---
language: zh
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- zh
- Chinese
- Anime
inference: true
widget:
- text: "1个女孩,绿色头发,毛衣,看向阅图者,上半身,帽子,户外,下雪,高领毛衣"
example_title: 1个女孩
- text: "1个男孩,上半身,看向阅图者,闭嘴,单人,金发,蓝天,白云"
example_title: 1个男孩
- text: "城市,风景,无人,蓝天,白云"
example_title: 城市
- text: "乡村,风景,无人,蓝天,白云"
example_title: 乡村
extra_gated_prompt: |-
One more step before getting this model.
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. IDEA-CCNL claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
By clicking on "Access repository" below, you accept that your *contact information* (email address and username) can be shared with the model authors as well.
extra_gated_fields:
I have read the License and agree with its terms: checkbox
---
# Taiyi-Stable-Diffusion-1B-Chinese-v0.1
- - Main Page:[Fengshenbang](https://fengshenbang-lm.com/)
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
## 简介 Brief Introduction
首个开源的中文Stable Diffusion动漫模型,基于100万筛选过的动漫中文图文对训练。训练细节可见[开源版二次元生成器!IDEA研究院封神榜团队发布第一个中文动漫Stable Diffussion模型](https://zhuanlan.zhihu.com/p/598766181),更多text2img案例可见[太乙动漫绘画使用手册1.0](https://docs.qq.com/doc/DUFRMZ25wUFRWaEl0)
The first open source Chinese Stable diffusion Anime model, which was trained on M1 filtered Chinese Anime image-text pairs. See details in [IDEA Research Institute Fengshenbang team released the first opensource Chinese anime Stable Diffussion model](https://zhuanlan.zhihu.com/p/598766181), see more text2img examples in [Taiyi-Anime handbook](https://docs.qq.com/doc/DUFRMZ25wUFRWaEl0)
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :------------: | :-----------------: | :-----------: | :----------------: | :--------------: | :----------: |
| 特殊 Special | 多模态 Multimodal | 太乙 Taiyi | Stable Diffusion | 1B | Chinese |
## 模型信息 Model Information
我们将两份动漫数据集(100万低质量数据和1万高质量数据),基于[IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1](https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1) 模型进行了两阶段的微调训练,计算开销是4 x A100 训练了大约100小时。该版本只是一个初步的版本,我们将持续优化并开源后续模型,欢迎交流。
We use two anime dataset(1 million low-quality data and 10k high-qualty data) for two-staged training the chinese anime model based our pretrained model [IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1](https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1). It takes 100 hours to train this model based on 4 x A100. This model is a preliminary version and we ~~will~~ update this model continuously and open sourse. Welcome to exchange!
### Result
首先一个小窍门是善用超分模型给图片质量upup:
The first tip is to make good use of the super resolution model to give the image quality a boost:
比如这个例子:
```
1个女孩,绿眼,棒球帽,金色头发,闭嘴,帽子,看向阅图者,短发,简单背景,单人,上半身,T恤
Negative prompt: 水彩,漫画,扫描件,简朴的画作,动画截图,3D,像素风,原画,草图,手绘,铅笔
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 3900970600, Size: 512x512, Model hash: 7ab6852a
```
生成图片的图片是512 * 512(大小为318kb):

在webui里面选择extra里的R-ESRGAN 4x+ Anime6B模型对图片质量进行超分:
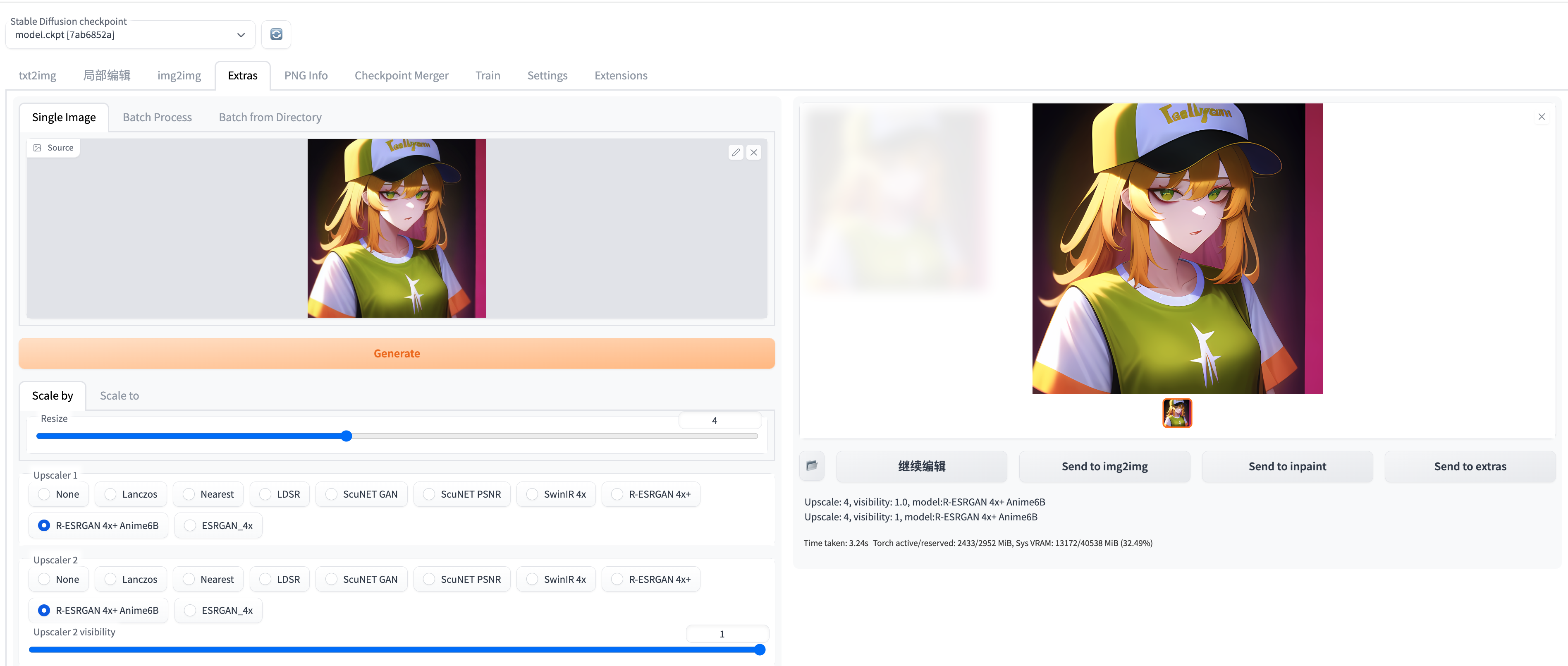
就可以超分得到2048 * 2048(大小为2.6Mb)的超高清大图,放大两张图片就可以看到清晰的区别,512 * 512的图片一放大就会变糊,2048 * 2048的高清大图就可以一直放大还不模糊:

以下例子是模型在webui运行获得。
These example are got from an model running on webui.
首先是风格迁移的例子:
Firstly some img2img examples:

下面则是一些文生图的例子:
The Next are some text2img examples:
| prompt1 | prompt2 |
| ----------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------- |
| 1个男生,帅气,微笑,看着阅图者,简单背景,白皙皮肤,
上半身,衬衫,短发,单人 | 1个女孩,绿色头发,毛衣,看向阅图者,上半身,帽子,户外,下雪,高领毛衣 |
|  |  |
| 户外,天空,云,蓝天,无人,多云的天空,风景,日出,草原 | 室内,杯子,书,无人,窗,床,椅子,桌子,瓶子,窗帘,阳光,
风景,盘子,木地板,书架,蜡烛,架子,书堆,绿植,梯子,地毯,小地毯 |
|  |  |
| 户外,天空,水,树,无人,夜晚,建筑,风景,反射,灯笼,船舶,
建筑学,灯笼,船,反射水,东亚建筑 | 建筑,科幻,城市,城市风景,摩天大楼,赛博朋克,人群 |
|  |  |
| 无人,动物,(猫:1.5),高清,棕眼 | 无人,动物,(兔子:1.5),高清,棕眼 |
|  |  |
## 使用 Usage
### webui配置 Configure webui
非常推荐使用webui的方式使用本模型,webui提供了可视化的界面加上一些高级修图、超分功能。
It is highly recommended to use this model in a webui way. webui provides a visual interface plus some advanced retouching features.
[Taiyi Stable Difffusion WebUI](https://github.com/IDEA-CCNL/stable-diffusion-webui/blob/master/README.md)
### 半精度 Half precision FP16 (CUDA)
添加 `torch_dtype=torch.float16` 和 `device_map="auto"` 可以快速加载 FP16 的权重,以加快推理速度。
更多信息见 [the optimization docs](https://huggingface.co/docs/diffusers/main/en/optimization/fp16#half-precision-weights)。
```py
# !pip install git+https://github.com/huggingface/accelerate
import torch
from diffusers import StableDiffusionPipeline
torch.backends.cudnn.benchmark = True
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1", torch_dtype=torch.float16)
pipe.to('cuda')
prompt = '1个女孩,绿色头发,毛衣,看向阅图者,上半身,帽子,户外,下雪,高领毛衣'
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("1个女孩.png")
```
### 使用手册 Handbook for Taiyi
- [太乙handbook](https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md)
- [太乙绘画手册v1.1](https://docs.qq.com/doc/DWklwWkVvSFVwUE9Q)
- [太乙动漫绘画手册v1.0](https://docs.qq.com/doc/DUFRMZ25wUFRWaEl0)
### 怎样微调 How to finetune
[finetune code](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion)
### DreamBooth
[DreamBooth code](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/stable_diffusion_dreambooth)
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[总论文](https://arxiv.org/abs/2209.02970):
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2209.02970):
```text
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
也可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```