What to do when you get an error

In this section we’ll look at some common errors that can occur when you’re trying to generate predictions from your freshly tuned Transformer model. This will prepare you for section 4, where we’ll explore how to debug the training phase itself.
We’ve prepared a template model repository for this section, and if you want to run the code in this chapter you’ll first need to copy the model to your account on the Hugging Face Hub. To do so, first log in by running either the following in a Jupyter notebook:
from huggingface_hub import notebook_login
notebook_login()or the following in your favorite terminal:
huggingface-cli login
This will prompt you to enter your username and password, and will save a token under ~/.cache/huggingface/. Once you’ve logged in, you can copy the template repository with the following function:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clone the repo and extract the local path
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Create an empty repo on the Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clone the empty repo
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copy files
copy_tree(template_repo_dir, new_repo_dir)
# Push to Hub
repo.push_to_hub()Now when you call copy_repository_template(), it will create a copy of the template repository under your account.
Debugging the pipeline from 🤗 Transformers
To kick off our journey into the wonderful world of debugging Transformer models, consider the following scenario: you’re working with a colleague on a question answering project to help the customers of an e-commerce website find answers about consumer products. Your colleague shoots you a message like:
G’day! I just ran an experiment using the techniques in Chapter 7 of the Hugging Face course and got some great results on SQuAD! I think we can use this model as a starting point for our project. The model ID on the Hub is “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. Feel free to test it out :)
and the first thing you think of is to load the model using the pipeline from 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Oh no, something seems to have gone wrong! If you’re new to programming, these kind of errors can seem a bit cryptic at first (what even is an OSError?!). The error displayed here is just the last part of a much larger error report called a Python traceback (aka stack trace). For example, if you’re running this code on Google Colab, you should see something like the following screenshot:
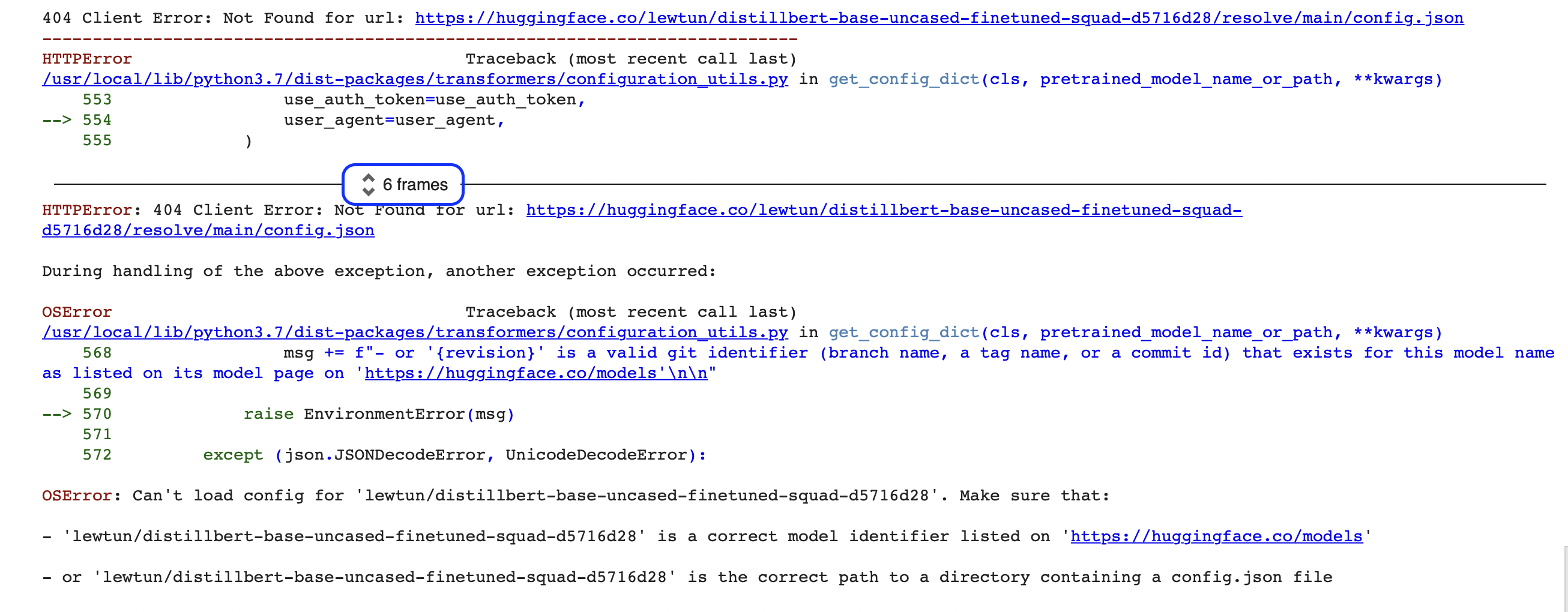
There’s a lot of information contained in these reports, so let’s walk through the key parts together. The first thing to note is that tracebacks should be read from bottom to top. This might sound weird if you’re used to reading English text from top to bottom, but it reflects the fact that the traceback shows the sequence of function calls that the pipeline makes when downloading the model and tokenizer. (Check out Chapter 2 for more details on how the pipeline works under the hood.)
🚨 See that blue box around “6 frames” in the traceback from Google Colab? That’s a special feature of Colab, which compresses the traceback into “frames.” If you can’t seem to find the source of an error, make sure you expand the full traceback by clicking on those two little arrows.
This means that the last line of the traceback indicates the last error message and gives the name of the exception that was raised. In this case, the exception type is OSError, which indicates a system-related error. If we read the accompanying error message, we can see that there seems to be a problem with the model’s config.json file, and we’re given two suggestions to fix it:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 If you encounter an error message that is difficult to understand, just copy and paste the message into the Google or Stack Overflow search bar (yes, really!). There’s a good chance that you’re not the first person to encounter the error, and this is a good way to find solutions that others in the community have posted. For example, searching for OSError: Can't load config for on Stack Overflow gives several hits that could be used as a starting point for solving the problem.
The first suggestion is asking us to check whether the model ID is actually correct, so the first order of business is to copy the identifier and paste it into the Hub’s search bar:

Hmm, it indeed looks like our colleague’s model is not on the Hub… aha, but there’s a typo in the name of the model! DistilBERT only has one “l” in its name, so let’s fix that and look for “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28” instead:

Okay, this got a hit. Now let’s try to download the model again with the correct model ID:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, foiled again — welcome to the daily life of a machine learning engineer! Since we’ve fixed the model ID, the problem must lie in the repository itself. A quick way to access the contents of a repository on the 🤗 Hub is via the list_repo_files() function of the huggingface_hub library:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Interesting — there doesn’t seem to be a config.json file in the repository! No wonder our pipeline couldn’t load the model; our colleague must have forgotten to push this file to the Hub after they fine-tuned it. In this case, the problem seems pretty straightforward to fix: we could ask them to add the file, or, since we can see from the model ID that the pretrained model used was distilbert-base-uncased, we can download the config for this model and push it to our repo to see if that resolves the problem. Let’s try that. Using the techniques we learned in Chapter 2, we can download the model’s configuration with the AutoConfig class:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 The approach we’re taking here is not foolproof, since our colleague may have tweaked the configuration of distilbert-base-uncased before fine-tuning the model. In real life, we’d want to check with them first, but for the purposes of this section we’ll assume they used the default configuration.
We can then push this to our model repository with the configuration’s push_to_hub() function:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Now we can test if this worked by loading the model from the latest commit on the main branch:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}Woohoo, it worked! Let’s recap what you’ve just learned:
- The error messages in Python are known as tracebacks and are read from bottom to top. The last line of the error message usually contains the information you need to locate the source of the problem.
- If the last line does not contain sufficient information, work your way up the traceback and see if you can identify where in the source code the error occurs.
- If none of the error messages can help you debug the problem, try searching online for a solution to a similar issue.
- The
huggingface_hub// 🤗 Hub? library provides a suite of tools that you can use to interact with and debug repositories on the Hub.
Now that you know how to debug a pipeline, let’s take a look at a trickier example in the forward pass of the model itself.
Debugging the forward pass of your model
Although the pipeline is great for most applications where you need to quickly generate predictions, sometimes you’ll need to access the model’s logits (say, if you have some custom post-processing that you’d like to apply). To see what can go wrong in this case, let’s first grab the model and tokenizer from our pipeline:
tokenizer = reader.tokenizer model = reader.model
Next we need a question, so let’s see if our favorite frameworks are supported:
question = "Which frameworks can I use?"As we saw in Chapter 7, the usual steps we need to take are tokenizing the inputs, extracting the logits of the start and end tokens, and then decoding the answer span:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Oh dear, it looks like we have a bug in our code! But we’re not afraid of a little debugging. You can use the Python debugger in a notebook:
or in a terminal:
Here, reading the error message tells us that 'list' object has no attribute 'size', and we can see a --> arrow pointing to the line where the problem was raised in model(**inputs).You can debug this interactively using the Python debugger, but for now we’ll simply print out a slice of inputs to see what we have:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]This certainly looks like an ordinary Python list, but let’s double-check the type:
type(inputs["input_ids"])listYep, that’s a Python list for sure. So what went wrong? Recall from Chapter 2 that the AutoModelForXxx classes in 🤗 Transformers operate on tensors (either in PyTorch or TensorFlow), and a common operation is to extract the dimensions of a tensor using Tensor.size() in, say, PyTorch. Let’s take another look at the traceback, to see which line triggered the exception:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'It looks like our code tried to call input_ids.size(), but this clearly won’t work for a Python list, which is just a container. How can we solve this problem? Searching for the error message on Stack Overflow gives quite a few relevant hits. Clicking on the first one displays a similar question to ours, with the answer shown in the screenshot below:
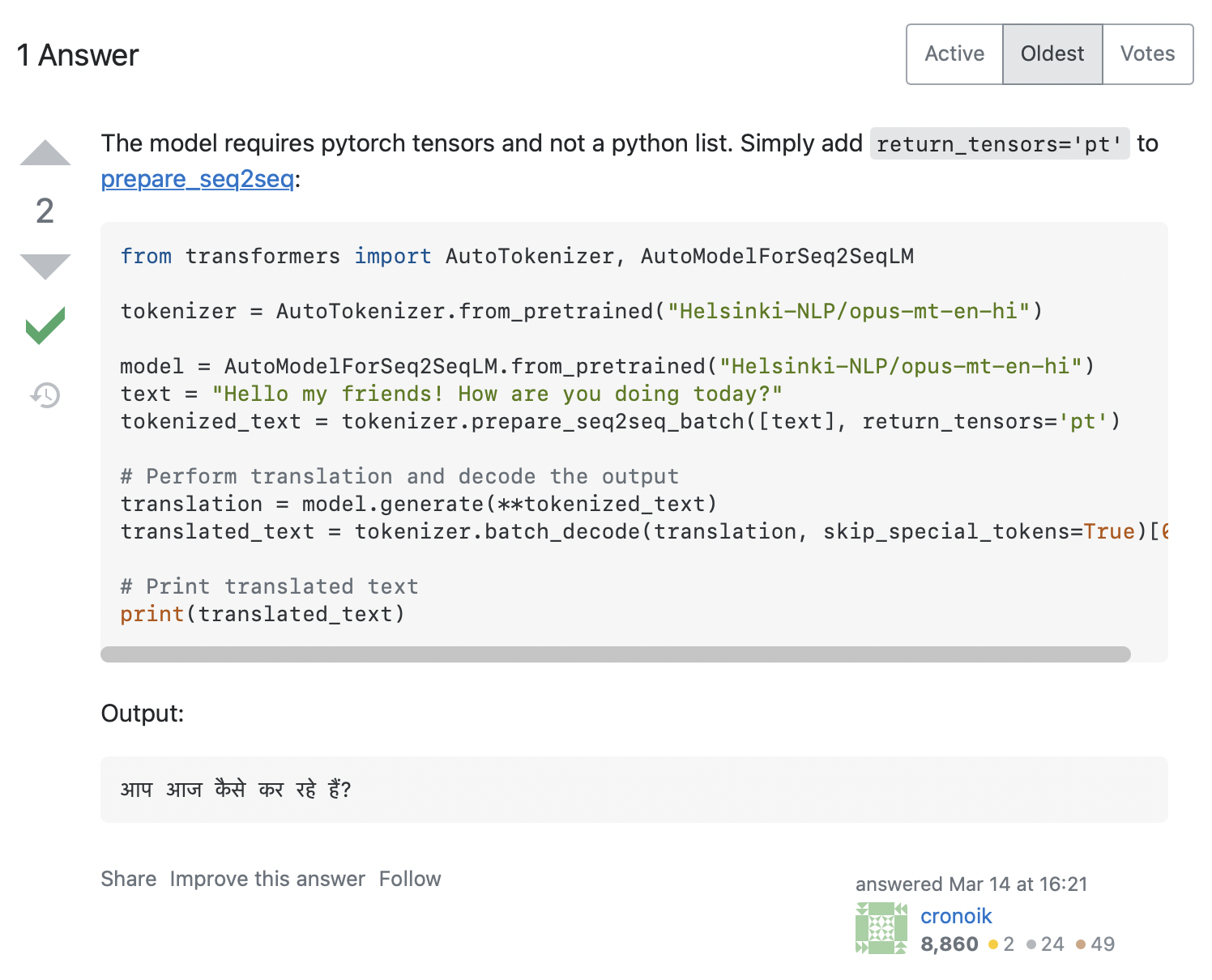
The answer recommends that we add return_tensors='pt' to the tokenizer, so let’s see if that works for us:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Nice, it worked! This is a great example of how useful Stack Overflow can be: by identifying a similar problem, we were able to benefit from the experience of others in the community. However, a search like this won’t always yield a relevant answer, so what can you do in such cases? Fortunately, there is a welcoming community of developers on the Hugging Face forums that can help you out! In the next section, we’ll take a look at how you can craft good forum questions that are likely to get answered.