---
license: mit
---
https://github.com/baaivision/EVA/tree/master/EVA-CLIP
## Summary of EVA-CLIP performance
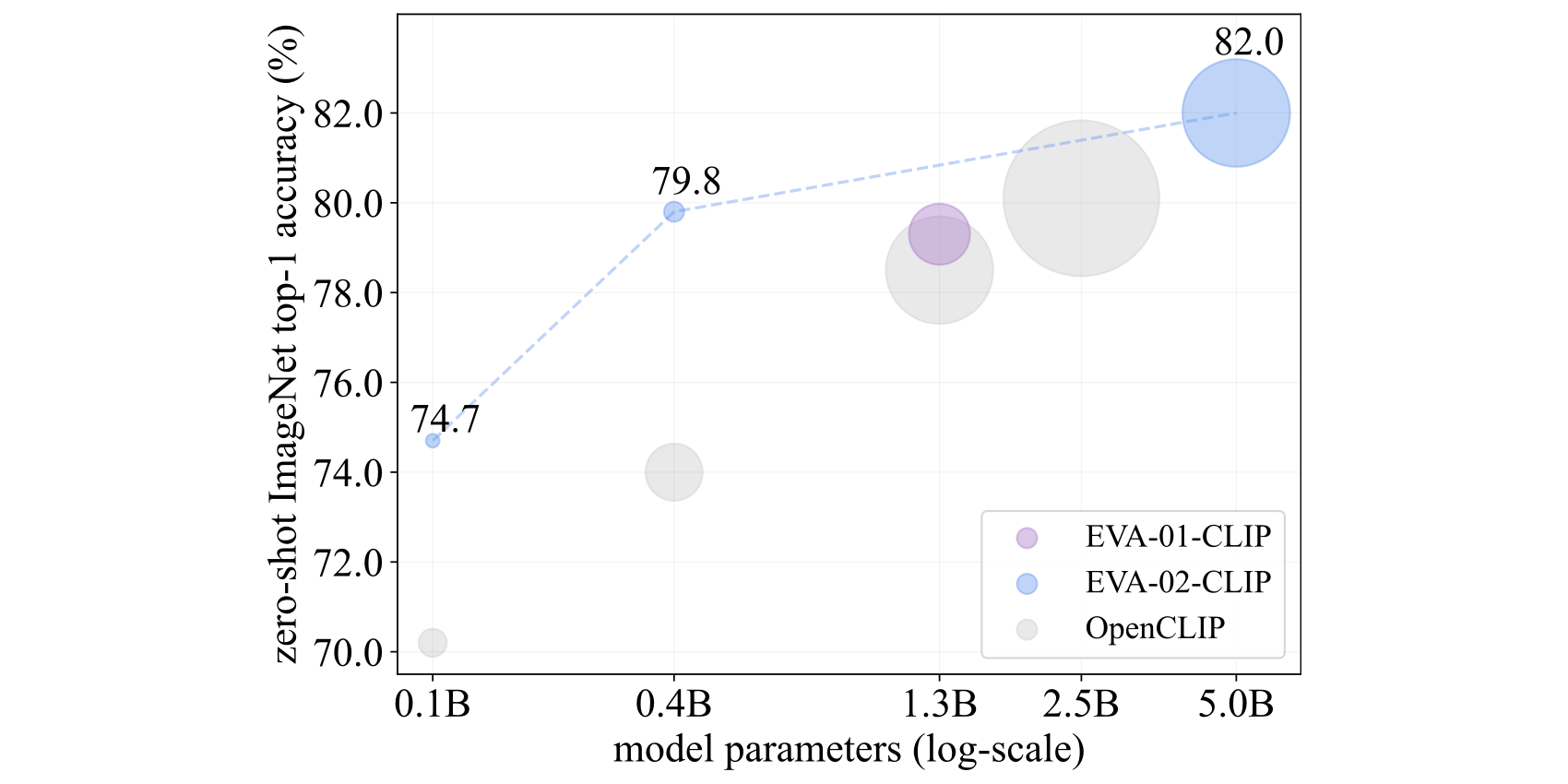
## Model Card
### EVA-01-CLIP Series (MIM teacher: [OpenAI CLIP-Large](https://github.com/openai/CLIP))
| model name | total #params | training precision | training data | training batch size | gpus for training | IN-1K zero-shot top-1 | MSCOCO T2I R@5 | weight |
|:-----------|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|
| `EVA01_CLIP_g_14_psz14_s11B` | 1.1B | `fp16` | [LAION-400M](https://laion.ai/blog/laion-400-open-dataset/) | 41K | 256 A100(40GB) | 78.5 | 68.5 | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA01_CLIP_g_14_psz14_s11B.pt) (`2.2GB`) |
| `EVA01_CLIP_g_14_plus_psz14_s11B` | 1.3B | `fp16` | Merged-2B | 114K | 112 A100(40GB) | 79.3 | 74.0 | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA01_CLIP_g_14_plus_psz14_s11B.pt) (`2.7GB`) |
### EVA-02-CLIP Series (MIM teacher: ``EVA01_CLIP_g_14_psz14_s11B``)
| model name | image enc. init. ckpt | text enc. init. ckpt | total #params | training precision | training data | training batch size | gpus for training | IN-1K zero-shot top-1 | MSCOCO T2I R@5 | weight |
|:-----|:-----|:-----------|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|
| `EVA02_CLIP_B_psz16_s8B` | `EVA02_B_psz14to16` | `openai/clip-vit-base-patch16` | 149M | `fp16` | Merged-2B | 131K | 64 A100(40GB) | **74.7** | **66.9** | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_B_psz16_s8B.pt) (`300MB`) |
| `EVA02_CLIP_L_psz14_s4B` | `EVA02_L_psz14` | `openai/clip-vit-large-patch14` | 428M | `fp16` | Merged-2B | 131K | 128 A100(40GB) | **79.8** | **71.2** | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_L_psz14_s4B.pt) (`856MB`) |
| `EVA02_CLIP_L_336_psz14_s6B` | `EVA02_CLIP_L_psz14_224to336` | `EVA02_CLIP_L_psz14_224to336` | 428M | `fp16` | Merged-2B | 61K | 128 A100(40GB) | **80.4** | **71.7** | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_L_336_psz14_s6B.pt) (`856MB`) |
| `EVA02_CLIP_E_psz14_s4B.pt` | `EVA02_E_psz14` | `laion/CLIP-ViT-H-14-laion2B-s32B-b79K` | 4.7B | `fp16` | [LAION-2B](https://laion.ai/blog/laion-5b/) | 115K | 144 A100(80GB) | **81.9** | **74.7** | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_E_psz14_s4B.pt) (`9.4GB`) |
| `EVA02_CLIP_E_psz14_plus_s9B.pt` | `EVA02_E_psz14` | `laion/CLIP-ViT-bigG-14-laion2B-39B-b160k` | 5.0B | `bf16` | [LAION-2B](https://laion.ai/blog/laion-5b/) | 144K | 144 A100(80GB) | **82.0** | **75.0** | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_E_psz14_plus_s9B.pt) (`10.1GB`) |
- To construct Merged-2B, we merged 1.6 billion samples from [LAION-2B](https://laion.ai/blog/laion-5b/) dataset with 0.4 billion samples from [COYO-700M](https://github.com/kakaobrain/coyo-dataset).
- To our knowledge, EVA-CLIP series are the most performant open-sourced CLIP models at all scales, evaluated via zero-shot classification performance, especially on mainstream classification benchmarks such as ImageNet along with its variants.
For more details about EVA-CLIP, please refer to our [paper](http://arxiv.org/abs/2303.15389).
### Pretrained
| model name | total #params | training precision | download link |
|:-----------|:------:|:------:|:------:|
| `EVA01_g_psz14` | 1.0B | `fp16` | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA01_g_psz14.pt) (`2.0GB`) |
| `EVA02_B_psz14to16` | 86M | `fp16` | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_B_psz14to16.pt) (`176MB`) |
| `EVA02_L_psz14` | 304M | `fp16` | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_L_psz14.pt) (`609MB`) |
| `EVA02_CLIP_L_psz14_224to336` | 428M | `fp16` | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_CLIP_L_psz14_224to336.pt) (`857MB`) |
| `EVA02_E_psz14` | 4.4B | `fp16` | [🤗 HF link](https://huggingface.co/QuanSun/EVA-CLIP/blob/main/EVA02_E_psz14.pt) (`8.7GB`) |
| `openai/clip-vit-base-patch16`| 149M | `fp16` | [🤗 HF link](https://huggingface.co/openai/clip-vit-base-patch16/blob/main/pytorch_model.bin) (`599MB`) |
| `openai/clip-vit-large-patch14`| 428M | `fp16` | [🤗 HF link](https://huggingface.co/openai/clip-vit-large-patch14/blob/main/pytorch_model.bin) (`1.7GB`) |
| `laion/CLIP-ViT-H-14-laion2B-s32B-b79K`| 1.0B | `bf16` | [🤗 HF link](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/blob/main/pytorch_model.bin) (`3.9GB`) |
| `laion/CLIP-ViT-bigG-14-laion2B-39B-b160k`| 1.8B | `bf16` | 🤗 HF link [part1](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/pytorch_model-00001-of-00002.bin) [part2](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/pytorch_model-00002-of-00002.bin)(`9.9GB`+`169M`) |
- EVA02_B_psz14to16 interpolates the kernel size of patch_embed from 14x14 to 16x16, and interpolate the pos_embed from 16x16 to 14x14.
- EVA02_CLIP_L_psz14_224to336 interpolates the pos_embed from 16x16 to 24x24 for training EVA02_CLIP_L_336_psz14_s6B.
- laion/CLIP-ViT-bigG-14-laion2B-39B-b160k consists of 2 parts of weights, [part1](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/pytorch_model-00001-of-00002.bin) and [part2](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/pytorch_model-00002-of-00002.bin).