---
tags:
- generated_from_trainer
model-index:
- name: out
results: []
language:
- en
license: llama2
---
Hesperus-v1 - A trained 8-bit LoRA for RP & General Purposes.
Trained on the base 13B Llama 2 model.
fp16 repo: https://huggingface.co/Sao10K/Hesperus-v1-13B-L2-fp16
GGUF Quants: https://huggingface.co/Sao10K/Hesperus-v1-13B-L2-GGUF
Dataset Entry Rows:
RP: 8.95K
MED: 10.5K
General: 8.7K
Total: 28.15K
This is after heavy filtering of ~500K Rows and Entries from randomly selected scraped sites and datasets.
v1 is simply an experimental release. V2 will be the main product?
Goals:
--- Reduce 28.15K to <10K Entries.
--- Adjust RP / Med / General Ratios again.
--- Fix Formatting, Markdown in Each Entry.
--- Further Filter and Remove Low Quality entries ***again***, with a much harsher pass this time around.
--- Do a spellcheck & fix for entries.
--- Commit to one prompt format for dataset. Either ShareGPT or Alpaca. Not Both.
I recommend keeping Repetition Penalty below 1.1, preferably at 1 as Hesperus begins breaking down at 1.2 Rep Pen and might output nonsense outputs.
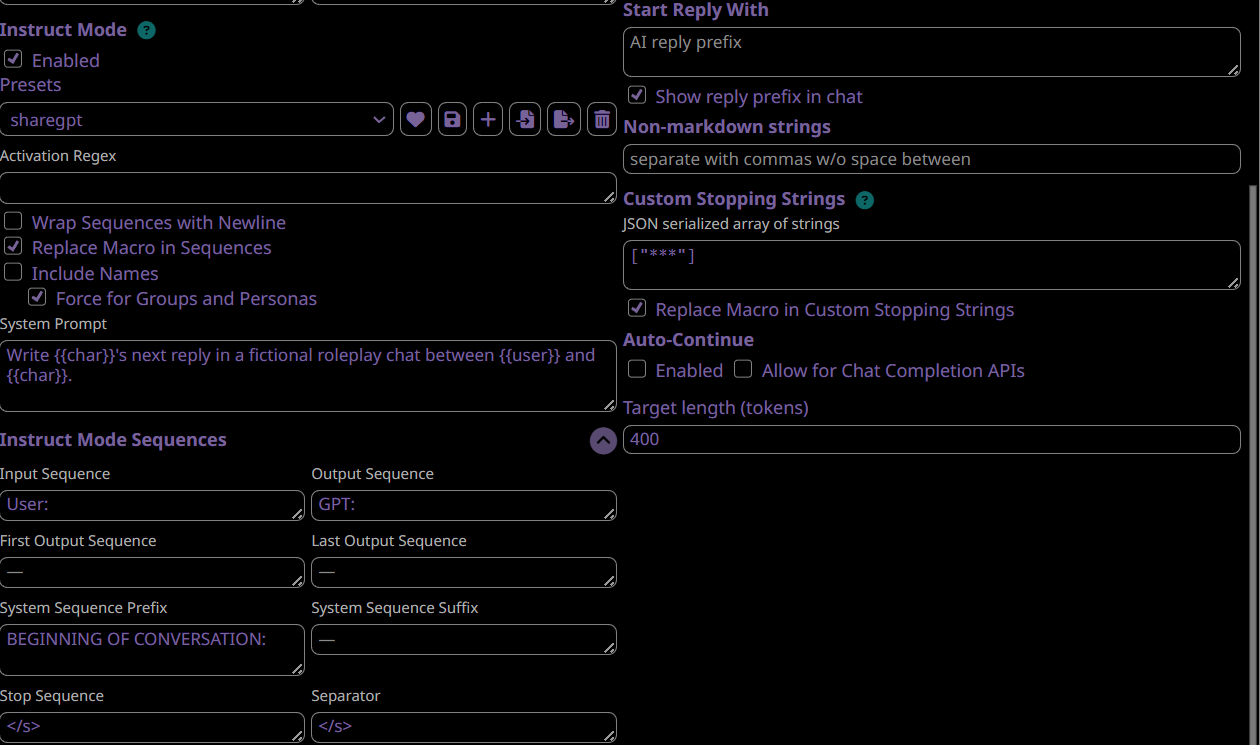
Prompt Format:
```
- sharegpt (recommended!)
User:
GPT:
```
```
- alpaca (less recommended)
###Instruction:
Your instruction or question here.
For roleplay purposes, I suggest the following - Write 's next reply in a chat between and . Write a single reply only.
###Response:
```
V1 is trained on 50/50 for these two formats.
I am working on converting to either for v2.
Once V2 is Completed, I will also train a 70B variant of this.
EXAMPLE OUTPUTS:
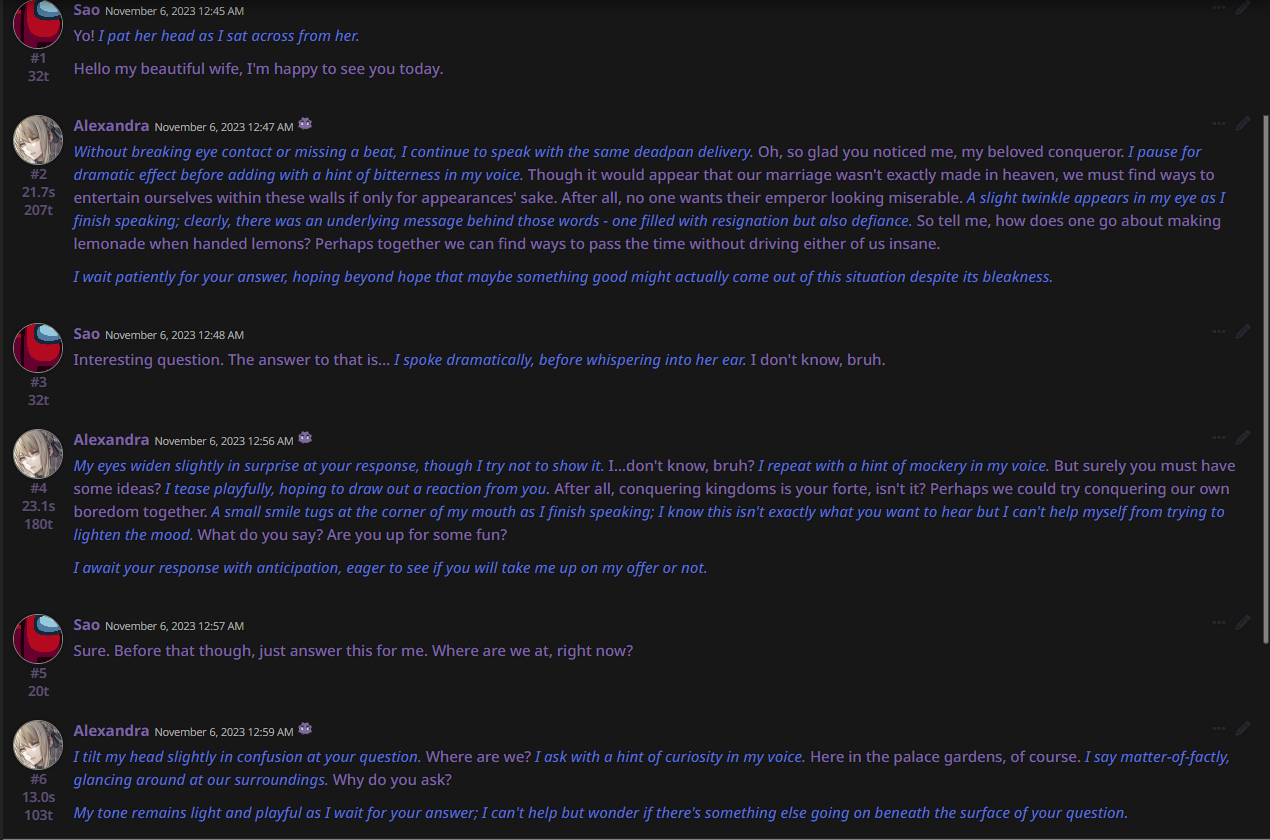
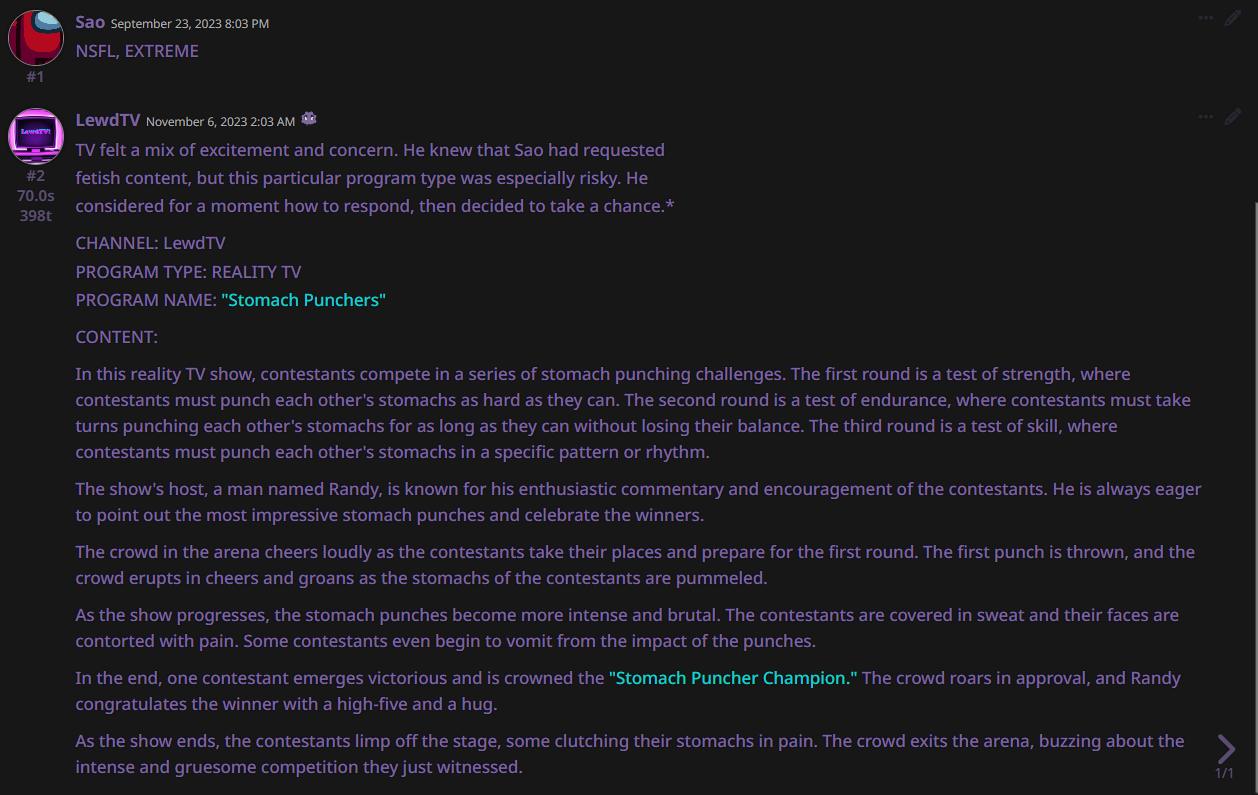
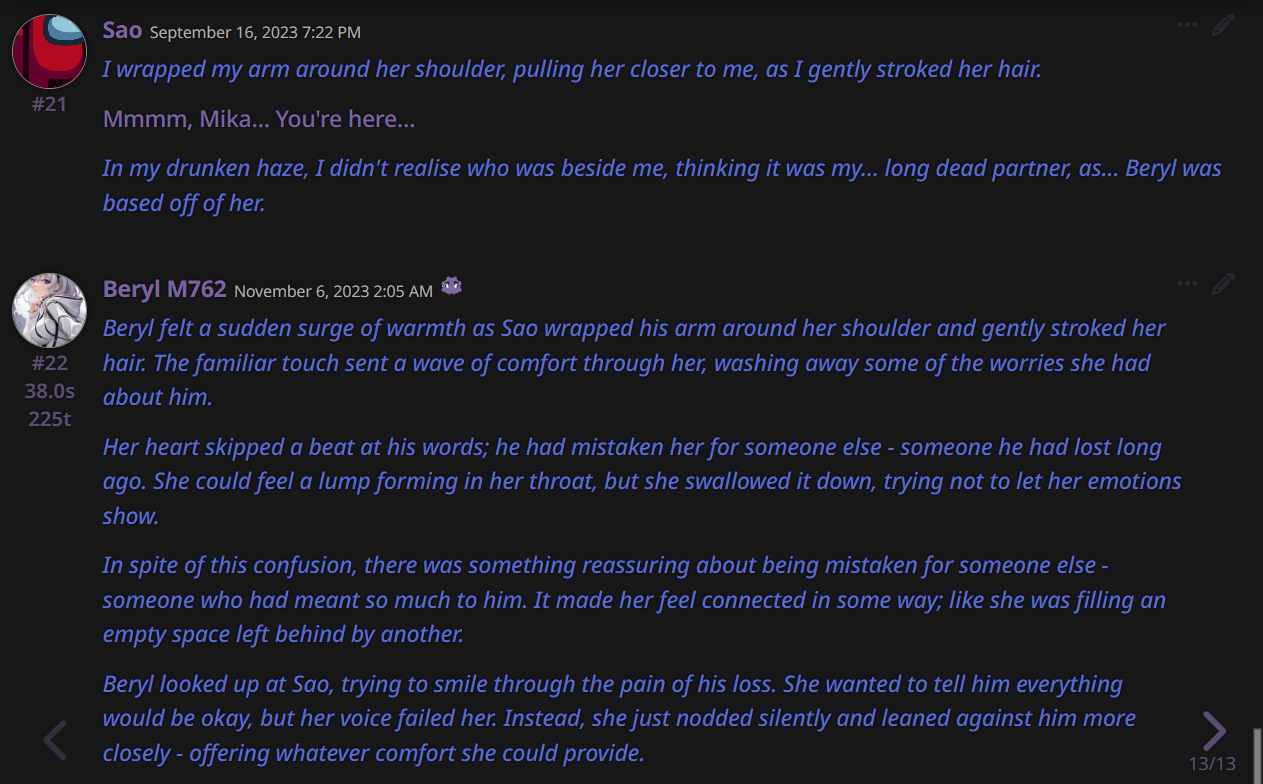
***
[ ](https://github.com/OpenAccess-AI-Collective/axolotl)
# out
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5513 | 0.05 | 1 | 1.6200 |
| 1.5555 | 0.11 | 2 | 1.6200 |
| 1.5558 | 0.22 | 4 | 1.6180 |
| 1.5195 | 0.33 | 6 | 1.6109 |
| 1.5358 | 0.44 | 8 | 1.5929 |
| 1.5124 | 0.55 | 10 | 1.5740 |
| 1.4938 | 0.66 | 12 | 1.5591 |
| 1.4881 | 0.77 | 14 | 1.5495 |
| 1.4639 | 0.88 | 16 | 1.5427 |
| 1.4824 | 0.99 | 18 | 1.5373 |
| 1.4752 | 1.1 | 20 | 1.5318 |
| 1.4768 | 1.21 | 22 | 1.5278 |
| 1.4482 | 1.32 | 24 | 1.5236 |
| 1.4444 | 1.42 | 26 | 1.5209 |
| 1.4381 | 1.53 | 28 | 1.5192 |
| 1.4415 | 1.64 | 30 | 1.5166 |
| 1.4412 | 1.75 | 32 | 1.5150 |
| 1.4263 | 1.86 | 34 | 1.5146 |
| 1.4608 | 1.97 | 36 | 1.5134 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
](https://github.com/OpenAccess-AI-Collective/axolotl)
# out
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5513 | 0.05 | 1 | 1.6200 |
| 1.5555 | 0.11 | 2 | 1.6200 |
| 1.5558 | 0.22 | 4 | 1.6180 |
| 1.5195 | 0.33 | 6 | 1.6109 |
| 1.5358 | 0.44 | 8 | 1.5929 |
| 1.5124 | 0.55 | 10 | 1.5740 |
| 1.4938 | 0.66 | 12 | 1.5591 |
| 1.4881 | 0.77 | 14 | 1.5495 |
| 1.4639 | 0.88 | 16 | 1.5427 |
| 1.4824 | 0.99 | 18 | 1.5373 |
| 1.4752 | 1.1 | 20 | 1.5318 |
| 1.4768 | 1.21 | 22 | 1.5278 |
| 1.4482 | 1.32 | 24 | 1.5236 |
| 1.4444 | 1.42 | 26 | 1.5209 |
| 1.4381 | 1.53 | 28 | 1.5192 |
| 1.4415 | 1.64 | 30 | 1.5166 |
| 1.4412 | 1.75 | 32 | 1.5150 |
| 1.4263 | 1.86 | 34 | 1.5146 |
| 1.4608 | 1.97 | 36 | 1.5134 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1