---
language:
- {en} # Example: fr
license: mit
widget:
- text: "Lou Gehrig who works for XCorp and lives in New York suffers from [MASK]"
example_title: "Test for entity type: Disease"
- text: "Overexpression of [MASK] occurs across a wide range of cancers"
example_title: "Test for entity type: Gene"
- text: "Patients treated with [MASK] are vulnerable to infectious diseases"
example_title: "Test for entity type: Drug"
- text: "A eGFR level below [MASK] indicates chronic kidney disease"
example_title: "Test for entity type: Measure "
- text: "In the [MASK], increased daily imatinib dose induced MMR"
example_title: "Test for entity type: STUDY/TRIAL"
- text: "Paul Erdos died at [MASK]"
example_title: "Test for entity type: TIME"
inference:
parameters:
top_k: 10
tags:
- {fill-mask} # Example: audio
- exbert
---
This **cased model** was pretrained from scratch using a custom vocabulary on the following corpora
- Pubmed
- Clinical trials corpus
- and a small subset of Bookcorpus
The pretrained model was used to do NER **as is, with no fine-tuning**. The approach is described [in this post](https://ajitrajasekharan.github.io/2021/01/02/my-first-post.html). [Towards Data Science review](https://twitter.com/TDataScience/status/1486300137366466560?s=20)
[App in Spaces](https://huggingface.co/spaces/ajitrajasekharan/self-supervised-ner-biomedical) demonstrates this approach.
[Github link](https://github.com/ajitrajasekharan/unsupervised_NER) to perform NER using this model in an ensemble with bert-base cased.
The ensemble detects 69 entity subtypes (17 broad entity groups)
 ### Ensemble model performance
### Ensemble model performance
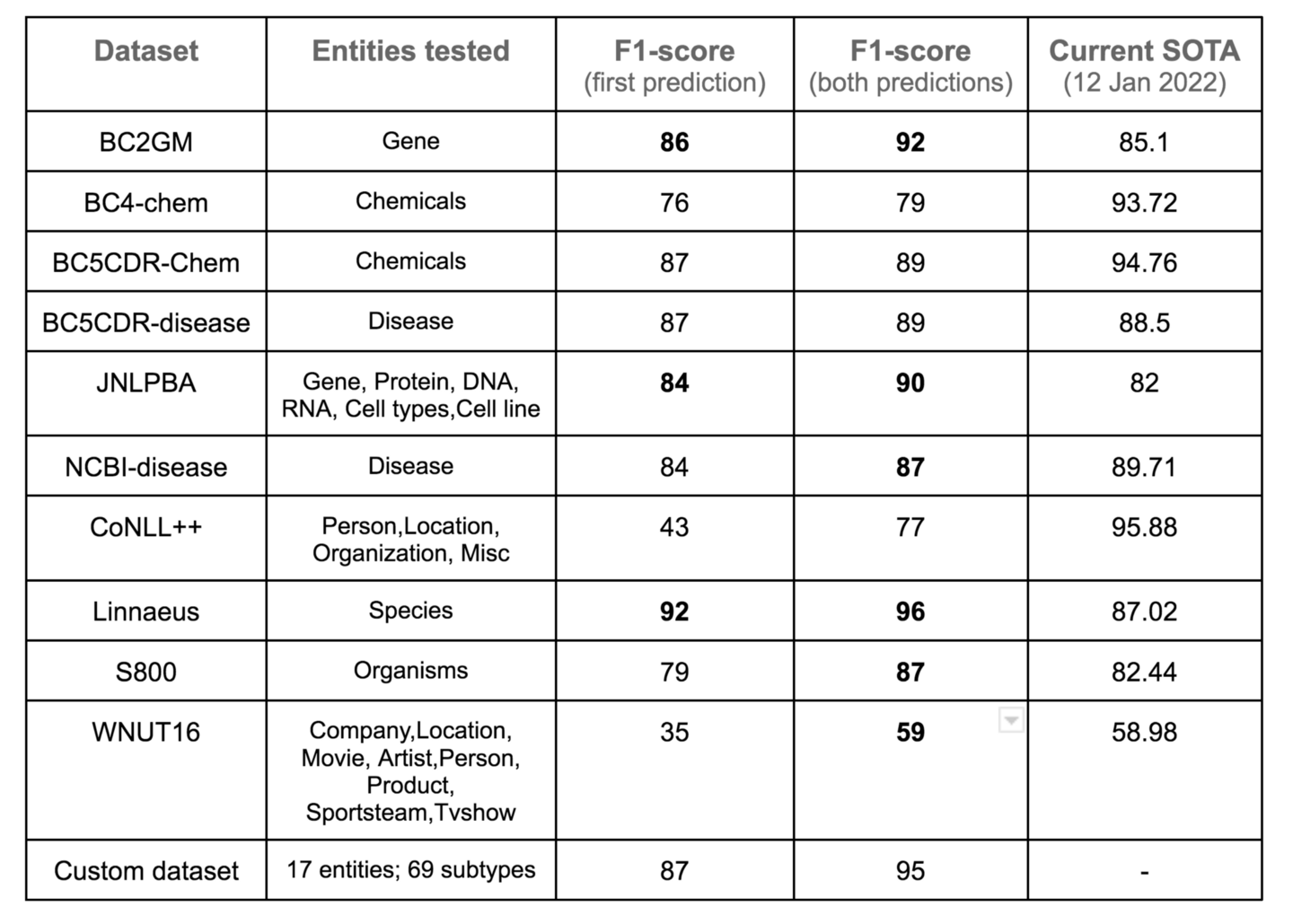 ### Additional notes
- The model predictions on the right do not include [CLS] predictions. Hosted inference API only returns the masked position predictions. In practice, the [CLS] predictions are just as useful as the model predictions for the masked position _(if the next sentence prediction loss was low during pretraining)_ and are used for NER.
- Some of the top model predictions like "a", "the", punctuations, etc. while valid predictions, bear no entity information. These are filtered when harvesting descriptors for NER. The examples on the right are unfiltered results.
- [Use this link](https://huggingface.co/spaces/ajitrajasekharan/Qualitative-pretrained-model-evaluation) to examine both fill-mask prediction and [CLS] predictions
### License
MIT license
### Additional notes
- The model predictions on the right do not include [CLS] predictions. Hosted inference API only returns the masked position predictions. In practice, the [CLS] predictions are just as useful as the model predictions for the masked position _(if the next sentence prediction loss was low during pretraining)_ and are used for NER.
- Some of the top model predictions like "a", "the", punctuations, etc. while valid predictions, bear no entity information. These are filtered when harvesting descriptors for NER. The examples on the right are unfiltered results.
- [Use this link](https://huggingface.co/spaces/ajitrajasekharan/Qualitative-pretrained-model-evaluation) to examine both fill-mask prediction and [CLS] predictions
### License
MIT license
