---
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ' TransNormerLLM'
---
TransNormerLLM2 -- A Faster and Better LLM
💻 GitHub • 💬 Discord • 💬 Wechat
# Table of Contents
- [Introduction](#introduction)
- [Diff of TransNormerLLM2](#diff-of-transnormerllm2)
- [Released Weights](#released-weights)
- [Benchmark Results](#benchmark-results)
- [Inference and Deployment](#inference-and-deployment)
- [Dependency Installation](#dependency-installation)
- [Inference](#inference)
- [Fine-tuning the Model](#fine-tuning-the-model)
- [Community and Ecosystem](#community-and-ecosystem)
- [Disclaimer, License and Citation](#disclaimer-license-and-citation)
# Introduction
This official repo introduces the TransNormerLLM model, featuring its open-source weights. Additionally, it provides codes for Supervised Fine-tuning (SFT) and inference.
[TransNormerLLM](https://arxiv.org/abs/2307.14995) evolving from [TransNormer](https://arxiv.org/abs/2210.10340), standing out as the first LLM within the linear transformer architecture. Additionally, it distinguishes itself by being the first non-Transformer LLM to exceed both traditional Transformer and other efficient Transformer models (such as, RetNet and Mamba) in terms of speed and performance.
- **TransNormerLLM1** is released in Nov 2023, featuring three versions with **385M**, **1B**, and **7B** parameters, trained on **1.4 trillion** tokens.
- The **latest update** transitions from TransNormerLLM1 to **TransNormerLLM2**, offering three updated versions with **1B**, **3B**, and **7B** parameters, trained on **0.3 trillion** tokens.
- All versions are available as open-source under the Apache-2.0 license.
## Diff of TransNormerLLM2
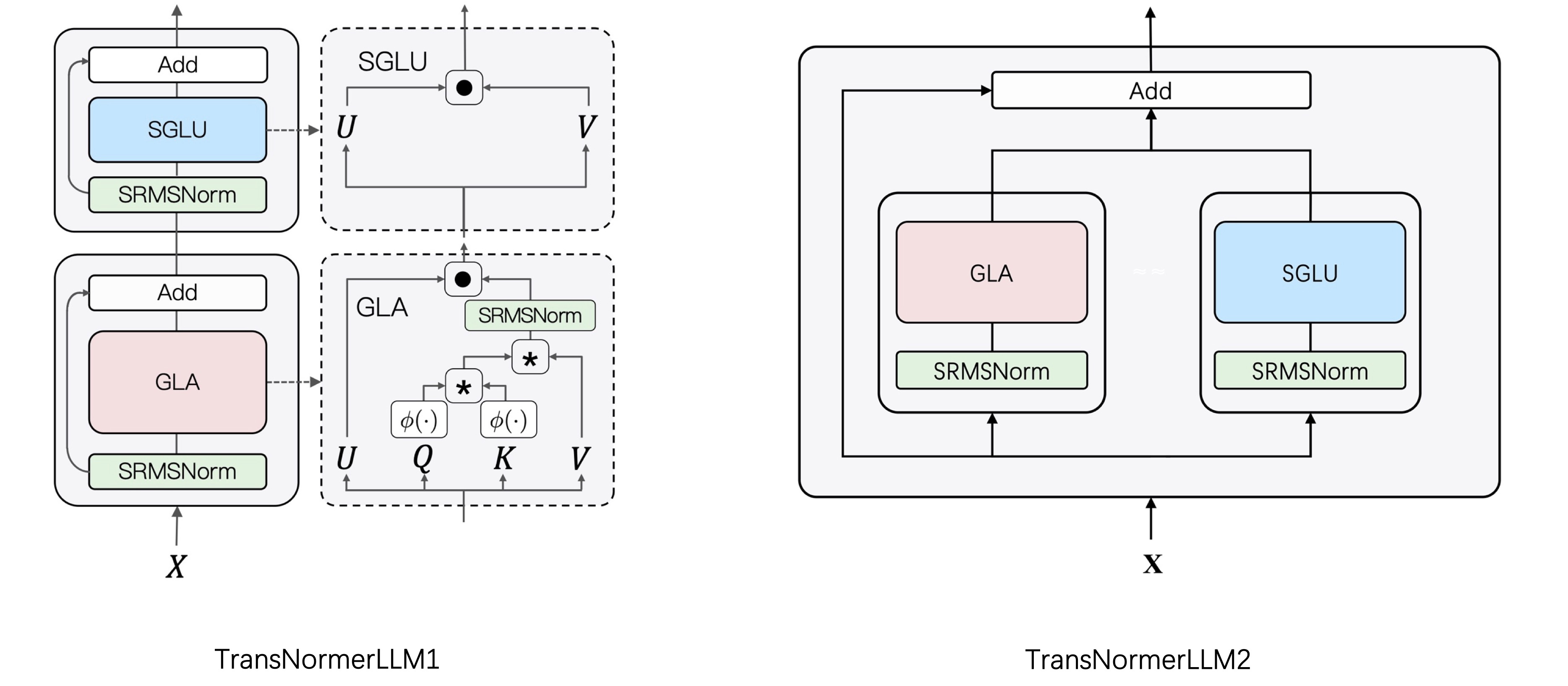
- **TransNormerLLM1** incorporates Simple GLU in its channel mixer, GLA in the token mixer, and SRMSNorm for normalization. In this model, the channel and token mixers function sequentially in a pipeline arrangement.
- **TransNormerLLM2** also utilizes Simple GLU in the channel mixer, GLA in the token mixer, and SRMSNorm for normalization. However, in this version, the channel and token mixers operate concurrently, in parallel.
# Released Weights
The specific released versions and download links are shown as below:
| param | token | Base Models |
| :-------: | :---: | :------------------------------------------------------------------------------------: |
| v1-385M | 1400B | 🤗 [TransNormerLLM-385M](https://huggingface.co/OpenNLPLab/TransNormerLLM-385M) |
| v1-1B | 1400B | 🤗 [TransNormerLLM-1B](https://huggingface.co/OpenNLPLab/TransNormerLLM-1B) |
| v1-7B | 1400B | 🤗 [TransNormerLLM-7B](https://huggingface.co/OpenNLPLab/TransNormerLLM-7B) |
| **v2-1B** | 300B | 🤗 [TransNormerLLM2-1B-300B](https://huggingface.co/OpenNLPLab/TransNormerLLM2-1B-300B) |
| **v2-3B** | 300B | 🤗 [TransNormerLLM2-3B-300B](https://huggingface.co/OpenNLPLab/TransNormerLLM2-3B-300B) |
| **v2-7B** | 300B | 🤗 [TransNormerLLM2-7B-300B](https://huggingface.co/OpenNLPLab/TransNormerLLM2-7B-300B) |
# Benchmark Results
TransNormerLLM are evaluated on Commonsense Reasoning tasks and Multiple-Choice questions. For comparison, a range of open-source models are chosen for comparison, encompassing both Transformer-based and non-Transformer-based architectures. The evaluations of all models are conducted using the official settings and the [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) framework.
| Model | P | T | BoolQ | PIQA | HS | WG | ARC-e | ARC-c | OBQA | MMLU | CMMLU | C-Eval |
| ---------------------- | --- | ---- | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ------ |
| TransNormerLLM2-1B | 1.0 | 0.3 | 59.45 | 69.70 | 45.96 | 52.49 | 54.29 | 25.60 | 33.00 | 26.10 | 24.97 | 26.30 |
| **TransNormerLLM2-3B** | 3.0 | 0.3 | 60.64 | 71.22 | 56.64 | 57.93 | 59.01 | 29.52 | 35.60 | 26.70 | 25.12 | 25.26 |
> **P**: parameter size (billion). **T**: tokens (trillion). **BoolQ**: acc. **PIQA**: acc. **HellaSwag**: acc_norm. **WinoGrande**: acc. **ARC-easy**: acc. **ARC-challenge**: acc_norm. **OpenBookQA**: acc_norm. **MMLU**: 5-shot acc. **CMMLU**: 5-shot acc. **C-Eval**: 5-shot acc.
# Inference and Deployment
## Dependency Installation
**📝Note** Please configure the following environment before using the model:
```shell
pip install triton==2.0.0
pip install einops
```
### Notice
If you experience errors associated with Triton, it is advisable to disable Triton.
```
export use_triton=False
```
## Inference
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("OpenNLPLab/TransNormerLLM2-3B-300B", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("TransNormerLLM2-3B-300B", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('今天是美好的一天', return_tensors='pt')
>>> pred = model.generate(**inputs, max_new_tokens=2048, repetition_penalty=1.0)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
```
* **Note**: we recommend to use `bfloat16` in `TransNormerLLM`, `float16` might lead `nan` error, please check your divce compatibility!
# Fine-tuning the Model
## Dependency Installation
```shell
git clone https://github.com/OpenNLPLab/TransNormerLLM.git
cd TransNormerLLM/fine-tune
pip install -r requirements.txt
```
- To use lightweight fine-tuning methods like LoRA, you must additionally install [peft](https://github.com/huggingface/peft).
## Training
Below, we provide an example of fine-tuning the TransNormerLLM-1B on a single machine with ZeRO-3.
Training Data: `alpaca_data.json`. This sample data was drawn from [alpaca_data.json](https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json), consisting of a selection of 52,002 entries, and has been reformatted. The main purpose is to demonstrate how to SFT our model, and effectiveness is not guaranteed.
```shell
torchrun \
--nproc_per_node=8 \
train.py \
--model_name_or_path OpenNLPLab/TransNormerLLM-1B \
--data_path ./alpaca_data.json \
--output_dir output \
--num_train_epochs 1 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--bf16 true \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 5000 \
--save_total_limit 30 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--warmup_ratio 0.1 \
--lr_scheduler_type "cosine" \
--deepspeed 'configs/zero3.json' \
--logging_steps 1 \
--dataloader_num_workers 24 \
--ddp_find_unused_parameters false \
--tf32 true \
```
# Community and Ecosystem
**📢📢📢 We will continuously update the support for TransNormerLLM from the community and ecosystem here 😀😀😀**
- [nanoTransnormer](https://github.com/Doraemonzzz/nanoTransNormer)
# Disclaimer, License and Citation
## Disclaimer
Our team has not created any applications using TransNormerLLM models for any platform including iOS, Android, and web. We urge users not to use these models for illegal activities or anything that could harm national or social security. We also advise against using these models for online services that haven't passed security reviews and legal procedures. We hope everyone will follow these guidelines to ensure technology develops in a safe and lawful way.
We've tried hard to make sure the data in our model training is compliant, but because the model and data are complex, there might still be unexpected issues. If any problems occur from using TransNormerLLM open-source models, like data security issues, public opinion risks, or problems caused by misuse or improper use of the model, we will not be responsible.
## License
The community usage of TransNormerLLM model requires adherence to [Apache 2.0](https://github.com/OpenNLPLab/TransNormerLLM/blob/main/LICENSE) and [Community License for TransNormerLLM Model](https://huggingface.co/OpenNLPLab/TransNormerLLM-1B/blob/main/TransNormerLLM模型社区许可协议.pdf). The TransNormerLLM model supports commercial use. If you plan to use the TransNormerLLM model or its derivatives for commercial purposes, please ensure that you have submit the application materials required by the TransNormerLLM Model Community License Agreement via the following contact email: opennlplab@gmail.com.
## Acknowledgments
Our project is developed based on the following open source projects:
- [Baichuan](https://github.com/baichuan-inc/Baichuan-7B) for the tokenizer.
- [metaseq](https://github.com/facebookresearch/metaseq) for training.
- [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) for evaluation.
## Citation
If you wish to cite our work, please use the following reference:
```
@article{qin2023scaling,
title={Scaling transnormer to 175 billion parameters},
author={Qin, Zhen and Li, Dong and Sun, Weigao and Sun, Weixuan and Shen, Xuyang and Han, Xiaodong and Wei, Yunshen and Lv, Baohong and Yuan, Fei and Luo, Xiao and others},
journal={arXiv preprint arXiv:2307.14995},
year={2023}
}
```
 - OpenNLPLab @2024 -
- OpenNLPLab @2024 -