

license: gpl-3.0
language:
- en
- zh
Ziya-BLIP2-14B-Visual-v1
- Main Page:Fengshenbang
- Github: Fengshenbang-LM
姜子牙系列模型
简介 Brief Introduction
Ziya-Visual多模态大模型基于姜子牙通用大模型V1训练,具有视觉问答和对话能力。今年3月份OpenAI发布具有识图能力的多模态大模型GPT-4,遗憾的是,时至今日绝大部分用户也都还没有拿到GPT-4输入图片的权限,Ziya-Visual参考了Mini-GPT4、LLaVA等优秀的开源实现,补齐了Ziya的识图能力,使中文用户群体可以体验到结合视觉和语言两大模态的大模型的卓越能力。
The Ziya-Visual multimodal Big Model is based on the Ziya-LLaMA-13B-v1 training and has visual question and answer and dialogue capabilities. In March this year, OpenAI released GPT-4, a multimodal big model with image recognition capabilities. Unfortunately, to date, the vast majority of users have not yet been given access to GPT-4 for image input, so Ziya-Visual refers to Mini-GPT4, LLaVA and other excellent open source implementations to complement Ziya's image recognition capabilities, so that the Chinese user community can experience the superior capabilities of a large model combining two modalities: visual and language.
软件依赖
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers
模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|---|---|---|---|---|---|
| 多模态 Multi-Modal | 通用 General | 姜子牙-多模态 Ziya-Visual | BLIP2 LLaMA | 14B | English&Chinese |
模型信息 Model Information
效果展示 Showcase
这个例子展示了模型的识图能力、知识能力和创作能力。首先第一个问题中,模型识别出了图片中是电影《泰坦尼克号》的场景,并给出电影导演、发布时间、奖项成就等信息;第二个问题,模型根据用户的需求创作了一首现代爱情诗。
This example demonstrates the model's ability to read pictures, its knowledge and its ability to compose. Firstly in the first problem, the model identifies the picture as a scene from the movie Titanic and gives information about the movie director, release date and award achievements; in the second problem, the model creates a modern love poem based on the user's needs.

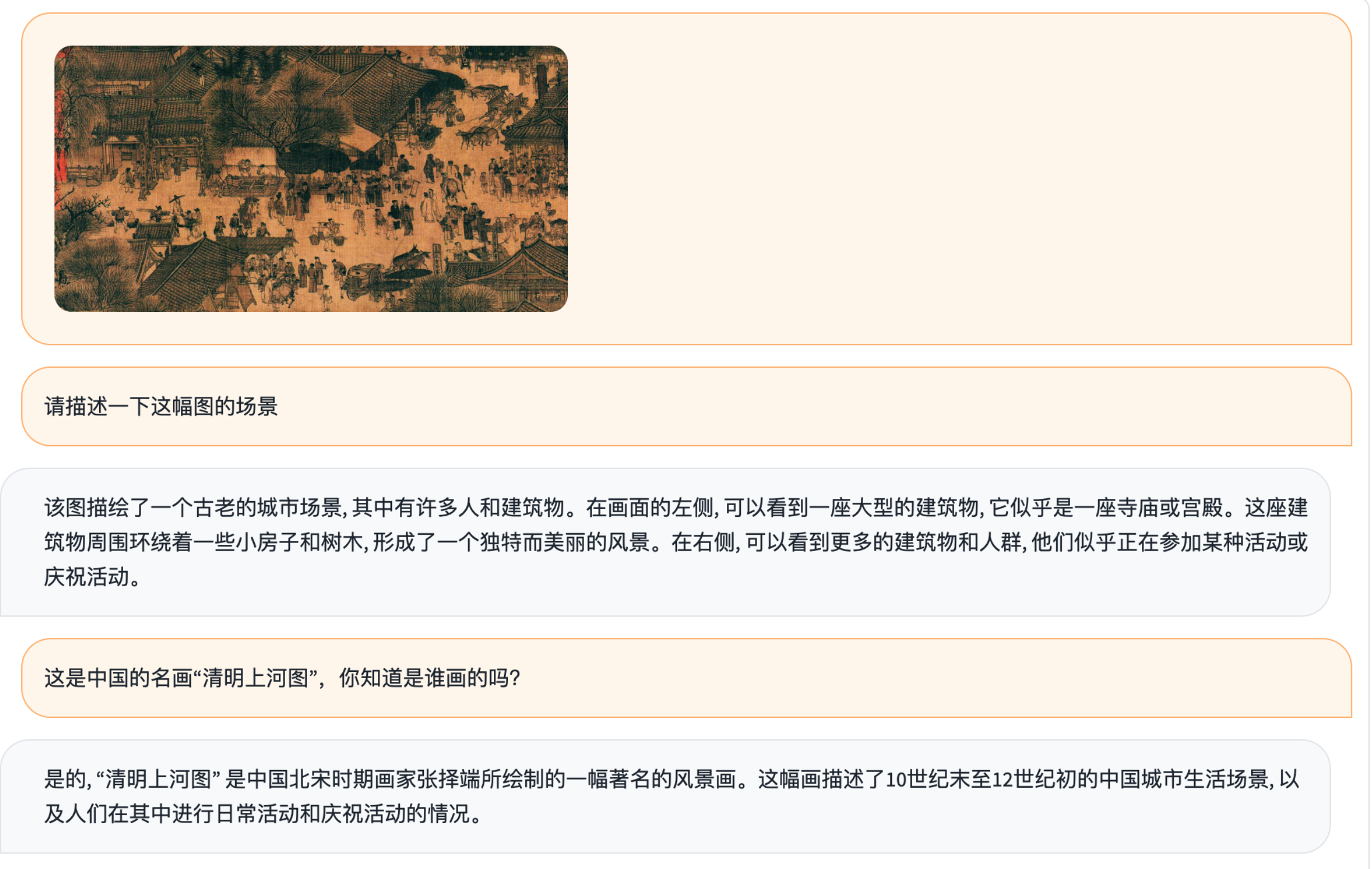
这个例子展示了Ziya-Visual传统中国文化的识别和理解能力,模型识别出了中国画中的信息,在得到提示《清明上河图》之后给出了也给出画家张择端和北宋的历史背景。
This example demonstrates Ziya-Visual's ability to recognise and understand traditional Chinese culture. The model identifies information in Chinese paintings, and after getting the hint 'Qingming Shanghe Tu' gives also gives the historical context of the painter Zhang Zeduan and the Northern Song Dynasty.
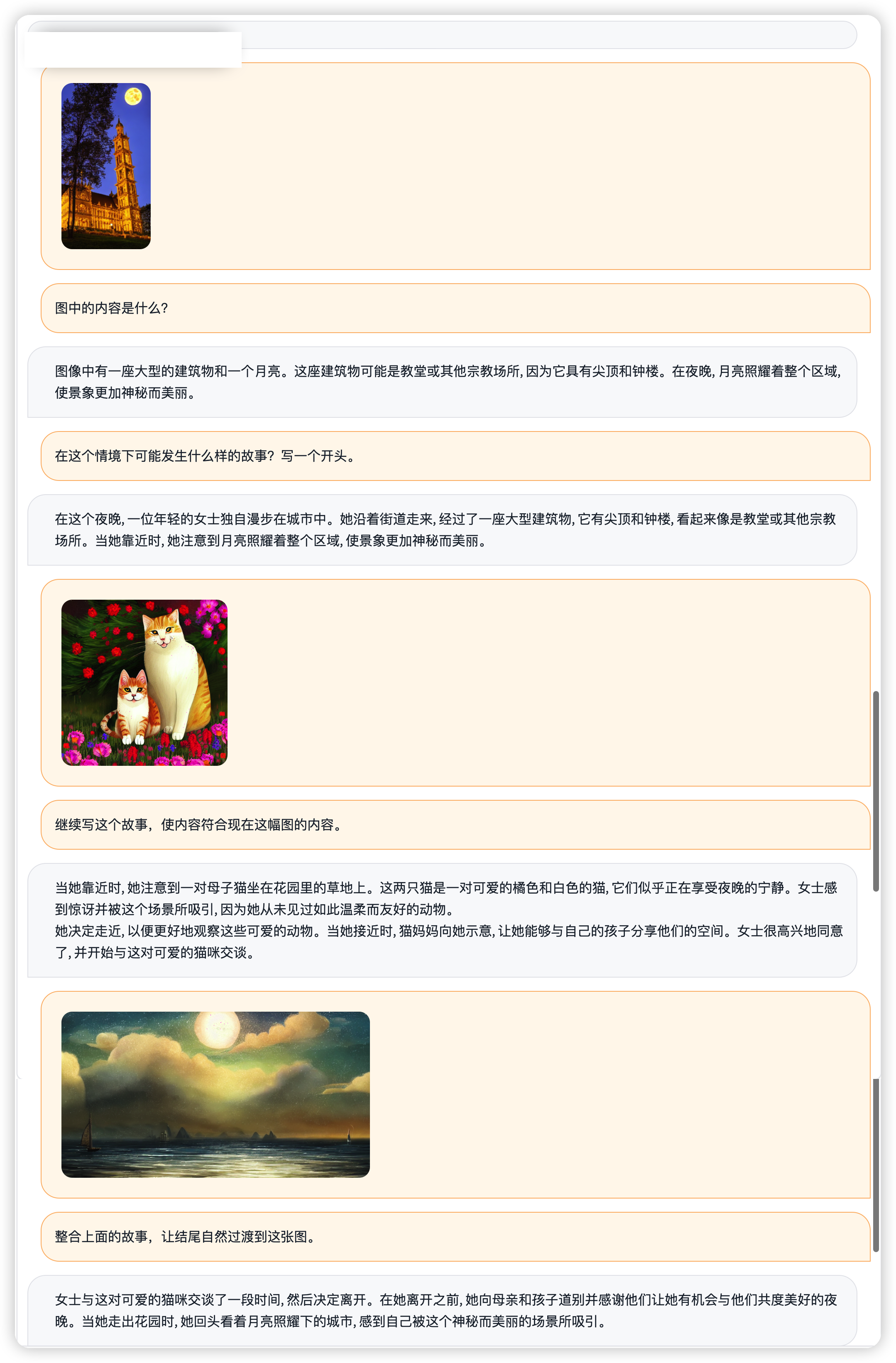
如果输入多张图片进行问答呢?Ziya-Visual也是胜任的,在这个例子中,Ziya-Visual展现了强大的多图和多轮交互能力,根据用户给的三张图片,叙述了一个女士在城市夜景中邂逅一对母子猫咪,并与之交谈、分别的小故事。
What if multiple images are entered for a quiz? Ziya-Visual is also up to the task. In this example, Ziya-Visual demonstrates the power of multiple images and multiple rounds of interaction, narrating a short story of a lady who encounters a mother and son cat in a city night scene, talks to them and separates them, based on three images given by the user.
训练 Training
数据 Train data
在中文视觉问答模型训练上,最大的问题就是数据量少,数据质量差。首先,封神榜团队在开源数据的基础上清洗、积累了一部分高质量数据;其次,我们通过翻译api得到了一部分英-中双语数据集,我们发现虽然翻译数据集会有“翻译腔”等问题,但是借助Ziya-v1的双语能力,最终的语言输出是能够缓解这一问题的;最后,团队结合BLIP,Grounded SAM等先进视觉技术,抽取图像描述的粗粒度信息和图像中物体、方位等细粒度信息,转化为语言描述形式,构造了一部分高质量数据。最终,Ziya-Visual构造了约2千万的优质数据进行训练。和Mini-GPT4、LLaVA一样,Ziya-Visual-v1主要是一个以数据为中心的工作,因此数据的数量和质量非常重要。
In the training of Chinese visual quiz model, the biggest problem is the small amount of data and poor data quality. Firstly, the team cleaned and accumulated some high-quality data based on open source data; secondly, we obtained a part of the English-Chinese bilingual dataset through translation api, and we found that although the translated dataset would have problems such as "translation accent", the final language output was able to alleviate this problem with Ziya-v1's bilingual capability. Finally, the team combined BLIP, Grounded SAM and other advanced vision technologies to extract coarse-grained information from image descriptions and fine-grained information such as objects and orientation in images, and transform them into linguistic descriptions to construct a portion of high-quality data. Ultimately, Ziya-Visual constructed approximately 20 million pieces of high quality data for training. Like Mini-GPT4 and LLaVA, Ziya-Visual-v1 is primarily a data-centric exercise, so the quantity and quality of data is very important.
模型结构 Model Architecture
为了更好的结合视觉预训练模型和LLM的能力,和Mini-GPT4和LLaVA工作一样,Ziya-Visual-v1的训练遵循了BLIP2提出的经典网络结构和两阶段训练的范式。而且我们在实验过程中发现,是否训练Vision Encoder的参数对于最终的生成效果影响很小。因此,在整体模型上,视觉处理部分我们继承了BLIP2的ViT + QFormer参数,LLM部分继承了Ziya-v1的权重,这两个部分权重都是冻结不参与训练的。我们主要训练的部分是视觉映射层(Projection Layer)。第一阶段,我们使用图像Caption数据训练映射层,使Vision Encder抽取出来的图像特征能够和LLM中的文本特征空间进行对齐;第二阶段,我们使用图像问答数据集,进一步微调Ziya-Visual的视觉-语言能力。
In order to better combine the capabilities of the vision pre-training model and the LLM, as in the Mini-GPT4 and LLaVA work, the training of Ziya-Visual-v1 followed the classical network structure and the two-stage training paradigm proposed by BLIP2. Moreover, we found during our experiments that whether or not the parameters of the Vision Encoder are trained has very little impact on the final generation results. Therefore, for the overall model, we inherited the ViT + QFormer parameters from BLIP2 for the vision processing part and the Ziya-v1 weights for the LLM part, both of which were frozen from training. Our main training component is the visual mapping layer (Projection Layer). In the first stage, we use the image Caption data to train the mapping layer so that the image features extracted by Vision Encder can be aligned with the text feature space in LLM; in the second stage, we use the image Q & A dataset to further fine-tune the visual-verbal capabilities of Ziya-Visual.

效果评估 Performance
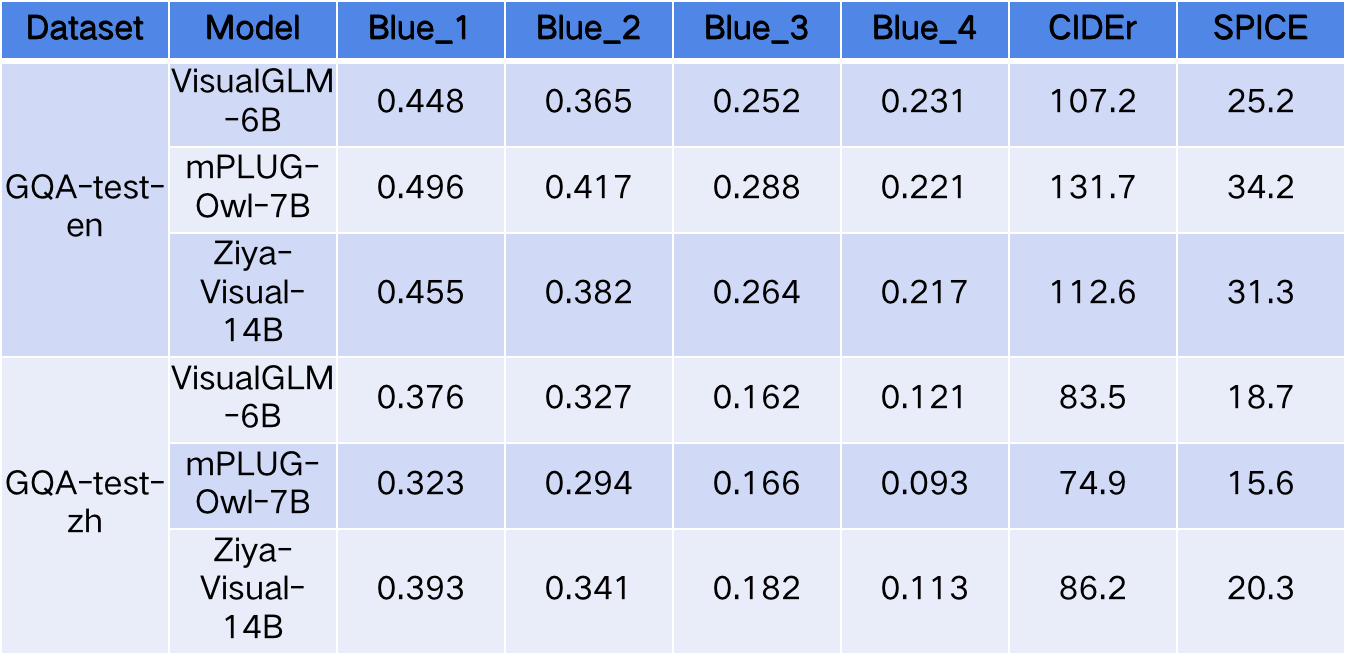
首先是VQA效果上的评价,可以看到Ziya-Visual模型在GQA的中文和英文测试集上大部分指标均高于VisualGLM,而在BLUE-4上分数较低,这表明Ziya-Visual在大多数开放域的多模态问答上生成的答案更为泛化和准确,但在一些发散性的问题上生成答案具有自主性。对于mPLUG-Owl模型,英文采用了 mPLUG-Owl 7B Instruction tuning (LoRA) 版本,中文则采用了多语言的mPLUG-Owl 7B (Multilingual) Instruction tuning (LoRA) 版本。因此在英文测评分数上高于双语版本的Ziya-Visual,另一方面,由于Ziya-Visual采用的LLaMA具备更优秀的多语言理解和生成能力,并且在Ziya-Visual二阶段训练时也通过翻译工具引入了多语言多模态训练语料,因此在中文数据的测评结果上更有优势。
Firstly, the evaluation on the VQA effectiveness shows that the Ziya-Visual model outperforms VisualGLM on most of the metrics on both the Chinese and English test sets of GQA, while scoring lower on BLUE-4, indicating that Ziya-Visual generates more generalized and accurate answers on most open domain multimodal questions and answers, but generates some discrete questions on answers have autonomy. For the mPLUG-Owl model, the mPLUG-Owl 7B Instruction tuning (LoRA) version was used for English and the multilingual mPLUG-Owl 7B (Multilingual) Instruction tuning (LoRA) version was used for Chinese. On the other hand, Ziya-Visual's LLaMA has better multilingual comprehension and generation capabilities, and the multilingual multimodal training corpus was introduced in the second phase of Ziya-Visual training through a translation tool, so it has an advantage in the Chinese data.
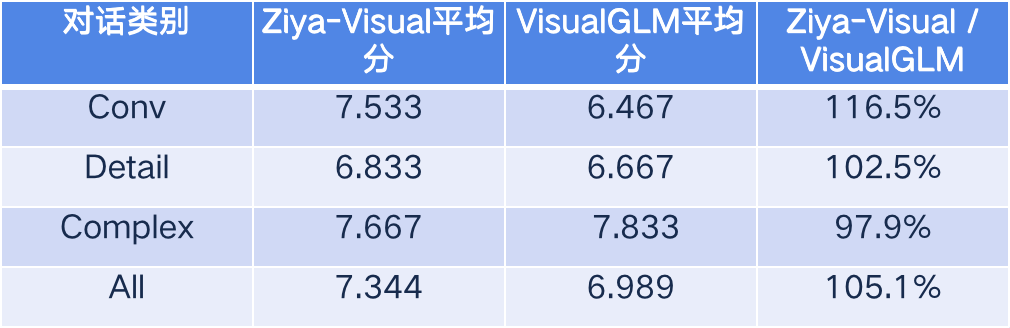
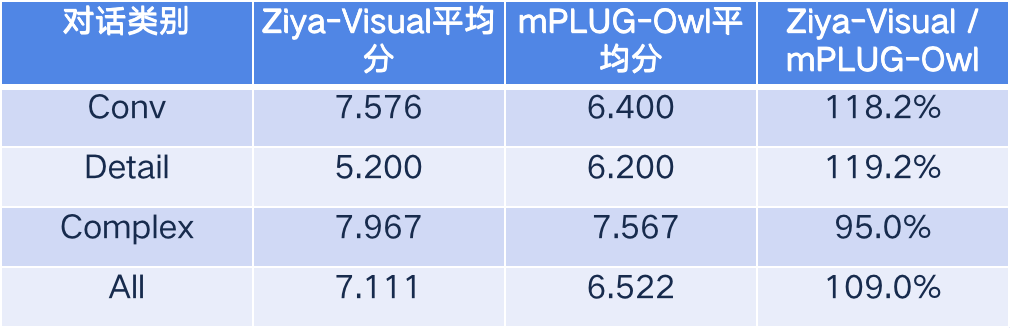
Secondly, we used the LLaVA approach to score the evaluation using the GPT-4, which uses the caption and object detection box information from the coco dataset to input to the GPT-4; the responses to the image quiz from Ziya-Visual and VisualGLM are then input to the GPT-4, which is asked to score the responses in terms of usefulness, relevance, accuracy, and The responses were then fed back into GPT-4, which was asked to rate the responses in terms of usefulness, relevance, accuracy, and level of detail (on a scale of 1-10); LLaVA divided the dialogue tasks into conv (simple dialogue), detail (detailed dialogue) and complex (complex reasoning), and all was the combined average score of the three dialogue tasks. The final evaluation results are as follows, and it can be seen that Ziya-Viusual outperforms VisualGLM in simple and detail dialogues, slightly loses out to VisualGLM in complex reasoning, and finally outperforms VisualGLM in overall average results. In comparing mPLUG-Owl we reach a similar conclusion, with Ziya-Viusual outperforming mPLUG-Owl on average overall.
使用 Usage
首先加载Ziya-Visual模型:需要注意的是Visual-Ziya的模型仓库只包含视觉模型部分的参数,Ziya LLM部分的参数通过Ziya-LLaMA-13B-v1获得。得到这两部分的模型参数后,我们加载模型:
First load the Ziya-Visual model: it should be noted that the model repository of Visual-Ziya contains only the parameters of the visual model part, the parameters of the Ziya LLM part are obtained through Ziya-LLaMA-13B-v1. Once we have the parameters for both parts of the model, we load the model:
from transformers import LlamaForCausalLM, LlamaTokenizer, BlipImageProcessor
from modeling_ziya_blip2 import ZiyaBLIP2ForConditionalGeneration
from PIL import Image
# model path of IDEA-CCNL/Ziya-LLaMA-13B-v1
LM_MODEL_PATH="local path of model Ziya-LLaMA-13B-v1"
lm_model = LlamaForCausalLM.from_pretrained(LM_MODEL_PATH)
tokenizer = LlamaTokenizer.from_pretrained(LM_MODEL_PATH)
# visual model
OPENAI_CLIP_MEAN = [0.48145466, 0.4578275, 0.40821073]
OPENAI_CLIP_STD = [0.26862954, 0.26130258, 0.27577711]
# demo.py is in the project path, so we can use local path ".". Otherwise you should use "IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1"
model = ZiyaBLIP2ForConditionalGeneration.from_pretrained(".", language_model=lm_model)
image_size = model.config.vision_config.image_size
image_processor = BlipImageProcessor(
size={"height": image_size, "width": image_size},
image_mean=OPENAI_CLIP_MEAN,
image_std=OPENAI_CLIP_STD,
)
model.cuda() # if you use on cpu, comment this line
模型加载完毕后,我们就可以愉快地使用Ziya-Visual模型了:
Once the model has been loaded, we can happily use the Ziya-Visual model:
generate_config = {
"max_new_tokens": 128,
"top_p": 0.1,
"temperature": 0.7
}
output = model.chat(
tokenizer=tokenizer,
pixel_values=image_processor(Image.open("wzry.jpg"), return_tensors="pt").pixel_values.to(model.device),
query="这是什么游戏",
previous_querys=[],
previous_outputs=[],
**generate_config,
)
print(output)
# 这是一款名为《王者荣耀》的多人在线竞技游戏。在游戏中,玩家扮演不同的角色,并与其他玩家进行战斗。游戏中的人物和环境都是虚拟的,但它们看起来非常逼真。玩家需要使用各种技能和策略来击败对手,并获得胜利。
引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的论文:
If you are using the resource for your work, please cite the our paper:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
You can also cite our website:
欢迎引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}