---
license: apache-2.0
---
# Diagram Formalization Enhanced Multi-Modal Geometry Problem Solver
## Model Structure
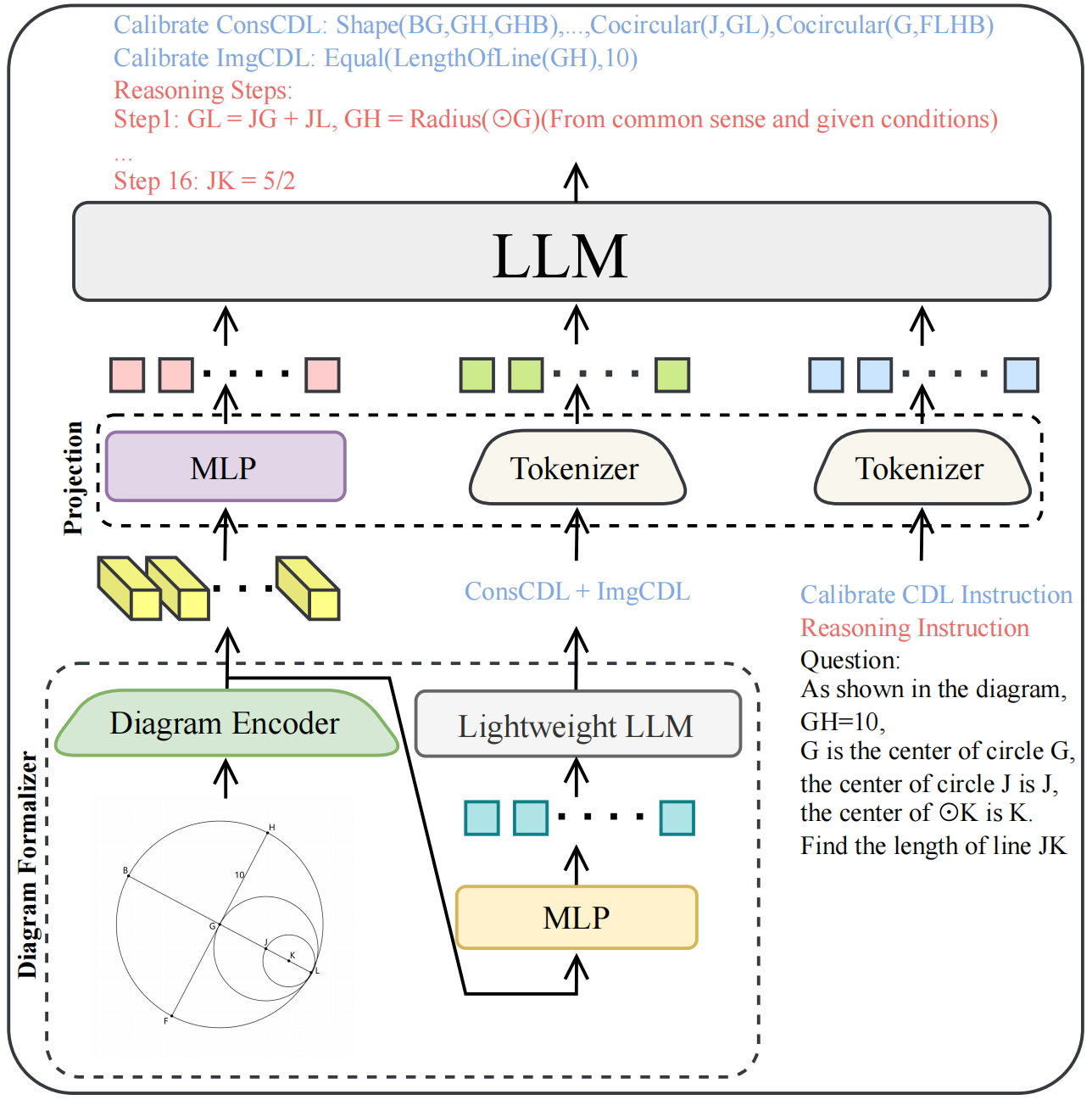
- **Diagram Encoder**: [siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384)
- **Lightweight LLM**: [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct)
- **LLM**: [Yi-1.5-34B-Chat](https://huggingface.co/01-ai/Yi-1.5-34B-Chat)
## Quick Start
Before running the script, install the following necessary dependencies.
```shell
pip install torch transformers==4.40.0 accelerate pillow sentencepiece
```
You can solve geometric problems using the following script. First, formalize the geometric images with the [Diagram Formalizer](https://huggingface.co/NaughtyDog97/DiagramFormalizer), and then use the multi-modal reasing model for problem-solving:
```python
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import warnings
import numpy as np
import re
def tokenizer_image_token(prompt, tokenizer, image_token_index, return_tensors=None):
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split('')]
def insert_separator(X, sep):
return [ele for sublist in zip(X, [sep] * len(X)) for ele in sublist][:-1]
input_ids = []
offset = 0
if len(prompt_chunks) > 0 and len(prompt_chunks[0]) > 0 and prompt_chunks[0][0] == tokenizer.bos_token_id:
offset = 1
input_ids.append(prompt_chunks[0][0])
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
input_ids.extend(x[offset:])
if return_tensors is not None:
if return_tensors == 'pt':
return torch.tensor(input_ids, dtype=torch.long)
raise ValueError(f'Unsupported tensor type: {return_tensors}')
return input_ids
def parse_cdl(input_string):
patterns = {
'construction_cdl': r'(?:The )?(?:calibrate )?construction_cdl(?: is)?:\n(.*?)(?=\n(?:The )?(?:calibrate )?\w+_cdl is:|\n(?:The )?(?:calibrate )?\w+_cdl:|\nSolution is:|\Z)',
'image_cdl': r'(?:The )?(?:calibrate )?image_cdl(?: is)?:\n(.*?)(?=\n(?:The )?(?:calibrate )?\w+_cdl is:|\n(?:The )?(?:calibrate )?\w+_cdl:|\nSolution is:|\Z)',
'text_cdl': r'(?:The )?text_cdl(?: is)?:\n(.*?)(?=\n(?:The )?\w+_cdl is:|\n(?:The )?\w+_cdl:|\nSolution is:|\Z)',
'goal_cdl': r'(?:The )?goal_cdl(?: is)?:\n(.*?)(?=\n(?:The )?\w+_cdl is:|\n(?:The )?\w+_cdl:|\nSolution is:|\Z)'
}
results = {}
for key, pattern in patterns.items():
pattern = pattern.replace("(?:calibrate )?", "(?:calibrate )")
match = re.search(pattern, input_string, re.DOTALL)
if match:
results[key] = match.group(1).strip()
else:
pattern = pattern.replace("(?:calibrate )", "(?:calibrate )?")
match = re.search(pattern, input_string, re.DOTALL)
if match:
results[key] = match.group(1).strip()
return results
# set device
device = 'cuda' # or cpu
torch.set_default_device(device)
# create model
formalization_model = AutoModelForCausalLM.from_pretrained(
'NaughtyDog97/DiagramFormalizer',
torch_dtype=torch.float16, # float32 for cpu
device_map='auto',
trust_remote_code=True)
formalization_tokenizer = AutoTokenizer.from_pretrained(
'NaughtyDog97/DiagramFormalizer',
use_fast=True,
padding_side="right",
trust_remote_code=True)
reason_model = AutoModelForCausalLM.from_pretrained(
'NaughtyDog97/DFE-GPS-34B',
torch_dtype=torch.float16, # float32 for cpu
device_map='auto',
trust_remote_code=True)
reason_tokenizer = AutoTokenizer.from_pretrained(
'NaughtyDog97/DFE-GPS-34B',
use_fase=False,
trust_remote_code=True)
img_path = 'sample/4927.png'
image = Image.open(img_path).convert('RGB')
# formalization
prompt = 'Based on the image, first describe what you see in the figure, then predict the construction_cdl and image_cdl and calibrate it.'
text = f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n\n{prompt}<|im_end|>\n<|im_start|>assistant\n'
input_ids = tokenizer_image_token(text, formalization_tokenizer, -200, return_tensors='pt').unsqueeze(0).cuda()
# generate
image_tensor = formalization_model.process_images([image], formalization_model.config).to(dtype=formalization_model.dtype, device=device)
with torch.inference_mode():
output_ids = formalization_model.generate(
input_ids,
images=image_tensor,
do_sample=False,
temperature=None,
top_p=None,
top_k=None,
num_beams=1,
max_new_tokens=3500,
eos_token_id=formalization_tokenizer.eos_token_id,
repetition_penalty=None,
use_cache=True
)[0]
respones = formalization_tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip()
print(f'Formalization result is\n{respones}')
cdl_info = parse_cdl(respones)
predict_consCDL = cdl_info['construction_cdl']
predict_imgCDL = cdl_info['image_cdl']
# reasoning
qs = 'As shown in the diagram, AE/AB=1/4, M is the midpoint of segment AC, BE is parallel to CP, EA is parallel to CP. Find the ratio of the length of line BC to the length of line CD.'
prompt = f'Using the provided geometric image and the possibly erroneous construction_cdl and image_cdl, first calibrate the construction_cdl and image_cdl, then give a detailed step-by-step solution to the question.\nThe initial construction_cdl is:\n{predict_consCDL}\nThe initial image_cdl is:\n{predict_imgCDL}\nThe question is:\n{qs}'
text = f'<|im_start|>user\n\n{prompt}<|im_end|>\n<|im_start|>assistant\n'
input_ids = tokenizer_image_token(text, reason_tokenizer, -200, return_tensors='pt').unsqueeze(0).cuda()
# generate
image_tensor = reason_model.process_images([image], reason_model.config).to(dtype=reason_model.dtype, device=device)
with torch.inference_mode():
output_ids = reason_model.generate(
input_ids,
images=image_tensor,
do_sample=False,
temperature=None,
top_p=None,
top_k=None,
num_beams=1,
max_new_tokens=3500,
eos_token_id=reason_tokenizer.eos_token_id,
repetition_penalty=None,
use_cache=True
)[0]
respones = reason_tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip()
print(f'Reasoning steps is\n{respones}')
```
## Performance of DFE-GPS on formalgeo7k test set
| Model | Choice Acc | OpenEnd ACC | Process Evaluation Score |
|-------|------------|-------------|--------------------------|
| DFE-GPS-9B | 77.05 | 68.67 | 76.00 |
| DFE-GPS-34B | **82.38** | **75.33** | **79.07** |