---
datasets:
- Open-Orca/SlimOrca-Dedup
- teknium/openhermes
- meta-math/MetaMathQA
- migtissera/Synthia-v1.3
- THUDM/AgentInstruct
- LeoLM/German_Songs
- LeoLM/German_Poems
- LeoLM/OpenSchnabeltier
- bjoernp/ultrachat_de
- LDJnr/Capybara
language:
- en
- de
library_name: transformers
pipeline_tag: text-generation
license: llama2
model_creator: DiscoResearch
model_type: llama
tags:
- goliath
- deutsch
- llama2
- discoresearch
---

# DiscoLM 70b
**DiscoLM 70b** is a 70b model based on [Laion's LeoLM 70b](https://huggingface.co/LeoLM/leo-hessianai-70b) which underwent additional continued pretraining for 65b tokens of German
text, strengthening it's multilingual capabilities while retaining (and partially improving) English capabilities.
This was then further finetuned on a combination of some the most popular open-source instruction sets.
DiscoLM 70b is a [DiscoResearch](https://huggingface.co/DiscoResearch) project and was trained by [Björn Plüster](https://huggingface.co/bjoernp).
Many thanks to [LAION](https://laion.ai) and [HessianAI](https://hessian.ai/) for scientific supervision, coordination and compute resources provided for this project on supercomputer 42 by [HessianAI](https://hessian.ai/)!

 ## Table of Contents
1. [Download](#download)
2. [Benchmarks](#benchmarks)
3. [Prompt Format](#prompt-format)
4. [Dataset](#dataset)
5. [Acknowledgements](#acknowledgements)
6. [Contact](#contact)
7. [About DiscoResearch](#about-discoresearch)
8. [Disclaimer](#disclaimer)
## Download
| Huggingface | GPTQ | GGUF | AWQ | *Base Model* |
|-------|-------|-------|-------|-------|
| [Link](https://huggingface.co/DiscoResearch/DiscoLM-70b) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-GPTQ) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-GGUF) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-AWQ) | [LeoLM 70b](https://huggingface.co/LeoLM/leo-hessianai-70b) |
## Benchmarks
### Hugginface Leaderboard
This models is still an early Alpha and we can't guarantee that there isn't any contamination.
The following are the scores from our own evaluation.
| Metric | Value |
|-----------------------|-------|
| ARC (25-shot) | 68.77 |
| HellaSwag (10-shot) | 85.41 |
| MMLU (5-shot) | 68.64 |
| TruthfulQA (0-shot) | 57.69 |
| Winogrande (5-shot) | 83.27 |
| GSM8k (5-shot) | 63.68 |
| **Avg.** | **71.24** |
The model is now also officially ranked on the Open LLM Leaderboard as #6 overall and as the second strongest Llama-2-70b based model (ranking only begind TigerBot 70b):

(Screenshot from the 05. of December 2023)
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
### FastEval
| Metric | Value |
|-----------------------|-------|
| GSM8K | 70.6 |
| Math | 17.8 |
| BBH | 63.4 |
| MMLU | 64.7 |
| **Avg.** | **48.87** |
Screenshot of the current (sadly no longer maintained) FastEval CoT leaderboard:
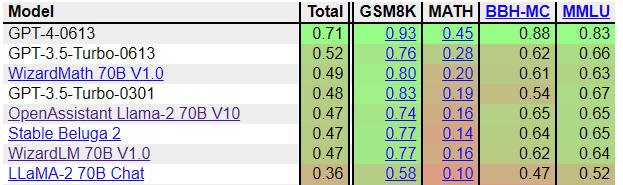
### MTBench
```json
{
"first_turn": 7.9,
"second_turn": 7.0625,
"categories": {
"writing": 9.55,
"roleplay": 8.35,
"reasoning": 6.15,
"math": 4.7,
"coding": 4.8,
"extraction": 7.35,
"stem": 9.1,
"humanities": 9.85
},
"average": 7.48125
}
```
Screenshot of the current FastEval MT Bench leaderboard:
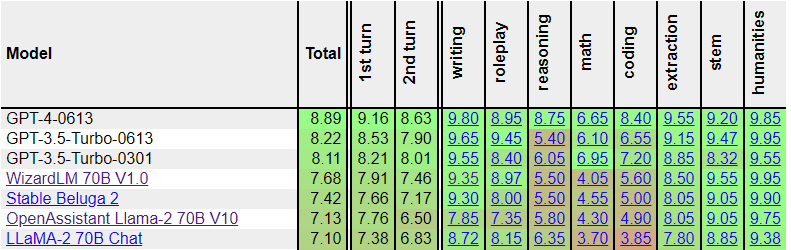
## Prompt Format
This model follows the ChatML format:
```
<|im_start|>system
You are DiscoLM, a helpful assistant.
<|im_end|>
<|im_start|>user
Please tell me possible reasons to call a research collective "Disco Research"<|im_end|>
<|im_start|>assistant
```
This formatting is also available via a pre-defined Transformers chat template, which means that lists of messages can be formatted for you with the apply_chat_template() method:
```python
chat = [
{"role": "system", "content": "You are DiscoLM, a helpful assistant."},
{"role": "user", "content": "Please tell me possible reasons to call a research collective Disco Research"}
]
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
If you use `tokenize=True` and `return_tensors="pt"` instead, then you will get a tokenized and formatted conversation ready to pass to `model.generate()`.
## Dataset
The dataset curation for DiscoLM 70b followed a "brute force"/"PoC" approach.
The following datasets were used for training DiscoLM 70b:
* [SlimOrca-Dedup](https://huggingface.co/datasets/Open-Orca/SlimOrca-Dedup)
* [OpenSchnabeltier](https://huggingface.co/datasets/LeoLM/OpenSchnabeltier) translated to DE from [OpenPlatypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus)
* [OpenHermes](https://huggingface.co/datasets/teknium/openhermes)
* [MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)
* [UltraChat DE](https://huggingface.co/datasets/bjoernp/ultrachat_de) translated to DE from [UltraChat](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k)
* [Synthia v.1.3](https://huggingface.co/datasets/migtissera/Synthia-v1.3)
* [German_Songs](https://huggingface.co/datasets/LeoLM/German_Songs)
* [German_Poems](https://huggingface.co/datasets/LeoLM/German_Poems)
* Capybara Dataset by [LDJnr](https://huggingface.co/LDJnr)
* Vezora/Tested-188k-Python (No longer available? Version changed to [Vezora/Tested-22k-Python-Alpaca](https://huggingface.co/datasets/Vezora/Tested-22k-Python-Alpaca))
Many thanks for all dataset providers/curators!
## Contact
Best way to reach us is on our [Discord](https://discord.gg/S8W8B5nz3v).
## About DiscoResearch
DiscoResearch is an aspiring open research community. Disco should be a place where researchers from many communities can come together to combine their expertise and create innovative and groundbreaking LLMs. Come join our Discord, share your opinions and ideas, and advance open LLM research with us!
## Acknowledgements
Disco 70b is a [DiscoResearch](https://huggingface.co/DiscoResearch) project and was trained by [Björn Plüster](https://huggingface.co/bjoernp). [Jan Harries](https://huggingface.co/jphme) helped with technical adivce, logistics and the Model Card.
[AutoMeta](https://huggingface.co/Alignment-Lab-AI) also provided helpful technical advice and rounded up his connections to select a set of high-quality datasets.
The model was trained with compute provided by [HessianAI](https://hessian.ai/) in collaboration with [LAION](https://laion.ai) - many thanks in particular to [Patrick Schramowski](https://huggingface.co/PSaiml) for his support.
We are standing on the shoulders of giants; many thanks in no particular order to [Laion](https://laion.ai) for LeoLM 70b
(especially to [Christoph Schuhmann](https://laion.ai) who got us all connected),
[TheBloke](https://huggingface.co/TheBloke) for providing quantized versions, [winglian](https://huggingface.co/winglian) for Axolotl which was used to train the model and the SlimOrca dataset, [garage-bAInd](https://huggingface.co/garage-bAInd), [Teknium](https://huggingface.co/teknium), [Migel Tissera](https://huggingface.co/migtissera), [MetaMath](https://huggingface.co/meta-math), and [LDJnr](https://huggingface.co/LDJnr) for their great datasets (please contact us if we forgot to mention you here!).
[
## Table of Contents
1. [Download](#download)
2. [Benchmarks](#benchmarks)
3. [Prompt Format](#prompt-format)
4. [Dataset](#dataset)
5. [Acknowledgements](#acknowledgements)
6. [Contact](#contact)
7. [About DiscoResearch](#about-discoresearch)
8. [Disclaimer](#disclaimer)
## Download
| Huggingface | GPTQ | GGUF | AWQ | *Base Model* |
|-------|-------|-------|-------|-------|
| [Link](https://huggingface.co/DiscoResearch/DiscoLM-70b) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-GPTQ) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-GGUF) | [@TheBloke](https://huggingface.co/TheBloke/DiscoLM-70B-AWQ) | [LeoLM 70b](https://huggingface.co/LeoLM/leo-hessianai-70b) |
## Benchmarks
### Hugginface Leaderboard
This models is still an early Alpha and we can't guarantee that there isn't any contamination.
The following are the scores from our own evaluation.
| Metric | Value |
|-----------------------|-------|
| ARC (25-shot) | 68.77 |
| HellaSwag (10-shot) | 85.41 |
| MMLU (5-shot) | 68.64 |
| TruthfulQA (0-shot) | 57.69 |
| Winogrande (5-shot) | 83.27 |
| GSM8k (5-shot) | 63.68 |
| **Avg.** | **71.24** |
The model is now also officially ranked on the Open LLM Leaderboard as #6 overall and as the second strongest Llama-2-70b based model (ranking only begind TigerBot 70b):

(Screenshot from the 05. of December 2023)
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
### FastEval
| Metric | Value |
|-----------------------|-------|
| GSM8K | 70.6 |
| Math | 17.8 |
| BBH | 63.4 |
| MMLU | 64.7 |
| **Avg.** | **48.87** |
Screenshot of the current (sadly no longer maintained) FastEval CoT leaderboard:

### MTBench
```json
{
"first_turn": 7.9,
"second_turn": 7.0625,
"categories": {
"writing": 9.55,
"roleplay": 8.35,
"reasoning": 6.15,
"math": 4.7,
"coding": 4.8,
"extraction": 7.35,
"stem": 9.1,
"humanities": 9.85
},
"average": 7.48125
}
```
Screenshot of the current FastEval MT Bench leaderboard:

## Prompt Format
This model follows the ChatML format:
```
<|im_start|>system
You are DiscoLM, a helpful assistant.
<|im_end|>
<|im_start|>user
Please tell me possible reasons to call a research collective "Disco Research"<|im_end|>
<|im_start|>assistant
```
This formatting is also available via a pre-defined Transformers chat template, which means that lists of messages can be formatted for you with the apply_chat_template() method:
```python
chat = [
{"role": "system", "content": "You are DiscoLM, a helpful assistant."},
{"role": "user", "content": "Please tell me possible reasons to call a research collective Disco Research"}
]
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
If you use `tokenize=True` and `return_tensors="pt"` instead, then you will get a tokenized and formatted conversation ready to pass to `model.generate()`.
## Dataset
The dataset curation for DiscoLM 70b followed a "brute force"/"PoC" approach.
The following datasets were used for training DiscoLM 70b:
* [SlimOrca-Dedup](https://huggingface.co/datasets/Open-Orca/SlimOrca-Dedup)
* [OpenSchnabeltier](https://huggingface.co/datasets/LeoLM/OpenSchnabeltier) translated to DE from [OpenPlatypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus)
* [OpenHermes](https://huggingface.co/datasets/teknium/openhermes)
* [MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)
* [UltraChat DE](https://huggingface.co/datasets/bjoernp/ultrachat_de) translated to DE from [UltraChat](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k)
* [Synthia v.1.3](https://huggingface.co/datasets/migtissera/Synthia-v1.3)
* [German_Songs](https://huggingface.co/datasets/LeoLM/German_Songs)
* [German_Poems](https://huggingface.co/datasets/LeoLM/German_Poems)
* Capybara Dataset by [LDJnr](https://huggingface.co/LDJnr)
* Vezora/Tested-188k-Python (No longer available? Version changed to [Vezora/Tested-22k-Python-Alpaca](https://huggingface.co/datasets/Vezora/Tested-22k-Python-Alpaca))
Many thanks for all dataset providers/curators!
## Contact
Best way to reach us is on our [Discord](https://discord.gg/S8W8B5nz3v).
## About DiscoResearch
DiscoResearch is an aspiring open research community. Disco should be a place where researchers from many communities can come together to combine their expertise and create innovative and groundbreaking LLMs. Come join our Discord, share your opinions and ideas, and advance open LLM research with us!
## Acknowledgements
Disco 70b is a [DiscoResearch](https://huggingface.co/DiscoResearch) project and was trained by [Björn Plüster](https://huggingface.co/bjoernp). [Jan Harries](https://huggingface.co/jphme) helped with technical adivce, logistics and the Model Card.
[AutoMeta](https://huggingface.co/Alignment-Lab-AI) also provided helpful technical advice and rounded up his connections to select a set of high-quality datasets.
The model was trained with compute provided by [HessianAI](https://hessian.ai/) in collaboration with [LAION](https://laion.ai) - many thanks in particular to [Patrick Schramowski](https://huggingface.co/PSaiml) for his support.
We are standing on the shoulders of giants; many thanks in no particular order to [Laion](https://laion.ai) for LeoLM 70b
(especially to [Christoph Schuhmann](https://laion.ai) who got us all connected),
[TheBloke](https://huggingface.co/TheBloke) for providing quantized versions, [winglian](https://huggingface.co/winglian) for Axolotl which was used to train the model and the SlimOrca dataset, [garage-bAInd](https://huggingface.co/garage-bAInd), [Teknium](https://huggingface.co/teknium), [Migel Tissera](https://huggingface.co/migtissera), [MetaMath](https://huggingface.co/meta-math), and [LDJnr](https://huggingface.co/LDJnr) for their great datasets (please contact us if we forgot to mention you here!).
[ ](https://github.com/OpenAccess-AI-Collective/axolotl)
## Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model.
This model should only be used for research purposes. The original Llama2 license and all restrictions of datasets used to train this model apply.
](https://github.com/OpenAccess-AI-Collective/axolotl)
## Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model.
This model should only be used for research purposes. The original Llama2 license and all restrictions of datasets used to train this model apply.