
Upload 10 files
Browse files- README.md +61 -0
- configs/beit-base-p16_224px.py +19 -0
- data/fc.pkl +3 -0
- data/imagenet_test.pkl +3 -0
- data/imagenet_train.pkl +3 -0
- imgs/DTD_cracked_0004.jpg +0 -0
- imgs/framework.png +0 -0
- imgs/moodv2_table.png +0 -0
- pretrain/beitv2-base.pth +3 -0
- src/demo.py +305 -0
README.md
CHANGED
|
@@ -1,3 +1,64 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
pipeline_tag: zero-shot-image-classification
|
| 6 |
+
tags:
|
| 7 |
+
- ood-detection
|
| 8 |
+
- outlier-detection
|
| 9 |
---
|
| 10 |
+
|
| 11 |
+
<p style="font-size:28px;" align="center">
|
| 12 |
+
🏠 MOODv2
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
<p align="center">
|
| 16 |
+
• 🤗 <a href="https://huggingface.co/datasets/JingyaoLi/MOODv2" target="_blank">Model </a>
|
| 17 |
+
• 🐱 <a href="https://github.com/dvlab-research/MOOD" target="_blank">Code</a>
|
| 18 |
+
• 📃 <a href="https://arxiv.org/abs/2302.02615" target="_blank">Paper</a> <br>
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
## Abstract
|
| 22 |
+
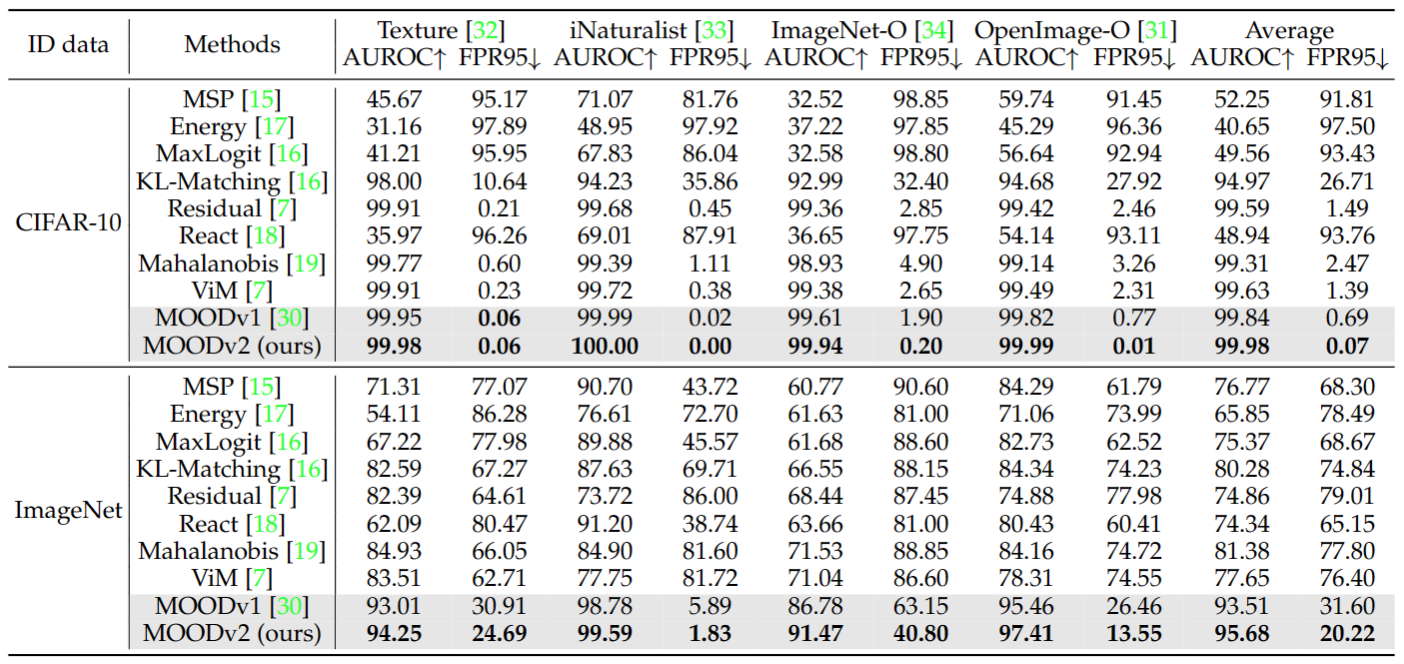
The crux of effective out-of-distribution (OOD) detection lies in acquiring a robust in-distribution (ID) representation, distinct from OOD samples. While previous methods predominantly leaned on recognition-based techniques for this purpose, they often resulted in shortcut learning, lacking comprehensive representations. In our study, we conducted a comprehensive analysis, exploring distinct pretraining tasks and employing various OOD score functions. The results highlight that the feature representations pre-trained through reconstruction yield a notable enhancement and narrow the performance gap among various score functions. This suggests that even simple score functions can rival complex ones when leveraging reconstruction-based pretext tasks. Reconstruction-based pretext tasks adapt well to various score functions. As such, it holds promising potential for further expansion. Our OOD detection framework, MOODv2, employs the masked image modeling pretext task. Without bells and whistles, MOODv2 impressively enhances 14.30% AUROC to 95.68% on ImageNet and achieves 99.98% on CIFAR-10.
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
## Performance
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
## Usage
|
| 29 |
+
To predict an input image is in-distribution or out-of-distribution, we support the following OOD detection methods:
|
| 30 |
+
- `MSP`
|
| 31 |
+
- `MaxLogit`
|
| 32 |
+
- `Energy`
|
| 33 |
+
- `Energy+React`
|
| 34 |
+
- `ViM`
|
| 35 |
+
- `Residual`
|
| 36 |
+
- `GradNorm`
|
| 37 |
+
- `Mahalanobis`
|
| 38 |
+
- `KL-Matching`
|
| 39 |
+
|
| 40 |
+
```bash
|
| 41 |
+
python src/demo.py \
|
| 42 |
+
--img_path imgs/DTD_cracked_0004.jpg \ # change to your image path if needed
|
| 43 |
+
--cfg configs/beit-base-p16_224px.py \
|
| 44 |
+
--checkpoint pretrain/beitv2-base_3rdparty_in1k_20221114-73e11905.pth \
|
| 45 |
+
--fc_save_path data/fc.pkl \
|
| 46 |
+
--id_train_feature data/imagenet_train.pkl \
|
| 47 |
+
--id_val_feature data/imagenet_test.pkl \
|
| 48 |
+
--methods MSP MaxLogit Energy Energy+React ViM Residual GradNorm Mahalanobis
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
For the example OOD image `imgs/DTD_cracked_0004.jpg`, you are supposed to get:
|
| 52 |
+
```
|
| 53 |
+
MSP evaluation: out-of-distribution
|
| 54 |
+
MaxLogit evaluation: out-of-distribution
|
| 55 |
+
Energy evaluation: out-of-distribution
|
| 56 |
+
Energy+React evaluation: out-of-distribution
|
| 57 |
+
ViM evaluation: out-of-distribution
|
| 58 |
+
Residual evaluation: out-of-distribution
|
| 59 |
+
GradNorm evaluation: out-of-distribution
|
| 60 |
+
Mahalanobis evaluation: out-of-distribution
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
## Benchmark
|
| 64 |
+
For reproduce the results in our paper, please refer to our [repository](https://github.com/dvlab-research/MOOD) for details.
|
configs/beit-base-p16_224px.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='ImageClassifier',
|
| 3 |
+
backbone=dict(
|
| 4 |
+
type='BEiTViT',
|
| 5 |
+
arch='base',
|
| 6 |
+
img_size=224,
|
| 7 |
+
patch_size=16,
|
| 8 |
+
out_type='avg_featmap',
|
| 9 |
+
use_abs_pos_emb=False,
|
| 10 |
+
use_rel_pos_bias=True,
|
| 11 |
+
use_shared_rel_pos_bias=False,
|
| 12 |
+
),
|
| 13 |
+
neck=None,
|
| 14 |
+
head=dict(
|
| 15 |
+
type='LinearClsHead',
|
| 16 |
+
num_classes=1000,
|
| 17 |
+
in_channels=768,
|
| 18 |
+
),
|
| 19 |
+
)
|
data/fc.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1d44fc481b6c5704e55a515594038992c19d64d3040b7338f29653447baa73e
|
| 3 |
+
size 3076201
|
data/imagenet_test.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:36ef3379d4b85893d00baffa94e988a7988d2b448a6b5f37b7b98291e5a7ae88
|
| 3 |
+
size 153600163
|
data/imagenet_train.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed78756744b40626a9d57e5a327dd1397633c66031e9f90b2874551356324e00
|
| 3 |
+
size 614400165
|
imgs/DTD_cracked_0004.jpg
ADDED

|
imgs/framework.png
ADDED

|
imgs/moodv2_table.png
ADDED
|
pretrain/beitv2-base.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:73e11905570316ca4361bd0766f166ae4d36f568067775d265f6cc2fe83a2b31
|
| 3 |
+
size 176847080
|
src/demo.py
ADDED
|
@@ -0,0 +1,305 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import argparse
|
| 3 |
+
import json
|
| 4 |
+
from os.path import basename, splitext
|
| 5 |
+
import os
|
| 6 |
+
import mmengine
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pandas as pd
|
| 9 |
+
import torch
|
| 10 |
+
from numpy.linalg import norm, pinv
|
| 11 |
+
from scipy.special import logsumexp, softmax
|
| 12 |
+
from sklearn import metrics
|
| 13 |
+
from sklearn.covariance import EmpiricalCovariance
|
| 14 |
+
from sklearn.metrics import pairwise_distances_argmin_min
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
import pickle
|
| 17 |
+
from os.path import dirname
|
| 18 |
+
import torchvision as tv
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from mmpretrain.apis import init_model
|
| 21 |
+
|
| 22 |
+
def parse_args():
|
| 23 |
+
parser = argparse.ArgumentParser(description='Detect an image')
|
| 24 |
+
parser.add_argument(
|
| 25 |
+
'--cfg', help='Path to config',
|
| 26 |
+
default='/dataset/jingyaoli/AD/MOOD_/MOODv2/configs/beit-base-p16_224px.py')
|
| 27 |
+
parser.add_argument('--ood_feature',
|
| 28 |
+
default=None, help='Path to ood feature file')
|
| 29 |
+
parser.add_argument(
|
| 30 |
+
'--checkpoint', help='Path to checkpoint',
|
| 31 |
+
default='/dataset/jingyaoli/AD/MOODv2/pretrain/beit-base_3rdparty_in1k_20221114-c0a4df23.pth',)
|
| 32 |
+
parser.add_argument('--img_path', help='Path to image',
|
| 33 |
+
default='/dataset/jingyaoli/AD/MOOD_/MOODv2/imgs/DTD_cracked_0004.jpg')
|
| 34 |
+
parser.add_argument('--fc',
|
| 35 |
+
default='/dataset/jingyaoli/AD/MOODv2/outputs/beit-224px/fc.pkl', help='Path to fc path')
|
| 36 |
+
parser.add_argument('--id_data', default='imagenet', help='id data name')
|
| 37 |
+
parser.add_argument('--id_train_feature',
|
| 38 |
+
default='/dataset/jingyaoli/AD/MOODv2/outputs/beit-224px/imagenet_train.pkl', help='Path to data')
|
| 39 |
+
parser.add_argument('--id_val_feature',
|
| 40 |
+
default='/dataset/jingyaoli/AD/MOODv2/outputs/beit-224px/imagenet_test.pkl', help='Path to output file')
|
| 41 |
+
parser.add_argument('--ood_features',
|
| 42 |
+
default=None, nargs='+', help='Path to ood features')
|
| 43 |
+
parser.add_argument(
|
| 44 |
+
'--methods', nargs='+',
|
| 45 |
+
default=['MSP', 'MaxLogit', 'Energy', 'Energy+React', 'ViM', 'Residual', 'GradNorm', 'Mahalanobis', ], # 'KL-Matching'
|
| 46 |
+
help='methods')
|
| 47 |
+
parser.add_argument(
|
| 48 |
+
'--train_label',
|
| 49 |
+
default='datalists/imagenet2012_train_random_200k.txt',
|
| 50 |
+
help='Path to train labels')
|
| 51 |
+
parser.add_argument(
|
| 52 |
+
'--clip_quantile', default=0.99, help='Clip quantile to react')
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
'--fpr', default=95, help='False Positive Rate')
|
| 55 |
+
return parser.parse_args()
|
| 56 |
+
|
| 57 |
+
def evaluate(method, score_id, score_ood, target_fpr):
|
| 58 |
+
threhold = np.percentile(score_id, 100 - target_fpr)
|
| 59 |
+
if score_ood >= threhold:
|
| 60 |
+
print('\033[94m', method, '\033[0m', 'evaluation:', '\033[92m', 'in-distribution', '\033[0m')
|
| 61 |
+
else:
|
| 62 |
+
print('\033[94m', method, '\033[0m', 'evaluation:', '\033[91m', 'out-of-distribution', '\033[0m')
|
| 63 |
+
|
| 64 |
+
def kl(p, q):
|
| 65 |
+
return np.sum(np.where(p != 0, p * np.log(p / q), 0))
|
| 66 |
+
|
| 67 |
+
def gradnorm(x, w, b, num_cls):
|
| 68 |
+
fc = torch.nn.Linear(*w.shape[::-1])
|
| 69 |
+
fc.weight.data[...] = torch.from_numpy(w)
|
| 70 |
+
fc.bias.data[...] = torch.from_numpy(b)
|
| 71 |
+
fc.cuda()
|
| 72 |
+
|
| 73 |
+
x = torch.from_numpy(x).float().cuda()
|
| 74 |
+
logsoftmax = torch.nn.LogSoftmax(dim=-1).cuda()
|
| 75 |
+
|
| 76 |
+
confs = []
|
| 77 |
+
|
| 78 |
+
for i in tqdm(x, desc='Computing Gradnorm ID/OOD score'):
|
| 79 |
+
targets = torch.ones((1, num_cls)).cuda()
|
| 80 |
+
fc.zero_grad()
|
| 81 |
+
loss = torch.mean(
|
| 82 |
+
torch.sum(-targets * logsoftmax(fc(i[None])), dim=-1))
|
| 83 |
+
loss.backward()
|
| 84 |
+
layer_grad_norm = torch.sum(torch.abs(
|
| 85 |
+
fc.weight.grad.data)).cpu().numpy()
|
| 86 |
+
confs.append(layer_grad_norm)
|
| 87 |
+
|
| 88 |
+
return np.array(confs)
|
| 89 |
+
|
| 90 |
+
def extract_image_feature(args):
|
| 91 |
+
torch.backends.cudnn.benchmark = True
|
| 92 |
+
|
| 93 |
+
print('=> Loading model')
|
| 94 |
+
cfg = mmengine.Config.fromfile(args.cfg)
|
| 95 |
+
model = init_model(cfg, args.checkpoint, 0).cuda().eval()
|
| 96 |
+
|
| 97 |
+
print('=> Loading image')
|
| 98 |
+
if hasattr(cfg.model.backbone, 'img_size'):
|
| 99 |
+
img_size = cfg.model.backbone.img_size
|
| 100 |
+
else:
|
| 101 |
+
img_size = 224
|
| 102 |
+
|
| 103 |
+
transform = tv.transforms.Compose([
|
| 104 |
+
tv.transforms.Resize((img_size, img_size)),
|
| 105 |
+
tv.transforms.ToTensor(),
|
| 106 |
+
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
|
| 107 |
+
])
|
| 108 |
+
|
| 109 |
+
x = transform(Image.open(args.img_path).convert('RGB')).unsqueeze(0)
|
| 110 |
+
|
| 111 |
+
print('=> Extracting feature')
|
| 112 |
+
with torch.no_grad():
|
| 113 |
+
x = x.cuda()
|
| 114 |
+
if cfg.model.backbone.type == 'BEiTPretrainViT':
|
| 115 |
+
# (B, L, C) -> (B, C)
|
| 116 |
+
feat_batch = model.backbone(
|
| 117 |
+
x, mask=None)[0].mean(1)
|
| 118 |
+
elif cfg.model.backbone.type == 'SwinTransformer':
|
| 119 |
+
# (B, C, H, W) -> (B, C)
|
| 120 |
+
feat_batch = model.backbone(x)[0]
|
| 121 |
+
B, C, H, W = feat_batch.shape
|
| 122 |
+
feat_batch = feat_batch.reshape(B, C, -1).mean(-1)
|
| 123 |
+
else:
|
| 124 |
+
# (B, C)
|
| 125 |
+
feat_batch = model.backbone(x)[0]
|
| 126 |
+
assert len(feat_batch.shape) == 2
|
| 127 |
+
feature = feat_batch.cpu().numpy()
|
| 128 |
+
|
| 129 |
+
print(f'Extracted Feature: {feature.shape}')
|
| 130 |
+
return feature
|
| 131 |
+
|
| 132 |
+
def main():
|
| 133 |
+
args = parse_args()
|
| 134 |
+
if args.ood_feature and os.path.exists(args.ood_feature):
|
| 135 |
+
feature_ood = mmengine.load(args.ood_feature)
|
| 136 |
+
else:
|
| 137 |
+
feature_ood = extract_image_feature(args)
|
| 138 |
+
|
| 139 |
+
if os.path.exists(args.fc):
|
| 140 |
+
w, b = mmengine.load(args.fc)
|
| 141 |
+
print(f'{w.shape=}, {b.shape=}')
|
| 142 |
+
num_cls = len(b)
|
| 143 |
+
|
| 144 |
+
train_labels = np.array([
|
| 145 |
+
int(line.rsplit(' ', 1)[-1])
|
| 146 |
+
for line in mmengine.list_from_file(args.train_label)
|
| 147 |
+
], dtype=int)
|
| 148 |
+
|
| 149 |
+
print(f'image path: {args.img_path}')
|
| 150 |
+
|
| 151 |
+
print('=> Loading features')
|
| 152 |
+
feature_id_train = mmengine.load(args.id_train_feature).squeeze()
|
| 153 |
+
feature_id_val = mmengine.load(args.id_val_feature).squeeze()
|
| 154 |
+
|
| 155 |
+
print(f'{feature_id_train.shape=}, {feature_id_val.shape=}')
|
| 156 |
+
|
| 157 |
+
if os.path.exists(args.fc):
|
| 158 |
+
print('=> Computing logits...')
|
| 159 |
+
logit_id_train = feature_id_train @ w.T + b
|
| 160 |
+
logit_id_val = feature_id_val @ w.T + b
|
| 161 |
+
logit_ood = feature_ood @ w.T + b
|
| 162 |
+
|
| 163 |
+
print('=> Computing softmax...')
|
| 164 |
+
softmax_id_train = softmax(logit_id_train, axis=-1)
|
| 165 |
+
softmax_id_val = softmax(logit_id_val, axis=-1)
|
| 166 |
+
softmax_ood = softmax(logit_ood, axis=-1)
|
| 167 |
+
|
| 168 |
+
u = -np.matmul(pinv(w), b)
|
| 169 |
+
|
| 170 |
+
# ---------------------------------------
|
| 171 |
+
method = 'MSP'
|
| 172 |
+
if method in args.methods:
|
| 173 |
+
score_id = softmax_id_val.max(axis=-1)
|
| 174 |
+
score_ood = softmax_ood.max(axis=-1)
|
| 175 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 176 |
+
|
| 177 |
+
# ---------------------------------------
|
| 178 |
+
method = 'MaxLogit'
|
| 179 |
+
if method in args.methods:
|
| 180 |
+
score_id = logit_id_val.max(axis=-1)
|
| 181 |
+
score_ood = logit_ood.max(axis=-1)
|
| 182 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 183 |
+
|
| 184 |
+
# ---------------------------------------
|
| 185 |
+
method = 'Energy'
|
| 186 |
+
if method in args.methods:
|
| 187 |
+
score_id = logsumexp(logit_id_val, axis=-1)
|
| 188 |
+
score_ood = logsumexp(logit_ood, axis=-1)
|
| 189 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 190 |
+
|
| 191 |
+
# ---------------------------------------
|
| 192 |
+
method = 'Energy+React'
|
| 193 |
+
if method in args.methods:
|
| 194 |
+
clip = np.quantile(feature_id_train, args.clip_quantile)
|
| 195 |
+
logit_id_val_clip = np.clip(
|
| 196 |
+
feature_id_val, a_min=None, a_max=clip) @ w.T + b
|
| 197 |
+
score_id = logsumexp(logit_id_val_clip, axis=-1)
|
| 198 |
+
|
| 199 |
+
logit_ood_clip = np.clip(feature_ood, a_min=None, a_max=clip) @ w.T + b
|
| 200 |
+
score_ood = logsumexp(logit_ood_clip, axis=-1)
|
| 201 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 202 |
+
|
| 203 |
+
# ---------------------------------------
|
| 204 |
+
method = 'ViM'
|
| 205 |
+
if method in args.methods:
|
| 206 |
+
if feature_id_val.shape[-1] >= 2048:
|
| 207 |
+
DIM = num_cls
|
| 208 |
+
elif feature_id_val.shape[-1] >= 768:
|
| 209 |
+
DIM = 512
|
| 210 |
+
else:
|
| 211 |
+
DIM = feature_id_val.shape[-1] // 2
|
| 212 |
+
|
| 213 |
+
ec = EmpiricalCovariance(assume_centered=True)
|
| 214 |
+
ec.fit(feature_id_train - u)
|
| 215 |
+
eig_vals, eigen_vectors = np.linalg.eig(ec.covariance_)
|
| 216 |
+
NS = np.ascontiguousarray(
|
| 217 |
+
(eigen_vectors.T[np.argsort(eig_vals * -1)[DIM:]]).T)
|
| 218 |
+
vlogit_id_train = norm(np.matmul(feature_id_train - u, NS), axis=-1)
|
| 219 |
+
alpha = logit_id_train.max(axis=-1).mean() / vlogit_id_train.mean()
|
| 220 |
+
|
| 221 |
+
vlogit_id_val = norm(np.matmul(feature_id_val - u, NS), axis=-1) * alpha
|
| 222 |
+
energy_id_val = logsumexp(logit_id_val, axis=-1)
|
| 223 |
+
score_id = -vlogit_id_val + energy_id_val
|
| 224 |
+
|
| 225 |
+
energy_ood = logsumexp(logit_ood, axis=-1)
|
| 226 |
+
vlogit_ood = norm(np.matmul(feature_ood - u, NS), axis=-1) * alpha
|
| 227 |
+
score_ood = -vlogit_ood + energy_ood
|
| 228 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 229 |
+
|
| 230 |
+
# ---------------------------------------
|
| 231 |
+
method = 'Residual'
|
| 232 |
+
if method in args.methods:
|
| 233 |
+
if feature_id_val.shape[-1] >= 2048:
|
| 234 |
+
DIM = 1000
|
| 235 |
+
elif feature_id_val.shape[-1] >= 768:
|
| 236 |
+
DIM = 512
|
| 237 |
+
else:
|
| 238 |
+
DIM = feature_id_val.shape[-1] // 2
|
| 239 |
+
ec = EmpiricalCovariance(assume_centered=True)
|
| 240 |
+
ec.fit(feature_id_train - u)
|
| 241 |
+
eig_vals, eigen_vectors = np.linalg.eig(ec.covariance_)
|
| 242 |
+
NS = np.ascontiguousarray(
|
| 243 |
+
(eigen_vectors.T[np.argsort(eig_vals * -1)[DIM:]]).T)
|
| 244 |
+
|
| 245 |
+
score_id = -norm(np.matmul(feature_id_val - u, NS), axis=-1)
|
| 246 |
+
|
| 247 |
+
score_ood = -norm(np.matmul(feature_ood - u, NS), axis=-1)
|
| 248 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 249 |
+
|
| 250 |
+
# ---------------------------------------
|
| 251 |
+
method = 'GradNorm'
|
| 252 |
+
if method in args.methods:
|
| 253 |
+
score_ood = gradnorm(feature_ood, w, b, num_cls)
|
| 254 |
+
score_id = gradnorm(feature_id_val, w, b, num_cls)
|
| 255 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 256 |
+
|
| 257 |
+
# ---------------------------------------
|
| 258 |
+
method = 'Mahalanobis'
|
| 259 |
+
if method in args.methods:
|
| 260 |
+
train_means = []
|
| 261 |
+
train_feat_centered = []
|
| 262 |
+
for i in tqdm(range(train_labels.max() + 1), desc='Computing classwise mean feature'):
|
| 263 |
+
fs = feature_id_train[train_labels == i]
|
| 264 |
+
_m = fs.mean(axis=0)
|
| 265 |
+
train_means.append(_m)
|
| 266 |
+
train_feat_centered.extend(fs - _m)
|
| 267 |
+
|
| 268 |
+
ec = EmpiricalCovariance(assume_centered=True)
|
| 269 |
+
ec.fit(np.array(train_feat_centered).astype(np.float64))
|
| 270 |
+
|
| 271 |
+
mean = torch.from_numpy(np.array(train_means)).cuda().float()
|
| 272 |
+
prec = torch.from_numpy(ec.precision_).cuda().float()
|
| 273 |
+
|
| 274 |
+
score_id = -np.array(
|
| 275 |
+
[(((f - mean) @ prec) * (f - mean)).sum(axis=-1).min().cpu().item()
|
| 276 |
+
for f in tqdm(torch.from_numpy(feature_id_val).cuda().float(), desc='Computing Mahalanobis ID score')])
|
| 277 |
+
|
| 278 |
+
score_ood = -np.array([
|
| 279 |
+
(((f - mean) @ prec) * (f - mean)).sum(axis=-1).min().cpu().item()
|
| 280 |
+
for f in tqdm(torch.from_numpy(feature_ood).cuda().float(), desc='Computing Mahalanobis OOD score')
|
| 281 |
+
])
|
| 282 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 283 |
+
|
| 284 |
+
# ---------------------------------------
|
| 285 |
+
method = 'KL-Matching'
|
| 286 |
+
if method in args.methods:
|
| 287 |
+
|
| 288 |
+
pred_labels_train = np.argmax(softmax_id_train, axis=-1)
|
| 289 |
+
mean_softmax_train = []
|
| 290 |
+
for i in tqdm(range(num_cls), desc='Computing classwise mean softmax'):
|
| 291 |
+
mean_softmax = softmax_id_train[pred_labels_train == i]
|
| 292 |
+
if mean_softmax.shape[0] == 0:
|
| 293 |
+
mean_softmax_train.append(np.zeros((num_cls)))
|
| 294 |
+
else:
|
| 295 |
+
mean_softmax_train.append(np.mean(mean_softmax, axis=0))
|
| 296 |
+
|
| 297 |
+
score_id = -pairwise_distances_argmin_min(
|
| 298 |
+
softmax_id_val, np.array(mean_softmax_train), metric=kl)[1]
|
| 299 |
+
|
| 300 |
+
score_ood = -pairwise_distances_argmin_min(
|
| 301 |
+
softmax_ood, np.array(mean_softmax_train), metric=kl)[1]
|
| 302 |
+
result = evaluate(method, score_id, score_ood, args.fpr)
|
| 303 |
+
|
| 304 |
+
if __name__ == '__main__':
|
| 305 |
+
main()
|