---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- nlp
- llm
---
# Amber
 We present Amber, the first model in the LLM360 family. Amber is an
7B English language model with the LLaMA architecture.
## About LLM360
LLM360 is an initiative for comprehensive and fully open-sourced LLMs,
where all training details, model checkpoints, intermediate results, and
additional analyses are made available to the community. Our goal is to advance
the field by inviting the community to deepen the understanding of LLMs
together. As the first step of the project LLM360, we release all intermediate
model checkpoints, our fully-prepared pre-training dataset, all source code and
configurations, and training details. We are
committed to continually pushing the boundaries of LLMs through this open-source
effort.
Get access now at [LLM360 site](https://www.llm360.ai/)
## Model Description
- **Model type:** Language model with the same architecture as LLaMA-7B
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Resources for more information:**
- [Training Code](https://github.com/LLM360/amber-train)
- [Data Preparation](https://github.com/LLM360/amber-data-prep)
- [Metrics](https://github.com/LLM360/Analysis360)
- [Fully processed Amber pretraining data](https://huggingface.co/datasets/LLM360/AmberDatasets)
# Loading Amber
To load a specific checkpoint, simply set the `CHECKPOINT_NUM` to a value between `0` and `359`. By default, checkpoints will be cached and not re-downloaded for future runs of the script.
```python
from huggingface_hub import snapshot_download
from transformers import LlamaTokenizer, LlamaForCausalLM
CHECKPOINT_NUM = 359
model_path = snapshot_download(
repo_id="LLM360/Amber",
repo_type="model",
allow_patterns=[f"ckpt_{CHECKPOINT_NUM:03}/*"],
)
tokenizer = LlamaTokenizer.from_pretrained(f"{model_path}/ckpt_{CHECKPOINT_NUM:03}")
model = LlamaForCausalLM.from_pretrained(f"{model_path}/ckpt_{CHECKPOINT_NUM:03}")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
# Amber Training Details
## DataMix
| Subset | Tokens (Billion) |
| ----------- | ----------- |
| Arxiv | 30.00 |
| Book | 28.86 |
| C4 | 197.67 |
| Refined-Web | 665.01 |
| StarCoder | 291.92 |
| StackExchange | 21.75 |
| Wikipedia | 23.90 |
| Total | 1259.13 |
## Hyperparameters
| Hyperparameter | Value |
| ----------- | ----------- |
| Total Parameters | 6.7B |
| Hidden Size | 4096 |
| Intermediate Size (MLPs) | 11008 |
| Number of Attention Heads | 32 |
| Number of Hidden Lyaers | 32 |
| RMSNorm ɛ | 1e^-6 |
| Max Seq Length | 2048 |
| Vocab Size | 32000 |
| Training Loss |
|------------------------------------------------------------|
|
We present Amber, the first model in the LLM360 family. Amber is an
7B English language model with the LLaMA architecture.
## About LLM360
LLM360 is an initiative for comprehensive and fully open-sourced LLMs,
where all training details, model checkpoints, intermediate results, and
additional analyses are made available to the community. Our goal is to advance
the field by inviting the community to deepen the understanding of LLMs
together. As the first step of the project LLM360, we release all intermediate
model checkpoints, our fully-prepared pre-training dataset, all source code and
configurations, and training details. We are
committed to continually pushing the boundaries of LLMs through this open-source
effort.
Get access now at [LLM360 site](https://www.llm360.ai/)
## Model Description
- **Model type:** Language model with the same architecture as LLaMA-7B
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Resources for more information:**
- [Training Code](https://github.com/LLM360/amber-train)
- [Data Preparation](https://github.com/LLM360/amber-data-prep)
- [Metrics](https://github.com/LLM360/Analysis360)
- [Fully processed Amber pretraining data](https://huggingface.co/datasets/LLM360/AmberDatasets)
# Loading Amber
To load a specific checkpoint, simply set the `CHECKPOINT_NUM` to a value between `0` and `359`. By default, checkpoints will be cached and not re-downloaded for future runs of the script.
```python
from huggingface_hub import snapshot_download
from transformers import LlamaTokenizer, LlamaForCausalLM
CHECKPOINT_NUM = 359
model_path = snapshot_download(
repo_id="LLM360/Amber",
repo_type="model",
allow_patterns=[f"ckpt_{CHECKPOINT_NUM:03}/*"],
)
tokenizer = LlamaTokenizer.from_pretrained(f"{model_path}/ckpt_{CHECKPOINT_NUM:03}")
model = LlamaForCausalLM.from_pretrained(f"{model_path}/ckpt_{CHECKPOINT_NUM:03}")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
# Amber Training Details
## DataMix
| Subset | Tokens (Billion) |
| ----------- | ----------- |
| Arxiv | 30.00 |
| Book | 28.86 |
| C4 | 197.67 |
| Refined-Web | 665.01 |
| StarCoder | 291.92 |
| StackExchange | 21.75 |
| Wikipedia | 23.90 |
| Total | 1259.13 |
## Hyperparameters
| Hyperparameter | Value |
| ----------- | ----------- |
| Total Parameters | 6.7B |
| Hidden Size | 4096 |
| Intermediate Size (MLPs) | 11008 |
| Number of Attention Heads | 32 |
| Number of Hidden Lyaers | 32 |
| RMSNorm ɛ | 1e^-6 |
| Max Seq Length | 2048 |
| Vocab Size | 32000 |
| Training Loss |
|------------------------------------------------------------|
| 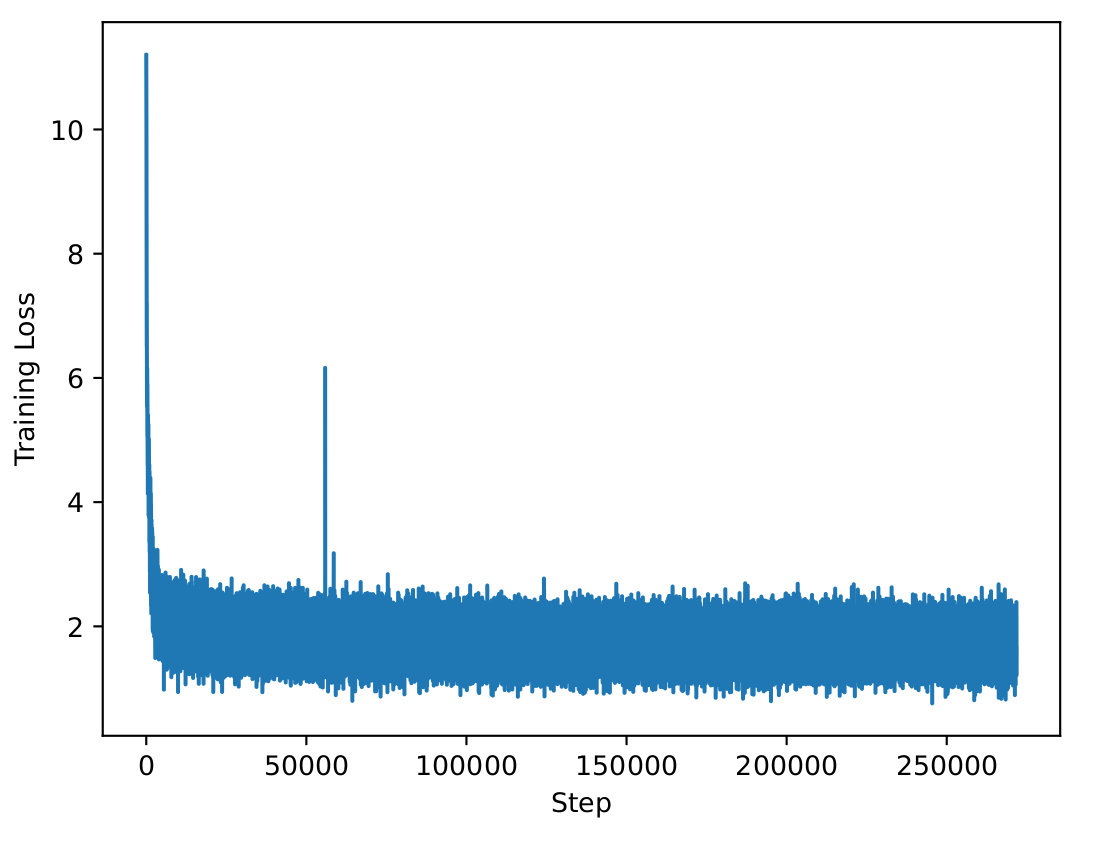 |
# Evaluation
Please refer to our [W&B project page](https://wandb.ai/llm360/CrystalCoder) for complete training logs and evaluation results.
| ARC | HellSwag |
|------------------------------------------------------|------------------------------------------------------------|
|
|
# Evaluation
Please refer to our [W&B project page](https://wandb.ai/llm360/CrystalCoder) for complete training logs and evaluation results.
| ARC | HellSwag |
|------------------------------------------------------|------------------------------------------------------------|
| 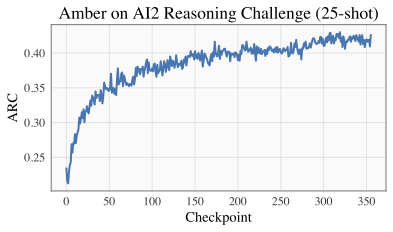 |
| 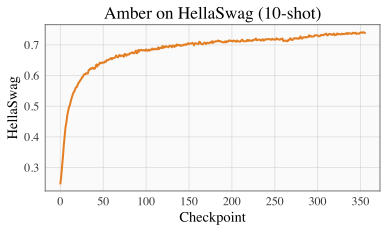 |
|MMLU | TruthfulQA |
|-----------------------------------------------------|-----------------------------------------------------------|
|
|
|MMLU | TruthfulQA |
|-----------------------------------------------------|-----------------------------------------------------------|
| |
|  |
# Citation
Coming soon...
|
# Citation
Coming soon...