---
license: mit
---
# 🔥 SPHINX: A Mixer of Tasks, Domains, and Embeddings
Official implementation of ['SPHINX: A Mixer of Tasks, Domains, and Embeddings Advances Multi-modal Large Language Models'](https://github.com/Alpha-VLLM/LLaMA2-Accessory/tree/main/SPHINX).
Try out our [web demo 🚀](http://imagebind-llm.opengvlab.com/) here!
Github link: Github • 👋 join our WeChat
## Introduction
We present SPHINX, a versatile multi-modal large language model (MLLM) with a mixer of training tasks, data domains, and visual embeddings.
- **Task Mix.** For all-purpose capabilities, we mix a variety of vision-language tasks for mutual improvement: VQA, REC, REG, OCR, DET, POSE, REL DET, T2I, etc.
- **Embedding Mix.** We capture robust visual representations by fusing distinct visual architectures, pre-training, and granularity.
- **Domain Mix.** For data from real-world and synthetic domains, we mix the weights of two domain-specific models for complementarity.
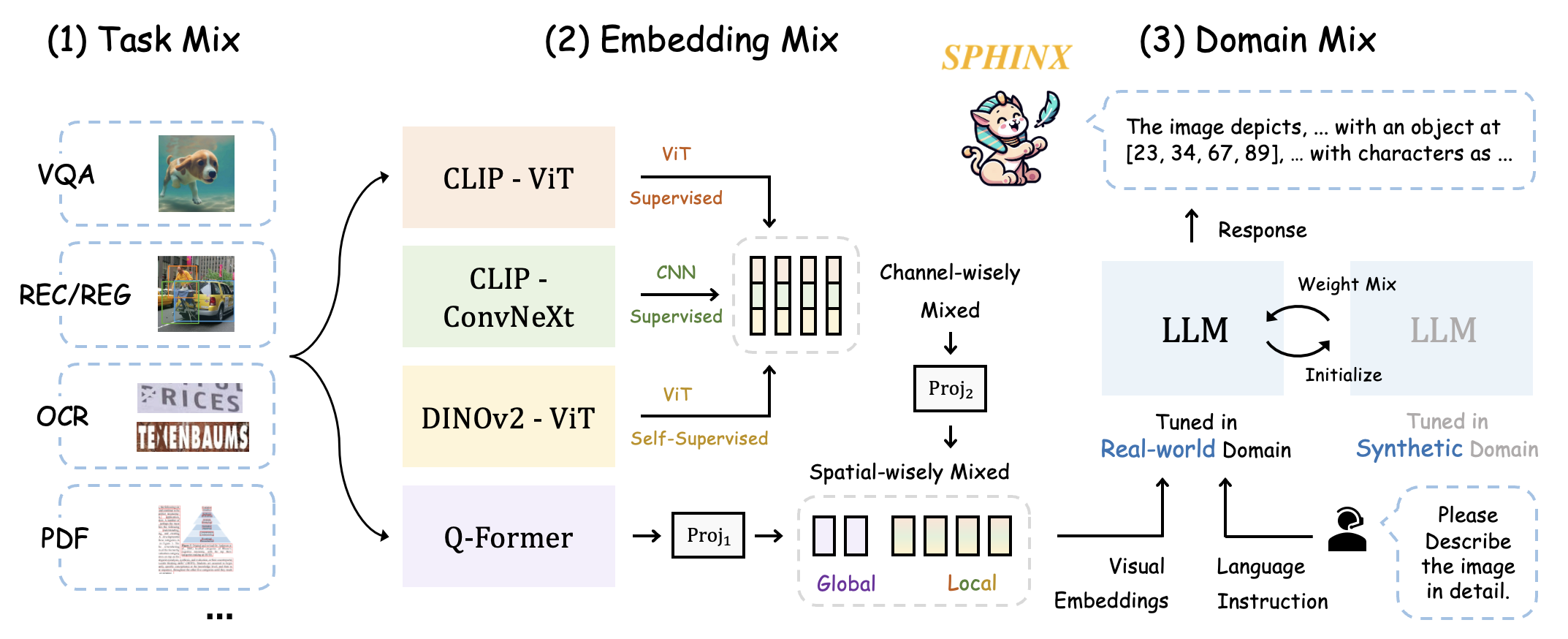
On top of SPHINX, we propose to further mix visual scales and sub-images for better capture fine-grained semantics on high-resolution images.

### Installation
SPHINX is built upon LLaMA2-Accessory, please follow the instructions [here](https://llama2-accessory.readthedocs.io/en/latest/install.html) for environment setup.
## Inference
This section provides a step-by-step guide for hosting a local SPHINX demo. If you're already familiar with the LLAMA2-Accessory toolkit, note that hosting a SPHINX demo follows the same pipeline as hosting demos for the other models supported by LLAMA2-Accessory.
### Weights
We provide the beta-version checkpoints on [HuggingFace🤗](https://huggingface.co/Alpha-VLLM/LLaMA2-Accessory/tree/main/finetune/mm/SPHINX). Please download them to your own machine. The file structure should appear as follows:
```
ckpt_path/
├── consolidated.00-of-02.model.pth
└── consolidated.01-of-02.model.pth
```
### Host Local Demo
Please follow the instructions [here](https://github.com/Alpha-VLLM/LLaMA2-Accessory/tree/main/SPHINX#host-local-demo) to see the instruction and complete the use of the model.
## Result
We provide a comprehensive evaluation of SPHINX and showcase results across multiple benchmarks.
Our evaluation encompasses both **quantitative metrics** and **qualitative assessments**, providing a holistic understanding of our VLM model's performance.
**Evaluation Prompt Design**
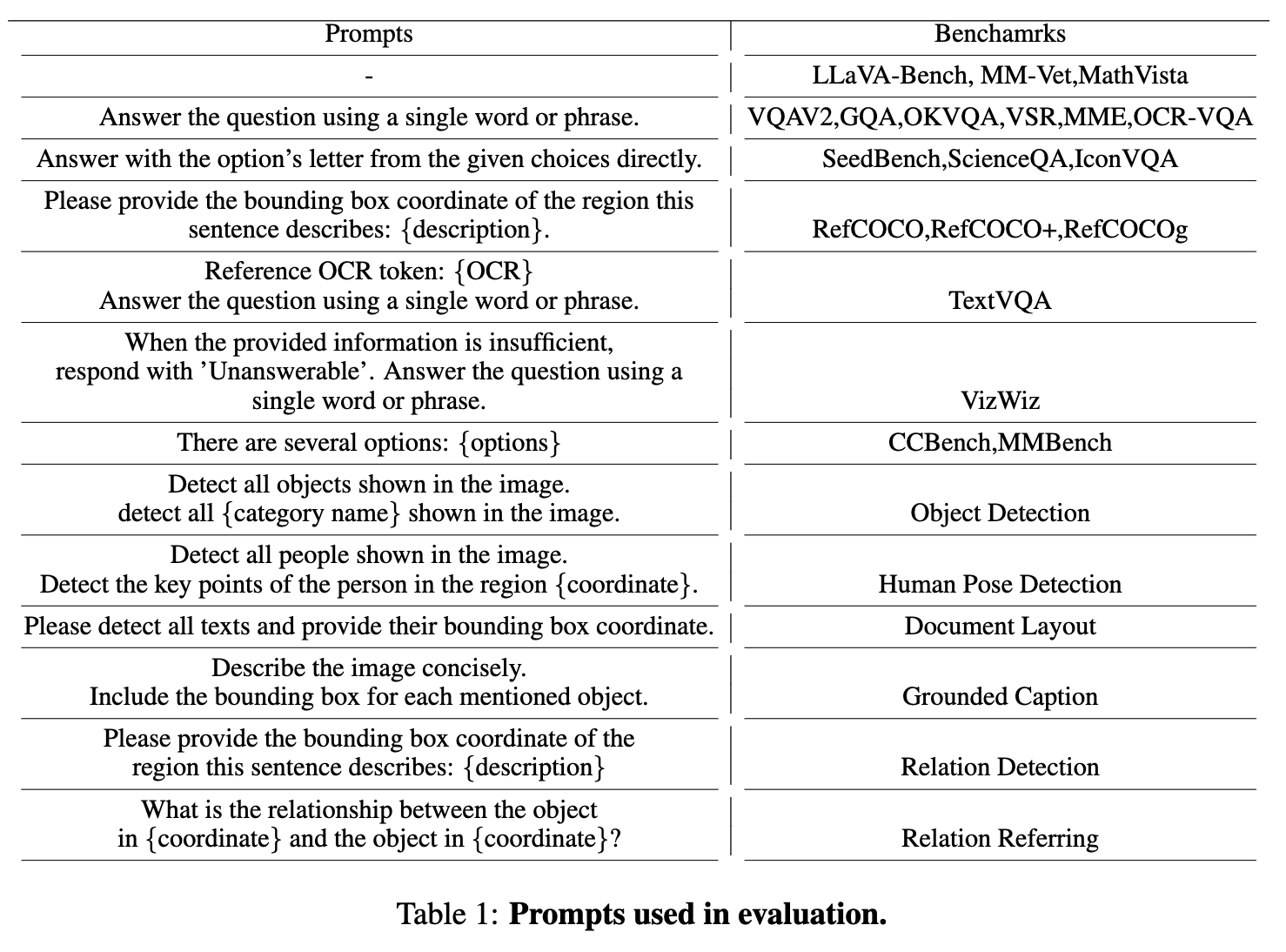
* In evaluation, we prioritize aligning with each benchmark's desired output format.
* We employ distinct prompts tailored to benchmarks that necessitate long answers, short answers, and multiple-choice responses.
* For tasks involving visual grounding, we directly utilize the prompts during training to enhance the model's performance on these particular challenges.
**Benchmarks on Multimodal Large Language Models**
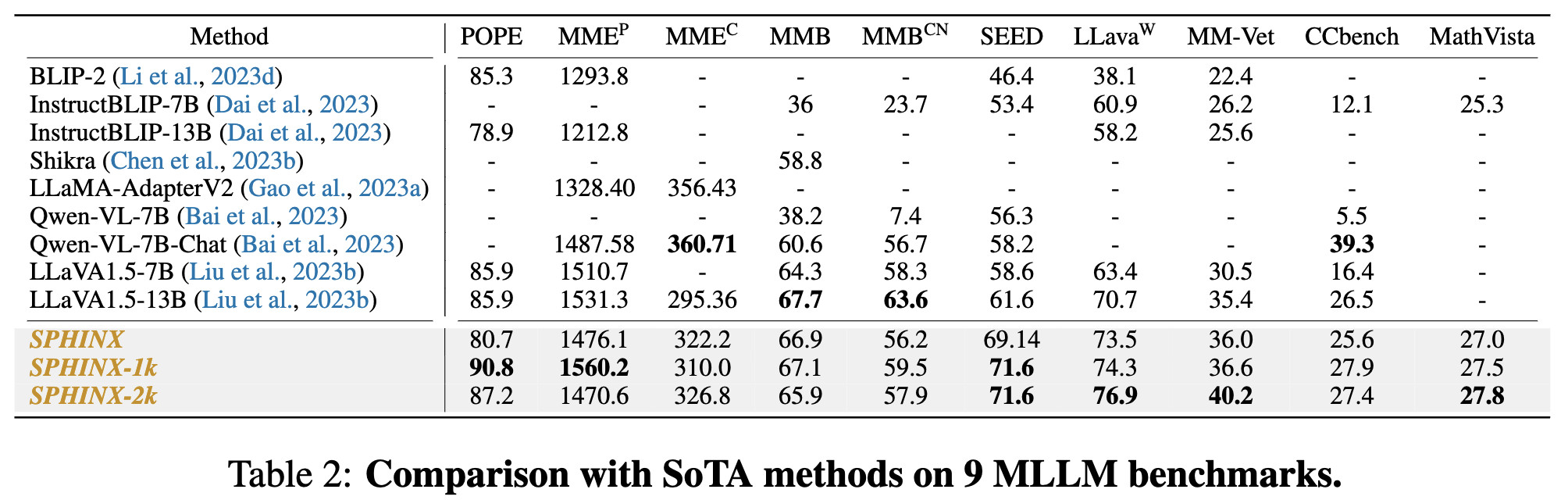
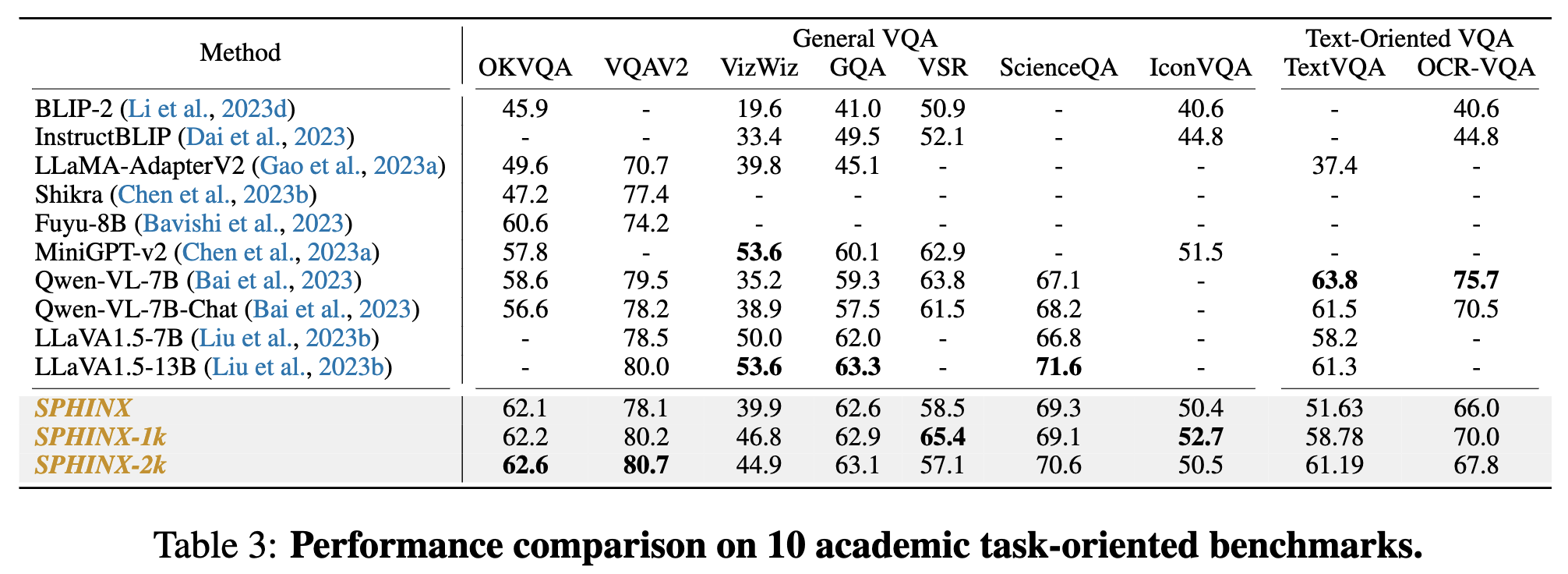
* We evaluate general VQA benchmarks, such as VQAV2, OKVQA, GQA, vizwiz, scienceQA, visual spatial reasoning (VSR), IconQA.
* Additionally, we conduct experiments on Text-oriented VQA such as TextVQA,OCR-VQA.
* Long-Sphinx achieve comparative results across all benchmarks. We observe that Long-Sphinx outperforms Sphinx in VQA datasets that demand fine-grained visual information, showcasing the effectiveness of our visual mixed-up approach for achieving high resolution without relying on a visual encoder trained specifically on high-resolution images.
**Visual Grounding**
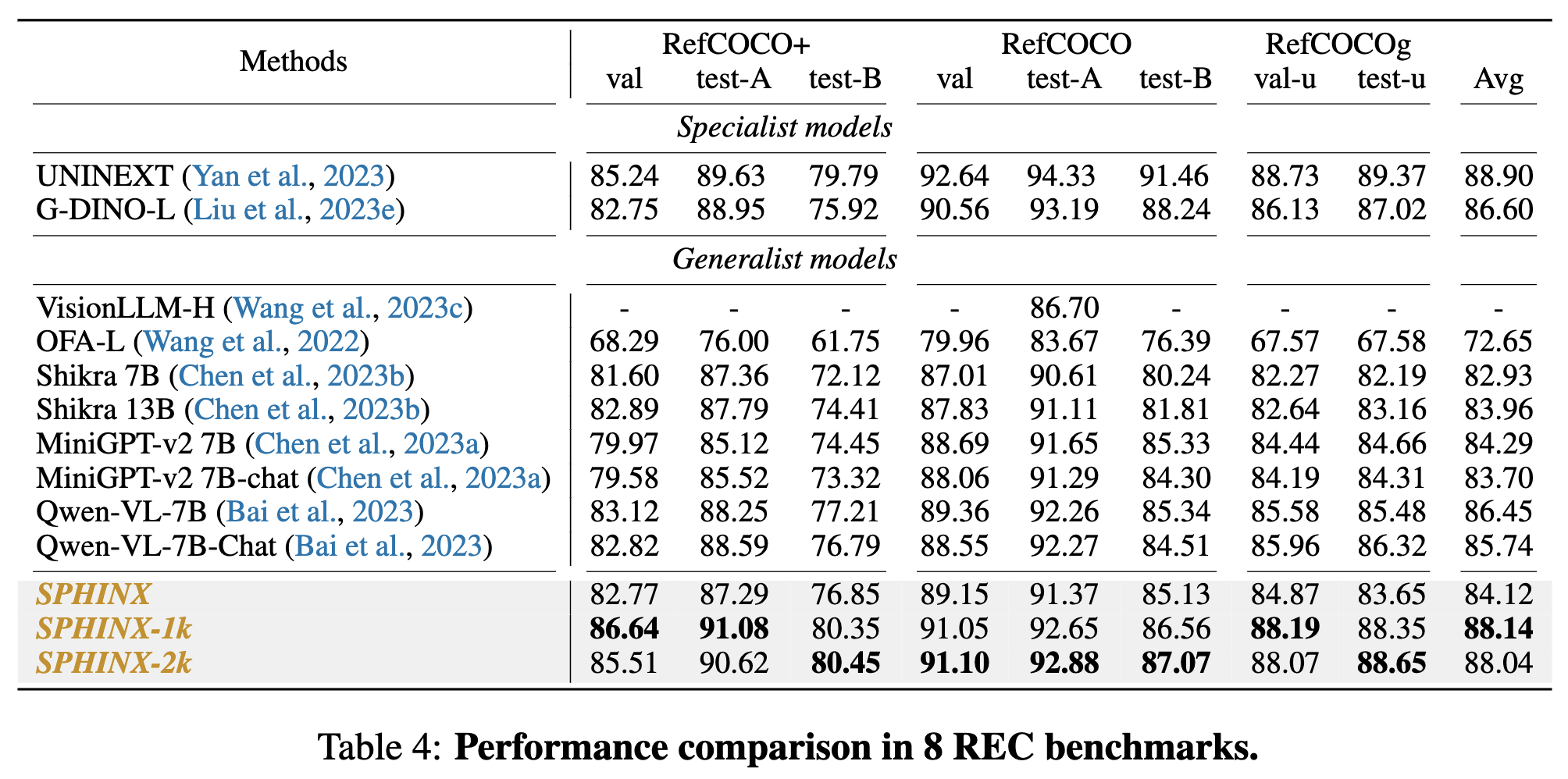
* The SPHINX model and baseline models on REC benchmarks results on table4.
* SPHINX exhibits robust performance in visual grounding tasks such as RefCOCO, RefCOCO+, and RefCOCOg, **surpassing other vision-language generalist models**.
* Notably, SPHINX outperforms specialist models G-DINO-L by **more than 1.54%** in accuracy across all tasks within RefCOCO/RefCOCO+/RefCOCOg.
## Frequently Asked Questions (FAQ)
❓ Encountering issues or have further questions? Find answers to common inquiries [here](https://llama2-accessory.readthedocs.io/en/latest/faq.html). We're here to assist you!
## License
Llama 2 is licensed under the [LLAMA 2 Community License](LICENSE_llama2), Copyright (c) Meta Platforms, Inc. All Rights Reserved.