English | 简体中文 |
We opensource our **Aquila2** series, now including **Aquila2**, the base language models, namely **Aquila2-7B** and **Aquila2-34B**, as well as **AquilaChat2**, the chat models, namely **AquilaChat2-7B** and **AquilaChat2-34B**, as well as the long-text chat models, namely **AquilaChat2-7B-16k** and **AquilaChat2-34B-16k**
The additional details of the Aquila model will be presented in the official technical report. Please stay tuned for updates on official channels.
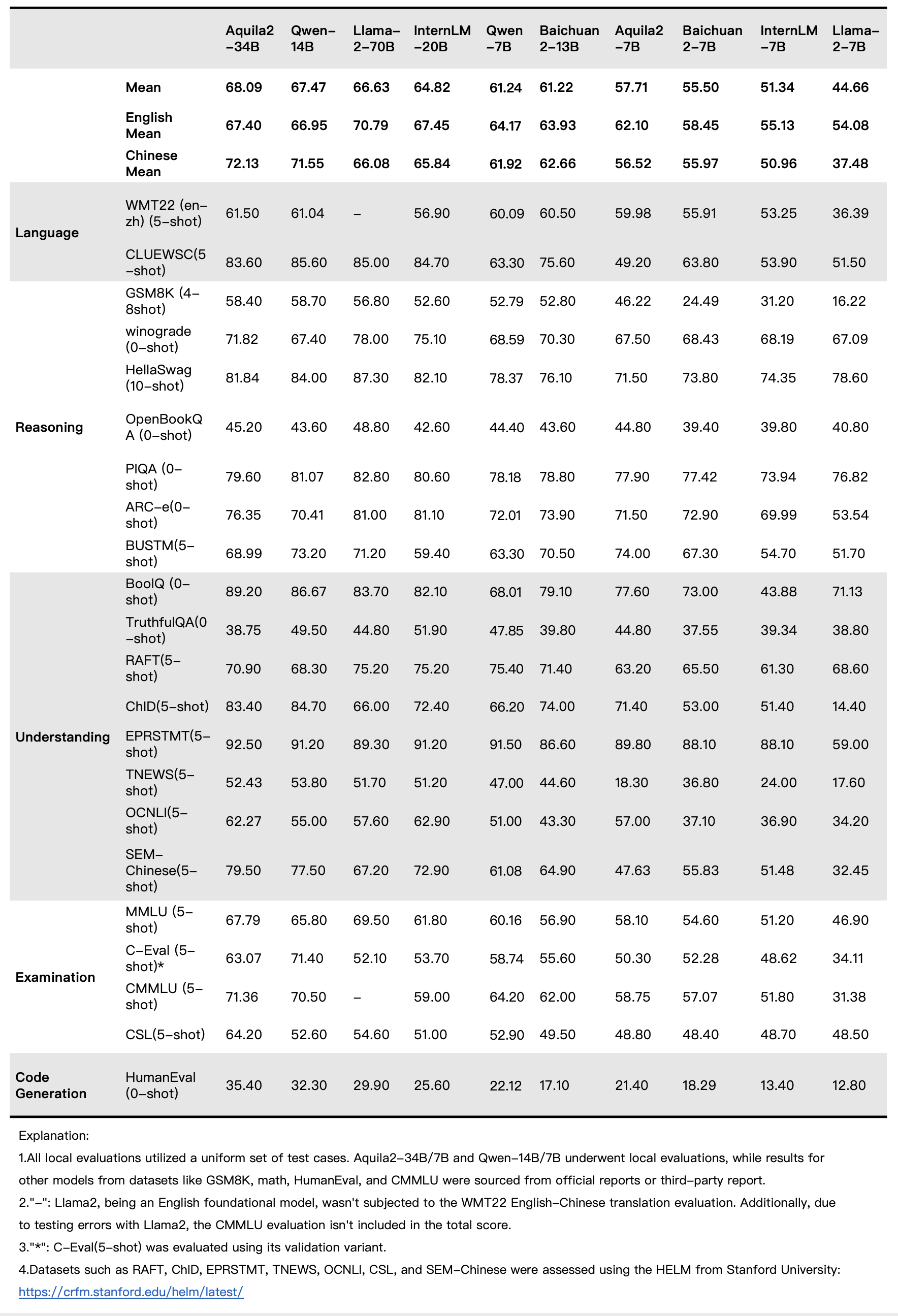
## Base Model Performance
## Quick Start Aquila2-7B
### 1. Inference
Aquila2-7B is a base model that can be used for continuation.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import BitsAndBytesConfig
device = torch.device("cuda")
model_info = "BAAI/Aquila2-7B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True, torch_dtype=torch.float16,
# quantization_config=quantization_config, # Uncomment this line for 4bit quantization
)
model.eval()
model.to(device)
text = "杭州亚运会的亮点和期待 2023年9月23日至10月8日,杭州将举办第19届亚洲运动会"
tokens = tokenizer.encode_plus(text)['input_ids']
tokens = torch.tensor(tokens)[None,].to(device)
stop_tokens = ["###", "[UNK]", ""]
with torch.no_grad():
out = model.generate(tokens, do_sample=True, max_length=512, eos_token_id=100007, bad_words_ids=[[tokenizer.encode(token)[0] for token in stop_tokens]])[0]
out = tokenizer.decode(out.cpu().numpy().tolist())
print(out)
```
## License
Aquila2 series open-source model is licensed under [ BAAI Aquila Model Licence Agreement](https://huggingface.co/BAAI/Aquila2-7B/blob/main/BAAI-Aquila-Model-License%20-Agreement.pdf)