---
pipeline_tag: robotics
library_name: transformers
license: apache-2.0
tags: [robotics, agent, computer-vision, llm]
---
# STEVE-R1: Towards Long Reasoning Computer-use Agents
[](https://huggingface.co/papers/2503.12532)
[](https://huggingface.co/Fanbin/STEVE-R1-7B-SFT)
[](https://huggingface.co/datasets/Fanbin/waa_steve_trajectories)
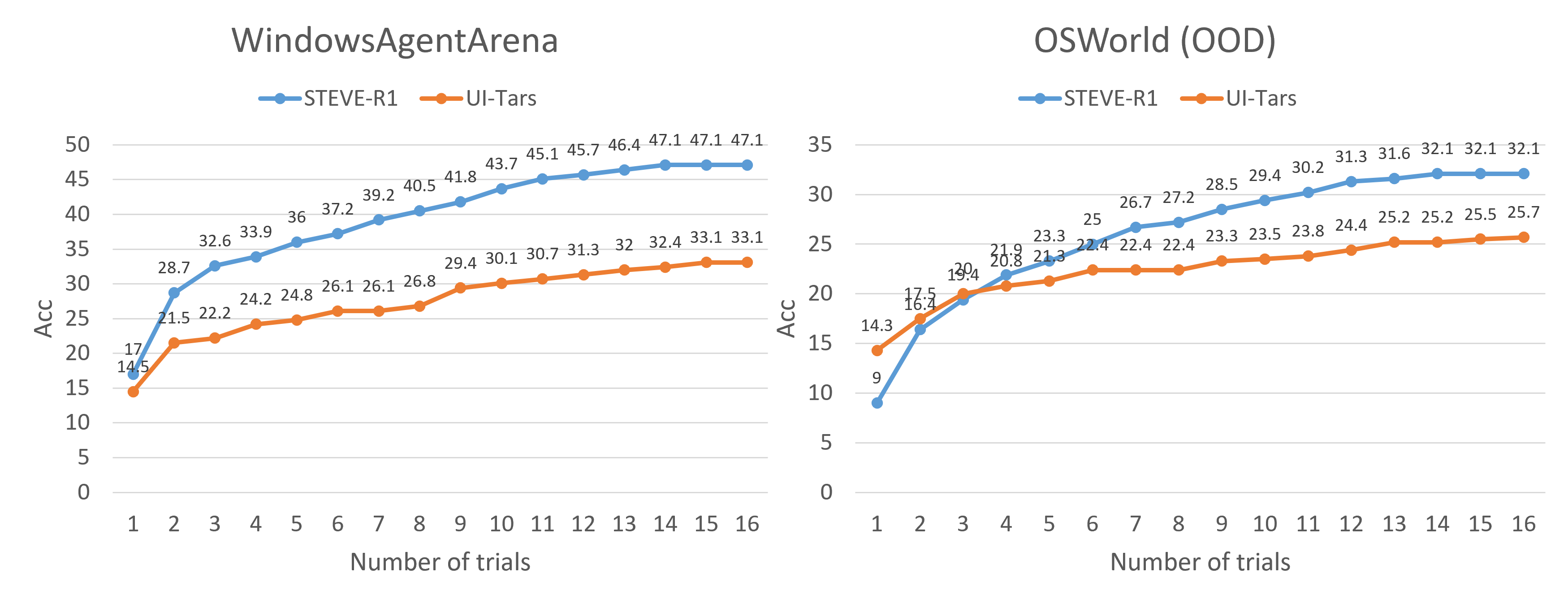
We evaluate the performance of the **STEVE-R1 agent** on both in-domain WindowsAgentArena (Windows 11 OS) and out-of-domain OSWorld (Ubuntu OS) benchmarks. The evaluation involves 16 attempts per task, with task completion rates recorded as the primary metric. In the in-domain Windows 11 setting, the STEVE-R1 agent demonstrated a **14%** higher task completion rate compared to the previous open-source state-of-the-art model, UI-TARS-7B-DPO. Furthermore, in the out-of-domain Ubuntu OS environment, where STEVE-R1 was not explicitly trained, it still achieved a **7%** higher task completion rate than UI-TARS-7B-DPO.
## Release
- Currently only the SFT STEVE-R1 model with step-verified training data is released. RL tunning is in progress.
- 🔥 An improved version **STEVE-R1** is released with long reasoning ability and long image context. We extend the model context length to 128K with at most 32 screenshot inputs for a single task. The model response length is greatly improved with deepseek-R1 distillation, see the [examples](https://github.com/FanbinLu/STEVE-R1/tree/main/examples). We release the [training data](), [models](https://huggingface.co/Fanbin/STEVE-R1-7B-SFT), and [evaluation trajectories](https://huggingface.co/datasets/Fanbin/waa_steve_trajectories).
- We release the paper of STEVE: Step Verification Pipeline for Computer-use Agent Training. We propose a single-frame computer-use 7B agent trained with SFT & step-verified KTO.
## Performance
| Method | WinAgentArena | OSWorld |
|--------|-------------------|------------------|
| UI-TARS-7B-DPO (20 steps) | 15.4 ± 1.6 | 14.6 ± 1.0 |
| UI-TARS-7B-DPO (40 steps) | 17.8 ± 1.3 | 15.7 ± 0.8 |
| UI-TARS-7B-DPO (60 steps) | 19.3 ± 1.6 | 16.2 ± 1.0 |
| **Our Model** | | |
| STEVE-R1-SFT (20 steps) | 17.5 ± 2.0 | 9.6 ± 1.1(OOD)|
| STEVE-R1-SFT (40 steps) | 20.1 ± 2.2 | 11.5 ± 1.2 (OOD) |
| STEVE-R1-SFT (60 steps) | **22.3** ± 2.1 | 12.8 ± 1.2 (OOD) |
| **Multiple Trials** | | |
| UI-TARS-7B-DPO (20 steps, pass@16) | 33.1 | 25.2 |
| STEVE-R1-SFT (20 steps, pass@16) | **46.8** | **31.4** (OOD) |
## Trajectory Data
Evaluation trajectories on WindowsAgentArena and OSWorld: https://huggingface.co/datasets/Fanbin/waa_steve_trajectories
Project page: https://github.com/FanbinLu/STEVE-R1
Paper: https://arxiv.org/abs/2503.12532