# IndT5: A Text-to-Text Transformer for 10 Indigenous Languages
 In this work, we introduce IndT5, the first Transformer language model for Indigenous languages. To train IndT5, we build IndCorpu, a new corpus for 10 Indigenous languages and Spanish. We also present the application of IndT5 to machine translation by investigating different approaches to translate between Spanish and the Indigenous languages as part of our contribution to theAmericasNLP 2021 Shared Task on OpenMachine Translation.
# IndT5
We train an Indigenous language model adopting the unified and flexible
text-to-text transfer Transformer (T5) approach . T5 treats every
text-based language task as a “text-to-text" problem, taking text format
as input and producing new text format as output. T5 is essentially an
encoder-decoder Transformer , with the encoder and decoder similar in
configuration and size to a BERTBase but with some
architectural modifications. Modifications include applying a
normalization layer before a sub-block and adding a pre-norm (i.e.,
initial input to the sub-block output).
# IndCourpus
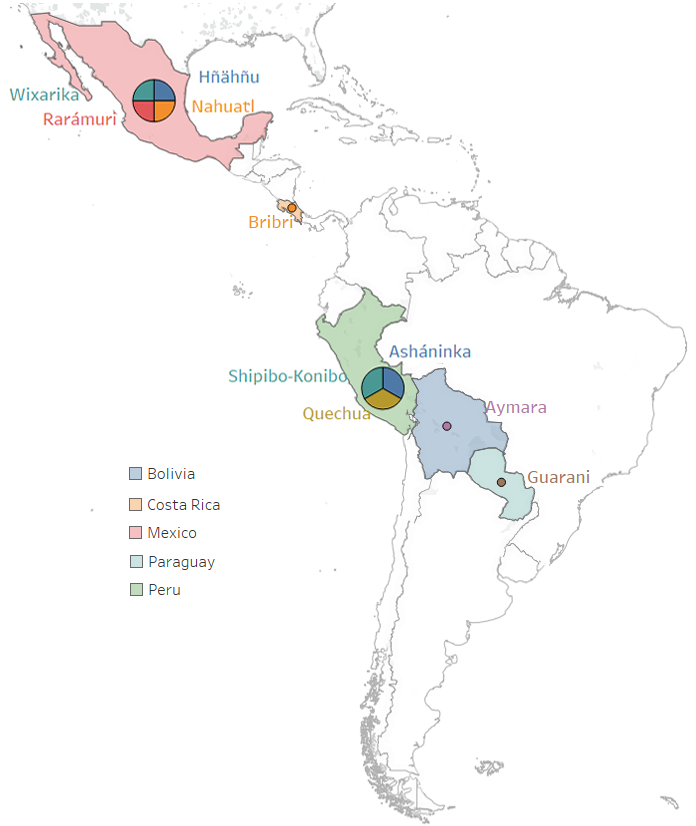
We build IndCorpus, a collection of 10 Indigeous languages and Spanish comprising 1.17GB of text, from both Wikipedia and the Bible.
### Demographic information of 10 Indigenous languages
| **Language** | **Language Code** | **Main Location** | **Number of Speakers** |
|------------------|-------------------|-------------------|------------------------|
| Aymara | aym | Bolivia | 1,677,100 |
| Asháninka | cni | Peru | 35,200 |
| Bribri | bzd | Costa Rica | 7,000 |
| Guarani | gn | Paraguay | 6,652,790 |
| Hñähñu | oto | Mexico | 88,500 |
| Nahuatl | nah | Mexico | 410,000 |
| Quechua | quy | Peru | 7,384,920 |
| Rarámuri | tar | Mexico | 9,230 |
| Shipibo-Konibo | shp | Peru | 22,500 |
| Wixarika | hch | Mexico | 52,500 |
### Data size and number of sentences in monolingual dataset (collected from Wikipedia and Bible)
| **Target Language** | **Wiki Size (MB)** | **Wiki #Sentences** | **Bible Size (MB)** | **Bible #Sentences**|
|-------------------|------------------|-------------------|------------------------|-|
|Hñähñu | - | - | 1.4 | 7.5K |
|Wixarika | - | - | 1.3 | 7.5K|
|Nahuatl | 5.8 | 61.1K | 1.5 | 7.5K|
|Guarani | 3.7 | 28.2K | 1.3 | 7.5K |
|Bribri | - | - | 1.5 | 7.5K |
|Rarámuri | - | - | 1.9 | 7.5K |
|Quechua | 5.9 | 97.3K | 4.9 | 31.1K |
|Aymara | 1.7 | 32.9K | 5 | 30.7K|
|Shipibo-Konibo | - | - | 1 | 7.9K |
|Asháninka | - | - | 1.4 | 7.8K |
|Spanish | 1.13K | 5M | - | - |
|Total | 1.15K | 5.22M | 19.8 | 125.3K|
# Github
More details about our model can be found here: https://github.com/UBC-NLP/IndT5
# BibTex
```@inproceedings{chen2021indt5,
title={IndT5: A Text-to-Text Transformer for 10 Indigenous Languages},
author={Chen, Wei-Rui and Abdul-Mageed, Muhammad and Cavusoglu, Hasan and others},
booktitle={Proceedings of the First Workshop on Natural Language Processing for Indigenous Languages of the Americas},
pages={265--271},
year={2021}
}
In this work, we introduce IndT5, the first Transformer language model for Indigenous languages. To train IndT5, we build IndCorpu, a new corpus for 10 Indigenous languages and Spanish. We also present the application of IndT5 to machine translation by investigating different approaches to translate between Spanish and the Indigenous languages as part of our contribution to theAmericasNLP 2021 Shared Task on OpenMachine Translation.
# IndT5
We train an Indigenous language model adopting the unified and flexible
text-to-text transfer Transformer (T5) approach . T5 treats every
text-based language task as a “text-to-text" problem, taking text format
as input and producing new text format as output. T5 is essentially an
encoder-decoder Transformer , with the encoder and decoder similar in
configuration and size to a BERTBase but with some
architectural modifications. Modifications include applying a
normalization layer before a sub-block and adding a pre-norm (i.e.,
initial input to the sub-block output).
# IndCourpus
We build IndCorpus, a collection of 10 Indigeous languages and Spanish comprising 1.17GB of text, from both Wikipedia and the Bible.
### Demographic information of 10 Indigenous languages
| **Language** | **Language Code** | **Main Location** | **Number of Speakers** |
|------------------|-------------------|-------------------|------------------------|
| Aymara | aym | Bolivia | 1,677,100 |
| Asháninka | cni | Peru | 35,200 |
| Bribri | bzd | Costa Rica | 7,000 |
| Guarani | gn | Paraguay | 6,652,790 |
| Hñähñu | oto | Mexico | 88,500 |
| Nahuatl | nah | Mexico | 410,000 |
| Quechua | quy | Peru | 7,384,920 |
| Rarámuri | tar | Mexico | 9,230 |
| Shipibo-Konibo | shp | Peru | 22,500 |
| Wixarika | hch | Mexico | 52,500 |
### Data size and number of sentences in monolingual dataset (collected from Wikipedia and Bible)
| **Target Language** | **Wiki Size (MB)** | **Wiki #Sentences** | **Bible Size (MB)** | **Bible #Sentences**|
|-------------------|------------------|-------------------|------------------------|-|
|Hñähñu | - | - | 1.4 | 7.5K |
|Wixarika | - | - | 1.3 | 7.5K|
|Nahuatl | 5.8 | 61.1K | 1.5 | 7.5K|
|Guarani | 3.7 | 28.2K | 1.3 | 7.5K |
|Bribri | - | - | 1.5 | 7.5K |
|Rarámuri | - | - | 1.9 | 7.5K |
|Quechua | 5.9 | 97.3K | 4.9 | 31.1K |
|Aymara | 1.7 | 32.9K | 5 | 30.7K|
|Shipibo-Konibo | - | - | 1 | 7.9K |
|Asháninka | - | - | 1.4 | 7.8K |
|Spanish | 1.13K | 5M | - | - |
|Total | 1.15K | 5.22M | 19.8 | 125.3K|
# Github
More details about our model can be found here: https://github.com/UBC-NLP/IndT5
# BibTex
```@inproceedings{chen2021indt5,
title={IndT5: A Text-to-Text Transformer for 10 Indigenous Languages},
author={Chen, Wei-Rui and Abdul-Mageed, Muhammad and Cavusoglu, Hasan and others},
booktitle={Proceedings of the First Workshop on Natural Language Processing for Indigenous Languages of the Americas},
pages={265--271},
year={2021}
}