---
license: apache-2.0
datasets:
- amaai-lab/MidiCaps
tags:
- music
- text-to-music
- symbolic-music
---
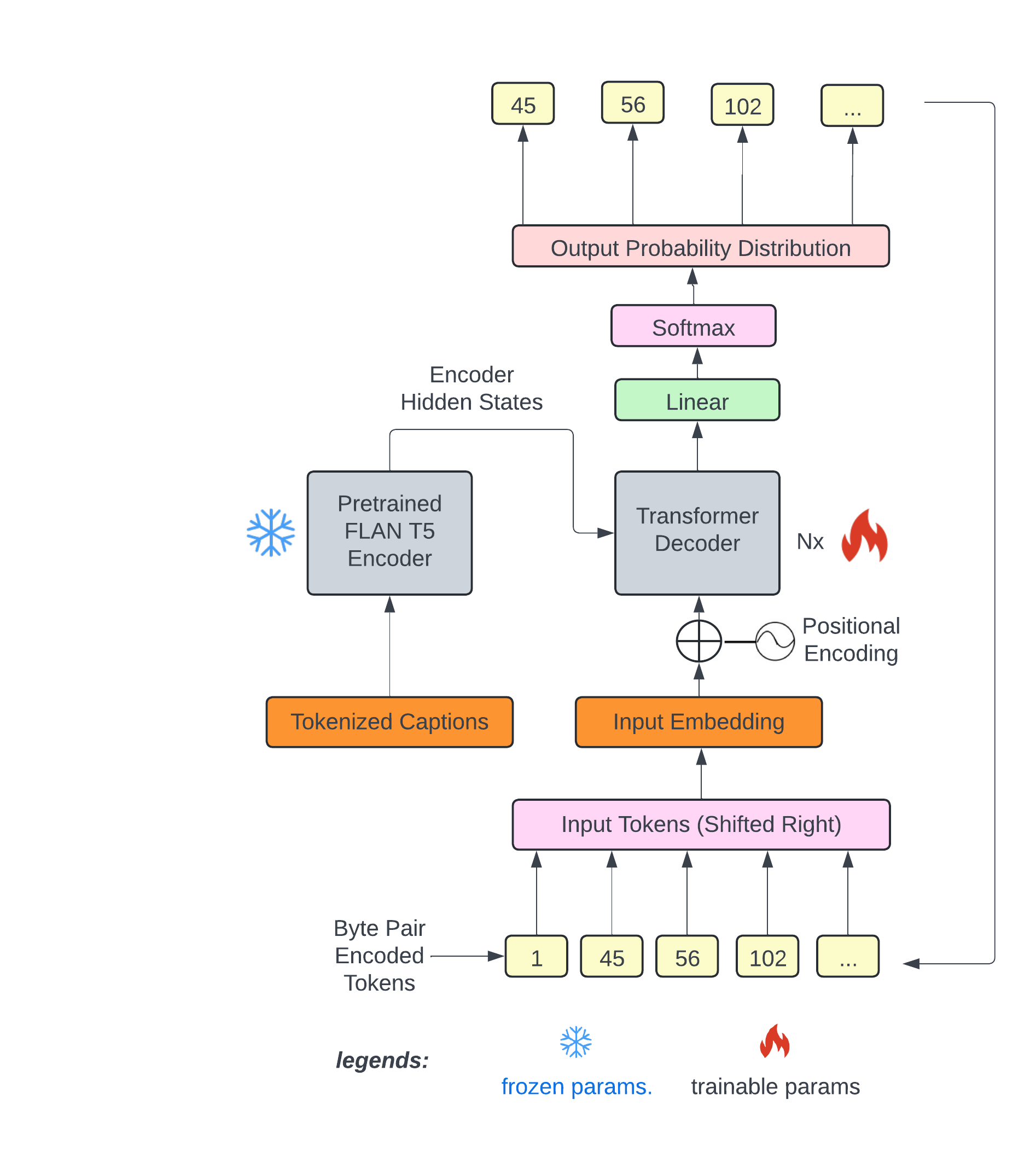
# Text2midi: Generating Symbolic Music from Captions
[Demo](https://huggingface.co/spaces/amaai-lab/text2midi) | [Model](https://huggingface.co/amaai-lab/text2midi) | [Website and Examples](https://github.com/AMAAI-Lab/text2midi) | [Paper](https://arxiv.org/abs/TBD) | [Dataset](https://huggingface.co/datasets/amaai-lab/MidiCaps)
[](https://huggingface.co/spaces/amaai-lab/text2midi)
**text2midi** is the first end-to-end model for generating MIDI files from textual descriptions. By leveraging pretrained large language models and a powerful autoregressive transformer decoder, **text2midi** allows users to create symbolic music that aligns with detailed textual prompts, including musical attributes like chords, tempo, and style.
🔥 Live demo available on [HuggingFace Spaces](https://huggingface.co/spaces/amaai-lab/text2midi).
## Quickstart Guide
Generate symbolic music from a text prompt:
```python
from transformers import T5Tokenizer
from model.transformer_model import Transformer
from miditok import REMI, TokenizerConfig
from pathlib import Path
device = 'cuda' if torch.cuda.is_available() else 'cpu'
artifact_folder = 'artifacts'
tokenizer_filepath = os.path.join(artifact_folder, "vocab_remi.pkl")
# Load the tokenizer dictionary
with open(tokenizer_filepath, "rb") as f:
r_tokenizer = pickle.load(f)
# Get the vocab size
vocab_size = len(r_tokenizer)
print("Vocab size: ", vocab_size)
model = Transformer(vocab_size, 768, 8, 5000, 18, 1024, False, 8, device=device)
model.load_state_dict(torch.load('/text2midi/artifacts/pytorch_model_140.bin', map_location=device))
model.eval()
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
src = "A melodic electronic song with ambient elements, featuring piano, acoustic guitar, alto saxophone, string ensemble, and electric bass. Set in G minor with a 4/4 time signature, it moves at a lively Presto tempo. The composition evokes a blend of relaxation and darkness, with hints of happiness and a meditative quality."
inputs = tokenizer(src, return_tensors='pt', padding=True, truncation=True)
input_ids = nn.utils.rnn.pad_sequence(inputs.input_ids, batch_first=True, padding_value=0)
input_ids = input_ids.to(device)
attention_mask =nn.utils.rnn.pad_sequence(inputs.attention_mask, batch_first=True, padding_value=0)
attention_mask = attention_mask.to(device)
output = model.generate(input_ids, attention_mask, max_len=2000,temperature = 1.0)
output_list = output[0].tolist()
generated_midi = r_tokenizer.decode(output_list)
generated_midi.dump_midi("output.mid")
post_processing("output.mid", "output.mid")
```
## Installation
```bash
git clone https://github.com/AMAAI-Lab/text-2-midi
cd text-2-midi
pip install -r requirements.txt
```
## Datasets
The MidiCaps dataset is a large-scale dataset of 168k MIDI files paired with rich text captions. These captions contain musical attributes such as key, tempo, style, and mood, making it ideal for text-to-MIDI generation tasks.
## Results of the Listening Study
Each question is rated on a Likert scale from 1 (very bad) to 7 (very good). The table shows the average ratings per question for each group of participants.
| **Question** | **General Audience (MidiCaps)** | **General Audience (text2midi)** | **Music Experts (MidiCaps)** | **Music Experts (text2midi)** |
|---------------------|---------------------------------|-----------------------------------|------------------------------|--------------------------------|
| Overall matching | 5.17 | 4.12 | 5.29 | 4.05 |
| Genre matching | 5.22 | 4.29 | 5.31 | 4.29 |
| Mood matching | 5.24 | 4.10 | 5.44 | 4.26 |
| Key matching | 4.72 | 4.24 | 4.63 | 4.05 |
| Chord matching | 4.65 | 4.23 | 4.05 | 4.06 |
| Tempo matching | 4.72 | 4.48 | 5.15 | 4.90 |
## Objective Evaluations
| Metric | text2midi | MidiCaps | MuseCoco |
|---------------------|-----------|----------|----------|
| CR ↑ | 2.156 | 3.4326 | 2.1288 |
| CLAP ↑ | 0.2204 | 0.2593 | 0.2158 |
| TB (%) ↑ | 34.03 | - | 21.71 |
| TBT (%) ↑ | 66.9 | - | 54.63 |
| CK (%) ↑ | 15.36 | - | 13.70 |
| CKD (%) ↑ | 15.80 | - | 14.59 |
**Note**:
CR = Compression ratio
CLAP = CLAP score
TB = Tempo Bin
TBT = Tempo Bin with Tolerance
CK = Correct Key
CKD = Correct Key with Duplicates
↑ = Higher score is better.
## Training
To train text2midi, we recommend using accelerate for multi-GPU support. First, configure accelerate by running:
```bash
accelerate config
```
Then, use the following command to start training:
```bash
accelerate launch train.py \
--encoder_model="google/flan-t5-large" \
--decoder_model="configs/transformer_decoder_config.json" \
--dataset_name="amaai-lab/MidiCaps" \
--pretrain_dataset="amaai-lab/SymphonyNet" \
--batch_size=16 \
--learning_rate=1e-4 \
--epochs=40 \
```
## Citation
If you use text2midi in your research, please cite:
```
@inproceedings{bhandari2025text2midi,
title={text2midi: Generating Symbolic Music from Captions},
author={Keshav Bhandari and Abhinaba Roy and Kyra Wang and Geeta Puri and Simon Colton and Dorien Herremans},
booktitle={Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI 2025)},
year={2025}
}
```