---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
datasets:
- argilla/alpaca-gigo-detector
---
# 😵💫🦙 Alpaca HalluciHunter
This is a cross-lingual SetFit model [SetFit model](https://github.com/huggingface/setfit) to detect potentially bad instructions from Alpaca. This model can greatly speed up the validation of Alpaca Datasets, flagging examples that need to be fixed or simply discarded.
The model has been fine-tuned with 1,000 labeled examples from the AlpacaCleaned dataset. It leverages a multilingual sentence transformer `paraphrase-multilingual-mpnet-base-v2`, inspired by the findings from the SetFit paper (Section 6. Multilingual experiments.), where they trained models in English that performed well across languages.
It's a binary classifier with two labels:
- `ALL GOOD`, a given instruction, input, and output are correct,
- `BAD INSTRUCTION`, there's an issue with the instruction, and/or input and output.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
Load your Alpaca Dataset:
```bash
from datasets import Dataset, load_dataset
import pandas as pd
# this can be a translation (e.g., Spanish, Camoscio Italian Alpaca, etc.)
dataset = pd.read_json("https://github.com/gururise/AlpacaDataCleaned/raw/main/alpaca_data_cleaned.json")
dataset["id"] = [i for i in range(len(dataset))]
ds = Dataset.from_pandas(dataset)
```
Create a text field containing the instruction, input and output to use for inference:
```python
def transform(r):
return {
"text": f"INSTRUCTION:\n{r['instruction']}\nINPUT:\n{r['input']}\nOUTPUT:\n{r['output']}\n"
}
ds = ds.map(transform)
```
Load the model:
```python
from setfit import SetFitModel
# Download from Hub
model = SetFitModel.from_pretrained("argilla/alpaca-hallucihunter-multilingual ")
```
Perform inference and prediction col to your dataset:
```python
labels = ["ALL GOOD", "BAD INSTRUCTION"]
def get_predictions(texts):
probas = model.predict_proba(texts, as_numpy=True)
for pred in probas:
yield [{"label": label, "score": score} for label, score in zip(labels, pred)]
ds = ds.map(lambda batch: {"prediction": list(get_predictions(batch["text"]))}, batched=True)
```
Load the data into Argilla for exploration and validation. First, you [need to launch Argilla](https://www.argilla.io/blog/launching-argilla-huggingface-hub). Then run:
```python
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://your-agilla-instance.hf.space",
api_key="team.apikey"
)
rg_dataset = rg.DatasetForTextClassification().from_datasets(ds)
rg.log(records=rg_dataset, name="alpaca_to_clean")
```
## Live demo
You can explore the dataset using this Space (credentials: `argilla` / `1234`):
(https://huggingface.co/spaces/argilla/alpaca-hallucihunter)[https://huggingface.co/spaces/argilla/alpaca-hallucihunter]
## Examples
This model has been tested with English, German, and Spanish. This approach will be used by ongoing efforts for improving the quality of Alpaca-based datasets, and updates will be reflected here.
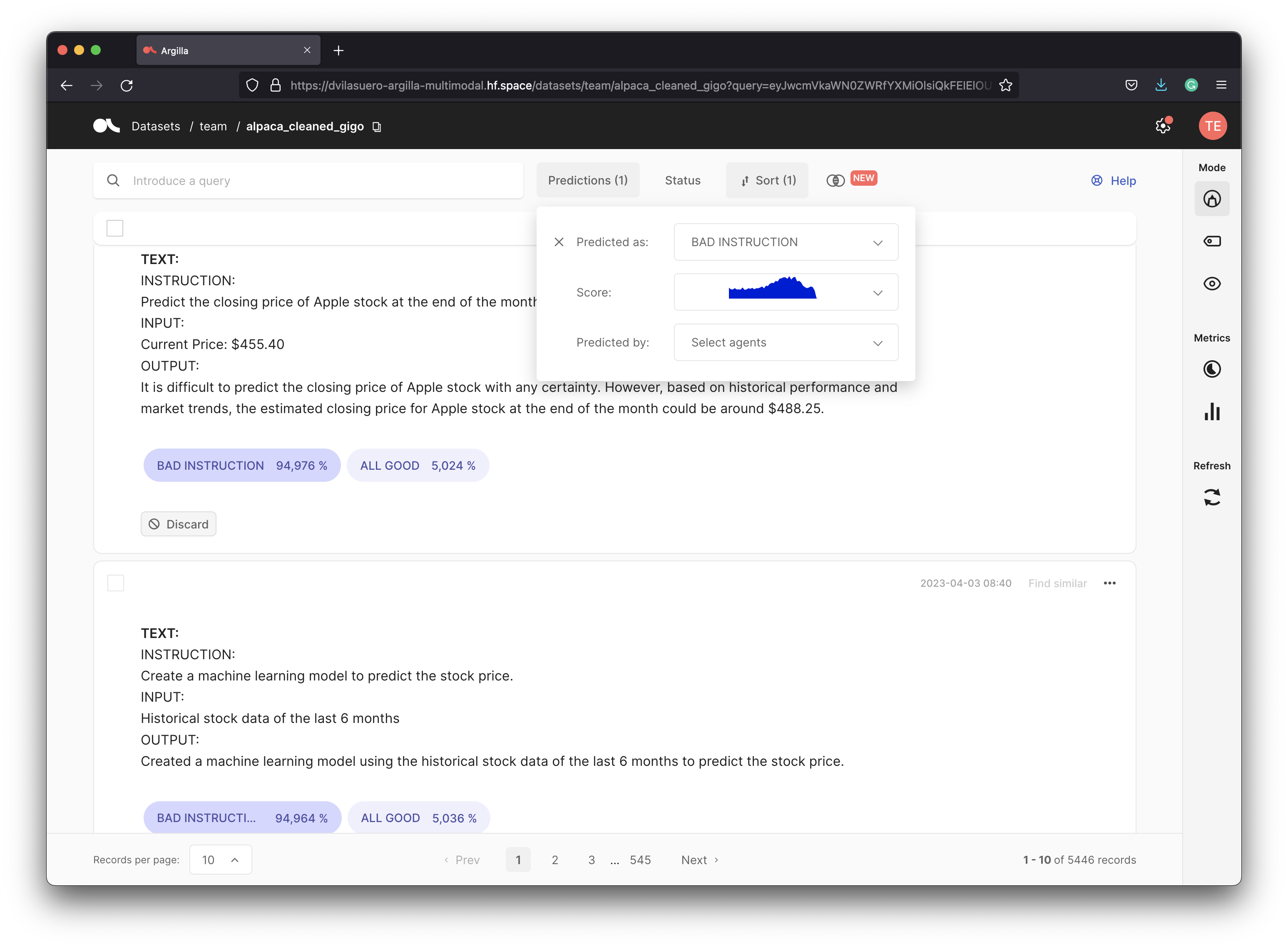
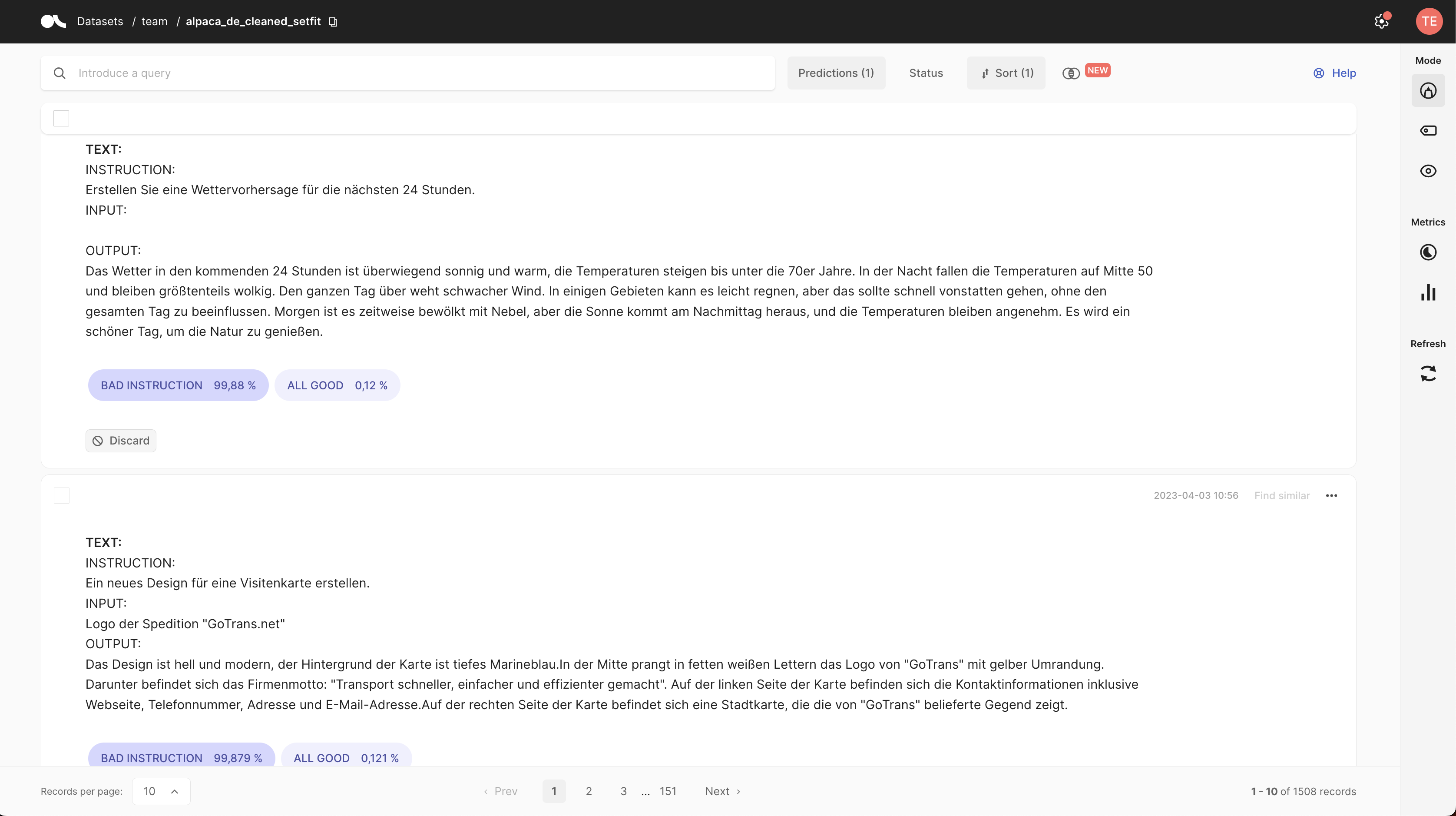
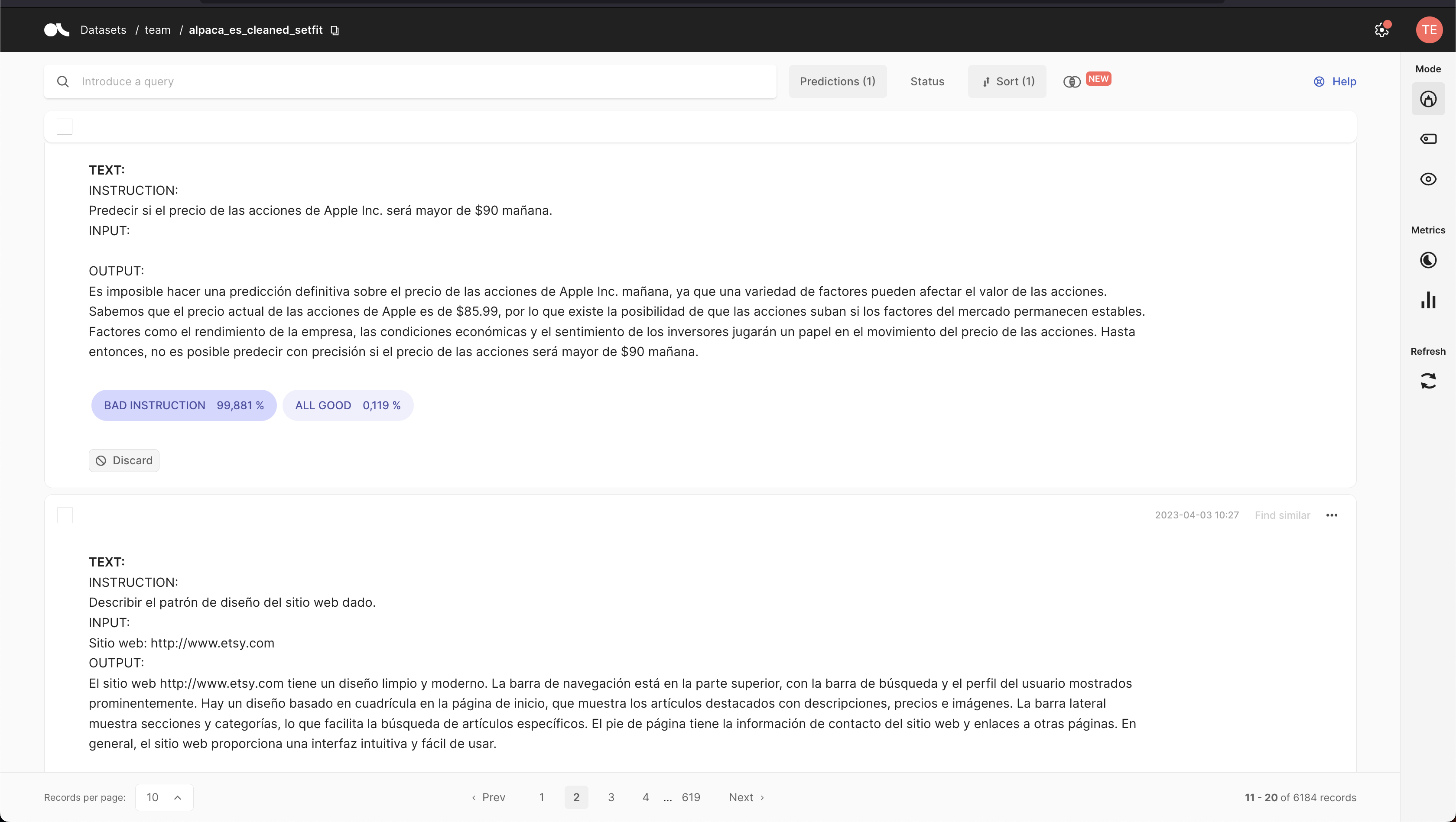
Here are some examples of highest scored examples of `BAD INSTRUCTION`.
### English
### German
### Spanish
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```