# AnimateDiff
This repository is the official implementation of [AnimateDiff](https://arxiv.org/abs/2307.04725).
**[AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning](https://arxiv.org/abs/2307.04725)**
Yuwei Guo,
Ceyuan Yang*,
Anyi Rao,
Yaohui Wang,
Yu Qiao,
Dahua Lin,
Bo Dai
*Corresponding Author
[](https://arxiv.org/abs/2307.04725)
[](https://animatediff.github.io/)
[](https://openxlab.org.cn/apps/detail/Masbfca/AnimateDiff)
[](https://huggingface.co/spaces/guoyww/AnimateDiff)
## Next
One with better controllability and quality is coming soon. Stay tuned.
## Features
- **[2023/11/10]** Release the Motion Module (beta version) on SDXL, available at [Google Drive](https://drive.google.com/file/d/1EK_D9hDOPfJdK4z8YDB8JYvPracNx2SX/view?usp=share_link
) / [HuggingFace](https://huggingface.co/guoyww/animatediff/blob/main/mm_sdxl_v10_beta.ckpt
) / [CivitAI](https://civitai.com/models/108836/animatediff-motion-modules). High resolution videos (i.e., 1024x1024x16 frames with various aspect ratios) could be produced **with/without** personalized models. Inference usually requires ~13GB VRAM and tuned hyperparameters (e.g., #sampling steps), depending on the chosen personalized models. Checkout to the branch [sdxl](https://github.com/guoyww/AnimateDiff/tree/sdxl) for more details of the inference. More checkpoints with better-quality would be available soon. Stay tuned. Examples below are manually downsampled for fast loading.
| Original SDXL |
Personalized SDXL |
Personalized SDXL |
 |
 |
 |
- **[2023/09/25]** Release **MotionLoRA** and its model zoo, **enabling camera movement controls**! Please download the MotionLoRA models (**74 MB per model**, available at [Google Drive](https://drive.google.com/drive/folders/1EqLC65eR1-W-sGD0Im7fkED6c8GkiNFI?usp=sharing) / [HuggingFace](https://huggingface.co/guoyww/animatediff) / [CivitAI](https://civitai.com/models/108836/animatediff-motion-modules) ) and save them to the `models/MotionLoRA` folder. Example:
```
python -m scripts.animate --config configs/prompts/v2/5-RealisticVision-MotionLoRA.yaml
```
| Zoom In |
Zoom Out |
Zoom Pan Left |
Zoom Pan Right |
 |
 |
 |
 |
 |
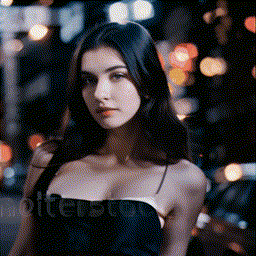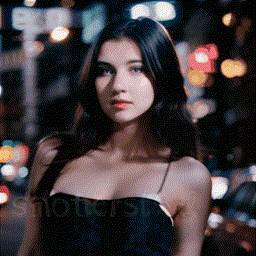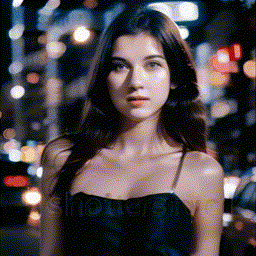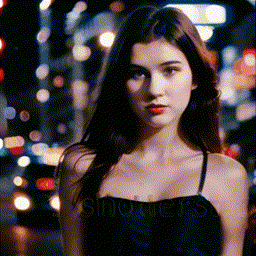 |
 |
 |
| Tilt Up |
Tilt Down |
Rolling Anti-Clockwise |
Rolling Clockwise |
 |
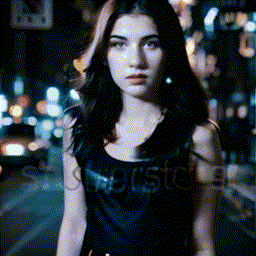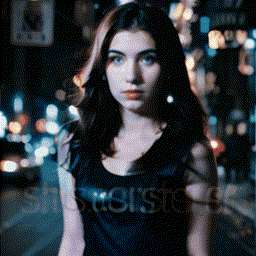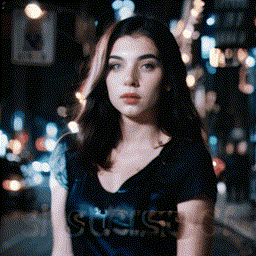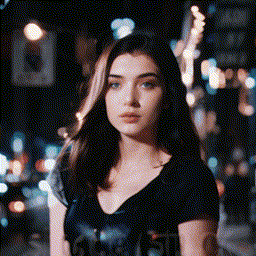 |
 |
 |
 |
 |
 |
 |
- **[2023/09/10]** New Motion Module release! `mm_sd_v15_v2.ckpt` was trained on larger resolution & batch size, and gains noticeable quality improvements. Check it out at [Google Drive](https://drive.google.com/drive/folders/1EqLC65eR1-W-sGD0Im7fkED6c8GkiNFI?usp=sharing) / [HuggingFace](https://huggingface.co/guoyww/animatediff) / [CivitAI](https://civitai.com/models/108836/animatediff-motion-modules) and use it with `configs/inference/inference-v2.yaml`. Example:
```
python -m scripts.animate --config configs/prompts/v2/5-RealisticVision.yaml
```
Here is a qualitative comparison between `mm_sd_v15.ckpt` (left) and `mm_sd_v15_v2.ckpt` (right):
- GPU Memory Optimization, ~12GB VRAM to inference
## Quick Demo
User Interface developed by community:
- A1111 Extension [sd-webui-animatediff](https://github.com/continue-revolution/sd-webui-animatediff) (by [@continue-revolution](https://github.com/continue-revolution))
- ComfyUI Extension [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved) (by [@Kosinkadink](https://github.com/Kosinkadink))
- Google Colab: [Colab](https://colab.research.google.com/github/camenduru/AnimateDiff-colab/blob/main/AnimateDiff_colab.ipynb) (by [@camenduru](https://github.com/camenduru))
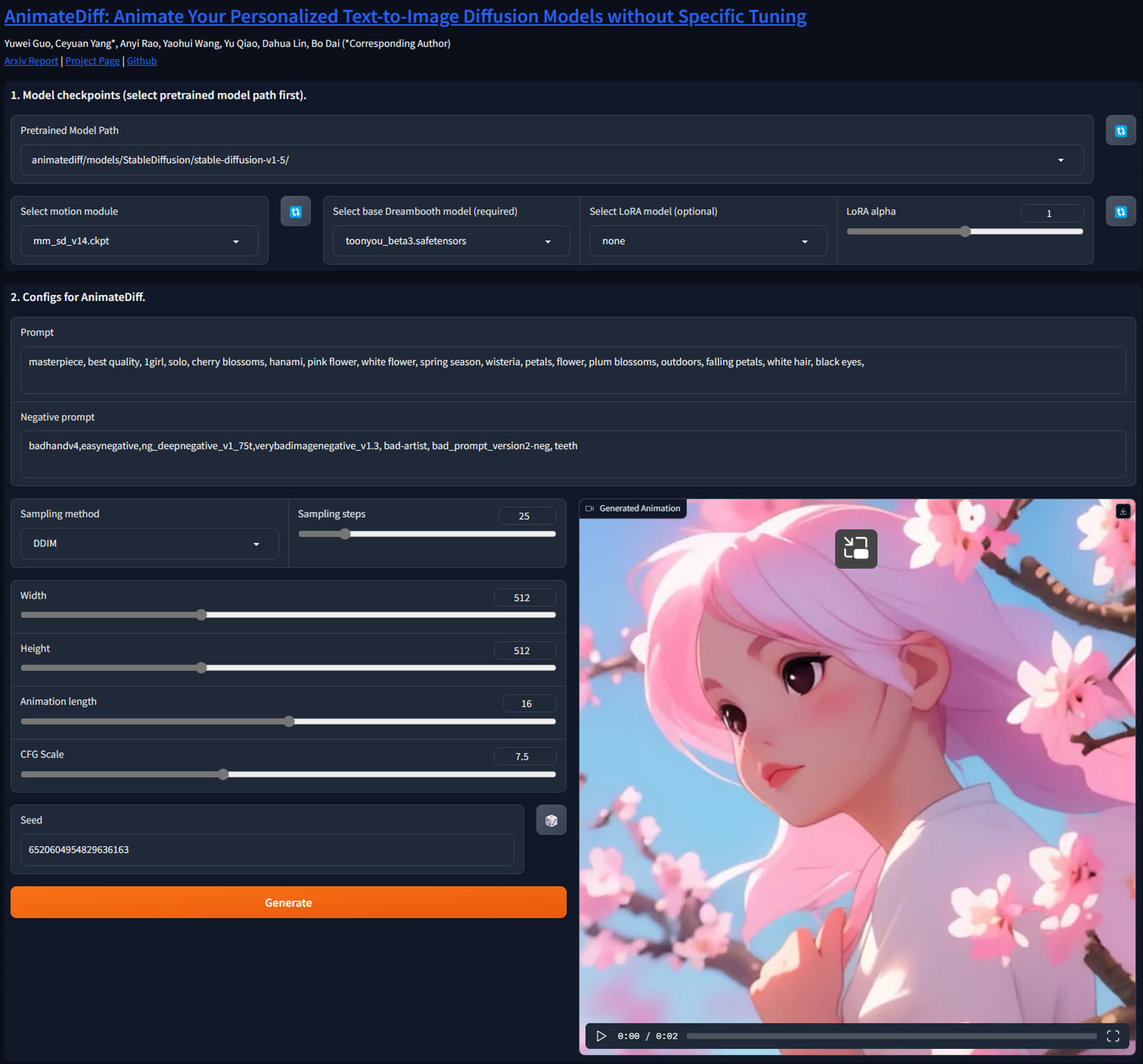
We also create a Gradio demo to make AnimateDiff easier to use. To launch the demo, please run the following commands:
```
conda activate animatediff
python app.py
```
By default, the demo will run at `localhost:7860`.
 ## Model Zoo
## Model Zoo
Motion Modules
| Name | Parameter | Storage Space |
|----------------------|-----------|---------------|
| mm_sd_v14.ckpt | 417 M | 1.6 GB |
| mm_sd_v15.ckpt | 417 M | 1.6 GB |
| mm_sd_v15_v2.ckpt | 453 M | 1.7 GB |
MotionLoRAs
| Name | Parameter | Storage Space |
|--------------------------------------|-----------|---------------|
| v2_lora_ZoomIn.ckpt | 19 M | 74 MB |
| v2_lora_ZoomOut.ckpt | 19 M | 74 MB |
| v2_lora_PanLeft.ckpt | 19 M | 74 MB |
| v2_lora_PanRight.ckpt | 19 M | 74 MB |
| v2_lora_TiltUp.ckpt | 19 M | 74 MB |
| v2_lora_TiltDown.ckpt | 19 M | 74 MB |
| v2_lora_RollingClockwise.ckpt | 19 M | 74 MB |
| v2_lora_RollingAnticlockwise.ckpt | 19 M | 74 MB |
## Common Issues
Installation
Please ensure the installation of [xformer](https://github.com/facebookresearch/xformers) that is applied to reduce the inference memory.
Various resolution or number of frames
Currently, we recommend users to generate animation with 16 frames and 512 resolution that are aligned with our training settings. Notably, various resolution/frames may affect the quality more or less.
How to use it without any coding
1) Get lora models: train lora model with [A1111](https://github.com/continue-revolution/sd-webui-animatediff) based on a collection of your own favorite images (e.g., tutorials [English](https://www.youtube.com/watch?v=mfaqqL5yOO4), [Japanese](https://www.youtube.com/watch?v=N1tXVR9lplM), [Chinese](https://www.bilibili.com/video/BV1fs4y1x7p2/))
or download Lora models from [Civitai](https://civitai.com/).
2) Animate lora models: using gradio interface or A1111
(e.g., tutorials [English](https://github.com/continue-revolution/sd-webui-animatediff), [Japanese](https://www.youtube.com/watch?v=zss3xbtvOWw), [Chinese](https://941ai.com/sd-animatediff-webui-1203.html))
3) Be creative togther with other techniques, such as, super resolution, frame interpolation, music generation, etc.
Animating a given image
We totally agree that animating a given image is an appealing feature, which we would try to support officially in future. For now, you may enjoy other efforts from the [talesofai](https://github.com/talesofai/AnimateDiff).
Contributions from community
Contributions are always welcome!! The dev branch is for community contributions. As for the main branch, we would like to align it with the original technical report :)
## Training and inference
Please refer to [ANIMATEDIFF](./__assets__/docs/animatediff.md) for the detailed setup.
## Gallery
We collect several generated results in [GALLERY](./__assets__/docs/gallery.md).
## BibTeX
```
@article{guo2023animatediff,
title={AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning},
author={Guo, Yuwei and Yang, Ceyuan and Rao, Anyi and Wang, Yaohui and Qiao, Yu and Lin, Dahua and Dai, Bo},
journal={arXiv preprint arXiv:2307.04725},
year={2023}
}
```
## Disclaimer
This project is released for academic use. We disclaim responsibility for user-generated content. Users are solely liable for their actions. The project contributors are not legally affiliated with, nor accountable for, users' behaviors. Use the generative model responsibly, adhering to ethical and legal standards.
## Contact Us
**Yuwei Guo**: [guoyuwei@pjlab.org.cn](mailto:guoyuwei@pjlab.org.cn)
**Ceyuan Yang**: [yangceyuan@pjlab.org.cn](mailto:yangceyuan@pjlab.org.cn)
**Bo Dai**: [daibo@pjlab.org.cn](mailto:daibo@pjlab.org.cn)
## Acknowledgements
Codebase built upon [Tune-a-Video](https://github.com/showlab/Tune-A-Video).







