---
license: apache-2.0
configs:
- config_name: pretrain_text
data_files:
- split: medicalBook_en
path: train/pretrain/medicalBook_en_text.json
- split: medicalBook_zh
path: train/pretrain/medicalBook_zh_text.json
- split: medicalGuideline_en
path: train/pretrain/medicalGuideline_en_text.json
- split: medicalPaper_en
path: train/pretrain/medicalPaper_en_text.json
- split: medicalPaper_es
path: train/pretrain/medicalPaper_es_text.json
- split: medicalPaper_fr
path: train/pretrain/medicalPaper_fr_text.json
- split: medicalPaper_zh
path: train/pretrain/medicalPaper_zh_text.json
- split: medicalWeb_en
path: train/pretrain/medicalWeb_en_text.json
- split: medicalWeb_es
path: train/pretrain/medicalWeb_es_text.json
- split: medicalWeb_zh
path: train/pretrain/medicalWeb_zh_text.json
- split: medicalWiki_en
path: train/pretrain/medicalWiki_en_text.json
- split: medicalWiki_fr
path: train/pretrain/medicalWiki_fr_text.json
- split: medicalWiki_hi
path: train/pretrain/medicalWiki_hi_text.json
# - config_name: pretrain_qa
# data_files:
# - split: medicalBook_en
# path: train/pretrain/medicalBook_en_qa.json
# - split: medicalBook_zh
# path: train/pretrain/medicalBook_zh_qa.json
# - split: medicalGuideline_en
# path: train/pretrain/medicalGuideline_en_qa.json
# - split: medicalPaper_en
# path: train/pretrain/medicalPaper_en_qa.json
# - split: medicalPaper_es
# path: train/pretrain/medicalPaper_es_qa.json
# - split: medicalPaper_fr
# path: train/pretrain/medicalPaper_fr_qa.json
# - split: medicalPaper_zh
# path: train/pretrain/medicalPaper_zh_qa.json
# - split: medicalWeb_en
# path: train/pretrain/medicalWeb_en_qa.json
# - split: medicalWeb_es
# path: train/pretrain/medicalWeb_es_qa.json
# - split: medicalWeb_zh
# path: train/pretrain/medicalWeb_zh_qa.json
# - split: medicalWiki_en
# path: train/pretrain/medicalWiki_en_qa.json
# - split: medicalWiki_fr
# path: train/pretrain/medicalWiki_fr_qa.json
# - split: medicalWiki_hi
# path: train/pretrain/medicalWiki_hi_qa.json
# - config_name: sft
# data_files:
# - split: code_en
# path: train/sft/code_en.json
# - split: code_zh
# path: train/sft/code_zh.json
# - split: general_ar
# path: train/sft/general_ar.json
# - split: general_en
# path: train/sft/general_en.json
# - split: general_es
# path: train/sft/general_es.json
# - split: general_fr
# path: train/sft/general_fr.json
# - split: general_hi
# path: train/sft/general_hi.json
# - split: general_zh
# path: train/sft/general_zh.json
# - split: math_en
# path: train/sft/math_en.json
# - split: math_zh
# path: train/sft/math_zh.json
# - split: medicalExam_en
# path: train/sft/medicalExam_en_clean.json
# - split: medicalExam_es
# path: train/sft/medicalExam_es_clean.json
# - split: medicalExam_fr
# path: train/sft/medicalExam_fr_clean.json
# - split: medicalExam_zh
# path: train/sft/medicalExam_zh_clean.json
# - split: medicalPatient_ar
# path: train/sft/medicalPatient_ar.json
# - split: medicalPatient_en
# path: train/sft/medicalPatient_en.json
# - split: medicalPatient_zh
# path: train/sft/medicalPatient_zh.json
---
# Multilingual Medicine: Model, Dataset, Benchmark, Code
Covering English, Chinese, French, Hindi, Spanish, Hindi, Arabic So far
👨🏻💻Github •📃 Paper • 🌐 Demo • 🤗 ApolloCorpus • 🤗 XMedBench
中文 | English

## 🌈 Update
* **[2024.03.07]** [Paper](https://arxiv.org/abs/2403.03640) released.
* **[2024.02.12]** ApolloCorpus and XMedBench is published!🎉
* **[2024.01.23]** Apollo repo is published!🎉
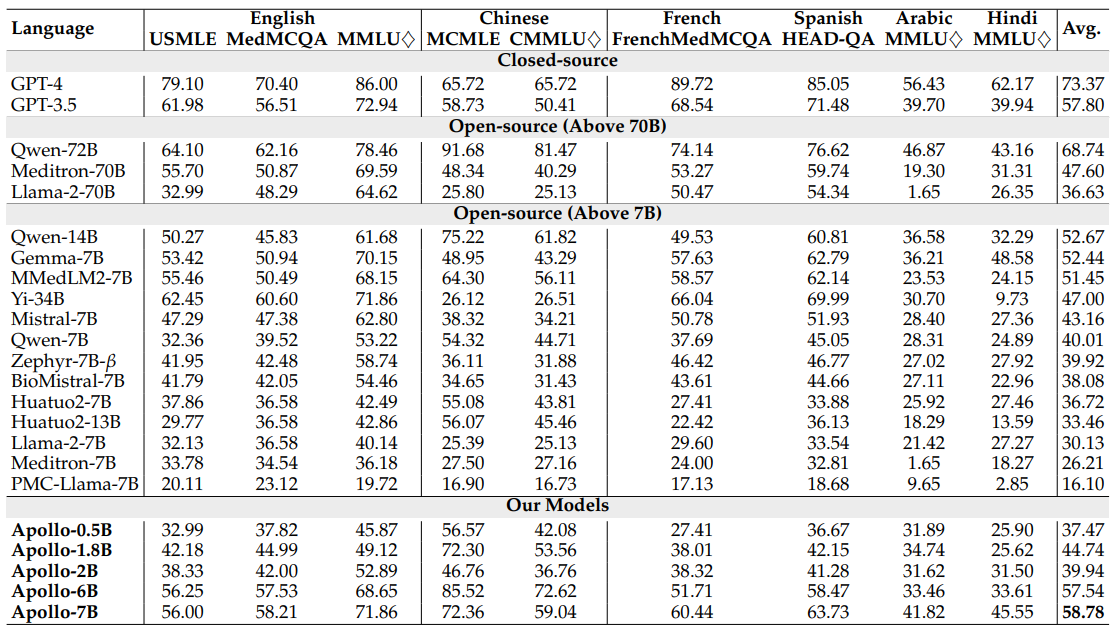
## Results
Apollo-0.5B • 🤗 Apollo-1.8B • 🤗 Apollo-2B • 🤗 Apollo-6B • 🤗 Apollo-7B
Click to expand