diff --git a/ICL/DAPO/verl-recipe/collabllm/config/agent.yaml b/ICL/DAPO/verl-recipe/collabllm/config/agent.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7a9c328de3bf5b8e548729c76ba5b9a29de35088
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/collabllm/config/agent.yaml
@@ -0,0 +1,2 @@
+- name: collabllm_agent
+ _target_: recipe.collabllm.collabllm_agent_loop.CollabLLMAgentLoop
diff --git a/ICL/DAPO/verl-recipe/collabllm/config/collabllm_interaction_config.yaml b/ICL/DAPO/verl-recipe/collabllm/config/collabllm_interaction_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4002d8a24ee59de1743419f720259b3f84283cdd
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/collabllm/config/collabllm_interaction_config.yaml
@@ -0,0 +1,10 @@
+interaction:
+ - name: "collabllm"
+ class_name: "recipe.collabllm.collabllm_interation.CollabLLMInteraction"
+ config: {
+ "user_model": "gpt-4o-mini",
+ "num_retries": 3,
+ "max_tokens": 512,
+ "temperature": 1.0,
+ "enable_log": True
+ }
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/collabllm/metrics/token_amount.py b/ICL/DAPO/verl-recipe/collabllm/metrics/token_amount.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ffc5d5d8dc41c213205087b2be9dd8dca4ff9e6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/collabllm/metrics/token_amount.py
@@ -0,0 +1,26 @@
+# Copyright 2025 CollabLLM team and/or its affiliates
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+def compute_score(data_source, messages, ground_truth, extra_info, **kwargs):
+ prompt = extra_info["prompt"]
+
+ # Calculate the token penalty based on the length of the prompt
+ future_conv = messages[len(prompt) :]
+
+ # simple length estimation
+ total_tokens = sum(len(m.content.split()) for m in future_conv)
+
+ return total_tokens
diff --git a/ICL/DAPO/verl-recipe/dapo/config/dapo_trainer.yaml b/ICL/DAPO/verl-recipe/dapo/config/dapo_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..47ac00fd6a055d6c22e3facfa855844302345701
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/dapo/config/dapo_trainer.yaml
@@ -0,0 +1,28 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+data:
+ gen_batch_size: ${data.train_batch_size}
+
+reward_model:
+ reward_manager: dapo
+ overlong_buffer:
+ enable: False # We try to avoid forgetting to set enable
+ len: 0
+ penalty_factor: 0.0
+ log: False
+
+algorithm:
+ filter_groups:
+ _target_: verl.trainer.config.FilterGroupsConfig
+ enable: False # We try to avoid forgetting to set enable
+ metric: null # acc / score / seq_reward / seq_final_reward / ...
+ max_num_gen_batches: 0 # Non-positive values mean no upper limit
+
+trainer:
+ project_name: verl-dapo
diff --git a/ICL/DAPO/verl-recipe/deepeyes/configs/deepeyes_multiturn_grpo.yaml b/ICL/DAPO/verl-recipe/deepeyes/configs/deepeyes_multiturn_grpo.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..5978f4dbd14290d9adbfbe4e6fd86887f46ce4d2
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/deepeyes/configs/deepeyes_multiturn_grpo.yaml
@@ -0,0 +1,32 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+data:
+ max_prompt_length: 2048
+ max_response_length: 2048
+ train_batch_size: 256
+ return_raw_chat: True
+ return_multi_modal_inputs: False
+ custom_cls:
+ path: "recipe/deepeyes/deepeyes.py"
+ name: CustomRLHFDataset
+
+actor_rollout_ref:
+ hybrid_engine: True
+ model:
+ custom_chat_template: "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{%- if tools %}{{- '<|im_start|>system\\n' }}{%- if messages[0]['role'] == 'system' %}{%- if messages[0]['content'] is string %}{{- messages[0]['content'] }}{%- else %}{{- messages[0]['content'][0]['text'] }}{%- endif %}{%- else %}{{- 'You are a helpful assistant.' }}{%- endif %}{{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within XML tags:\\n\" }}{%- for tool in tools %}{{- \"\\n\" }}{{- tool | tojson }}{%- endfor %}{{- \"\\n\\n\\nFor each function call, return a json object with function name and arguments within XML tags:\\n\\n{\\\"name\\\": , \\\"arguments\\\": }\\n<|im_end|>\\n\" }}{% for message in messages %}{% if message['role'] != 'system' or loop.first == false %}{%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{%- elif message.role == \"assistant\" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\\n\\n{\"name\": \"' }}{{- tool_call.name }}{{- '\", \"arguments\": ' }}{{- tool_call.arguments | tojson }}{{- '}\\n' }}{%- endfor %}{{- '<|im_end|>\\n' }}{%- elif message.role == \"tool\" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\\n\\n' }}{% if message['content'] is string %}{{ message.content }}{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif content['type'] == 'text' or 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}{% endif %}{{- '\\n' }}{%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}{{- '<|im_end|>\\n' }}{%- endif %}{%- endif %}{% endif %}{% endfor %}{%- else %}{% for message in messages %}{% if loop.first and message['role'] != 'system' %}<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n{% endif %}{%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{%- elif message.role == \"assistant\" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\\n\\n{\"name\": \"' }}{{- tool_call.name }}{{- '\", \"arguments\": ' }}{{- tool_call.arguments | tojson }}{{- '}\\n' }}{%- endfor %}{{- '<|im_end|>\\n' }}{%- elif message.role == \"tool\" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\\n\\n' }}{% if message['content'] is string %}{{ message.content }}{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif content['type'] == 'text' or 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}{% endif %}{{- '\\n' }}{%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}{{- '<|im_end|>\\n' }}{%- endif %}{%- endif %}{% endfor %}{%- endif %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}"
+ rollout:
+ name: sglang
+ multi_turn:
+ enable: True
+ max_assistant_turns: 5
+ tool_config_path: "recipe/deepeyes/config/image_zoom_in_tool_config.yaml"
+
+custom_reward_function:
+ path: "recipe/deepeyes/deepeyes.py"
+ name: compute_score
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/entropy/config/entropy_trainer.yaml b/ICL/DAPO/verl-recipe/entropy/config/entropy_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..969c72946af0989aa592e10e3dbfc1d63bdd084e
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/entropy/config/entropy_trainer.yaml
@@ -0,0 +1,39 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+data:
+ gen_batch_size: ${data.train_batch_size}
+
+reward_model:
+ reward_kwargs:
+ overlong_buffer_cfg: ${reward_model.overlong_buffer}
+ reward_manager: dapo
+ overlong_buffer:
+ enable: False
+ len: 0
+ penalty_factor: 0.0
+ log: False
+
+algorithm:
+ filter_groups:
+ enable: False # We try to avoid forgetting to set enable
+ metric: null # acc / score / seq_reward / seq_final_reward / ...
+ max_num_gen_batches: 0 # Non-positive values mean no upper limit
+
+trainer:
+ project_name: verl-entropy
+
+actor_rollout_ref:
+ actor:
+ policy_loss:
+ loss_mode: "vanilla" # /clip-cov / kl-cov from https://arxiv.org/abs/2505.
+ clip_cov_ratio: 0.0002 # for clip-cov loss
+ clip_cov_lb: 1.0 # for clip-cov loss
+ clip_cov_ub: 5.0 # for clip-cov loss
+ kl_cov_ratio: 0.0002 # for kl-cov loss
+ ppo_kl_coef: 0.1 # for kl-cov loss
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/entropy/reward_score/__init__.py b/ICL/DAPO/verl-recipe/entropy/reward_score/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7224bf3c37113dea3ea9d75b20567078ab0b3501
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/entropy/reward_score/__init__.py
@@ -0,0 +1,38 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# from . import gsm8k, math, prime_math, prime_code
+
+import traceback
+
+from . import entropy_math
+
+
+def _default_compute_score(
+ data_source, solution_str, ground_truth, extra_info=None, sandbox_fusion_url=None, concurrent_semaphore=None
+):
+ try:
+ res = entropy_math.compute_score(solution_str, str(ground_truth))
+ # print(f"data_source: {data_source}")
+ # raise NotImplementedError(f"Reward function is not implemented for {data_source=}")
+
+ if isinstance(res, dict):
+ return res
+ elif isinstance(res, int | float | bool):
+ return float(res)
+ else:
+ return float(res[0])
+ except Exception as e:
+ print(f"[ERROR] Error in process_completion for task : {str(e)}")
+ traceback.print_exc() # 打印完整堆栈
+ raise # 重新抛出异常以便上层捕获
diff --git a/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/__init__.py b/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..57cd99e61659ce3fba5929f163dda50566e30ba3
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/__init__.py
@@ -0,0 +1,1062 @@
+# Copyright 2024 PRIME team and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except Exception in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Provides a math answer grading function with high recall.
+Based on HF math_verify, verl, open reasoner zero, etc.
+"""
+
+import os
+import re
+import signal
+from itertools import islice, zip_longest
+from math import isclose
+from typing import Optional
+
+import sympy
+from latex2sympy2_extended import latex2sympy
+from math_verify import ExprExtractionConfig, LatexExtractionConfig, parse, verify
+from pylatexenc import latex2text
+from sympy import N, simplify
+from sympy.parsing import sympy_parser
+from sympy.parsing.latex import parse_latex
+from sympy.parsing.sympy_parser import parse_expr
+
+"""
+This code is adapted from: Dr. GRPO (https://github.com/sail-sg/understand-r1-zero/blob/main/understand_r1_zero/math_grader.py).
+"""
+
+
+def timeout_ours(timeout_seconds: int = 8):
+ if os.name == "posix":
+ import signal
+
+ def decorator(func):
+ def handler(signum, frame):
+ raise TimeoutError("Operation timed out!")
+
+ def wrapper(*args, **kwargs):
+ old_handler = signal.getsignal(signal.SIGALRM)
+ signal.signal(signal.SIGALRM, handler)
+ signal.alarm(timeout_seconds)
+
+ try:
+ return func(*args, **kwargs)
+ finally:
+ signal.alarm(0)
+ signal.signal(signal.SIGALRM, old_handler)
+
+ return wrapper
+
+ return decorator
+ else:
+ raise NotImplementedError(f"Unsupported OS: {os.name}")
+
+
+# Dan Hendrycks' code
+def mathd_normalize_answer(answer: Optional[str]) -> Optional[str]:
+ if answer is None:
+ return None
+ answer = answer.strip()
+ try:
+ # Remove enclosing `\text{}`.
+ m = re.search(r"^\\text\{(?P.+?)\}$", answer)
+ if m is not None:
+ answer = m.group("text").strip()
+ return _strip_string(answer)
+ except Exception:
+ return answer
+
+
+# units mainly from MathQA
+unit_texts = [
+ "east",
+ "degree",
+ "mph",
+ "kmph",
+ "ft",
+ "m square",
+ " m east",
+ "sq m",
+ "deg",
+ "mile",
+ "q .",
+ "monkey",
+ "prime",
+ "ratio",
+ "profit of rs",
+ "rd",
+ "o",
+ "gm",
+ "p . m",
+ "lb",
+ "tile",
+ "per",
+ "dm",
+ "lt",
+ "gain",
+ "ab",
+ "way",
+ "west",
+ "a .",
+ "b .",
+ "c .",
+ "d .",
+ "e .",
+ "f .",
+ "g .",
+ "h .",
+ "t",
+ "a",
+ "h",
+ "no change",
+ "men",
+ "soldier",
+ "pie",
+ "bc",
+ "excess",
+ "st",
+ "inches",
+ "noon",
+ "percent",
+ "by",
+ "gal",
+ "kmh",
+ "c",
+ "acre",
+ "rise",
+ "a . m",
+ "th",
+ "π r 2",
+ "sq",
+ "mark",
+ "l",
+ "toy",
+ "coin",
+ "sq . m",
+ "gallon",
+ "° f",
+ "profit",
+ "minw",
+ "yr",
+ "women",
+ "feet",
+ "am",
+ "pm",
+ "hr",
+ "cu cm",
+ "square",
+ "v â € ™",
+ "are",
+ "rupee",
+ "rounds",
+ "cubic",
+ "cc",
+ "mtr",
+ "s",
+ "ohm",
+ "number",
+ "kmph",
+ "day",
+ "hour",
+ "minute",
+ "min",
+ "second",
+ "man",
+ "woman",
+ "sec",
+ "cube",
+ "mt",
+ "sq inch",
+ "mp",
+ "∏ cm ³",
+ "hectare",
+ "more",
+ "sec",
+ "unit",
+ "cu . m",
+ "cm 2",
+ "rs .",
+ "rs",
+ "kg",
+ "g",
+ "month",
+ "km",
+ "m",
+ "cm",
+ "mm",
+ "apple",
+ "liter",
+ "loss",
+ "yard",
+ "pure",
+ "year",
+ "increase",
+ "decrease",
+ "d",
+ "less",
+ "Surface",
+ "litre",
+ "pi sq m",
+ "s .",
+ "metre",
+ "meter",
+ "inch",
+]
+
+unit_texts.extend([t + "s" for t in unit_texts])
+
+
+def _strip_string(string):
+ def _fix_fracs(string):
+ substrs = string.split("\\frac")
+ new_str = substrs[0]
+ if len(substrs) > 1:
+ substrs = substrs[1:]
+ for substr in substrs:
+ new_str += "\\frac"
+ if substr[0] == "{":
+ new_str += substr
+ else:
+ try:
+ assert len(substr) >= 2
+ except Exception:
+ return string
+ a = substr[0]
+ b = substr[1]
+ if b != "{":
+ if len(substr) > 2:
+ post_substr = substr[2:]
+ new_str += "{" + a + "}{" + b + "}" + post_substr
+ else:
+ new_str += "{" + a + "}{" + b + "}"
+ else:
+ if len(substr) > 2:
+ post_substr = substr[2:]
+ new_str += "{" + a + "}" + b + post_substr
+ else:
+ new_str += "{" + a + "}" + b
+ string = new_str
+ return string
+
+ def _fix_a_slash_b(string):
+ if len(string.split("/")) != 2:
+ return string
+ a = string.split("/")[0]
+ b = string.split("/")[1]
+ try:
+ a = int(a)
+ b = int(b)
+ assert string == "{}/{}".format(a, b)
+ new_string = "\\frac{" + str(a) + "}{" + str(b) + "}"
+ return new_string
+ except Exception:
+ return string
+
+ def _remove_right_units(string):
+ # "\\text{ " only ever occurs (at least in the val set) when describing units
+ if "\\text{ " in string:
+ splits = string.split("\\text{ ")
+ assert len(splits) == 2
+ return splits[0]
+ else:
+ return string
+
+ def _fix_sqrt(string):
+ if "\\sqrt" not in string:
+ return string
+ splits = string.split("\\sqrt")
+ new_string = splits[0]
+ for split in splits[1:]:
+ if split[0] != "{":
+ a = split[0]
+ new_substr = "\\sqrt{" + a + "}" + split[1:]
+ else:
+ new_substr = "\\sqrt" + split
+ new_string += new_substr
+ return new_string
+
+ # linebreaks
+ string = string.replace("\n", "")
+ # print(string)
+
+ # remove inverse spaces
+ string = string.replace("\\!", "")
+ # print(string)
+
+ # replace \\ with \
+ string = string.replace("\\\\", "\\")
+ # print(string)
+
+ # matrix
+ string = re.sub(r"\\begin\{array\}\{.*?\}", r"\\begin{pmatrix}", string)
+ string = re.sub(r"\\end\{array\}", r"\\end{pmatrix}", string)
+ string = string.replace("bmatrix", "pmatrix")
+
+ # replace tfrac and dfrac with frac
+ string = string.replace("tfrac", "frac")
+ string = string.replace("dfrac", "frac")
+ string = string.replace("\\neq", "\\ne").replace("\\leq", "\\le").replace("\\geq", "\\ge")
+ # print(string)
+
+ # remove \left and \right
+ string = string.replace("\\left", "")
+ string = string.replace("\\right", "")
+ # print(string)
+
+ # Remove unit: miles, dollars if after is not none
+ _string = re.sub(r"\\text{.*?}$", "", string).strip()
+ if _string != "" and _string != string:
+ # print("Warning: unit not removed: '{}' -> '{}'".format(string, _string))
+ string = _string
+
+ # Remove unit: texts
+ for _ in range(2):
+ for unit_text in unit_texts:
+ # use regex, the prefix should be either the start of the string or a non-alphanumeric character
+ # the suffix should be either the end of the string or a non-alphanumeric character
+ _string = re.sub(r"(^|\W)" + unit_text + r"($|\W)", r"\1\2", string)
+ if _string != "":
+ string = _string
+
+ # Remove circ (degrees)
+ string = string.replace("^{\\circ}", "")
+ string = string.replace("^\\circ", "")
+
+ # remove dollar signs
+ string = string.replace("\\$", "")
+
+ # remove units (on the right)
+ string = _remove_right_units(string)
+
+ # remove percentage
+ string = string.replace("\\\\%", "")
+ string = string.replace("\\%", "")
+
+ # " 0." equivalent to " ." and "{0." equivalent to "{." Alternatively, add "0" if "." is the start of the string
+ string = string.replace(" .", " 0.")
+ string = string.replace("{.", "{0.")
+ # if empty, return empty string
+ if len(string) == 0:
+ return string
+ if string[0] == ".":
+ string = "0" + string
+
+ # to consider: get rid of e.g. "k = " or "q = " at beginning
+ if len(string.split("=")) == 2:
+ if len(string.split("=")[0]) <= 2:
+ string = string.split("=")[1]
+
+ # fix sqrt3 --> sqrt{3}
+ string = _fix_sqrt(string)
+
+ # remove spaces
+ string = string.replace(" ", "")
+
+ # \frac1b or \frac12 --> \frac{1}{b} and \frac{1}{2}, etc. Even works with \frac1{72} (but not \frac{72}1).
+ # Also does a/b --> \\frac{a}{b}
+ string = _fix_fracs(string)
+
+ # manually change 0.5 --> \frac{1}{2}
+ if string == "0.5":
+ string = "\\frac{1}{2}"
+
+ # NOTE: X/Y changed to \frac{X}{Y} in dataset, but in simple cases fix in case the model output is X/Y
+ string = _fix_a_slash_b(string)
+
+ return string
+
+
+SUBSTITUTIONS = [
+ ("an ", ""),
+ ("a ", ""),
+ (".$", "$"),
+ ("\\$", ""),
+ (r"\ ", ""),
+ (" ", ""),
+ ("mbox", "text"),
+ (",\\text{and}", ","),
+ ("\\text{and}", ","),
+ ("\\text{m}", "\\text{}"),
+]
+
+
+REMOVED_EXPRESSIONS = [
+ "square",
+ "ways",
+ "integers",
+ "dollars",
+ "mph",
+ "inches",
+ "ft",
+ "hours",
+ "km",
+ "units",
+ "\\ldots",
+ "sue",
+ "points",
+ "feet",
+ "minutes",
+ "digits",
+ "cents",
+ "degrees",
+ "cm",
+ "gm",
+ "pounds",
+ "meters",
+ "meals",
+ "edges",
+ "students",
+ "childrentickets",
+ "multiples",
+ "\\text{s}",
+ "\\text{.}",
+ "\\text{\ns}",
+ "\\text{}^2",
+ "\\text{}^3",
+ "\\text{\n}",
+ "\\text{}",
+ r"\mathrm{th}",
+ r"^\circ",
+ r"^{\circ}",
+ r"\;",
+ r",\!",
+ "{,}",
+ '"',
+ "\\dots",
+]
+
+
+def normalize_final_answer(final_answer: str) -> str:
+ """
+ Normalize a final answer to a quantitative reasoning question.
+ This code comes from https://arxiv.org/pdf/2206.14858.pdf, page18.
+ """
+ # final_answer = final_answer.split("=")[-1]
+
+ for before, after in SUBSTITUTIONS:
+ final_answer = final_answer.replace(before, after)
+ for expr in REMOVED_EXPRESSIONS:
+ final_answer = final_answer.replace(expr, "")
+
+ # Extract answer that is in LaTeX math, is bold,
+ # is surrounded by a box, etc.
+ final_answer = re.sub(r"(.*?)(\$)(.*?)(\$)(.*)", "$\\3$", final_answer)
+ final_answer = re.sub(r"(\\text\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\textbf\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\overline\{)(.*?)(\})", "\\2", final_answer)
+ final_answer = re.sub(r"(\\boxed\{)(.*)(\})", "\\2", final_answer)
+
+ # Normalize shorthand TeX:
+ # \fracab -> \frac{a}{b}
+ # \frac{abc}{bef} -> \frac{abc}{bef}
+ # \fracabc -> \frac{a}{b}c
+ # \sqrta -> \sqrt{a}
+ # \sqrtab -> sqrt{a}b
+ final_answer = re.sub(r"(frac)([^{])(.)", "frac{\\2}{\\3}", final_answer)
+ final_answer = re.sub(r"(sqrt)([^{])", "sqrt{\\2}", final_answer)
+ final_answer = final_answer.replace("$", "")
+
+ # Normalize 100,000 -> 100000
+ if final_answer.replace(",", "").isdigit():
+ final_answer = final_answer.replace(",", "")
+
+ return final_answer
+
+
+def repeatness(s: str):
+ def ranks(seq):
+ index = {v: i for i, v in enumerate(sorted(set(seq)))}
+ return [index[v] for v in seq]
+
+ def suffixArray(s):
+ line = ranks(s)
+ n, k, ans, sa = len(s), 1, line, [0] * len(s)
+ while k < n - 1:
+ line = ranks(list(zip_longest(line, islice(line, k, None), fillvalue=-1)))
+ ans, k = line, k << 1
+ for i, k in enumerate(ans):
+ sa[k] = i
+ return ans, sa
+
+ def lcp(arr, suffixArr, inv_suff):
+ n, ans, k = len(arr), [0] * len(arr), 0
+
+ for i in range(n):
+ if inv_suff[i] == n - 1:
+ k = 0
+ continue
+
+ j = suffixArr[inv_suff[i] + 1]
+ while i + k < n and j + k < n and arr[i + k] == arr[j + k]:
+ k += 1
+
+ ans[inv_suff[i]] = k
+ if k > 0:
+ k -= 1
+
+ return ans
+
+ arr = [ord(i) for i in s]
+ n = len(arr)
+ if n <= 1:
+ return 0
+ c, sa = suffixArray(arr)
+ cnt = sum(lcp(arr, sa, c))
+
+ return (cnt * 2 / (n * (n + 1))) > 0.2
+
+
+class timeout:
+ def __init__(self, seconds=1, error_message="Timeout"):
+ self.seconds = seconds
+ self.error_message = error_message
+
+ def handle_timeout(self, signum, frame):
+ raise TimeoutError(self.error_message)
+
+ def __enter__(self):
+ signal.signal(signal.SIGALRM, self.handle_timeout)
+ signal.alarm(self.seconds)
+
+ def __exit__(self, type, value, traceback):
+ signal.alarm(0)
+
+
+def latex_eval(latex):
+ sym = parse_latex(latex)
+ val = sym.evalf()
+ return sym, val
+
+
+def numeric_equal(prediction: float, reference: float):
+ # Note that relative tolerance has significant impact
+ # on the result of the synthesized GSM-Hard dataset
+ # if reference.is_integer():
+ # return isclose(reference, round(prediction), abs_tol=1e-4)
+ # else:
+ # prediction = round(prediction, len(str(reference).split(".")[-1]))
+ return isclose(reference, prediction, rel_tol=1e-4)
+
+
+@timeout_ours(timeout_seconds=5)
+def symbolic_equal(a, b):
+ def _parse(s):
+ for f in [parse_latex, parse_expr, latex2sympy]:
+ try:
+ return f(s.replace("\\\\", "\\"))
+ except Exception:
+ try:
+ return f(s)
+ except Exception:
+ pass
+ return s
+
+ a = _parse(a)
+ b = _parse(b)
+
+ # direct equal
+ try:
+ if str(a) == str(b) or a == b:
+ return True
+ except Exception:
+ pass
+
+ # simplify equal
+ try:
+ if a.equals(b) or simplify(a - b) == 0:
+ return True
+ except Exception:
+ pass
+
+ # equation equal
+ try:
+ if (abs(a.lhs - a.rhs)).equals(abs(b.lhs - b.rhs)):
+ return True
+ except Exception:
+ pass
+
+ try:
+ if numeric_equal(float(N(a)), float(N(b))):
+ return True
+ except Exception:
+ pass
+
+ # matrix
+ try:
+ # if a and b are matrix
+ if a.shape == b.shape:
+ _a = a.applyfunc(lambda x: round(x, 3))
+ _b = b.applyfunc(lambda x: round(x, 3))
+ if _a.equals(_b):
+ return True
+ except Exception:
+ pass
+
+ return False
+
+
+def _is_latex_equal(str1, str2):
+ try:
+ sym1, val1 = latex_eval(str1)
+ sym2, val2 = latex_eval(str2)
+ if sym1 == sym2 or val1 == val2:
+ return True
+ else:
+ raise ValueError
+ except Exception:
+ try:
+ norm1, norm2 = normalize_final_answer(str1), normalize_final_answer(str2)
+ sym1, val1 = latex_eval(norm1)
+ sym2, val2 = latex_eval(norm2)
+ if sym1 == sym2 or val1 == val2:
+ return True
+ except Exception:
+ return norm1 == norm2
+ return False
+
+
+def is_latex_equal(given_answer: str, ground_truth: str) -> bool:
+ try:
+ with timeout(1):
+ try:
+ if (len(given_answer) > 128 and repeatness(given_answer)) or (
+ len(ground_truth) > 128 and repeatness(ground_truth)
+ ):
+ return False
+ # First conduct normalized string matching.
+ ground_truth_normalized = _normalize(ground_truth)
+ given_normalized = _normalize(given_answer)
+ if ground_truth_normalized is None:
+ return False
+ if ground_truth_normalized == given_normalized:
+ return True
+
+ # Next call math verify.
+ given_answer.replace("\n", "")
+ ground_truth.replace("\n", "")
+ if "$" not in given_answer:
+ given_answer = f"${given_answer}$"
+ if "$" not in ground_truth:
+ ground_truth = f"${ground_truth}$"
+ return verify(
+ parse(
+ ground_truth,
+ extraction_config=(
+ LatexExtractionConfig(boxed_match_priority=0),
+ ExprExtractionConfig(),
+ ),
+ fallback_mode="no_fallback",
+ extraction_mode=["first_match"],
+ parsing_timeout=1,
+ ),
+ parse(
+ given_answer,
+ extraction_config=(
+ LatexExtractionConfig(boxed_match_priority=0),
+ ExprExtractionConfig(),
+ ),
+ fallback_mode="no_fallback",
+ extraction_mode=["first_match"],
+ parsing_timeout=1,
+ ),
+ timeout_seconds=1,
+ )
+ # or symbolic_equal(ground_truth, given_answer)
+ except Exception:
+ return False
+ except TimeoutError:
+ return False
+
+
+def is_value_equal(given_answer: str, ground_truth: str) -> bool:
+ assert ground_truth is not None
+ ground_truth_normalized_mathd = mathd_normalize_answer(ground_truth)
+ given_answer_normalized_mathd = mathd_normalize_answer(given_answer)
+
+ str_equal = ground_truth_normalized_mathd == given_answer_normalized_mathd
+ try:
+ number_equal = float(ground_truth_normalized_mathd) == float(given_answer_normalized_mathd)
+ return str_equal or number_equal
+ except Exception:
+ return str_equal
+
+
+# sympy might hang -- we don't care about trying to be lenient in these cases
+BAD_SUBSTRINGS = ["^{", "^("]
+BAD_REGEXES = [r"\^[0-9]+\^", r"\^[0-9][0-9]+"]
+TUPLE_CHARS = "()[]"
+
+
+def _sympy_parse(expr: str):
+ """Parses an expression with sympy."""
+ py_expr = expr.replace("^", "**")
+ return sympy_parser.parse_expr(
+ py_expr,
+ transformations=(sympy_parser.standard_transformations + (sympy_parser.implicit_multiplication_application,)),
+ )
+
+
+def _parse_latex(expr: str) -> str:
+ """Attempts to parse latex to an expression sympy can read."""
+ expr = expr.replace("\\tfrac", "\\frac")
+ expr = expr.replace("\\dfrac", "\\frac")
+ expr = expr.replace("\\frac", " \\frac") # Play nice with mixed numbers.
+ expr = latex2text.LatexNodes2Text().latex_to_text(expr)
+
+ # Replace the specific characters that this parser uses.
+ expr = expr.replace("√", "sqrt")
+ expr = expr.replace("π", "pi")
+ expr = expr.replace("∞", "inf")
+ expr = expr.replace("∪", "U")
+ expr = expr.replace("·", "*")
+ expr = expr.replace("×", "*")
+
+ return expr.strip()
+
+
+def _is_float(num: str) -> bool:
+ try:
+ float(num)
+ return True
+ except ValueError:
+ return False
+
+
+def _is_int(x: float) -> bool:
+ try:
+ return abs(x - int(round(x))) <= 1e-7
+ except Exception:
+ return False
+
+
+def _is_frac(expr: str) -> bool:
+ return bool(re.search(r"^-?[0-9]+.?/0*[1-9][0-9]*.?$", expr))
+
+
+def _str_is_int(x: str) -> bool:
+ try:
+ x = _strip_properly_formatted_commas(x)
+ x = float(x)
+ return abs(x - int(round(x))) <= 1e-7
+ except Exception:
+ return False
+
+
+def _str_to_int(x: str) -> bool:
+ x = x.replace(",", "")
+ x = float(x)
+ return int(x)
+
+
+def _inject_implicit_mixed_number(step: str):
+ """
+ Automatically make a mixed number evalable
+ e.g. 7 3/4 => 7+3/4
+ """
+ p1 = re.compile("([0-9]) +([0-9])")
+ step = p1.sub("\\1+\\2", step) ## implicit mults
+ return step
+
+
+def _strip_properly_formatted_commas(expr: str):
+ # We want to be careful because we don't want to strip tuple commas
+ p1 = re.compile(r"(\d)(,)(\d\d\d)($|\D)")
+ while True:
+ next_expr = p1.sub("\\1\\3\\4", expr)
+ if next_expr == expr:
+ break
+ expr = next_expr
+ return next_expr
+
+
+def _normalize(expr: str) -> str:
+ """Normalize answer expressions."""
+ if expr is None:
+ return None
+
+ # Remove enclosing `\text{}`.
+ m = re.search(r"^\\text\{(?P.+?)\}$", expr)
+ if m is not None:
+ expr = m.group("text")
+
+ expr = expr.replace("\\%", "%")
+ expr = expr.replace("\\$", "$")
+ expr = expr.replace("$", "")
+ expr = expr.replace("%", "")
+ expr = expr.replace(" or ", " , ")
+ expr = expr.replace(" and ", " , ")
+
+ expr = expr.replace("million", "*10^6")
+ expr = expr.replace("billion", "*10^9")
+ expr = expr.replace("trillion", "*10^12")
+
+ for unit in [
+ "degree",
+ "cm",
+ "centimeter",
+ "meter",
+ "mile",
+ "second",
+ "minute",
+ "hour",
+ "day",
+ "week",
+ "month",
+ "year",
+ "foot",
+ "feet",
+ "inch",
+ "yard",
+ ]:
+ expr = re.sub(f"{unit}(es)?(s)? *(\\^[0-9]+)?", "", expr)
+ expr = re.sub(r"\^ *\\circ", "", expr)
+
+ if len(expr) > 0 and expr[0] == "{" and expr[-1] == "}":
+ expr = expr[1:-1]
+
+ expr = re.sub(",\\\\! *", "", expr)
+ if _is_float(expr) and _is_int(float(expr)):
+ expr = str(int(round(float(expr))))
+ if "\\" in expr:
+ try:
+ expr = _parse_latex(expr)
+ except Exception:
+ pass
+
+ # edge case with mixed numbers and negative signs
+ expr = re.sub("- *", "-", expr)
+
+ expr = _inject_implicit_mixed_number(expr)
+ expr = expr.replace(" ", "")
+
+ # if we somehow still have latex braces here, just drop them
+ expr = expr.replace("{", "")
+ expr = expr.replace("}", "")
+
+ # don't be case sensitive for text answers
+ expr = expr.lower()
+
+ if _str_is_int(expr):
+ expr = str(_str_to_int(expr))
+
+ return expr
+
+
+def count_unknown_letters_in_expr(expr: str):
+ expr = expr.replace("sqrt", "")
+ expr = expr.replace("frac", "")
+ letters_in_expr = set([x for x in expr if x.isalpha()])
+ return len(letters_in_expr)
+
+
+def should_allow_eval(expr: str):
+ # we don't want to try parsing unknown text or functions of more than two variables
+ if count_unknown_letters_in_expr(expr) > 2:
+ return False
+
+ for bad_string in BAD_SUBSTRINGS:
+ if bad_string in expr:
+ return False
+
+ for bad_regex in BAD_REGEXES:
+ if re.search(bad_regex, expr) is not None:
+ return False
+
+ return True
+
+
+@timeout_ours(timeout_seconds=5)
+def are_equal_under_sympy(ground_truth_normalized: str, given_normalized: str):
+ are_equal = False
+ try:
+ expr = f"({ground_truth_normalized})-({given_normalized})"
+ if should_allow_eval(expr):
+ sympy_diff = _sympy_parse(expr)
+ simplified = sympy.simplify(sympy_diff)
+ if simplified == 0:
+ are_equal = True
+ except Exception:
+ pass
+ return are_equal
+
+
+def split_tuple(expr: str):
+ """
+ Split the elements in a tuple/interval, while handling well-formatted commas in large numbers
+ """
+ expr = _strip_properly_formatted_commas(expr)
+ if len(expr) == 0:
+ return []
+ if (
+ len(expr) > 2
+ and expr[0] in TUPLE_CHARS
+ and expr[-1] in TUPLE_CHARS
+ and all([ch not in expr[1:-1] for ch in TUPLE_CHARS])
+ ):
+ elems = [elem.strip() for elem in expr[1:-1].split(",")]
+ else:
+ elems = [expr]
+ return elems
+
+
+def last_boxed_only_string(string):
+ idx = string.rfind("\\boxed")
+ if idx < 0:
+ idx = string.rfind("\\fbox")
+ if idx < 0:
+ return None
+
+ i = idx
+ right_brace_idx = None
+ num_left_braces_open = 0
+ while i < len(string):
+ if string[i] == "{":
+ num_left_braces_open += 1
+ if string[i] == "}":
+ num_left_braces_open -= 1
+ if num_left_braces_open == 0:
+ right_brace_idx = i
+ break
+ i += 1
+ if right_brace_idx is None:
+ retval = None
+ else:
+ retval = string[idx : right_brace_idx + 1]
+
+ return retval
+
+
+def remove_boxed(s):
+ left = "\\boxed{"
+ try:
+ assert s[: len(left)] == left
+ assert s[-1] == "}"
+ return s[len(left) : -1]
+ except Exception:
+ return None
+
+
+def extract_boxed_answer(solution: str) -> str:
+ """Extract the answer from inside a LaTeX \\boxed{} command"""
+ solution = last_boxed_only_string(solution)
+ solution = remove_boxed(solution)
+ return solution
+
+
+def grade_answer_sympy(given_answer: str, ground_truth: str) -> bool:
+ ground_truth_normalized = _normalize(ground_truth)
+ given_normalized = _normalize(given_answer)
+
+ if ground_truth_normalized is None:
+ return False
+
+ if ground_truth_normalized == given_normalized:
+ return True
+
+ if len(given_normalized) == 0:
+ return False
+
+ ground_truth_elems = split_tuple(ground_truth_normalized)
+ given_elems = split_tuple(given_normalized)
+
+ if len(ground_truth_elems) > 1 and (
+ ground_truth_normalized[0] != given_normalized[0] or ground_truth_normalized[-1] != given_normalized[-1]
+ ):
+ is_correct = False
+ elif len(ground_truth_elems) != len(given_elems):
+ is_correct = False
+ else:
+ for ground_truth_elem, given_elem in zip(ground_truth_elems, given_elems, strict=True):
+ if _is_frac(ground_truth_elem) and _is_frac(given_elem):
+ # if fractions aren't reduced, then shouldn't be marked as correct
+ # so, we don't want to allow sympy.simplify in this case
+ is_correct = ground_truth_elem == given_elem
+ elif _str_is_int(ground_truth_elem) != _str_is_int(given_elem):
+ # if the ground truth answer is an integer, we require the given answer to be a strict match
+ # (no sympy.simplify)
+ is_correct = False
+ else:
+ is_correct = are_equal_under_sympy(ground_truth_elem, given_elem)
+ if not is_correct:
+ break
+
+ return is_correct
+
+
+def grade_answer_mathd(given_answer: str, ground_truth: str) -> bool:
+ ground_truth_normalized_mathd = mathd_normalize_answer(ground_truth)
+ given_answer_normalized_mathd = mathd_normalize_answer(given_answer)
+
+ # be at least as lenient as mathd
+ if ground_truth_normalized_mathd == given_answer_normalized_mathd:
+ return True
+ return False
+
+
+def extract_answer(passage: str) -> str:
+ if "\\boxed" in passage:
+ return extract_boxed_answer(passage)
+ return None
+
+
+def grade(model_answer: str, gt_answer: str, fast: bool = True):
+ if "\\boxed" in gt_answer:
+ gt_answer = extract_answer(gt_answer)
+ correct = grade_answer_mathd(model_answer, gt_answer) or grade_answer_sympy(model_answer, gt_answer)
+ if not fast:
+ # This mode further uses math_verify to recall originally false positives.
+ # Will be a bit slower, and sensitive to bad inputs.
+ correct = correct or is_latex_equal(
+ model_answer,
+ gt_answer,
+ )
+ return correct
+
+
+def compute_score(model_response, gt_answer, fast=False):
+ model_answer = extract_answer(model_response)
+ if model_answer is None:
+ return {
+ "score": 0.0,
+ "format_score": 0.0,
+ "acc": False,
+ "extracted_gt": gt_answer,
+ # "extracted_pred": None,
+ }
+ # return 0.0, 0.0 # Cannot even parse anything.
+ is_correct = False
+ if isinstance(gt_answer, float) or isinstance(gt_answer, int):
+ gt_answer = str(gt_answer)
+ if isinstance(gt_answer, str):
+ is_correct = grade(model_answer, gt_answer, fast)
+ elif isinstance(gt_answer, list):
+ is_correct = False
+ for gt in gt_answer:
+ is_correct |= grade(model_answer, gt, fast)
+ if is_correct:
+ return {
+ "score": 1.0,
+ "format_score": 1.0,
+ "acc": True,
+ "extracted_gt": gt_answer,
+ # "extracted_pred": None,
+ }
+ else:
+ return {
+ "score": 0.0,
+ "format_score": 1.0,
+ "acc": False,
+ "extracted_gt": gt_answer,
+ # "extracted_pred": None,
+ }
diff --git a/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/grader.py b/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/grader.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ee09ef99e255828a757b2e6a248ea95da3eed9c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/entropy/reward_score/entropy_math/grader.py
@@ -0,0 +1,384 @@
+# Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Copyright (c) Microsoft Corporation.
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE
+
+# Copyright (c) 2023 OpenAI
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+# Copyright (c) 2021 Dan Hendrycks
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+# Copyright 2024 PRIME team and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This logic is largely copied from the Hendrycks' MATH release (math_equivalence), and borrowed from:
+- https://github.com/microsoft/ToRA/blob/main/src/eval/grader.py
+- https://github.com/microsoft/ProphetNet/tree/master/CRITIC
+- https://github.com/openai/prm800k
+"""
+
+import contextlib
+import math
+import re
+from math import isclose
+
+# sympy related
+from sympy import N, simplify
+from sympy.parsing.latex import parse_latex
+from sympy.parsing.sympy_parser import parse_expr
+
+# verl related
+from verl.utils.py_functional import timeout_limit
+
+
+def is_digit(s):
+ try:
+ if "{,}" in str(s):
+ num = float(str(s).replace("{,}", ""))
+ return True, num
+
+ num = float(str(s).replace(",", ""))
+ return True, num
+ except ValueError:
+ return False, None
+
+
+def normalize(answer, pi) -> str:
+ # checking if answer is $ and removing $ in that case to compare
+ if isinstance(answer, str) and bool(re.match(r"\$\d+(\.\d+)?", answer)):
+ return answer[1:]
+
+ # checking if answer is % or \\% and removing %
+ if isinstance(answer, str) and (
+ bool(re.match(r"^\d+(\.\d+)?%$", answer)) or bool(re.match(r"^\d+(\.\d+)?\\%$", answer))
+ ):
+ return answer.replace("\\%", "").replace("%", "")
+
+ # handle base
+ answer = handle_base(answer)
+
+ # handle pi
+ answer = handle_pi(answer, pi)
+
+ return answer
+
+
+def handle_base(x) -> str:
+ if isinstance(x, str) and "_" in x:
+ # Due to base
+ x = x.split("_")[0]
+ x = float(x)
+ return int(x)
+ return x
+
+
+def handle_pi(string, pi):
+ if isinstance(string, str) and "\\pi" in string:
+ # Find the first occurrence of "\pi"
+ idx = string.find("\\pi")
+
+ # Iterate over the string and find all occurrences of "\pi" with a valid previous character
+ while idx != -1:
+ if idx > 0 and string[idx - 1].isdigit():
+ # Replace "\pi" with "*math.pi" if the previous character is a digit
+ string = string[:idx] + f"*{pi}" + string[idx + 3 :]
+ else:
+ # Replace "\pi" with "1*math.pi" if the previous character is not a digit
+ string = string[:idx] + f"1*{pi}" + string[idx + 3 :]
+
+ # Find the next occurrence of "\pi"
+ idx = string.find("\\pi", idx + 1)
+
+ # Evaluate the expression using eval() function
+ with contextlib.suppress(Exception):
+ string = eval(string)
+
+ return string
+
+
+def math_equal(
+ prediction: bool | float | str,
+ reference: float | str,
+ include_percentage: bool = True,
+ tolerance: float = 1e-4,
+ timeout: float = 10.0,
+ pi: float = math.pi,
+) -> bool:
+ """
+ Exact match of math if and only if:
+ 1. numerical equal: both can convert to float and are equal
+ 2. symbolic equal: both can convert to sympy expression and are equal
+ """
+
+ prediction = normalize(prediction, pi)
+ reference = normalize(reference, pi)
+
+ if isinstance(prediction, str) and len(prediction) > 1000: # handling weird corner-cases
+ prediction = prediction[:1000]
+
+ # 0. string comparison
+ if isinstance(prediction, str) and isinstance(reference, str):
+ if prediction.strip().lower() == reference.strip().lower():
+ return True
+ if prediction.replace(" ", "") == reference.replace(" ", ""):
+ return True
+
+ try: # 1. numerical equal
+ if is_digit(prediction)[0] and is_digit(reference)[0]:
+ prediction = is_digit(prediction)[1]
+ reference = is_digit(reference)[1]
+ # number questions
+ gt_result = [reference / 100, reference, reference * 100] if include_percentage else [reference]
+ for item in gt_result:
+ try:
+ if isclose(item, prediction, rel_tol=tolerance):
+ return True
+ except Exception:
+ continue
+ return False
+ except Exception:
+ pass
+
+ if not prediction and prediction not in [0, False]:
+ return False
+
+ # 2. symbolic equal
+ reference = str(reference).strip()
+ prediction = str(prediction).strip()
+
+ ## deal with [], (), {}
+ prediction = format_intervals(prediction)
+
+ pred_str, ref_str = prediction, reference
+ if (prediction.startswith("[") and prediction.endswith("]") and not reference.startswith("(")) or (
+ prediction.startswith("(") and prediction.endswith(")") and not reference.startswith("[")
+ ):
+ pred_str = pred_str.strip("[]()")
+ ref_str = ref_str.strip("[]()")
+ for s in ["{", "}", "(", ")"]:
+ ref_str = ref_str.replace(s, "")
+ pred_str = pred_str.replace(s, "")
+ if pred_str == ref_str:
+ return True
+
+ ## [a, b] vs. [c, d], return a==c and b==d
+ if (
+ prediction
+ and reference
+ and prediction[0] in "(["
+ and prediction[-1] in ")]"
+ and prediction[0] == reference[0]
+ and prediction[-1] == reference[-1]
+ ):
+ pred_parts = prediction[1:-1].split(",")
+ ref_parts = reference[1:-1].split(",")
+ if len(pred_parts) == len(ref_parts) and all(
+ [
+ math_equal(pred_pt, ref_pt, include_percentage, tolerance)
+ for pred_pt, ref_pt in zip(pred_parts, ref_parts, strict=True)
+ ]
+ ):
+ return True
+
+ if "," in prediction and "," in reference:
+ pred_parts = [item.strip() for item in prediction.split(",")]
+ ref_parts = [item.strip() for item in reference.split(",")]
+
+ if len(pred_parts) == len(ref_parts):
+ return bool(
+ all(
+ [
+ math_equal(pred_parts[i], ref_parts[i], include_percentage, tolerance)
+ for i in range(len(pred_parts))
+ ]
+ )
+ )
+
+ # if we have point == tuple of values
+ if prediction.startswith("Point") and reference[0] == "(" and reference[-1] == ")":
+ pred_parts = prediction[prediction.find("(") + 1 : -1].split(",")
+ ref_parts = reference[1:-1].split(",")
+ if len(pred_parts) == len(ref_parts) and all(
+ [
+ math_equal(pred_pt, ref_pt, include_percentage, tolerance)
+ for pred_pt, ref_pt in zip(pred_parts, ref_parts, strict=True)
+ ]
+ ):
+ return True
+
+ # if reference is a matrix
+ if r"\begin{pmatrix}" in reference and prediction.startswith("Matrix"):
+ try:
+ pred_matrix = parse_expr(prediction)
+ ref_matrix_items = reference.split()[1:-1:2]
+ if len(pred_matrix) == len(ref_matrix_items) and all(
+ [
+ math_equal(pred, ref, include_percentage, tolerance)
+ for ref, pred in zip(ref_matrix_items, pred_matrix, strict=True)
+ ]
+ ):
+ return True
+ except Exception:
+ pass
+ elif r"\begin{pmatrix}" in reference and prediction.startswith("[") and prediction.endswith("]"):
+ if isinstance(eval(prediction), list):
+ try:
+ pred_matrix = eval(prediction)
+ # ref_matrix_items = reference.split()[1:-1:2]
+ ref_matrix_items = (
+ reference.removeprefix(r"\\begin{pmatrix}")
+ .removeprefix(r"\begin{pmatrix}")
+ .removesuffix(r"\\end{pmatrix}")
+ .removesuffix(r"\end{pmatrix}")
+ )
+ ref_matrix_items = ref_matrix_items.split("\\")
+ ref_matrix_items = [row.split("&") if "&" in row else row for row in ref_matrix_items]
+ if len(pred_matrix) == len(ref_matrix_items) and all(
+ [
+ math_equal(pred, ref, include_percentage, tolerance)
+ for ref, pred in zip(ref_matrix_items, pred_matrix, strict=True)
+ ]
+ ):
+ return True
+ except Exception:
+ pass
+
+ return symbolic_equal(prediction, reference, tolerance, timeout)
+
+
+def symbolic_equal(a, b, tolerance, timeout=10.0):
+ def _parse(s):
+ for f in [parse_expr, parse_latex]:
+ try:
+ with timeout_limit(seconds=timeout):
+ return f(s)
+ except TimeoutError:
+ print(f"Parsing timed out for {s}")
+ continue
+ except Exception:
+ continue
+ return s
+
+ a = _parse(a)
+ b = _parse(b)
+
+ try:
+ with timeout_limit(seconds=timeout):
+ if simplify(a - b) == 0:
+ return True
+ except TimeoutError:
+ print(f"Simplification timed out for {a} - {b}")
+ pass
+ except Exception:
+ pass
+
+ try:
+ with timeout_limit(seconds=timeout):
+ if isclose(N(a), N(b), rel_tol=tolerance):
+ return True
+ except TimeoutError:
+ print(f"Numerical evaluation timed out for {a}, {b}")
+ pass
+ except Exception:
+ pass
+ return False
+
+
+def format_intervals(prediction):
+ patterns = {
+ "Interval(": r"^Interval\((.*)\)$",
+ "Interval.Ropen(": r"^Interval\.Ropen\((.*)\)$",
+ "Interval.Lopen(": r"^Interval\.Lopen\((.*)\)$",
+ "Interval.open(": r"^Interval\.open\((.*)\)$",
+ }
+
+ for key, pattern in patterns.items():
+ match = re.match(pattern, prediction)
+ if match:
+ inner_content = match.group(1)
+
+ if key == "Interval(": # Intarval(a, b) == [a, b]
+ return f"[{inner_content}]"
+ elif key == "Interval.Ropen(": # Intarval.Ropen(a, b) == [a, b)
+ return f"[{inner_content})"
+ elif key == "Interval.Lopen(": # Intarval.Lopen(a, b) == (a, b]
+ return f"({inner_content}]"
+ elif key == "Interval.open(": # Intarval.open(a, b) == (a, b)
+ return f"({inner_content})"
+
+ return prediction
diff --git a/ICL/DAPO/verl-recipe/fapo/config/rm_config.yaml b/ICL/DAPO/verl-recipe/fapo/config/rm_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..6c7c9aeeea5beea7361c09c60aa7015cc32d9982
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fapo/config/rm_config.yaml
@@ -0,0 +1,49 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+reward_model:
+ _target_: verl.workers.config.RewardModelConfig
+
+ reward_manager: dapo
+ enable: False
+
+ # Whether to deploy the model to a separate resource pool.
+ enable_resource_pool: False
+ n_gpus_per_node: 0
+ nnodes: 0
+
+ model:
+ type: discriminative
+ path: ~/models/FsfairX-LLaMA3-RM-v0.1
+ external_lib: ${actor_rollout_ref.model.external_lib}
+ trust_remote_code: False
+
+ rollout:
+ _target_: verl.workers.config.RolloutConfig
+ name: ???
+ dtype: bfloat16
+ gpu_memory_utilization: 0.5
+ enforce_eager: true
+ cudagraph_capture_sizes: null
+ free_cache_engine: true
+ data_parallel_size: 1
+ expert_parallel_size: 1
+ tensor_model_parallel_size: 2
+ max_num_batched_tokens: 8192
+ max_model_len: null
+ max_num_seqs: 1024
+ load_format: auto
+ engine_kwargs: {}
+ limit_images: null
+ enable_chunked_prefill: true
+ enable_prefix_caching: true
+ disable_log_stats: true
+ skip_tokenizer_init: true
+
+ prompt_length: 512
+ response_length: 512
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/fapo/run_fapo_genrm_train.sh b/ICL/DAPO/verl-recipe/fapo/run_fapo_genrm_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..0bb8ea1b73d1eb8e932b52ec4e65530ad4b2b9ab
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fapo/run_fapo_genrm_train.sh
@@ -0,0 +1,138 @@
+#!/usr/bin/env bash
+set -xeuo pipefail
+
+project_name='FAPO-Reproduce'
+exp_name='FAPO-GenRM-4B'
+
+adv_estimator=grpo
+
+use_kl_in_reward=False
+kl_coef=0.0
+use_kl_loss=False
+kl_loss_coef=0.0
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+max_prompt_length=$((1024 * 5))
+max_response_length=$((1024 * 8))
+enable_overlong_buffer=True
+overlong_buffer_len=$((1024 * 4))
+overlong_penalty_factor=1.0
+
+loss_agg_mode="token-mean"
+
+train_prompt_bsz=512
+n_resp_per_prompt=16
+train_prompt_mini_bsz=32
+
+# Ray
+RAY_ADDRESS=${RAY_ADDRESS:-"http://localhost:8265"}
+WORKING_DIR=${WORKING_DIR:-"${PWD}"}
+RUNTIME_ENV=${RUNTIME_ENV:-"${WORKING_DIR}/verl/trainer/runtime_env.yaml"}
+NNODES=${NNODES:-4}
+NGPUS_PER_NODE=${NGPUS_PER_NODE:-8}
+# Paths
+RAY_DATA_HOME=${RAY_DATA_HOME:-"${HOME}/verl"}
+# very important! please modify the max_position_embeddings in config.json to 32768 after downloading from huggingface
+MODEL_PATH=${MODEL_PATH:-"${RAY_DATA_HOME}/models/Qwen3-4B-Instruct-2507"}
+CKPTS_DIR=${CKPTS_DIR:-"${RAY_DATA_HOME}/ckpts/${project_name}/${exp_name}"}
+TRAIN_FILE=${TRAIN_FILE:-"${RAY_DATA_HOME}/data/train.parquet"}
+TEST_FILE=${TEST_FILE:-"${RAY_DATA_HOME}/data/test.parquet"}
+
+# Algorithm
+temperature=1.2
+top_p=1.0
+top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
+val_temperature=0.6
+val_top_p=0.95
+
+# Performance Related Parameter
+sp_size=1
+use_dynamic_bsz=True
+actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 2))
+infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 3))
+offload=True
+gen_tp=1
+fsdp_size=8
+
+ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \
+ --address "${RAY_ADDRESS}" \
+ --working-dir "${WORKING_DIR}" \
+ -- python3 -m verl.trainer.main_ppo \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.prompt_key=prompt \
+ data.truncation='left' \
+ data.max_prompt_length=${max_prompt_length} \
+ data.max_response_length=${max_response_length} \
+ data.train_batch_size=${train_prompt_bsz} \
+ data.return_raw_chat=True \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.rollout.n=${n_resp_per_prompt} \
+ algorithm.adv_estimator=${adv_estimator} \
+ algorithm.use_kl_in_reward=${use_kl_in_reward} \
+ algorithm.kl_ctrl.kl_coef=${kl_coef} \
+ actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \
+ actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \
+ actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \
+ actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \
+ actor_rollout_ref.actor.clip_ratio_c=10.0 \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \
+ actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
+ actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
+ actor_rollout_ref.rollout.name=vllm \
+ actor_rollout_ref.rollout.mode=async \
+ actor_rollout_ref.model.path="${MODEL_PATH}" \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.actor.optim.lr_warmup_steps=10 \
+ actor_rollout_ref.actor.optim.weight_decay=0.1 \
+ actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz} \
+ actor_rollout_ref.actor.fsdp_config.param_offload=${offload} \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.actor.grad_clip=1.0 \
+ actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.80 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
+ actor_rollout_ref.rollout.enable_chunked_prefill=True \
+ actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \
+ actor_rollout_ref.rollout.temperature=${temperature} \
+ actor_rollout_ref.rollout.top_p=${top_p} \
+ actor_rollout_ref.rollout.top_k=${top_k} \
+ actor_rollout_ref.rollout.val_kwargs.temperature=${val_temperature} \
+ actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \
+ actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \
+ actor_rollout_ref.rollout.val_kwargs.do_sample=True \
+ actor_rollout_ref.rollout.val_kwargs.n=1 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=${offload} \
+ actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.actor.fsdp_config.fsdp_size=${fsdp_size} \
+ reward_model.reward_manager=dapo \
+ +reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \
+ +reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \
+ +reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \
+ +reward_model.reward_kwargs.overlong_buffer_cfg.log=True \
+ +reward_model.reward_kwargs.max_resp_len=${max_response_length} \
+ custom_reward_function.path=recipe/fapo/reward_fn_genrm.py \
+ custom_reward_function.name=compute_score_fapo_genrm \
+ trainer.logger='["console","wandb"]' \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \
+ trainer.nnodes="${NNODES}" \
+ trainer.val_before_train=True \
+ trainer.test_freq=10 \
+ trainer.save_freq=10 \
+ trainer.total_epochs=10 \
+ trainer.total_training_steps=500 \
+ trainer.default_local_dir="${CKPTS_DIR}" \
+ trainer.resume_mode=auto \
+ trainer.log_val_generations=10
diff --git a/ICL/DAPO/verl-recipe/fapo/runtime_env.yaml b/ICL/DAPO/verl-recipe/fapo/runtime_env.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..13f4b2ba230b892a277026d53a98cb42afc4ae4d
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fapo/runtime_env.yaml
@@ -0,0 +1,5 @@
+working_dir: ./
+excludes: ["/.git/"]
+env_vars:
+ TORCH_NCCL_AVOID_RECORD_STREAMS: "1"
+ VLLM_USE_V1: "1"
diff --git a/ICL/DAPO/verl-recipe/fault_recover/agent_loop/__init__.py b/ICL/DAPO/verl-recipe/fault_recover/agent_loop/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a13fb64445378722f943c8c09b1a82ac3b7fe51b
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fault_recover/agent_loop/__init__.py
@@ -0,0 +1,20 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .fault_recover_agent_loop import FaultRecoverAgentLoopManager
+from .fault_recover_single_turn_agent_loop import FaultRecoverSingleTurnAgentLoop
+
+_ = [FaultRecoverSingleTurnAgentLoop, FaultRecoverAgentLoopManager]
+
+__all__ = ["FaultRecoverSingleTurnAgentLoop", "FaultRecoverAgentLoopManager"]
diff --git a/ICL/DAPO/verl-recipe/fault_recover/agent_loop/fault_recover_single_turn_agent_loop.py b/ICL/DAPO/verl-recipe/fault_recover/agent_loop/fault_recover_single_turn_agent_loop.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd1c49d2bd273c9b836a57187a19b73f8e9ff5ef
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fault_recover/agent_loop/fault_recover_single_turn_agent_loop.py
@@ -0,0 +1,111 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import logging
+import os
+from typing import Any
+from uuid import uuid4
+
+from verl.experimental.agent_loop.agent_loop import AgentLoopBase, AgentLoopOutput, register
+from verl.tools.utils.tool_registry import initialize_tools_from_config
+from verl.utils.profiler import simple_timer
+
+logger = logging.getLogger(__file__)
+logger.setLevel(os.getenv("VERL_LOGGING_LEVEL", "WARN"))
+
+
+@register("fault_recover_single_turn_agent")
+class FaultRecoverSingleTurnAgentLoop(AgentLoopBase):
+ """Naive agent loop that only do single turn chat completion."""
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.prompt_length = self.config.actor_rollout_ref.rollout.prompt_length
+ self.response_length = self.config.actor_rollout_ref.rollout.response_length
+
+ tool_config_path = self.config.data.tool_config_path
+ tool_list = initialize_tools_from_config(tool_config_path) if tool_config_path else []
+ self.tool_schemas = [tool.tool_schema.model_dump(exclude_unset=True, exclude_none=True) for tool in tool_list]
+
+ async def run(self, sampling_params: dict[str, Any], **kwargs) -> AgentLoopOutput:
+ messages = list(kwargs["raw_prompt"])
+
+ # 1. extract images and videos from messages
+ multi_modal_data = await self.process_vision_info(messages)
+ images = multi_modal_data.get("images")
+ videos = multi_modal_data.get("videos")
+
+ # 2. apply chat template and tokenize
+ prompt_ids = await self.apply_chat_template(
+ messages,
+ tools=self.tool_schemas,
+ images=images,
+ videos=videos,
+ )
+
+ # 3. generate sequences
+ metrics = {}
+ request_id = uuid4().hex
+ new_token_ids = kwargs.get("new_token_ids", [])
+ finished = kwargs.get("finished", False)
+ num_preempted = kwargs.get("num_preempted")
+ if finished:
+ with simple_timer("generate_sequences", metrics):
+ response_mask = [1] * len(new_token_ids)
+ if metrics.get("num_preempted") is None:
+ metrics["num_preempted"] = num_preempted if num_preempted is not None else -1
+ return AgentLoopOutput(
+ prompt_ids=prompt_ids,
+ response_ids=new_token_ids[: self.response_length],
+ response_mask=response_mask[: self.response_length],
+ response_logprobs=kwargs.get("log_probs"),
+ routed_experts=kwargs.get("routed_experts"),
+ multi_modal_data=multi_modal_data,
+ num_turns=2,
+ metrics=metrics,
+ )
+
+ origin_prompt_length = len(prompt_ids)
+ prompt_ids += new_token_ids
+
+ with simple_timer("generate_sequences", metrics):
+ output = await self.server_manager.generate(
+ request_id=request_id,
+ prompt_ids=prompt_ids,
+ sampling_params=sampling_params,
+ image_data=images,
+ video_data=videos,
+ global_id=kwargs.get("global_id"),
+ )
+
+ if metrics.get("num_preempted") is None:
+ metrics["num_preempted"] = output.num_preempted if output.num_preempted is not None else -1
+
+ all_token_ids = new_token_ids + output.token_ids
+ response_mask = [1] * len(all_token_ids)
+
+ output = AgentLoopOutput(
+ prompt_ids=prompt_ids[:origin_prompt_length],
+ response_ids=all_token_ids[: self.response_length],
+ response_mask=response_mask[: self.response_length],
+ response_logprobs=output.log_probs[: self.response_length] if output.log_probs else None,
+ routed_experts=(
+ output.routed_experts[: len(prompt_ids) + self.response_length]
+ if output.routed_experts is not None
+ else None
+ ),
+ multi_modal_data=multi_modal_data,
+ num_turns=2,
+ metrics=metrics,
+ )
+ return output
diff --git a/ICL/DAPO/verl-recipe/fault_recover/config/fault_recover_ppo_megatron_trainer.yaml b/ICL/DAPO/verl-recipe/fault_recover/config/fault_recover_ppo_megatron_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0ab6ee434aff2f0868af13707311930a375cd016
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fault_recover/config/fault_recover_ppo_megatron_trainer.yaml
@@ -0,0 +1,265 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+# specify the default per-component configs
+defaults:
+ # @.:
+ # actor_rollout_ref.actor: trainer/config/actor/megatron_actor.yaml
+ - actor@actor_rollout_ref.actor: megatron_actor
+ # data: trainer/config/data/legacy_data.yaml
+ - data@data: legacy_data
+ # (Rule-based) Reward manager config.
+ - reward_manager@reward_manager
+ # load the reference default config, then apply the fields in the current yaml
+ # Reference model config.
+ # Reference model will be enabled when actor.use_kl_loss or/and algorithm.use_kl_in_reward is/are True.
+ - ref@actor_rollout_ref.ref: megatron_ref
+ # Rollout model config.
+ - rollout@actor_rollout_ref.rollout: rollout
+ # Model config.
+ - model@actor_rollout_ref.model: hf_model
+ # Critic model config.
+ - critic@critic: megatron_critic
+ # Reward model config.
+ - reward_model@reward_model: megatron_reward_loop
+ # Rollout correction config.
+ - algorithm@algorithm.rollout_correction: rollout_correction
+ - _self_
+
+actor_rollout_ref:
+ hybrid_engine: True
+
+ nccl_timeout: 600 # seconds, default is 10 minutes for torch, you can set it to a larger value if you have long-running operations like 32B or 72B model using megatron
+
+ model:
+ override_config:
+ model_config: {}
+ moe_config:
+ freeze_moe_router: False
+
+ use_fused_kernels: False # Whether to use custom fused kernels (PostProcessing, for memory efficiency)
+
+ trust_remote_code: False
+
+ # Whether to remove padding tokens in inputs during training
+ use_remove_padding: false
+
+ # LoRA (Low-Rank Adaptation) configuration for parameter-efficient fine-tuning
+ lora:
+ # LoRA type: "lora", "vlm_lora", "canonical_lora", or "dora"
+ type: lora
+
+ # LoRA rank (Dimension of the low-rank projection space.). Set to 0 to disable LoRA
+ rank: 0 # typical values: 8, 16, 32, 64
+
+ # Weighting factor for the low-rank projection. Defaults to 32
+ alpha: 32
+
+ # Dropout rate for the low-rank projection. Defaults to 0.0
+ dropout: 0.0
+
+ # A list of module names to apply LoRA to.
+ # For fused LoRA, Defaults to all linear layers ['linear_qkv', 'linear_proj', 'linear_fc1', 'linear_fc2'].
+ # For canonical LoRA: ["linear_q", "linear_k", "linear_v", "linear_proj", "linear_fc1_up", "linear_fc1_gate", "linear_fc2"]
+ # - 'linear_qkv': Apply LoRA to the fused linear layer used for query, key, and value projections in self-attention
+ # - 'linear_proj': Apply LoRA to the linear layer used for projecting the output of self-attention
+ # - 'linear_fc1': Apply LoRA to the first fully-connected layer in MLP
+ # - 'linear_fc2': Apply LoRA to the second fully-connected layer in MLP
+ # Target modules can also contain wildcards. For example, you can specify
+ # target_modules=['*.layers.0.*.linear_qkv', '*.layers.1.*.linear_qkv'] to add LoRA to only linear_qkv on the first two layers
+ target_modules:
+ - linear_qkv
+ - linear_proj
+ - linear_fc1
+ - linear_fc2
+
+ # A list of module names not to apply LoRa to. It will match all nn.Linear & nn.Linear-adjacent modules whose name
+ # does not match any string in exclude_modules. If used, will require target_modules to be empty list or None
+ exclude_modules: []
+
+ # Position for applying dropout, can be 'pre' (before the low-rank projection) or 'post' (after). Defaults to 'pre'
+ dropout_position: pre
+
+ # Initialization method for the low-rank matrix A. Defaults to "xavier".
+ lora_A_init_method: xavier
+
+ # Initialization method for the low-rank matrix B. Defaults to "zero".
+ lora_B_init_method: zero
+
+ # Enables the experimental All-to-All (A2A) communication strategy. Defaults to False
+ a2a_experimental: False
+
+ # Parameter data type for LoRA weights. Default to null, which will use model's dtype.
+ dtype: null
+
+ # Path to pre-trained LoRA adapter weights (null to train from scratch)
+ adapter_path: null
+
+ # VLMLoRA additionally allows the user to specify whether the language or vision models should be frozen.
+ # For example, a common finetuning workload for multimodal models is to apply adapters to language model and fully
+ # finetune the vision model.
+ freeze_vision_model: True
+ freeze_vision_projection: True
+ freeze_language_model: True
+
+ rollout:
+ quantization: null
+
+ layer_name_map:
+ qkv_layer_name: qkv
+ gate_proj_layer_name: gate_up
+
+custom_reward_function:
+ path: null
+ name: compute_score
+
+algorithm:
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.AlgoConfig
+ gamma: 1.0
+ lam: 1.0
+ adv_estimator: gae
+ norm_adv_by_std_in_grpo: True
+ use_kl_in_reward: False
+ kl_penalty: kl # how to estimate kl divergence
+ kl_ctrl:
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.KLControlConfig
+ type: fixed
+ kl_coef: 0.001
+ horizon: 10000
+ target_kl: 0.1
+ use_pf_ppo: False
+ pf_ppo:
+ reweight_method: pow # ["pow", "max_min", "max_random"]
+ weight_pow: 2.0
+
+trainer:
+ balance_batch: True
+ total_epochs: 30
+ total_training_steps: null
+ project_name: verl_examples
+ experiment_name: gsm8k
+ logger: ["console", "wandb"]
+ log_val_generations: 0
+ nnodes: 1
+ n_gpus_per_node: 8
+ save_freq: -1
+ esi_redundant_time: 0
+
+ # auto: find the last ckpt to resume. If can't find, start from scratch
+ resume_mode: auto # or disable or resume_path if resume_from_path is set
+ resume_from_path: null
+ del_local_ckpt_after_load: False
+ val_before_train: True
+ test_freq: -1
+ critic_warmup: 0
+ default_hdfs_dir: null
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ max_actor_ckpt_to_keep: null
+ max_critic_ckpt_to_keep: null
+ # The timeout for ray worker group to wait for the register center to be ready
+ ray_wait_register_center_timeout: 300
+ device: cuda
+ # Directory for logging rollout data; no dump if null
+ rollout_data_dir: null
+
+ # whether to use legacy worker implementation
+ # mode: "auto", "enable", or "disable"
+ use_legacy_worker_impl: auto
+
+global_profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: null # choose between nsys, npu, torch, torch_memory
+ steps: null # profile steps
+ profile_continuous_steps: False
+ save_path: "outputs/profile" # profiler saving path
+ # Specific tool configs, can use +profiler.tool_config.[tool].xxx to config
+ global_tool_config:
+ # nsys config
+ nsys:
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # controller Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ ## reference https://docs.nvidia.com/nsight-systems/UserGuide/index.html
+ ## reference https://docs.ray.io/en/latest/ray-observability/user-guides/profiling.html
+ controller_nsight_options:
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # worker Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ worker_nsight_options:
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # Profiling only in a range of torch.cuda.profiler.start and stop. Do not change this config.
+ capture-range: "cudaProfilerApi"
+
+ # Specify the desired behavior when a capture range ends.
+ # In verl we need the torch.cuda.profiler.start/stop pair to repeats n times.
+ # valid values are "repeat-shutdown:n" or null.
+ # For normal whole step profiling, n = len(profile_steps);
+ # but for discrete profiling, n = len(profile_steps) * Number(subtasks).
+ # Or you can just leave it null and the program will use n = len(profile_steps) * 6;
+ capture-range-end: null
+
+ # Send signal to the target application's process group. We let the program to exit by itself.
+ kill: none
+
+ # enable memory visualization for debugging memory usage
+ torch_memory:
+ # Maximum number of allocation entries to record
+ trace_alloc_max_entries: 100_000
+ # The depth of the call stack to capture for each allocation
+ stack_depth: 32
+ # 'alloc': records only allocation events || 'state': records memory state changes || 'all': records both.
+ context: "all"
+ # 'python': records Python stacks || 'cpp': records C++ stacks (available in some versions) || 'all': records both.
+ stacks: "all"
+ # devices, record_context etc.
+ kw_args: {}
+
+# configs for TransferQueue
+transfer_queue:
+ # Whether to enable transfer queue
+ enable: False
+
+ray_kwargs:
+ ray_init:
+ num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
+ timeline_json_file: null
+
+fault_manager:
+ enable: False
+ # max retry times for other training phases except rollout (restart ray)
+ max_reschedule_times: 1
+ # max retry times for rollout phase (rebuild worker group)
+ max_rebuild_times: 1
+ # timeout of waiting cluster to be ready for reschedule
+ timeout_reschedule: 300
+ # timeout of waiting cluster to be ready for rebuild
+ timeout_rebuild: 300
+ # check chips usage interval during rollout, set -1 to disable timeout check
+ timeout_task_check_interval: 10
+ # timeout of chips usage being free, set -1 to disable chip check and
+ # 'timeout_task_check_interval' will be the whole time limit of rollout
+ # which means you should increase it
+ timeout_chip_free: 30
+ # file path for token saving
+ tokens_save_file: ./tokens_ckpt/tokens.pt
+ # interval of saving tokens to disk
+ tokens_save_interval: 10
diff --git a/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/__init__.py b/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ce90c5eb352d85c59105c0dc85b5f1dd576f095
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/__init__.py
@@ -0,0 +1,13 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/vllm_async_server.py b/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/vllm_async_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..c643f17943af0c2732b287faad27af2cfdfb05a6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/fault_recover/vllm_rollout/vllm_async_server.py
@@ -0,0 +1,104 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import inspect
+import logging
+from typing import Any
+
+import ray
+import vllm
+from packaging import version
+from vllm.engine.arg_utils import AsyncEngineArgs
+from vllm.entrypoints.openai.api_server import (
+ build_app,
+ init_app_state,
+)
+from vllm.usage.usage_lib import UsageContext
+
+from verl.workers.config import HFModelConfig, RolloutConfig
+from verl.workers.rollout.utils import run_unvicorn
+from verl.workers.rollout.vllm_rollout.vllm_async_server import vLLMHttpServer, vLLMReplica
+
+_VLLM_VERSION = version.parse(vllm.__version__)
+
+logger = logging.getLogger(__file__)
+logger.setLevel(logging.INFO)
+
+
+class FaultRecovervLLMHttpServer(vLLMHttpServer):
+ """vLLM http server in single node, this is equivalent to launch server with command line:
+ ```
+ vllm serve --tensor-parallel-size=8 ...
+ ```
+ """
+
+ async def run_server(self, args: argparse.Namespace):
+ from recipe.fault_recover.async_llm import AsyncFaultRecoverLLM as AsyncLLM
+
+ engine_args = AsyncEngineArgs.from_cli_args(args)
+ usage_context = UsageContext.OPENAI_API_SERVER
+ vllm_config = engine_args.create_engine_config(usage_context=usage_context)
+ vllm_config.parallel_config.data_parallel_master_port = self._dp_master_port
+
+ fn_args = set(dict(inspect.signature(AsyncLLM.from_vllm_config).parameters).keys())
+ kwargs = {}
+ if "enable_log_requests" in fn_args:
+ kwargs["enable_log_requests"] = engine_args.enable_log_requests
+ if "disable_log_stats" in fn_args:
+ kwargs["disable_log_stats"] = engine_args.disable_log_stats
+
+ engine_client = AsyncLLM.from_vllm_config(vllm_config=vllm_config, usage_context=usage_context, **kwargs)
+
+ # Don't keep the dummy data in memory
+ await engine_client.reset_mm_cache()
+ await engine_client.collective_rpc(
+ method="monkey_patch_model", kwargs={"vocab_size": len(self.model_config.tokenizer)}
+ )
+
+ build_app_sig = inspect.signature(build_app)
+ supported_tasks: tuple[Any, ...] = ()
+ if "supported_tasks" in build_app_sig.parameters:
+ supported_tasks = await engine_client.get_supported_tasks()
+ app = build_app(args, supported_tasks)
+ else:
+ app = build_app(args)
+
+ init_app_sig = inspect.signature(init_app_state)
+ if "vllm_config" in init_app_sig.parameters:
+ await init_app_state(engine_client, vllm_config, app.state, args)
+ elif "supported_tasks" in init_app_sig.parameters:
+ await init_app_state(engine_client, app.state, args, supported_tasks)
+ else:
+ await init_app_state(engine_client, app.state, args)
+ if self.replica_rank == 0 and self.node_rank == 0:
+ logger.info(f"Initializing a V1 LLM engine with config: {vllm_config}")
+
+ self.engine = engine_client
+ self._server_port, self._server_task = await run_unvicorn(app, args, self._server_address)
+
+ def clear_engine(self):
+ self.engine.shutdown()
+
+
+class FaultRecovervLLMReplica(vLLMReplica):
+ def __init__(
+ self,
+ replica_rank: int,
+ config: RolloutConfig,
+ model_config: HFModelConfig,
+ gpus_per_node: int = 8,
+ is_reward_model: bool = False,
+ ):
+ super().__init__(replica_rank, config, model_config, gpus_per_node, is_reward_model)
+ self.server_class = ray.remote(FaultRecovervLLMHttpServer)
diff --git a/ICL/DAPO/verl-recipe/flowrl/config/flowrl_trainer.yaml b/ICL/DAPO/verl-recipe/flowrl/config/flowrl_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a52601288c5e64996734894b00ec51c151c5a2fe
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/flowrl/config/flowrl_trainer.yaml
@@ -0,0 +1,33 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+data:
+ gen_batch_size: ${data.train_batch_size}
+
+reward_model:
+ reward_manager: dapo
+ overlong_buffer:
+ enable: False # We try to avoid forgetting to set enable
+ len: 0
+ penalty_factor: 0.0
+ log: False
+
+algorithm:
+ # _target_: verl.trainer.config.AlgoConfig
+
+ # # FlowRL trajectory balance coefficient (β)
+ # tb_coef: 15.0
+
+ filter_groups:
+ _target_: verl.trainer.config.FilterGroupsConfig
+ enable: False # We try to avoid forgetting to set enable
+ metric: null # acc / score / seq_reward / seq_final_reward / ...
+ max_num_gen_batches: 0 # Non-positive values mean no upper limit
+
+trainer:
+ project_name: verl-flowrl
diff --git a/ICL/DAPO/verl-recipe/flowrl/figures/file.svg b/ICL/DAPO/verl-recipe/flowrl/figures/file.svg
new file mode 100644
index 0000000000000000000000000000000000000000..1c93dcc9f816d2d6a997d6393503e544cfa3ca46
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/flowrl/figures/file.svg
@@ -0,0 +1,135 @@
+
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/flowrl/figures/flowrl.pdf b/ICL/DAPO/verl-recipe/flowrl/figures/flowrl.pdf
new file mode 100644
index 0000000000000000000000000000000000000000..07cc7df2a393a3b5a7e3f1340102ee24d94e01b2
Binary files /dev/null and b/ICL/DAPO/verl-recipe/flowrl/figures/flowrl.pdf differ
diff --git a/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_data.sh b/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_data.sh
new file mode 100644
index 0000000000000000000000000000000000000000..d0f7f32bd1133ec62f2f626407c470836943fa2b
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_data.sh
@@ -0,0 +1,43 @@
+#!/usr/bin/env bash
+set -uxo pipefail
+
+export DOWNLOAD_DIR=${DOWNLOAD_DIR:-"downloads"}
+export DATA_DIR=${DATA_DIR:-"${DOWNLOAD_DIR}/data"}
+
+# Create final data directory
+mkdir -p "${DATA_DIR}"
+
+# Download DAPO-Math-17k dataset
+DATASET_NAME_TRAIN="BytedTsinghua-SIA/DAPO-Math-17k"
+echo "Downloading ${DATASET_NAME_TRAIN}..."
+huggingface-cli download $DATASET_NAME_TRAIN \
+ --repo-type dataset \
+ --resume-download \
+ --local-dir ${DOWNLOAD_DIR}/${DATASET_NAME_TRAIN} \
+ --local-dir-use-symlinks False
+
+# Move the parquet file to data directory
+if [ -f "${DOWNLOAD_DIR}/${DATASET_NAME_TRAIN}/data/dapo-math-17k.parquet" ]; then
+ mv "${DOWNLOAD_DIR}/${DATASET_NAME_TRAIN}/data/dapo-math-17k.parquet" "${DATA_DIR}/dapo-math-17k.parquet"
+ echo "✓ Moved dapo-math-17k.parquet to ${DATA_DIR}/"
+fi
+
+# Download AIME-2024 dataset
+DATASET_NAME_TEST="BytedTsinghua-SIA/AIME-2024"
+echo "Downloading ${DATASET_NAME_TEST}..."
+huggingface-cli download $DATASET_NAME_TEST \
+ --repo-type dataset \
+ --resume-download \
+ --local-dir ${DOWNLOAD_DIR}/${DATASET_NAME_TEST} \
+ --local-dir-use-symlinks False
+
+# Move the parquet file to data directory
+if [ -f "${DOWNLOAD_DIR}/${DATASET_NAME_TEST}/data/aime-2024.parquet" ]; then
+ mv "${DOWNLOAD_DIR}/${DATASET_NAME_TEST}/data/aime-2024.parquet" "${DATA_DIR}/aime-2024.parquet"
+ echo "✓ Moved aime-2024.parquet to ${DATA_DIR}/"
+fi
+
+echo ""
+echo "Data preparation completed!"
+echo "Training file: ${DATA_DIR}/dapo-math-17k.parquet"
+echo "Test file: ${DATA_DIR}/aime-2024.parquet"
diff --git a/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_model.sh b/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_model.sh
new file mode 100644
index 0000000000000000000000000000000000000000..39380b62224ad3d9dfbc9505c2bea8bf2f404562
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/flowrl/prepare/prepare_model.sh
@@ -0,0 +1,10 @@
+#!/bin/bash
+
+MODEL_NAME=Qwen/Qwen2.5-7B
+
+huggingface-cli download $MODEL_NAME \
+ --repo-type model \
+ --resume-download \
+ --local-dir downloads/models/$MODEL_NAME \
+ --local-dir-use-symlinks False \
+ --exclude *.pth
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/gkd/megatron/megatron_utils.py b/ICL/DAPO/verl-recipe/gkd/megatron/megatron_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d057fa5e130898e00be1a4cb97066c7d0ede9e39
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/gkd/megatron/megatron_utils.py
@@ -0,0 +1,200 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved.
+# Copyright 2023-2024 SGLang Team
+# Copyright 2025 ModelBest Inc. and/or its affiliates
+# Copyright 2025 Individual Contributor: Brilliant Hanabi, furunding
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import torch
+from megatron.core import parallel_state as mpu
+
+import verl.utils.megatron.tensor_parallel as tp_utils
+from verl.utils.device import get_device_id
+from verl.utils.megatron_utils import default_tp_concat_fn, unwrap_model
+from verl.utils.model import normalize_model_name
+
+
+def per_tensor_generator(
+ actor_module,
+ model_config,
+ weight_converter,
+ transformer_config,
+ layer_name_mapping,
+ convert_qkv_gate_up_by_simple_split=True,
+):
+ tp_rank = mpu.get_tensor_model_parallel_rank()
+ pp_rank = mpu.get_pipeline_model_parallel_rank()
+ ep_rank = mpu.get_expert_model_parallel_rank()
+ etp_rank = mpu.get_expert_tensor_parallel_rank()
+ ep_size = mpu.get_expert_model_parallel_world_size()
+ etp_size = mpu.get_expert_tensor_parallel_world_size()
+ ep_group = mpu.get_expert_model_parallel_group()
+ etp_group = mpu.get_expert_tensor_parallel_group()
+ vpp_size = len(actor_module)
+ tp_group = mpu.get_tensor_model_parallel_group()
+ tp_size = torch.distributed.get_world_size(group=tp_group)
+
+ def tensor_generator():
+ for scan_vpp_idx in range(vpp_size):
+ existing_keys = set()
+ model = unwrap_model(actor_module[scan_vpp_idx])
+ for name, param in model.named_parameters():
+ existing_keys.add(name)
+ yield name, param
+ # note
+ # there is a bug in megatron GPTModel
+ # decoder.layers[n].mlp.router.expert_bias" in GPTModel is not registered in named_parameter, but in
+ # state_dict(). for now we patch it by adding those keys to extra_keys.
+ extra_keys = [x for x in model.state_dict().keys() if "_extra_state" not in x and x not in existing_keys]
+ for name in extra_keys:
+ yield name, model.state_dict()[name].to(get_device_id())
+
+ def get_tensor_spec(tensor):
+ shape = tensor.shape
+ dtype = tensor.dtype
+ tensor_parallel = getattr(tensor, "tensor_model_parallel", None)
+ partition_dim = getattr(tensor, "partition_dim", None)
+ tensor_spec = (shape, dtype, tensor_parallel, partition_dim)
+ return tensor_spec
+
+ def make_tensor(tensor_spec):
+ tensor = torch.empty(size=tensor_spec[0], dtype=tensor_spec[1], device=get_device_id())
+ if tensor_spec[2] is not None:
+ tensor.tensor_model_parallel = tensor_spec[2]
+ if tensor_spec[3] is not None:
+ tensor.partition_dim = tensor_spec[3]
+ return tensor
+
+ # we need first make all rank get full model information
+ meta_info = []
+ for scan_vpp_idx in range(vpp_size):
+ existing_keys = set()
+ model = unwrap_model(actor_module[scan_vpp_idx])
+ for idx, (name, param) in enumerate(model.named_parameters()):
+ existing_keys.add(name)
+ meta_info.append((pp_rank, scan_vpp_idx, idx, name, get_tensor_spec(param)))
+ extra_keys = [
+ (x, y) for x, y in model.state_dict().items() if "_extra_state" not in x and x not in existing_keys
+ ]
+ for name, param in extra_keys:
+ meta_info.append((pp_rank, scan_vpp_idx, idx, name, get_tensor_spec(param)))
+
+ obj_spec_output = [None] * mpu.get_pipeline_model_parallel_world_size()
+ torch.distributed.all_gather_object(
+ object_list=obj_spec_output, obj=meta_info, group=mpu.get_pipeline_model_parallel_group()
+ )
+ layer_list_meta = [item for sublist in obj_spec_output for item in sublist]
+
+ gen_func = tensor_generator()
+
+ # lazy load tensor for full model
+ for cur_pp_rank, scan_vpp_idx, idx, name, tensor_spec in layer_list_meta:
+ # fp.write(f"DEBUG: ({cur_pp_rank}, {scan_vpp_idx}, {name})\n")
+ if model_config.tie_word_embeddings and ("output_layers" in name):
+ import warnings
+
+ warnings.warn(
+ "Current model sharing word and embedding weights, skip output layer conversion", stacklevel=2
+ )
+ continue
+
+ cur_name = normalize_model_name(name, cur_pp_rank, scan_vpp_idx, transformer_config)
+
+ if cur_pp_rank == pp_rank:
+ _, cur_tensor = next(gen_func)
+
+ else:
+ cur_tensor = None
+
+ if pp_rank == 0:
+ if cur_tensor is None:
+ cur_tensor = make_tensor(tensor_spec)
+ torch.distributed.recv(cur_tensor, group=mpu.get_pipeline_model_parallel_group(), group_src=cur_pp_rank)
+ else:
+ if cur_tensor is None:
+ cur_tensor = make_tensor(tensor_spec)
+ else:
+ torch.distributed.send(cur_tensor, group=mpu.get_pipeline_model_parallel_group(), group_dst=0)
+
+ # (xya): this is a hack to fix the name of the parameters
+ while cur_name.startswith("module."):
+ cur_name = cur_name[len("module.") :]
+
+ def gather(tensor, gather_list, group, group_dst, group_rank):
+ if group_rank == group_dst:
+ torch.distributed.gather(tensor, gather_list, group=group, group_dst=group_dst)
+ else:
+ torch.distributed.gather(tensor, None, group=group, group_dst=group_dst)
+
+ # EP
+ if ".mlp.experts.linear_fc" in cur_name and ep_size > 1:
+ num_experts = weight_converter.mcore_config.num_moe_experts
+ num_experts_per_rank = num_experts // ep_size
+ infer_params = [torch.empty_like(cur_tensor) for _ in range(ep_size)]
+ gather(cur_tensor, infer_params, group=ep_group, group_dst=0, group_rank=ep_rank)
+
+ name_prefix, local_expert_id = cur_name.split(".weight")
+ local_expert_id = int(local_expert_id)
+ global_expert_ids = [num_experts_per_rank * _ep_rank + local_expert_id for _ep_rank in range(ep_size)]
+ global_expert_names = [f"{name_prefix}.weight{expert_id}" for expert_id in global_expert_ids]
+
+ for name, param in zip(global_expert_names, infer_params, strict=True):
+ if etp_size > 1:
+ # gather etp
+ etp_params = [torch.empty_like(param) for _ in range(etp_size)]
+ gather(param, etp_params, group=etp_group, group_dst=0, group_rank=etp_rank)
+ params = etp_params
+ else:
+ params = [param]
+
+ merge_params = default_tp_concat_fn(
+ layer_name_mapping,
+ name,
+ cur_tensor,
+ params,
+ model_config,
+ weight_converter.hf_config,
+ convert_qkv_gate_up_by_simple_split,
+ )
+ if not isinstance(merge_params, list):
+ merge_params = [merge_params]
+ converted_names, converted_params = weight_converter.convert_param(name, merge_params)
+
+ yield from zip(converted_names, [param.detach() for param in converted_params], strict=True)
+
+ continue
+ # tp all gather
+ if tp_utils.is_tensor_parallel_param(cur_tensor):
+ # allocate a new tensor with proper size
+ if tp_size <= 1:
+ infer_params = [cur_tensor]
+ else:
+ infer_params = [torch.empty_like(cur_tensor) for _ in range(tp_size)]
+ gather(cur_tensor, infer_params, tp_group, group_dst=0, group_rank=tp_rank)
+ infer_params = default_tp_concat_fn(
+ layer_name_mapping,
+ cur_name,
+ cur_tensor,
+ infer_params,
+ model_config,
+ weight_converter.hf_config,
+ convert_qkv_gate_up_by_simple_split,
+ )
+ else:
+ infer_params = cur_tensor
+
+ if not isinstance(infer_params, list):
+ infer_params = [infer_params]
+ converted_names, converted_params = weight_converter.convert_param(cur_name, infer_params)
+
+ yield from zip(converted_names, [param.detach() for param in converted_params], strict=True)
diff --git a/ICL/DAPO/verl-recipe/gvpo/config/gvpo_trainer.yaml b/ICL/DAPO/verl-recipe/gvpo/config/gvpo_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..841fefc40b5fab7b013139d7adffc6bb5b8b0282
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/gvpo/config/gvpo_trainer.yaml
@@ -0,0 +1,15 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+actor_rollout_ref:
+ actor:
+ _target_: recipe.gvpo.gvpo_actor_config.FSDPActorConfig
+ gvpo_beta: 0.1
+
+trainer:
+ project_name: gvpo
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/README.md b/ICL/DAPO/verl-recipe/langgraph_agent/example/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4540c51b4e9382afbefe9651f6754a6037f292ee
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/README.md
@@ -0,0 +1,138 @@
+# MathExpression: LangGraph Agent Example
+
+MathExpression is a tiny example to demonstrate multi-turn rollout with [LangGraph ReactAgent](https://langchain-ai.github.io/langgraph/agents/overview/).
+
+### Define react agent with tool
+Firstly, to force ReactAgent to evaluate math expression by tool, we define a special operand `@`:
+```python
+@tool(parse_docstring=True)
+def calculate(a: int, b: int, operand: str) -> int:
+ """
+ Compute the results using operand with two integers
+
+ Args:
+ a: the first operand
+ b: the second operand
+ operand: '+' or '-' or '*' or '@'
+ """
+ assert operand in ["+", "-", "*", "@"], f"unknown operand {operand}"
+ if operand == "@":
+ return 3 * a - 2 * b
+ return eval(f"{a} {operand} {b}")
+```
+
+Without calling `calculate`, ReactAgent is impossible to evaluate math expression correctly.
+
+Then, we can equip ReactAgent with `calculate` tool:
+```python
+class MathExpressionReactAgentLoop(ReactAgentLoop):
+ @classmethod
+ def init_class(cls, config, tokenizer):
+ cls.tools = [calculate]
+ super().init_class(config, tokenizer)
+```
+
+We can define agent loop config in yaml file, which will be used by AgentLoopWorker to dynamic load custom AgentLoop class.
+```yaml
+- name: math_expression
+ _target_: recipe.langgraph_agent.example.math_expression.MathExpressionReactAgentLoop
+```
+
+### Prepare dataset
+Now, let's prepare two small datasets for training and evaluation:
+```bash
+python recipe/langgraph_agent/example/create_dataset.py
+```
+
+- Parameters: `--train_size` (default: 5000), `--test_size` (default: 500), `--output_dir` (default: `data/math_expression_tool`).
+- Example with custom sizes/output:
+```bash
+python recipe/langgraph_agent/example/create_dataset.py \
+ --train_size 10000 \
+ --test_size 1000 \
+ --output_dir data/math_expression_tool
+```
+
+Note that dataset should contain a column `agent_name` with `math_expression`, which is used by `AgentLoopWorker` to select the
+agent loop class.
+| prompt | reward_model | agent_name |
+|--------------------------------------|------------------------------|-----------------|
+| [{'role': 'user', 'content': '...'}] | {'ground_truth': '-10', ...} | math_expression |
+| [{'role': 'user', 'content': '...'}] | {'ground_truth': '-10', ...} | math_expression |
+
+Generated math expressions are like below, requiring model to call `calculate` multiple times to solve sub expressions.
+```
+(2 @ (8 @ 8 @ 5 @ 5 @ 3) @ 6 @ (1 @ 4 @ 4 @ 4) @ 2) @ 6
+(4.6 @ (9.05 @ 4.0) @ 8.3 @ 1.21) @ 8.6
+9 @ 4
+((2 @ 2) @ (3 @ 3)) @ 4
+```
+
+### Training
+Hook all these up and start training:
+```bash
+bash recipe/langgraph_agent/example/run_qwen2.5_3b.sh 2>&1 | tee train.log
+```
+
+To submit on a SLURM cluster (the script contains SBATCH headers):
+```bash
+sbatch recipe/langgraph_agent/example/run_qwen2.5_3b.sh
+```
+
+**Note on `GPUS_PER_NODE` and `NNODES`:**
+
+- `GPUS_PER_NODE`: GPUs per node.
+ Detection order: `SLURM_GPUS_ON_NODE` (if set) → `GPUS_PER_NODE` → `2`.
+- `NNODES`: number of nodes.
+ Detection order: `SLURM_JOB_NUM_NODES` (if set) → `NNODES` → `1`.
+- Total GPUs = `GPUS_PER_NODE × NNODES` (must be ≥ 2).
+
+Local override (no `SLURM_*` set):
+```bash
+GPUS_PER_NODE=4 NNODES=2 bash recipe/langgraph_agent/example/run_qwen2.5_3b.sh
+```
+
+After total 39 steps, model should achieve 100% accuray on test dataset:
+- val-aux/lighteval/MATH/reward: 1.0
+- val-aux/num_turns/mean: 9.0, average number of messages include assistant and tool turns.
+
+We can see model can solve math expression by calling `calculate` tool:
+```
+system
+You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
+user
+We define a new math operator @, where you can only call an external tool to compute. Please put your final answer inside \boxed{} only in the last turn. Now answer the following questions:
+Compute 5 @ (3 @ 6 @ 8)
+assistant
+Sure, let's break this down step by step. We need to compute the expression \(5 @ (3 @ 6 @ 8)\). First, we need to compute the inner expression \(3 @ 6 @ 8\).
+
+Let's compute \(3 @ 6\) first using the external tool.
+
+{"name": "calculate", "arguments": {"a": 3, "b": 6, "operand": "@"}}
+user
+
+-3
+
+assistant
+We have computed that \(3 @ 6 = -3\). Now we need to compute \(-3 @ 8\).
+
+Let's use the external tool to compute this.
+
+{"name": "calculate", "arguments": {"a": -3, "b": 8, "operand": "@"}}
+user
+
+-25
+
+assistant
+We have computed that \(-3 @ 8 = -25\). Now we can put this result into the original expression to get the final result of \(5 @ (3 @ 6 @ 8)\), which is \(5 @ (-25)\).
+
+Let's compute \(5 @ (-25)\) using the external tool.
+
+{"name": "calculate", "arguments": {"a": 5, "b": -25, "operand": "@"}}
+user
+
+65
+
+assistant
+The final result of \(5 @ (3 @ 6 @ 8)\) is \(\boxed{65}\).
+```
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/agent.yaml b/ICL/DAPO/verl-recipe/langgraph_agent/example/agent.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..cbd8fb9ebb9023c2368cd5bce94b3a589262cbe7
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/agent.yaml
@@ -0,0 +1,2 @@
+- name: math_expression
+ _target_: recipe.langgraph_agent.example.math_expression.MathExpressionReactAgentLoop
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/create_dataset.py b/ICL/DAPO/verl-recipe/langgraph_agent/example/create_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..45ce131f83f491d7a470c1015993207ec2ebe22e
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/create_dataset.py
@@ -0,0 +1,290 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Create dataset for calculator
+"""
+
+import argparse
+import os
+import random
+
+import pandas as pd
+
+
+def generate_math_expression(min_terms=2, max_terms=5, min_number=1, max_number=10, allow_decimals=False, max_depth=2):
+ """
+ Generate a random mathematical expression with operators +, -, *, /, and parentheses.
+
+ Args:
+ min_terms (int): Minimum number of terms in the expression.
+ max_terms (int): Maximum number of terms in the expression.
+ max_number (int): Maximum value for numbers in the expression.
+ allow_decimals (bool): Whether to allow decimal numbers.
+ max_depth (int): Maximum nesting depth for parentheses.
+
+ Returns:
+ str: A valid mathematical expression as a string.
+ """
+
+ def generate_number():
+ """Generate a random number (integer or float)."""
+ assert min_number < max_number
+ num = random.uniform(min_number, max_number)
+ if not allow_decimals:
+ num = int(num)
+ else:
+ num = round(num, random.randint(0, 2)) # Round to 0-2 decimal places
+ return str(num)
+
+ def generate_term(depth=0):
+ """Generate a term (number or parenthesized expression)."""
+ if depth < max_depth and random.random() < 0.5: # 50% chance to add parentheses
+ expr = generate_expression(depth + 1)
+ return f"({expr})"
+ else:
+ return generate_number()
+
+ def generate_expression(depth=0):
+ """Generate a full expression with multiple terms and operators."""
+ num_terms = random.randint(min_terms, max_terms)
+ terms = [generate_term(depth) for _ in range(num_terms)]
+
+ # Randomly select operators
+ operators = ["+", "-", "*", "/", "@"]
+ expr = terms[0]
+
+ for i in range(1, num_terms):
+ # Bias towards + and - for readability
+ op = random.choices(
+ operators,
+ weights=[0, 0, 0, 0, 1], # + and - are 1.5x more likely than * and /
+ )[0]
+ expr += f" {op} " + terms[i]
+
+ return expr
+
+ return generate_expression()
+
+
+def test():
+ # Example 1: Basic integer expression
+ print(generate_math_expression())
+ # Output: (3 + 7) * 2 - 5
+
+ # Example 2: Expression with decimals
+ print(generate_math_expression(allow_decimals=True))
+ # Output: 4.5 / (2.1 + 3.7) - 1.2
+
+ # Example 3: More complex expression with higher depth
+ print(generate_math_expression(max_terms=6, max_depth=3))
+ # Output: ((5 * 2) - (3 + 1)) / (7 - 2) + 4
+
+ # Example 4: Simplified expression
+ print(generate_math_expression(min_terms=2, max_terms=3, max_number=5))
+ # Output: 4 - 2 * 3
+
+
+def calculate(expression: str) -> float:
+ """
+ Evaluate a mathematical expression with +, -, *, /, @, and parentheses.
+ The @ operator is defined as: a @ b = 3a - 2b.
+
+ Args:
+ expression (str): Input mathematical expression (e.g., "3@2+4").
+
+ Returns:
+ float: Result of the evaluated expression.
+
+ Raises:
+ ValueError: For invalid expressions (e.g., mismatched parentheses, division by zero).
+ """
+
+ def tokenize(s: str) -> list:
+ """Convert the input string into tokens (numbers, operators, parentheses)."""
+ tokens = []
+ i = 0
+ while i < len(s):
+ if s[i].isdigit() or s[i] == ".":
+ # Parse number (integer or float)
+ j = i
+ while j < len(s) and (s[j].isdigit() or s[j] == "."):
+ j += 1
+ tokens.append(s[i:j])
+ i = j
+ elif s[i] in "+-*/@()":
+ # Operator or parenthesis
+ tokens.append(s[i])
+ i += 1
+ elif s[i].isspace():
+ # Skip whitespace
+ i += 1
+ else:
+ raise ValueError(f"Invalid character: {s[i]}")
+ return tokens
+
+ def infix_to_postfix(tokens: list) -> list:
+ """Convert infix notation to postfix notation (Reverse Polish Notation)."""
+ output = []
+ stack = []
+ # Higher precedence for @ (between * and +)
+ precedence = {"@": 3, "*": 2, "/": 2, "+": 1, "-": 1}
+
+ for token in tokens:
+ if token.isdigit() or "." in token:
+ output.append(token)
+ elif token == "(":
+ stack.append(token)
+ elif token == ")":
+ while stack and stack[-1] != "(":
+ output.append(stack.pop())
+ if not stack or stack[-1] != "(":
+ raise ValueError("Mismatched parentheses")
+ stack.pop() # Discard '('
+ else: # Operator
+ while stack and stack[-1] != "(" and precedence.get(stack[-1], 0) >= precedence.get(token, 0):
+ output.append(stack.pop())
+ stack.append(token)
+
+ # Pop remaining operators
+ while stack:
+ if stack[-1] in "()":
+ raise ValueError("Mismatched parentheses")
+ output.append(stack.pop())
+
+ return output
+
+ def evaluate_postfix(postfix: list) -> float:
+ """Evaluate postfix expression using a stack."""
+ stack = []
+ for token in postfix:
+ if token.isdigit() or "." in token:
+ stack.append(float(token))
+ else:
+ if len(stack) < 2:
+ raise ValueError("Invalid expression")
+ b = stack.pop()
+ a = stack.pop()
+ if token == "+":
+ res = a + b
+ elif token == "-":
+ res = a - b
+ elif token == "*":
+ res = a * b
+ elif token == "/":
+ if b == 0:
+ raise ValueError("Division by zero")
+ res = a / b
+ elif token == "@":
+ res = 3 * a - 2 * b # Custom @ operator implementation
+ else:
+ raise ValueError(f"Invalid operator: {token}")
+ stack.append(res)
+
+ if len(stack) != 1:
+ raise ValueError("Invalid expression")
+ return stack[0]
+
+ # Remove spaces and validate parentheses
+ expression = expression.replace(" ", "")
+ if expression.count("(") != expression.count(")"):
+ raise ValueError("Mismatched parentheses")
+
+ tokens = tokenize(expression)
+ postfix = infix_to_postfix(tokens)
+ result = evaluate_postfix(postfix)
+
+ # Convert integers to integer representation
+ if result.is_integer():
+ return int(result)
+ return result
+
+
+def generate_data(total_num_dataset, split, agent_name="math_expression"):
+ rl_dataset = {
+ "prompt": [],
+ "data_source": [],
+ "ability": [],
+ "reward_model": [],
+ "extra_info": [],
+ "agent_name": [],
+ }
+
+ for idx in range(total_num_dataset):
+ while True:
+ try:
+ expression: str = generate_math_expression(
+ min_terms=2, max_terms=3, min_number=1, max_number=10, allow_decimals=False, max_depth=1
+ )
+
+ num_plus = expression.count("+")
+ num_minus = expression.count("-")
+ num_mul = expression.count("*")
+ num_star = expression.count("@")
+
+ answer = str(calculate(expression))
+ # answer = str(eval(expression))
+ break
+ except Exception as e:
+ print(e)
+ continue
+
+ num_tool_calls = num_plus + num_minus + num_mul + num_star
+
+ prompt = (
+ f"We define a new math operator @, where you can only call an external tool to compute. "
+ f"Please put your final answer inside \\boxed{{}} only in the last turn. Now answer the "
+ f"following questions:\nCompute {expression}"
+ )
+ prompt_with_template = [
+ {
+ "role": "user",
+ "content": prompt,
+ }
+ ]
+
+ rl_dataset["prompt"].append(prompt_with_template)
+ rl_dataset["data_source"].append("lighteval/MATH")
+ rl_dataset["ability"].append("math")
+ rl_dataset["reward_model"].append({"style": "lighteval/MATH", "ground_truth": answer})
+ rl_dataset["extra_info"].append(
+ {"index": idx, "expression": expression, "split": split, "expected_tool_calls": num_tool_calls}
+ )
+ rl_dataset["agent_name"].append(agent_name)
+
+ rl_dataset = pd.DataFrame(data=rl_dataset)
+ return rl_dataset
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Math Expression Dataset Generator")
+ parser.add_argument("--train_size", type=int, default=5000, help="Number of training samples")
+ parser.add_argument("--test_size", type=int, default=500, help="Number of testing samples")
+ parser.add_argument("--output_dir", default="data/math_expression_tool", help="Directory to save the dataset")
+ parser.add_argument("--agent_name", default="math_expression", help="Name of the agent")
+ args = parser.parse_args()
+
+ # print(calculate("3@2")) # Output: 5 (3*3 - 2*2)
+ # print(calculate("3@2+4")) # Output: 9 (5 + 4)
+ # print(calculate("3*(4@2)")) # Output: 24 (3 * 8)
+ # print(calculate("(5@3)*2")) # Output: 18 (9 * 2)
+
+ train_dataset = generate_data(total_num_dataset=args.train_size, split="train", agent_name=args.agent_name)
+ test_dataset = generate_data(total_num_dataset=args.test_size, split="test", agent_name=args.agent_name)
+
+ # Make sure the dataset directory exists
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Save the datasets to parquet files
+ train_dataset.to_parquet(os.path.join(args.output_dir, "train.parquet"))
+ test_dataset.to_parquet(os.path.join(args.output_dir, "test.parquet"))
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/math_expression.py b/ICL/DAPO/verl-recipe/langgraph_agent/example/math_expression.py
new file mode 100644
index 0000000000000000000000000000000000000000..77dd301701869f381076e7fa3b9e9d592cc3e61c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/math_expression.py
@@ -0,0 +1,38 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from langchain_core.tools import tool
+from recipe.langgraph_agent.react_agent_loop import ReactAgentLoop
+
+
+@tool(parse_docstring=True)
+def calculate(a: int, b: int, operand: str) -> int:
+ """
+ Compute the results using operand with two integers
+
+ Args:
+ a: the first operand
+ b: the second operand
+ operand: '+' or '-' or '*' or '@'
+ """
+ assert operand in ["+", "-", "*", "@"], f"unknown operand {operand}"
+ if operand == "@":
+ return 3 * a - 2 * b
+ return eval(f"{a} {operand} {b}")
+
+
+class MathExpressionReactAgentLoop(ReactAgentLoop):
+ @classmethod
+ def init_class(cls, config, tokenizer, **kwargs):
+ cls.tools = [calculate]
+ super().init_class(config, tokenizer)
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/run_gpt_oss_20b_bf16.sh b/ICL/DAPO/verl-recipe/langgraph_agent/example/run_gpt_oss_20b_bf16.sh
new file mode 100644
index 0000000000000000000000000000000000000000..9abd7b0105f9028534d2566417f9f36bbe8013e5
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/run_gpt_oss_20b_bf16.sh
@@ -0,0 +1,143 @@
+#!/usr/bin/env bash
+#SBATCH --job-name=rl-langgraph-3B
+#SBATCH --partition=main
+#SBATCH --nodes=1
+#SBATCH --ntasks-per-node=1
+#SBATCH --cpus-per-task=64
+#SBATCH --gres=gpu:4
+#SBATCH --mem=0
+#SBATCH --time=10:00:00
+#SBATCH --output=%x_%j.out
+#SBATCH --error=%x_%j.err
+
+set -xeuo pipefail
+
+# ================= cluster topology =================
+export GPUS_PER_NODE=${SLURM_GPUS_ON_NODE:-${GPUS_PER_NODE:-2}} # GPUs on this node
+NNODES=${SLURM_JOB_NUM_NODES:-${NNODES:-1}}
+export NNODES
+export RAY_NUM_NODES=$NNODES
+
+# Require at least 2 GPUs
+TOTAL_GPUS=$((GPUS_PER_NODE * NNODES))
+if [ "$TOTAL_GPUS" -lt 2 ]; then
+ echo "Error: at least 2 GPUs are required, detected $TOTAL_GPUS." >&2
+ exit 1
+fi
+
+echo "Using $NNODES nodes and $GPUS_PER_NODE GPUs per node..."
+
+# ================= data/model/tool =================
+HDFS_ROOT=${HDFS_ROOT:-$PWD}
+DATA_ROOT=${DATA_ROOT:-$PWD}
+
+# Prefer local model if present, otherwise fall back to HF hub path
+model_path="lmsys/gpt-oss-20b-bf16"
+
+# Use the default output directory produced by create_dataset.py
+train_files=$DATA_ROOT/data/math_expression_tool/train.parquet
+test_files=$DATA_ROOT/data/math_expression_tool/test.parquet
+
+# Agent config
+agent_loop_config_path=recipe/langgraph_agent/example/agent.yaml
+
+# =================== wandb ===================
+project_name=math_expression_tool
+experiment_name=gpt-oss-20b-bf16
+default_local_dir=$DATA_ROOT/checkpoint/$experiment_name
+
+# ================= algorithm =================
+adv_estimator=grpo
+
+use_kl_in_reward=false
+kl_coef=0.0
+use_kl_loss=false
+kl_loss_coef=0.0
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+max_turns=8
+max_prompt_length=1024
+max_response_length=8192
+actor_lr=1e-6
+
+train_batch_size=128
+ppo_mini_batch_size=16
+n_resp_per_prompt=8
+n_resp_per_prompt_val=1
+
+# =================== logging ===================
+export RAY_LOGGING_LEVEL=DEBUG
+export HYDRA_FULL_ERROR=1
+
+# ================= performance =================
+export NCCL_IBEXT_DISABLE=1
+export NCCL_NVLS_ENABLE=1
+export NCCL_IB_HCA=mlx5
+export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1
+export VLLM_USE_V1=1
+export VLLM_ATTENTION_BACKEND=FLASH_ATTN
+
+infer_tp=2 # vLLM tensor parallel size
+train_sp=4 # Ulysses sequence parallel size for actor
+offload=true
+
+actor_max_token_len_per_gpu=$(( (max_prompt_length + max_response_length) * 4 ))
+log_prob_max_token_len_per_gpu=$(( actor_max_token_len_per_gpu * 2 ))
+
+train_files="['$train_files']"
+test_files="['$test_files']"
+
+python3 -m verl.trainer.main_ppo \
+ algorithm.adv_estimator=$adv_estimator \
+ algorithm.use_kl_in_reward=$use_kl_in_reward \
+ algorithm.kl_ctrl.kl_coef=$kl_coef \
+ data.train_files="$train_files" \
+ data.val_files="$test_files" \
+ data.return_raw_chat=true \
+ data.train_batch_size=$train_batch_size \
+ data.max_prompt_length=$max_prompt_length \
+ data.max_response_length=$max_response_length \
+ data.filter_overlong_prompts=true \
+ data.truncation='error' \
+ actor_rollout_ref.model.path="$model_path" \
+ actor_rollout_ref.model.use_remove_padding=true \
+ actor_rollout_ref.model.enable_gradient_checkpointing=true \
+ actor_rollout_ref.actor.use_kl_loss=$use_kl_loss \
+ actor_rollout_ref.actor.kl_loss_coef=$kl_loss_coef \
+ actor_rollout_ref.actor.clip_ratio_low=$clip_ratio_low \
+ actor_rollout_ref.actor.clip_ratio_high=$clip_ratio_high \
+ actor_rollout_ref.actor.clip_ratio_c=10.0 \
+ actor_rollout_ref.actor.optim.lr=$actor_lr \
+ actor_rollout_ref.actor.use_dynamic_bsz=true \
+ actor_rollout_ref.actor.ppo_mini_batch_size=$ppo_mini_batch_size \
+ actor_rollout_ref.actor.ppo_max_token_len_per_gpu=$actor_max_token_len_per_gpu \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=$train_sp \
+ actor_rollout_ref.actor.fsdp_config.param_offload=$offload \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=$offload \
+ actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=$log_prob_max_token_len_per_gpu \
+ actor_rollout_ref.rollout.name=sglang \
+ actor_rollout_ref.rollout.mode=async \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=$infer_tp \
+ actor_rollout_ref.rollout.multi_turn.max_user_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.max_assistant_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.format=gpt-oss \
+ +actor_rollout_ref.rollout.engine_kwargs.sglang.attention_backend=triton \
+ actor_rollout_ref.rollout.agent.agent_loop_config_path=$agent_loop_config_path \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.7 \
+ actor_rollout_ref.rollout.n=$n_resp_per_prompt \
+ actor_rollout_ref.rollout.val_kwargs.top_p=1.0\
+ actor_rollout_ref.rollout.val_kwargs.temperature=1.0 \
+ actor_rollout_ref.rollout.val_kwargs.n=$n_resp_per_prompt_val \
+ trainer.logger='["console","wandb"]' \
+ trainer.project_name=$project_name \
+ trainer.experiment_name=$experiment_name \
+ trainer.n_gpus_per_node="$GPUS_PER_NODE" \
+ trainer.val_before_train=true \
+ trainer.log_val_generations=50 \
+ trainer.nnodes="$NNODES" \
+ trainer.save_freq=-1 \
+ trainer.default_local_dir="$default_local_dir" \
+ trainer.test_freq=5 \
+ trainer.total_epochs=1 "$@"
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/langgraph_agent/example/run_qwen2.5_3b.sh b/ICL/DAPO/verl-recipe/langgraph_agent/example/run_qwen2.5_3b.sh
new file mode 100644
index 0000000000000000000000000000000000000000..4e4cc020ae05db344ea995a4f8310068b84a8670
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/langgraph_agent/example/run_qwen2.5_3b.sh
@@ -0,0 +1,145 @@
+#!/usr/bin/env bash
+#SBATCH --job-name=rl-langgraph-3B
+#SBATCH --partition=main
+#SBATCH --nodes=1
+#SBATCH --ntasks-per-node=1
+#SBATCH --cpus-per-task=64
+#SBATCH --gres=gpu:4
+#SBATCH --mem=0
+#SBATCH --time=10:00:00
+#SBATCH --output=%x_%j.out
+#SBATCH --error=%x_%j.err
+
+set -xeuo pipefail
+
+# ================= cluster topology =================
+export GPUS_PER_NODE=${SLURM_GPUS_ON_NODE:-${GPUS_PER_NODE:-2}} # GPUs on this node
+NNODES=${SLURM_JOB_NUM_NODES:-${NNODES:-1}}
+export NNODES
+export RAY_NUM_NODES=$NNODES
+
+# Require at least 2 GPUs
+TOTAL_GPUS=$((GPUS_PER_NODE * NNODES))
+if [ "$TOTAL_GPUS" -lt 2 ]; then
+ echo "Error: at least 2 GPUs are required, detected $TOTAL_GPUS." >&2
+ exit 1
+fi
+
+echo "Using $NNODES nodes and $GPUS_PER_NODE GPUs per node..."
+
+# ================= data/model/tool =================
+HDFS_ROOT=${HDFS_ROOT:-$PWD}
+DATA_ROOT=${DATA_ROOT:-$PWD}
+
+# Prefer local model if present, otherwise fall back to HF hub path
+model_path=${model_path:-$DATA_ROOT/model/Qwen2.5-3B-Instruct}
+if [ ! -d "$model_path" ]; then
+ model_path=Qwen/Qwen2.5-3B-Instruct
+fi
+
+# Use the default output directory produced by create_dataset.py
+train_files=$DATA_ROOT/data/math_expression_tool/train.parquet
+test_files=$DATA_ROOT/data/math_expression_tool/test.parquet
+
+# Agent config
+agent_loop_config_path=recipe/langgraph_agent/example/agent.yaml
+
+# =================== wandb ===================
+project_name=math_expression_tool
+experiment_name=qwen2.5-3b
+default_local_dir=$DATA_ROOT/checkpoint/$experiment_name
+
+# ================= algorithm =================
+adv_estimator=grpo
+
+use_kl_in_reward=false
+kl_coef=0.0
+use_kl_loss=false
+kl_loss_coef=0.0
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+max_turns=8
+max_prompt_length=1024
+max_response_length=2048
+actor_lr=1e-6
+
+train_batch_size=128
+ppo_mini_batch_size=16
+n_resp_per_prompt=8
+n_resp_per_prompt_val=1
+
+# =================== logging ===================
+export RAY_LOGGING_LEVEL=DEBUG
+export HYDRA_FULL_ERROR=1
+
+# ================= performance =================
+export NCCL_IBEXT_DISABLE=1
+export NCCL_NVLS_ENABLE=1
+export NCCL_IB_HCA=mlx5
+export UCX_NET_DEVICES=mlx5_0:1,mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1
+export VLLM_USE_V1=1
+export VLLM_ATTENTION_BACKEND=FLASH_ATTN
+
+infer_tp=2 # vLLM tensor parallel size
+train_sp=4 # Ulysses sequence parallel size for actor
+offload=true
+
+actor_max_token_len_per_gpu=$(( (max_prompt_length + max_response_length) * 4 ))
+log_prob_max_token_len_per_gpu=$(( actor_max_token_len_per_gpu * 2 ))
+
+train_files="['$train_files']"
+test_files="['$test_files']"
+
+python3 -m verl.trainer.main_ppo \
+ algorithm.adv_estimator=$adv_estimator \
+ algorithm.use_kl_in_reward=$use_kl_in_reward \
+ algorithm.kl_ctrl.kl_coef=$kl_coef \
+ data.train_files="$train_files" \
+ data.val_files="$test_files" \
+ data.return_raw_chat=true \
+ data.train_batch_size=$train_batch_size \
+ data.max_prompt_length=$max_prompt_length \
+ data.max_response_length=$max_response_length \
+ data.filter_overlong_prompts=true \
+ data.truncation='error' \
+ actor_rollout_ref.model.path="$model_path" \
+ actor_rollout_ref.model.use_remove_padding=true \
+ actor_rollout_ref.model.enable_gradient_checkpointing=true \
+ actor_rollout_ref.actor.use_kl_loss=$use_kl_loss \
+ actor_rollout_ref.actor.kl_loss_coef=$kl_loss_coef \
+ actor_rollout_ref.actor.clip_ratio_low=$clip_ratio_low \
+ actor_rollout_ref.actor.clip_ratio_high=$clip_ratio_high \
+ actor_rollout_ref.actor.clip_ratio_c=10.0 \
+ actor_rollout_ref.actor.optim.lr=$actor_lr \
+ actor_rollout_ref.actor.use_dynamic_bsz=true \
+ actor_rollout_ref.actor.ppo_mini_batch_size=$ppo_mini_batch_size \
+ actor_rollout_ref.actor.ppo_max_token_len_per_gpu=$actor_max_token_len_per_gpu \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=$train_sp \
+ actor_rollout_ref.actor.fsdp_config.param_offload=$offload \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=$offload \
+ actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=$log_prob_max_token_len_per_gpu \
+ actor_rollout_ref.rollout.name=vllm \
+ actor_rollout_ref.rollout.mode=async \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=$infer_tp \
+ actor_rollout_ref.rollout.multi_turn.max_user_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.max_assistant_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.format=hermes \
+ actor_rollout_ref.rollout.agent.agent_loop_config_path=$agent_loop_config_path \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.9 \
+ actor_rollout_ref.rollout.n=$n_resp_per_prompt \
+ actor_rollout_ref.rollout.val_kwargs.top_p=0.6 \
+ actor_rollout_ref.rollout.val_kwargs.temperature=1.0 \
+ actor_rollout_ref.rollout.val_kwargs.n=$n_resp_per_prompt_val \
+ trainer.logger='["console","wandb"]' \
+ trainer.project_name=$project_name \
+ trainer.experiment_name=$experiment_name \
+ trainer.n_gpus_per_node="$GPUS_PER_NODE" \
+ trainer.val_before_train=true \
+ trainer.log_val_generations=50 \
+ trainer.nnodes="$NNODES" \
+ trainer.save_freq=-1 \
+ trainer.default_local_dir="$default_local_dir" \
+ trainer.test_freq=5 \
+ trainer.total_epochs=1 "$@"
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/open_math_reasoning/run_eval.sh b/ICL/DAPO/verl-recipe/open_math_reasoning/run_eval.sh
new file mode 100644
index 0000000000000000000000000000000000000000..f1760460a1706cf2ccfd47c71991e968645e300f
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/open_math_reasoning/run_eval.sh
@@ -0,0 +1,7 @@
+#!/usr/bin/env bash
+
+# Evaluation
+python3 -m verl.trainer.main_eval \
+ data.path=$HOME/data/gen/qwen_8b_gen_test.parquet \
+ custom_reward_function.path=recipe/open_math_reasoning/compute_score.py \
+ custom_reward_function.name=compute_score_data_source
diff --git a/ICL/DAPO/verl-recipe/prime/config/prime_trainer.yaml b/ICL/DAPO/verl-recipe/prime/config/prime_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2f8c98a5f000102e426cae2779dd361fce6e29b6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/prime/config/prime_trainer.yaml
@@ -0,0 +1,77 @@
+# the prime config will override default ppo_trainer.yaml
+
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+data:
+ filter_accuracy: True
+ accuracy_lower_bound: 0.2
+ accuracy_upper_bound: 0.8
+ oversample_factor: 4.0 # Sample more responses than the batch size. prompts satisfying the filter will be prioritized.
+ filter_truncate: True
+ truncation: right
+
+actor_rollout_ref:
+ hybrid_engine: True
+ model:
+ use_remove_padding: True
+ rollout:
+ mode: sync
+ # number of responses (i.e. num sample times)
+ n: 4
+ actor:
+ entropy_coeff: 0.001
+
+reward_model:
+ enable: True
+ strategy: fsdp
+ model:
+ ref_path: ${reward_model.model.path}
+ use_remove_padding: True
+ use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
+ fused_kernel_options:
+ impl_backend: torch # triton, torch
+ tokenizer_path: ${actor_rollout_ref.model.path}
+ enable_gradient_checkpointing: ${actor_rollout_ref.model.enable_gradient_checkpointing}
+ ref_type: freeze
+ fsdp_config:
+ min_num_params: 0
+ param_offload: ${actor_rollout_ref.actor.fsdp_config.param_offload}
+ optimizer_offload: ${actor_rollout_ref.actor.fsdp_config.optimizer_offload}
+ update: before # ``before`` for double-forward, ``after`` for single-forward
+ optim:
+ lr: 1e-6
+ lr_warmup_steps: -1 # Prioritized. Negative values mean delegating to lr_warmup_steps_ratio.
+ lr_warmup_steps_ratio: 0. # the total steps will be injected during runtime
+ min_lr_ratio: null
+ warmup_style: null # deprecated
+ lr_scheduler_type: constant
+ total_training_steps: -1 # must be overridden by program
+ weight_decay: 0.
+ grad_clip: 10.0
+ beta_train: 0.05
+ loss_type: ce # currently only supports ce loss
+ prime_granularity: token
+ prime_norm: batch_norm # batch_norm or none. if set to none, the normalizer is beta_train
+ mini_batch_size: ${actor_rollout_ref.actor.ppo_mini_batch_size}
+ reward_manager: prime
+
+algorithm:
+ adv_estimator: rloo
+ # now supports rloo. it treats different source of reward separately.
+ kl_ctrl:
+ type: fixed
+ kl_coef: 0.000
+ reward_gt_coef: 5
+ reward_dpo_coef: 5
+
+trainer:
+ project_name: prime
+ experiment_name: examples
+ val_before_train: False
+ balance_batch: False
diff --git a/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a16.json b/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a16.json
new file mode 100644
index 0000000000000000000000000000000000000000..5c8968431a4c7860c3145b0dab9238f6be4b5142
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a16.json
@@ -0,0 +1,34 @@
+{
+ "quant_method": "compressed-tensors",
+ "format": "nvfp4-pack-quantized",
+ "quantization_status": "compressed",
+ "config_groups": {
+ "group_0": {
+ "format": "nvfp4-pack-quantized",
+ "targets": [
+ "Linear"
+ ],
+ "weights": {
+ "actorder": null,
+ "block_structure": null,
+ "dynamic": false,
+ "group_size": 16,
+ "num_bits": 4,
+ "observer": "minmax",
+ "observer_kwargs": {},
+ "strategy": "tensor_group",
+ "symmetric": true,
+ "type": "float"
+ },
+ "input_activations": null,
+ "output_activations": null
+ }
+ },
+ "ignore": [
+ "lm_head"
+ ],
+ "kv_cache_scheme": null,
+ "sparsity_config": {},
+ "transform_config": {},
+ "global_compression_ratio": null
+}
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a4.json b/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a4.json
new file mode 100644
index 0000000000000000000000000000000000000000..2b6b22bd4062b1fb47b7787ce482009a1a100e5b
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/qat/config/nvfp4_w4a4.json
@@ -0,0 +1,45 @@
+{
+ "quant_method": "compressed-tensors",
+ "format": "nvfp4-pack-quantized",
+ "quantization_status": "compressed",
+ "config_groups": {
+ "group_0": {
+ "format": "nvfp4-pack-quantized",
+ "targets": [
+ "Linear"
+ ],
+ "weights": {
+ "num_bits": 4,
+ "type": "float",
+ "symmetric": true,
+ "strategy": "tensor_group",
+ "group_size": 16,
+ "dynamic": false,
+ "observer": "minmax",
+ "observer_kwargs": {},
+ "actorder": null,
+ "block_structure": null
+ },
+ "input_activations": {
+ "num_bits": 4,
+ "type": "float",
+ "symmetric": true,
+ "strategy": "tensor_group",
+ "group_size": 16,
+ "dynamic": "local",
+ "observer": "minmax",
+ "observer_kwargs": {},
+ "actorder": null,
+ "block_structure": null
+ },
+ "output_activations": null
+ }
+ },
+ "ignore": [
+ "lm_head"
+ ],
+ "kv_cache_scheme": null,
+ "sparsity_config": {},
+ "transform_config": {},
+ "global_compression_ratio": null
+}
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/r1/config/evaluation.yaml b/ICL/DAPO/verl-recipe/r1/config/evaluation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4fe664ae43aa28584f8d946e11b06d346e9cab86
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/r1/config/evaluation.yaml
@@ -0,0 +1,14 @@
+data:
+ path: /tmp/math_Qwen2-7B-Instruct.parquet
+ prompt_key: prompt
+ response_key: responses
+ data_source_key: data_source
+ reward_model_key: reward_model
+
+custom_reward_function:
+ path: null
+ name: compute_score
+
+ray_kwargs:
+ ray_init:
+ num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/r1/tasks/math_reward.py b/ICL/DAPO/verl-recipe/r1/tasks/math_reward.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ecde5494ef8f7a21400cc2861abcdf4e3a48aa6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/r1/tasks/math_reward.py
@@ -0,0 +1,35 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import contextlib
+
+try:
+ from math_verify.metric import math_metric
+ from math_verify.parser import ExprExtractionConfig, LatexExtractionConfig
+except ImportError:
+ print("To use Math-Verify, please install it first by running `pip install math-verify`.")
+
+
+def compute_score(model_output: str, ground_truth: str) -> bool:
+ verify_func = math_metric(
+ gold_extraction_target=(LatexExtractionConfig(),),
+ pred_extraction_target=(ExprExtractionConfig(), LatexExtractionConfig()),
+ )
+ ret_score = 0.0
+
+ # Wrap the ground truth in \boxed{} format for verification
+ ground_truth_boxed = "\\boxed{" + ground_truth + "}"
+ with contextlib.suppress(Exception):
+ ret_score, _ = verify_func([ground_truth_boxed], [model_output])
+
+ return ret_score
diff --git a/ICL/DAPO/verl-recipe/r1_ascend/figures/response_len.png b/ICL/DAPO/verl-recipe/r1_ascend/figures/response_len.png
new file mode 100644
index 0000000000000000000000000000000000000000..531d7f69b82ddd5b4511f35de7e97a76604395c9
Binary files /dev/null and b/ICL/DAPO/verl-recipe/r1_ascend/figures/response_len.png differ
diff --git a/ICL/DAPO/verl-recipe/r1_ascend/figures/rewards.png b/ICL/DAPO/verl-recipe/r1_ascend/figures/rewards.png
new file mode 100644
index 0000000000000000000000000000000000000000..55e907caf6af42815f6837b4245e74df04dd827f
Binary files /dev/null and b/ICL/DAPO/verl-recipe/r1_ascend/figures/rewards.png differ
diff --git a/ICL/DAPO/verl-recipe/r1_ascend/figures/val_score.png b/ICL/DAPO/verl-recipe/r1_ascend/figures/val_score.png
new file mode 100644
index 0000000000000000000000000000000000000000..3193506883e07adb9992db2c914bd6e6ecf82e05
Binary files /dev/null and b/ICL/DAPO/verl-recipe/r1_ascend/figures/val_score.png differ
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_megatron_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_megatron_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..630a0c9e6120fb2024f74f7d1e6270f395c694c4
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_megatron_trainer.yaml
@@ -0,0 +1,594 @@
+# This reference configration yaml is automatically generated via 'scripts/generate_trainer_config.sh'
+# in which it invokes 'python3 scripts/print_cfg.py --cfg job --config-name=ppo_megatron_trainer.yaml' to flatten the 'verl/trainer/config/ppo_megatron_trainer.yaml' config fields into a single file.
+# Do not modify this file directly.
+# The file is usually only for reference and never used.
+
+actor_rollout_ref:
+ actor:
+ optim:
+ _target_: verl.workers.config.McoreOptimizerConfig
+ lr: 1.0e-06
+ lr_warmup_steps_ratio: 0.0
+ total_training_steps: -1
+ weight_decay: 0.01
+ lr_warmup_steps: -1
+ betas:
+ - 0.9
+ - 0.999
+ clip_grad: 1.0
+ optimizer: adam
+ lr_warmup_init: 0.0
+ lr_decay_steps: null
+ lr_decay_style: constant
+ min_lr: 0.0
+ weight_decay_incr_style: constant
+ lr_wsd_decay_style: exponential
+ lr_wsd_decay_steps: null
+ use_checkpoint_opt_param_scheduler: false
+ override_optimizer_config: {}
+ megatron:
+ _target_: verl.workers.config.McoreEngineConfig
+ param_offload: false
+ grad_offload: false
+ optimizer_offload: false
+ tensor_model_parallel_size: 1
+ expert_model_parallel_size: 1
+ expert_tensor_parallel_size: null
+ pipeline_model_parallel_size: 1
+ virtual_pipeline_model_parallel_size: null
+ context_parallel_size: 1
+ sequence_parallel: true
+ use_distributed_optimizer: true
+ use_dist_checkpointing: false
+ dist_checkpointing_path: null
+ dist_checkpointing_prefix: ''
+ seed: 42
+ override_ddp_config: {}
+ override_transformer_config:
+ recompute_granularity: null
+ recompute_modules:
+ - core_attn
+ recompute_method: null
+ recompute_num_layers: null
+ attention_backend: flash
+ override_mcore_model_config: {}
+ use_mbridge: false
+ forward_only: false
+ dtype: bfloat16
+ _target_: verl.workers.config.McoreActorConfig
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: megatron
+ ppo_mini_batch_size: 256
+ ppo_micro_batch_size: null
+ ppo_micro_batch_size_per_gpu: null
+ use_dynamic_bsz: false
+ ppo_max_token_len_per_gpu: 16384
+ clip_ratio: 0.2
+ clip_ratio_low: 0.2
+ clip_ratio_high: 0.2
+ freeze_vision_tower: false
+ policy_loss:
+ _target_: verl.workers.config.PolicyLossConfig
+ loss_mode: vanilla
+ clip_cov_ratio: 0.0002
+ clip_cov_lb: 1.0
+ clip_cov_ub: 5.0
+ kl_cov_ratio: 0.0002
+ ppo_kl_coef: 0.1
+ clip_ratio_c: 3.0
+ loss_agg_mode: token-mean
+ entropy_coeff: 0
+ use_kl_loss: false
+ use_torch_compile: true
+ kl_loss_coef: 0.001
+ kl_loss_type: low_var_kl
+ ppo_epochs: 1
+ shuffle: false
+ checkpoint:
+ _target_: verl.trainer.config.CheckpointConfig
+ save_contents:
+ - model
+ - optimizer
+ - extra
+ load_contents: ${.save_contents}
+ async_save: false
+ use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ data_loader_seed: 42
+ load_weight: true
+ ref:
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: megatron
+ use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
+ log_prob_micro_batch_size: null
+ log_prob_micro_batch_size_per_gpu: null
+ log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ megatron:
+ _target_: verl.workers.config.McoreEngineConfig
+ param_offload: ${oc.select:actor_rollout_ref.actor.megatron.param_offload,False}
+ grad_offload: false
+ optimizer_offload: false
+ tensor_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.tensor_model_parallel_size,1}
+ expert_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.expert_model_parallel_size,1}
+ expert_tensor_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.expert_tensor_parallel_size,null}
+ pipeline_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.pipeline_model_parallel_size,1}
+ virtual_pipeline_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.virtual_pipeline_model_parallel_size,null}
+ context_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.context_parallel_size,1}
+ sequence_parallel: true
+ use_distributed_optimizer: true
+ use_dist_checkpointing: false
+ dist_checkpointing_path: null
+ dist_checkpointing_prefix: ''
+ seed: ${oc.select:actor_rollout_ref.actor.megatron.seed,42}
+ override_ddp_config: {}
+ override_transformer_config: ${oc.select:actor_rollout_ref.actor.megatron.override_transformer_config,{}}
+ override_mcore_model_config: {}
+ use_mbridge: ${oc.select:actor_rollout_ref.actor.megatron.use_mbridge,False}
+ forward_only: true
+ dtype: bfloat16
+ _target_: verl.workers.config.McoreActorConfig
+ load_weight: true
+ rollout:
+ _target_: verl.workers.config.RolloutConfig
+ name: ???
+ mode: async
+ temperature: 1.0
+ top_k: -1
+ top_p: 1
+ prompt_length: ${oc.select:data.max_prompt_length,512}
+ response_length: ${oc.select:data.max_response_length,512}
+ dtype: bfloat16
+ gpu_memory_utilization: 0.5
+ ignore_eos: false
+ enforce_eager: false
+ cudagraph_capture_sizes: null
+ free_cache_engine: true
+ tensor_model_parallel_size: 2
+ data_parallel_size: 1
+ expert_parallel_size: 1
+ pipeline_model_parallel_size: 1
+ max_num_batched_tokens: 8192
+ max_model_len: null
+ max_num_seqs: 1024
+ enable_chunked_prefill: true
+ enable_prefix_caching: true
+ load_format: dummy
+ log_prob_micro_batch_size: null
+ log_prob_micro_batch_size_per_gpu: null
+ log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+ disable_log_stats: true
+ do_sample: true
+ 'n': 1
+ over_sample_rate: 0
+ multi_stage_wake_up: false
+ engine_kwargs:
+ vllm: {}
+ sglang: {}
+ val_kwargs:
+ _target_: verl.workers.config.SamplingConfig
+ top_k: -1
+ top_p: 1.0
+ temperature: 0
+ 'n': 1
+ do_sample: false
+ multi_turn:
+ _target_: verl.workers.config.MultiTurnConfig
+ enable: false
+ max_assistant_turns: null
+ tool_config_path: null
+ max_user_turns: null
+ max_parallel_calls: 1
+ max_tool_response_length: 256
+ tool_response_truncate_side: middle
+ interaction_config_path: null
+ use_inference_chat_template: false
+ tokenization_sanity_check_mode: strict
+ format: hermes
+ num_repeat_rollouts: null
+ calculate_log_probs: false
+ agent:
+ _target_: verl.workers.config.AgentLoopConfig
+ num_workers: 8
+ default_agent_loop: single_turn_agent
+ agent_loop_config_path: null
+ custom_async_server:
+ _target_: verl.workers.config.CustomAsyncServerConfig
+ path: null
+ name: null
+ update_weights_bucket_megabytes: 512
+ trace:
+ _target_: verl.workers.config.TraceConfig
+ backend: null
+ token2text: false
+ max_samples_per_step_per_worker: null
+ skip_rollout: false
+ skip_dump_dir: /tmp/rollout_dump
+ skip_tokenizer_init: true
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
+ all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
+ ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
+ prometheus:
+ _target_: verl.workers.config.PrometheusConfig
+ enable: false
+ port: 9090
+ file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
+ served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
+ quantization: null
+ layer_name_map:
+ qkv_layer_name: qkv
+ gate_proj_layer_name: gate_up
+ model:
+ _target_: verl.workers.config.HFModelConfig
+ path: ~/models/deepseek-llm-7b-chat
+ hf_config_path: null
+ tokenizer_path: null
+ use_shm: false
+ trust_remote_code: false
+ custom_chat_template: null
+ external_lib: null
+ override_config:
+ model_config: {}
+ moe_config:
+ freeze_moe_router: false
+ enable_gradient_checkpointing: true
+ enable_activation_offload: false
+ use_remove_padding: false
+ lora_rank: 0
+ lora_alpha: 16
+ target_modules: all-linear
+ exclude_modules: null
+ lora_adapter_path: null
+ use_liger: false
+ use_fused_kernels: false
+ fused_kernel_options:
+ impl_backend: torch
+ hybrid_engine: true
+ nccl_timeout: 600
+data:
+ tokenizer: null
+ use_shm: false
+ train_files: ~/data/rlhf/gsm8k/train.parquet
+ val_files: ~/data/rlhf/gsm8k/test.parquet
+ train_max_samples: -1
+ val_max_samples: -1
+ prompt_key: prompt
+ reward_fn_key: data_source
+ max_prompt_length: 512
+ max_response_length: 512
+ train_batch_size: 1024
+ val_batch_size: null
+ tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
+ null}
+ return_raw_input_ids: false
+ return_raw_chat: true
+ return_full_prompt: false
+ shuffle: true
+ seed: null
+ dataloader_num_workers: 8
+ image_patch_size: 14
+ validation_shuffle: false
+ filter_overlong_prompts: false
+ filter_overlong_prompts_workers: 1
+ truncation: error
+ image_key: images
+ video_key: videos
+ trust_remote_code: false
+ custom_cls:
+ path: null
+ name: null
+ return_multi_modal_inputs: true
+ sampler:
+ class_path: null
+ class_name: null
+ datagen:
+ path: null
+ name: null
+ apply_chat_template_kwargs: {}
+critic:
+ optim:
+ _target_: verl.workers.config.McoreOptimizerConfig
+ lr: 1.0e-05
+ lr_warmup_steps_ratio: 0.0
+ total_training_steps: -1
+ weight_decay: 0.01
+ lr_warmup_steps: -1
+ betas:
+ - 0.9
+ - 0.999
+ clip_grad: 1.0
+ optimizer: adam
+ lr_warmup_init: 0.0
+ lr_decay_steps: null
+ lr_decay_style: constant
+ min_lr: 0.0
+ weight_decay_incr_style: constant
+ lr_wsd_decay_style: exponential
+ lr_wsd_decay_steps: null
+ use_checkpoint_opt_param_scheduler: false
+ override_optimizer_config: {}
+ megatron:
+ _target_: verl.workers.config.McoreEngineConfig
+ param_offload: false
+ grad_offload: false
+ optimizer_offload: false
+ tensor_model_parallel_size: 1
+ expert_model_parallel_size: 1
+ expert_tensor_parallel_size: null
+ pipeline_model_parallel_size: 1
+ virtual_pipeline_model_parallel_size: null
+ context_parallel_size: 1
+ sequence_parallel: true
+ use_distributed_optimizer: true
+ use_dist_checkpointing: false
+ dist_checkpointing_path: null
+ dist_checkpointing_prefix: ''
+ seed: 42
+ override_ddp_config: {}
+ override_transformer_config:
+ recompute_granularity: null
+ recompute_modules:
+ - core_attn
+ recompute_method: null
+ recompute_num_layers: null
+ attention_backend: flash
+ override_mcore_model_config: {}
+ use_mbridge: false
+ forward_only: false
+ dtype: bfloat16
+ _target_: verl.workers.config.McoreCriticConfig
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: megatron
+ enable: null
+ model:
+ path: ~/models/deepseek-llm-7b-chat
+ tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
+ override_config:
+ model_config: {}
+ moe_config:
+ freeze_moe_router: false
+ external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
+ trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
+ _target_: verl.trainer.config.BaseModelConfig
+ ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
+ ppo_micro_batch_size: null
+ ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
+ use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ ppo_max_token_len_per_gpu: 32768
+ forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
+ ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
+ shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
+ cliprange_value: 0.5
+ loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
+ checkpoint:
+ _target_: verl.trainer.config.CheckpointConfig
+ save_contents:
+ - model
+ - optimizer
+ - extra
+ load_contents: ${.save_contents}
+ async_save: false
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ nccl_timeout: 600
+ load_weight: true
+ data_loader_seed: ${oc.select:actor_rollout_ref.actor.data_loader_seed,null}
+reward_model:
+ enable: false
+ enable_resource_pool: false
+ n_gpus_per_node: 0
+ nnodes: 0
+ strategy: megatron
+ model:
+ input_tokenizer: ${actor_rollout_ref.model.path}
+ path: ~/models/FsfairX-LLaMA3-RM-v0.1
+ external_lib: ${actor_rollout_ref.model.external_lib}
+ trust_remote_code: false
+ micro_batch_size: null
+ micro_batch_size_per_gpu: null
+ max_length: null
+ use_dynamic_bsz: ${critic.use_dynamic_bsz}
+ forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
+ reward_manager: naive
+ launch_reward_fn_async: false
+ sandbox_fusion:
+ url: null
+ max_concurrent: 64
+ memory_limit_mb: 1024
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
+ nccl_timeout: 600
+ megatron:
+ _target_: verl.workers.config.MegatronEngineConfig
+ param_offload: false
+ tensor_model_parallel_size: 1
+ expert_model_parallel_size: 1
+ expert_tensor_parallel_size: null
+ pipeline_model_parallel_size: 1
+ virtual_pipeline_model_parallel_size: null
+ context_parallel_size: 1
+ sequence_parallel: true
+ use_distributed_optimizer: false
+ use_dist_checkpointing: false
+ dist_checkpointing_path: null
+ dist_checkpointing_prefix: ''
+ seed: ${oc.select:actor_rollout_ref.actor.megatron.seed,42}
+ override_transformer_config: ${oc.select:actor_rollout_ref.actor.megatron.override_transformer_config,{}}
+ use_mbridge: ${oc.select:actor_rollout_ref.actor.megatron.use_mbridge,False}
+ dtype: bfloat16
+ load_weight: true
+algorithm:
+ rollout_correction:
+ rollout_is: null
+ rollout_is_threshold: 2.0
+ rollout_rs: null
+ rollout_rs_threshold: null
+ rollout_rs_threshold_lower: null
+ rollout_token_veto_threshold: null
+ bypass_mode: false
+ use_policy_gradient: false
+ rollout_is_batch_normalize: false
+ _target_: verl.trainer.config.AlgoConfig
+ gamma: 1.0
+ lam: 1.0
+ adv_estimator: gae
+ norm_adv_by_std_in_grpo: true
+ use_kl_in_reward: false
+ kl_penalty: kl
+ kl_ctrl:
+ _target_: verl.trainer.config.KLControlConfig
+ type: fixed
+ kl_coef: 0.001
+ horizon: 10000
+ target_kl: 0.1
+ use_pf_ppo: false
+ pf_ppo:
+ reweight_method: pow
+ weight_pow: 2.0
+custom_reward_function:
+ path: null
+ name: compute_score
+trainer:
+ balance_batch: true
+ total_epochs: 30
+ total_training_steps: null
+ project_name: verl_examples
+ experiment_name: gsm8k
+ logger:
+ - console
+ - wandb
+ log_val_generations: 0
+ nnodes: 1
+ n_gpus_per_node: 8
+ save_freq: -1
+ esi_redundant_time: 0
+ resume_mode: auto
+ resume_from_path: null
+ del_local_ckpt_after_load: false
+ val_before_train: true
+ test_freq: -1
+ critic_warmup: 0
+ default_hdfs_dir: null
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ max_actor_ckpt_to_keep: null
+ max_critic_ckpt_to_keep: null
+ ray_wait_register_center_timeout: 300
+ device: cuda
+ rollout_data_dir: null
+ use_legacy_worker_impl: auto
+global_profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: null
+ steps: null
+ profile_continuous_steps: false
+ save_path: outputs/profile
+ global_tool_config:
+ nsys:
+ discrete: false
+ controller_nsight_options:
+ trace: cuda,nvtx,cublas,ucx
+ cuda-memory-usage: 'true'
+ cuda-graph-trace: graph
+ worker_nsight_options:
+ trace: cuda,nvtx,cublas,ucx
+ cuda-memory-usage: 'true'
+ cuda-graph-trace: graph
+ capture-range: cudaProfilerApi
+ capture-range-end: null
+ kill: none
+ torch_memory:
+ trace_alloc_max_entries: 100000
+ stack_depth: 32
+ context: all
+ stacks: all
+ kw_args: {}
+transfer_queue:
+ enable: false
+ray_kwargs:
+ ray_init:
+ num_cpus: null
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7a59adc935887e0e0250429c75cffe375deffb2f
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/_generated_ppo_trainer.yaml
@@ -0,0 +1,563 @@
+# This reference configration yaml is automatically generated via 'scripts/generate_trainer_config.sh'
+# in which it invokes 'python3 scripts/print_cfg.py --cfg job ' to flatten the 'verl/trainer/config/ppo_trainer.yaml' config fields into a single file.
+# Do not modify this file directly.
+# The file is usually only for reference and never used.
+
+actor_rollout_ref:
+ actor:
+ optim:
+ _target_: verl.workers.config.FSDPOptimizerConfig
+ optimizer: AdamW
+ optimizer_impl: torch.optim
+ lr: 1.0e-06
+ lr_warmup_steps_ratio: 0.0
+ total_training_steps: -1
+ weight_decay: 0.01
+ lr_warmup_steps: -1
+ betas:
+ - 0.9
+ - 0.999
+ clip_grad: 1.0
+ min_lr_ratio: 0.0
+ num_cycles: 0.5
+ lr_scheduler_type: constant
+ warmup_style: null
+ override_optimizer_config: null
+ fsdp_config:
+ _target_: verl.workers.config.FSDPEngineConfig
+ wrap_policy:
+ min_num_params: 0
+ param_offload: false
+ optimizer_offload: false
+ offload_policy: false
+ reshard_after_forward: true
+ fsdp_size: -1
+ forward_prefetch: false
+ model_dtype: fp32
+ use_orig_params: false
+ ulysses_sequence_parallel_size: 1
+ entropy_from_logits_with_chunking: false
+ use_torch_compile: true
+ entropy_checkpointing: false
+ forward_only: false
+ strategy: fsdp
+ dtype: bfloat16
+ _target_: verl.workers.config.FSDPActorConfig
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: fsdp
+ ppo_mini_batch_size: 256
+ ppo_micro_batch_size: null
+ ppo_micro_batch_size_per_gpu: null
+ use_dynamic_bsz: false
+ ppo_max_token_len_per_gpu: 16384
+ clip_ratio: 0.2
+ clip_ratio_low: 0.2
+ clip_ratio_high: 0.2
+ freeze_vision_tower: false
+ policy_loss:
+ _target_: verl.workers.config.PolicyLossConfig
+ loss_mode: vanilla
+ clip_cov_ratio: 0.0002
+ clip_cov_lb: 1.0
+ clip_cov_ub: 5.0
+ kl_cov_ratio: 0.0002
+ ppo_kl_coef: 0.1
+ clip_ratio_c: 3.0
+ loss_agg_mode: token-mean
+ entropy_coeff: 0
+ use_kl_loss: false
+ use_torch_compile: true
+ kl_loss_coef: 0.001
+ kl_loss_type: low_var_kl
+ ppo_epochs: 1
+ shuffle: false
+ checkpoint:
+ _target_: verl.trainer.config.CheckpointConfig
+ save_contents:
+ - model
+ - optimizer
+ - extra
+ load_contents: ${.save_contents}
+ async_save: false
+ use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ grad_clip: 1.0
+ ulysses_sequence_parallel_size: 1
+ entropy_from_logits_with_chunking: false
+ entropy_checkpointing: false
+ use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
+ ref:
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: ${actor_rollout_ref.actor.strategy}
+ use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
+ log_prob_micro_batch_size: null
+ log_prob_micro_batch_size_per_gpu: null
+ log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ fsdp_config:
+ _target_: verl.workers.config.FSDPEngineConfig
+ wrap_policy:
+ min_num_params: 0
+ param_offload: false
+ optimizer_offload: false
+ offload_policy: false
+ reshard_after_forward: true
+ fsdp_size: -1
+ forward_prefetch: false
+ model_dtype: fp32
+ use_orig_params: false
+ ulysses_sequence_parallel_size: 1
+ entropy_from_logits_with_chunking: false
+ use_torch_compile: true
+ entropy_checkpointing: false
+ forward_only: true
+ strategy: fsdp
+ dtype: bfloat16
+ _target_: verl.workers.config.FSDPActorConfig
+ ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
+ entropy_from_logits_with_chunking: false
+ entropy_checkpointing: false
+ rollout:
+ _target_: verl.workers.config.RolloutConfig
+ name: ???
+ mode: async
+ temperature: 1.0
+ top_k: -1
+ top_p: 1
+ prompt_length: ${oc.select:data.max_prompt_length,512}
+ response_length: ${oc.select:data.max_response_length,512}
+ dtype: bfloat16
+ gpu_memory_utilization: 0.5
+ ignore_eos: false
+ enforce_eager: false
+ cudagraph_capture_sizes: null
+ free_cache_engine: true
+ tensor_model_parallel_size: 2
+ data_parallel_size: 1
+ expert_parallel_size: 1
+ pipeline_model_parallel_size: 1
+ max_num_batched_tokens: 8192
+ max_model_len: null
+ max_num_seqs: 1024
+ enable_chunked_prefill: true
+ enable_prefix_caching: true
+ load_format: dummy
+ log_prob_micro_batch_size: null
+ log_prob_micro_batch_size_per_gpu: null
+ log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+ disable_log_stats: true
+ do_sample: true
+ 'n': 1
+ over_sample_rate: 0
+ multi_stage_wake_up: false
+ engine_kwargs:
+ vllm: {}
+ sglang: {}
+ val_kwargs:
+ _target_: verl.workers.config.SamplingConfig
+ top_k: -1
+ top_p: 1.0
+ temperature: 0
+ 'n': 1
+ do_sample: false
+ multi_turn:
+ _target_: verl.workers.config.MultiTurnConfig
+ enable: false
+ max_assistant_turns: null
+ tool_config_path: null
+ max_user_turns: null
+ max_parallel_calls: 1
+ max_tool_response_length: 256
+ tool_response_truncate_side: middle
+ interaction_config_path: null
+ use_inference_chat_template: false
+ tokenization_sanity_check_mode: strict
+ format: hermes
+ num_repeat_rollouts: null
+ calculate_log_probs: false
+ agent:
+ _target_: verl.workers.config.AgentLoopConfig
+ num_workers: 8
+ default_agent_loop: single_turn_agent
+ agent_loop_config_path: null
+ custom_async_server:
+ _target_: verl.workers.config.CustomAsyncServerConfig
+ path: null
+ name: null
+ update_weights_bucket_megabytes: 512
+ trace:
+ _target_: verl.workers.config.TraceConfig
+ backend: null
+ token2text: false
+ max_samples_per_step_per_worker: null
+ skip_rollout: false
+ skip_dump_dir: /tmp/rollout_dump
+ skip_tokenizer_init: true
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
+ all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
+ ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
+ prometheus:
+ _target_: verl.workers.config.PrometheusConfig
+ enable: false
+ port: 9090
+ file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
+ served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
+ layered_summon: false
+ model:
+ _target_: verl.workers.config.HFModelConfig
+ path: ~/models/deepseek-llm-7b-chat
+ hf_config_path: null
+ tokenizer_path: null
+ use_shm: false
+ trust_remote_code: false
+ custom_chat_template: null
+ external_lib: null
+ override_config: {}
+ enable_gradient_checkpointing: true
+ enable_activation_offload: false
+ use_remove_padding: false
+ lora_rank: 0
+ lora_alpha: 16
+ target_modules: all-linear
+ exclude_modules: null
+ lora_adapter_path: null
+ use_liger: false
+ use_fused_kernels: false
+ fused_kernel_options:
+ impl_backend: torch
+ hybrid_engine: true
+ nccl_timeout: 600
+data:
+ tokenizer: null
+ use_shm: false
+ train_files: ~/data/rlhf/gsm8k/train.parquet
+ val_files: ~/data/rlhf/gsm8k/test.parquet
+ train_max_samples: -1
+ val_max_samples: -1
+ prompt_key: prompt
+ reward_fn_key: data_source
+ max_prompt_length: 512
+ max_response_length: 512
+ train_batch_size: 1024
+ val_batch_size: null
+ tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
+ null}
+ return_raw_input_ids: false
+ return_raw_chat: true
+ return_full_prompt: false
+ shuffle: true
+ seed: null
+ dataloader_num_workers: 8
+ image_patch_size: 14
+ validation_shuffle: false
+ filter_overlong_prompts: false
+ filter_overlong_prompts_workers: 1
+ truncation: error
+ image_key: images
+ video_key: videos
+ trust_remote_code: false
+ custom_cls:
+ path: null
+ name: null
+ return_multi_modal_inputs: true
+ sampler:
+ class_path: null
+ class_name: null
+ datagen:
+ path: null
+ name: null
+ apply_chat_template_kwargs: {}
+critic:
+ optim:
+ _target_: verl.workers.config.FSDPOptimizerConfig
+ optimizer: AdamW
+ optimizer_impl: torch.optim
+ lr: 1.0e-05
+ lr_warmup_steps_ratio: 0.0
+ total_training_steps: -1
+ weight_decay: 0.01
+ lr_warmup_steps: -1
+ betas:
+ - 0.9
+ - 0.999
+ clip_grad: 1.0
+ min_lr_ratio: 0.0
+ num_cycles: 0.5
+ lr_scheduler_type: constant
+ warmup_style: null
+ override_optimizer_config: null
+ model:
+ fsdp_config:
+ _target_: verl.workers.config.FSDPEngineConfig
+ wrap_policy:
+ min_num_params: 0
+ param_offload: false
+ optimizer_offload: false
+ offload_policy: false
+ reshard_after_forward: true
+ fsdp_size: -1
+ forward_prefetch: false
+ model_dtype: fp32
+ use_orig_params: false
+ ulysses_sequence_parallel_size: 1
+ entropy_from_logits_with_chunking: false
+ use_torch_compile: true
+ entropy_checkpointing: false
+ forward_only: false
+ strategy: fsdp
+ dtype: bfloat16
+ path: ~/models/deepseek-llm-7b-chat
+ tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
+ override_config: {}
+ external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
+ trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
+ _target_: verl.workers.config.FSDPCriticModelCfg
+ use_shm: false
+ enable_gradient_checkpointing: true
+ enable_activation_offload: false
+ use_remove_padding: false
+ lora_rank: 0
+ lora_alpha: 16
+ target_modules: all-linear
+ _target_: verl.workers.config.FSDPCriticConfig
+ rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+ strategy: fsdp
+ enable: null
+ ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
+ ppo_micro_batch_size: null
+ ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
+ use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+ ppo_max_token_len_per_gpu: 32768
+ forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
+ ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
+ shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
+ cliprange_value: 0.5
+ loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
+ checkpoint:
+ _target_: verl.trainer.config.CheckpointConfig
+ save_contents:
+ - model
+ - optimizer
+ - extra
+ load_contents: ${.save_contents}
+ async_save: false
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+ npu:
+ _target_: verl.utils.profiler.config.NPUToolConfig
+ contents: []
+ level: level1
+ analysis: true
+ discrete: false
+ torch:
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+ step_start: 0
+ step_end: null
+ torch_memory:
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+ forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
+ forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
+ ulysses_sequence_parallel_size: 1
+ grad_clip: 1.0
+reward_model:
+ enable: false
+ enable_resource_pool: false
+ n_gpus_per_node: 0
+ nnodes: 0
+ strategy: fsdp
+ model:
+ input_tokenizer: ${actor_rollout_ref.model.path}
+ path: ~/models/FsfairX-LLaMA3-RM-v0.1
+ external_lib: ${actor_rollout_ref.model.external_lib}
+ trust_remote_code: false
+ use_shm: false
+ use_remove_padding: false
+ use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
+ fsdp_config:
+ _target_: verl.workers.config.FSDPEngineConfig
+ wrap_policy:
+ min_num_params: 0
+ param_offload: false
+ reshard_after_forward: true
+ fsdp_size: -1
+ forward_prefetch: false
+ micro_batch_size: null
+ micro_batch_size_per_gpu: null
+ max_length: null
+ use_dynamic_bsz: ${critic.use_dynamic_bsz}
+ forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
+ reward_manager: naive
+ launch_reward_fn_async: false
+ sandbox_fusion:
+ url: null
+ max_concurrent: 64
+ memory_limit_mb: 1024
+ profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: ${oc.select:global_profiler.tool,null}
+ enable: false
+ all_ranks: false
+ ranks: []
+ save_path: ${oc.select:global_profiler.save_path,null}
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
+ ulysses_sequence_parallel_size: 1
+algorithm:
+ rollout_correction:
+ rollout_is: null
+ rollout_is_threshold: 2.0
+ rollout_rs: null
+ rollout_rs_threshold: null
+ rollout_rs_threshold_lower: null
+ rollout_token_veto_threshold: null
+ bypass_mode: false
+ use_policy_gradient: false
+ rollout_is_batch_normalize: false
+ _target_: verl.trainer.config.AlgoConfig
+ gamma: 1.0
+ lam: 1.0
+ adv_estimator: gae
+ norm_adv_by_std_in_grpo: true
+ use_kl_in_reward: false
+ kl_penalty: kl
+ kl_ctrl:
+ _target_: verl.trainer.config.KLControlConfig
+ type: fixed
+ kl_coef: 0.001
+ horizon: 10000
+ target_kl: 0.1
+ use_pf_ppo: false
+ pf_ppo:
+ reweight_method: pow
+ weight_pow: 2.0
+custom_reward_function:
+ path: null
+ name: compute_score
+trainer:
+ balance_batch: true
+ total_epochs: 30
+ total_training_steps: null
+ project_name: verl_examples
+ experiment_name: gsm8k
+ logger:
+ - console
+ - wandb
+ log_val_generations: 0
+ rollout_data_dir: null
+ validation_data_dir: null
+ nnodes: 1
+ n_gpus_per_node: 8
+ save_freq: -1
+ esi_redundant_time: 0
+ resume_mode: auto
+ resume_from_path: null
+ val_before_train: true
+ val_only: false
+ test_freq: -1
+ critic_warmup: 0
+ default_hdfs_dir: null
+ del_local_ckpt_after_load: false
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ max_actor_ckpt_to_keep: null
+ max_critic_ckpt_to_keep: null
+ ray_wait_register_center_timeout: 300
+ device: cuda
+ use_legacy_worker_impl: auto
+global_profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: null
+ steps: null
+ profile_continuous_steps: false
+ save_path: outputs/profile
+ global_tool_config:
+ nsys:
+ _target_: verl.utils.profiler.config.NsightToolConfig
+ discrete: false
+ controller_nsight_options:
+ trace: cuda,nvtx,cublas,ucx
+ cuda-memory-usage: 'true'
+ cuda-graph-trace: graph
+ worker_nsight_options:
+ trace: cuda,nvtx,cublas,ucx
+ cuda-memory-usage: 'true'
+ cuda-graph-trace: graph
+ capture-range: cudaProfilerApi
+ capture-range-end: null
+ kill: none
+ torch_memory:
+ trace_alloc_max_entries: 100000
+ stack_depth: 32
+ context: all
+ stacks: all
+ kw_args: {}
+transfer_queue:
+ enable: false
+ray_kwargs:
+ ray_init:
+ num_cpus: null
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/actor/actor.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/actor/actor.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..504b367e6b0de53f0c42eeee5bb9bf6f8b63806a
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/actor/actor.yaml
@@ -0,0 +1,215 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# Target class for this configuration
+_target_: verl.workers.config.ActorConfig
+
+# Number of rollouts per update (mirrors actor rollout_n)
+rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+
+# the abstract actor configs
+# fsdp, fsdp2 or megatron. must be set.
+strategy: ???
+
+# Split each sample into sub-batches of this size for PPO
+ppo_mini_batch_size: 256
+
+# [Deprecated] Global micro batch size
+ppo_micro_batch_size: null
+
+# Local per-GPU micro batch size
+ppo_micro_batch_size_per_gpu: null
+
+# Whether to automatically adjust batch size at runtime
+# oc.select: the default val for ref.log_prob_use_dynamic_bsz
+use_dynamic_bsz: false
+
+# Max tokens per GPU in one PPO batch; affects gradient accumulation
+# Typically it should be: n * ${data.max_prompt_length} + ${data.max_response_length}
+# oc.select: the default val for ref.log_prob_max_token_len_per_gpu
+ppo_max_token_len_per_gpu: 16384
+
+# PPO clip ratio
+clip_ratio: 0.2
+
+# Lower bound for asymmetric clipping (used in dual-clip PPO)
+clip_ratio_low: 0.2
+
+# Upper bound for asymmetric clipping (used in dual-clip PPO)
+clip_ratio_high: 0.2
+
+# Whether to freeze vision model, if set true, it will be freeze vision model
+freeze_vision_tower: false
+
+# policy loss config
+policy_loss:
+
+ # # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.PolicyLossConfig
+
+ # Loss function mode: vanilla / clip-cov / kl-cov /gpg from https://arxiv.org/abs/2505.22617
+ loss_mode: "vanilla"
+
+ # Ratio of tokens to be clipped for clip-cov loss
+ clip_cov_ratio: 0.0002
+
+ # Lower bound for clip-cov loss
+ clip_cov_lb: 1.0
+
+ # Upper bound for clip-cov loss
+ clip_cov_ub: 5.0
+
+ # Ratio of tokens to be applied kl penalty for kl-cov loss
+ kl_cov_ratio: 0.0002
+
+ # KL divergence penalty coefficient
+ ppo_kl_coef: 0.1
+
+# Constant C in Dual-clip PPO; clips when advantage < 0 and ratio > C
+clip_ratio_c: 3.0
+
+# Loss aggregation mode: "token-mean", "seq-mean-token-sum", or "seq-mean-token-mean"
+loss_agg_mode: token-mean
+
+# Entropy regularization coefficient in PPO loss
+entropy_coeff: 0
+
+# Whether to use KL loss instead of KL reward penalty. True for GRPO
+use_kl_loss: false
+
+# Whether to use torch.compile()
+# oc.select: the default val for ref.use_torch_compile
+use_torch_compile: true
+
+# KL loss coefficient when use_kl_loss is enabled. For GRPO
+kl_loss_coef: 0.001
+
+# Type of KL divergence loss. Options: "kl"(k1), "abs", "mse"(k2), "low_var_kl"(k3), "full"
+kl_loss_type: low_var_kl
+
+# Number of PPO epochs per batch
+ppo_epochs: 1
+
+# Shuffle training data across PPO epochs
+shuffle: false
+
+# checkpoint configs
+checkpoint:
+
+ # Target dataclass for this configuration
+ _target_: verl.trainer.config.CheckpointConfig
+
+ # What to include in saved checkpoints
+ # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save space
+ save_contents: ['model', 'optimizer', 'extra']
+
+ # For more flexibility, you can specify the contents to load from the checkpoint.
+ # .xxx refers to the local variable xxx from the same level of hierarchy similar to python pkg
+ load_contents: ${.save_contents}
+
+ # Whether to save checkpoints asynchronously. Only effective for Megatron as of now.
+ async_save: False
+
+# optimizer configs
+optim:
+
+ # Learning rate
+ lr: 1e-6
+
+ # Warmup steps ratio (used if lr_warmup_steps is 0 or negative)
+ lr_warmup_steps_ratio: 0.0
+
+ # Total training steps (must be overridden at runtime)
+ total_training_steps: -1
+
+ # Weight decay
+ weight_decay: 0.01
+
+ # Prioritized. None, 0 or Negative values mean delegating to lr_warmup_steps_ratio.
+ lr_warmup_steps: -1
+
+
+# Whether to use custom fused kernels (e.g., FlashAttention, fused MLP)
+use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
+
+# profile the actor model in `update_policy`
+profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # profiler tool, default same as profiler.tool in global config
+ # choices: nsys, npu, torch
+ tool: ${oc.select:global_profiler.tool,null}
+
+ # whether enable profile on Actor
+ enable: False
+
+ # Whether to profile all ranks.
+ all_ranks: False
+
+ # The ranks that will be profiled. [] or [0,1,...]
+ ranks: []
+
+ # profile results saving path
+ save_path: ${oc.select:global_profiler.save_path,null}
+
+ # specific tool config which only related to the role
+ tool_config:
+
+ # nsys tool config
+ nsys:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NsightToolConfig
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+
+ # npu config
+ npu:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NPUToolConfig
+
+ # Contents to profile, can be empty
+ # options: npu, cpu, memory, shapes, module, stack
+ contents: []
+
+ # Collection level, optional values: level_none, level0, level1, level2.
+ level: "level1"
+
+ # Whether to automatically parse the data.
+ analysis: True
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # torch profiler config
+ torch:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+
+ # start profile mini-batch in training
+ # NOTICE: different with global steps config which refers to iteration
+ # This field only related with mini-batch
+ step_start: 0
+
+ # stop profile mini-batch in training
+ step_end: null
+
+ # torch memory profiler config
+ torch_memory:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+
+ # Maximum number of memory allocation entries to track
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+
+ # Stack trace depth for memory allocations
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/actor/dp_actor.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/actor/dp_actor.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..742ea5488115c8e1e55f645148af0a7e2b99d568
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/actor/dp_actor.yaml
@@ -0,0 +1,43 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# defaults specify the default config from each component
+defaults:
+
+ # fsdp optimizer config
+ - ../optim@optim: fsdp
+
+ # fsdp engine config
+ - ../engine@fsdp_config: fsdp
+
+ # dp actor config, inheriting from trainer/config/actor/actor.yaml
+ - actor
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+# Target class for this configuration
+_target_: verl.workers.config.FSDPActorConfig
+
+# TODO(haibin.lin): switch to fsdp2
+strategy: fsdp
+
+# Gradient clipping for actor updates, specific to the strategy.
+grad_clip: 1.0
+
+# Sequence parallelism size for Ulysses-style model parallelism
+# oc.select: the default val for ref.ulysses_sequence_parallel_size
+# [DEPRECATED] use fsdp_config.ulysses_sequence_parallel_size instead
+ulysses_sequence_parallel_size: 1
+
+# calculate entropy with chunking to reduce memory peak
+entropy_from_logits_with_chunking: False
+
+# recompute entropy
+entropy_checkpointing: False
+
+# Whether to remove padding tokens in inputs during training
+use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/actor/megatron_actor.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/actor/megatron_actor.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a632fe4380b75aabdaf5ed6d2f88ac29d093a8b0
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/actor/megatron_actor.yaml
@@ -0,0 +1,20 @@
+# megatron actor config, inheriting from trainer/config/actor/actor.yaml
+defaults:
+ # megatron optimizer config
+ - ../optim@optim: megatron
+
+ # megatron engine config
+ - ../engine@megatron: megatron
+
+ - actor
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+_target_: verl.workers.config.McoreActorConfig
+
+strategy: megatron
+
+data_loader_seed: 42
+
+load_weight: True
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/algorithm/rollout_correction.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/algorithm/rollout_correction.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7c958c5ee7659cdde50687fc0e8441c645536947
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/algorithm/rollout_correction.yaml
@@ -0,0 +1,30 @@
+# Rollout Correction: corrects off-policy distribution shifts
+# See documentation: docs/algo/rollout_corr.md
+# Use presets: RolloutCorrectionConfig.decoupled_seq_is(), .pg_is(), etc.
+
+# IS aggregation level: null (disabled), "token" (per-token), "sequence" (per-sequence)
+rollout_is: null
+
+# Upper threshold for IS weight truncation (typical: 2.0-5.0)
+rollout_is_threshold: 2.0
+
+# RS aggregation level: null (disabled), "token", "sequence", "geometric"
+rollout_rs: null
+
+# Upper threshold for rejection sampling (null = use rollout_is_threshold)
+rollout_rs_threshold: null
+
+# Lower threshold for rejection sampling (null = auto-compute as 1/upper)
+rollout_rs_threshold_lower: null
+
+# Per-token veto threshold for catastrophic outliers (null = disabled)
+rollout_token_veto_threshold: null
+
+# Operating mode: false = Decoupled (3 policies), true = Bypass (2 policies)
+bypass_mode: false
+
+# Loss function: false = PPO with clipping, true = Policy gradient (no clipping)
+use_policy_gradient: false
+
+# Batch normalize IS weights: false = raw weights, true = normalize to mean=1.0
+rollout_is_batch_normalize: false
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/critic/critic.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/critic/critic.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..f201a34b40c36c5a45f3dda61084bc7dc78dd70a
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/critic/critic.yaml
@@ -0,0 +1,176 @@
+# Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+_target_: verl.workers.config.CriticConfig
+
+# Number of rollouts per update (mirrors actor rollout_n)
+rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+
+# fsdp or fsdp2 strategy used for critic model training
+strategy: ???
+
+# whether to enable the critic worker.
+# by default it is only enabled if advantage estimator is gae
+# set it to True manually if you always want to enable critic worker
+enable: null
+
+# optimizer configs
+optim:
+
+ # Learning rate
+ lr: 1e-5
+
+ # Warmup steps ratio; total steps will be injected at runtime
+ lr_warmup_steps_ratio: 0.0
+
+ # Total training steps (must be overridden at runtime)
+ total_training_steps: -1
+
+ # Weight decay
+ weight_decay: 0.01
+
+ # Prioritized. None, 0 or Negative values mean delegating to lr_warmup_steps_ratio.
+ lr_warmup_steps: -1
+
+
+# model config for the critic
+model:
+
+ # Path to pretrained model weights
+ path: ~/models/deepseek-llm-7b-chat
+
+ # Tokenizer path (defaults to actor's model path)
+ tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
+
+ # Hugging Face config override
+ override_config: {}
+
+ # External model implementation (optional)
+ external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
+
+ # Whether to trust remote code from Hugging Face models
+ trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
+
+# PPO mini-batch size per update
+ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
+
+# [Deprecated] Global micro batch size
+ppo_micro_batch_size: null
+
+# Local per-GPU micro batch size
+ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
+
+# Whether to automatically adjust batch size at runtime
+use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+
+# Max tokens per GPU in one PPO batch (doubled for critic)
+ppo_max_token_len_per_gpu: 32768
+
+# Max token length per GPU in forward pass
+forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
+
+# Number of PPO epochs per batch
+ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
+
+# Shuffle training data across PPO epochs
+shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
+
+# PPO value function clipping range
+cliprange_value: 0.5
+
+# Loss aggregation mode: "token-mean", "seq-mean-token-sum", or "seq-mean-token-mean"
+loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
+
+# checkpoint configs
+checkpoint:
+
+ # Target dataclass for this configuration
+ _target_: verl.trainer.config.CheckpointConfig
+
+ # What to include in saved checkpoints
+ # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save space
+ save_contents: ['model', 'optimizer', 'extra']
+
+ # What to include when loading checkpoints
+ load_contents: ${.save_contents}
+
+ # Whether to save checkpoints asynchronously. Only effective for Megatron as of now.
+ async_save: False
+
+# profile the critic model in `update_critic`
+profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # profiler tool, default same as profiler.tool in global config
+ # choices: nsys, npu, torch, torch_memory
+ tool: ${oc.select:global_profiler.tool,null}
+
+ # whether enable profile on Critic
+ enable: False
+
+ # Whether to profile all ranks.
+ all_ranks: False
+
+ # The ranks that will be profiled. [] or [0,1,...]
+ ranks: []
+
+ # profile results saving path
+ save_path: ${oc.select:global_profiler.save_path,null}
+
+ # specific tool config which only related to the role
+ tool_config:
+
+ # nsys tool config
+ nsys:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NsightToolConfig
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+
+ # npu config
+ npu:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NPUToolConfig
+
+ # Contents to profile, can be empty
+ # options: npu, cpu, memory, shapes, module, stack
+ contents: []
+
+ # Collection level, optional values: level_none, level0, level1, level2.
+ level: "level1"
+
+ # Whether to automatically parse the data.
+ analysis: True
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # torch profiler config
+ torch:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+
+ # start profile mini-batch in training
+ # NOTICE: different with global steps config which refers to iteration
+ # This field only related with mini-batch
+ step_start: 0
+
+ # stop profile mini-batch in training
+ step_end: null
+
+ # torch memory profiler config
+ torch_memory:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+
+ # Maximum number of memory allocation entries to track
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+
+ # Stack trace depth for memory allocations
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
+
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/critic/dp_critic.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/critic/dp_critic.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c040a32244a59793d2abd020f24dd190a05bcb16
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/critic/dp_critic.yaml
@@ -0,0 +1,66 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# defaults specify the default config from each component
+defaults:
+
+ # fsdp optimizer config
+ - ../optim@optim: fsdp
+
+ # fsdp engine config
+ - ../engine@model.fsdp_config: fsdp
+
+ # dp actor config, inheriting from trainer/config/critic/critic.yaml
+ - critic
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+# Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+_target_: verl.workers.config.FSDPCriticConfig
+
+# distribution strategy. Options: fsdp (deprecating), fsdp2
+strategy: fsdp
+
+# model config for the critic
+model:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.FSDPCriticModelCfg
+
+ # Whether to use shared memory for loading the model
+ use_shm: False
+
+ # Enable gradient checkpointing to save memory
+ enable_gradient_checkpointing: True
+
+ # Offload activations to CPU to reduce GPU memory usage
+ enable_activation_offload: False
+
+ # Use remove padding optimization (saves compute)
+ use_remove_padding: False
+
+ # Set to positive value to enable LoRA (e.g., 32)
+ lora_rank: 0
+
+ # LoRA scaling factor
+ lora_alpha: 16
+
+ # LoRA target modules: "all-linear" or list of linear projection layers
+ target_modules: all-linear
+
+# Forward-only batch size during inference (global)
+forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
+
+# Forward-only batch size during inference (per GPU)
+forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
+
+# Sequence parallelism size for Ulysses-style model parallelism
+# [DEPRECATED] use fsdp_config.ulysses_sequence_parallel_size instead
+ulysses_sequence_parallel_size: 1
+
+# Gradient clipping for critic updates
+grad_clip: 1.0
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/critic/megatron_critic.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/critic/megatron_critic.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a4a8509f2278a7ad845b7659196792683b6eaeb5
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/critic/megatron_critic.yaml
@@ -0,0 +1,43 @@
+# defaults specify the default config from each component
+defaults:
+
+ # megatron optimizer config
+ - ../optim@optim: megatron
+
+ # megatron engine config
+ - ../engine@megatron: megatron
+
+ # dp actor config, inheriting from trainer/config/critic/critic.yaml
+ - critic
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+# Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+_target_: verl.workers.config.McoreCriticConfig
+
+strategy: megatron
+
+# seconds, default is 10 minutes for torch, you can set it to a larger value if you have long-running operations like 32B or 72B model using megatron
+nccl_timeout: 600
+
+# model config for the critic
+model:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.BaseModelConfig
+
+ # override default empty mapping
+ override_config:
+
+ model_config: {}
+
+ moe_config:
+
+ freeze_moe_router: False
+
+# Whether to load initial weights
+load_weight: True
+
+# seed for data loader
+data_loader_seed: ${oc.select:actor_rollout_ref.actor.data_loader_seed,null}
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/data/legacy_data.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/data/legacy_data.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..60818f9e198e86266f51c5ac6c997fe73fe38300
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/data/legacy_data.yaml
@@ -0,0 +1,131 @@
+# Tokenizer class or path. If null, it will be inferred from the model.
+tokenizer: null
+
+# Whether to use shared memory for data loading.
+use_shm: False
+
+# Training set parquet. Can be a list or a single file.
+# The program will read all files into memory, so it can't be too large (< 100GB).
+# The path can be either a local path or an HDFS path.
+# For HDFS path, we provide utils to download it to DRAM and convert it to a local path.
+train_files: ~/data/rlhf/gsm8k/train.parquet
+
+# Validation parquet. Can be a list or a single file.
+val_files: ~/data/rlhf/gsm8k/test.parquet
+
+# Maximum sample length to be used.
+# Set to -1 to use full dataset, otherwise, randomly
+# select the specified number of samples from train dataset
+train_max_samples: -1
+
+# Maximum sample length to be used.
+# Set to -1 to use full dataset, otherwise, randomly
+# select the specified number of samples from val dataset
+val_max_samples: -1
+
+# The field in the dataset where the prompt is located. Default is 'prompt'.
+prompt_key: prompt
+
+# The field used to select the reward function (if using different ones per example).
+reward_fn_key: data_source
+
+# Maximum prompt length. All prompts will be left-padded to this length.
+# An error will be reported if the length is too long.
+# oc.select: default val for rollout.prompt_length
+max_prompt_length: 512
+
+# Maximum response length. Rollout in RL algorithms (e.g. PPO) generates up to this length.
+# oc.select: default val for rollout.response_length
+max_response_length: 512
+
+# Batch size sampled for one training iteration of different RL algorithms.
+train_batch_size: 1024
+
+# Batch size used during validation. Can be null.
+val_batch_size: null
+
+# use tool config to calculate true prompt length
+tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path, null}
+
+# Whether to return the original input_ids without adding chat template.
+# This is used when the reward model's chat template differs from the policy.
+# If using a model-based RM with different templates, this should be True.
+return_raw_input_ids: False
+
+# Whether to return the original chat (prompt) without applying chat template.
+return_raw_chat: True
+
+# Whether to return the full prompt with chat template.
+return_full_prompt: False
+
+# Whether to shuffle the data in the dataloader.
+shuffle: True
+
+# Seed to use when shuffling the data
+seed: null
+
+# num dataloader workers
+dataloader_num_workers: 8
+
+# image patch size
+image_patch_size: 14
+
+# Whether to shuffle the validation set.
+validation_shuffle: False
+
+# Whether to filter overlong prompts.
+filter_overlong_prompts: False
+
+# Number of workers for filtering overlong prompts.
+# For large-scale datasets, filtering can be time-consuming.
+# Use multiprocessing to speed up. Default is 1.
+filter_overlong_prompts_workers: 1
+
+# Truncate the input_ids or prompt if they exceed max_prompt_length.
+# Options: 'error', 'left', 'right', 'middle'. Default is 'error'.
+truncation: error
+
+# The field in the multi-modal dataset where the image is located. Default is 'images'.
+image_key: images
+
+# The field in the multi-modal dataset where the video is located.
+video_key: videos
+
+# If the remote tokenizer has a Python file, this flag determines whether to allow using it.
+trust_remote_code: False
+
+# Optional: specify a custom dataset class path and name if overriding default loading behavior.
+custom_cls:
+
+ # The path to the file containing your customized dataset class. If not specified, pre-implemented dataset will be used.
+ path: null
+
+ # The name of the dataset class within the specified file.
+ name: null
+
+# Whether to return multi-modal inputs in the dataset. Set to False if rollout generates new multi-modal inputs.
+return_multi_modal_inputs: True
+
+# settings related to data sampler
+sampler:
+
+ # the path to the module containing a curriculum class which implements the
+ # AbstractSampler interface
+ class_path: null
+
+ # the name of the curriculum class like `MySampler`
+ class_name: null
+
+# Data generation configuration for augmenting the dataset.
+datagen:
+
+ # The path to the file containing your customized data generation class.
+ # E.g. 'pkg://verl.experimental.dynamic_dataset.dynamicgen_dataset'
+ path: null
+
+ # The class name of the data generation class within the specified file.
+ # E.g. 'MockDataGenerator'
+ name: null
+
+# Additional kwargs when calling tokenizer.apply_chat_template
+apply_chat_template_kwargs: {}
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/engine/fsdp.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/engine/fsdp.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..561d50bacc6f62ef5f50bb6046fd83f316d4fdb7
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/engine/fsdp.yaml
@@ -0,0 +1,56 @@
+# Target class for this configuration
+_target_: verl.workers.config.FSDPEngineConfig
+
+# policy for wrapping the model
+wrap_policy:
+
+ # Minimum number of parameters to trigger wrapping a layer with FSDP
+ min_num_params: 0
+
+# Whether to offload model parameters to CPU (trades speed for memory)
+# Note that this differs from the offload_policy in FSDP
+param_offload: false
+
+# Whether to offload optimizer state to CPU
+# Note that this differs from the offload_policy in FSDP
+optimizer_offload: false
+
+# Only for FSDP2: offload param/grad/optimizer during train
+offload_policy: false
+
+# Only for FSDP2: Reshard after forward pass to reduce memory footprint
+reshard_after_forward: true
+
+# Number of GPUs in each FSDP shard group; -1 means auto
+fsdp_size: -1
+
+# Only for FSDP1: FSDP1 configuration, prefetch the next forward-pass all-gather
+# before the current forward computation.
+forward_prefetch: False
+
+# model dtype of fsdp
+model_dtype: fp32
+
+# Whether to use original parameters in fsdp. Only avaiable in fsdp1
+use_orig_params: false
+
+# ulysses sequence parallel size
+ulysses_sequence_parallel_size: 1
+
+# Whether to use entropy_from_logits_with_chunking in fsdp.
+entropy_from_logits_with_chunking: false
+
+# Whether to use torch compile in fsdp.
+use_torch_compile: true
+
+# Whether to use entropy checkpointing in fsdp.
+entropy_checkpointing: false
+
+# Whether to use forward only in fsdp.
+forward_only: false
+
+# fsdp or fsdp2
+strategy: fsdp
+
+# Mixed precision training param dtype
+dtype: bfloat16 # ["bfloat16", "float16"]
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/engine/megatron.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/engine/megatron.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..907f32526b7c6495d45aef7dd3975b6e8836a7f4
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/engine/megatron.yaml
@@ -0,0 +1,84 @@
+# Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+_target_: verl.workers.config.McoreEngineConfig
+
+# Whether to offload model parameters to CPU
+param_offload: False
+
+# Whether to offload gradients to CPU
+grad_offload: False
+
+# Whether to offload optimizer state to CPU
+optimizer_offload: False
+
+# tensor model parallel size
+tensor_model_parallel_size: 1
+
+# expert model parallel size
+expert_model_parallel_size: 1
+
+# expert tensor parallel size (null to be same as TP)
+expert_tensor_parallel_size: null
+
+# pipeline model parallel size
+pipeline_model_parallel_size: 1
+
+# virtual pipeline model parallel size
+virtual_pipeline_model_parallel_size: null
+
+# context parallel size
+context_parallel_size: 1
+
+# sequence parallel
+sequence_parallel: True
+
+# Whether to use distributed optimizer
+use_distributed_optimizer: True
+
+# Whether to use distributed checkpointing
+use_dist_checkpointing: False
+
+# distributed checkpointing path
+dist_checkpointing_path: null
+
+# distributed checkpointing prefix, e.g. Nemo2 will append prefix 'module.' to the state dict keys
+dist_checkpointing_prefix: ''
+
+# oc.select: default val for ref.megatron.seed
+seed: 42
+
+# Allow to override Distributed Data Parallel (DDP) config
+override_ddp_config: {}
+
+# additional transformer config like: num_layers_in_first(/last)_pipeline_stage
+# oc.select: default val for ref.megatron.override_transformer_config
+override_transformer_config:
+ # Recompute configuration, same as in megatron.training.arguments
+ # default use minimal performance-interference recompute methods
+ # Recompute granualarity, choices: ["full", "selective"]
+ recompute_granularity: null
+
+ # Recompute modules, multiple choices: ["core_attn", "moe_act", "layernorm", "mla_up_proj", "mlp", "moe"]
+ # Please use correct module in matched model
+ recompute_modules: ["core_attn"]
+
+ # 'uniform', 'block'
+ # 'uniform' divides the total number of transformer layers and checkpoints the input activation of each chunk
+ # 'block' checkpoints the specified number of layers per pipeline stage at the specified granularity
+ recompute_method: null
+
+ # 'full' will checkpoint the entire transformer layer and 'selective' only checkpoints memory intensive part of attention
+ recompute_num_layers: null
+
+ # Attention backend to use (flash,fused,unfused,local,auto). Defaults to auto in mcore, flash in verl
+ attention_backend: flash
+
+override_mcore_model_config: {}
+
+# oc.select: default val for ref.megatron.use_mbridge
+use_mbridge: False
+
+# whether to use forward only
+forward_only: False
+
+# Mixed precision training param dtype
+dtype: bfloat16 # ["bfloat16", "float16"]
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/evaluation.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/evaluation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..6a88d77f1e73b6c3cce1972f639fcafb412669fa
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/evaluation.yaml
@@ -0,0 +1,15 @@
+data:
+ path: /tmp/math_Qwen2-7B-Instruct.parquet
+ prompt_key: prompt
+ response_key: responses
+ data_source_key: data_source
+ reward_model_key: reward_model
+
+custom_reward_function:
+ path: null
+ name: compute_score
+
+ray_kwargs:
+ ray_init:
+ num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/generation.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/generation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e542d61596608ca5c09f0c5eb76564eeef4e3019
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/generation.yaml
@@ -0,0 +1,58 @@
+trainer:
+ nnodes: 1
+ n_gpus_per_node: 8
+ device: cuda
+
+data:
+ path: ~/data/rlhf/math/test.parquet
+ prompt_key: prompt
+ n_samples: 5
+ output_path: /opt/tiger/math_Qwen2-7B-Instruct.parquet
+ batch_size: 128
+
+model:
+ path: ~/models/Qwen2-7B-Instruct
+ external_lib: null
+rollout:
+ _target_: verl.workers.config.RolloutConfig
+ name: vllm
+ mode: sync # sync: LLM, async: AsyncLLM
+ temperature: 1.0
+ top_k: 50 # 0 for hf rollout, -1 for vllm rollout
+ top_p: 0.7
+ prompt_length: 1536
+ response_length: 512
+ # for vllm rollout
+ dtype: bfloat16 # should align with FSDP
+ gpu_memory_utilization: 0.5
+ ignore_eos: False
+ enforce_eager: True
+ free_cache_engine: True
+ load_format: auto
+ tensor_model_parallel_size: 1
+ data_parallel_size: 1
+ max_num_batched_tokens: 8192
+ max_model_len: null
+ max_num_seqs: 1024
+ log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu
+ log_prob_micro_batch_size_per_gpu: 8
+ # for hf rollout
+ do_sample: True
+ disable_log_stats: True
+ enable_chunked_prefill: True
+ n: 1
+ # support logging rollout prob for debugging purpose
+ calculate_log_probs: False
+actor:
+ strategy: fsdp # This is for backward-compatibility
+ ulysses_sequence_parallel_size: 1 # sp size
+ entropy_from_logits_with_chunking: False # calculate entropy with chunking to reduce memory peak
+ entropy_checkpointing: False # recompute entropy
+ fsdp_config:
+ fsdp_size: -1
+ forward_prefetch: False # FSDP1 forward_prefetch configuration
+
+ray_kwargs:
+ ray_init:
+ num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/model/hf_model.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/model/hf_model.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..6d02b8eac898c88e3806dbe8f1641901d334a404
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/model/hf_model.yaml
@@ -0,0 +1,67 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+_target_: verl.workers.config.HFModelConfig
+
+# path to the huggingface model
+path: ~/models/deepseek-llm-7b-chat
+
+# config to the huggingface config. In case it is not the same as path
+hf_config_path: null
+
+# path to the huggingface tokenizer. In case it is not the same as path
+tokenizer_path: null
+
+# whether to use shared memory for model loading
+use_shm: False
+
+# whether to trust remote code.
+trust_remote_code: False
+
+# custom chat template for the model
+custom_chat_template: null
+
+# whether to use external libs for the model
+external_lib: null
+
+# override hf config
+override_config: {}
+
+# whether to enable gradient checkpointing. Only valid when we use hf model definition
+enable_gradient_checkpointing: True
+
+# whether to enable activation offload. Only valid when we use hf model definition
+enable_activation_offload: False
+
+# whether to use remove padding. Only valid when we use hf model definition
+use_remove_padding: False
+
+# Set to positive value to enable LoRA (e.g., 32)
+lora_rank: 0
+
+# LoRA scaling factor
+lora_alpha: 16
+
+# Target modules for LoRA adaptation
+target_modules: all-linear
+
+# Exclude modules from LoRA adaptation
+exclude_modules: null
+
+# Path to pre-trained LoRA adapter to load for continued training
+lora_adapter_path: null
+
+# whether to use liger. Only valid when we use hf model definition
+use_liger: False
+
+# whether to use fused kernels.
+use_fused_kernels: False
+
+# fused kernel options.
+fused_kernel_options:
+
+ # the implementation backend for fused kernels.
+ impl_backend: torch
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/npu_profile/npu_profile.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/npu_profile/npu_profile.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..52bb52d3f40d7d6695708b7414c82c0136d8fba2
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/npu_profile/npu_profile.yaml
@@ -0,0 +1,34 @@
+# Options for the npu profiler
+options:
+
+ # Storage path of collected data.
+ save_path: ./profiler_data
+
+ # The roles that will be profiled. Only takes effect in discrete mode.
+ # optional values: all, rollout_generate, actor_compute_log_prob, actor_update and ref_compute_log_prob.
+ # "all" means all roles will be profiled.
+ roles: ["all"]
+
+ # Collection level, optional values: level_none, level0, level1, level2.
+ level: level1
+
+ # Whether to enable memory analysis.
+ with_memory: False
+
+ # Whether to record tensor shape.
+ record_shapes: False
+
+ # Whether to record Device-side performance data.
+ with_npu: True
+
+ # Whether to record Host-side performance data.
+ with_cpu: True
+
+ # Whether to record Python call stack information.
+ with_module: False
+
+ # Whether to record operator call stack information.
+ with_stack: False
+
+ # Whether to automatically parse the data.
+ analysis: True
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/optim/fsdp.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/optim/fsdp.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a7dd99b1ee2a3c724dd2b45b4db75b86dadcffa0
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/optim/fsdp.yaml
@@ -0,0 +1,50 @@
+# Target class for this configuration
+_target_: verl.workers.config.FSDPOptimizerConfig
+
+# Optimizer class name (e.g., "AdamW", "AdamW8bit", "_AdamW", "Adam")
+optimizer: AdamW
+
+# Module path to import optimizer
+# Examples: "torch.optim", "torchao.optim", "bitsandbytes.optim"
+optimizer_impl: torch.optim
+
+# Learning rate
+lr: 1e-3
+
+# LR warmup steps ratio
+lr_warmup_steps_ratio: 0.0
+
+# Total training steps
+total_training_steps: -1
+
+# Weight decay
+weight_decay: 0.01
+
+# LR warmup steps
+lr_warmup_steps: -1
+
+# Betas for Adam optimizer
+betas: [0.9, 0.999]
+
+# Clip gradient
+clip_grad: 1.0
+
+# Minimum LR ratio for cosine schedule
+min_lr_ratio: 0.0
+
+# Number of cosine cycles in LR schedule
+num_cycles: 0.5
+
+# LR scheduler type: "constant" or "cosine"
+lr_scheduler_type: constant
+
+# deprecated
+warmup_style: null
+
+# Additional optimizer-specific keyword arguments
+# Example for torchao with bf16 stochastic rounding:
+# optimizer_impl: torchao.optim
+# optimizer: _AdamW
+# override_optimizer_config:
+# bf16_stochastic_round: true
+override_optimizer_config: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/optim/megatron.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/optim/megatron.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c3e49b7df8e59d33f51b50b943d9353af66d296c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/optim/megatron.yaml
@@ -0,0 +1,49 @@
+_target_: verl.workers.config.McoreOptimizerConfig
+
+# Learning rate
+lr: 1e-3
+
+# LR warmup steps ratio
+lr_warmup_steps_ratio: 0.0
+
+# Total training steps
+total_training_steps: -1
+
+# Weight decay
+weight_decay: 0.01
+
+# LR warmup steps
+lr_warmup_steps: -1
+
+# Betas for Adam optimizer
+betas: [0.9, 0.999]
+
+# Clip gradient
+clip_grad: 1.0
+
+# optimizer type
+optimizer: adam
+
+# initial learning rate for warmup, default to 0.0
+lr_warmup_init: 0.0
+
+lr_decay_steps: null
+
+# select from constant/linear/cosine/inverse_square_root
+lr_decay_style: constant
+
+# minimum learning rate, default to 0.0
+min_lr: 0.0
+
+# select from constant/linear/cosine
+weight_decay_incr_style: constant
+
+# select from constant/exponential/cosine
+lr_wsd_decay_style: exponential
+
+lr_wsd_decay_steps: null
+
+# use checkpoint optimizer parameter scheduler
+use_checkpoint_opt_param_scheduler: False
+
+override_optimizer_config: {}
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/ppo_megatron_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/ppo_megatron_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..670b2ca7ba4dcbedf068b5fb1839d19e0d9d0c22
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/ppo_megatron_trainer.yaml
@@ -0,0 +1,173 @@
+# specify the default per-component configs
+defaults:
+ # @.:
+ # actor_rollout_ref.actor: trainer/config/actor/megatron_actor.yaml
+ - actor@actor_rollout_ref.actor: megatron_actor
+ # data: trainer/config/data/legacy_data.yaml
+ - data@data: legacy_data
+ # load the reference default config, then apply the fields in the current yaml
+ # Reference model config.
+ # Reference model will be enabled when actor.use_kl_loss or/and algorithm.use_kl_in_reward is/are True.
+ - ref@actor_rollout_ref.ref: megatron_ref
+ # Rollout model config.
+ - rollout@actor_rollout_ref.rollout: rollout
+ # Model config.
+ - model@actor_rollout_ref.model: hf_model
+ # Critic model config.
+ - critic@critic: megatron_critic
+ # Reward model config.
+ - reward_model@reward_model: megatron_reward_model
+ # Rollout correction config.
+ - algorithm@algorithm.rollout_correction: rollout_correction
+ - _self_
+
+actor_rollout_ref:
+ hybrid_engine: True
+
+ nccl_timeout: 600 # seconds, default is 10 minutes for torch, you can set it to a larger value if you have long-running operations like 32B or 72B model using megatron
+
+ model:
+ override_config:
+ model_config: {}
+ moe_config:
+ freeze_moe_router: False
+
+ rollout:
+ quantization: null
+
+ layer_name_map:
+ qkv_layer_name: qkv
+ gate_proj_layer_name: gate_up
+
+custom_reward_function:
+ path: null
+ name: compute_score
+
+algorithm:
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.AlgoConfig
+ gamma: 1.0
+ lam: 1.0
+ adv_estimator: gae
+ norm_adv_by_std_in_grpo: True
+ use_kl_in_reward: False
+ kl_penalty: kl # how to estimate kl divergence
+ kl_ctrl:
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.KLControlConfig
+ type: fixed
+ kl_coef: 0.001
+ horizon: 10000
+ target_kl: 0.1
+ use_pf_ppo: False
+ pf_ppo:
+ reweight_method: pow # ["pow", "max_min", "max_random"]
+ weight_pow: 2.0
+
+trainer:
+ balance_batch: True
+ total_epochs: 30
+ total_training_steps: null
+ project_name: verl_examples
+ experiment_name: gsm8k
+ logger: ["console", "wandb"]
+ log_val_generations: 0
+ nnodes: 1
+ n_gpus_per_node: 8
+ save_freq: -1
+ esi_redundant_time: 0
+
+ # auto: find the last ckpt to resume. If can't find, start from scratch
+ resume_mode: auto # or disable or resume_path if resume_from_path is set
+ resume_from_path: null
+ del_local_ckpt_after_load: False
+ val_before_train: True
+ test_freq: -1
+ critic_warmup: 0
+ default_hdfs_dir: null
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ max_actor_ckpt_to_keep: null
+ max_critic_ckpt_to_keep: null
+ # The timeout for ray worker group to wait for the register center to be ready
+ ray_wait_register_center_timeout: 300
+ device: cuda
+ # Directory for logging rollout data; no dump if null
+ rollout_data_dir: null
+
+ # whether to use legacy worker implementation
+ # mode: "auto", "enable", or "disable"
+ use_legacy_worker_impl: auto
+
+global_profiler:
+ _target_: verl.utils.profiler.ProfilerConfig
+ tool: null # choose between nsys, npu, torch, torch_memory
+ steps: null # profile steps
+ profile_continuous_steps: False
+ save_path: "outputs/profile" # profiler saving path
+ # Specific tool configs, can use +profiler.tool_config.[tool].xxx to config
+ global_tool_config:
+ # nsys config
+ nsys:
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # controller Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ ## reference https://docs.nvidia.com/nsight-systems/UserGuide/index.html
+ ## reference https://docs.ray.io/en/latest/ray-observability/user-guides/profiling.html
+ controller_nsight_options:
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # worker Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ worker_nsight_options:
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # Profiling only in a range of torch.cuda.profiler.start and stop. Do not change this config.
+ capture-range: "cudaProfilerApi"
+
+ # Specify the desired behavior when a capture range ends.
+ # In verl we need the torch.cuda.profiler.start/stop pair to repeats n times.
+ # valid values are "repeat-shutdown:n" or null.
+ # For normal whole step profiling, n = len(profile_steps);
+ # but for discrete profiling, n = len(profile_steps) * Number(subtasks).
+ # Or you can just leave it null and the program will use n = len(profile_steps) * 6;
+ capture-range-end: null
+
+ # Send signal to the target application's process group. We let the program to exit by itself.
+ kill: none
+
+ # enable memory visualization for debugging memory usage
+ torch_memory:
+ # Maximum number of allocation entries to record
+ trace_alloc_max_entries: 100_000
+ # The depth of the call stack to capture for each allocation
+ stack_depth: 32
+ # 'alloc': records only allocation events || 'state': records memory state changes || 'all': records both.
+ context: "all"
+ # 'python': records Python stacks || 'cpp': records C++ stacks (available in some versions) || 'all': records both.
+ stacks: "all"
+ # devices, record_context etc.
+ kw_args: {}
+
+# configs for TransferQueue
+transfer_queue:
+ # Whether to enable transfer queue
+ enable: False
+
+ray_kwargs:
+ ray_init:
+ num_cpus: null # `None` means using all CPUs, which might cause hang if limited in systems like SLURM. Please set to a number allowed then.
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/ppo_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/ppo_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..39a338ea39c37bbdc1110dff9d4bce9d39488651
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/ppo_trainer.yaml
@@ -0,0 +1,317 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# specify the default per-component configs
+defaults:
+
+ # @.:
+ # actor_rollout_ref.actor: trainer/config/actor/dp_actor.yaml
+ - actor@actor_rollout_ref.actor: dp_actor
+
+ # data: trainer/config/data/legacy_data.yaml
+ - data@data: legacy_data
+
+ # Reference model config.
+ # Reference model will be enabled when actor.use_kl_loss or/and algorithm.use_kl_in_reward is/are True.
+ - ref@actor_rollout_ref.ref: dp_ref
+
+ # Rollout model config.
+ - rollout@actor_rollout_ref.rollout: rollout
+
+ # Model config.
+ - model@actor_rollout_ref.model: hf_model
+
+ # Critic model config.
+ - critic@critic: dp_critic
+
+ # Reward model config.
+ - reward_model@reward_model: dp_reward_model
+
+ # Rollout correction config.
+ - algorithm@algorithm.rollout_correction: rollout_correction
+
+ # load the reference default config, then apply the fields in the current yaml
+ # self config override anything above
+ - _self_
+
+# config for actor, rollout and reference model
+actor_rollout_ref:
+
+ # Whether it's a hybrid engine, currently only supports hybrid engine
+ hybrid_engine: true
+
+ # Timeout for operations executed against the process group
+ nccl_timeout: 600
+
+ # Rollout model config.
+ rollout:
+
+ # for huge model, layered summon can save memory (prevent OOM) but make it slower
+ layered_summon: False
+
+# custom reward function definition
+custom_reward_function:
+
+ # The path to the file containing your customized reward function.
+ # If not specified, pre-implemented reward functions will be used.
+ path: null
+
+ # The name of the reward function within the specified file. Default is 'compute_score'.
+ name: compute_score
+
+# config for the algorithm
+algorithm:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.AlgoConfig
+
+ # Discount factor for future rewards
+ gamma: 1.0
+
+ # Trade-off between bias and variance in the GAE estimator
+ lam: 1.0
+
+ # Advantage estimator type: "gae", "grpo", "reinforce_plus_plus", etc.
+ adv_estimator: gae
+
+ # Whether to normalize advantages by std (specific to GRPO)
+ norm_adv_by_std_in_grpo: True
+
+ # Whether to enable in-reward KL penalty
+ use_kl_in_reward: False
+
+ # How to estimate KL divergence: "kl", "abs", "mse", "low_var_kl", or "full"
+ kl_penalty: kl
+
+ # KL control configuration
+ kl_ctrl:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.trainer.config.KLControlConfig
+
+ # KL control type: "fixed" or "adaptive"
+ type: fixed
+
+ # Initial coefficient for KL penalty
+ kl_coef: 0.001
+
+ # Horizon value for adaptive controller (if enabled)
+ horizon: 10000
+
+ # Target KL divergence (used for adaptive controller)
+ target_kl: 0.1
+
+ # Whether to enable preference feedback PPO
+ use_pf_ppo: False
+
+ # Preference feedback PPO settings
+ pf_ppo:
+
+ # Method for reweighting samples: "pow", "max_min", or "max_random"
+ reweight_method: pow
+
+ # Power used for weight scaling in "pow" method
+ weight_pow: 2.0
+
+# config for the trainer
+trainer:
+
+ # Whether to balance batch sizes across distributed workers
+ balance_batch: True
+
+ # Number of epochs in training
+ total_epochs: 30
+
+ # Total training steps (can be set explicitly or derived from epochs)
+ total_training_steps: null
+
+ # Project name for experiment tracking (e.g., wandb)
+ project_name: verl_examples
+
+ # Experiment name for run identification in tracking tools
+ experiment_name: gsm8k
+
+ # Logging backends to use: "console", "wandb", etc.
+ logger: ["console", "wandb"]
+
+ # Number of generations to log during validation
+ log_val_generations: 0
+
+ # Directory for logging rollout data; no dump if null
+ rollout_data_dir: null
+
+ # Directory for logging validation data; no dump if null
+ validation_data_dir: null
+
+ # Number of nodes used in the training
+ nnodes: 1
+
+ # Number of GPUs per node
+ n_gpus_per_node: 8
+
+ # Save frequency (by iteration) for model checkpoints
+ save_freq: -1
+
+ # ESI refers to the elastic server instance used during training, similar to the training plan. For example,
+ # if you purchase 10 hours of computing power, the ESI will automatically shut down after 10 hours of training.
+ # To ensure a checkpoint is saved before ESI shuts down, the system will start saving a checkpoint in advance.
+ # The advance time is calculated as: Advance Time = Longest historical step duration + Checkpoint save duration + esi_redundant_time.
+ # Here, esi_redundant_time is a user-defined value that further extends the advance time for added safety.
+ esi_redundant_time: 0
+
+ # Resume mode: "auto", "disable", or "resume_path"
+ # "auto": resume from last checkpoint if available
+ # "disable": start from scratch
+ # "resume_path": resume from a user-defined path
+ resume_mode: auto
+
+ # Path to resume training from (only used when resume_mode is "resume_path")
+ resume_from_path: null
+
+ # Whether to run validation before training begins
+ val_before_train: True
+
+ # Whether to run validation only
+ val_only: False
+
+ # Validation frequency (in training iterations)
+ test_freq: -1
+
+ # Number of iterations to warm up the critic before updating policy
+ critic_warmup: 0
+
+ # Default path to distributed filesystem for saving checkpoints
+ default_hdfs_dir: null
+
+ # Whether to delete local checkpoints after loading
+ del_local_ckpt_after_load: False
+
+ # Default local directory for saving checkpoints
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+
+ # Maximum number of actor checkpoints to keep
+ max_actor_ckpt_to_keep: null
+
+ # Maximum number of critic checkpoints to keep
+ max_critic_ckpt_to_keep: null
+
+ # Timeout (in seconds) for Ray worker to wait for registration
+ ray_wait_register_center_timeout: 300
+
+ # Device to run training on (e.g., "cuda", "cpu")
+ device: cuda
+
+ # whether to use legacy worker implementation
+ # mode: "auto", "enable", or "disable"
+ use_legacy_worker_impl: auto
+
+# profiler configs
+global_profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # Profiling tool: choose between nsys, npu, torch, torch_memory
+ tool: null
+
+ # profile steps
+ steps: null
+
+ # Whether to combine continuous steps into one database.
+ ## If True, worker.profiler.discrete must be False, [1,2] in one, [5] in another.
+ ## If False, [1] in one, [2] in another, [5] in another.
+ profile_continuous_steps: False
+
+ # Path to save profiling contents
+ save_path: "outputs/profile"
+
+ # Specific tool configs, can use +profiler.tool_config.[tool].xxx to config
+ global_tool_config:
+
+ # nsys config
+ nsys:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NsightToolConfig
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # controller Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ ## reference https://docs.nvidia.com/nsight-systems/UserGuide/index.html
+ ## reference https://docs.ray.io/en/latest/ray-observability/user-guides/profiling.html
+ controller_nsight_options:
+
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # worker Nvidia Nsight Systems Options. Must set when profile_steps is not None.
+ worker_nsight_options:
+
+ # Select the API(s) to be traced.
+ trace: "cuda,nvtx,cublas,ucx"
+
+ # Track the GPU memory usage by CUDA kernels. Must be string type "true" or "false".
+ cuda-memory-usage: "true"
+
+ # CUDA graphs will be traced as a whole
+ cuda-graph-trace: "graph"
+
+ # Profiling only in a range of torch.cuda.profiler.start and stop. Do not change this config.
+ capture-range: "cudaProfilerApi"
+
+ # Specify the desired behavior when a capture range ends.
+ # In verl we need the torch.cuda.profiler.start/stop pair to repeats n times.
+ # valid values are "repeat-shutdown:n" or null.
+ # For normal whole step profiling, n = len(profile_steps);
+ # but for discrete profiling, n = len(profile_steps) * Number(subtasks).
+ # Or you can just leave it null and the program will use n = len(profile_steps) * 6;
+ capture-range-end: null
+
+ # Send signal to the target application's process group. We let the program to exit by itself.
+ kill: none
+
+ # enable memory visualization for debugging memory usage
+ torch_memory:
+
+ # Maximum number of allocation entries to record
+ trace_alloc_max_entries: 100_000
+
+ # The depth of the call stack to capture for each allocation
+ stack_depth: 32
+
+ # 'alloc': records only allocation events || 'state': records memory state changes || 'all': records both.
+ context: "all"
+
+ # 'python': records Python stacks || 'cpp': records C++ stacks (available in some versions) || 'all': records both.
+ stacks: "all"
+
+ # devices, record_context etc.
+ kw_args: {}
+
+# configs for TransferQueue
+transfer_queue:
+
+ # Whether to enable transfer queue
+ enable: False
+
+# configs related to ray
+ray_kwargs:
+
+ # configs related to ray initialization
+ ray_init:
+
+ # Number of CPUs for Ray. Use a fixed number instead of null when using SLURM.
+ num_cpus: null
+
+ # Path to save Ray timeline JSON for performance profiling
+ timeline_json_file: null
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/ref/dp_ref.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/ref/dp_ref.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..64b7d2abbc0fe920f7ad3bf3424f9198865e9811
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/ref/dp_ref.yaml
@@ -0,0 +1,30 @@
+# defaults specify the default config from each component
+defaults:
+
+ # dp ref config, inheriting from trainer/config/ref/ref.yaml
+ - ref
+
+ # fsdp engine config
+ - ../engine@fsdp_config: fsdp
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+# Target class for this configuration
+_target_: verl.workers.config.FSDPActorConfig
+
+# fsdp config
+fsdp_config:
+
+ # ref model is forward only
+ forward_only: True
+
+# sequence parallel size
+# same as actor_rollout_ref.actor.ulysses_sequence_parallel_size if it exists, otherwise 1
+ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
+
+# calculate entropy with chunking to reduce memory peak
+entropy_from_logits_with_chunking: False
+
+# recompute entropy
+entropy_checkpointing: False
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/ref/megatron_ref.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/ref/megatron_ref.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..838d6a856831cb636e14c550ad77893918701a44
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/ref/megatron_ref.yaml
@@ -0,0 +1,28 @@
+# megatron ref config, inheriting from trainer/config/ref/ref.yaml
+defaults:
+ - ref
+
+ # megatron engine config
+ - ../engine@megatron: megatron
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+_target_: verl.workers.config.McoreActorConfig
+
+strategy: megatron
+
+megatron:
+ seed: ${oc.select:actor_rollout_ref.actor.megatron.seed,42}
+ override_transformer_config: ${oc.select:actor_rollout_ref.actor.megatron.override_transformer_config,{}}
+ use_mbridge: ${oc.select:actor_rollout_ref.actor.megatron.use_mbridge,False}
+ tensor_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.tensor_model_parallel_size,1}
+ pipeline_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.pipeline_model_parallel_size,1}
+ virtual_pipeline_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.virtual_pipeline_model_parallel_size,null}
+ context_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.context_parallel_size,1}
+ expert_model_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.expert_model_parallel_size,1}
+ expert_tensor_parallel_size: ${oc.select:actor_rollout_ref.actor.megatron.expert_tensor_parallel_size,null}
+ param_offload: ${oc.select:actor_rollout_ref.actor.megatron.param_offload,False}
+ forward_only: True
+
+load_weight: True
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/ref/ref.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/ref/ref.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..72b7ff048b23f7edd2a5fdf81687e1ccddd87289
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/ref/ref.yaml
@@ -0,0 +1,102 @@
+# Number of rollouts per update (mirrors actor rollout_n)
+rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
+
+# actor_rollout_ref.ref: FSDP config same as actor. For models larger than 7B, it’s recommended to turn on offload for ref by default
+strategy: ${actor_rollout_ref.actor.strategy}
+
+# whether to enable torch.compile
+# same as actor_rollout_ref.actor.use_torch_compile if it exists, otherwise 1
+use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
+
+# [Will be deprecated, use log_prob_micro_batch_size_per_gpu]
+# The batch size for one forward pass in the computation of log_prob. Global batch size.
+log_prob_micro_batch_size: null
+
+# The batch size for one forward pass in the computation of log_prob. Local batch size per GPU.
+log_prob_micro_batch_size_per_gpu: null
+
+# enable dynamic batch size (sequence packing) for log_prob computation
+# same as actor_rollout_ref.actor.use_dynamic_bsz if it exists, otherwise false
+log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+
+# the max token length per GPU
+# same as actor_rollout_ref.actor.ppo_max_token_len_per_gpu if it exists, otherwise 16384
+log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+
+# profile the ref model in `compute_log_prob`
+profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # choices: nsys, npu, torch, torch_memory
+ tool: ${oc.select:global_profiler.tool,null}
+
+ # whether enable profile on Ref
+ enable: False
+
+ # Whether to profile all ranks.
+ all_ranks: False
+
+ # The ranks that will be profiled. [] or [0,1,...]
+ ranks: []
+
+ # profile results saving path
+ save_path: ${oc.select:global_profiler.save_path,null}
+
+ # specific tool config which only related to the role
+ tool_config:
+
+ # nsys tool config
+ nsys:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NsightToolConfig
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
+
+ # npu config
+ npu:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.NPUToolConfig
+
+ # Contents to profile, can be empty
+ # options: npu, cpu, memory, shapes, module, stack
+ contents: []
+
+ # Collection level, optional values: level_none, level0, level1, level2.
+ level: "level1"
+
+ # Whether to automatically parse the data.
+ analysis: True
+
+ # True for each task has its own database, False for all tasks in one training step share one database.
+ discrete: False
+
+ # torch profiler config
+ torch:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchProfilerToolConfig
+
+ # start profile mini-batch in training
+ # NOTICE: different with global steps config which refers to iteration
+ # This field only related with mini-batch
+ step_start: 0
+
+ # stop profile mini-batch in training
+ step_end: null
+
+ # torch memory profiler config
+ torch_memory:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.config.TorchMemoryToolConfig
+
+ # Maximum number of memory allocation entries to track
+ trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
+
+ # Stack trace depth for memory allocations
+ stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/rep_exp_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/rep_exp_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..bd229439bff3bf9a6b498c4481e4bcf6a6a9aa06
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/rep_exp_trainer.yaml
@@ -0,0 +1,29 @@
+defaults:
+ - ppo_trainer
+ - _self_
+
+reward_model:
+ elliptical:
+ enable: True
+ lamb: 0.01
+ normalization: none # none, rnd, z_score
+ reward_type: leave_one_out # leave_one_out, leverage
+ sparse_dim: 512
+ randomize_sparse_matrix: True
+ persist_covariance: False
+
+ reward_kwargs:
+ elliptical:
+ alpha: 1.0
+ beta: 1.0
+ turn_off_elliptical_if_none_correct: True
+ turn_off_elliptical_if_some_correct: False
+ turn_off_elliptical_if_all_correct: False
+ turn_off_elliptical_if_rollout_incorrect: False
+
+actor_rollout_ref:
+ rollout:
+ val_kwargs:
+ temperature: 1.0
+ n: 128
+ do_sample: True
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/dp_reward_model.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/dp_reward_model.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..fff1f9f1f1d32100e77357781ee29a5728ef298c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/dp_reward_model.yaml
@@ -0,0 +1,55 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# defaults specify the default config from each component
+defaults:
+
+ # dp actor config, inheriting from trainer/config/reward_model/reward_model.yaml
+ - reward_model
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+strategy: fsdp
+
+model:
+
+ # Whether to use shared memory for loading the model
+ use_shm: False
+
+ # Use remove padding optimization (saves compute)
+ use_remove_padding: False
+
+ # Whether to use fused reward kernels for speedup
+ use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
+
+ # FSDP-specific config
+ fsdp_config:
+
+ # Target configuration dataclass
+ _target_: verl.workers.config.FSDPEngineConfig
+
+ # Policy for wrapping layers with FSDP
+ wrap_policy:
+
+ # Minimum number of parameters to trigger wrapping
+ min_num_params: 0
+
+ # Whether to offload model parameters to CPU
+ param_offload: False
+
+ # Only for FSDP2: Reshard after forward pass to reduce memory footprint
+ reshard_after_forward: True
+
+ # Number of GPUs in each FSDP shard group; -1 means auto
+ fsdp_size: -1
+
+ # Only for FSDP1: FSDP1 configuration, prefetch the next forward-pass all-gather
+ # before the current forward computation.
+ forward_prefetch: False
+
+# Sequence parallelism size for Ulysses-style model parallelism
+ulysses_sequence_parallel_size: 1
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/megatron_reward_model.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/megatron_reward_model.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..a2bab2c10e51cf3e434925c5d1369b88340182dc
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/megatron_reward_model.yaml
@@ -0,0 +1,70 @@
+# defaults specify the default config from each component
+defaults:
+
+ # dp actor config, inheriting from trainer/config/reward_model/reward_model.yaml
+ - reward_model
+
+ # load the reference default config, then apply the fields in the current yaml
+ - _self_
+
+strategy: megatron
+
+# seconds, default is 10 minutes for torch, you can set it to a larger value
+# if you have long-running operations like 32B or 72B model using megatron
+nccl_timeout: 600
+
+# Megatron parallelism & checkpointing config
+megatron:
+
+ # Target configuration dataclass
+ _target_: verl.workers.config.MegatronEngineConfig
+
+ # Whether to offload model parameters to CPU
+ param_offload: False
+
+ # Number of GPUs in tensor model parallel group
+ tensor_model_parallel_size: 1
+
+ # Number of GPUs in expert model parallel group
+ expert_model_parallel_size: 1
+
+ # Expert tensor parallel size (null to be same as TP)
+ expert_tensor_parallel_size: null
+
+ # Number of pipeline model parallel stages
+ pipeline_model_parallel_size: 1
+
+ # change VPP interface for parallelism tests
+ virtual_pipeline_model_parallel_size: null
+
+ # Context parallel size
+ context_parallel_size: 1
+
+ # Whether to use sequence parallelism
+ sequence_parallel: True
+
+ # Whether to use distributed optimizer
+ use_distributed_optimizer: False
+
+ # Whether to enable distributed checkpointing
+ use_dist_checkpointing: False
+
+ # Path for distributed checkpoints
+ dist_checkpointing_path: null
+
+ # distributed checkpointing prefix, e.g. Nemo2 will append prefix 'module.' to the state dict keys
+ dist_checkpointing_prefix: ''
+
+ # RNG seed for megatron
+ seed: ${oc.select:actor_rollout_ref.actor.megatron.seed,42}
+
+ # Any overrides to transformer config
+ override_transformer_config: ${oc.select:actor_rollout_ref.actor.megatron.override_transformer_config,{}}
+
+ # Whether to use mbridge for faster comms
+ use_mbridge: ${oc.select:actor_rollout_ref.actor.megatron.use_mbridge,False}
+
+ dtype: bfloat16
+
+# Whether to load weights (default True)
+load_weight: True
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/reward_model.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/reward_model.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e9ffc60fbc614377b81579454e7f88023db70d91
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/reward_model/reward_model.yaml
@@ -0,0 +1,97 @@
+# configs for the reward model
+
+# Whether to enable reward model. If False, we compute the reward only with the user-defined reward functions.
+# In GSM8K and Math examples, we disable reward model.
+# For RLHF alignment example using full_hh_rlhf, we utilize reward model to assess the responses.
+# If False, the following parameters are not effective
+enable: False
+
+# Whether to deploy the model to a separate resource pool.
+# If true, n_gpus_per_node & nnodes will be used to determine the resource node.
+enable_resource_pool: False
+n_gpus_per_node: 0
+nnodes: 0
+
+# FSDP strategy: "fsdp" or "fsdp2"
+strategy: ???
+
+# model config for reward scoring
+model:
+
+ # Input tokenizer. If the reward model's chat template is inconsistent with the policy,
+ # we need to first decode to plaintext, then apply the rm's chat_template.
+ # Then score with RM. If chat_templates are consistent, it can be set to null.
+ # set this to null if the chat template is identical
+ input_tokenizer: ${actor_rollout_ref.model.path}
+
+ # RM’s HDFS path or local path. Note that RM only supports AutoModelForSequenceClassification.
+ # Other model types need to define their own RewardModelWorker and pass it from the code.
+ path: ~/models/FsfairX-LLaMA3-RM-v0.1
+
+ # External model implementation (optional)
+ external_lib: ${actor_rollout_ref.model.external_lib}
+
+ # Whether to enable loading a remote code model, default to False
+ trust_remote_code: False
+
+# [Deprecated] Global micro batch size
+# will be deprecated, use micro_batch_size_per_gpu
+micro_batch_size: null
+
+# Local per-GPU micro batch size
+micro_batch_size_per_gpu: null
+
+# Maximum sequence length to process for scoring
+max_length: null
+
+# Whether to dynamically adjust batch size at runtime
+use_dynamic_bsz: ${critic.use_dynamic_bsz}
+
+# Maximum number of tokens per GPU in one forward pass
+forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
+
+# Reward Manager. This defines the mechanism of computing rule-based reward and handling different reward sources.
+# Default is naive. If all verification functions are multiprocessing-safe,
+# the reward manager can be set to prime for parallel verification.
+reward_manager: naive
+
+# Whether to launch custom reward function asynchronously during log_prob
+# custom reward function executed async on CPU, during log_prob
+launch_reward_fn_async: False
+
+# Cloud/local sandbox fusion configuration for custom reward logic
+sandbox_fusion:
+
+ # Cloud /local function URL for sandbox execution
+ url: null
+
+ # Max concurrent requests allowed to sandbox
+ max_concurrent: 64
+
+ # Max memory limit for each sandbox process in MB
+ memory_limit_mb: 1024
+
+# profile the reward model in `compute_reward`
+profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # profiler tool, default same as profiler.tool in global config
+ # choices: nsys, npu, torch
+ tool: ${oc.select:global_profiler.tool,null}
+
+ # whether enable profile on ref
+ enable: False
+
+ # Whether to profile all ranks.
+ all_ranks: False
+
+ # The ranks that will be profiled. [] or [0,1,...]
+ ranks: []
+
+ # profile results saving path
+ save_path: ${oc.select:global_profiler.save_path,null}
+
+ # specific tool config
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/rollout/rollout.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/rollout/rollout.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..b1931344bccbbec02116e71a7e46050f65c2a830
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/rollout/rollout.yaml
@@ -0,0 +1,322 @@
+# Target class for this configuration
+_target_: verl.workers.config.RolloutConfig
+
+# actor_rollout_ref.rollout.name: hf/vllm/sglang. The default value will be removed in the future
+name: ???
+
+# sync: LLM, async: AsyncLLM
+mode: async
+
+# Sampling temperature for rollout.
+temperature: 1.0
+
+# Top-k sampling parameter. -1 for vLLM rollout, 0 for HF rollout.
+top_k: -1
+
+# Top-p sampling parameter. Default 1.0.
+top_p: 1
+
+# typically the same as data max prompt length
+# same as data.max_prompt_length if it exists
+prompt_length: ${oc.select:data.max_prompt_length,512}
+
+# typically the same as data max response length
+# same as data.max_response_length if it exists
+response_length: ${oc.select:data.max_response_length,512}
+
+# for vllm rollout
+# Rollout model parameters type. Align with actor model's FSDP/Megatron type.
+dtype: bfloat16
+
+# Fraction of GPU memory used by vLLM/SGLang for KV cache.
+gpu_memory_utilization: 0.5
+
+# Whether to ignore EOS and continue generating after EOS is hit.
+ignore_eos: False
+
+# Whether to disable CUDA graph. Default False to best performance.
+enforce_eager: False
+
+# batch size of cudagraph to capture. Require enforce_eager: False to use this option
+# Since cudagraph in inference engine can not be offloaded during update policy,
+# you can use smaller batch size to save memory used in cuda graph, eg: [1 ,2, 4, 8, 16, 32]
+# supported engines: vllm
+cudagraph_capture_sizes: null
+
+# Whether to free engine KVCache after generation.
+free_cache_engine: True
+
+# TP size for rollout. Not effective for hf
+tensor_model_parallel_size: 2
+
+# DP size for rollout
+data_parallel_size: 1
+
+# EP size for rollout
+expert_parallel_size: 1
+
+# PP size for rollout.
+pipeline_model_parallel_size: 1
+
+# max number of tokens in a batch
+max_num_batched_tokens: 8192
+
+# max length for rollout
+max_model_len: null
+
+# max length of sequences
+max_num_seqs: 1024
+
+# may get higher throughput when set to True. When activated, Please increase max_num_batched_tokens or decrease max_model_len.
+enable_chunked_prefill: True
+
+# Prefix caching kv-cache blocks is a popular optimization in LLM inference to avoid redundant prompt computations.
+enable_prefix_caching: True
+
+# Which loader to use for rollout model weights: dummy, hf, megatron, etc.
+# safetensors (for huge model, and set use_shm=True); dummy: randomly init model weight
+load_format: dummy
+
+# [Will be deprecated, use log_prob_micro_batch_size_per_gpu] The batch size for one forward pass in the computation of log_prob. Global batch size.
+log_prob_micro_batch_size: null
+
+# The batch size for one forward pass in the computation of log_prob. Local batch size per GPU.
+log_prob_micro_batch_size_per_gpu: null
+
+# enable dynamic batch size (sequence packing) for log_prob computation
+# same as actor_rollout_ref.actor.use_dynamic_bsz if it exists, otherwise false
+log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
+
+# max token length for log_prob computation
+# same as actor_rollout_ref.actor.ppo_max_token_len_per_gpu if it exists, otherwise 16384
+log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
+
+# disable logging statistics
+disable_log_stats: True
+
+# for hf rollout
+# Whether to sample during training rollout. False uses greedy sampling.
+do_sample: True
+
+# number of responses (i.e. num sample times). > 1 for grpo
+n: 1
+
+# The over_sample_rate parameter controls the early termination threshold for training rollouts,
+# where the system will abort remaining requests when (1 - over_sample_rate) * total_requests completions are reached.
+over_sample_rate: 0
+
+# Whether to wake up inference engine in multi-stage for SGLang
+# to reduce peak memory during training-rollout transition.
+# This is only effective for SGLang rollout.
+multi_stage_wake_up: false
+
+# Extra inference engine arguments (vllm, sglang), please refer vllm/sglang official doc for detail
+engine_kwargs:
+
+ # vllm engine config
+ vllm: {}
+
+ # sglang engine config
+ sglang: {}
+
+# Sampling parameters used during validation.
+val_kwargs:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.SamplingConfig
+
+ # sampling parameters for validation
+ # Top-k sampling parameter. -1 for vLLM rollout, 0 for HF rollout.
+ top_k: -1
+
+ # Top-p sampling parameter. Default 1.0.
+ top_p: 1.0
+
+ # Sampling temperature for rollout.
+ temperature: 0
+
+ # whether to repeat n times for validation
+ n: 1
+
+ # Whether to sample during training rollout. False uses greedy sampling.
+ do_sample: False
+
+# Multi-turn interaction config for tools or chat.
+multi_turn:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.MultiTurnConfig
+
+ # set to True for multi-turn tool interaction tasks; should set rollout.name to sglang as well
+ enable: False
+
+ # null for no limit (default max_length // 3)
+ max_assistant_turns: null
+
+ # null for no tool
+ tool_config_path: null
+
+ # null for no limit (default max_length // 3)
+ max_user_turns: null
+
+ # max parallel call for tools in single turn
+ max_parallel_calls: 1
+
+ # max length of tool response
+ max_tool_response_length: 256
+
+ # truncate side of tool response: left, middle, right
+ tool_response_truncate_side: middle
+
+ # null for no interaction
+ interaction_config_path: null
+
+ # - When set to True, the model's default chat template is used for multi-turn rollout, which typically matches production behavior.
+ # - When set to False, the token ids recorded for training are used instead; unlike the default chat template, these always include the model's full output,
+ # which may contain additional content such as reasoning content. This maintains the consistency between training and rollout, but it will lead to longer prompts.
+ use_inference_chat_template: False
+
+ # Tokenization is performed turn by turn and the resulting token ids are concatenated to form the full conversation.
+ # To ensure this matches the result of tokenizing the entire conversation at once, a sanity check is run at the end of each multi-turn rollout to compare the two sets of token ids.
+ # Some models are known to produce different tokenization results when tokenizing turn by turn vs. all at once. aThis behavior has already been validated for them.
+ # To reduce excessive warnings, you can turn off the sanity check for these models if you are using their default chat template:
+ # Qwen/QwQ-32B, Qwen/Qwen3-xxB
+ # - disable: disable tokenization sanity check
+ # - strict: enable strict tokenization sanity check (default)
+ # - ignore_strippable: ignore strippable tokens when checking tokenization sanity
+ tokenization_sanity_check_mode: strict
+
+ # Format of the multi-turn interaction. Options: hermes, llama3_json, ...
+ format: hermes
+
+ # Number of repeat rollouts for each interaction
+ num_repeat_rollouts: null
+
+# support logging rollout prob for debugging purpose
+# "Truncated importance sampling" requires rollout log probs, set to True when turning on Truncated importance sampling
+calculate_log_probs: False
+
+# [Experimental] agent loop based rollout configs
+agent:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.AgentLoopConfig
+
+ # Number of agent loop workers
+ num_workers: 8
+
+ # default agent loop to use if `agent_name` not set in RL dataset
+ default_agent_loop: single_turn_agent
+
+ # custom agent loop config path, which should contain list of configs to intialize AgentLoop instances.
+ # https://hydra.cc/docs/advanced/instantiate_objects/overview/
+ #
+ # - name: react_agent
+ # _target_: recipe.langgraph_agent.react_agent_loop.ReactAgentLoop
+ # tools: ["get_current_temperature"]
+ # - name: math_expression
+ # _target_: recipe.langgraph_agent.example.math_expression.MathExpressionReactAgentLoop
+ # min_terms: 2
+ # max_terms: 6
+ agent_loop_config_path: null
+
+ # custom async server configs
+ custom_async_server:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.CustomAsyncServerConfig
+
+ # Path to the custom async server implementation
+ path: null
+
+ # Class name of the custom async server class (e.g. AsyncvLLMServer)
+ name: null
+
+# Specifies the tensor bucket size (in megabytes) for batch weight updates during rollout operations.
+# This parameter controls the maximum payload size for a single weight update request.
+# Reference: https://github.com/volcengine/verl/pull/2418
+# Currently only supported in SGLang rollout implementations
+# Larger values may improve throughput but increase memory overhead
+# Detailed performance comparison:
+# https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/issues/169#issuecomment-3070686720
+# Default value (512MB) is optimized for typical GPU memory configurations
+# For the best performance of `rebuild_cuda_tensor`, it is recommended to:
+# 1. Enable `RAY_EXPERIMENTAL_NOSET_CUDA_VISIBLE_DEVICES`
+# 2. Manually set `CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7`
+# when using Tensor Parallelism (TP) >= 8.
+update_weights_bucket_megabytes: 512
+
+# trace rollout data
+trace:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.TraceConfig
+
+ # trace backend, support mlflow, weave
+ backend: null
+
+ # whether translate token id to text in output
+ token2text: False
+
+ # Maximum number of unique samples to trace per agent worker per training step.
+ # If null, all samples are traced. If set to N, each agent loop worker will randomly
+ # select N unique samples to trace (including all their rollouts for GRPO).
+ # Total traces per step = max_samples_per_step_per_worker * num_workers * n_rollouts_per_sample
+ max_samples_per_step_per_worker: null
+
+# When enabled (True), the trainer will attempt to load previously generated rollout data from the specified directory instead of computing new rollouts.
+# If no cached data is found or loading fails, new rollouts will be generated and automatically saved.
+# This feature is useful for debugging or when you want to reuse computation results across multiple runs.
+skip_rollout: False
+
+# Specifies the filesystem path where rollout data should be cached when skip_rollout is enabled.
+# Note: Giving path under /tmp/ray/session* is not recommended as these are temporary Ray cluster directories.
+skip_dump_dir: /tmp/rollout_dump
+
+# Whether to skip tokenizer initialization for rollout engine
+# When enabled (True), the rollout assume token in token out for generation
+skip_tokenizer_init: True
+
+# profile the rollout model in `generate_sequence`
+profiler:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.utils.profiler.ProfilerConfig
+
+ # profiler tool, default same as profiler.tool in global config
+ # choices: nsys, npu, torch
+ tool: ${oc.select:global_profiler.tool,null}
+
+ # whether enable profile on ref
+ enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
+
+ # Whether to profile all ranks.
+ all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
+
+ # The ranks that will be profiled. [] or [0,1,...]
+ ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
+
+ # profile results saving path
+ save_path: ${oc.select:global_profiler.save_path,null}
+
+ # specific tool config
+ tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
+
+# prometheus configuration for vllm/sglang server mode
+prometheus:
+
+ # Required when using verl.utils.omega_conf_to_dataclass to instantiate dataclass configs
+ _target_: verl.workers.config.PrometheusConfig
+
+ # whether enable prometheus on server mode rollout
+ enable: false
+
+ # Port number that Prometheus listens on, default is 9090
+ port: 9090
+
+ # Path to Prometheus configuration file
+ file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
+
+ # Specify served_model_name to avoid displaying overly long model paths in Grafana
+ served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
+
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..b2308e39e44fdb1c0cca318133e145d42a222b90
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer.yaml
@@ -0,0 +1,91 @@
+defaults:
+ - optim: fsdp
+ - _self_
+
+data:
+ train_batch_size: 256
+ micro_batch_size: null # will be deprecated, use micro_batch_size_per_gpu
+ micro_batch_size_per_gpu: 4 # this is also val batch size
+ train_files: ~/data/gsm8k/train.parquet
+ val_files: ~/data/gsm8k/test.parquet
+ train_max_samples: -1 # set to -1 to use full dataset
+ val_max_samples: -1 # set to -1 to use full dataset
+ # Single-turn settings
+ prompt_key: question
+ response_key: answer
+ prompt_dict_keys: null
+ response_dict_keys: null
+ # Multi-turn settings
+ multiturn:
+ enable: false # Set to true to use multi-turn dataset
+ messages_key: messages # Key for messages list in multi-turn mode
+ tools_key: tools # Key for tools list in multi-turn mode
+ enable_thinking_key: enable_thinking # Whether to enable thinking in multi-turn mode
+ max_length: 1024
+ truncation: error
+ balance_dp_token: False
+ chat_template: null
+ custom_cls:
+ path: null
+ name: null
+ use_shm: False
+ apply_chat_template_kwargs: {}
+model:
+ partial_pretrain: ~/models/gemma-1.1-7b-it
+ use_shm: False
+ fsdp_config:
+ model_dtype: fp32
+ wrap_policy:
+ min_num_params: 0
+ cpu_offload: False
+ offload_params: False
+ external_lib: null
+ enable_gradient_checkpointing: True
+ trust_remote_code: False
+ lora_rank: 0 # Set to positive value to enable LoRA (e.g., 32)
+ lora_alpha: 16 # LoRA scaling factor
+ target_modules: all-linear # Target modules for LoRA adaptation
+ use_liger: False
+ strategy: fsdp2
+optim:
+ lr: 1e-5
+ betas: [0.9, 0.95]
+ weight_decay: 0.01
+ lr_warmup_steps_ratio: 0.1
+ clip_grad: 1.0
+ lr_scheduler: cosine
+ulysses_sequence_parallel_size: 1
+use_remove_padding: False
+trainer:
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ default_hdfs_dir: null
+ project_name: gsm8k-sft
+ experiment_name: test
+ total_epochs: 4
+ total_training_steps: null
+ logger: [ 'console', 'wandb' ]
+ seed: 1
+ save_freq: -1
+ test_freq: -1
+ nnodes: 1
+ n_gpus_per_node: 8
+ max_ckpt_to_keep: null # Maximum number of checkpoints to keep, set to null to keep all
+
+ # Resume mode: "auto", "disable", or "resume_path"
+ # "auto": resume from last checkpoint if available
+ # "disable": start from scratch
+ # "resume_path": resume from a user-defined path
+ resume_mode: auto
+
+ # Path to resume training from (used when resume_mode is "resume_path" or "auto")
+ resume_from_path: null
+
+ # Checkpoint configuration
+ checkpoint:
+ # What to include in saved checkpoints
+ # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save space
+ save_contents: ["model", "optimizer", "extra"]
+
+ # For more flexibility, you can specify the contents to load from the checkpoint.
+ load_contents: ${trainer.checkpoint.save_contents}
+ device: cuda
diff --git a/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer_engine.yaml b/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer_engine.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0f7491d5f9dd3ab5ddd23c7a614625046bcaddf2
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/config/sft_trainer_engine.yaml
@@ -0,0 +1,70 @@
+# Format checks enforced on CI:
+# 1. Comments must appear above each field.
+# 2. There must be a blank line between each field.
+# 3. Inline comments (after a field on the same line) are not allowed.
+# 4. Indentation level is respected for nested fields.
+
+# @.:
+
+defaults:
+ - model@model: hf_model
+ - engine@engine: fsdp
+ - optim@optim: fsdp
+ - _self_
+
+data:
+ train_batch_size: 256 # global batch size
+ micro_batch_size_per_gpu: 4 # this is also val batch size
+ max_token_len_per_gpu: 8192
+ use_dynamic_bsz: True
+ train_files: ~/data/gsm8k/train.parquet
+ val_files: null
+ train_max_samples: -1 # set to -1 to use full dataset
+ val_max_samples: -1 # set to -1 to use full dataset
+ # Multi-turn settings
+ messages_key: messages # Key for messages list in multi-turn mode
+ tools_key: tools # Key for tools list in multi-turn mode
+ enable_thinking_key: enable_thinking # Whether to enable thinking in multi-turn mode
+ pad_mode: no_padding
+ # for right padding
+ max_length: 1024
+ truncation: error
+ balance_dp_token: False # to be implement
+ custom_cls:
+ path: null
+ name: null
+ use_shm: False
+ apply_chat_template_kwargs: {}
+
+# Checkpoint configuration
+checkpoint:
+ _target_: verl.trainer.config.CheckpointConfig
+ # What to include in saved checkpoints
+ # with 'hf_model' you can save whole model as hf format, now only use sharded model checkpoint to save space
+ save_contents: ["model", "optimizer", "extra"]
+
+ # For more flexibility, you can specify the contents to load from the checkpoint.
+ load_contents: ${checkpoint.save_contents}
+
+trainer:
+ default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
+ default_hdfs_dir: null
+ project_name: gsm8k-sft
+ experiment_name: test
+ total_epochs: 4
+ total_training_steps: null
+ logger: [ 'console', 'wandb' ]
+ seed: 1
+ save_freq: -1
+ test_freq: -1
+ max_ckpt_to_keep: null # Maximum number of checkpoints to keep, set to null to keep all
+
+ # Resume mode: "auto", "disable", or "resume_path"
+ # "auto": resume from last checkpoint if available
+ # "disable": start from scratch
+ # "resume_path": resume from a user-defined path
+ resume_mode: auto
+
+ # Path to resume training from (used when resume_mode is "resume_path" or "auto")
+ resume_from_path: null
+ device: cuda
diff --git a/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/dapo_with_aime.py b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/dapo_with_aime.py
new file mode 100644
index 0000000000000000000000000000000000000000..db3dd03d42f8fa4959facc45088a8b674b3f594d
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/dapo_with_aime.py
@@ -0,0 +1,104 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Preprocess DAPO dataset to parquet format
+"""
+
+import argparse
+import os
+
+import datasets
+import numpy as np
+
+from verl.utils.hdfs_io import copy, makedirs
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--local_dir", default="~/data/dapo-with-aime24")
+ parser.add_argument("--hdfs_dir", default=None)
+ parser.add_argument("--dapo_dataset_path", type=str, default="ftajwar/deduplicated_dapo_dataset")
+ parser.add_argument("--aime24_part_1_dataset_path", type=str, default="MathArena/aime_2024_I")
+ parser.add_argument("--aime24_part_2_dataset_path", type=str, default="MathArena/aime_2024_II")
+ parser.add_argument("--train_size", type=int, default=4096)
+
+ args = parser.parse_args()
+
+ data_source = "math_dapo"
+
+ # Load DAPO dataset for training
+ dapo_dataset_path = args.dapo_dataset_path
+ dapo_dataset = datasets.load_dataset(dapo_dataset_path, trust_remote_code=True)
+
+ # Load AIME 2024 part 1 dataset for testing
+ aime24_dataset_path_part_1 = args.aime24_part_1_dataset_path
+ aime24_dataset_part_1 = datasets.load_dataset(aime24_dataset_path_part_1, trust_remote_code=True)
+
+ # Load AIME 2024 part 2 dataset for testing
+ aime24_dataset_path_part_2 = args.aime24_part_2_dataset_path
+ aime24_dataset_part_2 = datasets.load_dataset(aime24_dataset_path_part_2, trust_remote_code=True)
+
+ train_dataset = dapo_dataset["train"]
+ train_dataset = train_dataset.select(np.random.choice(len(train_dataset), size=args.train_size, replace=False))
+
+ dev_dataset_aime24_part_1 = aime24_dataset_part_1["train"]
+ dev_dataset_aime24_part_2 = aime24_dataset_part_2["train"]
+ dev_dataset = datasets.concatenate_datasets([dev_dataset_aime24_part_1, dev_dataset_aime24_part_2])
+
+ instruction_following = "Let's think step by step and output the final answer within \\boxed{}."
+
+ # add a row to each data item that represents a unique id
+ def make_map_fn(split):
+ def process_fn(example, idx):
+ if "prompt" in example:
+ question = example.pop("prompt")
+ elif "problem" in example:
+ question = example.pop("problem")
+ else:
+ raise ValueError(f"Unknown question type: {example}")
+
+ question = question + " " + instruction_following
+
+ if "answer" in example:
+ solution = example.pop("answer")
+ else:
+ raise ValueError(f"Unknown answer type: {example}")
+ solution = str(solution)
+
+ data = {
+ "data_source": data_source,
+ "prompt": [{"role": "user", "content": question}],
+ "ability": "math",
+ "reward_model": {
+ "style": "rule",
+ "ground_truth": solution,
+ },
+ "extra_info": {"split": split, "index": idx},
+ }
+ return data
+
+ return process_fn
+
+ train_dataset = train_dataset.map(function=make_map_fn("train"), with_indices=True)
+ dev_dataset = dev_dataset.map(function=make_map_fn("test"), with_indices=True)
+
+ local_dir = args.local_dir
+ hdfs_dir = args.hdfs_dir
+
+ train_dataset.to_parquet(os.path.join(local_dir, "train.parquet"))
+ dev_dataset.to_parquet(os.path.join(local_dir, "dev.parquet"))
+
+ if hdfs_dir is not None:
+ makedirs(hdfs_dir)
+
+ copy(src=local_dir, dst=hdfs_dir)
diff --git a/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/gsm8k.py b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/gsm8k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4d8cf4fc8597f50015d7ea1ae60d9cb37db1866
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/gsm8k.py
@@ -0,0 +1,112 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Preprocess the GSM8k dataset to parquet format
+"""
+
+import argparse
+import os
+import re
+
+import datasets
+import numpy as np
+
+from verl.utils.hdfs_io import copy, makedirs
+
+
+def extract_solution(solution_str):
+ solution = re.search("#### (\\-?[0-9\\.\\,]+)", solution_str)
+ assert solution is not None
+ final_solution = solution.group(0)
+ final_solution = final_solution.split("#### ")[1].replace(",", "")
+ return final_solution
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--local_dir", default=None, help="The save directory for the preprocessed dataset.")
+ parser.add_argument("--hdfs_dir", default=None)
+ parser.add_argument("--local_dataset_path", default=None, help="The local path to the raw dataset, if it exists.")
+ parser.add_argument(
+ "--local_save_dir", default="~/data/gsm8k", help="The save directory for the preprocessed dataset."
+ )
+
+ args = parser.parse_args()
+ local_dataset_path = args.local_dataset_path
+
+ data_source = "openai/gsm8k"
+
+ if local_dataset_path is not None:
+ dataset = datasets.load_dataset(local_dataset_path, "main")
+ else:
+ dataset = datasets.load_dataset(data_source, "main")
+
+ train_dataset = dataset["train"]
+ test_dataset = dataset["test"]
+
+ instruction_following = 'Let\'s think step by step and output the final answer after "####".'
+
+ # add a row to each data item that represents a unique id
+ def make_map_fn(split):
+ def process_fn(example, idx):
+ question_raw = example.pop("question")
+
+ question = question_raw + " " + instruction_following
+
+ answer_raw = example.pop("answer")
+ solution = extract_solution(answer_raw)
+ data = {
+ "data_source": data_source,
+ "prompt": [
+ {
+ "role": "user",
+ "content": question,
+ }
+ ],
+ "ability": "math",
+ "reward_model": {"style": "rule", "ground_truth": solution},
+ "extra_info": {
+ "split": split,
+ "index": idx,
+ "answer": answer_raw,
+ "question": question_raw,
+ },
+ }
+ return data
+
+ return process_fn
+
+ train_dataset = train_dataset.map(function=make_map_fn("train"), with_indices=True)
+ test_dataset = test_dataset.map(function=make_map_fn("test"), with_indices=True)
+ # split test into dev and test by picking random subset of 512 examples
+ all_test_indices = range(len(test_dataset))
+ all_test_indices = list(all_test_indices)
+ np.random.shuffle(all_test_indices)
+ dev_dataset = test_dataset.select(all_test_indices[:512])
+ test_dataset = test_dataset.select(all_test_indices[512:])
+
+ hdfs_dir = args.hdfs_dir
+ local_save_dir = args.local_dir
+ if local_save_dir is not None:
+ print("Warning: Argument 'local_dir' is deprecated. Please use 'local_save_dir' instead.")
+ else:
+ local_save_dir = args.local_save_dir
+
+ train_dataset.to_parquet(os.path.join(local_save_dir, "train.parquet"))
+ test_dataset.to_parquet(os.path.join(local_save_dir, "test.parquet"))
+
+ if hdfs_dir is not None:
+ makedirs(hdfs_dir)
+
+ copy(src=local_save_dir, dst=hdfs_dir)
diff --git a/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/math_dataset.py b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/math_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ae35ea93f489534d33bc0d5fd0149466b8dc7f3
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/data_preprocess/math_dataset.py
@@ -0,0 +1,595 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Preprocess the MATH-lighteval dataset to parquet format
+"""
+
+import argparse
+import os
+
+import datasets
+
+from verl.utils.hdfs_io import copy, makedirs
+from verl.utils.reward_score.math import last_boxed_only_string, remove_boxed
+
+# These are the MATH-500 indices
+DEV_INDICES = [
+ 4,
+ 6,
+ 15,
+ 18,
+ 34,
+ 36,
+ 37,
+ 41,
+ 45,
+ 64,
+ 66,
+ 85,
+ 92,
+ 100,
+ 120,
+ 127,
+ 133,
+ 136,
+ 149,
+ 160,
+ 161,
+ 162,
+ 166,
+ 168,
+ 202,
+ 215,
+ 243,
+ 247,
+ 256,
+ 260,
+ 270,
+ 320,
+ 361,
+ 367,
+ 381,
+ 392,
+ 396,
+ 411,
+ 450,
+ 451,
+ 452,
+ 460,
+ 496,
+ 501,
+ 503,
+ 505,
+ 511,
+ 513,
+ 520,
+ 534,
+ 563,
+ 564,
+ 571,
+ 576,
+ 579,
+ 587,
+ 596,
+ 601,
+ 607,
+ 609,
+ 612,
+ 615,
+ 622,
+ 666,
+ 673,
+ 683,
+ 684,
+ 695,
+ 700,
+ 703,
+ 709,
+ 718,
+ 722,
+ 738,
+ 748,
+ 757,
+ 761,
+ 762,
+ 782,
+ 805,
+ 817,
+ 834,
+ 840,
+ 849,
+ 853,
+ 854,
+ 859,
+ 882,
+ 885,
+ 888,
+ 906,
+ 909,
+ 933,
+ 941,
+ 962,
+ 978,
+ 985,
+ 988,
+ 991,
+ 1008,
+ 1033,
+ 1037,
+ 1046,
+ 1048,
+ 1054,
+ 1058,
+ 1067,
+ 1073,
+ 1085,
+ 1088,
+ 1095,
+ 1111,
+ 1119,
+ 1123,
+ 1127,
+ 1128,
+ 1131,
+ 1136,
+ 1144,
+ 1145,
+ 1150,
+ 1172,
+ 1173,
+ 1180,
+ 1188,
+ 1190,
+ 1194,
+ 1196,
+ 1215,
+ 1243,
+ 1250,
+ 1251,
+ 1258,
+ 1262,
+ 1271,
+ 1281,
+ 1285,
+ 1287,
+ 1290,
+ 1302,
+ 1308,
+ 1311,
+ 1312,
+ 1322,
+ 1339,
+ 1359,
+ 1374,
+ 1380,
+ 1402,
+ 1441,
+ 1442,
+ 1449,
+ 1513,
+ 1531,
+ 1540,
+ 1543,
+ 1552,
+ 1555,
+ 1576,
+ 1603,
+ 1612,
+ 1620,
+ 1690,
+ 1710,
+ 1715,
+ 1730,
+ 1764,
+ 1767,
+ 1769,
+ 1788,
+ 1790,
+ 1791,
+ 1801,
+ 1806,
+ 1820,
+ 1842,
+ 1843,
+ 1880,
+ 1890,
+ 1897,
+ 1901,
+ 1905,
+ 1908,
+ 1932,
+ 1935,
+ 1940,
+ 1963,
+ 1967,
+ 1981,
+ 1996,
+ 2001,
+ 2006,
+ 2011,
+ 2041,
+ 2047,
+ 2053,
+ 2057,
+ 2062,
+ 2063,
+ 2078,
+ 2110,
+ 2119,
+ 2120,
+ 2143,
+ 2148,
+ 2150,
+ 2151,
+ 2170,
+ 2186,
+ 2191,
+ 2196,
+ 2199,
+ 2210,
+ 2214,
+ 2215,
+ 2217,
+ 2231,
+ 2236,
+ 2237,
+ 2238,
+ 2246,
+ 2253,
+ 2263,
+ 2264,
+ 2275,
+ 2289,
+ 2294,
+ 2297,
+ 2303,
+ 2311,
+ 2323,
+ 2324,
+ 2325,
+ 2327,
+ 2328,
+ 2334,
+ 2352,
+ 2359,
+ 2360,
+ 2371,
+ 2382,
+ 2384,
+ 2397,
+ 2404,
+ 2409,
+ 2413,
+ 2416,
+ 2473,
+ 2505,
+ 2512,
+ 2515,
+ 2522,
+ 2536,
+ 2539,
+ 2546,
+ 2569,
+ 2571,
+ 2579,
+ 2602,
+ 2607,
+ 2609,
+ 2611,
+ 2622,
+ 2628,
+ 2637,
+ 2647,
+ 2681,
+ 2682,
+ 2700,
+ 2707,
+ 2731,
+ 2752,
+ 2758,
+ 2767,
+ 2799,
+ 2802,
+ 2808,
+ 2816,
+ 2838,
+ 2851,
+ 2863,
+ 2868,
+ 2876,
+ 2883,
+ 2896,
+ 2907,
+ 2937,
+ 2938,
+ 2946,
+ 2966,
+ 2977,
+ 2991,
+ 2994,
+ 3018,
+ 3019,
+ 3020,
+ 3022,
+ 3024,
+ 3035,
+ 3037,
+ 3046,
+ 3047,
+ 3058,
+ 3067,
+ 3072,
+ 3079,
+ 3080,
+ 3105,
+ 3126,
+ 3134,
+ 3141,
+ 3165,
+ 3181,
+ 3186,
+ 3187,
+ 3196,
+ 3200,
+ 3210,
+ 3220,
+ 3226,
+ 3236,
+ 3240,
+ 3246,
+ 3287,
+ 3295,
+ 3299,
+ 3317,
+ 3320,
+ 3323,
+ 3334,
+ 3341,
+ 3342,
+ 3344,
+ 3350,
+ 3352,
+ 3365,
+ 3366,
+ 3369,
+ 3375,
+ 3392,
+ 3404,
+ 3411,
+ 3417,
+ 3419,
+ 3420,
+ 3440,
+ 3444,
+ 3447,
+ 3460,
+ 3467,
+ 3474,
+ 3480,
+ 3498,
+ 3507,
+ 3511,
+ 3519,
+ 3529,
+ 3539,
+ 3541,
+ 3548,
+ 3549,
+ 3569,
+ 3586,
+ 3604,
+ 3607,
+ 3646,
+ 3647,
+ 3658,
+ 3669,
+ 3700,
+ 3711,
+ 3725,
+ 3730,
+ 3732,
+ 3738,
+ 3740,
+ 3741,
+ 3752,
+ 3768,
+ 3769,
+ 3773,
+ 3779,
+ 3802,
+ 3805,
+ 3824,
+ 3849,
+ 3856,
+ 3878,
+ 3913,
+ 3923,
+ 3941,
+ 3942,
+ 3951,
+ 3982,
+ 3990,
+ 3994,
+ 3999,
+ 4011,
+ 4034,
+ 4036,
+ 4042,
+ 4043,
+ 4046,
+ 4055,
+ 4071,
+ 4074,
+ 4088,
+ 4090,
+ 4104,
+ 4108,
+ 4127,
+ 4149,
+ 4150,
+ 4155,
+ 4157,
+ 4158,
+ 4160,
+ 4177,
+ 4181,
+ 4190,
+ 4193,
+ 4210,
+ 4222,
+ 4235,
+ 4242,
+ 4253,
+ 4265,
+ 4272,
+ 4279,
+ 4297,
+ 4303,
+ 4315,
+ 4326,
+ 4333,
+ 4352,
+ 4368,
+ 4384,
+ 4404,
+ 4413,
+ 4423,
+ 4425,
+ 4441,
+ 4449,
+ 4451,
+ 4479,
+ 4487,
+ 4500,
+ 4515,
+ 4523,
+ 4533,
+ 4535,
+ 4547,
+ 4549,
+ 4550,
+ 4569,
+ 4584,
+ 4590,
+ 4591,
+ 4597,
+ 4600,
+ 4603,
+ 4610,
+ 4626,
+ 4657,
+ 4666,
+ 4678,
+ 4697,
+ 4706,
+ 4713,
+ 4731,
+ 4744,
+ 4751,
+ 4753,
+ 4758,
+ 4765,
+ 4776,
+ 4796,
+ 4812,
+ 4834,
+ 4850,
+ 4857,
+ 4861,
+ 4866,
+ 4868,
+ 4871,
+ 4885,
+ 4896,
+ 4900,
+ 4909,
+ 4914,
+ 4924,
+ 4926,
+ 4947,
+ 4955,
+ 4964,
+ 4969,
+ 4978,
+ 4990,
+ 4992,
+ 4993,
+]
+
+
+def extract_solution(solution_str):
+ return remove_boxed(last_boxed_only_string(solution_str))
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--local_dir", default="~/data/math")
+ parser.add_argument("--hdfs_dir", default=None)
+
+ args = parser.parse_args()
+
+ # 'lighteval/MATH' is no longer available on huggingface.
+ # Use mirror repo: DigitalLearningGmbH/MATH-lighteval
+ data_source = "DigitalLearningGmbH/MATH-lighteval"
+ print(f"Loading the {data_source} dataset from huggingface...", flush=True)
+ dataset = datasets.load_dataset(data_source, trust_remote_code=True)
+
+ train_dataset = dataset["train"]
+ test_dataset = dataset["test"]
+
+ instruction_following = "Let's think step by step and output the final answer within \\boxed{}."
+
+ # add a row to each data item that represents a unique id
+ def make_map_fn(split):
+ def process_fn(example, idx):
+ question = example.pop("problem")
+
+ question = question + " " + instruction_following
+
+ answer = example.pop("solution")
+ solution = extract_solution(answer)
+ data = {
+ "data_source": data_source,
+ "prompt": [{"role": "user", "content": question}],
+ "ability": "math",
+ "reward_model": {"style": "rule", "ground_truth": solution},
+ "extra_info": {"split": split, "index": idx},
+ }
+ return data
+
+ return process_fn
+
+ train_dataset = train_dataset.map(function=make_map_fn("train"), with_indices=True)
+ test_dataset = test_dataset.map(function=make_map_fn("test"), with_indices=True)
+
+ # Split test into dev and test
+ dev_indices_set = set(DEV_INDICES)
+ dev_dataset = test_dataset.select(DEV_INDICES)
+
+ def filter_dev_indices(example, idx):
+ return idx not in dev_indices_set
+
+ test_dataset = test_dataset.filter(filter_dev_indices, with_indices=True)
+
+ local_dir = args.local_dir
+ hdfs_dir = args.hdfs_dir
+
+ train_dataset.to_parquet(os.path.join(local_dir, "train.parquet"))
+ dev_dataset.to_parquet(os.path.join(local_dir, "dev.parquet"))
+ test_dataset.to_parquet(os.path.join(local_dir, "test.parquet"))
+
+ if hdfs_dir is not None:
+ makedirs(hdfs_dir)
+
+ copy(src=local_dir, dst=hdfs_dir)
diff --git a/ICL/DAPO/verl-recipe/rep_exp/reward_score/__init__.py b/ICL/DAPO/verl-recipe/rep_exp/reward_score/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..124189fa228da0f1bc09acf7390932319d302c51
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/reward_score/__init__.py
@@ -0,0 +1,136 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# from . import gsm8k, math, prime_math, prime_code
+
+from verl.utils.import_utils import deprecated
+
+
+def default_compute_score(
+ data_source,
+ solution_str,
+ ground_truth,
+ extra_info=None,
+ sandbox_fusion_url=None,
+ concurrent_semaphore=None,
+ memory_limit_mb=None,
+ **kwargs,
+):
+ """Compute the score for a given solution based on the data source.
+
+ Args:
+ data_source (str): The source dataset identifier which determines the scoring method.
+ solution_str (str): The solution string to be evaluated.
+ ground_truth (str): The ground truth answer for comparison.
+ extra_info (dict, optional): Additional information that might be needed for scoring. Defaults to None.
+
+ Returns:
+ float: The computed score as a floating point number. If the result is a dictionary,
+ it returns the dictionary instead.
+
+ Raises:
+ NotImplementedError: If the reward function is not implemented for the given data source.
+ """
+ if data_source == "openai/gsm8k":
+ from verl.utils.reward_score import gsm8k
+
+ res = gsm8k.compute_score(solution_str, ground_truth)
+ elif data_source in ["lighteval/MATH", "DigitalLearningGmbH/MATH-lighteval", "HuggingFaceH4/MATH-500"]:
+ from verl.utils.reward_score import math_reward
+
+ res = math_reward.compute_score(solution_str, ground_truth)
+ # [Optional] Math-Verify Integration
+ # For enhanced accuracy, consider utilizing Math-Verify (https://github.com/huggingface/Math-Verify).
+ # Note: Math-Verify needs to be manually installed via pip: `pip install math-verify`.
+ # To use it, override the `compute_score` function with the following implementation:
+
+ # from . import math_verify
+ # res = math_verify.compute_score(solution_str, ground_truth)
+ elif data_source in ["math_dapo", "math", "math_dapo_reasoning"] or data_source.startswith("aime"):
+ # res = math_dapo.compute_score(solution_str, ground_truth)
+ from verl.utils.reward_score import math_verify
+
+ res = math_verify.compute_score(solution_str, ground_truth)
+ elif data_source in [
+ "numina_aops_forum",
+ "numina_synthetic_math",
+ "numina_amc_aime",
+ "numina_synthetic_amc",
+ "numina_cn_k12",
+ "numina_olympiads",
+ ]:
+ from verl.utils.reward_score import prime_math
+
+ res = prime_math.compute_score(solution_str, ground_truth)
+ elif data_source in ["codecontests", "apps", "codeforces", "taco"]:
+ # Use the passed sandbox_fusion_url if available
+ if sandbox_fusion_url:
+ from verl.utils.reward_score import sandbox_fusion
+
+ # Pass the URL directly, ground_truth likely contains test cases here
+ res = sandbox_fusion.compute_score(
+ sandbox_fusion_url, concurrent_semaphore, memory_limit_mb, solution_str, ground_truth, continuous=True
+ )
+ else:
+ # If no sandbox URL is provided, fall back to prime_code or raise error
+ from verl.utils.reward_score import prime_code
+
+ # Assuming prime_code doesn't need the URL
+ res = prime_code.compute_score(solution_str, ground_truth, continuous=True)
+ elif data_source in ["hiyouga/geometry3k"]:
+ from verl.utils.reward_score import geo3k
+
+ res = geo3k.compute_score(solution_str, ground_truth)
+ elif data_source in [
+ "searchR1_nq",
+ "searchR1_triviaqa",
+ "searchR1_popqa",
+ "searchR1_hotpotqa",
+ "searchR1_2wikimultihopqa",
+ "searchR1_musique",
+ "searchR1_bamboogle",
+ ]:
+ from verl.utils.reward_score import search_r1_like_qa_em
+
+ res = search_r1_like_qa_em.compute_score(solution_str, ground_truth)
+
+ else:
+ raise NotImplementedError(f"Reward function is not implemented for {data_source=}")
+
+ if isinstance(res, dict):
+ return res
+ elif isinstance(res, int | float | bool):
+ return float(res)
+ else:
+ return float(res[0])
+
+
+@deprecated("verl.utils.reward_score.default_compute_score")
+def _default_compute_score(
+ data_source,
+ solution_str,
+ ground_truth,
+ extra_info=None,
+ sandbox_fusion_url=None,
+ concurrent_semaphore=None,
+ memory_limit_mb=None,
+):
+ """
+ Legacy function API to be deprecated. Please use `default_compute_score` instead.
+ """
+ return default_compute_score(
+ data_source, solution_str, ground_truth, extra_info, sandbox_fusion_url, concurrent_semaphore, memory_limit_mb
+ )
+
+
+__all__ = ["default_compute_score"]
diff --git a/ICL/DAPO/verl-recipe/rep_exp/utils/aggregate_logger.py b/ICL/DAPO/verl-recipe/rep_exp/utils/aggregate_logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..54a70272d50ffa9c031abbc946cd2164ad9e8f05
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/utils/aggregate_logger.py
@@ -0,0 +1,49 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A Ray logger will receive logging info from different processes.
+"""
+
+import json
+import os
+
+
+class JsonEvalLogger:
+ """
+ A logger that logs to a json file.
+ Args:
+ save_path: The path to the checkpoint to resume from.
+ task: The task name, used to name the experiment.
+ """
+
+ def __init__(self, save_path: str, task: str):
+ self.root = "eval"
+ if save_path is not None and save_path != "":
+ self.experiment_name = save_path.split("/")[-2]
+ self.checkpoint_type = save_path.split("/")[-1]
+ else:
+ self.experiment_name = f"{task}_untrained"
+ self.checkpoint_type = ""
+
+ def flush(self):
+ pass
+
+ def log(self, data, step):
+ # Create eval folder
+ save_folder = os.path.join(self.root, self.experiment_name, self.checkpoint_type)
+ os.makedirs(save_folder, exist_ok=True)
+
+ # Save to json
+ with open(os.path.join(save_folder, "eval.json"), "w") as f:
+ json.dump(data, f)
diff --git a/ICL/DAPO/verl-recipe/rep_exp/utils/tracking.py b/ICL/DAPO/verl-recipe/rep_exp/utils/tracking.py
new file mode 100644
index 0000000000000000000000000000000000000000..898fc0f1aae12f9b92c0d1ae4a3685c8dc799d0d
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/utils/tracking.py
@@ -0,0 +1,517 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A unified tracking interface that supports logging data to different backend
+"""
+
+import dataclasses
+import json
+import os
+from enum import Enum
+from functools import partial
+from pathlib import Path
+from typing import Any
+
+
+class Tracking:
+ """A unified tracking interface for logging experiment data to multiple backends.
+
+ This class provides a centralized way to log experiment metrics, parameters, and artifacts
+ to various tracking backends including WandB, MLflow, SwanLab, TensorBoard, and console.
+
+ Attributes:
+ supported_backend: List of supported tracking backends.
+ logger: Dictionary of initialized logger instances for each backend.
+ """
+
+ supported_backend = [
+ "wandb",
+ "mlflow",
+ "swanlab",
+ "vemlp_wandb",
+ "tensorboard",
+ "console",
+ "clearml",
+ "trackio",
+ "file",
+ "json_eval",
+ ]
+
+ def __init__(self, project_name, experiment_name, default_backend: str | list[str] = "console", config=None):
+ if isinstance(default_backend, str):
+ default_backend = [default_backend]
+ for backend in default_backend:
+ if backend == "tracking":
+ import warnings
+
+ warnings.warn("`tracking` logger is deprecated. use `wandb` instead.", DeprecationWarning, stacklevel=2)
+ else:
+ assert backend in self.supported_backend, f"{backend} is not supported"
+
+ self.logger = {}
+
+ if "tracking" in default_backend or "wandb" in default_backend:
+ import os
+
+ import wandb
+
+ settings = None
+ if config and config["trainer"].get("wandb_proxy", None):
+ settings = wandb.Settings(https_proxy=config["trainer"]["wandb_proxy"])
+ entity = os.environ.get("WANDB_ENTITY", None)
+ wandb.init(project=project_name, name=experiment_name, entity=entity, config=config, settings=settings)
+ self.logger["wandb"] = wandb
+
+ if "trackio" in default_backend:
+ import trackio
+
+ trackio.init(project=project_name, name=experiment_name, config=config)
+ self.logger["trackio"] = trackio
+
+ if "mlflow" in default_backend:
+ import os
+
+ import mlflow
+
+ MLFLOW_TRACKING_URI = os.environ.get("MLFLOW_TRACKING_URI", "sqlite:////tmp/mlruns.db")
+ mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
+
+ # Project_name is actually experiment_name in MLFlow
+ # If experiment does not exist, will create a new experiment
+ experiment = mlflow.set_experiment(project_name)
+ mlflow.start_run(experiment_id=experiment.experiment_id, run_name=experiment_name)
+ mlflow.log_params(_compute_mlflow_params_from_objects(config))
+ self.logger["mlflow"] = _MlflowLoggingAdapter()
+
+ if "swanlab" in default_backend:
+ import os
+
+ import swanlab
+
+ SWANLAB_API_KEY = os.environ.get("SWANLAB_API_KEY", None)
+ SWANLAB_LOG_DIR = os.environ.get("SWANLAB_LOG_DIR", "swanlog")
+ SWANLAB_MODE = os.environ.get("SWANLAB_MODE", "cloud")
+ if SWANLAB_API_KEY:
+ swanlab.login(SWANLAB_API_KEY) # NOTE: previous login information will be overwritten
+
+ if config is None:
+ config = {} # make sure config is not None, otherwise **config will raise error
+ swanlab.init(
+ project=project_name,
+ experiment_name=experiment_name,
+ config={"FRAMEWORK": "verl", **config},
+ logdir=SWANLAB_LOG_DIR,
+ mode=SWANLAB_MODE,
+ )
+ self.logger["swanlab"] = swanlab
+
+ if "vemlp_wandb" in default_backend:
+ import os
+
+ import volcengine_ml_platform
+ from volcengine_ml_platform import wandb as vemlp_wandb
+
+ volcengine_ml_platform.init(
+ ak=os.environ["VOLC_ACCESS_KEY_ID"],
+ sk=os.environ["VOLC_SECRET_ACCESS_KEY"],
+ region=os.environ["MLP_TRACKING_REGION"],
+ )
+
+ vemlp_wandb.init(
+ project=project_name,
+ name=experiment_name,
+ config=config,
+ sync_tensorboard=True,
+ )
+ self.logger["vemlp_wandb"] = vemlp_wandb
+
+ if "tensorboard" in default_backend:
+ self.logger["tensorboard"] = _TensorboardAdapter(project_name, experiment_name)
+
+ if "console" in default_backend:
+ from verl.utils.logger import LocalLogger
+
+ self.console_logger = LocalLogger(print_to_console=True)
+ self.logger["console"] = self.console_logger
+
+ if "json_eval" in default_backend:
+ from .aggregate_logger import JsonEvalLogger
+
+ model_path = config["actor_rollout_ref"]["model"]["path"]
+ if model_path.endswith("actor/hf"):
+ # Case where the model path is a saved checkpoint
+ save_path = model_path.split("/")[-4:-2]
+ save_path = "/".join(save_path)
+ else:
+ # Case where the model is pretrained model from huggingface
+ save_path = ""
+
+ # Parse task from config
+ train_file = config["data"]["train_files"][0]
+ task = train_file.split("/")[-2]
+
+ self.json_eval_logger = JsonEvalLogger(save_path=save_path, task=task)
+ self.logger["json_eval"] = self.json_eval_logger
+
+ if "clearml" in default_backend:
+ self.logger["clearml"] = ClearMLLogger(project_name, experiment_name, config)
+
+ if "file" in default_backend:
+ self.logger["file"] = FileLogger(project_name, experiment_name)
+
+ def log(self, data, step, backend=None):
+ for default_backend, logger_instance in self.logger.items():
+ if backend is None or default_backend in backend:
+ logger_instance.log(data=data, step=step)
+
+ def __del__(self):
+ if "wandb" in self.logger:
+ self.logger["wandb"].finish(exit_code=0)
+ if "swanlab" in self.logger:
+ self.logger["swanlab"].finish()
+ if "vemlp_wandb" in self.logger:
+ self.logger["vemlp_wandb"].finish(exit_code=0)
+ if "tensorboard" in self.logger:
+ self.logger["tensorboard"].finish()
+ if "clearml" in self.logger:
+ self.logger["clearml"].finish()
+ if "trackio" in self.logger:
+ self.logger["trackio"].finish()
+ if "file" in self.logger:
+ self.logger["file"].finish()
+
+
+class ClearMLLogger:
+ def __init__(self, project_name: str, experiment_name: str, config):
+ self.project_name = project_name
+ self.experiment_name = experiment_name
+
+ import clearml
+
+ self._task: clearml.Task = clearml.Task.init(
+ task_name=experiment_name,
+ project_name=project_name,
+ continue_last_task=True,
+ output_uri=False,
+ )
+
+ self._task.connect_configuration(config, name="Hyperparameters")
+
+ def _get_logger(self):
+ return self._task.get_logger()
+
+ def log(self, data, step):
+ import numpy as np
+ import pandas as pd
+
+ # logs = self._rewrite_logs(data)
+ logger = self._get_logger()
+ for k, v in data.items():
+ title, series = k.split("/", 1)
+
+ if isinstance(v, int | float | np.floating | np.integer):
+ logger.report_scalar(
+ title=title,
+ series=series,
+ value=v,
+ iteration=step,
+ )
+ elif isinstance(v, pd.DataFrame):
+ logger.report_table(
+ title=title,
+ series=series,
+ table_plot=v,
+ iteration=step,
+ )
+ else:
+ logger.warning(
+ f'Trainer is attempting to log a value of "{v}" of type {type(v)} for key "{k}". This '
+ f"invocation of ClearML logger's function is incorrect so this attribute was dropped. "
+ )
+
+ def finish(self):
+ self._task.close()
+
+
+class FileLogger:
+ def __init__(self, project_name: str, experiment_name: str):
+ self.project_name = project_name
+ self.experiment_name = experiment_name
+
+ self.filepath = os.getenv("VERL_FILE_LOGGER_PATH", None)
+ if self.filepath is None:
+ root_path = os.path.expanduser(os.getenv("VERL_FILE_LOGGER_ROOT", "."))
+ directory = os.path.join(root_path, self.project_name)
+ os.makedirs(directory, exist_ok=True)
+ self.filepath = os.path.join(directory, f"{self.experiment_name}.jsonl")
+ print(f"Creating file logger at {self.filepath}")
+ self.fp = open(self.filepath, "w")
+
+ def log(self, data, step):
+ data = {"step": step, "data": data}
+ self.fp.write(json.dumps(data) + "\n")
+
+ def finish(self):
+ self.fp.close()
+
+
+class _TensorboardAdapter:
+ def __init__(self, project_name, experiment_name):
+ import os
+
+ from torch.utils.tensorboard import SummaryWriter
+
+ tensorboard_dir = os.environ.get("TENSORBOARD_DIR", f"tensorboard_log/{project_name}/{experiment_name}")
+ os.makedirs(tensorboard_dir, exist_ok=True)
+ print(f"Saving tensorboard log to {tensorboard_dir}.")
+ self.writer = SummaryWriter(tensorboard_dir)
+
+ def log(self, data, step):
+ for key in data:
+ self.writer.add_scalar(key, data[key], step)
+
+ def finish(self):
+ self.writer.close()
+
+
+class _MlflowLoggingAdapter:
+ def __init__(self):
+ import logging
+ import re
+
+ self.logger = logging.getLogger(__name__)
+ # MLflow metric key validation logic:
+ # https://github.com/mlflow/mlflow/blob/master/mlflow/utils/validation.py#L157C12-L157C44
+ # Only characters allowed: slashes, alphanumerics, underscores, periods, dashes, colons,
+ # and spaces.
+ self._invalid_chars_pattern = re.compile(
+ r"[^/\w.\- :]"
+ ) # Allowed: slashes, alphanumerics, underscores, periods, dashes, colons, and spaces.
+
+ def log(self, data, step):
+ import mlflow
+
+ def sanitize_key(key):
+ # First replace @ with _at_ for backward compatibility
+ sanitized = key.replace("@", "_at_")
+ # Then replace any other invalid characters with _
+ sanitized = self._invalid_chars_pattern.sub("_", sanitized)
+ if sanitized != key:
+ self.logger.warning(
+ "[MLflow] Metric key '%s' sanitized to '%s' due to invalid characters.", key, sanitized
+ )
+ return sanitized
+
+ results = {sanitize_key(k): v for k, v in data.items()}
+ mlflow.log_metrics(metrics=results, step=step)
+
+
+def _compute_mlflow_params_from_objects(params) -> dict[str, Any]:
+ if params is None:
+ return {}
+
+ return _flatten_dict(_transform_params_to_json_serializable(params, convert_list_to_dict=True), sep="/")
+
+
+def _transform_params_to_json_serializable(x, convert_list_to_dict: bool):
+ _transform = partial(_transform_params_to_json_serializable, convert_list_to_dict=convert_list_to_dict)
+
+ if dataclasses.is_dataclass(x):
+ return _transform(dataclasses.asdict(x))
+ if isinstance(x, dict):
+ return {k: _transform(v) for k, v in x.items()}
+ if isinstance(x, list):
+ if convert_list_to_dict:
+ return {"list_len": len(x)} | {f"{i}": _transform(v) for i, v in enumerate(x)}
+ else:
+ return [_transform(v) for v in x]
+ if isinstance(x, Path):
+ return str(x)
+ if isinstance(x, Enum):
+ return x.value
+
+ return x
+
+
+def _flatten_dict(raw: dict[str, Any], *, sep: str) -> dict[str, Any]:
+ import pandas as pd
+
+ ans = pd.json_normalize(raw, sep=sep).to_dict(orient="records")[0]
+ assert isinstance(ans, dict)
+ return ans
+
+
+@dataclasses.dataclass
+class ValidationGenerationsLogger:
+ project_name: str = None
+ experiment_name: str = None
+
+ def log(self, loggers, samples, step):
+ if "wandb" in loggers:
+ self.log_generations_to_wandb(samples, step)
+ if "swanlab" in loggers:
+ self.log_generations_to_swanlab(samples, step)
+ if "mlflow" in loggers:
+ self.log_generations_to_mlflow(samples, step)
+
+ if "clearml" in loggers:
+ self.log_generations_to_clearml(samples, step)
+ if "tensorboard" in loggers:
+ self.log_generations_to_tensorboard(samples, step)
+
+ if "vemlp_wandb" in loggers:
+ self.log_generations_to_vemlp_wandb(samples, step)
+
+ def log_generations_to_vemlp_wandb(self, samples, step):
+ from volcengine_ml_platform import wandb as vemlp_wandb
+
+ self._log_generations_to_wandb(samples, step, vemlp_wandb)
+
+ def log_generations_to_wandb(self, samples, step):
+ import wandb
+
+ self._log_generations_to_wandb(samples, step, wandb)
+
+ def _log_generations_to_wandb(self, samples, step, wandb):
+ """Log samples to wandb as a table"""
+
+ # Create column names for all samples
+ columns = ["step"] + sum(
+ [[f"input_{i + 1}", f"output_{i + 1}", f"score_{i + 1}"] for i in range(len(samples))], []
+ )
+
+ if not hasattr(self, "validation_table"):
+ # Initialize the table on first call
+ self.validation_table = wandb.Table(columns=columns)
+
+ # Create a new table with same columns and existing data
+ # Workaround for https://github.com/wandb/wandb/issues/2981#issuecomment-1997445737
+ new_table = wandb.Table(columns=columns, data=self.validation_table.data)
+
+ # Add new row with all data
+ row_data = []
+ row_data.append(step)
+ for sample in samples:
+ row_data.extend(sample)
+
+ new_table.add_data(*row_data)
+
+ # Update reference and log
+ wandb.log({"val/generations": new_table}, step=step)
+ self.validation_table = new_table
+
+ def log_generations_to_swanlab(self, samples, step):
+ """Log samples to swanlab as text"""
+ import swanlab
+
+ swanlab_table = swanlab.echarts.Table()
+
+ # Create column names
+ headers = ["step", "input", "output", "score"]
+
+ swanlab_row_list = [[step, *sample] for sample in samples]
+ swanlab_table.add(headers=headers, rows=swanlab_row_list)
+
+ # Log to swanlab
+ swanlab.log({"val/generations": swanlab_table}, step=step)
+
+ def log_generations_to_mlflow(self, samples, step):
+ """Log validation generation to mlflow as artifacts"""
+ # https://mlflow.org/docs/latest/api_reference/python_api/mlflow.html?highlight=log_artifact#mlflow.log_artifact
+
+ import json
+ import tempfile
+
+ import mlflow
+
+ try:
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ validation_gen_step_file = Path(tmp_dir, f"val_step{step}.json")
+ row_data = []
+ for sample in samples:
+ data = {"input": sample[0], "output": sample[1], "score": sample[2]}
+ row_data.append(data)
+ with open(validation_gen_step_file, "w") as file:
+ json.dump(row_data, file)
+ mlflow.log_artifact(validation_gen_step_file)
+ except Exception as e:
+ print(f"WARNING: save validation generation file to mlflow failed with error {e}")
+
+ def log_generations_to_clearml(self, samples, step):
+ """Log validation generation to clearml as table"""
+
+ import clearml
+ import pandas as pd
+
+ task: clearml.Task | None = clearml.Task.current_task()
+ if task is None:
+ return
+
+ table = [
+ {
+ "step": step,
+ "input": sample[0],
+ "output": sample[1],
+ "score": sample[2],
+ }
+ for sample in samples
+ ]
+
+ logger = task.get_logger()
+ logger.report_table(
+ series="Validation generations",
+ title="Validation",
+ table_plot=pd.DataFrame.from_records(table),
+ iteration=step,
+ )
+
+ def log_generations_to_tensorboard(self, samples, step):
+ """Log samples to tensorboard as text"""
+ # Initialize tensorboard writer if not exists
+ if not hasattr(self, "writer"):
+ from torch.utils.tensorboard import SummaryWriter
+
+ # Use the same directory structure as _TensorboardAdapter
+ if self.project_name and self.experiment_name:
+ default_dir = os.path.join("tensorboard_log", self.project_name, self.experiment_name)
+ else:
+ default_dir = "tensorboard_log"
+
+ tensorboard_dir = os.environ.get("TENSORBOARD_DIR", default_dir)
+ os.makedirs(tensorboard_dir, exist_ok=True)
+ self.writer = SummaryWriter(log_dir=tensorboard_dir)
+
+ # Format the samples data into readable text
+ text_content = f"**Generation Results - Step {step}**\n\n"
+
+ for i, sample in enumerate(samples):
+ text_content += f"### Sample {i + 1}\n"
+
+ # Assuming sample contains [input, output, score]
+ if len(sample) >= 3:
+ input_text, output_text, score = sample[0], sample[1], sample[2]
+
+ text_content += f"**Input:** {input_text}\n\n"
+ text_content += f"**Output:** {output_text}\n\n"
+ text_content += f"**Score:** {score}\n\n"
+ else:
+ # Handle cases where sample format might be different
+ text_content += f"**Data:** {sample}\n\n"
+
+ text_content += "---\n\n"
+
+ # Log to tensorboard as text
+ self.writer.add_text("val/generations", text_content, step)
+ # Flush to ensure data is written
+ self.writer.flush()
diff --git a/ICL/DAPO/verl-recipe/rep_exp/workers/elliptical_reward_model_worker.py b/ICL/DAPO/verl-recipe/rep_exp/workers/elliptical_reward_model_worker.py
new file mode 100644
index 0000000000000000000000000000000000000000..931779bf8c95c56e68862c4181c4c24da12ecfcd
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/rep_exp/workers/elliptical_reward_model_worker.py
@@ -0,0 +1,389 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+The main entry point to run the PPO algorithm
+"""
+
+import logging
+import os
+import warnings
+
+import numpy as np
+import torch
+from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+
+from verl import DataProto
+from verl.models.transformers.monkey_patch import apply_monkey_patch
+from verl.single_controller.base.decorator import Dispatch, Execute, register
+from verl.utils import hf_tokenizer
+from verl.utils.device import (
+ get_device_id,
+ get_device_name,
+)
+from verl.utils.fs import copy_to_local
+from verl.utils.fsdp_utils import (
+ CPUOffloadPolicy,
+ apply_fsdp2,
+ fsdp2_load_full_state_dict,
+ fsdp_version,
+ get_fsdp_wrap_policy,
+ get_init_weight_context_manager,
+ get_shard_placement_fn,
+ init_fn,
+)
+from verl.utils.profiler import DistProfiler
+from verl.workers.fsdp_workers import RewardModelWorker, get_sharding_strategy
+
+logger = logging.getLogger(__file__)
+logger.setLevel(os.getenv("VERL_LOGGING_LEVEL", "WARN"))
+
+device_name = get_device_name()
+
+
+class EllipticalRewardModelWorker(RewardModelWorker):
+ def __init__(self, config):
+ super().__init__(config)
+ self.lamb = config.elliptical.lamb
+ self.normalization = config.elliptical.normalization
+ self.sparse_dim = config.elliptical.sparse_dim
+ self.sparse_matrix = None
+ self.randomize_sparse_matrix = config.elliptical.randomize_sparse_matrix
+ self.persist_covariance = config.elliptical.persist_covariance
+ self.cov_inv_dict = {}
+ self.mean_hidden_states_mu_dict = {}
+ self.hidden_mean_counter_dict = {}
+
+ @staticmethod
+ def _construct_sparse_matrix(features: torch.Tensor, sparse_dim: int) -> torch.Tensor:
+ from sklearn.random_projection import SparseRandomProjection
+
+ sparse_proj = SparseRandomProjection(sparse_dim, density="auto")
+ sparse_proj.fit(features)
+ sparse_matrix = sparse_proj.components_
+ sparse_matrix_coo = sparse_matrix.tocoo()
+
+ # Convert the row and col lists to numpy arrays and then to a LongTensor (speed up)
+ indices = torch.LongTensor(np.array([sparse_matrix_coo.row, sparse_matrix_coo.col]))
+ values = torch.FloatTensor(sparse_matrix_coo.data)
+
+ sparse_mat = torch.sparse_coo_tensor(indices, values, [sparse_dim, features.shape[1]]).t()
+
+ return sparse_mat
+
+ def _build_model(self, config):
+ # the following line is necessary
+ from torch.distributed.fsdp import CPUOffload
+ from transformers import AutoConfig, AutoModel
+
+ use_shm = config.model.get("use_shm", False)
+ # download the checkpoint from hdfs
+ local_path = copy_to_local(config.model.path, use_shm=use_shm)
+
+ if self.config.model.input_tokenizer is None:
+ self._do_switch_chat_template = False
+ else:
+ self._do_switch_chat_template = True
+ input_tokenizer_local_path = copy_to_local(config.model.input_tokenizer, use_shm=use_shm)
+ self.input_tokenizer = hf_tokenizer(
+ input_tokenizer_local_path, trust_remote_code=config.model.get("trust_remote_code", False)
+ )
+ self.tokenizer = hf_tokenizer(local_path, trust_remote_code=config.model.get("trust_remote_code", False))
+
+ trust_remote_code = config.model.get("trust_remote_code", False)
+ model_config = AutoConfig.from_pretrained(local_path, trust_remote_code=trust_remote_code)
+ model_config.num_labels = 1
+
+ # note that we have to create model in fp32. Otherwise, the optimizer is in bf16, which is incorrect
+ init_context = get_init_weight_context_manager(
+ use_meta_tensor=not model_config.tie_word_embeddings, mesh=self.device_mesh
+ )
+
+ with init_context(), warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ model_config.classifier_dropout = 0.0
+ reward_module = AutoModel.from_pretrained(
+ pretrained_model_name_or_path=local_path,
+ config=model_config,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ trust_remote_code=trust_remote_code,
+ )
+
+ apply_monkey_patch(
+ model=reward_module,
+ use_remove_padding=config.model.get("use_remove_padding", False),
+ ulysses_sp_size=self.ulysses_sequence_parallel_size,
+ )
+
+ reward_module.to(torch.bfloat16)
+
+ auto_wrap_policy = get_fsdp_wrap_policy(module=reward_module, config=self.config.model.fsdp_config)
+
+ fsdp_mesh = self.device_mesh
+ sharding_strategy = get_sharding_strategy(fsdp_mesh)
+
+ if config.strategy == "fsdp":
+ reward_module = FSDP(
+ reward_module,
+ param_init_fn=init_fn,
+ use_orig_params=False,
+ auto_wrap_policy=auto_wrap_policy,
+ device_id=get_device_id(),
+ sharding_strategy=sharding_strategy, # zero3
+ sync_module_states=True,
+ cpu_offload=CPUOffload(offload_params=True),
+ forward_prefetch=self.config.model.fsdp_config.forward_prefetch,
+ device_mesh=self.device_mesh,
+ )
+ elif config.strategy == "fsdp2":
+ assert CPUOffloadPolicy is not None, "PyTorch version >= 2.4 is required for using fully_shard API (FSDP2)"
+ cpu_offload = CPUOffloadPolicy(pin_memory=True)
+ fsdp_kwargs = {
+ "mesh": fsdp_mesh,
+ "offload_policy": cpu_offload,
+ "reshard_after_forward": config.model.fsdp_config.reshard_after_forward,
+ "shard_placement_fn": get_shard_placement_fn(fsdp_size=self.device_mesh.shape[-1]),
+ }
+ full_state = reward_module.state_dict()
+ apply_fsdp2(reward_module, fsdp_kwargs, config.model.fsdp_config)
+ fsdp2_load_full_state_dict(reward_module, full_state, fsdp_mesh, cpu_offload)
+ else:
+ raise NotImplementedError(f"Unknown strategy: {config.strategy}")
+ return reward_module
+
+ def _forward_micro_batch(self, micro_batch, start_of_response: int):
+ with torch.no_grad(), torch.autocast(device_type=device_name, dtype=torch.bfloat16):
+ input_ids = micro_batch["input_ids"]
+ batch_size, seqlen = input_ids.shape
+ attention_mask = micro_batch["attention_mask"]
+ position_ids = micro_batch["position_ids"]
+ if position_ids.dim() == 3: # qwen2vl mrope
+ position_ids = position_ids.transpose(0, 1) # (bsz, 3, seqlen) -> (3, bsz, seqlen)
+
+ if self.use_remove_padding:
+ raise NotImplementedError("Remove padding is not implemented for elliptical reward model")
+ else:
+ output = self.reward_module(
+ input_ids=input_ids, attention_mask=attention_mask, position_ids=position_ids, use_cache=False
+ )
+
+ sequence_lengths = attention_mask[:, start_of_response:].sum(dim=1)
+ mean_hidden_states = []
+ for i, seq_len in enumerate(sequence_lengths):
+ mean_hidden_states.append(
+ output.last_hidden_state[i, start_of_response : start_of_response + seq_len].mean(dim=0)
+ )
+ mean_hidden_states = torch.stack(mean_hidden_states)
+
+ return mean_hidden_states
+
+ @register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
+ @DistProfiler.annotate(color="brown")
+ def compute_hidden_states(self, data: DataProto):
+ import itertools
+
+ from verl.utils.seqlen_balancing import get_reverse_idx, rearrange_micro_batches
+
+ # Support all hardwares
+ data = data.to(get_device_id())
+ if self._do_switch_chat_template:
+ rm_data = self._switch_chat_template(data)
+ else:
+ rm_input_ids = data.batch["input_ids"]
+ rm_attention_mask = data.batch["attention_mask"]
+ rm_position_ids = data.batch["position_ids"]
+ rm_inputs = {
+ "input_ids": rm_input_ids,
+ "attention_mask": rm_attention_mask,
+ "position_ids": rm_position_ids,
+ }
+ rm_data = DataProto.from_dict(rm_inputs)
+
+ # Support all hardwares
+ rm_data = rm_data.to(get_device_id())
+
+ # perform forward computation
+ with self.ulysses_sharding_manager:
+ use_dynamic_bsz = self.config.use_dynamic_bsz
+ if use_dynamic_bsz:
+ max_token_len = self.config.forward_max_token_len_per_gpu * self.ulysses_sequence_parallel_size
+ micro_batches, indices = rearrange_micro_batches(batch=rm_data.batch, max_token_len=max_token_len)
+ else:
+ micro_batches = rm_data.batch.split(self.config.micro_batch_size_per_gpu)
+ output = []
+ for micro_batch in micro_batches:
+ mean_hidden_states = self._forward_micro_batch(
+ micro_batch, start_of_response=data.batch["prompts"].shape[-1]
+ )
+ output.append(mean_hidden_states)
+ mean_hidden_states = torch.cat(output, dim=0) # (batch_size)
+
+ # NOTE(Jens): this has not been thoroughly checked
+ if use_dynamic_bsz:
+ indices = list(itertools.chain.from_iterable(indices))
+ assert len(indices) == mean_hidden_states.size(0), f"{len(indices)} vs. {mean_hidden_states.size()}"
+ revert_indices = torch.tensor(get_reverse_idx(indices), dtype=torch.long)
+ mean_hidden_states = mean_hidden_states[revert_indices]
+
+ # Note that this is only the scores, may not be the final rewards used to train RL
+ output = DataProto.from_dict(tensors={"mean_hidden_states": mean_hidden_states})
+
+ # https://pytorch.org/docs/stable/notes/fsdp.html#fsdp-notes
+ # unshard the root FSDP module
+ if self.world_size > 1 and fsdp_version(self.reward_module) == 1:
+ self.reward_module._handle.reshard(True)
+
+ output = output.to("cpu")
+ return output
+
+ def _compute_bonuses(self, hidden_states, cov_inv, prompt_index: int):
+ if self.config.elliptical.reward_type == "leave_one_out":
+ if self.persist_covariance:
+ raise NotImplementedError("Leave-one-out with persistence is not implemented")
+ else:
+ bonuses = []
+ for i, hidden_state in enumerate(hidden_states):
+ chosen_samp = hidden_state.unsqueeze(1)
+ middle_part = torch.inverse(1 - chosen_samp.t() @ cov_inv @ chosen_samp)
+ leave_one_out_cov_inv = cov_inv + cov_inv @ chosen_samp @ middle_part @ chosen_samp.t() @ cov_inv
+ bonus = (chosen_samp.t() @ leave_one_out_cov_inv @ chosen_samp).flatten().float()
+ bonuses.append(bonus)
+
+ bonuses = torch.concat(bonuses)
+
+ elif self.config.elliptical.reward_type == "leverage":
+ if self.persist_covariance:
+ hidden_mean = self.mean_hidden_states_mu_dict[prompt_index]
+ hidden_mean_counter = self.hidden_mean_counter_dict[prompt_index]
+
+ hidden_states = hidden_states - hidden_mean
+
+ numerator = cov_inv @ hidden_mean.unsqueeze(1) @ hidden_mean.unsqueeze(0) @ cov_inv
+ denominator = -1 / hidden_mean_counter + hidden_mean.t() @ cov_inv @ hidden_mean
+ cov_inv_mean_adjusted = cov_inv - numerator / denominator
+ batch_cov_inv = cov_inv_mean_adjusted.unsqueeze(0).expand(hidden_states.shape[0], -1, -1)
+ else:
+ batch_cov_inv = cov_inv.unsqueeze(0).expand(hidden_states.shape[0], -1, -1)
+
+ bonuses = (hidden_states.unsqueeze(1) @ batch_cov_inv @ hidden_states.unsqueeze(2)).flatten().float()
+
+ return bonuses
+
+ def _normalize_bonuses(self, bonuses):
+ if self.normalization == "none":
+ pass
+ elif self.normalization == "rnd":
+ std = torch.std(bonuses)
+ if std > 0:
+ bonuses = bonuses / std
+ elif self.normalization == "z_score":
+ mean = torch.mean(bonuses)
+ std = torch.std(bonuses)
+ if std > 0:
+ bonuses = (bonuses - mean) / std
+ else:
+ bonuses = bonuses - mean
+ else:
+ raise ValueError(f"Unknown normalization: {self.normalization}")
+
+ return bonuses
+
+ @register(dispatch_mode=Dispatch.ALL_TO_ALL, execute_mode=Execute.RANK_ZERO)
+ @DistProfiler.annotate(color="brown")
+ def compute_rm_score(self, data: DataProto):
+ if self.sparse_matrix is None:
+ d = data.batch["mean_hidden_states"].shape[-1]
+ sparse_matrix = self._construct_sparse_matrix(torch.randn(1, d), self.sparse_dim)
+ if not self.randomize_sparse_matrix:
+ self.sparse_matrix = sparse_matrix
+ else:
+ sparse_matrix = self.sparse_matrix
+
+ mean_hidden_states = data.batch["mean_hidden_states"].to(get_device_id()).float()
+
+ # sparse project
+ mean_hidden_states = mean_hidden_states @ sparse_matrix.to(get_device_id())
+
+ # upgrade to float64
+ mean_hidden_states = mean_hidden_states.to(torch.float64)
+
+ seen_uids = set()
+ reward_tensor = torch.zeros_like(data.batch["responses"], dtype=torch.float32).to(get_device_id())
+ raw_bonuses_tensor = torch.zeros_like(data.batch["responses"], dtype=torch.float32).to(get_device_id())
+ for i in range(len(data)):
+ data_item = data[i]
+ uid = data_item.non_tensor_batch["uid"]
+ if uid in seen_uids:
+ continue
+
+ seen_uids.add(uid)
+ mask = data.non_tensor_batch["uid"] == uid
+ filtered_mean_hidden_states = mean_hidden_states[mask]
+
+ prompt_index = data_item.non_tensor_batch["extra_info"]["index"]
+
+ if self.persist_covariance:
+ # first update the mean hidden states mu
+ if prompt_index not in self.mean_hidden_states_mu_dict:
+ self.mean_hidden_states_mu_dict[prompt_index] = filtered_mean_hidden_states.mean(dim=0)
+ self.hidden_mean_counter_dict[prompt_index] = mask.sum()
+ else:
+ total_count = self.hidden_mean_counter_dict[prompt_index] + mask.sum()
+ old_mu = self.mean_hidden_states_mu_dict[prompt_index]
+ new_mu = (
+ old_mu * self.hidden_mean_counter_dict[prompt_index]
+ + filtered_mean_hidden_states.mean(dim=0) * mask.sum()
+ ) / total_count
+ self.mean_hidden_states_mu_dict[prompt_index] = new_mu
+ self.hidden_mean_counter_dict[prompt_index] = total_count
+
+ # NOTE: we don't center here since otherwise the covariance will accumulate stale means
+ final_mean_hidden_states = filtered_mean_hidden_states
+
+ if prompt_index not in self.cov_inv_dict:
+ d = final_mean_hidden_states.shape[-1]
+ self.cov_inv_dict[prompt_index] = (
+ torch.eye(d, dtype=torch.float64).to(get_device_id()) * self.lamb**-1
+ )
+ cov_inv = self.cov_inv_dict[prompt_index]
+ else:
+ centered_mean_hidden_states = filtered_mean_hidden_states - filtered_mean_hidden_states.mean(dim=0)
+ final_mean_hidden_states = centered_mean_hidden_states
+
+ d = final_mean_hidden_states.shape[-1]
+ cov_inv = torch.eye(d, dtype=torch.float64).to(get_device_id()) * self.lamb**-1
+
+ # update inverse covariance matrix with rank-1 updates
+ for hidden_state in final_mean_hidden_states:
+ chosen_samp = hidden_state.unsqueeze(1)
+ middle_part = torch.inverse(1 + chosen_samp.t() @ cov_inv @ chosen_samp)
+ cov_inv = cov_inv - cov_inv @ chosen_samp @ middle_part @ chosen_samp.t() @ cov_inv
+
+ if self.persist_covariance:
+ self.cov_inv_dict[prompt_index] = cov_inv
+
+ raw_bonuses = self._compute_bonuses(final_mean_hidden_states, cov_inv, prompt_index)
+ normalized_bonuses = self._normalize_bonuses(raw_bonuses)
+
+ prompt_ids = data.batch["prompts"][mask]
+ prompt_length = prompt_ids.shape[-1]
+ valid_response_lengths = data.batch["attention_mask"][mask, prompt_length:].sum(-1)
+
+ raw_bonuses_tensor[mask, valid_response_lengths - 1] = raw_bonuses
+ reward_tensor[mask, valid_response_lengths - 1] = normalized_bonuses
+
+ output = DataProto.from_dict(
+ tensors={"rm_scores": reward_tensor}, non_tensors={"raw_bonuses": raw_bonuses_tensor.cpu().numpy()}
+ )
+ return output.to("cpu")
diff --git a/ICL/DAPO/verl-recipe/retool/run_qwen2_7b_sft.sh b/ICL/DAPO/verl-recipe/retool/run_qwen2_7b_sft.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e4369e167e3bb62ffe11d1658d155a76c58af510
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/retool/run_qwen2_7b_sft.sh
@@ -0,0 +1,44 @@
+#!/bin/bash
+set -x
+
+nnodes=1
+nproc_per_node=8
+master_addr=
+master_port=
+node_rank=${ARNOLD_ID:-0}
+
+project_name=retool
+experiment_name=multiturn-sft-qwen-2.5-7b-instruct
+
+HDFS_ROOT=${HDFS_ROOT:-$PWD}
+DATA_ROOT=${DATA_ROOT:-$PWD}
+
+TRAIN_DATA=$DATA_ROOT/dataset/wuxibin/ReTool-SFT/data/train-00000-of-00001.parquet
+EVAL_DATA=$DATA_ROOT/dataset/wuxibin/ReTool-SFT/data/train-00000-of-00001.parquet
+MODEL_PATH=$HDFS_ROOT/model/Qwen2.5-7B-Instruct
+SAVE_PATH=$DATA_ROOT/checkpoint/$experiment_name
+
+torchrun --nnodes=$nnodes \
+ --nproc_per_node=$nproc_per_node \
+ --master-addr=$master_addr \
+ --master-port=$master_port \
+ --node-rank=$node_rank \
+ -m verl.trainer.fsdp_sft_trainer \
+ data.train_files=$TRAIN_DATA \
+ data.val_files=$EVAL_DATA \
+ data.max_length=16384 \
+ data.train_batch_size=32 \
+ data.multiturn.enable=true \
+ data.multiturn.messages_key=messages \
+ data.multiturn.tools_key=tools \
+ data.micro_batch_size_per_gpu=4 \
+ model.partial_pretrain=$MODEL_PATH \
+ model.strategy=fsdp \
+ trainer.default_local_dir=$SAVE_PATH \
+ trainer.project_name=wuxibin-multiturn-sft \
+ trainer.experiment_name=$experiment_name \
+ trainer.logger='["console","wandb"]' \
+ trainer.total_epochs=6 \
+ trainer.save_freq=62 \
+ ulysses_sequence_parallel_size=4 \
+ use_remove_padding=true
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/README.md b/ICL/DAPO/verl-recipe/specRL/histoSpec/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..de1fc3dd708f36f7ef3d777d46a9de36783e2d27
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/README.md
@@ -0,0 +1,67 @@
+# Accelerating RL Rollout with Model-free Speculative Decoding
+
+## Introduction
+
+In many scenarios, the RL training datasets are recycled across multiple epochs.
+Between adjacent epochs, responses to the same prompts often exhibit high similarity, particularly in structured tasks such as mathematics and code generation.
+HistoSpec exploits this observation by leveraging speculative decoding to accelerate RL rollout.
+It uses token segments from historical responses as draft sequences, achieving up to **2.1× speedup**.
+
+As a model-free drafting approach, HistoSpec offers distinct advantages over methods relying on smaller models (e.g., small LLMs or Eagle models):
+
+1. **Low Drafting Cost**: No GPU inference is required for drafting, making it effective even with large rollout batch sizes.
+2. **Training Stability**: No need to train draft models during RL, ensuring consistent performance and ease of deployment.
+3. **High Flexibility**: Compatible with synchronous RL, multi-turn RL, and asynchronous RL.
+
+HistoSpec operates in conjunction with the **Suffix-Tree-based Distributed Draft Server**, which efficiently caches historical responses, distributes them to workers, and indexes them using suffix trees for fast retrieval.
+
+## Evaluation Results
+
+Our evaluations on Qwen2.5 and Qwen3 models demonstrate up to **2.1× speedup** in rollout and validation phases.
+
+**Experiment results.** Qwen3-14B-Base trained with DAPO, temperature = 1, max response length = 8K, FSDP backend, 32 H100 GPU, batch size = 256, rollout.n = 16.
+
+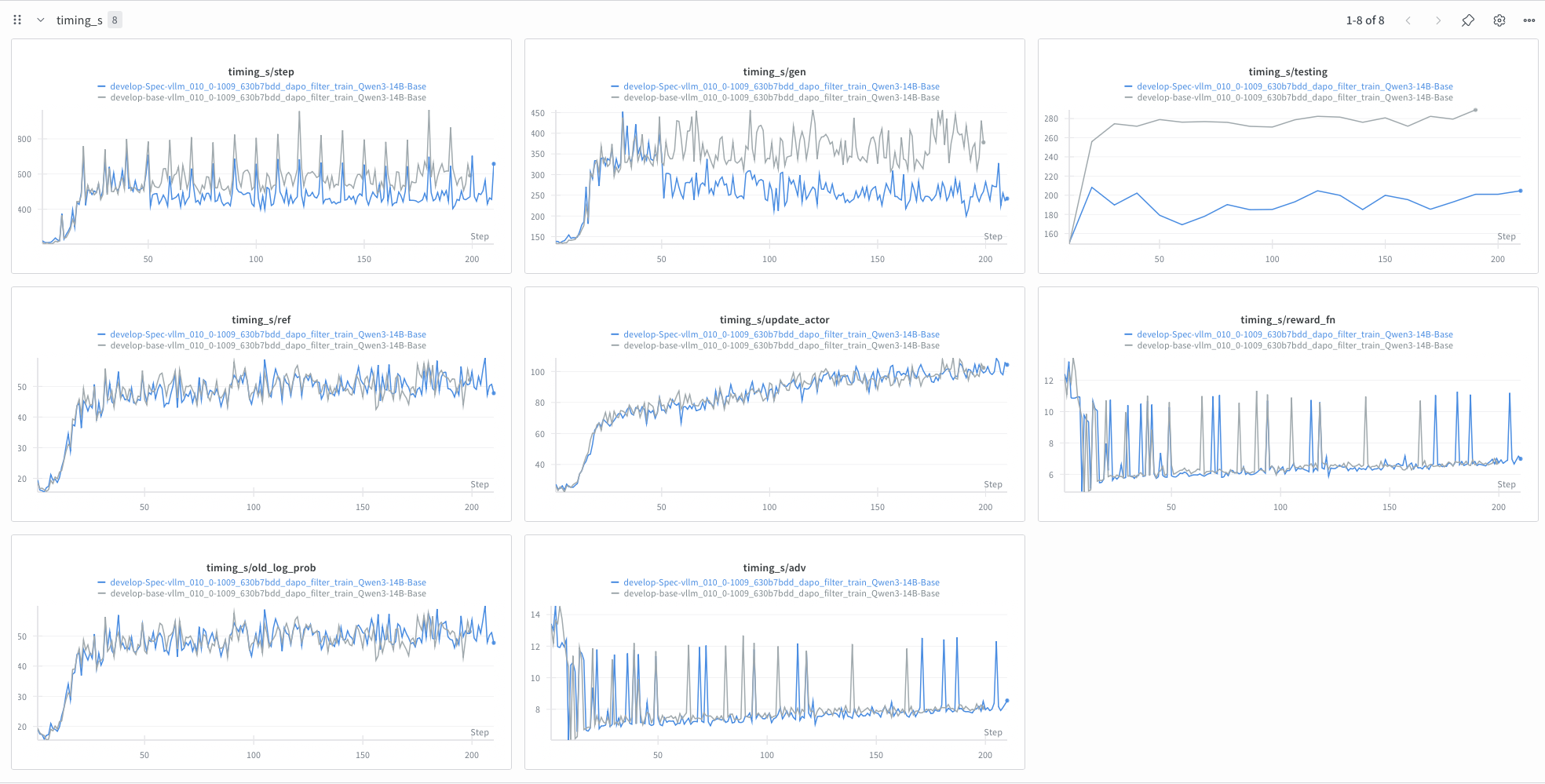
+
+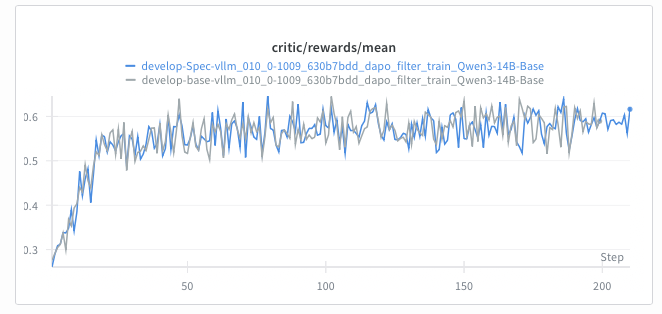
+
+## Installation
+
+This recipe is based on verl commit `ccd7d93`. Please contact the authors for any adaptability issues.
+
+```sh
+# Install the Distributed Draft Server and its C++ dependencies
+sudo apt install -y libprotobuf-dev protobuf-compiler libprotoc-dev \
+ libgrpc-dev libgrpc++-dev protobuf-compiler-grpc \
+ libxxhash-dev libboost-all-dev cmake
+
+pip install verl@git+https://github.com/volcengine/verl.git@ccd7d934f91be98bb3732c78bd1870fa39c399ad
+pip install git+https://github.com/He-Jingkai/specRL.git --no-build-isolation -v
+```
+
+## Usage
+
+Replace `verl.trainer.main_ppo` with `recipe.specRL.histoSpec.main_ppo` in your training scripts. Speculative decoding is enabled by default. To disable it, use `+actor_rollout_ref.rollout.enable_spec_decoding=False`.
+
+## Contact
+
+HistoSpec is migrated from the internal environment.
+If you encounter any issues or have suggestions, please contact:
+- Jingkai He: `hjk020101@sjtu.edu.cn`
+- Tianjian Li: `litianjian@bytedance.com`
+
+```
+@inproceedings{histoRL,
+ title={History Doesn’t Repeat Itself but Rollouts Rhyme: Accelerating Reinforcement Learning with HistoRL},
+ author={Jingkai He and Tianjian Li and Erhu Feng and Dong Du and Qian Liu and Tao Liu and Yubin Xia and Haibo Chen},
+ booktitle={Proceedings of the 31th ACM International Conference on Architectural Support for Programming Languages and Operating Systems},
+ year={2026},
+ series={ASPLOS'26}
+}
+```
+
+Paper: https://arxiv.org/abs/2508.18588
+
+## Acknowledgments
+
+HistoSpec leverages the vLLM patch implementation from Snowflake's [ArcticInference](https://github.com/snowflakedb/ArcticInference) as its code base.
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/cache_manager.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/cache_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..98f962900b3808c1979ad7956706d35b32415901
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/cache_manager.py
@@ -0,0 +1,378 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Cache Manager for distributed suffix cache in PPO training.
+Encapsulates cache servers, storage, and updater logic.
+"""
+
+import socket
+from concurrent.futures import ThreadPoolExecutor
+from multiprocessing import Process
+
+import psutil
+import ray
+
+from verl.trainer.ppo.utils import Role
+
+
+@ray.remote(num_cpus=1)
+class CacheWorker:
+ """Ray remote worker for running a gRPC-based rollout cache server on each GPU node.
+
+ This worker deploys a SuffixCache and RolloutCacheServer on each compute node
+ (excluding the master node). The cache server provides suffix caching capabilities
+ via gRPC to accelerate rollout generation during PPO training.
+ """
+
+ def __init__(self, port: int = 6378):
+ """Initialize and start the cache server.
+
+ Args:
+ port: Port number for the gRPC server (default: 6378)
+ """
+
+ self.port = port
+
+ from specrl.suffix_cache import RolloutCacheServer
+
+ # Initialize the rollout cache server with IPv6 support ([::])
+ self.server = RolloutCacheServer(f"[::]:{port}")
+ self.server.initialize()
+
+ # Start server in a separate process with CPU affinity to avoid interference with GPU workers
+ self.cache_server_process = Process(target=self._run_cache_server)
+ self.cache_server_process.daemon = True
+ self.cache_server_process.start()
+
+ # Set CPU affinity to cores 0-20 to keep cache server on separate CPU cores
+ process = psutil.Process(self.cache_server_process.pid)
+ affinity_cores = min(psutil.cpu_count() // 2, 21)
+ process.cpu_affinity(list(range(affinity_cores)))
+ print(f"Rollout cache server started on port {port} (PID: {self.cache_server_process.pid})")
+ print(f"CPU affinity set up to core {affinity_cores - 1}")
+
+ def _run_cache_server(self):
+ """Run the cache server in a separate process"""
+ try:
+ # Set CPU affinity for this process (additional safety measure)
+ current_process = psutil.Process()
+ affinity_cores = min(psutil.cpu_count() // 2, 21)
+ current_process.cpu_affinity(list(range(affinity_cores)))
+ print(f"Cache server process CPU affinity set up to core {affinity_cores - 1}")
+
+ self.server.start()
+ self.server.wait()
+ except Exception as e:
+ print(f"Cache server error: {e}")
+
+ def get_node_ip(self) -> str:
+ """Get the IPv6 address of the node this worker is running on.
+
+ Returns:
+ IPv6 address of the current node
+ """
+ # Get all address info for the hostname, filtering for IPv6
+ hostname = socket.gethostname()
+ addr_info = socket.getaddrinfo(hostname, None, socket.AF_INET6)
+ # Return the first IPv6 address found
+ if addr_info:
+ return addr_info[0][4][0]
+ # Fallback to localhost IPv6 if no address found
+ return "::1"
+
+ def shutdown(self):
+ """Shutdown the cache server and cleanup resources."""
+ if hasattr(self, "cache_server_process") and self.cache_server_process.is_alive():
+ try:
+ # Terminate the server process
+ self.cache_server_process.terminate()
+ self.cache_server_process.join(timeout=5)
+ if self.cache_server_process.is_alive():
+ self.cache_server_process.kill()
+ print(f"Cache server process terminated (PID: {self.cache_server_process.pid})")
+ except Exception as e:
+ print(f"Error terminating cache server process: {e}")
+
+ if hasattr(self, "server"):
+ try:
+ self.server.shutdown()
+ except Exception as e:
+ print(f"Error shutting down cache server: {e}")
+
+ def __del__(self):
+ """Clean up when the worker is destroyed."""
+ self.shutdown()
+
+
+class CacheManager:
+ """Manager for distributed suffix cache infrastructure.
+
+ This class encapsulates all cache-related components:
+ - Cache servers: One gRPC server per GPU node
+ - Cache storage: SuffixCache for storing prompt/response pairs
+ - Cache updater: Client for distributed async cache updates
+
+ Provides simple interface for initialization, updates, and cleanup.
+ """
+
+ def __init__(
+ self,
+ config,
+ role_worker_mapping: dict,
+ resource_pool_manager,
+ port: int = 6378,
+ ):
+ """Initialize cache manager if speculative decoding is enabled.
+
+ Args:
+ config: Training configuration
+ role_worker_mapping: Mapping from roles to worker types
+ resource_pool_manager: Ray resource pool manager
+ """
+ self.config = config
+ self.role_worker_mapping = role_worker_mapping
+ self.resource_pool_manager = resource_pool_manager
+
+ # Internal state
+ self._cache_servers = None
+ self._cache_updater = None
+ self._cache_update_futures = []
+ self._max_futures = 5
+ self._executor = None
+ self.port = port
+
+ # Check if cache is enabled
+ self._enabled = self._should_enable_cache()
+
+ if self._enabled:
+ self._initialize()
+
+ def _should_enable_cache(self) -> bool:
+ """Check if cache should be enabled based on configuration.
+
+ Returns:
+ True if speculative decoding with suffix cache is enabled
+ """
+ # Check if ActorRolloutRef role exists and has spec decoding enabled
+ from verl.trainer.ppo.utils import Role
+
+ actor_role = Role.ActorRolloutRef if Role.ActorRolloutRef in self.role_worker_mapping else Role.ActorRollout
+ if actor_role not in self.role_worker_mapping:
+ return False
+
+ rollout_config = self.config.actor_rollout_ref.rollout
+ enable_spec = rollout_config.get("enable_spec_decoding", True)
+
+ return enable_spec
+
+ def _initialize(self):
+ """Initialize cache servers, storage, and updater."""
+ # Get resource pool for actor/rollout workers
+ actor_role = Role.ActorRolloutRef if Role.ActorRolloutRef in self.role_worker_mapping else Role.ActorRollout
+ resource_pool = self.resource_pool_manager.get_resource_pool(actor_role)
+
+ # Create cache servers (one per GPU node)
+ self._cache_servers = self._create_cache_servers(resource_pool, self.port)
+
+ # Collect server addresses for distributed updates
+ server_addresses = self._get_server_addresses()
+
+ from specrl.cache_updater import SuffixCacheUpdater
+
+ # Initialize cache updater (it manages its own thread pool internally)
+ self._cache_updater = SuffixCacheUpdater(server_addresses=server_addresses)
+
+ # Thread pool executor for async cache updates from trainer
+ self._executor = ThreadPoolExecutor(max_workers=self._max_futures)
+
+ print(f"Cache manager initialized with {len(self._cache_servers)} servers on ports {self.port}")
+ print(f"Server addresses: {server_addresses}")
+
+ def _create_cache_servers(self, resource_pool, port: int) -> list[dict]:
+ """Create cache server workers on each GPU node.
+
+ Args:
+ resource_pool: Ray resource pool for placement
+ port: gRPC server port
+
+ Returns:
+ List of dicts with {server, ip, port} for each node
+ """
+ from ray.util.scheduling_strategies import NodeAffinitySchedulingStrategy
+
+ # Get placement groups and extract unique node IDs
+ pgs = resource_pool.get_placement_groups()
+
+ # Get node IDs from placement groups
+ node_ids = set()
+ for pg in pgs:
+ specs = ray._private.state.state.placement_group_table(pg.id)
+ # All bundles in a placement group should be on the same node
+ node_id = specs["bundles_to_node_id"][0]
+ node_ids.add(node_id)
+
+ servers = []
+ for node_id in node_ids:
+ # Create cache server worker on specific node
+ # Server starts automatically in __init__
+ strategy = NodeAffinitySchedulingStrategy(node_id=node_id, soft=False)
+ server = CacheWorker.options(
+ scheduling_strategy=strategy,
+ name=f"cache_server_{node_id}",
+ ).remote(port=port)
+
+ # Get node's IPv6 address
+ ip = ray.get(server.get_node_ip.remote())
+
+ servers.append(
+ {
+ "server": server,
+ "ip": ip,
+ "port": port,
+ }
+ )
+
+ return servers
+
+ def _get_server_addresses(self) -> list[str]:
+ """Get formatted gRPC addresses for all cache servers.
+
+ Returns:
+ List of addresses in format '[]:'
+ """
+ if not self._cache_servers:
+ return []
+
+ addresses = []
+ for server_info in self._cache_servers:
+ ip = server_info["ip"]
+ port = server_info["port"]
+ # Format IPv6 address with brackets for gRPC
+ address = f"[{ip}]:{port}"
+ addresses.append(address)
+
+ return addresses
+
+ def update_cache(
+ self,
+ batch,
+ responses_per_prompt: int,
+ ):
+ """Update the suffix cache with new generation results asynchronously.
+
+ This method extracts prompts and responses from the batch and submits them
+ to the cache updater for async processing. The cache is updated across all
+ cache servers in a distributed manner.
+
+ Args:
+ batch: DataProto containing prompts, responses, and attention masks
+ responses_per_prompt: Number of responses generated per prompt
+ """
+ if not self._enabled:
+ return
+
+ # Extract response length from the batch
+ response_length = batch.batch["responses"].shape[-1]
+
+ # Split attention mask into prompt and response parts
+ prompt_mask = batch.batch["attention_mask"][:, :-response_length]
+ response_mask = batch.batch["attention_mask"][:, -response_length:]
+
+ # Calculate actual lengths (excluding padding)
+ prompt_length = prompt_mask.sum(-1).float()
+ response_length_tensor = response_mask.sum(-1).float() # (batch_size,)
+
+ # Convert tensors to Python lists for gRPC transmission
+ prompts_ = batch.batch["prompts"].tolist()
+ responses_ = batch.batch["responses"].tolist()
+ prompt_lengths_ = prompt_length.tolist()
+ response_lengths_ = response_length_tensor.tolist()
+
+ # Limit concurrent futures to prevent memory overflow
+ # Wait for oldest future if we've reached the limit
+ if len(self._cache_update_futures) >= self._max_futures:
+ oldest_future = self._cache_update_futures.pop(0)
+ oldest_future.result() # Block until oldest update completes
+
+ # Submit cache update task to thread pool for async execution
+ # This allows training to continue while cache is being updated
+ future = self._executor.submit(
+ self._cache_updater.update_response_cache,
+ prompts=prompts_,
+ responses=responses_,
+ prompt_lengths=prompt_lengths_,
+ response_lengths=response_lengths_,
+ responses_per_prompt=responses_per_prompt,
+ )
+ self._cache_update_futures.append(future)
+
+ def get_server_addresses(self) -> list[str] | None:
+ """Get cache server addresses for rollout workers to connect.
+
+ Returns:
+ List of gRPC addresses in format '[]:' or None if disabled
+ """
+ if not self._enabled:
+ return None
+ return self._get_server_addresses()
+
+ @property
+ def enabled(self) -> bool:
+ """Check if cache manager is enabled.
+
+ Returns:
+ True if cache is initialized and active
+ """
+ return self._enabled
+
+ def shutdown(self):
+ """Clean up cache updater and server resources."""
+ if not self._enabled:
+ return
+
+ # Wait for all pending futures
+ for future in self._cache_update_futures:
+ if not future.done():
+ try:
+ future.result(timeout=5)
+ except Exception as e:
+ print(f"Cache update future failed: {e}")
+
+ # Shutdown executor
+ if self._executor is not None:
+ self._executor.shutdown(wait=True)
+
+ # Shutdown cache servers
+ if self._cache_servers:
+ shutdown_futures = []
+ for server_info in self._cache_servers:
+ try:
+ # Call shutdown method asynchronously
+ future = server_info["server"].shutdown.remote()
+ shutdown_futures.append(future)
+ except Exception as e:
+ print(f"Failed to initiate cache server shutdown: {e}")
+
+ # Wait for all shutdowns to complete
+ if shutdown_futures:
+ try:
+ ray.get(shutdown_futures, timeout=10)
+ except Exception as e:
+ print(f"Error waiting for cache server shutdowns: {e}")
+
+ print("Cache manager shutdown complete")
+
+ def __del__(self):
+ """Ensure cleanup on destruction."""
+ self.shutdown()
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/config/specRL_trainer.yaml b/ICL/DAPO/verl-recipe/specRL/histoSpec/config/specRL_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3ca7a21b4bd30d325f742374120625168ba6daea
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/config/specRL_trainer.yaml
@@ -0,0 +1,7 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/fsdp_workers.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/fsdp_workers.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa5b46a1da23028d99d92cd640c920e8e244c02
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/fsdp_workers.py
@@ -0,0 +1,71 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+from typing import Any, Optional
+
+from omegaconf import DictConfig
+from recipe.specRL.histoSpec.vllm_plugin.patch import specRL_plugin
+
+from verl.single_controller.base.decorator import Dispatch, register
+from verl.workers.fsdp_workers import ActorRolloutRefWorker
+
+
+class SpecRLActorRolloutRefWorker(ActorRolloutRefWorker):
+ """ActorRolloutRefWorker with specRL vLLM patch."""
+
+ def __init__(self, config: DictConfig, role: str, **kwargs):
+ super().__init__(config, role, **kwargs)
+ if self._is_rollout:
+ # Apply vLLM patches on this node before starting cache server
+ # This ensures all vLLM instances on this node will have suffix cache support
+ print("Applying vLLM patches on this node...")
+ specRL_plugin()
+ print("vLLM patches applied successfully on this node")
+
+
+class SpecRLAsyncActorRolloutRefWorker(SpecRLActorRolloutRefWorker):
+ @register(dispatch_mode=Dispatch.DIRECT_ROLLOUT_METHOD)
+ async def wake_up(self):
+ await self.rollout_mode()
+ return True
+
+ @register(dispatch_mode=Dispatch.DIRECT_ROLLOUT_METHOD)
+ async def sleep(self):
+ await self.trainer_mode()
+ return True
+
+ # ============================ vLLM related ============================
+
+ @register(dispatch_mode=Dispatch.DIRECT_ROLLOUT_METHOD)
+ def get_zeromq_address(self):
+ return self.rollout.get_zeromq_address()
+
+ # ============================ SGLang related ============================
+
+ @register(dispatch_mode=Dispatch.DIRECT_ROLLOUT_METHOD, blocking=False)
+ async def chat_completion(self, json_request):
+ ret = await self.rollout.chat_completion(json_request)
+ return ret
+
+ @register(dispatch_mode=Dispatch.DIRECT_ROLLOUT_METHOD, blocking=False)
+ async def generate(
+ self,
+ prompt_ids: list[int],
+ sampling_params: dict[str, Any],
+ request_id: str,
+ image_data: Optional[list[Any]] = None,
+ ) -> list[int]:
+ ret = await self.rollout.generate(prompt_ids, sampling_params, request_id, image_data=image_data)
+ return ret
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/main_ppo.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/main_ppo.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0314f8db259121a65c440fcbb38b1dbfa2cad3f
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/main_ppo.py
@@ -0,0 +1,379 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+Note that we don't combine the main with ray_trainer as ray_trainer is used by other mpain.
+"""
+
+import os
+import socket
+
+import hydra
+import ray
+from omegaconf import OmegaConf
+from recipe.specRL.histoSpec.ray_trainer import SpecRLRayPPOTrainer
+
+from verl.trainer.constants_ppo import get_ppo_ray_runtime_env
+from verl.trainer.histoSpec.main_ppo import create_rl_dataset, create_rl_sampler
+from verl.trainer.ppo.reward import load_reward_manager
+from verl.trainer.ppo.utils import need_critic, need_reference_policy
+from verl.utils.config import validate_config
+from verl.utils.device import is_cuda_available
+
+
+@hydra.main(config_path="config", config_name="specRL_trainer", version_base=None)
+def main(config):
+ """Main entry point for PPO training with Hydra configuration management.
+
+ Args:
+ config_dict: Hydra configuration dictionary containing training parameters.
+ """
+ run_ppo(config)
+
+
+# Define a function to run the PPO-like training process
+def run_ppo(config, task_runner_class=None) -> None:
+ """Initialize Ray cluster and run distributed PPO training process.
+
+ Args:
+ config: Training configuration object containing all necessary parameters
+ for distributed PPO training including Ray initialization settings,
+ model paths, and training hyperparameters.
+ task_runner_class: For recipe to change SpecRLTaskRunner.
+ """
+ # Check if Ray is not initialized
+ if not ray.is_initialized():
+ # Initialize Ray with a local cluster configuration
+ # Set environment variables in the runtime environment to control tokenizer parallelism,
+ # NCCL debug level, VLLM logging level, and allow runtime LoRA updating
+ # `num_cpus` specifies the number of CPU cores Ray can use, obtained from the configuration
+ default_runtime_env = get_ppo_ray_runtime_env()
+ ray_init_kwargs = config.ray_kwargs.get("ray_init", {})
+ runtime_env_kwargs = ray_init_kwargs.get("runtime_env", {})
+
+ if config.transfer_queue.enable:
+ # Add runtime environment variables for transfer queue
+ runtime_env_vars = runtime_env_kwargs.get("env_vars", {})
+ runtime_env_vars["TRANSFER_QUEUE_ENABLE"] = "1"
+ runtime_env_kwargs["env_vars"] = runtime_env_vars
+
+ runtime_env = OmegaConf.merge(default_runtime_env, runtime_env_kwargs)
+ ray_init_kwargs = OmegaConf.create({**ray_init_kwargs, "runtime_env": runtime_env})
+ print(f"ray init kwargs: {ray_init_kwargs}")
+ ray.init(**OmegaConf.to_container(ray_init_kwargs))
+
+ if task_runner_class is None:
+ task_runner_class = ray.remote(num_cpus=1)(
+ SpecRLTaskRunner
+ ) # please make sure main_task is not scheduled on head
+
+ # Create a remote instance of the SpecRLTaskRunner class, and
+ # Execute the `run` method of the SpecRLTaskRunner instance remotely and wait for it to complete
+ if (
+ is_cuda_available
+ and config.global_profiler.tool == "nsys"
+ and config.global_profiler.get("steps") is not None
+ and len(config.global_profiler.get("steps", [])) > 0
+ ):
+ from verl.utils.import_utils import is_nvtx_available
+
+ assert is_nvtx_available(), "nvtx is not available in CUDA platform. Please 'pip3 install nvtx'"
+ nsight_options = OmegaConf.to_container(
+ config.global_profiler.global_tool_config.nsys.controller_nsight_options
+ )
+ runner = task_runner_class.options(runtime_env={"nsight": nsight_options}).remote()
+ else:
+ runner = task_runner_class.remote()
+ ray.get(runner.run.remote(config))
+
+ # [Optional] get the path of the timeline trace file from the configuration, default to None
+ # This file is used for performance analysis
+ timeline_json_file = config.ray_kwargs.get("timeline_json_file", None)
+ if timeline_json_file:
+ ray.timeline(filename=timeline_json_file)
+
+
+class SpecRLTaskRunner:
+ """Ray remote class for executing distributed PPO training tasks.
+
+ This class encapsulates the main training logic and runs as a Ray remote actor
+ to enable distributed execution across multiple nodes and GPUs.
+
+ Attributes:
+ role_worker_mapping: Dictionary mapping Role enums to Ray remote worker classes
+ mapping: Dictionary mapping Role enums to resource pool IDs for GPU allocation
+ """
+
+ def __init__(self):
+ self.role_worker_mapping = {}
+ self.mapping = {}
+
+ def add_actor_rollout_worker(self, config):
+ """Add actor rollout worker based on the actor strategy."""
+ from verl.single_controller.ray import RayWorkerGroup
+ from verl.trainer.ppo.ray_trainer import Role
+
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+
+ # use new model engine implementation
+ if use_legacy_worker_impl == "disable":
+ raise NotImplementedError
+ # from verl.workers.engine_workers import ActorRolloutRefWorker
+
+ # actor_rollout_cls = ActorRolloutRefWorker
+ # ray_worker_group_cls = RayWorkerGroup
+ # # NOTE: In new model engine, ref policy and actor rollout are in same ActorRolloutRefWorker,
+ # # while in legacy model engine, ref policy is in a separate ActorRolloutRefWorker.
+ # if config.algorithm.use_kl_in_reward or config.actor_rollout_ref.actor.use_kl_loss:
+ # role = Role.ActorRolloutRef
+ # else:
+ # role = Role.ActorRollout
+ # self.role_worker_mapping[role] = ray.remote(actor_rollout_cls)
+ # self.mapping[role] = "global_pool"
+ # return actor_rollout_cls, ray_worker_group_cls
+
+ if config.actor_rollout_ref.rollout.mode == "sync":
+ raise ValueError(
+ "Rollout mode 'sync' has been removed. Please set "
+ "`actor_rollout_ref.rollout.mode=async` to use the native server rollout."
+ )
+
+ if config.actor_rollout_ref.actor.strategy in {"fsdp", "fsdp2"}:
+ from recipe.specRL.histoSpec.fsdp_workers import (
+ SpecRLActorRolloutRefWorker,
+ SpecRLAsyncActorRolloutRefWorker,
+ )
+
+ actor_rollout_cls = (
+ SpecRLAsyncActorRolloutRefWorker
+ if config.actor_rollout_ref.rollout.mode == "async"
+ else SpecRLActorRolloutRefWorker
+ )
+ ray_worker_group_cls = RayWorkerGroup
+
+ elif config.actor_rollout_ref.actor.strategy == "megatron":
+ raise NotImplementedError
+ # from verl.workers.megatron_workers import ActorRolloutRefWorker, AsyncActorRolloutRefWorker
+
+ # actor_rollout_cls = (
+ # AsyncActorRolloutRefWorker
+ # if config.actor_rollout_ref.rollout.mode == "async"
+ # else ActorRolloutRefWorker
+ # )
+ # ray_worker_group_cls = RayWorkerGroup
+
+ else:
+ raise NotImplementedError
+
+ self.role_worker_mapping[Role.ActorRollout] = ray.remote(actor_rollout_cls)
+ self.mapping[Role.ActorRollout] = "global_pool"
+ return actor_rollout_cls, ray_worker_group_cls
+
+ def add_critic_worker(self, config):
+ """Add critic worker to role mapping."""
+ if config.critic.strategy in {"fsdp", "fsdp2"}:
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if use_legacy_worker_impl in ["auto", "enable"]:
+ from verl.workers.fsdp_workers import CriticWorker
+ elif use_legacy_worker_impl == "disable":
+ from verl.workers.engine_workers import CriticWorker
+
+ print("Using new worker implementation")
+ else:
+ raise ValueError(f"Invalid use_legacy_worker_impl: {use_legacy_worker_impl}")
+
+ elif config.critic.strategy == "megatron":
+ from verl.workers.megatron_workers import CriticWorker
+
+ else:
+ raise NotImplementedError
+
+ from verl.trainer.ppo.ray_trainer import Role
+
+ self.role_worker_mapping[Role.Critic] = ray.remote(CriticWorker)
+ self.mapping[Role.Critic] = "global_pool"
+
+ def init_resource_pool_mgr(self, config):
+ """Initialize resource pool manager."""
+
+ global_pool_id = "global_pool"
+ resource_pool_spec = {
+ global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
+ }
+ # TODO Here you can use the new registration method to support dynamic registration of roles
+ if config.reward_model.enable_resource_pool:
+ if config.reward_model.n_gpus_per_node <= 0:
+ raise ValueError("config.reward_model.n_gpus_per_node must be greater than 0")
+ if config.reward_model.nnodes <= 0:
+ raise ValueError("config.reward_model.nnodes must be greater than 0")
+
+ reward_pool = [config.reward_model.n_gpus_per_node] * config.reward_model.nnodes
+ resource_pool_spec["reward_pool"] = reward_pool
+
+ from verl.trainer.ppo.ray_trainer import ResourcePoolManager
+
+ resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=self.mapping)
+ return resource_pool_manager
+
+ def add_reward_model_worker(self, config):
+ """Add reward model worker if enabled."""
+ from verl.trainer.ppo.ray_trainer import Role
+
+ if config.reward_model.enable:
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if use_legacy_worker_impl in ["auto", "enable", "disable"]:
+ if config.reward_model.strategy in {"fsdp", "fsdp2"}:
+ from verl.workers.fsdp_workers import RewardModelWorker
+ elif config.reward_model.strategy == "megatron":
+ from verl.workers.megatron_workers import RewardModelWorker
+ else:
+ raise NotImplementedError
+ # elif use_legacy_worker_impl == "disable":
+ # from verl.workers.engine_workers import RewardModelWorker
+ #
+ # print("Using new worker implementation")
+ else:
+ raise ValueError(f"Invalid use_legacy_worker_impl: {use_legacy_worker_impl}")
+
+ self.role_worker_mapping[Role.RewardModel] = ray.remote(RewardModelWorker)
+ if config.reward_model.enable_resource_pool:
+ self.mapping[Role.RewardModel] = "reward_pool"
+ else:
+ self.mapping[Role.RewardModel] = "global_pool"
+
+ def add_ref_policy_worker(self, config, ref_policy_cls):
+ """Add reference policy worker if KL loss or KL reward is used."""
+ from verl.trainer.ppo.ray_trainer import Role
+
+ # Ref policy has been fused into ActorRolloutRefWorker in new model engine,
+ # we don't need to add a separate ref policy worker group.
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if use_legacy_worker_impl == "disable":
+ return
+
+ if config.algorithm.use_kl_in_reward or config.actor_rollout_ref.actor.use_kl_loss:
+ self.role_worker_mapping[Role.RefPolicy] = ray.remote(ref_policy_cls)
+ self.mapping[Role.RefPolicy] = "global_pool"
+
+ def run(self, config):
+ """Execute the main PPO training workflow.
+
+ This method sets up the distributed training environment, initializes
+ workers, datasets, and reward functions, then starts the training process.
+
+ Args:
+ config: Training configuration object containing all parameters needed
+ for setting up and running the PPO training process.
+ """
+ # Print the initial configuration. `resolve=True` will evaluate symbolic values.
+ from pprint import pprint
+
+ from omegaconf import OmegaConf
+
+ from verl.utils.fs import copy_to_local
+
+ print(f"SpecRLTaskRunner hostname: {socket.gethostname()}, PID: {os.getpid()}")
+ pprint(OmegaConf.to_container(config, resolve=True))
+ OmegaConf.resolve(config)
+
+ actor_rollout_cls, ray_worker_group_cls = self.add_actor_rollout_worker(config)
+ self.add_critic_worker(config)
+
+ # We should adopt a multi-source reward function here:
+ # - for rule-based rm, we directly call a reward score
+ # - for model-based rm, we call a model
+ # - for code related prompt, we send to a sandbox if there are test cases
+ # finally, we combine all the rewards together
+ # The reward type depends on the tag of the data
+ self.add_reward_model_worker(config)
+
+ # Add a reference policy worker if KL loss or KL reward is used.
+ self.add_ref_policy_worker(config, actor_rollout_cls)
+
+ # validate config
+ validate_config(
+ config=config,
+ use_reference_policy=need_reference_policy(self.role_worker_mapping),
+ use_critic=need_critic(config),
+ )
+
+ # Download the checkpoint from HDFS to the local machine.
+ # `use_shm` determines whether to use shared memory, which could lead to faster model loading if turned on
+ local_path = copy_to_local(
+ config.actor_rollout_ref.model.path, use_shm=config.actor_rollout_ref.model.get("use_shm", False)
+ )
+
+ # Instantiate the tokenizer and processor.
+ from verl.utils import hf_processor, hf_tokenizer
+
+ trust_remote_code = config.data.get("trust_remote_code", False)
+ tokenizer = hf_tokenizer(local_path, trust_remote_code=trust_remote_code)
+ # Used for multimodal LLM, could be None
+ processor = hf_processor(local_path, trust_remote_code=trust_remote_code, use_fast=True)
+
+ # Load the reward manager for training and validation.
+ reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=0, **config.reward_model.get("reward_kwargs", {})
+ )
+ val_reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=1, **config.reward_model.get("reward_kwargs", {})
+ )
+
+ resource_pool_manager = self.init_resource_pool_mgr(config)
+
+ from verl.utils.dataset.rl_dataset import collate_fn
+
+ # Create training and validation datasets.
+ train_dataset = create_rl_dataset(
+ config.data.train_files,
+ config.data,
+ tokenizer,
+ processor,
+ is_train=True,
+ max_samples=config.data.get("train_max_samples", -1),
+ )
+ val_dataset = create_rl_dataset(
+ config.data.val_files,
+ config.data,
+ tokenizer,
+ processor,
+ is_train=False,
+ max_samples=config.data.get("val_max_samples", -1),
+ )
+ train_sampler = create_rl_sampler(config.data, train_dataset)
+
+ # Initialize the PPO trainer.
+ trainer = SpecRLRayPPOTrainer(
+ config=config,
+ tokenizer=tokenizer,
+ processor=processor,
+ role_worker_mapping=self.role_worker_mapping,
+ resource_pool_manager=resource_pool_manager,
+ ray_worker_group_cls=ray_worker_group_cls,
+ reward_fn=reward_fn,
+ val_reward_fn=val_reward_fn,
+ train_dataset=train_dataset,
+ val_dataset=val_dataset,
+ collate_fn=collate_fn,
+ train_sampler=train_sampler,
+ )
+ # Initialize the workers of the trainer.
+ trainer.init_workers()
+
+ # Start the training process.
+ trainer.fit()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/ray_trainer.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/ray_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4592ee0dd3cb0c4b380bedacd10e9182abe5289
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/ray_trainer.py
@@ -0,0 +1,759 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Copyright 2023-2024 SGLang Team
+# Copyright 2025 ModelBest Inc. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+PPO Trainer with Ray-based single controller.
+This trainer supports model-agonistic model initialization with huggingface
+"""
+
+import uuid
+from collections import defaultdict
+from copy import deepcopy
+from pprint import pprint
+from typing import Optional
+
+import numpy as np
+import ray
+import torch
+from omegaconf import OmegaConf
+from recipe.specRL.histoSpec.cache_manager import CacheManager
+from torch.utils.data import Dataset, Sampler
+from tqdm import tqdm
+
+from verl import DataProto
+from verl.experimental.dataset.sampler import AbstractCurriculumSampler
+from verl.protocol import pad_dataproto_to_divisor, unpad_dataproto
+from verl.single_controller.ray import RayClassWithInitArgs, RayWorkerGroup
+from verl.single_controller.ray.base import create_colocated_worker_cls
+from verl.trainer.ppo.core_algos import AdvantageEstimator, agg_loss
+from verl.trainer.ppo.metric_utils import (
+ compute_data_metrics,
+ compute_throughout_metrics,
+ compute_timing_metrics,
+ process_validation_metrics,
+)
+from verl.trainer.ppo.ray_trainer import (
+ RayPPOTrainer,
+ ResourcePoolManager,
+ apply_kl_penalty,
+ compute_advantage,
+ compute_response_mask,
+)
+from verl.trainer.ppo.reward import compute_reward, compute_reward_async
+from verl.trainer.ppo.utils import Role, WorkerType
+from verl.utils.checkpoint.checkpoint_manager import should_save_ckpt_esi
+from verl.utils.config import omega_conf_to_dataclass
+from verl.utils.debug import marked_timer
+from verl.utils.metric import reduce_metrics
+from verl.utils.rollout_skip import RolloutSkip
+
+
+class SpecRLRayPPOTrainer(RayPPOTrainer):
+ """Distributed PPO trainer using Ray for scalable reinforcement learning.
+
+ This trainer orchestrates distributed PPO training across multiple nodes and GPUs,
+ managing actor rollouts, critic training, and reward computation with Ray backend.
+ Supports various model architectures including FSDP, Megatron, vLLM, and SGLang integration.
+ """
+
+ # TODO: support each role have individual ray_worker_group_cls,
+ # i.e., support different backend of different role
+ def __init__(
+ self,
+ config,
+ tokenizer,
+ role_worker_mapping: dict[Role, WorkerType],
+ resource_pool_manager: ResourcePoolManager,
+ ray_worker_group_cls: type[RayWorkerGroup] = RayWorkerGroup,
+ processor=None,
+ reward_fn=None,
+ val_reward_fn=None,
+ train_dataset: Optional[Dataset] = None,
+ val_dataset: Optional[Dataset] = None,
+ collate_fn=None,
+ train_sampler: Optional[Sampler] = None,
+ device_name=None,
+ ):
+ super().__init__(
+ config,
+ tokenizer,
+ role_worker_mapping,
+ resource_pool_manager,
+ ray_worker_group_cls,
+ processor,
+ reward_fn,
+ val_reward_fn,
+ train_dataset,
+ val_dataset,
+ collate_fn,
+ train_sampler,
+ device_name,
+ )
+
+ # Cache manager for speculative decoding with suffix cache
+ self.cache_manager = None
+
+ def _validate(self):
+ data_source_lst = []
+ reward_extra_infos_dict: dict[str, list] = defaultdict(list)
+
+ # Lists to collect samples for the table
+ sample_inputs = []
+ sample_outputs = []
+ sample_gts = []
+ sample_scores = []
+ sample_turns = []
+ sample_uids = []
+
+ for test_data in self.val_dataloader:
+ test_batch = DataProto.from_single_dict(test_data)
+
+ if "uid" not in test_batch.non_tensor_batch:
+ test_batch.non_tensor_batch["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(test_batch.batch))], dtype=object
+ )
+
+ # repeat test batch
+ test_batch = test_batch.repeat(
+ repeat_times=self.config.actor_rollout_ref.rollout.val_kwargs.n, interleave=True
+ )
+
+ # we only do validation on rule-based rm
+ if self.config.reward_model.enable and test_batch[0].non_tensor_batch["reward_model"]["style"] == "model":
+ return {}
+
+ # Store original inputs
+ input_ids = test_batch.batch["input_ids"]
+ # TODO: Can we keep special tokens except for padding tokens?
+ input_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in input_ids]
+ sample_inputs.extend(input_texts)
+ sample_uids.extend(test_batch.non_tensor_batch["uid"])
+
+ ground_truths = [
+ item.non_tensor_batch.get("reward_model", {}).get("ground_truth", None) for item in test_batch
+ ]
+ sample_gts.extend(ground_truths)
+
+ test_gen_batch = self._get_gen_batch(test_batch)
+ test_gen_batch.meta_info = {
+ "eos_token_id": self.tokenizer.eos_token_id,
+ "pad_token_id": self.tokenizer.pad_token_id,
+ "recompute_log_prob": False,
+ "do_sample": self.config.actor_rollout_ref.rollout.val_kwargs.do_sample,
+ "validate": True,
+ "global_steps": self.global_steps,
+ }
+ print(f"test_gen_batch meta info: {test_gen_batch.meta_info}")
+
+ # pad to be divisible by dp_size
+ size_divisor = (
+ self.actor_rollout_wg.world_size
+ if not self.async_rollout_mode
+ else self.config.actor_rollout_ref.rollout.agent.num_workers
+ )
+ test_gen_batch_padded, pad_size = pad_dataproto_to_divisor(test_gen_batch, size_divisor)
+ if not self.async_rollout_mode:
+ test_output_gen_batch_padded = self.actor_rollout_wg.generate_sequences(test_gen_batch_padded)
+ else:
+ test_output_gen_batch_padded = self.async_rollout_manager.generate_sequences(test_gen_batch_padded)
+
+ # unpad
+ test_output_gen_batch = unpad_dataproto(test_output_gen_batch_padded, pad_size=pad_size)
+
+ print("validation generation end")
+
+ # Store generated outputs
+ output_ids = test_output_gen_batch.batch["responses"]
+ output_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in output_ids]
+ sample_outputs.extend(output_texts)
+
+ test_batch = test_batch.union(test_output_gen_batch)
+
+ # Update suffix cache with validation generation results if speculative decoding is enabled
+ if self.cache_manager and self.cache_manager.enabled:
+ self.cache_manager.update_cache(test_batch, self.config.actor_rollout_ref.rollout.val_kwargs.n)
+
+ test_batch.meta_info["validate"] = True
+
+ # evaluate using reward_function
+ if self.val_reward_fn is None:
+ raise ValueError("val_reward_fn must be provided for validation.")
+ result = self.val_reward_fn(test_batch, return_dict=True)
+ reward_tensor = result["reward_tensor"]
+ scores = reward_tensor.sum(-1).cpu().tolist()
+ sample_scores.extend(scores)
+
+ reward_extra_infos_dict["reward"].extend(scores)
+ if "reward_extra_info" in result:
+ for key, lst in result["reward_extra_info"].items():
+ reward_extra_infos_dict[key].extend(lst)
+
+ # collect num_turns of each prompt
+ if "__num_turns__" in test_batch.non_tensor_batch:
+ sample_turns.append(test_batch.non_tensor_batch["__num_turns__"])
+
+ data_source_lst.append(test_batch.non_tensor_batch.get("data_source", ["unknown"] * reward_tensor.shape[0]))
+
+ self._maybe_log_val_generations(inputs=sample_inputs, outputs=sample_outputs, scores=sample_scores)
+
+ # dump generations
+ val_data_dir = self.config.trainer.get("validation_data_dir", None)
+ if val_data_dir:
+ self._dump_generations(
+ inputs=sample_inputs,
+ outputs=sample_outputs,
+ gts=sample_gts,
+ scores=sample_scores,
+ reward_extra_infos_dict=reward_extra_infos_dict,
+ dump_path=val_data_dir,
+ )
+
+ for key_info, lst in reward_extra_infos_dict.items():
+ assert len(lst) == 0 or len(lst) == len(sample_scores), f"{key_info}: {len(lst)=}, {len(sample_scores)=}"
+
+ data_sources = np.concatenate(data_source_lst, axis=0)
+
+ data_src2var2metric2val = process_validation_metrics(data_sources, sample_uids, reward_extra_infos_dict)
+ metric_dict = {}
+ for data_source, var2metric2val in data_src2var2metric2val.items():
+ core_var = "acc" if "acc" in var2metric2val else "reward"
+ for var_name, metric2val in var2metric2val.items():
+ n_max = max([int(name.split("@")[-1].split("/")[0]) for name in metric2val.keys()])
+ for metric_name, metric_val in metric2val.items():
+ if (
+ (var_name == core_var)
+ and any(metric_name.startswith(pfx) for pfx in ["mean", "maj", "best"])
+ and (f"@{n_max}" in metric_name)
+ ):
+ metric_sec = "val-core"
+ else:
+ metric_sec = "val-aux"
+ pfx = f"{metric_sec}/{data_source}/{var_name}/{metric_name}"
+ metric_dict[pfx] = metric_val
+
+ if len(sample_turns) > 0:
+ sample_turns = np.concatenate(sample_turns)
+ metric_dict["val-aux/num_turns/min"] = sample_turns.min()
+ metric_dict["val-aux/num_turns/max"] = sample_turns.max()
+ metric_dict["val-aux/num_turns/mean"] = sample_turns.mean()
+
+ return metric_dict
+
+ def init_workers(self):
+ """Initialize distributed training workers using Ray backend.
+
+ Creates:
+ 1. Ray resource pools from configuration
+ 2. Worker groups for each role (actor, critic, etc.)
+ """
+ self.resource_pool_manager.create_resource_pool()
+
+ self.resource_pool_to_cls = {pool: {} for pool in self.resource_pool_manager.resource_pool_dict.values()}
+
+ # create actor and rollout
+ actor_role = Role.ActorRolloutRef if Role.ActorRolloutRef in self.role_worker_mapping else Role.ActorRollout
+ if self.hybrid_engine:
+ resource_pool = self.resource_pool_manager.get_resource_pool(actor_role)
+ actor_rollout_cls = RayClassWithInitArgs(
+ cls=self.role_worker_mapping[actor_role],
+ config=self.config.actor_rollout_ref,
+ role=str(actor_role),
+ )
+ self.resource_pool_to_cls[resource_pool][str(actor_role)] = actor_rollout_cls
+ else:
+ raise NotImplementedError
+
+ # create critic
+ if self.use_critic:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.Critic)
+ critic_cfg = omega_conf_to_dataclass(self.config.critic)
+ critic_cls = RayClassWithInitArgs(cls=self.role_worker_mapping[Role.Critic], config=critic_cfg)
+ self.resource_pool_to_cls[resource_pool][str(Role.Critic)] = critic_cls
+
+ # create reference policy if needed
+ if self.use_reference_policy and Role.RefPolicy in self.role_worker_mapping:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RefPolicy)
+ ref_policy_cls = RayClassWithInitArgs(
+ self.role_worker_mapping[Role.RefPolicy],
+ config=self.config.actor_rollout_ref,
+ role=str(Role.RefPolicy),
+ )
+ self.resource_pool_to_cls[resource_pool][str(Role.RefPolicy)] = ref_policy_cls
+
+ # create a reward model if reward_fn is None
+ if self.use_rm:
+ # we create a RM here
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ rm_cls = RayClassWithInitArgs(self.role_worker_mapping[Role.RewardModel], config=self.config.reward_model)
+ self.resource_pool_to_cls[resource_pool][str(Role.RewardModel)] = rm_cls
+
+ # initialize WorkerGroup
+ # NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
+ # you should not use `create_colocated_worker_cls`.
+ # Instead, directly pass different resource pool to different worker groups.
+ # See https://github.com/volcengine/verl/blob/master/examples/ray/tutorial.ipynb for more information.
+ all_wg = {}
+ wg_kwargs = {} # Setting up kwargs for RayWorkerGroup
+ if OmegaConf.select(self.config.trainer, "ray_wait_register_center_timeout") is not None:
+ wg_kwargs["ray_wait_register_center_timeout"] = self.config.trainer.ray_wait_register_center_timeout
+ if OmegaConf.select(self.config.global_profiler, "steps") is not None:
+ wg_kwargs["profile_steps"] = OmegaConf.select(self.config.global_profiler, "steps")
+ # Only require nsight worker options when tool is nsys
+ if OmegaConf.select(self.config.global_profiler, "tool") == "nsys":
+ assert (
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ is not None
+ ), "worker_nsight_options must be set when using nsys with profile_steps"
+ wg_kwargs["worker_nsight_options"] = OmegaConf.to_container(
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ )
+ wg_kwargs["device_name"] = self.device_name
+
+ for resource_pool, class_dict in self.resource_pool_to_cls.items():
+ worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
+ wg_dict = self.ray_worker_group_cls(
+ resource_pool=resource_pool,
+ ray_cls_with_init=worker_dict_cls,
+ **wg_kwargs,
+ )
+ spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
+ all_wg.update(spawn_wg)
+
+ if self.use_critic:
+ self.critic_wg = all_wg[str(Role.Critic)]
+ self.critic_wg.init_model()
+
+ if self.use_reference_policy and not self.ref_in_actor:
+ if str(Role.RefPolicy) in all_wg:
+ self.ref_policy_wg = all_wg[str(Role.RefPolicy)]
+ self.ref_policy_wg.init_model()
+ else:
+ # Model engine: ActorRolloutRefWorker
+ assert str(Role.ActorRolloutRef) in all_wg, f"{all_wg.keys()=}"
+ self.ref_policy_wg = all_wg[str(Role.ActorRolloutRef)]
+
+ self.rm_wg = None
+ # initalization of rm_wg will be deprecated in the future
+ if self.use_rm:
+ self.rm_wg = all_wg[str(Role.RewardModel)]
+ self.rm_wg.init_model()
+
+ # Initialize cache manager before rollout workers (applies vLLM patches)
+ self.cache_manager = CacheManager(
+ config=self.config,
+ role_worker_mapping=self.role_worker_mapping,
+ resource_pool_manager=self.resource_pool_manager,
+ )
+
+ # we should create rollout at the end so that vllm can have a better estimation of kv cache memory
+ self.actor_rollout_wg = all_wg[str(actor_role)]
+ self.actor_rollout_wg.init_model()
+
+ # create async rollout manager and request scheduler
+ self.async_rollout_mode = False
+ if self.config.actor_rollout_ref.rollout.mode == "async":
+ from verl.experimental.agent_loop import AgentLoopManager
+
+ self.async_rollout_mode = True
+ if self.config.reward_model.enable and self.config.reward_model.enable_resource_pool:
+ rm_resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ else:
+ rm_resource_pool = None
+
+ self.async_rollout_manager = AgentLoopManager(
+ config=self.config,
+ worker_group=self.actor_rollout_wg,
+ rm_resource_pool=rm_resource_pool,
+ )
+
+ def fit(self):
+ """
+ The training loop of PPO.
+ The driver process only need to call the compute functions of the worker group through RPC
+ to construct the PPO dataflow.
+ The light-weight advantage computation is done on the driver process.
+ """
+ from omegaconf import OmegaConf
+
+ from verl.utils.tracking import Tracking
+
+ logger = Tracking(
+ project_name=self.config.trainer.project_name,
+ experiment_name=self.config.trainer.experiment_name,
+ default_backend=self.config.trainer.logger,
+ config=OmegaConf.to_container(self.config, resolve=True),
+ )
+
+ self.global_steps = 0
+
+ # load checkpoint before doing anything
+ self._load_checkpoint()
+
+ current_epoch = self.global_steps // len(self.train_dataloader)
+
+ # perform validation before training
+ # currently, we only support validation using the reward_function.
+ if self.val_reward_fn is not None and self.config.trainer.get("val_before_train", True):
+ val_metrics = self._validate()
+ assert val_metrics, f"{val_metrics=}"
+ pprint(f"Initial validation metrics: {val_metrics}")
+ logger.log(data=val_metrics, step=self.global_steps)
+ if self.config.trainer.get("val_only", False):
+ return
+
+ if self.config.actor_rollout_ref.rollout.get("skip_rollout", False):
+ rollout_skip = RolloutSkip(self.config, self.actor_rollout_wg)
+ rollout_skip.wrap_generate_sequences()
+
+ # add tqdm
+ progress_bar = tqdm(total=self.total_training_steps, initial=self.global_steps, desc="Training Progress")
+
+ # we start from step 1
+ self.global_steps += 1
+ last_val_metrics = None
+ self.max_steps_duration = 0
+
+ prev_step_profile = False
+ curr_step_profile = (
+ self.global_steps in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ next_step_profile = False
+
+ for epoch in range(current_epoch, self.config.trainer.total_epochs):
+ for batch_dict in self.train_dataloader:
+ if hasattr(self.actor_rollout_wg, "async_calls_finalize_fn_exec"):
+ self.actor_rollout_wg.async_calls_finalize_fn_exec(blocking=False)
+ metrics = {}
+ timing_raw = {}
+
+ with marked_timer("start_profile", timing_raw):
+ self._start_profiling(
+ not prev_step_profile and curr_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+ batch: DataProto = DataProto.from_single_dict(batch_dict)
+ batch.meta_info["temperature"] = self.config.actor_rollout_ref.rollout.temperature
+
+ # add uid to batch
+ batch.non_tensor_batch["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(batch.batch))], dtype=object
+ )
+
+ gen_batch = self._get_gen_batch(batch)
+
+ # pass global_steps to trace
+ gen_batch.meta_info["global_steps"] = self.global_steps
+ gen_batch_output = gen_batch.repeat(
+ repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True
+ )
+
+ is_last_step = self.global_steps >= self.total_training_steps
+ with marked_timer("step", timing_raw):
+ # generate a batch
+ with marked_timer("gen", timing_raw, color="red"):
+ if not self.async_rollout_mode:
+ gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch_output)
+ else:
+ gen_batch_output = self.async_rollout_manager.generate_sequences(gen_batch_output)
+
+ timing_raw.update(gen_batch_output.meta_info["timing"])
+ gen_batch_output.meta_info.pop("timing", None)
+
+ if self.config.algorithm.adv_estimator == AdvantageEstimator.REMAX:
+ if self.reward_fn is None:
+ raise ValueError("A reward_fn is required for REMAX advantage estimation.")
+
+ with marked_timer("gen_max", timing_raw, color="purple"):
+ gen_baseline_batch = deepcopy(gen_batch)
+ gen_baseline_batch.meta_info["do_sample"] = False
+ if not self.async_rollout_mode:
+ gen_baseline_output = self.actor_rollout_wg.generate_sequences(gen_baseline_batch)
+ else:
+ gen_baseline_output = self.async_rollout_manager.generate_sequences(gen_baseline_batch)
+ batch = batch.union(gen_baseline_output)
+ # compute reward model score on batch
+ rm_scores = None
+ if self.use_rm and "rm_scores" not in batch.batch.keys():
+ rm_scores = self.rm_wg.compute_rm_score(batch)
+ batch = batch.union(rm_scores)
+ reward_baseline_tensor, _ = compute_reward(batch, self.reward_fn)
+ reward_baseline_tensor = reward_baseline_tensor.sum(dim=-1)
+
+ keys_to_pop = set(gen_baseline_output.batch.keys())
+ if rm_scores is not None:
+ keys_to_pop.update(rm_scores.batch.keys())
+ batch.pop(batch_keys=list(keys_to_pop))
+
+ batch.batch["reward_baselines"] = reward_baseline_tensor
+
+ del rm_scores, gen_baseline_batch, gen_baseline_output
+ # repeat to align with repeated responses in rollout
+ batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
+ batch = batch.union(gen_batch_output)
+
+ if "response_mask" not in batch.batch.keys():
+ batch.batch["response_mask"] = compute_response_mask(batch)
+
+ # Update suffix cache with training generation results if speculative decoding is enabled
+ # This helps improve cache hit rate for future generations
+ if self.cache_manager and self.cache_manager.enabled:
+ self.cache_manager.update_cache(batch, self.config.actor_rollout_ref.rollout.n)
+
+ # Balance the number of valid tokens across DP ranks.
+ # NOTE: This usually changes the order of data in the `batch`,
+ # which won't affect the advantage calculation (since it's based on uid),
+ # but might affect the loss calculation (due to the change of mini-batching).
+ if self.config.trainer.balance_batch:
+ self._balance_batch(batch, metrics=metrics)
+
+ # compute global_valid tokens
+ batch.meta_info["global_token_num"] = torch.sum(batch.batch["attention_mask"], dim=-1).tolist()
+
+ with marked_timer("reward", timing_raw, color="yellow"):
+ # compute reward model score
+ if self.use_rm and "rm_scores" not in batch.batch.keys():
+ reward_tensor = self.rm_wg.compute_rm_score(batch)
+ batch = batch.union(reward_tensor)
+
+ if self.config.reward_model.launch_reward_fn_async:
+ future_reward = compute_reward_async.remote(
+ data=batch, config=self.config, tokenizer=self.tokenizer
+ )
+ else:
+ reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)
+
+ # Operating Mode Selection:
+ # - Bypass mode: Sets old_log_probs = rollout_log_probs (2 policies: π_rollout, π_θ)
+ # - Decoupled mode: Recomputes old_log_probs as proximal anchor (3 policies: π_rollout, π_old, π_θ)
+ # Note: π_old computed once per data batch, serves as stable reference during mini-batch updates
+ rollout_corr_config = self.config.algorithm.get("rollout_correction", None)
+ bypass_recomputing_logprobs = rollout_corr_config and rollout_corr_config.get("bypass_mode", False)
+ if bypass_recomputing_logprobs: # Use `rollout_log_probs`
+ from verl.trainer.ppo.rollout_corr_helper import apply_rollout_correction
+
+ apply_rollout_correction(
+ batch=batch,
+ rollout_corr_config=rollout_corr_config,
+ policy_loss_config=self.config.actor_rollout_ref.actor.policy_loss,
+ )
+ else: # Recompute old_log_probs
+ with marked_timer("old_log_prob", timing_raw, color="blue"):
+ old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
+ entropys = old_log_prob.batch["entropys"]
+ response_masks = batch.batch["response_mask"]
+ actor_config = self.config.actor_rollout_ref.actor
+ entropy_agg = agg_loss(
+ loss_mat=entropys,
+ loss_mask=response_masks,
+ loss_agg_mode=actor_config.loss_agg_mode,
+ loss_scale_factor=actor_config.loss_scale_factor,
+ )
+ old_log_prob_metrics = {"actor/entropy": entropy_agg.detach().item()}
+ metrics.update(old_log_prob_metrics)
+ old_log_prob.batch.pop("entropys")
+ batch = batch.union(old_log_prob)
+ if "rollout_log_probs" in batch.batch.keys():
+ # TODO: we may want to add diff of probs too.
+ from verl.utils.debug.metrics import calculate_debug_metrics
+
+ metrics.update(calculate_debug_metrics(batch))
+
+ assert "old_log_probs" in batch.batch, f'"old_log_prob" not in {batch.batch.keys()=}'
+
+ if self.use_reference_policy:
+ # compute reference log_prob
+ with marked_timer(str(Role.RefPolicy), timing_raw, color="olive"):
+ if not self.ref_in_actor:
+ ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
+ else:
+ ref_log_prob = self.actor_rollout_wg.compute_ref_log_prob(batch)
+ batch = batch.union(ref_log_prob)
+
+ # compute values
+ if self.use_critic:
+ with marked_timer("values", timing_raw, color="cyan"):
+ values = self.critic_wg.compute_values(batch)
+ batch = batch.union(values)
+
+ with marked_timer("adv", timing_raw, color="brown"):
+ # we combine with rule-based rm
+ reward_extra_infos_dict: dict[str, list]
+ if self.config.reward_model.launch_reward_fn_async:
+ reward_tensor, reward_extra_infos_dict = ray.get(future_reward)
+ batch.batch["token_level_scores"] = reward_tensor
+
+ if reward_extra_infos_dict:
+ batch.non_tensor_batch.update({k: np.array(v) for k, v in reward_extra_infos_dict.items()})
+
+ # compute rewards. apply_kl_penalty if available
+ if self.config.algorithm.use_kl_in_reward:
+ batch, kl_metrics = apply_kl_penalty(
+ batch, kl_ctrl=self.kl_ctrl_in_reward, kl_penalty=self.config.algorithm.kl_penalty
+ )
+ metrics.update(kl_metrics)
+ else:
+ batch.batch["token_level_rewards"] = batch.batch["token_level_scores"]
+
+ # Compute rollout correction: IS weights, rejection sampling, and metrics
+ # Only runs in decoupled mode (computes once per batch using stable π_old)
+ # In bypass mode, this is skipped - actor computes metrics from evolving π_θ vs π_rollout
+ if (
+ rollout_corr_config is not None
+ and "rollout_log_probs" in batch.batch
+ and not bypass_recomputing_logprobs # Only in decoupled mode
+ ):
+ from verl.trainer.ppo.rollout_corr_helper import compute_rollout_correction_and_add_to_batch
+
+ # Compute IS weights, apply rejection sampling, compute metrics
+ batch, is_metrics = compute_rollout_correction_and_add_to_batch(batch, rollout_corr_config)
+ # IS and off-policy metrics already have rollout_corr/ prefix
+ metrics.update(is_metrics)
+
+ # compute advantages, executed on the driver process
+ norm_adv_by_std_in_grpo = self.config.algorithm.get(
+ "norm_adv_by_std_in_grpo", True
+ ) # GRPO adv normalization factor
+
+ batch = compute_advantage(
+ batch,
+ adv_estimator=self.config.algorithm.adv_estimator,
+ gamma=self.config.algorithm.gamma,
+ lam=self.config.algorithm.lam,
+ num_repeat=self.config.actor_rollout_ref.rollout.n,
+ norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
+ config=self.config.algorithm,
+ )
+
+ # update critic
+ if self.use_critic:
+ with marked_timer("update_critic", timing_raw, color="pink"):
+ critic_output = self.critic_wg.update_critic(batch)
+ critic_output_metrics = reduce_metrics(critic_output.meta_info["metrics"])
+ metrics.update(critic_output_metrics)
+
+ # implement critic warmup
+ if self.config.trainer.critic_warmup <= self.global_steps:
+ # update actor
+ with marked_timer("update_actor", timing_raw, color="red"):
+ rollout_config = self.config.actor_rollout_ref.rollout
+ batch.meta_info["multi_turn"] = rollout_config.multi_turn.enable
+ # TODO: Make "temperature" single source of truth from generation.
+ batch.meta_info["temperature"] = rollout_config.temperature
+ actor_output = self.actor_rollout_wg.update_actor(batch)
+ actor_output_metrics = reduce_metrics(actor_output.meta_info["metrics"])
+ metrics.update(actor_output_metrics)
+
+ # Log rollout generations if enabled
+ rollout_data_dir = self.config.trainer.get("rollout_data_dir", None)
+ if rollout_data_dir:
+ self._log_rollout_data(batch, reward_extra_infos_dict, timing_raw, rollout_data_dir)
+
+ # validate
+ if (
+ self.val_reward_fn is not None
+ and self.config.trainer.test_freq > 0
+ and (is_last_step or self.global_steps % self.config.trainer.test_freq == 0)
+ ):
+ with marked_timer("testing", timing_raw, color="green"):
+ val_metrics: dict = self._validate()
+ if is_last_step:
+ last_val_metrics = val_metrics
+ metrics.update(val_metrics)
+
+ # Check if the ESI (Elastic Server Instance)/training plan is close to expiration.
+ esi_close_to_expiration = should_save_ckpt_esi(
+ max_steps_duration=self.max_steps_duration,
+ redundant_time=self.config.trainer.esi_redundant_time,
+ )
+ # Check if the conditions for saving a checkpoint are met.
+ # The conditions include a mandatory condition (1) and
+ # one of the following optional conditions (2/3/4):
+ # 1. The save frequency is set to a positive value.
+ # 2. It's the last training step.
+ # 3. The current step number is a multiple of the save frequency.
+ # 4. The ESI(Elastic Server Instance)/training plan is close to expiration.
+ if self.config.trainer.save_freq > 0 and (
+ is_last_step or self.global_steps % self.config.trainer.save_freq == 0 or esi_close_to_expiration
+ ):
+ if esi_close_to_expiration:
+ print("Force saving checkpoint: ESI instance expiration approaching.")
+ with marked_timer("save_checkpoint", timing_raw, color="green"):
+ self._save_checkpoint()
+
+ with marked_timer("stop_profile", timing_raw):
+ next_step_profile = (
+ self.global_steps + 1 in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ self._stop_profiling(
+ curr_step_profile and not next_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+ prev_step_profile = curr_step_profile
+ curr_step_profile = next_step_profile
+
+ steps_duration = timing_raw["step"]
+ self.max_steps_duration = max(self.max_steps_duration, steps_duration)
+
+ # training metrics
+ metrics.update(
+ {
+ "training/global_step": self.global_steps,
+ "training/epoch": epoch,
+ }
+ )
+ # collect metrics
+ metrics.update(compute_data_metrics(batch=batch, use_critic=self.use_critic))
+ metrics.update(compute_timing_metrics(batch=batch, timing_raw=timing_raw))
+ # TODO: implement actual tflpo and theoretical tflpo
+ n_gpus = self.resource_pool_manager.get_n_gpus()
+ metrics.update(compute_throughout_metrics(batch=batch, timing_raw=timing_raw, n_gpus=n_gpus))
+ # Note: mismatch metrics (KL, PPL, etc.) are collected at line 1179 after advantage computation
+
+ # this is experimental and may be changed/removed in the future in favor of a general-purpose one
+ if isinstance(self.train_dataloader.sampler, AbstractCurriculumSampler):
+ self.train_dataloader.sampler.update(batch=batch)
+
+ # TODO: make a canonical logger that supports various backend
+ logger.log(data=metrics, step=self.global_steps)
+
+ progress_bar.update(1)
+ self.global_steps += 1
+
+ if (
+ hasattr(self.config.actor_rollout_ref.actor, "profiler")
+ and self.config.actor_rollout_ref.actor.profiler.tool == "torch_memory"
+ ):
+ self.actor_rollout_wg.dump_memory_snapshot(
+ tag=f"post_update_step{self.global_steps}", sub_dir=f"step{self.global_steps}"
+ )
+
+ if is_last_step:
+ if hasattr(self.actor_rollout_wg, "async_calls_finalize_fn_exec"):
+ self.actor_rollout_wg.async_calls_finalize_fn_exec(blocking=True)
+ pprint(f"Final validation metrics: {last_val_metrics}")
+ progress_bar.close()
+ return
+
+ # this is experimental and may be changed/removed in the future
+ # in favor of a general-purpose data buffer pool
+ if hasattr(self.train_dataset, "on_batch_end"):
+ # The dataset may be changed after each training batch
+ self.train_dataset.on_batch_end(batch=batch)
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/__init__.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f5d74a9cef8bedf4a8cc5d5523ddf899d0ba65b
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch.py
new file mode 100644
index 0000000000000000000000000000000000000000..874905a443059bd1496632e3ff1c91483e8b34c6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch.py
@@ -0,0 +1,58 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# Copyright 2025 Snowflake Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import logging
+import os
+
+import vllm
+
+logger = logging.getLogger(__name__)
+
+
+def specRL_plugin():
+ """vLLM plugin for FlexFlow.
+
+ This plugin enables FlexFlow to be used with vLLM. It consists of a
+ collection of patches that are applied to vLLM at runtime.
+ """
+
+ # To enable the plugin, set the environment variable VLLM_PLUGINS=specRL_plugin.
+ #
+ # The plugin is activated when vLLM is imported. It is only activated in the
+ # main process. It is not activated in vLLM's worker processes.
+
+ # The plugin is compatible with vLLM versions 0.3.2 and later.
+ # It is not compatible with vLLM versions prior to 0.3.2.
+
+ if os.getenv("VLLM_USE_V1") == "0":
+ logger.warning(
+ "specRL only supports vLLM V1, but detected V0 engine. "
+ "Ignoring plugin!\n"
+ "Hint: To strictly enforce the V1 vLLM engine, please set "
+ "VLLM_USE_V1=1."
+ )
+ return
+
+ if vllm.__version__.startswith("0.10.0"):
+ from .v0_10_0 import patch
+ # elif vllm.__version__.startswith("0.8.3"):
+ # from .v0_8_3 import patch
+ else:
+ logger.warning(f"specRL requires vllm==0.10.0 but found vllm=={vllm.__version__}. Ignoring plugin!")
+ return
+
+ # Patches that make later patches work properly.
+ patch.WorkerBasePatch.apply_patch()
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch_utils.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa18bc612ce77de56ba302ec4d42ccbfec33aa45
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/patch_utils.py
@@ -0,0 +1,141 @@
+# Copyright 2025 Snowflake Inc.
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+from types import MethodType, ModuleType
+
+logger = logging.getLogger(__name__)
+
+Patchable = type | ModuleType
+
+
+class specRLPatch:
+ """
+ specRLPatch provides a mechanism for cleanly patching (extending or
+ modifying) existing classes or modules.
+
+ This class uses a subscription syntax to specify the target class or
+ module to be patched. Subclasses of specRLPatch should define new or
+ replacement attributes and methods that will be applied in-place to the
+ target when `apply_patch()` is called.
+
+ Example 1: Patching a class
+
+ ```python
+ # Define a class patch with new methods
+ class ExamplePatch(specRLPatch[SomeClass]):
+
+ new_field = "This field will be added to SomeClass"
+
+ def new_method(self):
+ return "This method will be added to SomeClass"
+
+ @classmethod
+ def new_classmethod(cls):
+ return "This classmethod will be added to SomeClass"
+
+ # Apply the patch to the target class
+ ExamplePatch.apply_patch()
+
+ # Now these methods are available on the original class
+ instance = SomeClass()
+ instance.new_method() # Works!
+ SomeClass.new_class_method() # Works!
+ ```
+
+ Example 2: Patching a module
+
+ ```python
+ # Define a module patch
+ class ModulePatch(specRLPatch[some_module]):
+ NEW_CONSTANT = "This will be added to some_module"
+
+ @staticmethod
+ def new_function():
+ return "This function will be added to some_module"
+
+ ModulePatch.apply_patch()
+
+ # The constant and function are now available in the module
+ some_module.NEW_CONSTANT # Works!
+ some_module.new_function() # Works!
+ ```
+ """
+
+ def __init_subclass__(cls, **kwargs):
+ super().__init_subclass__(**kwargs)
+ # Ensure that subclasses are created using the subscript syntax.
+ if not hasattr(cls, "_specRL_patch_target"):
+ raise TypeError(
+ "Subclasses of specRLPatch must be defined as specRLPatch[Target] to specify a patch target"
+ )
+
+ @classmethod
+ def __class_getitem__(cls, target: Patchable) -> type:
+ # The dynamic type created here will carry the target class as
+ # _specRL_patch_target.
+ if not isinstance(target, Patchable):
+ raise TypeError(f"specRLPatch can only target a class or module, not {type(target)}")
+ return type(f"{cls.__name__}[{target.__name__}]", (cls,), {"_specRL_patch_target": target})
+
+ @classmethod
+ def apply_patch(cls):
+ """
+ Patches the target class or module by replacing its attributes with
+ those defined on the specRLPatch subclass. Attributes are directly
+ assigned to the target, and classmethods are re-bound to the target
+ class before assignment.
+
+ Raises:
+ TypeError: If the specRLPatch subclass is not defined with a target
+ class or module.
+ ValueError: If an attribute is already patched on the target.
+ """
+ if cls is specRLPatch or not issubclass(cls, specRLPatch):
+ raise TypeError("apply_patch() must be called on a subclass of specRLPatch")
+
+ target = cls._specRL_patch_target
+
+ if "_specRL_patches" not in target.__dict__:
+ target._specRL_patches = {}
+
+ for name, attr in cls.__dict__.items():
+ # Skip special names and the '_specRL_patch_target' itself
+ if name in (
+ "_specRL_patch_target",
+ "__dict__",
+ "__weakref__",
+ "__module__",
+ "__doc__",
+ "__parameters__",
+ ):
+ continue
+
+ # Check if the attribute has already been patched
+ if name in target._specRL_patches:
+ patch = target._specRL_patches[name]
+ raise ValueError(f"{target.__name__}.{name} is already patched by {patch.__name__}")
+ target._specRL_patches[name] = cls
+
+ # If classmethod, re-bind it to the target
+ if isinstance(attr, MethodType):
+ attr = MethodType(attr.__func__, target)
+
+ # Patch the target with the new attribute
+ replace = hasattr(target, name)
+ setattr(target, name, attr)
+ action = "replaced" if replace else "added"
+ logger.info(f"{cls.__name__} {action} {target.__name__}.{name}")
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/__init__.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f5d74a9cef8bedf4a8cc5d5523ddf899d0ba65b
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/__init__.py
@@ -0,0 +1,14 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/patch.py b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/patch.py
new file mode 100644
index 0000000000000000000000000000000000000000..5006e4acc397f48cb62904c37040f5b370532f8c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/specRL/histoSpec/vllm_plugin/v0_10_0/patch.py
@@ -0,0 +1,705 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# SPDX-License-Identifier: Apache-2.0
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from concurrent.futures import Future, ThreadPoolExecutor
+from typing import TYPE_CHECKING, Optional
+
+import torch
+from vllm.config import VllmConfig
+from vllm.distributed.parallel_state import get_pp_group, get_tp_group
+from vllm.forward_context import set_forward_context
+from vllm.sequence import IntermediateTensors
+from vllm.v1.outputs import EMPTY_MODEL_RUNNER_OUTPUT, ModelRunnerOutput
+from vllm.v1.worker.gpu_model_runner import GPUModelRunner
+
+if TYPE_CHECKING:
+ from vllm.v1.core.sched.output import SchedulerOutput
+
+
+import vllm.envs as envs
+
+# Import specRLPatch from the correct location
+from recipe.specRL.histoSpec.vllm_plugin.patch_utils import specRLPatch
+from specrl.suffix_cache import SuffixCache
+from vllm.distributed.kv_transfer import has_kv_transfer_group
+from vllm.logger import init_logger
+from vllm.multimodal.inputs import MultiModalKwargs
+from vllm.triton_utils import tl, triton
+from vllm.utils import round_up
+from vllm.v1.sample.metadata import SamplingMetadata
+from vllm.v1.sample.rejection_sampler import (
+ GREEDY_TEMPERATURE,
+ MAX_SPEC_LEN,
+ PLACEHOLDER_TOKEN_ID,
+ RejectionSampler,
+ compute_probs,
+ generate_uniform_probs,
+ rejection_greedy_sample_kernel,
+ rejection_random_sample_kernel,
+)
+from vllm.v1.spec_decode.metadata import SpecDecodeMetadata
+from vllm.v1.worker.worker_base import WorkerBase
+
+SPEC_START_LEN = 4
+SPECRL_MIN_TOKEN_PROB = 0.1
+SPECRL_PREFIX_LEN = 7
+
+logger = init_logger(__name__)
+
+
+@triton.jit
+def sample_recovered_tokens_kernel_bugfix(
+ output_token_ids_ptr, # [num_tokens]
+ cu_num_draft_tokens_ptr, # [batch_size]
+ draft_token_ids_ptr, # [num_tokens]
+ draft_probs_ptr, # [num_tokens, vocab_size] or None
+ target_probs_ptr, # [num_tokens, vocab_size]
+ q_ptr, # [batch_size, vocab_size]
+ vocab_size,
+ PADDED_VOCAB_SIZE: tl.constexpr,
+ NO_DRAFT_PROBS: tl.constexpr,
+):
+ req_idx = tl.program_id(0)
+ if req_idx == 0:
+ start_idx = 0
+ else:
+ start_idx = tl.load(cu_num_draft_tokens_ptr + req_idx - 1)
+ end_idx = tl.load(cu_num_draft_tokens_ptr + req_idx)
+ num_draft_tokens = end_idx - start_idx
+
+ # Early exit for out-of-range positions.
+ pos = tl.program_id(1)
+ if pos >= num_draft_tokens:
+ return
+
+ vocab_offset = tl.arange(0, PADDED_VOCAB_SIZE)
+ if NO_DRAFT_PROBS:
+ draft_token_id = tl.load(draft_token_ids_ptr + start_idx + pos)
+ prob = tl.load(
+ target_probs_ptr + (start_idx + pos) * vocab_size + vocab_offset,
+ mask=((vocab_offset < vocab_size) & (vocab_offset != draft_token_id)),
+ other=0,
+ )
+ else:
+ draft_prob = tl.load(
+ draft_probs_ptr + (start_idx + pos) * vocab_size + vocab_offset, mask=vocab_offset < vocab_size, other=0
+ )
+ target_prob = tl.load(
+ target_probs_ptr + (start_idx + pos) * vocab_size + vocab_offset, mask=vocab_offset < vocab_size, other=0
+ )
+ prob = tl.maximum(target_prob - draft_prob, 0)
+ # NOTE(woosuk): We don't need `prob = prob / tl.sum(prob)` here because
+ # `tl.argmax` will select the maximum value.
+
+ q = tl.load(q_ptr + req_idx * vocab_size + vocab_offset, mask=vocab_offset < vocab_size, other=float("-inf"))
+ recovered_id = tl.argmax(prob / q, axis=-1)
+ tl.store(output_token_ids_ptr + start_idx + pos, recovered_id)
+
+
+def sample_recovered_tokens_bugfix(
+ max_spec_len: int,
+ num_draft_tokens: list[int],
+ # [batch_size]
+ cu_num_draft_tokens: torch.Tensor,
+ # [num_tokens]
+ draft_token_ids: torch.Tensor,
+ # [num_tokens, vocab_size]
+ draft_probs: Optional[torch.Tensor],
+ # [num_tokens, vocab_size]
+ target_probs: torch.Tensor,
+ sampling_metadata: SamplingMetadata,
+ device: torch.device,
+) -> torch.Tensor:
+ # NOTE(woosuk): Create only one distribution for each request.
+ batch_size = len(num_draft_tokens)
+ vocab_size = target_probs.shape[-1]
+ q = torch.empty(
+ (batch_size, vocab_size),
+ dtype=torch.float32,
+ device=device,
+ )
+ q.exponential_()
+ for i, generator in sampling_metadata.generators.items():
+ # Do not generate random numbers for requests with no draft tokens.
+ # This can be important for reproducibility.
+ if num_draft_tokens[i] > 0:
+ q[i].exponential_(generator=generator)
+
+ recovered_token_ids = torch.empty_like(draft_token_ids)
+ sample_recovered_tokens_kernel_bugfix[(batch_size, max_spec_len)](
+ recovered_token_ids,
+ cu_num_draft_tokens,
+ draft_token_ids,
+ draft_probs,
+ target_probs,
+ q,
+ vocab_size,
+ triton.next_power_of_2(vocab_size),
+ NO_DRAFT_PROBS=draft_probs is None,
+ )
+ return recovered_token_ids
+
+
+def rejection_sample_bugfix(
+ # [num_tokens]
+ draft_token_ids: torch.Tensor,
+ # [batch_size]
+ num_draft_tokens: list[int],
+ max_spec_len: int,
+ # [batch_size]
+ cu_num_draft_tokens: torch.Tensor,
+ # [num_tokens, vocab_size]
+ draft_probs: Optional[torch.Tensor],
+ # [num_tokens, vocab_size]
+ target_probs: torch.Tensor,
+ # [batch_size, 1]
+ bonus_token_ids: torch.Tensor,
+ sampling_metadata: SamplingMetadata,
+) -> torch.Tensor:
+ assert draft_token_ids.ndim == 1
+ assert draft_probs is None or draft_probs.ndim == 2
+ assert cu_num_draft_tokens.ndim == 1
+ assert target_probs.ndim == 2
+
+ batch_size = len(num_draft_tokens)
+ num_tokens = draft_token_ids.shape[0]
+ vocab_size = target_probs.shape[-1]
+ device = target_probs.device
+ assert draft_token_ids.is_contiguous()
+ assert draft_probs is None or draft_probs.is_contiguous()
+ assert target_probs.is_contiguous()
+ assert bonus_token_ids.is_contiguous()
+ assert target_probs.shape == (num_tokens, vocab_size)
+
+ # Create output buffer.
+ output_token_ids = torch.empty(
+ (batch_size, max_spec_len + 1),
+ dtype=torch.int32, # Consistent with SamplerOutput.sampled_token_ids.
+ device=device,
+ )
+ output_token_ids.fill_(PLACEHOLDER_TOKEN_ID)
+
+ if sampling_metadata.all_greedy:
+ is_greedy = None
+ else:
+ is_greedy = sampling_metadata.temperature == GREEDY_TEMPERATURE
+ if not sampling_metadata.all_random:
+ # Rejection sampling for greedy sampling requests.
+ target_argmax = target_probs.argmax(dim=-1)
+ rejection_greedy_sample_kernel[(batch_size,)](
+ output_token_ids,
+ cu_num_draft_tokens,
+ draft_token_ids,
+ target_argmax,
+ bonus_token_ids,
+ is_greedy,
+ max_spec_len,
+ num_warps=1,
+ )
+ if sampling_metadata.all_greedy:
+ return output_token_ids
+
+ # Generate uniform probabilities for rejection sampling.
+ # [num_tokens]
+ uniform_probs = generate_uniform_probs(
+ num_tokens,
+ num_draft_tokens,
+ sampling_metadata.generators,
+ device,
+ )
+
+ # Sample recovered tokens for each position.
+ # [num_tokens]
+ recovered_token_ids = sample_recovered_tokens_bugfix(
+ max_spec_len,
+ num_draft_tokens,
+ cu_num_draft_tokens,
+ draft_token_ids,
+ draft_probs,
+ target_probs,
+ sampling_metadata,
+ device,
+ )
+
+ # Rejection sampling for random sampling requests.
+ rejection_random_sample_kernel[(batch_size,)](
+ output_token_ids,
+ cu_num_draft_tokens,
+ draft_token_ids,
+ draft_probs,
+ target_probs,
+ bonus_token_ids,
+ recovered_token_ids,
+ uniform_probs,
+ is_greedy,
+ max_spec_len,
+ vocab_size,
+ NO_DRAFT_PROBS=draft_probs is None,
+ num_warps=1,
+ )
+ return output_token_ids
+
+
+class RejectionSamplerPatch(specRLPatch[RejectionSampler]):
+ def forward(
+ self,
+ metadata: SpecDecodeMetadata,
+ # [num_tokens, vocab_size]
+ draft_probs: Optional[torch.Tensor],
+ # [num_tokens, vocab_size]
+ target_logits: torch.Tensor,
+ # [batch_size, 1]
+ bonus_token_ids: torch.Tensor,
+ sampling_metadata: SamplingMetadata,
+ ) -> torch.Tensor:
+ """
+ Args:
+ metadata:
+ Metadata for spec decoding.
+ draft_probs (Optional[torch.Tensor]):
+ Probability distribution for the draft tokens. Shape is
+ [num_tokens, vocab_size]. Can be None if probabilities are
+ not provided, which is the case for ngram spec decode.
+ target_logits (torch.Tensor):
+ Target model's logits probability distribution.
+ Shape is [num_tokens, vocab_size]. Here, probabilities from
+ different requests are flattened into a single tensor because
+ this is the shape of the output logits.
+ NOTE: `target_logits` can be updated in place to save memory.
+ bonus_token_ids_tensor (torch.Tensor):
+ A tensor containing bonus tokens. Shape is [batch_size, 1].
+ Bonus tokens are added to the end of the sequence if all
+ proposed tokens are accepted. We generate the bonus tokens
+ outside of the rejection sampler with the default sampling
+ strategy. It allows for more flexibility in the sampling
+ process such as top_p, top_k sampling.
+ sampling_metadata (vllm.v1.sample.metadata.SamplingMetadata):
+ Additional metadata needed for sampling, such as temperature,
+ top-k/top-p parameters, or other relevant information.
+ Returns:
+ output_token_ids (torch.Tensor):
+ A tensor containing the final output token IDs.
+ """
+ assert metadata.max_spec_len <= MAX_SPEC_LEN
+ # [num_tokens, vocab_size]
+ # NOTE(woosuk): `target_logits` can be updated in place inside the
+ # `compute_probs` function.
+ target_probs = compute_probs(
+ target_logits,
+ metadata.cu_num_draft_tokens,
+ sampling_metadata,
+ )
+
+ output_token_ids = rejection_sample_bugfix(
+ metadata.draft_token_ids,
+ metadata.num_draft_tokens,
+ metadata.max_spec_len,
+ metadata.cu_num_draft_tokens,
+ draft_probs,
+ target_probs,
+ bonus_token_ids,
+ sampling_metadata,
+ )
+ return output_token_ids
+
+
+class GPUModelRunnerPatch(specRLPatch[GPUModelRunner]):
+ _orig_init = GPUModelRunner.__init__
+
+ def __init__(self: GPUModelRunner, vllm_config: VllmConfig, *args, **kwargs):
+ self._orig_init(vllm_config, *args, **kwargs)
+
+ # Set up speculative decoding.
+ self._suffix_cache = None
+ self.use_spec_decode = True
+
+ if get_pp_group().is_last_rank:
+ self._suffix_cache = SuffixCache()
+ self.rejection_sampler = RejectionSampler()
+
+ self.verl_cache_updater = ThreadPoolExecutor(max_workers=1)
+
+ def __del__(self):
+ self.verl_cache_updater.shutdown()
+
+ def generate_draft_token_ids_suffix(self, sampled_token_ids: list[list[int]]) -> list[list[int]]:
+ draft_token_ids: list[list[int]] = []
+
+ # spec_req_ids = []
+ # for i, sampled_ids in enumerate(sampled_token_ids):
+ # num_sampled_ids = len(sampled_ids)
+ # if num_sampled_ids:
+ # req_id = self.input_batch.req_ids[i]
+ # spec_req_ids.append(req_id)
+
+ # with open('/opt/tiger/BaseRepo/verl/jk_log.txt', 'a') as f:
+ # f.write(f"speculating {spec_req_ids}\n")
+
+ patterns = []
+ req_ids = []
+
+ for i, sampled_ids in enumerate(sampled_token_ids):
+ num_sampled_ids = len(sampled_ids)
+ if not num_sampled_ids:
+ # Skip speculative decoding.
+ patterns.append([])
+ req_ids.append("")
+ continue
+
+ req_id = self.input_batch.req_ids[i]
+
+ # Add sampled_token_ids to token_ids_cpu.
+ # start_idx = self.input_batch.num_tokens_no_spec[i]
+ # end_idx = start_idx + num_sampled_ids
+ # self.input_batch.token_ids_cpu[i, start_idx:end_idx] = sampled_ids
+ num_tokens = self.input_batch.num_tokens_no_spec[i]
+
+ size = min(num_tokens, SPECRL_PREFIX_LEN)
+ pattern = self.input_batch.token_ids_cpu[i, num_tokens - size : num_tokens]
+ pattern = pattern.tolist()
+
+ patterns.append(pattern)
+ req_ids.append(req_id)
+
+ # print(patterns)
+
+ draft_token_ids = self._suffix_cache.speculate(req_ids, patterns, min_token_prob=SPECRL_MIN_TOKEN_PROB)
+
+ # print(draft_token_ids)
+
+ return draft_token_ids
+
+ @torch.inference_mode()
+ def execute_model(
+ self,
+ scheduler_output: "SchedulerOutput",
+ intermediate_tensors: Optional[IntermediateTensors] = None,
+ ) -> ModelRunnerOutput | IntermediateTensors:
+ self._update_states(scheduler_output)
+
+ for req_id in scheduler_output.finished_req_ids:
+ self._suffix_cache.evict_responses(req_id)
+
+ if not scheduler_output.total_num_scheduled_tokens:
+ if not has_kv_transfer_group():
+ # Return empty ModelRunnerOutput if there's no work to do.
+ return EMPTY_MODEL_RUNNER_OUTPUT
+
+ return self.kv_connector_no_forward(scheduler_output)
+
+ # Prepare the decoder inputs.
+ (
+ attn_metadata,
+ attention_cuda_graphs,
+ logits_indices,
+ spec_decode_metadata,
+ num_scheduled_tokens_np,
+ spec_decode_common_attn_metadata,
+ ) = self._prepare_inputs(scheduler_output)
+ num_scheduled_tokens = scheduler_output.total_num_scheduled_tokens
+ if self.use_cuda_graph and num_scheduled_tokens <= self.cudagraph_batch_sizes[-1]:
+ # Use piecewise CUDA graphs.
+ # Add padding to the batch size.
+ num_input_tokens = self.vllm_config.pad_for_cudagraph(num_scheduled_tokens)
+ else:
+ # Eager mode.
+ # Pad tokens to multiple of tensor_parallel_size when
+ # enabled collective fusion for SP
+ tp_size = self.vllm_config.parallel_config.tensor_parallel_size
+ if self.compilation_config.pass_config.enable_sequence_parallelism and tp_size > 1:
+ num_input_tokens = round_up(num_scheduled_tokens, tp_size)
+ else:
+ num_input_tokens = num_scheduled_tokens
+
+ # Padding for DP
+ num_pad, num_tokens_across_dp = self.get_dp_padding(num_input_tokens)
+ num_input_tokens += num_pad
+
+ # _prepare_inputs may reorder the batch, so we must gather multi
+ # modal outputs after that to ensure the correct order
+ if self.is_multimodal_model:
+ # Run the multimodal encoder if any.
+ self._execute_mm_encoder(scheduler_output)
+ mm_embeds = self._gather_mm_embeddings(scheduler_output)
+ else:
+ mm_embeds = []
+
+ if self.is_multimodal_model and get_pp_group().is_first_rank:
+ # NOTE(woosuk): To unify token ids and soft tokens (vision
+ # embeddings), we always use embeddings (rather than token ids)
+ # as input to the multimodal model, even when the input is text.
+ input_ids = self.input_ids[:num_scheduled_tokens]
+
+ model_kwargs = self._init_model_kwargs_for_multimodal_model(scheduler_output=scheduler_output)
+ inputs_embeds = self.model.get_input_embeddings(
+ input_ids=input_ids,
+ multimodal_embeddings=mm_embeds or None,
+ )
+
+ # TODO(woosuk): Avoid the copy. Optimize.
+ self.inputs_embeds[:num_scheduled_tokens].copy_(inputs_embeds)
+ inputs_embeds = self.inputs_embeds[:num_input_tokens]
+ input_ids = None
+ else:
+ # For text-only models, we use token ids as input.
+ # While it is possible to use embeddings as input just like the
+ # multimodal models, it is not desirable for performance since
+ # then the embedding layer is not included in the CUDA graph.
+ input_ids = self.input_ids[:num_input_tokens]
+ inputs_embeds = None
+ model_kwargs = {}
+ if self.uses_mrope:
+ positions = self.mrope_positions[:, :num_input_tokens]
+ else:
+ positions = self.positions[:num_input_tokens]
+
+ if get_pp_group().is_first_rank:
+ intermediate_tensors = None
+ else:
+ intermediate_tensors = self.sync_and_slice_intermediate_tensors(
+ num_input_tokens, intermediate_tensors, True
+ )
+
+ # Some attention backends only support CUDA Graphs in pure decode.
+ # If attention doesn't support CUDA Graphs for this batch, but we
+ # compiled with full CUDA graphs, we have to skip them entirely.
+ skip_cuda_graphs = self.full_cuda_graph and not attention_cuda_graphs
+
+ if scheduler_output.scheduled_new_reqs:
+
+ def fetch_suffix_responses():
+ req_ids = [new_req_data.req_id for new_req_data in scheduler_output.scheduled_new_reqs]
+ req_prompts = [new_req_data.prompt_token_ids for new_req_data in scheduler_output.scheduled_new_reqs]
+ self._suffix_cache.fetch_responses_by_prompts_batch(req_ids, req_prompts)
+ return 1
+
+ future = self.verl_cache_updater.submit(fetch_suffix_responses)
+ else:
+ future = Future()
+ future.set_result(1)
+
+ # Run the model.
+ # Use persistent buffers for CUDA graphs.
+ with set_forward_context(
+ attn_metadata,
+ self.vllm_config,
+ num_tokens=num_input_tokens,
+ num_tokens_across_dp=num_tokens_across_dp,
+ skip_cuda_graphs=skip_cuda_graphs,
+ ):
+ self.maybe_setup_kv_connector(scheduler_output)
+
+ model_output = self.model(
+ input_ids=input_ids,
+ positions=positions,
+ intermediate_tensors=intermediate_tensors,
+ inputs_embeds=inputs_embeds,
+ **MultiModalKwargs.as_kwargs(
+ model_kwargs,
+ device=self.device,
+ ),
+ )
+
+ self.maybe_wait_for_kv_save()
+ finished_sending, finished_recving = self.get_finished_kv_transfers(scheduler_output)
+
+ if self.use_aux_hidden_state_outputs:
+ hidden_states, _ = model_output
+ else:
+ hidden_states = model_output
+
+ # Broadcast PP output for external_launcher (torchrun)
+ # to make sure we are synced across pp ranks
+ # TODO: Support overlapping mirco-batches
+ # https://github.com/vllm-project/vllm/issues/18019
+ broadcast_pp_output = (
+ self.parallel_config.distributed_executor_backend == "external_launcher" and len(get_pp_group().ranks) > 0
+ )
+ if not get_pp_group().is_last_rank:
+ # For mid-pipeline stages, return the hidden states.
+ if not broadcast_pp_output:
+ if finished_sending or finished_recving:
+ hidden_states.finished_sending = finished_sending
+ hidden_states.finished_recving = finished_recving
+ return hidden_states
+ assert isinstance(hidden_states, IntermediateTensors)
+ get_pp_group().send_tensor_dict(hidden_states.tensors, all_gather_group=get_tp_group())
+ logits = None
+ else:
+ if self.input_batch.pooling_params:
+ return self._pool(
+ hidden_states, num_scheduled_tokens, num_scheduled_tokens_np, finished_sending, finished_recving
+ )
+
+ sample_hidden_states = hidden_states[logits_indices]
+ logits = self.model.compute_logits(sample_hidden_states, None)
+ if broadcast_pp_output:
+ model_output_broadcast_data = (
+ {
+ "logits": logits.contiguous(),
+ }
+ if logits is not None
+ else {}
+ )
+ model_output_broadcast_data = get_pp_group().broadcast_tensor_dict(
+ model_output_broadcast_data, src=len(get_pp_group().ranks) - 1
+ )
+ assert model_output_broadcast_data is not None
+ logits = model_output_broadcast_data["logits"]
+
+ # Apply structured output bitmasks if present
+ if scheduler_output.grammar_bitmask is not None:
+ self.apply_grammar_bitmask(scheduler_output, logits)
+
+ # Sample the next token and get logprobs if needed.
+ sampling_metadata = self.input_batch.sampling_metadata
+ if spec_decode_metadata is None:
+ sampler_output = self.sampler(
+ logits=logits,
+ sampling_metadata=sampling_metadata,
+ )
+ else:
+ # When indexing with a tensor (bonus_logits_indices), PyTorch
+ # creates a new tensor with separate storage from the original
+ # logits tensor. This means any in-place operations on bonus_logits
+ # won't affect the original logits tensor.
+ assert logits is not None
+ bonus_logits = logits[spec_decode_metadata.bonus_logits_indices]
+ sampler_output = self.sampler(
+ logits=bonus_logits,
+ sampling_metadata=sampling_metadata,
+ )
+ bonus_token_ids = sampler_output.sampled_token_ids
+
+ # Just like `bonus_logits`, `target_logits` is a new tensor with
+ # separate storage from the original `logits` tensor. Therefore,
+ # it is safe to update `target_logits` in place.
+ target_logits = logits[spec_decode_metadata.target_logits_indices]
+ output_token_ids = self.rejection_sampler(
+ spec_decode_metadata,
+ None, # draft_probs
+ target_logits,
+ bonus_token_ids,
+ sampling_metadata,
+ )
+ sampler_output.sampled_token_ids = output_token_ids
+
+ num_nans_in_logits = {}
+ if envs.VLLM_COMPUTE_NANS_IN_LOGITS:
+ num_nans_in_logits = self._get_nans_in_logits(logits)
+
+ # TODO(woosuk): The following loop can be slow since it iterates over
+ # the requests one by one. Optimize.
+ discard_sampled_tokens_req_indices = []
+ for i, req_id in enumerate(self.input_batch.req_ids):
+ req_state = self.requests[req_id]
+ seq_len = req_state.num_computed_tokens + scheduler_output.num_scheduled_tokens[req_id]
+ if seq_len < req_state.num_tokens:
+ # Ignore the sampled token for partial prefills.
+ # Rewind the generator state as if the token was not sampled.
+ # This relies on cuda-specific torch-internal impl details
+ generator = self.input_batch.generators.get(i)
+ if generator is not None:
+ generator.set_offset(generator.get_offset() - 4)
+ # Record the index of the request that should not be sampled,
+ # so that we could clear the sampled tokens before returning.
+ discard_sampled_tokens_req_indices.append(i)
+
+ # NOTE: GPU -> CPU Sync happens here.
+ # Move as many CPU operations as possible before this sync point.
+ logprobs_tensors = sampler_output.logprobs_tensors
+ logprobs_lists = logprobs_tensors.tolists() if logprobs_tensors is not None else None
+
+ # Compute prompt logprobs if needed.
+ prompt_logprobs_dict = self._get_prompt_logprobs_dict(
+ hidden_states[:num_scheduled_tokens],
+ scheduler_output,
+ )
+
+ # Get the valid generated tokens.
+ sampled_token_ids = sampler_output.sampled_token_ids
+ max_gen_len = sampled_token_ids.shape[-1]
+ if max_gen_len == 1:
+ # No spec decode tokens.
+ valid_sampled_token_ids = sampled_token_ids.tolist()
+ else:
+ # Includes spec decode tokens.
+ valid_sampled_token_ids = self.rejection_sampler.parse_output(
+ sampled_token_ids,
+ self.input_batch.vocab_size,
+ )
+ # Mask out the sampled tokens that should not be sampled.
+ for i in discard_sampled_tokens_req_indices:
+ valid_sampled_token_ids[i].clear()
+
+ future.result()
+ for i, token_ids in enumerate(valid_sampled_token_ids):
+ self._suffix_cache.update_spec_len(self.input_batch.req_ids[i], len(token_ids))
+
+ # Cache the sampled tokens in the model runner, so that the scheduler
+ # doesn't need to send them back.
+ # NOTE(woosuk): As an exception, when using PP, the scheduler sends
+ # the sampled tokens back, because there's no direct communication
+ # between the first-stage worker and the last-stage worker.
+ for req_idx, sampled_ids in enumerate(valid_sampled_token_ids):
+ if not sampled_ids:
+ continue
+
+ start_idx = self.input_batch.num_tokens_no_spec[req_idx]
+ end_idx = start_idx + len(sampled_ids)
+ assert end_idx <= self.max_model_len, (
+ "Sampled token IDs exceed the max model length. "
+ f"Total number of tokens: {end_idx} > max_model_len: "
+ f"{self.max_model_len}"
+ )
+
+ self.input_batch.token_ids_cpu[req_idx, start_idx:end_idx] = sampled_ids
+ self.input_batch.num_tokens_no_spec[req_idx] = end_idx
+ self.input_batch.num_tokens[req_idx] = end_idx
+ req_id = self.input_batch.req_ids[req_idx]
+ req_state = self.requests[req_id]
+ req_state.output_token_ids.extend(sampled_ids)
+
+ spec_token_ids = self.generate_draft_token_ids_suffix(valid_sampled_token_ids)
+
+ self.eplb_step()
+
+ return ModelRunnerOutput(
+ req_ids=self.input_batch.req_ids,
+ req_id_to_index=self.input_batch.req_id_to_index,
+ sampled_token_ids=valid_sampled_token_ids,
+ spec_token_ids=spec_token_ids,
+ logprobs=logprobs_lists,
+ prompt_logprobs_dict=prompt_logprobs_dict,
+ pooler_output=[],
+ finished_sending=finished_sending,
+ finished_recving=finished_recving,
+ num_nans_in_logits=num_nans_in_logits,
+ )
+
+
+class WorkerBasePatch(specRLPatch[WorkerBase]):
+ _orig_init = WorkerBase.__init__
+
+ def __init__(self, *args, **kwargs):
+ # Some patches like the GPUModelRunner will import CUDA libraries when
+ # they are initialized, which will cause process forking to fail. For
+ # these patches, we need to delay the initialization until after the
+ # process has been forked (i.e., in the WorkerBase initializer).
+ RejectionSamplerPatch.apply_patch()
+ GPUModelRunnerPatch.apply_patch()
+
+ return self._orig_init(*args, **kwargs)
diff --git a/ICL/DAPO/verl-recipe/spin/config/spin_trainer.yaml b/ICL/DAPO/verl-recipe/spin/config/spin_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ee105c4213efa9e67a7c59e3548fa0c3998423a1
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spin/config/spin_trainer.yaml
@@ -0,0 +1,28 @@
+# the sppo config will override default ppo_trainer.yaml
+
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+actor_rollout_ref:
+ actor:
+ dpo_beta: 0.1
+ optim:
+ lr_warmup_steps: 15
+ rollout:
+ name: sglang
+ tensor_model_parallel_size: 2
+ gpu_memory_utilization: 0.5
+ val_kwargs:
+ n: 2 # 2 will trigger validation, 1 will bypass
+
+algorithm:
+ adv_estimator: null
+
+trainer:
+ log_val_generations: 0
+ ref_update_freq: 1
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/spo/agent_loop/__init__.py b/ICL/DAPO/verl-recipe/spo/agent_loop/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccb27ea4d18aedacaf7811e6a277c9276da47af6
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/agent_loop/__init__.py
@@ -0,0 +1,18 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Modifications Copyright 2025 SPO authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .spo_agent_loop import SPOAgentLoopManager
+
+__all__ = ["SPOAgentLoopManager"]
diff --git a/ICL/DAPO/verl-recipe/spo/config/spo_agent.yaml b/ICL/DAPO/verl-recipe/spo/config/spo_agent.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..8f65dbeccf79ba801427fd9fad8b99351dca889c
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/config/spo_agent.yaml
@@ -0,0 +1,21 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Modifications Copyright 2025 SPO authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# SPO Agent Loop Configuration
+# This file registers the SPO tool agent for code generation and execution
+# The agent uses a code interpreter to execute Python code within sandboxed environments
+
+- name: spo_tool_agent
+ _target_: recipe.spo.agent_loop.spo_tool_agent_loop.SPOToolAgentLoop
diff --git a/ICL/DAPO/verl-recipe/spo/config/spo_trainer.yaml b/ICL/DAPO/verl-recipe/spo/config/spo_trainer.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..0cc0659d6a92058b60aad99f457b5b1a9ec04d12
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/config/spo_trainer.yaml
@@ -0,0 +1,20 @@
+# the spo config will override default ppo_trainer.yaml
+
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_trainer
+ - _self_
+
+trainer:
+ debug: false
+ spo:
+ enable: False
+ offline_values: null
+ offline_N: 8
+ rho:
+ type: "kl"
+ value: 0.875
+ clip_lower: 0.875
\ No newline at end of file
diff --git a/ICL/DAPO/verl-recipe/spo/estimate_offline_values/eval.sh b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/eval.sh
new file mode 100644
index 0000000000000000000000000000000000000000..eaa958200ab2a1a11808cc215917cc3216b2462a
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/eval.sh
@@ -0,0 +1,124 @@
+set -x
+
+export VLLM_USE_V1=1
+export CUDA_DEVICE_MAX_CONNECTIONS=1
+export VLLM_ALLREDUCE_USE_SYMM_MEM=0
+
+# ================= data/model/tool =================
+OUTPUT_DIR=${OUTPUT_DIR:-"."}
+DATA_FILE=${DATA_FILE:-""}
+EXP_NAME=${EXP_NAME:-"offline_value_estimation"}
+MODEL_PATH=${MODEL_PATH:-""}
+RESPONSE_LENGTH=${RESPONSE_LENGTH:-8192}
+N_VAL=${N_VAL:-8}
+DEBUG=${DEBUG:-"False"}
+
+train_files="['${DATA_FILE}']"
+val_files="$train_files"
+echo "Evaluating on train_files"
+
+# tool
+tool_config_path=recipe/spo/spo_tool_config.yaml
+
+# wandb
+project_name=spo
+experiment_name=$EXP_NAME
+default_local_dir=$OUTPUT_DIR/$project_name/$experiment_name/checkpoints
+validation_data_dir=$OUTPUT_DIR/$project_name/$experiment_name/validation_data
+
+# ================= algorithm =================
+adv_estimator=grpo
+
+use_kl_in_reward=False
+kl_coef=0.0
+use_kl_loss=False
+kl_loss_coef=0.0
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+max_turns=8
+max_prompt_length=2048
+max_response_length=$RESPONSE_LENGTH
+actor_lr=1e-6
+
+train_batch_size=64
+val_batch_size=96
+if [ "$DEBUG" = "True" ]; then
+ train_batch_size=16
+ val_batch_size=16
+fi
+ppo_mini_batch_size=16
+n_resp_per_prompt=8
+n_resp_per_prompt_val=$N_VAL
+
+# ================= perfomance =================
+infer_tp=4 # vllm
+train_sp=8 # train
+offload=True
+
+actor_max_token_len_per_gpu=$(( (max_prompt_length + max_response_length) * 1 ))
+log_prob_max_token_len_per_gpu=$(( actor_max_token_len_per_gpu * 4 ))
+
+TENSORBOARD_DIR=$OUTPUT_DIR/${project_name}/${experiment_name}/tensorboard \
+python3 -m recipe.spo.spo_main_ppo \
+ algorithm.adv_estimator=$adv_estimator \
+ algorithm.use_kl_in_reward=$use_kl_in_reward \
+ algorithm.kl_ctrl.kl_coef=$kl_coef \
+ data.train_files="$train_files" \
+ data.val_files="$val_files" \
+ data.return_raw_chat=True \
+ data.train_batch_size=$train_batch_size \
+ data.val_batch_size=$val_batch_size \
+ data.max_prompt_length=$max_prompt_length \
+ data.max_response_length=$max_response_length \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ data.custom_cls.path=recipe/spo/spo_retool.py \
+ data.custom_cls.name=CustomRLHFDataset \
+ custom_reward_function.path=recipe/spo/spo_retool.py \
+ custom_reward_function.name=compute_score \
+ actor_rollout_ref.model.path=$MODEL_PATH \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.use_kl_loss=$use_kl_loss \
+ actor_rollout_ref.actor.kl_loss_coef=$kl_loss_coef \
+ actor_rollout_ref.actor.clip_ratio_low=$clip_ratio_low \
+ actor_rollout_ref.actor.clip_ratio_high=$clip_ratio_high \
+ actor_rollout_ref.actor.clip_ratio_c=10.0 \
+ actor_rollout_ref.actor.optim.lr=$actor_lr \
+ actor_rollout_ref.actor.use_dynamic_bsz=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=$ppo_mini_batch_size \
+ actor_rollout_ref.actor.ppo_max_token_len_per_gpu=$actor_max_token_len_per_gpu \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=$train_sp \
+ actor_rollout_ref.actor.fsdp_config.param_offload=$offload \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=$offload \
+ actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=$log_prob_max_token_len_per_gpu \
+ actor_rollout_ref.rollout.name=vllm \
+ actor_rollout_ref.rollout.mode=async \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=$infer_tp \
+ actor_rollout_ref.rollout.multi_turn.enable=True \
+ actor_rollout_ref.rollout.multi_turn.max_user_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.max_assistant_turns=$max_turns \
+ actor_rollout_ref.rollout.multi_turn.tool_config_path=$tool_config_path \
+ actor_rollout_ref.rollout.multi_turn.format=spo \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
+ actor_rollout_ref.rollout.n=$n_resp_per_prompt \
+ actor_rollout_ref.rollout.val_kwargs.temperature=0.6 \
+ actor_rollout_ref.rollout.val_kwargs.top_p=0.95 \
+ actor_rollout_ref.rollout.val_kwargs.top_k=20 \
+ actor_rollout_ref.rollout.val_kwargs.n=$n_resp_per_prompt_val \
+ trainer.logger=['console','tensorboard'] \
+ trainer.project_name=$project_name \
+ trainer.experiment_name=$experiment_name \
+ trainer.n_gpus_per_node=8 \
+ trainer.val_before_train=True \
+ trainer.val_only=True \
+ trainer.log_val_generations=20 \
+ trainer.nnodes=1 \
+ trainer.save_freq=20 \
+ trainer.default_local_dir=$default_local_dir \
+ trainer.validation_data_dir=$validation_data_dir \
+ trainer.test_freq=10 \
+ trainer.total_epochs=100 \
+ trainer.debug=$DEBUG
diff --git a/ICL/DAPO/verl-recipe/spo/estimate_offline_values/merge_offline_values.py b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/merge_offline_values.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bbf8b6d4d91cab758c7ea1e18035e07aaaa02eb
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/merge_offline_values.py
@@ -0,0 +1,178 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# Copyright 2025 SPO authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import concurrent.futures
+import glob
+import json
+import os
+import random
+from collections import defaultdict
+
+
+def load_and_parse(file_path):
+ """
+ Reads a JSONL file where each line is a JSON object, and returns a list of parsed objects.
+
+ Args:
+ file_path: Path to the JSONL file
+
+ Returns:
+ List of parsed JSON objects
+ """
+ try:
+ with open(file_path) as file:
+ data = [json.loads(line) for line in file]
+ print(f"Successfully loaded {len(data)} items from {file_path}")
+ return data
+ except Exception as e:
+ print(f"Error processing file {file_path}: {e}")
+ return []
+
+
+def merge_offline_values(
+ input_dir, output_file, pattern="offline_value_estimation_subset_*/validation_data/0.jsonl", max_scores_per_prompt=8
+):
+ """
+ Merge offline value estimates from multiple subset directories.
+
+ Args:
+ input_dir: Directory containing all subset outputs
+ output_file: Path to save the merged offline values JSON file
+ pattern: Glob pattern to match subset result files
+ max_scores_per_prompt: Maximum number of scores to keep per prompt (default: 8)
+ """
+ # Find all subset dump files
+ search_pattern = os.path.join(input_dir, pattern)
+ subset_files = glob.glob(search_pattern)
+
+ if not subset_files:
+ print(f"Warning: No files found matching pattern: {search_pattern}")
+ return
+
+ print(f"Found {len(subset_files)} subset dump files:")
+ for f in sorted(subset_files):
+ print(f" - {f}")
+
+ # Load all subset data using concurrent processing
+ all_subset_data = []
+ with concurrent.futures.ThreadPoolExecutor() as executor:
+ future_to_file = {executor.submit(load_and_parse, f): f for f in subset_files}
+
+ for future in concurrent.futures.as_completed(future_to_file):
+ file_name = future_to_file[future]
+ try:
+ result = future.result()
+ all_subset_data.extend(result)
+ except Exception as exc:
+ print(f"{file_name} generated an exception: {exc}")
+
+ print(f"\nTotal items loaded: {len(all_subset_data)}")
+
+ # Merge scores by prompt
+ merged_prompt_to_scores = defaultdict(list)
+ for item in all_subset_data:
+ # Extract the prompt/question from the input field
+ # This assumes the format: "...user\n\nassistant..."
+ try:
+ key = item["input"].split("user\n")[-1].split("\nassistant")[0].strip()
+ merged_prompt_to_scores[key].append(item["score"])
+ except (KeyError, IndexError) as e:
+ print(f"Warning: Failed to parse item: {e}")
+ continue
+
+ merged_prompts = list(merged_prompt_to_scores.keys())
+ print(f"Merged into {len(merged_prompts)} unique prompts")
+
+ # Subsample scores if more than max_scores_per_prompt
+ num_prompts_exceeding_max = 0
+ for prompt, scores in merged_prompt_to_scores.items():
+ if len(scores) > max_scores_per_prompt:
+ num_prompts_exceeding_max += 1
+ # Randomly sample max_scores_per_prompt scores
+ merged_prompt_to_scores[prompt] = random.sample(scores, max_scores_per_prompt)
+
+ if num_prompts_exceeding_max > 0:
+ print(
+ f"\nSubsampling: {num_prompts_exceeding_max} prompts had more than {max_scores_per_prompt} "
+ "scores and were randomly subsampled to {max_scores_per_prompt}"
+ )
+
+ # Save merged results
+ os.makedirs(os.path.dirname(output_file) if os.path.dirname(output_file) else ".", exist_ok=True)
+ with open(output_file, "w") as f:
+ json.dump(merged_prompt_to_scores, f, indent=2)
+
+ print(f"\nMerged offline values saved to: {output_file}")
+
+ # Print statistics
+ score_counts = [len(scores) for scores in merged_prompt_to_scores.values()]
+ score_sums = [sum(scores) for scores in merged_prompt_to_scores.values()]
+
+ if score_counts:
+ print("\nStatistics (Score Counts per Prompt):")
+ print(f" - Min scores per prompt: {min(score_counts)}")
+ print(f" - Max scores per prompt: {max(score_counts)}")
+ print(f" - Avg scores per prompt: {sum(score_counts) / len(score_counts):.2f}")
+ print(f" - Prompts with >{max_scores_per_prompt} scores (before subsampling): {num_prompts_exceeding_max}")
+
+ if score_sums:
+ print("\nStatistics (Sum of Scores per Prompt):")
+ print(f" - Min sum of scores: {min(score_sums):.4f}")
+ print(f" - Max sum of scores: {max(score_sums):.4f}")
+ print(f" - Avg sum of scores: {sum(score_sums) / len(score_sums):.4f}")
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Merge offline value estimates from multiple subsets into a single file"
+ )
+ parser.add_argument(
+ "--input_dir",
+ type=str,
+ required=True,
+ help="Directory containing all subset outputs (e.g., the trainer.validation_data_dir)",
+ )
+ parser.add_argument(
+ "--output_file", type=str, required=True, help="Path to save the merged offline values JSON file"
+ )
+ parser.add_argument(
+ "--pattern",
+ type=str,
+ default="offline_value_estimation_subset_*/validation_data/0.jsonl",
+ help="Glob pattern to match subset result files",
+ )
+ parser.add_argument(
+ "--max_scores_per_prompt",
+ type=int,
+ default=8,
+ help="Maximum number of scores to keep per prompt.",
+ )
+
+ args = parser.parse_args()
+
+ print("=" * 80)
+ print("Merging Offline Value Estimates")
+ print("=" * 80)
+ print(f"Input directory: {args.input_dir}")
+ print(f"Output file: {args.output_file}")
+ print(f"File pattern: {args.pattern}")
+ print(f"Max scores per prompt: {args.max_scores_per_prompt}")
+ print("=" * 80 + "\n")
+
+ merge_offline_values(args.input_dir, args.output_file, args.pattern, args.max_scores_per_prompt)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/ICL/DAPO/verl-recipe/spo/estimate_offline_values/split_dapo_into_subsets.py b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/split_dapo_into_subsets.py
new file mode 100644
index 0000000000000000000000000000000000000000..2fd0765a250d240379ad9aef250de29d9996f132
--- /dev/null
+++ b/ICL/DAPO/verl-recipe/spo/estimate_offline_values/split_dapo_into_subsets.py
@@ -0,0 +1,56 @@
+# Copyright 2025 Bytedance Ltd. and/or its affiliates
+# Copyright 2025 SPO authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+
+from datasets import load_dataset
+
+
+def main():
+ parser = argparse.ArgumentParser(description="Split DAPO dataset into subsets")
+ parser.add_argument(
+ "--dataset",
+ type=str,
+ default="open-r1/DAPO-Math-17k-Processed",
+ help="Path to the dataset to load (default: open-r1/DAPO-Math-17k-Processed)",
+ )
+ parser.add_argument("--output_dir", type=str, required=True, help="Directory to save the subset parquet files")
+ parser.add_argument("--num_subsets", type=int, default=5, help="Number of subsets to split into (default: 5)")
+
+ args = parser.parse_args()
+
+ # Set split and language based on dataset
+ if args.dataset == "open-r1/DAPO-Math-17k-Processed":
+ split = "train"
+ language = "en"
+ else:
+ raise NotImplementedError(
+ f"Dataset '{args.dataset}' is not supported. Only 'open-r1/DAPO-Math-17k-Processed' is currently supported."
+ )
+
+ # Load dataset
+ dataset = load_dataset(args.dataset, language)[split]
+ print(f"Loading dataset: {args.dataset}, config: {language}, split: {split}")
+ print(f"There are {len(dataset)} samples in total.")
+
+ # Split into N shards and save as Parquet
+ for i in range(args.num_subsets):
+ subset = dataset.shard(num_shards=args.num_subsets, index=i)
+ subset_path = f"{args.output_dir}/subset_{i}.parquet"
+ subset.to_parquet(subset_path)
+ print(f"Saved subset {i} with {len(subset)} samples to {subset_path}")
+
+
+if __name__ == "__main__":
+ main()