---
inference: false
license: apache-2.0
---
# Model Card

📖 [Technical report](https://arxiv.org/abs/2402.11530) | 🏠 [Code](https://github.com/BAAI-DCAI/Bunny) | 🐰 [Demo](https://wisemodel.cn/spaces/baai/Bunny)
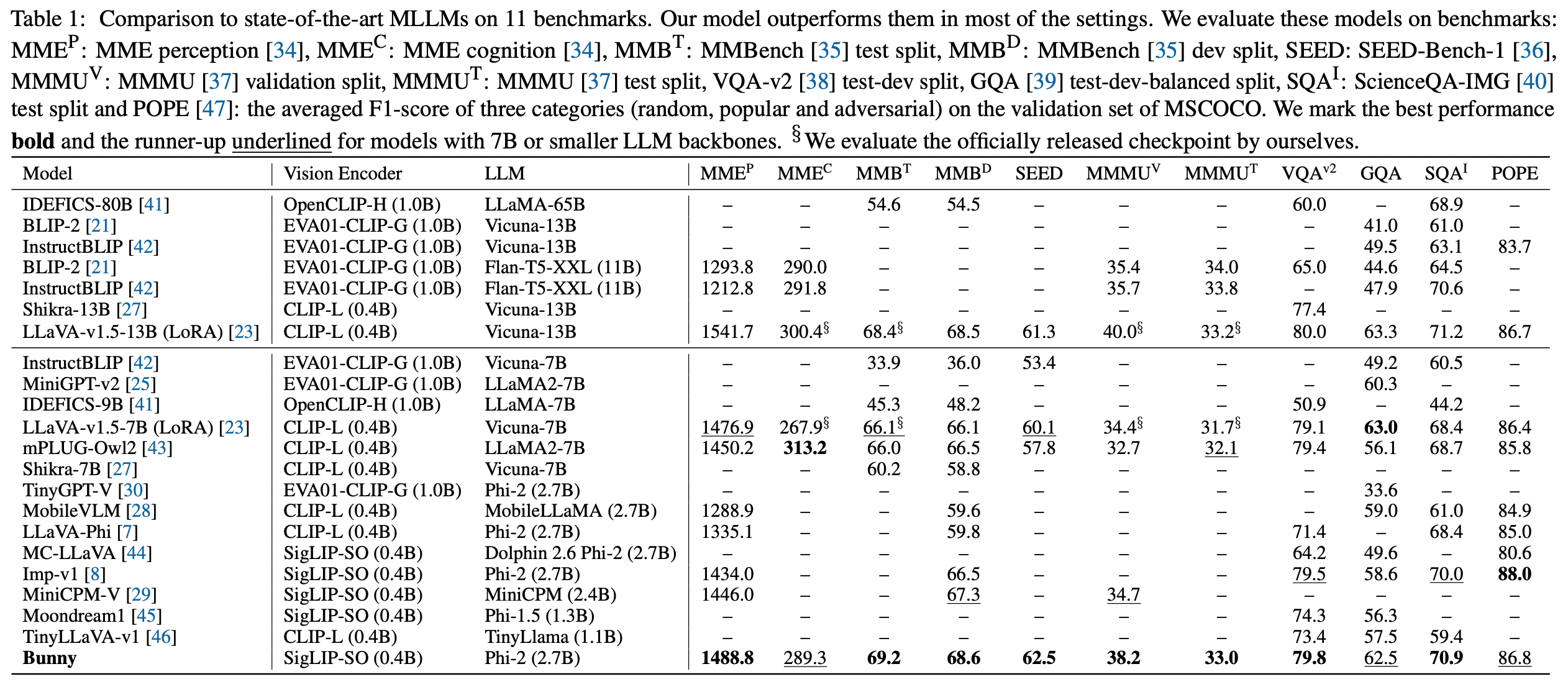
Bunny is a family of lightweight but powerful multimodal models. It offers multiple plug-and-play vision encoders, like EVA-CLIP, SigLIP and language backbones, including Phi-1.5, StableLM-2, Qwen1.5 and Phi-2. To compensate for the decrease in model size, we construct more informative training data by curated selection from a broader data source. Remarkably, our Bunny-3B model built upon SigLIP and Phi-2 outperforms the state-of-the-art MLLMs, not only in comparison with models of similar size but also against larger MLLM frameworks (7B), and even achieves performance on par with 13B models.
The model is pretrained on LAION-2M and finetuned on Bunny-695K.
More details about this model can be found in [GitHub](https://github.com/BAAI-DCAI/Bunny).
# Quickstart
The merged weights can be found in [Bunny-v1_0-3B](https://huggingface.co/BAAI/Bunny-v1_0-3B).
To use the model with transformers, use the merged weights instead of the LoRA weights.
Before running the snippet, you need to install the following dependencies:
```shell
pip install torch transformers accelerate pillow
```
```python
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import warnings
# disable some warnings
transformers.logging.set_verbosity_error()
transformers.logging.disable_progress_bar()
warnings.filterwarnings('ignore')
# set device
torch.set_default_device('cpu') # or 'cuda'
# create model
model = AutoModelForCausalLM.from_pretrained(
'BAAI/Bunny-v1_0-3B',
torch_dtype=torch.float16,
device_map='auto',
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(
'BAAI/Bunny-v1_0-3B',
trust_remote_code=True)
# text prompt
prompt = 'Why is the image funny?'
text = f"A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: \n{prompt} ASSISTANT:"
text_chunks = [tokenizer(chunk).input_ids for chunk in text.split('')]
input_ids = torch.tensor(text_chunks[0] + [-200] + text_chunks[1], dtype=torch.long).unsqueeze(0)
# image, sample images can be found in images folder
image = Image.open('example_2.png')
image_tensor = model.process_images([image], model.config).to(dtype=model.dtype)
# generate
output_ids = model.generate(
input_ids,
images=image_tensor,
max_new_tokens=100,
use_cache=True)[0]
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())
```
# License
This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses.
The content of this project itself is licensed under the Apache license 2.0.