---
license: apache-2.0
widget:
- src: >-
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: 音乐表演, 体育运动
example_title: 猫和狗
pipeline_tag: zero-shot-classification
---
[**中文说明**](README_CN.md) | [**English**](README.md)
# Introduction
This project aims to provide a better Chinese CLIP model. The training data used in this project consists of publicly accessible image URLs and related Chinese text descriptions, totaling 400 million. After screening, we ultimately used 100 million data for training.
This project is produced by QQ-ARC Joint Lab, Tencent PCG. We have also open-sourced our code on GitHub, [QA-CLIP](https://github.com/TencentARC-QQ/QA-CLIP), and welcome to star!
# Models and Results
## Model Card
QA-CLIP currently has three different open-source models of different sizes, and their model information and download links are shown in the table below:
| Model | Ckp | Params | Vision | Params of Vision | Text | Params of Text | Resolution |
| QA-CLIPRN50 | Download | 77M | ResNet50 | 38M | RBT3 | 39M | 224 |
| QA-CLIPViT-B/16 | Download | 188M | ViT-B/16 | 86M | RoBERTa-wwm-Base | 102M | 224 |
| QA-CLIPViT-L/14 | Download | 406M | ViT-L/14 | 304M | RoBERTa-wwm-Base | 102M | 224 |
## Results
We conducted zero-shot tests on [MUGE Retrieval](https://tianchi.aliyun.com/muge), [Flickr30K-CN](https://github.com/li-xirong/cross-lingual-cap), and [COCO-CN](https://github.com/li-xirong/coco-cn) datasets for image-text retrieval tasks. For the image zero-shot classification task, we tested on the ImageNet dataset. The test results are shown in the table below:
**Flickr30K-CN Zero-shot Retrieval (Official Test Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 48.8 | 76.0 | 84.6 | 60.0 | 85.9 | 92.0 |
| QA-CLIPRN50 | 50.5 | 77.4 | 86.1 | 67.1 | 87.9 | 93.2 |
| CN-CLIPViT-B/16 | 62.7 | 86.9 | 92.8 | 74.6 | 93.5 | 97.1 |
| QA-CLIPViT-B/16 | 63.8 | 88.0 | 93.2 | 78.4 | 96.1 | 98.5 |
| CN-CLIPViT-L/14 | 68.0 | 89.7 | 94.4 | 80.2 | 96.6 | 98.2 |
| AltClipViT-L/14 | 69.7 | 90.1 | 94.8 | 84.8 | 97.7 | 99.1 |
| QA-CLIPViT-L/14 | 69.3 | 90.3 | 94.7 | 85.3 | 97.9 | 99.2 |
**MUGE Zero-shot Retrieval (Official Validation Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 42.6 | 68.5 | 78.0 | 30.0 | 56.2 | 66.9 |
| QA-CLIPRN50 | 44.0 | 69.9 | 79.5 | 32.4 | 59.5 | 70.3 |
| CN-CLIPViT-B/16 | 52.1 | 76.7 | 84.4 | 38.7 | 65.6 | 75.1 |
| QA-CLIPViT-B/16 | 53.2 | 77.7 | 85.1 | 40.7 | 68.2 | 77.2 |
| CN-CLIPViT-L/14 | 56.4 | 79.8 | 86.2 | 42.6 | 69.8 | 78.6 |
| AltClipViT-L/14 | 29.6 | 49.9 | 58.8 | 21.4 | 42.0 | 51.9 |
| QA-CLIPViT-L/14 | 57.4 | 81.0 | 87.7 | 45.5 | 73.0 | 81.4 |
**COCO-CN Zero-shot Retrieval (Official Test Set)**:
| Task | Text-to-Image | Image-to-Text |
| Metric | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CN-CLIPRN50 | 48.1 | 81.3 | 90.5 | 50.9 | 81.1 | 90.5 |
| QA-CLIPRN50 | 50.1 | 82.5 | 91.7 | 56.7 | 85.2 | 92.9 |
| CN-CLIPViT-B/16 | 62.2 | 87.1 | 94.9 | 56.3 | 84.0 | 93.3 |
| QA-CLIPViT-B/16 | 62.9 | 87.7 | 94.7 | 61.5 | 87.6 | 94.8 |
| CN-CLIPViT-L/14 | 64.9 | 88.8 | 94.2 | 60.6 | 84.4 | 93.1 |
| AltClipViT-L/14 | 63.5 | 87.6 | 93.5 | 62.6 | 88.5 | 95.9 |
| QA-CLIPViT-L/14 | 65.7 | 90.2 | 95.0 | 64.5 | 88.3 | 95.1 |
**Zero-shot Image Classification on ImageNet**:
| Task | ImageNet |
| CN-CLIPRN50 | 33.5 |
| QA-CLIPRN50 | 35.5 |
| CN-CLIPViT-B/16 | 48.4 |
| QA-CLIPViT-B/16 | 49.7 |
| CN-CLIPViT-L/14 | 54.7 |
| QA-CLIPViT-L/14 | 55.8 |
# Getting Started
## Installation Requirements
Environment configuration requirements:
* python >= 3.6.4
* pytorch >= 1.8.0 (with torchvision >= 0.9.0)
* CUDA Version >= 10.2
Install required packages:
```bash
cd /yourpath/QA-CLIP-main
pip install --upgrade pip
pip install -r requirements.txt
```
## Inference Code
```bash
export PYTHONPATH=/yourpath/QA-CLIP-main
```
Inference code example:
```python
import torch
from PIL import Image
import clip as clip
from clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'RN50']
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./')
model.eval()
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# Normalize the features. Please use the normalized features for downstream tasks.
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
```
## Prediction and Evaluation
### Download Image-text Retrieval Test Dataset
In Project [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP), the test set has already been preprocessed. Here is the download link they provided:
MUGE dataset:[download link](https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/MUGE.zip)
Flickr30K-CN dataset:[download link](https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/Flickr30k-CN.zip)
Additionally, obtaining the [COCO-CN](https://github.com/li-xirong/coco-cn) dataset requires applying to the original author.
### Download ImageNet Dataset
Please download the raw data yourself,[Chinese Label](http://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/ImageNet-1K/label_cn.txt) and [English Label](http://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/datasets/ImageNet-1K/label.txt) are provided by Project [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)
### Image-text Retrieval Evaluation
The image-text retrieval evaluation code can be referred to as follows:
```bash
split=test # Designate the computation of features for the valid or test set
resume=your_ckp_path
DATAPATH=your_DATAPATH
dataset_name=Flickr30k-CN
# dataset_name=MUGE
python -u eval/extract_features.py \
--extract-image-feats \
--extract-text-feats \
--image-data="${DATAPATH}/datasets/${dataset_name}/lmdb/${split}/imgs" \
--text-data="${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl" \
--img-batch-size=32 \
--text-batch-size=32 \
--context-length=52 \
--resume=${resume} \
--vision-model=ViT-B-16 \
--text-model=RoBERTa-wwm-ext-base-chinese
python -u eval/make_topk_predictions.py \
--image-feats="${DATAPATH}/datasets/${dataset_name}/${split}_imgs.img_feat.jsonl" \
--text-feats="${DATAPATH}/datasets/${dataset_name}/${split}_texts.txt_feat.jsonl" \
--top-k=10 \
--eval-batch-size=32768 \
--output="${DATAPATH}/datasets/${dataset_name}/${split}_predictions.jsonl"
python -u eval/make_topk_predictions_tr.py \
--image-feats="${DATAPATH}/datasets/${dataset_name}/${split}_imgs.img_feat.jsonl" \
--text-feats="${DATAPATH}/datasets/${dataset_name}/${split}_texts.txt_feat.jsonl" \
--top-k=10 \
--eval-batch-size=32768 \
--output="${DATAPATH}/datasets/${dataset_name}/${split}_tr_predictions.jsonl"
python eval/evaluation.py \
${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl \
${DATAPATH}/datasets/${dataset_name}/${split}_predictions.jsonl \
${DATAPATH}/datasets/${dataset_name}/output1.json
cat ${DATAPATH}/datasets/${dataset_name}/output1.json
python eval/transform_ir_annotation_to_tr.py \
--input ${DATAPATH}/datasets/${dataset_name}/${split}_texts.jsonl
python eval/evaluation_tr.py \
${DATAPATH}/datasets/${dataset_name}/${split}_texts.tr.jsonl \
${DATAPATH}/datasets/${dataset_name}/${split}_tr_predictions.jsonl \
${DATAPATH}/datasets/${dataset_name}/output2.json
cat ${DATAPATH}/datasets/${dataset_name}/output2.json
```
### ImageNet Zero-shot Classification
The ImageNet zero-shot classification code can be referred to as follows
```bash
bash scripts/zeroshot_eval.sh 0 \
${DATAPATH} imagenet \
ViT-B-16 RoBERTa-wwm-ext-base-chinese \
./pretrained_weights/QA-CLIP-base.pt
```
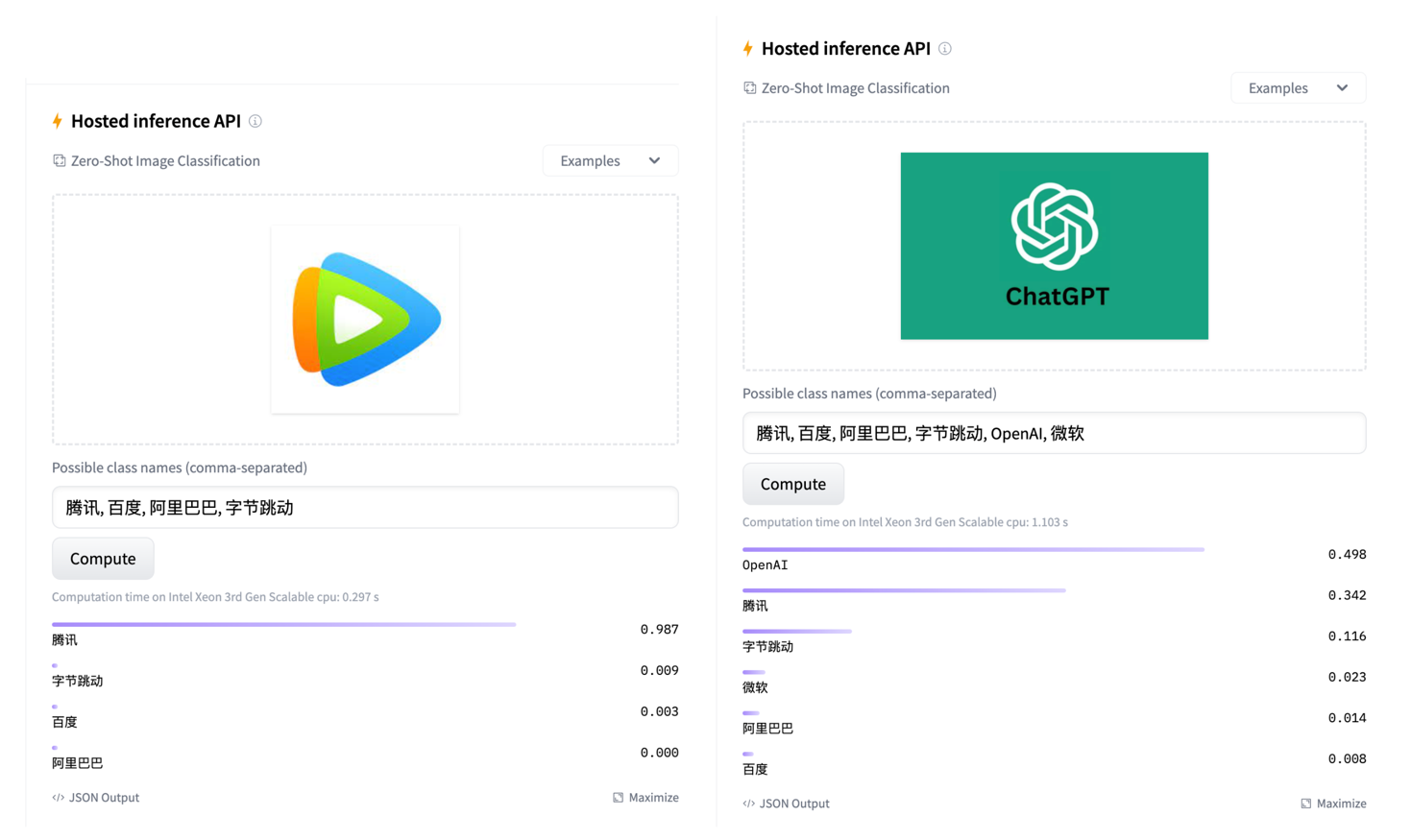
# Huggingface Model and Online Demo
We have open-sourced our model on the HuggingFace for easier access and utilization. Additionally, we have prepared a simple online demo for zero-shot classification, allowing everyone to experience it firsthand. We encourage you to give it a try!
[⭐️QA-CLIP-ViT-B-16⭐️](https://huggingface.co/TencentARC/QA-CLIP-ViT-B-16)
[⭐️QA-CLIP-ViT-L-14⭐️](https://huggingface.co/TencentARC/QA-CLIP-ViT-L-14)
Here are some examples for demonstration:
# Acknowledgments
The project code is based on implementation of [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP), and we are very grateful for their outstanding open-source contributions.