---
license: other
license_name: model-license
license_link: https://github.com/modelscope/FunASR/blob/main/MODEL_LICENSE
library: SenseVoice
---
# Introduction
SenseVoice is a speech foundation model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), and audio event detection (AED).
# Highlights
**SenseVoice** focuses on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection.
- **Multilingual Speech Recognition:** Trained with over 400,000 hours of data, supporting more than 50 languages, the recognition performance surpasses that of the Whisper model.
- **Rich transcribe:**
- Possess excellent emotion recognition capabilities, achieving and surpassing the effectiveness of the current best emotion recognition models on test data.
- Offer sound event detection capabilities, supporting the detection of various common human-computer interaction events such as bgm, applause, laughter, crying, coughing, and sneezing.
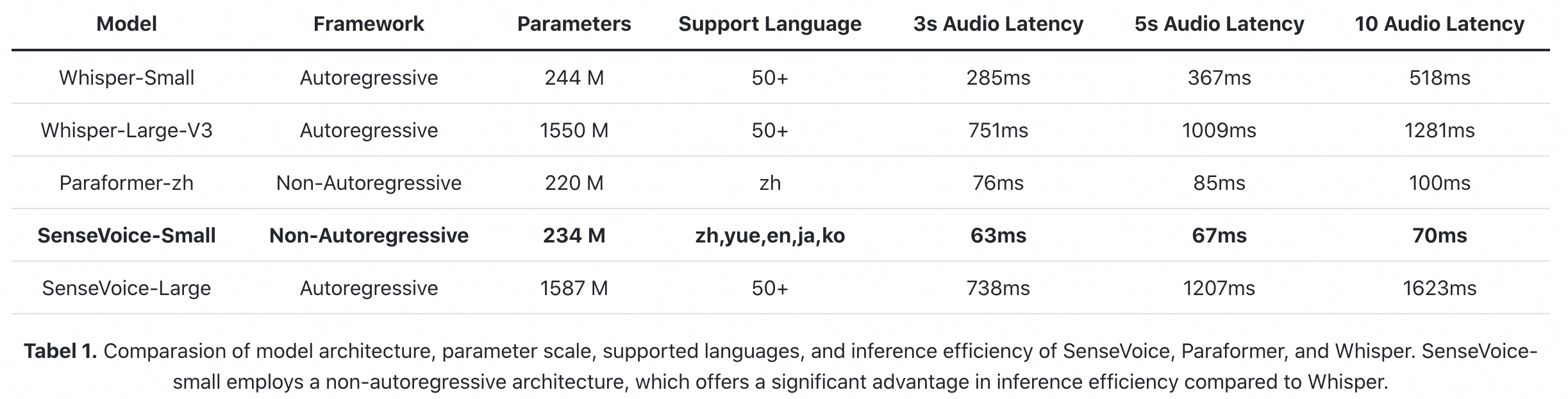
- **Efficient Inference:** The SenseVoice-Small model utilizes a non-autoregressive end-to-end framework, leading to exceptionally low inference latency. It requires only 70ms to process 10 seconds of audio, which is 15 times faster than Whisper-Large.
- **Convenient Finetuning:** Provide convenient finetuning scripts and strategies, allowing users to easily address long-tail sample issues according to their business scenarios.
- **Service Deployment:** Offer service deployment pipeline, supporting multi-concurrent requests, with client-side languages including Python, C++, HTML, Java, and C#, among others.
## [SenseVoice Project]()
[SenseVoice]() is a speech foundation model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), and acoustic event detection (AED).
[**github**]()
| [**What's New**]()
| [**Requirements**]()
# SenseVoice Model
SenseVoice-Small is an encoder-only speech foundation model designed for rapid voice understanding. It encompasses a variety of features including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), acoustic event detection (AED), and Inverse Text Normalization (ITN). SenseVoice-Small supports multilingual recognition for Chinese, English, Cantonese, Japanese, and Korean.
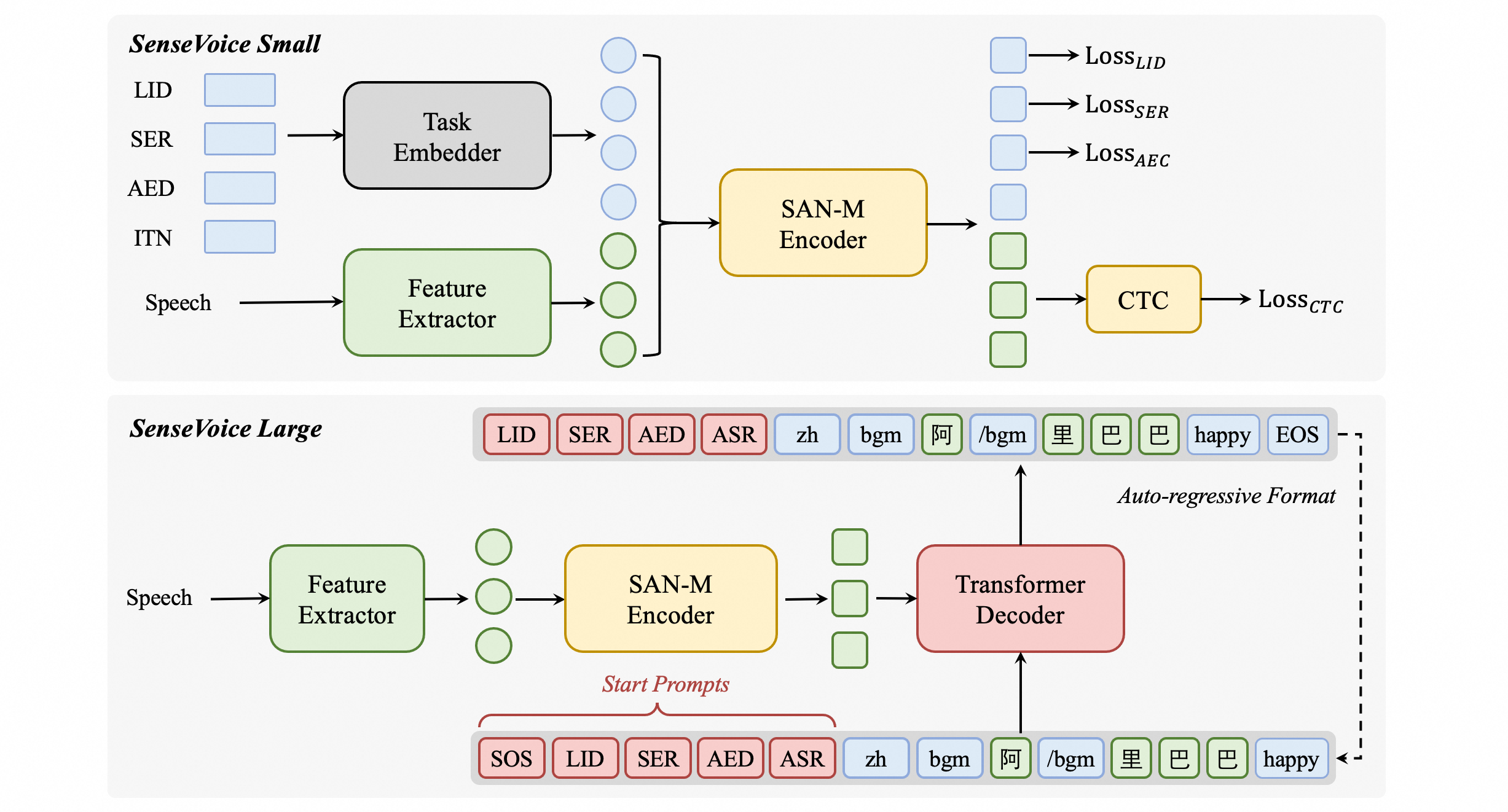
The SenseVoice-Small model is based on a non-autoregressive end-to-end framework. For a specified task, we prepend four embeddings as input to the encoder:
LID: For predicting the language id of the audio.
SER: For predicting the emotion label of the audio.
AED: For predicting the event label of the audio.
ITN: Used to specify whether the recognition output text is subjected to inverse text normalization.
# Usage
## Inference
### Method 1
```python
from model import SenseVoiceSmall
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir)
res = m.inference(
data_in="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav",
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
**kwargs,
)
print(res)
```
### Method 2
```python
from funasr import AutoModel
model_dir = "iic/SenseVoiceSmall"
input_file = (
"https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav"
)
model = AutoModel(model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
trust_remote_code=True, device="cuda:0")
res = model.generate(
input=input_file,
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size_s=0,
)
print(res)
```
The funasr version has integrated the VAD (Voice Activity Detection) model and supports audio input of any duration, with `batch_size_s` in seconds.
If all inputs are short audios, and batch inference is needed to speed up inference efficiency, the VAD model can be removed, and `batch_size` can be set accordingly.
```python
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=input_file,
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size=64,
)
```
For more usage, please ref to [docs](https://github.com/modelscope/FunASR/blob/main/docs/tutorial/README.md)
### Export and Test
```python
# pip3 install -U funasr-onnx
from funasr_onnx import SenseVoiceSmall
model_dir = "iic/SenseVoiceCTC"
model = SenseVoiceSmall(model_dir, batch_size=1, quantize=True)
wav_path = [f'~/.cache/modelscope/hub/{model_dir}/example/asr_example.wav']
result = model(wav_path)
print(result)
```
## Service
Undo
## Finetune
### Requirements
```shell
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
```
### Data prepare
Data examples
```text
{"key": "YOU0000008470_S0000238_punc_itn", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|withitn|>", "target": "Including legal due diligence, subscription agreement, negotiation.", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/YOU0000008470_S0000238.wav", "target_len": 7, "source_len": 140}
{"key": "AUD0000001556_S0007580", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|woitn|>", "target": "there is a tendency to identify the self or take interest in what one has got used to", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/AUD0000001556_S0007580.wav", "target_len": 18, "source_len": 360}
```
Full ref to `data/train_example.jsonl`
### Finetune
Ensure to modify the train_tool in finetune.sh to the absolute path of `funasr/bin/train_ds.py` from the FunASR installation directory you have set up earlier.
```shell
bash finetune.sh
```
# Performance
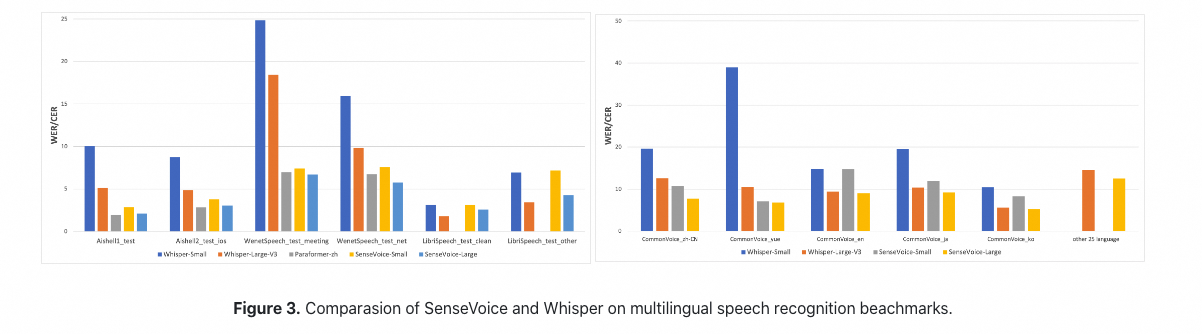
## Multilingual Speech Recognition
We compared the performance of multilingual speech recognition between SenseVoice and Whisper on open-source benchmark datasets, including AISHELL-1, AISHELL-2, Wenetspeech, LibriSpeech, and Common Voice. n terms of Chinese and Cantonese recognition, the SenseVoice-Small model has advantages.
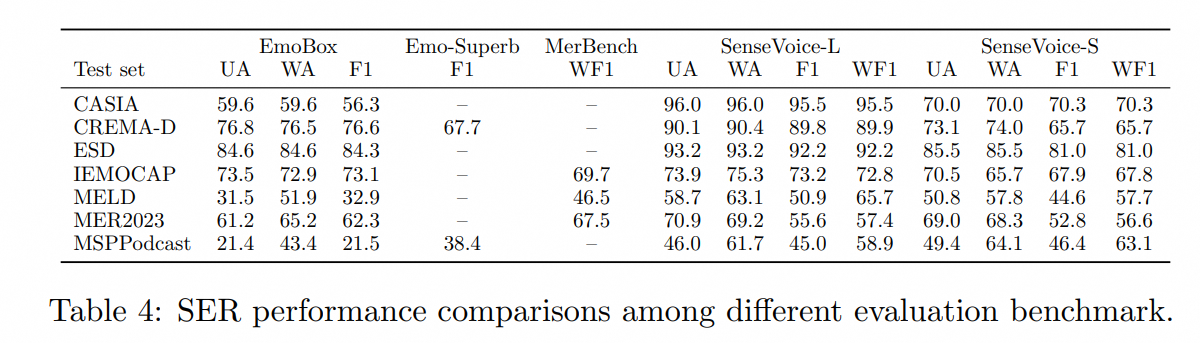
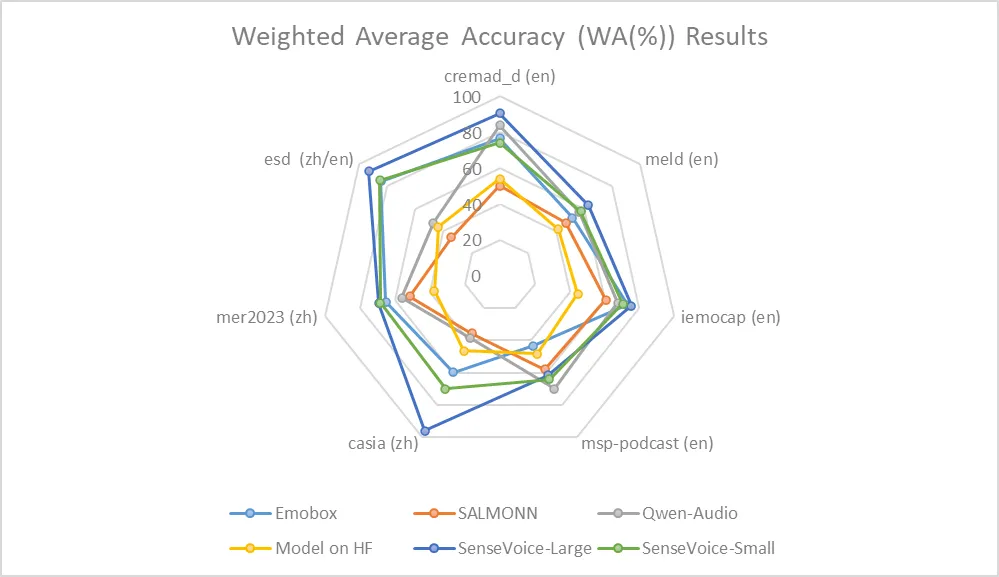
## Speech Emotion Recognition
Due to the current lack of widely-used benchmarks and methods for speech emotion recognition, we conducted evaluations across various metrics on multiple test sets and performed a comprehensive comparison with numerous results from recent benchmarks. The selected test sets encompass data in both Chinese and English, and include multiple styles such as performances, films, and natural conversations. Without finetuning on the target data, SenseVoice was able to achieve and exceed the performance of the current best speech emotion recognition models.
Furthermore, we compared multiple open-source speech emotion recognition models on the test sets, and the results indicate that the SenseVoice-Large model achieved the best performance on nearly all datasets, while the SenseVoice-Small model also surpassed other open-source models on the majority of the datasets.
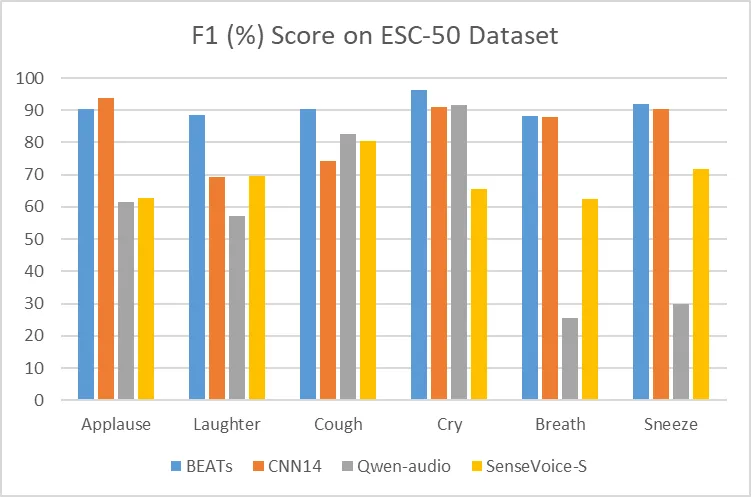
## Audio Event Detection
Although trained exclusively on speech data, SenseVoice can still function as a standalone event detection model. We compared its performance on the environmental sound classification ESC-50 dataset against the widely used industry models BEATS and PANN. The SenseVoice model achieved commendable results on these tasks. However, due to limitations in training data and methodology, its event classification performance has some gaps compared to specialized AED models.
## Computational Efficiency
The SenseVoice-Small model non-autoregressive end-to-end architecture, resulting in extremely low inference latency. With a similar number of parameters to the Whisper-Small model, it infers 7 times faster than Whisper-Small and 17 times faster than Whisper-Large.