[**中文说明**](README_CN.md) | [**English**](README.md)
# 项目介绍
本项目旨在提供更好的中文CLIP模型。该项目使用的训练数据均为公开可访问的图像URL及相关中文文本描述,总量达到400M。经过筛选后,我们最终使用了100M的数据进行训练。
本项目于QQ-ARC Joint Lab, Tencent PCG完成。我们也在github上开源了模型,[QA-CLIP](https://github.com/TencentARC-QQ/QA-CLIP),welcome to star!
# 模型及实验
## 模型规模 & 下载链接
QA-CLIP目前开源3个不同规模,其模型信息和下载方式见下表:
| 模型规模 | 下载链接 | 参数量 | 视觉侧骨架 | 视觉侧参数量 | 文本侧骨架 | 文本侧参数量 | 分辨率 |
| QA-CLIPRN50 | Download | 77M | ResNet50 | 38M | RBT3 | 39M | 224 |
| QA-CLIPViT-B/16 | Download | 188M | ViT-B/16 | 86M | RoBERTa-wwm-Base | 102M | 224 |
| QA-CLIPViT-L/14 | Download | 406M | ViT-L/14 | 304M | RoBERTa-wwm-Base | 102M | 224 |
## 实验结果
针对图文检索任务,我们在[MUGE Retrieval](https://tianchi.aliyun.com/muge)、[Flickr30K-CN](https://github.com/li-xirong/cross-lingual-cap)和[COCO-CN](https://github.com/li-xirong/coco-cn)上进行了zero-shot测试。
针对图像零样本分类任务,我们在ImageNet数据集上进行了测试。测试结果见下表:
**Flickr30K-CN Zero-shot Retrieval (Official Test Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 48.8 | 76.0 | 84.6 | 60.0 | 85.9 | 92.0 |
| QA-CLIPRN50 | 50.5 | 77.4 | 86.1 | 67.1 | 87.9 | 93.2 |
| CN-CLIPViT-B/16 | 62.7 | 86.9 | 92.8 | 74.6 | 93.5 | 97.1 |
| QA-CLIPViT-B/16 | 63.8 | 88.0 | 93.2 | 78.4 | 96.1 | 98.5 |
| CN-CLIPViT-L/14 | 68.0 | 89.7 | 94.4 | 80.2 | 96.6 | 98.2 |
| AltClipViT-L/14 | 69.7 | 90.1 | 94.8 | 84.8 | 97.7 | 99.1 |
| QA-CLIPViT-L/14 | 69.3 | 90.3 | 94.7 | 85.3 | 97.9 | 99.2 |
**MUGE Zero-shot Retrieval (Official Validation Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 42.6 | 68.5 | 78.0 | 30.0 | 56.2 | 66.9 |
| QA-CLIPRN50 | 44.0 | 69.9 | 79.5 | 32.4 | 59.5 | 70.3 |
| CN-CLIPViT-B/16 | 52.1 | 76.7 | 84.4 | 38.7 | 65.6 | 75.1 |
| QA-CLIPViT-B/16 | 53.2 | 77.7 | 85.1 | 40.7 | 68.2 | 77.2 |
| CN-CLIPViT-L/14 | 56.4 | 79.8 | 86.2 | 42.6 | 69.8 | 78.6 |
| AltClipViT-L/14 | 29.6 | 49.9 | 58.8 | 21.4 | 42.0 | 51.9 |
| QA-CLIPViT-L/14 | 57.4 | 81.0 | 87.7 | 45.5 | 73.0 | 81.4 |
**COCO-CN Zero-shot Retrieval (Official Test Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 48.1 | 81.3 | 90.5 | 50.9 | 81.1 | 90.5 |
| QA-CLIPRN50 | 50.1 | 82.5 | 91.7 | 56.7 | 85.2 | 92.9 |
| CN-CLIPViT-B/16 | 62.2 | 87.1 | 94.9 | 56.3 | 84.0 | 93.3 |
| QA-CLIPViT-B/16 | 62.9 | 87.7 | 94.7 | 61.5 | 87.6 | 94.8 |
| CN-CLIPViT-L/14 | 64.9 | 88.8 | 94.2 | 60.6 | 84.4 | 93.1 |
| AltClipViT-L/14 | 63.5 | 87.6 | 93.5 | 62.6 | 88.5 | 95.9 |
| QA-CLIPViT-L/14 | 65.7 | 90.2 | 95.0 | 64.5 | 88.3 | 95.1 |
**Zero-shot Image Classification on ImageNet**:
| Task | ImageNet |
| CN-CLIPRN50 | 33.5 |
| QA-CLIPRN50 | 35.5 |
| CN-CLIPViT-B/16 | 48.4 |
| QA-CLIPViT-B/16 | 49.7 |
| CN-CLIPViT-L/14 | 54.7 |
| QA-CLIPViT-L/14 | 55.8 |
# 使用教程
## 安装要求
环境配置要求:
* python >= 3.6.4
* pytorch >= 1.8.0 (with torchvision >= 0.9.0)
* CUDA Version >= 10.2
安装本项目所需库
```bash
cd /yourpath/QA-CLIP-main
pip install --upgrade pip
pip install -r requirements.txt
```
## 推理代码
```bash
export PYTHONPATH=/yourpath/QA-CLIP-main
```
推理代码示例:
```python
import torch
from PIL import Image
import clip as clip
from clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'RN50']
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./')
model.eval()
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 对特征进行归一化,请使用归一化后的图文特征用于下游任务
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
```
## 预测及评估
### 图文检索测试数据集下载
[Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)项目中已经预处理好测试集,这是他们提供的下载链接:
MUGE数据:[下载链接](https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/MUGE.zip)
Flickr30K-CN数据:[下载链接](https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/Flickr30k-CN.zip)
另外[COCO-CN](https://github.com/li-xirong/coco-cn)数据的获取需要向原作者进行申请
### ImageNet数据集下载
原始数据请自行下载,[中文标签](http://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/ImageNet-1K/label_cn.txt)和[英文标签](http://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/ImageNet-1K/label.txt)同样由[Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)项目提供
### 图文检索评估
图文检索评估代码可以参考如下:
```bash
split=test # 指定计算valid或test集特征
resume=your_ckp_path
DATAPATH=your_DATAPATH
dataset_name=Flickr30k-CN
# dataset_name=MUGE
python -u eval/extract_features.py \
--extract-image-feats \
--extract-text-feats \
--image-data="${DATAPATH}/datasets/${dataset_name}/lmdb/${split}/imgs" \
--text-data="${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl" \
--img-batch-size=32 \
--text-batch-size=32 \
--context-length=52 \
--resume=${resume} \
--vision-model=ViT-B-16 \
--text-model=RoBERTa-wwm-ext-base-chinese
python -u eval/make_topk_predictions.py \
--image-feats="${DATAPATH}/datasets/${dataset_name}/${split}_imgs.img_feat.jsonl" \
--text-feats="${DATAPATH}/datasets/${dataset_name}/${split}_texts.txt_feat.jsonl" \
--top-k=10 \
--eval-batch-size=32768 \
--output="${DATAPATH}/datasets/${dataset_name}/${split}_predictions.jsonl"
python -u eval/make_topk_predictions_tr.py \
--image-feats="${DATAPATH}/datasets/${dataset_name}/${split}_imgs.img_feat.jsonl" \
--text-feats="${DATAPATH}/datasets/${dataset_name}/${split}_texts.txt_feat.jsonl" \
--top-k=10 \
--eval-batch-size=32768 \
--output="${DATAPATH}/datasets/${dataset_name}/${split}_tr_predictions.jsonl"
python eval/evaluation.py \
${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl \
${DATAPATH}/datasets/${dataset_name}/${split}_predictions.jsonl \
${DATAPATH}/datasets/${dataset_name}/output1.json
cat ${DATAPATH}/datasets/${dataset_name}/output1.json
python eval/transform_ir_annotation_to_tr.py \
--input ${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl
python eval/evaluation_tr.py \
${DATAPATH}/datasets/${dataset_name}/${split}_texts.tr.jsonl \
${DATAPATH}/datasets/${dataset_name}/${split}_tr_predictions.jsonl \
${DATAPATH}/datasets/${dataset_name}/output2.json
cat ${DATAPATH}/datasets/${dataset_name}/output2.json
```
### ImageNet零样本分类
ImageNet零样本分类的代码参考如下
```bash
bash scripts/zeroshot_eval.sh 0 \
${DATAPATH} imagenet \
ViT-B-16 RoBERTa-wwm-ext-base-chinese \
./pretrained_weights/QA-CLIP-base.pt
```
# Huggingface模型及在线Demo
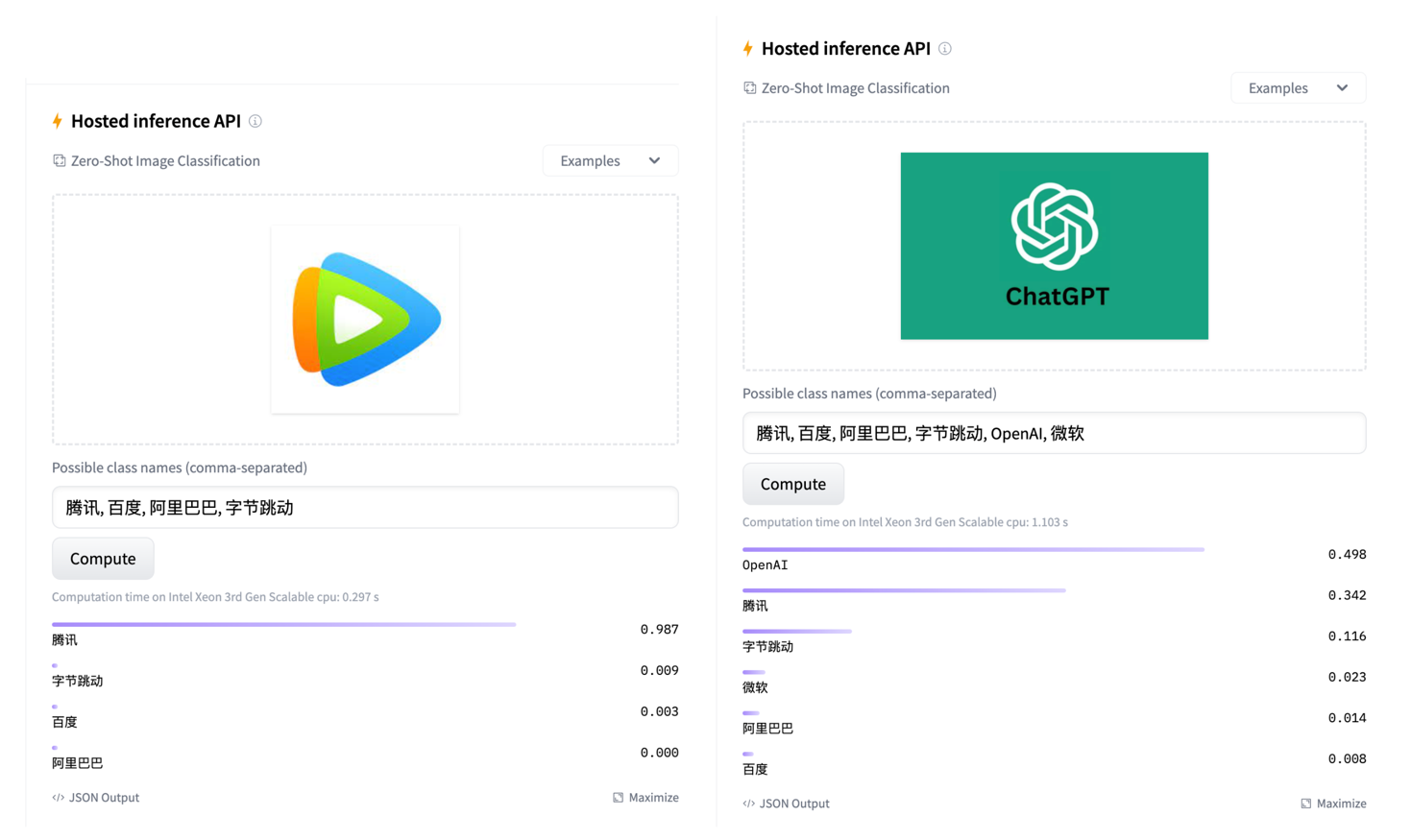
我们在huggingface网站上也开源了我们的模型,可以更方便的使用。并且也准备了一个简单的零样本分类的在线Demo供大家体验,欢迎大家来多多尝试!
[⭐️QA-CLIP-ViT-B-16⭐️](https://huggingface.co/TencentARC/QA-CLIP-ViT-B-16)
[⭐️QA-CLIP-ViT-L-14⭐️](https://huggingface.co/TencentARC/QA-CLIP-ViT-L-14)
下面是一些展示的例子:
# 致谢
项目代码基于[Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)实现,非常感谢他们优秀的开源工作。