatorics problem:\n\n\n“What is the largest subset  of  such that no two distinct pairs of elements of  have the same sum?”\n\n\nFor convenience of notation let  denote the size of . A simple upper bound is , since there are 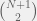 pairs to take a sum of, and all pairwise sums lie between  and 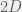. We therefore have 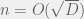.\n\n\nWhat about lower bounds on n? If we let S be the powers of 2 less than or equal to D, then we get a lower bound of ; we can do slightly better by taking the Fibonacci numbers instead, but this still only gives us logarithmic growth. So the question is, can we find sets that grow polynomially in D?\n\n\nIt turns out the answer is yes, and we can do so by choosing randomly. Let each element of  be placed in S with probability p. Now consider any k, . If k is odd, then there are (k-1)/2 possible pairs that could add up to k: (1,k-1), (2,k-2),…,((k-1)/2,(k+1)/2). The probability of each such pair existing is 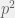. Note that each of these events is independent.\n\n\nS is invalid if and only if there exists some k such that more than one of these pairs is active in S. The probability of any two given pairs being simultaneously active is , and there are 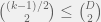 such pairs for a given , hence  such pairs total (since we were just looking at odd k). Therefore, the probability of an odd value of k invalidating S is at most .\n\n\nFor even  we get much the same result except that the probability for a given value of  comes out to the slightly more complicated formula , so that the total probability of an even value of k invalidating S is at most 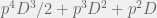.\n\n\nPutting this all together gives us a bound of 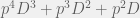. If we set p to be $\\frac{1}{2}D^{-\\frac{3}{4}}$ then the probability of S being invalid is then at most 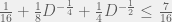, so with probability at least  a set S with elements chosen randomly with probability  will be valid. On the other hand, such a set has 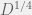 elements in expectation, and asymptotically the probability of having at least this many elements is . Therefore, with probability at least  a randomly chosen set will be both valid and have size greater than , which shows that the largest value of  is at least .\n\n\nWe can actually do better: if all elements are chosen with probability 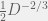, then one can show that the expected number of invalid pairs is at most , and hence we can pick randomly with probability 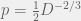, remove one element of each of the invalid pairs, and still be left with  elements in S.\n\n\nSo, to recap: choosing elements randomly gives us S of size ; choosing randomly and then removing any offending pairs gives us S of size ; and we have an upper bound of . What is the actual asymptotic answer? I don’t actually know the answer to this, but I thought I’d share what I have so far because I think the techniques involved are pretty cool.\n\n", "url": "https://jsteinhardt.wordpress.com/2013/01/31/quadratically-independent-monomials/", "title": "Quadratically Independent Monomials", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2013-01-31T08:42:05+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "38adfdaed141fa8ec78955fd108ba379", "summary": []}
+{"text": "Exponential Families\n\nIn my [last post](https://jsteinhardt.wordpress.com/2012/12/06/log-linear-models/) I discussed log-linear models. In this post I’d like to take another perspective on log-linear models, by thinking of them as members of an *exponential family*. There are many reasons to take this perspective: exponential families give us efficient representations of log-linear models, which is important for continuous domains; they always have conjugate priors, which provide an analytically tractable regularization method; finally, they can be viewed as maximum-entropy models for a given set of sufficient statistics. Don’t worry if these terms are unfamiliar; I will explain all of them by the end of this post. Also note that most of this material is available on the Wikipedia page on exponential families, which I used quite liberally in preparing the below exposition.\n\n\n**1. Exponential Families** \n\n\nAn *exponential family* is a family of probability distributions, parameterized by , of the form\n\n\n\n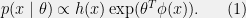\n\n\n\n\nNotice the similarity to the definition of a log-linear model, which is\n\n\n\n\n\nSo, a log-linear model is simply an exponential family model with . Note that we can re-write the right-hand-side of ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnexp-def-0)) as 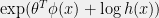, so an exponential family is really just a log-linear model with one of the coordinates of  constrained to equal . Also note that the normalization constant in ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnexp-def-0)) is a function of  (since  fully specifies the distribution over ), so we can express ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnexp-def-0)) more explicitly as\n\n\n\n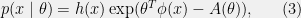\n\n\n\n\nwhere\n\n\n\n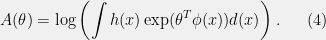\n\n\n\n\nExponential families are capable of capturing almost all of the common distributions you are familiar with. There is an extensive [table](http://en.wikipedia.org/wiki/Exponential_family#Table_of_distributions) on Wikipedia; I’ve also included some of the most common below:\n\n\n1. *Gaussian distributions.* Let ![{\\phi(x) = \\left[ \\begin{array}{c} x \\\\ x^2\\end{array} \\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+x%5E2%5Cend%7Barray%7D+%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002). Then . If we let ![{\\theta = \\left[\\frac{\\mu}{\\sigma^2},-\\frac{1}{2\\sigma^2}\\right]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%3D+%5Cleft%5B%5Cfrac%7B%5Cmu%7D%7B%5Csigma%5E2%7D%2C-%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002), then . We therefore see that Gaussian distributions are an exponential family for ![{\\phi(x) = \\left[ \\begin{array}{c} x \\\\ x^2 \\end{array} \\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+x%5E2+%5Cend%7Barray%7D+%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).\n2. *Poisson distributions.* Let ![{\\phi(x) = [x]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Bx%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) and . Then . If we let 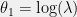 then we get 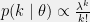; we thus see that Poisson distributions are also an exponential family.\n3. *Multinomial distributions.* Suppose that . Let  be an 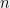-dimensional vector whose 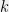th element is  and where all other elements are zero. Then . If 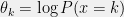, then we obtain an arbitrary multinomial distribution. Therefore, multinomial distributions are also an exponential family.\n\n\n**2. Sufficient Statistics** \n\n\nA *statistic* of a random variable  is any deterministic function of that variable. For instance, if ![{X = [X_1,\\ldots,X_n]^T}](https://s0.wp.com/latex.php?latex=%7BX+%3D+%5BX_1%2C%5Cldots%2CX_n%5D%5ET%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is a vector of Gaussian random variables, then the sample mean  and sample variance  are both statistics.\n\n\nLet  be a family of distributions parameterized by , and let  be a random variable with distribution given by some unknown . Then a vector 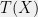 of statistics are called *sufficient statistics* for  if they contain all possible information about , that is, for any function 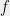, we have\n\n\n\n![\\displaystyle \\mathbb{E}[f(X) \\mid T(X) = T_0, \\theta = \\theta_0] = S(f,T_0), \\ \\ \\ \\ \\ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%3D+S%28f%2CT_0%29%2C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\n\n\nfor some function 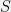 that has no dependence on .\n\n\nFor instance, let  be a vector of 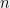 independent Gaussian random variables  with unknown mean 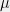 and variance . It turns out that ![{T(X) := [\\hat{\\mu},\\hat{\\sigma}^2]}](https://s0.wp.com/latex.php?latex=%7BT%28X%29+%3A%3D+%5B%5Chat%7B%5Cmu%7D%2C%5Chat%7B%5Csigma%7D%5E2%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is a sufficient statistic for 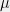 and . This is not immediately obvious; a very useful tool for determining whether statistics are sufficient is the **Fisher-Neyman factorization theorem**:\n\n\n\n> **Theorem 1 (Fisher-Neyman)** *Suppose that  has a probability density function . Then the statistics 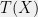 are sufficient for  if and only if  can be written in the form*\n> \n> \n> \n> \n> \n> \n> \n> \n> In other words, the probability of  can be factored into a part that does not depend on , and a part that depends on  only via 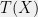.\n> \n> \n\n\nWhat is going on here, intuitively? If  depended only on 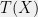, then 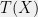 would definitely be a sufficient statistic. But that isn’t the only way for 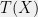 to be a sufficient statistic —  could also just not depend on  at all, in which case 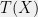 would trivially be a sufficient statistic (as would anything else). The Fisher-Neyman theorem essentially says that the only way in which 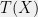 can be a sufficient statistic is if its density is a product of these two cases.\n\n\n*Proof:* If ([6](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnfisher-neyman)) holds, then we can check that ([5](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnsuff-def)) is satisfied:\n\n\n![\\displaystyle \\begin{array}{rcl} \\mathbb{E}[f(X) \\mid T(X) = T_0, \\theta = \\theta_0] &=& \\frac{\\int_{T(X) = T_0} f(X) dp(X \\mid \\theta=\\theta_0)}{\\int_{T(X) = T_0} dp(X \\mid \\theta=\\theta_0)}\\\\ \\\\ &=& \\frac{\\int_{T(X)=T_0} f(X)h(X)g_\\theta(T_0) dX}{\\int_{T(X)=T_0} h(X)g_\\theta(T_0) dX}\\\\ \\\\ &=& \\frac{\\int_{T(X)=T_0} f(X)h(X)dX}{\\int_{T(X)=T_0} h(X) dX}, \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29+%3D+T_0%7D+f%28X%29+dp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%7B%5Cint_%7BT%28X%29+%3D+T_0%7D+dp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%5C%5C+%5C%5C+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29%3DT_0%7D+f%28X%29h%28X%29g_%5Ctheta%28T_0%29+dX%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+h%28X%29g_%5Ctheta%28T_0%29+dX%7D%5C%5C+%5C%5C+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29%3DT_0%7D+f%28X%29h%28X%29dX%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+h%28X%29+dX%7D%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nwhere the right-hand-side has no dependence on .\n\n\nOn the other hand, if we compute ![{\\mathbb{E}[f(X) \\mid T(X) = T_0, \\theta = \\theta_0]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) for an arbitrary density 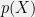, we get\n\n\n![\\displaystyle \\begin{array}{rcl} \\mathbb{E}[f(X) \\mid T(X) = T_0, \\theta = \\theta_0] &=& \\int_{T(X) = T_0} f(X) \\frac{p(X \\mid \\theta=\\theta_0)}{\\int_{T(X)=T_0} p(X \\mid \\theta=\\theta_0) dX} dX. \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%26%3D%26+%5Cint_%7BT%28X%29+%3D+T_0%7D+f%28X%29+%5Cfrac%7Bp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+p%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29+dX%7D+dX.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nIf the right-hand-side cannot depend on  for *any* choice of 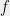, then the term that we multiply 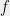 by must not depend on ; that is, 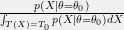 must be some function  that depends only on  and  and not on . On the other hand, the denominator  depends only on  and 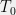; call this dependence 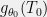. Finally, note that 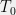 is a deterministic function of , so let 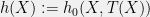. We then see that , which is the same form as ([6](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnfisher-neyman)), thus completing the proof of the theorem. \n\n\nNow, let us apply the Fisher-Neyman theorem to exponential families. By definition, the density for an exponential family factors as\n\n\n\n\n\nIf we let  and , then the Fisher-Neyman condition is met; therefore,  is a vector of sufficient statistics for the exponential family. In fact, we can go further:\n\n\n\n> **Theorem 2** *Let  be drawn independently from an exponential family distribution with fixed parameter . Then the empirical expectation 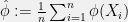 is a sufficient statistic for .* \n> \n> \n\n\n*Proof:* The density for  given  is\n\n\n![\\displaystyle \\begin{array}{rcl} p(X_1,\\ldots,X_n \\mid \\theta) &=& h(X_1)\\cdots h(X_n) \\exp(\\theta^T\\sum_{i=1}^n \\phi(X_i) - nA(\\theta)) \\\\ &=& h(X_1)\\cdots h(X_n)\\exp(n [\\hat{\\phi}-A(\\theta)]). \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+p%28X_1%2C%5Cldots%2CX_n+%5Cmid+%5Ctheta%29+%26%3D%26+h%28X_1%29%5Ccdots+h%28X_n%29+%5Cexp%28%5Ctheta%5ET%5Csum_%7Bi%3D1%7D%5En+%5Cphi%28X_i%29+-+nA%28%5Ctheta%29%29+%5C%5C+%26%3D%26+h%28X_1%29%5Ccdots+h%28X_n%29%5Cexp%28n+%5B%5Chat%7B%5Cphi%7D-A%28%5Ctheta%29%5D%29.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nLetting  and ![{g_\\theta(\\hat{\\phi}) = \\exp(n[\\hat{\\phi}-A(\\theta)])}](https://s0.wp.com/latex.php?latex=%7Bg_%5Ctheta%28%5Chat%7B%5Cphi%7D%29+%3D+%5Cexp%28n%5B%5Chat%7B%5Cphi%7D-A%28%5Ctheta%29%5D%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002), we see that the Fisher-Neyman conditions are satisfied, so that 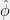 is indeed a sufficient statistic. \n\n\nFinally, we note (without proof) the same relationship as in the log-linear case to the gradient and Hessian of  with respect to the model parameters:\n\n\n\n> **Theorem 3** *Again let  be drawn from an exponential family distribution with parameter . Then the gradient of  with respect to  is*\n> \n> \n> ![\\displaystyle n \\times \\left(\\hat{\\phi}-\\mathbb{E}[\\phi \\mid \\theta]\\right) ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n+%5Ctimes+%5Cleft%28%5Chat%7B%5Cphi%7D-%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5Cright%29+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n> \n> \n> and the Hessian is\n> \n> \n> ![\\displaystyle n \\times \\left(\\mathbb{E}[\\phi \\mid \\theta]\\mathbb{E}[\\phi \\mid \\theta]^T - \\mathbb{E}[\\phi\\phi^T \\mid \\theta]\\right). ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n+%5Ctimes+%5Cleft%28%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5ET+-+%5Cmathbb%7BE%7D%5B%5Cphi%5Cphi%5ET+%5Cmid+%5Ctheta%5D%5Cright%29.+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n> \n> \n> \n\n\nThis theorem provides an efficient algorithm for fitting the parameters of an exponential family distribution (for details on the algorithm, see the part near the end of the [log-linear models post](https://jsteinhardt.wordpress.com/2012/12/06/log-linear-models/) on parameter estimation).\n\n\n**3. Moments of an Exponential Family** \n\n\nIf  is a real-valued random variable, then the *th moment* of  is ![{\\mathbb{E}[X^p]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BX%5Ep%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002). In general, if ![{X = [X_1,\\ldots,X_n]^T}](https://s0.wp.com/latex.php?latex=%7BX+%3D+%5BX_1%2C%5Cldots%2CX_n%5D%5ET%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is a random variable on 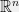, then for every sequence  of non-negative integers, there is a corresponding moment ![{M_{p_1,\\cdots,p_n} := \\mathbb{E}[X_1^{p_1}\\cdots X_n^{p_n}]}](https://s0.wp.com/latex.php?latex=%7BM_%7Bp_1%2C%5Ccdots%2Cp_n%7D+%3A%3D+%5Cmathbb%7BE%7D%5BX_1%5E%7Bp_1%7D%5Ccdots+X_n%5E%7Bp_n%7D%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).\n\n\nIn exponential families there is a very nice relationship between the normalization constant 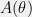 and the moments of . Before we establish this relationship, let us define the *moment generating function* of a random variable  as ![{f(\\lambda) = \\mathbb{E}[\\exp(\\lambda^TX)]}](https://s0.wp.com/latex.php?latex=%7Bf%28%5Clambda%29+%3D+%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ETX%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).\n\n\n\n> **Lemma 4** *The moment generating function for a random variable  is equal to*\n> \n> \n> \n> \n> \n> \n\n\nThe proof of Lemma [4](https://jsteinhardt.wordpress.com/feed/?paged=3#lemmgf) is a straightforward application of Taylor’s theorem, together with linearity of expectation (note that in one dimension, the expression in Lemma [4](https://jsteinhardt.wordpress.com/feed/?paged=3#lemmgf) would just be ![{\\sum_{p=0}^{\\infty} \\mathbb{E}[X^p] \\frac{\\lambda^p}{p!}}](https://s0.wp.com/latex.php?latex=%7B%5Csum_%7Bp%3D0%7D%5E%7B%5Cinfty%7D+%5Cmathbb%7BE%7D%5BX%5Ep%5D+%5Cfrac%7B%5Clambda%5Ep%7D%7Bp%21%7D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002)).\n\n\nWe now see why 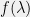 is called the moment generating function: it is the [exponential generating function](http://en.wikipedia.org/wiki/Generating_function#Exponential_generating_function) for the moments of . The moment generating function for the sufficient statistics of an exponential family is particularly easy to compute:\n\n\n\n> **Lemma 5** *If 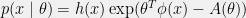, then ![{\\mathbb{E}[\\exp(\\lambda^T\\phi(x))] = \\exp(A(\\theta+\\lambda)-A(\\theta))}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ET%5Cphi%28x%29%29%5D+%3D+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).* \n> \n> \n\n\n*Proof:*\n\n\n![\\displaystyle \\begin{array}{rcl} \\mathbb{E}[\\exp(\\lambda^Tx)] &=& \\int \\exp(\\lambda^Tx) p(x \\mid \\theta) dx \\\\ &=& \\int \\exp(\\lambda^Tx)h(x)\\exp(\\theta^T\\phi(x)-A(\\theta)) dx \\\\ &=& \\int h(x)\\exp((\\theta+\\lambda)^T\\phi(x)-A(\\theta)) dx \\\\ &=& \\int h(x)\\exp((\\theta+\\lambda)^T\\phi(x)-A(\\theta+\\lambda))dx \\times \\exp(A(\\theta+\\lambda)-A(\\theta)) \\\\ &=& \\int p(x \\mid \\theta+\\lambda) dx \\times \\exp(A(\\theta+\\lambda)-A(\\theta)) \\\\ &=& \\exp(A(\\theta+\\lambda)-A(\\theta)), \\end{array} ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ETx%29%5D+%26%3D%26+%5Cint+%5Cexp%28%5Clambda%5ETx%29+p%28x+%5Cmid+%5Ctheta%29+dx+%5C%5C+%26%3D%26+%5Cint+%5Cexp%28%5Clambda%5ETx%29h%28x%29%5Cexp%28%5Ctheta%5ET%5Cphi%28x%29-A%28%5Ctheta%29%29+dx+%5C%5C+%26%3D%26+%5Cint+h%28x%29%5Cexp%28%28%5Ctheta%2B%5Clambda%29%5ET%5Cphi%28x%29-A%28%5Ctheta%29%29+dx+%5C%5C+%26%3D%26+%5Cint+h%28x%29%5Cexp%28%28%5Ctheta%2B%5Clambda%29%5ET%5Cphi%28x%29-A%28%5Ctheta%2B%5Clambda%29%29dx+%5Ctimes+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29+%5C%5C+%26%3D%26+%5Cint+p%28x+%5Cmid+%5Ctheta%2B%5Clambda%29+dx+%5Ctimes+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29+%5C%5C+%26%3D%26+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nwhere the last step uses the fact that  is a probability density and hence . \n\n\nNow, by Lemma [4](https://jsteinhardt.wordpress.com/feed/?paged=3#lemmgf),  is just the  coefficient in the Taylor series for the moment generating function , and hence we can compute  as . Combining this with Lemma [5](https://jsteinhardt.wordpress.com/feed/?paged=3#lemmgf-exp) gives us a closed-form expression for  in terms of the normalization constant :\n\n\n\n> **Lemma 6** *The moments of an exponential family can be computed as*\n> \n> \n> \n> \n> \n> \n\n\nFor those who prefer [cumulants](http://en.wikipedia.org/wiki/Cumulant) to moments, I will note that there is a version of Lemma [6](https://jsteinhardt.wordpress.com/feed/?paged=3#lemexp-moment) for cumulants with an even simpler formula.\n\n\n**Exercise:** Use Lemma [6](https://jsteinhardt.wordpress.com/feed/?paged=3#lemexp-moment) to compute ![{\\mathbb{E}[X^6]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BX%5E6%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002), where  is a Gaussian with mean  and variance 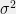.\n\n\n**4. Conjugate Priors** \n\n\nGiven a family of distributions , a *conjugate prior family* 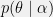 is a family that has the property that\n\n\n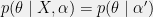\n\n\nfor some  depending on  and . In other words, if the prior over  lies in the conjugate family, and we observe , then the posterior over  also lies in the conjugate family. This is very useful algebraically as it means that we can get our posterior simply by updating the parameters of the prior. The following are examples of conjugate families:\n\n\n1. (Gaussian-Gaussian) Let 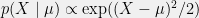, and let . Then, by Bayes’ rule,\n\n\n\n\n\nTherefore,  parameterize a family of priors over  that is conjugate to .\n\n\n* (Beta-Bernoulli) Let , ![{\\theta \\in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%5Cin+%5B0%2C1%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002), , and . The distribution over  given  is then called a *Bernoulli distribution*, and that of  given  and  is called a *beta distribution*. Note that  can also be written as . From this, we see that the family of beta distributions is a conjugate prior to the family of Bernoulli distributions, since\n\n\n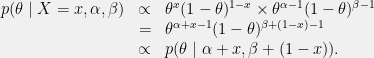\n\n\n* (Gamma-Poisson) Let 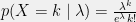 for 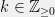. Let . As noted before, the distribution for  given  is called a *Poisson distribution*; the distribution for  given  and  is called a *gamma distribution*. We can check that the family of gamma distributions is conjugate to the family of Poisson distributions.***Important note:*** unlike in the last two examples, the normalization constant for the Poisson distribution actually depends on , and so we need to include it in our calculations:\n\n\n\nNote that, in general, a family of distributions will always have some conjugate family, as if nothing else the family of all probability distributions over  will be a conjugate family. What we really care about is a conjugate family that itself has nice properties, such as tractably computable moments.\n\n\nConjugate priors have a very nice relationship to exponential families, established in the following theorem:\n\n\n\n> **Theorem 7** *Let  be an exponential family. Then  is a conjugate prior for  for any choice of . The update formula is . Furthermore,  is itself an exponential family, with sufficient statistics ![{[\\theta; A(\\theta)]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctheta%3B+A%28%5Ctheta%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).* \n> \n> \n\n\nChecking the theorem is a matter of straightforward algebra, so I will leave the proof as an exercise to the reader. Note that, as before, there is no guarantee that  will be tractable; however, in many cases the conjugate prior given by Theorem [7](https://jsteinhardt.wordpress.com/feed/?paged=3#thmconjugate) is a well-behaved family. See [this Wikipedia page](http://en.wikipedia.org/wiki/Conjugate_prior#Table_of_conjugate_distributions) for examples of conjugate priors, many of which correspond to exponential family distributions.\n\n\n**5. Maximum Entropy and Duality** \n\n\nThe final property of exponential families I would like to establish is a certain *duality property*. What I mean by this is that exponential families can be thought of as the maximum entropy distributions subject to a constraint on the expected value of their sufficient statistics. For those unfamiliar with the term, the *entropy* of a distribution over  with density 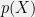 is ![{\\mathbb{E}[-\\log p(X)] := -\\int p(x)\\log(p(x)) dx}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B-%5Clog+p%28X%29%5D+%3A%3D+-%5Cint+p%28x%29%5Clog%28p%28x%29%29+dx%7D&bg=f0f0f0&fg=000000&s=0&c=20201002). Intuitively, higher entropy corresponds to higher uncertainty, so a maximum entropy distribution is one specifying as much uncertainty as possible given a certain set of information (such as the values of various moments). This makes them appealing, at least in theory, from a modeling perspective, since they “encode exactly as much information as is given and no more”. (Caveat: this intuition isn’t entirely valid, and in practice maximum-entropy distributions aren’t always necessarily appropriate.)\n\n\nIn any case, the duality property is captured in the following theorem:\n\n\n\n> **Theorem 8** *The distribution over  with maximum entropy such that ![{\\mathbb{E}[\\phi(X)] = T}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cphi%28X%29%5D+%3D+T%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) lies in the exponential family with sufficient statistic  and .* \n> \n> \n\n\nProving this fully rigorously requires the calculus of variations; I will instead give the “physicist’s proof”. *Proof:* } Let 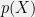 be the density for . Then we can view  as the solution to the constrained maximization problem:\n\n\n\n\n\nBy the method of Lagrange multipliers, there exist  and  such that\n\n\n![\\displaystyle \\frac{d}{dp}\\left(-\\int p(X)\\log p(X) dX - \\alpha [\\int p(X) dX-1] - \\lambda^T[\\int \\phi(X) p(X) dX-T]\\right) = 0. ](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7Bd%7D%7Bdp%7D%5Cleft%28-%5Cint+p%28X%29%5Clog+p%28X%29+dX+-+%5Calpha+%5B%5Cint+p%28X%29+dX-1%5D+-+%5Clambda%5ET%5B%5Cint+%5Cphi%28X%29+p%28X%29+dX-T%5D%5Cright%29+%3D+0.+&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nThis simplifies to:\n\n\n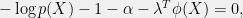\n\n\nwhich implies\n\n\n\n\n\nfor some  and . In particular, if we let 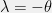 and , then we recover the exponential family with , as claimed. \n\n\n**6. Conclusion** \n\n\nHopefully I have by now convinced you that exponential families have many nice properties: they have conjugate priors, simple-to-fit parameters, and easily-computed moments. While exponential families aren’t always appropriate models for a given situation, their tractability makes them the model of choice when no other information is present; and, since they can be obtained as maximum-entropy families, they are actually appropriate models in a wide family of circumstances.\n", "url": "https://jsteinhardt.wordpress.com/2012/12/21/exponential-families/", "title": "Exponential Families", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2012-12-21T08:06:24+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "482df5f7969555a8f08ab5501b98beef", "summary": []}
+{"text": "Algebra trick of the day\n\nI’ve decided to start recording algebra tricks as I end up using them. Today I actually have two tricks, but they end up being used together a lot. I don’t know if they have more formal names, but I call them the “trace trick” and the “rank 1 relaxation”.\n\n\nSuppose that we want to maximize the [Rayleigh quotient](http://en.wikipedia.org/wiki/Rayleigh_quotient)  of a matrix . There are many reasons we might want to do this, for instance of  is symmetric then the maximum corresponds to the largest eigenvalue. There are also many ways to do this, and the one that I’m about to describe is definitely not the most efficient, but it has the advantage of being flexible, in that it easily generalizes to constrained maximizations, etc.\n\n\nThe first observation is that  is homogeneous, meaning that scaling  doesn’t affect the result. So, we can assume without loss of generality that 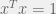, and we end up with the optimization problem:\n\n\nmaximize \n\n\nsubject to 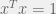\n\n\nThis is where the trace trick comes in. Recall that the trace of a matrix is the sum of its diagonal entries. We are going to use two facts: first, the trace of a number is just the number itself. Second, trace(AB) = trace(BA). (Note, however, that trace(ABC) is *not* in general equal to trace(BAC), although trace(ABC) *is* equal to trace(CAB).) We use these two properties as follows — first, we re-write the optimization problem as:\n\n\nmaximize \n\n\nsubject to 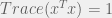\n\n\nSecond, we re-write it again using the invariance of trace under cyclic permutations:\n\n\nmaximize \n\n\nsubject to \n\n\nNow we make the substitution :\n\n\nmaximize \n\n\nsubject to \n\n\nFinally, note that a matrix  can be written as  if and only if  is positive semi-definite and has rank 1. Therefore, we can further write this as\n\n\nmaximize \n\n\nsubject to \n\n\nAside from the rank 1 constraint, this would be a [semidefinite program](http://en.wikipedia.org/wiki/Semidefinite_programming#Equivalent_formulations), a type of problem that can be solved efficiently. What happens if we drop the rank 1 constraint? Then I claim that the solution to this program would be the same as if I had kept the constraint in! Why is this? Let’s look at the eigendecomposition of , written as , with 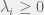 (by positive semidefiniteness) and 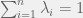 (by the trace constraint). Let’s also look at , which can be written as 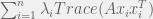. Since  is just a convex combination of the 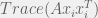, we might as well have just picked  to be 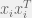, where  is chosen to maximize 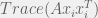. If we set that 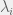 to 1 and all the rest to 0, then we maintain all of the constraints while increasing , meaning that we couldn’t have been at the optimum value of  unless  was equal to 1. What we have shown, then, is that the rank of  must be 1, so that the rank 1 constraint was unnecessary.\n\n\nTechnically,  could be a linear combination of rank 1 matrices that all have the same value of , but in that case we could just pick any one of those matrices. So what I have really shown is that *at least one* optimal point has rank 1, and we can recover such a point from any solution, even if the original solution was not rank 1.\n\n\nHere is a problem that uses a similar trick. Suppose we want to find  that simultaneously satisfies the equations:\n\n\n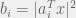\n\n\nfor each  (this example was inspired from the recent NIPS paper by [Ohlsson, Yang, Dong, and Sastry](http://www.eecs.berkeley.edu/~yang/paper/nips2012.pdf), although the idea itself goes at least back to [Candes, Strohmer, and Voroninski](http://arxiv.org/abs/1109.4499)). Note that this is basically equivalent to solving a system of linear equations where we only know each equation up to a sign (or a phase, in the complex case). Therefore, in general, this problem will not have a unique solution. To ensure the solution is unique, let us assume the very strong condition that whenever 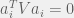 for all , the matrix 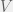 must itself be zero (note: Candes et al. get away with a much weaker condition). Given this, can we phrase the problem as a semidefinite program? I highly recommend trying to solve this problem on your own, or at least reducing it to a rank-constrained SDP, so I’ll include the solution below a fold.\n\n\n\n**Solution.** We can, as before, re-write the equations as:\n\n\n\n\n\nand further write this as\n\n\n\n\n\nAs before, drop the rank 1 constraint and let 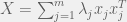. Then we get:\n\n\n,\n\n\nwhich we can re-write as 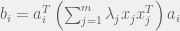. But if 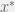 is the true solution, then we also know that , so that  for all . By the non-degeneracy assumption, this implies that\n\n\n,\n\n\nso in particular 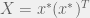. Therefore, 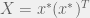 is the only solution to the semidefinite program even after dropping the rank constraint.\n\n", "url": "https://jsteinhardt.wordpress.com/2012/12/17/algebra-trick-of-the-day/", "title": "Algebra trick of the day", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2012-12-17T04:43:19+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "ebf77cdee9fec512aec1ffe7a1196447", "summary": []}
+{"text": "Log-Linear Models\n\nI’ve spent most of my research career trying to build big, complex [nonparametric models](http://jmlr.csail.mit.edu/proceedings/papers/v22/steinhardt12/steinhardt12.pdf); however, I’ve more recently delved into the realm of natural language processing, where how awesome your model looks on paper is irrelevant compared to how well it models your data. In the spirit of this new work (and to lay the groundwork for a later post on NLP), I’d like to go over a family of models that I think is often overlooked due to not being terribly sexy (or at least, I overlooked it for a good while). This family is the family of log-linear models, which are models of the form:\n\n\n\n\n\nwhere  maps a data point to a feature vector; they are called log-linear because the log of the probability is a linear function of . We refer to  as the *score* of .\n\n\nThis model class might look fairly restricted at first, but the real magic comes in with the feature vector . In fact, every probabilistic model that is [absolutely continuous](http://en.wikipedia.org/wiki/Radon-Nikodym_theorem) with respect to Lebesgue measure can be represented as a log-linear model for sufficient choices of  and . This is actually trivially true, as we can just take  to be  and  to be .\n\n\nYou might object to this choice of , since it maps into  rather than 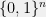, and feature vectors are typically discrete. However, we can do just as well by letting , where the th coordinate of  is the th digit in the binary representation of , then let  be the vector 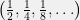.\n\n\nIt is important to distinguish between the ability to represent an arbitrary model as log-linear and the ability to represent an arbitrary *family* of models as a log-linear family (that is, as the set of models we get if we fix a choice of features  and then vary ). When we don’t know the correct model in advance and want to learn it, this latter consideration can be crucial. Below, I give two examples of model families and discuss how they fit (or do not fit) into the log-linear framework. **Important caveat:** in both of the models below, it is typically the case that at least some of the variables involved are unobserved. However, we will ignore this for now, and assume that, at least at training time, all of the variables are fully observed (in other words, we can see  and 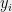 in the hidden Markov model and we can see the full tree of productions in the probabilistic context free grammar).\n\n\n**Hidden Markov Models.** A hidden Markov model, or HMM, is a model with *latent* (unobserved) variables  together with observed variables . The distribution for 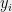 depends only on , and the distribution for  depends only on  (in the sense that  is conditionally independent of  given ). We can thus summarize the information in an HMM with the distributions  and .\n\n\nWe can express a hidden Markov model as a log-linear model by defining two classes of features: (i) features 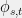 that count the number of 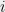 such that  and ; and (ii) features  that count the number of 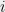 such that  and 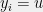. While this choice of features yields a model family capable of expressing an arbitrary hidden Markov model, it is also capable of learning models that are not hidden Markov models. In particular, we would like to think of  (the index of  corresponding to 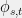) as , but there is no constraint that  for each , whereas we do necessarily have 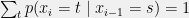 for each . If  is fixed, we still do obtain an HMM for any setting of , although  will have no simple relationship with . Furthermore, the relationship depends on 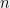, and will therefore not work if we care about multiple Markov chains with different lengths.\n\n\nIs the ability to express models that are not HMMs good or bad? It depends. If we know for certain that our data satisfy the HMM assumption, then expanding our model family to include models that violate that assumption can only end up hurting us. If the data do not satisfy the HMM assumption, then increasing the size of the model family may allow us to overcome what would otherwise be a model mis-specification. I personally would prefer to have as much control as possible about what assumptions I make, so I tend to see the over-expressivity of HMMs as a bug rather than a feature.\n\n\n**Probabilistic Context Free Grammars.** A probabilistic context free grammar, or PCFG, is simply a context free grammar where we place a probability distribution over the production rules for each non-terminal. For those unfamiliar with context free grammars, a *context free grammar* is specified by:\n\n\n1. A set  of non-terminal symbols, including a distinguished *initial symbol* .\n2. A set  of terminal symbols.\n3. For each 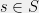, one or more *production rules* of the form , where  and 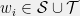.\n\n\nFor instance, a context free grammar for arithmetic expressions might have 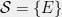, , and the following production rules:\n\n\n*  for all \n* \n* \n* \n* \n* 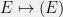\n\n\nThe *language* corresponding to a context free grammar is the set of all strings that can be obtained by starting from  and applying production rules until we only have terminal symbols. The language corresponding to the above grammar is, in fact, the set of well-formed arithmetic expressions, such as , , and .\n\n\nAs mentioned above, a probabilistic context free grammar simply places a distribution over the production rules for any given non-terminal symbol. By repeatedly sampling from these distributions until we are left with only terminal symbols, we obtain a probability distribution over the language of the grammar.\n\n\nWe can represent a PCFG as a log-linear model by using a feature 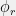 for each production rule . For instance, we have a feature that counts the number of times that the rule  gets applied, and another feature that counts the number of times that 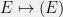 gets applied. Such features yield a log-linear model family that contains all probabilistic context free grammars for a given (deterministic) context free grammar. However, it also contains additional models that do not correspond to PCFGs; this is because we run into the same problem as for HMMs, which is that the sum of 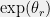 over production rules of a given non-terminal does not necessarily add up to . In fact, the problem is even worse here. For instance, suppose that  in the model above. Then the expression  gets a score of , and longer chains of s get even higher scores. In particular, there is an infinite sequence of expressions with increasing scores and therefore the model doesn’t normalize (since the sum of the exponentiated scores of all possible productions is infinite).\n\n\nSo, log-linear models over-represent PCFGs in the same way as they over-represent HMMs, but the problems are even worse than before. Let’s ignore these issues for now, and suppose that we want to learn PCFGs with an *unknown* underlying CFG. To be a bit more concrete, suppose that we have a large collection of possible production rules for each non-terminal , and we think that a small but unknown subset of those production rules should actually appear in the grammar. Then there is no way to encode this directly within the context of a log-linear model family, although we can encode such “sparsity constraints” using simple extensions to log-linear models (for instance, by adding a penalty for the number of non-zero entries in ). So, we have found another way in which the log-linear representation is not entirely adequate.\n\n\n**Conclusion.** Based on the examples above, we have seen that log-linear models have difficulty placing constraints on latent variables. This showed up in two different ways: first, we are unable to constrain subsets of variables to add up to  (what I call “local normalization” constraints); second, we are unable to encode sparsity constraints within the model. In both of these cases, it is possible to extend the log-linear framework to address these sorts of constraints, although that is outside the scope of this post.\n\n\n **Parameter Estimation for Log-Linear Models** \n\n\nI’ve explained what a log-linear model is, and partially characterized its representational power. I will now answer the practical question of how to estimate the parameters of a log-linear model (i.e., how to fit  based on observed data). Recall that a log-linear model places a distribution over a space  by choosing 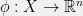 and  and defining\n\n\n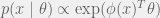\n\n\nMore precisely (assuming  is a discrete space), we have\n\n\n\n\n\nGiven observations , which we assume to be independent given , our goal is to choose  maximizing , or, equivalently, . In equations, we want\n\n\n\n![\\displaystyle \\theta^* = \\arg\\max\\limits_{\\theta} \\sum_{i=1}^n \\left[\\phi(x_i)^T\\theta - \\log\\left(\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)\\right) \\right]. \\ \\ \\ \\ \\ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctheta%5E%2A+%3D+%5Carg%5Cmax%5Climits_%7B%5Ctheta%7D+%5Csum_%7Bi%3D1%7D%5En+%5Cleft%5B%5Cphi%28x_i%29%5ET%5Ctheta+-+%5Clog%5Cleft%28%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%5Cright%29+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\n\n\nWe typically use gradient methods (such as [gradient descent](http://en.wikipedia.org/wiki/Gradient_descent), [stochastic gradient descent](http://en.wikipedia.org/wiki/Stochastic_gradient_descent), or [L-BFGS](http://en.wikipedia.org/wiki/Limited-memory_BFGS)) to minimize the right-hand side of ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnobj)). If we compute the gradient of ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnobj)) then we get:\n\n\n\n\n\n\n\n\nWe can re-write ([2](https://jsteinhardt.wordpress.com/feed/?paged=3#eqngrad)) in the following more compact form:\n\n\n\n![\\displaystyle \\sum_{i=1}^n \\left(\\phi(x_i) - \\mathbb{E}[\\phi(x) \\mid \\theta]\\right). \\ \\ \\ \\ \\ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28%5Cphi%28x_i%29+-+%5Cmathbb%7BE%7D%5B%5Cphi%28x%29+%5Cmid+%5Ctheta%5D%5Cright%29.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\n\n\nIn other words, the contribution of each training example  to the gradient is the extent to which the features values for  exceed their expected values conditioned on .\n\n\nOne important consideration for such gradient-based numerical optimizers is *convexity*. If the objective function we are trying to minimize is convex (or concave), then gradient methods are guaranteed to converge to the global optimum. If the objective function is non-convex, then a gradient-based approach (or any other type of local search) may converge to a *local optimum* that is very far from the global optimum. In order to assess convexity, we compute the *Hessian* (matrix of second derivatives) and check whether it is positive definite. (In this case, we actually care about concavity, so we want the Hessian to be negative definite.) We can compute the Hessian by differentiating ([2](https://jsteinhardt.wordpress.com/feed/?paged=3#eqngrad)), which gives us\n\n\n\n![\\displaystyle n \\times \\left[\\left(\\frac{\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)\\phi(x)}{\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)}\\right)\\left(\\frac{\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)\\phi(x)}{\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)}\\right)^T-\\frac{\\sum_{x \\in X} \\exp(\\phi(x)^T\\theta)\\phi(x)\\phi(x)^T}{\\sum_{x \\in X} \\exp(\\phi(x)^T \\theta)}\\right]. \\ \\ \\ \\ \\ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n+%5Ctimes+%5Cleft%5B%5Cleft%28%5Cfrac%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%5Cphi%28x%29%7D%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%7D%5Cright%29%5Cleft%28%5Cfrac%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%5Cphi%28x%29%7D%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%7D%5Cright%29%5ET-%5Cfrac%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET%5Ctheta%29%5Cphi%28x%29%5Cphi%28x%29%5ET%7D%7B%5Csum_%7Bx+%5Cin+X%7D+%5Cexp%28%5Cphi%28x%29%5ET+%5Ctheta%29%7D%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%284%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\n\n\nAgain, we can re-write this more compactly as\n\n\n\n![\\displaystyle n\\times \\left(\\mathbb{E}[\\phi(x) \\mid \\theta]\\mathbb{E}[\\phi(x) \\mid \\theta]^T - \\mathbb{E}[\\phi(x)\\phi(x)^T \\mid \\theta]\\right). \\ \\ \\ \\ \\ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n%5Ctimes+%5Cleft%28%5Cmathbb%7BE%7D%5B%5Cphi%28x%29+%5Cmid+%5Ctheta%5D%5Cmathbb%7BE%7D%5B%5Cphi%28x%29+%5Cmid+%5Ctheta%5D%5ET+-+%5Cmathbb%7BE%7D%5B%5Cphi%28x%29%5Cphi%28x%29%5ET+%5Cmid+%5Ctheta%5D%5Cright%29.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\n\n\nThe term inside the parentheses of ([5](https://jsteinhardt.wordpress.com/feed/?paged=3#eqnhess2)) is exactly the negative of the [covariance matrix](http://en.wikipedia.org/wiki/Covariance_matrix) of  given , and is therefore necessarily negative definite, so the objective function we are trying to minimize is indeed concave, which, as noted before, implies that our gradient methods will always reach the global optimum.\n\n\n **Regularization and Concavity** \n\n\nWe may in practice wish to encode additional prior knowledge about  in our model, especially if the dimensionality of  is large relative to the amount of data we have. Can we do this and still maintain concavity? The answer in many cases is yes: since the [-norm](http://en.wikipedia.org/wiki/Lp_space#The_p-norm_in_finite_dimensions) is convex for all , we can add an  penalty to the objective for any such  and still have a concave objective function.\n\n\n **Conclusion** \n\n\nLog-linear models provide a universal representation for individual probability distributions, but not for arbitrary families of probability distributions (for instance, due to the inability to capture local normalization constraints or sparsity constraints). However, for the families they do express, parameter optimization can be performed efficiently due to a likelihood function that is log-concave in its parameters. Log-linear models also have tie-ins to many other beautiful areas of statistics, such as exponential families, which will be the subject of the next post.\n\n", "url": "https://jsteinhardt.wordpress.com/2012/12/06/log-linear-models/", "title": "Log-Linear Models", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2012-12-06T19:46:23+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "4b8ac96a4e7f95c595bdbf067d350d66", "summary": []}
+{"text": "Beyond Bayesians and Frequentists\n\n(This is available in pdf form [here](http://web.mit.edu/jsteinha/www/stats-essay.pdf).)\n\n\nIf you are a newly initiated student into the field of machine learning, it won’t be long before you start hearing the words “Bayesian” and “frequentist” thrown around. Many people around you probably have strong opinions on which is the “right” way to do statistics, and within a year you’ve probably developed your own strong opinions (which are suspiciously similar to those of the people around you, despite there being a much greater variance of opinion between different labs). In fact, now that the year is 2012 the majority of new graduate students are being raised as Bayesians (at least in the U.S.) with frequentists thought of as stodgy emeritus professors stuck in their ways.\n\n\nIf you are like me, the preceding set of facts will make you very uneasy. They will make you uneasy because simple pattern-matching — the strength of people’s opinions, the reliability with which these opinions split along age boundaries and lab boundaries, and the ridicule that each side levels at the other camp – makes the “Bayesians vs. frequentists” debate look far more like politics than like scholarly discourse. Of course, that alone does not necessarily prove anything; these disconcerting similarities could just be coincidences that I happened to cherry-pick.\n\n\nMy next point, then, is that we are right to be uneasy, because such debate makes us less likely to evaluate the strengths and weaknesses of both approaches in good faith. This essay is a push against that — I summarize the justifications for Bayesian methods and where they fall short, show how frequentist approaches can fill in some of their shortcomings, and then present my personal (though probably woefully under-informed) guidelines for choosing which type of approach to use.\n\n\nBefore doing any of this, though, a bit of background is in order…\n\n\n**1. Background on Bayesians and Frequentists** \n\n\n **1.1. Three Levels of Argument** \n\n\nAs Andrew Critch [6] insightfully points out, the Bayesians vs. frequentists debate is really three debates at once, centering around one or more of the following arguments:\n\n\n1. Whether to interpret subjective beliefs as probabilities\n2. Whether to interpret probabilities as subjective beliefs (as opposed to asymptotic frequencies)\n3. Whether a Bayesian or frequentist algorithm is better suited to solving a particular problem.\n\n\nGiven my own research interests, I will add a fourth argument:\n\n\n4. Whether Bayesian or frequentist techniques are better suited to engineering an artificial intelligence.\n\n\nAndrew Gelman [9] has his own well-written essay on the subject, where he expands on these distinctions and presents his own more nuanced view.\n\n\nWhy are these arguments so commonly conflated? I’m not entirely sure; I would guess it is for historical reasons but I have so far been unable to find said historical reasons. Whatever the reasons, what this boils down to in the present day is that people often form opinions on 1. and 2., which then influence their answers to 3. and 4. This is *not good*, since 1. and 2. are philosophical in nature and difficult to resolve correctly, whereas 3. and 4. are often much easier to resolve and extremely important to resolve correctly in practice. Let me re-iterate: *the Bayes vs. frequentist discussion should center on the practical employment of the two methods, or, if epistemology must be discussed, it should be clearly separated from the day-to-day practical decisions*. Aside from the difficulties with correctly deciding epistemology, the relationship between generic epistemology and specific practices in cutting-edge statistical research is only via a long causal chain, and it should be completely unsurprising if Bayesian epistemology leads to the employment of frequentist tools or vice versa.\n\n\nFor this reason and for reasons of space, I will spend the remainder of the essay focusing on *statistical algorithms* rather than on *interpretations of probability*. For those who really want to discuss interpretations of probability, I will address that in a later essay.\n\n\n **1.2. Recap of Bayesian Decision Theory** \n\n\n(What follows will be review for many.) In Bayesian decision theory, we assume that there is some underlying world state  and a *likelihood function*  over possible observations. (A *likelihood function* is just a conditional probability distribution where the parameter conditioned on can vary.) We also have a space  of possible actions and a utility function  that gives the utility of performing action  if the underlying world state is . We can incorporate notions like planning and value of information by defining  recursively in terms of an identical agent to ourselves who has seen one additional observation (or, if we are planning against an adversary, in terms of the adversary). For a more detailed overview of this material, see the tutorial by North [11].\n\n\nWhat distinguishes the Bayesian approach in particular is one additional assumption, a *prior distribution*  over possible world states. To make a decision with respect to a given prior, we compute the posterior distribution 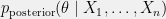 using Bayes’ theorem, then take the action  that maximizes ![{\\mathbb{E}_{p_{\\mathrm{posterior}}}[U(\\theta; a)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp_%7B%5Cmathrm%7Bposterior%7D%7D%7D%5BU%28%5Ctheta%3B+a%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002).\n\n\nIn practice, 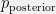 can be quite difficult to compute, and so we often attempt to approximate it. Such attempts are known as *approximate inference algorithms*.\n\n\n **1.3. Steel-manning Frequentists** \n\n\nThere are many different ideas that fall under the broad umbrella of frequentist techniques. While it would be impossible to adequately summarize all of them even if I attempted to, there are three in particular that I would like to describe, and which I will call *frequentist decision theory*, *frequentist guarantees*, and *frequentist analysis tools*.\n\n\nFrequentist decision theory has a very similar setup to Bayesian decision theory, with a few key differences. These are discussed in detail and contrasted with Bayesian decision theory in [10], although we summarize the differences here. There is still a likelihood function 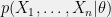 and a utility function . However, we do not assume the existence of a prior on , and instead choose the decision rule  that maximizes\n\n\n![\\displaystyle \\min\\limits_{\\theta} \\mathbb{E}[U(a(X_1,\\ldots,X_n); \\theta) \\mid \\theta]. \\ \\ \\ \\ \\ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmin%5Climits_%7B%5Ctheta%7D+%5Cmathbb%7BE%7D%5BU%28a%28X_1%2C%5Cldots%2CX_n%29%3B+%5Ctheta%29+%5Cmid+%5Ctheta%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=f0f0f0&fg=000000&s=0&c=20201002)\n\n\nIn other words, we ask for a worst case guarantee rather than an average case guarantee. As an example of how these would differ, imagine a scenario where we have no data to observe, an unknown , and we choose an action 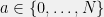. Furthermore, 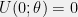 for all , 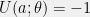 if , and  if  and . Then a frequentist will always choose  because any other action gets 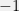 utility in the worst case; a Bayesian, on the other hand, will happily choose any non-zero value of  since such an action gains 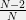 utility in expectation. (I am purposely ignoring more complex ideas like mixed strategies for the purpose of illustration.).\n\n\nNote that the frequentist optimization problem is more complicated than in the Bayesian case, since the value of ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqn1)) depends on the joint behavior of , whereas with Bayes we can optimize  for each set of observations separately.\n\n\nAs a result of this more complex optimization problem, it is often not actually possible to maximize ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqn1)), so many frequentist techniques instead develop tools to lower-bound ([1](https://jsteinhardt.wordpress.com/feed/?paged=3#eqn1)) for a given decision procedure, and then try to construct a decision procedure that is reasonably close to the optimum. Support vector machines [2], which try to pick separating hyperplanes that minimize generalization error, are one example of this where the algorithm is explicitly trying to maximize worst-case utility. Another example of a frequentist decision procedure is L1-regularized least squares for sparse recovery [3], where the procedure itself does not look like it is explicitly maximizing any utility function, but a separate analysis shows that it is close to the optimal procedure anyways.\n\n\nThe second sort of frequentist approach to statistics is what I call a *frequentist guarantee*. A frequentist guarantee on an algorithm is a guarantee that, with high probability with respect to how the data was generated, the output of the algorithm will satisfy a given property. The most familiar example of this is any algorithm that generates a frequentist confidence interval: to generate a 95% frequentist confidence interval for a parameter  is to run an algorithm that outputs an interval, such that with probability at least 95%  lies within the interval. An important fact about most such algorithms is that the size of the interval only grows logarithmically with the amount of confidence we require, so getting a 99.9999% confidence interval is only slightly harder than getting a 95% confidence interval (and we should probably be asking for the former whenever possible).\n\n\nIf we use such algorithms to test hypotheses or to test discrete properties of , then we can obtain algorithms that take in probabilistically generated data and produce an output that with high probability depends *only on how the data was generated*, not on the specific random samples that were given. For instance, we can create an algorithm that takes in samples from two distributions, and is guaranteed to output 1 whenever they are the same, 0 whenever they differ by at least  in total variational distance, and could have arbitrary output if they are different but the total variational distance is less than . This is an amazing property — it takes in random input and produces an essentially deterministic answer.\n\n\nFinally, a third type of frequentist approach seeks to construct *analysis tools* for understanding the behavior of random variables. Metric entropy, the Chernoff and Azuma-Hoeffding bounds [12], and Doob’s optional stopping theorem are representative examples of this sort of approach. Arguably, everyone with the time to spare should master these techniques, since being able to analyze random variables is important no matter what approach to statistics you take. Indeed, frequentist analysis tools have no conflict at all with Bayesian methods — they simply provide techniques for understanding the behavior of the Bayesian model.\n\n\n**2. Bayes vs. Other Methods** \n\n\n **2.1. Justification for Bayes** \n\n\nWe presented Bayesian decision theory above, but are there any reasons why we should actually use it? One commonly-given reason is that Bayesian statistics is merely the application of Bayes’ Theorem, which, being a theorem, describes the only correct way to update beliefs in response to new evidence; anything else can only be justified to the extent that it provides a good approximation to Bayesian updating. This may be true, but Bayes’ Theorem only applies if we already have a prior, and if we accept probability as the correct framework for expressing uncertain beliefs. We might want to avoid one or both of these assumptions. Bayes’ theorem also doesn’t explain why we care about expected utility as opposed to some other statistic of the distribution over utilities (although note that frequentist decision theory also tries to maximize expected utility).\n\n\nOne compelling answer to this is **Cox’s Theorem**, which shows that any agent must implicitly be using a probability model to make decisions, or else they can be *dutch-booked* — meaning there is a series of bets that they would be willing to make that causes them to lose money with certainty. Another answer is the **complete class theorem**, which shows that any non-Bayesian decision procedure is *strictly dominated* by a Bayesian decision procedure — meaning that the Bayesian procedure performs at least as well as the non-Bayesian procedure in all cases with certainty. In other words, if you are doing anything non-Bayesian, then either it is secretly a Bayesian procedure or there is another procedure that does strictly better than it. Finally, the **VNM Utility Theorem** states that any agent with consistent preferences over distributions of outcomes must be implicitly maximizing the expected value of some scalar-valued function, which we can then use as our choice of utility function . These theorems, however, ignore the issue of computation — while the best decision procedure may be Bayesian, the best computationally-efficient decision procedure could easily be non-Bayesian.\n\n\nAnother justification for Bayes is that, in contrast to ad hoc frequentist techniques, it actually provides a general theory for constructing statistical algorithms, as well as for incorporating side information such as expert knowledge. Indeed, when trying to model complex and highly structured situations it is difficult to obtain any sort of frequentist guarantees (although analysis tools can still often be applied to gain intuition about parts of the model). A prior lets us write down the sorts of models that would allow us to capture structured situations (for instance, when trying to do language modeling or transfer learning). Non-Bayesian methods exist for these situations, but they are often ad hoc and in many cases ends up looking like an approximation to Bayes. One example of this is Kneser-Ney smoothing for n-gram models, an ad hoc algorithm that ended up being very similar to an approximate inference algorithm for the hierarchical Pitman-Yor process [15, 14, 17, 8]. This raises another important point *against* Bayes, which is that the proper Bayesian interpretation may be very mathematically complex. Pitman-Yor processes are on the cutting-edge of Bayesian nonparametric statistics, which is itself one of the more technical subfields of statistical machine learning, so it was probably much easier to come up with Kneser-Ney smoothing than to find the interpretation in terms of Pitman-Yor processes.\n\n\n **2.2. When the Justifications Fail** \n\n\nThe first and most common objection to Bayes is that a Bayesian method is only as good as its prior. While for simple models the performance of Bayes is relatively independent of the prior, such models can only capture data where frequentist techniques would also perform very well. For more complex (especially nonparametric) Bayesian models, the performance can depend strongly on the prior, and designing good priors is still an open problem. As one example I point to my own research on hierarchical nonparametric models, where the most straightforward attempts to build a hierarchical model lead to severe pathologies [13].\n\n\nEven if a Bayesian model does have a good prior, it may be computationally intractable to perform posterior inference. For instance, structure learning in Bayesian networks is NP-hard [4], as is topic inference in the popular latent Dirichlet allocation model (and this continues to hold even if we only want to perform approximate inference). Similar stories probably hold for other common models, although a theoretical survey has yet to be made; suffice to say that in practice approximate inference remains a difficult and unsolved problem, with many models not even considered because of the apparent hopelessness of performing inference in them.\n\n\nBecause frequentist methods often come with an analysis of the specific algorithm being employed, they can sometimes overcome these computational issues. One example of this mentioned already is L1 regularized least squares [3]. The problem setup is that we have a linear regression task 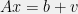 where 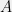 and  are known,  is a noise vector, and  is believed to be sparse (typically  has many more rows than , so without the sparsity assumption  would be underdetermined). Let us suppose that  has 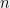 rows and 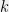 non-zero rows — then the number of possible sparsity patterns is 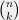 — large enough that a brute force consideration of all possible sparsity patterns is intractable. However, we can show that solving a certain semidefinite program will with high probability yield the appropriate sparsity pattern, after which recovering x reduces to a simple least squares problem. (A *semidefinite program* is a certain type of optimization problem that can be solved efficiently [16].)\n\n\nFinally, Bayes has no good way of dealing with adversaries or with cases where the data was generated in a complicated way that could make it highly biased (for instance, as the output of an optimization procedure). A toy example of an adversary would be playing rock-paper-scissors — how should a Bayesian play such a game? The straightforward answer is to build up a model of the opponent based on their plays so far, and then to make the play that maximizes the expected score (probability of winning minus probability of losing). However, such a strategy fares poorly against any opponent with access to the model being used, as they can then just run the model themselves to predict the Bayesian’s plays in advance, thereby winning every single time. In contrast, there is a frequentist strategy called the **multiplicative weights update method** that fairs well against an arbitrary opponent (even one with superior computational resources and access to our agent’s source code). The multiplicative weights method does far more than winning at rock-paper-scissors — it is also a key component of the fastest algorithm for solving many important optimization problems (including the network flow algorithm), and it forms the theoretical basis for the widely used AdaBoost algorithm [1, 5, 7].\n\n\n **2.3. When To Use Each Method** \n\n\nThe essential difference between Bayesian and frequentist decision theory is that Bayes makes the additional assumption of a prior over , and optimizes for average-case performance rather than worst-case performance. *It follows, then, that Bayes is the superior method whenever we can obtain a good prior and when good average-case performance is sufficient.* However, if we have no way of obtaining a good prior, or when we need guaranteed performance, frequentist methods are the way to go. For instance, if we are trying to build a software package that should be widely deployable, we might want to use a frequentist method because users can be sure that the software will work as long as some number of easily-checkable assumptions are met.\n\n\nA nice middle-ground between purely Bayesian and purely frequentist methods is to use a Bayesian model coupled with frequentist model-checking techniques; this gives us the freedom in modeling afforded by a prior but also gives us some degree of confidence that our model is correct. This approach is suggested by both Gelman [9] and Jordan [10].\n\n\n**3. Conclusion** \n\n\nWhen the assumptions of Bayes’ Theorem hold, and when Bayesian updating can be performed computationally efficiently, then it is indeed tautological that Bayes is the optimal approach. Even when some of these assumptions fail, Bayes can still be a fruitful approach. However, by working under weaker (sometimes even adversarial) assumptions, frequentist approaches can perform well in very complicated domains even with fairly simple models; this is because, with fewer assumptions being made at the outset, less work has to be done to ensure that those assumptions are met.\n\n\nFrom a research perspective, we should be far from satisfied with either approach — Bayesian methods make stronger assumptions than may be warranted, and frequentists methods provide little in the way of a coherent framework for constructing models, and ask for worst-case guarantees, which probably cannot be obtained in general. We should seek to develop a statistical modeling framework that, unlike Bayes, can deal with unknown priors, adversaries, and limited computational resources.\n\n\n**4. Acknowledgements** \n\n\nThanks to Emma Pierson, Vladimir Slepnev, and Wei Dai for reading preliminary versions of this work and providing many helpful comments.\n\n\n**5. References**\n\n\n[1] Sanjeev Arora, Elad Hazan, and Satyen Kale. The multiplicative weights update method: a meta algorithm and applications. *Working Paper*, 2005.\n\n\n[2] Christopher J.C. Burges. A tutorial on support vector machines for pattern recognition. *Data Mining and Knowledge Discovery*, 2:121–167, 1998.\n\n\n[3] Emmanuel J. Candes. Compressive sampling. In *Proceedings of the International Congress of Mathematicians*. European Mathematical Society, 2006.\n\n\n[4] D.M. Chickering. Learning bayesian networks is NP-complete. *LECTURE NOTES IN STATISTICS-NEW YORK-SPRINGER VERLAG-*, pages 121–130, 1996.\n\n\n[5] Paul Christiano, Jonathan A. Kelner, Aleksander Madry, Daniel Spielman, and Shang-Hua Teng. Electrical flows, laplacian systems, and faster approximation of maximum flow in undirected graphs. In *Proceedings of the 43rd ACM Symposium on Theory of Computing*, 2011.\n\n\n[6] Andrew Critch. Frequentist vs. bayesian breakdown: Interpretation vs. inference. http://lesswrong.com/lw/7ck/frequentist\\_vs\\_bayesian\\_breakdown\\_interpretation/.\n\n\n[7] Yoav Freund and Robert E. Schapire. A short introduction to boosting. *Journal of Japanese Society for Artificial Intelligence*, 14(5):771–780, Sep. 1999.\n\n\n[8] J. Gasthaus and Y.W. Teh. Improvements to the sequence memoizer. In *Advances in Neural Information Processing Systems*, 2011.\n\n\n[9] Andrew Gelman. Induction and deduction in bayesian data analysis. *RMM*, 2:67–78, 2011.\n\n\n[10] Michael I. Jordan. Are you a bayesian or a frequentist? Machine Learning Summer School 2009 (video lecture at ).\n\n\n[11] D. Warner North. A tutorial introduction to decision theory. *IEEE Transactions on Systems Science and Cybernetics*, SSC-4(3):200–210, Sep. 1968.\n\n\n[12] Igal Sason. On refined versions of the Azuma-Hoeffding inequality with applications in information theory. *CoRR*, abs/1111.1977, 2011.\n\n\n[13] Jacob Steinhardt and Zoubin Ghahramani. Pathological properties of deep bayesian hierarchies. In *NIPS Workshop on Bayesian Nonparametrics*, 2011. Extended Abstract.\n\n\n[14] Y.W. Teh. A bayesian interpretation of interpolated Kneser-Ney. Technical Report TRA2/06, School of Computing, NUS, 2006.\n\n\n[15] Y.W. Teh. A hierarchical bayesian language model based on pitman-yor processes. *Coling/ACL*, 2006.\n\n\n[16] Lieven Vandenberghe and Stephen Boyd. Semidefinite programming. *SIAM Review*, 38(1):49–95, Mar. 1996.\n\n\n[17] F.~Wood, C.~Archambeau, J.~Gasthaus, L.~James, and Y.W. Teh. A stochastic memoizer for sequence data. In *Proceedings of the 26th International Conference on Machine Learning*, pages 1129–1136, 2009.\n\n", "url": "https://jsteinhardt.wordpress.com/2012/10/31/beyond-bayesians-and-frequentists/", "title": "Beyond Bayesians and Frequentists", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2012-10-31T06:39:00+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "ce9e5a96ef2024997d351ffd00d246fb", "summary": []}
+{"text": "Verifying Stability of Stochastic Systems\n\nI just finished presenting my recent paper on stochastic verification at RSS 2011. There is a [conference version online](http://www.roboticsproceedings.org/rss07/p41.html), with a journal article to come later. In this post I want to go over the problem statement and my solution.\n\n\n**Problem Statement**\n\n\nAbstractly, the goal is to be given some sort of description of a system, and of a goal for that system, and then verify that the system will reach that goal. The difference between our work and a lot (but not all) of the previous work is that we want to work with an explicit noise model for the system. So, for instance, I tell you that the system satisfies\n\n\n\n\n\nwhere 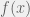 represents the nominal dynamics of the system,  represents how noise enters the system, and $dw(t)$ is a standard Wiener process (the continuous-time version of Gaussian noise). I would like to, for instance, verify that 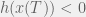 for some function  and some final time . For example, if  is one-dimensional then I could ask that , which is asking for  to be within a distance of  of the origin at time 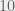. For now, I will focus on time-invariant systems and stability conditions. This means that  and  are not functions of , and the condition we want to verify is that  for all ![t \\in [0,T]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2CT%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). However, it is not too difficult to extend these ideas to the time-varying case, as I will show in the results at the end.\n\n\nThe tool we will use for our task is a *supermartingale*, which allows us to prove bounds on the probability that a system leaves a certain region.\n\n\n**Supermartingales**\n\n\nLet us suppose that I have a non-negative function  of my state  such that ![\\mathbb{E}[\\dot{V}(x(t))] \\leq c](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%28t%29%29%5D+%5Cleq+c&bg=f0f0f0&fg=555555&s=0&c=20201002) for all  and . Here we define ![\\mathbb{E}[\\dot{V}(x(t))]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%28t%29%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) as\n\n\n![\\lim\\limits_{\\Delta t \\to 0^+} \\frac{\\mathbb{E}[V(x(t+\\Delta t)) \\mid x(t)]-V(x(t))}{\\Delta t}.](https://s0.wp.com/latex.php?latex=%5Clim%5Climits_%7B%5CDelta+t+%5Cto+0%5E%2B%7D+%5Cfrac%7B%5Cmathbb%7BE%7D%5BV%28x%28t%2B%5CDelta+t%29%29+%5Cmid+x%28t%29%5D-V%28x%28t%29%29%7D%7B%5CDelta+t%7D.&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nThen, just by integrating, we can see that ![\\mathbb{E}[V(x(t)) \\mid x(0)] \\leq V(x(0))+ct](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BV%28x%28t%29%29+%5Cmid+x%280%29%5D+%5Cleq+V%28x%280%29%29%2Bct&bg=f0f0f0&fg=555555&s=0&c=20201002). By Markov’s inequality, the probability that  is at most .\n\n\nWe can actually prove something stronger as follows: note that if we re-define our Markov process to stop evolving as soon as , then this only sets ![\\mathbb{E}[\\dot{V}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) to zero in certain places. Thus the probability that  for this new process is at most . Since the process stops as soon as , we obtain the stronger result that the probability that  for *any* ![s \\in [0,t]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5B0%2Ct%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) is at most . Finally, we only need the condition ![\\mathbb{E}[\\dot{V}] \\leq c](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%5Cleq+c&bg=f0f0f0&fg=555555&s=0&c=20201002) to hold when 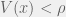. We thus obtain the following:\n\n\n**Theorem.** Let  be a non-negative function such that ![\\mathbb{E}[\\dot{V}(x(t))] \\leq c](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%28t%29%29%5D+%5Cleq+c&bg=f0f0f0&fg=555555&s=0&c=20201002) whenever 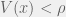. Then with probability at least ,  for all .\n\n\nWe call the condition ![\\mathbb{E}[\\dot{V}] \\leq c](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%5Cleq+c&bg=f0f0f0&fg=555555&s=0&c=20201002) the *supermartingale condition*, and a function that satisfies the martingale condition is called a *supermartingale*. If we can construct supermartingales for our system, then we can bound the probability that trajectories of the system leave a given region.\n\n\nNOTE: for most people, a supermartingale is something that satisfies the condition ![\\mathbb{E}[\\dot{V}] \\leq 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%5Cleq+0&bg=f0f0f0&fg=555555&s=0&c=20201002). However, this condition is often impossible to satisfy for systems we might care about. For instance, just consider exponential decay driven by Gaussian noise:\n\n\n[](http://postimage.org/image/ikg7ci90/full/)\n\n\nOnce the system gets close enough to the origin, the exponential decay ceases to matter much and the system is basically just getting bounced around by the Gaussian noise. In particular, if the system is ever at the origin, it will get perturbed away again, so you cannot hope to find a non-constant function of  that is decreasing in expectation everywhere (~~just consider the global minimum of such a function: in all cases, there is a non-zero probability that the Gaussian noise will cause  to increase, but a zero probability that  will decrease because we are already at the global minimum~~ this argument doesn’t actually work, but I am pretty sure that my claim is true at least subject to sufficient technical conditions).\n\n\n**Applying the Martingale Theorem**\n\n\nNow that we have this theorem, we need some way to actually use it. First, let us try to get a more explicit version of the Martingale condition for the systems we are considering, which you will recall are of the form 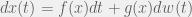. Note that .\n\n\nThen ![\\mathbb{E}[\\dot{V}(x)] = \\lim_{\\Delta t \\to 0^+} \\frac{\\frac{\\partial V}{\\partial x} \\mathbb{E}[\\Delta x]+\\frac{1}{2}Trace\\left(\\mathbb{E}[\\Delta x^T \\frac{\\partial^2 V}{\\partial x^2}\\Delta x\\right)+O(\\Delta x^3)}{\\Delta t}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%29%5D+%3D+%5Clim_%7B%5CDelta+t+%5Cto+0%5E%2B%7D+%5Cfrac%7B%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+x%7D+%5Cmathbb%7BE%7D%5B%5CDelta+x%5D%2B%5Cfrac%7B1%7D%7B2%7DTrace%5Cleft%28%5Cmathbb%7BE%7D%5B%5CDelta+x%5ET+%5Cfrac%7B%5Cpartial%5E2+V%7D%7B%5Cpartial+x%5E2%7D%5CDelta+x%5Cright%29%2BO%28%5CDelta+x%5E3%29%7D%7B%5CDelta+t%7D&bg=f0f0f0&fg=555555&s=0&c=20201002). A Wiener process satisfies ![\\mathbb{E}[dw(t)] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bdw%28t%29%5D+%3D+0&bg=f0f0f0&fg=555555&s=0&c=20201002) and ![\\mathbb{E}[dw(t)^2] = dt](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bdw%28t%29%5E2%5D+%3D+dt&bg=f0f0f0&fg=555555&s=0&c=20201002), so only the nominal dynamics () affect the limit of the first-order term while only the noise () affects the limit of the second-order term (the third-order and higher terms in  all go to zero). We thus end up with the formula\n\n\n![\\mathbb{E}[\\dot{V}(x)] = \\frac{\\partial V}{\\partial x}f(x)+\\frac{1}{2}Trace\\left(g(x)^T\\frac{\\partial^2 V}{\\partial x^2}g(x)\\right).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%29%5D+%3D+%5Cfrac%7B%5Cpartial+V%7D%7B%5Cpartial+x%7Df%28x%29%2B%5Cfrac%7B1%7D%7B2%7DTrace%5Cleft%28g%28x%29%5ET%5Cfrac%7B%5Cpartial%5E2+V%7D%7B%5Cpartial+x%5E2%7Dg%28x%29%5Cright%29.&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nIt is not that difficult to construct a supermartingale, but most supermartingales that you construct will yield a pretty poor bound. To illustrate this, consider the system . This is the example in the image from the previous section. Now consider a quadratic function . The preceding formula tells us that ![\\mathbb{E}[\\dot{V}(x)] = -2x^2+1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%29%5D+%3D+-2x%5E2%2B1&bg=f0f0f0&fg=555555&s=0&c=20201002). We thus have ![\\mathbb{E}[\\dot{V}(x)] \\leq 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%29%5D+%5Cleq+1&bg=f0f0f0&fg=555555&s=0&c=20201002), which means that the probability of leaving the region  is at most . This is not particularly impressive: it says that we should expect  to grow roughly as , which is how quickly  would grow if it was a random walk with no stabilizing component at all.\n\n\nOne way to deal with this is to have a state-dependent bound $\\mathbb{E}[\\dot{V}] \\leq c-kV$. This has been considered for instance by [Pham, Tabareau, and Slotine](http://web.mit.edu/nsl/www/preprints/stochastic_contraction09.pdf) (see Lemma 2 and Theorem 2), but I am not sure whether their results still work if the supermartingale condition only holds locally instead of globally; I haven’t spent much time on this, so they could generalize quite trivially.\n\n\nAnother way to deal with this is to pick a more quickly-growing candidate supermartingale. For instance, we could pick . Then ![\\mathbb{E}[\\dot{V}] = -4x^4+6x^2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%3D+-4x%5E4%2B6x%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002), which has a global maximum of  at $x = \\frac{\\sqrt{3}}{2}$. This bounds then says that  grows at a rate of at most 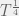, which is better than before, but still much worse than reality.\n\n\nWe could keep improving on this bound by considering successively faster-growing polynomials. However, automating such a process becomes expensive once the degree of the polynomial gets large. Instead, let’s consider a function like . Then ![\\mathbb{E}[\\dot{V}] = e^{0.5x^2}(0.5-0.5x^2)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%3D+e%5E%7B0.5x%5E2%7D%280.5-0.5x%5E2%29&bg=f0f0f0&fg=555555&s=0&c=20201002), which has a maximum of 0.5 at x=0. Now our bound says that we should expect x to grow like , which is a much better growth rate (and roughly the true growth rate, at least in terms of the largest value of  over the time interval ![[0,T]](https://s0.wp.com/latex.php?latex=%5B0%2CT%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)).\n\n\nThis leads us to our overall strategy for finding good supermartingales. We will search across functions of the form  where  is a matrix (the  means “positive semidefinite”, which roughly means that the graph of the function  looks like a bowl rather than a saddle/hyperbola). This begs two questions: how to upper-bound the global maximum of ![\\mathbb{E}[\\dot{V}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) for this family, and how to search efficiently over this family. The former is done by doing some careful work with inequalities, while the latter is done with semidefinite programming. I will explain both below.\n\n\n**Upper-bounding ![\\mathbb{E}[\\dot{V}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)**\n\n\nIn general, if , then ![\\mathbb{E}[\\dot{V}(x)] = e^{x^TSx}\\left(2x^TSf(x)+Trace(g(x)^TSg(x))+2x^TSg(x)g(x)^TSx\\right)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%28x%29%5D+%3D+e%5E%7Bx%5ETSx%7D%5Cleft%282x%5ETSf%28x%29%2BTrace%28g%28x%29%5ETSg%28x%29%29%2B2x%5ETSg%28x%29g%28x%29%5ETSx%5Cright%29&bg=f0f0f0&fg=555555&s=0&c=20201002). We would like to show that such a function is upper-bounded by a constant . To do this, move the exponential term to the right-hand-side to get the equivalent condition 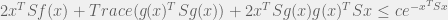. Then we can lower-bound  by 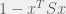 and obtain the sufficient condition\n\n\n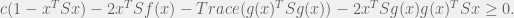\n\n\nIt is still not immediately clear how to check such a condition, but somehow the fact that this new condition only involves polynomials (assuming that f and g are polynomials) seems like it should make computations more tractable. This is indeed the case. While checking if a polynomial is positive is NP-hard, checking whether it is a **sum of squares** of other polynomials can be done in polynomial time. While sum of squares is not the same as positive, it is a sufficient condition (since the square of a real number is always positive).\n\n\nThe way we check whether a polynomial p(x) is a sum of squares is to formulate it as the semidefinite program: 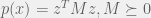, where  is a vector of monomials. The condition 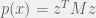 is a set of affine constraints on the entries of , so that the above program is indeed semidefinite and can be solved efficiently.\n\n\n**Efficiently searching across all matrices S**\n\n\nWe can extend on the sum-of-squares idea in the previous section to search over . Note that if  is a parameterized polynomial whose coefficient are affine in a set of decision variables, then the condition 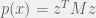 is again a set of affine constraints on . This almost solves our problem for us, but not quite. The issue is the form of  in our case:\n\n\n\n\n\nDo you see the problem? There are two places where the constraints do not appear linearly in the decision variables:  and  multiply each other in the first term, and  appears quadratically in the last term. While the first non-linearity is not so bad ( is a scalar so it is relatively cheap to search over  exhaustively), the second non-linearity is more serious. Fortunately, we can resolve the issue with Schur complements. The idea behind Schur complements is that, assuming , the condition  is equivalent to ![\\left[ \\begin{array}{cc} A & B \\\\ B^T & C \\end{array} \\right] \\succeq 0](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+B+%5C%5C+B%5ET+%26+C+%5Cend%7Barray%7D+%5Cright%5D+%5Csucceq+0&bg=f0f0f0&fg=555555&s=0&c=20201002). In our case, this means that our condition is equivalent to the condition that\n\n\n![\\left[ \\begin{array}{cc} 0.5I & g^TSx \\\\ x^TSg & c(1-x^TSx)-2x^TSf(x)-Trace(g(x)^TSg(x))\\end{array} \\right] \\succeq 0](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0.5I+%26+g%5ETSx+%5C%5C+x%5ETSg+%26+c%281-x%5ETSx%29-2x%5ETSf%28x%29-Trace%28g%28x%29%5ETSg%28x%29%29%5Cend%7Barray%7D+%5Cright%5D+%5Csucceq+0&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nwhere  is the identity matrix. Now we have a condition that is linear in the decision variable , but it is no longer a polynomial condition, it is a condition that a matrix polynomial be positive semidefinite. Fortunately, we can reduce this to a purely polynomial condition by creating a set of dummy variables  and asking that\n\n\n![y^T\\left[ \\begin{array}{cc} 0.5I & g^TSx \\\\ x^TSg & c(1-x^TSx)-2x^TSf(x)-Trace(g(x)^TSg(x))\\end{array} \\right]y \\geq 0](https://s0.wp.com/latex.php?latex=y%5ET%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0.5I+%26+g%5ETSx+%5C%5C+x%5ETSg+%26+c%281-x%5ETSx%29-2x%5ETSf%28x%29-Trace%28g%28x%29%5ETSg%28x%29%29%5Cend%7Barray%7D+%5Cright%5Dy+%5Cgeq+0&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nWe can then do a line search over  and solve a semidefinite program to determine a feasible value of . If we care about remaining within a specific region, we can maximize  such that  implies that we stay in the region. Since our bound on the probability of leaving the grows roughly as , this is a pretty reasonable thing to maximize (we would actually want to maximize , but this is a bit more difficult to do).\n\n\nOftentimes, for instance if we are verifying stability around a trajectory, we would like  to be time-varying. In this case an exhaustive search is no longer feasible. Instead we alternate between searching over  and searching over . In the step where we search over , we maximize . In the step where we search over , we maximize the amount by which we could change  and still satisfy the constraints (the easiest way to do this is by first maximizing , then minimizing , then taking the average; the fact that semidefinite constraints are convex implies that this optimizes the margin on  for a fixed ).\n\n\nA final note is that systems are often only stable locally, and so we only want to check the constraint ![\\mathbb{E}[\\dot{V}] \\leq c](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cdot%7BV%7D%5D+%5Cleq+c&bg=f0f0f0&fg=555555&s=0&c=20201002) in a region where 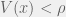. We can do this by adding a *Lagrange multiplier* to our constraints. For instance, if we want to check that  whenever , it suffices to find a polynomial  such that 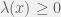 and 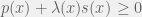. (You should convince yourself that this is true; the easiest proof is just by casework on the sign of 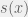.) This again introduces a non-linearity in the constraints, but if we fix  and 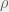 then the constraints are linear in  and , and vice-versa, so we can perform the same alternating maximization as before.\n\n\n**Results**\n\n\nBelow is the most exciting result, it is for an airplane with a noisy camera trying to avoid obstacles. Using the verification methods above, we can show that with probability at least  that the plane trajectory will not leave the gray region:\n\n\n[](http://postimage.org/image/iktfna78/full/)\n\n", "url": "https://jsteinhardt.wordpress.com/2011/07/03/verifying-stability-of-stochastic-systems/", "title": "Verifying Stability of Stochastic Systems", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2011-07-03T00:52:25+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=3", "authors": ["jsteinhardt"], "id": "2bc933e24438c65d96f54622b05eabe1", "summary": []}
+{"text": "Useful Math\n\nI have spent the last several months doing applied math, culminating in a submission of a paper to a [robotics conference](http://www.roboticsconference.org/) (although culminating might be the wrong word, since I’m still working on the project).\n\n\nUnfortunately the review process is double-blind so I can’t talk about that specifically, but I’m more interested in going over the math I ended up using (not expositing on it, just making a list, more or less). This is meant to be a moderate amount of empirical evidence for which pieces of math are actually useful, and which aren’t (of course, the lack of appearance on this list doesn’t imply uselessness, but should be taken as [Bayesian evidence against](http://lesswrong.com/lw/ih/absence_of_evidence_is_evidence_of_absence/) usefulness).\n\n\nI’ll start with the stuff that I actually used in the paper, then stuff that helped me formulate the ideas in the paper, then stuff that I’ve used in other work that hasn’t yet come to fruition. These will be labelled I, II, and III below. Let me know if you think something should be in III that isn’t [in other words, you think there’s a piece of math that is useful but not listed here, preferably with the application you have in mind], or if you have better links to any of the topics below.\n\n\nI. Ideas used directly\n\n\nOptimization: [semidefinite optimization](http://en.wikipedia.org/wiki/Semidefinite_programming), [convex optimization](http://en.wikipedia.org/wiki/Convex_optimization), [sum-of-squares programming](http://www.cds.caltech.edu/sostools/), [Schur complements](http://en.wikipedia.org/wiki/Schur_complement#Schur_complement_condition_for_positive_definiteness), [Lagrange multipliers](http://en.wikipedia.org/wiki/Lagrange_multiplier), [KKT conditions](http://en.wikipedia.org/wiki/Karush–Kuhn–Tucker_conditions)\n\n\nDifferential equations: [Lyapunov functions](http://en.wikipedia.org/wiki/Lyapunov_function), [linear differential equations](http://en.wikipedia.org/wiki/Linear_differential_equation), [Poincaré return map](http://en.wikipedia.org/wiki/Poincaré_map), [exponential stability](http://en.wikipedia.org/wiki/Exponential_stability), [Ito calculus](http://en.wikipedia.org/wiki/Itō_calculus)\n\n\nLinear algebra: [matrix exponential](http://en.wikipedia.org/wiki/Matrix_exponential), [trace](http://en.wikipedia.org/wiki/Trace_(linear_algebra)), [determinant](http://en.wikipedia.org/wiki/Determinant), [Cholesky decomposition](http://en.wikipedia.org/wiki/Cholesky_decomposition), plus general matrix manipulation and familiarity with [eigenvalues](http://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors) and [quadratic forms](http://en.wikipedia.org/wiki/Quadratic_form)\n\n\nProbability theory: [Markov’s inequality](http://en.wikipedia.org/wiki/Markov's_inequality), [linearity of expectation](http://en.wikipedia.org/wiki/Expected_value#Linearity), [martingales](http://en.wikipedia.org/wiki/Martingale_(probability_theory)), [multivariate normal distribution](http://en.wikipedia.org/wiki/Multivariate_normal_distribution), [stochastic processes](http://en.wikipedia.org/wiki/Stochastic_process) ([Wiener process](http://en.wikipedia.org/wiki/Wiener_process), [Poisson process](http://en.wikipedia.org/wiki/Poisson_process), [Markov process](http://en.wikipedia.org/wiki/Markov_process), [Lévy process](http://en.wikipedia.org/wiki/Lévy_process), [stopped process](http://en.wikipedia.org/wiki/Stopped_process))\n\n\nMultivariable calculus: [partial derivative](http://en.wikipedia.org/wiki/Partial_derivative), [full derivative](http://en.wikipedia.org/wiki/Total_derivative), [gradient](http://en.wikipedia.org/wiki/Gradient), [Hessian](http://en.wikipedia.org/wiki/Hessian_matrix), [Matrix calculus](http://en.wikipedia.org/wiki/Matrix_calculus), [Taylor expansion](http://en.wikipedia.org/wiki/Taylor_series)\n\n\nII. Indirectly helpful ideas\n\n\nInequalities: [Jensen’s inequality](http://en.wikipedia.org/wiki/Jensen's_inequality), [testing critical points](http://en.wikipedia.org/wiki/Differential_calculus#Applications_of_derivatives)\n\n\nOptimization: [(non-convex) function minimization](http://en.wikipedia.org/wiki/Optimization_(mathematics))\n\n\nIII. Other useful ideas\n\n\nCalculus: [calculus of variations](http://en.wikipedia.org/wiki/Calculus_of_variations), [extended binomial theorem](http://en.wikipedia.org/wiki/Binomial_theorem#Newton.27s_generalized_binomial_theorem)\n\n\nFunction Approximation: [variational approximation](http://people.csail.mit.edu/tommi/papers/Jaa-var-tutorial.ps), [neural networks](http://en.wikipedia.org/wiki/Artificial_neural_network)\n\n\nGraph Theory: random walks and relation to Markov Chains, Perron-Frobenius Theorem, combinatorial linear algebra, graphical models (Bayesian networks, Markov random fields, factor graphs)\n\n\nMiscellaneous: [Kullback-Leibler divergence](http://en.wikipedia.org/wiki/Kullback–Leibler_divergence), [Riccati equation](http://en.wikipedia.org/wiki/Algebraic_Riccati_equation), [homogeneity](http://en.wikipedia.org/wiki/Homogeneous_function) / [dimensional analysis](http://en.wikipedia.org/wiki/Dimensional_analysis), [AM-GM](http://en.wikipedia.org/wiki/Inequality_of_arithmetic_and_geometric_means), induced maps (in a general algebraic sense, not just the homotopy sense; unfortunately I have no good link for this one)\n\n\nProbability: [Bayes’ rule](http://en.wikipedia.org/wiki/Bayes'_theorem), [Dirichlet process](http://en.wikipedia.org/wiki/Dirichlet_process), [Beta and Bernoulli processes](http://jmlr.csail.mit.edu/proceedings/papers/v2/thibaux07a/thibaux07a.pdf), details balance and Markov Chain Monte Carlo\n\n\nSpectral analysis: [Fourier transform](http://en.wikipedia.org/wiki/Fourier_transform), [windowing](http://en.wikipedia.org/wiki/Window_function), [aliasing](http://en.wikipedia.org/wiki/Aliasing), [wavelets](http://en.wikipedia.org/wiki/Wavelet), [Pontryagin duality](http://en.wikipedia.org/wiki/Pontryagin_duality)\n\n\nLinear algebra: [change of basis](http://en.wikipedia.org/wiki/Change_of_basis), [Schur complement](http://en.wikipedia.org/wiki/Schur_complement), [adjoints](http://en.wikipedia.org/wiki/Adjoint), [kernels](http://en.wikipedia.org/wiki/Kernel_(linear_operator)), [injectivity/surjectivity/bijectivity of linear operators](http://en.wikipedia.org/wiki/Linear_map), [natural](http://en.wikipedia.org/wiki/Coordinate-free) [transformations](http://en.wikipedia.org/wiki/Natural_transformation) / [characteristic subspaces](http://en.wikipedia.org/wiki/Characteristic_subgroup)\n\n\nTopology: [compactness](http://en.wikipedia.org/wiki/Compact_space), [open](http://en.wikipedia.org/wiki/Open_set)/[closed](http://en.wikipedia.org/wiki/Closed_set) sets, [dense sets](http://en.wikipedia.org/wiki/Dense_set), [continuity](http://en.wikipedia.org/wiki/Continuity_(topology)#Continuous_functions_between_topological_spaces), [uniform continuity](http://en.wikipedia.org/wiki/Uniform_continuity), [connectedness](http://en.wikipedia.org/wiki/Connected_space), [path-connectedness](http://en.wikipedia.org/wiki/Connected_space#Path_connectedness)\n\n\nAnalysis: [Lipschitz continuity](http://en.wikipedia.org/wiki/Lipschitz_continuity), [Lesbesgue measure](http://en.wikipedia.org/wiki/Lebesgue_measure), [Haar measure](http://en.wikipedia.org/wiki/Haar_measure), [manifolds](http://en.wikipedia.org/wiki/Manifold), [algebraic manifolds](http://en.wikipedia.org/wiki/Algebraic_manifold)\n\n\nOptimization: [quasiconvexity](http://en.wikipedia.org/wiki/Quasiconvex_function)\n\n", "url": "https://jsteinhardt.wordpress.com/2011/01/23/useful-math/", "title": "Useful Math", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2011-01-23T23:38:56+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "899c88c952c103816ce70215bae3a275", "summary": []}
+{"text": "Generalizing Across Categories\n\nHumans are very good at correctly generalizing rules across categories (at least, compared to computers). In this post I will examine mechanisms that would allow us to do this in a reasonably rigorous manner. To this end I will present a probabilistic model such that conditional inference on that model leads to generalization across a category.\n\n\nThere are three questions along these lines that I hope to answer:\n\n\n* How does one generalize rules across categories?\n* How does one determine which rules should generalize across which categories?\n* How does one determine when to group objects into a category in the first place?\n\n\nI suspect that the mechanisms for each of these is rather complex, but I am reasonably confident that the methods I present make up at least part of the actual answer. A good exercise is to come up with examples where these methods fail.\n\n\n**Generalizing Across Categories**\n\n\nFor simplicity I’m going to consider just some sort of binary rule, such as the existence of an attribute. So as an example, let’s suppose that we see a bunch of ducks, which look to varying degrees to be [mallards](http://en.wikipedia.org/wiki/Mallard). In addition to this, we notice that some of the ducks have three toes, and some have four toes. In this case the category is “mallards”, and the attribute is “has three toes”.\n\n\nA category is going to be represented as a probabilistic relation for each potential member, of the form , where  is the category and  is the object in question. This essentially indicates the degree to which the object  belongs to the category . For instance, if the category is “birds”, then pigeons, sparrows, and eagles all fit into the category very well, so we assign a high probability (close to 1) to pigeons, sparrows, and eagles belonging in the category “birds”. On the other hand, flamingos, penguins, ostriches, and pterodactyls, while still being bird-like, don’t necessarily fit into our archetypal notion of what it means to be a bird. So they get lower probabilities (I’d say around 0.8 for the first 3 and around 0.1 for pterodactyls, but that is all pretty subjective). Finally, dogs and cats get a near-zero probability of being birds, and a table, the plus operator, or Beethoven’s Ninth Symphony would get even-closer-to-zero probabilities of being a bird.\n\n\nIn the example with ducks, the probability of being a mallard will probably be based on how many observed characteristics the duck in question has in common with mallards.\n\n\nFor now we will think of a rule or an attribute as an observable binary property about various objects. Let’s let 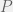 be the set of all things that have this property. Now we assume that membership in 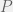 has some base probability of occurrence , together with some probability of occurrence within  of . We will assume that there are objects 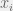, , and , such that the 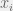 were all observed to lie in 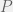, the  were all observed to not lie in 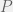, and membership in 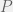 has been unobserved for the .\n\n\nFurthermore, 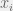 has probability  of belonging to ,  has probability  of belonging to , and  has probability  of belonging to .\n\n\nAgain, going back to the ducks example, the 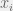 are the ducks observed to have three toes, the  are the ducks observed to have four toes, and the  are the ducks whose number of toes we have not yet observed. The , , and  are the aforementioned probabilities that each of these ducks is a mallard.\n\n\nSo to summarize, we have three classes of objects — those which certainly lie in P, those which certainly don’t lie in P, and those for which we have no information about P. For each element in each of these classes, we have a measure of the extent to which it belongs in C.\n\n\nGiven this setup, how do we actually go about specifying a model explicitly? Basically, we say that if something lies in  then it has property  with probability , and otherwise it has it with probability . Thus we end up with\n\n\n\n\n\nWhat this ends up meaning is that  will shift to accommodate the objects that (most likely) don’t lie in , and  will shift to accommodate the objects that (most likely) do lie in . At the same time, if for instance most elements in  also lie in , then the elements that don’t lie in 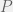 will have a relatively lower posterior probability of lying in  (compared to its prior probability). So this model not only has the advantage of generalizing across all of  based on the given observations, it also has the advantage of re-evaluating whether an object is likely to lie in a category based on whether it shares attributes with the other objects in that category.\n\n\nLet’s go back to the mallards example one more time. Suppose that after we make all of our observations, we notice that most of the ducks that we think are mallards also have three toes. Then  in this case (the probability that a mallard has three toes) will be close to 1. Furthermore, any duck that we observe to have four toes, we will think much less likely to be a mallard, even if it otherwise looks similar (although it wouldn’t be impossible; it could be a genetic mutant, for instance). At the same time, if non-mallards seem to have either three or four toes with roughly equal frequency, then  will be close to 0.5.\n\n\nThere is one thing that I am dissatisfied with in the above model, though. As it stands,  measures the probability of an object *not* lying in  to have property 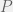, rather than the probability of a generic object to have property 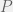. This is mainly a problem because, later on, I would like to be able to talk about an object lying in multiple categories, and I don’t have a good way of doing that yet.\n\n\nAn important thing to realize here is that satisfying a rule or having an attribute is just another way of indicating membership in a set. So we can think of both the category and the attribute as potential sets that an object could lie in; as before, we’ll call the category  and we will call the set of objects having a given attribute . Then  is something like 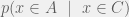, whereas  (should be) , although as I’ve set it up now it’s more like .\n\n\nAs a final note, this same setup can be applied to the case when there are multiple attributes under consideration. We can also apply it to the case when the objects are themselves categories, and so instead of having strict observations about each attribute, we have some sort of probability that the object will possess an attribute. In this latter case we just treat these probabilities as [uncertain observations](https://jsteinhardt.wordpress.com/2010/09/18/uncertain-observations/), as discussed previously.\n\n\n**When To Generalize**\n\n\nAnother important question is which rules / attributes we should expect to generalize across a category, and which we should not. For instance, if we would expect “number of toes” to generalize across all animals in a given species, but not “age”.\n\n\nI think that for binary attributes we will always have to generalize, although our generalization could just be “occurs at the base rate in the population”. However, for more complicated attributes (for instance, age, which has an entire continuum of possible values), we can think about whether to generalize based on whether our posterior distribution ends up very tightly concentrated or very spread out. Even if it ends up fairly spread out, there is still some degree of generalization — for instance, we expect that most insects have fairly short lifespans compared to mammals. You could say that this is actually a scientific fact (since we can measure lifespan), but even if you ran into a completely new species of insect, you would expect it to have a relatively short lifespan.\n\n\nOn the other hand, if we went to a college town, we might quickly infer that everyone there was in their 20s; if we went to a bridge club, we would quickly infer that everyone there was past retirement age.\n\n\nWhat I would say is that we can always generalize across a category, but sometimes the posterior distribution we end up with is very spread out, and so our generalization isn’t particularly strong. In some cases, the posterior distribution might not even be usefully different from the prior distribution; in this case, from a computational standpoint it doesn’t make sense to keep track of it, and so it *feels like* an attribute shouldn’t generalize across a category, while what we really mean is that we *don’t bother* to keep track of that generalization.\n\n\nAn important thing to keep in mind on this topic is that *everything* that we do when we construct models is a computational heuristic. If we didn’t care about computational complexity and only wanted to arrive at an answer, we would use [Solomonoff](http://singinst.org/blog/2007/06/25/solomonoff-induction/) [induction](http://wiki.lesswrong.com/wiki/Solomonoff_induction), or some computable approximation to it. So whenever I talk about something in probabilistic modeling, I’m partially thinking about whether the method is computationally feasible at all, and what sort of heuristics might be necessary to actually implement something in practice.\n\n\nTo summarize:\n\n\n* attributes always generalize across a category\n* but the generalization might be so weak as to be indistinguishable from the prior distribution\n* it would be interesting to figure out how we decide which generalizations to keep track of, and which not to\n\n\n**Forming Categories**\n\n\nMy final topic of consideration is when to actually form a category. Before going into this, I’d like to share some intuition with you. This is the intuition of explanatory “cheapness” or “expensiveness”. The idea is that events that have low probability under a given hypothesis are “expensive”, and events that have relatively high probability are “cheap”. When a fixed event is expensive under a model, that is evidence against that model; when it is cheap under a model, that is evidence for the model.\n\n\nThe reason that forming clusters can be cheaper is that it allows us to explain many related events simultaneously, which is cheaper than explaining them all separately. Let’s take an extreme example — suppose that 70% of all ducks have long beaks, and 70% have three toes (the remaining 30% in both cases have short beaks and four toes). Then the “cheapest” explanation would be to assign both long beaks and three toes a probability of 0.7, and the probability of our observations would be (supposing there were 100 ducks) 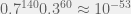. However, suppose that we also observe that the ducks with long beaks are exactly the ducks with three toes. Then we can instead postulate that there are two categories, “(long,3)” and “(short,4)”, and that the probability of ending up in the first category is 0.7 while the probability of ending up in the second category is 0.3. This is a *much* cheaper explanation, as the probability of our observations in this scenario becomes . We have to balance this slightly with the fact that an explanation that involves creating an extra category is more expensive (because it has a lower prior probability / higher complexity) than one that doesn’t, but the extra category can’t possibly be 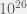 times more expensive, so we should still always favor it.\n\n\nThis also demonstrates that it will become progressively cheaper to form categories as we get large amounts of similar evidence, which corresponds with our intuitive notion of categories as similarity clusters.\n\n\nSo, now that I’ve actually given you this intuition, how do we actually go about forming categories? Each time we form a category, we will have some base probability of membership in that category, together with a probability of each member of that category possessing each attribute under consideration. If we simply pick prior distributions for each of these parameters, then they will naturally adopt posterior distributions based on the observed data, although these distributions might have multiple high-probability regions if multiple categories can be formed from the data. At the same time, each object will naturally end up with some probability of being in each category, based on how well that category explains its characteristics (as well as the base probability that objects should end up in that category). Putting these together, we see that clusters will naturally form to accommodate the data.\n\n\nAs an example of how we would have multiple high-probability regions, suppose that, as before, there are long-billed, three-toed ducks and short-billed, four-toed ducks. But we also notice that ducks with orange beaks have white feathers and ducks with yellow beaks have brown feathers. If we form a single category, then there are two good candidates, so that category is likely to be either the (long,3) category or the (orange,white) category (or their complements). If we form two categories, each category in isolation is still likely to be either the (long,3) or (orange,white) category, although if the first category is (long,3), then the second is very likely to be (orange,white), and vice versa. In other words, it would be silly to make both categories (long,3), or both categories (orange,white).\n\n\nThe only thing that is left to do is to specify some prior probability of forming a category. While there are various ways to do this, the most commonly used way is the [Indian Buffet Process](http://www.cs.princeton.edu/courses/archive/fall07/cos597C/scribe/20071119.pdf). I won’t explain it in detail here, but I might explain it later.\n\n\n**Future Considerations**\n\n\nThere are still some unresolved questions here. First of all, in reality something has the potential to be in many, many categories, and it is not entirely clear how to resolve such issues in the above framework. Secondly, keeping track of all of our observations about a given category can be quite difficult computationally (updating in the above scenarios requires performing computations on high-degree polynomials), so we need efficient algorithms for dealing with all of the data we get.\n\n\nI’m not sure yet how to deal with the first issue, although I’ll be thinking about it in the coming weeks. To deal with the second issue, I intend to use an approach based on streaming algorithms, which will hopefully make up a good final project for a class I’m taking this semester (Indyk and Rubinfeld’s class on Sublinear Algorithms, if you know about MIT course offerings).\n\n", "url": "https://jsteinhardt.wordpress.com/2010/10/02/generalizing-across-categories/", "title": "Generalizing Across Categories", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-10-02T19:10:31+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "ff61c7df1a2f9383a415501ae149d9f5", "summary": []}
+{"text": "Uncertain Observations\n\nWhat happens when you are uncertain about observations you made? For instance, you remember something happening, but you don’t remember who did it. Or you remember some fact you read on wikipedia, but you don’t know whether it said that hydrogen or helium was used in some chemical process.\n\n\nHow do we take this information into account in the context of Bayes’ rule? First, I’d like to note that there are different ways something could be uncertain. It could be that you observed X, but you don’t remember if it was in state A or state B. Or it could be that you think you observed X in state A, but you aren’t sure.\n\n\nThese are different because in the first case you don’t know whether to concentrate probability mass towards A or B, whereas in the second case you don’t know whether to concentrate probability mass at all.\n\n\nFortunately, both cases are pretty straightforward as long as you are careful about using Bayes’ rule. However, today I am going to focus on the latter case. In fact, I will restrict my attention to the following problem:\n\n\n\n> You have a coin that has some probability  of coming up heads. You also know that all flips of this coin are independent. But you don’t know what  is. However, you have observed this coin  times in the past. But for each observation, you aren’t completely sure that this was the coin you were observing. In particular, you only assign a probability  to your th observation actually being about this coin. Given this, and the sequence of heads and tails you remember, what is your estimate of \n> \n> \n\n\nTo use Bayes’ rule, let’s first figure out what we need to condition on. In this case, we need to condition on remembering the sequence of coin flips that we remembered. So we are looking for\n\n\np( | we remember the given sequence of flips),\n\n\nwhich is proportional to\n\n\np(we remember the given sequence of flips | )  p().\n\n\nThe only thing that the uncertain nature of our observations does is cause there to be multiple ways to eventually land in the set of universes where we remember the sequence of flips; in particular, for any observation we remember, it could have actually happened, or we could have incorrectly remembered it. Thus if , and we remember the th coin flip as being heads, then this could happen with probability  if we incorrectly remembered a coin flip of heads. In the remaining probability  case, it could happen with probability  by actually coming up heads. Therefore the probability of us remembering that the th flip was heads is .\n\n\nA similar computation shows that the probability of us remembering that the th flip was tails is 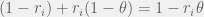.\n\n\nFor convenience of notation, let’s actually split up our remembered flips into those that were heads and those that were tails. The probability of the th remembered heads being real is , and the probability of the th remembered tails being real is 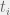. There are  heads and  tails. Then we get\n\n\n\n\n\nNote that when we consider values of  close to , the term from the remembered tails becomes close to  raised to the power of the expected number of tails, whereas the term from the remembered heads becomes close to the probability that we incorrectly remembered each of the heads. A similar phenomenon will happen when  gets close to . This is an instance of a more general phenomenon whereby unlikely observations get “explained away” by whatever means possible.\n\n\n**A Caveat**\n\n\nApplying the above model in practice can be quite tricky. The reason is that your memories are intimately tied to all sorts of events that happen to you; in particular, your assessment of how likely you are to remember an event probably *already takes into account* how well that event fits into your existing model. So if you saw 100 heads, and then a tails, you would place *more weight than normal* on your recollection of the tails being incorrect, even though that is the job of the above model. In essence, you are conditioning on your data twice — once intuitively, and once as part of the model. This is bad because it assumes that you made each observation twice as many times as you actually did.\n\n\nWhat is interesting, though, is that you can actually compute things like the probability that you incorrectly remembered an event, *given the rest of the data*, and it will be different from the prior probability. So in addition to a posterior estimate of , you get posterior estimates of the likelihood of each of your recollections. Just be careful not to take these posterior estimates and use them as if they were prior estimates (which, as explained above, is what we are likely to do intuitively).\n\n\nThere are other issues to using this in practice, as well. For instance, if you *really want* the coin to be fair, or unfair, or be biased in a certain direction, it is very easy to fool yourself into assigning skewed probability estimates towards each of your recollections, thus ending up with a biased answer at the end. It’s not even difficult — if I take a fair coin, and underestimate my recollection of each tails by 20%, and overestimate my recollection of each heads by 20%, then all of a sudden I “have a coin” that is 50% more likely to come up heads than tails.\n\n\nFortunately, my intended application of this model will be in a less slippery domain (hopefully). The purpose is to finally answer the question I posed in the last post, which I’ll repeat here for convenience:\n\n\n\n> Suppose that you have never played a sport before, and you play soccer, and enjoy it. Now suppose instead that you have never played a sport before, and play soccer, and hate it. In the first case, you will think yourself more likely to enjoy other sports in the future, relative to in the second case. Why is this?\n> \n> \n> Or if you disagree with the premises of the above scenario, simply “If X and Y belong to the same category C, why is it that *in certain cases* we think it more likely that Y will have attribute A upon observing that X has attribute A?”\n> \n> \n> \n\n\nIn the interest of making my posts shorter, I will leave that until next time, but hopefully I’ll get to it in the next week.\n\n", "url": "https://jsteinhardt.wordpress.com/2010/09/18/uncertain-observations/", "title": "Uncertain Observations", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-09-18T19:26:46+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "1f91023d339511661a6f18dde93ad726", "summary": []}
+{"text": "Nobody Understands Probability\n\nThe goal of this post is to give an overview of Bayesian statistics as well as to correct errors about probability that even mathematically sophisticated people commonly make. Hopefully by the end of this post I will convince you that you don’t actually understand probability theory as well as you think, and that probability itself is something worth thinking about.\n\n\nI will try to make this post somewhat shorter than the previous posts. As a result, this will be only the first of several posts on probability. Even though this post will be shorter, I will summarize its organization below:\n\n\n* Bayes’ theorem: the fundamentals of conditional probability\n* modeling your sources: how not to calculate conditional probabilities; the difference between “you are given X” and “you are given that you are given X”\n* **how to build models: examples using toy problems**\n* probabilities are statements about your beliefs (not the world)\n* re-evaluating a standard statistical test\n\n\nI bolded the section on models because I think it is very important, so I hope that bolding it will make you more likely to read it.\n\n\nAlso, I should note that when I say that nobody understands probability, I don’t mean it in the sense that most people are bad at combinatorics. Indeed, I expect that most of the readers of this blog are quite proficient at combinatorics, and that many of them even have sophisticated mathematical definitions of probability. Rather I would say that actually using probability theory in practice is non-trivial. This is partially because there are some subtleties (or at least, I have found myself tripped up by certain points, and did not realize this until much later). It is also because whenever you use probability theory in practice, you end up employing various heuristics, and it’s not clear which ones are the “right” ones.\n\n\nIf you disagree with me, and think that everything about probability is trivial, then I challenge you to come up with a probability-theoretic explanation of the following phenomenon:\n\n\n\n> Suppose that you have never played a sport before, and you play soccer, and enjoy it. Now suppose instead that you have never played a sport before, and play soccer, and hate it. In the first case, you will think yourself more likely to enjoy other sports in the future, relative to in the second case. Why is this?\n> \n> \n\n\nOr if you disagree with the premises of the above scenario, simply “If X and Y belong to the same category C, why is it that *in certain cases* we think it more likely that Y will have attribute A upon observing that X has attribute A?”\n\n\n**Bayes’ Theorem**\n\n\nBayes’ theorem is a fundamental result about conditional probability. It says the following:\n\n\n\n\n\nHere  and  are two events, and 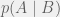 means the probability of  conditioned on . In other words, if we already know that  occurred, what is the probability of ? The above theorem is quite easy to prove, using the fact that 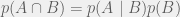, and thus also equals 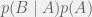, so that 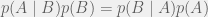, which implies Bayes’ theorem. So, why is it useful, and how do we use it?\n\n\nOne example is the following famous problem: A doctor has a test for a disease that is 99% accurate. In other words, it has a 1% chance of telling you that you have a disease even if you don’t, and it has a 1% chance of telling you that you don’t have a disease even if you do. Now suppose that the disease that this tests for is extremely rare, and only affects 1 in 1,000,000 people. If the doctor performs the test on you, and it comes up positive, how likely are you to have the disease?\n\n\nThe answer is close to , since it is roughly 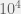 times as likely for the test to come up positive due to an error in the test relative to you actually having the disease. To actually compute this with Bayes’ rule, you can say\n\n\np(Disease | Test is positive) = p(Test is positive | Disease)p(Disease)/p(Test is positive),\n\n\nwhich comes out to 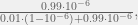 which is quite close to .\n\n\nIn general, we can use Bayes’ law to test hypotheses:\n\n\np(Hypothesis | Data) = p(Data | Hypothesis) p(Hypothesis) / p(Data)\n\n\nLet’s consider each of these terms separately:\n\n\n* p(Hypothesis | Data) — the weight we assign to a given hypothesis being correct under our observed data\n* p(Data | Hypothesis) — the likelihood of seeing the data we saw under our hypothesis; note that this should be quite easy to compute. If it isn’t, then we haven’t yet fully specified our hypothesis.\n* p(Hypothesis) — the prior weight we give to our hypothesis. This is subjective, but should intuitively be informed by the consideration that “simpler hypotheses are better”.\n* p(Data) — how likely we are to see the data in the first place. This is quite hard to compute, as it involves considering all possible hypotheses, how likely each of those hypotheses is to be correct, and how likely the data is to occur under each hypothesis.\n\n\nSo, we have an expression for p(Hypothesis | Data), one of which is easy to compute, the other of which can be chosen subjectively, and the last of which is hard to compute. How do we get around the fact that p(Data) is hard to compute? Note that p(Data) is independent of which hypothesis we are testing, so Bayes’ theorem actually gives us a very good way for comparing the relative merits of two hypotheses:\n\n\np(Hypothesis 1 | Data) / p(Hypothesis 2 | Data) = [p(Data | Hypothesis 1) / p(Data | Hypothesis 2)] \\* p(Hypothesis 1) / p(Hypothesis 2)\n\n\nLet’s consider the following toy example. There is a stream of digits going past us, too fast for us to tell what the numbers are. But we are allowed to push a button that will stop the stream and allow us to see a single number (whichever one is currently in front of us). We push this button three times, and see the numbers 3, 5, and 3. How many different numbers would we estimate are in the stream?\n\n\nFor simplicity, we will make the (somewhat unnatural) assumption that each number between 0 and 9 is selected to be in the stream with probability 0.5, and that each digit in the stream is chosen uniformly from the set of selected numbers. It is worth noting now that making this assumption, rather than some other assumption, will change our final answer.\n\n\nNow under this assumption, what is the probability, say, of there being exactly 2 numbers (3 and 5) in the stream? By Bayes’ theorem, we have\n\n\n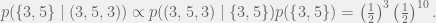\n\n\nHere  means “is proportional to”.\n\n\nWhat about the probability of there being 3 numbers (3, 5, and some other number)? For any given other number, this would be\n\n\n\n\n\nHowever, there are 8 possibilities for  above, all of which correspond to disjoint scenarios, so the probability of there being 3 numbers is proportional to . If we compare this to the probability of there being 2 numbers, we get\n\n\np(2 numbers | (3,5,3)) / p(3 numbers | (3,5,3)) = 3/8.\n\n\nEven though we have only seen two numbers in our first three samples, we still think it is more likely that there are 3 numbers than 2, just because the prior likelihood of there being 3 numbers is so much higher. However, suppose that we made 6 draws, and they were 3,5,3,3,3,5. Then we would get\n\n\np(2 numbers | (3,5,3,3,5)) / p(3 numbers | (3,5,3,3,5)) = (1/2)^6 / [9 \\* (1/3)^6] = 81/64.\n\n\nNow we find it more likely that there are only 2 numbers. This is what tends to happen in general with Bayes’ rule — over time, more restrictive hypotheses become exponentially more likely than less restrictive hypotheses, provided that they correctly explain the data. Put another way, hypotheses that concentrate probability density towards the actual observed events will do best in the long run. This is a nice feature of Bayes’ rule because it means that, even if the prior you choose is not perfect, you can still arrive at the “correct” hypothesis through enough observations (provided that the hypothesis is among the set of hypotheses you consider).\n\n\nI will use Bayes’ rule extensively through the rest of this post and the next few posts, so you should make sure that you understand it. If something is unclear, post a comment and I will try to explain in more detail.\n\n\n**Model Your Sources**\n\n\nAn important distinction that I think most people don’t think about is the difference between experiments you *perform*, and experiments you *observe*. To illustrate what I mean by this, I would point to the difference between biology and particle physics — where scientists set out to test a hypothesis by creating an experiment specifically designed to do so — and astrophysics and economics, where many “experiments” come from seeking out existing phenomena that can help evaluate a hypothesis.\n\n\nTo illustrate why one might need to be careful in the latter case, consider empirical estimates of average long-term GDP growth rate. How would one do this? Since it would be inefficient to wait around for the next 10 years and record the data of all currently existing countries, instead we go back and look at countries that kept records allowing us to compute GDP. But in this case we are only sampling from countries that kept such records, which implies a stable government as well as a reasonable degree of economics expertise within that government. So such a study almost certainly overestimates the actual average growth rate.\n\n\nOr as another example, we can argue that a scientist is more likely to try to publish a paper if it *doesn’t* agree with prevalent theories than if it does, so looking merely at the *proportion* of papers that lend support to or take support away from a theory (even if weighted by the convincingness of each paper) is probably not a good way to determine the validity of a theory.\n\n\nSo why are we safer in the case that we forcibly gather our own data? By gathering our own data, we understand much better (although still not perfectly) the way in which it was constructed, and so there is less room for confounding parameters. In general, we would like it to be the case that the likelihood of observing something that we want to observe does not depend on anything else that we care about — or at the very least, we would like it to depend in a well-defined way.\n\n\nLet’s consider an example. Suppose that a man comes up to you and says “I have two children. At least one of them is a boy.” What is the probability that they are both boys?\n\n\nThe standard way to solve this is as follows: Assuming that male and female children are equally likely, there is a  chance of two girls or two boys, and a  chance of having one girl and one boy. Now by Bayes’ theorem,\n\n\np(Two boys | At least one boy) = p(At least one boy | Two boys) \\* p(Two boys) / p(At least one boy) = 1 \\* (1/4) / (1/2+1/4) = 1/3.\n\n\nSo the answer should be 1/3 (if you did math contests in high school, this problem should look quite familiar). However, the answer is not, in fact, 1/3. Why is this? We were given that the man had at least one boy, and we just computed the probability that the man had at two boys given that he had at least one boy using Bayes’ theorem. So what’s up? Is Bayes’ theorem wrong?\n\n\nNo, the answer comes from an unfortunate namespace collision in the word “given”. The man “gave” us the information that he has at least one male child. By this we mean that he asserted the statement “I have at least one male child.” Now our issue is when we confuse this with being “given” that the man has at least one male child, in the sense that we should restrict to the set of universes in which the man has at least one male child. This is a very different statement than the previous one. For instance, it rules out universes where the man has two girls, but is lying to us.\n\n\nEven if we decide to ignore the possibility that the man is lying, we should note that most universes where the man has at least one son don’t even involve him informing us of this fact, and so it may be the case that proportionally more universes where the man has two boys involve him telling us “I have at least one male child”, relative to the proportion of such universes where the man has one boy and one girl. In this case the probability that he has two boys would end up being greater than 1/3.\n\n\nThe most accurate way to parse this scenario would be to say that we are given (restricted to the set of possible universes) that we are given (the man told us that) that the man has at least one male child. The correct way to apply Bayes’ rule in this case is\n\n\np(X has two boys | X says he has >= 1 boy) = p(X says he has >= 1 boy | X has two boys) \\* p(X has two boys) / p(X says he has >=1 boy)\n\n\nIf we further assume that the man is not lying, and that male and female children are equally likely and uncorrelated, then we get\n\n\np(X has two boys | X says he has >= 1 boy) = [p(X says he has >= 1 boy | X has two boys) \\* 1/4]/[p(X says he has >= 1 boy | X has two boys) \\* 1/4 + p(X says he has >= 1 boy | X has one boy) \\* 1/2]\n\n\nSo if we think that the man is  times more likely to tell us that he has at least one boy when he has two boys, then\n\n\np(X has two boys | X says he has >= 1 boy) = .\n\n\nNow this means that if we want to claim that the probability that the man has two boys is , what we are really claiming is that he is equally likely to inform us that he has at least one boy, in all situations where it is true, independent of the actual gender distribution of his children.\n\n\nI would argue that this is quite unlikely, as if he has a boy and a girl, then he could equally well have told us that he has at least one girl, whereas he couldn’t tell us that if he has only boys. So I would personally put  closer to 2, which yields an answer of . On the other hand, situations where someone walks up to me and tells me strange facts about the gender distribution of their children are, well, strange. So I would also have to take into account the likely psychology of such a person, which would end up changing my estimate of $\\alpha$.\n\n\nThe whole point here is that, because we were an *observer receiving information*, rather than an *experimenter acquiring information*, there are all sorts of confounding factors that are difficult to estimate, making it difficult to get a good probability estimate (more on that later). That doesn’t mean that we should give up and blindly guess , though — it might *feel* like doing so gets away without making unwarranted assumptions, but it in fact implicitly makes the assumption that , which as discussed above is almost certainly unwarranted.\n\n\nWhat it *does* mean, though, is that, as scientists, we should try to avoid situations like the one above where there are lots of confounding factors between what we care about and our observations. In particular, we should avoid uncertainties in the source of our information by collecting the information ourselves.\n\n\nI should note that, even when we construct our own experiments, we should still model the source of our information. But doing so is often much easier. In fact, if we wanted to be particularly pedantic, we really need to restrict to the set of universes in which our personal consciousness receives a particular set of stimuli, but that set of stimuli has almost perfect correlation with photons hitting our eyes, which has almost perfect correlation with the set of objects in front of us, so going to such lengths is rarely necessary — we can usually stop at the level of our personal observations, as long as we remember where they come from.\n\n\n**How to Build Models**\n\n\nNow that I’ve told you that you need to model your information sources, you perhaps care about how to do said modeling. Actually, constructing probabilistic models is an extremely important skill, so even if you ignore the rest of this post, I recommend paying attention to this section.\n\n\nThis section will have the following examples:\n\n\n* determining if a coin is fair\n* finding clusters\n\n\nDetermining if a Coin is Fair\n\n\nSuppose that you have occasion to observe a coin being flipped (or better yet, you flip it yourself). You do this several times and observe a particular sequence of heads and tails. If you see all heads or all tails, you will probably think the coin is unfair. If you see roughly half heads and half tails, you will probably think the coin is fair. But how do we quantify such a calculation? And what if there are noticeably many more heads than tails, but not so many as to make the coin obviously unfair?\n\n\nWe’ll solve this problem by building up a model in parts. First, there is the thing we care about, namely whether the coin is fair or unfair. So we will construct a random variable X that can take the values Fair and Unfair. Then p(X = Fair) is the probability we assign to a generic coin being fair, and p(X = Unfair) is the probability we assign to a generic coin being unfair.\n\n\nNow supposing the coin is fair, what do we expect? We expect each flip of the coin to be independent, and have a  probability of coming up heads. So if we let F1, F2, …, Fn be the flips of the coin, then p(Fi = Heads | X = Fair) = 0.5.\n\n\nWhat if the coin is unfair? Let’s go ahead and blindly assume that the flips will still be independent, and furthermore that each possible weight of the coin is equally likely (this is unrealistic, as weights near 0 or 1 are much more likely than weights near 0.5). Then we have to have an extra variable , the probability that the unfair coin comes up heads. So we have p(Unfair coin weight = ) = 1. Note that this is a probability density, not an actual probability (as opposed to p(Fi = Heads | X = Fair), which was a probability).\n\n\nContinuing, if F1, F2, …, Fn are the flips of the coin, then p(Fi = Heads | X = Fair, Weight = ) = .\n\n\nNow we’ve set up a model for this problem. How do we actually calculate a posterior probability of the coin being fair for a given sequence of heads and tails? (A posterior probability is just the technical term for the conditional probability of a hypothesis given a set of data; this is to distinguish it from the prior probability of the hypothesis before seeing any data.)\n\n\nWell, we’ll still just use Bayes’ rule:\n\n\np(Fair | F1, …, Fn)  p(F1, …, Fn | Fair) p(Fair) =  p(Fair)\n\n\np(Unfair | F1, …, Fn)  p(F1, …, Fn | Unfair) p(Unfair) =  p(Unfair)\n\n\nHere H is the number of heads and T is the number of tails. In this case we can fortunately actually compute the integral in question and see that it is equal to . So we get that\n\n\np(Fair | F1, …, Fn) / p(Unfair | F1, …, Fn) = p(Fair)/p(Unfair) \\* .\n\n\nIt is often useful to draw a [diagram of our model](http://en.wikipedia.org/wiki/Graphical_model) to help keep track of it:\n\n\n\n\n\nNow suppose that we, being specialists in determining if coins are fair, have been called in to study a large collection of coins. We get to one of the coins in the collection, flip it several times, and observe the following sequence of heads and tails:\n\n\nHHHHTTTHHTTT\n\n\nSince there are an equal number of heads and tails, our previous analysis will certainly conclude that the coin is fair, but its behavior does seem rather suspicious. In particular, different flips don’t look like they are really independent, so perhaps our previous model is wrong. Maybe the right model is one where the next coin value is usually the same as the previous coin value, but flips with some probability. Now we have a new value of X, which we’ll call Weird, and a parameter  (basically the same as ) that tells us how likely a weird coin is to have a given probability of switching. We’ll again give 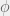 a uniform distribution over [0,1], so p(Switching probability of weird coin = 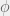) = 1.\n\n\nTo predict the actual coin flips, we get p(F1 = Heads | X = Weird, Switching probability = 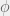) = 1, p(F(i+1) = Heads | Fi = Heads, X = Weird, Switching probability = 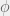) = , and p(F(i+1) = Heads | Fi = Tails, X = Weird, Switching probability = 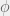) = . We can represent this all with the following graphical model:\n\n\n\n\n\nNow we are ready to evaluate whether the coin we saw was a Weird coin or not.\n\n\np(X = Weird | HHHHTTTHHTTT)  p(HHHHTTTHHTTT | X = Weird) p(X = Weird) = $\\int\\_{0}^{1} \\frac{1}{2}(1-\\phi)^8 \\phi^3 d\\phi$ p(X = Weird)\n\n\nEvaluating that integral gives . So p(X = Weird | Data) = p(X = Weird) / 3960, compared to p(X = Fair | Data), which is p(X = Fair) / 4096. In other words, positing a Weird coin only explains the data slightly better than positing a Fair coin, and since the vast majority of coins we encounter are fair, it is quite likely that this one is, as well.\n\n\n**Note:** I’d like to draw your attention to a particular subtlety here. Note that I referred to, for instance, “Probability that an unfair coin weight is “, as opposed to “Probability that a coin weight is  given that it is unfair”. This really is an important distinction, because the distribution over  really is the probability distribution over the weights of a *generic unfair coin*, and this distribution doesn’t change based on whether our current coin happens to be fair or unfair. Of course, we can still condition on our coin being fair or unfair, but that won’t change the probability distribution over  one bit.\n\n\nFinding Clusters\n\n\nNow let’s suppose that we have a bunch of points (for simplicity, we’ll say in two-dimensional Euclidean space). We would like to group the points into a collection of clusters. Let’s also go ahead and assume that we know in advance that there are  clusters. How do we actually find those clusters?\n\n\nWe’ll make the further heuristic assumption that clusters tend to arise from a “true” version of the cluster, and some Gaussian deviation from that true version. So in other words, if we let there be k means for our clusters, , and [multivariate Gaussians](http://en.wikipedia.org/wiki/Multivariate_normal_distribution) about their means with covariance matrices , and finally assume that the probability that a point belongs to cluster i is , then the probability of a set of points  is\n\n\n\n\n\nFrom this, once we pick probability distributions over the , , and 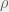, we can calculate the posterior probability of a given set of clusters as\n\n\np(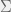, , 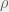 | )  p() p() p(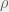) 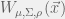\n\n\nThis corresponds to the following graphical model:\n\n\n\n\n\nNote that once we have a set of clusters, we can also determine the probability that a given point belongs to each cluster:\n\n\np( belongs to cluster 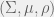)  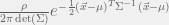.\n\n\nYou might notice, though, that in this case it is much less straightforward to actually find clusters with high posterior probability (as opposed to in the previous case, where it was quite easy to distinguish between Fair, Unfair, and Weird, and furthermore to figure out the most likely values of  and ). One reason why is that, in the previous case, we really only needed to make one-dimensional searches over  and  to figure out what the most likely values were. In this case, we need to search over all of the , , and  simultaneously, which gives us, essentially, a -dimensional search problem, which becomes exponentially hard quite quickly.\n\n\nThis brings us to an important point, which is that, even if we write down a model, *searching over that model can be difficult.* So in addition to the model, I will go over a good algorithm for finding the clusters from this model, known as the [EM algorithm](http://en.wikipedia.org/wiki/Expectation-maximization_algorithm). For the version of the EM algorithm described below, I will assume that we have uniform priors over , , and  (in the last case, we have to do this by picking a set of un-normalized  uniformly over  and then normalizing). We’ll ignore the problem that it is not clear how to define a uniform distribution over a non-compact space.\n\n\nThe way the EM algorithm works is that we start by initializing  , and  arbitrarily. Then, given these values, we compute the probability that each point belongs to each cluster. Once we have these probabilities, we re-compute the maximum-likelihood values of the  (as the expected mean of each cluster given how likely each point is to belong to it). Then we find the maximum-likelihood values of the  (as the expected covariance relative to the means we just found). Finally, we find the maximum-likelihood values of the  (as the expected portion of points that belong to each cluster). We then repeat this until converging on an answer.\n\n\nFor a visualization of how the EM algorithm actually works, and a more detailed description of the two steps, I recommend taking a look at [Josh Tenenbaum’s lecture notes](http://stellar.mit.edu/S/course/9/fa09/9.66J/courseMaterial/topics/topic11/lectureNotes/Nov_17_2009_-_pdf/Nov_17_2009_-_pdf.pdf) starting at slide 38.\n\n\n \n\n\n**The Mind Projection Fallacy**\n\n\nThis is perhaps a nitpicky point, but I have found that keeping it in mind has led me to better understanding what I am doing, or at least to ask interesting questions.\n\n\nThe point here is that people often intuitively think of probabilities as a fact about the world, when in reality probabilities are a fact about our model of the world. For instance, one might say that the probability of a child being male versus female is 0.5. And perhaps this is a good thing to say in a generic case. But we also have a much better model of gender, and we know that it is based on X and Y chromosomes. If we could look at a newly conceived ball of cells in a mother’s womb, and read off the chromosomes, then we could say with near certainty whether the child would end up being male or female.\n\n\nYou could also argue that I can *empirically measure the probability* that a person is male or female, by counting up all the people ever, and looking at the proportion of males and females. But this runs into two issues — first of all, the portion of males will be slightly off of 0.5. So how do we justify just randomly rounding off to 0.5? Or do we not?\n\n\nSecond of all, you can do this all you want, but it doesn’t give me any reason why I should take this information, and use it to form a *conjecture* about how likely the next person I meet is to be male or female. Once we do that, we are taking into account my model of the world.\n\n\n**Statistics**\n\n\nThis final section seeks to look at a result from classical statistics and re-interpret it in a Bayesian framework.\n\n\nIn particular, I’d like to consider the following strategy for rejecting a hypothesis. In abstract terms, it says that, if we have a random variable Data’ that consists of re-drawing our data assuming that our hypothesis is correct, then\n\n\np(Hypothesis) < p(p(Data’ | Hypothesis) <= p(Data | Hypothesis))\n\n\nIn other words, suppose that the probability of drawing data less likely (under our hypothesis) than the data we actually saw is less than . Then the likelihood of our hypothesis is at most .\n\n\nOr actually, this is not quite true. But it is true that there is an algorithm that will only reject correct hypotheses with probability , and this algorithm is to reject a hypothesis when p(p(Data’ | Hypothesis) <= p(Data | Hypothesis)) < . I will leave the proof of this to you, as it is quite easy.\n\n\nTo illustrate this example, let’s suppose (as in a previous section) that we have a coin and would like to determine whether it is fair. In the above method, we would flip it many times, and record the number H of heads. If there is less than an  chance of coming up with a less likely number of heads than H, then we can reject the hypothesis that the coin is fair with confidence . For instance, if there are 80 total flips, and H = 25, then we would calculatae\n\n\n.\n\n\nSo this seems like a pretty good test, especially if we choose  to be extremely small (e.g.,  or so). The mere fact that we reject good hypotheses with probability less than  is not helpful. What we really want is to also reject bad hypotheses with a reasonably large probability. I think you can get around this by repeating the same experiment many times, though.\n\n\nOf course, Bayesian statistics also can’t ever say that a hypothesis is good, but when given two hypotheses it will always say which one is better. On the other hand, Bayesian statistics has the downside that it is extremely aggressive at making inferences. It will always output an answer, even if it really doesn’t have enough data to arrive at that answer confidently.\n\n\n \n\n\n \n\n\n \n\n\n \n\n\n \n\n\n \n\n", "url": "https://jsteinhardt.wordpress.com/2010/09/13/nobody-understands-probability/", "title": "Nobody Understands Probability", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-09-13T02:23:53+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "41e905d380457bcde3a6a35779411fb9", "summary": []}
+{"text": "Least Squares and Fourier Analysis\n\nI ended my last post on a somewhat dire note, claiming that least squares can do pretty terribly when fitting data. It turns out that things aren’t quite as bad as I thought, but most likely worse than you would expect.\n\n\nThe theme of this post is going to be things you use all the time (or at least, would use all the time if you were an electrical engineer), but probably haven’t ever thought deeply about. I’m going to include a combination of mathematical proofs and matlab demonstrations, so there should hopefully be something here for everyone.\n\n\nMy first topic is going to be, as promised, least squares curve fitting. I’ll start by talking about situations when it can fail, and also about situations when it is “optimal” in some well-defined sense. To do that, I’ll have to use some Fourier analysis, which will present a good opportunity to go over when frequency-domain methods can be very useful, when they can fail, and what you can try to do when they fail.\n\n\n**When Least Squares Fails**\n\n\nTo start, I’m going to do a simple matlab experiment. I encourage you to follow along if you have matlab (if you have MIT certificates you can get it for free at [http://matlab.mit.edu/](http://matlab.mit.edu)).\n\n\nLet’s pretend we have some simple discrete-time process, y(n+1) = a\\*y(n) + b\\*u(n), where y is the variable we care about and u is some input signal. We’ll pick a = 0.8, b = 1.0 for our purposes, and u is chosen to be a discrete version of a random walk. The code below generates the y signal, then uses least squares to recover a and b. (I recommend taking advantage of cell mode if you’re typing this in yourself.)\n\n\n\n> %% generate data\n> \n> \n> a = 0.8; b = 1.0;\n> \n> \n> N = 1000;\n> \n> \n> ntape = 1:N; y = zeros(N,1); u = zeros(N-1,1);\n> \n> \n> for n=1:N-2\n> \n> \n> if rand < 0.02\n> \n> \n> u(n+1) = 1-u(n);\n> \n> \n> else\n> \n> \n> u(n+1) = u(n);\n> \n> \n> end\n> \n> \n> end\n> \n> \n> for n=1:N-1\n> \n> \n> y(n+1) = a\\*y(n)+b\\*u(n);\n> \n> \n> end\n> \n> \n> plot(ntape,y);\n> \n> \n> %% least squares fit (map y(n) and u(n) to y(n+1))\n> \n> \n> A = [y(1:end-1) u]; b = y(2:end);\n> \n> \n> params = A\\b;\n> \n> \n> afit = params(1)\n> \n> \n> bfit = params(2)\n> \n> \n\n\nThe results are hardly surprising (you get afit = 0.8, bfit = 1.0). For the benefit of those without matlab, here is a plot of y against n:\n\n\n[](https://jsteinhardt.files.wordpress.com/2010/08/plot1-2.pdf)\n\n\nNow let’s add some noise to the signal. The code below generates noise whose size is about 6% of the size of the data (in the sense of [L2 norm](http://mathworld.wolfram.com/L2-Norm.html)).\n\n\n\n> %%\n> \n> \n> yn = y + 0.1\\*randn(N,1); % gaussian noise with standard deviation 0.2\n> \n> \n> A = [yn(1:end-1) u]; b = yn(2:end);\n> \n> \n> params = A\\b;\n> \n> \n> afit = params(1)\n> \n> \n> bfit = params(2)\n> \n> \n\n\nThis time the results are much worse: afit = 0.7748, bfit = 1.1135. You might be tempted to say that this isn’t so much worse than we might expect — the accuracy of our parameters is roughly the accuracy of our data. The problem is that, if you keep running the code above (which will generate new noise each time), you will always end up with afit close to 0.77 and bfit close to 1.15. In other words, the parameters are **systematically biased** by the noise. Also, we should expect our accuracy to increase with more samples, but that isn’t the case here. If we change N to 100,000, we get afit = 0.7716, bfit = 1.1298. More samples *will* decrease the standard deviation of our answer (running the code multiple times will yield increasingly similar results), but not necessarily its correctness.\n\n\nA more dire way of thinking about this is that increasing the number of samples will increase how “certain” we are of our answer, but it won’t change the fact that our answer is wrong. So we will end up being quite certain of an incorrect answer.\n\n\nWhy does this happen? It turns out that when we use least squares, we are making certain assumptions about the *structure* of our noise, and those assumptions don’t hold in the example above. In particular, in a model like the one above, least squares assumes that all noise is **process noise**, meaning that noise at one step gets propagated to future steps. Such noise might come from a system with unmodelled friction or some external physical disturbance. In contrast, the noise we have is **output noise**, meaning that the reading of our signal is slightly off. What the above example shows is that a model constructed via least squares will be systematically biased by output noise.\n\n\nThat’s the intuition, now let’s get into the math.When we do least squares, we are trying to solve some equation Ax=b for x, where A and b are both noisy. So we really have something like A+An and b+bn, where An and bn are the noise on A and b.\n\n\nBefore we continue, I think it’s best to stop and think about [what we really want](http://lesswrong.com/lw/nm/disguised_queries). So what is it that we actually want? We observe a bunch of data as input, and some more data as output. We would like a way of predicting, given the input, what the output should be. In this sense, then, the distinction between “input noise” (An) and “output noise” bn is meaningless, as we don’t get to see either and all they do is cause b to not be exactly Ax. (If we start with assumptions on what noise “looks like”, then distinguishing between different sources of noise turns out to be actually useful. More on that later.)\n\n\nIf the above paragraph isn’t satisfying, then we can use the more algebraic explanation that the noise An and bn induces a single random variable on the relationship between observed input and observed output. In fact, if we let A’=A+An then we end up fitting , so we can just define  and have a single noise term.\n\n\nNow, back to least squares. Least squares tries to minimize , that is, the squared error in the [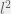 norm](http://mathworld.wolfram.com/L2-Norm.html). If we instead have a noisy , then we are trying to minimize , which will happen when  satisfies 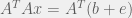.\n\n\nIf there actually exists an 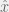 such that 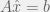 (which is what we are positing, subject to some error term), then minimizing 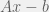 is achieved by setting  to 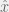. Note that 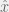 is what we would like to recover. So 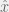 would be the solution to , and thus we see that an error  introduces a linear error in our estimate of . (To be precise, the error affects our answer for  via the operator .)\n\n\nNow all this can be seen relatively easily by just using the standard formula for the solution to least squares: 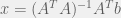. But I find that it is easy to get confused about what exactly the “true” answer is when you are fitting data, so I wanted to go through each step carefully.\n\n\nAt any rate, we have a formula for how the error  affects our estimate of , now I think there are two major questions to answer:\n\n\n(1) In what way can  *systematically bias* our estimate for ?\n\n\n(2) What can we say about the [*variance*](http://en.wikipedia.org/wiki/Variance#Discrete_case) on our estimate for ?\n\n\nTo calculate the bias on , we need to calculate , where  stands for [expected value](http://en.wikipedia.org/wiki/Expected_value). Since  is invertible, this is the same as . In particular, we will get an *unbiased* estimate exactly when  and  are uncorrelated. Most importantly, when we have noise on our inputs then  and  will (probably) be correlated, and we won’t get an unbiased result.\n\n\nHow bad is the bias? Well, if A actually has a noise component (i.e. 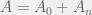), and e is , and we assume that our noise is uncorrelated with the constant matrix , then we get a correlation matrix equal to , which, assuming that  and  are uncorrelated, gives us . The overall bias then comes out to .\n\n\nI unfortunately don’t have as nice of an expression for the variance, although you can of course calculate it in terms of , and .\n\n\nAt any rate, if noise doesn’t show up in the input, and the noise that does show up is uncorrelated with the input, then we should end up with no bias. But if either of those things is true, we will end up with bias. When modelling a dynamical system, input noise corresponds to *measurement noise* (your sensors are imperfect), while output noise corresponds to *process noise* (the system doesn’t behave exactly as expected).\n\n\nOne way we can see how noise being correlated with  can lead to bias is if our “noise” is actually an unmodelled quadratic term. Imagine trying to fit a line to a parabola. You won’t actually fit the tangent line to the parabola, instead you’ll probably end up fitting something that looks like a secant. However, the exact slope of the line you pick will depend pretty strongly on the distribution of points you sample along the parabola. Depending on what you want the linear model for, this could either be fine (as long as you sample a distribution of points that matches the distribution of situations that you think you’ll end up using the model for), or very annoying (if you really wanted the tangent).\n\n\nIf you’re actually just dealing with a parabola, then you can still get the tangent by sampling symmetrically about the point you care about, but once you get to a cubic this is no longer the case.\n\n\nAs a final note, one reasonable way (although I’m not convinced it’s the best, or even a particularly robust way) of determining if a linear fit of your data is likely to return something meaningful is to look at the [condition number](http://en.wikipedia.org/wiki/Condition_number) of your matrix, which can be computed in matlab using the cond function and can also be realized as the square root of the ratio of the largest to the smallest eigenvalue of . Note that the condition number says nothing about whether your data has a reasonable linear fit (it can’t, since it doesn’t take  into account). Rather, it is a measure of how well-defined the coefficients of such a fit would be. In particular, it will be large if your data is close to lying on a lower-dimensional subspace (which can end up really screwing up your fit). In this case, you either need to collect better data or figure out why your data lies on a lower-dimensional subspace (it could be that there is some additional structure to your system that you didn’t think about; see point (3) below about a system that is heavily damped).\n\n\nI originally wanted to write down a lot more about specific ways that noise can come into the picture, but I haven’t worked it all out myself, and it’s probably too ambitious a project for a single blog post anyways. So instead I’m going to leave you with a bunch of things to think about. I know the answers to some of these, for others I have ideas, and for others I’m still trying to work out a good answer.\n\n\n1) Can anything be done to deal with measurement noise? In particular, can anything be done to deal with the sort of noise that comes from [encoders](http://en.wikipedia.org/wiki/Encoder#Transducers) (i.e., a discretization of the signal)?\n\n\n2) Is there a good way of measuring when noise will be problematic to our fit?\n\n\n3) How can we fit models to systems that evolve on multiple time-scales? For example, an extremely damped system such as\n\n\n\n\n\n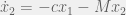\n\n\nwhere M >> c. You could take, for example, , , in which case the system behaves almost identically to the system\n\n\n\n\n\nwith  set to the derivative of . Then the data will all lie almost on a line, which can end up screwing up your fit. So in what exact ways can your fit get screwed up, and what can be done to deal with it? (This is essentially the problem that I’m working on right now.)\n\n\n4) Is there a way to defend against non-linearities in a system messing up our fit? Can we figure out when these non-linearities occur, and to what extent?\n\n\n5) What problems might arise when we try to fit a system that is unstable or only slightly stable, and what is a good strategy for modelling such a system?\n\n\n**When Least Squares Works**\n\n\nNow that I’ve convinced you that least squares can run into problems, let’s talk about when it can do well.\n\n\nAs Paul Christiano pointed out to me, when you have some system where you can actually give it inputs and measure the outputs, least squares is likely to do a fairly good job. This is because you can (in principle) draw the data you use to fit your model from the same distribution as you expect to encounter when the model is used in practice. However, you will still run into the problem that failure to measure the input accurately introduces biases. And no, these biases can’t be eradicated completely by averaging the result across many samples, because the bias is always a negative definite matrix applied to  (the parameters we are trying to find), and any convex combination of negative definite matrices will remain negative definite.\n\n\nIntuitively, what this says is that if you can’t trust your input, then you shouldn’t rely on it strongly as a predictor. Unfortunately, the only way that a linear model knows how to trust something less is by making the coefficient on that quantity “smaller” in some sense (in the negative definite sense here). So really the issue is that least squares is too “dumb” to deal with the issue of measurement error on the input.\n\n\nBut I said that I’d give examples of when least squares works, and here I am telling you more about why it fails. One powerful and unexpected aspect of least squares is that it can fit a wide variety of *non*-linear models. For example, if we have a system 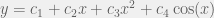, then we just form a matrix ![A = \\left[ \\begin{array}{cccc} 1 & x & x^2 & \\cos(x) \\end{array} \\right]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+x+%26+x%5E2+%26+%5Ccos%28x%29+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) and , where for example 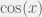 is actually a column vector where the th row is the cosine of the th piece of input data. This will often be the case in physical systems, and I think is always the case for systems solved via Newton’s laws (although you might have to consolide parameters, for example fitting both 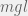 and  in the case of a pendulum). This isn’t necessarily the case for reduced models of complicated systems, for example the sort of models used for fluid dynamics. However, I think that the fact that linear fitting techniques can be applied to such a rich class of systems is quite amazing.\n\n\nThere is also a place where least squares not only works but is in some sense *optimal*: detecting the frequency response of a system. Actually, it is only optimal in certain situations, but even outside of those situations it has many advantages over a standard discrete Fourier transform. To get into the applications of least squares here, I’m going to have to take a detour into Fourier analysis.\n\n\n**Fourier Analysis**\n\n\nIf you already know Fourier analysis, you can probably skip most of this section (although I recommend reading the last two paragraphs).\n\n\nSuppose that we have a sequence of 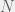 signals at equally spaced points in time. Call this sequence 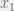, 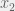, , . We can think of this as a function , or, more accurately, . For reasons that will become apparent later, we will actually think of this as a function .\n\n\nThis function is part of the vector space of all functions from  to . One can show that the functions on  defined by\n\n\n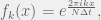\n\n\nwith  ranging from 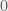 to , are all orthogonal to each other, and thus form a basis for the space of all functions from 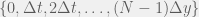 to  (now it is important to use  since the 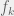 take on complex values). It follows that our function  can be written uniquely in the form , where the 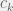 are constants. Now because of this we can associate with each  a function  given by .\n\n\nAn intuitive way of thinking about this is that any function can be uniquely decomposed as a superposition of complex exponential functions at different frequencies. The function 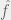 is a measure of the component of  at each of these frequencies. We refer to 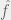 as the **Fourier transform** of .\n\n\nWhile there’s a lot more that could be said on this, and I’m tempted to re-summarize all of the major results in Fourier analysis, I’m going to refrain from doing so because there are plenty of texts on it and you can probably get the relevant information (such as how to compute the Fourier coefficients, the inverse Fourier transform, etc.) from those. In fact, you could start by checking out [Wikipedia’s article](http://en.wikipedia.org/wiki/Discrete_Fourier_transform). It is also worth noting that the Fourier transform can be computed in  time using any one of many “fast Fourier transform” algorithms (fft in matlab).\n\n\nI will, however, draw your attention to the fact that if we start with information about  at times 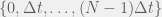, then we end up with frequency information at the frequencies . Also, you should really think of the frequencies as wrapping around cyclically (frequencies that differ from each other by a multiple of  are indistinguishable on the interval we sampled over), and also if  is real-valued then 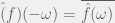, where the bar means complex conjugate and  is, as just noted, the same as 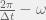.\n\n\nA final note before continuing is that we could have decomposed  into a set of almost any  frequencies (as long as they were still linearly independent), although we can’t necessarily do so in  time. We will focus on the set of frequencies obtained by a Fourier transform for now.\n\n\n**When Fourier Analysis Fails**\n\n\nThe goal of taking a Fourier transform is generally to decompose a signal into component frequencies, under the assumption that the signal itself was generated by some “true” superposition of frequencies. This “true” superposition would best be defined as the frequency spectrum we would get if we had an infinitely long continuous tape of noise-free measurements and then took the [continuous Fourier transform](http://en.wikipedia.org/wiki/Fourier_transform).\n\n\nI’ve already indicated one case in which Fourier analysis can fail, and this is given by the fact that the Fourier transform can’t distinguish between frequencies that are separated from each other by multiples of . In fact, what happens in general is that you run into problems when your signal contains frequencies that move faster than your sampling rate. The rule of thumb is that your signal should contain no significant frequency content above the [Nyquist rate](http://en.wikipedia.org/wiki/Nyquist_frequency), which is half the sampling frequency. One way to think of this is that the “larger” half of our frequencies (i.e.  up through ) are really just the negatives of the smaller half of our frequencies, and so we can measure frequencies up to roughly  before different frequencies start to run into each other.\n\n\nThe general phenomenon that goes on here is known as aliasing, and is the same sort of effect as what happens when you spin a bicycle wheel really fast and it appears to be moving backwards instead of forwards. The issue is that your eye only samples at a given rate and so rotations at speeds faster than that appear the same to you as backwards motion. See also [this image](http://en.wikipedia.org/wiki/File:AliasingSines.svg) from Wikipedia and the section in the [aliasing article](http://en.wikipedia.org/wiki/Aliasing) about sampling sinusoidal functions.\n\n\nThe take-away message here is that you need to sample fast enough to capture all of the actual motion in your data, and the way you solve aliasing issues is by increasing the sample rate.\n\n\nA trickier problem is the “windowing” problem, also known as [spectral leakage](http://en.wikipedia.org/wiki/Spectral_leakage). [Note: I really recommend reading the linked wikipedia article at some point, as it is a very well-written and insightful treatment of this issue.] The problem can be summarized intuitively as follows: nearby frequencies will “bleed into” each other, and the easiest way to reduce this phenomenon is to increase your sample time. Another intuitive statement to this effect is that the extent to which you can distinguish between two nearby frequencies is roughly proportional to the number of full periods that you observe of their difference frequency. I will make both of these statements precise below. First, though, let me convince you that spectral leakage is relevant by showing you what the Fourier transform of a periodic signal looks like when the period doesn’t fit into the sampling window. The first image below is a plot of y=cos(t), and the second is a snapshot of part of the Fourier transform (blue is real part, green is imaginary part). Note that the plot linearly interpolates between sample points. Also note that the sampling frequency was 100Hz, although that is almost completely irrelevant.\n\n\n[ from t=0 to t=20\")](https://jsteinhardt.files.wordpress.com/2010/08/plot2.pdf)\n\n\n[\")](https://jsteinhardt.files.wordpress.com/2010/08/plot2fft.pdf)The actual frequency content should be a single spike at , so windowing can in fact cause non-trivial issues with your data.\n\n\nNow let’s get down to the actual analytical reason for the windowing / spectral leakage issue. Recall the formula for the Fourier transform: . Now suppose that  is a complex exponential with some frequency , i.e. . Then some algebra will yield the formula\n\n\n,\n\n\nwhich tells us the extent to which a signal at a frequency of  will incorrectly contribute to the estimate of the frequency content at . The main thing to note here is that larger values of  will cause this function to become more concentrated horizontally, which means that, in general (although not necessarily at a given point), it will become smaller. At the same time, if you change the sampling rate without changing the total sampling time then you won’t significantly affect the function. This means that the easiest way to decrease windowing is to increase the amount of time that you sample your signal, but that sampling more often will not help you at all.\n\n\nAnother point is that spectral leakage is generically roughly proportional to the inverse of the distance between the two frequencies (although it goes to zero when the difference in frequencies is close to a multiple of 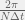), which quantifies the earlier statement about the extent to which two frequencies can be separated from each other.\n\n\nSome other issues to keep in mind: the Fourier transform won’t do a good job with quasi-periodic data (data that is roughly periodic with a slowly-moving phase shift), and there is also no guarantee that your data will have good structure in the frequency domain. It just happens that this is in theory the case for analytic systems with a periodic excitation (see note (1) in the last section of this post — “Answers to Selected Exercises” — for a more detailed explanation).\n\n\n**When Fourier Analysis Succeeds**\n\n\nDespite issues with aliasing and spectral leakage, there are some strong points to the Fourier transform. The first is that, since the Fourier transform is an orthogonal map, it does not amplify noise. More precisely, , so two signals that are close together have Fourier transforms that are also close together. This may be somewhat surprising since normally when one fits 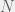 parameters to a signal of length , there are significant issues with overfitting that can cause noise to be amplified substantially.\n\n\nHowever, while the Fourier transform does not *amplify* noise, it can *concentrate* noise. In particular, if the noise has some sort of quasi-periodic structure then it will be concentrated over a fairly small range of frequencies.\n\n\nNote, though, that the L2 norm of the noise in the frequency domain will be roughly constant relative to the number of samples. This is because, if  is the “true” signal and  is the measured signal, then , so that . Now also note that the number of frequency measurements we get out of the Fourier transform within a fixed band is proportional to the sampling time, that is, it is . If we put these assumptions together, and also assume that the noise is quasi-periodic such that it will be concentrated over a fixed set of frequencies, then we get  noise distributed in the L2 sense over  frequencies, which implies that the level of noise at a given frequency should be . In other words, sampling for a longer time will increase our resolution on frequency measurements, which means that the noise at a *given* frequency will decrease as the square-root of the sampling time, which is nice.\n\n\nMy second point is merely that there is no spectral leakage between frequencies that differ by multiples of 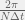, so in the special case when all significant frequency content of the signal occurs at frequencies that are multiples of 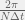 and that are less than  all problems with windowing and aliasing go away and we do actually get a perfect measure of the frequency content of the original signal.\n\n\n**Least Squares as a Substitute**\n\n\nThe Fourier transform gives us information about the frequency content at 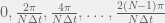. However, this set of frequencies is somewhat arbitrary and might not match up well to the “important” frequencies in the data. If we have extra information about the specific set of frequencies we should be caring about, then a good substitute for Fourier analysis is to do least squares fitting to the signal as a superposition of the frequencies you care about.\n\n\nIn the special case that the frequencies you care about are a subset of the frequencies provided by the Fourier transform, you will get identical results (this has to do with the fact that complex exponentials at these frequencies are all orthogonal to each other).\n\n\nIn the special case that you *exactly* identify which frequencies occur in the signal, you eliminate the spectral leakage problem entirely (it still occurs in theory, but not between any of the frequencies that actually occur). A good way to do this in the case of a dynamical system is to excite the system at a fixed frequency so that you know to look for that frequency plus small harmonics of that frequency in the output.\n\n\nIn typical cases least squares will be fairly resistant to noise unless that noise has non-trivial spectral content at frequencies near those being fit. This is almost tautologically true, as it just says that spectral leakage is small between frequencies that aren’t close together. However, this isn’t exactly true, as fitting non-orthogonal frequencies changes the sort of spectral leakage that you get, and picking a “bad” set of frequencies (usually meaning large condition number) can cause lots of spectral leakage even between far apart frequencies, or else drastically exacerbate the effects of noise.\n\n\nThis leads to one reason *not* to use least squares and to use the Fourier transform instead (other than the fact that the Fourier transform is more efficient in an algorithmic sense at getting data about large sets of frequencies —  instead of 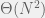). The Fourier transform always has a condition number of , whereas least squares will in general have a condition number greater than , and poor choices of frequencies can lead to very large condition numbers. I typically run into this problem when I attempt to gain lots of resolution on a fixed range of frequencies.\n\n\nThis makes sense, because there are information-theoretic limits on the amount of frequency data I can get out of a given amount of time-domain data, and if I could zoom in on a given frequency individually, then I could just do that for all frequencies one-by-one and break the information theory bounds. To beat these bounds you will have to at least implicitly make additional assumptions about the structure of the data. However, I think you can probably get pretty good results without making too strong of assumptions, but I unfortunately don’t personally know how to do that yet.\n\n\nSo to summarize, the Fourier transform is nice because it is orthogonal and can be computed quickly. Least squares is nice because it allows you to pick which frequencies you want and so gives you a way to encode additional information you might have about the structure of the signal.\n\n\nSome interesting questions to ask:\n\n\n(1) What does spectral leakage look like for non-orthogonal sets of frequencies? What do the “bad” cases look like?\n\n\n(2) What is a good set of assumptions to make that helps us get better frequency information? (The weaker the assumption and the more leverage you get out of it, the better it is.)\n\n\n(3) Perhaps we could try something like: “pick the smallest set of frequencies that gives us a good fit to the data”. How could we actually implement this in practice, and would it have any shortcomings? How good would it be at pulling weak signals out of noisy data?\n\n\n(4) What in general is a good strategy for pulling a weak signal out of noisy data?\n\n\n(5) What is a good way of dealing with quasi-periodic noise?\n\n\n(6) Is there a way to deal with windowing issues, perhaps by making statistical assumptions about the data that allows us to “sample” from possible hypothetical continuations of the signal to later points in time?\n\n\n**Take-away lessons**\n\n\nTo summarize, I would say the following:\n\n\n*Least squares*\n\n\n* good when you get to sample from a distribution of inputs that matches the actual distribution that you’re going to deal with in practice\n* bad due to systematic biases when noise is correlated with signal (usually occurs with “output noise” in the case of a dynamical system)\n\n\n*Fourier transform*\n\n\n* good for getting a large set of frequency data\n* good because of small condition number\n* can fail due to aliasing\n* also can be bad due to spectral leakage, which can be dealt with by using least squares if you have good information about which frequencies are important\n\n\n**Answers to selected exercises**\n\n\nOkay well mainly I just feel like some of the questions that I gave as exercises are important enough that you should know the answer. There isn’t necessarily a single answer, but I’ll at least give you a good way of doing something if I know of one. I’ve added a fold so you can avoid spoilers. It turns out that for this post I only have one good answer, which is about dealing with non-linear dynamical systems.\n\n\n\nWe can figure out if a dynamical system is non-linear (and get some quantitative data about the non-linearities we’re dealing with) by inputting a signal that has only a few frequencies (i.e., the superposition of a small number of sines and cosines) and then looking at the Fourier transform of the response. If the system is completely linear, then the response should contain the same set of frequencies as the input (plus a bit of noise). If the system is non-linear but still analytic then you will also see responses at integer linear combinations of the input frequencies. If the system is non-analytic (for example due to [Coulombic friction](http://en.wikipedia.org/wiki/Friction), the type of friction you usually assume in introductory physics classes) then you might see a weirder frequency response.\n\n", "url": "https://jsteinhardt.wordpress.com/2010/08/22/least-squares-and-fourier-analysis/", "title": "Least Squares and Fourier Analysis", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-08-22T00:33:43+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "4f5ce7e39fc5993c1b818f2fd7d33042", "summary": []}
+{"text": "Linear Control Theory: Part I\n\nLast time I talked about linear control, I presented a Linear Quadratic Regulator as a general purpose hammer for solving linear control problems. In this post I’m going to explain why LQR by itself is not enough (even for nominally linear systems). *(Author’s note: I got to the end of the post and realized I didn’t fulfill my promise in the previous sentence. So it’s redacted, but will hopefully be dealt with in a later post.)* Then I’m going to do my best to introduce a lot of the standard ideas in linear control theory.\n\n\nMy motivation for this is that, even though these ideas have a reasonably nice theory from a mathematical standpoint, they are generally presented from an engineering standpoint. And although all of the math is right there, and I’m sure that professional control theorists understand it much better than I do, I found that I had to go to a lot of effort to synthesize a good mathematical explanation of the underlying theory.\n\n\nHowever, this effort was not due to any inherent difficulties in the theory itself, but rather, like I said, a disconnect in the intuition of, and issues relevant to, an engineer versus a mathematician. I’m not going to claim that one way of thinking is better than the other, but my way of thinking, and I assume that of most of my audience, falls more in line with the mathematical viewpoint. What’s even better is that many of the techniques built up for control theory have interesting ramifications when considered as statements about vector spaces. I hope that you’ll find the exposition illuminating.\n\n\nAs before, we will consider a linear system\n\n\n\n\n\nwhere  and  are matrices and  is a vector of control inputs ( is the state of the system). However, in addition to a control input , we will have an output , such that  is a function of  and :\n\n\n\n\n\nIn some cases,  will be a set of observed states of a system, but in principal  can be any quantity we care about, provided that it is a linear function of state and control. We further assume that , , , and  are constant with respect to time. We call a system that follows this assumption a [linear time-invariant system](http://en.wikipedia.org/wiki/LTI_system_theory), or just LTI system.\n\n\nSince the system is linear, we have superposition and therefore can break up any function (for example, the function from  to 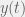) into a function from each coordinate of  to each coordinate of 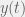. For each of these functions, we can take their Laplace transform. So, we start with\n\n\n\n\n\n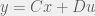\n\n\nand end up with (after taking the Laplace transform)\n\n\n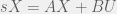\n\n\n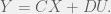\n\n\nSolving these two equations for  as a function of  gives . We call this mapping from  to  the *transfer function* of the system. [Cramer’s Rule](http://en.wikipedia.org/wiki/Cramer%27s_rule) implies that the transfer function of any linear time-invariant system will be a matrix where each entry is a ratio of two polynomials. We refer to such transfer functions as *rational*. I will show later that the converse is also true: any rational matrix is the transfer function of some LTI system. We call such an LTI system the *state-space representation* of the transfer function. (I apologize for throwing all this terminology at you, but it is used pretty unapologetically in control systems literature so I’d feel bad leaving it out.)\n\n\nAs an example, consider a damped harmonic oscillator with an external force  as a control input, and suppose that the outputs we care about are position and velocity. We will let  denote the position of the oscillator. This has the following state-space representation:\n\n\n![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{cc} 0 & 1 \\\\ -k & -b \\end{array} \\right] \\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right] + \\left[ \\begin{array}{c} 0 \\\\ 1 \\end{array} \\right] u](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+++%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+-k+%26+-b+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+++%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+++%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+u&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\n![\\left[ \\begin{array}{c} y_1 \\\\ y_2 \\end{array} \\right] = \\left[ \\begin{array}{cc} 1 & 0 \\\\ 0 & 1 \\end{array} \\right] \\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right] + 0 \\cdot u](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+y_1+%5C%5C+y_2+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+++%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+++%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+0+%5Ccdot+u&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nHere  is the spring constant of the oscillator and  is the damping factor. For convenience we will write  instead of ![\\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) and  instead of ![\\left[ \\begin{array}{c} y_1 \\\\ y_2 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+y_1+%5C%5C+y_2+++%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). Also, we will let  denote the  identity matrix. Then, after taking the Laplace transform, we get\n\n\n![sX = \\left[ \\begin{array}{cc} 0 & 1 \\\\ -k & -b \\end{array} \\right]X + \\left[ \\begin{array}{c} 0 \\\\ 1 \\end{array} \\right]U](https://s0.wp.com/latex.php?latex=sX+++%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+-k+%26+-b+%5Cend%7Barray%7D+++%5Cright%5DX+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5DU&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\n\n\n\nSolving the first equation gives\n\n\n![\\left[ \\begin{array}{cc} s & -1 \\\\ k & s+b \\end{array} \\right] X = \\left[ \\begin{array}{c} 0 \\\\ 1 \\end{array} \\right]U,](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+s+%26+-1+%5C%5C+k+%26+s%2Bb+%5Cend%7Barray%7D+%5Cright%5D+X+++%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5DU%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nor\n\n\n![X = \\frac{1}{s^2+bs+k}\\left[ \\begin{array}{cc} s+b & 1 \\\\ -k & s \\end{array} \\right]\\left[ \\begin{array}{c} 0 \\\\ 1 \\end{array}\\right]U = \\frac{1}{s^2+bs+k} \\left[ \\begin{array}{c} 1 \\\\ s \\end{array} \\right]U](https://s0.wp.com/latex.php?latex=X+%3D+++%5Cfrac%7B1%7D%7Bs%5E2%2Bbs%2Bk%7D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+s%2Bb+%26+1+%5C%5C+-k+%26+s+++%5Cend%7Barray%7D+%5Cright%5D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D%5Cright%5DU+%3D+++%5Cfrac%7B1%7D%7Bs%5E2%2Bbs%2Bk%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+s+%5Cend%7Barray%7D+%5Cright%5DU&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nTherefore, the transfer function from  to  is ![\\frac{1}{s^2+bs+k} \\left[ \\begin{array}{c} 1 \\\\ s \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Bs%5E2%2Bbs%2Bk%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+s+%5Cend%7Barray%7D+++%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002).\n\n\nWe can think of the transfer function as a multiplier on the frequency spectrum of  (note that  is allowed to be an arbitrary complex number; if  is non-real then we have oscillation at a frequency equal to the imaginary part of ; if 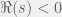 then we have damped oscillation, whereas if  then the magnitude of the oscillation increases exponentially. Note that 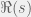 denotes the real part of .\n\n\nExercise: What does a pole of a transfer function correspond to? What about a zero? Answers below the fold.\n\n\nIf a transfer function has a pole, then it means that even if a given frequency doesn’t show up in the input , it can still show up in the output . Thus it is some self-sustaining, natural mode of the system. For LTI systems, this corresponds to an eigenvector of the matrix , and the location of the pole is the corresponding eigenvalue.\n\n\nA zero, on the other hand, means that a mode will not show up in the output even if it is present in the input. So for instance, the damped oscillator has poles at . Let us assume that  and  are both positive for the damped oscillator. Then, for , both of the poles are real and negative, meaning that the system is critically damped. For , the poles have negative real part and imaginary part equal to 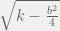, meaning that the system will exhibit damped oscillation. Finally, there is a zero in the second coordinate of the transfer matrix at . This corresponds to the fact that a harmonic oscillator can be held at a fixed distance from its natural fixed point by a fixed external force. Since the distance is fixed, the contribution to velocity is zero.\n\n\nThere is more to be said on transfer functions, but before I go into that I would like to give you a working picture of how  and  should be viewed mathematically. This is a view that I only recently acquired. For this I owe thanks to [Stefano Stramigioli](http://www.ce.utwente.nl/smi/Welcome.html), who gave a [very interesting talk on port-Hamiltonian methods](http://dynamicwalking.org/dw2010/node/6/#Stramigioli) at Dynamic Walking 2010. *(Update: Stefano recommends [this book](http://books.google.com/books?id=qFraVEzCTnUC&printsec=frontcover#v=onepage&q&f=false) as a resource for learning more.)*\n\n\n**Duality**\n\n\nHere is how I think you should think about linear control mathematically. First, you have a state-space . You also have a space of controls  and a space of outputs . Finally, you have a space , the tangent space to .\n\n\nIgnoring  and  for a moment, let’s just focus on  and . We can think of elements of  as generalized forces, and the elements of  as generalized velocities. I realize that state-space also takes position into account, but you will note that no external forces show up in the equations for position, so I think this view still makes sense.\n\n\nIf we have a set of forces and velocities, then we can compute power (if our system is in regular Cartesian coordinates, then this is just 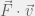). In this way, we can think of 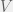 and 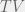 as dual to each other. I think that generalized velocities are actually somehow supposed to live in the cotangent space , rather than 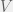, but I don’t know enough analysis to see why this is true. If someone else does, I would love to hear your explanation.\n\n\nAt any rate, we have these two spaces, 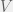 and 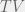, that are in duality with each other. The operator 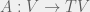 then induces a map  from  to 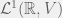, where  is the space of [Lesbegue-integrable functions](http://en.wikipedia.org/wiki/Lp_space) from  to  (although in practice all of our inputs and outputs will be real-valued, not complex-valued, since the systems we care about are all physical). Since 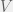 and 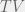 are in duality with each other, we can also think of this as assigning a power history to any force history (the power history being ](https://s0.wp.com/latex.php?latex=%5B%5Ctilde%7BA%7D%28f%29%5D%28f%29&bg=f0f0f0&fg=555555&s=0&c=20201002), where  is the force history).\n\n\nWhat’s more remarkable is that the transfer function from force histories to state histories is 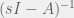 in the Laplace domain (as discussed above — just set  for the state-space representation). Therefore it is invertible except on a set of [measure zero](http://en.wikipedia.org/wiki/Measure_zero#Lebesgue_measure) (the poles of ) and so as far as 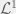 spaces are concerned it is an isomorphism; this is a bit of a technical point here, but I’m using the fact that  spaces are composed of equivalence classes of functions that differ on sets of measure zero, and also probably implicitly using some theorems from Fourier analysis about how the Fourier (Laplace) transform is an isomorphism from 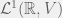 to itself. I’m still glossing over some technical details here; in particular, I think you might need to consider the intersection of  and  instead of just , and also the target space of the Fourier transform is really , not , but these details aren’t really important to the exposition.\n\n\nGetting back on track, we’ve just shown that the dynamics matrix  of a linear system induces an isomorphism between force histories and state histories. My guess is that you can also show this for reasonably nice non-linear systems, but I don’t have a proof off the top of my head. So, letting 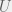 denote the space of control signals and  the space of outputs, what we have is something like this:\n\n\n\n\n\nIncidentally, that middle map (the isomorphism with ) is hideous-looking, and if someone has a good way to typeset such a thing I would like to know about it.\n\n\nIn any case, in this context it is pretty easy to see how the inputs and outputs play dual roles to each other, and in fact if we replaced , , and  each with their adjoints , , and , then we get a new dynamical system where the inputs and outputs actually switch places (as well as the matrices governing the inputs and outputs). Note that I’ve left  out of this for now. I’m not really sure yet of a good way to fit it into this picture; it’s possible that  is just unnatural mathematically but sometimes necessary physically (although usually we can assume that ).\n\n\nNow that we have this nice framework for thinking about linear control systems, I’m going to introduce controllers and observers, and it will be easy to see that they are dual to each other in the sense just described.\n\n\n**Controllability and Observability**\n\n\nGo back to the non-linear case for a moment and suppose that we have a system , or, in the notation I’ve been using, . We say that such a system is controllable if for any two states 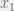 and 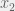, there exists a time  and a control signal  such that if 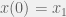 then  when the system is driven by the control signal . What this says intuitively is that we can get from any state to any other state in a finite amount of time.\n\n\nFor linear systems, controllability implies something stronger — we can actually get from any state to any other state arbitrarily quickly, and this is often times the definition given in the linear case. For non-linear systems, this is not the case, as a trivial example we could have\n\n\n\n\n\n\n\n\nThere are a few important properties of linear systems that are equivalent to controllability:\n\n\n(1) There is no proper subspace  of the state space such that 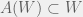 and , where  is the space of possible instantaneous control signals. The intuition is that there is no subspace that the passive dynamics (without control) can get stuck in such that the control input can’t move the dynamics out of that space.\n\n\n(2) There is no left eigenvector of  that is in the left null space of . In other words, it actually suffices to check the criterion (1) above just for one-dimensional subspaces.\n\n\n(3) The matrix ![[B \\ AB \\ A^2B \\ \\ldots \\ A^{n-1}B]](https://s0.wp.com/latex.php?latex=%5BB+%5C+AB+%5C+A%5E2B+%5C+%5Cldots+%5C+A%5E%7Bn-1%7DB%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), where  is the dimension of the state space of the system, has full row rank.\n\n\n(4) For any choice of  eigenvalues , there exists a matrix  such that  has generalized eigenvalues . We can think of this as saying that an appropriate linear feedback law 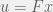 can be used to give the closed-loop (i.e. after control is applied) dynamics arbitrary eigenvalues.\n\n\nI will leave (1) and (2) to you as exercises. Note that this is because I actually think you can solve them, not because I’m being lazy. (3) I will prove shortly (it is a very useful computational criterion for testing controllability). (4) I will prove later in this post. I should also note that these criteria also hold for a discrete-time system\n\n\n\n\n\n\n\n\nProof of (3): In the case of a discrete-time system, if we have control inputs , then  will be\n\n\n\n\n\nIn particular, after  time steps we can affect 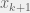 by an arbitrary linear combination of elements from the row spaces of , where  ranges from 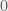 to . In other words, we can drive 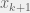 to an arbitrary state if and only if the row space of ![[A^{i}B]_{i=0}^{k-1}](https://s0.wp.com/latex.php?latex=%5BA%5E%7Bi%7DB%5D_%7Bi%3D0%7D%5E%7Bk-1%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) is the entire state space, i.e. ![[A^{i}B]_{i=0}^{k-1}](https://s0.wp.com/latex.php?latex=%5BA%5E%7Bi%7DB%5D_%7Bi%3D0%7D%5E%7Bk-1%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) has full row rank. So a discrete-time system is controllable if and only if ![[A^{i}B]_{i=0}^{k-1}](https://s0.wp.com/latex.php?latex=%5BA%5E%7Bi%7DB%5D_%7Bi%3D0%7D%5E%7Bk-1%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) has full row rank for some sufficiently large .\n\n\nTo finish the discrete-time case, we use the [Cayley-Hamilton theorem](http://en.wikipedia.org/wiki/Cayley-Hamilton_theorem), which shows that any 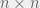 matrix satisfies a degree  polynomial, and so in particular it suffices to pick  above, since 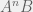 can be written as a linear combination of  for , and similarly for any larger powers of .\n\n\nNow we need to deal with the continuous time case. In this case, we can use the theory of linear differential equations to show that\n\n\n\n\n\nwhere  is the [matrix exponential](http://en.wikipedia.org/wiki/Matrix_exponential) of . But if we use the Cayley-Hamilton theorem a second time, we see that $e^{A\\tau}$ can be expressed as an st degree polynomial in , so that there exists some  such that\n\n\n\n\n\nFrom here it is clear that, in order for a continuous time system to be controllable, the controllability matrix must have full row rank (since 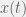 is equal to  plus something in the row space of the controllability matrix). The converse is less obvious. If the  were linearly independent functions, then we would be done, because the last term in the sum can be thought of as the inner product of  and 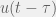, and we can just use [Gram-Schmidt orthogonalization](http://en.wikipedia.org/wiki/Gram%E2%80%93Schmidt_process) to show that those inner products can be chosen arbitrarily (if you don’t see this then figuring it out is a good linear algebra exercise).\n\n\nThe problem is that the  are not necessarily linearly independent. If  has all distinct eigenvalues, then they will be. This is because we have the relations  and  for any -eigenvector  of , so we can write  distinct exponential functions as a linear combination of the , and any relation among the 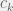 would imply a relation among the 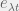, which is impossible (it is a basic result from Fourier analysis that exponential functions are linearly independent).\n\n\nHowever, this result actually needs  to have distinct eigenvalues. In particular, if one takes , the 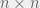 identity matrix, then you can show that all but one of the 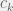 can be chosen arbitrarily. This is because , 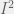,  are all equal to each other, and thus linearly dependent.\n\n\nWhat we need to do instead is let  be the degree of the minimal polynomial 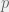 such that . Then we can actually write 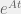 as  for some functions :\n\n\n\n\n\nBy the way in which the 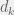 were constructed (by applying polynomial relations to an absolutely convergent Taylor series), we know that they are all infinitely differentiable, hence we can differentiate both sides 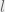 times and write\n\n\n\n\n\nNow look at these derivatives from  to 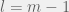. If the 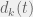 were linearly dependent, their derivatives would satisfy the same relation, and therefore (by evaluating everything at , the matrices 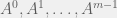 would satisfy a linear relation, which is impossible, since then  would satisfy a polynomial relation of degree less than .\n\n\nSo, the 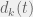 are linearly independent, and thus by the argument with Gram-Schmidt above we can write anything in the row space of  as\n\n\n\n\n\nfor any . So are we done? Almost. The last step we need to finish is to note that if  satisfies a polynomial of degree  then the row space of ![[B \\ AB \\ \\ldots \\ A^{m-1}B]](https://s0.wp.com/latex.php?latex=%5BB+%5C+AB+%5C+%5Cldots+%5C+A%5E%7Bm-1%7DB%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) is the same as the row space of ![[B \\ AB \\ \\ldots \\ A^{n-1}B]](https://s0.wp.com/latex.php?latex=%5BB+%5C+AB+%5C+%5Cldots+%5C+A%5E%7Bn-1%7DB%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), for .\n\n\nSo, that proves the result (3) about the controllability matrix. It was a lot of work in the continuous time case, although it matches our intuition for why it should be true (taking an exponential and taking a derivative are somewhat complementary to each other, so it made sense to do so; and I think there are probably results in analysis that make this connection precise and explain why we should get the controllability result in the continuous case more or less for free).\n\n\nAs I said before, (4) will have to wait until later.\n\n\nIn addition to controllability, we have a notion of stabilizability, which means that we can influence all unstable modes of . In other words, we can make sure that the system eventually converges to the origin (although not necessarily in finite time). Versions of criteria (2) and (4) exist for stabilizable systems. Criterion (2) becomes a requirement that no left eigenvector of  whose eigenvalue has non-negative real part is in the left null space of . Criterion (4) becomes a requirement that there exist  such that  has only eigenvalues with negative real part.\n\n\n**Observers**\n\n\nWe say that a system is *observable* if, for any initial state  and any control tape , it is possible in finite time to infer  given only  and the output 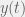. In particular, we are *not* given any information about the internal states 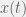 of the system (except through 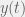), although it is assumed that , , , and  are known. If we have a non-linear system\n\n\n\n\n\n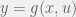\n\n\nthen it is assumed that  and 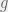 are known.\n\n\nIt turns out that observability for a system is exactly the same as controllability for the dual system, so all the criteria from the previous section hold in a suitably dual form. One thing worth thinking about is why these results still hold for *any* control tape .\n\n\n(1) There is no non-zero subspace  of 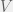 such that 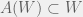 and . In other words, there is no space that doesn’t show up in the output and such that the natural dynamics of the system stay in that space.\n\n\n(2) There is no right eigenvector of  that is in the right null space of .\n\n\n(3) The matrix ![\\left[ \\begin{array}{c} C \\\\ CA \\\\ CA^2 \\\\ \\vdots \\\\ CA^{n-1} \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+C+%5C%5C+CA+%5C%5C+CA%5E2+%5C%5C+%5Cvdots+%5C%5C+CA%5E%7Bn-1%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) has full column rank.\n\n\n(4) The eigenvalues of  can be assigned arbitrarily by an appropriate choice of .\n\n\nJust as the matrix  from the previous section can be thought of as a linear feedback law that gives the system arbitrary eigenvalues, the matrix  is part of a feedback law for something called a Luenburger observer.\n\n\nAlso, just as there is stabilizability for a system, meaning that we can control all of the unstable modes, there is also detectability, which means that we can detect all of the unstable modes.\n\n\n**Luenburger Observers**\n\n\nAn observer is a process that estimates the state of an observable system given information about its outputs. If a system is detectable, and  is such that  has only eigenvalues with negative real part, then consider the system\n\n\n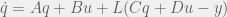\n\n\nUsing the fact that , we see that\n\n\n, so that  decays exponentially to zero (by the assumption on the eigenvalues of . Thus the dynamical system above, which is called a Luenburger observer, will asymptotically approach the true state of a system given arbitrary initial conditions.\n\n\nIf a system is both controllable and observable, can we design an observer and a controller that working together successfully control the system? (This question is non-trivial because the controller has to use the estimated state from the controller, rather than the actual state of the system, for feedback.) The answer is no in general, but it is yes for linear systems.\n\n\nLet $F$ be such that  is stable and let  be such that  is stable. (A matrix is stable if all of its eigenvalues have negative real part.) Now we will consider the system obtained by using  as a Luenburger observer and  as a linear feedback law. Let . Then we have\n\n\n\n\n\n\n\n\nIn matrix form, this gives\n\n\n![\\left[ \\begin{array}{c} \\dot{e} \\\\ \\dot{x} \\end{array} \\right] = \\left[ \\begin{array}{cc} A+LC & 0 \\\\ BF & A+BF \\end{array} \\right] \\left[ \\begin{array}{c} e \\\\ x \\end{array} \\right].](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Be%7D+%5C%5C+%5Cdot%7Bx%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A%2BLC+%26+0+%5C%5C+BF+%26+A%2BBF+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+e+%5C%5C+x+%5Cend%7Barray%7D+%5Cright%5D.&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nBecause of the block triangular form of the matrix, we can see that its eigenvalues are given by the eigenvalues of  and . Since  and  are both stable, so is the matrix given above, so we can successfully stabilize the above system to the origin. Of course, this is weaker than full controllability. However, if we have full controllability and observability, then we can set the eigenvalues of the above matrix arbitrarily, which should imply full controllability (I haven’t sat down and proved this rigorously, though).\n\n\nSo, now we know how to stabilize a linear system if it is detectable and stabilizable. The main thing to take away from this is the fact that the poles of the coupled dynamics of state and observation error are exactly the eigenvalues of  and  considered individually.\n\n\n**State-space representations**\n\n\nThe final topic I’d like to talk about in this post is state-space representations of transfer functions. It is here that I will prove all of the results that I promised to take care of later. There are plenty more topics in linear control theory, but I’ve been writing this post for a few days now and it’s at a good stopping point, so I’ll leave the rest of the topics for a later post.\n\n\nA state-space representation of a transfer function is exactly what it sounds like. Given a transfer function  from  to , find a state-space model\n\n\n\n\n\n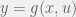\n\n\nthat has 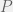 as a transfer function. We’ll be concerned with linear state-space representations only.\n\n\nThe first thing to note is that a linear state-space representation of 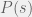 can always be reduced to a smaller representation unless the representation is both controllable and observable (by just restricting to the controllable and observable subspace).\n\n\nThe next thing to note is that, since the transfer function of a state-space representation is 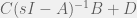, a transfer function 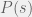 has an irreducible (in the sense of the preceding paragraph) linear state-space representation of degree  if and only if 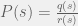, where  and  are polynomials with . Thus all controllable and observable linear state-space representations of 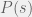 have the same dimension, and therefore there exists some non-canonical vector space isomorphism such that we can think of any two such representations as living in the same state space (though possibly with different matrices , , , and ).\n\n\nFinally, if two state-space representations over the same vector space have the same transfer function, then one can be obtained from the other by a chance of coordinates. I will now make this more precise and also prove it.\n\n\n**Claim:** Suppose that  and  are two (not necessarily linear) state-space representations with the same input-output mapping. If  is controllable and  is observable, then there is a canonical map from the state space of  to the state space of . If  is observable, then this map is injective. If  is controllable, then this map is surjective. If  and  are both linear representations, then the map is linear.\n\n\n**Proof:** Let the two representations be  and .\n\n\nSince  is controllable, we can take an input tape that sends  to an arbitrary state  at some time . Then by looking at  evolve under the same input tape, by the observability of  we will eventually be able to determine  uniquely. The canonical map sends the  we chose to .The fact that  for all 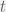 guarantees that  is well-defined (i.e., it doesn’t matter what  we choose to get there).\n\n\nIf  is controllable, then we can choose a  that causes us to end up with whatever  we choose, which implies that the map is surjective. Now for the purposes of actually computing the map, we can always assume that the control input becomes 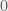 once we get to the desired . Then there is a one-to-one correspondence between possible output tapes after time 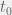 and possible values of . If  is observable, this is also true for , which implies injectivity. I will leave it to you to verify that the map is linear if both representations are linear.\n\n\nFinally, I would like to introduce a special case of *controllable canonical form* and use it to prove criterion (4) about controllability. It will also show, at least in a special case, that any transfer function that is a quotient of two polynomials (where the denominator has at least as high degree as the numerator) has a linear state-space representation.\n\n\nThe special case is when 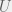 is one-dimensional. Then our transfer matrix can be written in the form\n\n\n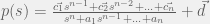\n\n\nIt turns out that this transfer function can be represented by the following transfer matrix:\n\n\n![A = \\left[ \\begin{array}{ccccc} -a_1 & -a_2 & \\ldots & -a_{n-1} & -a_n \\\\ 1 & 0 & \\ldots & 0 & 0 \\\\ 0 & 1 & \\ldots & 0 & 0 \\\\ \\vdots & \\vdots & \\ldots & \\vdots & \\vdots \\\\ 0 & 0 & \\ldots & 1 & 0 \\end{array} \\right], B = \\left[ \\begin{array}{c} 1 \\\\ 0 \\\\ 0 \\\\ \\vdots \\\\ 0 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+-a_1+%26+-a_2+%26+%5Cldots+++%26+-a_%7Bn-1%7D+%26+-a_n+%5C%5C+1+%26+0+%26+%5Cldots+%26+0++%26+0+%5C%5C+0+++%26+1+%26+%5Cldots+%26+0+%26+0+%5C%5C+%5Cvdots+%26+%5Cvdots+%26+++%5Cldots+%26+%5Cvdots+%26+%5Cvdots+%5C%5C+0+%26+0+%26+%5Cldots+%26+1+%26+++0+%5Cend%7Barray%7D+%5Cright%5D%2C+B+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5C%5C+0+%5C%5C+++%5Cvdots+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\n![C = \\left[ \\begin{array}{ccccc} \\vec{c_1} & \\vec{c_2} & \\cdots & \\vec{c_{n-1}} & \\vec{c_n} \\end{array} \\right], D = \\vec{d}](https://s0.wp.com/latex.php?latex=C+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+%5Cvec%7Bc_1%7D+%26+%5Cvec%7Bc_2%7D+%26+%5Ccdots+%26+%5Cvec%7Bc_%7Bn-1%7D%7D+%26+%5Cvec%7Bc_n%7D+%5Cend%7Barray%7D+%5Cright%5D%2C+D+%3D+%5Cvec%7Bd%7D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nThis might seem a bit contrived, but the construction for  is a nice trick for constructing a matrix with a given characteristic polynomial. Also note that $A$ will have a single [Jordan block](http://en.wikipedia.org/wiki/Jordan_normal_form) for each distinct eigenvalue (whose size is the number of times that eigenvalue appears in the list ). One can show directly that this is a necessary and sufficient condition for being controllable by a single input.\n\n\nI will leave it to you to check the details that the above state-space model actually has 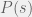 as a transfer function. (Bonus question: what is the equivalent *observable canonical form* for observable single-output systems?)I will wrap up this post by proving criterion (4) about controllability, as promised. I have reproduced it below for convenience:\n\n\n(4) An LTI system is controllable if and only if we can assign the eigenvalues of  arbitrarily by a suitable choice of .\n\n\nProof: I will prove the “only if” direction, since that is the difficult direction. First consider the case when we have a single-input system. Then take the transfer function from  to  (this is the same as assuming that , 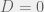). By the result above and the assumption of controllability, there exists a system with the same transfer function in controllable canonical form, and thus there is a change of coordinates that puts our system in controllable canonical form. Once we are in canonical form, it is easy to see that by choosing ![F = \\left[ \\begin{array}{ccccc} -b_1 & -b_2 & \\ldots & -b_{n-1} & -b_n \\end{array} \\right]](https://s0.wp.com/latex.php?latex=F+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+-b_1+%26+-b_2+%26+%5Cldots+%26+-b_%7Bn-1%7D+%26+-b_n+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), we end up with a system whose characteristic polynomial is . We can therefore give  an arbitrary characteristic polynomial, and thus choose its eigenvalues arbitrarily.\n\n\nThis proves the desired result in the case when we have a single input to our system. When we have multiple inputs, we have to consider them one-by-one, and use the fact that linear feedback can’t affect the eigenvalues of the parts of the system that are outside the controllable subspace. I haven’t checked this approach very carefully, so it might not work, but I am pretty sure it can be made to work. If you want more details, feel free to ask me and I will provide them. At this point, though, I’m writing more of a treatise than a blog post, so I really think I should cut myself off here. I hope the exposition hasn’t suffered at all from this, but if it has, feel free to call me on it and I will clarify myself.\n\n\nMy next post will take a break from linear control and tell you why using least squares is one of the worst ideas ever (because you think it will work when it actually won’t; if you don’t believe me I’ll show you how negligible sampling errors can easily cause you to be off by 10 percent in your model parameters).\n\n", "url": "https://jsteinhardt.wordpress.com/2010/07/17/linear-control-theory-part-i/", "title": "Linear Control Theory: Part I", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-07-17T04:37:19+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "217e1935a351a9bf59d301e92c75e560", "summary": []}
+{"text": "The Underwater Cartpole\n\nMy last few posts have been rather abstract. I thought I’d use this one to go into some details about the actual system we’re working with.\n\n\nAs I mentioned before, we are looking at a cart pole in a water tunnel. A cart pole is sometimes also called an [inverted pendulum](http://en.wikipedia.org/wiki/Inverted_pendulum). Here is a diagram from wikipedia:\n\n\nThe parameter we have control over is F, the force on the cart. We would like to use this to control both the position of the cart and the angle of the pendulum. If the cart is standing still, the only two possible fixed points of the system are  (the bottom, or “downright”) and  (the “upright”). Since  is easy to get to, we will be primarily interested with getting to .\n\n\nFor now, I’m just going to worry about the regular cart pole system, without introducing any fluid dynamics. This is because the fluid dynamics are complicated, even with a fairly rough model (called the Quasi-steady Model), and I don’t know how to derive them anyway. Before continuing, it would be nice to have an explicit parametrization of the system. There are two position states we care about: , the cart position; and , the pendulum angle, which we will set to 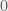 at the bottom with the counter-clockwise direction being positive. I realize that this is not what the picture indicates, and I apologize for any confusion. I couldn’t find any good pictures that parametrized it the way I wanted, and I’m going to screw up if I use a different parametrization than what I’ve written down.\n\n\nAt any rate, in addition to the two position states  and , we also care about the velocity states  and , so that we have four states total. For convenience, we’ll also name a variable , so that we have a control input  that directly affects the acceleration of the cart. We also have system parameters  (the mass of the cart), 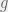 (the acceleration due to gravity), 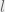 (the length of the pendulum arm), and  (the inertia of the pendulum arm). With these variables, we have the following equations of motion:\n\n\n![\\left[ \\begin{array}{c} \\dot{x} \\\\ \\dot{\\theta} \\\\ \\ddot{x} \\\\ \\ddot{\\theta} \\end{array} \\right] = \\left[ \\begin{array}{c} \\dot{x} \\\\ \\dot{\\theta} \\\\ 0 \\\\ -\\frac{mgl\\sin(\\theta)}{I} \\end{array} \\right] + \\left[ \\begin{array}{c} 0 \\\\ 0 \\\\ 1 \\\\ -\\frac{mg\\cos(\\theta)}{I} \\end{array} \\right] u](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bx%7D+%5C%5C+%5Cdot%7B%5Ctheta%7D+%5C%5C+%5Cddot%7Bx%7D+%5C%5C+%5Cddot%7B%5Ctheta%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bx%7D+%5C%5C+%5Cdot%7B%5Ctheta%7D+%5C%5C+0+%5C%5C+-%5Cfrac%7Bmgl%5Csin%28%5Ctheta%29%7D%7BI%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5C%5C+1+%5C%5C+-%5Cfrac%7Bmg%5Ccos%28%5Ctheta%29%7D%7BI%7D+%5Cend%7Barray%7D+%5Cright%5D+u&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nYou will note that the form of these equations is different from in my last post. This is because I misspoke last time. The actual form we should use for a general system is\n\n\n\n\n\nor, if we are assuming a second-order system, then\n\n\n![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{c} \\dot{q} \\\\ f(q,\\dot{q}) \\end{array} \\right] + B(q,\\dot{q}) u.](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+f%28q%2C%5Cdot%7Bq%7D%29+%5Cend%7Barray%7D+%5Cright%5D+%2B+B%28q%2C%5Cdot%7Bq%7D%29+u.&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nHere we are assuming that the natural system dynamics can be arbitrarily non-linear in , but the effect of control is still linear for any fixed system state (which, as I noted last time, is a pretty safe assumption). The time when we use the form  is when we are talking about a linear system — usually a [linear time-invariant system](http://en.wikipedia.org/wiki/LTI_system_theory), but we can also let  and  depend on time and get a [linear time-varying system](http://en.wikipedia.org/wiki/Linear_system).\n\n\nI won’t go into the derivation of the equations of motion of the above system, as it is a pretty basic mechanics problem and you can find the derivation on Wikipedia if you need it. Instead, I’m going to talk about some of the differences between this system and the underwater system, why this model is still important, and how we can apply the techniques from the last two posts to get a good controller for this system.\n\n\n**Differences from the Underwater System**\n\n\nIn the underwater system, instead of having gravity, we have a current (the entire system is on the plane perpendicular to gravity). I believe that the effect of current is much the same as the affect of gravity (although with a different constant), but that could actually be wrong. At any rate, the current plays the role that gravity used to play in terms of defining “up” and “down” for the system (as well as creating a stable fixed point at  and an unstable fixed point at ).\n\n\nMore importantly, there is significant drag on the pendulum, and the drag is non-linear. (There is always some amount of drag on a pendulum due to friction of the joint, but it’s usually fairly linear, or at least easily modelled.) The drag becomes the greatest when , which is also the point at which  becomes useless for controlling  (note the  term in the affect of  on 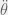). This means that getting past  is fairly difficult for the underwater system.\n\n\nAnother difference is that high accelerations will cause turbulence in the water, and I’m not sure what affect that will have. The model we’re currently using doesn’t account for this, and I haven’t had a chance to experiment with the general fluid model (using PDEs) yet.\n\n\n**Why We Care**\n\n\nSo with all these differences, why am I bothering to give you the equations for the regular (not underwater) system? More importantly, why would I care about them for analyzing the actual system in question?\n\n\nI have to admit that one of my reasons is purely pedagogical. I wanted to give you a concrete example of a system, but I didn’t want to just pull out a long string of equations from nowhere, so I chose a system that is complex enough to be interesting but that still has dynamics that are simple to derive. However, there are also better reasons for caring about this system. The qualitative behaviour of this system can still be good for giving intuition about the behaviour of the underwater system.\n\n\nFor instance, one thing we want to be able to do is swing-up. With limited magnitudes of acceleration and a limited space (in terms of ) to perform maneuvers in, it won’t be possible in general to perform a swing-up. However, there are various system parameters that could make it easier or harder to perform the swing-up. For instance, will increasing  (the inertia of the pendulum) make it easier or harder to perform a swing-up? (You should think about this if you don’t know the answer, so I’ve provided it below the fold.)\n\n\n\nThe answer is that higher inertia makes it easier to perform a swing-up (this is more obvious if you think about the limiting cases of  and ). The reason is that a higher moment of inertia makes it possible to store more energy in the system at the same velocity. Since the drag terms are going to depend on velocity and not energy, having a higher inertia means that we have more of a chance of building up enough energy to overcome the energy loss due to drag and get all the way to the top.\n\n\nIn general, various aspects of the regular system will still be true in a fluid on the proper time scales. I think one thing that will be helpful to do when we start dealing with the fluid mechanics is to figure out exactly which things are true on which time scales.\n\n\nWhat we’re currently using this system for is the base dynamics of a high-gain observer, which I’ll talk about in a post or two.\n\n\nI apologize for being vague on these last two justifications. The truth is that I don’t fully understand them myself. The first one will probably have to wait until I start toying with the full underwater system; the second (high-gain observers) I hope to figure out this weekend after I check out Khalil’s book on control from Barker Library.\n\n\nHopefully, though, I’ve at least managed somewhat to convince you that the dynamics of this simpler system can be informative for the more complicated system.\n\n\n**Controlling the Underwater Cartpole**\n\n\nNow we finally get to how to control the underwater cartpole. Our desired control task is to get to the point ![\\left[ \\begin{array}{cccc} 0 & \\pi & 0 & 0 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+0+%26+%5Cpi+%26+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). That is, we want to get to the unstable fixed point at . In the language of my last post, if we wanted to come up with a good objective function 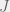, we could say that  is equal to the closest we ever get to  (assuming we never pass it), and if we do get to  then it is equal to the smallest velocities we ever get as we pass ; also,  is equal to infinity if  ever gets too large (because we run into a wall), or if  gets too large (because we can only apply a finite amount of acceleration).\n\n\nYou will notice that I am being pretty vague about how exactly to define  (my definition above wouldn’t really do, as it would favor policies that just barely fail to get to  over policies that go past it too quickly, which we will see is suboptimal). There are two reasons for my vagueness — first, there are really two different parts to the control action — swing-up and balancing. Each of these parts should really have its own cost function, as once you can do both individually it is pretty easy to combine them. Secondly, I’m not really going to care all that much about the cost function for what I say below. I did have occasion to use a more well-defined cost function for the swing-up when I was doing learning-based control, but this didn’t make its way (other than by providing motivation) into the final controller.\n\n\nI should point out that the actual physical device we have is more velocity-limited than acceleration-limited. It can apply pretty impressive accelerations, but it can also potentially damage itself at high velocities (by running into a wall too quickly). We can in theory push it to pretty high velocities as well, but I’m a little bit hesitant to do so unless it becomes clearly necessary, as breaking the device would suck (it takes a few weeks to get it repaired). As it stands, I haven’t (purposely) run it at higher velocities than 1.5 meters/sec, which is already reasonably fast if you consider that the range of linear motion is only 23.4 cm.\n\n\nBut now I’m getting sidetracked. Let’s get back to swing-up and balancing. As I said, we can really divide the overall control problem into two separate problems of swing-up and balancing. For swing-up, we just want to get enough energy into the system for it to get up to . We don’t care if it’s going too fast at  to actually balance. This is because it is usually harder to add energy to a system than to remove energy, so if we’re in a situation where we have more energy than necessary to get to the top, we can always just perform the same control policy less efficiently to get the right amount of energy.\n\n\nFor balancing, we assume that we are fairly close to the desired destination point, and we just want to get the rest of the way there. As I mentioned last time, balancing is generally the easier of the two problems because of LQR control.\n\n\nIn actuality, these problems cannot be completely separated, due to the finite amount of space we have to move the cart in. If the swing up takes us to the very edge of the available space, then the balancing controller might not have room to actually balance the pendulum.\n\n\n**Swing-up**\n\n\nI will first go in to detail on the problem of swing-up. The way I think about this is that the pendulum has some amount of energy, and that energy gets sapped away due to drag. In the underwater case, the drag is significant enough that we really just want to add as much energy as possible. How can we do this? You will recall from classical mechanics that the faster an object is moving, the faster you can add energy to that object. Also, the equations of motion show us that an acceleration in  has the greatest effect on  when  is largest, that is, when  or . At the same time, we expect the pendulum to be moving fastest when , since at that point it has the smallest potential energy, and therefore (ignoring energy loss due to drag), the highest kinetic energy. So applying force will always be most useful when .\n\n\nNow there is a slight problem with this argument. The problem is that, as I keep mentioning, the cart only has a finite distance in which to move. If we accelerate the cart in one direction, it will keep moving until we again accelerate it in the opposite direction. So even though we could potentially apply a large force at , we will have to apply a similarly large force later, in the opposite direction. I claim, however, that the following policy is still optimal: apply a large force at , sustain that force until it becomes necessary to decelerate (to avoid running into a wall), then apply a large decelerating force. I can’t prove rigorously that this is the optimal strategy, but the reasoning is that this adds energy when  is changing the fastest, so by the time we have to decelerate and remove energy  will be significantly smaller, and therefore our deceleration will have less effect on the total energy.\n\n\nTo do the swing-up, then, we just keep repeating this policy whenever we go past  (assuming that we can accelerate in the appropriate direction to add energy to the system). The final optimization is that, once we get past , the relationship between  and  flips sign, and so we would like to apply the same policy of rapid acceleration and deceleration in this regime as well. This time, however, we don’t wait until we get to , as at that point we’d be done. Instead, we should perform the energy pumping at , which will cause  to increase above 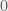 again, and then go in the opposite direction to pump more energy when  becomes 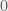 for the second time.\n\n\nI hope that wasn’t too confusing of an explanation. When I get back to lab on Monday, I’ll put up a video of a matlab simulation of this policy, so that it’s more clear what I mean. At any rate, that’s the idea behind swing-up: use up all of your space in the -direction to pump energy into the system at maximum acceleration, doing so at  and when  and we are past . Now, on to balancing.\n\n\n**Balancing**\n\n\nAs I mentioned, if we have a good linear model of our system, we can perform LQR control. So the only real problem here is to get a good linear model. To answer Arvind’s question from last time, if we want good performance out of our LQR controller, we should also worry about the cost matrices 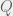 and 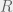; for this system, the amount of space we have to balance (23.4cm, down to 18cm after adding in safeties to avoid hitting the wall) is small enough that it’s actually necessary to worry about 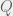 and 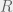 a bit, which I’ll get to later.\n\n\nFirst, I want to talk about how to get a good linear model. To balance, we really want a good linearization about . Unfortunately, this is an unstable fixed point so it’s hard to collect data around it. It’s easier to instead get a good linearization about  and then flip the signs of the appropriate variables to get a linear model about . My approach to getting this model was to first figure out what it would look like, then collect data, and finally do a least squares fit on that data.\n\n\nSince we can’t collect data continuously, we need a discrete time linear model. This will look like\n\n\n\n\n\nIn our specific case,  and  will look like this:\n\n\n![\\left[ \\begin{array}{c} \\theta_{n+1} \\\\ y_{n+1} \\\\ \\dot{theta}_{n+1} \\\\ \\dot{y}_{n+1} \\end{array} \\right] = \\left[ \\begin{array}{cccc} 1 & 0 & dt & 0 \\\\ 0 & 1 & 0 & dt \\\\ c_1 & 0 & c_2 & 0 \\\\ 0 & 0 & 0 & 1 \\end{array} \\right] \\left[ \\begin{array}{c} \\theta_n \\\\ y_n \\\\ \\dot{\\theta}_n \\\\ \\dot{y}_n \\end{array} \\right] + \\left[ \\begin{array}{c} 0 \\\\ 0 \\\\ c_3 \\\\ dt \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Ctheta_%7Bn%2B1%7D+%5C%5C+y_%7Bn%2B1%7D+%5C%5C+%5Cdot%7Btheta%7D_%7Bn%2B1%7D+%5C%5C+%5Cdot%7By%7D_%7Bn%2B1%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+0+%26+dt+%26+0+%5C%5C+0+%26+1+%26+0+%26+dt+%5C%5C+c_1+%26+0+%26+c_2+%26+0+%5C%5C+0+%26+0+%26+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Ctheta_n+%5C%5C+y_n+%5C%5C+%5Cdot%7B%5Ctheta%7D_n+%5C%5C+%5Cdot%7By%7D_n+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5C%5C+c_3+%5C%5C+dt+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nI got this form by noting that we definitely know how , , and  evolve with time, and the only question is what happens with . On the other hand, clearly  cannot depend on  or  (since we can set them arbitrarily by choosing a different inertial reference frame). This leaves only three variables to determine.\n\n\nOnce we have this form, we need to collect good data. The important thing to make sure of is that the structure of the data doesn’t show up in the model, since we care about the system, not the data. This means that we don’t want to input something like a sine or cosine wave, because that will only excite a single frequency of the system, and a linear system that is given something with a fixed frequency will output the same frequency. We should also avoid any sort of oscillation about , or else our model might end up thinking that it’s supposed to oscillate about  in general. I am sure there are other potential issues, and I don’t really know much about good experimental design, so I can’t talk much about this, but the two issues above are ones that I happened to run into personally.\n\n\nWhat I ended up doing was taking two different functions of  that had a linearly increasing frequency, then differentiating twice to get acceleration profiles to feed into the system. I used these two data sets to do a least squares fit on 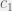, , and , and then I had my model. I transformed by discrete time model into a continuous time model (MATLAB has a function called d2c that can do this), inverted the appropriate variables, and got a model about the upright ().\n\n\nNow the only problem was how to choose 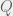 and 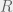. The answer was this: I made 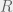 fairly small (), since we had a very strong actuator so large accelerations were fine. Then, I made the penalties on position larger than the penalties on velocity (since position is really what we care about). Finally, I thought about the amount that I would want the cart to slide to compensate for a given disturbance in , and used this to choose a ratio between costs on  and costs on . In the end, this gave me ![Q = \\left[ \\begin{array}{cccc} 40 & 0 & 0 & 0 \\\\ 0 & 10 & 0 & 0 \\\\ 0 & 0 & 4 & 0 \\\\ 0 & 0 & 0 & 1 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=Q+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+40+%26+0+%26+0+%26+0+%5C%5C+0+%26+10+%26+0+%26+0+%5C%5C+0+%26+0+%26+4+%26+0+%5C%5C+0+%26+0+%26+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002).\n\n\nI wanted to end with a video of the balancing controller in action, but unfortunately I can’t get my Android phone to upload video over the wireless, so that will have to wait.\n\n\n\n\n\n\n\n\n", "url": "https://jsteinhardt.wordpress.com/2010/06/26/the-underwater-cartpole/", "title": "The Underwater Cartpole", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-06-26T21:08:22+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "41e8bd5d50589b7b7487dad1aaa32797", "summary": []}
+{"text": "Linear Control Theory: Part 0\n\nThe purpose of this post is to introduce you to some of the basics of control theory and to introduce the [Linear-Quadratic Regulator](http://en.wikipedia.org/wiki/Linear-quadratic_regulator), an extremely good hammer for solving stabilization problems.\n\n\nTo start with, what do we mean by a control problem? We mean that we have some system with dynamics described by an equation of the form\n\n\n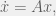\n\n\nwhere  is the state of the system and  is some matrix (which itself is allowed to depend on ). For example, we could have an object that is constrained to move in a line along a frictionless surface. In this case, the system dynamics would be\n\n\n![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{cc} 0 & 1 \\\\ 0 & 0 \\end{array} \\right]\\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right]. ](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D.+&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nHere  represents the position of the object, and  represents the velocity (which is a relevant component of the state, since we need it to fully determine the future behaviour of the system). If there was drag, then we could instead have the following equation of motion:\n\n\n![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{cc} 0 & 1 \\\\ 0 & -b \\end{array} \\right]\\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right], ](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C++%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+0++%26+-b+%5Cend%7Barray%7D+%5Cright%5D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D++%5Cend%7Barray%7D+%5Cright%5D%2C+&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nwhere  is the coefficient of drag.\n\n\nIf you think a bit about the form of these equations, you will realize that it is both redundant and not fully general. The form is redundant because  can be an arbitrary function of , yet it also acts on  as an argument, so the equation 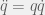, for example, could be written as\n\n\n![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{cc} 0 & 1 \\\\ \\alpha \\dot{q} & (1-\\alpha) q \\end{array} \\right] \\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+%5Calpha+%5Cdot%7Bq%7D+%26+%281-%5Calpha%29+q+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)\n\n\nfor any choice of . On the other hand, this form is also not fully general, since  will always be a fixed point of the system. (We could in principle fix this by making  affine, rather than linear, in , but for now we’ll use the form given here.)\n\n\nSo, if this representation doesn’t uniquely describe most systems, and can’t describe other systems, why do we use it? The answer is that, for most systems arising in classical mechanics, the equations naturally take on this form (I think there is a deeper reason for this coming from Lagrangian mechanics, but I don’t yet understand it).\n\n\nAnother thing you might notice is that in both of the examples above,  was of the form ![\\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002). This is another common phenomenon (although  and  may be vectors instead of scalars in general), owing to the fact that Newtonian mechanics produces second-order systems, and so we care about both the position and velocity of the system.\n\n\nSo, now we have a mathematical formulation, as well as some notation, for what we mean by the equations of motion of a system. We still haven’t gotten to what we mean by control. What we mean is that we assume that, in addition to the system state , we have a control input  (usually we can choose  independently from ), such that the actual equations of motion satisfy\n\n\n\n\n\nwhere again,  and  can both depend on . What this really means physically is that, for any configuration of the system, we can choose a control input , and  will affect the instantaneous change in state in a linear manner. We normally call each of the entries of  a torque.\n\n\nThe assumption of linearity might seem strong, but it is again true for most systems, in the sense that a linear increase in a given torque will induce a linear response in the kinematics of the system. But note that this is only true once we talk about mechanical torques. If we think of a control input as an electrical signal, then the system will usually respond non-linearly with respect to the signal. This is simply because the [actuator](http://en.wikipedia.org/wiki/Actuator) itself provides a force that is non-linear with its electrical input.\n\n\nWe can deal with this either by saying that we only care about a local model, and the actuator response is locally linear to its input; or, we can say that the problem of controlling the actuator itself is a disjoint problem that we will let someone worry about. In either case, I will shamelessly use the assumption that the system response is linear in the control input.\n\n\nSo, now we have a general form for equations of motion with a control input. The general goal of a control problem is to pick a function  such that if we let  then the trajectory $X(t)$ induced by the equation  minimizes some objective function . Sometimes our goals are more modest and we really just want to get to some final state, in which case we can make  just be a function of the final state that assigns a score based on how close we end up to the target state. We might also have hard constraints on  (because our actuators can only produce a finite amount of torque), in which case we can make  assign an infinite penalty to any  that violates these constraints.\n\n\nAs an examples, let’s return to our first example of an object moving in a straight line. This time we will say that ![\\left[ \\begin{array}{c} \\dot{q} \\\\ \\ddot{q} \\end{array} \\right] = \\left[ \\begin{array}{cc} 0 & 1 \\\\ 0 & 0 \\end{array} \\right] \\left[ \\begin{array}{c} q \\\\ \\dot{q} \\end{array} \\right]+\\left[ \\begin{array}{c} 0 \\\\ 1 \\end{array} \\right]u](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cdot%7Bq%7D+%5C%5C+%5Cddot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+1+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+q+%5C%5C+%5Cdot%7Bq%7D+%5Cend%7Barray%7D+%5Cright%5D%2B%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5Du&bg=f0f0f0&fg=555555&s=0&c=20201002), with the constraint that . We want to get to ![x = \\left[ \\begin{array}{c} 0 \\\\ 0 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=x+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) as quickly as possible, meaning we want to get to  and then stay there. We could have  just be the amount of time it takes to get to the desired endpoint, with a cost of infinity on any  that violates the torque limits. However, this is a bad idea, for two reasons.\n\n\nThe first reason is that, numerically, you will never really end up at exactly ![\\left[ \\begin{array}{c} 0 \\\\ 0 \\end{array} \\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002), just very close to it. So if we try to use this function on a computer, unless we are particularly clever we will assign a cost of  to every single control policy.\n\n\nHowever, we could instead have  be the amount of time it takes to get close to the desired endpoint. I personally still think this is a bad idea, and this brings me to my second reason. Once you come up with an objective function, you need to somehow come up with a controller (that is, a choice of ) that minimizes that objective function, or at the very least performs reasonably well as measured by the objective function. You could do this by being clever and constructing such a controller by hand, but in many cases you would much rather have a computer find the [optimal controller](http://en.wikipedia.org/wiki/Optimal_control). If you are going to have a computer search for a good controller, you want to make the search problem as easy as possible, or at least reasonable. This means that, if we think of 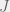 as a function on the space of control policies, we would like to make the problem of optimizing 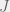 tractable. I don’t know how to make this precise, but there are a few properties we would like 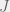 to satisfy — there aren’t too many local minima, and the minima aren’t approached too steeply (meaning that there is a reasonable large neighbourhood of small values around each local minimum). If we choose an objective function that assigns a value of  to almost everything, then we will end up spending most of our time wading through a sea of infinities without any direction (because all directions will just yield more values of ). So a very strict objective function will be very hard to optimize. Ideally, we would like a different choice of 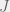 that has its minimum at the same location but that decreases gradually to that minimum, so that we can solve the problem using [gradient descent](http://en.wikipedia.org/wiki/Gradient_descent) or some similar method.\n\n\nIn practice, we might have to settle for an objective function that only is trying to minimize the same thing qualitatively, rather than in any precise manner. For example, instead of the choice of 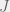 discussed above for the object moving in a straight line, we could choose\n\n\n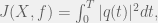\n\n\nwhere 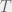 is some arbitrary final time. In this form, we are trying to minimize the time-integral of some function of the deviation of  from . With a little bit of work, we can deduce that, for large enough , the optimal controller is a [bang-bang controller](http://en.wikipedia.org/wiki/Bang%E2%80%93bang_control) that accelerates towards $0$ at the greatest rate possible, until accelerating any more would cause the object to overshoot , at which point the controller should decelerate at the greatest rate possible (there are some additional cases for when the object will overshoot the origin no matter what, but this is the basic idea).\n\n\nThis brings us to my original intention in making this post, which is LQR ([linear-quadratic regulator](http://en.wikipedia.org/wiki/Linear-quadratic_regulator)) control. In this case, we assume that  and  are both constant and that our cost function is of the form\n\n\n\n\n\nwhere the 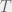 means transpose and 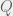 and 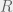 are both positive definite matrices. In other words, we assume that our goal is to get to , and we penalize both our distance from  and the amount of torque we apply at each point in time. If we have a cost function of this form, then we can actually solve analytically for the optimal control policy . The solution involves solving the [Hamilton-Bellman-Jacobi equations](http://en.wikipedia.org/wiki/Hamilton-Jacobi-Bellman_equation), and I won’t go into the details, but when the smoke clears we end up with a linear feedback policy 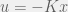, where , and 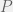 is given by the solution to the [algebraic Riccati equation](http://en.wikipedia.org/wiki/Algebraic_Riccati_equation)\n\n\n\n\n\nWhat’s even better is that MATLAB has a built-in function called lqr that will set up and solve the Riccati equation automatically.\n\n\nYou might have noticed that we had to make the assumption that both  and  were constant, which is a fairly strong assumption, as it implies that we have a LTI ([linear time-invariant](http://en.wikipedia.org/wiki/LTI_system_theory)) system. So what is LQR control actually good for? The answer is stabilization. If we want to design a controller that will stabilize a system about a point, we can shift coordinates so that the point is at the origin, then take a linear approximation about the origin. As long as we have a moderately accurate linear model for the system about that point, the LQR controller will successfully stabilize the system to that point within some basin of attraction. More technically, the LQR controller will make the system [locally asymptotically stable](http://en.wikipedia.org/wiki/Stability_theory), and the cost function 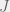 for the linear system will be a valid [local Lyapunov function](http://en.wikipedia.org/wiki/Lyapunov_function#Locally_asymptotically_stable_equilibrium).\n\n\nReally, the best reason to make use of LQR controllers is that they are a solution to stabilization problems that work out of the box. Many controllers that work in theory will actually require a ton of tuning in practice; this isn’t the case for an LQR controller. As long as you can identify a linear system about the desired stabilization point, even if your identification isn’t perfect, you will end up with a pretty good controller.\n\n\nI was thinking of also going into techniques for linear system identification, but I think I’ll save that for a future post. The short answer is that you find a least-squares fit of the data you collect. I’ll also go over how this all applies to the underwater cart-pole in a future post.\n\n", "url": "https://jsteinhardt.wordpress.com/2010/06/20/linear-control/", "title": "Linear Control Theory: Part 0", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-06-20T00:58:45+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "f3af5aecee559b7601fd7b17ce150477", "summary": []}
+{"text": "Robotics\n\nThis summer I am working in the Robotics Locomotion group at CSAIL (MIT’s Computer Science and Artificial Intelligence Laboratory). I’ve decided to start a blog to exposit on the ideas involved. This ranges from big theoretical ideas (like general system identification techniques) to problem-specific ideas (specific learning strategies for the system we’re interested in) to useful information on using computational tools (how to make MATLAB’s ode45 do what you want it to).\n\n\nTo start with, I’m going to describe the problem that I’m working on, together with John (a grad student in mechanical engineering).\n\n\nLast spring, I took 6.832 (Underactuated Robotics) at MIT. In that class, we learned multiple incredibly powerful techniques for nonlinear control. After taking it, I was more or less convinced that we could solve, at least off-line, pretty much any control problem once it was posed properly. After coming to the Locomotion group, I realized that this wasn’t quite right. What is actually true is that we can solve any control problem where we have a good model and a reasonable objective function (we can also run into problems in high dimensions, but even there you can make progress if the objective function is nice enough).\n\n\nSo, we can (almost) solve any problem once we have a good model. That means the clear next thing to do is to come up with really good modelling techniques. Again, this is sort of true. There are actually three steps to constructing a good controller: experimental design, system identification, and a control policy.\n\n\nSystem identification is the process of building a good model for your system given physical data from it. But to build a good model, you need good data. That’s where experimental design comes in. Many quick and dirty ways of collecting data (like measuring the response of a sinusoidal input) introduce flaws into the model (which cannot be fixed except by collecting more data). I will explain these issues in more detail in a later post. For simple systems, you can get away with still-quick but slightly-less-dirty methods (such as a [chirp](http://en.wikipedia.org/wiki/Chirp) input), but for more general systems you need better techniques. Ian (a research scientist in our lab) has a nice [paper](http://people.csail.mit.edu/ian/M_CDC_09.pdf) on this topic that involves semidefinite optimization.\n\n\nDesigning a control policy we have already discussed. It is the process of, once we have collected data and built a model, designing an algorithm that will guide our system to its desired end state.\n\n\nSo, we have three tasks — experimental design, system identification, and control policy. If we can do the first two well, then we already know how to do the third. So one solution is to do a really good job on the experimental design and system identification so that we can use our sophisticated control techniques. This is what Michael and Zack are working on with a walking robot. Zack has spent months building the robot in such a way that it will obey all of our idealized models and behave nicely enough that we can run [LQR-trees](https://jsteinhardt.wordpress.com/feed/groups.csail.mit.edu/robotics-center/public_papers/Tedrake09a.pdf) on it.\n\n\nAnother solution is to give up on having a perfect model and have a system identification algorithm that, instead of returning a single model, returns an entire space of models (for example, by giving an uncertainty on each parameter). Then, as long as we can build a controller that works for *every system in this space*, we’ll be good to go. This can be done by using techniques from robust control.\n\n\nA final idea is to give up on models entirely and try to build a controller that relies only on the qualitative behaviour of the system in question (for example, by using model-free learning techniques). This is what I am working on. More specifically, I’m working on control in fluids with reasonably high [Reynold’s number](http://en.wikipedia.org/wiki/Reynolds_number). Unless you can solve the [Navier-Stokes equations](http://en.wikipedia.org/wiki/Navier-stokes), you can’t hope to get a model for this system, so you’ll have to do something more clever.\n\n\nThe first system we’re working with is the underwater [cart-pole](http://en.wikipedia.org/wiki/Inverted_pendulum) system. This involves a pendulum attached to a cart. The pendulum itself is not actuated (meaning there is no motor to swing it up). Instead, the only way to control the pendulum is indirectly, by moving the cart around (the cart is constrained to move in a line). The fluid dynamics enter when we put the pendulum in a water tunnel and replace the arm of the pendulum with a water foil.\n\n\nWhen the pendulum is in a constant-velocity stream, the system becomes a cart and pendulum with non-linear damping. However, when we add objects to the stream, the objects [shed vortices](http://en.wikipedia.org/wiki/Vortex_shedding) and the dynamics become too complicated to model with an ordinary differential equation. Instead, we need to simulate the solution to a partial differential equation, which is significantly more difficult computationally.\n\n\nOur first goal is to design a controller that will stabilize the pendulum at the top in the case of a constant stream (we have already done this — more about that in a later post). Our next goal is to design a controller to swing the pendulum up to the top, again in a constant stream (this is what I hope to finish tomorrow — again, more details in a later post). Once we have these finished, the more interesting work begins — to accomplish the same tasks in the presence of vortices. If we were to use existing ideas, we would design a robust version of the controller for a constant stream, and treat the vortices as disturbances. And this will probably be the first thing we do, so that we have a standard of comparison. But there are many examples in nature of animals using vortices to their advantage. So our ultimate goal is to do the same in this simple system. Since vortices represent lots of extra energy in the water, our hope is to actually pull energy out of the vortex to aid in the swing-up task, thus actually using *less* energy than would be needed without vortices (if this sounds crazy, consider that [dead trout can swim upstream](http://www.oeb.harvard.edu/lauder/reprints_unzipped/Liao.2004.pdf) using vortices).\n\n\nHopefully this gives you a good overview of my project. This is my first attempt at maintaining a research blog, so if you have any comments to help improve the exposition, please give them to me. Also, if you’d like me to elaborate further on anything, let me know. I’ll hopefully have a post or two going into more specific details this weekend.\n\n", "url": "https://jsteinhardt.wordpress.com/2010/06/18/robotics/", "title": "Robotics", "source": "jsteinhardt.wordpress.com", "source_type": "wordpress", "date_published": "2010-06-18T04:05:50+00:00", "paged_url": "https://jsteinhardt.wordpress.com/feed?paged=4", "authors": ["jsteinhardt"], "id": "6e4dcb790ba724e0a7560699f522087f", "summary": []}