---
license: apache-2.0
base_model:
- cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser
- Locutusque/Hyperion-1.5-Mistral-7B
- ibm/merlinite-7b
library_name: transformers
tags:
- mergekit
- merge
- code
model-index:
- name: Magic-Dolphin-7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 65.78
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.61
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 58.01
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 51.18
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=InferenceIllusionist/Magic-Dolphin-7b
name: Open LLM Leaderboard
---
# Magic-Dolphin-7b
 The follow-up to this model has been released, check out the updated benchmarks here for [Excalibur-7b](https://huggingface.co/InferenceIllusionist/Excalibur-7b)
A full suite of GGUF quantizations can be found [here](https://huggingface.co/RichardErkhov/InferenceIllusionist_-_Magic-Dolphin-7b-gguf), courtesy of [RichardErkhov](https://huggingface.co/RichardErkhov/)
A linear merge of:
- [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
- [Locutusque/Hyperion-1.5-Mistral-7B](https://huggingface.co/Locutusque/Hyperion-1.5-Mistral-7B)
- [ibm/merlinite-7b](https://huggingface.co/ibm/merlinite-7b)
These three models showed excellent acumen in technical topics so I wanted to see how they would behave together in a merge. Several different ratios were tested before this release, in the end a higher weighting for merlinite-7b helped smooth out some edges. This model is a test of how LAB tuning is impacted by merges with models leveraging DPO.
### Benchmark Performance
| Name | Avg. | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| Magic-Dolphin-7b | 67.48 | 65.78 | 85.61 | 64.64 | 58.01 | 79.64 | 51.18 |
| dolphin-2.6-mistral-7b-dpo-laser | 67.28 | 66.3 | 85.73 | 63.16 | 61.71 | 79.16 | 47.61 |
| merlinite-7b | 64 | 63.65 | 84.52 | 64.91 | 50.15 | 79.72 | 41.09 |
| Hyperion-1.5-Mistral-7B | 61.43 | 60.49 | 83.64 | 63.57 | 41.78 | 78.61 | 40.49 |
This was my first experiment with merging models so any feedback is greatly appreciated.
Uses Alpaca template.
The follow-up to this model has been released, check out the updated benchmarks here for [Excalibur-7b](https://huggingface.co/InferenceIllusionist/Excalibur-7b)
A full suite of GGUF quantizations can be found [here](https://huggingface.co/RichardErkhov/InferenceIllusionist_-_Magic-Dolphin-7b-gguf), courtesy of [RichardErkhov](https://huggingface.co/RichardErkhov/)
A linear merge of:
- [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
- [Locutusque/Hyperion-1.5-Mistral-7B](https://huggingface.co/Locutusque/Hyperion-1.5-Mistral-7B)
- [ibm/merlinite-7b](https://huggingface.co/ibm/merlinite-7b)
These three models showed excellent acumen in technical topics so I wanted to see how they would behave together in a merge. Several different ratios were tested before this release, in the end a higher weighting for merlinite-7b helped smooth out some edges. This model is a test of how LAB tuning is impacted by merges with models leveraging DPO.
### Benchmark Performance
| Name | Avg. | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| Magic-Dolphin-7b | 67.48 | 65.78 | 85.61 | 64.64 | 58.01 | 79.64 | 51.18 |
| dolphin-2.6-mistral-7b-dpo-laser | 67.28 | 66.3 | 85.73 | 63.16 | 61.71 | 79.16 | 47.61 |
| merlinite-7b | 64 | 63.65 | 84.52 | 64.91 | 50.15 | 79.72 | 41.09 |
| Hyperion-1.5-Mistral-7B | 61.43 | 60.49 | 83.64 | 63.57 | 41.78 | 78.61 | 40.49 |
This was my first experiment with merging models so any feedback is greatly appreciated.
Uses Alpaca template.
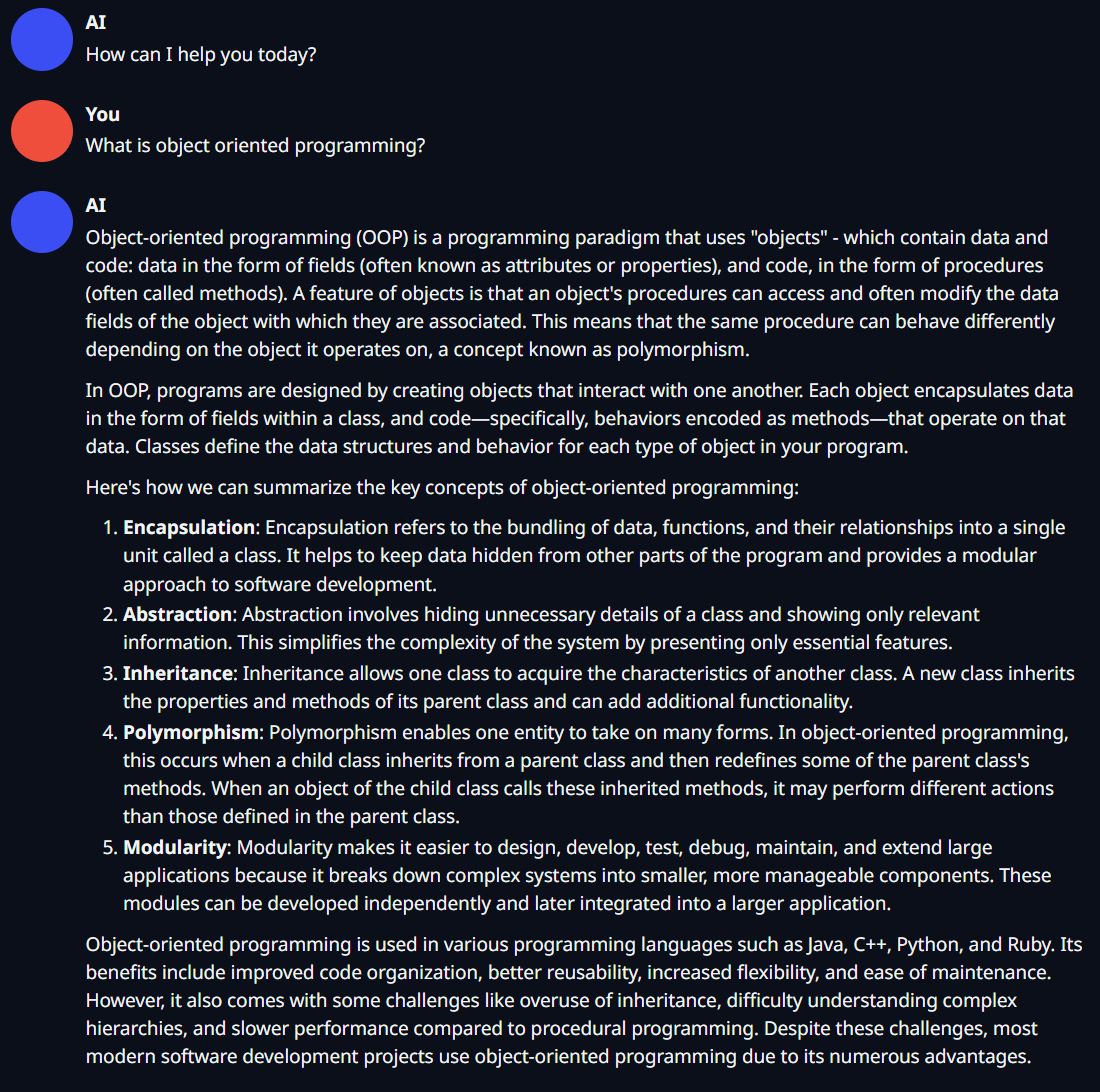
Sample Question
 ## Merge Details
### Merge Method
This model was merged using the [linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
* [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
* [Locutusque/Hyperion-1.5-Mistral-7B](https://huggingface.co/Locutusque/Hyperion-1.5-Mistral-7B)
* [ibm/merlinite-7b](https://huggingface.co/ibm/merlinite-7b)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: models/dolphin-2.6-mistral-7b-dpo-laser
parameters:
weight: 1.0
- model: models/Hyperion-1.5-Mistral-7B
parameters:
weight: 0.3
- model: models/merlinite-7b
parameters:
weight: 0.5
merge_method: linear
dtype: float16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_InferenceIllusionist__Magic-Dolphin-7b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |67.48|
|AI2 Reasoning Challenge (25-Shot)|65.78|
|HellaSwag (10-Shot) |85.61|
|MMLU (5-Shot) |64.64|
|TruthfulQA (0-shot) |58.01|
|Winogrande (5-shot) |79.64|
|GSM8k (5-shot) |51.18|
## Merge Details
### Merge Method
This model was merged using the [linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
* [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
* [Locutusque/Hyperion-1.5-Mistral-7B](https://huggingface.co/Locutusque/Hyperion-1.5-Mistral-7B)
* [ibm/merlinite-7b](https://huggingface.co/ibm/merlinite-7b)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: models/dolphin-2.6-mistral-7b-dpo-laser
parameters:
weight: 1.0
- model: models/Hyperion-1.5-Mistral-7B
parameters:
weight: 0.3
- model: models/merlinite-7b
parameters:
weight: 0.5
merge_method: linear
dtype: float16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_InferenceIllusionist__Magic-Dolphin-7b)
| Metric |Value|
|---------------------------------|----:|
|Avg. |67.48|
|AI2 Reasoning Challenge (25-Shot)|65.78|
|HellaSwag (10-Shot) |85.61|
|MMLU (5-Shot) |64.64|
|TruthfulQA (0-shot) |58.01|
|Winogrande (5-shot) |79.64|
|GSM8k (5-shot) |51.18|