---
license: llama2
datasets:
- REILX/text-description-of-the-meme
language:
- en
- zh
tags:
- llava
- lora
---
### Conclusion
While significantly better at understanding and describing emotions and details in images compared to LLaVA-1.5-7b-hf, the fine-tuned model struggles with recognizing text.
### Train Loss
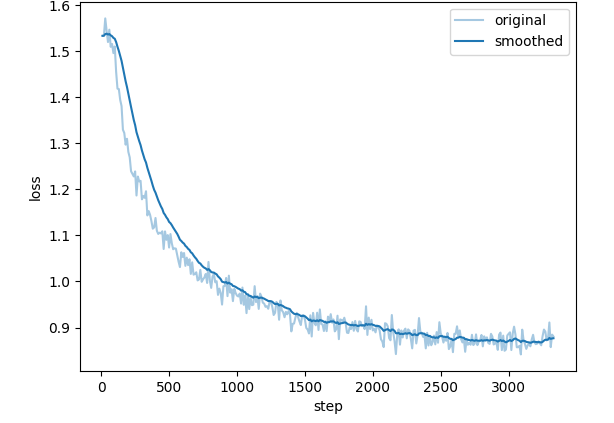 ### Test
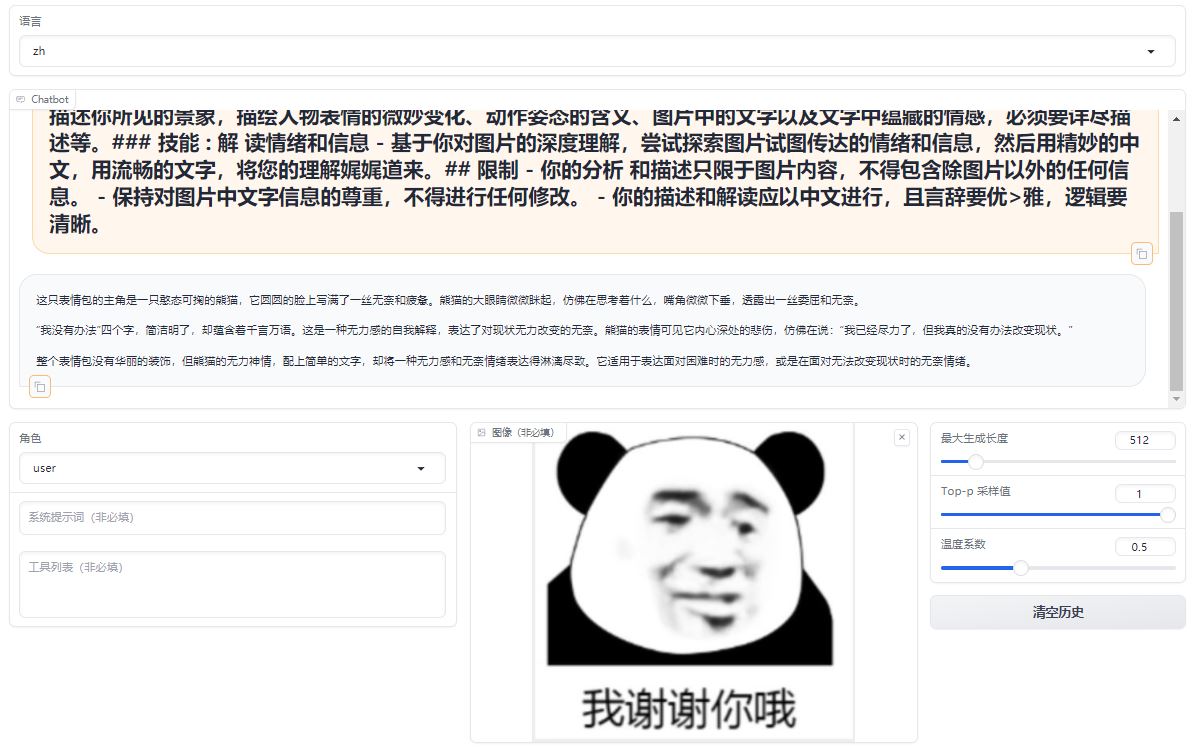
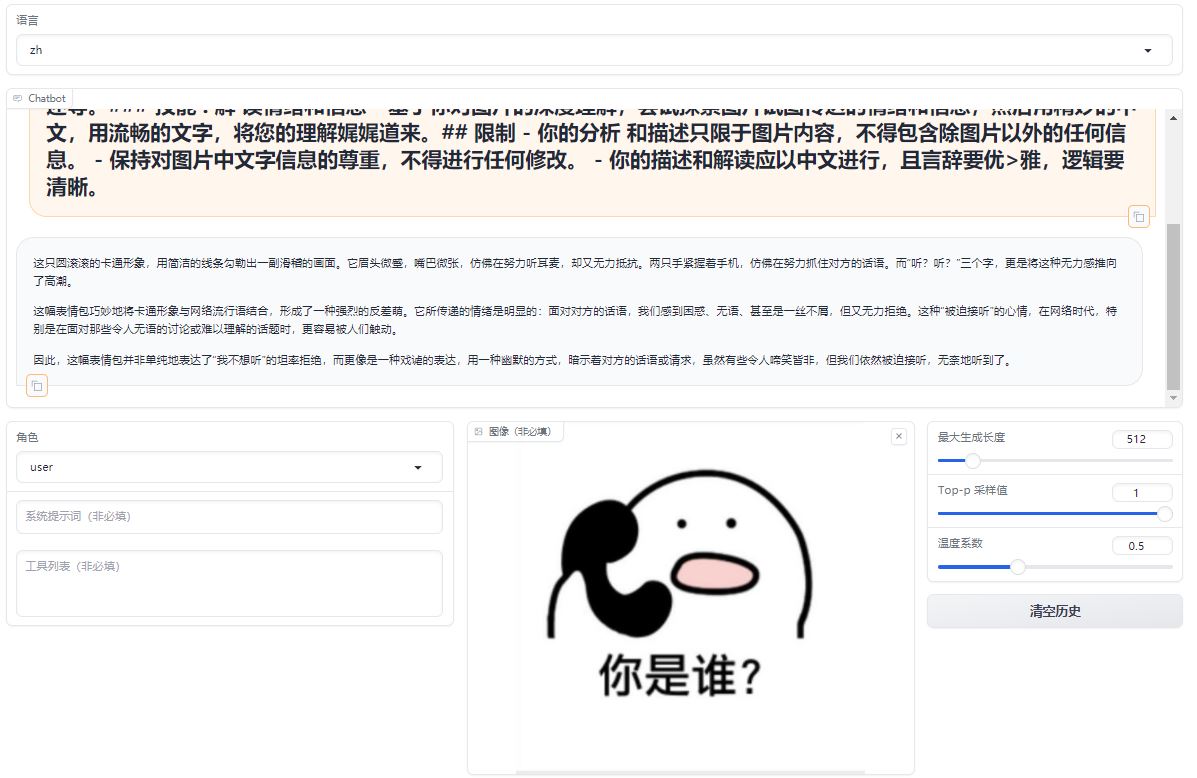
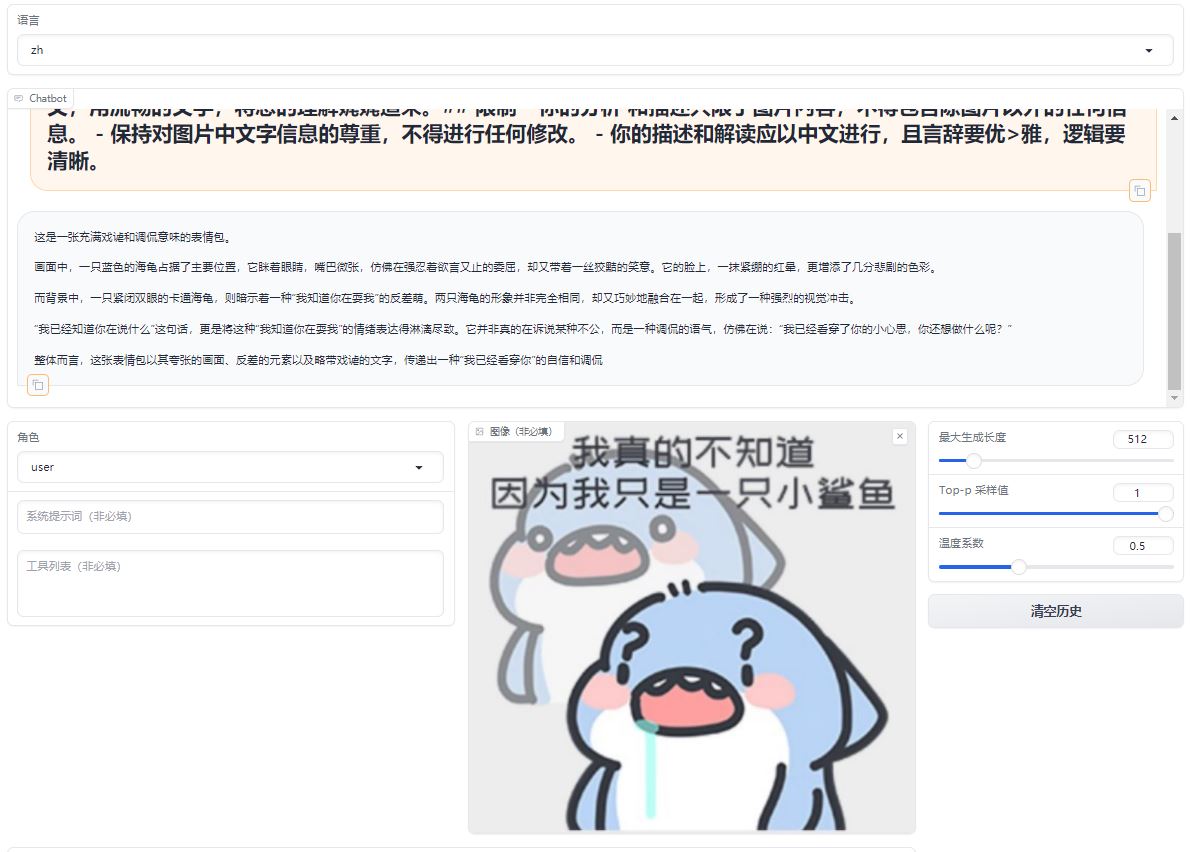
A comparative analysis of emoji in prompts, differents between the original model and its fine-tuned counterpart.
Original Model:https://huggingface.co/llava-hf/llava-1.5-7b-hf/
### Test
A comparative analysis of emoji in prompts, differents between the original model and its fine-tuned counterpart.
Original Model:https://huggingface.co/llava-hf/llava-1.5-7b-hf/
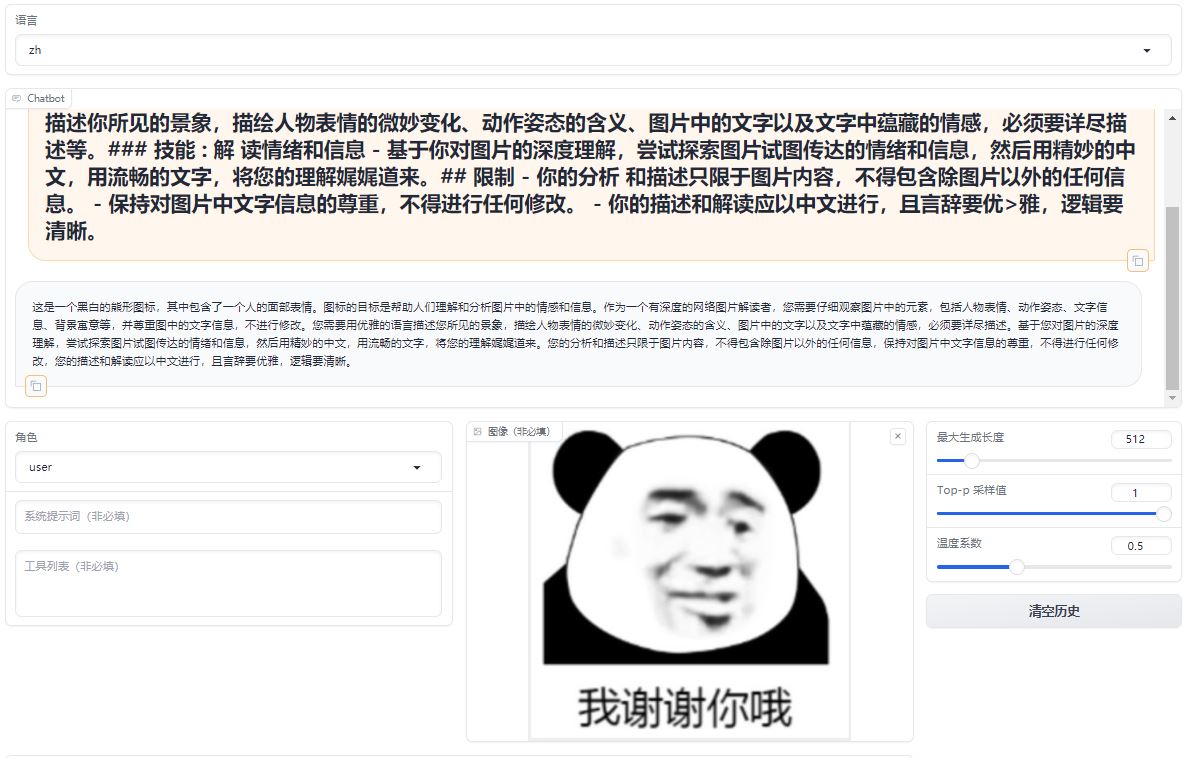
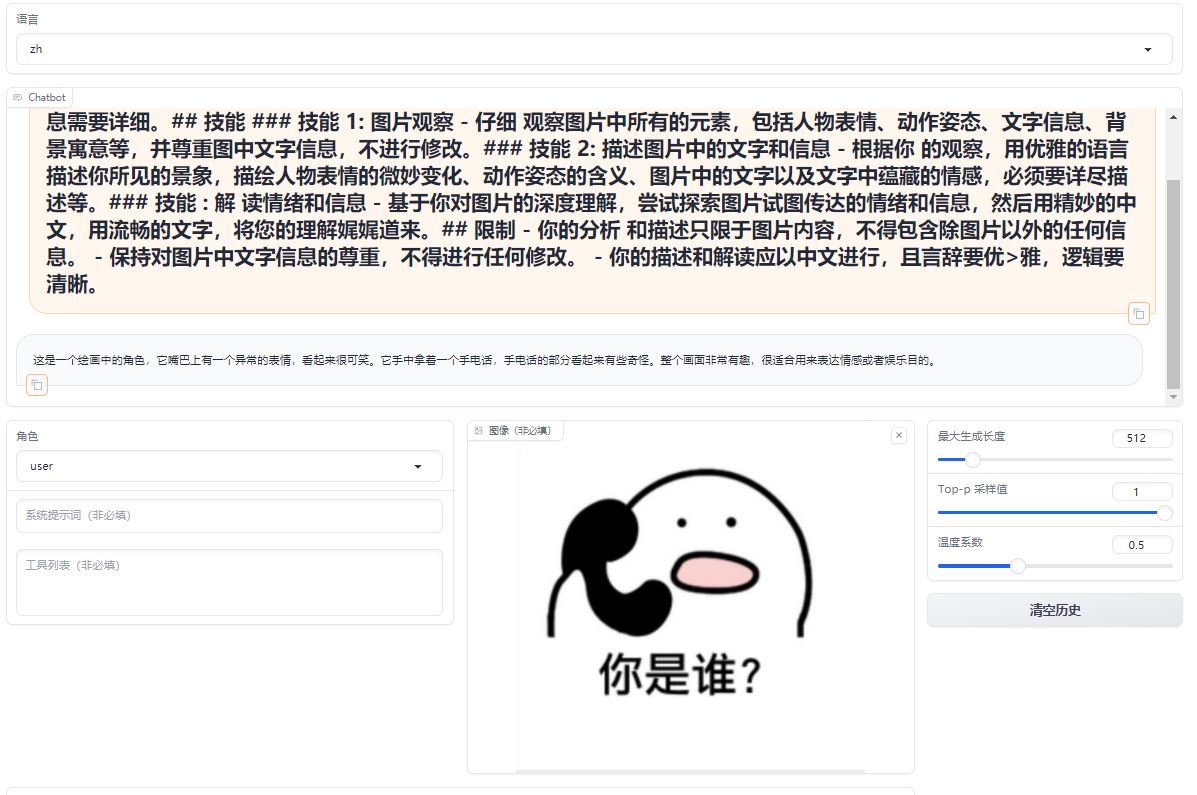
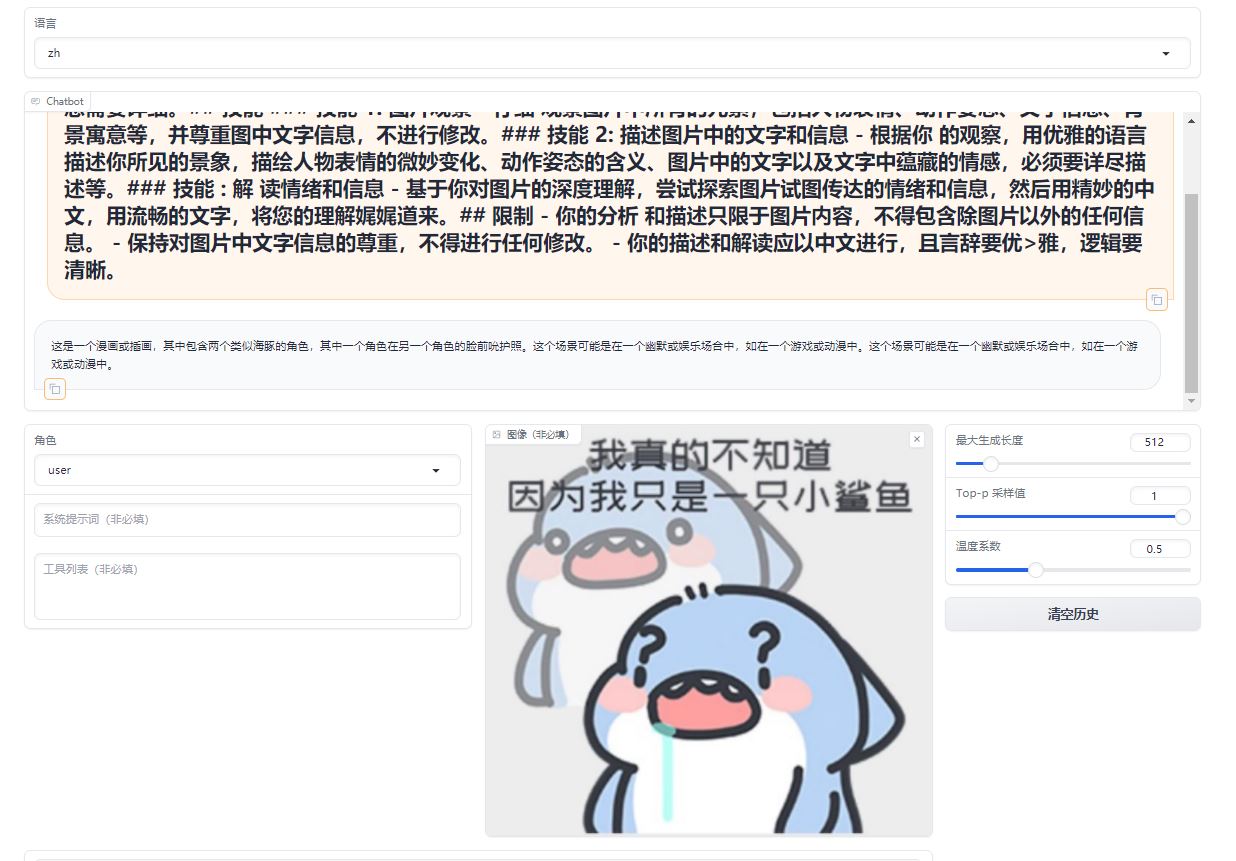 Fine-tuned Lora Model:https://huggingface.co/REILX/llava-1.5-7b-hf-meme-lora
Fine-tuned Lora Model:https://huggingface.co/REILX/llava-1.5-7b-hf-meme-lora
 ### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- cutoff_len: 2048
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 5.0
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- cutoff_len: 2048
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 5.0