---
license: creativeml-openrail-m
tags:
- stable-diffusion
- prompt-generator
- arxiv:2210.14140
widget:
- text: "amazing"
- text: "a photo of"
- text: "a sci-fi"
- text: "a portrait of"
- text: "a person standing"
- text: "a boy watching"
datasets:
- FredZhang7/stable-diffusion-prompts-2.47M
- poloclub/diffusiondb
- Gustavosta/Stable-Diffusion-Prompts
- bartman081523/stable-diffusion-discord-prompts
---
# Fast GPT2 PromptGen
Fast Anime PromptGen generates descriptive safebooru and danbooru tags for anime text-to-image models.
This model was trained on 2,470,000 descriptive stable diffusion prompts on the [FredZhang7/distilgpt2-stable-diffusion](https://huggingface.co/FredZhang7/distilgpt2-stable-diffusion) checkpoint for another 4,270,000 steps.
Compared to other prompt generation models using GPT2, this one runs with 50% faster forwardpropagation and 40% less disk space & RAM.
Major improvements from v1 are:
- 25% more variations
- faster and more fluent prompt generation
- cleaned training data
* removed prompts that generate images with nsfw scores > 0.5
* removed duplicates, including prompts that differ by capitalization and punctuations
* removed punctuations at random places
* removed prompts shorter than 15 characters
## Live WebUI Demo
See the Prompt Generator tab of [Paint Journey Demo](https://huggingface.co/spaces/FredZhang7/paint-journey-demo).
## Contrastive Search
```bash
pip install --upgrade transformers
```
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model = GPT2LMHeadModel.from_pretrained('FredZhang7/distilgpt2-stable-diffusion-v2')
prompt = r'a cat sitting' # the beginning of the prompt
temperature = 0.9 # a higher temperature will produce more diverse results, but with a higher risk of less coherent text
top_k = 8 # the number of tokens to sample from at each step
max_length = 80 # the maximum number of tokens for the output of the model
repitition_penalty = 1.2 # the penalty value for each repetition of a token
num_return_sequences=5 # the number of results to generate
# generate the result with contrastive search
input_ids = tokenizer(prompt, return_tensors='pt').input_ids
output = model.generate(input_ids, do_sample=True, temperature=temperature, top_k=top_k, max_length=max_length, num_return_sequences=num_return_sequences, repetition_penalty=repitition_penalty, penalty_alpha=0.6, no_repeat_ngram_size=1, early_stopping=True)
print('\nInput:\n' + 100 * '-')
print('\033[96m' + prompt + '\033[0m')
print('\nOutput:\n' + 100 * '-')
for i in range(len(output)):
print('\033[92m' + tokenizer.decode(output[i], skip_special_tokens=True) + '\033[0m\n')
```
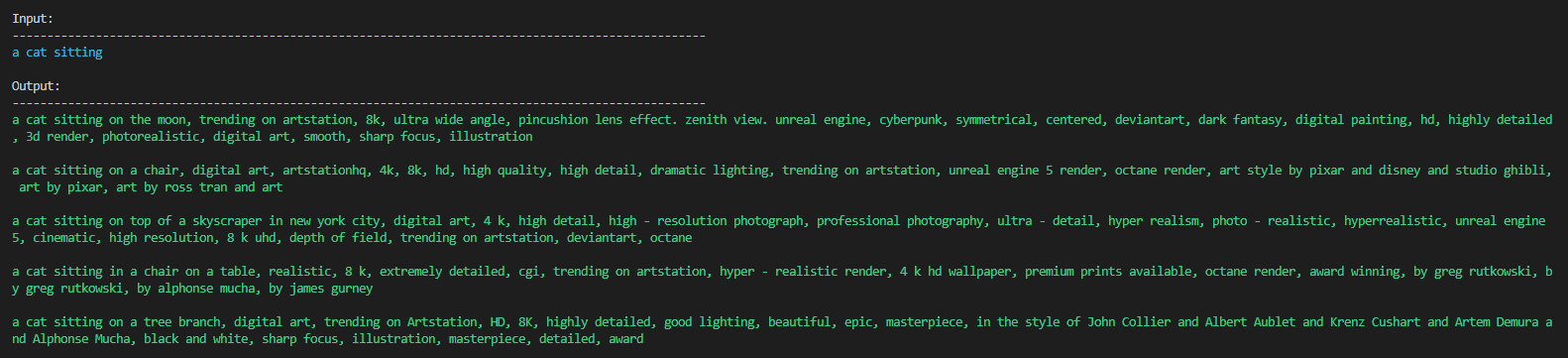
No comma style:
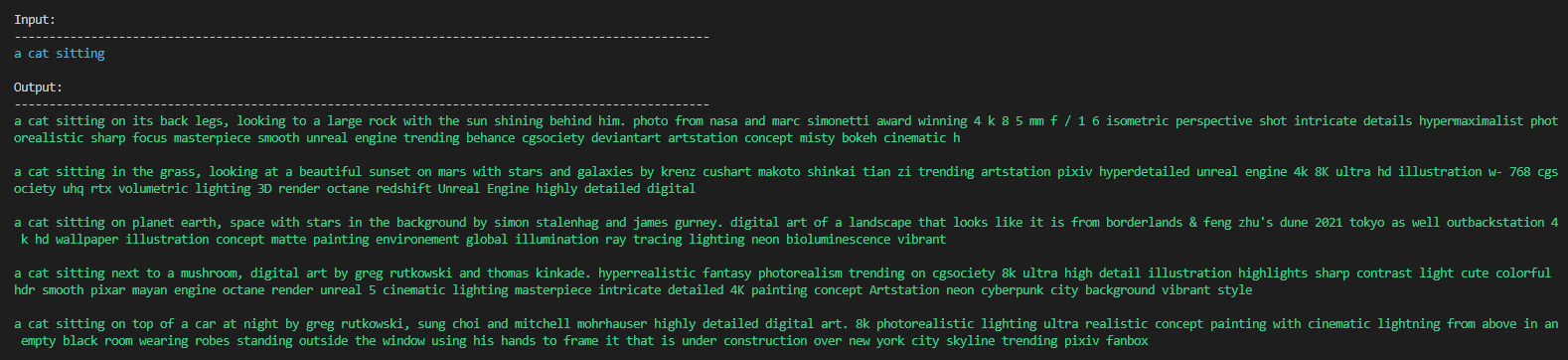
To bring back the commas, assign output without `penalty_alpha` and `no_repeat_ngram_size`:
```python
output = model.generate(input_ids, do_sample=True, temperature=temperature, top_k=top_k, max_length=max_length, num_return_sequences=num_return_sequences, repetition_penalty=repitition_penalty, early_stopping=True)
```