---
license: apache-2.0
---
# ADDP
The official implementation of the [paper](https://arxiv.org/abs/2306.05423) "ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denoising Diffusion Process" (ICLR 2024).
## Abstract
Image recognition and generation have long been developed independently of each other. With the recent trend towards general-purpose representation learning, the development of general representations for both recognition and generation tasks is also promoted. However, preliminary attempts mainly focus on generation performance, but are still inferior on recognition tasks. These methods are modeled in the vector-quantized (VQ) space, whereas leading recognition methods use pixels as inputs. Our key insights are twofold: (1) pixels as inputs are crucial for recognition tasks; (2) VQ tokens as reconstruction targets are beneficial for generation tasks. These observations motivate us to propose an Alternating Denoising Diffusion Process (ADDP) that integrates these two spaces within a single representation learning framework. In each denoising step, our method first decodes pixels from previous VQ tokens, then generates new VQ tokens from the decoded pixels. The diffusion process gradually masks out a portion of VQ tokens to construct the training samples. The learned representations can be used to generate diverse high-fidelity images and also demonstrate excellent transfer performance on recognition tasks. Extensive experiments show that our method achieves competitive performance on unconditional generation, ImageNet classification, COCO detection, and ADE20k segmentation. Importantly, our method represents the first successful development of general representations applicable to both generation and dense recognition tasks.
## Method
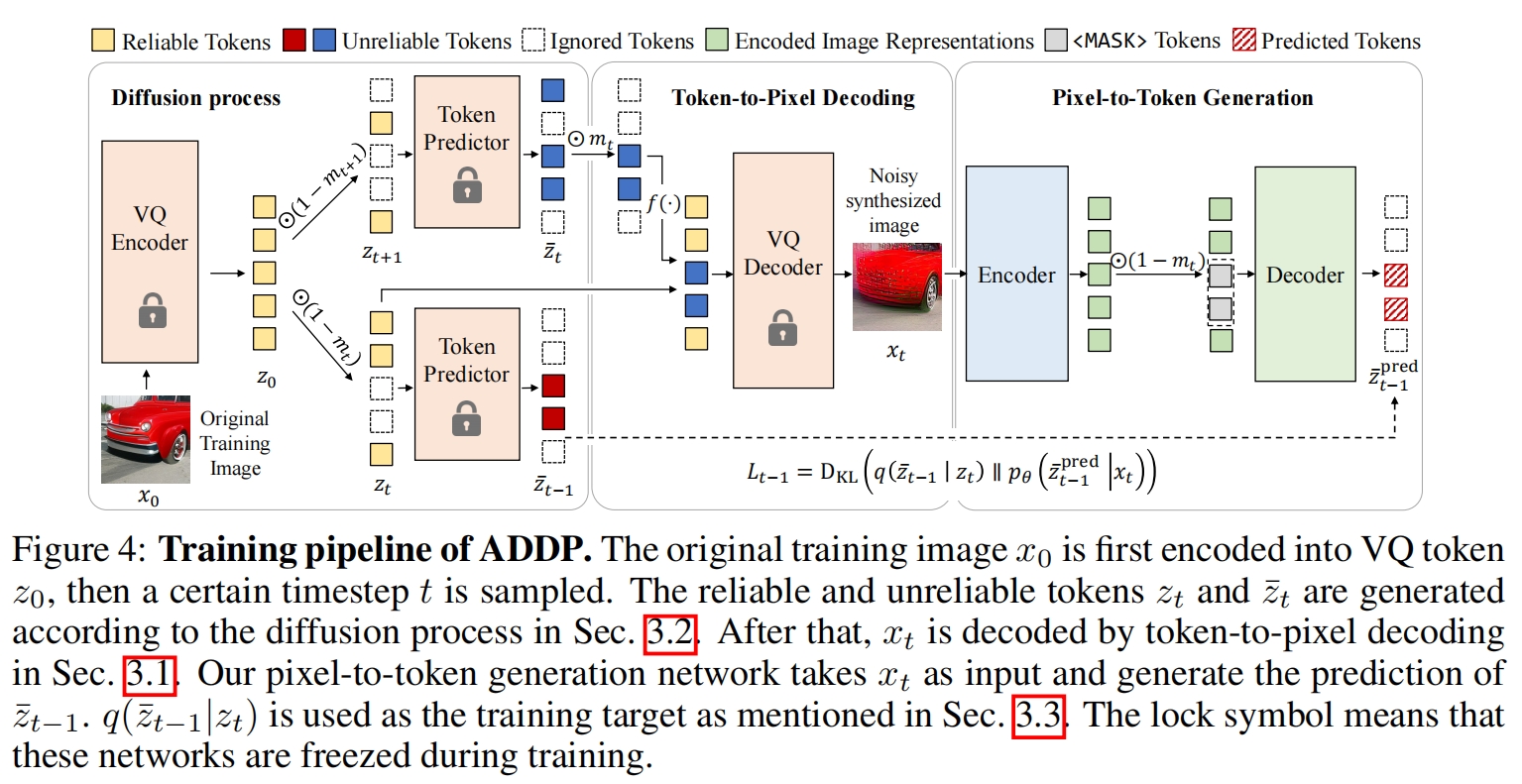
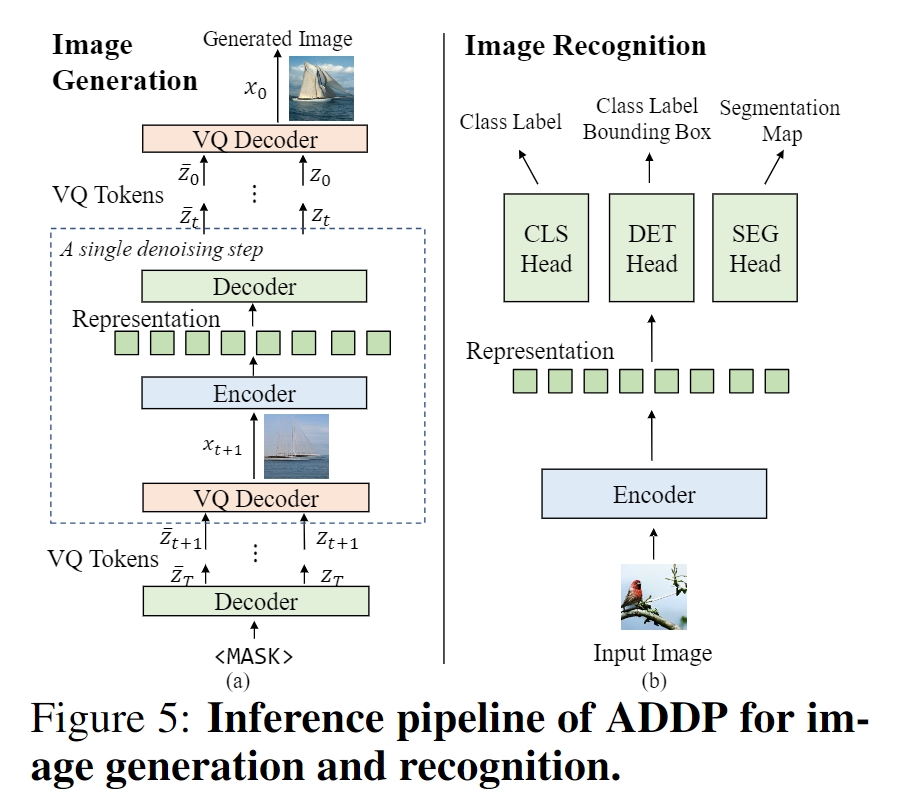
## Setup
Step 1, download [ImageNet](http://image-net.org/download) dataset, and place it in your `IMAGENET_DIR`.
Step 2, clone the repository and use pip to install all required packages.
```
git clone https://github.com/ChangyaoTian/ADDP.git
cd ADDP
pip install -r requirements.txt
```
Step 3, download the pre-trained VQGAN tokenizer and token predictor and put them under the `./exp/pretrained_model` directory.
| VQGAN tokenizer | Token Predictor (ViT-Base) | Token Predictor (ViT-Large) |
| :----------------------------------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
| this link | this link | this link |
## Usage
The following table provides the performance and weights of the pre-trained checkpoints (ViT-L/16 and ViT-B/16) used in the paper.
| | ViT-Large | ViT-Base |
| ---------------------------------- | ---- | -------- |
| Checkpoint | this link | this link |
| Class-unconditional Generation FID | 7.6 | 8.9 |
| Class-unconditional Generation IS | 105.1 | 95.3 |
| Fine-tuning Top-1 Accuracy | 85.9 | 83.9 |
| COCO APbox | 54.6 | 51.7 |
| ADE20k mIoU | 54.3 | 48.1 |
### Pre-training & Fine-tuning & Unconditional Generation
The following scripts are all conducted by default under the slurm distributed environment, feel free to change the environment settings by yourself. Please refer to our paper for detailed configurations of each task.
For Fine-tuning and generation, please first download the corresponding pre-trained checkpoint (mentioned in the table above) under the `./exp/release` directory.
#### ViT-Large
```bash
## pretrain
bash configs/release/large/pretrain_addp_large_800ep.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION}
## finetune
bash configs/release/large/finetune_addp_large_50ep.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION} exp/release/addp-vit-large-16.pth
## generate
### cosine schedule (default)
bash configs/release/large/generate_addp_large_steps20.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION} exp/release/addp-vit-large-16.pth
### linear schedule
bash configs/release/large/generate_addp_large_steps256_linear.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION} exp/release/addp-vit-large-16.pth
```
#### ViT-Base
```bash
## pretrain
bash configs/release/base/pretrain_addp_base_1600ep.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION}
## finetune
bash configs/release/base/finetune_addp_base_100ep.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION} exp/release/addp-vit-base-16.pth
## generate
bash configs/release/base/generate_addp_base_steps20.sh ${GPUS} ${GPUS_PER_NODE} ${JOB_NAME} ${QUOTATYPE} ${PARATITION} exp/release/addp-vit-base-16.pth
```
#### FID/IS Evaluation
We mainly follow [MAGE](https://github.com/LTH14/mage) for FID/IS Evaluation. Please first generate 256x256 ImageNet validation images using
```
python ./util/prepare_imagenet_val.py --data_path ${IMAGENET_DIR} --output_dir ${IMAGENET256X256_DIR}
```
Then use pip to install the torch-fidelity package
```
pip install torch-fidelity
```
Then use the above package to evaluate FID/IS of the images generated by our models against 256x256 ImageNet validation images by
```
fidelity --isc --fid --input1 ${GENERATED_IMAGES_DIR} --input2 ${IMAGENET256X256_DIR}
```
## Citation
If this work is helpful for your research, please consider citing the following BibTeX entry.
```
@article{tian2023addp,
title={Addp: Learning general representations for image recognition and generation with alternating denoising diffusion process},
author={Tian, Changyao and Tao, Chenxin and Dai, Jifeng and Li, Hao and Li, Ziheng and Lu, Lewei and Wang, Xiaogang and Li, Hongsheng and Huang, Gao and Zhu, Xizhou},
journal={arXiv preprint arXiv:2306.05423},
year={2023}
}
```
## License
This repository is released under the Apache 2.0 license as found in the [LICENSE](LICENSE.md) file.
## Contact
If you have any questions, feel free to contact me through email (tcyhost@link.cuhk.edu.hk) directly.