---
license: apache-2.0
datasets:
- REILX/text-description-of-the-meme
- SWHL/ChineseOCRBench
- priyank-m/chinese_text_recognition
- fly0331/ChineseTest
language:
- zh
pipeline_tag: image-text-to-text
tags:
- llava
- qwen2
- CLIP
- zh
---
### 模型 llava-Qwen2-7B-Instruct-Chinese-CLIP-v2 扩大中文图文训练数据集,增强中文文字识别能力和表情包内涵识别能力
 1. 模型结构:
llava-Qwen2-7B-Instruct-Chinese-CLIP = Qwen/Qwen2-7B-Instruct + multi_modal_projector + OFA-Sys/chinese-clip-vit-large-patch14-336px
2. 微调模块
- vision_tower和language_model的q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj模块进行lora训练
- mmp层全量训练
3. 微调参数
- lora_r=32,lora_alpha=64,num_train_epochs=3,per_device_train_batch_size=1,gradient_accumulation_steps=8,high_lr=5e-4,low_lr=1e-5,model_max_length=2048.
- 训练时长:68小时06分钟
4. 数据集
训练数据集对比上一代模型REILX/llava-Qwen2-7B-Instruct-Chinese-CLIP,扩大至四种中文数据集,图片总数扩大47倍,文字总数扩大5倍。
包括以下:
- 使用gemini-1.5-pro, gemini-1.5-flash, yi-vision, gpt4o,claude-3.5-sonnet模型描述emo-visual-data和ChineseBQB数据集。
文本描述信息通过[REILX/chinese-meme-description-dataset](https://huggingface.co/datasets/REILX/text-description-of-the-meme) 下载
图像可通过[emo-visual-data](https://github.com/LLM-Red-Team/emo-visual-data), [ChineseBQB](https://github.com/zhaoolee/ChineseBQB)下载
图片数据总量1.8G,约10835张中文表情包图片。文字总量42Mb,约24332个图像文本对描述信息。
- [priyank-m/chinese_text_recognition](https://huggingface.co/datasets/priyank-m/chinese_text_recognition)
图片数据总量2.0Gb,约500000张图片。文字总量207Mb,约500000个图像文本对描述信息。
- [SWHL/ChineseOCRBench](https://huggingface.co/datasets/SWHL/ChineseOCRBench)
图片数据总量134Mb,约3410张图片。文字总量1.3Mb,约3410个图像文本对描述信息。
- [fly0331/ChineseTest](https://huggingface.co/datasets/fly0331/ChineseTest)
图片数据总量530Mb,约6247张图片。文字总量5.4Mb,约6247个图像文本对描述信息。
为了提升模型对中文文字的识别能力,我们引入了 priyank-m/chinese_text_recognition、SWHL/ChineseOCRBench 和 fly0331/ChineseTest 三个基于中文文字领域图片的数据集。这些数据集的融入将有效弥补 REILX/llava-Qwen2-7B-Instruct-Chinese-CLIP 模型在中文文字识别方面的不足,使其能够更好地理解和处理中文文本信息。
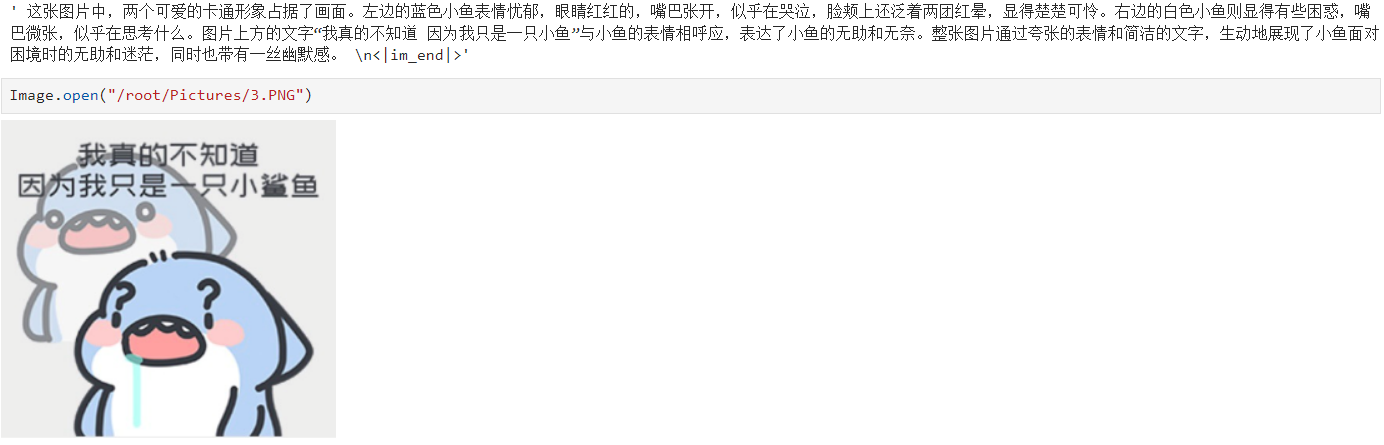
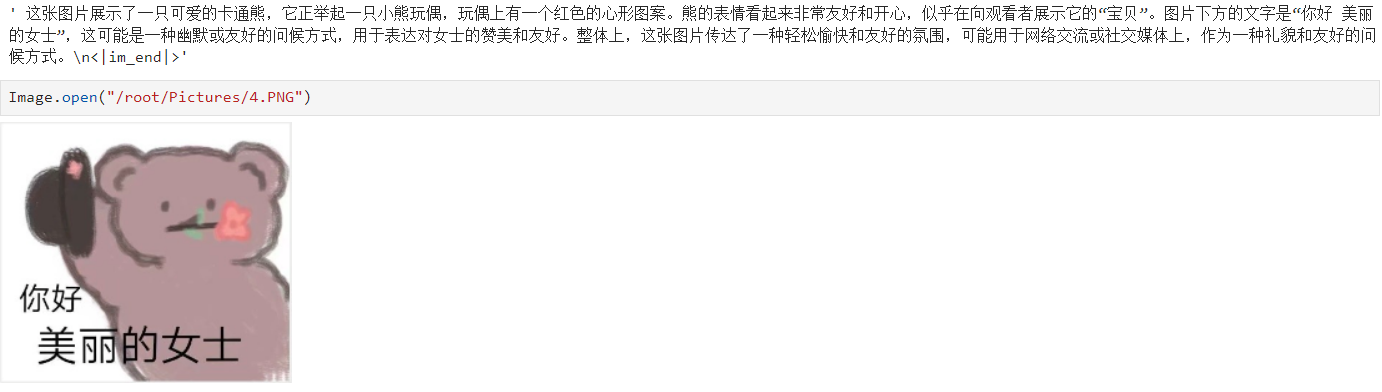
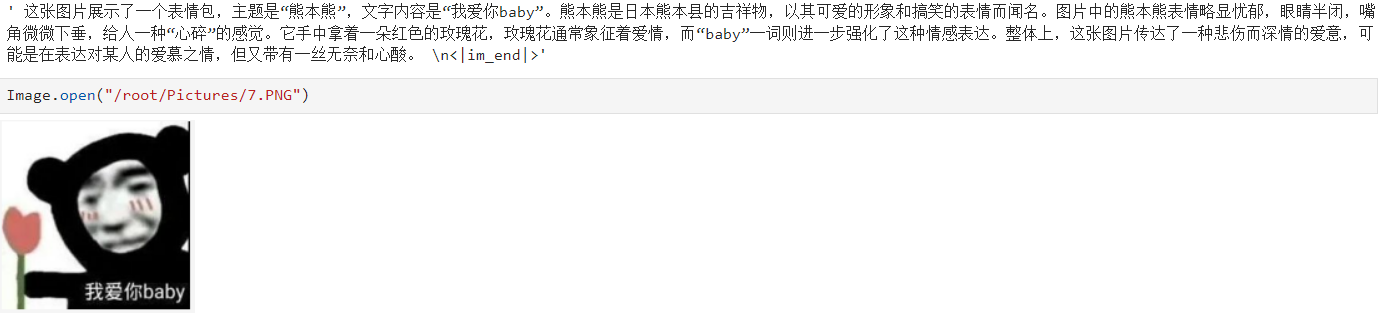
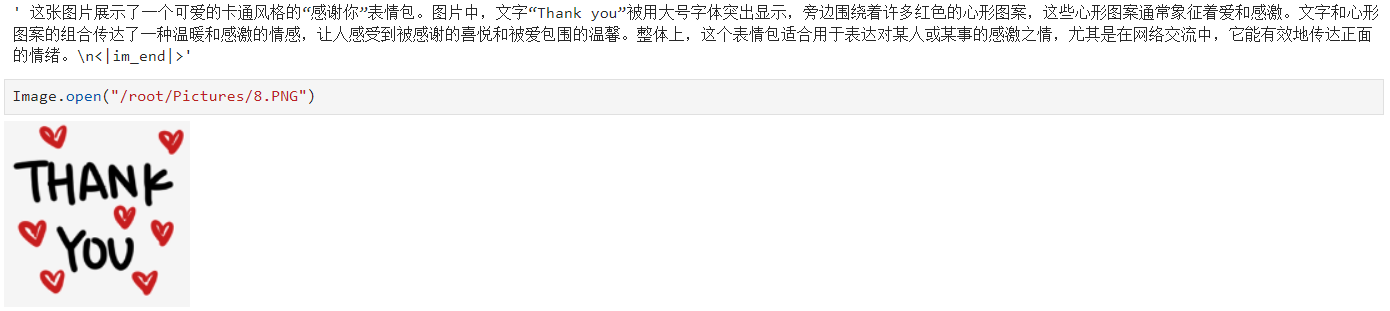
6. 效果展示
以下测试结果显示模型能识别图像中的文字信息,且能正确识别表情包想要表达的内涵
1. 模型结构:
llava-Qwen2-7B-Instruct-Chinese-CLIP = Qwen/Qwen2-7B-Instruct + multi_modal_projector + OFA-Sys/chinese-clip-vit-large-patch14-336px
2. 微调模块
- vision_tower和language_model的q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj模块进行lora训练
- mmp层全量训练
3. 微调参数
- lora_r=32,lora_alpha=64,num_train_epochs=3,per_device_train_batch_size=1,gradient_accumulation_steps=8,high_lr=5e-4,low_lr=1e-5,model_max_length=2048.
- 训练时长:68小时06分钟
4. 数据集
训练数据集对比上一代模型REILX/llava-Qwen2-7B-Instruct-Chinese-CLIP,扩大至四种中文数据集,图片总数扩大47倍,文字总数扩大5倍。
包括以下:
- 使用gemini-1.5-pro, gemini-1.5-flash, yi-vision, gpt4o,claude-3.5-sonnet模型描述emo-visual-data和ChineseBQB数据集。
文本描述信息通过[REILX/chinese-meme-description-dataset](https://huggingface.co/datasets/REILX/text-description-of-the-meme) 下载
图像可通过[emo-visual-data](https://github.com/LLM-Red-Team/emo-visual-data), [ChineseBQB](https://github.com/zhaoolee/ChineseBQB)下载
图片数据总量1.8G,约10835张中文表情包图片。文字总量42Mb,约24332个图像文本对描述信息。
- [priyank-m/chinese_text_recognition](https://huggingface.co/datasets/priyank-m/chinese_text_recognition)
图片数据总量2.0Gb,约500000张图片。文字总量207Mb,约500000个图像文本对描述信息。
- [SWHL/ChineseOCRBench](https://huggingface.co/datasets/SWHL/ChineseOCRBench)
图片数据总量134Mb,约3410张图片。文字总量1.3Mb,约3410个图像文本对描述信息。
- [fly0331/ChineseTest](https://huggingface.co/datasets/fly0331/ChineseTest)
图片数据总量530Mb,约6247张图片。文字总量5.4Mb,约6247个图像文本对描述信息。
为了提升模型对中文文字的识别能力,我们引入了 priyank-m/chinese_text_recognition、SWHL/ChineseOCRBench 和 fly0331/ChineseTest 三个基于中文文字领域图片的数据集。这些数据集的融入将有效弥补 REILX/llava-Qwen2-7B-Instruct-Chinese-CLIP 模型在中文文字识别方面的不足,使其能够更好地理解和处理中文文本信息。
6. 效果展示
以下测试结果显示模型能识别图像中的文字信息,且能正确识别表情包想要表达的内涵




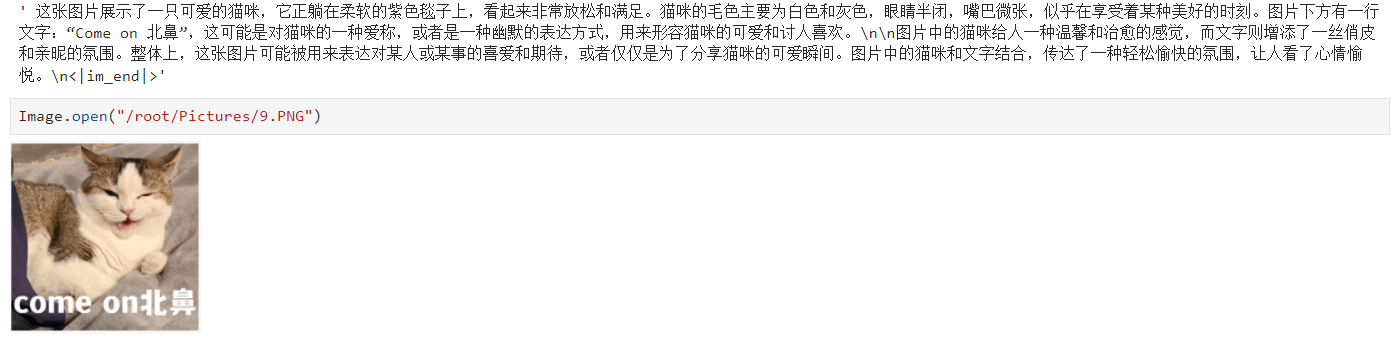 7. 代码
推理代码
```python
from transformers import LlavaForConditionalGeneration, AutoProcessor
import torch
from PIL import Image
raw_model_name_or_path = "/保存的完整模型路径"
model = LlavaForConditionalGeneration.from_pretrained(raw_model_name_or_path, device_map="cuda:0", torch_dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained(raw_model_name_or_path)
model.eval()
def build_model_input(model, processor):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "\n 你是一位有深度的网络图片解读者,擅长解读和描述网络图片。你能洞察图片中的细微之处,对图中的人物面部表情、文字信息、情绪流露和背景寓意具有超强的理解力,描述信息需要详细。"}
]
prompt = processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image = Image.open("01.PNG")
inputs = processor(text=prompt, images=image, return_tensors="pt", return_token_type_ids=False)
for tk in inputs.keys():
inputs[tk] = inputs[tk].to(model.device)
generate_ids = model.generate(**inputs, max_new_tokens=200)
generate_ids = [
oid[len(iids):] for oid, iids in zip(generate_ids, inputs.input_ids)
]
gen_text = processor.batch_decode(generate_ids, skip_special_tokens=False, clean_up_tokenization_spaces=False)[0]
return gen_text
build_model_input(model, processor)
```
7. 代码
推理代码
```python
from transformers import LlavaForConditionalGeneration, AutoProcessor
import torch
from PIL import Image
raw_model_name_or_path = "/保存的完整模型路径"
model = LlavaForConditionalGeneration.from_pretrained(raw_model_name_or_path, device_map="cuda:0", torch_dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained(raw_model_name_or_path)
model.eval()
def build_model_input(model, processor):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "\n 你是一位有深度的网络图片解读者,擅长解读和描述网络图片。你能洞察图片中的细微之处,对图中的人物面部表情、文字信息、情绪流露和背景寓意具有超强的理解力,描述信息需要详细。"}
]
prompt = processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image = Image.open("01.PNG")
inputs = processor(text=prompt, images=image, return_tensors="pt", return_token_type_ids=False)
for tk in inputs.keys():
inputs[tk] = inputs[tk].to(model.device)
generate_ids = model.generate(**inputs, max_new_tokens=200)
generate_ids = [
oid[len(iids):] for oid, iids in zip(generate_ids, inputs.input_ids)
]
gen_text = processor.batch_decode(generate_ids, skip_special_tokens=False, clean_up_tokenization_spaces=False)[0]
return gen_text
build_model_input(model, processor)
```