---
license: mit
language:
- en
---
**Exllamav2** quant (**exl2** / **6.5 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|**[2.2](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-2_2bpw_exl2)** | 20886 MB | 6 |
|**[2.5](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-2_5bpw_exl2)** | 23192 MB | 6 |
|**[3.0](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-3_0bpw_exl2)** | 27273 MB | 6 |
|**[3.5](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-3_5bpw_exl2)** | 31356 MB | 6 |
|**[3.75](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-3_75bpw_exl2)** | 33398 MB | 6 |
|**[4.0](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-4_0bpw_exl2)** | 35434 MB | 6 |
|**[4.25](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-4_25bpw_exl2)** | 37456 MB | 6 |
|**[5.0](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-5_0bpw_exl2)** | 43598 MB | 6 |
|**[6.0](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-6_0bpw_exl2)** | 51957 MB | 8 |
|**[6.5](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-6_5bpw_exl2)** | 56014 MB | 8 |
|**[8.0](https://huggingface.co/Zoyd/abacusai_Smaug-Llama-3-70B-Instruct-8_0bpw_exl2)** | 60211 MB | 8 |
# 🦣 MAmmoTH2: Scaling Instructions from the Web
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## Introduction
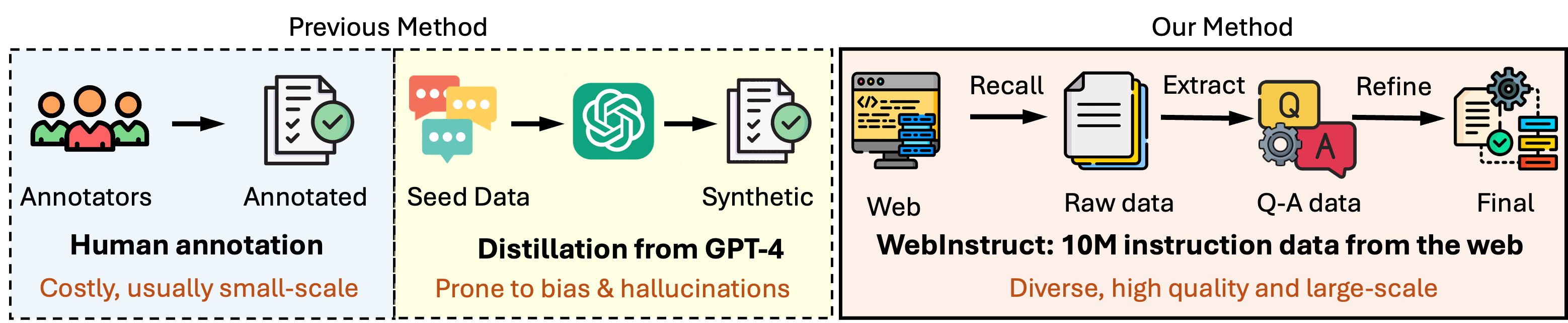
Introducing 🦣 MAmmoTH2, a game-changer in improving the reasoning abilities of large language models (LLMs) through innovative instruction tuning. By efficiently harvesting 10 million instruction-response pairs from the pre-training web corpus, we've developed MAmmoTH2 models that significantly boost performance on reasoning benchmarks. For instance, MAmmoTH2-7B (Mistral) sees its performance soar from 11% to 34% on MATH and from 36% to 67% on GSM8K, all without training on any domain-specific data. Further training on public instruction tuning datasets yields MAmmoTH2-Plus, setting new standards in reasoning and chatbot benchmarks. Our work presents a cost-effective approach to acquiring large-scale, high-quality instruction data, offering a fresh perspective on enhancing LLM reasoning abilities.
| | **Base Model** | **MAmmoTH2** | **MAmmoTH2-Plus** |
|:-----|:---------------------|:-------------------------------------------------------------------|:------------------------------------------------------------------|
| 7B | Mistral | 🦣 [MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) | 🦣 [MAmmoTH2-7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B-Plus) |
| 8B | Llama-3 | 🦣 [MAmmoTH2-8B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B) | 🦣 [MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus) |
| 8x7B | Mixtral | 🦣 [MAmmoTH2-8x7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B) | 🦣 [MAmmoTH2-8x7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B-Plus) |
## Training Data
Please refer to https://huggingface.co/datasets/TIGER-Lab/WebInstructSub for more details.
## Training Procedure
The models are fine-tuned with the WEBINSTRUCT dataset using the original Llama-3, Mistral and Mistal models as base models. The training procedure varies for different models based on their sizes. Check out our paper for more details.
## Evaluation
The models are evaluated using open-ended and multiple-choice math problems from several datasets. Here are the results:
| **Model** | **TheoremQA** | **MATH** | **GSM8K** | **GPQA** | **MMLU-ST** | **BBH** | **ARC-C** | **Avg** |
|:-----------------------|:--------------|:---------|:----------|:---------|:------------|:--------|:----------|:---------|
| **MAmmoTH2-7B** | 26.7 | 34.2 | 67.4 | 34.8 | 60.6 | 60.0 | 81.8 | 52.2 |
| **MAmmoTH2-8B** | 29.7 | 33.4 | 67.9 | 38.4 | 61.0 | 60.8 | 81.0 | 53.1 |
| **MAmmoTH2-8x7B** | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| **MAmmoTH2-7B-Plus** | 29.2 | 45.0 | 84.7 | 36.8 | 64.5 | 63.1 | 83.0 | 58.0 |
| **MAmmoTH2-8B-Plus** | 32.5 | 42.8 | 84.1 | 37.3 | 65.7 | 67.8 | 83.4 | 59.1 |
| **MAmmoTH2-8x7B-Plus** | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for more advanced use: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## Limitations
We've tried our best to build math generalist models. However, we acknowledge that the models' performance may vary based on the complexity and specifics of the math problem. Still not all mathematical fields can be covered comprehensively.
## Citation
If you use the models, data, or code from this project, please cite the original paper:
```
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}
```